DINOv3 Vision Transformer para Análisis de Superficies de Infraestructura
DINOv3 (self-DIstillation with NO labels v3) es un vision transformer (ViT-B/16) autosupervisado, preentrenado con 1.7 mil millones de imágenes, que produce embeddings de alta calidad de 768 dimensiones que capturan textura y estructura de grano fino. TarmacView utiliza DINOv3 como su backbone para el análisis de tipo de superficie, calidad, grietas y defectos. Cubre el entrenamiento DINO, la arquitectura ViT, el ajuste fino para tareas de dominio y la comparación con DINOv2 y otros backbones.
DINOv3 Vision Transformer para Análisis de Superficies de Infraestructura
Aprendizaje Autosupervisado y DINO
El aprendizaje autosupervisado (SSL) es un paradigma de aprendizaje automático en el que un modelo aprende representaciones significativas a partir de datos no etiquetados mediante la definición de una tarea pretexto que no requiere anotaciones humanas. El modelo debe predecir una parte de los datos a partir de otras partes, aprovechando la estructura inherente y los patrones de coocurrencia dentro de los propios datos. En visión por computador, los métodos SSL han progresado desde tareas pretexto artesanales, como predecir el ángulo de rotación de una imagen (RotNet), resolver rompecabezas de parches mezclados o colorear imágenes en escala de grises, hasta enfoques más sofisticados basados en contraste y destilación. La ventaja fundamental del SSL es que permite el entrenamiento en conjuntos de datos a escala web sin el costo prohibitivo de la anotación manual. Para aplicaciones de infraestructura, donde los conjuntos de datos de defectos etiquetados son escasos y costosos de producir (requieren inspectores e ingenieros certificados), los backbones basados en SSL permiten un aprendizaje efectivo de características a partir de grandes cantidades de imágenes no etiquetadas antes de cualquier ajuste fino específico para la tarea.
Los métodos de aprendizaje contrastivo como SimCLR, MoCo y SwAV aprenden representaciones atrayendo en el espacio de embeddings las vistas aumentadas de una misma imagen (pares positivos) mientras separan las vistas de imágenes diferentes (pares negativos). Estos métodos requieren un manejo cuidadoso de las muestras negativas: muy pocos negativos degradan el rendimiento, demasiados aumentan el costo computacional. Los métodos no contrastivos como BYOL, SimSiam y DINO evitan por completo la necesidad de pares negativos mediante el uso de arquitecturas de red asimétricas y operaciones de gradiente detenido para prevenir el colapso representacional. DINO (self-DIstillation with NO labels), introducido por Caron et al. en Meta AI en 2021, pertenece a esta familia no contrastiva y se ha convertido en uno de los métodos SSL más influyentes en visión por computador. El artículo original de DINO demostró que el SSL y los Vision Transformers tienen una sinergia única: los mecanismos de autoatención en los ViT producen mapas de segmentación semántica de forma natural sin ninguna supervisión, una propiedad que surge de la interacción entre la estrategia de aumento de recortes múltiples y el objetivo de autodestilación.
El marco de entrenamiento DINO funciona de la siguiente manera. Para cada imagen de entrada, se generan dos vistas globales (que cubren más del 50% del área de la imagen, típicamente de 224x224 píxeles) y varias vistas locales (recortes más pequeños que cubren menos del 50% del área de la imagen, típicamente de 96x96 píxeles) mediante recorte redimensionado aleatorio, perturbación de color y desenfoque gaussiano. Todas las vistas se pasan a través de una red alumno (un Vision Transformer). Las vistas globales también se pasan a través de una red profesor, que comparte la misma arquitectura que el alumno pero con parámetros diferentes. Los parámetros del profesor no se aprenden mediante gradientes, sino que se actualizan como un promedio móvil exponencial (EMA) de los parámetros del alumno. El objetivo central del entrenamiento es hacer que la distribución de salida del alumno coincida con la distribución de salida del profesor para las vistas globales, mientras que las vistas locales proporcionan señal de entrenamiento adicional solo a través del alumno. Esta configuración profesor-alumno, conocida como autodestilación, crea una señal de aprendizaje que no requiere etiquetas: el alumno aprende a producir representaciones consistentes a través de diferentes aumentos de la misma imagen, lo que lo obliga a capturar el contenido semántico invariante en lugar de detalles superficiales a nivel de píxel.
