FAISS
FAISS (Facebook AI Similarity Search) ist eine Open-Source-Bibliothek für effiziente Ähnlichkeitssuche und Clusterbildung dichter Vektoren, die von TarmacView v...
28 Min. Lesezeit
Vector Search
Similarity Search
+6
k-Nächste-Nachbarn (kNN) klassifiziert einen Abfragepunkt per Mehrheitsentscheidung unter seinen k ähnlichsten Referenzpunkten in einem Einbettungsraum. TarmacView verwendet kNN (k=10) mit Kosinus-Ähnlichkeit über FAISS-indizierte Referenz-Einbettungen, um Oberflächentyp und Qualitätsklasse vorherzusagen. Behandelt Algorithmus, Distanzmetriken, k-Auswahl, gewichtete Abstimmung und Vorteile für überprüfbare, interpretierbare Klassifikation.
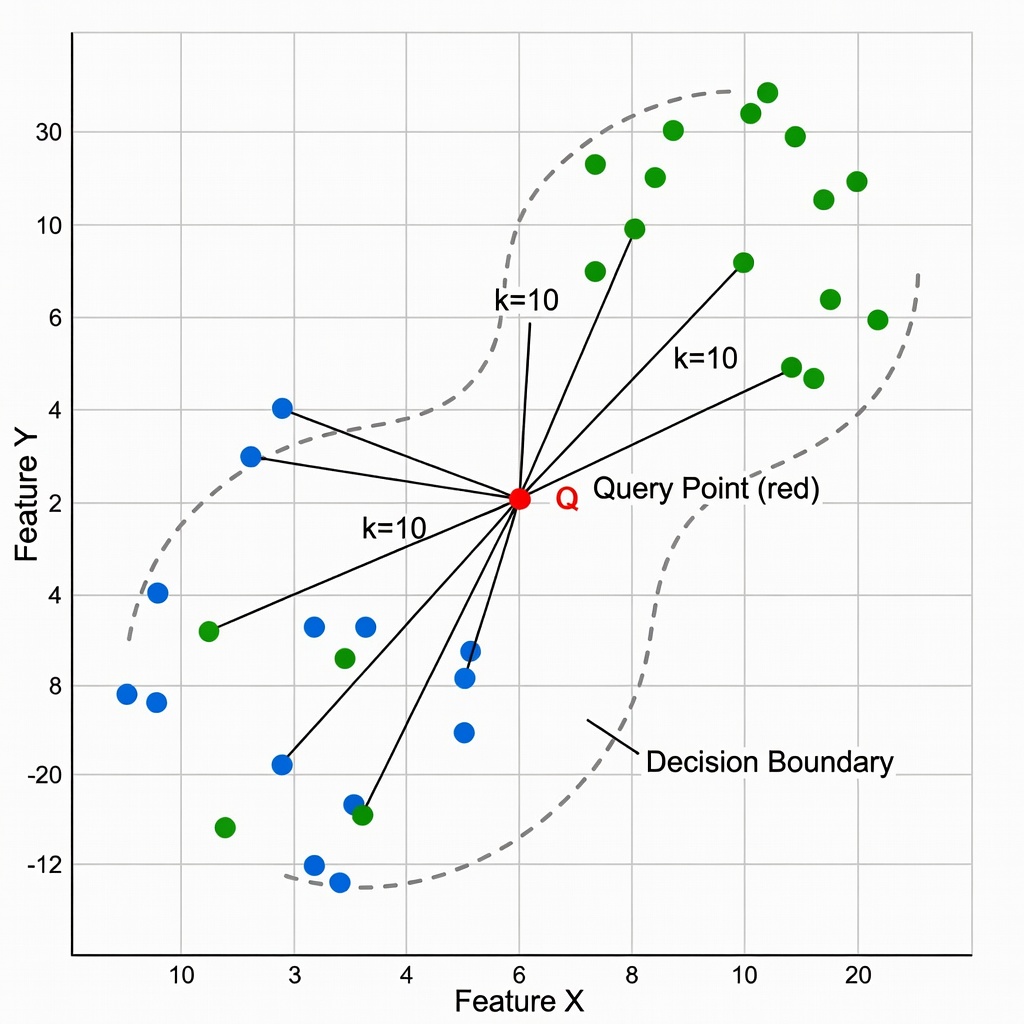
Der k-Nächste-Nachbarn-Algorithmus (kNN) ist eine nichtparametrische, instanzbasierte überwachte Lernmethode, die erstmals 1951 von Evelyn Fix und Joseph Hodges im Rahmen von Forschungsarbeiten für die United States Air Force School of Aviation Medicine formal beschrieben wurde. Ihr technischer Bericht „Discriminatory Analysis — Nonparametric Discrimination: Consistency Properties" legte die grundlegende Theorie für nichtparametrische Dichteschätzung und Klassifikation fest. 1967 veröffentlichten Thomas Cover und Peter Hart die wegweisende Arbeit „Nearest Neighbor Pattern Classification" in den IEEE Transactions on Information Theory, die bewies, dass die asymptotische Fehlerrate des 1-Nächste-Nachbarn-Klassifikators nach oben durch das Zweifache der optimalen Bayes-Fehlerrate begrenzt ist. Diese theoretische Garantie – dass ein einfacher, auf gespeicherten Trainingsdaten operierender Algorithmus Fehlerraten innerhalb eines Faktors zwei des theoretisch optimalen Klassifikators erreichen kann – etablierte kNN als fundamentale Methode der statistischen Mustererkennung.
Der Algorithmus basiert auf einem einfachen geometrischen Prinzip: Punkte, die im Merkmals- oder Einbettungsraum nahe beieinander liegen, gehören wahrscheinlich zur selben Klasse. Gegeben einen Abfragepunkt q in einem d-dimensionalen Einbettungsraum berechnet der Algorithmus die Distanz von q zu jedem Referenzpunkt in der Trainingsdatenbank gemäß einer gewählten Distanzmetrik, wählt die k Referenzpunkte mit den geringsten Distanzen aus und weist q die Klassenbezeichnung zu, die unter diesen k Nachbarn am häufigsten vorkommt. Bei Regressionsaufgaben gibt der Algorithmus den Mittelwert oder gewichteten Mittelwert der Zielwerte der k Nachbarn zurück, anstatt eine Mehrheitsentscheidung zu treffen.
kNN wird als träger Lerner (Lazy Learner) klassifiziert, da es während einer Trainingsphase keine explizite Generalisierung oder Abstraktion durchführt. Anstatt eine parametrische Entscheidungsgrenze zu lernen (wie logistische Regression, Support-Vektor-Maschinen oder neuronale Netze es tun), merkt sich kNN den gesamten Trainingsdatensatz und verschiebt alle Berechnungen auf die Inferenzzeit. Die Trainingsphase erfolgt augenblicklich – sie speichert die Referenzdaten lediglich im Speicher oder in einer Indexstruktur. Die praktische Konsequenz ist, dass kNN trivial parallelisierbar ist und keine Hyperparameter-Optimierung über die Wahl von k und der Distanzmetrik hinaus erfordert. Die Inferenzphase erfordert jedoch für jede Abfrage eine Nächste-Nachbarn-Suche durch die Referenzdatenbank, was eine brute-force Rechenkomplexität von O(N × d) hat, wobei N die Anzahl der Referenzpunkte und d die Einbettungsdimensionalität ist. Für die Referenzbibliothek von TarmacView, die Zehntausende von Fahrbahnoberflächenausschnitten enthält, die in 128-dimensionale Einbettungsvektoren kodiert sind, ist die brute-force Suche bei moderatem Maßstab machbar, wird aber mit zunehmender Bibliotheksgröße prohibitiv. FAISS-Indizierung reduziert die Inferenzkomplexität auf etwa O(log N × d) für approximative Suche.
