k-Nächste-Nachbarn (kNN)
k-Nächste-Nachbarn (kNN) klassifiziert einen Abfragepunkt per Mehrheitsentscheidung unter seinen k ähnlichsten Referenzpunkten in einem Einbettungsraum. TarmacV...
27 Min. Lesezeit
Machine Learning
Classification
+3
FAISS (Facebook AI Similarity Search) ist eine Open-Source-Bibliothek für effiziente Ähnlichkeitssuche und Clusterbildung dichter Vektoren, die von TarmacView verwendet wird, um etwa 9.000 beschriftete Referenz-Embeddings für die Nächste-Nachbarn-Klassifizierung der Oberflächenqualität zu speichern und abzufragen. Behandelt Indextypen (Flat, IVF, HNSW), Kosinus-Ähnlichkeit via innerem Produkt auf normalisierten Vektoren, GPU-Beschleunigung und Anwendung bei der Inspektionsbildersuche.
FAISS (Facebook AI Similarity Search) ist eine quelloffene C++-Bibliothek, die vom Fundamental AI Research (FAIR)-Team bei Meta für effiziente Ähnlichkeitssuche und Clusterbildung dichter Vektoren entwickelt wurde. Erstmals 2017 veröffentlicht, ist FAISS auf über 40.000 GitHub-Sterne und mehr als 5.200 Zitationen seines GPU-Implementierungspapiers angewachsen. Die FAISS-Pakete wurden mehr als 6 Millionen Mal aus Conda-Repositories heruntergeladen. Große Vektordatenbank-Unternehmen wie Zilliz (Milvus) und Pinecone setzen entweder auf FAISS als Kern-Engine oder haben FAISS-Algorithmen in ihren Produktionssystemen neu implementiert.
FAISS wurde gezielt entwickelt, um die rechnerische Herausforderung der Suche nach nächsten Nachbarn in hochdimensionalen Vektorräumen zu bewältigen. Die Kernoperation ist die Ähnlichkeitssuche: Gegeben einen Abfragevektor q, identifiziert FAISS die Vektoren in der Referenzmenge, die gemäß einer bestimmten Distanzmetrik am nächsten liegen. Formal berechnet FAISS für eine Menge von Referenzvektoren {x₁, …, xₙ} in Dimension d effizient j = argminᵢ ||q - xᵢ|| wobei ||·|| die euklidische Distanz ist. Die Bibliothek kann auch eine Suche nach dem maximalen inneren Produkt argmaxᵢ ⟨q, xᵢ⟩ durchführen und unterstützt zusätzliche Metriken wie L1-, Linf-, Canberra-, Bray-Curtis-, Jensen-Shannon- und Hamming-Distanzen durch ihre IndexFlat- und IndexHNSW-Implementierungen. FAISS gibt nicht nur den einzelnen nächsten Nachbarn zurück, sondern die k nächsten Nachbarn, unterstützt die Batch-Verarbeitung mehrerer Abfragen gleichzeitig und kann Bereichssuchen durchführen, die alle Elemente innerhalb eines bestimmten Radius zurückgeben.
Die Bibliothek arbeitet mit dichten Vektoren — Arrays mit fester Länge von 32-Bit-Gleitkommazahlen — die Datenpunkte repräsentieren, die in einen kontinuierlichen Vektorraum eingebettet sind. Diese Vektoren werden typischerweise von tiefen neuronalen Netzen wie Vision Transformers (ViT), Convolutional Neural Networks (CNNs) oder großen Sprachmodellen erzeugt. In modernen Pipelines des maschinellen Lernens dienen Embeddings als Zwischenrepräsentationen, die komplexe Eingabemedien in einen Vektorraum abbilden, in dem Lokalität Semantik kodiert. FAISS ist die Brücke zwischen der Embedding-Extraktion und nachgelagerten ähnlichkeitsbasierten Aufgaben: Es indiziert die extrahierten Embeddings und ermöglicht schnelle Abrufoperationen.
FAISS ist umfassend für moderne Hardwarearchitekturen optimiert. Auf der CPU nutzt es BLAS (Basic Linear Algebra Subprograms)-Bibliotheken wie Intel MKL, OpenBLAS oder Apple Accelerate, um schnelle Matrixoperationen durchzuführen. Es unterstützt SIMD-Vektorisierung (SSE, AVX2, AVX-512) auf x86-Architekturen und Neon-Intrinsics auf ARM-Prozessoren. Auf der GPU stellt FAISS native CUDA-Implementierungen bereit, die für typische Arbeitslasten 5- bis 10-fache Durchsatzverbesserungen gegenüber der CPU-Ausführung liefern können. Die GPU-Implementierung unterstützt mehrere GPUs parallel und ermöglicht so die verteilte Suche über mehrere Geräte hinweg.
FAISS ist keine Vektordatenbank — es ist eine Suchbibliothek, die direkt in Anwendungen eingebettet werden kann. Im Gegensatz zu vollständigen Datenbanksystemen (Pinecone, Milvus, Qdrant, Weaviate) bietet FAISS keine integrierte Persistenz, Replikation, Zugriffskontrolle, gleichzeitigen Schreibzugriff, Lastverteilung, Sharding, Transaktionsverwaltung oder Abfrageoptimierung. Stattdessen bietet es eine saubere C++- und Python-API zum Erstellen, Abfragen, Speichern und Laden von Indizes. Diese bewusste Beschränkung des Umfangs ermöglicht es FAISS, maximale Leistung für die Kernoperation der Nächste-Nachbarn-Suche zu erreichen. Der Umfang der Bibliothek ist bewusst auf die algorithmische Implementierung der Approximativen Nächste-Nachbarn-Suche (ANNS) beschränkt, und wie das ursprüngliche FAISS-Papier feststellt: “Faiss is not a database — it does not provide concurrent write access, load balancing, sharding, transaction management or query optimization.”

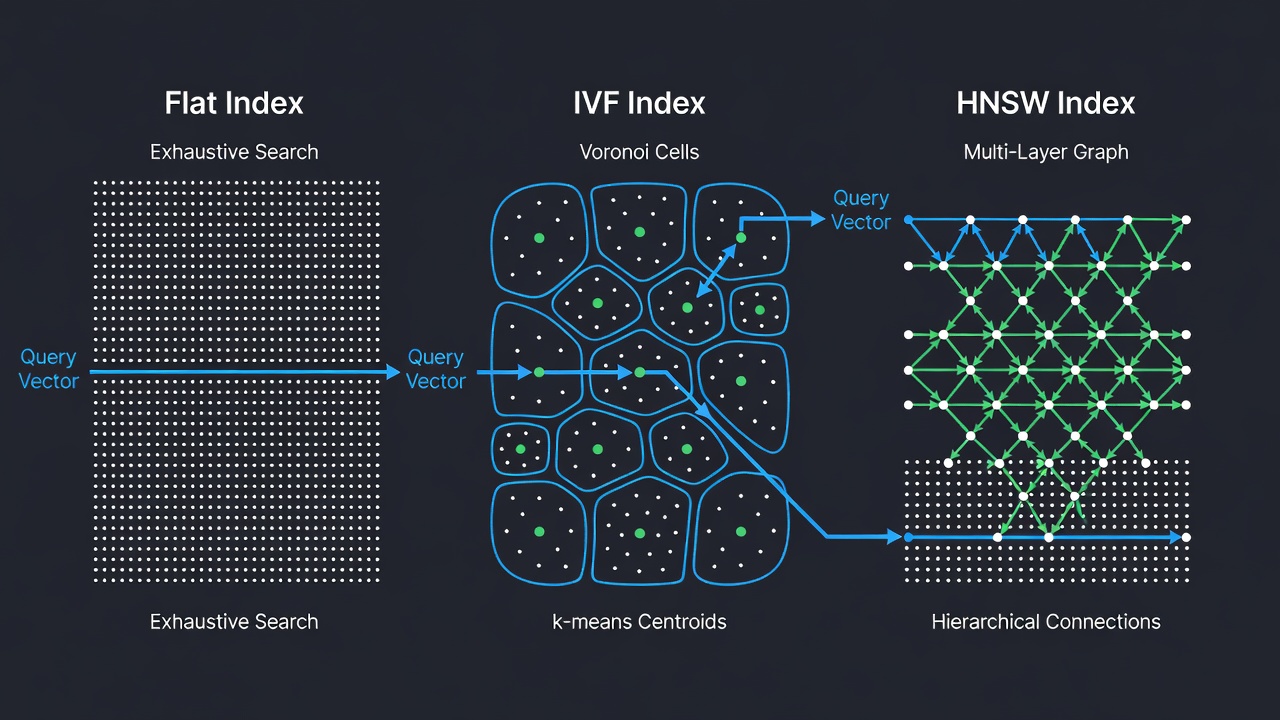
FAISS bietet über zwanzig verschiedene Indextypen, die jeweils für eine spezifische Kombination aus Genauigkeit, Geschwindigkeit und Speicherkompromissen ausgelegt sind. Die drei grundlegendsten und am weitesten verbreiteten Indextypen sind IndexFlat (exakte Suche), IndexIVF (Inverted File mit k-Means-Clustering) und IndexHNSW (hierarchischer navigierbarer Small-World-Graph). Jeder Indextyp ist mit verschiedenen Distanzmetriken und kodierten Varianten verfügbar (z. B. FlatIP für inneres Produkt, FlatL2 für L2-Distanz). FAISS-Indizes können hierarchisch zusammengesetzt werden — zum Beispiel durch Verwendung von HNSW als grobem Quantisierer für einen IVF-Index, was die IndexIVFPQ-Verbundstruktur ergibt, die Bereitstellungen im Milliardenmaßstab antreibt.
