Risssegmentierung ist die Computer-Vision-Aufgabe, jedes Pixel eines Bildes entweder als Riss oder als Nicht-Riss zu klassifizieren und eine binäre Maske zu erzeugen, die eine präzise Messung der Rissgeometrie — Fläche, Länge, Breite und Musteranalyse — ermöglicht. DINOv3-basierte dichte Segmentierungsköpfe und U-Net-Architekturen stellen den Stand der Technik für die Infrastrukturinspektion dar.
Pixelgenaue Risssegmentierung für die Infrastrukturinspektion
1. Definition und Unterschied zur Rissklassifizierung
Risssegmentierung ist eine dichte Pixelvorhersageaufgabe im Bereich Computer Vision, die jedem einzelnen Pixel in einem Eingabebild ein binäres Label (Riss oder Nicht-Riss) zuweist. Die Ausgabe ist eine binäre Segmentierungsmaske mit denselben räumlichen Abmessungen wie das Eingabebild, bei der Risspixel als Vordergrund (typischerweise weiß oder Wert 1) und Nicht-Riss-Pixel als Hintergrund (schwarz oder Wert 0) markiert sind. Diese Maske bewahrt die exakte Morphologie, Topologie und Geometrie jedes im Bild vorhandenen Risses, einschließlich Verzweigungen, isolierter Fragmente und submillimeterbreiter Spalten.
Rissklassifizierung arbeitet auf Bildebene — das Modell gibt einen einzelnen Skalar aus, der angibt, ob im Bild irgendwo ein Riss vorhanden ist. Ein Klassifizierungsmodell könnte „Riss vorhanden: 93 % Konfidenz" vorhersagen, aber nicht lokalisieren, wo sich der Riss befindet, wie lang er ist oder wie breit er geworden ist. Dies ist für die Infrastrukturinspektion grundsätzlich unzureichend, da präzise Messungen für die Priorisierung von Wartungsmaßnahmen, die Kostenschätzung von Reparaturen und die Bewertung der strukturellen Sicherheit erforderlich sind.
Rissdetektion mittels Objekterkennung (Faster R-CNN, YOLO, SSD) gibt Begrenzungsrahmen um Rissbereiche aus. Während die Detektion eine Lokalisierung bietet, enthält ein Begrenzungsrahmen um einen dünnen, langgestreckten Riss hauptsächlich Hintergrundpixel und liefert keine Informationen über Rissbreite, Topologie oder Verzweigungsstruktur. Ein Riss, der sich serpentinenartig über eine Startbahn zieht, kann Dutzende überlappender Begrenzungsrahmen ohne semantische Beziehung zueinander erfordern.
Risssegmentierung löst all diese Einschränkungen. Jedes Risspixel wird identifiziert, was direkte Messungen ermöglicht von:
Rissfläche in Quadratmillimetern (Pixelanzahl × räumliche Auflösung)
Risslänge entlang der skelettierten Mittellinie in Millimetern
Rissbreite (mittlere, maximale und pixelgenaue Breitenprofile)
Verzweigungsmuster (Anzahl der Verzweigungen, Knotenpunkte, fraktale Dimension)
Die International Civil Aviation Organization (ICAO) Annex 14 — Aerodromes, Volume I, legt fest, dass Startbahnoberflächen regelmäßig auf Verschlechterungen einschließlich Rissbildung untersucht werden müssen. ICAO Doc 9157, Part 3 — Pavements, enthält Leitlinien für Fahrbahnbewertungsmethoden. Die traditionelle manuelle Inspektion erfordert, dass Prüfer die Startbahn begehen, Risse mit Kreide oder Sprühfarbe markieren und Beobachtungen auf Papierformularen festhalten — ein Verfahren, das subjektiv, inkonsistent, gefährlich (Exposition gegenüber aktiven Luftseitigen Betriebsabläufen) und unmöglich mit submillimetergenauer Präzision durchführbar ist. Die automatisierte Risssegmentierung ersetzt die subjektive visuelle Schätzung durch reproduzierbare, quantitative, pixelgenaue Messungen, die über Inspektionen und Flughäfen hinweg verglichen werden können.
Aufgabe
Ausgabe
Rissposition
Rissgeometrie
Messpräzision
Klassifizierung
Einzelnes Label (Riss/kein Riss)
Keine
Keine
Bildebene
Detektion
Begrenzungsrahmen
Ungefähre Box
Keine
Box-Ebene
Segmentierung
Binäre Maske
Pixelgenau
Vollständige Geometrie
Pixelebene (sub-mm)
Der Übergang von der Klassifizierung zur Segmentierung stellt einen fundamentalen Leistungssprung dar. Die Klassifizierung beantwortet die Frage „Gibt es hier einen Riss?" Die Segmentierung beantwortet die Frage „Wo genau befindet sich jeder Riss, wie groß ist er, welche Form hat er und wie schwerwiegend ist der Schaden?" Bei TarmacViews crack_seg_head ist diese dichte Pixelvorhersagefähigkeit die Grundlage für die Erstellung hochpräziser Rissmasken, die direkt in Berechnungen des Fahrbahnzustandsindex, Schätzungen des Reparaturumfangs und Längsschnitt-Trendanalysen einfließen.
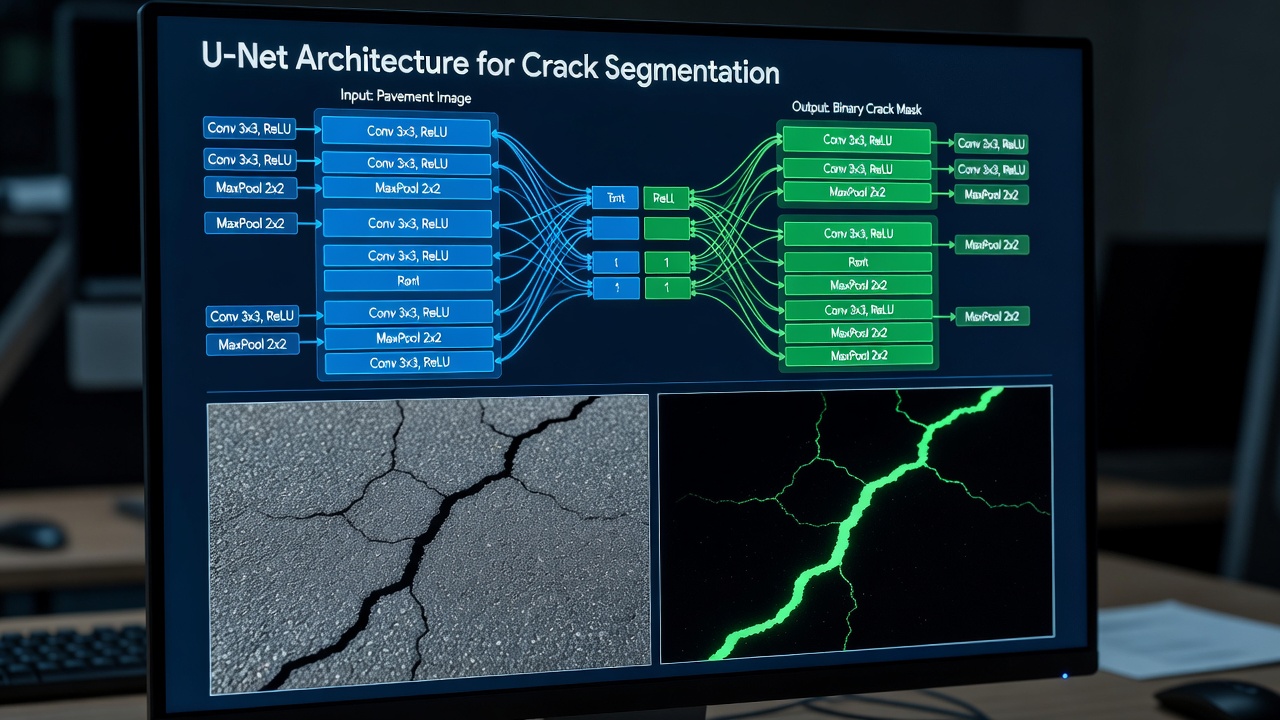
2. Segmentierungsarchitekturen
U-Net
Die U-Net-Architektur, eingeführt von Ronneberger, Fischer und Brox im Jahr 2015 für die biomedizinische Bildsegmentierung, hat sich zur am weitesten verbreiteten Architektur für die Risssegmentierung in Infrastrukturanwendungen entwickelt. U-Net besteht aus einer symmetrischen Encoder-Decoder-Struktur mit vier oder fünf Auflösungsstufen, die durch Skip-Verbindungen verbunden sind, welche hochauflösende räumliche Informationen direkt von den Encoder- zu den Decoder-Schichten übertragen.
Der Encoder (kontrahierender Pfad) wendet wiederholte 3×3-Faltungen gefolgt von ReLU-Aktivierung und 2×2-Max-Pooling an, wodurch die räumlichen Dimensionen schrittweise reduziert werden, während die Merkmalskanaltiefe von 64 auf 512 oder 1024 Kanäle erhöht wird. Jeder Encoder-Block lernt zunehmend abstraktere Repräsentationen — von einfachen Kantendetektoren in der ersten Schicht bis hin zu komplexen Detektoren für Risstextur und -morphologie in den tiefsten Schichten. Für die Risssegmentierung muss der Encoder lernen, echte Rissmerkmale von rissähnlichen Texturen zu unterscheiden, darunter Aggregatschatten, Reifenspuren, Baufugen, Oberflächenablagerungen und Dichtmittelstreifen.
