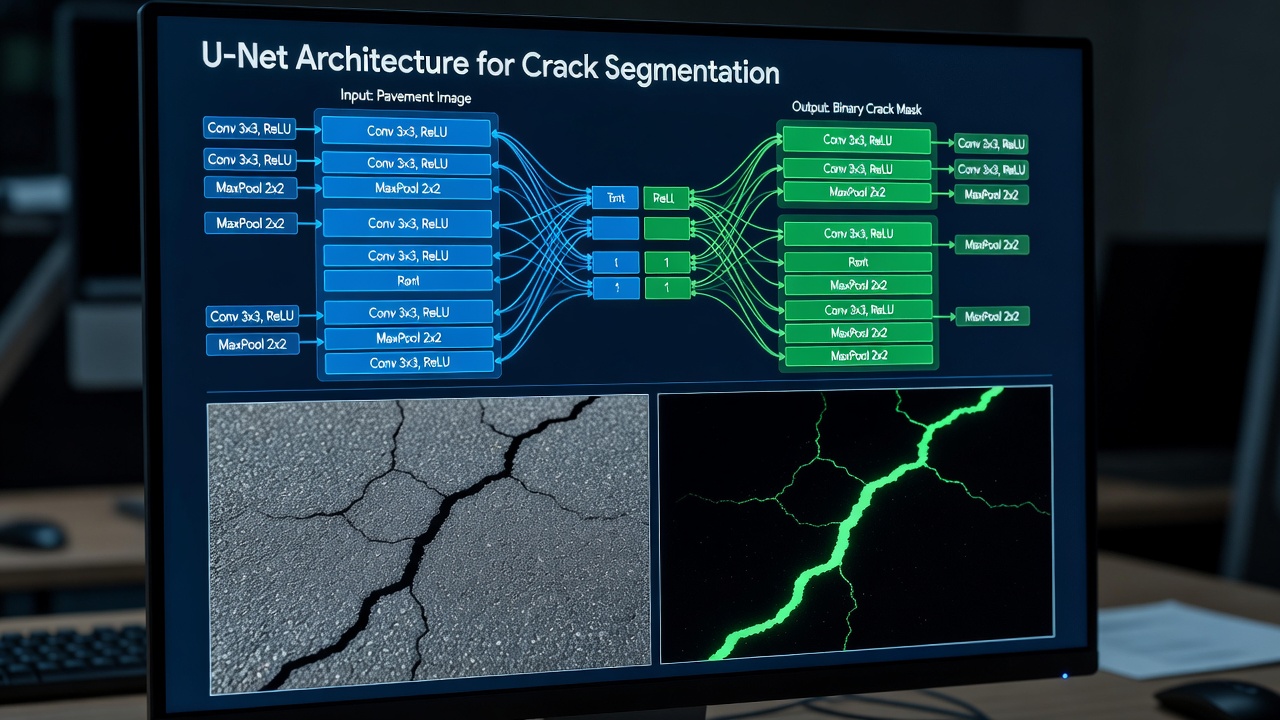
Segmentace trhlin je úloha počítačového vidění, která klasifikuje každý pixel obrazu jako trhlinu nebo netrhlínu, čímž vytváří binární masku umožňující přesné měření geometrie trhlin — plochy, délky, šířky a analýzu vzorů. Husté segmentační hlavy založené na DINOv3 a architektury U-Net představují nejmodernější přístup pro inspekci infrastruktury.
Segmentace trhlin na úrovni pixelů pro inspekci infrastruktury
1. Definice a rozdíl od klasifikace trhlin
Segmentace trhlin je úloha husté predikce pixelů v rámci počítačového vidění, která přiřazuje binární štítek (trhlina nebo netrhlína) každému jednotlivému pixelu ve vstupním obraze. Výstupem je binární segmentační maska stejných prostorových rozměrů jako vstup, kde pixely trhlin jsou označeny jako popředí (typicky bílá nebo hodnota 1) a pixely bez trhlin jako pozadí (černá nebo hodnota 0). Tato maska zachovává přesnou morfologii, topologii a geometrii každé trhliny přítomné v scéně, včetně větví, izolovaných fragmentů a fisur o šířce menší než milimetr.
Klasifikace trhlin pracuje na úrovni obrazu — model vydává jediný skalár indikující, zda je v obraze přítomna trhlina. Klasifikační model může předpovědět „trhlina přítomna: 93% spolehlivost", ale nedokáže lokalizovat, kde se trhlina nachází, jak je dlouhá nebo jak široká je. To je zásadně nedostatečné pro inspekci infrastruktury, kde přesná měření řídí priority údržby, odhad nákladů na opravy a hodnocení konstrukční bezpečnosti.
Detekce trhlin pomocí detekce objektů (Faster R-CNN, YOLO, SSD) vydává ohraničující rámečky kolem oblastí trhlin. Zatímco detekce poskytuje lokalizaci, ohraničující rámeček kolem tenké, protáhlé trhliny obsahuje převážně pixely pozadí a nenese žádnou informaci o šířce trhliny, topologii nebo struktuře větvení. Trhlina, která se klikatí napříč dráhou, může vyžadovat desítky překrývajících se ohraničujících rámečků bez sémantického vztahu mezi nimi.
Segmentace trhlin řeší všechna tato omezení. Každý pixel trhliny je identifikován, což umožňuje přímé měření:
Plochy trhliny v milimetrech čtverečních (počet pixelů × prostorové rozlišení)
Délky trhliny podél skeletonizované středové linie v milimetrech
Šířky trhliny (průměrná, maximální a profily šířky na pixel)
Statistik komponent (celkový počet různých trhlin, prostorová hustota, konektivita)
Mezinárodní organizace pro civilní letectví (ICAO) Annex 14 — Letiště, svazek I, stanovuje, že povrchy drah musí být pravidelně kontrolovány na degradaci včetně trhlin. ICAO Doc 9157, část 3 — Vozovky, poskytuje pokyny k metodám hodnocení vozovek. Tradiční manuální inspekce zahrnuje inspektory procházející dráhu, označující trhliny křídou nebo sprejem a zaznamenávající pozorování na papírové formuláře — proces, který je subjektivní, nejednotný, nebezpečný (expozice provozu na letišti) a nemožný k provedení s přesností na submilimetry. Automatizovaná segmentace trhlin nahrazuje subjektivní vizuální odhad reprodukovatelnými, kvantitativními, pixelově přesnými měřeními, která lze porovnávat napříč inspekcemi a letišti.
Úloha
Výstup
Lokalizace trhliny
Geometrie trhliny
Přesnost měření
Klasifikace
Jediný štítek (trhlina/bez trhliny)
Žádná
Žádná
Úroveň obrazu
Detekce
Ohraničující rámečky
Přibližný rámeček
Žádná
Úroveň rámečku
Segmentace
Binární maska
Pixelově přesná
Plná geometrie
Úroveň pixelů (sub-mm)
Přechod od klasifikace k segmentaci představuje zásadní skok v možnostech. Klasifikace odpovídá na otázku „je zde trhlina?" Segmentace odpovídá na otázku „kde přesně je každá trhlina, jak je velká, jaký má tvar a jak závažné je poškození?" Pro crack_seg_head od TarmacView je tato schopnost husté predikce pixelů základem pro vytváření vysoce přesných masků trhlin, které přímo vstupují do výpočtů indexu stavu vozovky, odhadu množství oprav a analýzy dlouhodobých trendů.
2. Segmentační architektury
U-Net
Architektura U-Net, představená Ronnebergerem, Fischerem a Broxem v roce 2015 pro segmentaci biomedicínských snímků, se stala nejpoužívanější architekturou pro segmentaci trhlin v infrastrukturních aplikacích. U-Net se skládá ze symetrické struktury kodéru a dekodéru se čtyřmi nebo pěti úrovněmi rozlišení propojenými přeskočenými spojeními, která přenášejí vysoce rozlišené prostorové informace přímo z vrstev kodéru do dekodéru.
