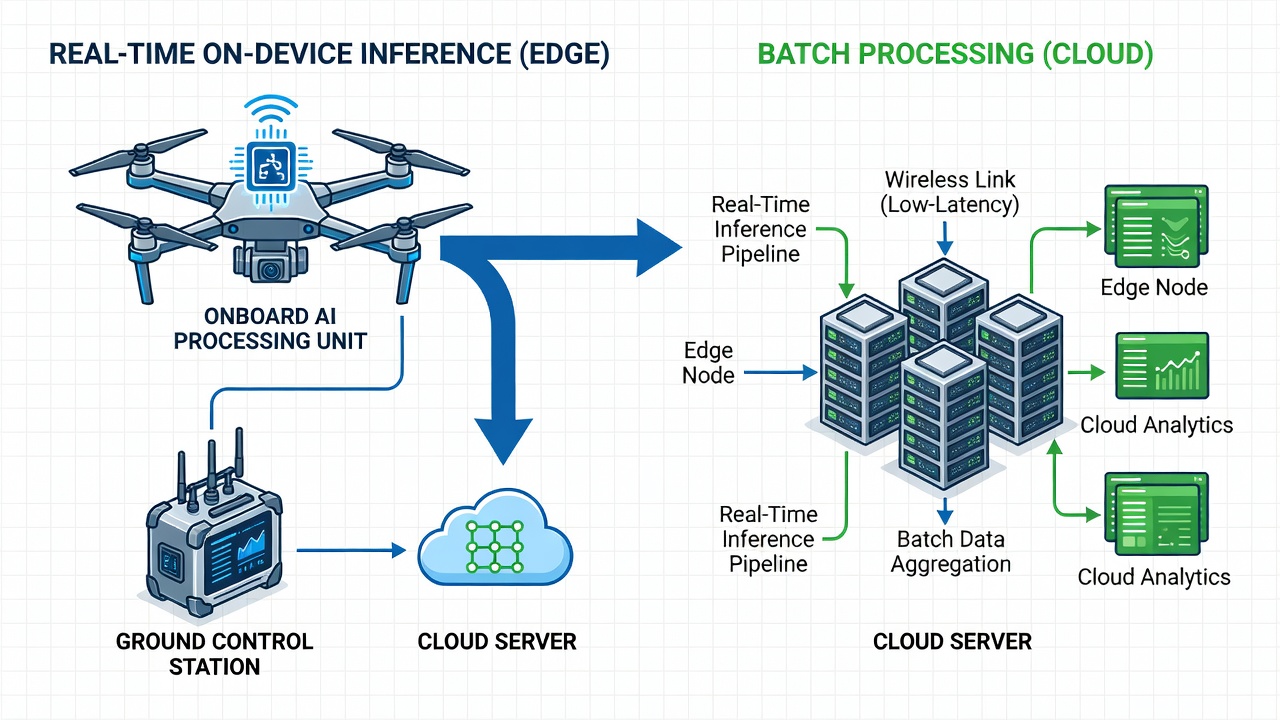
El edge computing realiza inferencia de IA directamente en el dron, vehículo o dispositivo portátil en el punto de captura de datos, permitiendo la detección de defectos en tiempo real, filtrado de calidad y soporte de decisiones sin cargar a la nube. Reduce la transmisión de datos, disminuye la latencia y acelera la respuesta en flujos de trabajo de inspección de infraestructura.
Edge Computing para Inspección en Tiempo Real
Definición y Fundamentos
Edge computing es un paradigma de computación distribuida donde el procesamiento de datos ocurre en o cerca de la ubicación física de generación de datos, en lugar de en un centro de datos centralizado en la nube. En el contexto de la inspección de infraestructura, el edge computing significa ejecutar inferencia de inteligencia artificial directamente en el dron, vehículo robótico o dispositivo portátil que captura los datos. El fundamento principal es directo: la latencia de ida y vuelta de enviar imágenes de alta resolución a la nube para su procesamiento es inaceptable para decisiones operativas en tiempo real.