Der Decoder (expandierender Pfad) führt die Spiegeloperation durch: 2×2-Hochkonvolution (transponierte Faltung) verdoppelt die räumliche Auflösung bei gleichzeitiger Halbierung der Kanaltiefe, konkateniert dann die entsprechende Encoder-Merkmalskarte über die Skip-Verbindung, gefolgt von zwei 3×3-Faltungen mit ReLU. Die letzte Schicht verwendet eine 1×1-Faltung mit Sigmoid-Aktivierung, um die binäre Rissmaske zu erzeugen.
Skip-Verbindungen sind die entscheidende Innovation bei U-Net. Bei Standard-Encoder-Decoder-Architekturen gehen während des Downsamplings alle räumlichen Details verloren und müssen im Decoder neu erlernt werden. Skip-Verbindungen übertragen feinkörnige räumliche Informationen — Risskanten, dünne Risslinien und präzise Grenzen — direkt vom Encoder zum Decoder auf jeder Auflösungsstufe. Dies ist für die Risssegmentierung unerlässlich, da Risse von Natur aus dünne Strukturen sind (oft 1-10 Pixel breit), die auf der Engpass-Ebene (32× herunterskaliert) vollständig verloren gehen würden.
Speziell für die Risssegmentierung umfassen U-Net-Varianten:
Attention U-Net: Fügt Aufmerksamkeitstore hinzu, die irrelevante Hintergrundmerkmale unterdrücken und gleichzeitig Rissbereiche hervorheben
Residual U-Net: Ersetzt Standardfaltungen durch Residualblöcke, was tiefere Netzwerke ohne verschwindende Gradienten ermöglicht
Dense U-Net: Verwendet dichte Blöcke (DenseNet-Stil) für verbesserte Merkmalsweitergabe und Gradientenfluss
U-Net++ : Fügt verschachtelte Skip-Verbindungen mit dichten Faltungsblöcken hinzu, wodurch die semantische Lücke zwischen Encoder- und Decoder-Merkmalen verringert wird
U-Net erzielt eine Spitzenleistung bei Risssegmentierungs-Benchmarks, einschließlich CRACK500 (IoU 0,65-0,72) und DeepCrack (IoU 0,70-0,78), wenn es mit geeigneten Verlustfunktionen und Datenaugmentierung trainiert wird.
DeepLabV3+
DeepLabV3+, entwickelt von Google Research (Chen et al., 2018), erweitert die DeepLab-Familie um eine Encoder-Decoder-Struktur, die durch Atrous Spatial Pyramid Pooling (ASPP) ergänzt wird. Die Kerninnovation ist die Verwendung von atrous (dilatierten) Faltungen mit mehreren parallel angewendeten Dilationsraten, um mehrskalige Kontextinformationen zu erfassen, ohne die räumliche Auflösung zu reduzieren.
ASPP wendet 3×3-Faltungen mit verschiedenen Dilationsraten an — typischerweise Raten von 6, 12 und 18 bei einer Ausgabeschrittweite von 16 — plus einer 1×1-Faltung und globalem Durchschnitts-Pooling. Jede Dilationsrate erfasst Rissmerkmale auf einer anderen Skala: Rate 6 erfasst feine, schmale Risse (1-3 Pixel breit), Rate 12 erfasst mittlere Risse und Rate 18 erfasst breite Risse und Rissnetzwerke. Die parallelen Zweige werden konkateniert und durch eine 1×1-Faltung verarbeitet, um die mehrskalige Merkmalsrepräsentation zu erzeugen.
Für die Risssegmentierung zeichnet sich DeepLabV3+ durch die Bewältigung der extremen Skalenvariation im Risserscheinungsbild aus. Ein einzelnes Startbahnbild kann Haarrisse (0,5 mm breit, 1-2 Pixel) neben breiten, ausgebrochenen Rissen (15+ mm breit, 30+ Pixel) enthalten. Das ASPP-Modul verarbeitet all diese Skalen gleichzeitig. Das Decoder-Modul vergrößert die ASPP-Merkmale um den Faktor 4, konkateniert sie mit Encoder-Merkmalen aus einer Zwischenschicht (vor dem ersten atrous-Block) und wendet zwei 3×3-Faltungen gefolgt von bilinearer Hochskalierung auf die ursprüngliche Auflösung an.
Zu den für die Risssegmentierung häufig verwendeten DeepLabV3+-Backbones gehören ResNet-50, ResNet-101 und Xception. In jüngerer Zeit wurden auch EfficientNet- und ConvNeXt-Backbones untersucht, die verbesserte Genauigkeits-Parameter-Verhältnisse bieten. DeepLabV3+ mit ResNet-101-Backbone erreicht IoU-Werte von 0,68-0,75 auf CRACK500, wenn es auf fahrbahnspezifischen Datensätzen trainiert wird.
SegFormer
SegFormer (Xie et al., 2021) führt einen hierarchischen Transformer-Encoder mit einem leichten MLP (mehrschichtiges Perceptron)-Decoder ein, was eine Abkehr von CNN-basierten Segmentierungsarchitekturen darstellt. Der Encoder verwendet eine Reihe von Mix Transformer (MiT)-Blöcken mit schrittweise abnehmender Auflösung (von 1/4 auf 1/32 der Eingabegröße) und zunehmenden Kanaldimensionen. Jeder MiT-Block verwendet effiziente Selbstaufmerksamkeit mit einem reduzierten räumlichen Reduktionsverhältnis, was ihn für hochauflösende Rissbilder recheneffizient macht.
Der Hauptvorteil von SegFormer für die Risssegmentierung ist das globale rezeptive Feld des Transformators ab der ersten Schicht. Im Gegensatz zu CNNs, bei denen jede Schicht nur eine lokale Nachbarschaft sieht (z. B. 3×3-Faltung = 1-Pixel-Nachbarschaft nach einer Schicht), berechnen Transformatoren die Aufmerksamkeit über die gesamte Merkmalskarte. Dies ermöglicht es SegFormer, weitreichende Abhängigkeiten zu erfassen — ein Riss, der sich durch eine gesamte 1024×1024-Kachel schlängelt, behält Pixel-zu-Pixel-Beziehungen durch den Aufmerksamkeitsmechanismus bei.
Der MLP-Decoder in SegFormer ist bemerkenswert einfach im Vergleich zu U-Net- oder DeepLabV3+-Decodern. Er aggregiert mehrstufige Merkmale aus allen vier Encoder-Stufen (durch Hochskalierung auf 1/4-Auflösung und Konkatenation), wendet eine einzelne MLP-Schicht zur Merkmalsmischung an, dann ein weiteres MLP zur Erzeugung der endgültigen Segmentierung. Trotz seiner Einfachheit erzielt der MLP-Decoder eine starke Leistung, da der hierarchische Transformer-Encoder bereits gut strukturierte Merkmale erzeugt.
SegFormer-B3 erreicht eine wettbewerbsfähige IoU (0,66-0,74) auf Risssegmentierungsdatensätzen und ist dabei parameter-effizienter als DeepLabV3+ mit ResNet-101. Die B0-B5-Modellfamilie bietet einen Kompromiss zwischen Geschwindigkeit und Genauigkeit, wobei B0 für Echtzeit-Randbereitstellung und B5 für maximale Genauigkeit auf Server-Hardware geeignet ist.
DINOv2- und DINOv3-Dichte-Vorhersageköpfe
DINOv2 (Oquab et al., 2023) und DINOv3 repräsentieren die neueste Generation von Vision Transformer (ViT)-Modellen, die durch selbstüberwachtes Lernen auf kuratierten Bilddatensätzen trainiert wurden. Im Gegensatz zum überwachten Vortraining auf ImageNet-1K verwendet DINO einen Selbst-Destillationsansatz, bei dem ein Studentennetzwerk lernt, die Ausgabe eines Lehrernetzwerks zu reproduzieren, das auf verschiedenen Ansichten desselben Bildes arbeitet (lokale Ausschnittsansichten vs. globale Ansichten).
Der Durchbruch von DINO für die Segmentierung liegt darin, dass die selbstüberwachten ViT-Merkmale — insbesondere die Key (K)- und Value (V)-Aufmerksamkeitsköpfe in den letzten Schichten — auf natürliche Weise Objektgrenzen und feinkörnige semantische Informationen kodieren, ohne jegliches überwachtes Segmentierungstraining. Eine dünnbesetzte Menge von Patch-Token (z. B. 0,05 % der Patches) kann linear sondiert werden, um Segmentierungskarten zu erzeugen, die mit vollständig überwachten Modellen konkurrieren.