Kodér (kontrakční cesta) aplikuje opakované 3×3 konvoluce následované ReLU aktivací a 2×2 max poolingem, čímž postupně zmenšuje prostorové rozměry při současném zvyšování hloubky příznakových kanálů z 64 na 512 nebo 1024 kanálů. Každý blok kodéru se učí stále abstraktnější reprezentace — od jednoduchých detektorů hran v první vrstvě po komplexní detektory textury a morfologie trhlin v nejhlubších vrstvách. Pro segmentaci trhlin se musí kodér naučit rozlišovat skutečné rysy trhlin od struktur připomínajících trhliny, včetně stínů kameniva, stop pneumatik, dilatačních spár, povrchových nečistot a pruhů tmelu.
Dekodér (expanzní cesta) provádí zrcadlovou operaci: 2×2 up-konvoluce (transponovaná konvoluce) zdvojnásobuje prostorové rozlišení při poloviční hloubce kanálů, poté připojuje odpovídající mapu příznaků z kodéru přes přeskočené spojení, následované dvěma 3×3 konvolucemi s ReLU. Poslední vrstva používá 1×1 konvoluci se sigmoidní aktivací k vytvoření binární masky trhlin.
Přeskočená spojení jsou klíčovou inovací U-Netu. U standardních architektur kodér-dekodér se všechny prostorové detaily ztrácejí během podvzorkování a musí být znovu naučeny v dekodéru. Přeskočená spojení přímo přenášejí jemnozrnné prostorové informace — okraje trhlin, tenké linie trhlin a přesné hranice — z kodéru do dekodéru na každé úrovni rozlišení. To je nezbytné pro segmentaci trhlin, protože trhliny jsou inherently tenké struktury (často 1–10 pixelů široké), které by byly na úrovni úzkého hrdla (16×–32× podvzorkované) zcela ztraceny.
Pro segmentaci trhlin konkrétně zahrnují varianty U-Netu:
Attention U-Net: Přidává pozornostní brány, které potlačují irelevantní rysy pozadí a zdůrazňují oblasti trhlin
Residual U-Net: Nahrazuje standardní konvoluce reziduálními bloky, umožňující hlubší sítě bez mizejících gradientů
Dense U-Net: Používá husté bloky (styl DenseNet) pro lepší šíření příznaků a tok gradientů
U-Net++ : Přidává vnořená přeskočená spojení s hustými konvolučními bloky, čímž snižuje sémantickou mezeru mezi příznaky kodéru a dekodéru
U-Net dosahuje nejmodernějšího výkonu na benchmarkových sadách pro segmentaci trhlin včetně CRACK500 (IoU 0,65–0,72) a DeepCrack (IoU 0,70–0,78) při trénování s vhodnými ztrátovými funkcemi a augmentací dat.
DeepLabV3+
DeepLabV3+, vyvinutý společností Google Research (Chen et al., 2018), rozšiřuje rodinu DeepLab o strukturu kodér-dekodér rozšířenou o Atrous Spatial Pyramid Pooling (ASPP) . Hlavní inovací je použití atrous (dilatovaných) konvolucí s více rychlostmi dilatace aplikovanými paralelně pro zachycení víceúrovňových kontextuálních informací bez snížení prostorového rozlišení.
ASPP aplikuje 3×3 konvoluce při různých rychlostech dilatace — typicky rychlosti 6, 12 a 18 pro výstupní krok 16 — plus 1×1 konvoluci a globální průměrové sdružování. Každá rychlost dilatace zachycuje rysy trhlin v jiném měřítku: rychlost 6 zachycuje jemné, úzké trhliny (1–3 pixely široké), rychlost 12 zachycuje střední trhliny a rychlost 18 zachycuje široké trhliny a sítě trhlin. Paralelní větve jsou zřetězeny a zpracovány 1×1 konvolucí k vytvoření víceúrovňové příznakové reprezentace.
Pro segmentaci trhlin vyniká DeepLabV3+ při zpracování extrémní variability měřítek ve vzhledu trhlin. Jeden snímek dráhy může obsahovat vlasové trhliny (0,5 mm široké, 1–2 pixely) vedle širokých, odštěpených trhlin (15+ mm širokých, 30+ pixelů). Modul ASPP zpracovává všechna tato měřítka současně. Dekódovací modul vzorkuje ASPP příznaky nahoru o faktor 4, připojuje příznaky kodéru z prostřední vrstvy (před prvním atrous blokem) a aplikuje dvě 3×3 konvoluce následované bilineárním vzorkováním na původní rozlišení.
Backbone sítě DeepLabV3+ běžně používané pro segmentaci trhlin zahrnují ResNet-50, ResNet-101 a Xception. V poslední době byly zkoumány backbone EfficientNet a ConvNeXt s lepším poměrem přesnosti k počtu parametrů. DeepLabV3+ s backbone ResNet-101 dosahuje skóre IoU 0,68–0,75 na CRACK500 při trénování na datasetech specifických pro vozovky.
SegFormer
SegFormer (Xie et al., 2021) zavádí hierarchický Transformer kodér s lehkým MLP (vícevrstvý perceptron) dekodérem, což představuje odklon od CNN segmentačních architektur. Kodér používá sérii Mix Transformer (MiT) bloků s postupně klesajícím rozlišením (od 1/4 po 1/32 vstupní velikosti) a rostoucími rozměry kanálů. Každý MiT blok používá efektivní self-attention se sníženým poměrem prostorové redukce, což jej činí výpočetně proveditelným pro vysoce rozlišené snímky trhlin.
Klíčovou výhodou SegFormeru pro segmentaci trhlin je globální receptivní pole transformeru již od první vrstvy. Na rozdíl od CNN, kde každá vrstva vidí pouze lokální okolí (např. 3×3 konvoluce = okolí 1 pixelu po jedné vrstvě), Transformery počítají attention napříč celou mapou příznaků. To umožňuje SegFormeru zachycovat závislosti na dlouhé vzdálenosti — trhlina, která se vine napříč celou dlaždicí 1024×1024, udržuje vztahy mezi pixely prostřednictvím attention mechanismu.
MLP dekodér v SegFormeru je pozoruhodně jednoduchý ve srovnání s dekodéry U-Net nebo DeepLabV3+. Agreguje příznaky z více úrovní ze všech čtyř fází kodéru (vzorkováním na 1/4 rozlišení a zřetězením), aplikuje jednu MLP vrstvu pro míchání příznaků a poté další MLP pro vytvoření finální segmentace. Navzdory své jednoduchosti dosahuje MLP dekodér silného výkonu, protože hierarchický Transformer kodér již produkuje dobře strukturované příznaky.
SegFormer-B3 dosahuje konkurenceschopného IoU (0,66–0,74) na datových sadách segmentace trhlin při větší parametrové efektivitě než DeepLabV3+ s ResNet-101. Rodina modelů B0–B5 poskytuje kompromis mezi rychlostí a přesností, přičemž B0 je vhodný pro nasazení v reálném čase na okrajových zařízeních a B5 pro maximální přesnost na serverovém hardwaru.
Husté predikční hlavy DINOv2 a DINOv3
DINOv2 (Oquab et al., 2023) a DINOv3 představují nejnovější generaci modelů Vision Transformer (ViT) trénovaných pomocí samoučícího se učení na kurátorských datových sadách. Na rozdíl od supervizovaného předtrénování na ImageNet-1K používá DINO přístup samodestilace, kde se studentská síť učí shodovat výstup učitelské sítě pracující na různých pohledech stejného obrazu (lokální oříznuté pohledy vs. globální pohledy).
