Embedding Space
Embedding space je vícerozměrný matematický prostor, ve kterém jsou objekty, jako jsou obrázky, text nebo senzorová data, reprezentovány jako vektory, což umožň...
AI
Machine Learning
+2
FAISS (Facebook AI Similarity Search) je open-source knihovna pro efektivní vyhledávání podobnosti a shlukování hustých vektorů, kterou TarmacView používá k ukládání a dotazování přibližně 9 000 označených referenčních embeddingů pro klasifikaci kvality povrchu na základě nejbližších sousedů. Pokrývá typy indexů (Flat, IVF, HNSW), kosinovou podobnost pomocí skalárního součinu na normalizovaných vektorech, GPU akceleraci a aplikaci při vyhledávání inspekčních snímků.
FAISS (Facebook AI Similarity Search) je open-source knihovna v jazyce C++ vyvinutá týmem Fundamental AI Research (FAIR) společnosti Meta pro efektivní vyhledávání podobnosti a shlukování hustých vektorů. Poprvé vydána v roce 2017, FAISS získal přes 40 000 hvězdiček na GitHubu a více než 5 200 citací svého článku o GPU implementaci. Balíčky FAISS byly staženy více než 6 milionůkrát z Conda repozitářů. Hlavní společnosti zabývající se vektorovými databázemi, včetně Zilliz (Milvus) a Pinecone, buď spoléhají na FAISS jako své jádro, nebo ve svých produkčních systémech implementovaly algoritmy FAISS.
FAISS je navržen speciálně pro řešení výpočetní výzvy hledání nejbližších sousedů ve vícerozměrných vektorových prostorech. Základní operací je vyhledávání podobnosti: pro daný dotazovací vektor q FAISS identifikuje vektory v referenční sadě, které jsou nejbližší podle zadané metriky vzdálenosti. Formálně, pro množinu referenčních vektorů {x₁, …, xₙ} v dimenzi d, FAISS efektivně počítá j = argminᵢ ||q - xᵢ|| kde ||·|| je Euklidovská vzdálenost. Knihovna také umožňuje maximalizaci skalárního součinu argmaxᵢ ⟨q, xᵢ⟩ a podporuje další metriky včetně L1, Linf, Canberra, Bray-Curtis, Jensen-Shannon a Hammingovy vzdálenosti prostřednictvím svých implementací IndexFlat a IndexHNSW. FAISS vrací nejen jediného nejbližšího souseda, ale k nejbližších sousedů, podporuje dávkové zpracování více dotazů současně a může provádět rozsahová vyhledávání vracející všechny prvky v daném okruhu.
Knihovna pracuje s hustými vektory – poli s pevnou délkou 32bitových čísel s plovoucí desetinnou čárkou – která reprezentují datové body vložené do spojitého vektorového prostoru. Tyto vektory jsou typicky generovány hlubokými neuronovými sítěmi, jako jsou Vision Transformery (ViT), konvoluční neuronové sítě (CNN) nebo velké jazykové modely. V moderních pipeline strojového učení slouží embeddingy jako mezilehlé reprezentace, které mapují komplexní vstupní média do vektorového prostoru, kde poloha kóduje sémantiku. FAISS je mostem mezi extrakcí embeddingů a úlohami založenými na podobnosti: indexuje extrahované embeddingy a umožňuje rychlé vyhledávací operace.
FAISS je rozsáhle optimalizován pro moderní hardwarové architektury. Na CPU využívá BLAS (Basic Linear Algebra Subprograms) knihovny jako Intel MKL, OpenBLAS nebo Apple Accelerate k provádění rychlých maticových operací. Podporuje SIMD vektorizaci (SSE, AVX2, AVX-512) na x86 architekturách a Neon instrukce na procesorech ARM. Na GPU poskytuje FAISS nativní CUDA implementace, které mohou u typických úloh přinést 5–10× zlepšení propustnosti oproti CPU. GPU implementace podporuje více GPU paralelně, což umožňuje distribuované vyhledávání napříč několika zařízeními současně.
FAISS není vektorová databáze – je to vyhledávací knihovna, kterou lze vestavět přímo do aplikací. Na rozdíl od plnohodnotných databázových systémů (Pinecone, Milvus, Qdrant, Weaviate) FAISS neposkytuje vestavěnou perzistenci, replikaci, řízení přístupu, souběžný zápis, load balancing, sharding, správu transakcí ani optimalizaci dotazů. Místo toho nabízí čisté C++ a Python API pro stavbu, dotazování, ukládání a načítání indexů. Toto záměrné omezení rozsahu umožňuje FAISS dosáhnout maximálního výkonu pro základní operaci vyhledávání nejbližšího souseda. Rozsah knihovny je záměrně omezen na implementaci algoritmů Approximate Nearest Neighbor Search (ANNS) a jak uvádí původní článek FAISS: “Faiss není databáze – neposkytuje souběžný zápis, load balancing, sharding, správu transakcí ani optimalizaci dotazů.”

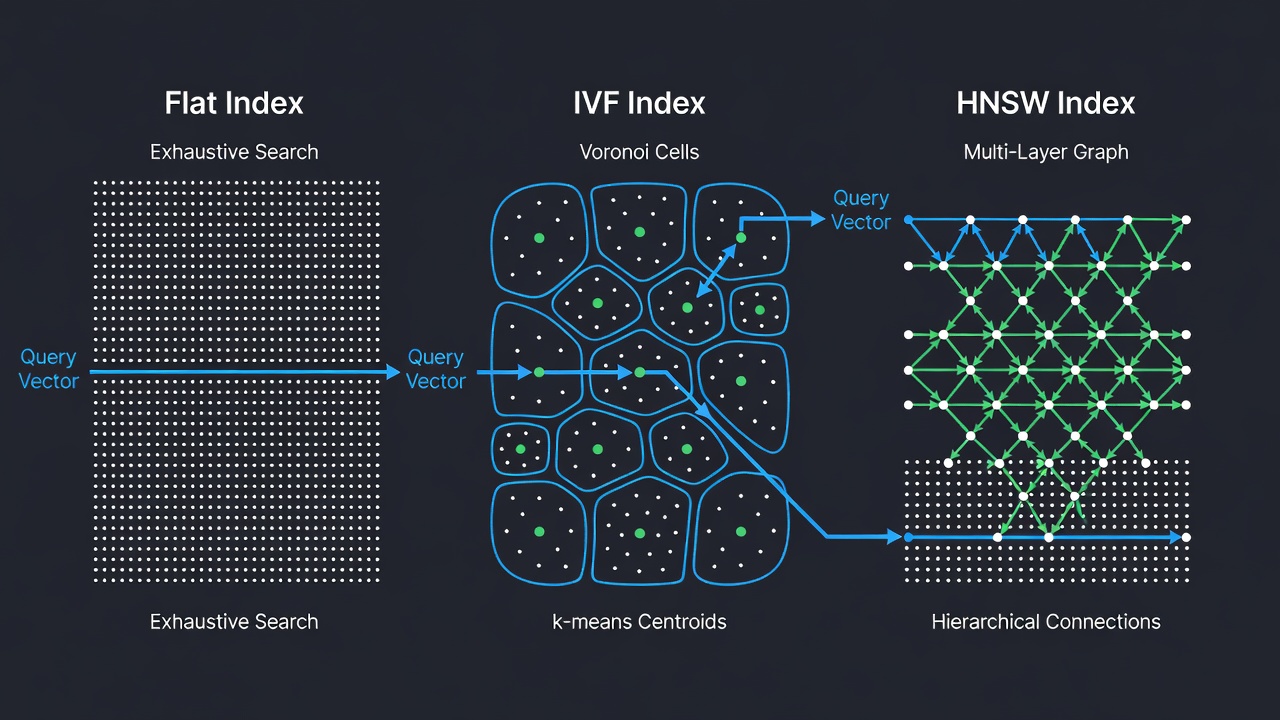
FAISS poskytuje přes dvacet různých typů indexů, z nichž každý je navržen pro specifickou kombinaci kompromisů mezi přesností, rychlostí a pamětí. Tři nejzákladnější a nejpoužívanější typy indexů jsou IndexFlat (exaktní vyhledávání), IndexIVF (invertovaný soubor s k-means shlukováním) a IndexHNSW (hierarchický navigovatelný malý světový graf). Každý typ indexu je k dispozici s různými metrikami vzdálenosti a kódovanými variantami (např. FlatIP pro skalární součin, FlatL2 pro L2 vzdálenost). Indexy FAISS lze hierarchicky skládat – například použít HNSW jako hrubý kvantizér pro IVF index, čímž vznikne složená struktura IndexIVFPQ, která pohání nasazení v miliardovém měřítku.
