Risssegmentierung
Risssegmentierung ist die Computer-Vision-Aufgabe, jedes Pixel eines Bildes entweder als Riss oder als Nicht-Riss zu klassifizieren und eine binäre Maske zu erz...
30 Min. Lesezeit
Computer Vision
Deep Learning
+2
Instanzsegmentierung erkennt und grenzt jedes einzelne Objekt oder jede Schadensinstanz auf Pixelebene ab und weist jedem Riss, Abplatzung oder Schlagloch eine eindeutige ID zu. Dies ermöglicht die Zählung, Größenbestimmung und zeitliche Verfolgung pro Schaden. Behandelt Mask R-CNN und andere Instanzarchitekturen, Unterschiede zur semantischen Segmentierung und die Anwendung auf Infrastrukturschäden.
Instanzsegmentierung ist eine Computer-Vision-Aufgabe, die jede einzelne Objektinstanz auf Pixelebene identifiziert, klassifiziert und abgrenzt, indem sie jedem erkannten Objekt eine eindeutige Instanzkennung zuweist. Für die Infrastrukturinspektion bedeutet Instanzsegmentierung, dass jeder einzelne Riss, jede Abplatzung, jedes Schlagloch, jede Fugenstörung oder jede Oberflächenverschlechterung eine eigene pixelgenaue Maske mit einer eindeutigen ID erhält – sodass Ingenieure jeden Schaden unabhängig zählen, messen und verfolgen können, anstatt alle Schäden derselben Art als eine einzige undifferenzierte Masse zu behandeln.
Die Instanzsegmentierung nimmt eine besondere Position in der Computer-Vision-Hierarchie ein, die zwischen der Objekterkennung (Begrenzungsrahmen mit Klassenbezeichnungen) und der semantischen Segmentierung (Pixelgenaue Klassenbezeichnungen ohne Instanzunterscheidung) liegt. Sie löst ein Problem, das keine dieser Aufgaben allein adressieren kann: die Fähigkeit, sowohl jedes Pixel, das zu einer Kategorie gehört, zu klassifizieren als auch zu unterscheiden, welche Pixel zu welchem spezifischen Objekt innerhalb dieser Kategorie gehören.
Semantische Segmentierung kennzeichnet jedes Pixel in einem Bild entsprechend der Klasse, zu der es gehört. Auf einem Bild einer Flughafen-Startbahnoberfläche mit drei Längsrissen würde ein semantisches Segmentierungsmodell alle Risspixel mit derselben Klassenfarbe einfärben (z. B. rot). Die Ausgabe ist eine einzige binäre oder multi-class-Maske, bei der alle Risse, unabhängig davon, ob es sich um separate physische Schäden handelt, zu einer einzigen durchgehenden Klassenregion verschmolzen werden. Dieser Ansatz liefert die gesamte Rissfläche in Pixeln, gibt jedoch keine Auskunft darüber, wie viele einzelne Risse existieren, welche individuellen Größen sie haben oder wie ihre räumliche Verteilung als diskrete Schäden aussieht.
Objekterkennung platziert Begrenzungsrahmen um jedes erkannte Objekt und weist eine Klassenbezeichnung zu. Ein Detektor auf demselben Startbahnbild würde drei rechteckige Rahmen um die drei Risse zeichnen. Die Ausgabe liefert die Rissanzahl und die ungefähre Position, aber Begrenzungsrahmen bringen eine grundlegende Einschränkung mit sich: Sie enthalten auch nicht geschädigten Fahrbahnbelag innerhalb des Rechtecks, was eine präzise Flächenmessung unmöglich macht. Ein Begrenzungsrahmen um einen gewundenen Riss erfasst weit mehr Nicht-Riss-Pixel als Riss-Pixel.
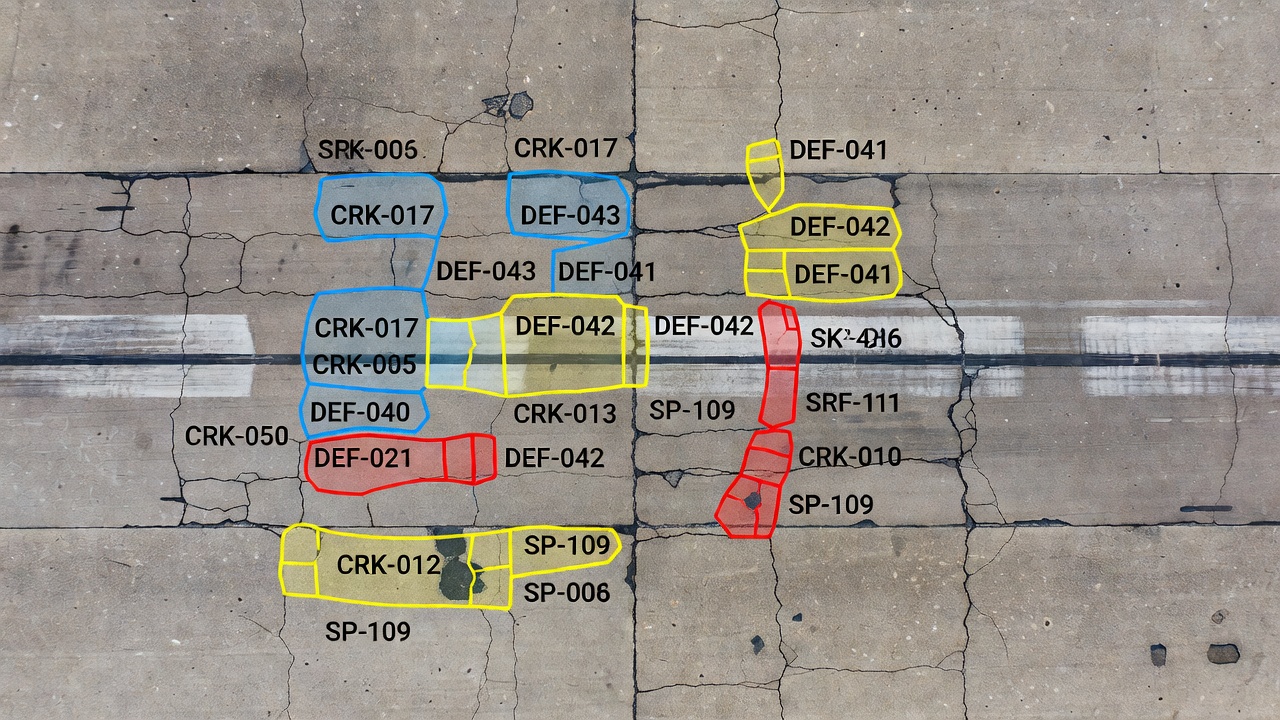
Instanzsegmentierung löst diese Einschränkungen vollständig. Das Modell gibt eine Reihe von Binärmasken aus – eine pro erkannter Instanz – jeweils gepaart mit einer Klassenbezeichnung und einer eindeutigen Instanz-ID. Für die drei Risse wäre die Ausgabe drei verschiedene Binärmasken: Riss-001, Riss-002 und Riss-003, die jeweils genau die Pixel zeigen, die zu diesem bestimmten Riss gehören, und keine anderen. Die Masken folgen der exakten Kontur jedes Schadens und umschließen jede Verzweigung, Kurve und Unregelmäßigkeit. Dies liefert eine pixelgenaue Geometrie pro Instanz, die präzise Flächenmessung, Morphologieanalyse und individuelle Schadensverfolgung ermöglicht.
