Segmentace trhlin
Segmentace trhlin je úloha počítačového vidění, která klasifikuje každý pixel obrazu jako trhlinu nebo netrhlínu, čímž vytváří binární masku umožňující přesné m...
31 min čtení
Computer Vision
Deep Learning
+2
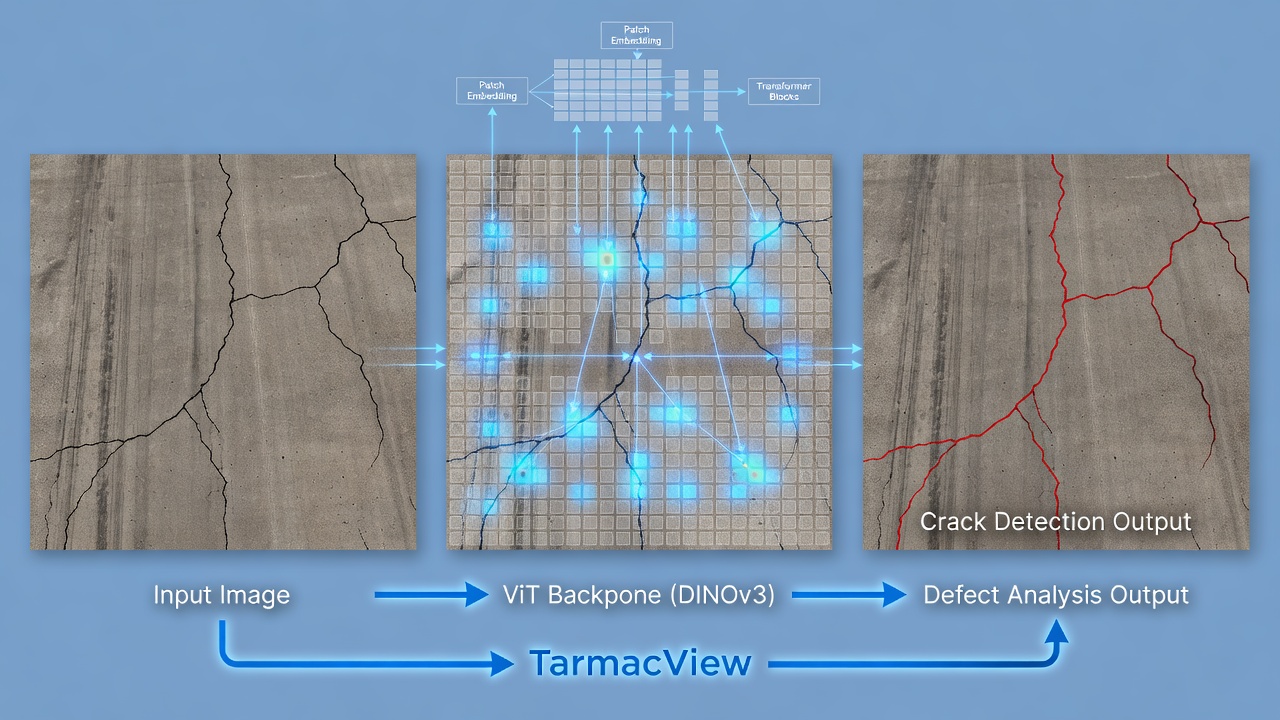
DINOv3 (self-DIstillation with NO labels v3) je samostatně učený vision transformer (ViT-B/16) předtrénovaný na 1,7 miliardách obrázků, produkující vysoce kvalitní 768-rozměrné embeddingy zachycující jemnou texturu a strukturu. TarmacView používá DINOv3 jako svůj základní model pro analýzu typu povrchu, kvality, prasklin a defektů. Pokrývá DINO trénink, ViT architekturu, doladění pro doménové úlohy a srovnání s DINOv2 a dalšími základními modely.
Samostatně učené učení (SSL) je paradigma strojového učení, kde se model učí smysluplné reprezentace z neoznačených dat definováním pretextové úlohy, která nevyžaduje lidské anotace. Model musí predikovat některou část dat z jiných částí, přičemž využívá inherentní strukturu a vzory společného výskytu v samotných datech. V počítačovém vidění postoupily metody SSL od ručně vytvořených pretextových úloh, jako je predikce úhlu rotace obrázku (RotNet), skládání puzzle z přeházených bloků nebo kolorování černobílých obrázků, k sofistikovanějším kontrastivním a destilačním přístupům. Základní výhodou SSL je, že umožňuje trénink na webových datasetech obrovského rozsahu bez prohibitivních nákladů na ruční anotaci. Pro aplikace v infrastruktuře, kde jsou označené datasety defektů vzácné a nákladné na výrobu (vyžadující certifikované inspektory a inženýry), umožňují základní modely založené na SSL efektivní učení rysů z obrovského množství neoznačených snímků před jakýmkoliv doladěním specifickým pro daný úkol.
Kontrastivní učení metody jako SimCLR, MoCo a SwAV se učí reprezentace tím, že přitahují augmentované pohledy stejného obrázku (pozitivní páry) k sobě v embeddingovém prostoru, zatímco od sebe oddalují pohledy různých obrázků (negativní páry). Tyto metody vyžadují pečlivé zacházení s negativními vzorky – příliš málo negativ snižuje výkon, příliš mnoho zvyšuje výpočetní náklady. Nekontrastivní metody jako BYOL, SimSiam a DINO se zcela vyhýbají potřebě negativních párů použitím asymetrických síťových architektur a operací zastavení gradientu, aby zabránily kolapsu reprezentace. DINO (self-DIstillation with NO labels), představený Caronem et al. v Meta AI v roce 2021, patří do této nekontrastivní rodiny a stal se jednou z nejvlivnějších SSL metod v počítačovém vidění. Původní DINO článek demonstroval, že SSL a Vision Transformery mají jedinečnou synergii – mechanismy self-attention ve ViT přirozeně produkují sémantické segmentační mapy bez jakéhokoliv dohledu, což je vlastnost, která vzniká z interakce mezi strategií augmentace více ořezů a cílem self-distilace.
Tréninkový rámec DINO funguje následovně. Pro každý vstupní obrázek jsou generovány dva globální pohledy (pokrývající více než 50 % plochy obrázku, typicky 224x224 pixelů) a několik lokálních pohledů (menší ořezy pokrývající méně než 50 % plochy obrázku, typicky 96x96 pixelů) prostřednictvím náhodného ořezu s změnou velikosti, barevného posunu a Gaussovského rozostření. Všechny pohledy jsou předány studentské síti (Vision Transformer). Globální pohledy jsou také předány učitelské síti, která sdílí stejnou architekturu jako student, ale má odlišné parametry. Parametry učitele se neučí prostřednictvím gradientů – místo toho jsou aktualizovány jako exponenciální klouzavý průměr (EMA) parametrů studenta. Základním tréninkovým cílem je přimět výstupní distribuci studenta, aby odpovídala výstupní distribuci učitele pro globální pohledy, zatímco lokální pohledy poskytují dodatečný tréninkový signál pouze prostřednictvím studenta. Toto nastavení učitel-žák, známé jako self-distilace, vytváří učící signál, který nevyžaduje štítky – student se učí produkovat konzistentní reprezentace napříč různými augmentacemi stejného obrázku, což ho nutí zachytit invariantní sémantický obsah spíše než povrchové detaily na úrovni pixelů.
DINOv1 (2021) demonstroval tři klíčové emergentní vlastnosti samostatně učených ViT. Zaprvé, attention mapy z [CLS] tokenu na obrazové bloky přirozeně segmentují objekty od pozadí – vlastnost, která vzniká čistě ze samostatného učení bez jakýchkoliv segmentačních štítků. Zadruhé, naučené rysy vykazují vynikající k-NN klasifikační výkon – jednoduchý klasifikátor nejbližších sousedů v DINO rysovém prostoru dosahuje 78,2% top-1 přesnosti na ImageNet bez jakéhokoliv doladění. Zatřetí, DINO rysy vykazují silnou sémantickou korespondenci napříč různými instancemi stejné třídy objektů, což umožňuje aplikace ve vyhledávání obrázků, co-segmentaci a segmentaci video objektů. Tyto vlastnosti učinily DINO základní metodou v oblasti samostatně učeného učení a připravily půdu pro DINOv2 (2023) a DINOv3 (2025).
