Smoke-Test
Ein Smoke-Test ist eine schnelle End-to-End-Überprüfung, ob eine Software-Pipeline mit repräsentativen Daten ohne Absturz ausgeführt wird und erwartete Ergebnis...
29 Min. Lesezeit
testing
technology
+4
Der Defektkopf-Smoke-Test validiert, dass TarmacViews Pipeline zur Strukturdefekterkennung — DINOv3-Backbone + 5-Label-MLP-Kopf für Riss/Abplatzung/Ausblühung/freiliegender Bewehrung/Korrosion — erwartete Ausgaben auf Testdaten produziert. Umfasst Test-Assertions (Checkpoint existiert; AP-Metriken; Kachel-/Bilddefektspalten in Analyseausgabe) und was Smoke-Tests im Vergleich zur vollständigen Evaluierung verifizieren.
Defektkopf-Smoke-Testing ist ein automatisiertes Überprüfungsverfahren, das die strukturelle Integrität und grundlegende Funktionalität einer Pipeline zur maschinellen Defekterkennung validiert. Es bestätigt, dass die Pipeline — von der Eingabebildvorverarbeitung über das DINOv3-Vision-Transformer-Backbone bis zum 5-Label-Multi-Layer-Perceptron (MLP)-Klassifikationskopf — erwartete Ausgaben auf synthetischen oder kleinen statischen Testdaten produziert, ohne abzustürzen, numerische Fehler zu erzeugen oder strukturell ungültige Vorhersagen zu generieren. Der Smoke-Test unterscheidet sich von einer vollständigen Evaluierung: Er überprüft, ob die Pipeline korrekt verdrahtet und betriebsbereit ist, nicht ob sie auf unbekannten Daten mit hoher Genauigkeit generalisiert.
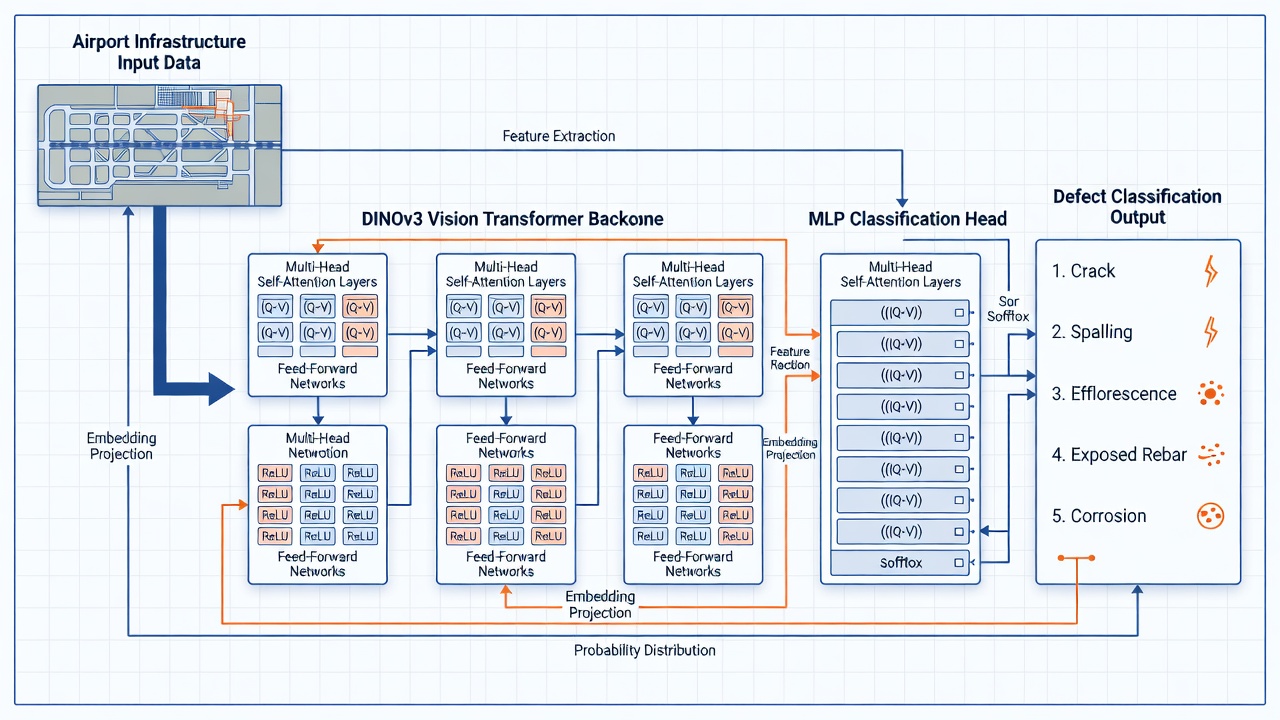
Der Defektkopf ist die finale Komponente von TarmacViews Pipeline zur Strukturdefekterkennung, verantwortlich für die Abbildung der reichhaltigen Merkmalsrepräsentationen, die vom Backbone-Netzwerk extrahiert wurden, auf diskrete Defektklassenvorhersagen. Das Verständnis der Architektur sowohl des Backbones als auch des Kopfes ist wesentlich für die Entwicklung effektiver Smoke-Tests, die die Integrität jeder Komponente validieren.
Der DINOv3 (Self-DIstillation with NO labels, Version 3) Vision Transformer, entwickelt von Meta AI und veröffentlicht im Jahr 2023, dient als Merkmalsextraktions-Backbone. DINOv3 wurde mit einem selbstüberwachten Lernparadigma auf einem kuratierten Datensatz von 142 Millionen unbeschrifteten Bildern (LVD-142M) trainiert und lernt allgemeine visuelle Repräsentationen ohne menschliche Annotationen. Dieser Ansatz produziert Merkmale, die effektiv auf nachgelagerte Aufgaben einschließlich Defektklassifikation, Segmentierung und Erkennung übertragen werden können — und übertrifft oft überwachtes Vortraining auf ImageNet-1K.
DINOv3 ist in mehreren Modellvarianten mit unterschiedlichen Rechenprofilen verfügbar:
| Variante | Parameter | Einbettungsdim. | Patch-Größe | Schichten | Köpfe |
|---|---|---|---|---|---|
| ViT-S/14 | 22 Millionen | 384 | 14×14 | 12 | 6 |
| ViT-B/14 | 86 Millionen | 768 | 14×14 | 12 | 12 |
| ViT-L/14 | 300 Millionen | 1024 | 14×14 | 24 | 16 |
| ViT-g/14 | 1,1 Milliarden | 1536 | 14×14 | 40 | 24 |
Für TarmacViews Pipeline zur Defekterkennung ist die ViT-B/14-Variante die Standardkonfiguration. Mit 86 Millionen Parametern und einem 768-dimensionalen Einbettungsraum balanciert sie Repräsentationskapazität mit Recheneffizienz, die für die Verarbeitung großer Mengen von Startbahn-Inspektionsbildern geeignet ist. Die Patch-Größe von 14×14 bedeutet, dass ein 224×224 Pixel großes Eingabebild in 16×16 = 256 nicht überlappende Patches unterteilt wird, die jeweils durch eine gelernte lineare Projektion in den 768-dimensionalen Einbettungsraum projiziert werden.
Die DINOv3-Trainingsmethodik kombiniert mehrere Schlüsseltechniken. Self-Distillation mit Teacher-Student-Architektur stellt sicher, dass das Student-Netzwerk lernt, die Repräsentationen des Teachers nachzuahmen, wobei der Teacher ein exponentiell gleitender Durchschnitt des Students ist. iBOT (image BERT Pre-training with Online Tokenizer) wendet maskierte Bildmodellierung an, bei der zufällige Patches maskiert werden und das Modell die maskierten Patch-Repräsentationen vorhersagen muss. Sinkhorn-Knopp-Zentrierung aus der SwAV-Methode verhindert den Kollaps von Repräsentationen, indem sie eine gleichmäßige Verteilung über Batch-Stichproben erzwingt. KoLeo-Regularisierer fördert die Diversität der gelernten Merkmale, indem er die Merkmalsähnlichkeit zwischen benachbarten Stichproben bestraft.
Für den Anwendungsfall der Defekterkennung wird DINOv3 mit vortrainierten Gewichten geladen und während des Defektkopf-Trainings typischerweise eingefroren. Das eingefrorene Backbone extrahiert allgemeine visuelle Merkmale — Kanten, Texturen, Gradienten, Oberflächenmuster — die für die Unterscheidung zwischen intaktem Belag und den fünf Defektklassen hochrelevant sind. Das Einfrieren des Backbones reduziert die Anzahl der trainierbaren Parameter von 86 Millionen auf etwa 1-3 Millionen (abhängig von der Tiefe des MLP-Kopfes), was die Trainingszeit, den GPU-Speicherbedarf und das Risiko des katastrophalen Vergessens auf kleinen domänenspezifischen Datensätzen drastisch reduziert.