Průlomem DINO pro segmentaci je, že samoučící se ViT příznaky — zejména attention hlavy klíčů (K) a hodnot (V) v posledních vrstvách — přirozeně kódují hranice objektů a jemnozrnné sémantické informace bez jakéhokoli supervizovaného segmentačního tréninku. Malá množina patch tokenů (např. 0,05 % patchů) může být lineárně dotazována k vytvoření segmentačních map, které se vyrovnají plně supervizovaným modelům.
Pro segmentaci trhlin je k backbone DINO připojena hustá predikční hlava. Typický přístup extrahuje víceúrovňové příznaky z posledních 4–6 vrstev ViT, zřetězí je a aplikuje konvoluční dekodér, který vzorkuje na původní rozlišení obrazu. Dekodér může být:
Lehká Lineární hlava: Jednoduše 1×1 konvoluce po vzorkování ViT patch tokenů (velikost patchů 14×14 pro ViT-L/14)
Feature Pyramid Network (FPN) hlava: Víceúrovňová extrakce příznaků s laterálními spojeními a cestou shora dolů
Hlava stylu MaskFormer: Transformer dekodér, který křížově attenduje k DINO příznakům a vytváří binární masky
Segmentace trhlin založená na DINOv3 dosahuje skóre IoU přesahujícího 0,78 na CRACK500 a 0,82 na DeepCrack při end-to-end dolaďování s datovými sadami masků trhlin. Samoučící se předtrénování poskytuje silné příznakové reprezentace, které se lépe zobecňují na nové povrchy a světelné podmínky ve srovnání se supervizovanými ImageNet backbone.
Architektura
Parametry
CRACK500 IoU
Rychlost inference (MP/s)
Klíčová výhoda
U-Net (ResNet-34)
24M
0,68
45
Efektivita s malými daty
DeepLabV3+ (ResNet-101)
63M
0,72
28
Víceúrovňové ASPP
SegFormer-B3
47M
0,70
22
Globální attention
DINOv2-ViT-L/14 + hustá hlava
307M
0,78
8
Samoučící se příznaky
3. Datové sady s maskami referenční pravdy
Kvalita a rozmanitost tréninkových datových sad přímo určuje výkon modelu segmentace trhlin. Všechny supervizované metody segmentace trhlin vyžadují pixelově přesné masky referenční pravdy — binární obrazy, kde expertní anotátoři pečlivě označili každý pixel trhliny. Následující datové sady představují nejpoužívanější benchmarky ve výzkumu segmentace trhlin.
CRACK500
CRACK500 (Zhang et al., 2016) obsahuje 500 RGB snímků povrchů vozovek pořízených spotřebitelským fotoaparátem s vzdáleností vzorkování na zemi (GSD) přibližně 0,05 mm/pixel. Každý snímek má rozlišení 2048×1536 pixelů, což poskytuje fyzickou plochu přibližně 100×75 mm. Datová sada je rozdělena na 250 tréninkových, 50 validačních a 200 testovacích snímků.
Masky referenční pravdy byly ručně anotovány vyškolenými inspektory a křížově ověřeny. Trhliny jsou označeny s přesností na sub-pixel, včetně trhlin úzkých až 0,1–0,2 mm (2–4 pixely). Datová sada převážně obsahuje asfaltovou vozovku s různými typy trhlin: příčné trhliny, podélné trhliny, aligátorové (únavové) praskání, blokové praskání a okrajové praskání. Pozadí zahrnuje texturu kameniva, směs hrubých a jemných asfaltových částic, záplaty a tmely.
CRACK500 je nejčastěji benchmarkovaná datová sada v literatuře o segmentaci trhlin díky své konzistentní kvalitě, přiměřené velikosti a veřejné dostupnosti. Základní modely U-Net dosahují přibližně 0,65–0,68 IoU na testovací sadě, přičemž nedávné modely založené na DINOv2 dosahují 0,78–0,80 IoU.
DeepCrack
DeepCrack (Zou et al., 2019) obsahuje 537 RGB snímků trhlin na betonových a kamenných površích v rozlišení 512×512 pixelů. Datová sada byla navržena speciálně pro segmentaci trhlin pomocí hlubokého učení a zahrnuje různé typy povrchů, které se nenacházejí v datasetech pouze s vozovkami: betonové zdi, mostní pilíře, tunelové ostění, fasády budov a kamenné povrchy. Anotace referenční pravdy byly vytvořeny více anotátory a doladěny konsenzuálním procesem.
Snímky DeepCrack zahrnují náročné podmínky: stíny, skvrny od vlhkosti, přerůstající vegetaci, graffiti a drsnost povrchu, která vizuálně napodobuje rysy trhlin. Datová sada poskytuje oficiální rozdělení na trénovací (400 snímků) a testovací (137 snímků) sadu. DeepCrack je zvláště cenný pro hodnocení zobecnění napříč povrchy — modely trénované pouze na DeepCrack mívají dobrý výkon na nových betonových površích, ale mohou mít potíže na asfaltu.
Nejmodernější modely dosahují na DeepCrack 0,70–0,78 IoU. Vyšší základní obtížnost datasetu (ve srovnání s CRACK500) pramení z větší vizuální komplexity a nejednoznačnosti trhlina-pozadí na kamenných a betonových površích.
CrackForest (CFD)
CrackForest Dataset (CFD) (Shi et al., 2016) obsahuje 118 snímků asfaltových silničních vozovek pořízených v rozlišení 320×480 pixelů. Navzdory své malé velikosti je CFD široce používán pro křížovou validaci díky pečlivé anotaci a konzistentnímu typu povrchu. Datová sada obsahuje převážně příčné a podélné trhliny na silnicích se střední dopravní zátěží.
Výkon na CFD je u moderních modelů téměř saturován — DINOv2 dosahuje 0,84–0,87 IoU — ale malá evaluační sada znamená, že statistická významnost rozdílů je omezená. CFD se nejčastěji používá jako test transferového učení pro ověření, zda si modely trénované na větších datasetech (CRACK500, DeepCrack) zachovávají přesnost v této odlišné doméně snímání.
CrackAirport
CrackAirport je specializovaná datová sada pro segmentaci trhlin na letištních vozovkách, obsahující snímky drah, pojezdových drah a odbavovacích ploch pořízené během běžných letištních inspekcí. Letištní vozovky představují jedinečné výzvy, které se nevyskytují v silničních datasetech: drážkované povrchy drah (příčné drážky s rozestupy ~30 mm určené pro odvod vody), pryžové depozity z dotyku pneumatik letadel (snižující kontrast trhlina-vozovka), skvrny od paliva a hydraulické kapaliny a specializované systémy spár a tmelů.
Datová sada zahrnuje snímky při více hodnotách GSD (0,1–0,5 mm/pixel) pořízené z kamer namontovaných na vozidlech a z ručních zařízení. Typy trhlin specifické pro letištní vozovky — rohové lomy (tuhé vozovky), pumpování (ztráta materiálu pod spárami) a výstupky (ztráta kameniva) — jsou anotovány vedle standardních typů trhlin. CrackAirport je kritický pro trénování modelů, které musí fungovat na reálných letištních površích, kde by model trénovaný na silnicích produkoval nepřijatelné falešně pozitivní výsledky na drážkovaných texturách nebo pryžových depozitech.
CrackSeg9k — Kompilovaná datová sada
CrackSeg9k (Kulkarni et al., 2022) představuje největší sjednocenou kompilaci pro segmentaci trhlin, kombinující snímky z 9+ dílčích datasetů: AigleRN (38 snímků), CFD (118), Crack500 (500), DeepCrack (537), CrackTree200 (200), GAPs384 (384), CrackLS315 (315), Stone331 (331) a dalších vlastních kolekcí v celkovém počtu přes 9000 snímků po filtraci kvality. Autoři aplikovali zpřesnění pomocí zpracování obrazu ke sjednocení nekonzistentních anotací referenční pravdy — některé dílčí datasety používaly anotace tenkých linií (středové linie široké 1–3 pixely), jiné používaly anotace oblastí v plné tloušťce.