Für die Risssegmentierung wird ein dichter Vorhersagekopf am DINO-Backbone angebracht. Der typische Ansatz extrahiert mehrskalige Merkmale aus den letzten 4-6 Schichten des ViT, konkateniert sie und wendet einen Faltungs-Decoder an, der auf die ursprüngliche Bildauflösung hochskaliert. Der Decoder kann sein:
Ein leichter Linear Head: Einfach eine 1×1-Faltung nach der Hochskalierung der ViT-Patch-Token (Patch-Größe 14×14 für ViT-L/14)
Ein Feature Pyramid Network (FPN)-Kopf: Mehrskalige Merkmalsextraktion mit lateralen Verbindungen und Top-Down-Pfad
Ein MaskFormer-artiger Kopf: Transformer-Decoder, der Kreuzaufmerksamkeit auf DINO-Merkmale anwendet und binäre Masken erzeugt
DINOv3-basierte Risssegmentierung erreicht IoU-Werte von über 0,78 auf CRACK500 und 0,82 auf DeepCrack, wenn sie End-to-End mit Rissmasken-Datensätzen feinabgestimmt wird. Das selbstüberwachte Vortraining liefert starke Merkmalsrepräsentationen, die besser auf neue Oberflächen und Lichtverhältnisse verallgemeinern als überwachte ImageNet-Backbones.
Architektur
Parameter
CRACK500 IoU
Inferenzgeschwindigkeit (MP/s)
Hauptvorteil
U-Net (ResNet-34)
24M
0,68
45
Dateneffizienz bei kleinen Mengen
DeepLabV3+ (ResNet-101)
63M
0,72
28
Mehrskaliges ASPP
SegFormer-B3
47M
0,70
22
Globale Aufmerksamkeit
DINOv2-ViT-L/14 + dichter Kopf
307M
0,78
8
Selbstüberwachte Merkmale
3. Ground-Truth-Masken-Datensätze
Die Qualität und Vielfalt der Trainingsdatensätze bestimmt direkt die Leistung von Risssegmentierungsmodellen. Alle überwachten Risssegmentierungsmethoden erfordern pixelgenaue Ground-Truth-Masken — binäre Bilder, bei denen Expertenannotatoren jedes Risspixel sorgfältig gekennzeichnet haben. Die folgenden Datensätze stellen die am weitesten verbreiteten Benchmarks in der Risssegmentierungsforschung dar.
CRACK500
CRACK500 (Zhang et al., 2016) enthält 500 RGB-Bilder von Fahrbahnoberflächen, die mit einer handelsüblichen Kamera mit einem Bodenabtastabstand (GSD) von etwa 0,05 mm/Pixel aufgenommen wurden. Jedes Bild hat 2048×1536 Pixel und deckt eine physische Fläche von etwa 100×75 mm ab. Der Datensatz ist aufgeteilt in 250 Trainings-, 50 Validierungs- und 200 Testbilder.
Die Ground-Truth-Masken wurden von geschulten Prüfern manuell annotiert und kreuzverifiziert. Risse werden mit Subpixel-Genauigkeit gekennzeichnet, einschließlich Risse mit einer Breite von nur 0,1-0,2 mm (2-4 Pixel). Der Datensatz zeigt hauptsächlich Asphaltfahrbahnen mit einer Vielzahl von Risstypen: Querrisse, Längsrisse, Netzrisse (Ermüdungsrisse), Blockrisse und Kantenrisse. Der Hintergrund umfasst Aggregatstruktur, eine Mischung aus groben und feinen Asphaltpartikeln, Flickreparaturen und Dichtmaterialien.
CRACK500 ist der am häufigsten als Benchmark verwendete Datensatz in der Risssegmentierungsliteratur aufgrund seiner gleichbleibenden Qualität, angemessenen Größe und öffentlichen Verfügbarkeit. Basis-U-Net-Modelle erreichen etwa 0,65-0,68 IoU auf dem Testsplit, während aktuelle DINOv2-basierte Modelle 0,78-0,80 IoU erreichen.
DeepCrack
DeepCrack (Zou et al., 2019) enthält 537 RGB-Bilder von Rissen auf Beton- und Mauerwerksoberflächen mit einer Auflösung von 512×512 Pixeln. Der Datensatz wurde speziell für die Deep-Learning-Risssegmentierung entwickelt und umfasst verschiedene Oberflächentypen, die in reinen Fahrbahndatensätzen nicht vorkommen: Betonwände, Brückenpfeiler, Tunnelauskleidungen, Gebäudefassaden und Steinoberflächen. Ground-Truth-Annotationen wurden von mehreren Annotatoren erstellt und durch einen Konsensprozess verfeinert.
DeepCrack-Bilder enthalten anspruchsvolle Bedingungen: Schatten, Feuchtigkeitsflecken, Bewuchs, Graffiti und Oberflächenrauigkeiten, die optisch Rissmerkmale imitieren. Der Datensatz bietet offizielle Trainings- (400 Bilder) und Testsplits (137 Bilder). DeepCrack ist besonders wertvoll für die Bewertung der oberflächenübergreifenden Verallgemeinerung — Modelle, die nur auf DeepCrack trainiert wurden, liefern auf neuen Betonoberflächen tendenziell gute Ergebnisse, können aber auf Asphalt Probleme bereiten.
State-of-the-Art-Modelle erreichen 0,70-0,78 IoU auf DeepCrack. Die höhere Basisschwierigkeit des Datensatzes (im Vergleich zu CRACK500) ergibt sich aus der größeren visuellen Komplexität und der Riss-Hintergrund-Mehrdeutigkeit bei Mauerwerks- und Betonoberflächen.
CrackForest (CFD)
CrackForest Dataset (CFD) (Shi et al., 2016) enthält 118 Bilder von Asphaltstraßenbelägen, aufgenommen mit einer Auflösung von 320×480 Pixeln. Trotz seiner geringen Größe wird CFD aufgrund seiner sorgfältigen Annotation und des konsistenten Oberflächentyps häufig für die Kreuzvalidierung verwendet. Der Datensatz zeigt hauptsächlich Quer- und Längsrisse auf Straßen mit mittlerem Verkehrsaufkommen.
Die Leistung auf CFD liegt für moderne Modelle nahe der Sättigung — DINOv2 erreicht 0,84-0,87 IoU — aber der kleine Evaluierungssatz bedeutet, dass die statistische Signifikanz von Unterschieden begrenzt ist. CFD wird am häufigsten als Transfer-Learning-Test verwendet, um zu sehen, ob Modelle, die auf größeren Datensätzen (CRACK500, DeepCrack) trainiert wurden, ihre Genauigkeit auf diesem abweichenden Aufnahmebereich beibehalten.
CrackAirport
CrackAirport ist ein spezialisierter Datensatz für die Risssegmentierung von Flughafenfahrbahnen, der Bilder von Start- und Landebahnen, Rollwegen und Vorfeldern enthält, die bei routinemäßigen Flugplatzinspektionen aufgenommen wurden. Flughafenfahrbahnen stellen einzigartige Herausforderungen dar, die in Straßendatensätzen nicht vorkommen: gerillte Startbahnoberflächen (Querrillen mit etwa 30 mm Abstand zur Wasserableitung), Gummiablagerungen durch Flugzeugreifenaufsetzpunkte (die den Riss-Fahrbahn-Kontrast verringern), Kraftstoff- und Hydraulikflüssigkeitsflecken sowie spezielle Fugen- und Dichtungssysteme.
Der Datensatz enthält Bilder mit mehreren GSD-Werten (0,1-0,5 mm/Pixel), die mit fahrzeugmontierten Kameras und Handgeräten aufgenommen wurden. Rissspezifische Typen für Flughafenfahrbahnen — Eckabbrüche (starre Fahrbahn), Pumpen (Materialverlust unter Fugen) und Ausbrüche (Zuschlagstoffverlust) — werden neben Standardrisstypen annotiert. CrackAirport ist entscheidend für das Training von Modellen, die auf echten Flughafenoberflächen eingesetzt werden müssen, wo ein straßentrainiertes Modell inakzeptable falsch positive Ergebnisse auf gerillten Texturen oder Gummiablagerungen produzieren würde.
CrackSeg9k Zusammengestellter Datensatz
CrackSeg9k (Kulkarni et al., 2022) stellt die größte einheitliche Risssegmentierungszusammenstellung dar und kombiniert Bilder aus 9+ Unterdatensätzen: AigleRN (38 Bilder), CFD (118), Crack500 (500), DeepCrack (537), CrackTree200 (200), GAPs384 (384), CrackLS315 (315), Stone331 (331) und zusätzliche benutzerdefinierte Sammlungen mit insgesamt über 9000 Bildern nach Qualitätsfilterung. Die Autoren wendeten eine bildverarbeitende Verfeinerung an, um inkonsistente Ground-Truth-Annotationen zu vereinheitlichen — einige Unterdatensätze verwendeten dünne Linienannotationen (1-3 Pixel breite Mittellinien), andere verwendeten vollflächige Regionsannotationen.