IndexFlatIP je nejjednodušší index FAISS. Ukládá všechny vektory v plochém poli a provádí vyčerpávající vyhledávání hrubou silou vůči každému vektoru v datové sadě. Pro každý dotaz vypočítá skalární součin mezi dotazem a každým uloženým vektorem a poté vrátí indexy a vzdálenosti top-k výsledků. Tento index zaručuje vrácení exaktních nejbližších sousedů – žádné aproximace, žádné snížení recallu. Je to jediný index FAISS, který poskytuje tuto záruku; všechny ostatní indexy jsou přibližné a obětují určitý recall za vyšší rychlost nebo nižší spotřebu paměti.
Výpočetní komplexita IndexFlatIP je O(N × D) na dotaz, kde N je počet referenčních vektorů a D je dimenzionalita. Index používá vysoce optimalizovanou rutinu BLAS gemm (general matrix multiply) k výpočtu všech skalárních součinů v jediném násobení matic. Pro datovou sadu 100 000 vektorů o 768 dimenzích (typická velikost embeddingu z DINOv2 ViT) trvá jediný dotaz na CPU přibližně 5–15 milisekund v závislosti na hardwaru a optimalizaci BLAS. V dávkovém režimu s 1 000 dotazy zpracovává index všechny současně pomocí násobení matice maticí, čímž dosahuje výrazně vyšší propustnosti než 1 000 jednotlivých dotazů.
IndexFlatIP hraje klíčovou roli v ekosystému FAISS jako orákulum základní pravdy pro vyhodnocení přesnosti přibližných indexů. Praktici vytváří plochý index vedle svého přibližného indexu, spouští identické dotazy vůči oběma a počítají metriky recallu. Standardní benchmarková sada FAISS (faiss_benchmarks) používá tuto metodiku ke kvantifikaci degradace přesnosti u IVF, HNSW a PQ indexů. V TarmacView je IndexFlatIP používán jako baseline reference pro validaci systému, čímž se zajišťuje, že přibližné indexy používané v produkci udržují přijatelný recall.
Index se vytváří s minimem kódu: index = faiss.IndexFlatIP(d) kde d je dimenzionalita embeddingu. Vektory se přidávají pomocí index.add(embeddings). Vyhledávání se provádí pomocí index.search(query, k), což vrací dvě pole float32: vzdálenosti (tvar [n_queries, k]) a indexy (tvar [n_queries, k], dtype int64). U skalárního součinu větší hodnoty vzdálenosti značí větší podobnost. Index nevyžaduje trénovací krok, protože nejsou žádné parametry k učení – vektory jsou uloženy a porovnávány beze změny.
IndexIVFFlat je přibližný index nejbližších sousedů, který rozděluje vektorový prostor na Voroného buňky pomocí k-means shlukování. Architektura je odvozena z průlomového článku “Video Google” od Sivice a Zissermana (ICCV 2003), který adaptoval techniky vyhledávání v textu na vizuální přiřazování objektů. Během indexování je datová sada shlukována do nlist shluků pomocí k-means a každý vektor je přiřazen k nejbližšímu centroidu shluku. Centroidy jsou uloženy v hrubém kvantizéru (typicky IndexFlatL2). Během vyhledávání jsou zkoumány pouze vektory v nprobe nejbližších shlucích k dotazu, což dramaticky snižuje počet potřebných výpočtů vzdálenosti.
Zrychlení oproti IndexFlatIP je přibližně N / ((N / nlist) × nprobe). Při nlist=100 a nprobe=5 je prohledáváno pouze 5 % databáze – dotazy, které trvaly 10 ms na plochém indexu, mohou být dokončeny za 0,5 ms. Cenou je snížení recallu: některé skutečné nejbližší sousedy mohou ležet mimo prohledávané shluky a být tak zmeškany. Trénovací krok k-means je kritický pro kvalitu recallu – centroidy musí přesně reprezentovat distribuci dat. FAISS vyžaduje, aby trénovací sada obsahovala alespoň 30 × nlist vektorů pro spolehlivý odhad centroidů.
Klíčové parametry IndexIVFFlat:
| Parametr | Popis | Typický rozsah | Dopad |
|---|---|---|---|
| nlist | Počet Voroného buněk (shluků) | 10 – 100 000 | Vyšší = jemnější rozdělení, více paměti pro centroidy, pomalejší k-means trénování |
| nprobe | Počet buněk prohledávaných při dotazu | 1 – 100+ | Vyšší = lepší recall (až 99%), lineárně pomalejší vyhledávání |
| metric | Metrika vzdálenosti (L2 nebo IP) | L2 nebo IP | Určuje, jak se počítají vzdálenosti mezi vektory a centroidy |
Parametr nprobe je obzvláště důležitý, protože řídí kompromis mezi rychlostí a přesností při vyhledávání bez nutnosti rekonstrukce indexu. Během dotazování lze nprobe dynamicky nastavit: na vysokou hodnotu (např. 20–50) během offline operací kritických z hlediska kvality, kde je přesnost prvořadá, a na nízkou hodnotu (např. 1–5) během vysoce propustných produkčních běhů, kde je prioritou rychlost. FAISS poskytuje mechanismus automatického ladění (AutoTune), který prohledává hodnoty nprobe a hledá optimální konfiguraci pro cílový recall.