Zpřesňovací pipeline zahrnovala:
Ruční revizi a přeznačení nesprávně anotovaných snímků
Morfologickou dilataci pro rozšíření anotací tenkých linií na standardy referenční pravdy v plné tloušťce
Odstranění šumu (izolované shluky pixelů menší než 5 pixelů odstraněny)
Zarovnání masky pomocí registrace obrazu pro korekci prostorového posunu mezi obrazem a anotací
CrackSeg9k kategorizuje trhliny do morfologických tříd lineární (jednoduché, nevětvené), větvené (rozvětvení do tvaru Y nebo T) a síťové (síťové, aligátorového typu). Tato kategorizace umožňuje trénování třídně specifických segmentačních hlav, které lépe zachycují morfologickou variabilitu. Modely trénované na CrackSeg9k vykazují výrazně lepší zobecnění napříč povrchy ve srovnání s modely trénovanými na jediném datasetu.
Srovnávací tabulka datasetů
Dataset
Snímky
Rozlišení
Typ povrchu
Typy trhlin
GSD (mm/pixel)
Veřejný
CRACK500
500
2048×1536
Asfaltová vozovka
Všechny typy
0,05
Ano
DeepCrack
537
512×512
Beton, zdivo
Lineární, větvené
0,1–0,3
Ano
CrackForest
118
320×480
Asfaltová silnice
Příčné, podélné
0,15
Ano
CrackAirport
~300
Variabilní
Dráha/pojezdová dráha
Specifické pro letiště
0,1–0,5
Omezený
CrackSeg9k
9000+
Smíšené
Všechny povrchy
Všechny typy
Smíšené
Ano
4. Ztrátové funkce pro segmentaci trhlin
Segmentace trhlin je v podstatě třídně nevyvážený binární segmentační problém. Na typickém snímku dráhy tvoří pixely trhlin 0,1 % až 5 % všech pixelů. Naivní ztrátová funkce, která zachází se všemi pixely stejně, by vytvořila model, který jednoduše předpovídá „pozadí" pro každý pixel a dosahuje 95%+ přesnosti, přičemž detekuje nulové trhliny. Specializované ztrátové funkce jsou nezbytné k tomu, aby model donutily učit se minoritní třídu trhlin.
Binární křížová entropie (BCE)
BCE ztráta (také nazývaná logistická ztráta) počítá pixelovou binární křížovou entropii mezi mapou predikovaných pravděpodobností a maskou referenční pravdy:
kde (w_+) (váha pozitivní třídy) je nastavena na (N / (2 \cdot N_{crack})) a (w_-) (váha negativní třídy) je nastavena na (N / (2 \cdot N_{bg})). To invertně váží třídy podle jejich četnosti — pokud trhliny tvoří 1 % pixelů, každý pixel trhliny dostane 50× větší váhu než pixel pozadí.
BCE ztráta zachází s každým pixelem nezávisle a explicitně neoptimalizuje překryv mezi predikcí a referenční pravdou. Je dobře chovaná pro gradientovou optimalizaci, ale má tendenci produkovat mírně rozmazané predikce na okrajích trhlin.
Dice ztráta
Dice ztráta přímo optimalizuje Dice koeficient (F1-skóre) — překryv mezi predikovanými a skutečnými oblastmi trhlin:
kde (\epsilon) je malá vyhlazovací konstanta (typicky 1×10⁻⁶) pro zabránění dělení nulou.
Kritickou vlastností Dice ztráty je, že je založena na regionech, nikoli na pixelech. Měří překryv mezi predikovanou oblastí trhlin a skutečnou oblastí trhlin jako celek, přirozeně řeší třídní nevyváženost, protože oba členy ve jmenovateli jsou přes celý obraz. Dice ztráta je obzvláště účinná pro segmentaci trhlin, protože:
Přímo optimalizuje evaluační metriku (Dice/IoU) používanou pro finální hodnocení modelu
Řeší extrémní třídní nevyváženost bez vážení (trhliny mohou tvořit 0,1 % pixelů a Dice stále funguje)
Produkuje ostré predikční hranice, protože je maximalizován překryv regionů
Gradient Dice ztráty je dobře definovaný, ale může být nestabilní, když se predikční maska a referenční pravda nepřekrývají (čitatel i jmenovatel blízko nuly). Vyhlazovací člen (\epsilon) to zmírňuje.
Focal loss
Focal loss (Lin et al., 2017) byla zavedena pro hustou detekci objektů (RetinaNet) a adaptuje BCE snížením váhy dobře klasifikovaných pixelů a zaměřením na obtížné příklady:
kde (p_t = p_i) pokud (y_i = 1) a (p_t = 1-p_i) pokud (y_i = 0), (\alpha_t) je třídně vyvažovací váha a (\gamma) je zaostřovací parametr (typicky 2,0).
Modulační faktor ((1-p_t)^\gamma) snižuje příspěvek snadných příkladů (kde (p_t) je blízko 1) a zaměřuje trénink na obtížné příklady (kde (p_t) je blízko 0,5). Pro segmentaci trhlin to znamená, že se model soustředí na učení:
Pixelů na okrajích trhlin (kde se trhlina setkává s pozadím a predikce jsou nejisté)
Velmi tenkých trhlin, které by model jinak ignoroval
Pixelů trhlin v náročném pozadí (stíny, skvrny, hrubé textury)
Focal loss s (\gamma = 2,0) a (\alpha = 0,25) (váha trhlin) dosahuje silných výsledků na benchmarkových sadách segmentace trhlin, typicky zlepšuje IoU o 3–5 % oproti samotné BCE.
Kombinovaná ztráta (Combo loss)
Kombinovaná ztráta (také nazývaná hybridní ztráta) kombinuje více ztrátových funkcí pro využití jejich komplementárních silných stránek. Nejběžnější formulace pro segmentaci trhlin jsou:
s (\lambda) typicky nastaveným na 0,5–0,7. Dice ztráta poskytuje optimalizaci překryvu na úrovni regionů; BCE poskytuje stabilitu gradientu na úrovni pixelů a jemnozrnné informace o hranách.
Tato kombinace se ukázala jako nejúčinnější pro segmentaci trhlin v několika studiích (F. Zhao et al., 2023), dosahujíc zlepšení IoU o 2–4 % oproti samotné Dice. Dice člen zajišťuje překryv oblasti trhlin, zatímco Focal člen nutí model zaměřit se na obtížné pixely trhlin — tenké trhliny, body větvení, nízko-kontrastní trhliny.
Tverskyho ztráta je zobecněním Dice ztráty, které přidává oddělené vážení pro falešně pozitivní a falešně negativní výsledky:
kde (\beta) řídí penalizaci falešně pozitivních výsledků. Pro segmentaci trhlin je (\beta = 0,7) (vyšší penalizace falešně negativních — nezjištěných trhlin) běžný, protože nezjištěná trhlina, která se časem rozrůstá, představuje větší bezpečnostní riziko než falešně označený netrhlínový prvek.
Ztrátová funkce
Třídní nevyváženost
Ostrost hran
Zaměření na obtížné
Typické IoU
BCE
Špatná (vyžaduje vážení)
Nízká
Ne
0,55–0,62
Vážená BCE
Dobrá
Střední
Ne
0,62–0,68
Dice
Výborná
Vysoká
Slabé
0,65–0,72
Focal
Dobrá
Střední
Silné
0,64–0,70
Dice + Focal Combo
Výborná
Vysoká
Silné
0,68–0,76
Tversky ((\beta=0,7))
Výborná
Vysoká
Zaměřená na FN
0,67–0,74
5. Následné zpracování segmentačních výstupů
Surové predikce modelu vytvářejí mapu pravděpodobností (hodnoty s plovoucí desetinnou čárkou mezi 0,0 a 1,0), která musí být převedena na čistou binární masku pomocí sekvence operací následného zpracování. Kvalita těchto operací přímo ovlivňuje přesnost navazujících měření geometrie.