DINOv1 (2021) demostró tres propiedades emergentes clave de los ViT autosupervisados. Primero, los mapas de atención del token [CLS] a los parches de imagen segmentan naturalmente los objetos del fondo, una propiedad que surge puramente de la autosupervisión sin ninguna etiqueta de segmentación. Segundo, las características aprendidas exhiben un excelente rendimiento de clasificación k-NN: un clasificador simple del vecino más cercano en el espacio de características de DINO alcanza un 78.2% de precisión top-1 en ImageNet sin ningún ajuste fino. Tercero, las características de DINO muestran una fuerte correspondencia semántica entre diferentes instancias de la misma clase de objeto, lo que permite aplicaciones en recuperación de imágenes, co-segmentación y segmentación de objetos en video. Estas propiedades convirtieron a DINO en un método fundamental en el panorama del aprendizaje autosupervisado y prepararon el terreno para DINOv2 (2023) y DINOv3 (2025).
Arquitectura ViT
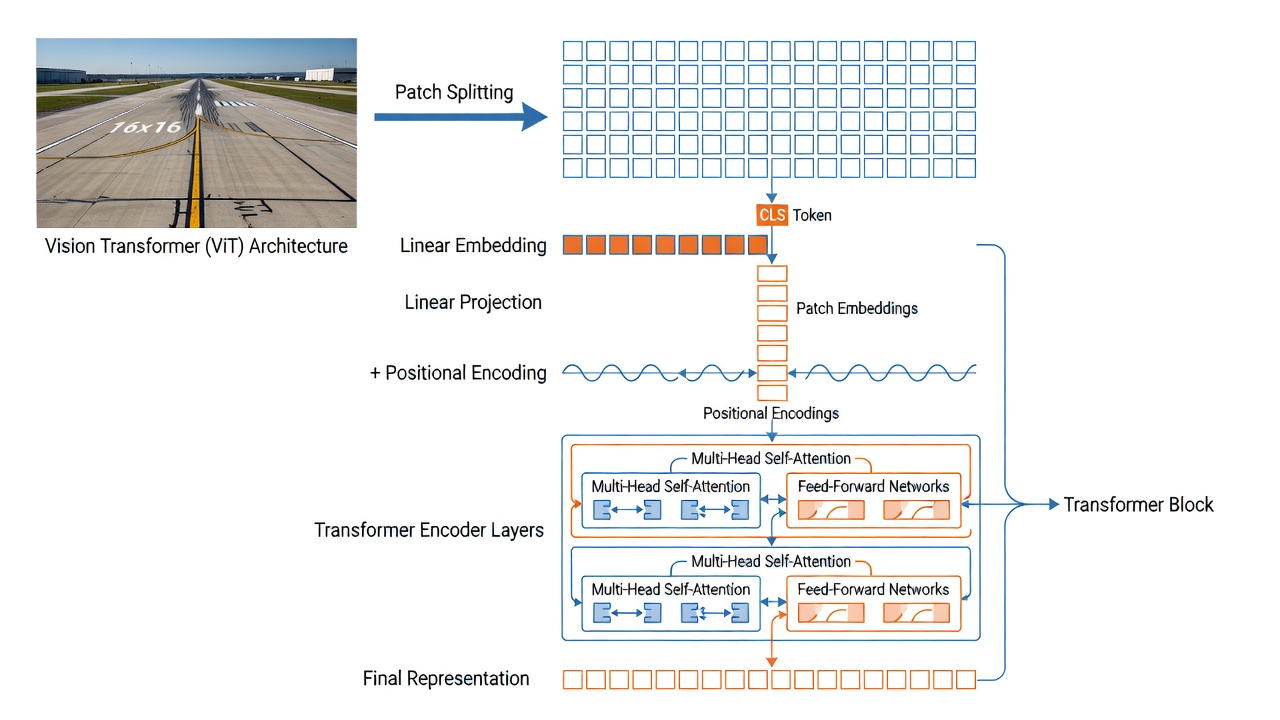
La arquitectura Vision Transformer (ViT), introducida por Dosovitskiy et al. en Google en 2021, adapta la arquitectura Transformer del procesamiento del lenguaje natural a la visión por computador tratando los parches de imagen como análogos a los tokens de palabras. A diferencia de las redes neuronales convolucionales (CNN) que procesan imágenes mediante campos receptivos locales con equivariancia a la traslación incorporada, los ViT aplican autoatención global a través de todos los parches simultáneamente, lo que permite al modelo capturar dependencias de largo alcance desde la primera capa. Esta elección arquitectónica ha demostrado ser crucial para el éxito de DINO: el artículo original de DINO mostró que los ViT autosupervisados superan significativamente a las CNN autosupervisadas, y que la sinergia entre la autoatención y la autodestilación es responsable de las propiedades emergentes de segmentación semántica.