Der kritische operationelle Unterschied zeigt sich im Inspektionsergebnis. Ein semantischer Segmentierungsbericht könnte aussagen: „Gesamte Rissfläche: 45.230 Pixel." Ein Instanzsegmentierungsbericht sagt: „Drei Risse erkannt. Riss-001: 12.400 px², Riss-002: 18.100 px², Riss-003: 14.730 px²." Letzteres ist für die Instandhaltungsplanung weitaus aussagekräftiger – es teilt dem Fahrbahningenieur die genaue Anzahl der zu reparierenden Schäden und deren individuellen Schweregrad mit.
Diese Unterscheidung pro Instanz ist im COCO-Datensatzstandard (Common Objects in Context) formalisiert, der Instanzsegmentierungs-Annotationen als eine Liste von Objekten definiert, die jeweils ein Segmentierungspolygon (Liste von x,y-Koordinaten, die die Objektkontur bilden), einen Begrenzungsrahmen, eine Kategorie-ID und eine Bild-ID enthalten. Die im COCO verwendeten Bewertungsmetriken – insbesondere Average Precision (AP) – sind der De-facto-Standard für den Vergleich von Instanzsegmentierungsmodellen und gelten direkt für Modelle zur Erkennung von Infrastrukturschäden.
Für die Instanzsegmentierung wurden mehrere Deep-Learning-Architekturen entwickelt, die jeweils unterschiedliche Abwägungen zwischen Genauigkeit, Geschwindigkeit und architektonischer Komplexität aufweisen.
Mask R-CNN, 2017 von He et al. bei Facebook AI Research vorgestellt, erweitert Faster R-CNN um einen Maskenvorhersagezweig parallel zu den bestehenden Zweigen für Begrenzungsrahmen-Regression und Klassifikation. Die Architektur folgt einem zweistufigen Design. In der ersten Stufe durchsucht ein Region Proposal Network (RPN) die von einem Backbone-CNN (typischerweise ResNet-50, ResNet-101 oder ResNeXt) extrahierten Merkmalskarten und schlägt Kandidatenobjektregionen (RoIs oder Regions of Interest) vor. In der zweiten Stufe wird jede RoI durch RoIAlign verarbeitet – ein kritischer Beitrag von Mask R-CNN, der bilineare Interpolation verwendet, um exakte Merkmalswerte an jedem Abtastpunkt zu berechnen und so die Quantisierungsfehler von RoIPool zu eliminieren – um Merkmalskarten fester Größe zu erzeugen. Diese Merkmalskarten werden in drei parallele Köpfe eingespeist: einen Klassifikationskopf (Klassenvorhersage), einen Begrenzungsrahmen-Regressionskopf (Boxkoordinaten) und einen Maskenkopf (ein vollständig convolutional Netzwerk, das für jede RoI eine Binärmaske pro Klasse ausgibt).
Der Maskenkopf gibt eine Maske mit einer Auflösung von 28×28 Pixeln pro RoI und pro Klasse aus. Während des Trainings kombiniert die Verlustfunktion den Klassifikationsverlust, den Begrenzungsrahmenverlust und den Maskenverlust (binäre Kreuzentropie gemittelt über Pixel). Die wesentliche Erkenntnis ist, dass Maskenvorhersage und Klassifikation entkoppelt sind: Der Maskenkopf sagt Masken für alle Klassen voraus, aber nur die Maske, die der Grundwahrheitsklasse entspricht, trägt zum Verlust bei. Diese klassenweise Maskenvorhersage zwingt das Modell, klassenspezifische Formmerkmale zu lernen.
Mask R-CNN erreicht 37-47 AP auf der COCO-Instanzsegmentierung (abhängig vom Backbone), wobei ResNet-50-FPN etwa 37,1 AP und ResNeXt-101-FPN 39,4-47,1 AP erreicht. Die Inferenzgeschwindigkeit liegt zwischen 5-10 FPS auf einer modernen GPU. Für Infrastrukturanwendungen ist ein Mask R-CNN mit ResNet-50-FPN-Backbone die am häufigsten verwendete Konfiguration, mit berichteten Leistungen von 33,3 AP auf Fahrbahnriss-Datensätzen und 40-55 AP auf Schlagloch-Datensätzen.
YOLACT (You Only Look At CoefficienTs) wurde 2019 von Bolya et al. als erste Echtzeit-Instanzsegmentierungsmethode vorgestellt, die mit 30+ FPS laufen kann. Im Gegensatz zum zweistufigen Ansatz von Mask R-CNN ist YOLACT eine einstufige, vollständig convolutionale Methode, die die Instanzsegmentierung in zwei parallele Teilaufgaben aufteilt: die Erzeugung einer Reihe von Prototypmasken für das gesamte Bild und die Vorhersage von linearen Kombinationskoeffizienten pro Instanz.
In der ersten Teilaufgabe erzeugt ein Feature-Pyramid-Network-Backbone eine Reihe von Prototypmasken – k Maskenkoeffizienten (typischerweise 32), die das gesamte Bild abdecken. Diese Prototypen erfassen häufige Formmuster (z. B. horizontal, vertikal, gebogen, kreisförmig). In der zweiten Teilaufgabe gibt der Vorhersagekopf einen Vektor von linearen Koeffizienten für jede erkannte Instanz aus. Die endgültige Maske für jede Instanz wird als lineare Kombination der Prototypen, gewichtet mit dem Koeffizientenvektor der Instanz, berechnet, gefolgt von einer Sigmoid-Aktivierung und einem Zuschnitt mit dem vorhergesagten Begrenzungsrahmen.
YOLACT erreicht 29-31 AP auf COCO bei 30-45 FPS auf einer Titan X GPU. Die schnellere YOLACT-550-Variante erreicht 28,2 AP bei 56 FPS. YOLACT++ verbessert die Maskenqualität durch hinzugefügte deformierbare Faltungen und besseres Prototyp-Upsampling und erreicht 34,1 AP bei 33,5 FPS. Für die Infrastrukturinspektion wurde YOLACT erfolgreich für die Echtzeit-Erkennung von Betonrissen eingesetzt und erzielt konkurrenzfähige Ergebnisse bei Geschwindigkeiten, die für die UAV-gestützte Verarbeitung geeignet sind. Der Nachteil ist eine geringere Maskenrandgenauigkeit im Vergleich zu Mask R-CNN, was die genaue Rissbreitenmessung beeinträchtigen kann.