Prahování
Prvním krokem následného zpracování je převod spojité mapy pravděpodobností na binární masku. Globální prahování aplikuje pevný práh (T) (typicky 0,3–0,5) na každý pixel. Optimální práh se určuje vyhodnocením IoU na validační sadě napříč rozsahem hodnot prahu (např. 0,1 až 0,9 v krocích po 0,05). Modely trénované s Dice ztrátou obecně fungují nejlépe s prahem 0,3–0,4; modely trénované s BCE vyžadují vyšší prahy 0,4–0,5.
Otsuovo prahování automaticky určuje optimální práh maximalizací rozptylu mezi třídami v histogramu pravděpodobností. Pro segmentaci trhlin má Otsuova metoda tendenci nastavit práh na 0,4–0,6 v závislosti na poměru trhlina-pozadí v obraze. Je zvláště užitečná, když se rozložení pravděpodobností liší napříč snímky (např. různé světelné podmínky během průzkumu dráhy).
Morfologické čištění
Po prahování obsahuje binární maska šum typu sůl a pepř: izolované pixely popředí (spekle) tam, kde model nesprávně klasifikoval pozadí jako trhlinu, a malé díry v oblastech popředí, kde model nezachytil pixely trhliny.
Otevření (eroze následovaná dilatací) odstraňuje malý šum popředí:
Eroze: U každého pixelu popředí zkontrolujte, zda jsou všichni jeho 4- nebo 8-spojití sousedé také popředí; pokud ne, označte jej jako pozadí. Tím se odstraní izolované pixely trhlin.
Dilatace: U každého pixelu pozadí sousedícího s popředím jej označte jako popředí. Tím se obnoví zbývající pixely trhlin na původní tloušťku.
Strukturní element (typicky 3×3 nebo 5×5 křížové jádro) řídí operaci. Pro segmentaci trhlin odstraňuje 3×3 jádro jednotlivé pixelové spekle bez výrazného zužování skutečných linií trhlin.
Uzavření (dilatace následovaná erozí) vyplňuje malé díry a mezery v oblastech trhlin:
Dilatace: Rozšíření hranic trhlin o 1–2 pixely pro překlenutí úzkých mezer (přerušení trhlin o 1–3 pixely způsobená nejistotou modelu)
Eroze: Obnovení hranic trhlin na přibližnou původní šířku
Operace uzavření je kritická pro trhliny na letištních vozovkách, kde pryžové depozity nebo částice kameniva mohou způsobit, že model rozdělí souvislou trhlinu do více segmentů. Jediný průchod uzavření s 5×5 jádrem dokáže překlenout mezery až do velikosti 3 pixelů a obnovit kontinuitu trhliny.
Analýza spojených komponent
Analýza spojených komponent (CCA) označuje každou odlišnou oblast trhliny v binární masce jedinečným identifikátorem. Standardní CCA používá buď 4-spojitost (sousedé pixelu pouze nahoře/dole/vlevo/vpravo) nebo 8-spojitost (zahrnuje diagonály). Pro segmentaci trhlin je preferována 8-spojitost, protože trhliny se mohou spojovat diagonálně napříč obrazem.
Po označení filtrování plochy odstraňuje komponenty menší než minimální plošný práh (typicky 10–100 pixelů v závislosti na GSD). Pro snímek dráhy s GSD 0,1 mm/pixel odpovídá minimální plocha 50 pixelů fyzické ploše trhliny 0,5 mm² — hluboko pod hranicí akčních velikostí trhlin, ale účinně odstraňuje spekle. Komponenty pod tímto prahem jsou téměř vždy falešně pozitivní výsledky z textury kameniva nebo povrchových nečistot.
Statistiky na úrovni komponent počítané během CCA zahrnují:
Plochu komponenty v pixelech (převod na mm² pomocí GSD)
Excentricitu (míra protáhlosti; komponenty podobné trhlinám mají excentricitu > 0,9)
Konvexitu (poměr obvodu k obvodu konvexního obalu; trhliny jsou nekonvexní)
Skeletonizace
Skeletonizace (také nazývaná ztenčování) redukuje každou komponentu trhliny na středovou linii o šířce jednoho pixelu při zachování topologické struktury trhliny — spojitosti, větvení a koncových bodů. Skeleton je nezbytný pro měření délky a výpočet profilu šířky.
Algoritmus ztenčování Zhang-Suen (1984) je nejpoužívanější pro skeletonizaci trhlin. Pracuje iterativně:
Sub-iterace 1: Označ okrajové pixely (pixely popředí s alespoň jedním sousedem v pozadí) k odstranění, pokud splňují:
2 ≤ B(P1) ≤ 6 (počet sousedů v popředí mezi 2 a 6)
A(P1) = 1 (číslo spojitosti — právě jeden spojitý přechod pozadí-popředí)
P2 × P4 × P6 = 0
P4 × P6 × P8 = 0
Sub-iterace 2: Stejné podmínky, ale s jinými kontrolami sousedství:
P2 × P4 × P8 = 0
P2 × P6 × P8 = 0
Opakuj, dokud nejsou odstraněny žádné pixely (dosaženo stabilního skeletonu)
Algoritmus Guo-Hall produkuje pro tlusté trhliny (>10 pixelů široké) více centrovaný skeleton pomocí paralelních sub-iterací, které odstraňují pixely z obou stran současně. Je preferován pro silně odštěpené nebo aligátorové trhliny, kde je oblast trhliny dostatečně široká, aby měla vnitřní plochu.
Po skeletonizaci analýza větví a spojení identifikuje:
Koncové body: Pixely skeletonu s přesně 1 sousedem (zakončení trhlin)
Spojovací body: Pixely skeletonu se 3 nebo více sousedy (body větvení trhlin)
Segmenty větví: Cesty mezi koncovými body a spojovacími body
Tato analýza vytváří strukturu grafu trhlin — matematickou reprezentaci topologie trhlin jako množiny vrcholů (koncových bodů, spojení) a hran (segmentů trhlin mezi nimi).
6. Extrakce geometrie trhlin z binárních masek
Pixelová maska trhlin kombinovaná se skeletonizací umožňuje kvantitativní extrakci geometrie trhlin. Tato měření jsou kritická pro hodnocení stavu vozovky podle norem ICAO a FAA, kde je závažnost trhlin klasifikována na základě rozsahů šířky (vlasové: <3 mm, střední: 3–6 mm, závažné: >6 mm pro vozovky drah).
Plocha trhliny
Plocha trhliny je nejpřímější měření:
[
A_{crack} = N_{crack} \times GSD^2
]
kde (N_{crack}) je celkový počet pixelů trhlin v binární masce a (GSD) je vzdálenost vzorkování na zemi (mm/pixel) určená z kalibrace kamery nebo fiduciálních značek v obraze.
Pro crack_seg_head od TarmacView se GSD počítá z intrinsických parametrů kamerového systému (ohnisková vzdálenost, rozteč pixelů senzoru) a výšky snímání nebo vzdálenosti od cíle. Kamera s ohniskovou vzdáleností 20 mm, roztečí pixelů 3,45 µm, snímající ze vzdálenosti 2 metrů od povrchu vozovky, produkuje GSD přibližně 0,069 mm/pixel (3,45 µm × 2000 mm / 20 mm).
Plocha po komponentách umožňuje výpočet hustoty trhlin:
kde (E) je množina skeletonových hran (segmentů větví) a ((x_i, y_i)) jsou po sobě jdoucí souřadnice pixelů podél každé hrany. Diagonální kroky (roh k rohu) jsou násobeny (\sqrt{2}) ve srovnání s ortogonálními kroky, což činí měření délky přesné na sub-pixelovou přesnost.
Délku lze počítat po komponentách, po úhlu větve nebo jako celkovou délku na povrchu. Hustota délky trhlin ((L_{total} / A_{surface}), v mm/mm² nebo m/m²) je běžně používaná metrika stavu vozovky.