IndexFlatIP ist der einfachste FAISS-Index. Er speichert alle Vektoren in einem flachen Array und führt eine erschöpfende Brute-Force-Suche gegen jeden Vektor im Datensatz durch. Für jede Abfrage berechnet er das innere Produkt zwischen der Abfrage und jedem gespeicherten Vektor und gibt dann die Indizes und Distanzen der Top-k-Ergebnisse zurück. Dieser Index garantiert die Rückgabe der exakten nächsten Nachbarn — keine Approximationen, keine Verschlechterung des Recall. Es ist der einzige FAISS-Index, der diese Garantie bietet; alle anderen Indizes sind approximativ und tauschen einen gewissen Recall gegen verbesserte Geschwindigkeit oder reduzierten Speicherverbrauch.
Die Rechenkomplexität von IndexFlatIP beträgt O(N × D) pro Abfrage, wobei N die Anzahl der Referenzvektoren und D die Dimensionalität ist. Der Index verwendet die hochoptimierte BLAS gemm (General Matrix Multiply)-Routine, um alle inneren Produkte in einer einzigen Matrixmultiplikation zu berechnen. Bei einem Datensatz von 100.000 Vektoren mit 768 Dimensionen (eine typische Embedding-Größe von DINOv2 ViT) dauert eine einzelne Abfrage auf der CPU etwa 5–15 Millisekunden, abhängig von Hardware und BLAS-Optimierung. Im Batch-Modus mit 1.000 Abfragen verarbeitet der Index alle gleichzeitig mittels Matrix-Matrix-Multiplikation und erreicht einen deutlich höheren Durchsatz als 1.000 einzelne Abfragen.
IndexFlatIP dient eine entscheidende Rolle im FAISS-Ökosystem als Ground-Truth-Orakel zur Bewertung der approximativen Indexgenauigkeit. Praktiker erstellen einen Flat-Index neben ihrem approximativen Index, führen identische Abfragen gegen beide durch und berechnen Recall-Metriken. Die standardmäßige FAISS-Benchmarking-Suite (faiss_benchmarks) verwendet diese Methodik, um die Genauigkeitsverschlechterung von IVF-, HNSW- und PQ-Indizes zu quantifizieren. In TarmacView wird IndexFlatIP als Basislinienreferenz für die Systemvalidierung verwendet, um sicherzustellen, dass approximative Indizes, die in der Produktion eingesetzt werden, einen akzeptablen Recall beibehalten.
Der Index wird mit minimalem Code erstellt: index = faiss.IndexFlatIP(d) wobei d die Embedding-Dimensionalität ist. Vektoren werden mit index.add(embeddings) hinzugefügt. Die Suche wird mit index.search(query, k) durchgeführt, was zwei float32-Arrays zurückgibt: Distanzen (Shape [n_queries, k]) und Indizes (Shape [n_queries, k], dtype int64). Beim inneren Produkt zeigen größere Distanzwerte eine größere Ähnlichkeit an. Der Index erfordert keinen Trainingsschritt, da es keine zu lernenden Parameter gibt – die Vektoren werden unverändert gespeichert und verglichen.
IndexIVFFlat ist ein approximativer Nächste-Nachbarn-Index, der den Vektorraum mit k-Means-Clustering in Voronoi-Zellen unterteilt. Die Architektur leitet sich vom wegweisenden “Video Google”-Papier von Sivic und Zisserman (ICCV 2003) ab, das Textabruftechniken auf visuellen Objektabgleich übertrug. Während der Indizierung wird der Datensatz mittels k-Means in nlist Cluster geclustert, und jeder Vektor wird seinem nächsten Clusterzentroid zugeordnet. Die Zentroide werden in einem groben Quantisierer (typischerweise IndexFlatL2) gespeichert. Während der Suche werden nur Vektoren in den nprobe nächsten Clustern zur Abfrage untersucht, was die Anzahl der erforderlichen Distanzberechnungen drastisch reduziert.
Die Beschleunigung gegenüber IndexFlatIP beträgt ungefähr N / ((N / nlist) × nprobe) . Mit nlist=100 und nprobe=5 werden nur 5 % der Datenbank durchsucht – Abfragen, die 10 ms auf einem Flat-Index dauerten, können in 0,5 ms abgeschlossen werden. Der Kompromiss ist jedoch eine Verschlechterung des Recall: Einige wahre nächste Nachbarn könnten außerhalb der durchsuchten Cluster liegen und übersehen werden. Der k-Means-Trainingsschritt ist entscheidend für die Recall-Qualität – die Zentroide müssen die Datenverteilung genau repräsentieren. FAISS erfordert, dass der Trainingssatz mindestens 30 × nlist Vektoren für eine zuverlässige Zentroid-Schätzung enthält.
Wichtige Parameter für IndexIVFFlat:
| Parameter | Beschreibung | Typischer Bereich | Auswirkung |
|---|---|---|---|
| nlist | Anzahl der Voronoi-Zellen (Cluster) | 10 – 100.000 | Höher = feinere Partitionierung, mehr Speicher für Zentroide, langsameres k-Means-Training |
| nprobe | Anzahl der bei der Abfrage durchsuchten Zellen | 1 – 100+ | Höher = besserer Recall (bis zu 99 %), linear langsamere Suche |
| metric | Distanzmetrik (L2 oder IP) | L2 oder IP | Bestimmt, wie Distanzen zwischen Vektoren und Zentroiden berechnet werden |
Der nprobe-Parameter ist besonders wichtig, da er den Geschwindigkeits-Genauigkeits-Kompromiss zur Suchzeit steuert, ohne dass eine Indexrekonstruktion erforderlich ist. Zur Abfragezeit kann nprobe dynamisch angepasst werden: Auf einen hohen Wert (z. B. 20–50) für offline-qualitätskritische Operationen, bei denen Genauigkeit von größter Bedeutung ist, und auf einen niedrigen Wert (z. B. 1–5) für produktive Durchläufe mit hohem Durchsatz, bei denen Geschwindigkeit priorisiert wird. FAISS bietet einen Auto-Tuning-Mechanismus (AutoTune), der über nprobe-Werte sucht, um die optimale Konfiguration für einen Ziel-Recall zu finden.