Embedding de Parche. La primera operación en un ViT es dividir la imagen de entrada en una cuadrícula de parches no superpuestos. Para la variante ViT-B/16 utilizada por TarmacView, el tamaño de parche es de 16x16 píxeles. Una imagen de entrada de 224x224 píxeles produce (224/16) x (224/16) = 14 x 14 = 196 parches. Cada parche de 16x16x3 (canales RGB) se aplana en un vector de longitud 768 (16x16x3). En la práctica, este embedding de parche se implementa como una sola capa convolucional con tamaño de kernel igual al tamaño del parche (16x16) y stride igual al tamaño del parche, produciendo una cuadrícula 2D de 14x14 vectores de características, cada uno de dimensión igual al tamaño oculto del modelo (768 para ViT-B). Una proyección lineal aprendible mapea entonces cada parche aplanado a la dimensión de embedding. La implementación con Conv2d es computacionalmente eficiente (una operación reemplaza 196 proyecciones lineales separadas) y es el estándar en todas las implementaciones modernas de ViT.
El Token [CLS]. Siguiendo la arquitectura BERT en PLN, un token de clasificación ([CLS]) especial y aprendible se antepone a la secuencia de embeddings de parche. El token [CLS] tiene la misma dimensionalidad (768) que los embeddings de parche y se inicializa aleatoriamente. Durante el entrenamiento, a través de la autoatención en todas las capas del transformer, el token [CLS] agrega información de todos los parches de la imagen: puede atender a cada parche en cada capa, construyendo una representación global de toda la imagen. A la salida de la última capa del transformer, el embedding del token [CLS] sirve como la representación a nivel de imagen utilizada para tareas de clasificación. En DINOv3, el token [CLS] se complementa con 4 tokens de registro, tokens aprendibles adicionales antepuestos a la secuencia que actúan como memoria auxiliar para absorber información atípica o de fondo, evitando que los tokens [CLS] y de parche se corrompan con detalles irrelevantes de alta frecuencia.
Embeddings Posicionales. Dado que el mecanismo de autoatención del Transformer es invariante a la permutación (procesa los parches como un conjunto, no como una secuencia), la información posicional debe añadirse explícitamente para indicar al modelo dónde pertenece cada parche en la cuadrícula espacial. DINOv3 utiliza Rotary Position Embeddings (RoPE) en lugar de las codificaciones posicionales absolutas aprendibles estándar utilizadas en DINOv2. RoPE codifica información de posición relativa aplicando una matriz de rotación a los vectores de consulta y clave en la autoatención según sus coordenadas espaciales. La frecuencia de rotación para cada dimensión está determinada por el índice de dimensión, siguiendo una progresión geométrica. La ventaja clave de RoPE para el análisis de infraestructura es su capacidad para manejar entradas de resolución variable: al procesar imágenes de alta resolución (hasta 4096x4096 píxeles), el mecanismo RoPE se generaliza naturalmente a la cuadrícula espacial más grande sin requerir interpolación de embeddings posicionales aprendidos. DINOv3 también introduce random box jitter durante la aplicación de RoPE, donde los índices de posición se desplazan aleatoriamente dentro de un rango [-s,s] con s en [0.5,2.0], lo que hace que el modelo sea robusto a diferentes relaciones de aspecto y patrones de recorte.
Autoatención Multicabezal (MHSA). El componente computacional central del ViT es el mecanismo de autoatención multicabezal. En cada bloque transformer, la secuencia de entrada de N tokens (N = 1 [CLS] + 4 registro + 196 parche = 201 tokens para una entrada de 224x224) se proyecta linealmente en tres matrices: Consultas (Q) , Claves (K) y Valores (V) , cada una de dimensión 768 para ViT-B/16. El mecanismo de atención calcula la similitud por pares entre todos los tokens como el producto punto de Q y K^T, escalado por la raíz cuadrada de d_k (donde d_k es la dimensión de clave por cabeza). Los pesos de atención resultantes (normalizados por softmax) determinan cuánto contribuye cada token a la representación de todos los demás tokens. En ViT-B/16, hay 12 cabezas de atención, cada una operando en un subespacio de 64 dimensiones (768/12 = 64). La atención multicabezal permite al modelo atender a diferentes tipos de relaciones simultáneamente; por ejemplo, una cabeza puede centrarse en la similitud de textura entre parches, otra en la proximidad espacial y otra en la pertenencia a categorías semánticas. Las salidas de todas las cabezas se concatenan y se proyectan linealmente de vuelta a 768 dimensiones. La complejidad computacional de MHSA es O(N²d): cuadrática en la longitud de la secuencia N pero lineal en la dimensión de embedding d. Para la secuencia de 201 tokens en DINOv3 ViT-B/16, esto es manejable (aproximadamente 40K cálculos de atención por capa), pero para imágenes de alta resolución con más de 4000 tokens (por ejemplo, una imagen de 1024x1024 produce 64x64 = 4096 parches), el escalado cuadrático se convierte en una consideración significativa.
