La segmentación de grietas es la tarea de visión por computadora que clasifica cada píxel de una imagen como grieta o no grieta, produciendo una máscara binaria que permite medir con precisión la geometría de la grieta: área, longitud, ancho y análisis de patrones. Los cabezales de segmentación densa basados en DINOv3 y las arquitecturas U-Net son el estado del arte para la inspección de infraestructura.
Segmentación de Grietas a Nivel de Píxel para la Inspección de Infraestructura
1. Definición y Diferencia con la Clasificación de Grietas
La segmentación de grietas es una tarea de predicción densa de píxeles dentro de la visión por computadora que asigna una etiqueta binaria (grieta o no grieta) a cada píxel individual en una imagen de entrada. La salida es una máscara de segmentación binaria de las mismas dimensiones espaciales que la entrada, donde los píxeles de grieta se marcan como primer plano (típicamente blanco o valor 1) y los píxeles sin grieta como fondo (negro o valor 0). Esta máscara preserva la morfología, topología y geometría exactas de cada grieta presente en la escena, incluyendo ramas, fragmentos aislados y fisuras de ancho submilimétrico.
La clasificación de grietas opera a nivel de imagen — el modelo genera un único escalar que indica si hay una grieta presente en algún lugar de la imagen. Un modelo de clasificación podría predecir “grieta presente: 93% de confianza”, pero no puede localizar dónde está la grieta, cuánto mide o qué tan ancha es. Esto es fundamentalmente insuficiente para la inspección de infraestructura, donde las mediciones precisas impulsan la priorización del mantenimiento, la estimación de costos de reparación y la evaluación de la seguridad estructural.
La detección de grietas mediante detección de objetos (Faster R-CNN, YOLO, SSD) genera cajas delimitadoras alrededor de las regiones de grietas. Si bien la detección proporciona localización, una caja delimitadora alrededor de una grieta delgada y alargada contiene principalmente píxeles de fondo y no transmite información sobre el ancho, la topología o la estructura de ramificación de la grieta. Una grieta que serpentea a lo largo de una pista puede requerir docenas de cajas delimitadoras superpuestas sin relación semántica entre ellas.
La segmentación de grietas resuelve todas estas limitaciones. Cada píxel de grieta se identifica, lo que permite la medición directa de:
Área de la grieta en milímetros cuadrados (recuento de píxeles × resolución espacial)
Longitud de la grieta a lo largo de la línea central esqueletizada en milímetros
Ancho de la grieta (perfiles de ancho medio, máximo y por píxel)
Patrones de ramificación (número de ramas, puntos de unión, dimensión fractal)
Estadísticas de componentes (número total de grietas distintas, densidad espacial, conectividad)
El Anexo 14 de la Organización de Aviación Civil Internacional (OACI) — Aeródromos, Volumen I, especifica que las superficies de las pistas deben inspeccionarse regularmente para detectar deterioro, incluyendo grietas. El Doc 9157 de la OACI, Parte 3 — Pavimentos, proporciona orientación sobre métodos de evaluación de pavimentos. La inspección manual tradicional implica que los inspectores recorran la pista, marquen las grietas con tiza o pintura en aerosol y registren las observaciones en formularios de papel — un proceso que es subjetivo, inconsistente, peligroso (exposición a operaciones activas en el lado aire) e imposible de realizar con precisión submilimétrica. La segmentación automatizada de grietas reemplaza la estimación visual subjetiva con mediciones reproducibles, cuantitativas y precisas a nivel de píxel que pueden compararse entre inspecciones y entre aeropuertos.
Tarea
Salida
Ubicación de la Grieta
Geometría de la Grieta
Precisión de Medición
Clasificación
Etiqueta única (grieta/sin grieta)
Ninguna
Ninguna
A nivel de imagen
Detección
Cajas delimitadoras
Caja aproximada
Ninguna
A nivel de caja
Segmentación
Máscara binaria
Precisión de píxel
Geometría completa
A nivel de píxel (sub-mm)
La transición de la clasificación a la segmentación representa un salto fundamental en capacidad. La clasificación responde “¿hay una grieta aquí?” La segmentación responde “¿dónde está exactamente cada grieta, qué tan grande es, qué forma tiene y qué tan severo es el daño?” Para el crack_seg_head de TarmacView, esta capacidad de predicción densa de píxeles es la base para producir máscaras de grietas de alta precisión que alimentan directamente los cálculos del índice de condición del pavimento, la estimación de cantidades de reparación y el análisis de tendencias longitudinales.
2. Arquitecturas de Segmentación
U-Net
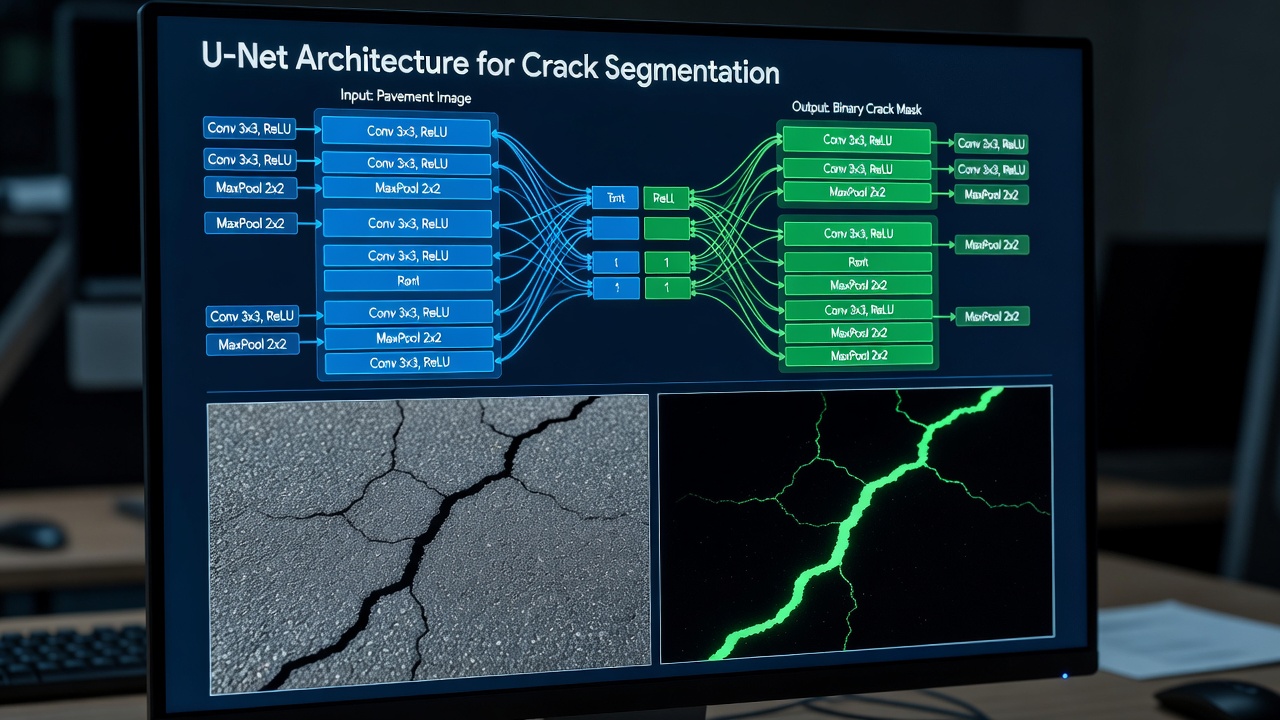
La arquitectura U-Net, introducida por Ronneberger, Fischer y Brox en 2015 para la segmentación de imágenes biomédicas, se ha convertido en la arquitectura más adoptada para la segmentación de grietas en aplicaciones de infraestructura. U-Net consiste en una estructura simétrica de codificador-decodificador con cuatro o cinco niveles de resolución conectados por conexiones de salto que transmiten información espacial de alta resolución directamente desde las capas del codificador a las del decodificador.