Die Verfeinerungspipeline umfasste:
Manuelle Überprüfung und Neukennzeichnung falsch annotierter Bilder
Morphologische Dilatation zur Erweiterung von Dünnlinienannotationen auf den Standard vollflächiger Ground-Truth
Rauschentfernung (isolierte Pixelcluster kleiner als 5 Pixel wurden entfernt)
Maskenausrichtung mittels Bildregistrierung zur Korrektur räumlicher Versätze zwischen Bild und Annotation
CrackSeg9k kategorisiert Risse in lineare (einfach, unverzweigt), verzweigte (Y-förmige oder T-förmige Aufspaltungen) und vernetzte (Netzwerk-, Alligator-Typ) Morphologieklassen. Diese Kategorisierung ermöglicht das Training klassenspezifischer Segmentierungsköpfe, die die morphologische Variabilität besser erfassen können. Modelle, die auf CrackSeg9k trainiert wurden, zeigen eine deutlich verbesserte oberflächenübergreifende Verallgemeinerung im Vergleich zu Einzeldatensatz-Modellen.
Vergleichstabelle der Datensätze
Datensatz
Bilder
Auflösung
Oberflächentyp
Risstypen
GSD (mm/Pixel)
Öffentlich
CRACK500
500
2048×1536
Asphaltfahrbahn
Alle Typen
0,05
Ja
DeepCrack
537
512×512
Beton, Mauerwerk
Linear, verzweigt
0,1-0,3
Ja
CrackForest
118
320×480
Asphaltstraße
Quer, längs
0,15
Ja
CrackAirport
~300
Variabel
Startbahn/Rollweg
Flughafenspezifisch
0,1-0,5
Eingeschränkt
CrackSeg9k
9000+
Gemischt
Alle Oberflächen
Alle Typen
Gemischt
Ja
4. Verlustfunktionen für die Risssegmentierung
Risssegmentierung ist grundsätzlich ein klassenungleichgewichtiges binäres Segmentierungsproblem. In einem typischen Startbahnbild machen Risspixel 0,1 % bis 5 % der Gesamtpixel aus. Eine naive Verlustfunktion, die alle Pixel gleich behandelt, würde ein Modell erzeugen, das einfach für jedes Pixel „Hintergrund" vorhersagt und dabei 95 %+ Genauigkeit erreicht, aber null Risse erkennt. Spezialisierte Verlustfunktionen sind unerlässlich, um das Modell zu zwingen, die Minderheitsklasse der Risse zu erlernen.
Binary Cross-Entropy (BCE) Loss
Der BCE-Verlust (auch Logistik-Verlust genannt) berechnet die pixelweise binäre Kreuzentropie zwischen der vorhergesagten Wahrscheinlichkeitskarte und der Ground-Truth-Maske:
wobei (y_i) das Ground-Truth-Label (0 oder 1) für Pixel (i) ist, (p_i) die vorhergesagte Wahrscheinlichkeit für Pixel (i) und (N) die Gesamtzahl der Pixel.
Standard-BCE gewichtet jedes Pixel gleich. Für die Risssegmentierung wird häufig eine gewichtete BCE-Variante verwendet:
wobei (w_+) (Positivklassen-Gewicht) auf (N / (2 \cdot N_{crack})) und (w_-) (Negativklassen-Gewicht) auf (N / (2 \cdot N_{bg})) gesetzt wird. Dies gewichtet Klassen umgekehrt zu ihrer Häufigkeit — wenn Risse 1 % der Pixel ausmachen, erhält jedes Risspixel das 50-fache Gewicht eines Hintergrundpixels.
Der BCE-Verlust behandelt jedes Pixel unabhängig und optimiert nicht explizit die Überlappung zwischen Vorhersage und Ground Truth. Er verhält sich gut für gradientenbasierte Optimierung, neigt jedoch dazu, leicht unscharfe Vorhersagen an Risskanten zu erzeugen.
Dice Loss
Der Dice-Verlust optimiert direkt den Dice-Koeffizienten (F1-Score) — die Überlappung zwischen vorhergesagten und tatsächlichen Rissregionen:
wobei (\epsilon) eine kleine Glättungskonstante (typischerweise 1×10⁻⁶) ist, um eine Division durch Null zu verhindern.
Die entscheidende Eigenschaft des Dice-Verlustes ist, dass er regionsbasiert und nicht pixelbasiert ist. Er misst die Überlappung zwischen der vorhergesagten Rissregion und der Ground-Truth-Rissregion als Ganzes und behandelt das Klassenungleichgewicht auf natürliche Weise, da beide Terme im Nenner über das gesamte Bild berechnet werden. Der Dice-Verlust ist besonders effektiv für die Risssegmentierung, weil:
Er direkt die Bewertungsmetrik (Dice/IoU) optimiert, die für die endgültige Modellbewertung verwendet wird
Er extremes Klassenungleichgewicht ohne Gewichtung bewältigt (Risse können 0,1 % der Pixel ausmachen und Dice funktioniert trotzdem)
Er scharfe Vorhersagegrenzen erzeugt, da die Regionsüberlappung maximiert wird
Der Gradient des Dice-Verlustes ist wohldefiniert, kann aber instabil sein, wenn die Vorhersagemaske und der Ground Truth keine Überlappung aufweisen (sowohl Zähler als auch Nenner nahe Null). Der Glättungsterm (\epsilon) mildert dies.
Focal Loss
Der Focal Loss (Lin et al., 2017) wurde für die dichte Objekterkennung (RetinaNet) eingeführt und passt BCE an, indem er gut klassifizierte Pixel heruntergewichtet und sich auf schwierige Beispiele konzentriert:
wobei (p_t = p_i) wenn (y_i = 1) und (p_t = 1-p_i) wenn (y_i = 0), (\alpha_t) ein Klassenausgleichsgewicht ist und (\gamma) der Fokussierungsparameter (typischerweise 2,0).
Der Modulationsfaktor ((1-p_t)^\gamma) reduziert den Beitrag einfacher Beispiele (bei denen (p_t) nahe 1 liegt) und konzentriert das Training auf schwierige Beispiele (bei denen (p_t) nahe 0,5 liegt). Für die Risssegmentierung bedeutet dies, dass das Modell das Lernen auf folgende Bereiche konzentriert:
Risskantenpixel (wo Riss auf Hintergrund trifft und Vorhersagen unsicher sind)
Sehr dünne Risse, die das Modell sonst ignorieren würde
Risspixel in anspruchsvollen Hintergründen (Schatten, Flecken, raue Texturen)
Focal Loss mit (\gamma = 2,0) und (\alpha = 0,25) (Rissgewicht) erzielt starke Ergebnisse auf Risssegmentierungs-Benchmarks und verbessert die IoU typischerweise um 3-5 % gegenüber BCE allein.
Combo Loss
Combo Loss (auch Hybridverlust genannt) kombiniert mehrere Verlustfunktionen, um deren komplementäre Stärken zu nutzen. Die gebräuchlichsten Formulierungen für die Risssegmentierung sind:
mit (\lambda) typischerweise zwischen 0,5-0,7. Der Dice-Verlust bietet Regionsüberlappungsoptimierung; BCE bietet pixelweise Gradientenstabilität und feinkörnige Kanteninformationen.
Diese Kombination hat sich in mehreren Studien als am effektivsten für die Risssegmentierung erwiesen (F. Zhao et al., 2023) und erzielt eine IoU-Verbesserung von 2-4 % gegenüber Dice allein. Der Dice-Term stellt die Rissregionenüberlappung sicher, während der Focal-Term das Modell zwingt, sich auf schwierige Risspixel zu konzentrieren — dünne Risse, Verzweigungspunkte, kontrastarme Risse.
Tversky Loss ist eine Verallgemeinerung des Dice-Verlustes, die eine separate Gewichtung für falsch positive und falsch negative Ergebnisse hinzufügt:
wobei (\beta) die Bestrafung falsch positiver Ergebnisse steuert. Für die Risssegmentierung ist (\beta = 0,7) (höhere Bestrafung für falsch negative Ergebnisse — übersehene Risse) üblich, da ein übersehener Riss, der mit der Zeit wächst, ein größeres Sicherheitsrisiko darstellt als ein fälschlicherweise markiertes Nicht-Riss-Merkmal.
Verlustfunktion
Klassenungleichgewicht
Kantenschärfe
Fokus auf schwierige Beispiele
Typische IoU
BCE
Schlecht (benötigt Gewichtung)
Niedrig
Nein
0,55-0,62
Weighted BCE
Gut
Mittel
Nein
0,62-0,68
Dice
Hervorragend
Hoch
Schwach
0,65-0,72
Focal
Gut
Mittel
Stark
0,64-0,70
Dice + Focal Combo
Hervorragend
Hoch
Stark
0,68-0,76
Tversky ((\beta=0,7))
Hervorragend
Hoch
FN-fokussiert
0,67-0,74
5. Nachbearbeitung von Segmentierungsausgaben
Rohmodellvorhersagen erzeugen eine Wahrscheinlichkeitskarte (Gleitkommawerte zwischen 0,0 und 1,0), die durch eine Abfolge von Nachbearbeitungsschritten in eine saubere binäre Maske umgewandelt werden muss. Die Qualität dieser Operationen beeinflusst direkt die Genauigkeit der nachgelagerten Geometriemessungen.
Thresholding
Der erste Nachbearbeitungsschritt wandelt die kontinuierliche Wahrscheinlichkeitskarte in eine binäre Maske um. Globales Thresholding wendet einen festen Schwellenwert (T) (typischerweise 0,3-0,5) auf jedes Pixel an. Der optimale Schwellenwert wird durch Evaluierung der IoU auf dem Validierungssatz über eine Reihe von Schwellenwerten (z. B. 0,1 bis 0,9 in 0,05-Schritten) bestimmt. Mit Dice Loss trainierte Modelle arbeiten am besten mit Schwellenwerten von 0,3-0,4; mit BCE trainierte Modelle benötigen höhere Schwellenwerte von 0,4-0,5.