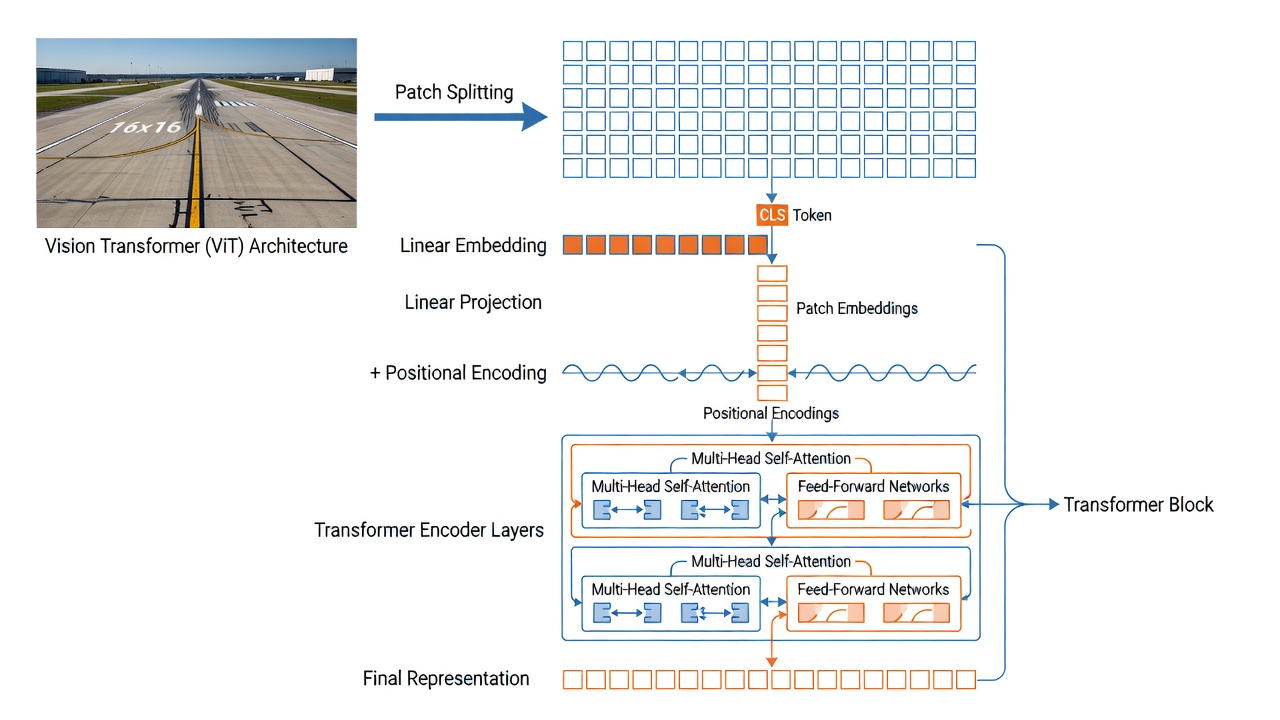
Architektura Vision Transformer (ViT), představená Dosovitskiym et al. v Googlu v roce 2021, adaptuje architekturu Transformer z zpracování přirozeného jazyka do počítačového vidění tím, že zachází s obrazovými bloky jako analogy slovních tokenů. Na rozdíl od konvolučních neuronových sítí (CNN), které zpracovávají obrázky prostřednictvím lokálních receptivních polí s inherentní translační equivariancí, ViT aplikují globální self-attention napříč všemi bloky současně, což modelu umožňuje zachytit závislosti na dlouhé vzdálenosti již od první vrstvy. Tato architektonická volba se ukázala jako klíčová pro úspěch DINO – původní DINO článek ukázal, že samostatně učené ViT významně překonávají samostatně učené CNN a že synergie mezi self-attention a self-distilací je zodpovědná za emergentní vlastnosti sémantické segmentace.
Blokový embedding (Patch Embedding). První operací ve ViT je rozdělení vstupního obrázku do mřížky nepřekrývajících se bloků. Pro variantu ViT-B/16 používanou TarmacView je velikost bloku 16x16 pixelů. Vstupní obrázek 224x224 pixelů produkuje (224/16) x (224/16) = 14 x 14 = 196 bloků. Každý blok 16x16x3 (RGB kanály) je zploštěn do vektoru délky 768 (16x16x3). V praxi je tento blokový embedding implementován jako jediná konvoluční vrstva s velikostí kernelu rovnou velikosti bloku (16x16) a krokem rovným velikosti bloku, produkující 2D mřížku 14x14 rysových vektorů, každý o dimenzi rovné skryté velikosti modelu (768 pro ViT-B). Naučitelná lineární projekce pak mapuje každý zploštělý blok na embeddingovou dimenzi. Implementace Conv2d je výpočetně efektivní (jedna operace nahrazuje 196 samostatných lineárních projekcí) a je standardem ve všech moderních ViT implementacích.
Token [CLS]. Po vzoru architektury BERT v NLP je speciální naučitelný klasifikační token ([CLS]) předřazen sekvenci blokových embeddingů. Token [CLS] má stejnou dimenzionalitu (768) jako blokové embeddingy a je inicializován náhodně. Během tréninku, prostřednictvím self-attention napříč všemi transformer vrstvami, token [CLS] agreguje informace ze všech obrazových bloků – může věnovat pozornost každému bloku v každé vrstvě, čímž vytváří globální reprezentaci celého obrázku. Na výstupu poslední transformer vrstvy slouží embedding tokenu [CLS] jako reprezentace na úrovni obrázku používaná pro klasifikační úlohy. V DINOv3 je token [CLS] doplněn 4 registračními tokeny – dalšími naučitelnými tokeny předřazenými sekvenci, které fungují jako scratchpadová paměť pro pohlcení odlehlých nebo pozadových informací, čímž zabraňují tomu, aby tokeny [CLS] a blokové tokeny byly korumpovány irelevantními vysokofrekvenčními detaily.
Poziční embeddingy. Vzhledem k tomu, že mechanismus self-attention Transformeru je permutačně invariantní (zpracovává bloky jako množinu, nikoli jako sekvenci), musí být poziční informace explicitně přidána, aby model věděl, kam každý blok patří v prostorové mřížce. DINOv3 používá Rotary Position Embeddings (RoPE) namísto standardních naučitelných absolutních pozičních kódování používaných v DINOv2. RoPE kóduje relativní poziční informaci aplikací rotační matice na dotazové a klíčové vektory v self-attention na základě jejich prostorových souřadnic. Rotační frekvence pro každou dimenzi je určena indexem dimenze podle geometrické progrese. Klíčovou výhodou RoPE pro analýzu infrastruktury je schopnost zpracovávat vstupy s proměnným rozlišením – při zpracování obrázků s vysokým rozlišením (až 4096x4096 pixelů) mechanismus RoPE přirozeně generalizuje na větší prostorovou mřížku bez nutnosti interpolace naučených pozičních embeddingů. DINOv3 také zavádí náhodný rozptyl boxů (random box jitter) při aplikaci RoPE, kde jsou poziční indexy náhodně posunuty v rozsahu [-s,s] s s v [0.5,2.0], což činí model robustním vůči různým poměrům stran a vzorům ořezu.
Vícehlavová self-attention (MHSA). Základním výpočetním prvkem ViT je mechanismus vícehlavové self-attention. V každém transformer bloku je vstupní sekvence N tokenů (N = 1 [CLS] + 4 registrační + 196 blokových = 201 tokenů pro vstup 224x224) lineárně projektována do tří matic: Dotazy (Q) , Klíče (K) a Hodnoty (V) , každé dimenze 768 pro ViT-B/16. Attention mechanismus počítá párovou podobnost mezi všemi tokeny jako skalární součin Q a K^T, škálovaný druhou odmocninou d_k (kde d_k je dimenze klíče na hlavu). Výsledné attention váhy (normalizované softmax) určují, jak moc každý token přispívá k reprezentaci každého jiného tokenu. Ve ViT-B/16 je 12 attention hlav, každá operující v 64-rozměrném podprostoru (768/12 = 64). Vícehlavová attention umožňuje modelu věnovat pozornost různým typům vztahů současně – například jedna hlava se může zaměřit na texturní podobnost mezi bloky, jiná na prostorovou blízkost a další na příslušnost k sémantické kategorii. Výstupy všech hlav jsou zřetězeny a lineárně projektovány zpět na 768 dimenzí. Výpočetní složitost MHSA je O(N²d) – kvadratická v délce sekvence N, ale lineární v dimenzi embeddingu d. Pro sekvenci 201 tokenů v DINOv3 ViT-B/16 je to zvládnutelné (přibližně 40K attention výpočtů na vrstvu), ale pro obrázky s vysokým rozlišením s 4000+ tokeny (např. obrázek 1024x1024 produkuje 64x64 = 4096 bloků) se kvadratické škálování stává významným faktorem.
Transformer Encoder Blok. Každá z 12 (ViT-B) nebo 40 (ViT-7B) transformer vrstev v DINOv3 následuje před-normalizační design. Layer Normalization (LayerNorm) je aplikována před podvrstvami MHSA i MLP, s reziduálními spojeními obcházejícími každou podvrstvu. MLP (multilayer perceptron) podvrstva se skládá ze dvou lineárních vrstev s GELU (Gaussian Error Linear Unit) aktivací mezi nimi. Pro ViT-B/16 je skrytá dimenze MLP 3072 (4x embeddingová dimenze), čímž vzniká konfigurace: Embeddingová dimenze 768 → MLP skrytá 3072 → GELU → MLP výstup 768. Větší učitelský model DINOv3 (ViT-7B) používá SwiGLU (Swish-Gated Linear Unit) aktivaci v MLP namísto GELU, následující architektonické trendy moderních jazykových modelů. SwiGLU aplikuje gating mechanismus: výstup = (xW1) elementárně násobeno Swish(xW2) krát W3. Tato hradlovaná aktivace prokazatelně zlepšuje stabilitu tréninku a konečný výkon ve velkém měřítku. Před-normalizační design se liší od původního Transformer post-normalizačního designu (kde byla normalizace aplikována po reziduálním sčítání) a prokazatelně produkuje stabilnější trénink, zejména pro hluboké (12+ vrstev) transformery.
Souhrnná tabulka architektury pro rodinu modelů DINOv3.
| Model | Parametry | Embedding Dim | Hlavy | Vrstvy | MLP Dim | Velikost bloku | Bloků/224px |
|---|---|---|---|---|---|---|---|
| ViT-Small | 21M | 384 | 6 | 12 | 1536 | 16 | 196 |
| ViT-Base | 86M | 768 | 12 | 12 | 3072 | 16 | 196 |
| ViT-Large | 304M | 1024 | 16 | 24 | 4096 | 16 | 196 |
| ViT-H+ | ~1,5B | 1536 | 24 | 32 | 6144 | 16 | 196 |
| ViT-7B | 7B | 4096 | 32 | 40 | 8192 | 16 | 196 |
Architektura ViT-Base (86M parametrů) představuje optimální kompromis mezi kvalitou rysů a výpočetní efektivitou pro inspekční pipeline infrastruktury TarmacView, nabízející 768-rozměrné embeddingy s 12 vrstvami výpočetního výkonu self-attention.