SOLO (Segmenting Objects by LOcations), 2020 von Wang et al. vorgestellt, verfolgt einen grundlegend anderen Ansatz: Es eliminiert den Detektionszweig vollständig und sagt Instanzmasken direkt mit einer vollständig convolutional Architektur voraus. Die Kernidee ist, dass jede Instanz eindeutig durch ihre Mittelpunktposition und Objektgröße identifiziert werden kann. SOLO unterteilt das Eingabebild in ein S×S-Gitter. Jede Gitterzelle ist dafür verantwortlich, die Binärmaske jeder Instanz vorherzusagen, deren Mittelpunkt in diese Zelle fällt. Jede Gitterzelle sagt C-Kanal-Masken (eine pro Klasse) plus Klassenwahrscheinlichkeiten voraus.
Die Architektur von SOLO besteht aus einem Backbone (ResNet-FPN), einem Kategoriezweig, der Klassenwahrscheinlichkeiten für jede Gitterzelle vorhersagt, und einem Maskenzweig, der S² Binärmasken pro Bild vorhersagt (eine pro Gitterposition). Während der Inferenz werden die zellenweise Klassen- und Maskenvorhersage kombiniert: Für jede Gitterzelle wählt die vorhergesagte Klasse mit einer Konfidenz über dem Schwellenwert den entsprechenden Maskenkanal aus. SOLOv2 verbessert das Original durch die Einführung von Maskenkernel-Vorhersage und Maskenmerkmal-Korrelation und erreicht 37,8 AP auf COCO bei vergleichbarer Geschwindigkeit wie Mask R-CNN.
Das positionsbasierte Paradigma von SOLO ist besonders interessant für Infrastrukturschäden, da es jeden Schaden natürlich seiner räumlichen Position zuordnet, ohne auf Begrenzungsrahmen-Vorschläge angewiesen zu sein, die bei stark länglichen Schäden wie Rissen, die sich über große Teile des Bildes erstrecken, problematisch sein können.
Mask2Former, 2022 von Cheng et al. bei Facebook AI Research (CVPR 2022) vorgestellt, repräsentiert den Stand der Technik bei der transformerbasierten Segmentierung. Mask2Former vereinheitlicht semantische, Instanz- und panoptische Segmentierung in einer einzigen Architektur, indem es alle Segmentierungsaufgaben als Maskenklassifikation behandelt. Die Architektur besteht aus drei Komponenten: einem Backbone (Swin Transformer oder ResNet), das mehrskalige Merkmale extrahiert, einem Pixel-Decoder, der Merkmale auf hochauflösende pixelweise Einbettungen hochskaliert, und einem Transformer-Decoder mit maskierter Aufmerksamkeit, der eine Menge von N Abfragen (typischerweise 32) vorhersagt, die jeweils eine Binärmaske und eine Klassenbezeichnung erzeugen.
Die wesentliche Neuerung ist die maskierte Aufmerksamkeit – ein Mechanismus, bei dem jede Transformer-Decoder-Abfrage nur auf die vorhergesagte Maskenregion aus der vorherigen Decoderschicht achtet, anstatt auf die gesamte Merkmalskarte. Dies reduziert den Rechenaufwand um das 3-fache im Vergleich zu standardmäßigen Transformer-Modellen und zwingt jede Abfrage, sich auf eine bestimmte Region zu spezialisieren, was die Konvergenzgeschwindigkeit und Maskenqualität verbessert.
Mask2Former erreicht 50,1 AP auf der COCO-Instanzsegmentierung mit einem Swin-L-Backbone und 57,8 PQ auf der COCO-panoptischen Segmentierung. Sein Training konvergiert 3× schneller als frühere transformerbasierte Ansätze (z. B. MaskFormer, DETR). Für Infrastrukturanwendungen macht die Fähigkeit von Mask2Former, überlappende und benachbarte Schadensinstanzen durch gelernte abfragebasierte Maskenvorhersage zu verarbeiten, es besonders effektiv für dichte Schadensfelder wie Netzrisse oder Krokodilrissmuster.
| Architektur | Typ | COCO AP | FPS | Stärken | Infrastruktureinsatz |
|---|---|---|---|---|---|
| Mask R-CNN | Zweistufiges CNN | 37-47 | 5-10 | Hohe Maskengenauigkeit, etabliert | Offline-Schadensanalyse |
| YOLACT | Einstufiges CNN | 29-34 | 30-56 | Echtzeitgeschwindigkeit | UAV-Bordverarbeitung |
| SOLOv2 | Detektionsfreies CNN | 37,8 | ~10 | Keine Anchor/Proposal-Abhängigkeit | Langgestreckte Schadensinstanzen |
| Mask2Former | Transformer | 50,1 | ~15 | Modernste Genauigkeit, einheitliches Framework | Dichte Schadensfelder |
Die Wahl zwischen Instanz- und semantischer Segmentierung für die Risserkennung hängt von den spezifischen Analyseanforderungen des Inspektionsprogramms ab, und die beiden Ansätze liefern grundlegend unterschiedliche Ergebnisse.
Semantische Segmentierung für Risse behandelt das gesamte Rissnetzwerk als eine einzige Vordergrundklasse. Das Modell lernt, jedes Pixel als „Riss" oder „Hintergrund" zu klassifizieren. Die Ausgabe ist eine Binärmaske, bei der alle Risspixel weiß und alle Nicht-Riss-Pixel schwarz sind. Dieser Ansatz hat mehrere gut dokumentierte Stärken: Er behandelt verbundene Rissnetzwerke natürlich (ein verzweigter Riss ist eine einzige verbundene Komponente), er erfordert einfachere Annotationen (Pinselstriche auf Pixelebene statt Polygone pro Instanz), und die Trainingskomplexität ist geringer mit weniger Ausgabekanälen. Semantische Segmentierungsmodelle für Risse auf dem neuesten Stand – wie DeepCrack (93% F1 auf CrackTree260), CrackU-Net (97,5% F1 auf CRACK500) und SwinUNETR (90,5% F1 auf multitemporalen Rissdatensätzen) – erzielen eine hervorragende pixelgenaue Genauigkeit.
Die semantische Segmentierung hat jedoch eine entscheidende Einschränkung für die Infrastrukturzustandsbewertung: Sie kann einzelne Risse nicht zählen. Wenn die semantische Segmentierung 5.000 Riss-Pixel meldet, gibt sie keine Auskunft darüber, ob diese Pixel zu einem einzigen 5.000-Pixel-Riss oder zu fünfzig 100-Pixel-Rissen gehören. Diese Unterscheidung ist entscheidend für die Berechnung des Fahrbahnzustandsindex (PCI), bei dem die Rissdichte (Anzahl der Risse pro Flächeneinheit) und der individuelle Riss-Schweregrad gemäß den Inspektionsprotokollen ASTM D5340 und ICAO Annex 14 separate Bewertungsparameter sind.
Instanzsegmentierung für Risse weist jeder einzelnen Rissinstanz eine eindeutige ID zu. Für ein Fahrbahnbild mit mehreren Rissen besteht die Ausgabe aus N Binärmasken, die jeweils einem Riss entsprechen, mit einer zugehörigen Klassenbezeichnung und Instanz-ID. Die von Zhao et al. (2024) vorgeschlagene, mit CrackMover angereicherte Instanzsegmentierungsmethode erreicht 33,3 AP bei der Risserkennung und übertrifft Standard-Mask-R-CNN um 8,6% durch spezialisierte Datenerweiterung für langgestreckte Rissformen.
