+++ title = “Transfer Learning” description = “Transfer Learning wendet Wissen aus vortrainierten Modellen auf großen, allgemeinen Datensätzen...
7 Min. Lesezeit
Technology
Machine Learning
+2
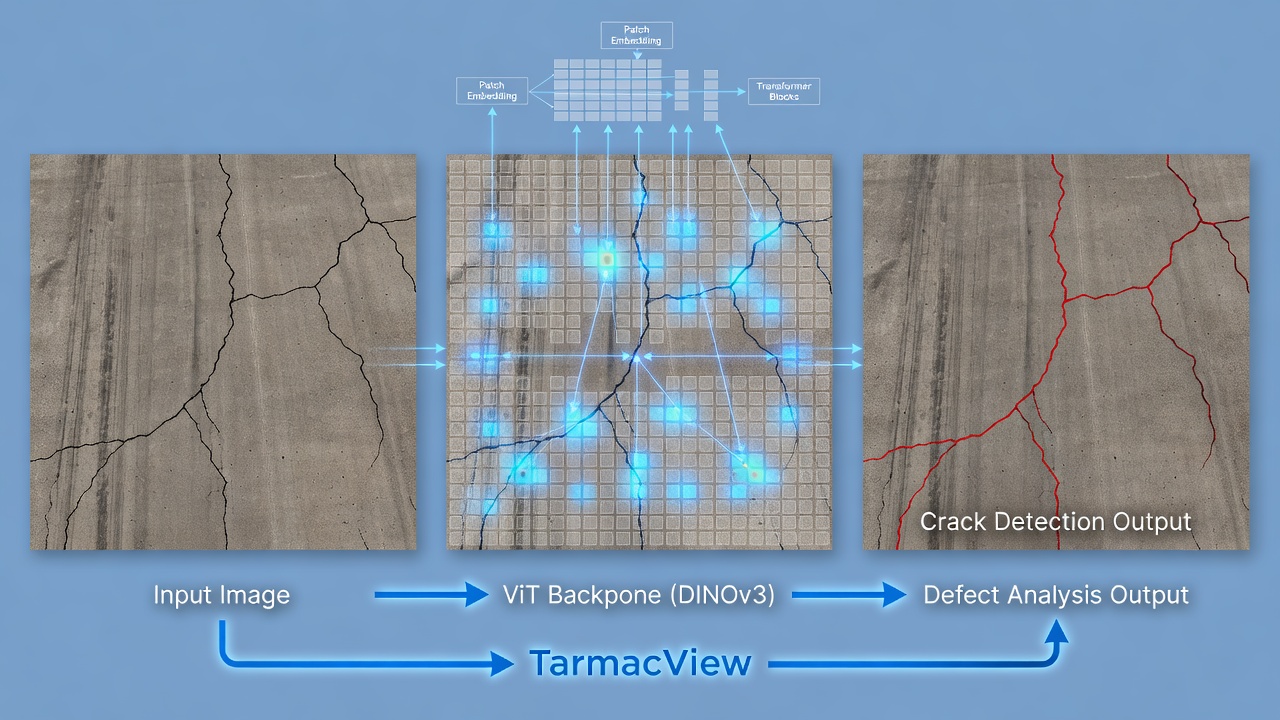
DINOv3 (self-DIstillation with NO labels v3) ist ein selbstüberwachter Vision Transformer (ViT-B/16), der auf 1,7 Milliarden Bildern vortrainiert wurde und hochwertige 768-dimensionale Embeddings erzeugt, die feinkörnige Textur und Struktur erfassen. TarmacView verwendet DINOv3 als Backbone für die Analyse von Oberflächentyp, -qualität, Rissen und Defekten. Behandelt DINO-Training, ViT-Architektur, Feintuning für domänenspezifische Aufgaben sowie einen Vergleich mit DINOv2 und anderen Backbones.
Selbstüberwachtes Lernen (SSL) ist ein Paradigma des maschinellen Lernens, bei dem ein Modell aussagekräftige Repräsentationen aus unbeschrifteten Daten erlernt, indem eine Voraufgabe (Pretext Task) definiert wird, die keine menschlichen Annotationen erfordert. Das Modell muss einen Teil der Daten aus anderen Teilen vorhersagen und nutzt dabei die inhärente Struktur und Ko-Okkurrenzmuster innerhalb der Daten selbst. Im Computersehen haben sich SSL-Methoden von handgefertigten Voraufgaben wie der Vorhersage des Rotationswinkels eines Bildes (RotNet), dem Lösen von Puzzles aus gemischten Patches oder dem Kolorieren von Graustufenbildern zu anspruchsvolleren kontrastiven und destillationsbasierten Ansätzen entwickelt. Der grundlegende Vorteil von SSL besteht darin, dass es das Training auf Web-Scale-Datensätzen ohne die prohibitiv hohen Kosten manueller Annotation ermöglicht. Für Infrastrukturanwendungen, bei denen beschriftete Defektdatensätze rar und teuer in der Erstellung sind (zertifizierte Prüfer und Ingenieure erforderlich), ermöglichen SSL-basierte Backbones ein effektives Feature-Lernen aus großen Mengen unbeschrifteter Bilddaten, bevor ein aufgabenspezifisches Feintuning erfolgt.
Contrastive Learning-Methoden wie SimCLR, MoCo und SwAV lernen Repräsentationen, indem sie augmentierte Ansichten desselben Bildes (positive Paare) im Embedding-Raum zusammenziehen und Ansichten verschiedener Bilder (negative Paare) voneinander wegstoßen. Diese Methoden erfordern eine sorgfältige Handhabung negativer Stichproben – zu wenige Negative verschlechtern die Leistung, zu viele erhöhen die Rechenkosten. Nicht-kontrastive Methoden wie BYOL, SimSiam und DINO vermeiden die Notwendigkeit negativer Paare vollständig, indem sie asymmetrische Netzwerkarchitekturen und Stop-Gradient-Operationen verwenden, um einen Repräsentationskollaps zu verhindern. DINO (self-DIstillation with NO labels), eingeführt von Caron et al. bei Meta AI im Jahr 2021, gehört zu dieser nicht-kontrastiven Familie und ist zu einer der einflussreichsten SSL-Methoden im Computersehen geworden. Die ursprüngliche DINO-Veröffentlichung zeigte, dass SSL und Vision Transformer eine einzigartige Synergie aufweisen – die Self-Attention-Mechanismen in ViTs erzeugen auf natürliche Weise semantische Segmentierungskarten ohne jegliche Überwachung, eine Eigenschaft, die aus der Interaktion zwischen der Multi-Crop-Augmentierungsstrategie und dem Selbst-Destillationsziel entsteht.
Das DINO-Trainingsframework funktioniert wie folgt. Für jedes Eingabebild werden zwei globale Ansichten (die mehr als 50 % der Bildfläche abdecken, typischerweise 224x224 Pixel) und mehrere lokale Ansichten (kleinere Ausschnitte, die weniger als 50 % der Bildfläche abdecken, typischerweise 96x96 Pixel) durch zufälliges zugeschnittenes Resizing, Farbverzerrung und Gaußsches Weichzeichnen erzeugt. Alle Ansichten werden durch ein Student-Netzwerk (einen Vision Transformer) geleitet. Die globalen Ansichten werden auch durch ein Teacher-Netzwerk geleitet, das dieselbe Architektur wie der Student hat, aber andere Parameter besitzt. Die Parameter des Teachers werden nicht durch Gradienten gelernt – stattdessen werden sie als exponential moving average (EMA) der Student-Parameter aktualisiert. Das zentrale Trainingsziel ist es, die Ausgabeverteilung des Students an die Ausgabeverteilung des Teachers für die globalen Ansichten anzupassen, während die lokalen Ansichten nur durch den Studenten zusätzliches Trainingssignal liefern. Diese Teacher-Student-Konfiguration, bekannt als Selbst-Destillation, erzeugt ein Lernsignal, das keine Beschriftungen benötigt – der Student lernt, konsistente Repräsentationen über verschiedene Augmentierungen desselben Bildes hinweg zu erzeugen, was ihn zwingt, die invarianten semantischen Inhalte statt oberflächlicher Pixel-Details zu erfassen.
DINOv1 (2021) zeigte drei wesentliche emergente Eigenschaften selbstüberwachter ViTs. Erstens segmentieren die Attention Maps vom [CLS]-Token zu Bild-Patches auf natürliche Weise Objekte vom Hintergrund – eine Eigenschaft, die rein aus der Selbstüberwachung ohne jegliche Segmentierungslabels entsteht. Zweitens zeigen die gelernten Features eine hervorragende k-NN-Klassifikationsleistung – ein einfacher Nächste-Nachbarn-Klassifikator im DINO-Feature-Raum erreicht 78,2 % Top-1-Genauigkeit auf ImageNet ohne jedes Feintuning. Drittens zeigen DINO-Features eine starke semantische Korrespondenz über verschiedene Instanzen derselben Objektklasse hinweg, was Anwendungen in der Bildrückgewinnung, Co-Segmentierung und Videoobjektsegmentierung ermöglicht. Diese Eigenschaften machten DINO zu einer grundlegenden Methode in der Landschaft des selbstüberwachten Lernens und bereiteten den Weg für DINOv2 (2023) und DINOv3 (2025).