El codificador (ruta de contracción) aplica convoluciones repetidas de 3×3 seguidas de activación ReLU y agrupación máxima de 2×2, reduciendo progresivamente las dimensiones espaciales mientras aumenta la profundidad de los canales de características de 64 a 512 o 1024 canales. Cada bloque del codificador aprende representaciones cada vez más abstractas — desde detectores de bordes simples en la primera capa hasta detectores complejos de textura y morfología de grietas en las capas más profundas. Para la segmentación de grietas, el codificador debe aprender a distinguir las características reales de las grietas de texturas similares a grietas, incluyendo sombras de agregados, marcas de neumáticos, juntas de construcción, residuos superficiales y selladores.
El decodificador (ruta de expansión) realiza la operación inversa: la up-convolución de 2×2 (convolución transpuesta) duplica la resolución espacial mientras reduce la profundidad del canal a la mitad, luego concatena el mapa de características del codificador correspondiente a través de la conexión de salto, seguido de dos convoluciones de 3×3 con ReLU. La capa final utiliza una convolución de 1×1 con activación sigmoide para producir la máscara binaria de grietas.
Las conexiones de salto son la innovación crítica en U-Net. En las arquitecturas estándar de codificador-decodificador, todo el detalle espacial se pierde durante el submuestreo y debe reaprenderse en el decodificador. Las conexiones de salto transfieren directamente información espacial de grano fino — bordes de grietas, líneas de grietas delgadas y límites precisos — desde el codificador al decodificador en cada nivel de resolución. Esto es esencial para la segmentación de grietas porque las grietas son estructuras inherentemente delgadas (a menudo de 1 a 10 píxeles de ancho) que se perderían por completo en el nivel del cuello de botella (submuestreado 32 veces).
Para la segmentación de grietas específicamente, las variantes de U-Net incluyen:
Attention U-Net: Agrega puertas de atención que suprimen características de fondo irrelevantes mientras enfatizan las regiones de grietas
Residual U-Net: Reemplaza las convoluciones estándar con bloques residuales, permitiendo redes más profundas sin gradientes evanescentes
Dense U-Net: Utiliza bloques densos (estilo DenseNet) para una mejor propagación de características y flujo de gradiente
U-Net++ : Agrega conexiones de salto anidadas con bloques convolucionales densos, reduciendo la brecha semántica entre las características del codificador y el decodificador
U-Net logra un rendimiento de vanguardia en puntos de referencia de segmentación de grietas, incluidos CRACK500 (IoU 0.65-0.72) y DeepCrack (IoU 0.70-0.78) cuando se entrena con funciones de pérdida y aumento de datos apropiados.
DeepLabV3+
DeepLabV3+, desarrollado por Google Research (Chen et al., 2018), extiende la familia DeepLab con una estructura de codificador-decodificador aumentada por Agrupación Piramidal Espacial Atrosa (ASPP) . La innovación central es el uso de convoluciones atrosas (dilatadas) con múltiples tasas de dilatación aplicadas en paralelo para capturar información contextual a múltiples escalas sin reducir la resolución espacial.
ASPP aplica convoluciones de 3×3 a diferentes tasas de dilatación — típicamente tasas de 6, 12 y 18 para un paso de salida de 16 — más una convolución de 1×1 y agrupación promedio global. Cada tasa de dilatación captura características de grietas a una escala diferente: la tasa 6 captura grietas finas y estrechas (1-3 píxeles de ancho), la tasa 12 captura grietas medianas y la tasa 18 captura grietas anchas y redes de grietas. Las ramas paralelas se concatenan y procesan mediante una convolución de 1×1 para producir la representación de características multiescala.
Para la segmentación de grietas, DeepLabV3+ sobresale en el manejo de la variación de escala extrema en la apariencia de las grietas. Una sola imagen de pista puede contener grietas capilares (0.5 mm de ancho, 1-2 píxeles) junto con grietas anchas y desconchadas (15+ mm de ancho, 30+ píxeles). El módulo ASPP procesa todas estas escalas simultáneamente. El módulo decodificador sobremuestrea las características ASPP por un factor de 4, concatena con características del codificador de una capa intermedia (antes del primer bloque atroso) y aplica dos convoluciones de 3×3 seguidas de sobremuestreo bilineal a la resolución original.
Los backbones de DeepLabV3+ comúnmente utilizados para la segmentación de grietas incluyen ResNet-50, ResNet-101 y Xception. Más recientemente, se han explorado backbones de EfficientNet y ConvNeXt, que ofrecen relaciones de precisión a parámetros mejoradas. DeepLabV3+ con backbone ResNet-101 logra puntuaciones IoU de 0.68-0.75 en CRACK500 cuando se entrena en conjuntos de datos específicos de pavimentos.
SegFormer
SegFormer (Xie et al., 2021) introduce un codificador Transformer jerárquico con un decodificador MLP (perceptrón multicapa) liviano, lo que representa una desviación de las arquitecturas de segmentación basadas en CNN. El codificador utiliza una serie de bloques Mix Transformer (MiT) con resolución progresivamente decreciente (de 1/4 a 1/32 del tamaño de entrada) y dimensiones de canal crecientes. Cada bloque MiT utiliza autoatención eficiente con una relación de reducción espacial reducida, lo que lo hace computacionalmente factible para imágenes de grietas de alta resolución.
La ventaja clave de SegFormer para la segmentación de grietas es el campo receptivo global del transformer desde la primera capa. A diferencia de las CNN, donde cada capa solo ve una vecindad local (por ejemplo, convolución 3×3 = vecindad de 1 píxel después de una capa), los Transformers calculan la atención en todo el mapa de características. Esto permite que SegFormer capture dependencias de largo alcance — una grieta que serpentea a través de un mosaico completo de 1024×1024 mantiene relaciones píxel a píxel a través del mecanismo de atención.
El decodificador MLP en SegFormer es notablemente simple en comparación con los decodificadores U-Net o DeepLabV3+. Agrega características de múltiples niveles de las cuatro etapas del codificador (sobremuestreando a 1/4 de resolución y concatenando), aplica una sola capa MLP para la mezcla de características, luego otro MLP para producir la segmentación final. A pesar de su simplicidad, el decodificador MLP logra un rendimiento sólido porque el codificador Transformer jerárquico ya produce características bien estructuradas.
SegFormer-B3 logra un IoU competitivo (0.66-0.74) en conjuntos de datos de segmentación de grietas, siendo más eficiente en parámetros que DeepLabV3+ con ResNet-101. La familia de modelos B0-B5 proporciona un equilibrio entre velocidad y precisión, siendo B0 adecuado para implementación en tiempo real en el borde y B5 para máxima precisión en hardware de clase servidor.
Cabezales de Predicción Densa DINOv2 y DINOv3
DINOv2 (Oquab et al., 2023) y DINOv3 representan la última generación de modelos de Transformador de Visión (ViT) entrenados mediante aprendizaje auto-supervisado en conjuntos de datos de imágenes curados. A diferencia del preentrenamiento supervisado en ImageNet-1K, DINO utiliza un enfoque de autodestilación donde una red estudiante aprende a igualar la salida de una red profesora que opera en diferentes vistas de la misma imagen (vistas recortadas locales vs. vistas globales).
El gran avance de DINO para la segmentación es que las características ViT auto-supervisadas — particularmente los cabezales de atención clave (K) y valor (V) en las últimas capas — codifican naturalmente los límites de objetos e información semántica de grano fino sin ningún entrenamiento de segmentación supervisada. Un conjunto disperso de tokens de parche (por ejemplo, 0.05% de los parches) puede ser sondeado linealmente para producir mapas de segmentación que rivalizan con los modelos completamente supervisados.