Konstrukce IndexIVFFlat vyžaduje třífázovou pipeline: trénování, přidávání a vyhledávání. Během trénování běží k-means na reprezentativním vzorku, aby se naučily centroidy shluků. Během přidávání je každý databázový vektor přiřazen k nejbližšímu centroidu a připojen k invertovanému seznamu tohoto centroidu. Během vyhledávání je dotaz porovnán se všemi centroidy, je vybráno nprobe nejbližších a pouze vektory v těchto vybraných seznamech jsou porovnávány vyčerpávajícím způsobem. Tovární řetězec pro IndexIVFFlat se skalárním součinem je "IVF100,Flat", kde 100 je hodnota nlist. V Pythonu: index = faiss.index_factory(d, "IVF100,Flat", faiss.METRIC_INNER_PRODUCT).
| Velikost datové sady | Doporučené nlist | Doporučené nprobe | Očekávaný recall | Zrychlení oproti Flat |
|---|---|---|---|---|
| 10 000 | 10 – 100 | 1 – 5 | 95–98% | 5–20× |
| 100 000 | 100 – 1 000 | 5 – 20 | 95–99% | 20–100× |
| 1 000 000 | 1 000 – 10 000 | 10 – 50 | 95–99% | 100–500× |
| 10 000 000 | 10 000 – 100 000 | 20 – 100 | 90–98% | 500–5000× |
IndexHNSWFlat je grafový přibližný index nejbližších sousedů, který vytváří vícevrstvý hierarchický graf známý jako Navigovatelný malý svět. Algoritmus, původně publikovaný Malkovem a Yashuninem (2016), je inspirován datovou strukturou skip-list. Index organizuje vektory do vrstev: spodní vrstva (vrstva 0) obsahuje všechny vektory a každá následující vrstva obsahuje postupně menší podmnožinu generovanou pravděpodobnostním přiřazením úrovní. Při vkládání je každému vektoru přiřazena úroveň l = floor(-ln(uniform(0,1)) × mL) kde mL = 1/ln(M). Vstupní bod je v nejvyšší existující vrstvě, což zajišťuje logaritmické procházení grafu.
Vyhledávání začíná v nejvyšší vrstvě (nejhrubší, s nejméně uzly) a sestupuje skrze vrstvy, přičemž v každém kroku zpřesňuje množinu kandidátů. V každé vrstvě hladové vyhledávání prochází graf směrem k dotazu tím, že se vždy přesouvá k sousedovi, který minimalizuje vzdálenost. Po nalezení lokálního minima v aktuální vrstvě algoritmus sestoupí do další vrstvy a opakuje proces s použitím výsledku z nadřazené vrstvy jako výchozího bodu. Tato hierarchická struktura umožňuje logaritmickou komplexitu vyhledávání O(log N), což činí HNSW jedním z nejrychlejších přibližných algoritmů pro vyhledávání nejbližších sousedů pro středně velké až velké datové sady.
HNSW index má tři kritické parametry:
| Parametr | Popis | Typický rozsah | Dopad |
|---|---|---|---|
| M | Maximální počet obousměrných spojení na uzel | 8 – 64 (výchozí 32) | Vyšší M = hustěji propojený graf, lepší recall, více paměti |
| efConstruction | Velikost dynamického seznamu kandidátů při stavbě grafu | 40 – 200 (výchozí 40) | Vyšší = důkladnější vyhledávání při stavbě, kvalitnější graf, pomalejší stavba |
| efSearch | Velikost dynamického seznamu kandidátů při vyhledávání | 10 – 200 (nastavuje se při dotazu) | Vyšší = lepší recall, pomalejší vyhledávání (lze ladit bez přestavby) |
Parametr M řídí přímo propojenost grafu. Každý vektor udržuje až M obousměrných hran ke svým nejbližším sousedům. Graf používá heuristiku podporující různorodost při výběru sousedů: když je přidán nový uzel, jeho kandidáti na sousedy jsou ořezáni, aby byla zajištěna různorodá konektivita, která zabraňuje tomu, aby uzly-huby dominovaly struktuře grafu. Vyšší hodnoty M vytvářejí robustnější směrování, ale zvyšují spotřebu paměti: přibližně 4d + M × 2 × 4 bajty na vektor pro strukturu grafu plus úložiště vektorů.
Parametr efConstruction řídí důkladnost vyhledávání během stavby indexu. Větší hodnoty vytvářejí kvalitnější grafy, ale lineárně zvyšují dobu stavby. Jako pravidlo platí, že efConstruction ≈ M × 2 poskytuje dobrou rovnováhu pro většinu úloh. Parametr efSearch je analogický nprobe u IVF indexů – řídí důkladnost vyhledávání při dotazování a lze jej dynamicky upravovat bez rekonstrukce indexu.
HNSW indexy nabízejí několik výhod oproti IVF indexům. Obvykle dosahují vyššího recallu při ekvivalentní rychlosti vyhledávání, zejména u vícerozměrných dat (d > 256). Nevyžadují samostatný trénovací krok (na rozdíl od IVF, které potřebuje k-means shlukování, což činí HNSW vhodným pro dynamické datové sady, kde vektory přibývají postupně). Vykazují pozvolnou degradaci recallu při snižování efSearch – recall se zlepšuje plynule bez ostrých prahů. HNSW indexy však spotřebovávají více paměti na vektor (seznamy sousedů v grafu přidávají režii) a jsou pomalejší na stavbu než IVF indexy. HNSW také nativně nepodporuje mazání vektorů, protože odstraňování uzlů z grafové struktury by narušilo konektivitu.
Pro referenční sadu TarmacView o přibližně 9 000 embeddingech dosahuje IndexHNSWFlat s M=32 a efSearch=64 >99% recallu při časech dotazu pod 200 mikrosekund na CPU – 50× zrychlení oproti IndexFlatIP se zanedbatelnou ztrátou přesnosti. Tovární řetězec "HNSW32,Flat" vytváří tento index. V Pythonu: index = faiss.index_factory(d, "HNSW32,Flat", faiss.METRIC_INNER_PRODUCT).
Kosinová podobnost měří kosinus úhlu mezi dvěma nenulovými vektory – kvantifikuje, jak podobné jsou dva vektory bez ohledu na jejich velikost. Kosinová podobnost mezi vektory a a b je definována jako cos(θ) = (a · b) / (||a|| × ||b||) kde a · b je skalární součin a ||a|| je L2 norma a. Výsledek se pohybuje od -1 (zcela opačný směr) do +1 (identický směr), přičemž 0 značí ortogonalitu.
FAISS neposkytuje vyhrazenou metriku kosinové podobnosti. Místo toho je kosinová podobnost implementována pomocí dvoukrokové transformace, kterou vývojový tým FAISS považuje za kanonickou. Nejprve jsou všechny vektory L2-normalizovány na jednotkovou délku – každý vektor je vydělen svou L2 normou tak, aby ||a|| = 1 a ||b|| = 1. Za druhé je METRIC_INNER_PRODUCT použit jako metrika vzdálenosti. U jednotkově normalizovaných vektorů se skalární součin rovná kosinové podobnosti: a · b = cos(θ). Tato ekvivalence vyplývá přímo z kosinového vzorce: když je jmenovatel roven 1, vzorec se redukuje na skalární součin.
Tato normalizační technika je standardní napříč systémy vektorového vyhledávání, protože skalární součin lze efektivně počítat pomocí vysoce optimalizovaných BLAS rutin pro násobení matic. Výpočetní náklady normalizace všech vektorů v indexu jsou jednorázovou operací O(N × D) při stavbě indexu a normalizace každého dotazu je O(D) – zanedbatelné v porovnání s náklady samotného vyhledávání. L2 normalizace se aplikuje před přidáním vektorů do indexu a před odesláním dotazů, čímž se zajišťuje, že všechna porovnání probíhají v prostoru kosinové podobnosti.