Šířka trhliny
Měření šířky trhliny vyžaduje výpočet vzdálenosti od každého skeletonového pixelu k nejbližšímu pixelu pozadí v původní binární masce. Toho se dosahuje pomocí Euklidovské vzdálenostní transformace (EDT):
Vypočítej EDT na binární masce: pro každý pixel popředí (trhlina) vypočítej jeho euklidovskou vzdálenost k nejbližšímu pixelu pozadí
Vzorkuj hodnoty EDT v každém skeletonovém pixelu: hodnota EDT v skeletonovém pixelu se rovná polovině lokální šířky trhliny (vzdálenost od skeletonu k nejbližší hraně)
Vynásob 2 pro získání šířky, poté vynásob GSD pro fyzické jednotky
Lokální šířka trhliny v skeletonovém pixelu (i) je:
Podle vykazování stavu povrchu drah ICAO jsou trhliny přesahující šířku 6 mm na asfaltových površích nebo 3 mm na betonových površích klasifikovány jako „závažné zhoršení" vyžadující okamžitý zásah údržby.
Statistiky na úrovni komponent
Pro každou spojenou komponentu (jednotlivou trhlinu) počítá pipeline extrakce geometrie:
Metrika
Jednotka
Výpočet
Účel
Plocha
mm²
Počet pixelů × GSD²
Celkový rozsah poškození
Délka
mm
Délka skeletonu × GSD
Rozsah šíření trhliny
Průměrná šířka
mm
Průměr EDT na skeletonu × GSD
Klasifikace závažnosti
Max. šířka
mm
Max EDT na skeletonu × GSD
Maximální měřítko degradace
Excentricita
bezrozměrná
(Poměr stran komponenty)
Klasifikace tvaru trhliny
Rozpětí
mm
Max šířka komponenty
Klasifikace závažnosti
Orientace
stupně
Úhel hlavní osy skeletonu
Typ trhliny (příčná/podélná)
7. Metriky hodnocení
Modely segmentace trhlin jsou hodnoceny pomocí metrik na úrovni pixelů, které porovnávají predikovanou binární masku s maskou referenční pravdy. Tyto metriky musí zvládat extrémní třídní nevyváženost inherentní segmentaci trhlin.
Intersection over Union (IoU / Jaccardův index)
IoU je primární metrikou pro hodnocení segmentace trhlin:
kde (P) je množina predikovaných pixelů trhlin, (T) je množina skutečných pixelů trhlin, (TP) = true positives (správně segmentované pixely trhlin), (FP) = false positives (pozadí klasifikované jako trhlina), (FN) = false negatives (trhlina klasifikovaná jako pozadí).
IoU se pohybuje od 0,0 (žádný překryv) do 1,0 (dokonalý překryv). Pro segmentaci trhlin se typické hodnoty IoU pohybují od 0,65 (slušný, práh pro praktické použití) do 0,85 (nejmodernější). IoU je metrikou volby, protože stejně penalizuje falešně pozitivní i falešně negativní výsledky — model, který agresivně predikuje trhliny všude (vysoký recall, nízká preciznost), získává nízké IoU.
Dice koeficient (F1 skóre)
Dice koeficient (také nazývaný Sørensen-Dice nebo F1-skóre na úrovni pixelů):
Dice je matematicky příbuzný IoU: (Dice = 2 \times IoU / (1 + IoU)). IoU 0,75 odpovídá Dice 0,857. Dice zdůrazňuje true positives, váží je dvojnásobně oproti IoU. Pro segmentaci trhlin je Dice druhou nejčastěji uváděnou metrikou a poskytuje o něco optimističtější pohled než IoU.
Pixelová preciznost a recall
Pixelová preciznost měří, jaký podíl predikovaných pixelů trhlin jsou skutečně trhliny:
[
Precision = \frac{TP}{TP + FP}
]
Vysoká preciznost znamená málo falešně pozitivních výsledků — model nezaměňuje texturu kameniva, stíny nebo povrchové nečistoty za trhliny. Falešně pozitivní výsledky při inspekci drah jsou nákladné, protože plýtvají zdroji údržby na neexistující poškození.
Pixelový recall (senzitivita) měří, jaký podíl skutečných pixelů trhlin model úspěšně identifikoval:
[
Recall = \frac{TP}{TP + FN}
]
Vysoký recall znamená málo nezjištěných trhlin — model detekuje většinu skutečné plochy trhlin. Falešně negativní výsledky při inspekci drah jsou kritické z hlediska bezpečnosti, protože nezjištěná trhlina se může šířit pod zatížením letadla a vést ke konstrukčnímu selhání.
Kompromis mezi precizností a recall je řízen prahem (T). Nízký práh (např. 0,2) maximalizuje recall na úkor preciznosti; vysoký práh (např. 0,7) maximalizuje preciznost, ale přehlíží skutečné trhliny. Optimální práh je typicky tam, kde jsou preciznost a recall přibližně stejné — F1-vyvážený bod.
Pixelová přesnost
Pixelová přesnost je nejjednodušší metrika, ale vysoce zavádějící pro segmentaci trhlin:
[
Accuracy = \frac{TP + TN}{TP + TN + FP + FN}
]
Pokud trhliny zabírají 1 % pixelů, model, který predikuje všechno jako pozadí, dosahuje 99% přesnosti při detekci nulových trhlin. Přesnost je uváděna pouze jako sekundární metrika v literatuře o segmentaci trhlin a nikdy by neměla být používána jako primární hodnotící kritérium.
Složené metriky
F-beta skóre zobecňuje F1 s nastavitelnou vahou na recall:
Pro segmentaci trhlin na drahách se někdy používá (F_2) (recall vážený 2× oproti preciznosti), protože nezjištění trhliny je nebezpečnější než falešné označení. (\beta = 2) znamená, že recall je dvakrát důležitější než preciznost.
Boundary F1 (BF1) hodnotí kvalitu segmentace specificky na okrajích trhlin, počítá preciznost a recall v úzkém pásmu (např. 2–3 pixely) kolem hranic referenční pravdy. BF1 je přísnější metrikou pro aplikace, kde přesnost okrajů trhlin závisí na měření šířky.
8. Celosnímková vs. dlaždicová segmentace
Segmentace trhlin na površích drah představuje zásadní výpočetní výzvu: dráhy se měří v tisících lineárních metrů (dráha kategorie E je 45 metrů široká × 3 000+ metrů dlouhá), ale segmentační modely přijímají vstupní tenzory typicky 512×512 až 1536×1536 pixelů kvůli omezením paměti GPU. Dva přístupy řeší tento nesoulad měřítek.
Celosnímková segmentace
Celosnímková segmentace zpracovává celý obraz dráhy v jediném dopředném průchodu modelem. V praxi je skutečný celosnímkový přístup proveditelný pouze pro malé povrchy (obrázky ze sociálních médií, detailní fotografie z telefonu) nebo na extrémně výkonném hardwaru (80 GB A100 GPU s velikostí obrazu až 4000×4000 pixelů).
Pro letištní inspekci pokrývá jeden snímek průzkumu dráhy pořízený při GSD 0,2 mm/pixel zhruba 1×1 metr při 5000×5000 pixelech — což vyžaduje 100 MB úložného prostoru pro 32bitová float data na snímek. Spuštění U-Net na obraze 5000×5000 vyžaduje přibližně 200 GB GPU paměti pro mezilehlé mapy příznaků — 40× více, než je k dispozici na A100 (80 GB).
Celosnímková segmentace se vyhýbá artefaktům na hranicích dlaždic — žádné spoje, žádné překrývající se predikce, žádné prolínání — poskytuje nejkvalitnější výsledky pro oblast, kterou dokáže zpracovat. Paměťová omezení však brání skutečnému celosnímkovému zpracování realistických povrchů drah.