Para la segmentación de grietas, se adjunta un cabezal de predicción densa al backbone DINO. El enfoque típico extrae características multiescala de las últimas 4-6 capas del ViT, las concatena y aplica un decodificador convolucional que sobremuestrea a la resolución original de la imagen. El decodificador puede ser:
Un Cabezal Lineal liviano: Simplemente una convolución de 1×1 después de sobremuestrear los tokens de parche ViT (tamaño de parche 14×14 para ViT-L/14)
Un cabezal de Red Piramidal de Características (FPN) : Extracción de características multiescala con conexiones laterales y vía de arriba hacia abajo
Un cabezal de estilo MaskFormer: Decodificador Transformer que atiende de forma cruzada a las características DINO y produce máscaras binarias
La segmentación de grietas basada en DINOv3 logra puntuaciones IoU superiores a 0.78 en CRACK500 y 0.82 en DeepCrack cuando se ajusta de extremo a extremo con conjuntos de datos de máscaras de grietas. El preentrenamiento auto-supervisado proporciona representaciones de características sólidas que se generalizan mejor a nuevas superficies y condiciones de iluminación en comparación con los backbones supervisados de ImageNet.
Arquitectura
Parámetros
IoU CRACK500
Velocidad de Inferencia (MP/s)
Ventaja Clave
U-Net (ResNet-34)
24M
0.68
45
Eficiencia con pocos datos
DeepLabV3+ (ResNet-101)
63M
0.72
28
ASPP multiescala
SegFormer-B3
47M
0.70
22
Atención global
DINOv2-ViT-L/14 + cabezal denso
307M
0.78
8
Características auto-supervisadas
3. Conjuntos de Datos de Máscaras de Verdad Fundamental
La calidad y diversidad de los conjuntos de datos de entrenamiento determinan directamente el rendimiento del modelo de segmentación de grietas. Todos los métodos de segmentación de grietas supervisados requieren máscaras de verdad fundamental precisas a nivel de píxel — imágenes binarias donde anotadores expertos han etiquetado meticulosamente cada píxel de grieta. Los siguientes conjuntos de datos representan los puntos de referencia más utilizados en la investigación de segmentación de grietas.
CRACK500
CRACK500 (Zhang et al., 2016) contiene 500 imágenes RGB de superficies de pavimento capturadas con una cámara de grado comercial a una distancia de muestreo en el suelo (GSD) de aproximadamente 0.05 mm/píxel. Cada imagen es de 2048×1536 píxeles, proporcionando un área física de aproximadamente 100×75 mm. El conjunto de datos se divide en 250 imágenes de entrenamiento, 50 de validación y 200 de prueba.
Las máscaras de verdad fundamental fueron anotadas manualmente por inspectores capacitados y verificadas de forma cruzada. Las grietas se etiquetan con precisión subpíxel, incluyendo grietas de hasta 0.1-0.2 mm de ancho (2-4 píxeles). El conjunto de datos presenta predominantemente pavimento asfáltico con una variedad de tipos de grietas: grietas transversales, grietas longitudinales, grietas de cocodrilo (fatiga), grietas en bloque y grietas de borde. El fondo incluye textura de agregados, una mezcla de partículas de asfalto gruesas y finas, reparaciones de parches y materiales sellantes.
CRACK500 es el conjunto de datos comparado con mayor frecuencia en la literatura de segmentación de grietas debido a su calidad consistente, tamaño razonable y disponibilidad pública. Los modelos U-Net de referencia logran aproximadamente 0.65-0.68 IoU en la división de prueba, y los modelos recientes basados en DINOv2 alcanzan 0.78-0.80 IoU.
DeepCrack
DeepCrack (Zou et al., 2019) contiene 537 imágenes RGB de grietas en superficies de hormigón y mampostería con resolución de 512×512 píxeles. El conjunto de datos fue diseñado específicamente para la segmentación de grietas con aprendizaje profundo e incluye diversos tipos de superficies que no se encuentran en conjuntos de datos solo de pavimentos: muros de hormigón, pilares de puentes, revestimientos de túneles, fachadas de edificios y superficies de piedra. Las anotaciones de verdad fundamental fueron generadas por múltiples anotadores y refinadas mediante un proceso de consenso.
Las imágenes de DeepCrack incluyen condiciones desafiantes: sombras, manchas de humedad, vegetación crecida, grafiti y rugosidad superficial que imita visualmente las características de las grietas. El conjunto de datos proporciona divisiones oficiales de entrenamiento (400 imágenes) y prueba (137 imágenes). DeepCrack es particularmente valioso para evaluar la generalización entre superficies — los modelos entrenados solo en DeepCrack tienden a funcionar bien en superficies de hormigón nuevas, pero pueden tener dificultades en asfalto.
Los modelos de vanguardia logran 0.70-0.78 IoU en DeepCrack. La mayor dificultad de referencia del conjunto de datos (en comparación con CRACK500) se deriva de la mayor complejidad visual y la ambigüedad entre grieta y fondo en superficies de mampostería y hormigón.
CrackForest (CFD)
CrackForest Dataset (CFD) (Shi et al., 2016) contiene 118 imágenes de pavimentos de carreteras asfálticas capturadas con una resolución de 320×480 píxeles. A pesar de su pequeño tamaño, CFD se utiliza ampliamente para validación cruzada debido a su anotación cuidadosa y tipo de superficie consistente. El conjunto de datos presenta principalmente grietas transversales y longitudinales en carreteras de tráfico medio.
El rendimiento en CFD está cerca de la saturación para los modelos modernos — DINOv2 logra 0.84-0.87 IoU — pero el pequeño conjunto de evaluación significa que la significancia estadística de las diferencias es limitada. CFD se utiliza más comúnmente como una prueba de aprendizaje por transferencia para ver si los modelos entrenados en conjuntos de datos más grandes (CRACK500, DeepCrack) mantienen la precisión en este dominio de captura distinto.
CrackAirport
CrackAirport es un conjunto de datos especializado para la segmentación de grietas en pavimentos aeroportuarios, que contiene imágenes de pistas, calles de rodaje y plataformas capturadas durante inspecciones rutinarias de campos de aviación. Los pavimentos aeroportuarios presentan desafíos únicos que no se encuentran en los conjuntos de datos de carreteras: superficies de pista ranuradas (ranuras transversales con un espaciado de ~30 mm diseñadas para el drenaje de agua), depósitos de caucho de los aterrizajes de aeronaves (que reducen el contraste entre la grieta y el pavimento), manchas de combustible y fluido hidráulico, y sistemas especializados de juntas y selladores.
El conjunto de datos incluye imágenes con múltiples valores de GSD (0.1-0.5 mm/píxel) capturadas desde cámaras montadas en vehículos y dispositivos de mano. Los tipos de grietas específicos de pavimentos aeroportuarios — roturas de esquina (pavimento rígido), bombeo (pérdida de material debajo de las juntas) y desconchados (pérdida de agregados) — se anotan junto con los tipos de grietas estándar. CrackAirport es fundamental para entrenar modelos que deben operar en superficies aeroportuarias reales, donde un modelo entrenado en carreteras produciría falsos positivos inaceptables en texturas ranuradas o depósitos de caucho.
Conjunto de Datos Compilado CrackSeg9k
CrackSeg9k (Kulkarni et al., 2022) representa la compilación unificada de segmentación de grietas más grande, combinando imágenes de más de 9 subconjuntos de datos: AigleRN (38 imágenes), CFD (118), Crack500 (500), DeepCrack (537), CrackTree200 (200), GAPs384 (384), CrackLS315 (315), Stone331 (331) y colecciones personalizadas adicionales que suman más de 9000 imágenes después del filtrado de calidad. Los autores aplicaron refinamiento de procesamiento de imágenes para unificar anotaciones de verdad fundamental inconsistentes — algunos subconjuntos usaban anotaciones de líneas finas (líneas centrales de 1-3 píxeles de ancho), otros usaban anotaciones de regiones de espesor completo.