Der MLP (Multi-Layer Perceptron)-Defektkopf ist ein kleines Feedforward-Neuronales Netzwerk, das die eingefrorenen DINOv3-Einbettungen als Eingabe nimmt und eine 5-dimensionale Wahrscheinlichkeitsverteilung über die fünf Defektklassen produziert: Riss, Abplatzung, Ausblühung, freiliegende Bewehrung und Korrosion.
Die Standardarchitektur besteht aus:
Eingabeschicht: Nimmt die DINOv3-Einbettung entgegen — entweder den [CLS]-Token (einen 768-dimensionalen Vektor, der den globalen Bildinhalt repräsentiert) oder eine gepoolte Repräsentation aller Patch-Token. Der [CLS]-Token-Ansatz ist Standard, da DINOv3 speziell darauf trainiert ist, während der Self-Distillation reichhaltige Informationen im [CLS]-Token zu produzieren.
Versteckte Schichten: Typischerweise 1-2 vollständig verbundene Schichten mit ReLU- oder GELU-Aktivierungsfunktionen. Eine Konfiguration mit einer versteckten Schicht könnte 768 → 256 → 5 sein, während eine tiefere Konfiguration 768 → 512 → 128 → 5 sein könnte. Jede versteckte Schicht wird von Batch-Normalisierung oder Layer-Normalisierung gefolgt, um das Training zu stabilisieren und interne Kovariateverschiebungen zu reduzieren. Dropout (Rate 0,2-0,5) wird während des Trainings zwischen versteckten Schichten als Regularisierer angewendet, um Überanpassung zu verhindern, da Datensätze für Infrastrukturdefekte typischerweise klein sind (500-5000 Bilder).
Ausgabeschicht: Eine lineare Projektion auf 5 Einheiten entsprechend den fünf Defektklassen, gefolgt von einer Softmax-Aktivierung, die Logits in eine Wahrscheinlichkeitsverteilung über die Klassen umwandelt. Die Softmax-Funktion stellt sicher, dass der Ausgabevektor sich zu 1,0 summiert, wobei jedes Element die vorhergesagte Wahrscheinlichkeit repräsentiert, dass das Eingabebild zu dieser Defektklasse gehört.
Trainingsverfahren: Der MLP-Kopf wird durch überwachtes Fine-Tuning trainiert, während das DINOv3-Backbone eingefroren bleibt. Die Verlustfunktion ist kategoriale Kreuzentropie, die die vorhergesagte Wahrscheinlichkeitsverteilung mit den One-Hot-kodierten Ground-Truth-Labels vergleicht. Das Training verwendet typischerweise den AdamW-Optimierer mit einer Lernrate von 1e-3 bis 1e-4, einer Batch-Größe von 32-128 und frühzeitigen Stopp basierend auf dem Validierungsverlust. Datenanreicherung (zufällige Rotation, horizontales Spiegeln, Farbveränderung, zufälliger Zuschnitt) wird während des Trainings angewendet, um die Generalisierung zu verbessern.
Für die Inferenz verarbeitet das DINOv3-Backbone jedes Eingabebild in Patch- und [CLS]-Token-Einbettungen in einem einzigen Vorwärtsdurchlauf. Die [CLS]-Einbettung wird extrahiert und durch den MLP-Kopf geleitet. Die Softmax-Ausgabewahrscheinlichkeiten werden mit einem Schwellenwert versehen (typischerweise bei 0,5 oder optimiert durch ROC-Analyse), um eine binäre Vorhersage für jede Defektklasse zu erzeugen. Da die fünf Defektklassen nicht gegenseitig ausschließend sind — ein einzelner Belagsbereich kann gleichzeitig Risse und Abplatzungen aufweisen — sind die schwellenwertbasierten Vorhersagen für jede Klasse unabhängig, und die Ausgabe wird korrekt als Multi-Label-Vorhersage interpretiert, nicht als Einzelklassenvorhersage.
In der TarmacView-Analysepipeline arbeitet der Defektkopf auf zwei Granularitätsebenen.
Analyse auf Kachelebene: Die Startbahnoberfläche wird in ein Gitter von Bildkacheln unterteilt (typischerweise 224×224 oder 512×512 Pixel bei der Inspektionsauflösung von 0,5-2,0 mm/Pixel). Jede Kachel wird unabhängig durch das DINOv3-Backbone und den MLP-Defektkopf verarbeitet, was einen 5-Elemente-Wahrscheinlichkeitsvektor pro Kachel produziert. Vorhersagen auf Kachelebene werden als pro-Kachel-Spalten in der Analyseausgabe gespeichert: tile_crack_conf, tile_spalling_conf, tile_efflorescence_conf, tile_exposed_rebar_conf, tile_corrosion_conf.
Aggregation auf Bildebene: Einzelne Kachelvorhersagen innerhalb eines Kamerabildes oder Startbahnabschnitts werden aggregiert, um Defektbewertungen auf Bildebene zu erzeugen. Aggregationsmethoden umfassen: Max-Pooling (die maximale Konfidenz über alle Kacheln im Bild), Mean-Pooling (durchschnittliche Konfidenz), Top-k-Abstimmung (der Anteil der Kacheln, die einen Schwellenwert überschreiten) und räumliche Dichte (die Anzahl der Defektkacheln pro Flächeneinheit). Spalten auf Bildebene in der Ausgabe umfassen frame_defect_count, frame_spalling_flag, frame_defect_count und frame_max_defect_conf.
Das Schema der Analyseausgabe ist eine kritische Komponente, die Smoke-Tests validieren müssen. Wenn die Konfidenzspalten auf Kachelebene oder die Aggregationsspalten auf Bildebene fehlen, umbenannt wurden oder ungültige Werte enthalten (NaN, inf, negative Wahrscheinlichkeiten), werden nachgelagerte Berechnungen des PCI (Pavement Condition Index) und Berichts-Pipelines fehlschlagen.
Smoke-Test-Assertions sind die spezifischen, automatisierten Prüfungen, die überprüfen, ob die Defektkopf-Pipeline korrekt funktioniert. Jede Assertion zielt auf eine bestimmte Fehlerart ab und erzeugt ein klares Bestehen/Nichtbestehen-Ergebnis, das in die CI/CD-Pipeline-Steuerung integriert werden kann.
Die erste Kategorie von Smoke-Test-Assertions überprüft, ob der Defektkopf-Checkpoint — die gespeicherte Modellgewichtedatei — gültig und ladbar ist. Die Assertions umfassen:
Existenz der Checkpoint-Datei: Der Test stellt fest, dass die Checkpoint-Datei am angegebenen Pfad existiert. Dies erfasst Probleme, bei denen ein Trainingslauf fehlgeschlagen ist, der Checkpoint nicht in die Modellregistrierung hochgeladen wurde oder der Dateipfad in der Bereitstellungsumgebung falsch konfiguriert wurde. Die Assertion lautet: assert os.path.exists(checkpoint_path), f"Checkpoint nicht gefunden unter {checkpoint_path}".
Dateigrößen- und Prüfsummenvalidierung: Der Test überprüft, dass die Checkpoint-Datei eine Dateigröße größer als Null hat und optional ihre MD5- oder SHA256-Prüfsumme gegen einen gespeicherten Basiswert validiert. Eine Null-Byte-Datei oder eine beschädigte Herunterladung wird hier erfasst. Die Assertion lautet: assert os.path.getsize(checkpoint_path) > 0 und optional assert sha256(datei) == expected_sha256.
Torch-Ladbarkeit: Der Test lädt den Checkpoint mit torch.load() und stellt fest, dass der Vorgang ohne Ausnahme abgeschlossen wird. Dies erfasst beschädigte Dateien, Versionsinkompatibilitäten (z. B. ein mit PyTorch 2.0 gespeicherter Checkpoint, der mit PyTorch 1.8 geladen werden soll) und fehlende Abhängigkeiten. Die Assertion umschließt den Ladevorgang in einem Try/Except-Block und schlägt bei jeder Ausnahme fehl.
Struktur des Zustandswörterbuchs: Nach dem Laden stellt der Test fest, dass der Checkpoint die erwarteten Schlüssel des Zustandswörterbuchs enthält. Für das DINOv3-Backbone umfassen erwartete Schlüssel backbone.cls_token, backbone.patch_embed.proj.weight und Transformer-Block-Parameter. Für den MLP-Kopf umfassen erwartete Schlüssel head.0.weight, head.0.bias, head.2.weight, head.2.bias (für einen 2-schichtigen MLP). Der Test überprüft auch, dass alle erwarteten Schlüssel vorhanden sind und keine unerwarteten Schlüssel existieren, was auf eine Fehlanpassung der Modellarchitektur hindeuten könnte.
Die zweite Kategorie überprüft, ob ein Vorwärtsdurchlauf durch das kombinierte Backbone und den Kopf gültige Ausgaben produziert.
Tensorform-Validierung: Der Test erstellt einen synthetischen Eingabetensor der erwarteten Form (typischerweise [batch_size, 3, höhe, breite] mit batch_size=1-4, höhe=breite=224 für ViT-B/14), leitet ihn durch das Modell und stellt fest, dass die Ausgabetensorform [batch_size, 5] ist — genau 5 Logits entsprechend den 5 Defektklassen. Die Assertion lautet: assert output.shape == (batch_size, 5), f"Erwartete Form (batch_size, 5), erhalten {output.shape}".