Dlaždicová segmentace (klouzavé okno)
Dlaždicová segmentace rozděluje vstupní obraz na menší dlaždice (typicky 512×512 nebo 1024×1024 pixelů), provádí inferenci nezávisle na každé dlaždici a spojuje výsledky do masky v plném rozlišení. To je standardní přístup pro segmentaci trhlin v měřítku letišť.
Překryv a prolínání: Sousední dlaždice se překrývají o 10–25 %, aby se zabránilo řezání trhlin na hranicích dlaždic. Oblast překryvu přijímá predikce z obou dlaždic, které jsou kombinovány pomocí:
Váženého průměrování: Pixely blízko okrajů dlaždic dostávají nižší váhu; pixely blízko středu dlaždice dostávají plnou váhu
Prošívání zohledňujícího spoje: Predikce jsou prolínány pomocí vzdálenostní transformace — čím dále od spoje, tím vyšší váha predikce této dlaždice
Mediánového prolínání: Pro každý pixel v oblasti překryvu se bere medián všech predikcí pokrývajících tento pixel
Volba velikosti dlaždice zahrnuje kompromis:
512×512 dlaždice: Rychlá inference, nízká GPU paměť (4–8 GB), ale více artefaktů na hranicích; vhodné pro nasazení v reálném čase na okrajových zařízeních
1024×1024 dlaždice: Lepší kontext pro velké trhliny, méně spojů, ale vyšší paměť (16–32 GB) a pomalejší zpracování
Pro crack_seg_head od TarmacView poskytuje velikost dlaždice 1024×1024 s 15% překryvem optimální rovnováhu pro povrchy drah. Úsek dráhy 45 m × 45 m při GSD 0,2 mm/pixel (225 000 × 225 000 pixelů) vyžaduje přibližně 45 000 dlaždic při této konfiguraci — 37 minut inference na RTX 4090 (20 dlaždic/sekundu).
Víceúrovňové dlaždice zlepšují detekci trhlin při různých šířkách. Stejná oblast obrazu je zpracována ve více měřítcích (0,5×, 1,0×, 2,0×) a výsledky jsou spojeny. Malé dlaždice při 2,0× zoomu zachycují tenké trhliny; velké dlaždice při 0,5× zachycují široké sítě trhlin.
9. Výzvy celosnímkové segmentace drah
Segmentace letištních drah představuje jedinečné výzvy nad rámec segmentace silničních vozovek:
Drážkování povrchu: Většina primárních drah má příčné drážky (3–6 mm hluboké, 25–35 mm rozestupy) vyříznuté do povrchu pro odvod vody a zvýšení tření. Tyto drážky se v obraze jeví jako paralelní tmavé linie, které vizuálně připomínají trhliny. Modely se musí naučit rozlišovat drážky (pravidelný rozestup, jednotná šířka, paralelní orientace přes celou šířku dráhy) od trhlin (nepravidelné, proměnná šířka, neparalelní). Model trénovaný na silnicích typicky produkuje 10–30 % falešně pozitivních výsledků na drážkovaných drahách.
Pryžové depozity: Zóny dotyku pneumatik letadel akumulují vrstvy pryže — polymerové depozity, které se v obraze jeví jako tmavé, nepravidelné skvrny. Pryžové depozity mohou zakrývat podkladové trhliny (snižující recall) a vytvářet struktury podobné trhlinám podél hranic depozitů (zvyšující falešně pozitivní výsledky). Předzpracování pomocí odhadu pryže (s využitím multispektrálního zobrazování — pryž má ve spektru NIR odlišný spektrální podpis) a maskování zlepšuje přesnost segmentace trhlin v zónách dotyku o 5–15 %.
Záměna spár a tmelu: Betonové vozovky drah mají smršťovací spáry každých 4–6 metrů, vyplněné tmelem (typicky tmavý, pružný polymer). Spáry se ve výstupu segmentace jeví jako struktury podobné trhlinám. Spáry jsou však záměrné, očekávané a konstrukčně nezbytné — neměly by být klasifikovány jako trhliny. Detekce spár pomocí geometrických apriorních informací (pravidelný rozestup, lineární orientace kolmá k ose dráhy) umožňuje maskování spár před měřením trhlin.
Variabilita osvětlení: Celkové snímky drah pokrývají stovky metrů s proměnlivým osvětlením. Jeden konec snímku dráhy může být na přímém slunci (vysoký kontrast, ostré stíny trhlin), zatímco druhý je ve stínu (nízký kontrast, žádné stíny). Modely musí být invariantní vůči osvětlení. Augmentace dat zahrnující náhodné posuny jasu/kontrastu, ekvalizaci histogramu a syntetické generování stínů během tréninku zlepšuje robustnost napříč světelnými podmínkami.
Variabilita vozovek: Dráhy mají více typů vozovek (asfaltové dojezdové dráhy, betonová hlavní dráha, asfaltové pojezdové spoje) s různými texturami, barvami a morfologií trhlin. Jediný inspekční let zachycuje všechny typy vozovek, což vyžaduje, aby segmentační model zobecňoval napříč těmito povrchy bez samostatných modelů pro každý typ vozovky.
10. Zobecnění na nové povrchy
Modely segmentace trhlin jsou zranitelné vůči doménovému posunu — zhoršení výkonu při aplikaci na povrchy, kamery nebo podmínky, které nejsou zastoupeny v tréninkových datech. Model trénovaný výhradně na CRACK500 (asfalt snímán při GSD 0,05 mm/pixel, osvětlení podobné interiéru, blízká vzdálenost), který je nasazen na betonovou dráhu (jiná textura, GSD 0,2 mm/pixel, venkovní osvětlení, proměnná vzdálenost), může zaznamenat pokles IoU z 0,72 na 0,35–0,45.
Zdroje doménového posunu
Textura povrchu: Asfalt má tmavou, drsnou, nepravidelnou texturu kameniva; beton má světlejší, hladší, jednotnější texturu s viditelným jemným kamenivem. Modely trénované na asfaltové textuře se učí ignorovat tmavé, vysokofrekvenční variace textury — betonové povrchy tuto naučenou invarianci porušují.
Rozlišení: Vzhled trhlin se mění s GSD. Při 0,05 mm/pixel je 2 mm široká trhlina široká 40 pixelů s ostrými, dobře definovanými okraji. Při 0,2 mm/pixel je stejná trhlina široká 10 pixelů s měkčími okraji. Modely trénované při vysokém rozlišení produkují rozmazané, nejisté predikce při nižším rozlišení.
Osvětlení: Venkovní snímky drah mají směrové sluneční světlo vytvářející stíny trhlin (zvyšující viditelnost trhlin, ale vytvářející stínové artefakty), zatímco vnitřní nebo zatažené snímky mají difúzní osvětlení (méně stínů, nižší kontrast). Stíny trhlin mohou zvýšit recall za slunečných podmínek, ale způsobit falešně pozitivní výsledky na nekřehkých stupních (tepelné trhliny, změny výšky povrchu).
Kamerový systém: Různé kamery mají různou spektrální odezvu senzoru, rozteč pixelů, zkreslení objektivu a charakteristiky šumu. Model trénovaný na 20 MP DSLR (nízký šum, nízké zkreslení) může degradovat na 12 MP dronové kameře (vyšší šum, rolovací závěrka, chromatická aberace objektivu).
Zlepšení zobecnění
Doménová randomizace: Během tréninku aplikujte náhodné augmentace pokrývající očekávanou doménu nasazení: náhodné GSD (změna velikosti obrázků na 0,5×–2,0×), náhodné osvětlení (jas ±30 %, kontrast ±30 %, gamma ±0,3), náhodný šum (Gaussovský šum s σ=5–25), náhodné rozmazání (Gaussovské rozmazání s jádrem 1–5 pixelů), náhodné barevné posuny (HSV posun hue ±15, saturace ±30, value ±30). Modely trénované s dostatečnou doménovou randomizací udržují IoU v rozmezí 5–10 % svého výkonu na tréninkové doméně při nasazení na nové povrchy.