Otsus Thresholding bestimmt automatisch den optimalen Schwellenwert durch Maximierung der Zwischenklassenvarianz im Wahrscheinlichkeitshistogramm. Für die Risssegmentierung setzt Otsus Methode den Schwellenwert tendenziell auf 0,4-0,6, abhängig vom Riss-zu-Hintergrund-Verhältnis im Bild. Sie ist besonders nützlich, wenn die Wahrscheinlichkeitsverteilung zwischen Bildern variiert (z. B. unterschiedliche Lichtverhältnisse während einer Startbahnvermessung).
Morphologische Bereinigung
Nach dem Thresholding enthält die binäre Maske Salz-und-Pfeffer-Rauschen: isolierte Vordergrundpixel (Rauschen), bei denen das Modell fälschlicherweise Hintergrund als Riss klassifiziert hat, und kleine Löcher in Vordergrundregionen, in denen das Modell Risspixel übersehen hat.
Opening (Erosion gefolgt von Dilatation) entfernt kleines Vordergrundrauschen:
Erosion: Für jedes Vordergrundpixel wird geprüft, ob alle seine 4- oder 8-verbundenen Nachbarn ebenfalls Vordergrund sind; falls nicht, wird es als Hintergrund markiert. Dies entfernt isolierte Risspixel.
Dilatation: Für jedes an Vordergrund angrenzende Hintergrundpixel wird es als Vordergrund markiert. Dies stellt die verbleibenden Risspixel wieder auf ihre ursprüngliche Dicke her.
Ein Strukturelement (typischerweise 3×3- oder 5×5-Kreuzkernel) steuert die Operation. Für die Risssegmentierung entfernt ein 3×3-Kernel einzelne Pixelrauschen, ohne echte Risslinien signifikant zu verschmälern.
Closing (Dilatation gefolgt von Erosion) füllt kleine Löcher und Lücken in Rissregionen:
Dilatation: Rissgrenzen um 1-2 Pixel erweitern, um schmale Lücken zu überbrücken (Rissunterbrechungen von 1-3 Pixeln durch Modellunsicherheit)
Erosion: Rissgrenzen auf ungefähre ursprüngliche Breite zurückführen
Die Closing-Operation ist entscheidend für Flughafenfahrbahnrisse, bei denen Gummiablagerungen oder Zuschlagstoffpartikel dazu führen können, dass das Modell einen durchgehenden Riss in mehrere Segmente zerteilt. Ein einzelner Closing-Durchlauf mit einem 5×5-Kernel kann Lücken von bis zu 3 Pixeln überbrücken und die Risskontinuität wiederherstellen.
Connected Component Analysis
Die Connected Component Analysis (CCA) kennzeichnet jede einzelne Rissregion in der binären Maske mit einer eindeutigen Kennung. Standard-CCA verwendet entweder 4-Konnektivität (Pixel-Nachbarn nur oben/unten/links/rechts) oder 8-Konnektivität (einschließlich Diagonalen). Für die Risssegmentierung wird 8-Konnektivität bevorzugt, da Risse diagonal über das Bild verbunden sein können.
Nach der Kennzeichnung entfernt die Flächenfilterung Komponenten unterhalb eines Mindestflächenschwellenwerts (typischerweise 10-100 Pixel, abhängig vom GSD). Bei einem 0,1 mm/Pixel Startbahnbild entspricht eine Mindestfläche von 50 Pixeln einer physischen Rissfläche von 0,5 mm² — weit unterhalb aktionsrelevanter Rissgrößen, aber effektiv zur Entfernung von Rauschen. Komponenten unterhalb dieses Schwellenwerts sind fast immer falsch positive Ergebnisse durch Aggregatstruktur oder Oberflächenablagerungen.
Die Komponentenstatistiken, die während der CCA berechnet werden, umfassen:
Komponentenfläche in Pixeln (Umrechnung in mm² mittels GSD)
Begrenzungsrahmenkoordinaten (zur Lokalisierung)
Schwerpunktkoordinaten (zur Kartierung)
Exzentrizität (Streckungsmaß; rissähnliche Komponenten haben eine Exzentrizität > 0,9)
Konvexität (Verhältnis von Umfang zu konvexem Hüllumfang; Risse sind nicht konvex)
Skelettierung
Skelettierung (auch Ausdünnung genannt) reduziert jede Risskomponente auf eine ein Pixel breite Mittellinie, während die topologische Struktur des Risses erhalten bleibt — Konnektivität, Verzweigungen und Endpunkte. Das Skelett ist für die Längenmessung und die Berechnung des Breitenprofils unerlässlich.
Der Zhang-Suen-Ausdünnungsalgorithmus (1984) ist der am weitesten verbreitete für die Riss-Skelettierung. Er arbeitet iterativ:
Subiteration 1: Markiere Randpixel (Vordergrundpixel mit mindestens einem Hintergrundnachbarn) zur Löschung, wenn sie erfüllen:
2 ≤ B(P1) ≤ 6 (Anzahl der Vordergrundnachbarn zwischen 2 und 6)
A(P1) = 1 (Konnektivitätszahl — genau ein verbundener Hintergrund-zu-Vordergrund-Übergang)
P2 × P4 × P6 = 0
P4 × P6 × P8 = 0
Subiteration 2: Gleiche Bedingungen, aber mit anderen Nachbarschaftsprüfungen:
P2 × P4 × P8 = 0
P2 × P6 × P8 = 0
Wiederholen, bis keine Pixel mehr gelöscht werden (stabiles Skelett erreicht)
Der Guo-Hall-Algorithmus erzeugt ein zentrierteres Skelett für dicke Risse (>10 Pixel breit), indem er parallele Subiterationen verwendet, die Pixel von beiden Seiten gleichzeitig entfernen. Er wird für stark ausgebrochene oder Alligator-Risse bevorzugt, bei denen die Rissregion breit genug ist, um eine Innenfläche zu haben.
Nach der Skelettierung identifiziert die Verzweigungs- und Knotenanalyse:
Endpunkte: Skelettpixel mit genau 1 Nachbarn (Rissendigungen)
Knotenpunkte: Skelettpixel mit 3 oder mehr Nachbarn (Rissverzweigungspunkte)
Segmentzweige: Pfade zwischen Endpunkten und Knotenpunkten
Diese Analyse erzeugt die Rissgraphstruktur — eine mathematische Darstellung der Risstopologie als Menge von Knotenpunkten (Endpunkte, Knotenpunkte) und Kanten (Rissegmente zwischen ihnen).
6. Extrahieren der Rissgeometrie aus binären Masken
Die pixelgenaue Rissmaske in Kombination mit der Skelettierung ermöglicht die quantitative Extraktion der Rissgeometrie. Diese Messungen sind entscheidend für die Fahrbahnzustandsbewertung gemäß ICAO- und FAA-Standards, bei denen die Rissstärke basierend auf Breitenbereichen klassifiziert wird (Haarrisse: <3 mm, mittel: 3-6 mm, schwer: >6 mm für Startbahnfahrbahnen).
Rissfläche
Die Rissfläche ist die einfachste Messung:
[
A_{crack} = N_{crack} \times GSD^2
]
wobei (N_{crack}) die Gesamtzahl der Risspixel in der binären Maske und (GSD) der Bodenabtastabstand (mm/Pixel) ist, der aus der Kamerakalibrierung oder Referenzmarkierungen im Bild bestimmt wird.
Bei TarmacViews crack_seg_head wird der GSD aus den intrinsischen Parametern des Kamerasystems (Brennweite, Sensorpixelabstand) und der Aufnahmehöhe oder Zielentfernung berechnet. Eine Kamera mit 20 mm Brennweite, 3,45 µm Pixelabstand, aufgenommen aus 2 Metern Entfernung von der Fahrbahnoberfläche, erzeugt einen GSD von etwa 0,069 mm/Pixel (3,45 µm × 2000 mm / 20 mm).
Die flächenweise Komponentenberechnung ermöglicht die Rissdichteberechnung:
wobei (E) die Menge der Skelettkanten (Segmentzweige) ist und ((x_i, y_i)) aufeinanderfolgende Pixelkoordinaten entlang jeder Kante sind. Diagonale Schritte (Ecke zu Ecke) werden mit (\sqrt{2}) multipliziert im Vergleich zu orthogonalen Schritten, was die Längenmessung auf Subpixel-Genauigkeit bringt.
Die Länge kann pro Komponente, pro Verzweigungswinkel oder als Summe über die gesamte Oberfläche berechnet werden. Die Risslängendichte ((L_{total} / A_{surface}), in mm/mm² oder m/m²) ist eine häufig verwendete Fahrbahnzustandsmetrik.