Die theoretische Grundlage von kNN beruht auf der Glattheitsannahme (Smoothness Assumption): Die Funktion, die Eingaben auf Bezeichnungen abbildet, ist lokal konstant – Punkte in einer kleinen Nachbarschaft um q haben dieselbe Bezeichnung wie q. Diese Annahme ist gültig, wenn der Einbettungsraum so strukturiert ist, dass semantisch ähnliche Eingaben auf nahe Vektoren abgebildet werden. Die Qualität der kNN-Klassifikation hängt daher entscheidend von der Qualität des Einbettungsraums ab. Wenn der Encoder einen Einbettungsraum erzeugt, in dem gleichklassige Punkte eng gruppiert und verschiedenklassige Punkte gut getrennt sind – eine Eigenschaft namens Klassentrennbarkeit (Class Separability) – dann wird kNN mit kleinen k hohe Genauigkeit erreichen. Wenn der Einbettungsraum schlecht strukturiert ist, degeneriert kNN unabhängig vom k-Wert zu nahezu zufälliger Leistung. Der Einbettungsraum von TarmacView wird durch ein überwachtes kontrastives Lernziel (Supervised Contrastive Learning) erzeugt, das explizit die Klassentrennbarkeit optimiert: Das Trainingsziel zieht gleichklassige Oberflächenausschnitte (z. B. Asphalt PCI 70–80) im Einbettungsraum zusammen, während es verschiedenklassige Ausschnitte auseinanderdrückt. Dies erzeugt einen hochstrukturierten Einbettungsraum, in dem kNN mit k=10 eine Klassifikationsgenauigkeit von 96–98 % erreicht.
Eine kritische algorithmische Unterscheidung besteht zwischen Mehrheitsentscheidung (Majority Voting) und relativer Mehrheitsentscheidung (Plurality Voting) bei kNN. Die Mehrheitsentscheidung erfordert, dass eine einzelne Klasse mehr als 50 % der Stimmen erhält – dies ist der natürliche Mechanismus für binäre Klassifikation (zwei Klassen). Die relative Mehrheitsentscheidung, die der Standardmechanismus für Multiklassen-Probleme mit drei oder mehr Klassen ist, weist die Bezeichnung mit dem höchsten Stimmanteil zu, unabhängig davon, ob dieser 50 % überschreitet. Bei einer 10-Klassen-Oberflächentyp-Klassifikation mit k=10 gewinnt eine Klasse mit 4 Stimmen durch relative Mehrheit, obwohl 60 % der Nachbarn für andere Klassen gestimmt haben. Diese Unterscheidung ist wichtig für die Konfidenzinterpretation: Ein relativer Mehrheitssieg mit 40 % Übereinstimmung bedeutet, dass 60 % der Nachbarn anderer Meinung waren, was auf erhebliche Unsicherheit hinweist, obwohl eine Vorhersage getroffen wurde.
Die Distanzmetrik ist die folgenreichste algorithmische Wahl bei der kNN-Klassifikation, da sie definiert, was „am nächsten" im Einbettungsraum bedeutet. Die Metrik bestimmt die Geometrie der Nachbarschaften – sie kontrolliert die Form und Ausrichtung von Entscheidungsgrenzen und bestimmt direkt, welche Referenzpunkte jede Abfrage beeinflussen. Die Wahl der Metrik sollte von der Struktur des Einbettungsraums und den vom Anwendungsbereich geforderten Invarianzen geleitet werden.
Die Kosinus-Ähnlichkeit misst den Kosinus des Winkels zwischen zwei Vektoren im Einbettungsraum. Sie ist definiert als:
cos(θ) = (A · B) / (‖A‖ × ‖B‖)
wobei A · B das Skalarprodukt der Vektoren A und B und ‖A‖ die L2-Norm (euklidische Länge) ist. Die Kosinus-Ähnlichkeit reicht von -1 (Vektoren zeigen in genau entgegengesetzte Richtungen) bis +1 (Vektoren zeigen in identische Richtungen). Ein Wert von 0 zeigt orthogonale Vektoren ohne Korrelation an. Der entsprechende Kosinus-Abstand, der als Distanzmetrik bei der kNN-Suche verwendet wird, ist definiert als:
d_cos(A, B) = 1 − cos(θ)
Der Kosinus-Abstand reicht von 0 (identische Richtung) bis 2 (genau entgegengesetzt). Die Kosinus-Ähnlichkeit ist invariant gegenüber der Vektorgröße – zwei Vektoren mit identischer Richtung, aber unterschiedlichen Längen werden als perfekt ähnlich betrachtet. Dies ist die Metrik, die TarmacView für alle kNN-Oberflächenklassifikationen verwendet.
Die Schlüsseleigenschaft der Kosinus-Ähnlichkeit ist die Größeninvarianz (Magnitude Invariance). Merkmale des Fahrbahn-Erscheinungsbilds wie Oberflächentextur, Rissmusterdichte und Gesteinskörnungsexposition werden hauptsächlich in der Richtung des Einbettungsvektors erfasst, nicht in seiner Größe. Ein gut beleuchtetes Bild einer Rollbahnoberfläche und ein schwach beleuchtetes Bild derselben Oberfläche sollten Einbettungen mit ähnlichem Richtungsinhalt, aber möglicherweise unterschiedlichen Größen erzeugen. Die Kosinus-Ähnlichkeit bietet diese Beleuchtungsinvarianz auf natürliche Weise. Wenn das Encoder-Netzwerk darüber hinaus L2-normalisierte Einheitsvektoren erzeugt (eine Standardpraxis beim kontrastiven Lernen), reduziert sich die Kosinus-Ähnlichkeit auf ein einfaches Skalarprodukt: cos(θ) = A · B. Dies ermöglicht FAISS, seine optimierten Inner-Product (IP)-Suchroutinen zu verwenden, die von BLAS-Implementierungen des Skalarprodukts sowohl auf CPU- als auch auf GPU-Architekturen profitieren.
Im TarmacView-Einbettungsraum werden alle Referenz- und Abfrage-Einbettungen auf Einheitslänge normalisiert. Der FAISS-Index ist mit METRIC_INNER_PRODUCT konfiguriert, und da alle Vektoren einheitsnormalisiert sind, ist die Rangfolge des inneren Produkts identisch mit der Rangfolge der Kosinus-Ähnlichkeit. Diese Konfiguration ermöglicht es FAISS, effiziente SIMD-beschleunigte Skalarproduktberechnungen zu verwenden.
Die euklidische Distanz (auch L2-Distanz genannt) misst die geradlinige Entfernung zwischen zwei Punkten im Einbettungsraum:
d_euc(A, B) = sqrt(∑_(i=1)^d (A_i − B_i)²)
Die euklidische Distanz ist die gebräuchlichste Distanzmetrik in allen maschinellen Lernanwendungen. Sie reagiert sowohl auf die Richtung als auch auf die Größe von Einbettungsvektoren – zwei Bilder mit derselben Oberflächentextur, aber unterschiedlichen Helligkeitsstufen könnten Einbettungen mit derselben Richtung, aber unterschiedlichen Größen erzeugen, was zu einer großen euklidischen Distanz führt, obwohl der semantische Inhalt identisch ist. Für Anwendungsbereiche, in denen die Größe diagnostisch relevante Informationen kodiert – zum Beispiel, wenn der Schweregrad der Oberflächenverschlechterung proportional die Merkmalsgröße erhöht – kann die euklidische Distanz die geeignete Wahl sein.