Die Erstellung eines IndexIVFFlat erfordert eine dreistufige Pipeline: Training, Hinzufügen und Suchen. Während des Trainings läuft k-Means auf einer repräsentativen Stichprobe, um Clusterzentroide zu lernen. Beim Hinzufügen wird jeder Datenbankvektor seinem nächsten Zentroid zugeordnet und an die Inverted-Liste dieses Zentroids angehängt. Während der Suche wird die Abfrage mit allen Zentroiden verglichen, die nprobe nächsten werden ausgewählt, und nur Vektoren in diesen ausgewählten Listen werden erschöpfend verglichen. Die Factory-Zeichenkette für IndexIVFFlat mit innerem Produkt ist "IVF100,Flat" wobei 100 der nlist-Wert ist. In Python: index = faiss.index_factory(d, "IVF100,Flat", faiss.METRIC_INNER_PRODUCT).
| Datensatzgröße | Empfohlenes nlist | Empfohlenes nprobe | Erwarteter Recall | Beschleunigung vs. Flat |
|---|---|---|---|---|
| 10.000 | 10 – 100 | 1 – 5 | 95–98 % | 5–20x |
| 100.000 | 100 – 1.000 | 5 – 20 | 95–99 % | 20–100x |
| 1.000.000 | 1.000 – 10.000 | 10 – 50 | 95–99 % | 100–500x |
| 10.000.000 | 10.000 – 100.000 | 20 – 100 | 90–98 % | 500–5000x |
IndexHNSWFlat ist ein graphbasierter approximativer Nächste-Nachbarn-Index, der einen mehrschichtigen hierarchischen Graphen konstruiert, der als Navigable Small World bekannt ist. Der Algorithmus, ursprünglich von Malkov und Yashunin (2016) veröffentlicht, ist von der Skip-Liste-Datenstruktur inspiriert. Der Index organisiert Vektoren in Schichten: Die unterste Schicht (Schicht 0) enthält alle Vektoren, und jede nachfolgende Schicht enthält eine zunehmend kleinere Teilmenge, die durch eine probabilistische Ebenenzuweisung erzeugt wird. Beim Einfügen wird jedem Vektor eine Ebene l = floor(-ln(uniform(0,1)) × mL) zugewiesen, wobei mL = 1/ln(M). Der Einstiegspunkt befindet sich in der höchsten vorhandenen Schicht, was eine logarithmische Graphdurchquerung gewährleistet.
Die Suche beginnt in der obersten Schicht (gröbste, mit den wenigsten Knoten) und steigt durch die Schichten ab, wobei die Kandidatenmenge bei jedem Schritt verfeinert wird. In jeder Schicht durchläuft eine greedy search den Graphen in Richtung der Abfrage, indem sie sich immer zu dem Nachbarn bewegt, der die Distanz minimiert. Nachdem das lokale Minimum in der aktuellen Schicht gefunden wurde, steigt der Algorithmus zur nächsten Schicht ab und wiederholt den Prozess, wobei das Ergebnis der darüber liegenden Schicht als Ausgangspunkt dient. Diese hierarchische Struktur ermöglicht eine logarithmische Suchkomplexität O(log N), was HNSW zu einem der schnellsten approximativen Nächste-Nachbarn-Algorithmen für mittlere bis große Datensätze macht.
Der HNSW-Index hat drei kritische Parameter:
| Parameter | Beschreibung | Typischer Bereich | Auswirkung |
|---|---|---|---|
| M | Maximale Anzahl bidirektionaler Verbindungen pro Knoten | 8 – 64 (Standard 32) | Höheres M = dichter verbundener Graph, besserer Recall, mehr Speicher |
| efConstruction | Dynamische Kandidatenlistengröße während der Grapherstellung | 40 – 200 (Standard 40) | Höher = gründlichere Suche beim Aufbau, bessere Graphqualität, langsamerer Aufbau |
| efSearch | Dynamische Kandidatenlistengröße während der Suche | 10 – 200 (zur Abfragezeit gesetzt) | Höher = besserer Recall, langsamere Suche (kann ohne Neubau angepasst werden) |
Der M-Parameter steuert direkt die Graphkonnektivität. Jeder Vektor unterhält bis zu M bidirektionale Kanten zu seinen nächsten Nachbarn. Der Graph verwendet eine diversitätsfördernde Heuristik bei der Nachbarschaftsauswahl: Wenn ein neuer Knoten hinzugefügt wird, werden seine Nachbarkandidaten beschnitten, um eine vielfältige Konnektivität sicherzustellen, die vermeidet, dass Hub-Knoten die Graphstruktur dominieren. Höhere M-Werte erzeugen eine robustere Weiterleitung, erhöhen aber den Speicherverbrauch: etwa 4d + M × 2 × 4 Bytes pro Vektor für die Graphstruktur plus Vektorspeicher.
Der efConstruction-Parameter steuert die Gründlichkeit der Suche während der Indexerstellung. Größere Werte erzeugen qualitativ bessere Graphen, erhöhen aber die Aufbauzeit linear. Als Faustregel gilt: efConstruction ≈ M × 2 bietet ein gutes Gleichgewicht für die meisten Arbeitslasten. Der efSearch-Parameter ist analog zu nprobe bei IVF-Indizes – er steuert die Gründlichkeit der Suche zur Abfragezeit und kann dynamisch ohne Indexrekonstruktion angepasst werden.
HNSW-Indizes bieten mehrere Vorteile gegenüber IVF-Indizes. Sie erreichen typischerweise höheren Recall bei vergleichbarer Suchgeschwindigkeit, insbesondere bei hochdimensionalen Daten (d > 256). Sie erfordern keinen separaten Trainingsschritt (anders als IVF, das k-Means-Clustering benötigt, was HNSW für dynamische Datensätze geeignet macht, bei denen Vektoren inkrementell eintreffen). Sie zeigen eine sanfte Recall-Verschlechterung, wenn efSearch sinkt – der Recall verbessert sich gleichmäßig ohne scharfe Schwellenwerte. Allerdings verbrauchen HNSW-Indizes mehr Speicher pro Vektor (die Graph-Adjazenzlisten fügen Overhead hinzu) und sind langsamer aufzubauen als IVF-Indizes. HNSW unterstützt auch nativ keine Vektorlöschung, da das Entfernen von Knoten aus der Graphstruktur die Konnektivität beeinträchtigen würde.
Für TarmacViews Referenzmenge von etwa 9.000 Embeddings erreicht ein IndexHNSWFlat mit M=32 und efSearch=64 >99 % Recall bei Abfragezeiten unter 200 Mikrosekunden auf der CPU – eine 50-fache Beschleunigung gegenüber IndexFlatIP mit vernachlässigbarem Genauigkeitsverlust. Die Factory-Zeichenkette "HNSW32,Flat" erstellt diesen Index. In Python: index = faiss.index_factory(d, "HNSW32,Flat", faiss.METRIC_INNER_PRODUCT).
Kosinus-Ähnlichkeit misst den Kosinus des Winkels zwischen zwei Nicht-Null-Vektoren – sie quantifiziert, wie ähnlich zwei Vektoren unabhängig von ihrer Größe sind. Die Kosinus-Ähnlichkeit zwischen Vektoren a und b ist definiert als cos(θ) = (a · b) / (||a|| × ||b||) wobei a · b das Skalarprodukt und ||a|| die L2-Norm von a ist. Das Ergebnis reicht von -1 (vollständig entgegengesetzte Richtung) bis +1 (identische Richtung), wobei 0 Orthogonalität anzeigt.
FAISS bietet keine dedizierte Kosinus-Ähnlichkeitsmetrik. Stattdessen wird die Kosinus-Ähnlichkeit durch eine zweistufige Transformation implementiert, die das FAISS-Entwicklungsteam als kanonisch betrachtet. Zunächst werden alle Vektoren auf Einheitslänge L2-normalisiert – jeder Vektor wird durch seine L2-Norm geteilt, so dass ||a|| = 1 und ||b|| = 1 gilt. Zweitens wird METRIC_INNER_PRODUCT als Distanzmetrik verwendet. Bei einheitsnormalisierten Vektoren ist das innere Produkt gleich der Kosinus-Ähnlichkeit: a · b = cos(θ). Diese Äquivalenz folgt direkt aus der Kosinus-Formel: Wenn der Nenner gleich 1 ist, reduziert sich die Formel auf das Skalarprodukt.
Diese Normalisierungstechnik ist in Vektorsuchsystemen Standard, da das innere Produkt von hochoptimierten BLAS-Matrixmultiplikationsroutinen effizient berechnet werden kann. Die Rechenkosten für die Normalisierung aller Vektoren im Index sind eine einmalige O(N × D)-Operation zur Indexerstellungszeit, und die Normalisierung jeder Abfrage kostet O(D) – vernachlässigbar im Vergleich zu den Kosten der Suche selbst. Die L2-Normalisierung wird angewendet, bevor Vektoren zum Index hinzugefügt werden und bevor Abfragen eingereicht werden, um sicherzustellen, dass alle Vergleiche im Kosinus-Ähnlichkeitsraum stattfinden.