El proceso de refinamiento incluyó:
Revisión manual y reetiquetado de imágenes incorrectamente anotadas
Dilatación morfológica para expandir las anotaciones de líneas finas a los estándares de verdad fundamental de espesor completo
Eliminación de ruido (grupos de píxeles aislados de menos de 5 píxeles eliminados)
Alineación de máscaras mediante registro de imágenes para corregir el desplazamiento espacial entre la imagen y la anotación
CrackSeg9k categoriza las grietas en clases de morfología lineal (única, sin ramificar), ramificada (divisiones en forma de Y o T) y reticulada (en red, tipo cocodrilo). Esta categorización permite entrenar cabezales de segmentación específicos por clase que pueden capturar mejor la variabilidad morfológica. Los modelos entrenados en CrackSeg9k demuestran una generalización entre superficies significativamente mejorada en comparación con los modelos de un solo conjunto de datos.
Tabla Comparativa de Conjuntos de Datos
Conjunto de Datos
Imágenes
Resolución
Tipo de Superficie
Tipos de Grietas
GSD (mm/píxel)
Público
CRACK500
500
2048×1536
Pavimento asfáltico
Todos los tipos
0.05
Sí
DeepCrack
537
512×512
Hormigón, mampostería
Lineales, ramificadas
0.1-0.3
Sí
CrackForest
118
320×480
Carretera asfáltica
Transversales, longitudinales
0.15
Sí
CrackAirport
~300
Variable
Pista/calle de rodaje
Específicas de aeropuerto
0.1-0.5
Limitado
CrackSeg9k
9000+
Mixta
Todas las superficies
Todos los tipos
Mixta
Sí
4. Funciones de Pérdida para la Segmentación de Grietas
La segmentación de grietas es fundamentalmente una tarea de desequilibrio de clases — en una imagen típica de pista, los píxeles de grieta constituyen entre el 0.1% y el 5% del total de píxeles. Una función de pérdida ingenua que trate todos los píxeles por igual produciría un modelo que simplemente predice “fondo” para cada píxel y logra una precisión superior al 95% sin detectar ninguna grieta. Las funciones de pérdida especializadas son esenciales para forzar al modelo a aprender la clase minoritaria de grietas.
Pérdida de Entropía Cruzada Binaria (BCE)
La pérdida BCE (también llamada pérdida logística) calcula la entropía cruzada binaria píxel a píxel entre el mapa de probabilidad predicho y la máscara de verdad fundamental:
donde (y_i) es la etiqueta de verdad fundamental (0 o 1) para el píxel (i), (p_i) es la probabilidad predicha para el píxel (i), y (N) es el número total de píxeles.
La BCE estándar pondera cada píxel por igual. Para la segmentación de grietas, se utiliza comúnmente una variante BCE ponderada:
donde (w_+) (peso de clase positiva) se establece en (N / (2 \cdot N_{grieta})) y (w_-) (peso de clase negativa) se establece en (N / (2 \cdot N_{fondo})). Esto pondera inversamente las clases por su frecuencia — si las grietas son el 1% de los píxeles, cada píxel de grieta obtiene 50 veces el peso de un píxel de fondo.
La pérdida BCE trata cada píxel de forma independiente y no optimiza explícitamente la superposición entre la predicción y la verdad fundamental. Se comporta bien para la optimización basada en gradientes, pero tiende a producir predicciones ligeramente borrosas en los bordes de las grietas.
Pérdida Dice
La pérdida Dice optimiza directamente el coeficiente Dice (puntuación F1) — la superposición entre las regiones de grieta predichas y reales:
donde (\epsilon) es una pequeña constante de suavizado (típicamente 1×10⁻⁶) para evitar la división por cero.
La propiedad crítica de la pérdida Dice es que está basada en regiones en lugar de píxeles. Mide la superposición entre la región de grieta predicha y la región de grieta real en su conjunto, manejando naturalmente el desequilibrio de clases porque ambos términos en el denominador abarcan toda la imagen. La pérdida Dice es particularmente efectiva para la segmentación de grietas porque:
Optimiza directamente la métrica de evaluación (Dice/IoU) utilizada para la evaluación final del modelo
Maneja el desequilibrio extremo de clases sin ponderación (las grietas pueden ser el 0.1% de los píxeles y Dice sigue funcionando)
Produce límites de predicción nítidos porque se maximiza la superposición de regiones
El gradiente de la pérdida Dice está bien definido pero puede ser inestable cuando la máscara de predicción y la verdad fundamental no tienen superposición (tanto el numerador como el denominador cercanos a cero). El término de suavizado (\epsilon) mitiga esto.
Pérdida Focal
La pérdida focal (Lin et al., 2017) se introdujo para la detección densa de objetos (RetinaNet) y adapta la BCE reduciendo el peso de los píxeles bien clasificados y enfocándose en ejemplos difíciles:
donde (p_t = p_i) si (y_i = 1) y (p_t = 1-p_i) si (y_i = 0), (\alpha_t) es un peso de equilibrio de clases y (\gamma) es el parámetro de enfoque (típicamente 2.0).
El factor modulador ((1-p_t)^\gamma) reduce la contribución de ejemplos fáciles (donde (p_t) está cerca de 1) y enfoca el entrenamiento en ejemplos difíciles (donde (p_t) está cerca de 0.5). Para la segmentación de grietas, esto significa que el modelo concentra el aprendizaje en:
Píxeles de borde de grieta (donde la grieta se encuentra con el fondo y las predicciones son inciertas)
Grietas muy delgadas que el modelo podría ignorar de otro modo
Píxeles de grieta en fondos desafiantes (sombras, manchas, texturas rugosas)
La pérdida focal con (\gamma = 2.0) y (\alpha = 0.25) (peso de grieta) logra resultados sólidos en puntos de referencia de segmentación de grietas, típicamente mejorando el IoU en un 3-5% en comparación con BCE sola.
Pérdida Combinada
La pérdida combinada (también llamada pérdida híbrida) combina múltiples funciones de pérdida para aprovechar sus fortalezas complementarias. Las formulaciones más comunes para la segmentación de grietas son:
con (\lambda) típicamente establecido en 0.5-0.7. La pérdida Dice proporciona optimización de superposición a nivel de región; BCE proporciona estabilidad de gradiente a nivel de píxel e información de bordes de grano fino.
Esta combinación ha demostrado ser la más efectiva para la segmentación de grietas en varios estudios (F. Zhao et al., 2023), logrando una mejora del 2-4% en IoU sobre Dice solo. El término Dice asegura la superposición de la región de grieta, mientras que el término Focal obliga al modelo a enfocarse en píxeles de grieta difíciles — grietas delgadas, puntos de ramificación, grietas de bajo contraste.
Pérdida Tversky es una generalización de la pérdida Dice que agrega ponderación separada para falsos positivos y falsos negativos:
donde (\beta) controla la penalización por falsos positivos. Para la segmentación de grietas, (\beta = 0.7) (mayor penalización por falsos negativos — grietas no detectadas) es común porque una grieta no detectada que crece con el tiempo representa un mayor riesgo de seguridad que una característica sin grieta marcada incorrectamente.
Función de Pérdida
Desequilibrio de Clases
Nitidez de Bordes
Enfoque en Ejemplos Difíciles
IoU Típico
BCE
Deficiente (necesita ponderación)
Baja
No
0.55-0.62
BCE Ponderada
Buena
Media
No
0.62-0.68
Dice
Excelente
Alta
Débil
0.65-0.72
Focal
Buena
Media
Fuerte
0.64-0.70
Combinación Dice + Focal
Excelente
Alta
Fuerte
0.68-0.76
Tversky ((\beta=0.7))
Excelente
Alta
Centrada en FN
0.67-0.74
5. Posprocesamiento de las Salidas de Segmentación
Las predicciones del modelo en bruto producen un mapa de probabilidad (valores de punto flotante entre 0.0 y 1.0) que debe convertirse en una máscara binaria limpia mediante una secuencia de operaciones de posprocesamiento. La calidad de estas operaciones afecta directamente la precisión de las mediciones de geometría posteriores.
Umbralizado
El primer paso de posprocesamiento convierte el mapa de probabilidad continuo en una máscara binaria. El umbralizado global aplica un umbral fijo (T) (típicamente 0.3-0.5) a cada píxel. El umbral óptimo se determina evaluando IoU en el conjunto de validación a través de un barrido de valores de umbral (por ejemplo, 0.1 a 0.9 en incrementos de 0.05). Los modelos entrenados con pérdida Dice generalmente funcionan mejor con umbrales de 0.3-0.4; los modelos entrenados con BCE requieren umbrales más altos de 0.4-0.5.