Ve FAISS je normalizace implementována pomocí obalu IndexPreTransform v kombinaci s NormalizationTransform (v Pythonu faiss.NormalizationTransform). Vzor konstrukce je:
import faiss
import numpy as np
dimension = 768
# Vytvoření indexu skalárního součinu
base_index = faiss.IndexFlatIP(dimension)
# Zabaleni s L2 normalizací
index = faiss.IndexPreTransform(
faiss.NormalizationTransform(dimension),
base_index
)
# Vektory přidané zde jsou automaticky L2-normalizovány
index.add(reference_embeddings)
# Dotazy odeslané zde jsou automaticky L2-normalizovány
distances, indices = index.search(query_embeddings, k)
Alternativní přístupy zahrnují ruční normalizaci vektorů pomocí faiss.normalize_L2() před přidáním a dotazováním, nebo konstrukci indexu pomocí index_factory, která podporuje vestavěnou normalizaci pomocí kroku předzpracování "L2norm". S tovární metodou: index = faiss.index_factory(d, "L2norm,HNSW32,Flat") vytvoří index, který automaticky normalizuje vektory na jednotkovou délku před stavbou HNSW grafu.
Pro TarmacView je tento přístup zásadní, protože DINOv2 embeddingy, stejně jako většina výstupů Vision Transformerů, se liší velikostí napříč různými snímky. Rozdíly v expozici, světelných podmínkách a nastavení kamery při inspekci letištních vozovek vytvářejí embeddingy různých velikostí, i když zachycují identické textury povrchu. Normalizace odstraňuje složku velikosti a zaměřuje porovnání podobnosti na směrovou shodu – dva snímky povrchu, které zachycují stejnou texturu vozovky, ale při různých úrovních expozice, budou vyhodnoceny jako vysoce podobné, protože jejich normalizované embeddingy míří stejným směrem, i když se jejich surové velikosti výrazně liší.
FAISS FAQ výslovně uvádí: “Kosinová podobnost mezi vektory x a y je definována jako cos(x, y) = ⟨x, y⟩ / (|x| × |y|). Normalizací dotazovacích a databázových vektorů předem lze problém převést zpět na vyhledávání maxima skalárního součinu.” FAISS také poznamenává, že použití skalárního součinu na normalizovaných vektorech je matematicky ekvivalentní použití L2 vzdálenosti na normalizovaných vektorech, se vztahem ||x - y||² = 2 - 2 × ⟨x, y⟩ pro jednotkově normalizované vektory.
Životní cyklus FAISS indexu v produkci zahrnuje pět odlišných fází: konfiguraci, trénování, naplnění, serializaci a dotazování. Každá fáze má specifická API volání, výkonnostní aspekty a osvědčené postupy.
Konfigurace začíná výběrem typu indexu a metriky vzdálenosti. FAISS poskytuje mechanismus továrního řetězce – kompaktní textovou specifikaci, která vytváří komplexní indexy. Tovární vzor je doporučeným přístupem, protože abstrahuje specifickou hierarchii tříd a automaticky vybírá optimální implementaci:
| Tovární řetězec | Typ indexu | Paměť na vektor (d=768) | Případ použití |
|---|---|---|---|
"Flat" | IndexFlat (exaktní L2 vyhledávání) | 3 072 bajtů | Malé referenční sady, základní pravda |
"IVF100,Flat" | IndexIVFFlat se 100 centroidy | ~3 100 bajtů | Střední sady, rychlé přibližné vyhledávání |
"HNSW32,Flat" | IndexHNSWFlat s M=32 | ~3 328 bajtů | Rychlé přibližné vyhledávání, dynamická data |
"IVF100,PQ16" | IndexIVFPQ, 16 podvektorů | ~80 bajtů | Velké měřítko, omezená paměť |
"IVF100,SQ8" | IndexIVF se skalární kvantizací | ~784 bajtů | Vyvážené, vynikající rychlost |
Trénování je vyžadováno pouze pro indexy, které se učí distribuci dat (IVF, PQ, SQ atd.). Během trénování index provádí k-means shlukování na reprezentativním vzorku vektorů. Pro algoritmus k-means používá FAISS vícenásobné náhodné inicializace a vybírá tu s nejnižší deformací. Trénovací sada by měla být reprezentativní pro data, která budou indexována – běžnou praxí je použití náhodné podmnožiny 1–10 % celé datové sady. FAISS vyžaduje, aby trénovací vektory měly stejnou dimenzionalitu jako data, která budou indexována. Příznak index.is_trained indikuje, zda bylo trénování dokončeno. Volání trénování je: index.train(training_vectors). Pro datové sady, kde byl index již natrénován (např. předtrénované centroidy jsou načteny ze souboru), je volání train zbytečné a přepíše naučené parametry.
Naplnění přidává vektory do natrénovaného indexu: index.add(reference_vectors). Vlastnost ntotal sleduje počet přidaných vektorů. U IVF indexů je každý vektor při operaci add přiřazen k nejbližšímu centroidu a připojen k jeho invertovanému seznamu. U HNSW indexů je graf postupně budován: každému novému vektoru je přiřazena úroveň vrstvy a jsou vytvořeny hrany k jeho M nejbližším sousedům v každé vrstvě pomocí parametru efConstruction. Přidávání vektorů je typicky pomalejší než dotazování, zejména u HNSW, kde je třeba graf aktualizovat.
Serializace ukládá index na disk: faiss.write_index(index, "index.faissindex"). Index se načítá zpět pomocí index = faiss.read_index("index.faissindex"). Serializace zachovává kompletní stav indexu včetně natrénovaných centroidů, struktury grafu, všech uložených vektorů, konfigurace metriky vzdálenosti a interních parametrů. Standardní přípona souboru je .faissindex. Velikost serializace závisí na typu indexu a počtu vektorů – pro IndexFlat s N vektory dimenzionality D je velikost přibližně N × D × 4 bajty plus malá režie.
Dotazování získává k nejbližších sousedů: distances, indices = index.search(query_vectors, k). Pole distances obsahuje hodnoty podobnosti nebo vzdálenosti v závislosti na metrice. Pole indices obsahuje pozice odpovídajících referenčních vektorů v pořadí, v jakém byly přidány (0-indexované). Pro dávkové dotazy FAISS efektivně zpracovává více dotazů současně pomocí násobení matice maticí, čímž dosahuje výrazně lepší propustnosti než jednotlivá volání dotaz po dotazu. Objekty indexu jsou thread-safe pro vyhledávací operace na samostatných instancích indexu, což umožňuje paralelní obsluhu dotazů v produkčním nasazení.
FAISS se často používá k implementaci klasifikace metodou k-nejbližších sousedů (kNN) – neparametrické metody strojového učení, která klasifikuje dotazovaný bod na základě většinového labelu mezi jeho k nejbližšími sousedy v referenční sadě. Tento přístup je obzvláště atraktivní, když: (1) je referenční sada pravidelně aktualizována o nové označené vzorky, (2) embeddingový prostor zachycuje smysluplné sémantické vztahy mezi datovými body a (3) jsou preferována interpretovatelná rozhodnutí založená na instancích před černoschránkovými neuronovými klasifikátory.