El problema de la latencia se cuantifica mediante la física de redes. Un pipeline típico de inferencia en la nube implica captura de imagen, compresión, transmisión inalámbrica (Wi-Fi, 4G/5G o satélite), preprocesamiento en la nube, inferencia del modelo, empaquetado de resultados y transmisión de vuelta al operador. Incluso en condiciones óptimas de 5G con latencias de 10-20 milisegundos solo para el enlace de radio, la latencia de inferencia extremo a extremo en la nube oscila entre 200 milisegundos y 2 segundos dependiendo de la congestión de la red, la carga del servidor y la distancia geográfica a la región de la nube. Para un dron que viaja a 15 m/s (54 km/h), un viaje redondo de 2 segundos significa que la aeronave se ha movido 30 metros antes de recibir su resultado de detección — un margen inaceptable para inspección estructural de cerca donde deben identificarse grietas de 0,2 mm de ancho desde una distancia de 3-5 metros.
La inferencia en el borde elimina este problema por completo. En un NVIDIA Jetson AGX Orin que realiza 275 billones de operaciones por segundo (TOPS) de cómputo INT8, una sola pasada hacia adelante de un clasificador de imágenes ResNet-50 toma aproximadamente 3-5 milisegundos. Incluyendo preprocesamiento de imagen, escalado y decodificación de resultados, la latencia extremo a extremo por cuadro se mantiene por debajo de 50 milisegundos. Este bucle de retroalimentación de menos de 100 milisegundos permite comportamientos autónomos de circuito cerrado, como ajustar la trayectoria de vuelo para reexaminar un área sospechosa, activar una alerta inmediata a la estación terrestre o activar modalidades de sensor adicionales (ej. térmico o LiDAR) para confirmación cruzada.
Más allá de la latencia, el argumento del ancho de banda es igualmente convincente. Una imagen de inspección de 20 megapíxeles a profundidad RGB de 8 bits requiere aproximadamente 60 MB de datos sin comprimir, o 3-8 MB después de compresión JPEG dependiendo de la configuración de calidad. Un solo vuelo de inspección de 20 minutos capturando 1 cuadro por segundo genera 1.200 imágenes que totalizan 3,6-9,6 GB de datos. Para una flota de 10 drones realizando inspecciones diarias, esto se multiplica a 36-96 GB por día. Transmitir este volumen a través de enlaces celulares o satelitales es costoso, lento y a menudo imposible en ubicaciones de infraestructura remota como puentes de montaña, parques eólicos marinos o corredores de tuberías remotos donde la conectividad está limitada a 1-10 Mbps. El edge computing resuelve esto procesando las imágenes localmente y transmitiendo solo los resultados: coordenadas de detección, clasificaciones de severidad y, opcionalmente, recortes de 200x200 píxeles alrededor de los defectos detectados. Esto reduce el volumen de datos transmitidos en un 90-99%, comprimiendo un flujo de datos diario de 9,6 GB a menos de 100 MB.
Seguridad y cumplimiento normativo proporcionan una razón adicional. El procesamiento en el borde evita enviar imágenes sensibles de infraestructura — incluyendo pavimentos de aeropuertos, instalaciones militares o instalaciones energéticas críticas — a través de enlaces inalámbricos potencialmente inseguros. Para programas de inspección de defensa y gubernamentales, este modelo de procesamiento solo local satisface los requisitos de soberanía de datos que prohíben la exportación a la nube de imágenes clasificadas de sitios.
Plataformas de Hardware de IA de Borde
El despliegue práctico de inferencia en el borde depende de hardware especializado que equilibre el rendimiento computacional con las severas restricciones de energía, peso y térmicas de las cargas útiles de drones. Las siguientes plataformas dominan el mercado de inspección con IA de borde.
Familia NVIDIA Jetson
La serie Jetson de NVIDIA es la plataforma de IA de borde más ampliamente desplegada para inspección con drones, ofreciendo una arquitectura escalable desde el Nano de nivel básico hasta el AGX Orin insignia. Todos los módulos Jetson comparten un stack de software común — JetPack SDK — que incluye CUDA, cuDNN, TensorRT y bibliotecas de visión optimizadas, permitiendo portabilidad de código en toda la familia.