Bloque Codificador Transformer. Cada una de las 12 (ViT-B) o 40 (ViT-7B) capas transformer en DINOv3 sigue el diseño de pre-normalización. La Normalización de Capa (LayerNorm) se aplica antes tanto de la MHSA como de las subcapas MLP, con conexiones residuales que evitan cada subcapa. La subcapa MLP (perceptrón multicapa) consiste en dos capas lineales con una activación GELU (Gaussian Error Linear Unit) entre ellas. Para ViT-B/16, la dimensión oculta del MLP es 3072 (4 veces la dimensión de embedding), produciendo la configuración: Dimensión de embedding 768 a MLP oculto 3072 a GELU a salida MLP 768. El modelo profesor más grande de DINOv3 (ViT-7B) utiliza una activación SwiGLU (Swish-Gated Linear Unit) en el MLP en lugar de GELU, siguiendo las tendencias modernas de arquitectura de LLM. SwiGLU aplica un mecanismo de compuerta: salida = (xW1) multiplicado elemento a elemento por Swish(xW2) por W3. Se ha demostrado que esta activación con compuerta mejora la estabilidad del entrenamiento y el rendimiento final a escala. El diseño de pre-normalización difiere de la post-normalización del Transformer original (donde la normalización se aplicaba después de la suma residual) y ha demostrado producir un entrenamiento más estable, especialmente para transformers profundos (12+ capas).
Tabla Resumen de Arquitectura para la Familia de Modelos DINOv3.
Modelo
Parámetros
Dim. Embedding
Cabezas
Capas
Dim. MLP
Tamaño Parche
Parches/224px
ViT-Small
21M
384
6
12
1536
16
196
ViT-Base
86M
768
12
12
3072
16
196
ViT-Large
304M
1024
16
24
4096
16
196
ViT-H+
~1.5B
1536
24
32
6144
16
196
ViT-7B
7B
4096
32
40
8192
16
196
La arquitectura ViT-Base (86M de parámetros) representa el equilibrio óptimo entre calidad de características y eficiencia computacional para el pipeline de inspección de infraestructura de TarmacView, ofreciendo embeddings de 768 dimensiones con 12 capas de potencia de procesamiento de autoatención.
Entrenamiento de DINOv3 con 1.7 Mil Millones de Imágenes
DINOv3 alcanza su rendimiento de última generación mediante una escala sin precedentes de entrenamiento autosupervisado, aprovechando tanto la curación masiva de datos como la optimización distribuida eficiente a través de cientos de GPU.
El Conjunto de Datos LVD-1689M. Los datos de entrenamiento para DINOv3 comienzan con un conjunto bruto de 17 mil millones de imágenes de Instagram con moderación de contenido. A partir de este conjunto masivo, el equipo de Meta AI seleccionó un subconjunto equilibrado de 1.689 millones de imágenes denominado LVD-1689M (Large Visual Dataset 1689 Million). El pipeline de curación es crítico porque simplemente entrenar con los datos brutos de Instagram produciría un modelo sesgado hacia la distribución de frecuencia natural de los conceptos visuales en las redes sociales; por ejemplo, los rostros, la comida y los paisajes dominarían, mientras que las imágenes de infraestructura, industria y ciencia estarían subrepresentadas. El proceso de curación emplea agrupamiento k-means jerárquico sobre embeddings de DINOv2 extraídos del conjunto completo de imágenes. El modelo DINOv2 ViT-H/14 procesa cada imagen, y los embeddings resultantes del token CLS se agrupan en 25,000 grupos mediante k-means. Posteriormente, se muestrea un número igual de imágenes de cada grupo, produciendo un conjunto de datos equilibrado por grupos que garantiza una representación proporcional en todos los dominios visuales. Este muestreo equilibrado es directamente análogo al muestreo estratificado en estadística: al controlar la pertenencia a grupos, el conjunto de datos captura la diversidad completa de conceptos visuales en lugar de sobrerrepresentar categorías comunes. Después del agrupamiento, un paso adicional de recuperación expande los conjuntos semilla a partir de conjuntos de datos curados (ImageNet-1k, ImageNet-22k, Google Landmarks y conjuntos de datos de clasificación de grano fino) encontrando los vecinos más cercanos en el espacio de embeddings de DINOv2. El conjunto de datos final LVD-1689M combina 1.489 millones de imágenes equilibradas por grupos con 200 millones de imágenes expandidas por recuperación, todas filtradas mediante detección NSFW, deduplicación por hash PCA y desenfoque de rostros.