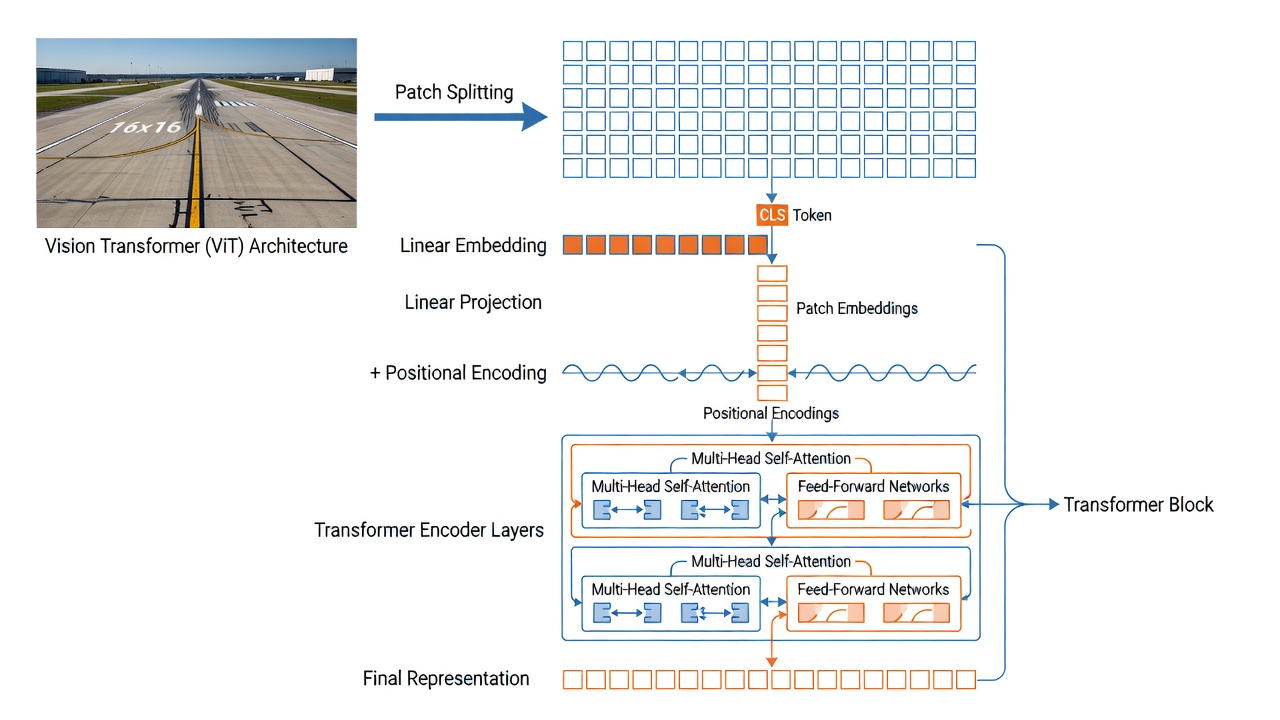
Die Vision Transformer (ViT)-Architektur, eingeführt von Dosovitskiy et al. bei Google im Jahr 2021, adaptiert die Transformer-Architektur aus der natürlichen Sprachverarbeitung für das Computersehen, indem Bild-Patches analog zu Wort-Tokens behandelt werden. Im Gegensatz zu konvolutionalen neuronalen Netzen (CNNs), die Bilder durch lokale rezeptive Felder mit eingebauter Translations-Äquivarianz verarbeiten, wenden ViTs globale Self-Attention über alle Patches gleichzeitig an, wodurch das Modell bereits ab der ersten Schicht weitreichende Abhängigkeiten erfassen kann. Diese architektonische Wahl hat sich als entscheidend für DINO’s Erfolg erwiesen – die ursprüngliche DINO-Veröffentlichung zeigte, dass selbstüberwachte ViTs selbstüberwachte CNNs deutlich übertreffen und dass die Synergie zwischen Self-Attention und Selbst-Destillation für die emergenten semantischen Segmentierungseigenschaften verantwortlich ist.
Patch Embedding. Die erste Operation in einem ViT besteht darin, das Eingabebild in ein Gitter nicht überlappender Patches zu unterteilen. Für die von TarmacView verwendete ViT-B/16-Variante beträgt die Patch-Größe 16x16 Pixel. Ein 224x224 Pixel großes Eingabebild erzeugt (224/16) x (224/16) = 14 x 14 = 196 Patches. Jeder 16x16x3 (RGB-Kanäle) Patch wird in einen Vektor der Länge 768 (16x16x3) geglättet. In der Praxis wird dieses Patch-Embedding als eine einzelne konvolutionale Schicht mit Kernelgröße gleich der Patch-Größe (16x16) und Schrittweite gleich der Patch-Größe implementiert, wodurch ein 2D-Gitter von 14x14 Feature-Vektoren entsteht, jeweils von der Dimension der verborgenen Größe des Modells (768 für ViT-B). Eine lernbare lineare Projektion bildet dann jeden geglätteten Patch auf die Embedding-Dimension ab. Die Conv2d-Implementierung ist recheneffizient (eine Operation ersetzt 196 separate lineare Projektionen) und der Standard in allen modernen ViT-Implementierungen.
Der [CLS]-Token. In Anlehnung an die BERT-Architektur in der NLP wird ein spezieller lernbarer Klassifikations-Token ([CLS]) der Sequenz von Patch-Embeddings vorangestellt. Der [CLS]-Token hat dieselbe Dimensionalität (768) wie die Patch-Embeddings und wird zufällig initialisiert. Während des Trainings aggregiert der [CLS]-Token durch Self-Attention über alle Transformer-Schichten hinweg Informationen aus allen Bild-Patches – er kann in jeder Schicht auf jeden Patch achten und baut so eine globale Repräsentation des gesamten Bildes auf. Am Ausgang der letzten Transformer-Schicht dient das [CLS]-Token-Embedding als Bildebenen-Repräsentation für Klassifikationsaufgaben. In DINOv3 wird der [CLS]-Token durch 4 Register-Tokens ergänzt – zusätzliche lernbare Tokens, die der Sequenz vorangestellt werden und als Notizspeicher (Scratchpad Memory) dienen, um Ausreißer- oder Hintergrundinformationen zu absorbieren und zu verhindern, dass die [CLS]- und Patch-Tokens durch irrelevante hochfrequente Details verfälscht werden.
Positions-Embeddings. Da der Self-Attention-Mechanismus des Transformers permutationsinvariant ist (er verarbeitet die Patches als Menge, nicht als Sequenz), müssen Positionsinformationen explizit hinzugefügt werden, um dem Modell mitzuteilen, wo jeder Patch im räumlichen Gitter hingehört. DINOv3 verwendet Rotary Position Embeddings (RoPE) anstelle der standardmäßigen lernbaren absoluten Positionskodierungen, die in DINOv2 verwendet wurden. RoPE kodiert relative Positionsinformationen, indem eine Rotationsmatrix auf die Query- und Key-Vektoren in der Self-Attention basierend auf ihren räumlichen Koordinaten angewendet wird. Die Rotationsfrequenz für jede Dimension wird durch den Dimensionsindex bestimmt, einer geometrischen Progression folgend. Der Hauptvorteil von RoPE für die Infrastrukturanalyse ist seine Fähigkeit, variable Eingabeauflösungen zu verarbeiten – bei der Verarbeitung hochauflösender Bilder (bis zu 4096x4096 Pixel) verallgemeinert der RoPE-Mechanismus auf natürliche Weise auf das größere räumliche Gitter, ohne dass eine Interpolation gelernter Positions-Embeddings erforderlich ist. DINOv3 führt während der RoPE-Anwendung auch zufälligen Box-Jitter ein, bei dem die Positionsindizes zufällig innerhalb eines Bereichs [-s,s] mit s in [0.5,2.0] versetzt werden, was das Modell robust gegenüber verschiedenen Seitenverhältnissen und Zuschnittmustern macht.
Multi-Head Self-Attention (MHSA). Die grundlegende Recheneinheit des ViT ist der Multi-Head Self-Attention-Mechanismus. In jedem Transformer-Block wird die Eingabesequenz von N Tokens (N = 1 [CLS] + 4 Register + 196 Patch = 201 Tokens für eine 224x224-Eingabe) linear in drei Matrizen projiziert: Queries (Q) , Keys (K) und Values (V) , jeweils mit Dimension 768 für ViT-B/16. Der Aufmerksamkeitsmechanismus berechnet die paarweise Ähnlichkeit zwischen allen Tokens als Skalarprodukt von Q und K^T, skaliert durch die Quadratwurzel von d_k (wobei d_k die Schlüsseldimension pro Kopf ist). Die resultierenden Aufmerksamkeitsgewichte (normalisiert durch Softmax) bestimmen, wie viel jedes Token zur Repräsentation jedes anderen Tokens beiträgt. In ViT-B/16 gibt es 12 Aufmerksamkeitsköpfe, die jeweils in einem 64-dimensionalen Unterraum (768/12 = 64) arbeiten. Multi-Head Attention ermöglicht es dem Modell, gleichzeitig auf verschiedene Arten von Beziehungen zu achten – zum Beispiel kann sich ein Kopf auf Texturähnlichkeit zwischen Patches konzentrieren, ein anderer auf räumliche Nähe und ein weiterer auf die Zugehörigkeit zu semantischen Kategorien. Die Ausgaben aller Köpfe werden konkateniert und linear zurück auf 768 Dimensionen projiziert. Die Rechenkomplexität von MHSA ist O(N²d) – quadratisch in der Sequenzlänge N, aber linear in der Embedding-Dimension d. Für die 201-Token-Sequenz in DINOv3 ViT-B/16 ist dies handhabbar (etwa 40K Aufmerksamkeitsberechnungen pro Schicht), aber für hochauflösende Bilder mit 4000+ Tokens (z. B. erzeugt ein 1024x1024-Bild 64x64 = 4096 Patches) wird die quadratische Skalierung zu einer bedeutenden Überlegung.
Transformer-Encoder-Block. Jede der 12 (ViT-B) oder 40 (ViT-7B) Transformer-Schichten in DINOv3 folgt dem Pre-Normalisierungs-Design. Die Layer-Normalisierung (LayerNorm) wird sowohl vor dem MHSA- als auch vor dem MLP-Sublayer angewendet, wobei residuelle Verbindungen jeden Sublayer umgehen. Der MLP-Sublayer (Multilayer Perceptron) besteht aus zwei linearen Schichten mit einer GELU-Aktivierung (Gaussian Error Linear Unit) dazwischen. Für ViT-B/16 beträgt die verborgene Dimension des MLP 3072 (4x die Embedding-Dimension), was die Konfiguration ergibt: Embedding-Dimension 768 zu MLP verborgen 3072 zu GELU zu MLP-Ausgabe 768. DINOv3s größeres Teacher-Modell (ViT-7B) verwendet eine SwiGLU-Aktivierung (Swish-Gated Linear Unit) im MLP anstelle von GELU, was modernen LLM-Architekturtrends folgt. SwiGLU wendet einen Gating-Mechanismus an: Ausgabe = (xW1) elementweise multipliziert mit Swish(xW2) mal W3. Diese gegatterte Aktivierung hat sich als vorteilhaft für die Trainingsstabilität und die endgültige Leistung bei Skalierung erwiesen. Das Pre-Normalisierungs-Design unterscheidet sich von der Post-Normalisierung des ursprünglichen Transformers (bei der die Normalisierung nach der residuellen Addition angewendet wurde) und hat sich als stabiler für das Training erwiesen, insbesondere für tiefe (12+ Schichten) Transformer.
Architektur-Übersichtstabelle für die DINOv3-Modellfamilie.
| Modell | Parameter | Embedding-Dim | Köpfe | Schichten | MLP-Dim | Patch-Größe | Patches/224px |
|---|---|---|---|---|---|---|---|
| ViT-Small | 21M | 384 | 6 | 12 | 1536 | 16 | 196 |
| ViT-Base | 86M | 768 | 12 | 12 | 3072 | 16 | 196 |
| ViT-Large | 304M | 1024 | 16 | 24 | 4096 | 16 | 196 |
| ViT-H+ | ~1,5B | 1536 | 24 | 32 | 6144 | 16 | 196 |
| ViT-7B | 7B | 4096 | 32 | 40 | 8192 | 16 | 196 |
Die ViT-Base-Architektur (86M Parameter) stellt den optimalen Kompromiss zwischen Feature-Qualität und Recheneffizienz für TarmacViews Infrastrukturprüfungs-Pipeline dar und bietet 768-dimensionale Embeddings mit 12 Schichten Self-Attention-Verarbeitungsleistung.