In FAISS wird die Normalisierung mit dem IndexPreTransform-Wrapper in Kombination mit einer NormalizationTransform implementiert (in Python, faiss.NormalizationTransform). Das Erstellungsmuster ist:
import faiss
import numpy as np
dimension = 768
# Erstellt den Inner-Product-Index
base_index = faiss.IndexFlatIP(dimension)
# Mit L2-Normalisierung umschließen
index = faiss.IndexPreTransform(
faiss.NormalizationTransform(dimension),
base_index
)
# Hier hinzugefügte Vektoren werden automatisch L2-normalisiert
index.add(reference_embeddings)
# Hier eingereichte Abfragen werden automatisch L2-normalisiert
distances, indices = index.search(query_embeddings, k)
Alternative Ansätze umfassen die manuelle Normalisierung von Vektoren mit faiss.normalize_L2() vor dem Hinzufügen und Abfragen oder die Indexerstellung über die index_factory, die eine integrierte Normalisierung über den "L2norm"-Vorverarbeitungsschritt unterstützt. Mit der Factory-Methode: index = faiss.index_factory(d, "L2norm,HNSW32,Flat") erstellt einen Index, der Vektoren automatisch auf Einheitslänge normalisiert, bevor der HNSW-Graph aufgebaut wird.
Für TarmacView ist dieser Ansatz wesentlich, da DINOv2-Embeddings, wie die meisten Vision-Transformer-Ausgaben, in ihrer Größe über verschiedene Bilder variieren. Variationen in Belichtung, Lichtverhältnissen und Kameraeinstellungen bei der Inspektion von Flughafenbelägen erzeugen Embeddings unterschiedlicher Größe, selbst wenn sie identische Oberflächentexturen erfassen. Die Normalisierung entfernt die Größenkomponente und konzentriert den Ähnlichkeitsvergleich auf die Richtungsausrichtung – zwei Oberflächenbilder, die dieselbe Belagstextur erfassen, aber unterschiedliche Belichtungsstufen aufweisen, werden als sehr ähnlich eingestuft, da ihre normalisierten Embeddings in dieselbe Richtung zeigen, selbst wenn sich ihre Rohgrößen deutlich unterscheiden.
Die FAISS-FAQ adressiert dies explizit: “The cosine similarity between vectors x and y is defined by cos(x, y) = ⟨x, y⟩ / (|x| × |y|). By normalizing query and database vectors beforehand, the problem can be mapped back to a maximum inner product search.” FAISS stellt auch fest, dass die Verwendung des inneren Produkts auf normalisierten Vektoren mathematisch äquivalent zur Verwendung der L2-Distanz auf normalisierten Vektoren ist, mit der Beziehung ||x - y||² = 2 - 2 × ⟨x, y⟩ für einheitsnormalisierte Vektoren.
Der Lebenszyklus eines FAISS-Index in der Produktion umfasst fünf verschiedene Phasen: Konfiguration, Training, Befüllung, Serialisierung und Abfrage. Jede Phase hat spezifische API-Aufrufe, Leistungsaspekte und bewährte Verfahren.
Konfiguration beginnt mit der Auswahl eines Indextyps und einer Distanzmetrik. FAISS bietet den Factory-String-Mechanismus – eine kompakte Zeichenkettenspezifikation, die komplexe Indizes erstellt. Das Factory-Muster ist der empfohlene Ansatz, da es die spezifische Klassenhierarchie abstrahiert und automatisch die optimale Implementierung auswählt:
| Factory-String | Indextyp | Speicher pro Vektor (d=768) | Anwendungsfall |
|---|---|---|---|
"Flat" | IndexFlat (exakte L2-Suche) | 3.072 Bytes | Kleine Referenzmengen, Ground Truth |
"IVF100,Flat" | IndexIVFFlat mit 100 Zentroiden | ~3.100 Bytes | Mittlere Mengen, schnelle approximative Suche |
"HNSW32,Flat" | IndexHNSWFlat mit M=32 | ~3.328 Bytes | Schnelle approx. Suche, dynamische Daten |
"IVF100,PQ16" | IndexIVFPQ, 16 Teilvektoren | ~80 Bytes | Großer Maßstab, speicherbeschränkt |
"IVF100,SQ8" | IndexIVF mit Skalarquantisierung | ~784 Bytes | Ausgewogen, hervorragende Geschwindigkeit |
Training ist nur für Indizes erforderlich, die eine Datenverteilung lernen (IVF, PQ, SQ usw.). Während des Trainings führt der Index k-Means-Clustering auf einer repräsentativen Stichprobe von Vektoren durch. Für den k-Means-Algorithmus verwendet FAISS mehrere zufällige Initialisierungen und wählt diejenige mit der geringsten Verzerrung aus. Der Trainingssatz sollte repräsentativ für die Daten sein, die indiziert werden sollen – die Verwendung einer zufälligen Teilmenge von 1–10 % des vollständigen Datensatzes ist gängige Praxis. FAISS erfordert, dass Trainingsvektoren dieselbe Dimensionalität haben wie die zu indizierenden Daten. Das Flag index.is_trained zeigt an, ob das Training abgeschlossen wurde. Der Trainingsaufruf lautet: index.train(training_vectors). Für Datensätze, bei denen der Index bereits trainiert wurde (z. B. vortrainierte Zentroide aus einer Datei geladen werden), ist ein erneuter Aufruf von train nicht erforderlich und würde die gelernten Parameter überschreiben.
Befüllung fügt Vektoren zum trainierten Index hinzu: index.add(reference_vectors). Die Eigenschaft ntotal verfolgt die Anzahl der hinzugefügten Vektoren. Bei IVF-Indizes wird jeder Vektor seinem nächsten Clusterzentroid zugeordnet und während der Hinzufügeoperation an die Inverted-Liste dieses Zentroids angehängt. Bei HNSW-Indizes wird der Graph inkrementell aufgebaut: Jeder neue Vektor erhält eine Ebenenstufe, und es werden Kanten zu seinen M nächsten Nachbarn auf jeder Ebene unter Verwendung des efConstruction-Parameters eingerichtet. Das Hinzufügen von Vektoren ist typischerweise langsamer als das Abfragen, insbesondere bei HNSW, wo der Graph aktualisiert werden muss.
Serialisierung speichert den Index auf der Festplatte: faiss.write_index(index, "index.faissindex"). Der Index wird zurückgeladen mit index = faiss.read_index("index.faissindex"). Die Serialisierung bewahrt den vollständigen Indexzustand einschließlich trainierter Zentroide, Graphstruktur, aller gespeicherten Vektoren, Distanzmetrikkonfiguration und interner Parameter. Die standardmäßige Dateierweiterung ist .faissindex. Die Serialisierungsgröße hängt vom Indextyp und der Vektoranzahl ab – für IndexFlat mit N Vektoren der Dimension D beträgt die Größe etwa N × D × 4 Bytes plus geringem Overhead.
Abfrage ruft die k nächsten Nachbarn ab: distances, indices = index.search(query_vectors, k). Das Array distances enthält Ähnlichkeits- oder Distanzwerte, abhängig von der Metrik. Das Array indices enthält die Positionen der übereinstimmenden Referenzvektoren, wie sie hinzugefügt wurden (0-basiert). Für Batch-Abfragen verarbeitet FAISS mehrere Abfragen gleichzeitig mittels Matrix-Matrix-Multiplikation und erzielt so einen deutlich besseren Durchsatz als einzelne Abfrage-für-Abfrage-Aufrufe. Die Indexobjekte sind threadsicher für Suchoperationen auf separaten Indexinstanzen, was eine parallele Abfragebereitstellung in Produktionsumgebungen ermöglicht.
FAISS wird häufig verwendet, um die k-Nächste-Nachbarn (kNN)-Klassifizierung zu implementieren – eine nicht-parametrische Methode des maschinellen Lernens, die einen Abfragepunkt basierend auf der Mehrheitskennzeichnung unter seinen k nächsten Nachbarn in der Referenzmenge klassifiziert. Dieser Ansatz ist besonders attraktiv, wenn: (1) die Referenzmenge regelmäßig mit neuen beschrifteten Stichproben aktualisiert wird, (2) der Embedding-Raum bedeutungsvolle semantische Beziehungen zwischen Datenpunkten erfasst und (3) interpretierbare, instanzbasierte Entscheidungen gegenüber Black-Box-Neuronalen-Klassifikatoren bevorzugt werden.