Bei einheitsnormalisierten Einbettungen (der TarmacView-Konfiguration) sind die euklidische Distanz und die Kosinus-Ähnlichkeit mathematisch über die Identität verknüpft:
‖A − B‖² = ‖A‖² + ‖B‖² − 2(A · B) = 2 − 2cos(θ)
Wenn beide Vektoren auf Einheitslänge normalisiert sind (‖A‖ = ‖B‖ = 1), erzeugt die Rangfolge nach euklidischer Distanz die gleiche Nächste-Nachbarn-Reihenfolge wie die Rangfolge nach Kosinus-Ähnlichkeit, da die Beziehung monoton ist: Kleinere euklidische Distanz entspricht größerer Kosinus-Ähnlichkeit. In diesem Spezialfall ist die Wahl zwischen den beiden Metriken rechnerisch irrelevant. Wenn die Einbettungen jedoch nicht normalisiert sind, erzeugen die beiden Metriken erheblich unterschiedliche Nachbarschaften, und die Wahl muss durch die Anforderungen der Domäne geleitet werden.
Der Fluch der Dimensionalität (Curse of Dimensionality) wirkt sich überproportional auf die euklidische Distanz aus. Mit zunehmender Einbettungsdimensionalität d konvergiert das Verhältnis der Abstände zwischen dem nächsten und dem entferntesten Punkt für unabhängige und identisch verteilte Daten gegen 1 – im Wesentlichen werden alle Punkte gleich weit entfernt, und die Nächste-Nachbarn-Suche verliert an Unterscheidungskraft. Für d=128 (die Einbettungsdimensionalität von TarmacView) ist dieser Effekt vorhanden, wird jedoch dadurch abgemildert, dass die Einbettungen nicht unabhängig sind: Kontrastives Lernen strukturiert den Raum explizit so, dass sinnvolle Distanzvariationen entlang semantisch relevanter Dimensionen entstehen.
Die Manhattan-Distanz (auch L1-Distanz oder Taxigeometrie genannt) summiert die absoluten Differenzen entlang jeder Dimension:
d_man(A, B) = ∑_(i=1)^d |A_i − B_i|
Im Gegensatz zur euklidischen Distanz, die Differenzen vor der Summierung quadriert (was großen Unterschieden in einer einzelnen Dimension unverhältnismäßiges Gewicht verleiht), behandelt die Manhattan-Distanz jede Dimension gleich. Dies macht sie robuster gegenüber Ausreißerdimensionen und dem Fluch der Dimensionalität – in hochdimensionalen Räumen bewahren L1-Metriken die Distanzunterscheidbarkeit besser als L2-Metriken, da sie keine quadrierten Terme verstärken.
Die Manhattan-Distanz eignet sich besonders für dünnbesetzte oder binäre Merkmalsvektoren, bei denen die meisten Dimensionen Null sind und die aussagekräftige Information darin liegt, welche Dimensionen nicht Null sind, und nicht in deren genauen Werten. Im Kontext der Bild-Einbettungs-kNN für die Fahrbahninspektion wird die Manhattan-Distanz selten verwendet, da das kontrastive Lernziel, das den Einbettungsraum strukturiert, typischerweise für euklidische (L2-)Geometrie optimiert ist. Die Verwendung der L1-Distanz in einem L2-strukturierten Einbettungsraum verschlechtert die Leistung, da die Nachbarschaftsgeometrie nicht mehr mit dem Trainingsziel übereinstimmt.
Die Minkowski-Distanz verallgemeinert sowohl die euklidische als auch die Manhattan-Distanz durch einen einzelnen Parameter p:
d_mink(A, B) = (∑_(i=1)^d |A_i − B_i|^p)^(1/p)
Wenn p = 1, reduziert sich Minkowski auf die Manhattan-Distanz (L1). Wenn p = 2, reduziert sie sich auf die euklidische Distanz (L2). Wenn p gegen unendlich geht, konvergiert die Distanz zur Tschebyschow-Distanz (Chebyshev-Distanz, L∞), definiert als die maximale absolute Differenz über alle Dimensionen: d_∞(A, B) = max_i |A_i − B_i|. Die Minkowski-Distanz mit p zwischen 1 und 2 (gebrochene Normen) wird manchmal für hochdimensionales kNN verwendet, da sie zwischen der Ausreißerempfindlichkeit von L2 und der Gleichgewichtseigenschaft von L1 interpoliert, bietet aber in der Praxis nur begrenzte Vorteile gegenüber der direkten Wahl von L1 oder L2.
Die Hamming-Distanz zählt die Anzahl der Positionen, an denen sich zwei binäre Vektoren gleicher Länge unterscheiden. Für zwei binäre Zeichenketten x und y der Länge d:
d_ham(x, y) = ∑_(i=1)^d [x_i ≠ y_i]
Die Hamming-Distanz wird für kNN bei binären Merkmalen, Hash-Codes oder quantisierten Repräsentationen verwendet. Im Kontext von FAISS komprimiert die Produktquantisierung (PQ) hochdimensionale Einbettungen in kurze Binärcodes, und die Hamming-Distanz ermöglicht extrem schnelle approximative Nächste-Nachbarn-Suche durch bitweise XOR-Operationen (POPCNT-Befehle auf modernen CPUs). Obwohl TarmacView keine binären Einbettungen für die endgültige Klassifikation verwendet, kann der FAISS-Index intern PQ für die verlustbehaftete Komprimierung der Referenzdatenbank zur Reduzierung des Speicherverbrauchs verwenden, wobei die asymmetrische Distanzberechnung (ADC) zur Berechnung von Distanzen verwendet wird, ohne die gespeicherten Vektoren vollständig zu dekomprimieren.
| Metrik | Formel | Bereich | Invariant gegenüber | Am besten geeignet für |
|---|---|---|---|---|
| Kosinus | 1 − cos(θ) | [0, 2] | Größe (Magnitude) | Text, normalisierte Einbettungen, Richtungsmerkmale |
| Euklidisch (L2) | √∑(A_i−B_i)² | [0, ∞) | Rotation (nicht Größe) | Kontinuierliche Merkmale, roher Pixelraum |
| Manhattan (L1) | ∑ | A_i−B_i | [0, ∞) | |
| Hamming | ∑[A_i≠B_i] | [0, d] | — | Binärcodes, Hash-Suche, PQ-Suche |
| Tschebyschow (L∞) | max | A_i−B_i | [0, ∞) |
Die Wahl der Distanzmetrik sollte empirisch durch Kreuzvalidierung auf dem Zieldatensatz validiert werden. Für TarmacView wurde die Wahl der Kosinus-Ähnlichkeit durch den Vergleich der kNN-Klassifikationsgenauigkeit über alle fünf Metriken auf einem zurückgehaltenen Validierungssatz von 2.000 Fahrbahnausschnitten validiert. Die Kosinus-Ähnlichkeit erzielte die höchste mittlere Genauigkeit (97,2 %), gefolgt von euklidisch (96,8 %), Manhattan (93,4 %), Tschebyschow (89,1 %) und Hamming (72,3 %). Die Leistungslücke zwischen Kosinus und euklidisch war gering, da die Einbettungen L2-normalisiert sind, aber die Kosinus-Ähnlichkeit wurde als primäre Metrik aufgrund ihrer theoretischen Übereinstimmung mit dem kontrastiven Lernziel (das die Kosinus-Ähnlichkeit in seiner Verlustfunktion verwendet) und ihrer Kompatibilität mit der FAISS-Inner-Product-Suche ausgewählt.