El umbralizado de Otsu determina automáticamente el umbral óptimo maximizando la varianza entre clases en el histograma de probabilidad. Para la segmentación de grietas, el método de Otsu tiende a establecer el umbral en 0.4-0.6 dependiendo de la relación grieta-fondo en la imagen. Es particularmente útil cuando la distribución de probabilidad varía entre imágenes (por ejemplo, diferentes condiciones de iluminación durante un estudio de pista).
Limpieza Morfológica
Después del umbralizado, la máscara binaria contiene ruido sal-y-pimienta: píxeles de primer plano aislados (ruido speckle) donde el modelo clasificó incorrectamente el fondo como grieta, y pequeños agujeros dentro de regiones de primer plano donde el modelo no detectó píxeles de grieta.
La apertura (erosión seguida de dilatación) elimina el ruido pequeño de primer plano:
Erosión: Para cada píxel de primer plano, verificar si todos sus vecinos conectados en 4 u 8 también son de primer plano; si no, marcarlo como fondo. Esto elimina píxeles de grieta aislados.
Dilatación: Para cada píxel de fondo adyacente al primer plano, marcarlo como primer plano. Esto restaura los píxeles de grieta restantes a su grosor original.
Un elemento estructurante (típicamente un kernel en forma de cruz de 3×3 o 5×5) controla la operación. Para la segmentación de grietas, un kernel de 3×3 elimina speckles de píxeles individuales sin estrechar significativamente las líneas de grieta reales.
El cierre (dilatación seguida de erosión) llena pequeños agujeros y espacios dentro de las regiones de grieta:
Dilatar: Expandir los límites de la grieta en 1-2 píxeles para puentear espacios estrechos (interrupciones de grieta de 1-3 píxeles causadas por incertidumbre del modelo)
Erosionar: Restaurar los límites de la grieta al ancho original aproximado
La operación de cierre es crítica para las grietas en pavimentos aeroportuarios donde los depósitos de caucho de neumáticos o las partículas de agregados pueden hacer que el modelo fragmente una grieta continua en múltiples segmentos. Un solo paso de cierre con un kernel de 5×5 puede puentear espacios de hasta 3 píxeles y restaurar la continuidad de la grieta.
Análisis de Componentes Conectados
El análisis de componentes conectados (CCA) etiqueta cada región de grieta distinta en la máscara binaria con un identificador único. El CCA estándar utiliza conectividad de 4 (vecinos de píxel solo arriba/abajo/izquierda/derecha) o conectividad de 8 (incluye diagonales). Para la segmentación de grietas, se prefiere la conectividad de 8 porque las grietas pueden conectarse diagonalmente a través de la imagen.
Después del etiquetado, el filtrado por área elimina componentes más pequeños que un umbral de área mínimo (típicamente 10-100 píxeles dependiendo de la GSD). Para una imagen de pista de 0.1 mm/píxel, un área mínima de 50 píxeles corresponde a un área física de grieta de 0.5 mm² — muy por debajo de los tamaños de grieta procesables, pero eliminando eficazmente el ruido speckle. Los componentes por debajo de este umbral son casi siempre falsos positivos de textura de agregados o residuos superficiales.
Las estadísticas a nivel de componente calculadas durante el CCA incluyen:
Área del componente en píxeles (convertir a mm² usando GSD)
Coordenadas de la caja delimitadora (para localización)
Coordenadas del centroide (para mapeo)
Excentricidad (medida de elongación; los componentes similares a grietas tienen excentricidad > 0.9)
Convexidad (relación del perímetro al perímetro del casco convexo; las grietas no son convexas)
Esqueletización
La esqueletización (también llamada adelgazamiento) reduce cada componente de grieta a una línea central de un píxel de ancho mientras preserva la estructura topológica de la grieta — conectividad, ramificación y puntos finales. El esqueleto es esencial para la medición de longitud y el cálculo del perfil de ancho.
El algoritmo de adelgazamiento de Zhang-Suen (1984) es el más utilizado para la esqueletización de grietas. Opera iterativamente:
Sub-iteración 1: Marcar píxeles de borde (píxeles de primer plano con al menos un vecino de fondo) para eliminación si cumplen:
2 ≤ B(P1) ≤ 6 (número de vecinos de primer plano entre 2 y 6)
A(P1) = 1 (número de conectividad — exactamente una transición conectada de fondo a primer plano)
P2 × P4 × P6 = 0
P4 × P6 × P8 = 0
Sub-iteración 2: Mismas condiciones pero con diferentes comprobaciones de vecindario:
P2 × P4 × P8 = 0
P2 × P6 × P8 = 0
Repetir hasta que no se eliminen píxeles (esqueleto estable alcanzado)
El algoritmo de Guo-Hall produce un esqueleto más centrado para grietas gruesas (>10 píxeles de ancho) mediante el uso de sub-iteraciones paralelas que eliminan píxeles de ambos lados simultáneamente. Se prefiere para grietas severamente desconchadas o de cocodrilo donde la región de la grieta es lo suficientemente ancha como para tener un área interior.
Después de la esqueletización, el análisis de ramas y uniones identifica:
Puntos finales: Píxeles del esqueleto con exactamente 1 vecino (terminaciones de grieta)
Puntos de unión: Píxeles del esqueleto con 3 o más vecinos (puntos de ramificación de grieta)
Segmentos de rama: Trayectorias entre puntos finales y uniones
Este análisis produce la estructura del gráfico de la grieta — una representación matemática de la topología de la grieta como un conjunto de vértices (puntos finales, uniones) y aristas (segmentos de grieta entre ellos).
6. Extracción de la Geometría de la Grieta a partir de Máscaras Binarias
La máscara de grieta a nivel de píxel combinada con la esqueletización permite la extracción cuantitativa de la geometría de la grieta. Estas mediciones son críticas para la evaluación del estado del pavimento según los estándares de la OACI y la FAA, donde la severidad de la grieta se clasifica según rangos de ancho (capilar: <3 mm, media: 3-6 mm, severa: >6 mm para pavimentos de pista).
Área de la Grieta
El área de la grieta es la medición más directa:
[
A_{grieta} = N_{grieta} \times GSD^2
]
donde (N_{grieta}) es el número total de píxeles de grieta en la máscara binaria y (GSD) es la distancia de muestreo en el suelo (mm/píxel) determinada a partir de la calibración de la cámara o marcadores fiduciarios en la imagen.
Para el crack_seg_head de TarmacView, la GSD se calcula a partir de los parámetros intrínsecos del sistema de cámara (distancia focal, paso de píxel del sensor) y la altitud de captura o distancia al objetivo. Una cámara con distancia focal de 20 mm, paso de píxel de 3.45 µm, capturada a 2 metros de la superficie del pavimento produce una GSD de aproximadamente 0.069 mm/píxel (3.45 µm × 2000 mm / 20 mm).
El área por componente permite el cálculo de la densidad de grietas:
donde (E) es el conjunto de aristas del esqueleto (segmentos de rama), y ((x_i, y_i)) son coordenadas de píxel consecutivas a lo largo de cada arista. Los pasos diagonales (esquina a esquina) se multiplican por (\sqrt{2}) en comparación con los pasos ortogonales, lo que hace que la medición de longitud sea precisa con precisión subpíxel.
La longitud se puede calcular por componente, por ángulo de rama o como un total en toda la superficie. La densidad de longitud de grietas ((L_{total} / A_{superficie}), en mm/mm² o m/m²) es una métrica de condición de pavimento comúnmente utilizada.