Módulo
Rendimiento de IA
Arquitectura de GPU
Potencia (TDP)
Factor de Forma
Caso de Uso Típico de Inspección
Jetson Nano
472 GFLOPS (FP16)
Maxwell 128 núcleos
5-10W
70x45mm
Clasificación ligera de grieta/sin grieta
Jetson TX2
1,3 TFLOPS (FP16)
Pascal 256 núcleos
7,5-15W
50x87mm
Detección de objetos en tiempo real (modelos tipo YOLO)
Segmentación semántica a resolución completa, procesamiento multiflujo
Jetson Orin Nano
40 TOPS (INT8)
Ampere 512 núcleos
7-15W
69,6x45mm
Eficiencia equilibrada para inspección en tiempo real con un solo modelo
El Jetson AGX Orin con 275 TOPS ofrece suficiente potencia de cómputo para ejecutar un modelo de segmentación U-Net a resolución 4K a más de 30 FPS, lo que lo hace adecuado para mapeo de grietas en pavimentos de alta resolución donde deben detectarse anchos de defecto submilimétricos en grandes áreas de superficie. El Jetson Orin Nano, con 40 TOPS y solo 7-15W, representa el punto óptimo de eficiencia para la mayoría de las cargas de trabajo de inspección con drones, ofreciendo 4 veces el rendimiento del Jetson Nano original con un consumo de energía similar.
Intel Movidius y Neural Compute Stick
La VPU (Unidad de Procesamiento de Visión) Intel Movidius Myriad X ofrece 4 TOPS de inferencia INT8 con solo 1-2,5W de consumo de energía, logrando una eficiencia de 2-4 TOPS/W. El Intel Neural Compute Stick 2 (NCS2) empaqueta el Myriad X en un factor de forma USB, haciéndolo accesible para prototipado. Sin embargo, el límite de 4 TOPS lo restringe a arquitecturas de modelos ligeros — MobileNetV2, EfficientNet-Lite o variantes pequeñas de YOLO — y tiene dificultades con los modelos ResNet o EfficientNet más profundos preferidos para detección de defectos de alta precisión. Para aplicaciones que requieren segmentación (U-Net, DeepLab) o detección de objetos de alta resolución (YOLOv5-large, RT-DETR), el Myriad X carece del ancho de banda de memoria y la densidad de cómputo necesarios para un rendimiento en tiempo real.
Qualcomm Snapdragon y Motor de IA
Las plataformas móviles Qualcomm Snapdragon integran DSP Hexagon y GPU Adreno con aceleradores de IA dedicados que brindan 10-30 TOPS (INT8) dependiendo de la generación. El Snapdragon 8 Gen 3 alcanza 34 TOPS con aproximadamente 5-8W para cargas de trabajo de inferencia sostenida. Las plataformas Snapdragon son particularmente relevantes para tabletas de inspección portátiles y herramientas de inspección basadas en smartphones, donde el procesador de IA ya está integrado en el sistema en chip y no consume peso o volumen adicional de carga útil. El Motor de IA de Qualcomm admite TensorFlow Lite, ONNX Runtime y el SNPE (Motor de Procesamiento Neuronal Snapdragon) propietario de Qualcomm para el despliegue de modelos.
Apple Neural Engine
Los chips A17 Pro y de la serie M de Apple integran un Neural Engine de 16 núcleos capaz de 35 TOPS (INT8) con un consumo de energía de aproximadamente 3-5W para cargas de trabajo de IA sostenidas. Si bien el Apple Neural Engine logra una eficiencia TOPS/watt excepcional, su despliegue está limitado al ecosistema Apple (iOS/iPadOS) y requiere conversión de modelos Core ML. Esto lo hace adecuado para herramientas de inspección de campo basadas en iPad comunes en flujos de trabajo de arquitectura, ingeniería y construcción (AEC), pero menos aplicable al edge computing montado en drones donde domina el ecosistema CUDA de NVIDIA.