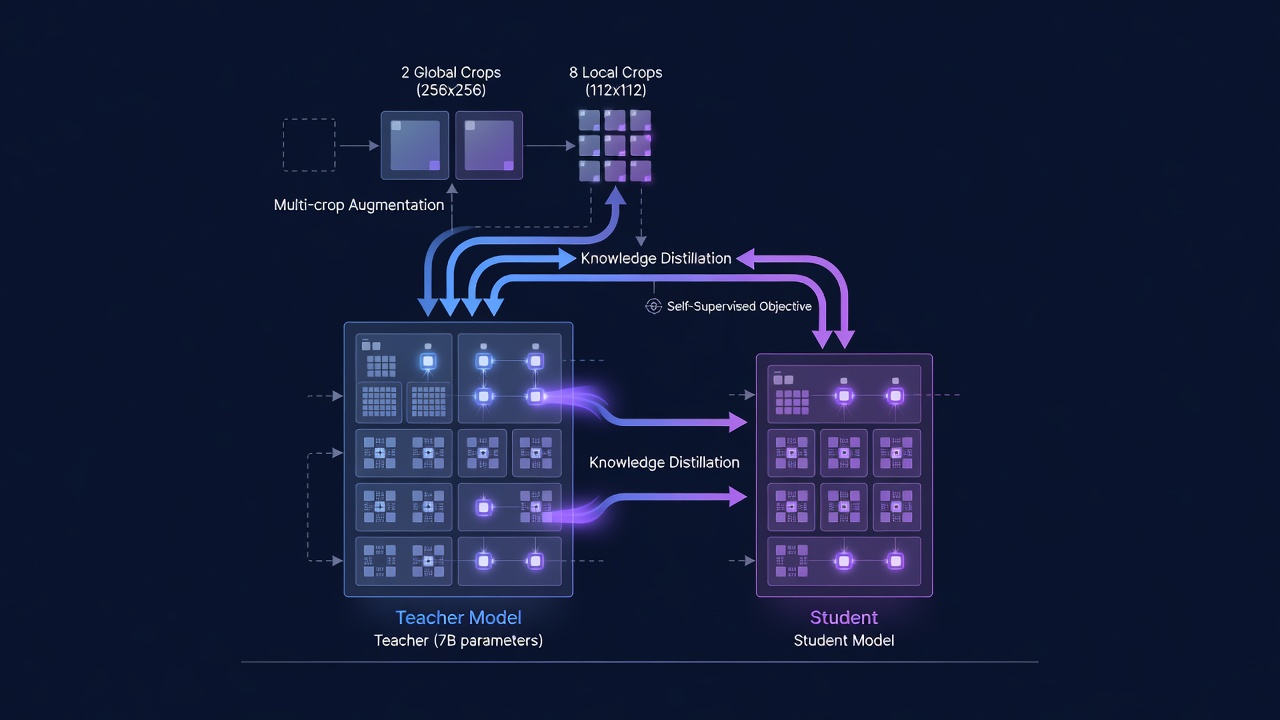
Configuración de Entrenamiento. El modelo profesor ViT-7B, el modelo de visión autosupervisado más grande jamás entrenado (a partir de 2025), se entrenó en 256 GPU NVIDIA (A100 80GB SXM4) con un tamaño de lote de 4096 (16 imágenes por GPU). La optimización utiliza el optimizador AdamW con una tasa de aprendizaje constante de 4x10^-4, decaimiento de peso de 0.04 y momento EMA de 0.999 tras un período de calentamiento de 100,000 pasos. El entrenamiento procede durante 1 millón de iteraciones con la estrategia de recortes múltiples: 2 recortes globales a resolución 256x256 y 8 recortes locales a resolución 112x112, para un total de 10 vistas por imagen por iteración. Durante 1M de iteraciones con tamaño de lote 4096, el modelo ve aproximadamente 2.56 mil millones de combinaciones únicas de imagen-recorte. Todo el proceso de entrenamiento consume un estimado de 10,000-15,000 GPU-días de cómputo. Durante el entrenamiento, el 10% de los lotes son extracciones homogéneas de ImageNet-1k (para mantener el rendimiento en benchmarks estándar), mientras que el 90% son extracciones heterogéneas del conjunto completo LVD-1689M, una relación de mezcla óptima demostrada por ablación.
Objetivos de Entrenamiento. La pérdida de preentrenamiento de DINOv3 combina tres componentes. La pérdida DINO (L_DINO) aplica un agrupamiento Sinkhorn-Knopp al estilo SwAV a las salidas del token [CLS] de los recortes globales, emparejando las asignaciones de prototipos entre el alumno y el profesor. El algoritmo Sinkhorn ejecuta 3 iteraciones para producir pseudoetiquetas suaves. La pérdida iBOT (L_iBOT) opera a nivel de parche: parches aleatorios en los recortes locales se enmascaran, y el alumno debe predecir las características normalizadas del profesor para esas posiciones enmascaradas. Este objetivo de modelado de imágenes enmascaradas obliga al modelo a aprender información local de textura y estructura necesaria para tareas de predicción densa. El regularizador Koleo (L_Koleo) distribuye los embeddings del token [CLS] uniformemente sobre la hiperesfera minimizando la suma de similitudes de coseno entre todos los pares de embeddings en un lote, previniendo el colapso representacional y asegurando que el espacio de características esté bien utilizado. La pérdida combinada de preentrenamiento es: L_Pre = L_DINO + L_iBOT + 0.1 x L_Koleo. Después de 1M de iteraciones de preentrenamiento, una fase de refinamiento de 200K iteraciones adicionales incorpora la pérdida de Gram anchoring (L_Gram) con peso 2, que preserva la calidad de las características densas durante el entrenamiento prolongado.