Die Instanzsegmentierung für Risse stellt besondere Herausforderungen dar. Risse sind stark langgestreckte, dünne und oft verzweigte Objekte – keine kompakten Klumpen wie Schlaglöcher. Standard-Instanzsegmentierungsarchitekturen, die für COCO-Objekte (kompakte, klar definierte Formen) entwickelt wurden, können einen einzelnen verzweigten Riss in mehrere Instanzen aufteilen oder es versäumen, benachbarte parallele Risse zu trennen. Spezialisierte Techniken umfassen die Modifikation der RoIAlign-Auflösung für die Extraktion langgestreckter Merkmale, die Verwendung von Atrous-Faltungen im Maskenkopf für die mehrskalige Risserfassung und die Anwendung von Cascade Refinement (Cascade Mask R-CNN), das qualitativ minderwertige Vorschläge iterativ verbessert.
Die praktische Entscheidung hängt von der zu beantwortenden Instandhaltungsfrage ab. Für die Quantifizierung der gesamten Rissfläche (z. B. Messung des prozentualen Rissanteils pro Startbahnabschnitt) kann die semantische Segmentierung ausreichen und ist recheneffizienter. Für die Risszählung, die individuelle Rissbreitenverfolgung und die Schweregradbewertung pro Riss (z. B. ASTM D5340 Riss-Schweregrad, bei dem der Schweregrad von der individuellen Rissbreite abhängt) ist die Instanzsegmentierung erforderlich. Ein wachsender Trend in der Infrastrukturinspektion ist die panoptische Segmentierung – die Kombination von semantischer und Instanzsegmentierung, um nicht zählbare Regionen (z. B. Fahrbahnoberfläche, Gras, Markierungen) semantisch zu klassifizieren, während zählbare Schäden (Risse, Abplatzungen, Schlaglöcher) nach Instanz segmentiert werden.
Abplatzungen und Schlaglöcher unterscheiden sich grundlegend von Rissen hinsichtlich ihrer Geometrie: Sie sind diskrete, begrenzte, kompakte Schäden mit klarer räumlicher Ausdehnung, klar definierten Rändern und messbarem Volumen. Dies macht sie von Natur aus für die Instanzsegmentierung geeignet, und Architekturen, die auf COCO-Instanzen (die meist kompakte Objekte sind) gut abschneiden, lassen sich effektiv auf die Erkennung von Abplatzungen und Schlaglöchern übertragen.
Ein Schlagloch ist eine schüsselförmige Vertiefung in der Fahrbahnoberfläche, die typischerweise entsteht, wenn Oberflächenrisse das Eindringen von Wasser ermöglichen, was zu einer Verschlechterung der Tragschicht und Materialverlust führt. Schlaglöcher sind per Definition diskrete Instanzen – jedes Schlagloch ist ein separater physikalischer Hohlraum. Die Instanzsegmentierung erfasst den genauen Umfang jedes Schlaglochs, was für eine genaue Reparaturvolumenschätzung entscheidend ist. Ein Begrenzungsrahmen-Ansatz (Objekterkennung) könnte je nach Unregelmäßigkeit der Schlaglochform 30-50% Nicht-Schadensfläche einschließen, während die Instanzsegmentierung die tatsächliche Schadensfläche liefert.
Eine Abplatzung ist ein ausgesplitterter oder gebrochener Bereich an einer Fugen- oder Risskante, typischerweise in Betonfahrbahnen. Abplatzungen sind ebenfalls diskrete Instanzen, die durch die Fugen- oder Risslinie begrenzt werden. Die Instanzsegmentierung für Abplatzungen muss deren geometrische Randbedingungen berücksichtigen: Abplatzungen entstehen immer an einer strukturellen Diskontinuität (Fuge, Risskante), haben eine durch die Fuge begrenzte Seite und erstrecken sich in die Plattenfläche. Spezialisierte Instanzsegmentierungsmodelle für Abplatzungen integrieren Aufmerksamkeitsmechanismen, die auf Fugenbereiche fokussieren.
Die Forschung belegt die Wirksamkeit dieser Ansätze. Mit Mask R-CNN zur Schlaglocherkennung auf Straßendatensätzen berichteten Nhat-Duc et al. (2020) AP@0,50 von 55,2 und AP@0,75 von 42,8. YOLACT, angewendet auf die Schlaglocherkennung, erreichte eine Inferenzgeschwindigkeit von 33 FPS mit AP@0,50 von 48,7, was die Echtzeit-Schlaglochzählung von fahrzeugmontierten Kameras ermöglicht. Für Betonabplatzungen erreichte Cascade Mask R-CNN mit einem ResNeXt-101-Backbone 44,6 AP auf einem Brückenfahrbahn-Abplatzungsdatensatz mit 2.400 annotierten Bildern.
Die Norm ASTM D5340 für den Flughafen-Fahrbahnzustandsindex definiert spezifische Messanforderungen für Abplatzungen und Schlaglöcher:
Die Instanzsegmentierung unterstützt all diese Messungen direkt. Die pixelgenaue Maske liefert genaue Längen- und Breitenabmessungen (in Kombination mit bekannter räumlicher Auflösung, z. B. 1mm/Pixel aus kalibrierter UAV-Bildgebung). Die eindeutige Instanz-ID ermöglicht die Zählung pro Schaden für Dichteberechnungen. In Kombination mit stereoskopischen oder Structure-from-Motion (SfM)-Tiefendaten können Instanzmasken auf 3D zur Volumenmessung erweitert werden.
Der Hauptvorteil gegenüber der semantischen Segmentierung für Abplatzungen und Schlaglöcher ist die Schadenszählung. Betrachten Sie einen Startbahnabschnitt mit 15 einzelnen Abplatzungen. Die semantische Segmentierung meldet „Abplatzungsfläche: 0,85 m²" – ohne Angabe der Schadensanzahl. Die Instanzsegmentierung meldet „15 Abplatzungen erkannt: Abplatzung-001 (0,12 m²), Abplatzung-002 (0,04 m²), …, Abplatzung-015 (0,03 m²)" – und informiert den Ingenieur darüber, dass 15 individuelle Reparaturbehandlungen erforderlich sind und welche am schwerwiegendsten sind.
Sobald jede Schadensinstanz durch ihre eindeutige Maske isoliert ist, kann eine umfassende Reihe von Messungen pro Instanz für die Zustandsbewertung und Instandhaltungsplanung extrahiert werden.
Flächenmessung ist die grundlegendste Metrik pro Schaden. Die Pixelanzahl innerhalb jeder Instanzmaske wird mithilfe der räumlichen Kalibrierung in die physikalische Fläche umgerechnet. Für UAV-erfasste Bilder mit bekannter Bodenabtastdistanz (GSD) – typischerweise 0,5-2,0 mm/Pixel für Startbahninspektionen – ergibt die Maskenpixelanzahl multipliziert mit (GSD)² die physikalische Fläche in mm² oder m². Für Risse ermöglicht die Flächenmessung die Berechnung der Rissbreite: mittlere Rissbreite = Maskenfläche / Skelettlänge. Für Schlaglöcher und Abplatzungen speist die Fläche direkt die Schwellenwerte für die Schweregradklassifizierung.