Google Coral Edge TPU
El Coral Edge TPU (Unidad de Procesamiento Tensorial) de Google ofrece 4 TOPS (INT8) con solo 2W, lo que lo convierte en la opción más eficiente en energía por inferencia. El sistema en módulo (SoM) Coral integra el Edge TPU con un controlador de sistema i.MX 8M, proporcionando una plataforma integrada completa en 40x48mm. Sin embargo, el límite de 4 TOPS restringe la complejidad del modelo, y el requisito de modelos TensorFlow Lite exclusivamente (con operaciones compiladas para Edge TPU) reduce el espacio de arquitectura compatible. Para clasificadores de defectos simples como los modelos MobileNetV2 de 10 clases utilizados en pipelines de filtrado de calidad, el Coral Edge TPU ofrece una extensión excepcional de la duración de la batería para herramientas de inspección portátiles.
Optimización de Modelos para Despliegue en el Borde
Desplegar redes neuronales profundas en hardware de borde requiere una optimización agresiva de modelos para cumplir con las restricciones de inferencia en tiempo real en memoria, cómputo y presupuestos de energía. Los modelos entrenados en clústeres de GPU con precisión de punto flotante de 32 bits deben comprimirse y acelerarse sin sacrificar la precisión de detección por debajo de los umbrales operativos.
Cuantización
La cuantización reduce la precisión numérica de los pesos y activaciones del modelo de punto flotante de 32 bits (FP32) a representaciones de menor bits como flotante de 16 bits (FP16) o entero de 8 bits (INT8). Esta es la optimización más impactante para la inferencia en el borde.
La cuantización INT8 convierte cada peso y activación de 4 bytes a 1 byte, reduciendo la huella de memoria del modelo en un 75%. En plataformas NVIDIA Jetson con soporte Tensor Core INT8, esto se traduce en una mejora de rendimiento de 2-4x en operaciones de multiplicación de matrices en comparación con FP32. Un modelo ResNet-50 que se ejecuta a 120 FPS en FP32 en un AGX Orin puede superar los 400 FPS en INT8. El costo de precisión del entrenamiento consciente de cuantización (QAT) — donde el modelo aprende a compensar la precisión reducida durante el entrenamiento — es típicamente de 0,1-0,5% de degradación de precisión Top-1 en tareas de clasificación a escala ImageNet. Para modelos específicos de inspección, un estudio sobre detección de grietas en concreto encontró que la cuantización INT8 usando TensorRT redujo el tamaño del modelo de 98 MB a 24,5 MB mientras mantenía un 95,2% de precisión de validación — una caída del 0,8% respecto a la línea base FP32 del 96,0%.
La cuantización FP16 reduce a la mitad el tamaño del modelo (reducción del 50%) y ofrece ganancias de rendimiento de aproximadamente 1,5-2x. Para la mayoría de los modelos de inspección, la inferencia FP16 produce una precisión idéntica a FP32 dentro del ruido de medición (±0,1%), lo que la convierte en una optimización de bajo riesgo. La familia Jetson Orin admite operaciones nativas Tensor Core FP16, logrando un rendimiento óptimo para modelos con tamaño de lote 1 — la configuración estándar para inferencia de imágenes individuales en tiempo real.
La cuantización INT4 está surgiendo como una técnica de próxima generación, comprimiendo modelos a 0,5 bytes por peso. Si bien INT4 introduce caídas de precisión del 1-3% para tareas de visión, el Optimizador de Modelos de NVIDIA y la biblioteca TensorRT Model Optimizer ahora admiten INT4 para despliegue en plataformas Jetson. Esto permite ejecutar un modelo de segmentación de 200 MB en solo 25 MB de memoria — crucial para el límite de memoria unificada de 8 GB de los módulos Jetson Orin NX.
Podado
El podado elimina pesos, neuronas o canales redundantes o de baja magnitud de una red neuronal para reducir su costo computacional y huella de memoria.
El podado no estructurado pone a cero pesos individuales por debajo de un umbral de importancia, convirtiendo matrices densas en matrices dispersas. Se pueden lograr relaciones de compresión típicas del 40-60% antes de que la precisión se degrade más de un 1%. Sin embargo, la dispersión no estructurada requiere soporte de hardware o bibliotecas para la multiplicación eficiente de matrices dispersas — la arquitectura Ampere de NVIDIA proporciona soporte de dispersión estructurada 2:4 que duplica el rendimiento para capas compatibles.