Der Parameter k – die Anzahl der nächsten Nachbarn, die während der Abstimmung konsultiert werden – ist der wichtigste Hyperparameter bei der kNN-Klassifikation. Er steuert direkt den Bias-Varianz-Kompromiss: Kleine k ergeben eine geringe Verzerrung (Bias) (das Modell kann feinkörnige Klassenstrukturen erfassen), aber eine hohe Varianz (das Modell ist empfindlich gegenüber Rauschen und einzelnen Referenzpunkten). Große k ergeben eine geringe Varianz (Vorhersagen sind stabil und über viele Punkte gemittelt), aber eine hohe Verzerrung (das Modell glättet wichtige Klassenstrukturen weg). Das optimale k balanciert diese konkurrierenden Druckfaktoren aus.
Kleine k-Werte (1–5) erzeugen hochflexible, lokal adaptive Entscheidungsgrenzen. Bei k=1 (dem 1-NN-Klassifikator) ist die Entscheidungsgrenze die Voronoi-Tessellation der Trainingspunkte – jeder Punkt im Raum wird der Klasse seines einzelnen nächsten Referenzpunkts zugeordnet. Diese Grenze interpoliert jeden Trainingspunkt perfekt (kein Trainingsfehler), kann aber hochgradig unregelmäßig sein und isolierte Entscheidungsinseln erzeugen, die Rauschen in den Trainingsbezeichnungen widerspiegeln. Die theoretische Garantie von Cover und Hart (1967) besagt, dass die asymptotische Fehlerrate des 1-NN-Klassifikators erfüllt:
R_1NN ≤ 2R_Bayes (1 − R_Bayes) ≤ 2R_Bayes
wobei R_Bayes die Bayes-optimale Fehlerrate ist (der minimal erreichbare Fehler bei gegebener wahrer Datenverteilung). Dies bedeutet, dass der 1-NN-Klassifikator nie besser als die doppelte optimale Fehlerrate sein kann, aber für Probleme mit kleinem R_Bayes (einfache Probleme) nähert sich der 1-NN-Klassifikator der optimalen Fehlerrate an. Kleine k-Werte sind geeignet, wenn die Klassengrenzen stark nichtlinear sind und die Referenzdaten sauber sind – dünne Risse in Asphaltbefestigungen können beispielsweise lokal adaptive Grenzen erfordern, die ein Klassifikator mit kleinem k bieten kann.
Große k-Werte (20+) glätten die Entscheidungsgrenze, indem sie über viele Nachbarn mitteln. Dies reduziert den Einfluss einzelner verrauschter Bezeichnungen und erzeugt stabilere, besser generalisierbare Vorhersagen. Die Entscheidungsgrenze wird konvex und nähert sich mit wachsendem k einem linearen Separator an, da die Mittelung über eine große Region effektiv einen lokalen Zentroidvergleich durchführt. Wenn k jedoch die typische Klassengröße überschreitet, beginnt die Nachbarschaft, Punkte aus anderen Klassen einzuschließen, was die Verzerrung (Bias) erhöht. Im Grenzfall k = N (wobei N die Gesamtgröße des Trainingssatzes ist) wird jede Abfrage der globalen Mehrheitsklasse zugewiesen – das Modell kollabiert zu einem konstanten Prädiktor, der alle lokale Struktur ignoriert. Große k-Werte sind geeignet, wenn die Referenzdaten verrauscht, aber die Klassen auf globaler Ebene gut getrennt sind – zum Beispiel bei der Klassifikation von Asphalt versus Beton, wo die globale Trennung groß ist.
Die Wahl ungerader k-Werte ist eine praktische Konvention bei der binären Klassifikation, um Stimmgleichheit zu vermeiden. Bei k=4 führt ein 2-2-Unentschieden zwischen zwei Klassen zu keiner klaren Mehrheit. Bei k=5 ergibt ein 3-2-Verhältnis immer eine Mehrheit. Bei der Multiklassen-Klassifikation mit mehr als zwei Klassen garantiert ein ungerades k keine klare Mehrheit – eine 3-2-2-Aufteilung unter drei Klassen ergibt immer noch einen Gewinner durch relative Mehrheit (3 Stimmen), obwohl der Mehrheitsanteil nur 43 % beträgt. Strategien zur Aufhebung von Stimmgleichheit bei geraden k umfassen: die Wahl der Klasse mit der geringeren Gesamtdistanz zum Abfragepunkt (gewichteter Tie-Break basierend auf kumulativer Nähe), zufällige Auswahl aus den gleichauf liegenden Klassen oder die Verwendung der Klasse mit der geringsten durchschnittlichen Distanz.
Kreuzvalidierung ist die standardmäßige empirische Methode zur Auswahl von k. Der Trainingsdatensatz wird in v Falten aufgeteilt (typischerweise v=5 oder v=10, wobei die 10-fache Kreuzvalidierung für die Modellauswahl am gebräuchlichsten ist). Für jeden Kandidaten-k-Wert in einem Bereich (z. B. k = 1, 3, 5, …, 51) wird das Modell auf v−1 Falten trainiert und auf der zurückgehaltenen Falte evaluiert. Dieser Prozess wird für alle v Falten wiederholt, und die durchschnittliche Genauigkeit über die Falten wird aufgezeichnet. Das k mit der höchsten kreuzvalidierten Genauigkeit wird als optimaler Wert ausgewählt. Die Ellbogenmethode (Elbow Method) stellt die Genauigkeit als Funktion von k dar: Die Genauigkeit steigt für kleine k steil an, erreicht ein Plateau im optimalen Bereich und fällt dann allmählich ab, wenn k zu groß wird und die Verzerrung (Bias) dominiert. Das optimale k liegt am oder nahe dem Ellbogen – dem Punkt, an dem die Genauigkeit vor dem Abfall gesättigt ist.
Eine einfache Faustregel für die anfängliche k-Auswahl ist k = √N, wobei N die Anzahl der Trainingsproben ist. Diese Faustregel stellt sicher, dass die Nachbarschaftsgröße proportional zur Dichte des Einbettungsraums wächst – größere Datenbanken können größere Nachbarschaften unterstützen, da es mehr Referenzpunkte pro Volumeneinheit des Einbettungsraums gibt. Für die Referenzbibliothek von TarmacView mit etwa 10.000 Fahrbahnausschnitten wäre √10.000 = 100 ein Ausgangspunkt für die Gittersuche. Das optimale k hängt jedoch von der effektiven Anzahl von Stichproben pro Klasse und der Einbettungsstruktur ab. TarmacView verwendet k=10 basierend auf domänenspezifischer Kreuzvalidierung: Mit bis zu 10 Oberflächentypen und annähernd ausgeglichener Klassenverteilung bietet k=10 eine ausreichende Nachbarschaft für stabile Abstimmungen, ohne über den lokalen Klassencluster hinauszugehen. Die Kreuzvalidierung auf zurückgehaltenen Rollbahnabschnitten bestätigte, dass k=10 den PCI-Vorhersage-RMSE bei 4,8 Punkten minimiert und gleichzeitig die Klassifikationsgenauigkeit des Oberflächentyps bei 97,2 % maximiert.