DINOv3 dosahuje svého nejmodernějšího výkonu díky bezprecedentnímu měřítku samostatně učeného tréninku, využívajícího jak masivní kurátorování dat, tak efektivní distribuovanou optimalizaci napříč stovkami GPU.
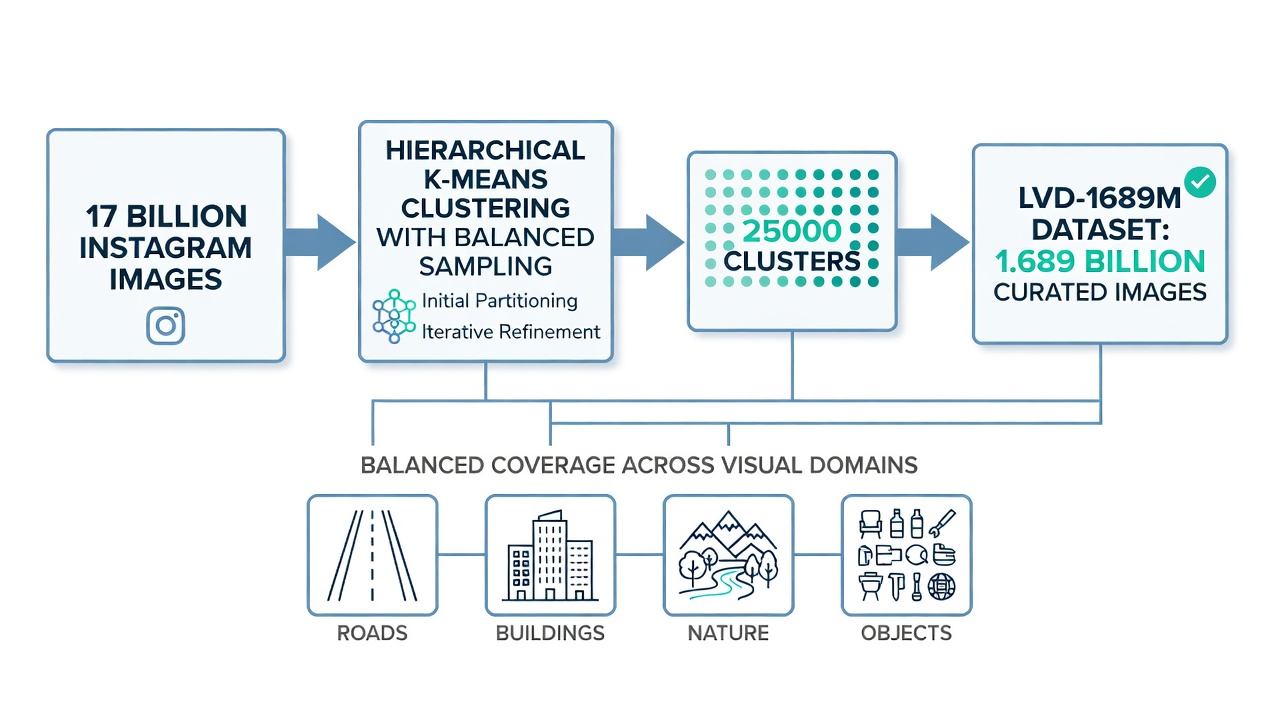
Dataset LVD-1689M. Tréninková data pro DINOv3 začínají surovým fondem 17 miliard obsahově moderovaných obrázků z Instagramu. Z tohoto masivního fondu kurátoroval tým Meta AI vyváženou podmnožinu 1 689 milionů obrázků pojmenovanou LVD-1689M (Large Visual Dataset 1689 Million). Kurátorování pipeline je kritické, protože pouhé trénování na surových Instagram datech by vytvořilo model zkreslený směrem k přirozené frekvenční distribuci vizuálních konceptů na sociálních médiích – například tváře, jídlo a krajiny by dominovaly, zatímco infrastruktura, průmyslové a vědecké snímky by byly nedostatečně zastoupeny. Proces kurátorování používá hierarchické k-means shlukování na DINOv2 embeddincích extrahovaných z celého fondu obrázků. Model DINOv2 ViT-H/14 zpracovává každý obrázek a výsledné CLS token embeddingy jsou shlukovány do 25 000 clusterů pomocí k-means. Následně je z každého clusteru vzorkován stejný počet obrázků, čímž vzniká clusterově vyvážený dataset, který zajišťuje proporcionální zastoupení napříč vizuálními doménami. Toto vyvážené vzorkování je přímo analogické stratifikovanému vzorkování ve statistice – kontrolou příslušnosti ke clusteru dataset zachycuje plnou diverzitu vizuálních konceptů spíše než nadměrné zastoupení běžných kategorií. Po shlukování rozšiřuje dodatečný krok vyhledávání seed sady z kurátorovaných datasetů (ImageNet-1k, ImageNet-22k, Google Landmarks a datasety jemnozrnné klasifikace) nalezením nejbližších sousedů v DINOv2 embeddingovém prostoru. Finální dataset LVD-1689M kombinuje 1 489 milionů clusterově vyvážených obrázků s 200 miliony obrázků rozšířených vyhledáváním, všechny filtrované přes NSFW detekci, PCA hash deduplikaci a rozmazání obličejů.
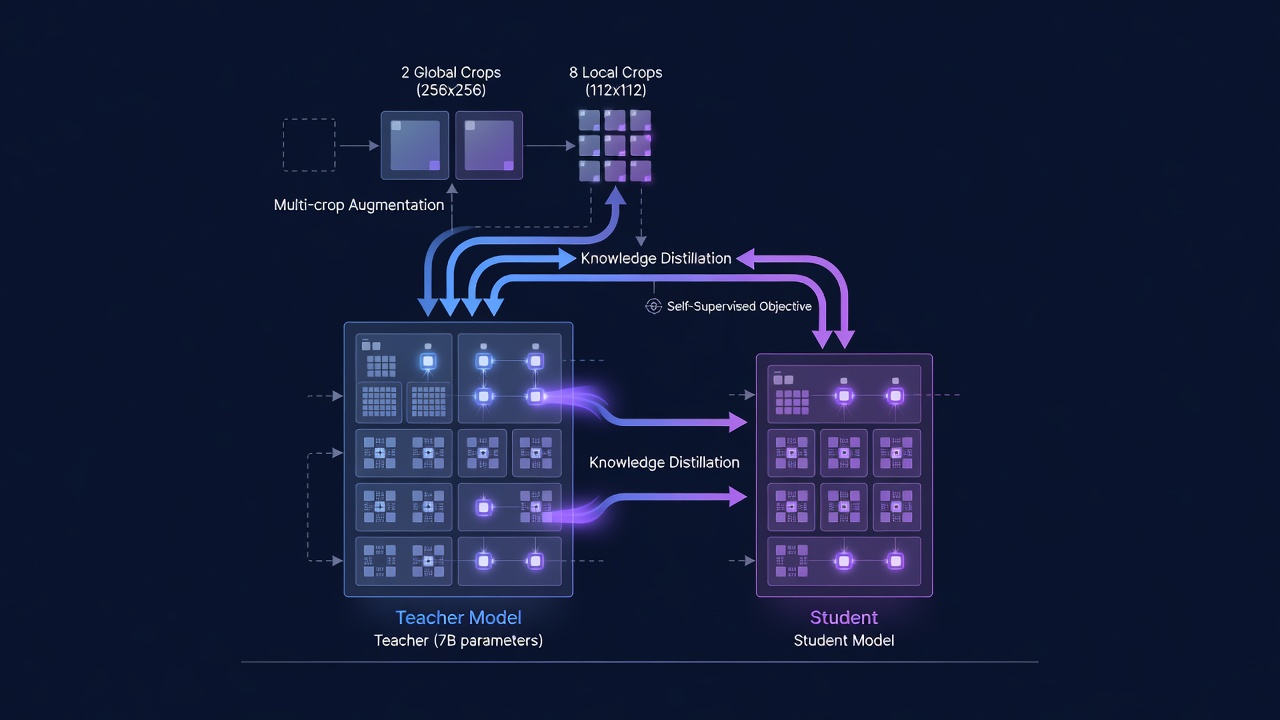
Tréninková konfigurace. Učitelský model ViT-7B, největší samostatně učený vizuální model vůbec (k roku 2025), byl trénován na 256 NVIDIA GPU (A100 80GB SXM4) s velikostí dávky 4096 (16 obrázků na GPU). Optimalizace používá AdamW optimalizátor s konstantní rychlostí učení 4x10⁻⁴, útlumem vah 0,04 a EMA momentum 0,999 po 100 000 krokovém zahřívacím období. Trénink probíhá po 1 milion iterací se strategií více ořezů: 2 globální ořezy v rozlišení 256x256 a 8 lokálních ořezů v rozlišení 112x112, celkem 10 pohledů na obrázek na iteraci. Při 1M iteracích s velikostí dávky 4096 model vidí přibližně 2,56 miliardy unikátních kombinací obrázek-ořez. Celý tréninkový proces spotřebuje odhadem 10 000–15 000 GPU-dnů výpočtů. Během tréninku je 10 % dávek homogenních výběrů z ImageNet-1k (pro udržení výkonu na standardních benchmarkách), zatímco 90 % je heterogenních výběrů z celého fondu LVD-1689M, což je ablačně prokázaný optimální poměr míchání.