Numerische Stabilitätsvalidierung: Der Test stellt fest, dass kein Ausgabewert NaN (Not a Number), unendlich oder negativ unendlich ist. NaN-Werte können aus numerischer Instabilität im Transformer-Backbone (z. B. Attention-Logit-Überlauf), Division durch Null in Normalisierungsschichten oder beschädigten Gewichten entstehen. Die Assertion lautet: assert not torch.isnan(output).any(), "Ausgabe enthält NaN-Werte" und assert not torch.isinf(output).any(), "Ausgabe enthält inf-Werte".
Softmax-Wahrscheinlichkeitsvalidierung: Der Test wendet Softmax auf die rohen Logits an und stellt fest, dass die resultierenden Wahrscheinlichkeiten für jede Stichprobe im Batch zu 1,0 summieren (innerhalb der Gleitkomma-Toleranz, typischerweise 1e-5). Dies bestätigt, dass die Ausgabeschicht korrekt konfiguriert ist und kein Nachbearbeitungsschritt die Wahrscheinlichkeitsverteilung verfälscht. Die Assertion lautet: assert torch.allclose(probs.sum(dim=1), torch.ones(batch_size), atol=1e-5).
Die dritte Kategorie überprüft, dass das Modell vernünftige Vorhersageverteilungen anstatt degenerierter Ausgaben produziert.
Prüfung auf nicht-gleichförmige Verteilung: Der Test stellt fest, dass die vorhergesagten Wahrscheinlichkeiten nicht gleichmäßig über alle Klassen verteilt sind (was auf ein Modell hindeuten würde, das keine diskriminierenden Merkmale gelernt hat). Die Entropie der vorhergesagten Verteilung wird berechnet und mit einem Mindestschwellenwert verglichen. Eine vollständig gleichmäßige Verteilung hat maximale Entropie (log(5) ≈ 1,61 nats für 5 Klassen), während eine sichere Vorhersage eine niedrige Entropie aufweist. Die Assertion lautet: assert entropy < 1.5, "Vorhersagen sind nahezu gleichmäßig, Modell wurde möglicherweise nicht trainiert".
Klassenabdeckungsprüfung: Der Test führt Inferenz auf einer kleinen Menge verschiedener Eingabebilder durch und stellt fest, dass jede der 5 Defektklassen für mindestens eine Eingabe die Vorhersage mit der höchsten Konfidenz ist. Dies überprüft, dass keine Klasse systematisch unterdrückt wird — ein Modell, das niemals “Ausblühung” vorhersagt, würde auf ein Ungleichgewicht der Trainingsdaten oder ein Problem mit der Kopfkonfiguration hindeuten. Die Assertion lautet: assert set(predicted_classes) == set(range(5)), f"Klassen {missing} nie vorhergesagt".
Behandlung der Hintergrundklasse: Wenn das Modell eine implizite Hintergrund- oder “Kein Defekt”-Klasse enthält, überprüft der Smoke-Test, dass ein Bild eines intakten Belags — frei von jeglichen Defekten — eine Hintergrundvorhersage mit einer Konfidenz über einem Schwellenwert (typischerweise 0,8) produziert. Dies bestätigt, dass das Modell negative Beispiele korrekt ablehnen kann, was entscheidend ist, um Fehlalarme in Produktionsinspektionen zu vermeiden.
Die Checkpoint-Validierung ist eine grundlegende Smoke-Test-Komponente, die bestätigt, dass das Modell-Artefakt — die gespeicherten neuronalen Netzwerkgewichte — intakt, ladbar und strukturell mit der erwarteten Architektur konsistent ist. In Produktions-ML-Systemen gehören Checkpoint-Beschädigung oder Versionskonflikte zu den häufigsten Fehlerarten, und deren frühzeitige Erkennung in CI/CD verhindert kaskadierende Fehler in nachgelagerten Systemen.
TarmacView-Defektkopf-Checkpoints werden in der Modellregistrierung gespeichert — einem zentralen Artefakt-Speicher mit Versionierung, Metadaten und Herkunftsverfolgung (MLflow Model Registry oder DVC). Jeder Checkpoint wird durch eine eindeutige Kombination aus Modellname, Versionsnummer und Run-ID identifiziert. Die Checkpoint-Datei selbst ist ein serialisiertes PyTorch-Zustandswörterbuch (typischerweise model.pt oder checkpoint.pt), das die gelernten Parameter sowohl des DINOv3-Backbones (falls feinabgestimmt) als auch des MLP-Kopfes enthält.
Der Smoke-Test löst zunächst den Checkpoint-Pfad aus der Modellregistrierung auf und behandelt dabei die folgenden Fälle:
defect-head:v3), und der Test lädt genau diese Version.Das DINOv3-Backbone ist ein großes Modell mit 86 Millionen Parametern für die ViT-B/14-Variante. Der Smoke-Test überprüft, dass das geladene Backbone mit der erwarteten Architektur übereinstimmt, indem Folgendes geprüft wird:
Gewichtstensor-Formen: Jeder Parameter-Tensor im geladenen Zustandswörterbuch wird mit der erwarteten Form verglichen. Beispielsweise sollte der backbone.patch_embed.proj.weight-Tensor die Form (768, 3, 14, 14) für ein ViT-B/14 mit 3 Eingabekanälen, 768 Ausgabekanälen und einem 14×14-Patch-Kernel haben. Eine Formabweichung würde darauf hindeuten, dass der Checkpoint mit einer anderen Konfiguration trainiert wurde (andere Patch-Größe, andere Einbettungsdimension, andere Eingabekanäle).
Numerische Bereichsplausibilität: Der Test überprüft, dass die Gewichtswerte innerhalb erwarteter numerischer Bereiche liegen. Transformer-Attention-Gewichte sollten Werte haben, die ungefähr als N(0, σ²) verteilt sind, wobei σ vom Initialisierungsschema abhängt. Extreme Werte (|w| > 10) über alle Schichten hinweg würden auf Trainingsdivergenz oder Checkpoint-Beschädigung hindeuten. Die Prüfung berechnet den Mittelwert und die Standardabweichung jedes Parameter-Tensors und markiert Ausreißer.
Konsistenz der Ausgabeeinbettung: Der Test führt eine feste synthetische Eingabe durch das Backbone und vergleicht die Verteilung der Ausgabeeinbettung mit einem gespeicherten Basiswert. Der Basiswert wird während des ersten erfolgreichen Smoke-Test-Laufs erzeugt und als Referenz gespeichert. Die Assertion prüft, dass der Mittelwert und die Varianz der Einbettung nicht über eine Toleranz hinaus abweichen (typischerweise ±5%). Dies erfasst stille Modellverschlechterungen, die keine NaN- oder inf-Werte produzieren, aber dennoch anomale Einbettungen erzeugen.
Der MLP-Kopf ist kleiner als das Backbone, aber ebenso kritisch. Der Smoke-Test überprüft:
Schichtenanzahl: Der Kopf sollte genau die erwartete Anzahl von Schichten haben. Für einen 2-schichtigen MLP mit versteckter Dimension 256 umfassen die erwarteten Schlüssel head.0.weight (768×256), head.0.bias (256), head.2.weight (256×5), head.2.bias (5). Die Schichtnummerierung berücksichtigt die Aktivierungsfunktion (Schicht 1) zwischen den linearen Schichten.
Ausgabedimension: Die Ausgabedimension der finalen linearen Schicht muss genau 5 sein, entsprechend den 5 Defektklassen. Dies wird durch Prüfen von head.2.weight.shape[0] == 5 überprüft.
Konsistenz der Gewichtsinitialisierung: Der Test prüft, dass Gewichte nicht bei Initialisierungswerten (alle Nullen oder alle Einsen) eingefroren sind. Ein Kopf mit Null-Gewichten würde unabhängig von der Eingabe gleichmäßige Logits produzieren, was auf einen Trainingsfehler hindeutet. Die Prüfung stellt sicher, dass head.2.weight.std() > 0.001.
Während der Smoke-Test hauptsächlich die Pipeline-Integrität und nicht die Modellqualität betrifft, bietet die Einbeziehung leichtgewichtiger Metrikberechnung in den Smoke-Test eine Frühwarnung vor signifikanter Modellregression. Der Smoke-Test berechnet Effektivitätsmetriken auf synthetischen oder kleinen statischen Testdaten und vergleicht sie mit Basiswerten, die von früheren validierten Läufen gespeichert wurden.
Average Precision (AP) ist die Fläche unter der Precision-Recall-Kurve, berechnet über Konfidenzschwellen von 0 bis 1. Der Smoke-Test berechnet AP für jede der 5 Defektklassen unter Verwendung der COCO-Bewertung:
Die Smoke-Test-AP-Assertions umfassen:
AP@0,50 (PASCAL VOC-Metrik): AP bei einem IoU-Schwellenwert von 0,50. Die Assertion lautet, dass AP@0,50 für jede Klasse einen Mindestschwellenwert überschreitet. Für synthetische Testdaten mit bekannten, sauberen Defektmustern beträgt ein typischer Schwellenwert AP@0,50 > 0,85 für alle 5 Klassen. Wenn das Modell AP@0,50 unter diesem Schwellenwert auf trivialen synthetischen Daten erreicht, deutet dies auf eine schwerwiegende Regression hin.