Rissbreite
Die Rissbreitenmessung erfordert die Berechnung des Abstands von jedem Skelettpixel zum nächsten Hintergrundpixel in der ursprünglichen binären Maske. Dies wird über die euklidische Distanztransformation (EDT) erreicht:
Berechne EDT auf der binären Maske: für jedes Vordergrund- (Riss-)Pixel, berechne seine euklidische Distanz zum nächsten Hintergrundpixel
Werte EDT an jedem Skelettpixel ab: der EDT-Wert an einem Skelettpixel entspricht der halben lokalen Rissbreite (Distanz vom Skelett zur nächsten Kante)
Multipliziere mit 2 für die volle Breite, dann multipliziere mit GSD für physikalische Einheiten
Maximale Rissbreite: (w_{max} = \max(w_i)) — typischerweise in ausgebrochenen oder Alligator-Bereichen
Breitenprofil: Breite als Funktion der Position entlang des Skeletts (für die Längsriss-Schweregradeinstufung)
Breitenhistogramm: Verteilung der Breitenwerte, die den Risstyp anzeigt (gleichmäßige Breite ≈ Querriss; variable Breite ≈ Alligatorriss)
Gemäß der ICAO-Berichterstattung über den Startbahnzustand werden Risse mit einer Breite von mehr als 6 mm auf Asphaltoberflächen oder 3 mm auf Betonoberflächen als „schwere Verschlechterung" eingestuft, die sofortige Wartungsmaßnahmen erfordert.
Komponentenstatistiken
Für jede verbundene Komponente (einzelner Riss) berechnet die Geometrieextraktions-Pipeline:
Metrik
Einheit
Berechnung
Zweck
Fläche
mm²
Pixelanzahl × GSD²
Gesamtschadensausmaß
Länge
mm
Skelettlänge × GSD
Rissausbreitungsausmaß
Mittlere Breite
mm
Mittlerer EDT am Skelett × GSD
Schweregradklassifizierung
Maximale Breite
mm
Maximaler EDT am Skelett × GSD
Maximales Verschlechterungsmaß
Exzentrizität
einheitslos
(Komponenten-Seitenverhältnis)
Rissformklassifizierung
Breite
mm
Maximale Breite der Komponente
Schweregradklassifizierung
Orientierung
Grad
Winkel der Skelett-Hauptachse
Risstyp (quer/längs)
7. Bewertungsmetriken
Risssegmentierungsmodelle werden mit pixelbasierten Metriken bewertet, die die vorhergesagte binäre Maske mit der Ground-Truth-Maske vergleichen. Diese Metriken müssen das extreme Klassenungleichgewicht bewältigen, das der Risssegmentierung inhärent ist.
Intersection over Union (IoU / Jaccard-Index)
IoU ist die primäre Metrik für die Bewertung der Risssegmentierung:
wobei (P) die Menge der vorhergesagten Risspixel ist, (T) die Menge der tatsächlichen Risspixel, (TP) = richtig positive (korrekt segmentierte Risspixel), (FP) = falsch positive (als Riss klassifizierter Hintergrund), (FN) = falsch negative (als Hintergrund klassifizierter Riss).
IoU reicht von 0,0 (keine Überlappung) bis 1,0 (perfekte Überlappung). Für die Risssegmentierung liegen typische IoU-Werte zwischen 0,65 (ordentlich, Schwelle für praktische Nutzung) und 0,85 (Stand der Technik). IoU ist die Metrik der Wahl, da sie sowohl falsch positive als auch falsch negative Ergebnisse gleichermaßen bestraft — ein Modell, das aggressiv überall Risse vorhersagt (hoher Recall, niedrige Präzision), erhält eine niedrige IoU.
Dice-Koeffizient (F1-Score)
Dice-Koeffizient (auch Sørensen-Dice oder F1-Score auf Pixelebene genannt):
Dice ist mathematisch mit IoU verwandt: (Dice = 2 \times IoU / (1 + IoU)). Eine IoU von 0,75 entspricht einem Dice von 0,857. Dice betont richtig positive Ergebnisse und gewichtet sie doppelt im Vergleich zu IoU. Für die Risssegmentierung ist Dice die zweithäufigst berichtete Metrik und bietet eine etwas optimistischere Sicht als IoU.
Pixel-Präzision und Recall
Die Pixel-Präzision misst, welcher Anteil der vorhergesagten Risspixel tatsächlich Risse sind:
[
Precision = \frac{TP}{TP + FP}
]
Hohe Präzision bedeutet wenige falsch positive Ergebnisse — das Modell verwechselt Aggregatstruktur, Schatten oder Oberflächenablagerungen nicht mit Rissen. Falsch positive Ergebnisse bei Startbahninspektionen sind kostspielig, da sie Wartungsressourcen für nicht vorhandene Schäden verschwenden.
Der Pixel-Recall (Sensitivität) misst, welcher Anteil der tatsächlichen Risspixel vom Modell erfolgreich identifiziert wurde:
[
Recall = \frac{TP}{TP + FN}
]
Hoher Recall bedeutet wenige übersehene Risse — das Modell erkennt den größten Teil der tatsächlichen Rissfläche. Falsch negative Ergebnisse bei Startbahninspektionen sind sicherheitskritisch, da ein unentdeckter Riss unter Flugzeugbelastung fortschreiten und zu strukturellem Versagen führen kann.
Der Präzisions-Recall-Zielkonflikt wird durch den Schwellenwert (T) gesteuert. Ein niedriger Schwellenwert (z. B. 0,2) maximiert den Recall auf Kosten der Präzision; ein hoher Schwellenwert (z. B. 0,7) maximiert die Präzision, übersieht aber echte Risse. Der optimale Schwellenwert liegt typischerweise dort, wo Präzision und Recall etwa gleich sind — der F1-ausgeglichene Punkt.
Pixel-Genauigkeit
Die Pixel-Genauigkeit ist die einfachste Metrik, aber für die Risssegmentierung höchst irreführend:
[
Accuracy = \frac{TP + TN}{TP + TN + FP + FN}
]
Wenn Risse 1 % der Pixel ausmachen, erreicht ein Modell, das durchgehend Hintergrund vorhersagt, 99 % Genauigkeit, während es null Risse erkennt. Die Genauigkeit wird in der Risssegmentierungsliteratur nur als sekundäre Metrik berichtet und sollte niemals als primäres Bewertungskriterium verwendet werden.
Zusammengesetzte Metriken
Der F-Beta-Score verallgemeinert F1 mit einem einstellbaren Gewicht auf den Recall:
Für die Startbahnrisssegmentierung wird manchmal (F_2) (Recall mit 2× Präzision gewichtet) verwendet, da das Übersehen eines Risses gefährlicher ist als das fälschliche Markieren eines solchen. (\beta = 2) bedeutet, dass Recall doppelt so wichtig ist wie Präzision.
Boundary F1 (BF1) bewertet die Segmentierungsqualität speziell an Risskanten und berechnet Präzision und Recall innerhalb eines schmalen Bandes (z. B. 2-3 Pixel) um die Ground-Truth-Rissgrenzen herum. BF1 ist eine strengere Metrik für Anwendungen, bei denen die Kantengenauigkeit von Rissen für die Breitenmessung wichtig ist.
8. Vollbild- vs. Kachelbasierte Segmentierung
Die Risssegmentierung auf Startbahnoberflächen stellt eine grundlegende rechenintensive Herausforderung dar: Startbahnen werden in tausenden laufenden Metern gemessen (eine Code E Startbahn ist 45 Meter breit × 3.000+ Meter lang), aber Segmentierungsmodelle akzeptieren aufgrund von GPU-Speicherbeschränkungen typischerweise Eingabetensoren von 512×512 bis 1536×1536 Pixeln. Zwei Ansätze bewältigen diese Maßstabsdifferenz.
Vollbildsegmentierung
Die Vollbildsegmentierung verarbeitet das gesamte Startbahnbild in einem einzigen Durchlauf durch das Modell. In der Praxis ist ein echter Vollbildansatz nur für kleine Oberflächen (Social-Media-Bilder, Nahaufnahmen von Smartphones) oder auf extrem speicherstarker Hardware (80 GB A100 GPUs mit Bildgrößen bis zu 4000×4000 Pixeln) machbar.
Für die Flughafeninspektion deckt ein einzelnes Startbahnvermessungsbild, aufgenommen mit 0,2 mm/Pixel GSD, grob 1×1 Meter bei 5000×5000 Pixeln ab — was 100 MB 32-Bit-Gleitkommaspeicher pro Bild erfordert. Die Ausführung von U-Net auf einem 5000×5000-Bild erfordert etwa 200 GB GPU-Speicher für Zwischenmerkmalskarten — 40× mehr als auf einer A100 (80 GB) verfügbar.
Die Vollbildsegmentierung vermeidet Kachelgrenzartefakte — keine Nähte, keine überlappenden Vorhersagen, keine Überblendung — und liefert die höchstmögliche Qualität für die Region, die verarbeitet werden kann. Speicherbeschränkungen verhindern jedoch eine echte Vollbildverarbeitung realistischer Startbahnoberflächen.
Kachelbasierte (Schiebefenster-)Segmentierung
Die kachelbasierte Segmentierung unterteilt das Eingabebild in kleinere Kacheln (typischerweise 512×512 oder 1024×1024 Pixel), führt auf jeder Kachel unabhängig eine Inferenz durch und setzt die Ergebnisse zu einer vollauflösenden Maske zusammen. Dies ist der Standardansatz für die Risssegmentierung im Flughafenmaßstab.