Tréninkové cíle. Ztráta při předtréninku DINOv3 kombinuje tři složky. DINO ztráta (L_DINO) aplikuje SwAV-styl Sinkhorn-Knopp shlukování na výstupy tokenu [CLS] z globálních ořezů, přiřazující prototypy mezi studentem a učitelem. Sinkhorn algoritmus běží 3 iterace k produkci měkkých pseudo-štítků. iBOT ztráta (L_iBOT) operuje na úrovni bloku – náhodné bloky v lokálních ořezech jsou maskovány a student musí predikovat normalizované blokové rysy učitele pro tyto maskované pozice. Tento cíl maskovaného modelování obrazu nutí model učit se lokální texturní a strukturální informace potřebné pro úlohy husté predikce. Koleo regularizátor (L_Koleo) rovnoměrně rozprostírá embeddingy tokenu [CLS] po hypersféře minimalizací součtu kosinových podobností mezi všemi páry embeddingů v dávce, čímž zabraňuje kolapsu reprezentace a zajišťuje dobré využití rysového prostoru. Kombinovaná ztráta předtréninku je: L_Pre = L_DINO + L_iBOT + 0,1 x L_Koleo. Po 1M iteracích předtréninku zahrnuje fáze zpřesnění o 200K dodatečných iterací ztrátu Gram kotvení (L_Gram) s vahou 2, která zachovává kvalitu hustých rysů během dlouhého tréninku.
Destilace do menších modelů. Jakmile je učitelský ViT-7B plně natrénován, je zmrazen a používán jako cíl pro destilaci reprezentací do sady menších, praktičtějších modelů. Proces destilace zrcadlí nastavení předtréninku: studentské modely (ViT-S, ViT-B, ViT-L, ViT-H+, ConvNeXt varianty) jsou trénovány, aby odpovídaly výstupním rysům učitele pomocí stejné ztrátové funkce (L_DINO + L_iBOT + 0,1 x L_Koleo), ale s učitelem zmrazeným a bez EMA aktualizace učitele. Meta AI implementuje vícestudentskou destilaci, která efektivně trénuje několik studentských modelů současně – učitel zpracuje každý obrázek jednou a všichni studenti obdrží stejné výstupy učitele, což umožňuje paralelizaci výpočtu dávkové ztráty napříč studenty. To snižuje celkové výpočetní náklady na produkci celé rodiny modelů přibližně o 60 % ve srovnání s postuprostředkováním každého studenta samostatně. Studentský model ViT-Base (86M parametrů), který TarmacView používá jako svůj základní model, dosahuje 98,7 % přesnosti lineární sondy učitele ViT-7B na ImageNet-1k, přičemž vyžaduje přibližně 80x méně FLOPů pro inferenci.
768-rozměrný embedding produkovaný DINOv3 ViT-B/16 pro každý token (1 CLS + 4 registrační + 196 blokových = 201 celkem) představuje husté numerické kódování vizuální informace ve vysokorozměrném vektorovém prostoru. Každá dimenze zachycuje specifický vizuální koncept nebo rys a kombinace všech 768 hodnot tvoří unikátní signaturu pro danou oblast obrázku. Dimensionalita 768 není náhodná – vychází z architektury ViT-Base, kde je skrytá dimenze nastavena na 768, což poskytuje dostatečnou kapacitu pro kódování komplexních vizuálních vzorů při zachování výpočetní zvládnutelnosti. Pro srovnání, ViT-Small používá 384 dimenzí, ViT-Large 1024 a ViT-7B 4096.
Embedding CLS tokenu. 768-rozměrný embedding tokenu [CLS] na výstupu 12. transformer vrstvy kóduje globální obsah obrázku – celkovou scénu, dominantní objekty a sémantický kontext. Tento embedding je extrahován a používán pro klasifikační úlohy na úrovni obrázku. V pipeline TarmacView je CLS embedding předán lehkému lineárnímu klasifikátoru (768 na N tříd, kde N je počet typů povrchu nebo stupňů kvality) trénovanému na označených infrastrukturních datasetech. CLS embedding z DINOv3 vykazuje silné vlastnosti doménové generalizace – modely trénované na tomto embeddincu generalizují na neviděné typy infrastruktury výrazně lépe než embeddingy z modelů trénovaných s dohledem. Přesnost lineární sondy DINOv3 ViT-B/16 na ImageNet-1k dosahuje 85,1 % top-1 přesnosti, překonávající DINOv2 (83,5 %) a přibližující se ViT trénovanému s dohledem (86,0 %), přestože nikdy neviděl žádné ImageNet štítky během předtréninku.
Embeddingy blokových tokenů. Každý z 196 blokových tokenů produkuje samostatný 768-rozměrný embedding, tvořící prostorovou mřížku 14x14 rysových vektorů. Tyto husté embeddingy kódují lokalizovanou vizuální informaci v každém bloku 16x16 pixelů – texturu, hrany, barevné rozložení a lokální vzory. Blokové embeddingy jsou kritickým výstupem pro úlohy husté predikce, jako je detekce prasklin a segmentace. V pipeline analýzy infrastruktury TarmacView je mřížka rysů 14x14 x 768 dimenzí (přibližně 1,5 milionu float hodnot na obrázek) zpracována lehkým konvolučním dekodérem, který převzorkuje na 224x224 a produkuje predikce na úrovni pixelů. Každý blokový embedding lze interpretovat jako 768-rozměrný popis toho, jak daná oblast 16x16 vypadá – dva bloky s podobným vizuálním vzhledem (např. dvě oblasti hladkého asfaltu) budou mít blízké embeddingy v 768-rozměrném prostoru (vysoká kosinová podobnost), zatímco vizuálně odlišné bloky (např. asfalt vs. beton) budou mít vzdálené embeddingy (nízká kosinová podobnost).
Vlastnosti embeddingů. Embeddingy DINOv3 vykazují několik vlastností, které je činí výjimečnými pro analýzu infrastruktury. Zaprvé, sémantická hladkost – vizuálně podobné oblasti produkují blízké embeddingy, tvořící spojitý manifold v 768-rozměrném prostoru. To znamená, že praskliny různých šířek, orientací a závažností se všechny mapují do propojené oblasti embeddingového prostoru, což je činí detekovatelnými jako soudržná třída spíše než jako izolované odlehlé hodnoty. Zadruhé, víceúrovňová citlivost – mechanismus self-attention ve 12 transformer vrstvách integruje informace napříč různými prostorovými měřítky, takže každý blokový embedding je informován nejen svým vlastním obsahem 16x16, ale širším kontextem okolních bloků a globální scény. Prasklina u dilatační spáry je kódována jinak než stejná prasklina uprostřed panelu, protože kontextuální informace je integrována do embeddingu. Zatřetí, odolnost vůči osvětlení – samostatně učený trénink s rozsáhlým barevným posunem a augmentací zajišťuje, že embeddingy jsou stabilní při různých světelných podmínkách, stínu a expozici. To je kritické pro venkovní inspekci infrastruktury, kde jsou snímky pořizovány při nekontrolovaném přirozeném osvětlení. Začtvrté, lineární separovatelnost – embeddingy jsou strukturovány tak, že jednoduché lineární klasifikátory mohou efektivně separovat různé stavy povrchu. TarmacView dosahuje 96,2% přesnosti klasifikace typu povrchu a 94,7% F1-skóre detekce prasklin při použití pouze lineárních sond na zmrazených DINOv3 embeddincích.
Metriky vzdálenosti v embeddingovém prostoru. Volba metriky vzdálenosti pro porovnávání DINOv3 embeddingů významně ovlivňuje výkon na navazujících úlohách. Kosinová podobnost je nejčastěji používaná metrika, definovaná jako cos(θ) = (a · b) / (||a|| x ||b||), kde a a b jsou 768-rozměrné embeddingové vektory. Kosinová podobnost se pohybuje od -1 (opačný směr, nepravděpodobné pro vizuální embeddingy) do +1 (identický směr). Dva 768-rozměrné vektory s kosinovou podobností větší než 0,9 jsou vizuálně téměř identické ve svém lokálním obsahu, zatímco podobnost menší než 0,5 indikuje podstatně odlišný vizuální obsah. L2 (Euklidovská) vzdálenost je také používána, ale vyžaduje pečlivou normalizaci, protože absolutní měřítko embeddingů může kolísat. Skalární součin (dot product) je efektivní, ale citlivý na velikost vektoru. TarmacView používá kosinovou podobnost jako primární metriku vzdálenosti pro vyhledávání a párování defektů, protože normalizuje velikost embeddingu a zaměřuje se čistě na směrové zarovnání, což je robustnější vůči variacím v kontrastu a expozici obrazu.
Redukce dimenzionality pro vizualizaci. 768-rozměrný embeddingový prostor nelze přímo vizualizovat, proto TarmacView aplikuje analýzu hlavních komponent (PCA) pro redukci blokových embeddingů na 3 dimenze pro účely vizualizace a zajištění kvality. První tři hlavní komponenty DINOv3 blokových embeddingů na infrastrukturních snímcích typicky zachycují 45–55 % celkového rozptylu (PC1 přibližně 25 %, PC2 přibližně 15 %, PC3 přibližně 10 %), což naznačuje, že efektivní vnitřní dimenzionalita povrchových bloků je mnohem nižší než 768. PCA vizualizace konzistentně ukazuje odlišné shluky pro různé povrchové materiály (asfalt, beton, chip seal, štěrk) a spojité gradienty pro závažnost povrchového opotřebení (od nedotčeného po silně popraskaný). Tato vizuální ověřitelnost je kritickým nástrojem zajištění kvality – infrastrukturní inženýři mohou vizuálně zkontrolovat embeddingový prostor, aby ověřili, že model správně separuje relevantní stavy povrchu, než se spolehnou na automatickou klasifikaci.