Gewichtetes kNN (auch distanzgewichtetes kNN genannt) erweitert das standardmäßige Abstimmungsschema, indem es jedem Nachbarn ein Stimmgewicht proportional zu seiner Nähe zum Abfragepunkt zuweist. Beim standardmäßigen (uniformen) kNN haben alle k Nachbarn gleiches Stimmrecht – der entfernteste Nachbar hat genau denselben Einfluss auf die Vorhersage wie der nächste Nachbar. Dies erzeugt eine Diskontinuität an der Nachbarschaftsgrenze: Ein Referenzpunkt knapp innerhalb der k-ten Grenze hat volles Stimmrecht, während ein Punkt knapp außerhalb (der (k+1)-te Nachbar) unabhängig von seiner Nähe null Einfluss hat. Gewichtetes kNN beseitigt diesen Grenzeffekt, indem es entfernte Nachbarn sanft heruntergewichtet und so eine weiche Nachbarschaft (Soft Neighborhood) schafft, in der der Einfluss kontinuierlich mit der Distanz abnimmt.
Die gebräuchlichste Gewichtsfunktion ist die inverse Distanzgewichtung:
w_i = 1 / (d(q, x_i) + ε)
wobei d(q, x_i) die Distanz (oder der Kosinus-Abstand) zwischen der Abfrage q und dem Nachbarn x_i ist, und ε eine kleine Konstante (typischerweise 1e−8), die eine Division durch Null verhindert, wenn die Abfrage exakt mit einem Referenzpunkt übereinstimmt (d = 0). Nach diesem Schema erhält der nächste Nachbar das größte Stimmgewicht, und die Gewichte fallen hyperbolisch mit zunehmender Distanz. Die Klassenvorhersage wird zu:
ŷ = argmax_c ∑_(i=1)^k w_i × 1[y_i = c]
wobei die Summe über die k nächsten Nachbarn gebildet wird, w_i das Gewicht ist und 1[y_i = c] die Indikatorfunktion ist (1, wenn Nachbar i die Klasse c hat, sonst 0). Für Regressionsaufgaben lautet die gewichtete Vorhersage:
ŷ = (∑(i=1)^k w_i × y_i) / (∑(i=1)^k w_i)
was dem Nadaraya-Watson-Kernel-Regressionsschätzer im Einbettungsraum entspricht – einem lokal gewichteten Mittelwert, der mit wachsender Anzahl von Referenzpunkten gegen die wahre bedingte Erwartung E[Y | X = q] konvergiert.
Alternative Gewichtungsschemata umfassen:
Gewichtetes kNN reduziert die Empfindlichkeit des Modells gegenüber der spezifischen Wahl von k. Selbst bei moderat großen k tragen entfernte Nachbarn nur minimal zur Abstimmung bei (ihre Gewichte sind nahe Null), sodass die effektive Nachbarschaftsgröße selbstbegrenzend ist. Für die Qualitätsklassenvorhersage von TarmacView – eine Regressionsaufgabe, bei der PCI ein kontinuierlicher, durch ASTM D5340 standardisierter Wert ist – erzeugt gewichtetes kNN mit inverser Distanzgewichtung eine glattere und genauere Vorhersagefläche als uniforme Abstimmung. Der vorhergesagte PCI für einen Abfrageausschnitt ist:
PCÎ = (∑(i=1)^k w_i × PCI_i) / (∑(i=1)^k w_i)
wobei w_i = 1 / (Kosinus_Abstand(q, x_i) + ε). Dieser Schätzer ist eine Nadaraya-Watson-Kernel-Regression im Einbettungsraum. Die Kreuzvalidierung auf zurückgehaltenen Inspektionsdaten zeigt, dass gewichtetes kNN den PCI-Schätz-RMSE von 5,6 Punkten (uniforme Abstimmung) auf 4,8 Punkte (inverse Distanzgewichtung) reduziert – eine Verbesserung um 14 %.
Im TarmacView-System ist die Oberflächentyp-Klassifikation die erste Stufe der Fahrbahnanalyse. Das System muss bestimmen, ob ein Inspektionsbildausschnitt Asphalt (flexible Befestigung), Beton (starre Befestigung), Verbund (Betonbasis mit Asphaltdeckschicht) oder Nicht-Befestigungsflächen wie Gras, Kies, Boden oder Markierungsfarbe zeigt. Dies ist ein Multiklassen-Klassifikationsproblem mit kategorialen, sich gegenseitig ausschließenden Bezeichnungen. Die Klassifikation muss über unterschiedliche Lichtverhältnisse, Oberflächenfeuchtigkeitszustände und Grade der Oberflächenverschlechterung hinweg genau sein.
Der Oberflächentyp-Klassifikator arbeitet auf Bildausschnitten, die aus von Drohnen aufgenommenen Orthomosaik-Bildern von Start- und Rollbahnen extrahiert wurden. Jeder Ausschnitt ist 224×224 Pixel bei einem Bodenabtastabstand (GSD) von 2–5 mm, was bedeutet, dass jedes Pixel 2–5 Millimeter tatsächlicher Fahrbahnoberfläche repräsentiert. Bei dieser Auflösung ist die visuelle Textur der Fahrbahnoberfläche – Korngröße und -form bei Asphalt, Fugenmuster und Gesteinskörnungsexposition bei Beton – deutlich sichtbar. Jeder Ausschnitt wird durch ein convolutional-Encoder-Netzwerk (ein ResNet-50-Rückgrat, trainiert mit überwachtem kontrastivem Lernen) geleitet, um einen 128-dimensionalen Einbettungsvektor zu erzeugen, der L2-normalisiert wird.
Die Referenzbibliothek enthält Zehntausende von Einbettungs-Bezeichnungs-Paaren, die aus zuvor inspizierten Flugplatzbefestigungen gesammelt wurden. Jeder Referenzausschnitt wurde manuell von einem zertifizierten Fahrbahninspektor gemäß der ASTM D5340 Standardtestmethode für Flugplatzbefestigungs-Zustandsindex-Erhebungen gekennzeichnet. Die Referenzbibliothek umfasst die gesamte Bandbreite an Oberflächentypen, Klimaregionen und Befestigungsaltern und stellt sicher, dass der Einbettungsraum eine dichte Abdeckung über den Betriebsbereich hinweg hat.
Zum Zeitpunkt der Inferenz verarbeitet das System jeden neuen Ausschnitt durch denselben Encoder, um eine Abfrage-Einbettung zu erzeugen, und führt dann eine FAISS-basierte kNN-Suche mit k=10 mittels Kosinus-Abstand durch. Die 10 nächsten Referenz-Einbettungen werden zusammen mit ihren Oberflächentyp-Bezeichnungen abgerufen. Die relative Mehrheitsentscheidung (Plurality Voting) bestimmt den vorhergesagten Oberflächentyp: Das System zählt, wie viele der 10 Nachbarn zu jeder Oberflächentyp-Klasse gehören, und die Klasse mit der höchsten Anzahl gewinnt. Ein Konfidenzwert wird berechnet als:
Konfidenz = (Anzahl der Nachbarn, die für die Gewinnerklasse stimmen) / k
Bei k=10 reichen die Konfidenzwerte in Schritten von 0,1 von 0,1 (ein einzelner Nachbar unterstützt die Vorhersage) bis 1,0 (alle 10 Nachbarn stimmen einstimmig überein). Ein Konfidenzschwellenwert von 0,6 (6 von 10 Nachbarn stimmen überein) wird verwendet, um Vorhersagen für die automatische Berichterstattung zu filtern.