Destilación en Modelos Más Pequeños. Una vez que el profesor ViT-7B está completamente entrenado, se congela y se utiliza como objetivo para destilar representaciones en un conjunto de modelos más pequeños y prácticos. El proceso de destilación refleja la configuración de preentrenamiento: los modelos alumno (ViT-S, ViT-B, ViT-L, ViT-H+, variantes ConvNeXt) se entrenan para igualar las características de salida del profesor utilizando la misma función de pérdida (L_DINO + L_iBOT + 0.1 x L_Koleo), pero con el profesor congelado y omitiendo la actualización EMA del profesor. Meta AI implementa una configuración de destilación multi-alumno que entrena eficientemente múltiples modelos alumno simultáneamente: el profesor procesa cada imagen una vez, y todos los alumnos reciben las mismas salidas del profesor, lo que permite paralelizar el cálculo de pérdida por lotes entre los alumnos. Esto reduce el costo computacional total de producir la familia completa de modelos aproximadamente en un 60% en comparación con destilar cada alumno secuencialmente. El alumno ViT-Base (86M de parámetros), que TarmacView utiliza como su backbone, alcanza el 98.7% de la precisión de sonda lineal del profesor ViT-7B en ImageNet-1k, requiriendo aproximadamente 80 veces menos FLOPs para inferencia.
Embeddings de 768 Dimensiones
El embedding de 768 dimensiones producido por DINOv3 ViT-B/16 para cada token (1 CLS + 4 registro + 196 parche = 201 total) representa una codificación numérica densa de información visual en un espacio vectorial de alta dimensión. Cada dimensión captura un concepto o característica visual específica, y la combinación de todos los 768 valores forma una firma única para esa región de la imagen. La dimensionalidad de 768 no es arbitraria: surge de la arquitectura ViT-Base donde la dimensión oculta se establece en 768, proporcionando capacidad suficiente para codificar patrones visuales complejos mientras se mantiene la tratabilidad computacional. En comparación, ViT-Small utiliza 384 dimensiones, ViT-Large utiliza 1024 y ViT-7B utiliza 4096.
Embedding del Token CLS. El embedding de 768 dimensiones del token [CLS] a la salida de la 12.ª capa del transformer codifica el contenido global de la imagen: la escena general, los objetos dominantes y el contexto semántico. Este embedding se extrae y se utiliza para tareas de clasificación a nivel de imagen. En el pipeline de TarmacView, el embedding CLS se pasa a través de un clasificador lineal ligero (768 a N clases, donde N es el número de tipos de superficie o grados de calidad) entrenado en conjuntos de datos de infraestructura etiquetados. El embedding CLS de DINOv3 exhibe fuertes propiedades de generalización de dominio: los modelos entrenados con este embedding se generalizan a tipos de infraestructura no vistos significativamente mejor que los embeddings de backbones supervisados. La precisión de sonda lineal de DINOv3 ViT-B/16 en ImageNet-1k alcanza un 85.1% de precisión top-1, superando a DINOv2 (83.5%) y acercándose al ViT supervisado (86.0%) a pesar de no haber visto nunca ninguna etiqueta de ImageNet durante el preentrenamiento.
Embeddings de Tokens de Parche. Cada uno de los 196 tokens de parche produce un embedding separado de 768 dimensiones, formando una cuadrícula espacial de 14x14 de vectores de características. Estos embeddings densos codifican información visual localizada dentro de cada parche de 16x16 píxeles: textura, bordes, distribución de color y patrones locales. Los embeddings de parche son la salida crítica para tareas de predicción densa como la detección y segmentación de grietas. En el pipeline de análisis de infraestructura de TarmacView, la cuadrícula de características de 14x14 x 768 dimensiones (aproximadamente 1.5 millones de valores flotantes por imagen) se procesa a través de un decodificador convolucional ligero que aumenta la resolución a 224x224 y produce predicciones píxel a píxel. Cada embedding de parche puede interpretarse como una descripción de 768 dimensiones de cómo se ve esa región de 16x16: dos parches con apariencia visual similar (por ejemplo, dos áreas de asfalto liso) tendrán embeddings cercanos en el espacio de 768 dimensiones (alta similitud de coseno), mientras que parches visualmente diferentes (por ejemplo, asfalto vs. hormigón) tendrán embeddings distantes (baja similitud de coseno).