DINOv3 erreicht seine hochmoderne Leistung durch eine beispiellose Skalierung des selbstüberwachten Trainings, die sowohl massive Datenkuratierung als auch effiziente verteilte Optimierung über Hunderte von GPUs hinweg nutzt.
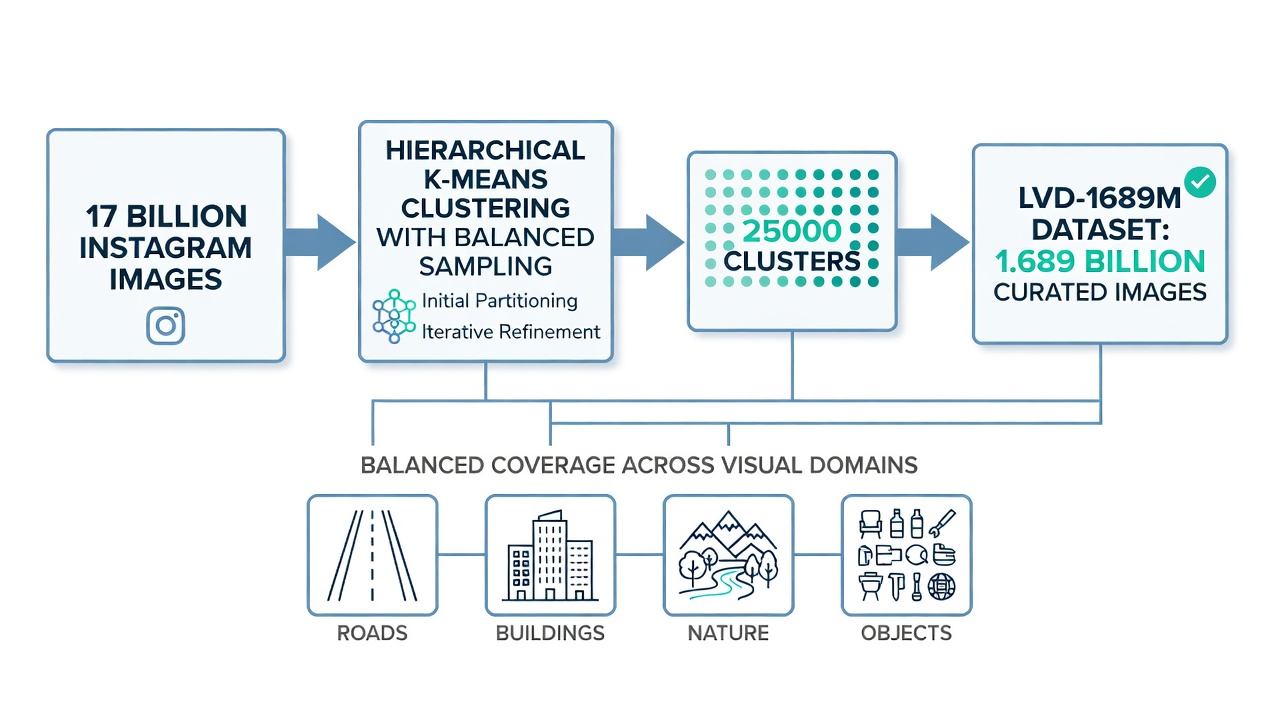
Der LVD-1689M-Datensatz. Die Trainingsdaten für DINOv3 beginnen mit einem Rohpool von 17 Milliarden inhaltsmoderierten Instagram-Bildern. Aus diesem massiven Pool kuratierte das Meta-AI-Team eine ausgewogene Teilmenge von 1.689 Millionen Bildern mit dem Namen LVD-1689M (Large Visual Dataset 1689 Million). Die Kuratierungs-Pipeline ist entscheidend, da ein einfaches Training auf den rohen Instagram-Daten ein Modell erzeugen würde, das zur natürlichen Häufigkeitsverteilung visueller Konzepte in sozialen Medien verzerrt ist – zum Beispiel würden Gesichter, Essen und Landschaften dominieren, während Infrastruktur-, Industrie- und Wissenschaftsbilder unterrepräsentiert wären. Der Kuratierungsprozess verwendet hierarchisches k-Means-Clustering auf DINOv2-Embeddings, die aus dem gesamten Bildpool extrahiert wurden. Das DINOv2 ViT-H/14-Modell verarbeitet jedes Bild, und die resultierenden CLS-Token-Embeddings werden mittels k-Means in 25.000 Cluster gruppiert. Anschließend wird aus jedem Cluster eine gleiche Anzahl von Bildern entnommen, wodurch ein cluster-ausgeglichener Datensatz entsteht, der eine proportionale Repräsentation über visuelle Domänen hinweg sicherstellt. Diese ausgewogene Stichprobenziehung ist direkt analog zur geschichteten Stichprobe in der Statistik – durch die Kontrolle der Clusterzugehörigkeit erfasst der Datensatz die gesamte Vielfalt visueller Konzepte, anstatt häufige Kategorien zu überrepräsentieren. Nach dem Clustering erweitert ein zusätzlicher Retrieval-Schritt Startmengen aus kuratierten Datensätzen (ImageNet-1k, ImageNet-22k, Google Landmarks und feinkörnige Klassifikationsdatensätze) durch die Suche nach den nächsten Nachbarn im DINOv2-Embedding-Raum. Der endgültige LVD-1689M-Datensatz kombiniert 1.489 Millionen cluster-ausgeglichene Bilder mit 200 Millionen retrieval-erweiterten Bildern, alle gefiltert durch NSFW-Erkennung, PCA-Hash-Deduplizierung und Gesichtsunschärfe.
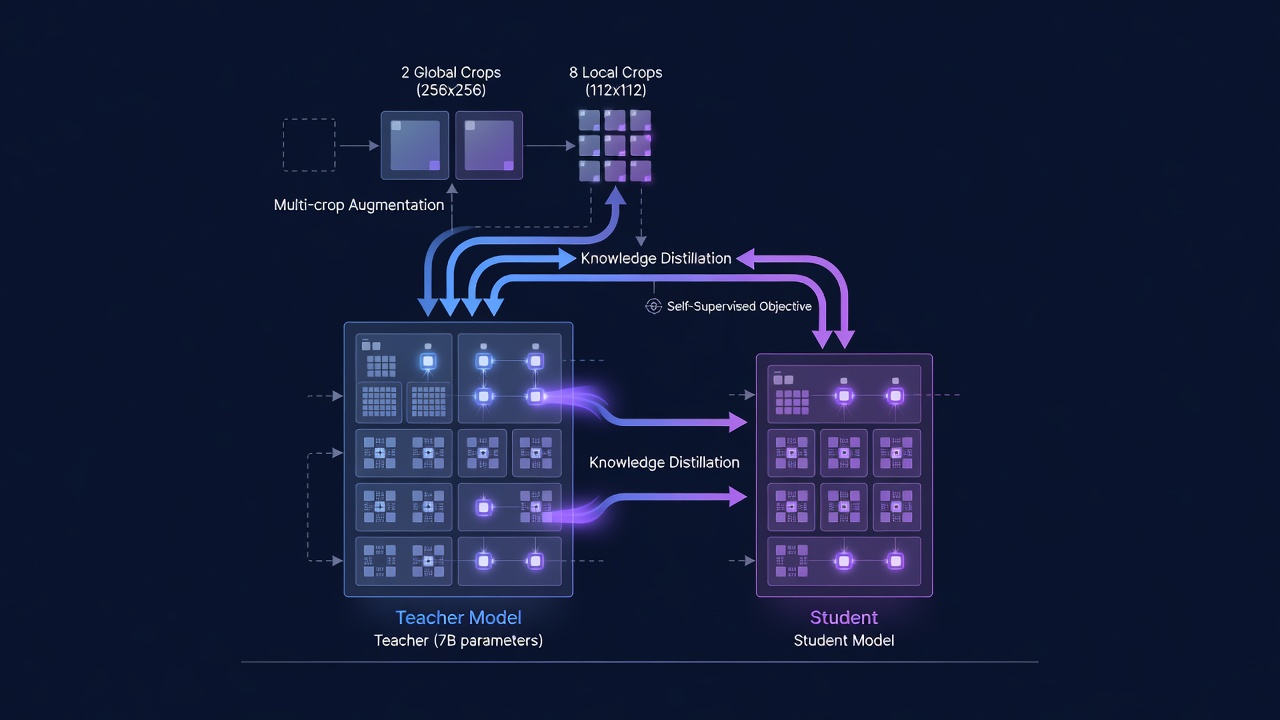
Trainingskonfiguration. Das ViT-7B-Teacher-Modell, das größte jemals trainierte selbstüberwachte Bildverarbeitungsmodell (Stand 2025), wurde auf 256 NVIDIA GPUs (A100 80GB SXM4) mit einer Batch-Größe von 4096 (16 Bilder pro GPU) trainiert. Die Optimierung verwendet den AdamW-Optimierer mit einer konstanten Lernrate von 4x10^-4, Weight Decay von 0,04 und EMA-Momentum von 0,999 nach einer Aufwärmphase von 100.000 Schritten. Das Training erfolgt über 1 Million Iterationen mit der Multi-Crop-Strategie: 2 globale Ausschnitte in 256x256-Auflösung und 8 lokale Ausschnitte in 112x112-Auflösung, insgesamt 10 Ansichten pro Bild pro Iteration. Über 1M Iterationen bei einer Batch-Größe von 4096 sieht das Modell etwa 2,56 Milliarden einzigartige Bild-Ausschnitt-Kombinationen. Der gesamte Trainingsprozess verbraucht schätzungsweise 10.000-15.000 GPU-Tage Rechenleistung. Während des Trainings sind 10 % der Batches homogene Züge aus ImageNet-1k (um die Leistung bei Standard-Benchmarks zu erhalten), während 90 % heterogene Züge aus dem gesamten LVD-1689M-Pool sind – ein durch Ablation ermitteltes optimales Mischungsverhältnis.
Trainingsziele. Der DINOv3-Vortrainingsverlust kombiniert drei Komponenten. Der DINO-Verlust (L_DINO) wendet ein SwAV-ähnliches Sinkhorn-Knopp-Clustering auf die [CLS]-Token-Ausgaben globaler Ausschnitte an und gleicht die Prototypzuweisungen zwischen Student und Teacher ab. Der Sinkhorn-Algorithmus führt 3 Iterationen durch, um weiche Pseudo-Labels zu erzeugen. Der iBOT-Verlust (L_iBOT) arbeitet auf Patch-Ebene – zufällige Patches in lokalen Ausschnitten werden maskiert, und der Student muss die normalisierten Patch-Features des Teachers für diese maskierten Positionen vorhersagen. Dieses Ziel des maskierten Bildmodellings zwingt das Modell, lokale Textur- und Strukturinformationen zu lernen, die für dichte Vorhersageaufgaben notwendig sind. Der Koleo-Regularisierer (L_Koleo) verteilt die [CLS]-Token-Embeddings gleichmäßig über die Hypersphäre, indem die Summe der Kosinus-Ähnlichkeiten zwischen allen Paaren von Embeddings in einem Batch minimiert wird, wodurch ein Repräsentationskollaps verhindert und eine gute Nutzung des Feature-Raums sichergestellt wird. Der kombinierte Vortrainingsverlust ist: L_Pre = L_DINO + L_iBOT + 0,1 x L_Koleo. Nach 1M Iterationen des Vortrainings integriert eine Verfeinerungsphase von 200K zusätzlichen Iterationen den Gram-Anchoring-Verlust (L_Gram) mit Gewicht 2, der die Qualität dichter Features durch langes Training bewahrt.