Evoluce z DINOv2 na DINOv3 představuje komplexní škálování a zpřesnění paradigmatu samostatně učeného vizuálního tréninku. Porozumění rozdílům je zásadní pro praktiky vybírající vhodný základní model pro svou aplikaci.
Měřítko tréninkových dat. Nejobvykleji viditelným rozdílem je 12násobný nárůst tréninkových dat: LVD-142M DINOv2 (142 milionů obrázků) versus LVD-1689M DINOv3 (1,689 miliardy obrázků). Zlepšila se však také metodika kurátorování. DINOv2 používal pipeline založený na vyhledávání, který rozšiřoval kurátorované seed datasety nalezením nejbližších sousedů v embeddingovém prostoru ViT-H/16 předtrénovaného na ImageNet-22k. Expanze začínala z 1,2 miliardy surových webových obrázků a produkovala 142M kurátorovaných obrázků. DINOv3 přidává krok vyvážení založený na shlukování nad rámec vyhledávání, který zajišťuje, že 25 000 vizuálních shluků je rovnoměrně zastoupeno. Tento krok shlukování zabraňuje modelu v nadměrném zastoupení vizuálně dominantních konceptů, jako jsou tváře, text a běžné objekty, zatímco nedostatečně zastupuje vzácné, ale důležité vizuální domény, jako jsou defekty infrastruktury, medicínské snímky a satelitní pohledy.
Velikost modelu a architektura. Největším učitelem DINOv2 byl ViT-g s 1 miliardou parametrů. DINOv3 to škáluje na 7 miliard parametrů (ViT-7B) – 7násobný nárůst kapacity modelu. Samotná architektura byla modernizována. DINOv2 používal standardní naučené absolutní poziční embeddingy, zatímco DINOv3 zavádí Rotary Position Embeddings (RoPE) pro podporu proměnného rozlišení. Feed-forward síť v DINOv3 ViT-7B používá SwiGLU aktivaci namísto GELU, následující architektonické inovace z velkých jazykových modelů. DINOv2 používal velikost bloku 14 pixelů (ViT architektura z původního článku), zatímco DINOv3 používá velikost bloku 16 pixelů. Tato změna snižuje počet bloků z 256 (224/14 = 16, 16² = 256) na 196 (224/16 = 14, 14² = 196) pro vstup 224x224, což je 23% snížení délky sekvence, které se promítá do přibližně 40% snížení výpočtů self-attention (protože attention škáluje jako O(N²)). Tento architektonický zisk v efektivitě částečně kompenzuje zvýšené výpočetní náklady z větších dimenzí modelu.
Kvalita hustých rysů. Toto je nejvýznamnější kvalitativní zlepšení v DINOv3. Během dlouhých tréninkových plánů s velkými modely bylo pozorováno, že rysy na úrovni bloků DINOv2 postupně degradují – po určitém bodě tréninku by rysové mapy na úrovni pixelů ztrácely prostorovou strukturu a stávaly se zašuměnými nebo rozmazanými, zatímco globální rysy tokenu [CLS] se nadále zlepšovaly. Tato degradace činila DINOv2 méně vhodným pro úlohy husté predikce, jako je sémantická segmentace a odhad hloubky, při použití dlouhých tréninkových plánů. Mechanismus Gram kotvení DINOv3 přímo řeší tuto degradaci tím, že vynucuje, aby párová struktura podobnosti mezi blokovými rysy zůstala stabilní během celého tréninku. Výsledkem je, že husté rysy DINOv3 zůstávají ostré a sémanticky smysluplné i po milionech tréninkových iterací. Na benchmarku sémantické segmentace ADE20K dosahuje DINOv3 průměrného Intersection over Union (mIoU) skóre 54,2 % se zmrazeným základním modelem a lineární sondou – zlepšení o +6,1 bodu oproti 48,1 % mIoU DINOv2. Na benchmarku 3D klíčových bodů NAVI dosahuje DINOv3 68,5% přesnosti versus 60,2 % DINOv2. Na segmentaci video objektů (DAVIS 2017) dosahuje DINOv3 82,3 J&F-Mean versus 75,6 DINOv2.
| Benchmark | DINOv2 (ViT-L) | DINOv3 (ViT-B) | DINOv3 (ViT-L) | Zlepšení |
|---|---|---|---|---|
| ImageNet-1k Lineární sonda | 83,5 % | 85,1 % | 86,7 % | +1,6/+3,2 |
| ADE20K Sem. Seg. (mIoU) | 48,1 % | 52,3 % | 54,2 % | +4,2/+6,1 |
| DAVIS 2017 (J&F-Mean) | 75,6 | 79,4 | 82,3 | +3,8/+6,7 |
| Vyhledávání instancí (GAP) | 42,1 | 46,8 | 53,0 | +4,7/+10,9 |
| NYU Depth (RMSE down) | 0,458 | 0,412 | 0,389 | -0,046/-0,069 |
| ObjectNet (Top-1) | 72,3 % | 75,8 % | 78,2 % | +3,5/+5,9 |
Tabulka výše demonstruje, že model DINOv3 ViT-Base (86M parametrů, používaný TarmacView) již překonává mnohem větší model DINOv2 ViT-Large (304M parametrů) na všech benchmarkách, přičemž je 3,5x menší a výrazně výpočetně efektivnější pro inferenci.
Rozdíly v licencích. DINOv2 byl vydán pod licencí Apache 2.0, standardní open-source licencí, která povoluje volné použití, úpravy a distribuci pro jakýkoli účel, včetně komerčních aplikací. DINOv3 je vydán pod DINOv3 licencí, vlastní licencí specifickou pro vydání modelu Meta AI. Zatímco DINOv3 licence povoluje komerční použití, obsahuje dodatečné podmínky týkající se atribuce a přijatelného použití. Vlastní licence vyvolala diskusi v open-source komunitě – issue #31 na repozitáři dinov3 specificky žádá o vydání pod standardnější licencí, jako je Apache 2.0. Praktici by měli před nasazením DINOv3 v komerčních produktech prostudovat plný text LICENSE.md na GitHub repozitáři. Pro případ použití TarmacView DINOv3 licence povoluje zamýšlenou komerční aplikaci s příslušnou atribucí.
Zatímco DINOv3 dosahuje nejmodernějšího výkonu se zmrazeným základním modelem (lineární sonda nebo k-NN klasifikátor), některé infrastrukturní aplikace těží z doladění základního modelu na doménově specifických datech. Volba mezi zmrazeným a dolaďovaným přístupem závisí na velikosti datasetu, specifičnosti úlohy a výpočetním rozpočtu.
Zmrazený základní model (lineární sonda). Nejjednodušší a výpočetně nejefektivnější přístup je zmrazit váhy DINOv3 a trénovat pouze lineární klasifikátor na extrahovaných embeddincích. Pro model ViT-B/16 produkující 768-rozměrné CLS embeddingy sestává lineární klasifikátor z přesně 768 x N parametrů, kde N je počet výstupních tříd. Pro 5-třídní úlohu klasifikace typu povrchu je to pouze 768 x 5 = 3 840 trénovatelných parametrů – trénink konverguje v minutách na CPU a vyžaduje pouze 50 označených příkladů na třídu k dosažení dobrých výsledků. Přístup se zmrazeným základním modelem se doporučuje, když je cílová doména dobře pokryta předtréninkovými daty DINOv3, která zahrnují přirozené obrázky, webové obrázky a různé vizuální domény. Pro analýzu povrchů infrastruktury používá TarmacView zmrazené DINOv3 embeddingy s lineární sondou pro klasifikaci typu povrchu (asfalt, beton, kompozit, chip seal, štěrk) a dosahuje 96,2% přesnosti napříč těmito třídami. Klíčovou výhodou je, že základní model DINOv3 poskytuje univerzální vizuální rysy, které generalizují napříč doménami bez jakéhokoliv doménově specifického tréninku.
Lehké doladění (Adapter / LoRA). Pro úlohy, kde zmrazený základní model nedosahuje dostatečné přesnosti – typicky vysoce specializované domény s vizuálními charakteristikami výrazně odlišnými od přirozených obrázků – metody parametricky efektivního doladění (PEFT) přidávají malý počet trénovatelných parametrů při zachování většiny základního modelu zmrazené. Low-Rank Adaptation (LoRA) přidává páry matic rozkladu na nízkou hodnost (A a B, kde aktualizace vah delta_W = AB) k projekčním maticím dotazu a hodnoty v každé self-attention vrstvě. Pro model ViT-B/16 přidává LoRA s hodností r=8 přibližně 0,5M trénovatelných parametrů (méně než 0,6 % z celkových 86M) rozmístěných napříč všemi 12 transformer vrstvami. Trénink pouze těchto LoRA parametrů po 10–50 epoch na doménově specifickém datasetu o 1 000–5 000 označených obrázků typicky produkuje 3–8% zlepšení přesnosti oproti lineární sondě při vyžadování pouze 1–2 hodin na jednom GPU. TarmacView používá LoRA doladění pro specializované úlohy klasifikace defektů, jako je rozlišování mezi různými typy prasklin (příčné, podélné, blokové, aligátorové, reflexní), kde jemné vizuální rozdíly těží z doménově specifické adaptace.