Die k=10-Konfiguration bietet eine praktische Balance für die Oberflächentyp-Klassifikation. Mit 4 primären Oberflächentypen in der typischen Referenzbibliothek stellt k=10 sicher, dass auch nahe an Entscheidungsgrenzen mehrere Stichproben aus jeder Klasse zur Abstimmung beitragen. Wenn k zu klein wäre (z. B. k=3), könnte eine einzelne anomale Referenz-Einbettung in der Nähe einer Entscheidungsgrenze die Vorhersage umkippen. Wenn k zu groß wäre (z. B. k=50), würde die Nachbarschaft über den lokalen Oberflächentyp-Cluster hinaus in benachbarte Klassen reichen, was die Abstimmung verwässert und die Verzerrung (Bias) erhöht.
Ein Zurückweisungsmechanismus (Rejection Mechanism) behandelt mehrdeutige Fälle durch den Konfidenzschwellenwert. Wenn der Konfidenzwert unter 0,6 fällt (oder, gleichbedeutend, wenn die 10 Nachbarn stärker als 6:4 zwischen den beiden führenden Klassen aufgeteilt sind), wird der Ausschnitt zur menschlichen Überprüfung markiert, anstatt automatisch gekennzeichnet zu werden. Dieser Mechanismus ist besonders wichtig für Übergangszonen, in denen sich der Oberflächentyp ändert – wie Asphalt-Beton-Übergänge an Startbahnenden oder Verbundbefestigungen, bei denen die obere Asphaltschicht den darunter liegenden Beton teilweise verdeckt. Diese Zonen erzeugen Ausschnitte, die von Natur aus visuell mehrdeutig sind, und das System identifiziert sie korrekt als solche, die menschliches Urteilsvermögen erfordern.
Die Oberflächentyp-Klassifikationsgenauigkeit auf zurückgehaltenen Testdaten übersteigt 98 % für Standard-Asphalt- und Betonoberflächen. Die primären Fehlermodi treten bei Verbundbefestigungen auf (bei denen die dünne Asphaltdeckschicht das Betonsubstrat durch reflektierende Rissbildung teilweise freilegt, was den Texturklassifikator verwirrt) und bei stark verschlissenen Oberflächen, bei denen ausgedehnte Rissnetzwerke und Flickstellen die zugrunde liegenden Oberflächentextur-Hinweise verdecken. Diese Fehlerfälle werden typischerweise durch den Konfidenzschwellenwert erfasst (die Übereinstimmung fällt unter 0,6) und an menschliche Prüfer weitergeleitet.

Die zweite Anwendung von kNN in TarmacView ist die Qualitätsklassen-Klassifikation – die Vorhersage des Befestigungszustandsindex (PCI) aus Bildausschnitten. PCI ist eine numerische Bewertung von 0 (ausgefallen) bis 100 (ausgezeichnet), standardisiert durch ASTM D5340 für Flugplatzbefestigungen und durch ASTM D6433 für Straßen und Parkplätze. Die PCI-Methodik, entwickelt vom US Army Corps of Engineers und anschließend von der FAA und ICAO übernommen, ist der internationale Standard zur Quantifizierung des Befestigungszustands. PCI wird durch eine visuelle Erhebung bestimmt, bei der ein Inspektor Typ, Schweregrad und Dichte jeder Schadensart (Rissbildung, Spurrillen, Ausbröckelung, Abplatzungen, Flickstellen usw.) in einer Probeeinheit identifiziert und dann ein Abzugswertverfahren anwendet, um einen zusammengesetzten Index zu berechnen.
In der Praxis wird die kontinuierliche 0-100-PCI-Skala für die Berichterstattung und Entscheidungsfindung in Qualitätsbänder (Grade Bands) zusammengefasst:
| Qualitätsband | PCI-Bereich | Beschreibung | Typische Instandhaltungsmaßnahme |
|---|---|---|---|
| Gut | 71–100 | Geringe oder keine Schäden | Routinemäßige Instandhaltung |
| Ausreichend | 56–70 | Mäßige Schäden | Vorbeugende Instandhaltung |
| Befriedigend | 41–55 | Erhebliche Schäden | Umfassende Instandsetzung |
| Schlecht | 26–40 | Umfangreiche Schäden | Erneuerung in Erwägung ziehen |
| Sehr schlecht | 11–25 | Schwere Schäden | Erneuerung erforderlich |
| Ausgefallen | 0–10 | Vollständige Zerstörung | Notfall-Erneuerung |
kNN kann entweder Regression (Vorhersage des kontinuierlichen PCI-Werts auf der 0-100-Skala) oder Klassifikation (Vorhersage des Qualitätsbands als kategoriale Bezeichnung) durchführen. TarmacView unterstützt beide Modi, abhängig von den Berichtsanforderungen.
Für die PCI-Regression berechnet gewichtetes kNN einen distanzgewichteten Durchschnitt der PCI-Werte der k nächsten Nachbarn. Gegeben eine Abfrage-Einbettung q ruft das System die k=10 nächsten Referenzausschnitte mit ihren zugehörigen PCI-Werten (Grundwahrheitswerte aus ASTM-konformen menschlichen Inspektionen) ab. Der vorhergesagte PCI ist:
PCÎ = (∑(i=1)^k w_i × PCI_i) / ∑(i=1)^k w_i
wobei w_i = 1 / (Kosinus_Abstand(q, x_i) + ε). Dieser Nadaraya-Watson-Kernel-Regressionsschätzer erzeugt eine glatte Vorhersagefläche im Einbettungsraum. Ausschnitte ähnlicher visueller Qualität gruppieren sich zusammen, da das kontrastive Lernziel den Raum nach visueller Ähnlichkeit organisiert, die stark mit dem PCI korreliert. Ein Ausschnitt, der ausgedehnte Netzrisse, Längsrisse und Spurrillen zeigt, wird in der Nähe anderer verschlissener Asphalt-Ausschnitte mit niedrigen PCI-Werten eingebettet, was einen korrekt niedrigen vorhergesagten PCI ergibt. Umgekehrt wird ein Ausschnitt, der eine intakte, gut gepflegte Oberfläche zeigt, in der Nähe anderer Referenzausschnitte mit hohem PCI eingebettet.
Für die Qualitätsband-Klassifikation ordnet die standardmäßige relative Mehrheitsentscheidung mit k=10 den Ausschnitt einem der sechs PCI-Qualitätsbänder zu. Dieser diskretisierte Ansatz ist robuster, wenn die Referenzbibliothek eine dünne Abdeckung bei exakten PCI-Werten (z. B. wenige Referenzausschnitte mit PCI genau 47), aber eine dichte Abdeckung innerhalb der Bänder (z. B. viele Ausschnitte mit PCI 40–55) aufweist. Der Qualitätsband-Ansatz entspricht den ASTM D5340-Berichtskonventionen, die in Flugplatzbefestigungs-Managementsystemen (APMS) verwendet werden, wo der Zustand typischerweise nach Kategorie und nicht nach exaktem numerischem Index gemeldet wird.
Die PCI-Schätzgenauigkeit hängt von der Dichte und Qualität der Referenzbibliothek ab. Mit einer Referenzbibliothek, die den gesamten PCI-Bereich sowohl für Asphalt- als auch für Betonoberflächen abdeckt, erreicht der kNN-Schätzer einen mittleren quadratischen Fehler (RMSE) von etwa ±5 PCI-Punkten auf zurückgehaltenen Testdaten. Dies schneidet im Vergleich zur ±10-PCI-Punkt-Interrater-Variabilität zwischen zertifizierten menschlichen Inspektoren gemäß ASTM D5340 Abschnitt 4.2 günstig ab – was bedeutet, dass der kNN-Schätzer konsistenter ist als menschliche Experten. Der primäre Fehlermodus ist die PCI-Schätzung für seltene Oberflächenzustände – wie eine neu asphaltierte Startbahn mit einer neuartigen polymer-modifizierten Asphaltmischung, für die es keine vergleichbaren Referenzproben gibt – bei denen der Schätzer auf den nächsten verfügbaren Zustand im Einbettungsraum zurückfällt und den wahren PCI möglicherweise über- oder unterschätzt. Die Konfidenzfilterung (Übereinstimmung < 0,6) erfasst die meisten dieser Fälle.