Klasifikační pipeline s FAISS sestává z pěti kroků:
Vytvoření označené referenční sady: Každý referenční vektor je spárován s labelzem základní pravdy (např. “asfalt – dobrý stav”, “beton – popraskaný povrch”, “tarmac – opravený”). Labely jsou uloženy v samostatném poli zarovnaném s pořadím FAISS indexu. TarmacView udržuje přibližně 9 000 takových označených referenčních embeddingů pokrývajících více typů povrchů a stavů kvality.
Indexování referenčních vektorů: Všechny referenční embeddingy jsou přidány do FAISS indexu. Pro exaktní vyhledávání s perfektním recalem se používá IndexFlatIP. Pro přibližné vyhledávání ve větším měřítku poskytují IndexHNSWFlat nebo IndexIVFFlat časy dotazů v řádu submilisekund s >99% recalem při správném naladění.
Odeslání dotazovaných embeddingů: Pro každý nový snímek ke klasifikaci se extrahuje jeho embedding pomocí stejného embeddingového modelu (DINOv2 s 768rozměrným výstupem) a normalizuje se na jednotkovou délku pro kosinovou podobnost.
Získání k nejbližších sousedů: FAISS vrací indexy a vzdálenosti k nejpodobnějších referenčních vektorů. Parametr k řídí kompromis mezi vychýlením a rozptylem. Menší k (např. 3–5) vytváří rozhodovací hranice citlivé na lokální strukturu, ale náchylné k přeučení na šum. Větší k (např. 15–20) vytváří hladší hranice s lepší generalizací, ale může ztratit jemné rozdíly. TarmacView používá k=10, což vyvažuje robustnost vůči odlehlým hodnotám s citlivostí na jemné variace kvality povrchu.
Provedení většinového hlasování: Spočítají se labely mezi k sousedy a vybere se nejčastější label jako výsledek klasifikace. Volitelně hlasování vážené vzdáleností přiřazuje vyšší váhu bližším sousedům: váha = 1,0 / (vzdálenost + ε) kde ε je malá konstanta zabraňující dělení nulou. Vážené hlasování je obzvláště výhodné, když má referenční sada nerovnoměrné rozložení tříd nebo když se hustota sousedů v embeddingovém prostoru liší.
| Hodnota k | Vychýlení | Rozptyl | Nejlepší pro |
|---|---|---|---|
| 1 – 3 | Nízké | Vysoký | Velké, čisté referenční sady, jemné hranice |
| 5 – 10 | Střední | Střední | Vyvážená, obecná klasifikace |
| 15 – 30 | Vyšší | Nižší | Zašuměné labely, hladké rozhodovací hranice |
Skóre vzdálenosti vrácená FAISS také slouží k odhadu spolehlivosti. Pokud všech top-k sousedů sdílí stejný label a mají vysoké skóre podobnosti (kosinová podobnost > 0,95), je klasifikace vysoce spolehlivá. Pokud je hlasování rozdělené (např. 6 z 10 pro vítězný label) nebo jsou skóre podobnosti nízká (< 0,70), systém může výsledek označit k lidské kontrole. Tato architektura uvědomující si spolehlivost je kritická pro bezpečnostně důležité aplikace, jako je inspekce letištních vozovek, kde by chybná klasifikace mohla ovlivnit priority údržby a provozní bezpečnost.
Embeddingový kontrakt mezi modelem DINOv2 a FAISS indexem je základem přesnosti klasifikace. Extraktor embeddingů je trénován pomocí samostatně řízeného učení tak, aby vzdálenosti mezi embeddingy odrážely vizuální podobnost mezi snímky povrchu vozovky. FAISS index věrně získává nejbližší sousedy podle metriky kosinové podobnosti. Když tento kontrakt platí – když vizuálně podobné stavy povrchu vytvářejí blízké embeddingy – dosahuje kNN klasifikace vysoké přesnosti s přirozenou interpretovatelností, která spočívá v tom, že ukazuje přesně ty referenční snímky, které ovlivnily každé klasifikační rozhodnutí.
GPU podpora ve FAISS je prvotřídní funkcí, která poskytuje výrazné zlepšení výkonu jak pro stavbu indexu, tak pro vyhledávání. GPU implementace, popsaná v článku “Billion-scale similarity search with GPUs” (Johnson, Douze, Jégou, 2017), je napsána v CUDA C++ a využívá architektury NVIDIA GPU od Kepler (Compute Capability 3.5) přes Hopper (Compute Capability 9.0+) a dále.
GPU akcelerace FAISS přináší měřitelné zlepšení výkonu: 5–10× zvýšení propustnosti vyhledávání oproti CPU u typických IVF a HNSW indexů; až 12× rychlejší stavba indexu pro IVF indexy, protože k-means shlukování je vysoce paralelizovatelné; 8× nižší latence u HNSW dotazů na GPU pomocí optimalizovaných kernelů pro procházení grafů; a nativní podpora dávkových dotazů, kde GPU vynikají ve zpracování stovek nebo tisíců dotazů současně pomocí operací matice-matice.
GPU implementace pokrývá nejpoužívanější typy indexů prostřednictvím vyhrazených CUDA tříd:
| Třída GPU indexu | CPU ekvivalent | Použité CUDA funkce |
|---|---|---|
| GpuIndexFlat | IndexFlat | BLAS gemm na GPU, sdílená paměť tiling |
| GpuIndexIVFFlat | IndexIVFFlat | Paralelní výpočet vzdálenosti, warp-level redukce |
| GpuIndexIVFPQ | IndexIVFPQ | PQ vyhledávací tabulky na GPU, rychlé přiřazování kódů |
| GpuIndexIVFScalarQuantizer | IndexIVFScalarQuantizer | podpora float16 na GPU Pascal+ |
GPU implementace používá warp shuffles (dostupné od Compute Capability 3.0+) a read-only texturovací cache pomocí ld.nc / __ldg (Compute Capability 3.5+). Algoritmus k-selection – nalezení top-k hodnot z velkého pole vzdáleností – pracuje až na 55 % teoretického špičkového výkonu GPU, což umožňuje implementaci nejbližších sousedů 8,5× rychlejší než předchozí GPU state-of-the-art podle článku z roku 2017. Pro správu GPU paměti objekt StandardGpuResources alokuje scratch prostor na GPU: přibližně 512 MiB na GPU s ≤4 GiB paměti a přibližně 1 536 MiB na větších GPU. Tento scratch prostor zabraňuje opakovaným voláním cudaMalloc / cudaFree během vyhledávání.