Die Klassifizierungspipeline mit FAISS folgt fünf Schritten:
Erstellen einer beschrifteten Referenzmenge: Jeder Referenzvektor wird mit einer Ground-Truth-Kennzeichnung gepaart (z. B. “Asphalt – guter Zustand”, “Beton – Oberfläche gerissen”, “Teerbelag – repariert”). Die Kennzeichnungen werden in einem separaten Array gespeichert, das an die FAISS-Index-Reihenfolge angepasst ist. TarmacView unterhält etwa 9.000 solcher beschrifteten Referenz-Embeddings, die mehrere Oberflächentypen und Qualitätszustände abdecken.
Indizieren der Referenzvektoren: Alle Referenz-Embeddings werden zu einem FAISS-Index hinzugefügt. Für exakte Suche mit perfektem Recall wird IndexFlatIP verwendet. Für approximative Suche im großen Maßstab bieten IndexHNSWFlat oder IndexIVFFlat Abfragezeiten im Sub-Millisekunden-Bereich mit >99 % Recall bei entsprechender Abstimmung.
Einreichen von Abfrage-Embeddings: Für jedes zu klassifizierende neue Bild wird sein Embedding mit demselben Embedding-Modell (DINOv2 mit 768-dimensionaler Ausgabe) extrahiert und für die Kosinus-Ähnlichkeit auf Einheitslänge normalisiert.
Abrufen der k nächsten Nachbarn: FAISS gibt die Indizes und Distanzen der k ähnlichsten Referenzvektoren zurück. Der k-Parameter steuert den Bias-Varianz-Kompromiss. Kleineres k (z. B. 3–5) erzeugt Entscheidungsgrenzen, die empfindlich auf lokale Struktur reagieren, aber anfällig für Rauschen sind. Größeres k (z. B. 15–20) erzeugt glattere Grenzen mit besserer Generalisierung, kann aber feine Unterschiede verlieren. TarmacView verwendet k=10, was ein Gleichgewicht zwischen Robustheit gegenüber Ausreißern und Empfindlichkeit gegenüber subtilen Oberflächenqualitätsvariationen bietet.
Durchführen einer Mehrheitsabstimmung: Zählen der Kennzeichnungen unter den k Nachbarn und Auswählen der häufigsten Kennzeichnung als Klassifizierungsergebnis. Optional weist die distanzgewichtete Abstimmung näheren Nachbarn ein höheres Gewicht zu: Gewicht = 1,0 / (Distanz + ε) wobei ε eine kleine Konstante zur Vermeidung einer Division durch Null ist. Gewichtete Abstimmung ist besonders vorteilhaft, wenn die Referenzmenge ungleiche Klassenverteilungen aufweist oder wenn die Nachbardichte im Embedding-Raum variiert.
| k-Wert | Bias | Varianz | Am besten geeignet für |
|---|---|---|---|
| 1 – 3 | Niedrig | Hoch | Große, saubere Referenzmengen, feinkörnige Grenzen |
| 5 – 10 | Moderat | Moderat | Ausgewogene, allgemeine Klassifizierung |
| 15 – 30 | Höher | Niedriger | Verrauschte Kennzeichnungen, glatte Entscheidungsgrenzen |
Die Distanzwerte, die von FAISS zurückgegeben werden, informieren auch über die Konfidenzschätzung. Wenn die Top-k-Nachbarn alle dieselbe Kennzeichnung teilen und hohe Ähnlichkeitswerte aufweisen (Kosinus-Ähnlichkeit > 0,95), ist die Klassifizierung hochgradig zuverlässig. Wenn die Abstimmung geteilt ist (z. B. 6 von 10 für die siegreiche Kennzeichnung) oder die Ähnlichkeitswerte niedrig sind (< 0,70), kann das System das Ergebnis zur manuellen Prüfung markieren. Diese konfidenzbasierte Architektur ist für sicherheitskritische Anwendungen wie die Inspektion von Flughafenbelägen von entscheidender Bedeutung, da eine Fehlklassifizierung die Instandhaltungspriorisierung und Betriebssicherheit beeinträchtigen könnte.
Der Embedding-Vertrag zwischen dem DINOv2-Modell und dem FAISS-Index ist grundlegend für die Klassifizierungsgenauigkeit. Der Embedding-Extraktor wird durch selbstüberwachtes Lernen so trainiert, dass Distanzen zwischen Embeddings die visuelle Ähnlichkeit zwischen Belagsoberflächenbildern widerspiegeln. Der FAISS-Index ruft zuverlässig nächste Nachbarn gemäß der Kosinus-Ähnlichkeitsmetrik ab. Wenn dieser Vertrag gilt – wenn visuell ähnliche Oberflächenzustände nahe beieinander liegende Embeddings erzeugen – erreicht die kNN-Klassifizierung eine hohe Genauigkeit bei der inhärenten Interpretierbarkeit, genau zu zeigen, welche Referenzbilder jede Klassifizierungsentscheidung beeinflusst haben.
Die GPU-Unterstützung von FAISS ist eine erstklassige Funktion, die erhebliche Leistungsverbesserungen sowohl beim Indexaufbau als auch bei der Suche bietet. Die GPU-Implementierung, beschrieben im Papier “Billion-scale similarity search with GPUs” (Johnson, Douze, Jégou, 2017), ist in CUDA C++ geschrieben und nutzt NVIDIA-GPU-Architekturen von Kepler (Compute Capability 3.5) bis Hopper (Compute Capability 9.0+) und darüber hinaus.
Die GPU-Beschleunigung von FAISS liefert messbare Leistungsverbesserungen: 5- bis 10-fache Verbesserung des Suchdurchsatzes gegenüber der CPU für typische IVF- und HNSW-Indizes; bis zu 12-mal schnellerer Indexaufbau für IVF-Indizes, da k-Means-Clustering hochgradig parallelisierbar ist; 8-mal niedrigere Latenz für HNSW-Abfragen auf der GPU unter Verwendung optimierter Graphdurchlauf-Kernel; und native Unterstützung für Batch-Abfragen, bei denen GPUs durch Matrix-Matrix-Operationen hervorragend darin sind, Hunderte oder Tausende von Abfragen gleichzeitig zu verarbeiten.
Die GPU-Implementierung deckt die am häufigsten verwendeten Indextypen durch dedizierte CUDA-Klassen ab:
| GPU-Index-Klasse | CPU-Äquivalent | Verwendete CUDA-Funktionen |
|---|---|---|
| GpuIndexFlat | IndexFlat | BLAS gemm auf GPU, Shared-Memory-Tiling |
| GpuIndexIVFFlat | IndexIVFFlat | Parallele Distanzberechnung, Warp-Level-Reduktionen |
| GpuIndexIVFPQ | IndexIVFPQ | PQ-Nachschlagetabellen auf GPU, schnelle Code-Zuweisung |
| GpuIndexIVFScalarQuantizer | IndexIVFScalarQuantizer | float16-Unterstützung auf Pascal+-GPUs |
Die GPU-Implementierung verwendet Warp-Shuffles (verfügbar ab Compute Capability 3.0+) und Read-Only-Texture-Caching via ld.nc / __ldg (Compute Capability 3.5+). Der k-Selektionsalgorithmus – das Finden der Top-k-Werte aus einem großen Array von Distanzen – arbeitet mit bis zu 55 % der theoretischen Spitzenleistung der GPU, was eine Nächste-Nachbarn-Implementierung ermöglicht, die laut dem Papier von 2017 8,5-mal schneller ist als der bisherige GPU-Stand. Für das GPU-Speichermanagement weist ein StandardGpuResources-Objekt Arbeitsspeicher auf der GPU zu: etwa 512 MiB auf GPUs mit ≤4 GiB Speicher und etwa 1.536 MiB auf größeren GPUs. Dieser Arbeitsspeicher vermeidet wiederholte cudaMalloc-/cudaFree-Aufrufe während der Suche.