AP@0,50:0,95 (COCO-Primärmetrik): Der Durchschnitt der AP-Werte, berechnet bei IoU-Schwellenwerten 0,50, 0,55, …, 0,95. Der Assertions-Schwellenwert ist niedriger — typischerweise AP@0,50:0,95 > 0,50 — da die strengen IoU-Schwellenwerte selbst auf synthetischen Daten anspruchsvoller sind.
Klassenübergreifende AP-Konsistenz: Die Varianz von AP über die 5 Klassen wird geprüft. Eine Standardabweichung von mehr als 0,15 würde darauf hindeuten, dass eine Klasse im Vergleich zu den anderen signifikant regrediert ist, was auf ein für diesen Defekttyp spezifisches Problem hindeutet (z. B. unzureichende Trainingsbeispiele für Ausblühung).
Der synthetische Testdatensatz wird sorgfältig konstruiert, um Metrikstabilität zu gewährleisten. Jedes synthetische Bild enthält genau einen Defekttyp, der über eine belagsähnliche Hintergrundtextur gelegt ist. Defekte werden mit prozeduralen Techniken generiert: Risse als dünne, verzweigte schwarze Linien mit Gaußschem Weichzeichner für Realismus; Abplatzungen als unregelmäßige kreisförmige/ovale Bereiche mit Kantenrauigkeit; Ausblühungen als weiße, amorphe Flecken mit variierender Deckkraft; freiliegende Bewehrung als periodische dunkle kreisförmige Muster; Korrosion als rostfarbene unregelmäßige Kleckse. Der synthetische Datensatz wird versioniert und in das Repository eingecheckt, um deterministische, reproduzierbare Smoke-Test-Ergebnisse zu gewährleisten.
F1-Score ist das harmonische Mittel von Präzision und Recall und bietet ein einzelnes ausgewogenes Maß der Modellleistung. Der Smoke-Test berechnet F1 bei einem festen Konfidenzschwellenwert (typischerweise 0,5) für jede Defektklasse.
Die F1-Assertions umfassen:
Mindest-F1 pro Klasse: Jede Klasse muss F1 > 0,80 auf dem synthetischen Testset erreichen. Die Multi-Label-Natur der Defektvorhersageaufgabe bedeutet, dass F1 unabhängig pro Klasse berechnet wird.
Makro-gemittelter F1: Der ungewichtete Durchschnitt von F1 über alle 5 Klassen wird berechnet. Der Assertions-Schwellenwert ist Makro-F1 > 0,85. Der Makro-Durchschnitt behandelt alle Klassen gleich, sodass eine Regression bei einer seltenen Klasse (z. B. freiliegende Bewehrung) sofort sichtbar ist.
Präzision-Recall-Gleichgewicht: Das Verhältnis von Präzision zu Recall wird für jede Klasse geprüft. Ein Verhältnis über 1,5 oder unter 0,67 deutet auf ein Ungleichgewicht hin — das Modell ist entweder zu konservativ (hohe Präzision, niedriger Recall, übersieht viele Defekte) oder zu aggressiv (hoher Recall, niedrige Präzision, erzeugt viele Fehlalarme). Die Assertion markiert jede Klasse, bei der das Verhältnis außerhalb von [0,67, 1,5] liegt.
| Metrik | Synthetischer Test-Schwellenwert | Zweck |
|---|---|---|
| AP@0,50 | > 0,85 | Grundlegende Erkennungsfähigkeit pro Klasse |
| AP@0,50:0,95 | > 0,50 | Umfassende Erkennungsqualität |
| Klassen-AP-Standardabw. | < 0,15 | Klassenbalance-Prüfung |
| F1 pro Klasse | > 0,80 | Ausgewogene Präzision-Recall pro Klasse |
| Makro-gemittelter F1 | > 0,85 | Gesamtmodellqualität |
| Präzision/Recall-Verhältnis | [0,67, 1,5] | Präzision-Recall-Gleichgewicht pro Klasse |
Der Smoke-Test speichert Metrik-Basiswerte vom letzten validierten Lauf und vergleicht aktuelle Metriken mit diesen Basiswerten. Ein signifikanter Abfall (>5% relative Verringerung) in einer Metrik löst einen Smoke-Test-Fehler aus, selbst wenn der absolute Metrikwert über dem Mindestschwellenwert liegt. Dies erfasst schleichende Verschlechterung — Modelle, die absolute Schwellenwerte bestehen, aber über aufeinanderfolgende Trainingsläufe oder Datenaktualisierungen hinweg konsequent in der Leistung nachlassen.
Metrikverläufe werden in einer Zeitreihendatenbank protokolliert (MLflow, Weights & Biases oder eine einfache CSV-Datei im Repository). Der Smoke-Test liest die letzten 10 validierten Metrikwerte und passt einen linearen Trend an. Wenn die Steigung negativ und statistisch signifikant ist (p < 0,05), gibt der Test eine Warnung aus, schlägt jedoch nicht fehl — eine Schwellenwert-basierte Fehlerkennung wird für CI/CD-Steuerung verwendet, um laute Pipeline-Unterbrechungen durch geringfügige Metrikschwankungen zu vermeiden.
Ein kritischer Smoke-Test validiert, dass die Analyseausgabe — die strukturierten Daten, die durch Ausführen des Defektkopfes auf Inspektionsbildern erzeugt werden — alle erwarteten Spalten mit korrekten Datentypen und gültigen Werten enthält. Dies überbrückt die Lücke zwischen Modellinferenz und nachgelagerter PCI-Berechnung (Pavement Condition Index), Berichterstellung und GIS-Integration.
Die TarmacView-Analyseausgabe ist ein tabellarisches Format (Parquet, CSV oder Datenbanktabelle) mit Spalten, die in Ebenen organisiert sind:
Defektkonfidenzspalten auf Kachelebene — eine Gleitkommaspalte pro Defektklasse, die die Softmax-Konfidenz des MLP-Kopfes repräsentiert, dass die Kachel diesen Defekt enthält:
| Spaltenname | Datentyp | Gültiger Bereich | Beschreibung |
|---|---|---|---|
tile_crack_conf | Float32 | [0,0, 1,0] | Wahrscheinlichkeit des Vorhandenseins von Rissen |
tile_spalling_conf | Float32 | [0,0, 1,0] | Wahrscheinlichkeit des Vorhandenseins von Abplatzungen |
tile_efflorescence_conf | Float32 | [0,0, 1,0] | Wahrscheinlichkeit des Vorhandenseins von Ausblühungen |
tile_exposed_rebar_conf | Float32 | [0,0, 1,0] | Wahrscheinlichkeit des Vorhandenseins freiliegender Bewehrung |
tile_corrosion_conf | Float32 | [0,0, 1,0] | Wahrscheinlichkeit des Vorhandenseins von Korrosion |
Aggregationsspalten auf Bildebene — Zusammenfassung des Defektvorkommens über alle Kacheln in einem Kamerabild oder Startbahnabschnitt:
| Spaltenname | Datentyp | Gültiger Bereich | Beschreibung |
|---|---|---|---|
frame_defect_count | Int32 | [0, max_tiles] | Anzahl der Kacheln mit einem Defekt über dem Schwellenwert |
frame_max_defect_conf | Float32 | [0,0, 1,0] | Maximale Konfidenz über alle Defekte und Kacheln |
frame_crack_flag | Boolean | {0, 1} | Eine Kachel hat crack_conf > Schwellenwert |
frame_spalling_flag | Boolean | {0, 1} | Eine Kachel hat spalling_conf > Schwellenwert |
frame_efflorescence_flag | Boolean | {0, 1} | Eine Kachel hat efflorescence_conf > Schwellenwert |
frame_exposed_rebar_flag | Boolean | {0, 1} | Eine Kachel hat exposed_rebar_conf > Schwellenwert |
frame_corrosion_flag | Boolean | {0, 1} | Eine Kachel hat corrosion_conf > Schwellenwert |
Metadatenspalten — Identifizierung des räumlichen und zeitlichen Kontexts jedes Analysedatensatzes:
| Spaltenname | Datentyp | Beschreibung |
|---|---|---|
image_id | String | Eindeutige Kennung für das Quellbild |
tile_x | Int32 | Kachelspaltenindex im Startbahnraster |
tile_y | Int32 | Kachelzeilenindex im Startbahnraster |
frame_timestamp | DateTime | Aufnahmezeitpunkt des Quellbildes |
gps_lat | Float64 | GPS-Breitengrad des Kachelmittelpunkts |
gps_lon | Float64 | GPS-Längengrad des Kachelmittelpunkts |
Der Smoke-Test lädt die Analyseausgabe und stellt fest, dass jede erwartete Spalte existiert, indem einfacher Spaltennamenabgleich verwendet wird:
expected_tile_cols = ["tile_crack_conf", "tile_spalling_conf",
"tile_efflorescence_conf", "tile_exposed_rebar_conf",
"tile_corrosion_conf"]
expected_frame_cols = ["frame_defect_count", "frame_max_defect_conf",
"frame_crack_flag", "frame_spalling_flag",
"frame_efflorescence_flag", "frame_exposed_rebar_flag",
"frame_corrosion_flag"]
expected_meta_cols = ["image_id", "tile_x", "tile_y",
"frame_timestamp", "gps_lat", "gps_lon"]
actual_cols = set(df.columns)
assert expected_cols.issubset(actual_cols), f"Fehlende Spalten: {expected_cols - actual_cols}"
Für jede Defektkonfidenzspalte stellt der Smoke-Test Folgendes fest:
Gleitkommatyp: Der Spaltendatentyp ist float32 oder float64. Unerwartete Typen (int, string, object) deuten auf einen Serialisierungs- oder Pipelinefehler hin. Die Assertion verwendet assert df[col].dtype in [np.float32, np.float64].