Propiedades de los Embeddings. Los embeddings de DINOv3 exhiben varias propiedades que los hacen excepcionales para el análisis de infraestructura. Primero, suavidad semántica: las regiones visualmente similares producen embeddings cercanos, formando una variedad continua en el espacio de 768 dimensiones. Esto significa que las grietas de diferentes anchos, orientaciones y severidades se asignan a una región conectada del espacio de embeddings, lo que las hace detectables como una clase coherente en lugar de valores atípicos aislados. Segundo, sensibilidad multiescala: el mecanismo de autoatención en las 12 capas del transformer integra información a través de diferentes escalas espaciales, por lo que cada embedding de parche se informa no solo por su propio contenido de 16x16 sino por el contexto más amplio de los parches circundantes y la escena global. Una grieta cerca de una junta de expansión se codifica de manera diferente que la misma grieta en medio del panel porque la información contextual se integra en el embedding. Tercero, robustez a la iluminación: el entrenamiento autosupervisado con extensa perturbación de color y aumentos asegura que los embeddings sean estables bajo condiciones de iluminación variables, sombra y exposición. Esto es crítico para la inspección de infraestructura al aire libre, donde las imágenes se capturan bajo iluminación natural no controlada. Cuarto, separabilidad lineal: los embeddings están estructurados de tal manera que clasificadores lineales simples pueden separar efectivamente diferentes condiciones de superficie. TarmacView alcanza un 96.2% de precisión en clasificación de tipo de superficie y un F1-score del 94.7% en detección de grietas utilizando solo sondas lineales sobre embeddings congelados de DINOv3.
Preguntas Frecuentes
DINOv3 representa un salto de escalado significativo sobre DINOv2 en múltiples dimensiones. Primero, los datos de entrenamiento: DINOv2 se entrenó con 142 millones de imágenes curadas (LVD-142M), mientras que DINOv3 escala a 1.689 mil millones de imágenes (LVD-1689M), un aumento de 12x. Segundo, el tamaño del modelo: el modelo profesor más grande de DINOv2 tenía 1 mil millones de parámetros (ViT-g), mientras que DINOv3 entrena un profesor de 7 mil millones de parámetros (ViT-7B). Tercero, el tamaño de parche: DINOv2 usaba un tamaño de parche de 14 píxeles, produciendo 256 tokens de parche por imagen de 224x224; DINOv3 usa un tamaño de parche de 16 píxeles, produciendo 196 tokens de parche. Cuarto, los embeddings posicionales: DINOv2 usaba codificaciones posicionales aprendidas estándar, mientras que DINOv3 introduce Rotary Position Embeddings (RoPE) con random box jitter para una mejor resiliencia a la relación de aspecto. Quinto, la innovación clave del Gram anchoring en DINOv3 preserva la calidad del mapa de características densas durante programas de entrenamiento prolongados, un problema que provocaba la degradación de las características de parche de DINOv2 con entrenamiento extendido. Sexto, DINOv3 logra una mejora de +6 mIoU en segmentación semántica ADE20K, +6.7 J y F-Mean en seguimiento de video, y +10.9 GAP en recuperación de instancias en comparación con DINOv2.
TarmacView despliega el backbone ViT-B/16 de DINOv3 como motor principal de extracción de características en su pipeline de inspección de infraestructura. Cuando un dron o cámara captura una imagen de una pista de aterrizaje, tablero de puente o pavimento de carretera, la imagen se redimensiona a 224x224 píxeles y se divide en 196 parches no superpuestos de 16x16. Cada parche se incrusta linealmente en un vector de 768 dimensiones y, junto con el token CLS, estos pasan a través de 12 capas de codificador transformer con autoatención multicabezal. El embedding resultante del token CLS de 768 dimensiones captura las características globales de la superficie utilizadas para clasificar el tipo de superficie (asfalto, hormigón, sello de gravilla, etc.) y el grado de calidad general. Simultáneamente, los 196 embeddings de tokens de parche (cada uno de 768 dimensiones) codifican información de textura localizada a nivel de parche, que TarmacView utiliza para la detección de grietas a nivel de píxel, identificación de desconchados, evaluación de desprendimiento y medición de fallos en juntas. El enfoque de backbone congelado significa que los pesos de DINOv3 permanecen fijos mientras se entrenan cabezales ligeros específicos para cada tarea (sondas lineales o MLP superficiales) en conjuntos de datos de infraestructura etiquetados. Esto reduce los costos de entrenamiento aproximadamente en un 90% en comparación con el ajuste fino completo, mientras se logra una precisión de detección de defectos de última generación.