FAISS bietet nahtlose CPU-GPU-Interoperabilität durch zwei Schlüsselfunktionen: faiss.index_cpu_to_gpu(cpu_index, device_id) überträgt einen CPU-Index auf ein bestimmtes GPU-Gerät, und faiss.index_gpu_to_cpu(gpu_index) überträgt einen GPU-Index zurück in den CPU-Speicher. Für Multi-GPU-Bereitstellungen verteilt faiss.index_cpu_to_gpu_multiple_py(resources, cpu_index) einen Index auf alle verfügbaren GPU-Geräte, und Abfragen werden automatisch lastverteilt. Der Multi-GPU-Ansatz kann auf Indizes mit Hunderten Millionen von Vektoren skaliert werden, indem er über GPU-Speicherräume partitioniert wird.
| Szenario | CPU | GPU (1x) | GPU (8x) |
|---|---|---|---|
| IndexFlat-Suche (100K x 768d), Batch=8192 | 50 ms | 5 ms | <1 ms |
| IVF-k-Means-Training (1M x 128d), nlist=1000 | 120 s | 10 s | 5 s |
| HNSW-Aufbau (100K x 128d), M=32 | 30 s | 8 s | — |
| Milliardenmaßstab k-NN-Graph | Tage | 12 Stunden | 4 Stunden |
Für TarmacView ist die GPU-Beschleunigung während der Indexaufbauphase wertvoll, wenn regelmäßig neue Referenzbilder hinzugefügt werden. Der Aufbau eines IVF-Index mit k-Means auf 9.000 768-dimensionalen Vektoren ist auf einer modernen GPU (NVIDIA A100 oder RTX 4090) in etwa 1–2 Sekunden abgeschlossen, verglichen mit 30–60 Sekunden auf der CPU. Während der Inferenz verbleibt der Index aus Kostengründen auf der CPU – die Abfragelatenz auf der CPU mit IndexHNSWFlat liegt bereits unter 200 Mikrosekunden für die 9K-Referenzmenge, und die Umstellung auf GPU würde PCIe-Übertragungsoverhead ohne signifikante Latenzvorteile hinzufügen.

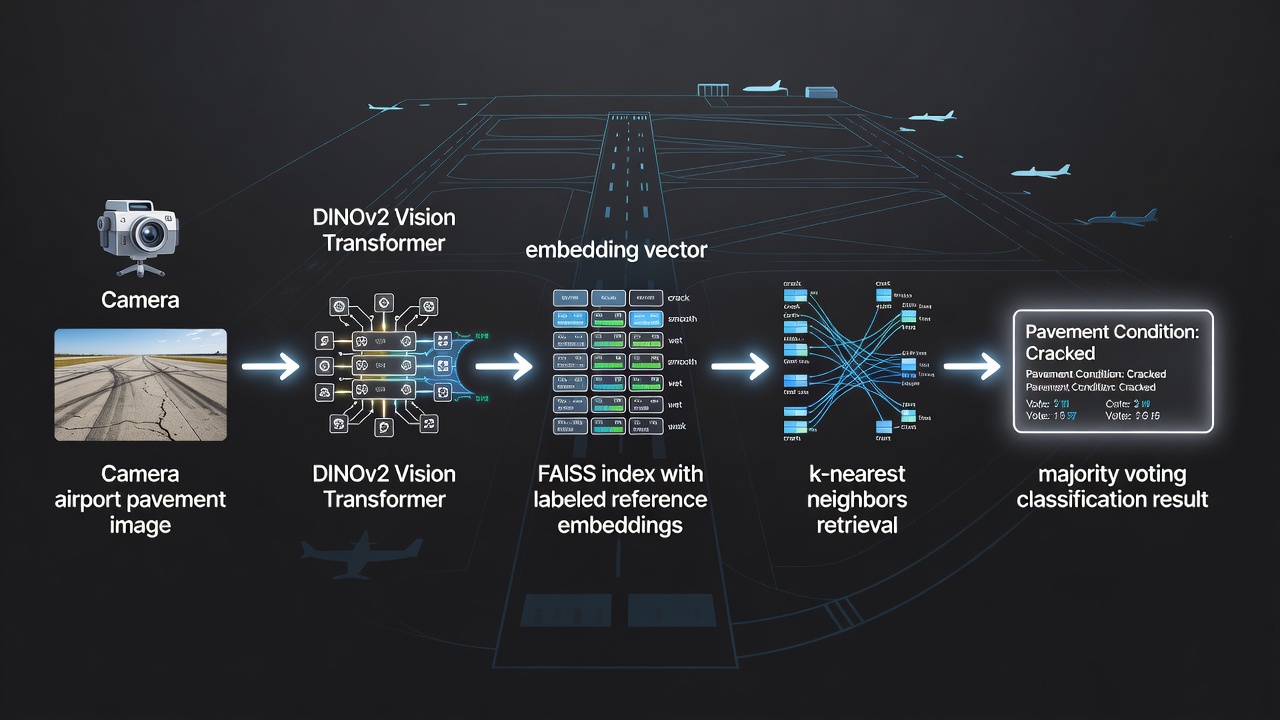
TarmacView integriert FAISS als zentrale Ähnlichkeitssuchmaschine für sein automatisiertes Klassifizierungssystem der Oberflächenqualität von Flughafenbelägen. Das System klassifiziert Belagsoberflächentypen (Asphalt, Beton, Teerbelag) und Oberflächenqualitätszustände (gut, mittel, schlecht, beschädigt, gerissen, repariert), indem es Inspektionsbilder mit einer kuratierten Referenzmenge von etwa 9.000 beschrifteten Embeddings vergleicht.
Referenzmengenaufbau: Jedes Referenz-Embedding wird aus einem hochauflösenden Belagsbild unter Verwendung eines DINOv2 Vision Transformer-Modells (ViT-B/14 oder äquivalent) extrahiert, das einen 768-dimensionalen Vektor erzeugt, der visuelle Merkmale wie Texturmuster, Farbverteilung, Rissmorphologie, Aggregatfreilegung, Oberflächenabnutzung und Reparaturhinweise erfasst. Jedes Embedding wird mit Ground-Truth-Kennzeichnungen annotiert, die von zertifizierten Belagsprüfern während einer anfänglichen Systemtrainingsphase festgelegt wurden. Die Referenzmenge erstreckt sich über mehrere Flughäfen, Klimazonen und Belagsalter, um eine robuste Klassifizierung unter verschiedenen Bedingungen sicherzustellen.
Indexauswahl: TarmacView wählt den Indextyp basierend auf den Bereitstellungsanforderungen:
| Bereitstellungsszenario | Indextyp | Abfragezeit | Recall | Speicher |
|---|---|---|---|---|
| Offline-QA / Validierung | IndexFlatIP | ~2 ms | 100 % | ~28 MB |
| Echtzeit-Feldeinsatz | IndexHNSWFlat (M=32, efSearch=64) | <200 μs | >99 % | ~30 MB |
| Edge-Gerät (begrenzter RAM) | IndexIVFFlat (nlist=100, nprobe=10) | ~300 μs | ~97 % | ~28 MB |
Klassifizierungs-Workflow:
Eine drohnengestützte Kamera (z. B. DJI Matrice-Serie mit hochauflösender Nutzlast) oder ein handgehaltenes Inspektionsgerät erfasst Belagsbilder während routinemäßiger Flughafenfeldinspektionen, gemäß den Richtlinien von ICAO Annex 14 und FAA AC 150/5380-7B für die Zustandsbewertung von Belägen.
Jedes Bild wird vorverarbeitet (zugeschnitten, um Nicht-Belagsbereiche zu entfernen, auf Standardauflösung normalisiert) und durch das auf einem Edge-Inferenzbeschleuniger (NVIDIA Jetson oder äquivalent) gehostete DINOv2-Embedding-Modell geleitet.
Das resultierende 768-dimensionale Embedding wird für die Kosinus-Ähnlichkeitsberechnung auf Einheitslänge L2-normalisiert. Die Normalisierung stellt sicher, dass Belichtungsunterschiede zwischen Inspektionsflügen die Ähnlichkeitsbewertung nicht beeinflussen.
FAISS fragt den IndexHNSWFlat-Index mit k=10 ab und gibt die 10 nächsten Referenz-Embedding-Indizes sowie ihre Inner-Product-Ähnlichkeitswerte (äquivalent zur Kosinus-Ähnlichkeit für normalisierte Vektoren) zurück.
Das System führt eine Mehrheitsabstimmung über die Kennzeichnungen der 10 Nachbarn durch. Wenn die siegreiche Kennzeichnung mindestens 6 von 10 Stimmen (60 % Konsens) hat, wird die Klassifizierung mit einem Konfidenzwert, berechnet als Verhältnis der Siegerstimmen zu Gesamtstimmen, akzeptiert.
Wenn die Abstimmung unter 60 % Konsens geteilt ist, werden das Bild-Embedding und die Top-10-Referenzbilder über die TarmacView-Weboberfläche zur manuellen Prüfung durch einen zertifizierten Belagsprüfer markiert.