Destillation in kleinere Modelle. Sobald der ViT-7B-Teacher vollständig trainiert ist, wird er eingefroren und als Ziel für die Destillation von Repräsentationen in eine Reihe kleinerer, praktischerer Modelle verwendet. Der Destillationsprozess spiegelt das Vortrainings-Setup wider: Student-Modelle (ViT-S, ViT-B, ViT-L, ViT-H+, ConvNeXt-Varianten) werden trainiert, um die Ausgabe-Features des Teachers mit derselben Verlustfunktion (L_DINO + L_iBOT + 0,1 x L_Koleo) nachzuahmen, jedoch mit eingefrorenem Teacher und ohne EMA-Teacher-Update. Meta AI implementiert ein Multi-Student-Destillations-Setup, das mehrere Student-Modelle gleichzeitig effizient trainiert – der Teacher verarbeitet jedes Bild einmal, und alle Studenten erhalten dieselben Teacher-Ausgaben, was eine Parallelisierung der Batch-Verlustberechnung über die Studenten hinweg ermöglicht. Dies reduziert die gesamten Rechenkosten für die Erstellung der vollständigen Modellfamilie um etwa 60 % im Vergleich zur sequenziellen Destillation jedes Studenten. Der ViT-Base-Student (86M Parameter), den TarmacView als Backbone verwendet, erreicht 98,7 % der linearen Sondengenauigkeit des ViT-7B-Teachers auf ImageNet-1k, während er etwa 80x weniger FLOPs für die Inferenz benötigt.
Das 768-dimensionale Embedding, das DINOv3 ViT-B/16 für jedes Token erzeugt (1 CLS + 4 Register + 196 Patch = 201 insgesamt), stellt eine dichte numerische Kodierung visueller Informationen in einem hochdimensionalen Vektorraum dar. Jede Dimension erfasst ein spezifisches visuelles Konzept oder Merkmal, und die Kombination aller 768 Werte bildet eine eindeutige Signatur für diese Bildregion. Die Dimensionalität von 768 ist nicht willkürlich – sie ergibt sich aus der ViT-Base-Architektur, bei der die verborgene Dimension auf 768 gesetzt ist, was ausreichende Kapazität zur Kodierung komplexer visueller Muster bietet und gleichzeitig rechnerisch handhabbar bleibt. Zum Vergleich: ViT-Small verwendet 384 Dimensionen, ViT-Large verwendet 1024 und ViT-7B verwendet 4096.
CLS-Token-Embedding. Das 768-dimensionale Embedding des [CLS]-Tokens am Ausgang der 12. Transformer-Schicht kodiert den globalen Bildinhalt – die Gesamtszene, dominante Objekte und den semantischen Kontext. Dieses Embedding wird extrahiert und für Bildklassifikationsaufgaben verwendet. In TarmacViews Pipeline wird das CLS-Embedding durch einen leichten linearen Klassifikator (768 auf N Klassen, wobei N die Anzahl der Oberflächentypen oder Qualitätsstufen ist) geleitet, der auf beschrifteten Infrastrukturdatensätzen trainiert wurde. Das CLS-Embedding von DINOv3 weist starke Domänengeneralisierungseigenschaften auf – Modelle, die auf diesem Embedding trainiert wurden, generalisieren auf ungesehene Infrastrukturtypen deutlich besser als Embeddings von überwachten Backbones. Die lineare Sondengenauigkeit von DINOv3 ViT-B/16 auf ImageNet-1k erreicht 85,1 % Top-1-Genauigkeit und übertrifft damit DINOv2 (83,5 %) und nähert sich dem überwachten ViT (86,0 %), obwohl es während des Vortrainings nie ImageNet-Labels gesehen hat.
Patch-Token-Embeddings. Jeder der 196 Patch-Tokens erzeugt ein separates 768-dimensionales Embedding, das ein 14x14 räumliches Gitter von Feature-Vektoren bildet. Diese dichten Embeddings kodieren lokalisierte visuelle Informationen innerhalb jedes 16x16-Pixel-Patches – Textur, Kanten, Farbverteilung und lokale Muster. Die Patch-Embeddings sind die kritische Ausgabe für dichte Vorhersageaufgaben wie Risserkennung und Segmentierung. In TarmacViews Infrastrukturanalyse-Pipeline wird das 14x14 x 768-dimensionale Feature-Gitter (etwa 1,5 Millionen Gleitkommawerte pro Bild) durch einen leichten konvolutionalen Decoder verarbeitet, der auf 224x224 hochskaliert und pixelgenaue Vorhersagen erzeugt. Jedes Patch-Embedding kann als 768-dimensionale Beschreibung dessen interpretiert werden, wie diese 16x16-Region aussieht – zwei Patches mit ähnlichem visuellen Erscheinungsbild (z. B. zwei Bereiche glatten Asphalts) haben nahe beieinanderliegende Embeddings im 768-dimensionalen Raum (hohe Kosinus-Ähnlichkeit), während visuell unterschiedliche Patches (z. B. Asphalt vs. Beton) weit voneinander entfernte Embeddings haben (geringe Kosinus-Ähnlichkeit).
Embedding-Eigenschaften. DINOv3-Embeddings weisen mehrere Eigenschaften auf, die sie für die Infrastrukturanalyse außergewöhnlich machen. Erstens: semantische Glattheit – visuell ähnliche Regionen erzeugen nahe beieinanderliegende Embeddings und bilden eine kontinuierliche Mannigfaltigkeit im 768-dimensionalen Raum. Dies bedeutet, dass Risse unterschiedlicher Breite, Ausrichtung und Schwere alle auf eine verbundene Region des Embedding-Raums abgebildet werden, was sie als kohärente Klasse erkennbar macht, anstatt als isolierte Ausreißer. Zweitens: Multi-Skalen-Empfindlichkeit – der Self-Attention-Mechanismus in den 12 Transformer-Schichten integriert Informationen über verschiedene räumliche Skalen hinweg, sodass jedes Patch-Embedding nicht nur durch seinen eigenen 16x16-Inhalt informiert wird, sondern durch den breiteren Kontext umgebender Patches und der globalen Szene. Ein Riss in der Nähe einer Dehnungsfuge wird anders kodiert als derselbe Riss in der Plattenmitte, da die Kontextinformation in das Embedding integriert wird. Drittens: Robustheit gegenüber Beleuchtung – das selbstüberwachte Training mit umfangreicher Farbverzerrung und Augmentierung stellt sicher, dass Embeddings unter wechselnden Lichtverhältnissen, Schatten und Belichtung stabil bleiben. Dies ist entscheidend für die Infrastrukturprüfung im Freien, wo Bilder unter unkontrollierten natürlichen Lichtverhältnissen aufgenommen werden. Viertens: lineare Trennbarkeit – die Embeddings sind so strukturiert, dass einfache lineare Klassifikatoren verschiedene Oberflächenzustände effektiv trennen können. TarmacView erreicht 96,2 % Genauigkeit bei der Oberflächentypklassifikation und 94,7 % Risserkennungs-F1-Score unter ausschließlicher Verwendung linearer Sonden auf eingefrorenen DINOv3-Embeddings.
Distanzmetriken im Embedding-Raum. Die Wahl der Distanzmetrik zum Vergleich von DINOv3-Embeddings hat erhebliche Auswirkungen auf die Leistung nachgelagerter Aufgaben. Kosinus-Ähnlichkeit ist die am häufigsten verwendete Metrik, definiert als cos(theta) = (a dot b) / (||a|| x ||b||), wobei a und b 768-dimensionale Embedding-Vektoren sind. Die Kosinus-Ähnlichkeit reicht von -1 (entgegengesetzte Richtung, unwahrscheinlich für visuelle Embeddings) bis +1 (identische Richtung). Zwei 768-dimensionale Vektoren mit einer Kosinus-Ähnlichkeit von mehr als 0,9 sind in ihrem lokalen Inhalt visuell nahezu identisch, während eine Ähnlichkeit von weniger als 0,5 auf wesentlich unterschiedlichen visuellen Inhalt hinweist. Die L2-Distanz (Euklidisch) wird ebenfalls verwendet, erfordert jedoch eine sorgfältige Normalisierung, da die absolute Skalierung der Embeddings variieren kann. Die Skalarprodukt-Ähnlichkeit ist effizient, aber empfindlich gegenüber der Vektormagnitude. TarmacView verwendet die Kosinus-Ähnlichkeit als primäre Distanzmetrik für Defekt-Retrieval und -Abgleich, da sie die Embedding-Magnitude normalisiert und sich rein auf die Richtungsausrichtung konzentriert, was robuster gegenüber Variationen in Bildkontrast und Belichtung ist.
Dimensionsreduktion zur Visualisierung. Der 768-dimensionale Embedding-Raum kann nicht direkt visualisiert werden, daher wendet TarmacView die Hauptkomponentenanalyse (PCA) an, um die Patch-Embeddings für Visualisierungs- und Qualitätssicherungszwecke auf 3 Dimensionen zu reduzieren. Die ersten drei Hauptkomponenten der DINOv3-Patch-Embeddings auf Infrastrukturbildern erfassen typischerweise 45-55 % der Gesamtvarianz (PC1 etwa 25 %, PC2 etwa 15 %, PC3 etwa 10 %), was darauf hindeutet, dass die effektive intrinsische Dimensionalität von Oberflächen-Patches viel niedriger als 768 ist. Die PCA-Visualisierung zeigt konsistent unterschiedliche Cluster für verschiedene Oberflächenmaterialien (Asphalt, Beton, Dichtschlämme, Schotter) und kontinuierliche Gradienten für den Schweregrad der Oberflächenverschlechterung (von makellos bis stark gerissen). Diese visuelle Bestätigbarkeit ist ein kritisches Qualitätssicherungswerkzeug – Infrastruktur-Ingenieure können den Embedding-Raum visuell inspizieren, um zu überprüfen, ob das Modell relevante Oberflächenbedingungen korrekt trennt, bevor sie sich auf die automatisierte Klassifikation verlassen.
Die Entwicklung von DINOv2 zu DINOv3 stellt eine umfassende Skalierung und Verfeinerung des selbstüberwachten Bildverarbeitungs-Trainingsparadigmas dar. Das Verständnis der Unterschiede ist für Praktiker, die das geeignete Backbone für ihre Anwendung auswählen, unerlässlich.