FAISS poskytuje bezproblémovou interoperabilitu mezi CPU a GPU prostřednictvím dvou klíčových funkcí: faiss.index_cpu_to_gpu(cpu_index, device_id) přenáší CPU index na zadané GPU zařízení a faiss.index_gpu_to_cpu(gpu_index) přenáší GPU index zpět do CPU paměti. Pro multi-GPU nasazení faiss.index_cpu_to_gpu_multiple_py(resources, cpu_index) distribuuje index napříč všemi dostupnými GPU zařízeními a dotazy jsou automaticky load-balanced. Multi-GPU přístup může škálovat na indexy obsahující stovky milionů vektorů rozdělením napříč paměťovými prostory GPU.
| Scénář | CPU | GPU (1×) | GPU (8×) |
|---|---|---|---|
| IndexFlat vyhledávání (100K × 768d), dávka=8192 | 50 ms | 5 ms | <1 ms |
| IVF k-means trénování (1M × 128d), nlist=1000 | 120 s | 10 s | 5 s |
| HNSW stavba (100K × 128d), M=32 | 30 s | 8 s | — |
| k-NN graf v miliardovém měřítku | dny | 12 hodin | 4 hodiny |
Pro TarmacView je GPU akcelerace cenná během fáze stavby indexu, kdy jsou pravidelně přidávány nové referenční snímky. Stavba IVF indexu s k-means na 9 000 768rozměrných vektorech je dokončena přibližně za 1–2 sekundy na moderním GPU (NVIDIA A100 nebo RTX 4090) oproti 30–60 sekundám na CPU. Během inference zůstává index na CPU pro nákladově efektivní nasazení – latence dotazu na CPU s IndexHNSWFlat je již pod 200 mikrosekund pro referenční sadu 9K a převod na GPU by přidal režii přenosu přes PCIe bez smysluplného snížení latence.

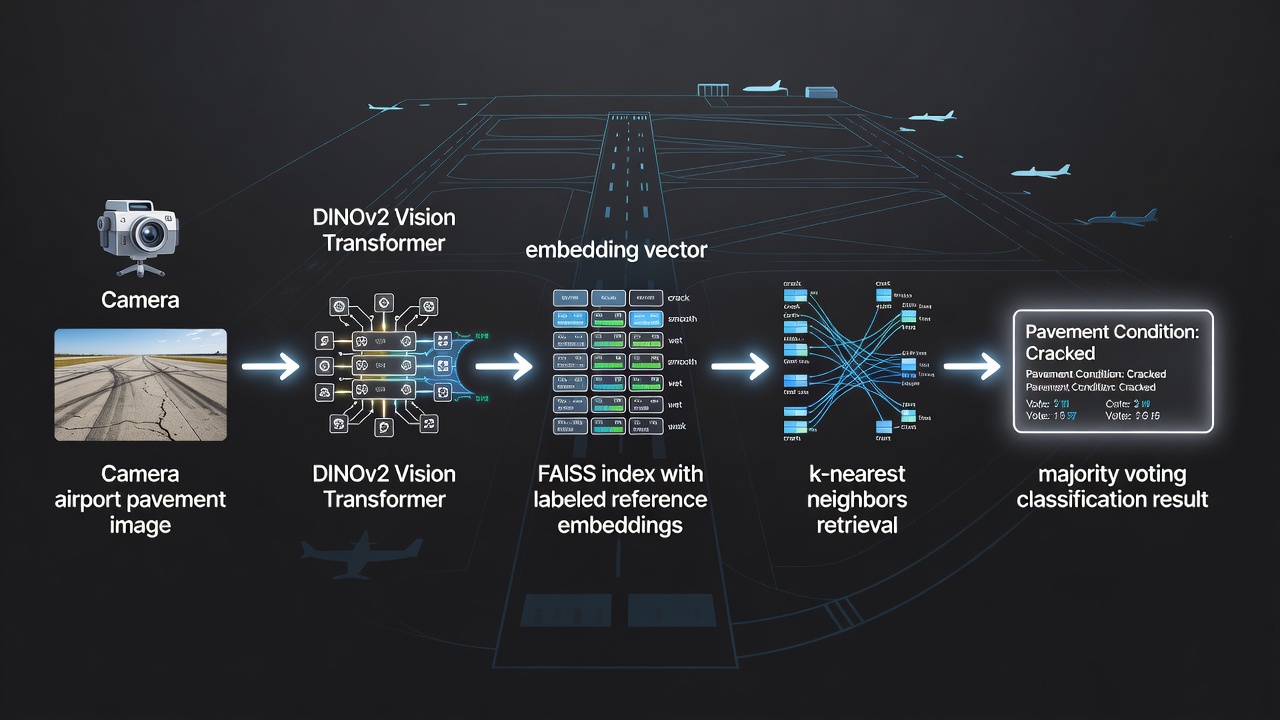
TarmacView integruje FAISS jako základní engine pro vyhledávání podobnosti ve svém automatizovaném systému klasifikace kvality povrchu letištních vozovek. Systém klasifikuje typy povrchu vozovek (asfalt, beton, tarmac) a stavy kvality povrchu (dobrý, uspokojivý, špatný, poškozený, popraskaný, opravený) porovnáváním inspekčních snímků s kurátorovanou referenční sadou přibližně 9 000 označených embeddingů.
Konstrukce referenční sady: Každý referenční embedding je extrahován z vysoce rozlišeného snímku vozovky pomocí modelu DINOv2 Vision Transformer (ViT-B/14 nebo ekvivalent), který produkuje 768rozměrný vektor zachycující vizuální charakteristiky jako texturové vzory, barevné rozložení, morfologii trhlin, expozici kameniva, opotřebení povrchu a stopy oprav. Každý embedding je anotován labelzy základní pravdy stanovenými certifikovanými inspektory vozovek během počáteční fáze trénování systému. Referenční sada pokrývá více letišť, klimatických zón a stáří vozovek, aby byla zajištěna robustní klasifikace napříč různými podmínkami.
Výběr indexu: TarmacView volí typ indexu na základě požadavků nasazení:
| Scénář nasazení | Typ indexu | Doba dotazu | Recall | Paměť |
|---|---|---|---|---|
| Offline QA / validace | IndexFlatIP | ~2 ms | 100% | ~28 MB |
| Reálné polní nasazení | IndexHNSWFlat (M=32, efSearch=64) | <200 μs | >99% | ~30 MB |
| Edge zařízení (omezená RAM) | IndexIVFFlat (nlist=100, nprobe=10) | ~300 μs | ~97% | ~28 MB |
Klasifikační workflow:
Kamera namontovaná na dronu (např. série DJI Matrice s vysokorozlišeným nákladem) nebo ruční inspekční zařízení zachycuje snímky vozovek během rutinních inspekcí letištních ploch v souladu s ICAO Annex 14 a FAA AC 150/5380-7B pro hodnocení stavu vozovek.
Každý snímek je předzpracován (oříznut pro odstranění ploch mimo vozovku, normalizován na standardní rozlišení) a projde embeddingovým modelem DINOv2 běžícím na edge inferenčním akcelerátoru (NVIDIA Jetson nebo ekvivalent).
Výsledný 768rozměrný embedding je L2-normalizován na jednotkovou délku pro výpočet kosinové podobnosti. Normalizace zajišťuje, že změny expozice mezi inspekčními lety neovlivní pořadí podobnosti.
FAISS dotazuje index IndexHNSWFlat s k=10 a vrací 10 indexů nejbližších referenčních embeddingů a jejich skóre skalárního součinu (ekvivalent kosinové podobnosti pro normalizované vektory).
Systém provádí většinové hlasování o labelech 10 sousedů. Pokud má vítězný label alespoň 6 z 10 hlasů (60% konsenzus), je klasifikace přijata se skóre spolehlivosti vypočítaným jako poměr vítězných hlasů k celkovému počtu hlasů.