Wertebereich: Alle Werte liegen in [0,0, 1,0]. Werte außerhalb dieses Bereichs deuten auf einen Softmax- oder Normalisierungsfehler hin. Die Assertion verwendet assert df[col].between(0.0, 1.0).all().
Fehlende Werteprüfung: Keine Werte sind NaN oder None. NaN-Werte in Konfidenzspalten deuten darauf hin, dass die Inferenz-Pipeline für einige Kacheln keine Ausgabe produziert hat — ein schwerwiegender Fehler. Die Assertion verwendet assert df[col].notna().all().
Die Spalten auf Bildebene sollten mit den Kachelebendaten, aus denen sie abgeleitet werden, konsistent sein. Der Smoke-Test validiert:
frame_defect_count entspricht der Anzahl der Kacheln, bei denen die maximale Konfidenz den Schwellenwert überschreitet: Für jede Bildgruppe berechnet der Test die Defektanzahl aus den Kachelebendaten neu und stellt fest, dass sie mit dem gespeicherten Bildwert übereinstimmt. Dies erfasst Aggregationslogikfehler in der Pipeline.
frame_max_defect_conf entspricht dem Maximum aller Kachelkonfidenzwerte: Der Test berechnet das Maximum aus den Kachelebendaten neu und stellt die Übereinstimmung fest.
frame_flag ist konsistent mit tile_conf: Für jedes Bild sollte das Flag 1 sein, wenn eine Kachel die entsprechende Konfidenz über dem Schwellenwert hat, andernfalls 0. Der Test überprüft dies für alle 5 Defektarten.
Diese Konsistenzprüfungen basieren auf dem Prinzip, dass die Spalten auf Bildebene deterministisch ableitbar aus den Spalten auf Kachelebene sein sollten. Wenn die Aggregationslogik korrekt ist, sollten die Prüfungen immer bestanden werden. Ein Fehler deutet auf einen Bug im Nachbearbeitungsschritt der Analyse-Pipeline hin, nicht im Modell selbst.
Der Smoke-Test vergleicht die erwartete Spaltenmenge mit der tatsächlichen Spaltenmenge und erzeugt Warnungen für:
tile_moisture_conf), warnt der Test, schlägt aber nicht fehl, da dies auf eine Pipeline-Verbesserung hindeuten kann, die nachgelagerte Integrationsaktualisierungen erfordert.tile_crack_conf → tile_cracking_conf), schlägt der Test fehl und verhindert so stillschweigende nachgelagerte Ausfälle, wenn Berichts-Dashboards, APIs oder Datenbanken auf die alten Spaltennamen verweisen.Die Steuerungslogik bestimmt, ob der Defektkopf den Smoke-Test als Ganzes besteht oder nicht, basierend auf einer gewichteten Kombination einzelner Assertionsergebnisse. Die Steuerung ist der Mechanismus, der verhindert, dass ein fehlschlagendes Modell in der Produktion bereitgestellt wird.
Nicht alle Smoke-Test-Assertions sind gleich kritisch. Das Steuerungssystem weist jeder Assertion eine Schweregradstufe zu:
| Stufe | Gewicht | Auswirkung auf Steuerung | Beispiele |
|---|---|---|---|
| Fatal | 1,0 | Steuert sofort | Checkpoint-Ladefehler, NaN in Ausgaben |
| Kritisch | 0,8 | Steuert bei >1 Fehler | Fehlende Spalten, Ausgabeform-Konflikt |
| Warnung | 0,4 | Steuert bei >3 Fehlern | Klassen-AP unter Schwellenwert |
| Info | 0,0 | Nur Protokollierung, keine Steuerung | Metrik-Trend-Warnungen, Spaltenverfallsmitteilungen |
Fatale Assertions sind solche, bei denen keine gültige Pipeline-Ausführung möglich ist — Checkpoint ist beschädigt, Modell kann nicht geladen werden oder Inferenz produziert ungültige numerische Werte. Ein einziger fataler Fehler blockiert die Bereitstellung.
Kritische Assertions zeigen an, dass die Pipeline strukturell gültige, aber potenziell falsche Ergebnisse produziert — fehlende Spalten würden zu nachgelagerten Berichtsfehlern führen, eine Ausgabeform-Abweichung deutet auf eine Fehlanpassung der Modellarchitektur mit der Serving-Infrastruktur hin.
Warnungs-Assertions zeigen an, dass die Modellmetriken unter den nominalen Schwellenwerten liegen, die Pipeline jedoch strukturell intakt ist. Diese werden aggregiert: Wenn mehr als 3 Warnungen in einem einzigen Lauf ausgelöst werden, wird die Steuerung aktiviert.
Info-Assertions sind rein beobachtend — sie protokollieren Metrik-Trends, Spaltenverfallsmitteilungen und Leistungsvergleiche mit früheren Läufen — steuern aber niemals die Bereitstellung.
Das gesamte Smoke-Test-Ergebnis wird wie folgt berechnet:
gate_score = max(fatal_failures,
critical_failures > 1 ? 1.0 : 0.0,
warning_failures > 3 ? 1.0 : 0.0)
Wenn gate_score >= 1.0, schlägt der Smoke-Test fehl und die Bereitstellung wird blockiert. Wenn gate_score < 1.0, besteht der Smoke-Test und die Pipeline fährt mit der vollständigen Evaluierung oder Bereitstellung fort.
Die zusammengesetzte Bestehen/Nichtbestehen-Meldung fasst das Ergebnis zusammen:
SMOKE-TEST: FEHLGESCHLAGEN
- Fatal: 1 [checkpoint_load_failure]
- Kritisch: 0
- Warnung: 2 [class_crack_ap_unter_schwellenwert, class_efflorescence_f1_unter_schwellenwert]
- Info: 1 [metrik_class_crack_ap um 3,2 % seit letztem Lauf gefallen]
Die Smoke-Test-Steuerung integriert sich mit der Bereitstellungs-Pipeline durch:
Post-Commit-Hook: Der Smoke-Test wird bei jedem Pull-Request-Commit ausgeführt. Wenn die Steuerung fehlschlägt, blockiert das CI/CD-System den Merge (GitHub-Branch-Schutzregel, GitLab-Merge-Request-Pipeline-Fehler).
Pre-Deployment-Gate: Bevor ein Modell vom Staging in die Produktion befördert wird, wird der Smoke-Test erneut auf dem genauen Bereitstellungskandidaten-Artefakt ausgeführt. Dies erfasst Probleme, die während der Entwicklung möglicherweise nicht vorhanden waren — beispielsweise eine Entwicklungsumgebung mit einer anderen CUDA-Version als der Produktions-Serving-Umgebung.
Rollback-Auslöser: Wenn der Smoke-Test die Bereitstellung besteht, aber ein nachfolgender Produktionsvorfall auf den Defektkopf zurückgeführt wird, wird die Smoke-Test-Steuerungslogik überprüft. Wenn eine Assertion auf Warnstufe eine kritische Assertion hätte sein sollen, wird die Steuerungskonfiguration aktualisiert, um ein erneutes Auftreten zu verhindern.
Domänenanwendbarkeitstests erweitern den grundlegenden Smoke-Test, um zu überprüfen, ob der Defektkopf korrekt über die spezifischen Betriebsbedingungen hinweg funktioniert, denen TarmacView bei der Inspektion von Flugplatzbefestigungen und Infrastruktur begegnet. Diese Tests stellen sicher, dass die Pipeline nicht nur funktionsfähig, sondern für den Zielbereich zweckmäßig ist.
Der Defektkopf muss konsistent über verschiedene Belagstypen hinweg funktionieren, die auf Flugplatzoberflächen vorkommen:
Asphalt-Beläge (flexibel): Start- und Landebahnen, Rollwege und Vorfelder aus Heißasphalt (HMA). Defekte auf Asphalt umfassen Ermüdungsrisse (Alligatormuster), Längsrisse, Querrisse, Spurrinnen und Absandung. Der Smoke-Test enthält synthetische Bilder mit asphaltähnlichen Texturen (dunkelgrau, sichtbares Gesteinskorn, variierende Oberflächenrauigkeit) und überprüft, dass die Riss- und Abplatzungserkennung nominale Konfidenzniveaus beibehält.