Positionsmessung weist jeder Schadensinstanz geografische Koordinaten zu. Der Schwerpunkt der Instanzmaske (mittlerer x,y-Wert der Maskenpixel) oder der untere Mittelpunkt (für orientierungsbewusste Positionierung) wird mithilfe der Georeferenzierungsparameter der Kamera (aus GPS/IMU-Metadaten oder aus photogrammetrischen Passpunkten) von Bildkoordinaten in reale Weltkoordinaten umgerechnet. Positionsdaten ermöglichen: räumliche Clusteranalyse zur Identifizierung von Zonen mit hoher Schadensdichte, Korrelation mit strukturellen Merkmalen (Fugen, Plattenecken, Entwässerungswegen) und Verknüpfung mit GIS-Datenbanken von Pavement-Management-Systemen (PMS) zur Erstellung von Instandhaltungsaufträgen.
Morphologiemessung charakterisiert die geometrischen Eigenschaften jeder Schadensinstanz über die reine Fläche hinaus. Wichtige morphologische Deskriptoren umfassen:
Diese Messungen werden effizient mit OpenCV-Konturanalysefunktionen (cv2.findContours, cv2.moments, cv2.convexHull) oder scikit-image-Morphologieoperationen (skimage.measure.regionprops, skimage.morphology.skeletonize) berechnet. Für einen typischen Startbahninspektionsdatensatz mit 10.000 Bildern und 50.000+ Schadensinstanzen dauert die Extraktion von Merkmalen pro Schaden auf einer Standard-Workstation nur Minuten.
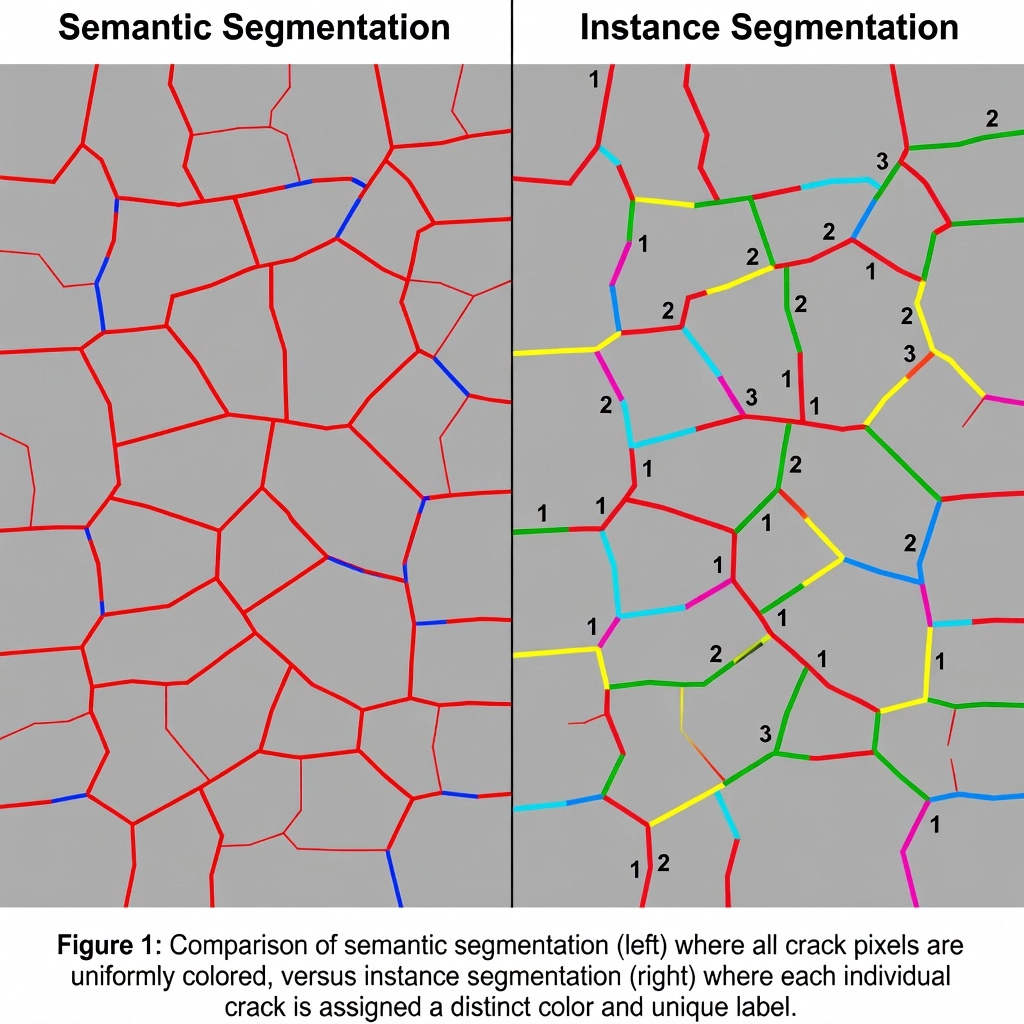
Die Instanzsegmentierung ermöglicht eine automatisierte Schadenszählung, die mit der reinen semantischen Segmentierung schlichtweg unmöglich ist. Die Schadensanzahl – die Anzahl der einzelnen diskreten Schäden pro Flächeneinheit – ist eine grundlegende Eingangsgröße für Infrastrukturzustandsindizes wie PCI (ASTM D5340), den Structural Condition Index (SCI) und den Runway Condition Index (RCI).
Zählung pro Schaden erfolgt wie folgt: Das Instanzsegmentierungsmodell gibt Instanzmasken mit eindeutigen IDs (typischerweise ganze Zahlen beginnend bei 1) aus. Die Anzahl der eindeutigen Instanz-IDs in jedem Bild oder Untersuchungsbereich ergibt direkt die Schadensanzahl. Für eine 3.000 Meter lange Startbahn, die mit 1 mm GSD untersucht wird, was etwa 3.000 Bildkacheln von 2000×2000 Pixeln entspricht, könnte ein Instanzsegmentierungsmodell 200-500 einzelne Risse, 50-100 Abplatzungen und 10-20 Schlaglöcher erkennen – jeweils einzeln gezählt und protokolliert.
Zählschichtung gruppiert Schäden nach Art und Schweregrad. Die eindeutigen Instanz-IDs werden zunächst nach vorhergesagter Klasse gruppiert (Riss, Abplatzung, Schlagloch, Fugenstörung, Verwitterung). Innerhalb jeder Klasse können Instanzen basierend auf Flächenschwellenwerten oder morphologischen Merkmalen weiter nach Schweregrad geschichtet werden:
Räumliche Verteilungskartierung aggregiert die Zählungen pro Schaden in räumliche Zellen. Die Startbahn wird gemäß ICAO/ASTM-Spezifikationen in Probeeinheiten unterteilt: typischerweise 20 aufeinanderfolgende Platten für Betonfahrbahnen (jede Platte ~5m × 5m = 25 m²) oder 25m × 25m = 625 m² rechteckige Einheiten für Asphaltfahrbahnen. Der Schwerpunkt jeder Schadensinstanz wird der sie enthaltenden Probeeinheit zugeordnet. Die Schadensdichte pro Einheit wird berechnet als: Anzahl der Schäden in der Einheit / Einheitsfläche. Diese Dichte fließt direkt in die PCI-Berechnungstabellen ein.