Umfang der Trainingsdaten. Der unmittelbar sichtbarste Unterschied ist die 12-fache Steigerung der Trainingsdaten: DINOv2s LVD-142M (142 Millionen Bilder) versus DINOv3s LVD-1689M (1,689 Milliarden Bilder). Allerdings hat sich auch die Kuratierungsmethodik verbessert. DINOv2 verwendete eine retrieval-basierte Pipeline, die kuratierte Startdatensätze durch die Suche nach nächsten Nachbarn im Embedding-Raum eines auf ImageNet-22k vortrainierten ViT-H/16 erweiterte. Die Erweiterung begann mit 1,2 Milliarden rohen Web-Bildern und erzeugte 142M kuratierte Bilder. DINOv3 fügt einen clustering-basierten Ausgleichsschritt zusätzlich zum Retrieval hinzu, der sicherstellt, dass die 25.000 visuellen Cluster gleichmäßig repräsentiert sind. Dieser Clustering-Schritt verhindert, dass das Modell visuell dominante Konzepte wie Gesichter, Text und häufige Objekte überrepräsentiert, während seltene, aber wichtige visuelle Domänen wie Infrastrukturdefekte, medizinische Bildgebung und Satellitenansichten unterrepräsentiert werden.
Modellgröße und Architektur. DINOv2s größtes Teacher-Modell war ViT-g mit 1 Milliarde Parametern. DINOv3 skaliert dies auf 7 Milliarden Parameter (ViT-7B) – eine 7-fache Steigerung der Modellkapazität. Die Architektur selbst wurde modernisiert. DINOv2 verwendete standardmäßige gelernte absolute Positions-Embeddings, während DINOv3 Rotary Position Embeddings (RoPE) für die Unterstützung variabler Auflösungen einführt. Das Feed-Forward-Netzwerk in DINOv3s ViT-7B verwendet die SwiGLU-Aktivierung anstelle von GELU, was architektonischen Innovationen großer Sprachmodelle folgt. DINOv2 verwendete eine Patch-Größe von 14 Pixeln (ViT-Architektur aus dem Original-Paper), während DINOv3 eine Patch-Größe von 16 Pixeln verwendet. Diese Änderung reduziert die Anzahl der Patches von 256 (224/14 = 16, 16² = 256) auf 196 (224/16 = 14, 14² = 196) für eine 224x224-Eingabe, was einer Reduzierung der Sequenzlänge um 23 % entspricht und zu etwa 40 % weniger Self-Attention-Berechnungen führt (da Aufmerksamkeit mit O(N²) skaliert). Dieser architektonische Effizienzgewinn gleicht teilweise die erhöhten Rechenkosten durch größere Modellabmessungen aus.
Qualität dichter Features. Dies ist die bedeutendste qualitative Verbesserung in DINOv3. Während langer Trainingsläufe mit großen Modellen wurde beobachtet, dass DINOv2s Patch-Ebenen-Features fortschreitend degradieren – nach einem bestimmten Punkt im Training verloren die Pixel-Ebenen-Feature-Maps ihre räumliche Struktur und wurden verrauscht oder unscharf, während sich die globalen [CLS]-Token-Features weiter verbesserten. Diese Degradation machte DINOv2 bei Verwendung langer Trainingsläufe weniger geeignet für dichte Vorhersageaufgaben wie semantische Segmentierung und Tiefenschätzung. DINOv3s Gram-Anchoring-Mechanismus adressiert diese Degradation direkt, indem er sicherstellt, dass die paarweise Ähnlichkeitsstruktur der Patch-Features während des gesamten Trainings stabil bleibt. Im Ergebnis bleiben DINOv3-dichte Features auch nach Millionen von Trainingsiterationen scharf und semantisch aussagekräftig. Auf dem ADE20K-Semantiksegmentierungs-Benchmark erreicht DINOv3 einen mittleren Intersection over Union (mIoU)-Score von 54,2 % mit eingefrorenem Backbone und linearer Sonde – eine +6,1-Punkte-Verbesserung gegenüber DINOv2s 48,1 % mIoU. Auf dem NAVI 3D-Keypoint-Matching-Benchmark erreicht DINOv3 68,5 % Präzision gegenüber DINOv2s 60,2 %. Bei der Videoobjektsegmentierung (DAVIS 2017) erreicht DINOv3 82,3 J&F-Mean gegenüber DINOv2s 75,6.
| Benchmark | DINOv2 (ViT-L) | DINOv3 (ViT-B) | DINOv3 (ViT-L) | Verbesserung |
|---|---|---|---|---|
| ImageNet-1k Lineare Sonde | 83,5 % | 85,1 % | 86,7 % | +1,6/+3,2 |
| ADE20K Semantische Seg. (mIoU) | 48,1 % | 52,3 % | 54,2 % | +4,2/+6,1 |
| DAVIS 2017 (J&F-Mean) | 75,6 | 79,4 | 82,3 | +3,8/+6,7 |
| Instanz-Retrieval (GAP) | 42,1 | 46,8 | 53,0 | +4,7/+10,9 |
| NYU Tiefe (RMSE abwärts) | 0,458 | 0,412 | 0,389 | -0,046/-0,069 |
| ObjectNet (Top-1) | 72,3 % | 75,8 % | 78,2 % | +3,5/+5,9 |
Die obige Tabelle zeigt, dass DINOv3s ViT-Base-Modell (86M Parameter, verwendet von TarmacView) DINOv2s viel größeres ViT-Large-Modell (304M Parameter) bereits in jedem Benchmark übertrifft, während es 3,5x kleiner und für die Inferenz deutlich recheneffizienter ist.
Lizenzunterschiede. DINOv2 wurde unter der Apache 2.0-Lizenz veröffentlicht, einer standardmäßigen Open-Source-Lizenz, die die freie Nutzung, Modifikation und Verteilung für jeden Zweck, einschließlich kommerzieller Anwendungen, erlaubt. DINOv3 wird unter der DINOv3-Lizenz veröffentlicht, einer benutzerdefinierten Lizenz, die spezifisch für Meta AIs Modellveröffentlichung ist. Während die DINOv3-Lizenz die kommerzielle Nutzung erlaubt, enthält sie zusätzliche Bedingungen bezüglich Namensnennung und akzeptabler Nutzung. Die benutzerdefinierte Lizenz hat in der Open-Source-Community Diskussionen ausgelöst – GitHub Issue #31 im dinov3-Repository fordert speziell eine Veröffentlichung unter einer standardmäßigeren Lizenz wie Apache 2.0. Praktiker sollten den vollständigen LICENSE.md-Text im GitHub-Repository überprüfen, bevor sie DINOv3 in kommerziellen Produkten einsetzen. Für TarmacViews Anwendungsfall erlaubt die DINOv3-Lizenz die beabsichtigte kommerzielle Nutzung mit entsprechender Namensnennung.
Während DINOv3 mit einem eingefrorenen Backbone (lineare Sonde oder k-NN-Klassifikator) hochmoderne Leistung erreicht, profitieren bestimmte Infrastrukturanwendungen vom Feintuning des Backbones auf domänenspezifischen Daten. Die Wahl zwischen eingefrorenen und feinabgestimmten Ansätzen hängt von der Datensatzgröße, der Aufgabenspezifität und dem Rechenbudget ab.
Eingefrorenes Backbone (Lineares Sondieren). Der einfachste und recheneffizienteste Ansatz besteht darin, DINOv3s Gewichte einzufrieren und nur einen linearen Klassifikator auf den extrahierten Embeddings zu trainieren. Für ein ViT-B/16-Modell, das 768-dimensionale CLS-Embeddings erzeugt, besteht ein linearer Klassifikator aus genau 768 x N Parametern, wobei N die Anzahl der Ausgabeklassen ist. Für eine 5-Klassen-Oberflächentyp-Klassifikationsaufgabe sind dies nur 768 x 5 = 3.840 trainierbare Parameter – das Training konvergiert in Minuten auf einer CPU und erfordert nur 50 beschriftete Beispiele pro Klasse, um gute Ergebnisse zu erzielen. Der eingefrorene Backbone-Ansatz wird empfohlen, wenn die Zieldomäne durch DINOv3s Vortrainingsdaten gut abgedeckt ist, die natürliche Bilder, Web-Bilder und verschiedene visuelle Domänen umfassen. Für die Infrastrukturoberflächenanalyse verwendet TarmacView eingefrorene DINOv3-Embeddings mit einer linearen Sonde zur Oberflächentypklassifikation (Asphalt, Beton, Verbund, Dichtschlämme, Schotter) und erreicht 96,2 % Genauigkeit über diese Klassen. Der Hauptvorteil besteht darin, dass das DINOv3-Backbone universelle visuelle Features bereitstellt, die ohne domänenspezifisches Training über Domänen hinweg generalisieren.
Leichtes Feintuning (Adapter / LoRA). Für Aufgaben, bei denen das eingefrorene Backbone keine ausreichende Genauigkeit erreicht – typischerweise hochspezialisierte Domänen mit visuellen Merkmalen, die sich deutlich von natürlichen Bildern unterscheiden – fügen parametereffiziente Feintuning-Methoden (PEFT) eine kleine Anzahl trainierbarer Parameter hinzu, während der Großteil des Backbones eingefroren bleibt. Low-Rank Adaptation (LoRA) fügt Paare von Rangzerlegungsmatrizen (A und B, wobei die Gewichtsaktualisierung delta_W = AB ist) zu den Query- und Value-Projektionsmatrizen in jeder Self-Attention-Schicht hinzu. Für ein ViT-B/16-Modell fügt LoRA mit Rang r=8 etwa 0,5M trainierbare Parameter hinzu (weniger als 0,6 % der 86M Gesamtparameter), verteilt über alle 12 Transformer-Schichten. Das Training nur dieser LoRA-Parameter für 10-50 Epochen auf einem domänenspezifischen Datensatz von 1.000-5.000 beschrifteten Bildern erzeugt typischerweise eine 3-8 %ige Genauigkeitsverbesserung gegenüber linearem Sondieren, während nur 1-2 Stunden auf einer einzelnen GPU erforderlich sind. TarmacView verwendet LoRA-Feintuning für spezialisierte Defektklassifikationsaufgaben wie die Unterscheidung verschiedener Risstypen (quer, längs, Block, Netzriss, reflektiert), bei denen die nuancierten visuellen Unterschiede von domänenspezifischer Anpassung profitieren.