Überlappung und Überblendung: Benachbarte Kacheln überlappen sich um 10-25 %, um zu verhindern, dass Risse an Kachelgrenzen durchtrennt werden. Der Überlappungsbereich erhält Vorhersagen von beiden Kacheln, die wie folgt kombiniert werden:
Gewichtete Mittelwertbildung: Pixel nahe Kachelkanten erhalten eine geringere Gewichtung; Pixel nahe der Kachelmitte erhalten volle Gewichtung
Nahtbewusste Zusammensetzung: Vorhersagen werden mittels einer Distanztransformation überblendet — je weiter von der Naht entfernt, desto höher das Gewicht der Vorhersage dieser Kachel
Median-Blending: Für jedes Pixel im Überlappungsbereich wird der Median aller dieses Pixel abdeckenden Vorhersagen genommen
Die Kachelgrößenauswahl beinhaltet einen Zielkonflikt:
512×512-Kacheln: Schnelle Inferenz, niedriger GPU-Speicher (4-8 GB), aber mehr Grenzartefakte; geeignet für Echtzeit-Randbereitstellung
1024×1024-Kacheln: Bessere Kontextinformationen für große Risse, weniger Nähte, aber höherer Speicher (16-32 GB) und langsamere Verarbeitung
Für TarmacViews crack_seg_head bietet eine Kachelgröße von 1024×1024 mit 15 % Überlappung die optimale Balance für Startbahnoberflächen. Ein 45 m × 45 m großer Startbahnabschnitt bei 0,2 mm/Pixel (225.000 × 225.000 Pixel) erfordert bei dieser Konfiguration etwa 45.000 Kacheln — 37 Minuten Inferenz auf einer RTX 4090 (20 Kacheln/Sekunde).
Mehrskalige Kacheln verbessern die Erkennung von Rissen in verschiedenen Breiten. Dieselbe Bildregion wird auf mehreren Skalen (0,5×, 1,0×, 2,0×) verarbeitet und die Ergebnisse werden fusioniert. Kleine Kacheln bei 2,0× Vergrößerung erfassen dünne Risse; große Kacheln bei 0,5× erfassen breite Rissnetzwerke.
9. Herausforderungen bei der Startbahn-Vollbildsegmentierung
Die Segmentierung von Flughafenstartbahnen stellt besondere Herausforderungen dar, die über die der Straßenfahrbahnsegmentierung hinausgehen:
Oberflächenrillen: Die meisten Hauptstartbahnen haben Querrillen (3-6 mm tief, 25-35 mm Abstand), die zur Wasserableitung und Reibungsverbesserung in die Oberfläche geschnitten wurden. Diese Rillen erscheinen in Bildern als parallele dunkle Linien, die optisch Rissen ähneln. Modelle müssen lernen, Rillen (regelmäßiger Abstand, gleichmäßige Breite, parallele Ausrichtung über die gesamte Startbahnbreite) von Rissen (unregelmäßig, variable Breite, nicht parallel) zu unterscheiden. Ein straßentrainiertes Modell produziert typischerweise 10-30 % falsch positive Ergebnisse auf gerillten Startbahnen.
Gummiablagerungen: Aufsetzzonen von Flugzeugreifen sammeln Gummischichten an — Polymerablagerungen, die in Bildern als dunkle, unregelmäßige Flecken erscheinen. Gummiablagerungen können darunterliegende Risse verdecken (Verringerung des Recalls) und rissähnliche Kantenmerkmale entlang der Ablagerungsgrenzen erzeugen (Erhöhung falsch positiver Ergebnisse). Die Vorverarbeitung mit Gummischätzung (unter Verwendung multispektraler Bildgebung — Gummi hat eine charakteristische spektrale Signatur in NIR-Bändern) und Maskierung verbessert die Risssegmentierungsgenauigkeit in Aufsetzzonen um 5-15 %.
Fugen- und Dichtmittelverwechslung: Startbahnbetonfahrbahnen haben alle 4-6 Meter Dehnungsfugen, die mit Fugendichtmittel (typischerweise dunkles, flexibles Polymer) gefüllt sind. Fugen erscheinen in der Segmentierungsausgabe als rissähnliche Merkmale. Fugen sind jedoch beabsichtigt, erwartet und strukturell notwendig — sie sollten nicht als Risse klassifiziert werden. Die Fugenerkennung mittels geometrischer A-priori-Informationen (regelmäßiger Abstand, lineare Ausrichtung senkrecht zur Startbahnmittellinie) ermöglicht eine Fugenmaskierung vor der Rissmessung.
Beleuchtungsvariation: Vollständige Startbahnvermessungsbilder erstrecken sich über Hunderte von Metern mit unterschiedlicher Beleuchtung. Ein Ende des Startbahnbildes kann sich in direktem Sonnenlicht befinden (hoher Kontrast, scharfe Risschatten), während das andere im Schatten liegt (niedriger Kontrast, keine Schatten). Modelle müssen beleuchtungsinvariant sein. Datenaugmentierung einschließlich zufälliger Helligkeits-/Kontrastverschiebungen, Histogrammegalisierung und synthetischer Schattenerzeugung während des Trainings verbessert die Robustheit über verschiedene Lichtverhältnisse hinweg.
Fahrbahnvariabilität: Startbahnen haben mehrere Fahrbahnarten (Asphalt-Stoppflächen, Beton-Hauptstartbahn, Asphalt-Rollweganbindungen) mit unterschiedlichen Texturen, Farben und Rissmorphologien. Ein einzelner Inspektionsflug erfasst alle Fahrbahnarten, was erfordert, dass das Segmentierungsmodell über diese Oberflächen hinweg verallgemeinern kann, ohne separate Modelle pro Fahrbahnart.
10. Verallgemeinerung auf neue Oberflächen
Risssegmentierungsmodelle sind anfällig für Domain-Shift — die Verschlechterung der Leistung, wenn sie auf Oberflächen, Kameras oder Bedingungen angewendet werden, die nicht in den Trainingsdaten repräsentiert sind. Ein Modell, das ausschließlich auf CRACK500 trainiert wurde (Asphalt, aufgenommen bei 0,05 mm/Pixel, innenraumähnliche Beleuchtung, Nahdistanz) und auf einer Betonstartbahn eingesetzt wird (andere Textur, GSD 0,2 mm/Pixel, Außenbeleuchtung, variable Distanz), kann einen IoU-Abfall von 0,72 auf 0,35-0,45 verzeichnen.
Ursachen von Domain-Shift
Oberflächentextur: Asphalt hat eine dunkle, raue, unregelmäßige Aggregatstruktur; Beton hat eine hellere, glattere, gleichmäßigere Textur mit sichtbarem Feinzuschlag. Modelle, die auf Asphaltstruktur trainiert wurden, lernen, dunkle, hochfrequente Texturvariationen zu ignorieren — Betonoberflächen verletzen diese erlernte Invarianz.
Auflösung: Das Risserscheinungsbild ändert sich mit dem GSD. Bei 0,05 mm/Pixel ist ein 2 mm breiter Riss 40 Pixel breit mit scharfen, gut definierten Kanten. Bei 0,2 mm/Pixel ist derselbe Riss 10 Pixel breit mit weicheren Kanten. Modelle, die mit hoher Auflösung trainiert wurden, erzeugen unscharfe, unsichere Vorhersagen bei niedrigerer Auflösung.
Beleuchtung: Außenaufnahmen von Startbahnen haben gerichtetes Sonnenlicht, das Risschatten erzeugt (verbessert die Risserkennbarkeit, erzeugt aber Schattenartefakte), während Innenaufnahmen oder bedeckte Aufnahmen diffuses Licht haben (weniger Schatten, niedrigerer Kontrast). Risschatten können den Recall bei Sonnenlicht verbessern, aber falsch positive Ergebnisse bei nicht rissbedingten Stufen verursachen (Temperaturrisse, Oberflächenhöhenänderungen).
Kamerasystem: Verschiedene Kameras haben unterschiedliche spektrale Sensorantworten, Pixelabstände, Objektivverzerrungen und Rauscheigenschaften. Ein Modell, das auf einer 20 MP DSLR (geringes Rauschen, geringe Verzerrung) trainiert wurde, kann auf einer 12 MP Drohnenkamera (höheres Rauschen, Rolling Shutter, chromatische Aberration) an Leistung verlieren.
Verbesserung der Verallgemeinerung
Domain-Randomisierung: Während des Trainings werden zufällige Augmentierungen angewendet, die den erwarteten Einsatzbereich abdecken: zufälliger GSD (Bilder auf 0,5×-2,0× skalieren), zufällige Beleuchtung (Helligkeit ±30 %, Kontrast ±30 %, Gamma ±0,3), zufälliges Rauschen (Gaußsches Rauschen mit σ=5-25), zufällige Unschärfe (Gaußsche Unschärfe mit Kernel 1-5 Pixel), zufällige Farbverschiebungen (HSV-Verschiebung Farbton ±15, Sättigung ±30, Wert ±30). Modelle, die mit ausreichender Domain-Randomisierung trainiert wurden, behalten eine IoU innerhalb von 5-10 % ihrer Trainingsbereichsleistung bei, wenn sie auf neuen Oberflächen eingesetzt werden.