Verteilungskarten zeigen Schadensclusterungsmuster auf. Eine Startbahn mit 500 einzelnen Rissen, verteilt auf 120 Probeeinheiten, könnte zeigen, dass 85% der Einheiten 0-5 Risse und 5% der Einheiten 20+ Risse aufweisen. Die geclusterten Einheiten weisen auf Bereiche hin, die gezielte Instandhaltung erfordern – typischerweise verbunden mit zugrunde liegenden strukturellen Problemen (Untergrundversagen, schlechte Entwässerung, Baufugen) und nicht mit gleichmäßigem Oberflächenverschleiß.
Die räumliche Punktmusteranalyse (Ripley’s K-Funktion, Kerndichteschätzung) kann die Clusterungsintensität weiter quantifizieren und statistisch signifikante Schadens-Hotspots identifizieren. In Kombination mit GIS-Überlagerungsanalysen können Schadenscluster mit Baufugenstandorten, Fahrbahn-Alterszonen, Entwässerungsmustern und stehenden Wasserflächen, früheren Instandhaltungs- und Reparaturstellen sowie der Verkehrsverteilung (Radspur-Konzentrationszonen) korreliert werden.
Die einzigartige Fähigkeit der Instanzsegmentierung, einzelnen Schäden dauerhafte IDs zuzuweisen, ermöglicht die zeitliche Verfolgung – die Quantifizierung, wie sich jeder Schaden zwischen Inspektionen entwickelt. Dies ist die Grundlage für vorausschauende Instandhaltung und zustandsbasiertes Anlagenmanagement.
Die zeitliche Verfolgungspipeline umfasst vier Phasen. Erstens wird die Startbahn in regelmäßigen Abständen neu vermessen (vierteljährlich, halbjährlich oder jährlich, gemäß ICAO-Empfehlung für Flugplatz-Fahrbahnzustandserhebungen). Zweitens wird die Instanzsegmentierung unabhängig auf jeden Untersuchungsdatensatz angewendet, wodurch Schadensmasken mit Instanz-IDs für jeden Zeitpunkt erzeugt werden. Drittens gleicht ein Instanzzuordnungsalgorithmus Schadensinstanzen zwischen aufeinanderfolgenden Untersuchungen anhand von räumlicher Nähe (Abstand zwischen Schwerpunkten < Schwellenwert), Maskenüberlappung (IoU ≥ 0,3-0,5) und morphologischer Ähnlichkeit (Flächenänderung <50%, Orientierungsänderung <15°) ab. Viertens erhalten zugeordnete Instanzen eine dauerhafte globale ID, die sie über alle Untersuchungsepochen hinweg verknüpft und so eine Zeitreihe für jeden Schaden erstellt.
Zuordnungsalgorithmen müssen mehrere Herausforderungen bewältigen. Schäden können zwischen Untersuchungen verschmelzen oder sich teilen (ein Riss, der sich gabelt; eine Abplatzung, die sich ausdehnt und mit einer benachbarten Abplatzung verbindet). Schäden können auftauchen oder verschwinden (neue Rissbildung, reparierte Schäden). Der Ungarische Algorithmus (Munkres-Zuordnung) löst das lineare Zuordnungsproblem für die Eins-zu-Eins-Zuordnung zwischen Instanzen in aufeinanderfolgenden Untersuchungen mit einem Rechenaufwand von O(n³). Für komplexe Fälle mit Teilungen und Verschmelzungen bietet die graphbasierte Verfolgung (Minimalkostenfluss in einem räumlich-zeitlichen Graph) eine robustere Zuordnung bei höherem Rechenaufwand.
Änderungsmetriken pro Schaden, die aus der abgeglichenen Zeitreihe berechnet werden, umfassen:
Genauigkeit der zeitlichen Verfolgung hängt von der Präzision der Untersuchungsregistrierung ab. Wiederholungsuntersuchungen müssen mit subzentimetergenauer Genauigkeit im selben Koordinatensystem georeferenziert werden. Dies wird durch permanent entlang der Startbahn installierte Passpunkte (GCPs), die mit RTK-GPS (±2cm Genauigkeit) vermessen werden, oder durch bildbasierte Koregistrierung mittels Merkmalsabgleich (SIFT/SuperPoint-Merkmale) zwischen Untersuchungsdatensätzen zur Berechnung von Homografietransformationen erreicht.
Vorausschauende Instandhaltung verwendet Zeitreihen pro Schaden, um vorherzusagen, wann ein Schaden einen kritischen Schweregrad erreicht. Ein lineares Regressionsmodell, das an die Breiten- oder Flächenzeitreihe jedes Schadens angepasst ist, prognostiziert das Datum, an dem der Schaden den Schweregradschwellenwert überschreitet (z. B. Rissbreite >3mm für hohen Schweregrad gemäß ASTM D5340). Dies erzeugt eine priorisierte Instandhaltungswarteschlange: Schäden, die voraussichtlich innerhalb des nächsten Inspektionszyklus einen kritischen Schweregrad erreichen, werden für die sofortige Reparatur markiert.
Das Training von Instanzsegmentierungsmodellen für Infrastrukturschäden stellt besondere Herausforderungen im Vergleich zu natürlichen Objektdatensätzen dar, hauptsächlich aufgrund der Annotationsanforderungen und Datencharakteristiken.
Annotationsformat: Die Instanzsegmentierung erfordert Polygon-Annotationen auf Instanzebene – jeder einzelne Schaden muss durch ein geschlossenes Polygon von Eckpunkten umrissen werden. Dies ist erheblich arbeitsintensiver als semantische Segmentierungsannotationen (die Pinselstriche oder Flood-Fill-Werkzeuge verwenden) oder Objekterkennungsannotationen (die achsenausgerichtete Rechtecke verwenden). Eine typische Rissannotation erfordert 20-100 Polygon-Eckpunkte, um den Rissverlauf genau nachzuzeichnen, abhängig von der Risskomplexität und -länge. Eine Abplatzungsannotation erfordert typischerweise 8-30 Eckpunkte. Branchenübliche Annotationswerkzeuge (CVAT, Labelbox, Supervisely, Scale AI) unterstützen Polygonannotationen mit halbautomatischen Werkzeugen (z. B. interaktive Segmentierung mit SAM – Segment Anything Model – zur Reduzierung der manuellen Eckpunktpositionszeit).
COCO-JSON-Format ist das standardmäßige Instanzsegmentierungs-Annotationsschema. Jeder Annotationsdatensatz enthält id (eindeutiger Annotationsbezeichner), image_id (Referenz zum Quellbild), category_id (Klassenbezeichnung wie 1=Riss, 2=Abplatzung, 3=Schlagloch), segmentation (Polygon dargestellt als abgeflachte Liste von x,y-Koordinaten), area (Polygonfläche in Pixeln), bbox (Begrenzungsrahmen als [x, y, Breite, Höhe]) und iscrowd (0 für einzelne Schadensinstanzen).