Ancho de la Grieta
La medición del ancho de la grieta requiere calcular la distancia desde cada píxel del esqueleto hasta el píxel de fondo más cercano en la máscara binaria original. Esto se logra mediante la Transformada de Distancia Euclidiana (EDT) :
Calcular EDT en la máscara binaria: para cada píxel de primer plano (grieta), calcular su distancia euclidiana al píxel de fondo más cercano
Muestrear valores EDT en cada píxel del esqueleto: el valor EDT en un píxel del esqueleto equivale a la mitad del ancho local de la grieta (distancia del esqueleto al borde más cercano)
Multiplicar por 2 para el ancho completo, multiplicar por GSD para unidades físicas
El ancho local de la grieta en el píxel del esqueleto (i) es:
[
w_i = 2 \times EDT(skel_i) \times GSD
]
Los resúmenes estadísticos incluyen:
Ancho medio de la grieta: (\bar{w} = \frac{1}{N_{skel}} \sum_{i=1}^{N_{skel}} w_i)
Ancho máximo de la grieta: (w_{max} = \max(w_i)) — típicamente en áreas desconchadas o de cocodrilo
Perfil de ancho: ancho en función de la posición a lo largo del esqueleto (para clasificación de severidad de grietas longitudinales)
Histograma de ancho: distribución de valores de ancho que indica el tipo de grieta (ancho uniforme ≈ grieta transversal; ancho variable ≈ grieta de cocodrilo)
Según los informes de condición de superficie de pista de la OACI, las grietas que superan los 6 mm de ancho en superficies asfálticas o 3 mm en superficies de hormigón se clasifican como “deterioro severo” que requiere intervención de mantenimiento inmediata.
Estadísticas a Nivel de Componente
Para cada componente conectado (grieta individual), el proceso de extracción de geometría calcula:
Métrica
Unidad
Cálculo
Propósito
Área
mm²
Recuento de píxeles × GSD²
Extensión total del daño
Longitud
mm
Longitud del esqueleto × GSD
Extensión de propagación de la grieta
Ancho medio
mm
EDT media en esqueleto × GSD
Clasificación de severidad
Ancho máximo
mm
EDT máxima en esqueleto × GSD
Escala máxima de deterioro
Excentricidad
adimensional
(Relación de aspecto del componente)
Clasificación de forma de grieta
Amplitud
mm
Ancho máximo del componente
Clasificación de severidad
Orientación
grados
Ángulo del eje mayor del esqueleto
Tipo de grieta (transversal/longitudinal)
7. Métricas de Evaluación
Los modelos de segmentación de grietas se evalúan utilizando métricas a nivel de píxel que comparan la máscara binaria predicha con la máscara de verdad fundamental. Estas métricas deben manejar el desequilibrio extremo de clases inherente a la segmentación de grietas.
Intersección sobre Unión (IoU / Índice Jaccard)
IoU es la métrica principal para la evaluación de la segmentación de grietas:
donde (P) es el conjunto de píxeles de grieta predichos, (V) es el conjunto de píxeles de grieta verdaderos, (VP) = verdaderos positivos (píxeles de grieta segmentados correctamente), (FP) = falsos positivos (fondo clasificado como grieta), (FN) = falsos negativos (grieta clasificada como fondo).
IoU varía de 0.0 (sin superposición) a 1.0 (superposición perfecta). Para la segmentación de grietas, los valores típicos de IoU oscilan entre 0.65 (decente, umbral para uso práctico) y 0.85 (estado del arte). IoU es la métrica preferida porque penaliza tanto los falsos positivos como los falsos negativos por igual — un modelo que predice agresivamente grietas en todas partes (alta exhaustividad, baja precisión) recibe un IoU bajo.
Coeficiente Dice (Puntuación F1)
Coeficiente Dice (también llamado Sørensen-Dice o puntuación F1 a nivel de píxel):
Dice está matemáticamente relacionado con IoU: (Dice = 2 \times IoU / (1 + IoU)). Un IoU de 0.75 corresponde a un Dice de 0.857. Dice enfatiza los verdaderos positivos, ponderándolos el doble en comparación con IoU. Para la segmentación de grietas, Dice es la segunda métrica más reportada y proporciona una visión ligeramente más optimista que IoU.
Precisión y Exhaustividad de Píxel
La precisión a nivel de píxel mide qué fracción de los píxeles de grieta predichos son realmente grietas:
[
Precisión = \frac{VP}{VP + FP}
]
Una alta precisión significa pocos falsos positivos — el modelo no confunde textura de agregados, sombras o residuos superficiales con grietas. Los falsos positivos en la inspección de pistas son costosos porque desperdician recursos de mantenimiento en daños inexistentes.
La exhaustividad a nivel de píxel (sensibilidad) mide qué fracción de los píxeles de grieta reales identificó exitosamente el modelo:
[
Exhaustividad = \frac{VP}{VP + FN}
]
Una alta exhaustividad significa pocas grietas no detectadas — el modelo detecta la mayor parte del área real de grieta. Los falsos negativos en la inspección de pistas son críticos para la seguridad porque una grieta no detectada puede propagarse bajo la carga de la aeronave y provocar fallos estructurales.
La relación de compromiso precisión-exhaustividad se controla mediante el umbral (T). Un umbral bajo (por ejemplo, 0.2) maximiza la exhaustividad a expensas de la precisión; un umbral alto (por ejemplo, 0.7) maximiza la precisión pero pasa por alto grietas reales. El umbral óptimo es típicamente donde la precisión y la exhaustividad son aproximadamente iguales — el punto equilibrado F1.
Exactitud de Píxel
La exactitud de píxel es la métrica más simple pero altamente engañosa para la segmentación de grietas:
[
Exactitud = \frac{VP + VN}{VP + VN + FP + FN}
]
Si las grietas ocupan el 1% de los píxeles, un modelo que predice todo fondo logra un 99% de exactitud mientras detecta cero grietas. La exactitud se reporta solo como una métrica secundaria en la literatura de segmentación de grietas y nunca debe usarse como el criterio de evaluación principal.
Métricas Compuestas
La puntuación F-beta generaliza F1 con peso ajustable en la exhaustividad:
Para la segmentación de grietas en pistas, a veces se utiliza (F_2) (exhaustividad ponderada 2× precisión) porque es más peligroso pasar por alto una grieta que marcar una falsamente. (\beta = 2) significa que la exhaustividad es dos veces más importante que la precisión.
F1 de Borde (BF1) evalúa la calidad de la segmentación específicamente en los bordes de las grietas, calculando la precisión y la exhaustividad dentro de una banda estrecha (por ejemplo, 2-3 píxeles) alrededor de los límites de la verdad fundamental de la grieta. BF1 es una métrica más estricta para aplicaciones donde la precisión del borde de la grieta es importante para la medición del ancho.
8. Segmentación de Fotograma Completo vs. Basada en Mosaicos
La segmentación de grietas en superficies de pista presenta un desafío computacional fundamental: las pistas se miden en miles de metros lineales (una pista Código E mide 45 metros de ancho × 3,000+ metros de largo), pero los modelos de segmentación aceptan tensores de entrada de típicamente 512×512 a 1536×1536 píxeles debido a las limitaciones de memoria de la GPU. Dos enfoques abordan esta discrepancia de escala.
Segmentación de Fotograma Completo
La segmentación de fotograma completo procesa toda la imagen de la pista en una sola pasada directa a través del modelo. En la práctica, un enfoque de fotograma completo verdadero solo es factible para superficies pequeñas (imágenes de redes sociales, fotos de teléfono en primer plano) o en hardware de memoria extremadamente alta (GPU A100 de 80 GB con tamaños de imagen de hasta 4000×4000 píxeles).
Para la inspección aeroportuaria, una sola imagen de estudio de pista capturada a 0.2 mm/píxel de GSD cubre aproximadamente 1×1 metro a 5000×5000 píxeles — requiriendo 100 MB de almacenamiento de punto flotante de 32 bits por imagen. Ejecutar U-Net en una imagen de 5000×5000 requiere aproximadamente 200 GB de memoria de GPU para mapas de características intermedios — 40 veces más de lo disponible en una A100 (80 GB).