Eine der wertvollsten Eigenschaften von kNN für Inspektionsanwendungen ist die natürliche Konfidenzmetrik, die sich aus der Nachbarübereinstimmung ergibt. Im Gegensatz zu neuronalen Netzklassifikatoren, die Softmax-Wahrscheinlichkeiten ausgeben – die bekanntermaßen schlecht kalibriert sind (systematisch überkonfident bei eingangsverteilungsfremden (OOD) Eingaben und unterkonfident bei eingangsverteilungskonformen Eingaben, wie von Guo et al., 2017 in „On Calibration of Modern Neural Networks" dokumentiert) – hat die kNN-Konfidenz eine geradlinige, interpretierbare und empirisch gut kalibrierte Bedeutung.
Für einen Abfragepunkt q mit k nächsten Nachbarn ist der Übereinstimmungswert (Agreement Score):
Übereinstimmung = (Anzahl der Nachbarn, die für die vorhergesagte Klasse stimmen) / k
Dieser Übereinstimmungswert reicht von 1/k (minimal mögliche Übereinstimmung – jeder Nachbar stimmt für eine andere Klasse) bis 1,0 (einstimmig – alle k Nachbarn stimmen für dieselbe Klasse). Eine Übereinstimmung von 1,0 bedeutet, dass die Abfrage tief in einer homogenen Region des Einbettungsraums liegt, umgeben von gleichklassigen Referenzpunkten – die Vorhersage ist hochzuverlässig. Eine Übereinstimmung von 1/k bedeutet, dass die Nachbarn maximal gespalten sind – die Abfrage liegt auf oder nahe einer Entscheidungsgrenze, und die Vorhersage ist grundsätzlich unsicher. In der Praxis reicht die Übereinstimmung bei k=10 von 0,1 (10 Nachbarn, 10 verschiedene Klassen – äußerst unwahrscheinlich in einem gut strukturierten Einbettungsraum) bis 1,0.
TarmacView verwendet den Übereinstimmungswert zur Implementierung der Konfidenzfilterung – eines produktionsreifen Qualitätskontrollmechanismus. Ausschnitte mit einer Übereinstimmung unter einem Schwellenwert (typischerweise 0,6 oder 6 von 10 übereinstimmenden Nachbarn) werden zur manuellen Überprüfung markiert, anstatt in automatisierte Inspektionsberichte aufgenommen zu werden. Diese Filterung erfasst drei Kategorien problematischer Eingaben:
Grenzfälle: Ausschnitte aus Übergangszonen zwischen Oberflächentypen oder Qualitätsklassen, bei denen die visuellen Merkmale tatsächlich mehrere Bezeichnungen unterstützen. Ein Ausschnitt, der die Grenzfläche zwischen einer Asphaltdeckschicht und einer Betonbasis erfasst – der beide Oberflächentexturen zeigt – wird Nachbarn haben, die zwischen „Asphalt"- und „Verbund"-Bezeichnungen aufgeteilt sind, was eine Übereinstimmung unter 0,6 ergibt und korrekterweise eine Überprüfung auslöst.
Eingangsverteilungsfremde (OOD) Eingaben: Ausschnitte, die neuartige Oberflächenbehandlungen, Nicht-Befestigungsinhalt oder Bildartefakte zeigen, die in der Referenzbibliothek nicht vertreten sind. Diese Ausschnitte werden in Regionen geringer Dichte des Einbettungsraums eingebettet, in denen selbst die nächsten Referenzpunkte relativ weit entfernt sind. Die Übereinstimmung ist niedrig, da die Nachbarn über mehrere Klassen verstreut sind – keine einzelne Klasse hat eine Mehrheit. Diese Eigenschaft – niedrige kNN-Übereinstimmung für OOD-Eingaben – ist ein gut dokumentiertes Phänomen in der Nächste-Nachbarn-Analyse und bietet einen integrierten OOD-Erkennungsmechanismus ohne einen separaten Klassifikator.
Anomale Oberflächen: Ausschnitte, die seltene Schadensarten zeigen, die in den Trainingsdaten nicht gut repräsentiert sind, wie Alkali-Kieselsäure-Reaktion (ASR) in Betonbefestigungen oder Kraftstoffverschmutzungen auf Asphalt. Diese Zustände erzeugen visuelle Texturen, die sich von der Standard-Referenzbibliothek unterscheiden, wodurch die Abfrage-Einbettung zwischen Klassenclustern und nicht innerhalb eines Clusters liegt.
Der Übereinstimmungswert ist interpretierbarer als Softmax-Entropie, randbasierte Konfidenz oder andere parametrische Konfidenzmaße, da er eine direkte instanzbasierte Erklärung hat: „6 der 10 ähnlichsten Referenzproben stimmen für Asphalt, 3 sagen Beton und 1 sagt Verbund." Ein Inspektor, der einen markierten Ausschnitt überprüft, kann die spezifischen nächsten Nachbarn untersuchen – ihre Bilder, Bezeichnungen und Distanzen – und verstehen, warum das Modell unsicher ist, und dann eine fundierte Entscheidung treffen. Diese Rückverfolgbarkeit ist bei Softmax-Ausgaben unmöglich.
Die Kalibrierung des Übereinstimmungswerts – wie gut er mit der wahren Wahrscheinlichkeit der Klassifikationskorrektheit übereinstimmt – verbessert sich mit größerem k, folgt aber abnehmenden Grenzerträgen. Die Kreuzvalidierung auf der TarmacView-Referenzbibliothek etabliert die folgende Kalibrierungskurve für k=10:
| Übereinstimmungsbereich | Mittlere tatsächliche Genauigkeit | Interpretation |
|---|---|---|
| 0,9 – 1,0 | 98,7 % | Hochkonfident, tief innerhalb eines Klassenclusters |
| 0,7 – 0,8 | 94,2 % | Konfident, nahe Clusterzentrum |
| 0,6 | 86,5 % | Mäßig konfident, nahe Clustergrenze |
| 0,5 | 78,3 % | Unsicher, auf Entscheidungsgrenze |
| ≤ 0,4 | 62,1 % | Niedrige Konfidenz, wahrscheinlich OOD oder Grenzfall |
Diese monotone Beziehung zwischen Übereinstimmung und Genauigkeit validiert den Konfidenzfilterungsansatz. Der Schwellenwert von 0,6 erfasst etwa 92 % der Fehlklassifikationen, während nur 8 % der korrekten Vorhersagen zur Überprüfung markiert werden – ein günstiger Precision-Recall-Kompromiss für die Produktionsinspektion.
Die Wahl zwischen kNN, einer linearen Sonde und einem neuronalen Netzklassifikator als Klassifikationskopf auf gelernten Einbettungen beinhaltet grundlegende Kompromisse zwischen Interpretierbarkeit, Generalisierung, Inferenzgeschwindigkeit und Anpassungsfähigkeit an neue Daten. Alle drei Methoden operieren auf demselben encoder-erzeugten Einbettungsraum, aber sie lernen oder fragen verschiedene Arten von Entscheidungsgrenzen mit unterschiedlichen Eigenschaften ab.