Datensatzgrößenanforderungen: Instanzsegmentierungsmodelle benötigen typischerweise 500-2.000+ annotierte Bilder pro Schadenskategorie für eine akzeptable Leistung (AP >35). Kleine Datensätze (<200 Bilder) riskieren Überanpassung und schlechte Generalisierung auf neue Fahrbahnarten, Beleuchtungsbedingungen und Schadensvarianten. Transferlernen von großen vortrainierten Backbones (ImageNet-1K, COCO) reduziert die erforderliche Datensatzgröße erheblich – ein Mask R-CNN, das mit COCO-vortrainierten Gewichten initialisiert und auf 500 Rissbildern feinabgestimmt wird, erreicht eine vergleichbare Leistung wie ein von Grund auf mit 2.000 Bildern trainierbares Modell.
Datenerweiterung ist entscheidend für Infrastrukturschadensdatensätze, die typischerweise kleiner sind als allgemeine Computer-Vision-Datensätze. Wirksame Erweiterungen umfassen zufällige Rotation (±180°), horizontale/vertikale Spiegelung, zufällige Skalierung (0,5×-2,0×), Helligkeits-/Kontrastanpassungen (±20%), zufälliges Zuschneiden, elastische Transformationen (Gaußsches Verschiebungsfeld) und Mosaik-Erweiterung (Kombination von vier Bildern zu einem). CrackMover, eine spezialisierte Erweiterung für die Riss-Instanzsegmentierung, resampelt Rissinstanzen aus einem Bild und fügt sie mit realistischer Überblendung in neue Hintergrundbilder ein, wodurch sowohl die Anzahl der Rissinstanzen als auch die Hintergrundvielfalt künstlich erhöht wird.
Synthetische Datengenerierung adressiert das grundlegende Problem der Annotationsknappheit in der Infrastrukturinspektion. Das UAV-basierte Flughafen-Fahrbahninspektionsframework (Alonso et al., 2024) zeigt, dass das Training mit gemischten realen und synthetischen Datensätzen den F1-Score der Risssegmentierung um 8-12% gegenüber dem Training nur mit realen Daten verbessert. Hyperrealistische virtuelle Umgebungen in Unreal Engine oder Unity können unbegrenzt annotierte Bilder mit perfekten Grundwahrheitsmasken, variierten Beleuchtungsbedingungen und verschiedenen Schadensgeometrien erzeugen. Domain Randomization – zufällige Variation von Texturen, Farben und Beleuchtung in synthetischen Szenen – verbessert die Übertragung von der Simulation in die Realität, indem sie das Modell zwingt, Geometrie statt Texturmuster zu lernen.
Instanzsegmentierungsmodelle werden mit Metriken bewertet, die sowohl aus der Objekterkennung als auch aus der semantischen Segmentierung übernommen wurden, wobei das COCO-Bewertungsprotokoll der Standard-Benchmark ist.
Average Precision (AP) ist die primäre Metrik. AP wird bei mehreren Intersection-over-Union (IoU)-Schwellenwerten zwischen vorhergesagten Masken und Grundwahrheitsmasken berechnet. Für jeden IoU-Schwellenwert t (von 0,50 bis 0,95 in 0,05-Schritten) werden Precision-Recall-Kurven für jede Klasse berechnet, und AP ist die Fläche unter der Precision-Recall-Kurve. Die primäre COCO-Metrik AP (oder mAP) mittelt über alle IoU-Schwellenwerte und Klassen.
Die wichtigsten AP-Varianten, die bei der Schadenserkennung verwendet werden, umfassen AP@IoU=0,50 (großzügiger Schwellenwert, der als Erkennungsschwelle gilt; eine vorhergesagte Maske, die zu 50% oder mehr mit der Grundwahrheit überlappt, gilt als korrekt), AP@IoU=0,75 (strenger Schwellenwert, der qualitativ hochwertige Masken erfordert, wichtig für Anwendungen, die eine präzise Schadensgrenzenabgrenzung erfordern, wie z. B. Rissbreitenmessung) und AP@klein, AP@mittel, AP@groß (nach Größe definierte Metriken durch Grundwahrheitsfläche: klein <32² Pixel, mittel 32²-96² Pixel, groß >96² Pixel).
Average Recall (AR) misst den Anteil der Grundwahrheitsinstanzen, die bei jedem IoU-Schwellenwert eine vorhergesagte Übereinstimmung haben. AR wird typischerweise als AR@max=100 (maximal 100 Erkennungen pro Bild) angegeben. Ein hoher Recall ist entscheidend für sicherheitskritische Infrastrukturinspektionen, bei denen übersehene Schäden zu unentdeckten Verschlechterungen führen könnten.
Masken-IoU ist das zentrale Abgleichskriterium. Für eine vorhergesagte Maske P und eine Grundwahrheitsmaske G gilt IoU = |P ∩ G| / |P ∪ G|. Eine Vorhersage gilt als True Positive (TP), wenn IoU ≥ Schwellenwert UND die vorhergesagte Klasse mit der Grundwahrheitsklasse übereinstimmt. False Positives (FP) treten auf, wenn Vorhersagen einen IoU < Schwellenwert mit jeder Grundwahrheitsmaske derselben Klasse haben oder die falsche Klasse vorhersagen. False Negatives (FN) sind Grundwahrheitsmasken, die mit keiner Vorhersage übereinstimmen.
Der COCO-Abgleichsalgorithmus behandelt doppelte Erkennungen: Wenn mehrere Vorhersagen mit einer einzigen Grundwahrheit übereinstimmen, wird nur die Vorhersage mit der höchsten Konfidenz als TP gezählt; der Rest gilt als FP. Dies belohnt Präzision und bestraft Übersegmentierung – wichtig für die Schadenserkennung, bei der mehrere sich überlappende Vorhersagen für denselben Riss auf Modellinstabilität hindeuten würden.
Die infrastrukturspezifische Bewertung fügt oft klassenweisen AP hinzu, aufgeschlüsselt nach Schadensart. Ein Risserkennungsmodell könnte AP_Riss=32,1, AP_Abplatzung=44,6, AP_Schlagloch=51,3 melden. Der deutlich niedrigere AP für Risse spiegelt die Schwierigkeit der Instanzsegmentierung für dünne, langgestreckte Objekte wider (die Masken-IoU ist bei dünnen Strukturen sehr empfindlich gegenüber kleinen Ausrichtungsfehlern).
F1-Score bei einem bestimmten IoU-Schwellenwert (typischerweise 0,50) wird in der Infrastrukturliteratur ebenfalls häufig berichtet: F1 = 2 × (Präzision × Recall) / (Präzision + Recall). F1 liefert ein einzelnes ausgewogenes Maß für den Präzisions-Recall-Kompromiss.