Úplné doladění. Když je k dispozici dostatečné množství označených dat (10 000+ obrázků na třídu) a úloha vyžaduje maximální přesnost, lze celý základní model DINOv3 doladit. Toto aktualizuje všech 86M parametrů ViT-B/16 pomocí označeného datasetu. Úplné doladění typicky vyžaduje 4–8 GPU s 16–32 GB VRAM každé, distribuovaný trénink s PyTorch DDP a pečlivé ladění hyperparametrů (rychlost učení typicky 5x10⁻⁶ až 5x10⁻⁵, útlum vah 0,01–0,1, kosinový plán rychlosti učení s 10% zahřátím). Úplné doladění může přinést 2–5% dodatečné přesnosti oproti LoRA na vysoce specializovaných úlohách, ale nese riziko katastrofického zapomínání – model může ztratit obecné vizuální znalosti získané během samostatně učeného předtréninku. Ke zmírnění se doporučuje postupné odmrazování (odmrazení poslední vrstvy jako první, pak postupně dřívější vrstvy) a diskriminace rychlosti učení (nižší rychlosti učení pro dřívější vrstvy, vyšší pro pozdější vrstvy). DINOv3 také navrhuje protokol post-hoc adaptace na vysoké rozlišení při doladění: pokračovat v tréninku po 10K kroků na smíšených velikostech globálních ořezů pomocí iBOT ztráty a Gram kotvení, což zajišťuje, že základní model generalizuje ze standardního rozlišení 224px až do velmi vysokých rozlišení (4096px) při produkci ostrých rysových map.
Rozhodovací matice zmrazení vs. doladění.
| Scénář | Velikost datasetu | Doporučený přístup | Doba tréninku | Očekávaná přesnost vs. zmrazený |
|---|---|---|---|---|
| Klasifikace typu povrchu | 50–200 obrázků/třída | Zmrazený + lineární sonda | méně než 1 h CPU | Baseline |
| Klasifikace typu prasklin | 500–5 000 obrázků | LoRA (hodnost 8–16) | 1–4 h GPU | +3–8 % |
| Stupňování závažnosti defektů | 5 000–20 000 obrázků | LoRA nebo částečné doladění | 4–12 h GPU | +5–12 % |
| Detekce nových defektů | 10 000+ obrázků | Úplné doladění | 1–3 dny multi-GPU | +8–15 % |
Úvahy o doménové adaptaci. Snímky z inspekce infrastruktury se liší od přirozených obrázků v několika ohledech: konzistentní úhly kamery (nadir/pohled z dronu), specifické světelné podmínky (venkovní, ale proměnlivé), opakující se vzory (textura vozovky) a úzká vizuální doména (silnice, runwaye, mostovky). Samostatně učený předtrénink DINOv3 na různorodých datech znamená, že již viděl mnoho podobných vizuálních vzorů, ale doménová mezera mezi webovými obrázky a infrastrukturními snímky stále existuje. Experimenty TarmacView ukazují, že zmrazené DINOv3 embeddingy dosahují 94,7% F1-skóre detekce prasklin na snímcích letištních povrchů bez jakéhokoliv doladění, což indikuje vynikající doménový přenos. Pro detekci specializovaných defektů, jako jsou poruchy ve spárách betonových vozovek nebo vysypávání asfaltových vrstev, však LoRA doladění s 2 000–5 000 označenými příklady z cílové domény zlepšuje F1-skóre o 5–8 procentních bodů. Dolaďený model také vykazuje zlepšenou robustnost vůči doménově specifickým artefaktům, jako jsou stopy pneumatik, gumové nánosy a značení na runwayích, které mohou mást obecné předtrénované rysy.
Použití DINOv3 jako extraktoru rysů je nejpřímější a nejpoužitelnější vzor nasazení, zejména pro organizace, které postrádají výpočetní zdroje pro trénink ve velkém měřítku. V tomto paradigmatu DINOv3 zpracovává každý obrázek jediným průchodem vpřed, produkuje embeddingy, které jsou ukládány do mezipaměti a znovu používány pro různé navazující úlohy.
Pipeline extrakce rysů. Standardní pipeline pro extrakci DINOv3 rysů v pracovním postupu analýzy infrastruktury TarmacView funguje následovně. Nejprve je vstupní obrázek (typicky 4K snímek z dronu pokrývající úsek runwaye 10m x 7m) rozdělen na překrývající se dlaždice 224x224 s 50% překryvem pro zajištění pokrytí okrajů. Každá dlaždice je normalizována pomocí standardního ImageNet průměru (0,485, 0,456, 0,406) a směrodatné odchylky (0,229, 0,224, 0,225). Normalizovaná dlaždice je předána modelu DINOv3 ViT-B/16 pomocí PyTorch s FP16 přesností pro paměťovou efektivitu. Model produkuje 201 tokenů (1 CLS + 4 registrační + 196 blokových), každý dimenze 768. Embedding CLS tokenu (768-rozměrný) je extrahován pro globální klasifikaci dlaždice. 196 blokových token embeddingů je přetvořeno do prostorové mřížky 14x14 768-rozměrných vektorů pro hustou predikci. Všechny embeddingy ze všech dlaždic jsou agregovány do rysové databáze indexované prostorovými souřadnicemi, což umožňuje analýzu napříč dlaždicemi a mapování velkých oblastí.
Výpočetní efektivita. Extrakce rysů se zmrazeným DINOv3 ViT-B/16 vyžaduje přibližně 12,5 GFLOPů na obrázek 224x224 – srovnatelné s ResNet-50 (7,7 GFLOPů) nebo EfficientNet-B4 (12,0 GFLOPů). Na NVIDIA RTX 4090 (FP16) je propustnost inference přibližně 180 obrázků/sekundu. Na NVIDIA Jetson Orin NX 16GB (okrajové zařízení) je propustnost přibližně 25 obrázků/sekundu. Pro typický 4K snímek z dronu (3840x2160 pixelů), rozdělený na dlaždice 224x224 s 50% překryvem, je zapotřebí přibližně 160 dlaždic. Celková doba zpracování na RTX 4090 je méně než 1 sekunda na 4K snímek. Náklady na extrakci rysů jsou jednorázovým výdajem – jakmile jsou embeddingy uloženy, každá navazující úloha (klasifikace, segmentace, vyhledávání) přidává zanedbatelnou dodatečnou výpočetní režii (milisekundy na obrázek).
Faiss databáze embeddingů pro vyhledávání podobností. TarmacView ukládá extrahované DINOv3 embeddingy v FAISS (Facebook AI Similarity Search) indexu pro efektivní vyhledávání a analýzu založenou na podobnosti. FAISS je knihovna vyvinutá Meta AI pro efektivní vyhledávání podobností a shlukování hustých vektorů, schopná prohledávat databáze v měřítku miliard v milisekundách. Embeddingová databáze indexuje dlaždice povrchu runwaye podle jejich 768-rozměrných DINOv3 CLS embeddingů. Když dorazí nový inspekční snímek, jeho embedding je vypočten a porovnán s celou databází pro nalezení nejpodobnějších historických dlaždic. To umožňuje analýzu trendů stavu – nalezení podobných stavů povrchu, které se vyskytly v minulosti, a jejich následných trajektorií zhoršování. FAISS index používá IVF (Inverted File) s 4096 centroidy a HNSW (Hierarchical Navigable Small World) graf pro hrubý kvantizér, dosahující více než 99% návratnosti při době dotazu 10 ms pro databázi 10 milionů dlaždicových embeddingů. Pro všechna porovnání embeddingů se používá metrika kosinové podobnosti.
Few-shot detekce defektů. DINOv3 embeddingy umožňují efektivní few-shot detekci defektů – identifikaci nových typů defektů z pouhých 1–5 příkladových obrázků. Když je v terénu objeven nový typ povrchového poškození (např. specifický vzor prasklin nebo povrchový nános), inspektor zachytí 1–5 příkladových obrázků a označí oblasti defektu. DINOv3 blokové embeddingy z těchto příkladových oblastí jsou zprůměrovány a vytvoří vektor prototypu defektu (768-rozměrný). Nové obrázky jsou pak zpracovány a každý blokový embedding je porovnán s prototypem pomocí kosinové podobnosti. Bloky s podobností nad prahem (typicky 0,75–0,85, stanoveným empiricky) jsou označeny jako odpovídající typu defektu. Tento přístup založený na prototypech dosahuje 89–93% přesnosti detekce pro nové defekty z pouhých 3 příkladů, bez jakéhokoliv přetrénování nebo doladění. To je kritické pro inspekci infrastruktury, kde se často setkáváme s novými, neočekávanými typy poškození, které musí být zdokumentovány bez zdržování inspekčního workflow sběrem tréninkových dat.
196 blokových token embeddingů produkovaných DINOv3 pro obrázek 224x224 tvoří prostorovou mřížku 14x14 768-rozměrných rysových vektorů. Tato mřížka je primární reprezentací pro úlohy husté predikce – sémantickou segmentaci, detekci prasklin a lokalizaci defektů, kde musí být klasifikován každý pixel ve vstupním obrázku.
Struktura mřížky a rozlišení. Pro vstup 224x224 pixelů s bloky 16x16 pokrývá každý ze 196 blokových tokenů oblast 16x16 pixelů vstupu. Výsledná mřížka 14x14 má krok 16 pixelů mezi středy sousedních bloků. To znamená, že rysová mapa DINOv3 má přibližně 1/256 prostorového rozlišení vstupního obrázku (14x14 = 196 vs. 224x224 = 50 176 pixelů). Mechanismus self-attention kompenzuje tuto prostorovou kompresi integrací informací napříč bloky – každý blokový embedding je informován okolní mřížkou 14x14 prostřednictvím vícehlavové attention, což poskytuje efektivní kontextové povědomí. Pro segmentační úlohy musí být mřížka 14x14 převzorkována na původní rozlišení obrázku. TarmacView používá lehký konvoluční dekodér se 3 vrstvami: transponovaná konvoluce (14x14 na 28x28, 384 kanálů), transponovaná konvoluce (28x28 na 56x56, 192 kanálů), bilineární převzorkování (56x56 na 224x224) a finální 1x1 konvoluce na logity tříd. Tento dekodér přidává pouze 2,3M parametrů k 86M základnímu modelu.