Eine lineare Sonde (Linear Probe) ist eine einzelne vollständig verbundene Schicht (dichte Schicht ohne Aktivierung, analog zur multinomialen logistischen Regression), die auf den eingefrorenen Einbettungen trainiert wird. Sie lernt eine Gewichtsmatrix W der Form (Einbettungsdimension × Anzahl_Klasse), die Einbettungen auf Klassen-Logits abbildet: logits = x·W + b. Die Entscheidungsgrenze im Einbettungsraum ist ein Satz linearer Hyperebenen – eine pro Klassenpaar – definiert durch die Entscheidungsgrenzengleichung (W_j − W_i)·x + (b_j − b_i) = 0. Lineare Sonden nehmen an, dass der Einbettungsraum linear trennbar ist, was im Allgemeinen zutrifft, wenn der Encoder mit einem kontrastiven oder Softmax-Klassifikationsziel trainiert wird.
Zu den Vorteilen linearer Sonden gehören die Inferenzgeschwindigkeit (eine einzelne Matrixmultiplikation mit O(d × C)-Komplexität, wobei d die Einbettungsdimension und C die Anzahl der Klassen ist), die geringe Modellgröße (d × C + C Parameter – für d=128 und C=10 sind das nur 1.290 Parameter) und die mäßige Interpretierbarkeit (Gewichtsgrößen pro Dimension können als Merkmalsbedeutung für jede Klasse interpretiert werden, auch wenn dies erfordert, dass die Einbettungsdimensionen semantisch bedeutungsvoll sind – eine Eigenschaft, die gelernte Einbettungen im Allgemeinen nicht besitzen). Die primäre Einschränkung ist die lineare Annahme: Wenn der Einbettungsraum eine nichtlineare Klassenstruktur aufweist (z. B. eine Klasse besetzt zwei nicht zusammenhängende Regionen im Einbettungsraum – was die lineare Trennbarkeitsannahme verletzt), kann eine lineare Sonde diese Struktur nicht erfassen und wird eine gerade Grenze ziehen, die beide Cluster halbiert, wodurch die Hälfte jedes Clusters falsch klassifiziert wird.
Ein neuronaler Netzklassifikator (eine oder mehrere verborgene Schichten auf dem Encoder-Embedding) kann beliebig komplexe, nichtlineare Entscheidungsgrenzen lernen. Ein zweischichtiges MLP mit einer verborgenen Dimension 64 und ReLU-Aktivierung, gefolgt von einer Softmax-Ausgabeschicht, kann den Einbettungsraum in nichtlineare Regionen aufteilen, die sich um Cluster wickeln und disjunkte Entscheidungsregionen bilden, die die lineare Sonde nicht darstellen kann. Dies bietet das höchste theoretische Genauigkeitspotenzial, wenn der Einbettungsraum eine nichttriviale Klassenstruktur aufweist.
Die Nachteile sind erheblich: Die MLP-Parameter erfordern Training mit Gradientenabstieg (zusätzliche Rechenkosten, Hyperparameter-Optimierung für Lernrate, Batch-Größe, Anzahl der Schichten, verborgene Dimensionen, L2-Regularisierung, Dropout-Rate und Optimierer-Wahl), das Modell ist nicht interpretierbar (man kann eine Vorhersage nicht auf eine bestimmte Referenzprobe zurückführen – die Vorhersage ist eine Funktion der gesamten Gewichtsmatrix und des Aktivierungsmusters), und das Hinzufügen neuer Klassen erfordert ein erneutes Training des gesamten Klassifikationskopfes. Für die Flugplatzbefestigungsinspektion, bei der Referenzbibliotheken mit jeder neuen Flugplatzinspektion inkrementell wachsen, führt die erneute Trainingsanforderung zu erheblicher operationeller Reibung – jede neue Oberflächentyp- oder Qualitätsklassen-Referenz erfordert einen vollständigen erneuten Trainingszyklus.
kNN liegt am entgegengesetzten Ende des Spektrums von parametrischen Klassifikatoren. Es erfordert kein Training, keinen Gradientenabstieg, keine Gewichtsaktualisierungen und keine Hyperparameter-Optimierung über die Wahl von k und der Distanzmetrik hinaus. Das Hinzufügen neuer Referenzproben zum FAISS-Index ändert sofort die Entscheidungsgrenzen – effektiv „trainiert" das Modell inkrementell bei jeder Datenhinzufügung mit null Rechenkosten. kNN bietet perfekte Interpretierbarkeit, da jede Vorhersage von ihren unterstützenden Beweisen begleitet wird: den Identitäten, Bezeichnungen und Distanzen der k nächsten Nachbarn.
Der Kompromiss ist die Inferenzgeschwindigkeit. Eine lineare Sonde benötigt O(d × C) Operationen pro Abfrage – eine einzelne Matrixmultiplikation, die unabhängig von der Datenbankgröße N ist. kNN mit brute-force Suche benötigt O(N × d) Operationen pro Abfrage – linear in der Datenbankgröße. Mit FAISS-Indizierung (IVF-, HNSW- oder PQ-Indizes) reduziert sich die kNN-Inferenz jedoch auf etwa O(log N × d) für approximative Nächste-Nachbarn-Suche, was bei N=10.000 und d=128 Abfragezeiten unter 10 Millisekunden ergibt – vergleichbar mit der linearen Sonde, aber mit allen Vorteilen der Interpretierbarkeit und Anpassungsfähigkeit.
| Eigenschaft | Lineare Sonde | MLP-Klassifikator | kNN (FAISS) |
|---|---|---|---|
| Erforderliches Training | Gradientenabstieg (Minuten) | Gradientenabstieg (Stunden) | Keines (sofort) |
| Inferenzkomplexität | O(d × C) | O(d × H + H × C) | O(log N × d) indiziert |
| Interpretierbarkeit | Niedrig (Gewichtsanalyse) | Keine (Black Box) | Hoch (Instanznachweise) |
| Anpassung an neue Klassen | Vollständiges Retraining | Vollständiges Retraining | Sofortig (zum Index hinzufügen) |
| Entscheidungsgrenzentyp | Lineare Hyperebenen | Nichtlinear, beliebig | Beliebig (Voronoi-basiert) |
| Trainingsdaten speichern | Nein (nur Gewichte) | Nein (nur Gewichte) | Ja (Referenzindex) |
| Konfidenzkalibrierung | Softmax (schlecht) | Softmax (schlecht) | Übereinstimmung (gut kalibriert) |
| Speicher für Inferenz | d × C Parameter | d×H + H×C Parameter | N × d Einbettungen |
| OOD-Erkennung | Separater Klassifikator nötig | Separater Klassifikator nötig | Integriert (niedrige Übereinstimmung) |
TarmacView nutzt kNN-Klassifikation auf gelernten Einbettungen für schnelle, interpretierbare Vorhersagen von Befestigungsoberflächentyp und Qualitätsklasse. Kontaktieren Sie uns, um zu erfahren, wie die Nächste-Nachbarn-Klassifikation automatisierte Flugplatzinspektionen ermöglicht.
FAISS (Facebook AI Similarity Search) ist eine Open-Source-Bibliothek für effiziente Ähnlichkeitssuche und Clusterbildung dichter Vektoren, die von TarmacView v...
DINOv3 (self-DIstillation with NO labels v3) ist ein selbstüberwachter Vision Transformer (ViT-B/16), der auf 1,7 Milliarden Bildern vortrainiert wurde und hoch...
Eine Konfusionsmatrix tabelliert Modellvorhersagen gegen Ground Truth: Zeilen sind tatsächliche Klassen, Spalten sind vorhergesagte Klassen. Die Diagonale zeigt...