Pokud je hlasování rozděleno pod 60% konsenzus, jsou embedding snímku a top-10 referenčních snímků označeny k lidské kontrole certifikovaným inspektorem vozovek prostřednictvím webového rozhraní TarmacView.
Klasifikace jsou zaznamenány v databázi TarmacView s časovými razítky, GPS souřadnicemi, typem povrchu, stavem kvality, skóre spolehlivosti a odkazy na podpůrné referenční snímky. To vytváří plně auditovatelnou stopu inspekce pro regulační soulad.
Tato klasifikační pipeline poháněná FAISS umožňuje TarmacView zpracovávat tisíce snímků vozovek denně s konzistentním, objektivním hodnocením kvality – čímž se snižuje závislost na subjektivní lidské vizuální inspekci a umožňuje škálovatelné monitorování stavu letištních ploch napříč celými letištními sítěmi.
FAISS zaujímá výraznou niku v ekosystému vektorového vyhledávání. Je to knihovna, nikoli databáze, a toto rozlišení má významné důsledky pro architekturu, nasazení a provozní charakteristiky. Knihovna FAISS poskytuje čistě funkcionalitu vyhledávání nejbližších sousedů bez režie plnohodnotného databázového systému.
| Funkce | FAISS | Pinecone | Milvus | Qdrant | Weaviate |
|---|---|---|---|---|---|
| Typ | Knihovna | Spravovaná služba | Databáze | Databáze | Databáze |
| Nasazení | Vestavěné | Cloud / SaaS | Self-hosted / Cloud | Self-hosted / Cloud | Self-hosted / Cloud |
| Perzistence | Ruční ukládání/načítání | Automatická | Automatická | Automatická | Automatická |
| CRUD | Není vestavěno | Plné CRUD | Plné CRUD | Plné CRUD | Plné CRUD |
| Filtrování metadat | Pouze na základě ID | Bohaté filtry | Atribut + skalární | Filtrování payloadu | Grafové |
| Škálování | Ruční sharding | Automatické škálování | Distribuované Raft/Paxos | Distribuované | Distribuované |
| GPU podpora | Nativní CUDA | Ne | Omezené (CUDA) | Ne | Ne |
| Latence dotazu | 10 μs – 1 ms | 2 – 10 ms | 1 – 10 ms | 1 – 5 ms | 1 – 10 ms |
| Licence | MIT | Proprietární | Apache 2.0 | Apache 2.0 | BSD-3 |
Klíčovou výhodou FAISS oproti plnohodnotným databázovým systémům je výkon a jednoduchost. Dotazy ve FAISS jsou typicky 10–100× rychlejší než ekvivalentní dotazy v databázových systémech, protože: knihovna běží v rámci procesu bez síťových cest; neexistuje režie parsování dotazů, autentizace nebo autorizace; neexistuje nepřímé úložiště ani správa buffer poolu; a FAISS indexy jsou optimalizované lineárně-algebraické datové struktury bez transakční režie. FAISS pracuje přímo s datovými strukturami v paměti pomocí optimalizovaných BLAS rutin, bez meziprocesové komunikace.
Klíčovou výhodou databázových systémů oproti FAISS je provozní pohodlí. Poskytují automatickou trvanlivost dat s write-ahead logováním a replikací, podporují bohaté filtrování metadat (např. “najdi podobné snímky pořízené po lednu 2025, které zobrazují betonovou vozovku v regionu jihozápad USA”), nabízejí REST nebo gRPC API pro jazykově nezávislý přístup, zahrnují monitorovací dashboardy a alerting a zvládají zálohování a disaster recovery. Podporují souběžné čtení a zápis s transakčními zárukami a vývojem schématu.
Pro TarmacView je použití FAISS přímo namísto vektorové databáze správným architektonickým rozhodnutím ze čtyř důvodů: (1) referenční sada je malá (~9K vektorů, přibližně 28 MB) a vejde se celá do paměti; (2) požadavky na latenci dotazu jsou agresivní (submilisekundová klasifikace pod 200 μs je dosažitelná s HNSW na CPU); (3) systém běží v edge nasazeních na letištích, kde by síťový přístup k databázovému serveru mohl být nepraktický nebo zavádět nepřijatelnou latenci; a (4) index je přestavován zřídka (týdně nebo měsíčně, jak přibývají nové referenční snímky po validaci inspektorem), což činí ruční serializaci a správu verzí zvládnutelnou.
Serializace FAISS indexu převádí objekt indexu v paměti na binární reprezentaci, kterou lze uložit na disk, přenést po síti nebo načíst do jiného procesu či počítače. Serializace zachovává kompletní stav indexu včetně všech uložených vektorů, natrénovaných centroidů (pro IVF a PQ indexy), struktury grafu (pro HNSW), konfigurace metriky vzdálenosti (L2 vs. IP vs. ostatní) a všech interních parametrů (efConstruction, M, nastavení normalizace atd.).
Primární serializační funkce jsou:
| Funkce | Popis | Výstup | Případ použití |
|---|---|---|---|
| write_index(index, filename) | Zapíše index do souboru | Soubor .faissindex | Trvalé úložiště na disku |
| read_index(filename) | Načte index ze souboru | Objekt indexu | Načtení pro obsluhu |
| serialize_index(index) | Zapíše index do bajtů | Python bytes objekt | Úložiště v databázi, fronty zpráv |
| deserialize_index(data) | Načte index z bajtů | Objekt indexu | Načtení z paměťového bufferu |
Velikost serializace závisí na typu indexu a počtu vektorů. Pro IndexFlatIP s N vektory dimenze D je velikost souboru přibližně N × D × 4 bajty (32bitové float úložiště) plus režie pro hlavičku a metadata. Pro IndexIVFFlat je další úložiště spotřebováno centroidy shluků: nlist × D × 4 bajty. Pro IndexHNSWFlat přidává struktura grafu N × M × 2 × 4 bajty pro seznamy sousedů (za předpokladu 32bitových indexů sousedů uložených obousměrně). Pro HNSW index TarmacView s 9 000 vektory o 768 dimenzích a M=32 je serializovaný soubor přibližně 25 MB: 9 000 × 768 × 4 = 27,6 MB pro vektory plus 9 000 × 32 × 2 × 4 = 2,3 MB pro strukturu grafu, minus skutečnost, že HNSW ukládá vektory interně v plochém indexu.
Serializace podporuje přenos mezi kontexty: index postavený na GPU lze uložit na disk a načíst na CPU. Doporučeným vzorem je vždy před serializací přenést GPU indexy na CPU:
cpu_index = faiss.index_gpu_to_cpu(gpu_index) # přenos na CPU
faiss.write_index(cpu_index, "production_index.faissindex") # uložení na disk
# Na jiném počítači (nebo později):
deployed_index = faiss.read_index("production_index.faissindex")
deployed_index.hnsw.efSearch = 64 # nastavení parametrů pro vyhledávání
D, I = deployed_index.search(queries, k)
Pro produkční nasazení může být serializovaný index verzován společně s kódem aplikace. TarmacView udržuje verzované soubory FAISS indexu ve svých artefaktech nasazení, čímž zajišťuje, že každé edge nasazení používá identickou referenční sadu pro reprodukovatelné výsledky klasifikace. Když jsou přidány a validovány nové referenční snímky, je natrénován nový index, jeho přesnost je srovnána s předchozím indexem pomocí základní pravdy IndexFlatIP a nový index je nasazen prostřednictvím standardní CI/CD pipeline.