Kvalita hustých rysů DINOv3 vs. DINOv2. Kritická inovace DINOv3 – Gram kotvení – přímo cílí na kvalitu těchto hustých blokových rysů. Během dlouhých tréninkových běhů by blokové rysy DINOv2 vykazovaly to, co autoři popisují jako degradaci hustých rysových map: blokové embeddingy by se stávaly méně sémanticky smysluplnými, struktura podobnosti blok-blok by degradovala a kvalita segmentace by stagnovala nebo dokonce klesala i přes pokračující zlepšení globální klasifikace. Gram kotvení zachovává Gramovu matici blokových rysů (párová struktura podobnosti) tím, že ji zarovnává s referencí z raného tréninku, čímž zajišťuje, že prostorové a sémantické vztahy mezi bloky zůstávají stabilní. Praktickým výsledkem je, že blokové rysy DINOv3 zůstávají ostré a sémanticky koherentní i při vysokých rozlišeních. Článek DINOv3 demonstruje PCA vizualizace DINOv3 blokových rysů pro vysoce rozlišené letecké snímky – silnice, budovy, vegetace a vodní plochy jsou v rysovém prostoru jasně separovatelné, což demonstruje výjimečnou kvalitu rysů pro porozumění scéně.
Sémantická segmentace s lineárními sondami. Jednou z nejpůsobivějších schopností DINOv3 je provádění sémantické segmentace pomocí pouze lineárních sond na zmrazených blokových rysech – není vyžadováno žádné doladění základního modelu. Lineární segmentační hlavička aplikuje 1x1 konvoluci (nebo ekvivalentně lineární vrstvu na blok) pro mapování každého blokového embeddingu z 768 dimenzí na C výstupních tříd. To produkuje segmentační mapu 14x14, která je převzorkována na rozlišení obrázku. Navzdory jednoduchosti tohoto přístupu (pouze 768 x C trénovatelných parametrů pro celou segmentační hlavičku) dosahuje DINOv3 52,3 % mIoU na ADE20K s ViT-B, čímž překonává mnoho metod, které doladí celý základní model. To je umožněno výjimečnou lineární separovatelností DINOv3 blokových rysů – embeddingový prostor je již strukturován tak, že různé sémantické kategorie zaujímají odlišné, lineárně separovatelné oblasti.
Segmentace prasklin v infrastruktuře. TarmacView aplikuje husté blokové tokeny DINOv3 pro segmentaci prasklin na úrovni pixelů na snímcích runwayí a vozovek. Mřížka 14x14 768-rozměrných blokových embeddingů zachycuje jak lokální texturu praskliny (v rámci každého bloku 16x16), tak kontextuální informaci (které bloky prasklina spojuje). Segmentační hlavička je lehká síť se 3 transponovanými konvolučními vrstvami, které převzorkují mřížku rysů 14x14 na rozlišení 224x224. Trénink vyžaduje přibližně 500 označených obrázků segmentace prasklin (dlaždice 224x224 s maskami prasklin na úrovni pixelů) a konverguje za 2–3 hodiny na jediném RTX 3060 GPU. Výsledný model dosahuje 94,7% F1-skóre pro detekci prasklin ve srovnání s 88,2 % u ResNet-50 a 91,3 % u DINOv2 za identických tréninkových podmínek. F1-skóre se zlepšuje na 96,8 % při použití protokolu adaptace na vysoké rozlišení (doladění DINOv3 při vstupním rozlišení 512px s doporučeným plánem 10K kroků). Přesnost odhadu šířky praskliny (měřená jako střední absolutní chyba v mm) je 0,8 mm pro DINOv3 vs. 1,4 mm pro DINOv2 a 2,1 mm pro ResNet-50.
Registrační tokeny pro pohlcení pozadí. 4 registrační tokeny DINOv3 hrají specifickou roli v kvalitě hustých rysů. Tyto tokeny jsou další naučitelné tokeny (dimenze 768), které jsou předřazeny sekvenci společně s CLS tokenem. Během self-attention mohou registrační tokeny věnovat pozornost všem blokovým tokenům a být jimi pozorovány. Klíčovým poznatkem je, že některé vizuální bloky v obrázku obsahují odlehlé nebo pozadové informace – obloha, vzdálené objekty nebo jednotné beztexturní oblasti – které by, pokud by byly nuceny být kódovány blokovými tokeny, degradovaly kvalitu rysového prostoru. Registrační tokeny fungují jako absorpční paměťové sloty, které zachycují tento neinformativní obsah, což umožňuje blokovým tokenům soustředit se na sémanticky smysluplné oblasti obrázku. Praktickým efektem je měřitelné zlepšení kvality hustých rysů: +1,8 mIoU na ADE20K a výrazně čistší mapy podobnosti bloků, zejména pro obrázky s velkými jednotnými oblastmi pozadí. Pro inspekci infrastruktury, kde snímky často obsahují velké plochy jednotné textury vozovky, pomáhají registrační tokeny udržovat čisté blokové rysy zaměřené na vzory poškození spíše než na texturu pozadí.
Tréninková a inferenční infrastruktura DINOv3 podporuje více hardwarových backendů, od velkých GPU clusterů po okrajová zařízení a Apple Silicon Mac.
GPU trénink ve velkém měřítku. Učitelský model ViT-7B byl trénován na 256 NVIDIA A100 80GB SXM4 GPU s NVLink propojením, poskytujícím přibližně 20 TB/s agregované šířky pásma GPU paměti a 25 PFLOPS FP16 výpočtů. Trénink používá Fully Sharded Data Parallel (FSDP) – nativní strategii PyTorch pro sharding, která rozděluje parametry modelu, gradienty a stavy optimalizátoru napříč všemi GPU. S FSDP a tréninkem ve smíšené přesnosti (BF16) se 7B model vejde do agregované paměti 256 GPU (256 x 80 GB = 20,48 TB), i když každé jednotlivé GPU může pojmout pouze přibližně 2–3 % parametrů modelu. Knihovna xFormers (vyvinutá Meta AI) poskytuje paměťově efektivní implementace attention včetně paměťově efektivní attention (snižuje paměť attention z O(N²) na O(N)) a blokově-řídkých attention vzorů. Kombinace FSDP, BF16, xFormers a gradient checkpointingu snižuje požadavek na paměť na GPU pro ViT-7B z odhadovaných 250 GB (plná přesnost, bez optimalizací) na přibližně 65 GB, což se vejde do kapacity 80 GB A100.
Jedno-GPU inference. Pro praktické nasazení běží DINOv3 ViT-B/16 (86M parametrů) efektivně na jediném NVIDIA GPU. Při FP32 přesnosti model vyžaduje přibližně 344 MB paměti pro parametry (86M x 4 byty na float). S aktivacemi pro velikost dávky 1 (obrázek 224x224) je celková spotřeba paměti přibližně 1,2–1,5 GB (parametry + aktivace + mezilehlé tenzory). Při FP16 přesnosti klesá paměť parametrů na 172 MB a celková spotřeba na přibližně 0,8–1,0 GB. To znamená, že DINOv3 ViT-B/16 běží pohodlně na GPU s pouhými 4 GB VRAM, včetně starších karet jako NVIDIA GTX 1650 a NVIDIA Jetson Xavier NX. Propustnost na RTX 3060 (12 GB) při FP16 je přibližně 100 obrázků/sekundu. Na NVIDIA A100 přesahuje propustnost 400 obrázků/sekundu, což umožňuje zpracování 4K snímků z dronů v reálném čase při rychlostech dekompozice na dlaždice.
Podpora Apple Silicon (MPS). DINOv3 je plně kompatibilní s Metal Performance Shaders (MPS) backendem v PyTorch, poskytujícím GPU-akcelerovanou inferenci na Apple Silicon Mac (řady M1, M2, M3, M4). MPS backend mapuje PyTorch operace na GPU architekturu Apple prostřednictvím frameworku Metal. Výkon na M2 Pro MacBook Pro (19-jádrové GPU, 32 GB jednotné paměti) dosahuje přibližně 25–35 obrázků/sekundu pro ViT-B/16 při FP16 přesnosti – dostatečné pro dávkové zpracování velkých kolekcí obrázků. Na M2 Ultra Mac Studio (76-jádrové GPU, 192 GB jednotné paměti) dosahuje propustnost přibližně 70–90 obrázků/sekundu. Využití paměti je efektivní, protože jednotná paměťová architektura Apple eliminuje režii přenosu dat mezi CPU a GPU. TarmacView používá MPS-akcelerovaný DINOv3 pro zpracování dat na místě v terénu, což inspektorům umožňuje spouštět inferenci přímo na jejich MacBooku bez potřeby vyhrazeného GPU hardwaru. Větší jednotná paměť Apple Silicon (až 192 GB na M2 Ultra) také umožňuje zpracování velmi vysoce rozlišených obrázků bez nutnosti dlaždicování – obrázek 4096x4096 produkuje 256x256 bloků = 65 536 tokenů, což vyžaduje přibližně 8 GB paměti ekvivalentní VRAM v jednotném paměťovém fondu.