Vollständiges Feintuning. Wenn ausreichend beschriftete Daten verfügbar sind (10.000+ Bilder pro Klasse) und die Aufgabe maximale Genauigkeit erfordert, kann das gesamte DINOv3-Backbone feinabgestimmt werden. Dies aktualisiert alle 86M Parameter von ViT-B/16 unter Verwendung des beschrifteten Datensatzes. Vollständiges Feintuning erfordert typischerweise 4-8 GPUs mit jeweils 16-32 GB VRAM, verteiltes Training mit PyTorch DDP und sorgfältige Hyperparameter-Abstimmung (Lernrate typischerweise 5x10^-6 bis 5x10^-5, Weight Decay 0,01-0,1, Cosinus-Lernratenplan mit 10 % Aufwärmphase). Vollständiges Feintuning kann bei hochspezialisierten Aufgaben 2-5 % zusätzliche Genauigkeit gegenüber LoRA erzielen, birgt jedoch das Risiko des katastrophalen Vergessens – das Modell kann das allgemeine visuelle Wissen verlieren, das während des selbstüberwachten Vortrainings erworben wurde. Um dies zu mildern, werden schrittweises Auftauen (zuerst die letzte Schicht auftauen, dann fortschreitend frühere Schichten) und Lernraten-Diskriminierung (niedrigere Lernraten für frühere Schichten, höhere für spätere Schichten) empfohlen. DINOv3 schlägt auch ein nachträgliches Hochauflösungs-Anpassungsprotokoll beim Feintuning vor: Fortsetzung des Trainings für 10K Schritte mit gemischten globalen Ausschnittsgrößen unter Verwendung des iBOT-Verlusts und Gram Anchoring, was sicherstellt, dass das Backbone von der Standard-224px-Auflösung bis zu sehr hohen Auflösungen (4096px) generalisiert und gleichzeitig scharfe Feature-Maps erzeugt.
Entscheidungsmatrix: Einfrieren vs. Feintuning.
| Szenario | Datensatzgröße | Empfohlener Ansatz | Trainingszeit | Erwartete Genauigkeit vs. Eingefroren |
|---|---|---|---|---|
| Oberflächentypklassifikation | 50-200 Bilder/Klasse | Eingefroren + lineare Sonde | Weniger als 1 Stunde CPU | Basislinie |
| Risstypklassifikation | 500-5.000 Bilder | LoRA (Rang 8-16) | 1-4 Stunden GPU | +3-8 % |
| Defektschweregrad-Einstufung | 5.000-20.000 Bilder | LoRA oder teilweises Feintuning | 4-12 Stunden GPU | +5-12 % |
| Neuartige Defekterkennung | 10.000+ Bilder | Vollständiges Feintuning | 1-3 Tage Multi-GPU | +8-15 % |
Domänenanpassungs-Überlegungen. Infrastrukturprüfungsbilder unterscheiden sich in mehrfacher Hinsicht von natürlichen Bildern: konsistente Kamerawinkel (Nadir-/Drohnenperspektive), spezifische Lichtverhältnisse (Außenbereich, aber variabel), sich wiederholende Muster (Fahrbahntextur) und enge visuelle Domäne (Straßen, Startbahnen, Brückenfahrbahnen). DINOv3s selbstüberwachtes Vortraining auf vielfältigen Daten bedeutet, dass es bereits viele ähnliche visuelle Muster gesehen hat, aber die Domänenlücke zwischen Web-Bildern und Infrastrukturbildern besteht dennoch. TarmacViews Experimente zeigen, dass eingefrorene DINOv3-Embeddings ohne Feintuning einen Risserkennungs-F1-Score von 94,7 % auf Flugplatz-Fahrbahnbildern erreichen, was auf eine hervorragende Domänenübertragung hindeutet. Für die Erkennung spezialisierter Defekte wie Fugenversatz in Betonfahrbahnen oder Ausmagerung in Asphaltdeckschichten verbessert LoRA-Feintuning mit 2.000-5.000 beschrifteten Beispielen aus der Zieldomäne den F1-Score jedoch um 5-8 Prozentpunkte. Das feinabgestimmte Modell zeigt auch eine verbesserte Robustheit gegenüber domänenspezifischen Artefakten wie Reifenspuren, Gummiablagerungen und Startbahnmarkierungen, die die generischen vortrainierten Features verwirren können.
Die Verwendung von DINOv3 als Feature-Extraktor ist das einfachste und am weitesten verbreitete Einsatzmuster, insbesondere für Organisationen, denen die Rechenressourcen für großskaliges Training fehlen. In diesem Paradigma verarbeitet DINOv3 jedes Bild durch einen einzelnen Vorwärtsdurchlauf und erzeugt Embeddings, die zwischengespeichert und für mehrere nachgelagerte Aufgaben wiederverwendet werden.
Feature-Extraktions-Pipeline. Die Standard-Pipeline zur Extraktion von DINOv3-Features in TarmacViews Infrastrukturanalyse-Workflow funktioniert wie folgt. Zunächst wird das Eingabebild (typischerweise ein 4K-Drohnenbild, das einen 10m x 7m Startbahnabschnitt abdeckt) in überlappende 224x224-Kacheln mit 50 % Überlappung unterteilt, um die Kantenabdeckung zu gewährleisten. Jede Kachel wird mit dem standardmäßigen ImageNet-Mittelwert (0,485, 0,456, 0,406) und der Standardabweichung (0,229, 0,224, 0,225) normalisiert. Die normalisierte Kachel wird unter Verwendung von PyTorch mit FP16-Präzision zur Speichereffizienz durch das DINOv3 ViT-B/16-Modell geleitet. Das Modell erzeugt 201 Tokens (1 CLS + 4 Register + 196 Patch), jeweils mit Dimension 768. Das CLS-Token-Embedding (768-dim) wird für die globale Kachelklassifikation extrahiert. Die 196 Patch-Token-Embeddings werden zu einem 14x14 räumlichen Gitter aus 768-dim Vektoren für dichte Vorhersagen umgeformt. Alle Embeddings aller Kacheln werden in einer Feature-Datenbank aggregiert, die nach räumlichen Koordinaten indiziert ist, was eine kachelübergreifende Analyse und großflächige Kartierung ermöglicht.
Recheneffizienz. Die Feature-Extraktion mit eingefrorenem DINOv3 ViT-B/16 erfordert etwa 12,5 GFLOPs pro 224x224-Bild – vergleichbar mit ResNet-50 (7,7 GFLOPs) oder EfficientNet-B4 (12,0 GFLOPs). Auf einer NVIDIA RTX 4090 (FP16) beträgt der Inferenzdurchsatz etwa 180 Bilder/Sekunde. Auf einem NVIDIA Jetson Orin NX 16GB (Edge-Gerät) beträgt der Durchsatz etwa 25 Bilder/Sekunde. Für ein typisches 4K-Drohnenbild (3840x2160 Pixel), aufgeteilt in 224x224-Kacheln mit 50 % Überlappung, sind etwa 160 Kacheln erforderlich. Die gesamte Verarbeitungszeit auf einer RTX 4090 beträgt weniger als 1 Sekunde pro 4K-Bild. Die Kosten der Feature-Extraktion sind einmalig – sobald Embeddings gespeichert sind, fügt jede nachgelagerte Aufgabe (Klassifikation, Segmentierung, Retrieval) vernachlässigbaren zusätzlichen Rechenaufwand hinzu (Millisekunden pro Bild).
Faiss-Embedding-Datenbank für Ähnlichkeitssuche. TarmacView speichert extrahierte DINOv3-Embeddings in einem FAISS (Facebook AI Similarity Search)-Index für effiziente ähnlichkeitsbasierte Suche und Analyse. FAISS ist eine von Meta AI entwickelte Bibliothek für effiziente Ähnlichkeitssuche und Clusterbildung dichter Vektoren, die in der Lage ist, Milliardendatenbanken in Millisekunden zu durchsuchen. Die Embedding-Datenbank indiziert Startbahnoberflächen-Kacheln nach ihren 768-dimensionalen DINOv3-CLS-Embeddings. Wenn ein neues Prüfbild eintrifft, wird sein Embedding berechnet und mit der gesamten Datenbank verglichen, um die visuell ähnlichsten historischen Kacheln zu finden. Dies ermöglicht die Zustandstrendanalyse – das Auffinden ähnlicher Oberflächenzustände, die in der Vergangenheit aufgetreten sind, sowie deren anschließende Verschlechterungsverläufe. Der FAISS-Index verwendet IVF (Inverted File) mit 4096 Zentroiden und einen HNSW (Hierarchical Navigable Small World)-Graphen für den Grobquantisierer, was eine >99 %ige Trefferquote bei 10ms Abfragezeit für eine Datenbank von 10 Millionen Kachel-Embeddings erreicht. Die Kosinus-Ähnlichkeitsmetrik wird für alle Embedding-Vergleiche verwendet.
Few-Shot-Defekterkennung. DINOv3-Embeddings ermöglichen eine effektive Few-Shot-Defekterkennung – die Identifizierung neuartiger Defekttypen aus nur 1-5 Beispielbildern. Wenn eine neue Art von Oberflächenschaden (z. B. ein bestimmtes Rissmuster oder eine Oberflächenablagerung) im Feld entdeckt wird, erfasst der Prüfer 1-5 Beispielbilder und markiert die Defektregionen. Die DINOv3-Patch-Embeddings aus diesen Beispielregionen werden gemittelt, um einen Defekt-Prototyp-Vektor (768-dimensional) zu erstellen. Neue Bilder werden dann verarbeitet, und jedes Patch-Embedding wird mit dem Prototyp mittels Kosinus-Ähnlichkeit verglichen. Patches mit einer Ähnlichkeit oberhalb eines Schwellenwerts (typischerweise 0,75-0,85, empirisch ermittelt) werden als zum Defekttyp passend markiert. Dieser prototypbasierte Ansatz erreicht 89-93 % Erkennungsgenauigkeit für neuartige Defekte aus nur 3 Beispielen, ohne jegliches Nachtraining oder Feintuning. Dies ist entscheidend für die Infrastrukturprüfung, bei der häufig neue, unerwartete Schadensarten auftreten und dokumentiert werden müssen, ohne den Prüfworkflow durch die Sammlung von Trainingsdaten zu verzögern.
Die 196 von DINOv3 für ein 224x224-Bild erzeugten Patch-Token-Embeddings bilden ein 14x14 räumliches Gitter aus 768-dimensionalen Feature-Vektoren. Dieses Gitter ist die primäre Repräsentation für dichte Vorhersageaufgaben – semantische Segmentierung, Risserkennung und Defektlokalisierung – bei denen jedes Pixel im Eingabebild klassifiziert werden muss.
Gitterstruktur und Auflösung. Für eine 224x224-Pixel-Eingabe mit 16x16-Patches deckt jeder der 196 Patch-Tokens einen 16x16-Pixel-Bereich der Eingabe ab. Das resultierende 14x14-Gitter hat einen Schritt von 16 Pixeln zwischen benachbarten Patch-Zentren. Dies bedeutet, dass die DINOv3-Feature-Map etwa 1/256 der räumlichen Auflösung des Eingabebildes hat (14x14 = 196 vs. 224x224 = 50.176 Pixel). Der Self-Attention-Mechanismus kompensiert diese räumliche Kompression, indem er Informationen über Patches hinweg integriert – jedes Patch-Embedding wird durch das umgebende 14x14-Gitter über Multi-Head Attention informiert, was eine effektive Kontextwahrnehmung bietet. Für Segmentierungsaufgaben muss das 14x14-Gitter auf die ursprüngliche Bildauflösung hochskaliert werden. TarmacView verwendet einen leichten konvolutionalen Decoder mit 3 Schichten: transponierte Faltung (14x14 auf 28x28, 384 Kanäle), transponierte Faltung (28x28 auf 56x56, 192 Kanäle), bilineare Hochskalierung (56x56 auf 224x224) und eine abschließende 1x1-Faltung auf klassenspezifische Logits. Dieser Decoder fügt nur 2,3M Parameter zum 86M-Parameter-Backbone hinzu.