La segmentación de fotograma completo evita los artefactos de borde de mosaico — sin costuras, sin predicciones superpuestas, sin fusión — proporcionando los resultados de mayor calidad para la región que puede procesar. Sin embargo, las limitaciones de memoria impiden el procesamiento de fotograma completo real de superficies de pista realistas.
Segmentación Basada en Mosaicos (Ventana Deslizante)
La segmentación basada en mosaicos divide la imagen de entrada en mosaicos más pequeños (típicamente 512×512 o 1024×1024 píxeles), ejecuta la inferencia de forma independiente en cada mosaico y une los resultados en una máscara de resolución completa. Este es el enfoque estándar para la segmentación de grietas a escala aeroportuaria.
Superposición y fusión: Los mosaicos adyacentes se superponen en un 10-25% para evitar que las grietas se corten en los límites de los mosaicos. La región de superposición recibe predicciones de ambos mosaicos, que se combinan utilizando:
Promediado ponderado: Los píxeles cerca de los bordes del mosaico reciben menor peso; los píxeles cerca del centro del mosaico reciben peso completo
Costura consciente de uniones: Las predicciones se fusionan utilizando una transformada de distancia — cuanto más lejos de la costura, mayor es el peso de la predicción de ese mosaico
Fusión de mediana: Para cada píxel en la región de superposición, se toma la mediana de todas las predicciones que cubren ese píxel
Selección del tamaño del mosaico implica una relación de compromiso:
Mosaicos de 512×512: Inferencia rápida, baja memoria de GPU (4-8 GB), pero más artefactos de borde; adecuado para implementación en tiempo real en el borde
Mosaicos de 1024×1024: Mejor contexto para grietas grandes, menos costuras, pero mayor memoria (16-32 GB) y procesamiento más lento
Para el crack_seg_head de TarmacView, un tamaño de mosaico de 1024×1024 con 15% de superposición proporciona el equilibrio óptimo para superficies de pista. Una sección de pista de 45 m × 45 m a 0.2 mm/píxel (225,000 × 225,000 píxeles) requiere aproximadamente 45,000 mosaicos en esta configuración — 37 minutos de inferencia en una RTX 4090 (20 mosaicos/segundo).
Los mosaicos multiescala mejoran la detección de grietas de diferentes anchos. La misma región de imagen se procesa a múltiples escalas (0.5×, 1.0×, 2.0×) y los resultados se fusionan. Los mosaicos pequeños con zoom 2.0× capturan grietas delgadas; los mosaicos grandes con zoom 0.5× capturan redes de grietas anchas.
9. Desafíos de la Segmentación de Fotograma Completo en Pistas
La segmentación de pistas aeroportuarias impone desafíos únicos más allá de los de la segmentación de pavimentos de carreteras:
Ranuras superficiales: La mayoría de las pistas principales tienen ranuras transversales (3-6 mm de profundidad, 25-35 mm de espaciado) cortadas en la superficie para el drenaje de agua y mejora de la fricción. Estas ranuras aparecen en las imágenes como líneas oscuras paralelas que visualmente se asemejan a grietas. Los modelos deben aprender a distinguir las ranuras (espaciado regular, ancho uniforme, orientación paralela a lo ancho de la pista) de las grietas (irregulares, ancho variable, no paralelas). Un modelo entrenado en carreteras típicamente produce 10-30% de falsos positivos en pistas ranuradas.
Depósitos de caucho: Las zonas de aterrizaje de neumáticos de aeronaves acumulan capas de caucho — depósitos poliméricos que aparecen como parches oscuros e irregulares en las imágenes. Los depósitos de caucho pueden ocultar grietas subyacentes (reduciendo la exhaustividad) y producir características de borde similares a grietas a lo largo de los límites del depósito (aumentando los falsos positivos). El preprocesamiento con estimación de caucho (utilizando imágenes multiespectrales — el caucho tiene una firma espectral distintiva en bandas NIR) y enmascaramiento mejora la precisión de la segmentación de grietas en zonas de aterrizaje en un 5-15%.
Confusión entre juntas y selladores: Los pavimentos de hormigón de pistas tienen juntas de contracción cada 4-6 metros, rellenas con sellador de juntas (típicamente un polímero flexible oscuro). Las juntas aparecen en la salida de segmentación como características similares a grietas. Sin embargo, las juntas son intencionales, esperadas y estructuralmente necesarias — no deben clasificarse como grietas. La detección de juntas utilizando priores geométricos (espaciado regular, orientación lineal perpendicular al eje central de la pista) permite el enmascaramiento de juntas antes de la medición de grietas.
Variación de iluminación: Las imágenes completas de estudio de pistas abarcan cientos de metros con iluminación variable. Un extremo de la imagen de la pista puede estar bajo luz solar directa (alto contraste, sombras nítidas de grietas) mientras que el otro está en sombra (bajo contraste, sin sombras). Los modelos deben ser invariantes a la iluminación. El aumento de datos que incluye cambios aleatorios de brillo/contraste, ecualización de histograma y generación sintética de sombras durante el entrenamiento mejora la robustez en diferentes condiciones de iluminación.
Variabilidad del pavimento: Las pistas tienen múltiples tipos de pavimento (zonas de parada de asfalto, pista principal de hormigón, conectores de calles de rodaje de asfalto) con diferentes texturas, colores y morfologías de grietas. Un solo vuelo de inspección captura todos los tipos de pavimento, lo que requiere que el modelo de segmentación se generalice entre estas superficies sin modelos separados por tipo de pavimento.
10. Generalización a Nuevas Superficies
Los modelos de segmentación de grietas son vulnerables al cambio de dominio — la degradación del rendimiento cuando se aplican a superficies, cámaras o condiciones no representadas en los datos de entrenamiento. Un modelo entrenado exclusivamente en CRACK500 (asfalto capturado a 0.05 mm/píxel, iluminación tipo interior, rango cercano) que se implementa en una pista de hormigón (diferente textura, GSD 0.2 mm/píxel, iluminación exterior, distancia variable) puede ver el IoU caer de 0.72 a 0.35-0.45.
Fuentes de Cambio de Dominio
Textura de la superficie: El asfalto tiene una textura de agregados oscura, rugosa e irregular; el hormigón tiene una textura más clara, más suave y más uniforme con agregados finos visibles. Los modelos entrenados en textura de asfalto aprenden a ignorar variaciones de textura oscuras de alta frecuencia — las superficies de hormigón violan esta invariancia aprendida.
Resolución: La apariencia de la grieta cambia con la GSD. A 0.05 mm/píxel, una grieta de 2 mm de ancho tiene 40 píxeles de ancho con bordes nítidos y bien definidos. A 0.2 mm/píxel, la misma grieta tiene 10 píxeles de ancho con bordes más suaves. Los modelos entrenados a alta resolución producen predicciones borrosas e inciertas a menor resolución.
Iluminación: Las imágenes de pistas exteriores tienen luz solar direccional que crea sombras de grietas (mejorando la visibilidad de las grietas pero produciendo artefactos de sombra), mientras que las imágenes interiores o nubladas tienen iluminación difusa (menos sombras, menor contraste). Las sombras de grietas pueden mejorar la exhaustividad en condiciones soleadas pero causar falsos positivos en escalones que no son grietas (grietas térmicas, cambios de elevación de la superficie).
Sistema de cámara: Diferentes cámaras tienen diferente respuesta espectral del sensor, paso de píxel, distorsión de lente y características de ruido. Un modelo entrenado en una DSLR de 20 MP (bajo ruido, baja distorsión) puede degradarse en una cámara de dron de 12 MP (mayor ruido, obturador rodante, aberración cromática de lente).
Mejora de la Generalización
Aleatorización de dominio: Durante el entrenamiento, aplicar aumentos aleatorios que abarquen el dominio de implementación esperado: GSD aleatoria (redimensionar imágenes a 0.5×-2.0×), iluminación aleatoria (brillo ±30%, contraste ±30%, gamma ±0.3), ruido aleatorio (ruido Gaussiano con σ=5-25), desenfoque aleatorio (desenfoque Gaussiano con kernel de 1-5 píxeles), cambios de color aleatorios (desplazamiento HSV: tono ±15, saturación ±30, valor ±30). Los modelos entrenados con suficiente aleatorización de dominio mantienen el IoU dentro del 5-10% de su rendimiento en el dominio de entrenamiento cuando se implementan en nuevas superficies.