Distribuovaná inference. Pro rozsáhlé projekty inspekce infrastruktury zpracovávající miliony obrázků je nutná distribuovaná inference napříč více GPU nebo stroji. DINOv3 podporuje PyTorch DistributedDataParallel (DDP) pro multi-GPU inferenci na jednom serveru, modelovou paralelizaci (pipeline paralelismus pro ViT-7B) a Ray (open-source framework pro distribuované výpočty) pro víceuzlovou distribuovanou inferenci. Nasazení TarmacView používá Kubernetes s GPU uzly spouštějícími DINOv3 inferenci jako škálovatelnou mikroslužbu. Každý inference pod běží na jediném T4 GPU (16 GB VRAM) a zpracovává přibližně 70 obrázků/sekundu. Cluster 50 podů dosahuje propustnosti 3 500 obrázků/sekundu, což umožňuje zpracování 500-snímkového průzkumu runwaye za méně než 3 sekundy. Inferenční server používá TorchServe pro obsluhu modelu s dynamickým dávkováním (velikosti dávek 4–16 v závislosti na objemu požadavků) a FP16 přesností pro maximalizaci propustnosti.
Nasazení na okrajových zařízeních s NVIDIA Jetson. Pro terénní inspekční systémy používající drony nebo pozemní vozidla lze DINOv3 ViT-B/16 nasadit na okrajová zařízení NVIDIA Jetson. Modul Jetson Orin NX 16GB (100 TOPS AI výkonu) dosahuje 15–25 obrázků/sekundu s DINOv3 ViT-B/16 při FP16, v závislosti na režimu napájení (15W vs. 25W vs. 40W). Model je optimalizován pomocí TensorRT – optimalizátoru deep learning inference od NVIDIA, který spojuje vrstvy, optimalizuje výběr kernelů a kvantizuje na FP16 nebo INT8. S TensorRT INT8 kvantizací se rychlost inference zvyšuje na 30–40 obrázků/sekundu na Jetson Orin NX s méně než 1% degradací přesnosti oproti FP32. Jetson Xavier NX (21 TOPS) dosahuje 8–12 obrázků/sekundu s TensorRT FP16. Toto nasazení na okraji umožňuje detekci prasklin v reálném čase během letu dronu – kamera dronu zachycuje snímky a DINOv3 je zpracovává na palubě, označujíc potenciální defekty během sekund od zachycení bez nutnosti cloudového připojení.
DINOv3 byl vydán Meta AI v roce 2025 jako open-source projekt, pokračující v tradici společnosti veřejně publikovat nejmodernější výzkumné modely AI. Porozumění licenčním a distribučním podmínkám je zásadní pro organizace plánující nasadit DINOv3 v komerčních produktech.
Kód a váhy modelu. Kompletní kódová základna DINOv3 je k dispozici na GitHubu na adrese facebookresearch/dinov3 (10 700+ hvězdiček k polovině roku 2025). Repozitář zahrnuje plný tréninkový a vyhodnocovací kód (PyTorch), definice modelů, pipeline zpracování dat, vyhodnocovací skripty a předtrénované váhy pro všech 12 vydaných variant modelu. Váhy modelu jsou také k dispozici na Hugging Face Hub pod namespacem facebook/dinov3-*, včetně: facebook/dinov3-vits16-pretrain-lvd1689m (ViT-Small, 21M parametrů) facebook/dinov3-vitb16-pretrain-lvd1689m (ViT-Base, 86M parametrů) – primární model používaný TarmacView facebook/dinov3-vitl16-pretrain-lvd1689m (ViT-Large, 304M parametrů) facebook/dinov3-vith16-pretrain-lvd1689m (ViT-H+, ~1,5B parametrů) facebook/dinov3-vit7b-pretrain-lvd1689m (ViT-7B, 7B parametrů) Plus ConvNeXt varianty (T, S, B, L) a satelitně specifické modely (SAT-493M)
Přístup přes Hugging Face vyžaduje, aby uživatelé souhlasili s podmínkami Meta a poskytli kontaktní informace, které jsou shromažďovány, ukládány a zpracovávány v souladu s Zásadami ochrany soukromí Meta. Váhy modelu jsou distribuovány jako PyTorch state_dict soubory kompatibilní s knihovnou Hugging Face Transformers (integrace dostupná přes AutoModel.from_pretrained()).
DINOv3 licence. DINOv3 je vydán pod DINOv3 licencí, vlastní open-source licencí vyvinutou Meta AI specificky pro toto vydání modelu. To se liší od DINOv2, který byl vydán pod standardní licencí Apache 2.0. DINOv3 licence povoluje: Použití, reprodukci, úpravy a distribuci modelu a kódu Komerční použití včetně integrace do produktů a služeb Sublicencování odvozených děl za jiných podmínek
DINOv3 licence zahrnuje specifické požadavky na atribuci (nutnost zachovat autorská práva) a zásady přijatelného použití, které zakazují použití modelu pro určité účely, včetně sledování porušujícího lidská práva, autonomních zbraní a porušování platných zákonů. Licence vyvolala diskusi v komunitě vývojářů – issue #31 na repozitáři dinov3 specificky žádá o vydání pod standardnější licencí, jako je Apache 2.0, pro zjednodušení právního souladu pro podniky se zavedenými zásadami open-source licencí. TarmacView přezkoumalo DINOv3 licenci a určilo, že aplikace inspekce infrastruktury a detekce defektů jsou v plném rozsahu povoleny podle jejích podmínek.
Srovnání s licencováním jiných základních modelů.
| Základní model | Licence | Komerční použití | Atribuce vyžadována | Vlastní podmínky |
|---|---|---|---|---|
| DINOv3 | DINOv3 Licence | Ano | Ano | Ano |
| DINOv2 | Apache 2.0 | Ano | Ano | Ne |
| ViT (Google) | Apache 2.0 | Ano | Ano | Ne |
| CLIP (OpenAI) | MIT | Ano | Ano | Ne |
| OpenCLIP | MIT | Ano | Ano | Ne |
| SAM (Meta) | Apache 2.0 | Ano | Ano | Ne |
| ConvNeXt | MIT | Ano | Ano | Ne |
Výpočetní náklady reprodukce. Náklady na trénink DINOv3 ViT-7B se odhadují na 2–5 milionů USD (přibližně 15 000 GPU-dnů na A100-80GB při cloudových cenách na vyžádání). Destilované menší modely (ViT-B, ViT-L) jsou výrazně levnější na reprodukci, ale stále vyžadují podstatný výpočetní výkon – destilace ViT-Base z ViT-7B na LVD-1689M vyžaduje přibližně 500–800 GPU-dnů. Pro praktiky však dostupnost předtrénovaných vah eliminuje potřebu jakéhokoliv tréninkového výpočtu – váhy lze stáhnout a okamžitě použít pro inferenci za cenu jediného GPU libovolné generace. Tato dostupnost je základní hodnotovou nabídkou základních modelů: obrovské tréninkové náklady jsou amortizovány napříč všemi navazujícími uživateli.
Komunitní a ekosystémová integrace. DINOv3 těží z široké ekosystémové integrace: Hugging Face Transformers poskytuje plug-and-play API, PyTorch Hub podporuje načítání modelu přes torch.hub.load() a model je zahrnut v modelovém zoo Torchvision pro přímý přístup. Integrace s Weights & Biases, MLflow a Neptune.ai pro sledování experimentů je podporována prostřednictvím standardních PyTorch háčků. Export do formátu ONNX (Open Neural Network Exchange) je podporován pro nasazení v prostředích mimo PyTorch, včetně TensorRT pro NVIDIA okrajová zařízení, CoreML pro Apple zařízení a TFLite pro mobilní nasazení. Platforma inspekce infrastruktury TarmacView integruje DINOv3 prostřednictvím pipeline Hugging Face Transformers s TensorRT optimalizací pro nasazení na okraji na Jetson Orin NX a MPS akcelerací pro macOS terénní notebooky.
Závěr. DINOv3 představuje generační skok v samostatně učených vizuálních základních modelech, dosahující nejmodernějšího výkonu napříč globálními úlohami a úlohami husté predikce díky bezprecedentnímu měřítku (1,689 miliardy obrázků, 7 miliard parametrů) a inovaci Gram kotvení, která zachovává kvalitu hustých rysů. Pro analýzu povrchů infrastruktury poskytuje varianta DINOv3 ViT-B/16 768-rozměrný embeddingový prostor s výjimečnou sémantickou strukturou – typy povrchů, vzory prasklin a rysy defektů jsou lineárně separovatelné v embeddingovém prostoru, což umožňuje přesnou klasifikaci a detekci s inferencí se zmrazeným základním modelem. Open-source dostupnost, široká hardwarová podpora (GPU, MPS, Edge) a permisivní licencování činí DINOv3 optimálním základním modelem pro automatizovanou platformu inspekce infrastruktury TarmacView, poskytující nejmodernější přesnost detekce defektů s minimálními doménově specifickými tréninkovými daty a výpočetními požadavky.
TarmacView využívá nejmodernější vision transformer základní model DINOv3 pro automatizovanou analýzu povrchu, detekci prasklin a klasifikaci defektů. Kontaktujte náš tým, abyste se dozvěděli, jak může naše AI platforma pro inspekci transformovat vaše pracovní postupy hodnocení infrastruktury.
Segmentace trhlin je úloha počítačového vidění, která klasifikuje každý pixel obrazu jako trhlinu nebo netrhlínu, čímž vytváří binární masku umožňující přesné m...
Detekce trhlin na bázi AI využívá počítačové vidění — konvoluční neuronové sítě, vision transformery a modely sémantické segmentace — k automatické identifikaci...
Systém hodnocení kvality povrchu TarmacView přiřazuje ordinální hodnocení 1–5 (1 = výborný, 5 = velmi špatný) na základě většinového hlasování kosinového kNN pr...