Klassifizierungen werden in der TarmacView-Datenbank mit Zeitstempeln, GPS-Koordinaten, Oberflächentyp, Qualitätszustand, Konfidenzwert und Links zu den unterstützenden Referenzbildern aufgezeichnet. Dies erzeugt eine vollständig prüfbare Inspektionskette für die Einhaltung gesetzlicher Vorschriften.
Diese FAISS-betriebene Klassifizierungspipeline ermöglicht es TarmacView, Tausende von Belagsbildern pro Tag mit konsistenter, objektiver Qualitätsbewertung zu verarbeiten – wodurch die Abhängigkeit von subjektiver menschlicher Sichtprüfung reduziert wird und eine skalierbare Überwachung des Flughafenbefestigungszustands über gesamte Flughafennetzwerke hinweg ermöglicht wird.
FAISS nimmt eine eigene Nische im Vektorsuch-Ökosystem ein. Es ist eine Bibliothek, keine Datenbank, und diese Unterscheidung hat erhebliche Auswirkungen auf Architektur, Bereitstellung und Betriebsmerkmale. Die FAISS-Bibliothek bietet reine Nächste-Nachbarn-Suchfunktionalität ohne den Overhead eines vollständigen Datenbankverwaltungssystems.
| Funktion | FAISS | Pinecone | Milvus | Qdrant | Weaviate |
|---|---|---|---|---|---|
| Typ | Bibliothek | Verwalteter Dienst | Datenbank | Datenbank | Datenbank |
| Bereitstellung | Eingebettet | Cloud / SaaS | Selbst gehostet / Cloud | Selbst gehostet / Cloud | Selbst gehostet / Cloud |
| Persistenz | Manuelles Speichern/Laden | Automatisch | Automatisch | Automatisch | Automatisch |
| CRUD | Nicht integriert | Vollständiges CRUD | Vollständiges CRUD | Vollständiges CRUD | Vollständiges CRUD |
| Metadatenfilterung | Nur ID-basiert | Umfangreiche Filter | Attribut + Skalar | Payload-Filterung | Graphbasiert |
| Skalierung | Manuelles Sharding | Automatische Skalierung | Verteiltes Raft/Paxos | Verteilt | Verteilt |
| GPU-Unterstützung | Natives CUDA | Nein | Eingeschränkt (CUDA) | Nein | Nein |
| Abfragelatenz | 10 μs – 1 ms | 2 – 10 ms | 1 – 10 ms | 1 – 5 ms | 1 – 10 ms |
| Lizenz | MIT | Proprietär | Apache 2.0 | Apache 2.0 | BSD-3 |
Der Hauptvorteil von FAISS gegenüber vollständigen Datenbanksystemen ist Leistung und Einfachheit. FAISS-Abfragen sind typischerweise 10- bis 100-mal schneller als äquivalente Abfragen auf Datenbanksystemen, weil: die Bibliothek prozessintern ohne Netzwerk-Roundtrips läuft; es keinen Abfrage-Parsing-, Authentifizierungs- oder Autorisierungs-Overhead gibt; es keine Speicher-Engine-Indirektion oder Buffer-Pool-Verwaltung gibt; und FAISS-Indizes optimierte Datenstrukturen der linearen Algebra ohne Transaktions-Overhead sind. FAISS arbeitet direkt auf speicherresidenten Datenstrukturen unter Verwendung optimierter BLAS-Routinen, ohne Interprozesskommunikation.
Der Hauptvorteil von Datenbanksystemen gegenüber FAISS ist die betriebliche Bequemlichkeit. Sie bieten automatische Datenhaltbarkeit mit Write-Ahead-Logging und Replikation, unterstützen umfangreiche Metadatenfilterung (z. B. “finde ähnliche Bilder, die nach Januar 2025 aufgenommen wurden und Betonbelag in der US-Südwestregion zeigen”), bieten REST- oder gRPC-APIs für sprachunabhängigen Zugriff, enthalten Überwachungs-Dashboards und Alarmierung und kümmern sich um Backup und Notfallwiederherstellung. Sie unterstützen gleichzeitige Lese- und Schreiboperationen mit Transaktionsgarantien und Schemaevolution.
Für TarmacView ist die direkte Verwendung von FAISS anstelle einer Vektordatenbank aus vier Gründen die richtige Architekturentscheidung: (1) die Referenzmenge ist klein (~9K Vektoren, etwa 28 MB) und passt vollständig in den Speicher; (2) die Anforderungen an die Abfragelatenz sind aggressiv (Sub-200-Mikrosekunden-Klassifizierung ist mit HNSW auf der CPU erreichbar); (3) das System läuft in Edge-Bereitstellungen an Flughäfen, wo der Netzwerkzugriff auf einen Datenbankserver unpraktisch oder mit inakzeptabler Latenz verbunden sein kann; und (4) der Index wird selten neu aufgebaut (wöchentlich oder monatlich, wenn nach Prüfervalidierung neue Referenzbilder hinzugefügt werden), was die manuelle Serialisierung und Versionskontrolle handhabbar macht.
Die FAISS-Index-Serialisierung konvertiert ein speicherresidentes Indexobjekt in eine binäre Darstellung, die auf der Festplatte gespeichert, über ein Netzwerk übertragen oder in einen anderen Prozess oder Rechner geladen werden kann. Die Serialisierung bewahrt den vollständigen Indexzustand einschließlich aller gespeicherten Vektoren, trainierter Zentroide (für IVF- und PQ-Indizes), Graphstruktur (für HNSW), Distanzmetrikkonfiguration (L2 vs. IP vs. andere) und aller internen Parameter (efConstruction, M, Normalisierungseinstellungen usw.).
Die primären Serialisierungsfunktionen sind:
| Funktion | Beschreibung | Ausgabe | Anwendungsfall |
|---|---|---|---|
| write_index(index, filename) | Schreibt Index in Datei | .faissindex-Datei | Dauerhafter Datenträgerspeicher |
| read_index(filename) | Lädt Index aus Datei | Index-Objekt | Zum Bereitstellen laden |
| serialize_index(index) | Schreibt Index in Bytes | Python bytes-Objekt | Datenbankspeicherung, Nachrichtenwarteschlangen |
| deserialize_index(data) | Lädt Index aus Bytes | Index-Objekt | Aus Speicherpuffer laden |
Die Serialisierungsgröße hängt vom Indextyp und der Vektoranzahl ab. Für IndexFlatIP mit N Vektoren der Dimension D beträgt die Dateigröße etwa N × D × 4 Bytes (32-Bit-Gleitkommaspeicher) plus Overhead für Header und Metadaten. Für IndexIVFFlat wird zusätzlicher Speicher durch Clusterzentroide verbraucht: nlist × D × 4 Bytes. Für IndexHNSWFlat fügt die Graphstruktur N × M × 2 × 4 Bytes für die Adjazenzlisten hinzu (bei Annahme von 32-Bit-Nachbarindizes, die bidirektional gespeichert werden). Für TarmacViews HNSW-Index mit 9.000 Vektoren bei 768 Dimensionen und M=32 beträgt die serialisierte Datei etwa 25 MB: 9.000 × 768 × 4 = 27,6 MB für Vektoren plus 9.000 × 32 × 2 × 4 = 2,3 MB für die Graphstruktur, abzüglich der Tatsache, dass HNSW Vektoren intern in einem Flat-Index speichert.
Die Serialisierung unterstützt die kontextübergreifende Übertragung: Ein auf der GPU erstellter Index kann auf der Festplatte gespeichert und auf der CPU geladen werden. Das empfohlene Muster ist, GPU-Indizes vor der Serialisierung immer auf die CPU zu übertragen:
cpu_index = faiss.index_gpu_to_cpu(gpu_index) # Auf CPU übertragen
faiss.write_index(cpu_index, "production_index.faissindex") # Auf Festplatte speichern
# Auf einem anderen Rechner (oder später):
deployed_index = faiss.read_index("production_index.faissindex")
deployed_index.hnsw.efSearch = 64 # Suchzeitparameter setzen
D, I = deployed_index.search(queries, k)
Für Produktionsbereitstellungen kann der serialisierte Index versionsverwaltet zusammen mit dem Anwendungscode werden. TarmacView unterhält versionierte FAISS-Indexdateien in seinen Bereitstellungsartefakten und stellt sicher, dass jede Edge-Bereitstellung eine identische Referenzmenge für reproduzierbare Klassifizierungsergebnisse verwendet. Wenn neue Referenzbilder hinzugefügt und validiert werden, wird ein neuer Index trainiert, seine Genauigkeit wird gegen den vorherigen Index unter Verwendung des Ground-Truth-IndexFlatIP gemessen, und der neue Index wird durch die standardmäßige CI/CD-Pipeline bereitgestellt.