Betonbeläge (starr): Start- und Landebahnen und Vorfelder aus Portlandzementbeton (PCC). Defekte umfassen Fugenabplatzungen, Eckabbrüche, lineare Risse, Ausblühungen (weiße Kalkablagerungen an Fugen), freiliegende Bewehrung (an abgeplatzten Stellen) und Korrosionsverfärbungen. Der Smoke-Test überprüft, dass das Modell Ausblühungen und freiliegende Bewehrung korrekt identifiziert — Defekte, die auf Betonoberflächen weitaus häufiger vorkommen als auf Asphalt.
Verbundbeläge: Asphaltdeckschichten auf vorhandenem Beton. Defekte umfassen Reflexionsrisse (Asphaltrisse, die dem darunterliegenden Betonfugenmuster folgen) und Delamination. Der Test überprüft, dass das Modell Risse auf Verbundoberflächen ohne Verwechslung mit dem darunterliegenden Fugenmuster erkennen kann.
Poröse Reibungsschichten (PFC): Hochdurchlässiger Asphalt, der auf Start- und Landebahnen für verbesserte Entwässerung und Reibung verwendet wird. PFC hat eine charakteristische offene Kornstruktur, die sich optisch von dichtem HMA unterscheidet. Der Test überprüft, dass das Modell keine erhöhten Falsch-Positiv-Raten auf PFC-Oberflächen produziert, wo die raue Textur mit Rissen oder Abplatzungen verwechselt werden könnte.
ICAO Annex 14 und FAA AC 150/5320-5D legen fest, dass Bewertungen des Startbahn-Oberflächenzustands unter Betriebsbedingungen gültig sein müssen. Der Domänenanwendbarkeits-Smoke-Test überprüft, dass der Defektkopf die Leistung unter folgenden Bedingungen beibehält:
Direktes Sonnenlicht: Hoher Kontrast, starke Schatten. Der Test überprüft, dass die Konfidenzwerte unter Hochkontrastbedingungen aufgrund von schattenbedingten Fehlalarmen nicht systematisch niedriger sind.
Bedecktes/diffuses Licht: Geringer Kontrast, keine Schatten. Der Test überprüft, dass feine Risse (schmal, geringer Kontrast zum Belag) bei reduzierten Konfidenzniveaus noch erkennbar sind.
Nasser Belag: Wasser in Rissen erhöht die Rissichtbarkeit, führt aber zu spiegelnden Reflexionen. Der Test überprüft, dass nasse Oberflächenkacheln keine erhöhten Falsch-Positiv-Raten aufgrund von spiegelnden Glanzlichtern produzieren, die mit Ausblühungen verwechselt werden (beide erscheinen als helle Bereiche).
Morgendämmerung/Abenddämmerung: Niedrige Lichtniveaus, lange Schatten. Der Test überprüft, dass das Modell Ausgaben innerhalb erwarteter Konfidenzbereiche produziert, selbst bei reduzierten Beleuchtungsniveaus.
Der Smoke-Test simuliert diese Bedingungen durch Anwendung kontrollierter photometrischer Transformationen auf die synthetischen Testbilder: Helligkeitsskalierung für Lichtsimulation, Gaußscher Weichzeichner für Dunst/Nebelsimulation und Sättigungsanpassung für Nassoberflächen-Simulation.
Inspektionsbilder variieren im Bodenabtastabstand (GSD) abhängig von der Aufnahmeplattform:
| Plattform | Typische Höhe | GSD (mm/Pixel) | Kachelabdeckung |
|---|---|---|---|
| UAV (hohe Auflösung) | 15-20 m | 0,5-1,0 | 0,1-0,5 m² |
| UAV (Standard) | 30-50 m | 1,0-2,0 | 0,5-2,0 m² |
| Fahrzeugmontiert | 2-3 m | 0,3-0,8 | 0,05-0,2 m² |
| Handheld | 1-1,5 m | 0,2-0,5 | 0,02-0,08 m² |
Der Smoke-Test überprüft, dass der Defektkopf konsistente Ausgaben über einen Bereich von Eingabeauflösungen hinweg produziert. Synthetische Testbilder werden in mehreren Maßstäben (0,5×, 1,0×, 2,0× des nominalen GSD) generiert und durch das Modell geleitet. Der Test stellt fest, dass sich die vorhergesagte Klassenverteilung zwischen den Auflösungen um nicht mehr als 10 % verschiebt, was sicherstellt, dass das Modell innerhalb des Betriebsbereichs annähernd skaleninvariant ist.
ASTM D5340 definiert drei Schweregrade (Niedrig, Mittel, Hoch) für jeden Defekttyp. Der Smoke-Test überprüft, dass die Konfidenzwerte des Defektkopfes mit dem Defektschweregrad korrelieren:
Niedriger Schweregrad: Haarrisse (<1 mm Breite), kleine Abplatzungen (<150 mm Länge), leichte Ausblühungen, minimale Korrosionsverfärbungen. Der Test stellt fest, dass diese Konfidenzwerte über dem Erkennungsschwellenwert (>0,5), aber nicht bei maximaler Konfidenz (<0,8) produzieren.
Mittlerer Schweregrad: Risse (1-3 mm Breite), Abplatzungen (150-600 mm Länge), mäßige Ausblühungsablagerungen, sichtbare freiliegende Bewehrung mit leichter Korrosion. Der Test stellt fest, dass die Konfidenzwerte hoch sind (>0,7).
Hoher Schweregrad: Weite Risse (>3 mm Breite), große Abplatzungen (>600 mm Länge), starke Ausblühungen mit Oberflächenstörung, freiliegende Bewehrung mit starker Korrosion und Querschnittsverlust. Der Test stellt fest, dass die Konfidenzwerte sehr hoch sind (>0,9).
Die Schweregrad-Korrelationsüberprüfung ist eine Warnstufen-Assertion im Steuerungssystem — das Modell kann auch bei unvollkommener Schweregradkorrelation korrekt funktionieren, aber der Test markiert es als Bereich für Modellverbesserungen.
Das Verständnis des Unterschieds zwischen Smoke-Testing und vollständiger Evaluierung ist entscheidend für die Entwicklung einer effektiven ML-Qualitätssicherungsstrategie. Die beiden Ansätze dienen grundlegend unterschiedlichen Zwecken und arbeiten an verschiedenen Punkten im Entwicklungs- und Bereitstellungslebenszyklus.
| Dimension | Smoke-Test | Vollständige Evaluierung |
|---|---|---|
| Ziel | Pipeline-Integrität überprüfen | Modellqualität messen |
| Beantwortete Frage | “Läuft die Pipeline korrekt?” | “Ist das Modell genau genug?” |
| Daten | Synthetischer / kleiner statischer Satz (10-100 Bilder) | Großer zurückgehaltener Validierungssatz (500-5000+ Bilder) |
| Dauer | Sekunden bis Minuten | Minuten bis Stunden |
| Rechenleistung | CPU oder minimale GPU | Volle GPU (oft Multi-GPU) |
| Häufigkeit | Jeder Commit / PR | Nächtlich, wöchentlich oder pro Release |
| Metrikschwellen | Großzügig (AP > 0,50) | Streng (AP > 0,75) |
| Abdeckung | Nur strukturelle Integrität | Statistische Generalisierung |
| Fehleraktion | Merge/Bereitstellung blockieren | Zur Überprüfung kennzeichnen |
Der Smoke-Test ist darauf ausgelegt, Pipeline-Fehler zu erfassen — die Art von Bugs, die das gesamte System zum Ausfall bringen oder bedeutungslose Ausgaben produzieren. Dazu gehören Checkpoint-Beschädigung, Versionsinkompatibilität, Unterbrechungen der Vorverarbeitungs-Pipeline, fehlende Spalten, NaN-Ausgaben und Formkonflikte. Branchendaten von ML-Engineering-Teams zeigen, dass Pipeline-Fehler 60-70 % der fehlgeschlagenen Trainingsläufe und 40 % der Bereitstellungs-Rollbacks ausmachen. Smoke-Tests erkennen diese Fehler in Sekunden, bevor teure vollständige Evaluierungsläufe gestartet werden.
Die vollständige Evaluierung ist darauf ausgelegt, die Modellqualität zu messen — die statistische Genauigkeit, Präzision, den Recall und die Generalisierung der Modellvorhersagen. Sie verwendet große, diverse, repräsentative Validierungsdatensätze, berechnet rigorose Metriken (AP@0,50:0,95, klassenweises F1, Konfusionsmatrizen, Precision-Recall-Kurven bei mehreren Schwellenwerten) und vergleicht Ergebnisse sowohl mit absoluten Schwellenwerten als auch mit relativen Basiswerten früherer Modellversionen. Vollständige Evaluierungsläufe sind rechenintensiv und zeitaufwändig, was sie für eine Ausführung pro Commit ungeeignet macht.