DINOv3-Dichte-Feature-Qualität vs. DINOv2. Die entscheidende Innovation in DINOv3 – Gram Anchoring – zielt direkt auf die Qualität dieser dichten Patch-Features ab. Während langer Trainingsläufe zeigten DINOv2s Patch-Features das, was die Autoren als Degradation dichter Feature-Maps beschreiben: die Patch-Embeddings wurden semantisch weniger aussagekräftig, die Patch-Patch-Ähnlichkeitsstruktur degradierte, und die Segmentierungsqualität stagnierte oder nahm sogar ab, trotz fortgesetzter Verbesserung der globalen Klassifikation. Gram Anchoring bewahrt die Gram-Matrix der Patch-Features (paarweise Ähnlichkeitsstruktur), indem sie sie an einer Referenz aus dem frühen Training ausrichtet, was sicherstellt, dass die räumlichen und semantischen Beziehungen zwischen Patches stabil bleiben. Das praktische Ergebnis ist, dass DINOv3-Patch-Features auch bei hohen Auflösungen scharf und semantisch kohärent bleiben. Das DINOv3-Paper zeigt PCA-Visualisierungen von DINOv3-Patch-Features für hochauflösende Luftbilder – Straßen, Gebäude, Vegetation und Gewässer sind im Feature-Raum klar trennbar, was eine außergewöhnliche Feature-Qualität für das Szenenverständnis demonstriert.
Semantische Segmentierung mit linearen Sonden. Eine der beeindruckendsten Fähigkeiten von DINOv3 ist die Durchführung semantischer Segmentierung unter ausschließlicher Verwendung von linearen Sonden auf eingefrorenen Patch-Features – kein Feintuning des Backbones ist erforderlich. Ein linearer Segmentierungskopf wendet eine 1x1-Faltung (oder äquivalent eine lineare Schicht pro Patch) an, um jedes Patch-Embedding von 768 Dimensionen auf C Ausgabeklassen abzubilden. Dies erzeugt eine 14x14-Segmentierungskarte, die auf Bildauflösung hochskaliert wird. Trotz der Einfachheit dieses Ansatzes (nur 768 x C trainierbare Parameter für den gesamten Segmentierungskopf) erreicht DINOv3 52,3 % mIoU auf ADE20K mit ViT-B und übertrifft damit viele Methoden, die das gesamte Backbone feinabstimmen. Dies wird durch die außergewöhnliche lineare Trennbarkeit der DINOv3-Patch-Features ermöglicht – der Embedding-Raum ist bereits so strukturiert, dass verschiedene semantische Kategorien unterschiedliche, linear trennbare Regionen belegen.
Risssegmentierung in der Infrastruktur. TarmacView wendet DINOv3s dichte Patch-Tokens für die pixelgenaue Risssegmentierung in Startbahn- und Fahrbahnbildern an. Das 14x14-Gitter aus 768-dimensionalen Patch-Embeddings erfasst sowohl die lokale Risstextur (innerhalb jedes 16x16-Patches) als auch Kontextinformationen (welche Patches der Riss verbindet). Der Segmentierungskopf ist ein leichtes Netzwerk mit 3 transponierten Faltungsschichten, das das 14x14-Feature-Gitter auf 224x224-Auflösung hochskaliert. Das Training erfordert etwa 500 beschriftete Risssegmentierungsbilder (224x224-Kacheln mit pixelgenauen Rissmasken) und konvergiert in 2-3 Stunden auf einer einzelnen RTX 3060 GPU. Das resultierende Modell erreicht einen F1-Score von 94,7 % für die Risserkennung, verglichen mit 88,2 % mit ResNet-50 und 91,3 % mit DINOv2 unter identischen Trainingsbedingungen. Der F1-Score verbessert sich auf 96,8 % bei Verwendung des Hochauflösungs-Anpassungsprotokolls (Feintuning von DINOv3 bei 512px Eingabeauflösung mit dem empfohlenen 10K-Schritt-Plan). Die Genauigkeit der Rissbreitenschätzung (gemessen als mittlerer absoluter Fehler in mm) beträgt 0,8mm für DINOv3 gegenüber 1,4mm für DINOv2 und 2,1mm für ResNet-50.
Register-Tokens zur Hintergrundabsorption. DINOv3s 4 Register-Tokens spielen eine spezifische Rolle bei der Qualität dichter Features. Diese Tokens sind zusätzliche lernbare Tokens (Dimension 768), die der Sequenz neben dem CLS-Token vorangestellt werden. Während der Self-Attention können Register-Tokens von allen Patch-Tokens beachten und beachtet werden. Die entscheidende Erkenntnis ist, dass einige visuelle Patches in einem Bild Ausreißer- oder Hintergrundinformationen enthalten – Himmel, entfernte Objekte oder gleichmäßige texturlose Regionen – die, wenn sie von den Patch-Tokens kodiert werden müssten, die Qualität des Feature-Raums verschlechtern würden. Register-Tokens wirken als absorbierende Speicherslots, die diese nicht-informativen Inhalte aufnehmen und es den Patch-Tokens ermöglichen, sich auf semantisch bedeutsame Bildregionen zu konzentrieren. Der praktische Effekt ist eine messbare Verbesserung der Qualität dichter Features: +1,8 mIoU auf ADE20K und deutlich sauberere Patch-Ähnlichkeitskarten, insbesondere für Bilder mit großen gleichmäßigen Hintergrundregionen. Für die Infrastrukturprüfung, bei der Bilder häufig große Flächen gleichmäßiger Fahrbahntextur enthalten, helfen Register-Tokens, saubere Patch-Features zu erhalten, die sich auf Schadensmuster und nicht auf Hintergrundtextur konzentrieren.
DINOv3s Trainings- und Inferenzinfrastruktur unterstützt mehrere Hardware-Backends, von großen GPU-Clustern über Edge-Geräte bis hin zu Apple Silicon Macs.
GPU-Training in großem Maßstab. Das ViT-7B-Teacher-Modell wurde auf 256 NVIDIA A100 80GB SXM4 GPUs mit NVLink-Verbindungen trainiert, was eine aggregierte GPU-Speicherbandbreite von etwa 20 TB/s und 25 PFLOPS FP16-Rechenleistung bietet. Das Training verwendet Fully Sharded Data Parallel (FSDP) – PyTorchs native Sharding-Strategie, die Modellparameter, Gradienten und Optimierzustände auf alle GPUs verteilt. Mit FSDP und Mixed-Precision-Training (BF16) passt das 7B-Modell in den aggregierten Speicher von 256 GPUs (256 x 80GB = 20,48 TB), obwohl jede einzelne GPU nur etwa 2-3 % der Modellparameter halten kann. Die xFormers-Bibliothek (entwickelt von Meta AI) bietet speichereffiziente Attention-Implementierungen, darunter speichereffiziente Attention (reduziert den Attention-Speicher von O(N²) auf O(N)) und block-sparse Attention-Muster. Die Kombination von FSDP, BF16, xFormers und Gradient-Checkpointing reduziert den Pro-GPU-Speicherbedarf für den ViT-7B von geschätzten 250GB (volle Präzision, keine Optimierungen) auf etwa 65GB, was innerhalb der 80GB A100-Kapazität liegt.
Einzel-GPU-Inferenz. Für den praktischen Einsatz läuft DINOv3 ViT-B/16 (86M Parameter) effizient auf einer einzelnen NVIDIA GPU. Bei FP32-Präzision benötigt das Modell etwa 344MB Speicher für Parameter (86M x 4 Bytes pro Float). Mit Aktivierungen für eine Batch-Größe von 1 (224x224-Bild) beträgt der gesamte Speicherverbrauch etwa 1,2-1,5GB (Parameter + Aktivierungen + Zwischentensoren). Bei FP16-Präzision sinkt der Parameterspeicher auf 172MB und die Gesamtnutzung auf etwa 0,8-1,0GB. Dies bedeutet, dass DINOv3 ViT-B/16 bequem auf GPUs mit nur 4 GB VRAM läuft, einschließlich älterer Karten wie der NVIDIA GTX 1650 und dem NVIDIA Jetson Xavier NX. Der Durchsatz auf einer RTX 3060 (12GB) bei FP16 beträgt etwa 100 Bilder/Sekunde. Auf einer NVIDIA A100 übersteigt der Durchsatz 400 Bilder/Sekunde, was eine Echtzeitverarbeitung von 4K-Drohnenbildern bei Kachelzerlegungsgeschwindigkeiten ermöglicht.
Apple Silicon (MPS)-Unterstützung. DINOv3 ist vollständig kompatibel mit Apples Metal Performance Shaders (MPS)-Backend in PyTorch und bietet GPU-beschleunigte Inferenz auf Apple Silicon Macs (M1, M2, M3, M4 Serie). Das MPS-Backend bildet PyTorch-Operationen über das Metal-Framework auf Apples GPU-Architektur ab. Die Leistung auf einem M2 Pro MacBook Pro (19-Kern-GPU, 32GB Unified Memory) erreicht etwa 25-35 Bilder/Sekunde für ViT-B/16 bei FP16-Präzision – ausreichend für die Batch-Verarbeitung großer Bildsammlungen. Auf einem M2 Ultra Mac Studio (76-Kern-GPU, 192GB Unified Memory) erreicht der Durchsatz etwa 70-90 Bilder/Sekunde. Die Speichernutzung ist effizient, da Apples Unified-Memory-Architektur den CPU-GPU-Datentransfer-Overhead eliminiert. TarmacView verwendet MPS-beschleunigtes DINOv3 für die Datenverarbeitung vor Ort im Feld, sodass Prüfer direkt auf ihren MacBooks Inferenz durchführen können, ohne dedizierte GPU-Hardware zu benötigen. Der größere Unified Memory von Apple Silicon (bis zu 192GB auf M2 Ultra) ermöglicht auch die Verarbeitung sehr hochauflösender Bilder ohne Kachelung – ein 4096x4096-Bild erzeugt 256x256 Patches = 65.536 Tokens, was etwa 8GB VRAM-äquivalenten Speicher auf dem Unified-Memory-Pool erfordert.