Die Instanzsegmentierung verwandelt die Infrastrukturinspektion von einem subjektiven, arbeitsintensiven Prozess in einen objektiven, quantitativen und skalierbaren digitalen Arbeitsablauf. Die Technologie wird in mehreren Infrastrukturbereichen eingesetzt, mit dokumentierten Verbesserungen der Inspektionsgenauigkeit, -konsistenz und -durchsatzleistung.
Flughafen-Startbahninspektion stellt die anspruchsvollste Anwendung dar. Qualifizierte Startbahninspektionen gemäß ICAO Annex 14 erfordern Fahrbahnzustandserhebungen alle 1-3 Jahre unter Verwendung standardisierter Verfahren (ASTM D5340, ASTM D6433, ICAO Aerodrome Design Manual Part 3). Die Instanzsegmentierung unterstützt diese Standards direkt, indem sie die Schadenszählung und -messung automatisiert. Das UAV-basierte automatisierte Startbahninspektionsframework (Krestenitis et al., 2026) demonstriert die durchgängige Bereitstellung: UAV-Vermessung → Bildaufnahme → Deep-Learning-Inferenz (EfficientNet + FPN semantische Segmentierung mit überlagerter Instanznachbearbeitung) → GIS-basierte Aggregation → PCI-Berechnung. Das System erreicht 95%+ Erkennungsgenauigkeit für Schäden >3mm Breite über die gesamte Startbahnlänge, mit einer Vermessungsdauer von 45 Minuten gegenüber 4-6 Stunden für die traditionelle manuelle Inspektion, die eine Startbahnsperrung erfordert.
Autobahn- und Straßenfahrbahninspektion verwendet fahrzeugmontierte Kamerasysteme, die bei Autobahngeschwindigkeiten (60-100 km/h) arbeiten. Instanzsegmentierungsmodelle (YOLACT, YOLOv8-seg) verarbeiten Videostreams mit 15-30 FPS und erkennen Risse, Schlaglöcher und Flickstellen pro Fahrspurmeile. Die automatisierte Fahrbahnzustandserhebung des Nevada DOT verwendet ein YOLOv8-basiertes Instanzsegmentierungssystem, das einen F1-Wert von 88% für die Risserkennung und 93% F1 für die Schlaglocherkennung auf über 5.000 Fahrspurmeilen erreicht, mit einer Messgenauigkeit pro Schaden innerhalb von 5% der manuellen Referenzmessungen.
Brückenfahrbahninspektion wendet Instanzsegmentierung auf Betonabplatzungen, Delaminationen und Fugenversagen an. Brückenfahrbahnen stellen besondere Herausforderungen dar: variable Beleuchtung unter der Brückenuntersicht, komplexe Hintergrundtexturen (Dehnungsfugen, Abläufe, Verkehrsmarkierungen) und die Notwendigkeit einer submillimetergenauen Rissauflösung für die Breitenmessung. Cascade Mask R-CNN, feinabgestimmt auf einem Brückenfahrbahn-Datensatz, erreicht 82% mAP@50 für die Abplatzungserkennung und ermöglicht die automatisierte Berechnung der SNBI-Zustandsbewertung (Specification for National Bridge Inspection) für Betonbrückenfahrbahnen.
Eisenbahninfrastrukturinspektion verwendet Instanzsegmentierung für Schienenoberflächenschäden (Head Checks, Squats, Shelling) und Gleisbettanomalien. Schienenmontierte Kamerasysteme erfassen hochauflösende Bilder bei 100+ km/h; auf eingebetteten GPUs laufende YOLACT-Modelle erkennen und klassifizieren einzelne Schienenschäden in Echtzeit. Die Deutsche Bahn berichtete eine Erkennungsrate von 96% für Oberflächenrisse >1mm mittels einer auf 30 Inspektionszügen eingesetzten Instanzsegmentierungspipeline, mit einer positionsgenauen Lokalisierung pro Schaden von ±5mm mittels Encoderrad-Odometrie.
Tunnelauskleidungsinspektion setzt Instanzsegmentierung auf Bildern ein, die von Multikamera-Arrays auf Inspektionsfahrzeugen bei 30-50 km/h aufgenommen werden. Betontunnelauskleidungen entwickeln Risse, Abplatzungen und Feuchtigkeitsflecken, die eine Analyse auf Instanzebene erfordern. Die Hauptherausforderung besteht in der Unterscheidung zwischen strukturellen Rissen (reparaturbedürftig) und nicht-strukturellen Oberflächenrissen (Schwindung, thermisch). Die Instanzsegmentierung in Kombination mit der Rissbreitenmessung (aus der Maskenanalyse pro Instanz) liefert die quantitativen Daten, die für diese Klassifizierung erforderlich sind. Das Tunnelinspektionssystem der Österreichischen Bundesbahnen (ÖBB) verwendet Mask R-CNN mit einem Aruco-Markierungs-basierten Kalibrierungsgitter, um eine Rissbreitenmessgenauigkeit von ±0,1mm bei einer Auflösung von 0,5mm/Pixel zu erreichen.
Vorteile gegenüber der traditionellen Inspektion sind für alle Infrastrukturtypen gut dokumentiert. Eine vergleichende Studie über 12 Verkehrsbehörden hinweg ergab, dass die automatisierte Instanzsegmentierungsinspektion die Inspektionszeit um 60-80% reduzierte, die Inter-Rater-Variabilität beseitigte (Kappa-Koeffizient verbesserte sich von 0,45-0,55 bei manueller Inspektion auf 0,88-0,94 bei automatisierter) und die Schadenserkennungsempfindlichkeit um 25-40% erhöhte (insbesondere bei Schäden mit geringem Schweregrad, die von menschlichen Prüfern aufgrund von Ermüdung häufig übersehen werden). Die Messfähigkeit pro Schaden ermöglicht einen Wandel von der zustandsindexbasierten Instandhaltung (Behandlung von Bereichen oberhalb eines Schweregradschwellenwerts) hin zur einzelfallbasierten Schadensinstandhaltung (Priorisierung von Reparaturen nach der Kritikalität einzelner Schäden), wodurch die gesamten Instandhaltungskosten durch gezielte Reparatur anstelle von flächendeckender Behandlung um schätzungsweise 15-30% gesenkt werden.

TarmacView verwendet modernste Instanzsegmentierungsmodelle, um jeden einzelnen Schaden auf Flugplatzbefestigungen, Brücken und Betoninfrastrukturen zu erkennen, zu zählen und zu verfolgen. Vereinbaren Sie eine Demo, um zu erfahren, wie die Analyse pro Schaden Ihre Instandhaltungsplanung verändern kann.
Risssegmentierung ist die Computer-Vision-Aufgabe, jedes Pixel eines Bildes entweder als Riss oder als Nicht-Riss zu klassifizieren und eine binäre Maske zu erz...
Die KI-basierte Risserkennung nutzt Computer Vision – Convolutional Neural Networks, Vision Transformer und semantische Segmentierungsmodelle – um Risse in Fahr...
Änderungserkennung vergleicht coregistrierte Bilder oder Punktwolken derselben Struktur, die zu unterschiedlichen Zeitpunkten aufgenommen wurden, um neue, sich ...