Smoke-Test-Daten werden synthetisch generiert, um einfach, sauber und deterministisch zu sein. Jedes synthetische Bild enthält genau einen Defekttyp auf einem gleichmäßigen Hintergrund, ohne Verdeckung, ohne überlappende Defekte und ohne herausfordernde Lichtbedingungen. Dies minimiert die Variabilität und stellt sicher, dass jede Metrikschwankung im Smoke-Test dem Modell und nicht der Datenvariabilität zuzuschreiben ist.
Vollständige Evaluierungsdaten sind reale Inspektionsbilder mit den folgenden Eigenschaften: verschiedene Belagstypen und -alter, alle Betriebslichtbedingungen, variierende Defektschweregrade, überlappende und benachbarte Defekte, reale Verdeckungen (Schutt, Reifenspuren, Wasser) und genaue Ground-Truth-Annotationen auf Polygon-Ebene. Diese Daten repräsentieren die tatsächliche Verteilung, der das Modell in der Produktion begegnet, und liefern eine zuverlässige Schätzung der Bereitstellungsleistung.
Datenleck-Prävention ist für die vollständige Evaluierung entscheidend, aber für Smoke-Tests irrelevant — da der Smoke-Test synthetische Daten verwendet, besteht kein Risiko, dass echte Testdaten in das Training gelangen. Der vollständige Evaluierungsdatensatz wird sorgfältig partitioniert: Trainings-, Validierungs- und Testsets werden auf Bild- oder Startbahnebene (nicht Kachelebene) aufgeteilt, um räumliche Autokorrelationslecks zu verhindern, bei denen benachbarte Kacheln derselben Startbahn sowohl in Trainings- als auch in Testsets erscheinen.
Ein typischer Smoke-Test-Lauf für die Defektkopf-Pipeline:
Ein typischer vollständiger Evaluierungslauf:
Der Smoke-Test ist 10-100× schneller als die vollständige Evaluierung und ermöglicht die Ausführung pro Commit. Die vollständige Evaluierung läuft in einem langsameren Rhythmus (pro Nacht, pro Release, pro Beförderung in die Produktion).
| Fehlermodus | Erkannt durch |
|---|---|
| Beschädigte Checkpoint-Datei | Smoke-Test (fatal) |
| NaN/inf in Modellausgaben | Smoke-Test (fatal) |
| Fehlende Ausgabespalten | Smoke-Test (kritisch) |
| Falsche Ausgabetensorform | Smoke-Test (kritisch) |
| Vorverarbeitungs-Normalisierungskonflikt | Smoke-Test (fatal) |
| Degenerierte Vorhersagen (alle gleiche Klasse) | Smoke-Test (Warnung) |
| 10 % AP-Abfall auf neuen Daten | Vollständige Evaluierung |
| Überanpassung an einen bestimmten Belagstyp | Vollständige Evaluierung |
| Kalibrierungsdrift | Vollständige Evaluierung |
| Label-Rauschen in Trainingsdaten | Vollständige Evaluierung |
Die Abdeckungsmatrix zeigt, dass Smoke-Tests und vollständige Evaluierungen komplementär sind — jede erfasst Fehlermodi, die die andere übersieht. Eine umfassende ML-Teststrategie erfordert beide.
Die Integration des Defektkopf-Smoke-Tests in Continuous-Integration (CI)-Pipelines ist unerlässlich, um Regressionen frühzeitig zu erkennen und sicherzustellen, dass jede Codeänderung validiert wird, bevor sie Produktionssysteme beeinträchtigt.
Die CI-Pipeline für TarmacViews Defekterkennungssystem ist in aufeinanderfolgende Stufen organisiert:
Stufe 1 — Code-Qualität: Linting (flake8, pylint), Typprüfung (mypy), Unit-Tests (pytest für Datenlade-Hilfsfunktionen, Vorverarbeitungsfunktionen und Metrikberechnungsfunktionen). Diese Stufe läuft auf CPU und wird in 1-3 Minuten abgeschlossen. Fehler blockieren alle nachgelagerten Stufen.
Stufe 2 — Datenvalidierung: Validierung von Trainings- und Evaluierungsdatensätzen mit Great Expectations oder TensorFlow Data Validation. Prüft Spaltenexistenz, Datentypen, Wertebereiche und Verteilungsstatistiken gegen Erwartungen aus dem Datenvertrag. Diese Stufe läuft auf CPU und wird in 2-5 Minuten abgeschlossen.
Stufe 3 — Defektkopf-Smoke-Test: Die vollständige Smoke-Test-Suite, wie in diesem Artikel beschrieben. Läuft auf CPU (oder minimaler GPU, falls verfügbar) und wird in 15-60 Sekunden abgeschlossen. Fehler blockieren den Merge auf Main.
Stufe 4 — Unit-Tests für Evaluierung: Kleinskalige Metrikberechnungstests, die überprüfen, ob AP-Berechnung, F1-Berechnung und Konfusionsmatrix-Erstellung korrekte Ausgaben auf handgekennzeichneten winzigen Datensätzen (5-10 Bilder mit bekanntem Ground Truth) produzieren. Läuft auf CPU, wird in 30 Sekunden abgeschlossen.
Stufe 5 — Training (auf Abruf): Wird nur ausgelöst, wenn sich die Modellgewichte voraussichtlich ändern (neue Trainingsdaten, Architekturänderungen, Hyperparameter-Optimierung). Wird nicht automatisch bei jedem Commit ausgelöst. Läuft auf GPU und dauert 1-8 Stunden, abhängig von der Datensatzgröße.
Stufe 6 — Vollständige Evaluierung (bei Merge auf Main): Wird ausgelöst, wenn Code in den Main-Branch gemergt wird. Führt die vollständige Evaluierungssuite auf dem zurückgehaltenen Validierungssatz aus, berechnet alle Metriken, vergleicht mit Basiswerten und veröffentlicht Ergebnisse in der Modellregistrierung. Läuft auf GPU und dauert 20-40 Minuten.
Der Smoke-Test wird ausgelöst bei:
CI-Artefakte aus dem Smoke-Test werden gespeichert und versioniert:
Diese Artefakte werden zusammen mit dem Modell-Artefakt selbst in der Modellregistrierung gespeichert und bieten eine vollständige Prüfkette: “Diese Version des Modells hat den Smoke-Test mit synthetischen Daten v3.2 auf CI-Lauf #4827 mit Commit a3f2c1 bestanden.”
Wenn der Smoke-Test fehlschlägt, werden Benachrichtigungen über mehrere Kanäle gesendet:
Die Benachrichtigung enthält einen strukturierten Fehlerbericht:
Betreff: [SMOKE-FEHLER] defect-head-pipeline - main - Lauf #4827
Text:
Commit: a3f2c1 (gemerged 12:34 UTC)
Checkpoint: defect-head:v3 (Produktionskandidat)
Ergebnis: FEHLGESCHLAGEN (Steuerungswert=1,0)
Fatal (1):
- [output_nan] Ausgabetensor enthält NaN-Werte
Backbone-Vorwärtsdurchlauf produzierte NaN bei Layer-Norm 8
Kritisch (0):
Warnung (2):
- [class_efflorescence_ap] AP@0,50 = 0,42 unter Schwellenwert 0,50
- [class_efflorescence_f1] F1 = 0,55 unter Schwellenwert 0,60
Erforderliche Maßnahme: Untersuchen Sie NaN in Backbone Layer-Norm 8.
Mögliche Ursachen: beschädigter Checkpoint, CUDA-Versionskonflikt,
oder numerische Instabilität in der Attention-Berechnung.
Die korrekte Interpretation der Smoke-Test-Ausgaben ist wesentlich für die Diagnose von Pipeline-Problemen und die Bestimmung geeigneter Abhilfemaßnahmen.
Der Smoke-Test erzeugt einen umfassenden JSON-Bericht, der wie folgt strukturiert ist:
{
"pipeline_id": "defect-head-smoke",
"run_id": "2026-06-16-4827",
"timestamp": "2026-06-16T12:34:56Z",
"commit_sha": "a3f2c1d4e5b6...",
"checkpoint_version": "defect-head:v3",
"synthetic_data_version": "v3.2",
"gate_result": "FEHLGESCHLAGEN",
"gate_score": 1.0,
"assertions": {
"checkpoint_file_exists": {"status": "BESTANDEN", "detail": "checkpoint.pt (842MB)"},
"checkpoint_loadable": {"status": "BESTANDEN", "detail": "Zustandswörterbuch erfolgreich geladen"},
"forward_pass_shape": {"status": "BESTANDEN", "detail": "Ausgabeform (8, 5)"},
"output_no_nan": {"status": "FEHLGESCHLAGEN", "detail": "NaN in 1 von 8 Batch-Stichproben gefunden"},
"output_no_inf": {"status": "BESTANDEN", "detail": "Keine inf-Werte"},
"softmax_sum": {"status": "BESTANDEN", "detail": "Alle Summen innerhalb von 1e-5 von 1,0"},
"tile_columns_exist": {"status": "BESTANDEN", "detail": "Alle 5 Kachelspalten vorhanden"},
"frame_columns_exist": {"status": "BESTANDEN", "detail": "Alle 7 Bildspalten vorhanden"},
"column_value_ranges": {"status": "BESTANDEN", "detail": "Alle Werte in [0,0, 1,0]"},
"class_crack_ap50": {"status": "BESTANDEN", "detail": "AP@0,50 = 0,92"},
"class_spalling_ap50": {"status": "BESTANDEN", "detail": "AP@0,50 = 0,88"},
"class_efflorescence_ap50": {"status": "WARNUNG", "detail": "AP@0,50 = 0,42"},
"class_exposed_rebar_ap50": {"status": "BESTANDEN", "detail": "AP@0,50 = 0,91"},
"class_corrosion_ap50": {"status": "BESTANDEN", "detail": "AP@0,50 = 0,90"}
}
}
Der Bericht sollte von oben nach unten gelesen werden, wobei zuerst fatale Fehler behandelt werden (da sie alle nachgelagerten Ergebnisse ungültig machen), dann kritische Fehler (strukturelle Probleme, die Produktionsausfälle verursachen würden) und schließlich Warnungs-Fehler (Qualitätsverschlechterungen, die möglicherweise untersucht werden müssen).