Generación sintética de grietas: Componer grietas sintéticas en imágenes de superficies sin grietas utilizando modelos de grietas basados en física o generación de grietas basada en GAN. La base de datos de superficies sin grietas (capturadas del dominio objetivo) combinada con grietas sintéticas proporciona datos de entrenamiento emparejados donde el modelo aprende a detectar características de grietas mientras ignora la textura específica de la superficie. Este enfoque ha demostrado mejoras de IoU del 8-12% al transferir de carretera asfáltica a pista de hormigón.
Adaptación de dominio no supervisada (UDA) : Técnicas como CycleGAN, CUT y AdaIN transfieren imágenes del dominio fuente a la apariencia del dominio objetivo preservando las anotaciones de grietas. Las características de grietas de un modelo entrenado en CRACK500 se extraen de imágenes que han sido estilizadas para parecerse a la superficie de pista objetivo. Los métodos UDA mejoran el IoU en el dominio objetivo en un 10-18% sin requerir ninguna anotación del dominio objetivo.
Ajuste fino con pocos ejemplos: Recopilar 5-20 imágenes anotadas de la nueva superficie y ajustar el modelo preentrenado con una tasa de aprendizaje baja (1×10⁻⁵ a 5×10⁻⁵) y un pequeño número de épocas (10-30). Este enfoque de ajuste fino supervisado típicamente recupera el IoU dentro del 2-4% de un modelo completamente supervisado entrenado en cientos de imágenes del dominio objetivo. Es el enfoque práctico más confiable para la implementación aeroportuaria, donde recopilar un pequeño número de imágenes anotadas es operativamente factible.
El crack_seg_head de TarmacView implementa un proceso de generalización que incluye preentrenamiento con dominio aleatorizado en CrackSeg9k, selección de mosaicos específica del dominio objetivo, ajuste fino opcional con pocos ejemplos con hasta 20 imágenes anotadas proporcionadas por el usuario de la superficie objetivo, y detección automática de anomalías de dominio (la confianza del modelo por debajo de un umbral activa una alerta para revisión manual).
Preguntas Frecuentes
La segmentación de grietas asigna una etiqueta de grieta o no grieta a cada píxel de una imagen, produciendo una máscara binaria que preserva la forma exacta, la topología y la geometría de las grietas. La clasificación de grietas solo predice si una imagen contiene una grieta (etiqueta a nivel de imagen). La segmentación permite medir con precisión el área, la longitud, el ancho y los patrones de ramificación de las grietas, mientras que la clasificación solo proporciona una respuesta de sí/no.
Las arquitecturas más comunes incluyen U-Net (codificador-decodificador con conexiones de salto), DeepLabV3+ (con Agrupación Piramidal Espacial Atrosa), SegFormer (codificador Transformer jerárquico con decodificador MLP) y backbones de Transformador de Visión como DINOv2/v3 con cabezales de predicción densa. U-Net sigue siendo la más adoptada debido a su eficiencia con datos limitados y su sólido rendimiento en estructuras de grietas delgadas y alargadas.
Los conjuntos de datos clave incluyen CRACK500 (500 imágenes de pavimento, 0.05 mm/píxel), DeepCrack (537 imágenes RGB de diversas superficies), CrackForest (118 imágenes de carreteras), CrackAirport (pavimento específico de aeropuertos), CrackTree200, CFD (Crack Forest Dataset), AEL y GAPs384. La compilación CrackSeg9k unificó más de 9000 imágenes de múltiples fuentes con máscaras de verdad fundamental refinadas.
La extracción de la geometría de la grieta comienza con la esqueletización (adelgazamiento iterativo hasta una línea central de un píxel de ancho), seguida del etiquetado de componentes conectados para aislar grietas individuales. La longitud de la grieta se mide a lo largo de la trayectoria esqueletizada. El ancho de la grieta se calcula mediante la transformada de distancia euclidiana perpendicular al esqueleto. El área de la grieta es el número total de píxeles de grieta multiplicado por la resolución espacial en mm²/píxel. Se informan los valores de ancho medio y máximo por componente.
Las métricas de evaluación estándar incluyen Intersección sobre Unión (IoU/Índice Jaccard), coeficiente Dice (puntuación F1 a nivel de píxel), precisión de píxel, exhaustividad de píxel y exactitud de píxel. IoU es la intersección de los píxeles de grieta predichos y reales dividida por su unión. Dice es 2×IoU/(1+IoU). Para la segmentación de grietas, tanto la precisión (fracción de píxeles de grieta predichos que son grietas reales) como la exhaustividad (fracción de píxeles de grieta reales detectados) son críticas, ya que los falsos positivos desperdician recursos de mantenimiento mientras que los falsos negativos pasan por alto defectos peligrosos.
La segmentación de fotograma completo procesa toda la imagen de la pista en una sola pasada directa, lo que está limitado por la memoria para superficies de alta resolución (las pistas pueden superar los 50 megapíxeles). La segmentación basada en mosaicos divide la imagen en parches superpuestos (por ejemplo, 512×512 o 1024×1024 píxeles), ejecuta la inferencia en cada mosaico y vuelve a unir los resultados. Las regiones de superposición utilizan promediado ponderado o fusión consciente de costuras para evitar artefactos en los bordes. Los enfoques basados en mosaicos permiten procesar superficies arbitrariamente grandes, pero requieren un manejo cuidadoso de las grietas que cruzan los límites de los mosaicos.
La generalización entre diferentes tipos de superficies (asfalto vs. hormigón, pavimento nuevo vs. desgastado, diferentes condiciones de iluminación) sigue siendo un desafío clave. El cambio de dominio — diferencias en textura, color, apariencia de grietas y rugosidad de la superficie — puede degradar significativamente el rendimiento. Las técnicas para mejorar la generalización incluyen aleatorización de dominio durante el entrenamiento, aumento de datos sintéticos, adaptación de dominio no supervisada (CycleGAN, transferencia de estilo) y ajuste fino supervisado con un pequeño número de imágenes del dominio objetivo. Conjuntos de datos de entrenamiento diversos y bien curados como CrackSeg9k mejoran la robustez entre superficies.
El Anexo 14 de la OACI y el Doc 9157 de la OACI especifican que la evaluación del estado de la superficie de las pistas debe identificar y medir grietas, deterioro y defectos que podrían afectar la seguridad de las aeronaves. La segmentación automatizada de grietas se alinea con el énfasis de la OACI en métodos de inspección objetivos, repetibles y documentados. El Formato de Notificación Global (GRF) de la OACI requiere informes estandarizados de las condiciones de la superficie de las pistas, y la segmentación automatizada proporciona datos cuantificables sobre la extensión, densidad y severidad de las grietas que pueden alimentar directamente los marcos de informes de condiciones.
Mejore Su Inspección de Infraestructura
Implemente la segmentación de grietas a nivel de píxel para una evaluación precisa y automatizada del estado del pavimento. Nuestra segmentación de grietas impulsada por IA ofrece precisión submilimétrica para pistas, calles de rodaje y plataformas.
Detección de Grietas Basada en IA para Inspección de Infraestructura
La detección de grietas basada en IA utiliza visión por computadora — redes neuronales convolucionales, transformadores de visión y modelos de segmentación semá...
Segmentación de Instancias para Identificación Individual de Defectos
La segmentación de instancias identifica y delimita cada objeto individual o instancia de defecto a nivel de píxel, asignando una ID única a cada grieta, descas...
Detección de Objetos para Defectos y Elementos de Infraestructura
La detección de objetos localiza y clasifica objetos en imágenes mediante cajas delimitadoras — para la inspección de infraestructura, esto incluye baches, parc...
41 min de lectura
technology
machine-learning
+6
Consentimiento de Cookies Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.