Verteilte Inferenz. Für groß angelegte Infrastrukturprüfungsprojekte, die Millionen von Bildern verarbeiten, ist verteilte Inferenz über mehrere GPUs oder Maschinen hinweg erforderlich. DINOv3 unterstützt PyTorch DistributedDataParallel (DDP) für Multi-GPU-Inferenz auf einem einzelnen Server, Modellparallelität (Pipeline-Parallelität für ViT-7B) und Ray (ein Open-Source-Framework für verteiltes Rechnen) für Multi-Node-verteilte Inferenz. TarmacViews Bereitstellung verwendet Kubernetes mit GPU-Knotenpools, die DINOv3-Inferenz als skalierbaren Mikroservice ausführen. Jeder Inferenz-Pod läuft auf einer einzelnen T4 GPU (16GB VRAM) und verarbeitet etwa 70 Bilder/Sekunde. Ein Cluster von 50 Pods erreicht einen Durchsatz von 3.500 Bildern/Sekunde, was die Verarbeitung einer 500-Bild-Startbahnvermessung in weniger als 3 Sekunden ermöglicht. Der Inferenzserver verwendet TorchServe zur Modellbereitstellung mit dynamischem Batching (Batch-Größen von 4-16, abhängig vom Anfragevolumen) und FP16-Präzision, um den Durchsatz zu maximieren.
Edge-Bereitstellung mit NVIDIA Jetson. Für feldbasierte Prüfsysteme mit Drohnen oder Bodenfahrzeugen kann DINOv3 ViT-B/16 auf NVIDIA Jetson Edge-Geräten bereitgestellt werden. Das Jetson Orin NX 16GB-Modul (100 TOPS KI-Leistung) erreicht 15-25 Bilder/Sekunde mit DINOv3 ViT-B/16 bei FP16, abhängig vom Strommodus (15W vs 25W vs 40W). Das Modell wird mit TensorRT optimiert – NVIDIAs Deep-Learning-Inferenzoptimierer, der Schichten fusioniert, die Kernelauswahl optimiert und auf FP16 oder INT8 quantisiert. Mit TensorRT INT8-Quantisierung steigt die Inferenzgeschwindigkeit auf 30-40 Bilder/Sekunde auf Jetson Orin NX bei weniger als 1 % Genauigkeitsverlust im Vergleich zu FP32. Der Jetson Xavier NX (21 TOPS) erreicht 8-12 Bilder/Sekunde mit TensorRT FP16. Diese Edge-Bereitstellung ermöglicht eine Echtzeit-Risserkennung während des Drohnenflugs – die Drohnenkamera nimmt Bilder auf, DINOv3 verarbeitet sie an Bord und markiert potenzielle Defekte innerhalb von Sekunden nach der Aufnahme, ohne dass eine Cloud-Verbindung erforderlich ist.
DINOv3 wurde 2025 von Meta AI als Open-Source-Projekt veröffentlicht, in der Tradition des Unternehmens, hochmoderne KI-Forschungsmodelle öffentlich zugänglich zu machen. Das Verständnis der Lizenz- und Vertriebsbedingungen ist für Organisationen, die DINOv3 in kommerziellen Produkten einsetzen möchten, unerlässlich.
Code und Modellgewichte. Die vollständige DINOv3-Codebasis ist auf GitHub unter facebookresearch/dinov3 verfügbar (10.700+ Sterne Mitte 2025). Das Repository enthält den vollständigen Trainings- und Evaluierungscode (PyTorch), Modelldefinitionen, Datenverarbeitungs-Pipelines, Evaluierungsskripte und vortrainierte Gewichte für alle 12 veröffentlichten Modellvarianten. Die Modellgewichte sind auch auf Hugging Face Hub unter dem facebook/dinov3-*-Namespace verfügbar, einschließlich: facebook/dinov3-vits16-pretrain-lvd1689m (ViT-Small, 21M Parameter) facebook/dinov3-vitb16-pretrain-lvd1689m (ViT-Base, 86M Parameter) – das primäre Modell, das von TarmacView verwendet wird facebook/dinov3-vitl16-pretrain-lvd1689m (ViT-Large, 304M Parameter) facebook/dinov3-vith16-pretrain-lvd1689m (ViT-H+, ~1,5B Parameter) facebook/dinov3-vit7b-pretrain-lvd1689m (ViT-7B, 7B Parameter) Plus ConvNeXt-Varianten (T, S, B, L) und satellitenspezifische Modelle (SAT-493M)
Der Hugging-Face-Zugriff erfordert, dass Benutzer den Bedingungen von Meta zustimmen und Kontaktinformationen angeben, die gemäß der Meta-Datenschutzrichtlinie erhoben, gespeichert und verarbeitet werden. Die Modellgewichte werden als PyTorch state_dict-Dateien verteilt, die mit der Hugging Face Transformers-Bibliothek kompatibel sind (Integration verfügbar über AutoModel.from_pretrained()).
Die DINOv3-Lizenz. DINOv3 wird unter der DINOv3-Lizenz veröffentlicht, einer benutzerdefinierten Open-Source-Lizenz, die von Meta AI speziell für diese Modellveröffentlichung entwickelt wurde. Dies unterscheidet sich von DINOv2, das unter der standardmäßigen Apache 2.0-Lizenz veröffentlicht wurde. Die DINOv3-Lizenz erlaubt: Nutzung, Vervielfältigung, Modifikation und Verteilung des Modells und Codes Kommerzielle Nutzung einschließlich Integration in Produkte und Dienstleistungen Unterlizenzierung abgeleiteter Werke unter anderen Bedingungen
Die DINOv3-Lizenz enthält spezifische Namensnennungsanforderungen (Urheberrechtshinweise müssen beibehalten werden) und eine Richtlinie zur akzeptablen Nutzung, die die Verwendung des Modells für bestimmte Zwecke verbietet, darunter Überwachung, die gegen Menschenrechte verstößt, autonome Waffen und Verstoß gegen geltendes Recht. Die Lizenz hat in der Entwickler-Community Diskussionen ausgelöst – GitHub Issue #31 im dinov3-Repository fordert speziell eine Veröffentlichung unter einer standardmäßigeren Lizenz wie Apache 2.0, um die rechtliche Compliance für Unternehmen mit etablierten Open-Source-Lizenzrichtlinien zu vereinfachen. TarmacView hat die DINOv3-Lizenz geprüft und festgestellt, dass Infrastrukturprüfungs- und Defekterkennungsanwendungen unter ihren Bedingungen vollständig zulässig sind.
Vergleich mit anderen Backbone-Lizenzen.
| Backbone | Lizenz | Kommerzielle Nutzung | Namensnennung erforderlich | Benutzerdefinierte Bedingungen |
|---|---|---|---|---|
| DINOv3 | DINOv3-Lizenz | Ja | Ja | Ja |
| DINOv2 | Apache 2.0 | Ja | Ja | Nein |
| ViT (Google) | Apache 2.0 | Ja | Ja | Nein |
| CLIP (OpenAI) | MIT | Ja | Ja | Nein |
| OpenCLIP | MIT | Ja | Ja | Nein |
| SAM (Meta) | Apache 2.0 | Ja | Ja | Nein |
| ConvNeXt | MIT | Ja | Ja | Nein |
Rechenkosten der Reproduktion. Die Trainingskosten für DINOv3 ViT-7B werden auf 2-5 Millionen USD geschätzt (ca. 15.000 GPU-Tage auf A100-80GB zu On-Demand-Cloud-Preisen). Die destillierten kleineren Modelle (ViT-B, ViT-L) sind deutlich günstiger zu reproduzieren, erfordern aber dennoch erhebliche Rechenleistung – die ViT-Base-Destillation von ViT-7B auf LVD-1689M erfordert etwa 500-800 GPU-Tage. Für Praktiker entfällt jedoch durch die Verfügbarkeit vortrainierter Gewichte der Bedarf an Trainingsrechenleistung – die Gewichte können heruntergeladen und sofort zur Inferenz verwendet werden, zu den Kosten einer einzelnen GPU beliebiger Generation. Diese Zugänglichkeit ist das grundlegende Wertversprechen von Foundation-Modellen: Die enormen Trainingskosten werden auf alle nachgelagerten Benutzer amortisiert.
Community- und Ökosystem-Integration. DINOv3 profitiert von einer breiten Ökosystem-Integration: Hugging Face Transformers bietet eine Plug-and-Play-API, PyTorch Hub unterstützt das Laden von Modellen über torch.hub.load(), und das Modell ist im Torchvision-Modellzoo für den direkten Zugriff enthalten. Die Integration mit Weights & Biases, MLflow und Neptune.ai zur Experimentverfolgung wird durch standardmäßige PyTorch-Hooks unterstützt. Der Export im ONNX (Open Neural Network Exchange)-Format wird für die Bereitstellung in Nicht-PyTorch-Umgebungen unterstützt, einschließlich TensorRT für NVIDIA Edge-Geräte, CoreML für Apple-Geräte und TFLite für mobile Bereitstellung. TarmacViews Infrastrukturprüfungsplattform integriert DINOv3 über die Hugging Face Transformers-Pipeline, mit TensorRT-Optimierung für die Edge-Bereitstellung auf Jetson Orin NX und MPS-Beschleunigung für macOS-Feld-Laptops.
Schlussfolgerung. DINOv3 stellt einen Generationssprung bei selbstüberwachten visuellen Foundation-Modellen dar und erreicht hochmoderne Leistung bei globalen und dichten Vorhersageaufgaben durch beispiellose Skalierung (1,689 Milliarden Bilder, 7 Milliarden Parameter) und die Gram-Anchoring-Innovation, die die Qualität dichter Features bewahrt. Für die Infrastrukturoberflächenanalyse bietet DINOv3s ViT-B/16-Variante einen 768-dimensionalen Embedding-Raum mit außergewöhnlicher semantischer Struktur – Oberflächentypen, Rissmuster und Defektmerkmale sind im Embedding-Raum linear trennbar, was eine genaue Klassifikation und Erkennung mit eingefrorenem Backbone ermöglicht. Die Open-Source-Verfügbarkeit, die breite Hardware-Unterstützung (GPU, MPS, Edge) und die großzügige Lizenzierung machen DINOv3 zum optimalen Backbone für TarmacViews automatisierte Infrastrukturprüfungsplattform, die hochmoderne Defekterkennungsgenauigkeit mit minimalen domänenspezifischen Trainingsdaten und Rechenanforderungen liefert.
TarmacView nutzt DINOv3s hochmodernes Vision-Transformer-Backbone für automatisierte Oberflächenanalyse, Risserkennung und Defektklassifizierung. Kontaktieren Sie unser Team, um zu erfahren, wie unsere KI-gestützte Prüfplattform Ihre Arbeitsabläufe bei der Infrastrukturbewertung transformieren kann.
+++ title = “Transfer Learning” description = “Transfer Learning wendet Wissen aus vortrainierten Modellen auf großen, allgemeinen Datensätzen...
Der Defektkopf-Smoke-Test validiert, dass TarmacViews Pipeline zur Strukturdefekterkennung — DINOv3-Backbone + 5-Label-MLP-Kopf für Riss/Abplatzung/Ausblühung/f...
Die KI-basierte Risserkennung nutzt Computer Vision – Convolutional Neural Networks, Vision Transformer und semantische Segmentierungsmodelle – um Risse in Fahr...