Syntetické generování trhlin: Kompozitně vytvářejte syntetické trhliny na obrázky povrchů bez trhlin pomocí fyzikálně založených modelů trhlin nebo GAN generování trhlin. Databáze povrchů bez trhlin (pořízených z cílové domény) kombinovaná se syntetickými trhlinami poskytuje párovaná tréninková data, kde se model učí detekovat rysy trhlin při ignorování specifické textury povrchu. Tento přístup prokázal zlepšení IoU o 8–12 % při přenosu z asfaltové silnice na betonovou dráhu.
Unsupervised doménová adaptace (UDA): Techniky jako CycleGAN, CUT a AdaIN převádějí obrazy ze zdrojové domény do vzhledu cílové domény při zachování anotací trhlin. Rysy trhlin modelu trénovaného na CRACK500 jsou extrahovány z obrázků, které byly stylizovány tak, aby vypadaly jako cílový povrch dráhy. Metody UDA zlepšují IoU v cílové doméně o 10–18 % bez potřeby jakýchkoli anotací v cílové doméně.
Dolaďování s malým počtem příkladů: Sesbírejte 5–20 anotovaných snímků z nového povrchu a dolaďte předtrénovaný model s nízkou rychlostí učení (1×10⁻⁵ až 5×10⁻⁵) a malým počtem epoch (10–30). Tento supervizovaný přístup dolaďování typicky obnoví IoU na 2–4 % od plně supervizovaného modelu trénovaného na stovkách snímků z cílové domény. Je to nejspolehlivější praktický přístup pro nasazení na letištích, kde je sběr malého počtu anotovaných snímků provozně proveditelný.
Crack_seg_head od TarmacView implementuje pipeline zobecnění, která zahrnuje doménově randomizované předtrénování na CrackSeg9k, výběr dlaždic specifický pro cílovou doménu, volitelné dolaďování s malým počtem příkladů s až 20 uživatelem poskytnutými anotovanými snímky z cílového povrchu a automatickou detekci doménové anomálie (spolehlivost modelu pod prahem spouští upozornění pro manuální revizi).
Často kladené otázky
Segmentace trhlin přiřazuje každému pixelu v obraze štítek trhlina nebo netrhlína a vytváří binární masku, která zachovává přesný tvar, topologii a geometrii trhlin. Klasifikace trhlin pouze předpovídá, zda obraz obsahuje trhlinu (štítek na úrovni obrazu). Segmentace umožňuje přesné měření plochy trhliny, délky, šířky a vzorů větvení, zatímco klasifikace poskytuje pouze odpověď ano/ne.
Mezi nejčastější architektury patří U-Net (kodér-dekodér s propojeními), DeepLabV3+ (s Atrous Spatial Pyramid Pooling), SegFormer (hierarchický Transformer kodér s MLP dekodérem) a Vision Transformer backbone jako DINOv2/v3 s hustými predikčními hlavami. U-Net zůstává nejpoužívanější díky své účinnosti s omezenými daty a silnému výkonu na tenkých, protáhlých strukturách trhlin.
Mezi klíčové datové sady patří CRACK500 (500 snímků vozovek, 0,05 mm/pixel), DeepCrack (537 RGB snímků různých povrchů), CrackForest (118 snímků silnic), CrackAirport (letištní vozovky), Crack500, CrackTree200, CFD (Crack Forest Dataset), AEL a GAPs384. Kompilace CrackSeg9k sjednotila přes 9000 snímků z více zdrojů s doladěnými maskami.
Extrakce geometrie trhlin začíná skeletonizací (iterativní ztenčování na středovou linii o šířce jednoho pixelu), následuje označování spojených komponent pro izolaci jednotlivých trhlin. Délka trhliny se měří podél skeletonizované cesty. Šířka trhliny se vypočítá pomocí euklidovské vzdálenostní transformace kolmé ke skeletonu. Plocha trhliny je celkový počet pixelů trhliny vynásobený prostorovým rozlišením v mm²/pixel. Pro každou komponentu se uvádí průměrná a maximální šířka.
Mezi standardní metriky hodnocení patří Intersection over Union (IoU/Jaccardův index), Dice koeficient (F1-skóre na úrovni pixelů), pixelová preciznost, pixelová recall a pixelová přesnost. IoU je průnik predikovaných a skutečných pixelů trhlin dělený jejich sjednocením. Dice je 2×IoU/(1+IoU). Pro segmentaci trhlin jsou kritické jak preciznost (podíl predikovaných pixelů trhlin, které jsou skutečnými trhlinami), tak recall (podíl skutečných pixelů trhlin, které byly detekovány), protože falešně pozitivní výsledky plýtvají zdroji na údržbu, zatímco falešně negativní přehlížejí nebezpečné vady.
Celosnímková segmentace zpracovává celý obraz dráhy v jednom průchodu, což je paměťově omezené pro vysoce rozlišené povrchy (dráhy mohou přesáhnout 50 megapixelů). Dlaždicová segmentace rozděluje obraz na překrývající se výřezy (např. 512×512 nebo 1024×1024 pixelů), provádí inferenci na každé dlaždici a výsledky spojuje zpět dohromady. Překrývající se oblasti používají vážené průměrování nebo prošívání zohledňující spoje, aby se předešlo artefaktům na okrajích. Dlaždicové přístupy umožňují zpracování libovolně velkých povrchů, vyžadují však pečlivé ošetření trhlin, které překračují hranice dlaždic.
Zobecnění na různé typy povrchů (asfalt vs. beton, nová vs. zvětralá vozovka, různé světelné podmínky) zůstává klíčovou výzvou. Doménový posun — rozdíly v textuře, barvě, vzhledu trhlin a drsnosti povrchu — může výrazně snížit výkon. Techniky pro zlepšení zobecnění zahrnují doménovou randomizaci během tréninku, syntetickou augmentaci dat, unsupervised doménovou adaptaci (CycleGAN, stylový přenos) a supervizované dolaďování s malým počtem snímků z cílové domény. Kvalitní různorodé tréninkové datové sady jako CrackSeg9k zlepšují robustnost napříč povrchy.
ICAO Annex 14 a ICAO Doc 9157 stanovují, že hodnocení stavu povrchu drah musí identifikovat a měřit trhliny, degradaci a vady, které by mohly ovlivnit bezpečnost letadel. Automatizovaná segmentace trhlin je v souladu s důrazem ICAO na objektivní, opakovatelné a dokumentované metody inspekce. Globální formát vykazování ICAO (GRF) vyžaduje standardizované vykazování stavu povrchu drah a automatizovaná segmentace poskytuje kvantifikovatelná data o rozsahu, hustotě a závažnosti trhlin, která lze přímo použít v rámcích pro vykazování stavu.
Vylepšete svou inspekci infrastruktury
Implementujte segmentaci trhlin na úrovni pixelů pro přesné a automatizované hodnocení stavu vozovek. Naše segmentace trhlin poháněná AI poskytuje přesnost na submilimetry pro dráhy, pojezdové dráhy a odbavovací plochy.
Detekce trhlin na bázi AI pro inspekci infrastruktury
Detekce trhlin na bázi AI využívá počítačové vidění — konvoluční neuronové sítě, vision transformery a modely sémantické segmentace — k automatické identifikaci...
Procento plochy trhlin v hodnocení vozovek a konstrukcí
Procento plochy trhlin (crack_area_pct) je poměr plochy masky trhlin k celkové ploše analyzovaného obrazu, vyjádřený v procentech. Jedná se o klíčovou kvantitat...
Skeletonizace trhlin je morfologická operace zpracování obrazu, která redukuje segmentovanou binární oblast trhliny na reprezentaci osy o šířce jednoho pixelu p...
22 min čtení
Image Processing
Computer Vision
+4
Souhlas s cookies Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.