Zatímco současná referenční sada TarmacView o přibližně 9 000 vektorech je skromná, FAISS je navržen tak, aby škáloval na miliardy vektorů na jediném serveru. Knihovna poskytuje komplexní sadu nástrojů pro zpracování rozsáhlých nasazení prostřednictvím tří doplňkových technik: vektorové komprese, nevyčerpávajícího vyhledávání a distribuovaného indexování.
Produktová kvantizace (PQ) je ztrátová kompresní technika, která dramaticky snižuje paměťovou stopu na vektor. PQ rozděluje každý D-rozměrný vektor na m podvektorů stejné velikosti (každý o D/m dimenzích). Každý podvektor je kvantizován nezávisle pomocí kódové knihy o 256 položkách (8 bitů) naučené pomocí k-means shlukování. Původní float32 vektor (4 × D bajtů) je komprimován na m bajtů kódových indexů plus malá kódová kniha. Kompresní poměry PQ 4× až 16× jsou běžné, což umožňuje jedinému počítači indexovat stovky milionů vektorů v hlavní paměti. FAISS IndexIVFPQ kombinuje IVF s PQ, přičemž používá centroidy shluků jako hrubý kvantizér a PQ kódy pro reziduální kompresi. Výpočet vzdálenosti používá Asymetrický výpočet vzdálenosti (ADC): dotaz zůstává nekomprimovaný a vzdálenosti k PQ-komprimovaným databázovým vektorům jsou počítány pomocí předpočítaných vyhledávacích tabulek, čímž se zabrání režii dekomprese.
| PQ konfigurace | Bajtů/vektor (d=768) | Paměť, N=100M | Recall vs. nekomprimovaný |
|---|---|---|---|
| PQ32 (m=32, 8-bit) | 40 | 3,7 GB | ~90–95% |
| PQ64 (m=64, 8-bit) | 72 | 6,7 GB | ~95–98% |
| PQ96 (m=96, 8-bit) | 104 | 9,7 GB | ~97–99% |
Skalární kvantizace (SQ) převádí každou float32 složku na 8bitové nebo 4bitové celé číslo bez znaménka, čímž snižuje úložiště 4× (SQ8) nebo 8× (SQ4) s minimální ztrátou přesnosti. Tovární řetězec "IVF100,SQ8" vytváří IVF index se skalární kvantizací. SQ je při dotazování rychlejší než PQ, protože výpočty vzdálenosti jsou prováděny přímo na kvantizovaných hodnotách bez předpočítávání vyhledávacích tabulek. SQ8 ukládá jeden bajt na dimenzi; SQ4 ukládá dvě dimenze na bajt.
Pro datové sady v miliardovém měřítku doporučená konfigurace FAISS kombinuje HNSW jako hrubý kvantizér s IVFPQ pro kompresi vektorů: quantizer = IndexHNSWFlat(d, hnsw_m); index = IndexIVFPQ(quantizer, d, nlist, M, nbits). HNSW kvantizér urychluje vyhledávání centroidů oproti plochému vyhledávání během dotazování a PQ komprimuje databázové vektory na zlomek jejich původní velikosti. Původní článek o FAISS (2017) benchmarkoval stavbu k-NN grafu na 95 milionech obrázků (z datové sady YFCC100M) za 35 minut na GPU a k-NN graf na 1 miliardě vektorů za méně než 12 hodin na 4× Maxwell Titan X GPU.
FAISS IndexShards rozděluje velkou datovou sadu napříč více podindexy, každý potenciálně na jiném počítači nebo GPU. Každý shard obdrží podmnožinu vektorů a zpracovává dotazy nezávisle. Výsledky jsou sloučeny pomocí k-way merge top-k výsledků z každého shardu. Tento přístup poskytuje lineární škálování s počtem dostupných serverů: zdvojnásobení počtu shardů snižuje dobu vyhledávání pro danou velikost datové sady na polovinu.
Pro datové sady přesahující dostupnou RAM poskytuje FAISS diskové indexy, které udržují strukturu indexu (invertované seznamy nebo graf) v paměti, ale ukládají vektorová data na SSD. Třída IndexOnDisk a související nástroje transparentně načítají vektorová data z disku během vyhledávání pomocí memory-mapped souborů nebo explicitních I/O operací. S moderními NVMe SSD poskytujícími 3–7 GB/s sekvenčního čtení se diskové vyhledávání může mnoha úlohám přiblížit výkonu v paměti, zejména když je udržována prostorová lokalita (sousední vektory uložené souvisle na disku).
Pro TarmacView je současná referenční sada 9K vektorů dobře v optimálním rozsahu FAISS pro exaktní vyhledávání s IndexFlatIP. Nicméně jak se systém rozšiřuje o referenční snímky ze stovek letišť a více inspekčních kampaní – potenciálně až na miliony označených embeddingů – poskytují škálovací mechanismy FAISS (IVF pro nevyčerpávající vyhledávání, PQ pro kompresi, diskové úložiště pro datové sady přesahující RAM) jasnou cestu upgradu bez nutnosti zásadně odlišné architektury. Typ indexu lze upgradovat z IndexFlatIP → IndexIVFFlat → IndexIVFPQ → IndexShards(IndexIVFPQ) jak referenční sada roste, přičemž každý krok obětuje minimální přesnost za řádové zlepšení rychlosti vyhledávání a paměťové efektivity.
Literatura FAISS (včetně komplexního arXiv článku z roku 2024 “The Faiss Library” od Douze, Guzhva, Deng, Johnson, Szilvasy, Mazaré, Lomeli, Hosseini a Jégou) poskytuje podrobné pokyny pro výběr indexu: “Existuje volba mezi tuctem typů indexů a optimální obvykle závisí na omezeních daného problému.” FAISS také zahrnuje komplexní benchmarkovou sadu (faiss_benchmarks), která měří recall a propustnost napříč různými konfiguracemi indexů, přičemž spouští vyhledávání s výsledky základní pravdy z IndexFlat pro kvantifikaci přesnosti. Praktici jsou vyzýváni, aby benchmarkovali svou specifickou distribuci dat – optimální index pro danou datovou sadu závisí na dimenzionalitě vektorů, velikosti datové sady, cílovém recallu, rozpočtu latence a dostupné paměti.
Využijte FAISS pro vysoce výkonné vyhledávání podobnosti na datech obrazových embeddingů. Kontaktujte nás a zjistěte, jak TarmacView integruje FAISS pro klasifikaci kvality povrchu v reálném čase a vyhledávání inspekčních snímků.
Embedding space je vícerozměrný matematický prostor, ve kterém jsou objekty, jako jsou obrázky, text nebo senzorová data, reprezentovány jako vektory, což umožň...
DINOv3 (self-DIstillation with NO labels v3) je samostatně učený vision transformer (ViT-B/16) předtrénovaný na 1,7 miliardách obrázků, produkující vysoce kvali...
Detekce trhlin na bázi AI využívá počítačové vidění — konvoluční neuronové sítě, vision transformery a modely sémantické segmentace — k automatické identifikaci...