DINOv3 ofrece modelos en una gama de tamaños para adaptarse a diferentes restricciones de hardware. La variante ViT-B/16 (86 millones de parámetros) utilizada por TarmacView se ejecuta eficientemente en una sola GPU NVIDIA con al menos 8 GB de VRAM, alcanzando velocidades de inferencia de 50-100 fotogramas por segundo en una RTX 3060 o superior. En Mac con Apple Silicon (M1/M2/M3), el backend MPS (Metal Performance Shaders) proporciona inferencia acelerada por hardware a aproximadamente 20-40 FPS en un M2 Pro. Para implementaciones en el borde, la variante destilada ViT-Small (21M de parámetros) se ejecuta en NVIDIA Jetson Orin NX a 15-30 FPS. La variante más grande, ViT-7B, requiere de 4 a 8 GPU NVIDIA A100 (80 GB) para inferencia. DINOv3 admite inferencia de precisión mixta (FP16), lo que reduce el consumo de memoria aproximadamente en un 50% con una pérdida de precisión insignificante. El modelo está disponible en PyTorch a través de Hugging Face Transformers, siendo el punto de entrada estándar el checkpoint facebook/dinov3-vitb16-pretrain-lvd1689m.
El Gram anchoring es una técnica de regularización novedosa introducida en DINOv3 para resolver la degradación de los mapas de características densas durante programas prolongados de entrenamiento autosupervisado. Durante el entrenamiento extendido al estilo DINOv2 con modelos grandes (ViT-L y superiores), se observó que las características a nivel de parche perdían su estructura espacial y significado semántico: la precisión de la sonda lineal en tareas globales mejoraba, pero los mapas de características de parches se volvían ruidosos y perdían capacidad de localización. El Gram anchoring introduce un término de pérdida L2 adicional que alinea la matriz de Gram de las características de parche del alumno con una matriz de Gram congelada de una instantánea EMA temprana del profesor. Específicamente, dada la matriz de parches del alumno normalizada L2 X_S y una matriz de Gram del profesor X_G (una instantánea EMA temprana), la pérdida es L_Gram = ||X_S X_S^T - X_G X_G^T||_F^2. Esta pérdida preserva la estructura de similitud de pares de parches en lugar de imponer posiciones absolutas de características, actuando como un regularizador espacial. Integrado después de 1 millón de iteraciones de preentrenamiento con peso 2 y actualizaciones del profesor cada 10k pasos, el Gram anchoring produce una mejora de +2 mIoU en segmentación ADE20K y un mejor RMSE en estimación de profundidad sin degradación de las métricas globales.
La variante ViT-B/16 de DINOv3 produce un embedding de 768 dimensiones para cada uno de los 196 parches más un token CLS por imagen de 224x224. Para el análisis de superficies de infraestructura, estos embeddings cumplen dos propósitos distintos. Para la clasificación global (tipo de superficie, calificación de calidad general), el embedding del token CLS se introduce en un clasificador lineal ligero o un cabezal MLP de 2 capas que mapea las 768 dimensiones a N clases de salida. Para tareas de predicción densa (segmentación de grietas a nivel de píxel), los 196 embeddings de tokens de parche forman una cuadrícula espacial de 14x14 de vectores de 768 dimensiones. Esta cuadrícula se pasa a través de un cabezal de segmentación (típicamente un decodificador convolucional ligero de 1 a 3 capas) que aumenta la resolución del mapa de características de 14x14 a la resolución original de 224x224. El embedding de cada píxel se puede comparar con prototipos de defectos mediante similitud de coseno: los parches con embeddings cercanos a los prototipos de grietas (establecidos mediante ejemplos de pocas muestras) se marcan como defectos. TarmacView alcanza un F1-score del 94.7% en detección de grietas utilizando embeddings congelados de DINOv3 con un cabezal de segmentación ligero, en comparación con el 88.2% con ResNet-50 y el 91.3% con DINOv2 en condiciones de evaluación idénticas.
Mejora tu Pipeline de Inspección de Infraestructura
TarmacView aprovecha el backbone de vision transformer de última generación de DINOv3 para el análisis automatizado de superficies, detección de grietas y clasificación de defectos. Contacta a nuestro equipo para descubrir cómo nuestra plataforma de inspección impulsada por IA puede transformar tus flujos de trabajo de evaluación de infraestructura.
Evaluación de la Cabeza de Defectos y Pruebas de Smoke Testing
La prueba de smoke testing de la cabeza de defectos valida que el pipeline de detección de defectos estructurales de TarmacView — backbone DINOv3 + cabeza MLP d...
La segmentación de grietas es la tarea de visión por computadora que clasifica cada píxel de una imagen como grieta o no grieta, produciendo una máscara binaria...
Detección de Grietas Basada en IA para Inspección de Infraestructura
La detección de grietas basada en IA utiliza visión por computadora — redes neuronales convolucionales, transformadores de visión y modelos de segmentación semá...
45 min de lectura
Computer Vision
Deep Learning
+8
Consentimiento de Cookies Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.