Synthetische Risserzeugung: Zusammensetzen synthetischer Risse auf rissfreien Oberflächenbildern mittels physikbasierter Rissmodelle oder GAN-basierter Risserzeugung. Die Datenbank rissfreier Oberflächen (aus dem Zielbereich aufgenommen) kombiniert mit synthetischen Rissen liefert gepaarte Trainingsdaten, bei denen das Modell lernt, Rissmerkmale zu erkennen, während es die spezifische Oberflächentextur ignoriert. Dieser Ansatz hat IoU-Verbesserungen von 8-12 % beim Transfer von Asphaltstraße zu Betonstartbahn gezeigt.
Unüberwachte Domain-Adaption (UDA): Techniken wie CycleGAN, CUT und AdaIN übertragen Bilder aus dem Quellbereich in das Erscheinungsbild des Zielbereichs, während die Rissannotationen erhalten bleiben. Die Rissmerkmale eines auf CRACK500 trainierten Modells werden aus Bildern extrahiert, die so stilisiert wurden, dass sie wie die Zielstartbahnoberfläche aussehen. UDA-Methoden verbessern die IoU im Zielbereich um 10-18 %, ohne dass eine Annotation des Zielbereichs erforderlich ist.
Few-Shot-Fine-Tuning: Sammeln von 5-20 annotierten Bildern von der neuen Oberfläche und Feinanpassen des vortrainierten Modells mit einer niedrigen Lernrate (1×10⁻⁵ bis 5×10⁻⁵) und einer geringen Anzahl von Epochen (10-30). Dieser überwachte Fine-Tuning-Ansatz stellt die IoU typischerweise auf 2-4 % eines vollständig überwachten Modells wieder her, das auf Hunderten von Zielbereichsbildern trainiert wurde. Es ist der zuverlässigste praktische Ansatz für den Flughafeneinsatz, bei dem das Sammeln einer kleinen Anzahl annotierter Bilder betrieblich machbar ist.
TarmacViews crack_seg_head implementiert eine Verallgemeinerungspipeline, die domain-randomisiertes Vortraining auf CrackSeg9k, zielbereichsspezifische Kachelauswahl, optionales Few-Shot-Fine-Tuning mit bis zu 20 vom Benutzer bereitgestellten annotierten Bildern der Zieloberfläche und automatische Erkennung von Domain-Anomalien umfasst (Modellkonfidenz unterhalb eines Schwellenwerts löst einen Alarm zur manuellen Überprüfung aus).
Häufig gestellte Fragen
Risssegmentierung weist jedem Pixel in einem Bild ein Riss- oder Nicht-Riss-Label zu und erzeugt eine binäre Maske, die die exakte Form, Topologie und Geometrie der Risse bewahrt. Die Rissklassifizierung sagt nur vorher, ob ein Bild einen Riss enthält (Label auf Bildebene). Die Segmentierung ermöglicht präzise Messungen von Rissfläche, -länge, -breite und Verzweigungsmustern, während die Klassifizierung lediglich eine Ja/Nein-Antwort liefert.
Zu den gebräuchlichsten Architekturen gehören U-Net (Encoder-Decoder mit Skip-Verbindungen), DeepLabV3+ (mit Atrous Spatial Pyramid Pooling), SegFormer (hierarchischer Transformer-Encoder mit MLP-Decoder) und Vision-Transformer-Backbones wie DINOv2/v3 mit dichten Vorhersageköpfen. U-Net bleibt aufgrund seiner Effizienz bei begrenzten Daten und seiner starken Leistung bei dünnen, langgestreckten Rissstrukturen am weitesten verbreitet.
Zu den wichtigsten Datensätzen gehören CRACK500 (500 Fahrbahnbilder, 0,05 mm/Pixel), DeepCrack (537 RGB-Bilder verschiedener Oberflächen), CrackForest (118 Straßenbilder), CrackAirport (flughafenspezifische Fahrbahn), Crack500, CrackTree200, CFD (Crack Forest Dataset), AEL und GAPs384. Die CrackSeg9k-Zusammenstellung vereint über 9000 Bilder aus mehreren Quellen mit verfeinerten Ground-Truth-Masken.
Die Extraktion der Rissgeometrie beginnt mit der Skelettierung (iteratives Ausdünnen auf eine ein Pixel breite Mittellinie), gefolgt von der Connected-Component-Kennzeichnung zur Isolierung einzelner Risse. Die Risslänge wird entlang des skelettierten Pfades gemessen. Die Rissbreite wird mittels der euklidischen Distanztransformation senkrecht zum Skelett berechnet. Die Rissfläche ergibt sich aus der Gesamtzahl der Risspixel multipliziert mit der räumlichen Auflösung in mm²/Pixel. Mittlere und maximale Breitenwerte werden pro Komponente angegeben.
Zu den standardmäßigen Bewertungsmetriken gehören Intersection over Union (IoU/Jaccard-Index), Dice-Koeffizient (F1-Score auf Pixelebene), Pixel-Präzision, Pixel-Recall und Pixel-Genauigkeit. IoU ist die Schnittmenge der vorhergesagten und der tatsächlichen Risspixel geteilt durch deren Vereinigung. Dice ist 2×IoU/(1+IoU). Für die Risssegmentierung sind sowohl die Präzision (Anteil der vorhergesagten Risspixel, die tatsächliche Risse sind) als auch der Recall (Anteil der tatsächlichen Risspixel, die erkannt wurden) entscheidend, da falsch positive Ergebnisse Wartungsressourcen verschwenden, während falsch negative Ergebnisse gefährliche Defekte übersehen.
Die Vollbildsegmentierung verarbeitet das gesamte Startbahnbild in einem einzigen Durchlauf, was bei hochauflösenden Oberflächen (Startbahnen können über 50 Megapixel umfassen) speicherbegrenzt ist. Die kachelbasierte Segmentierung unterteilt das Bild in überlappende Kacheln (z. B. 512×512 oder 1024×1024 Pixel), führt auf jeder Kachel eine Inferenz durch und setzt die Ergebnisse wieder zusammen. Überlappungsbereiche verwenden gewichtete Mittelwertbildung oder nahtbewusste Überblendung, um Grenzartefakte zu vermeiden. Kachelbasierte Ansätze ermöglichen die Verarbeitung beliebig großer Oberflächen, erfordern jedoch eine sorgfältige Behandlung von Rissen, die Kachelgrenzen überschreiten.
Die Verallgemeinerung auf verschiedene Oberflächentypen (Asphalt vs. Beton, neue vs. verwitterte Fahrbahn, unterschiedliche Lichtverhältnisse) bleibt eine zentrale Herausforderung. Domain-Shift — Unterschiede in Textur, Farbe, Risserscheinungsbild und Oberflächenrauigkeit — kann die Leistung erheblich beeinträchtigen. Techniken zur Verbesserung der Verallgemeinerung umfassen Domain-Randomisierung während des Trainings, synthetische Datenaugmentierung, unüberwachte Domain-Adaption (CycleGAN, Style Transfer) und überwachtes Fine-Tuning mit einer kleinen Anzahl von Zielbereichsbildern. Gut kuratierte, vielfältige Trainingsdatensätze wie CrackSeg9k verbessern die oberflächenübergreifende Robustheit.
ICAO Annex 14 und ICAO Doc 9157 legen fest, dass die Zustandsbewertung von Startbahnoberflächen Risse, Verschlechterungen und Defekte identifizieren und messen muss, die die Flugsicherheit beeinträchtigen könnten. Die automatisierte Risssegmentierung steht im Einklang mit dem Schwerpunkt der ICAO auf objektiven, reproduzierbaren und dokumentierten Inspektionsmethoden. Das ICAO Global Reporting Format (GRF) erfordert eine standardisierte Berichterstattung über den Zustand von Startbahnoberflächen, und die automatisierte Segmentierung liefert quantifizierbare Daten über Rissausmaß, -dichte und -schweregrad, die direkt in Zustandsberichtsrahmen einfließen können.
Verbessern Sie Ihre Infrastrukturinspektion
Implementieren Sie pixelgenaue Risssegmentierung für eine präzise, automatisierte Zustandsbewertung von Fahrbahnen. Unsere KI-gestützte Risssegmentierung liefert submillimetergenaue Ergebnisse für Start- und Landebahnen, Rollwege und Vorfelder.
KI-basierte Risserkennung für die Inspektion von Infrastruktur
Die KI-basierte Risserkennung nutzt Computer Vision – Convolutional Neural Networks, Vision Transformer und semantische Segmentierungsmodelle – um Risse in Fahr...
Instanzsegmentierung zur Identifizierung einzelner Schäden
Instanzsegmentierung erkennt und grenzt jedes einzelne Objekt oder jede Schadensinstanz auf Pixelebene ab und weist jedem Riss, Abplatzung oder Schlagloch eine ...
Rissflächenanteil in der Fahrbahn- und Strukturbewertung
Der Rissflächenanteil (crack_area_pct) ist das Verhältnis der Rissmaskenfläche zur gesamten analysierten Bildfläche, ausgedrückt in Prozent. Er ist eine zentral...
25 Min. Lesezeit
measurement
pavement
+3
Cookie-Zustimmung Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.