Fatale Fehler zeigen an, dass die Pipeline vollständig nicht funktionsfähig ist. Die häufigsten Ursachen und Abhilfemaßnahmen:
Checkpoint-Datei nicht gefunden: Der in der Pipeline-Konfiguration angegebene Checkpoint-Pfad verweist auf keine vorhandene Datei. Abhilfe: Überprüfen Sie den Pfad in der Modellregistrierung, stellen Sie sicher, dass der Trainingslauf abgeschlossen wurde und das Artefakt hochgeladen hat, oder aktualisieren Sie die Konfiguration mit dem korrekten Pfad.
Checkpoint-Ladefehler: torch.load() hat eine Ausnahme ausgelöst. Häufige Ursachen: Dateibeschädigung (Training wiederholen oder aus Backup wiederherstellen), PyTorch-Versionskonflikt (überprüfen, ob die Bereitstellungsumgebung dieselbe PyTorch-Version wie die Trainingumgebung hat — torch.save() mit PyTorch 2.0 erzeugt Dateien, die auf PyTorch 1.x anders geladen werden), oder CUDA/Nicht-CUDA-Konflikt (ein mit CUDA-Tensoren gespeicherter Checkpoint lässt sich möglicherweise nicht in einer CPU-only-Umgebung ohne map_location='cpu' laden).
NaN in Ausgaben: Der technisch anspruchsvollste fatale Fehler. Häufige Ursachen: numerische Instabilität im DINOv3-Attention-Mechanismus (Layer-Normalisierungsüberlauf bei extremen Eingabewerten), beschädigte Gewichte in einer bestimmten Schicht (überprüfen, welche Schicht das NaN produziert, durch Ausführen mit torch.autograd.set_detect_anomaly(True)), oder Vorverarbeitung, die Eingaben außerhalb des zulässigen Bereichs erzeugt (z. B. Pixelwerte außerhalb [0,1] nach Normalisierung).
Ausgabeform-Konflikt: Der Ausgabetensor hat eine andere Form als erwartet. Häufige Ursachen: Der MLP-Kopf wurde durch eine andere Architektur ersetzt (andere Anzahl von Ausgabeklassen), die Backbone-Einbettungsdimension hat sich geändert (Checkpoint von einer anderen DINOv3-Variante), oder die Batch-Dimension wurde im Nachbearbeitungscode falsch gequetscht/entquetscht.
Kritische Fehler zeigen strukturelle Probleme an, die zu falschem Produktionsverhalten führen würden.
Fehlende Spalten: Der Analyseausgabe-DataFrame vermisst erwartete Spalten. Häufige Ursachen: Die Spaltenbenennungskonvention wurde geändert, ohne nachgelagerte Verbraucher zu aktualisieren; die Aggregationslogik wurde modifiziert, um Spalten umzubenennen; oder die Defektkopfausgabe wurde geändert (z. B. von 5 Klassen auf 4 Klassen).
Wertebereichsverletzungen: Konfidenzwerte außerhalb [0,0, 1,0]. Dies deutet fast immer auf eine Softmax-Fehlfunktion hin — entweder wurde Softmax nicht auf die Logits angewendet oder die falsche Achse für die Softmax-Normalisierung verwendet. Überprüfen Sie, dass F.softmax(logits, dim=1) verwendet wird (Klassendimension, nicht Batch-Dimension).
NaN in Ausgabespalten: Ähnlich wie fatale NaN in Modellausgaben, tritt jedoch im Nachbearbeitungs-Aggregationsschritt auf. Überprüfen Sie auf Division durch Null in der Kachel-zu-Bild-Aggregation (z. B. Division durch Anzahl der Kacheln, wenn ein Bild null Kacheln hat), oder auf fehlende Wertweitergabe von NaN-Modellausgaben, die auf Modellebene nicht erfasst wurden.
Warnungsfehler zeigen Qualitätsverschlechterungen an, die möglicherweise keine sofortige Blockierung der Bereitstellung erfordern, aber untersucht werden sollten.
Klassenspezifische AP unter Schwellenwert: Eine einzelne Defektklasse zeigt eine deutlich geringere Leistung als andere. Häufige Ursachen: unzureichende synthetische Trainingsbeispiele für diese Klasse (der synthetische Datengenerator kann für einige Klassen unrealistische Beispiele produzieren), Klassenungleichgewicht in den realen Trainingsdaten, das die Unterscheidungsfähigkeit des Kopfes für seltene Klassen beeinträchtigt, oder die Backbone-Merkmale sind für bestimmte Defekttypen weniger informativ (z. B. ist Ausblühung eher durch Farbe (weiße Ablagerungen) als durch Textur gekennzeichnet, während DINOv3-Merkmale Textur über Farbe betonen können).
Präzision-Recall-Ungleichgewicht: Das Modell ist für bestimmte Klassen zu konservativ oder zu aggressiv. Häufige Ursachen: Der Konfidenzschwellenwert wurde für die Gesamtleistung optimiert, ist aber für einzelne Klassen suboptimal, oder die Trainingsdaten haben asymmetrisches Rauschen (mehr falsch Negative als falsch Positive für eine bestimmte Klasse).
Metrikdrift vom Basiswert: Metriken haben sich ohne Code- oder Datenänderungen um mehr als 5 % vom letzten validierten Lauf geändert. Dies kann auf Folgendes hindeuten: Nichtdeterminismus im Modell (Dropout- oder Batch-Norm-Schichten, die sich im Trainings- vs. Evaluierungsmodus unterschiedlich verhalten — stellen Sie sicher, dass model.eval() vor der Inferenz aufgerufen wird), numerischer Drift aufgrund von Hardwareunterschieden (CPU vs. GPU Gleitkomma-Additionsreihenfolge) oder Änderungen am synthetischen Datengenerator, die unterschiedliche Teststichproben produzieren.
Die Smoke-Test-Ausgabe enthält Abhilfevorschläge für häufige Fehlermodi:
| Fehler | Abhilfevorschlag |
|---|---|
| Checkpoint nicht gefunden | Pfad in Modellregistrierung überprüfen; Training ausführen, um Checkpoint zu erzeugen |
| NaN im Backbone | Auf float32-Genauigkeit umstellen, wenn float16 verwendet wird; Gradienten-Clipping hinzufügen |
| Fehlende Spalte | Spaltennamen in Aggregationslogik aktualisieren, um sie dem Schema anzupassen |
| Niedrige AP bei bestimmter Klasse | Mehr synthetische Trainingsbeispiele für diese Klasse hinzufügen; Klassenbalance prüfen |
| Metrikdrift | Inferenz mit torch.inference_mode() und model.eval() ausführen; auf nichtdeterministische Operationen prüfen |
Diese Vorschläge werden von einem regelbasierten System generiert, das Assertionsfehlermuster bekannten Abhilfemaßnahmen zuordnet, wodurch die mittlere Lösungszeit (MTTR) für häufige Fehlermodi reduziert wird.

TarmacView implementiert rigorose Smoke-Testing- und Evaluierungs-Pipelines für KI-basierte Strukturdefekterkennung auf Flugplatzbefestigungen und Betoninfrastruktur. Vereinbaren Sie eine Demo, um zu sehen, wie automatisierte Tests die Ausfallsicherheit bei der Bereitstellung gewährleisten.
Ein Smoke-Test ist eine schnelle End-to-End-Überprüfung, ob eine Software-Pipeline mit repräsentativen Daten ohne Absturz ausgeführt wird und erwartete Ergebnis...
DINOv3 (self-DIstillation with NO labels v3) ist ein selbstüberwachter Vision Transformer (ViT-B/16), der auf 1,7 Milliarden Bildern vortrainiert wurde und hoch...
Defect Gating ist eine Inferenzstrategie, die vorhergesagte Defektlabel nach Oberflächentyp und Strukturdomäne filtert, um Falschpositive zu unterdrücken – z. B...