Während TarmacViews aktuelle Referenzmenge von etwa 9.000 Vektoren bescheiden ist, ist FAISS darauf ausgelegt, auf Milliarden von Vektoren auf einem einzelnen Server zu skalieren. Die Bibliothek bietet ein umfassendes Toolkit für die Bewältigung von Großbereitstellungen durch drei sich ergänzende Techniken: Vektorkomprimierung, nicht-exhaustive Suche und verteilte Indizierung.
Produktquantisierung (PQ) ist eine verlustbehaftete Komprimierungstechnik, die den Speicherbedarf pro Vektor drastisch reduziert. PQ teilt jeden D-dimensionalen Vektor in m Teilvektoren gleicher Größe (D/m Dimensionen jeder). Jeder Teilvektor wird unabhängig mit einem Codebuch von 256 Einträgen (8 Bit) quantisiert, das mittels k-Means-Clustering gelernt wurde. Der ursprüngliche float32-Vektor (4 × D Bytes) wird auf m Bytes Code-Indizes plus einem kleinen Codebuch komprimiert. PQ-Komprimierungsverhältnisse von 4x bis 16x sind üblich und ermöglichen es einem einzelnen Rechner, Hunderte Millionen von Vektoren im Hauptspeicher zu indizieren. FAISS IndexIVFPQ kombiniert IVF mit PQ, wobei die Clusterzentroide als grober Quantisierer und PQ-Codes für die Restkomprimierung verwendet werden. Die Distanzberechnung verwendet die Asymmetrische Distanzberechnung (ADC): Die Abfrage bleibt unkomprimiert, und Distanzen zu PQ-komprimierten Datenbankvektoren werden über vorberechnete Nachschlagetabellen berechnet, wodurch der Dekomprimierungs-Overhead vermieden wird.
| PQ-Konfiguration | Bytes/Vektor (d=768) | Speicher, N=100M | Recall vs. unkomprimiert |
|---|---|---|---|
| PQ32 (m=32, 8-Bit) | 40 | 3,7 GB | ~90–95 % |
| PQ64 (m=64, 8-Bit) | 72 | 6,7 GB | ~95–98 % |
| PQ96 (m=96, 8-Bit) | 104 | 9,7 GB | ~97–99 % |
Skalarquantisierung (SQ) wandelt jede float32-Komponente in einen 8-Bit- oder 4-Bit-unsigned Integer um und reduziert den Speicher um das 4-fache (SQ8) oder 8-fache (SQ4) bei minimalem Genauigkeitsverlust. Die Factory-Zeichenkette "IVF100,SQ8" erstellt einen IVF-Index mit Skalarquantisierung. SQ ist zur Abfragezeit schneller als PQ, da Distanzberechnungen direkt auf den quantisierten Werten ohne Nachschlagetabellen-Vorberechnung durchgeführt werden. SQ8 speichert ein Byte pro Dimension; SQ4 speichert zwei Dimensionen pro Byte.
Für Datensätze im Milliardenmaßstab kombiniert die empfohlene FAISS-Konfiguration HNSW als groben Quantisierer mit IVFPQ zur Vektorkomprimierung: quantizer = IndexHNSWFlat(d, hnsw_m); index = IndexIVFPQ(quantizer, d, nlist, M, nbits). Der HNSW-Quantisierer beschleunigt die Zentroid-Suche im Vergleich zur Flat-Suche zur Abfragezeit, und PQ komprimiert Datenbankvektoren auf einen Bruchteil ihrer ursprünglichen Größe. Das ursprüngliche FAISS-Papier (2017) bewertete den Aufbau eines k-NN-Graphen auf 95 Millionen Bildern (aus dem YFCC100M-Datensatz) in 35 Minuten auf GPUs und einen k-NN-Graphen auf 1 Milliarde Vektoren in unter 12 Stunden auf 4x Maxwell Titan X GPUs.
FAISS IndexShards teilt einen großen Datensatz auf mehrere Unter-Indizes auf, die sich jeweils auf potenziell unterschiedlichen Rechnern oder GPUs befinden. Jeder Shard erhält eine Teilmenge der Vektoren und verarbeitet Abfragen unabhängig. Die Ergebnisse werden mittels einer k-Wege-Zusammenführung der Top-k-Ergebnisse jedes Shards zusammengeführt. Dieser Ansatz bietet lineare Skalierung mit der Anzahl der verfügbaren Server: Eine Verdoppelung der Shard-Anzahl halbiert die Suchzeit für eine feste Datensatzgröße.
Für Datensätze, die den verfügbaren RAM überschreiten, bietet FAISS On-Disk-Indizes, die die Indexstruktur (Inverted-Listen oder Graph) im Speicher halten, aber Vektordaten auf der SSD speichern. Die IndexOnDisk-Klasse und zugehörige Dienstprogramme laden Vektordaten während der Suche transparent von der Festplatte, wobei memory-mapped-Dateien oder explizite I/O-Operationen verwendet werden. Mit modernen NVMe-SSDs, die 3–7 GB/s sequentielle Lesegeschwindigkeiten bieten, kann die On-Disk-Suche für viele Arbeitslasten nahe an die In-Memory-Leistung herankommen, insbesondere wenn die räumliche Lokalität (benachbarte Vektoren, die auf der Festplatte zusammenhängend gespeichert sind) erhalten bleibt.
Für TarmacView liegt die aktuelle 9K-Referenzmenge gut im optimalen Bereich von FAISS für die exakte Suche mit IndexFlatIP. Wenn das System jedoch um Referenzbilder von Hunderten von Flughäfen und mehreren Inspektionskampagnen erweitert wird – möglicherweise auf Millionen von beschrifteten Embeddings anwachsend – bieten die Skalierungsmechanismen von FAISS (IVF für nicht-exhaustive Suche, PQ für Komprimierung, On-Disk-Speicherung für außerhalb des RAM liegende Datensätze) einen klaren Aufrüstpfad, ohne dass eine grundlegend andere Architektur erforderlich ist. Der Indextyp kann von IndexFlatIP → IndexIVFFlat → IndexIVFPQ → IndexShards(IndexIVFPQ) aufgerüstet werden, wenn die Referenzmenge wächst, wobei jeder Schritt minimale Genauigkeit gegen Größenordnungen an Verbesserungen bei Suchgeschwindigkeit und Speichereffizienz eintauscht.
Die FAISS-Literatur (einschließlich des umfassenden arXiv-Papiers von 2024 “The Faiss Library” von Douze, Guzhva, Deng, Johnson, Szilvasy, Mazaré, Lomeli, Hosseini und Jégou) bietet detaillierte Anleitungen zur Indexauswahl: “There exists a choice between a dozen index types, and the optimal one usually depends on the problem’s constraints.” FAISS enthält auch eine umfassende Benchmarking-Suite (faiss_benchmarks), die Recall und Durchsatz über verschiedene Indexkonfigurationen misst und Suchen mit Ground-Truth-Ergebnissen von IndexFlat durchführt, um die Genauigkeit zu quantifizieren. Praktiker werden ermutigt, ihre spezifische Datenverteilung zu benchmarken – der optimale Index für einen gegebenen Datensatz hängt von der Vektordimensionalität, der Datensatzgröße, dem Ziel-Recall, dem Latenzbudget und dem verfügbaren Speicher ab.
Nutzen Sie FAISS für hochleistungsfähige Ähnlichkeitssuche auf Ihren Bild-Embedding-Daten. Kontaktieren Sie uns, um zu erfahren, wie TarmacView FAISS für die Echtzeit-Klassifizierung der Oberflächenqualität und die Suche nach Inspektionsbildern integriert.
k-Nächste-Nachbarn (kNN) klassifiziert einen Abfragepunkt per Mehrheitsentscheidung unter seinen k ähnlichsten Referenzpunkten in einem Einbettungsraum. TarmacV...
DINOv3 (self-DIstillation with NO labels v3) ist ein selbstüberwachter Vision Transformer (ViT-B/16), der auf 1,7 Milliarden Bildern vortrainiert wurde und hoch...
Der Rissflächenanteil (crack_area_pct) ist das Verhältnis der Rissmaskenfläche zur gesamten analysierten Bildfläche, ausgedrückt in Prozent. Er ist eine zentral...