El podado estructurado (de canales) elimina canales de convolución o neuronas completos, produciendo un modelo más estrecho que se ejecuta eficientemente en cualquier hardware sin requerir soporte de cómputo disperso. Las relaciones de compresión del 30-50% son típicas. Para modelos de inspección, el podado de canales con ajuste fino recupera la mayor parte de la precisión — un MobileNetV2 podado al 50% del recuento original de canales y ajustado durante 10 épocas en datos de grietas de concreto logró un 93,7% de precisión frente al 94,5% de la línea base sin podar.
Destilación de Conocimiento
La destilación de conocimiento entrena un modelo "estudiante" compacto para replicar el comportamiento de un modelo "maestro" más grande minimizando la divergencia de sus distribuciones de probabilidad de salida. El estudiante aprende de las etiquetas suaves del maestro, que codifican información más rica que las etiquetas de verdad fundamental duras — incluyendo similitudes entre clases y estimaciones de incertidumbre.
Para el despliegue de inspección en el borde, la destilación permite usar un ResNet-152 o EfficientNet-B7 como maestro (200-600 MB, 50-100M parámetros) y un MobileNetV3-Small o EfficientNet-Lite0 como estudiante (5-15 MB, 2-5M parámetros). El estudiante alcanza el 94-96% de la precisión del maestro mientras consume solo el 2-10% del cómputo. Un flujo de trabajo típico de detección de grietas en puentes destiló un maestro ResNet-152 (97,2% de precisión) en un estudiante MobileNetV3-Large (95,8% de precisión) — una pérdida de precisión del 1,4% para una reducción de 12x en tamaño del modelo y una aceleración de 20x en inferencia en Jetson Nano.
TensorRT
NVIDIA TensorRT es el SDK de optimización para inferencia de aprendizaje profundo de alto rendimiento en GPUs NVIDIA. Realiza optimización de grafos, autoajuste de kernels, calibración de precisión y gestión de memoria para maximizar el rendimiento en hardware Jetson.
El pipeline de optimización de TensorRT incluye:
Fusión de capas: Fusiona operaciones adyacentes (convolución + normalización por lotes + ReLU) en kernels individuales, reduciendo la sobrecarga de lanzamiento de kernel y el ancho de banda de memoria.
Autoajuste de kernels: Selecciona la implementación de kernel CUDA óptima para cada capa y objetivo de hardware basándose en evaluaciones comparativas empíricas.
Calibración INT8: Utiliza un conjunto de datos de calibración representativo para calcular rangos dinámicos óptimos para las activaciones, minimizando el error de cuantización.
Inferencia de formas dinámicas: Maneja dimensiones de tensor de entrada variables sin recompilación — esencial para pipelines de inspección que procesan imágenes de resolución variable.
Un modelo de inspección típico desplegado sin TensorRT alcanza el 30-50% de la utilización máxima del hardware. Después de la optimización con TensorRT, la utilización alcanza el 70-85%, con una latencia extremo a extremo reducida en 2-5x en comparación con la inferencia en modo eager de PyTorch.
ONNX
ONNX (Open Neural Network Exchange) proporciona un formato de modelo interoperable que desacopla los frameworks de entrenamiento de modelos (PyTorch, TensorFlow) de los tiempos de ejecución de inferencia. Los modelos entrenados en PyTorch se exportan al formato ONNX, luego se convierten a motores TensorRT para despliegue en Jetson o se cargan en ONNX Runtime para objetivos que no son NVIDIA (CPU ARM, Qualcomm, Intel).
El flujo de trabajo ONNX-TensorRT es el pipeline estándar: PyTorch → ONNX → motor TensorRT. Esto desacopla el entrenamiento y el despliegue, permitiendo a los científicos de datos entrenar en frameworks familiares mientras los ingenieros de despliegue optimizan para hardware de borde específico sin necesidad de reentrenar.
Detección de Grietas en Tiempo Real en el Borde
La aplicación más madura de IA de borde en inspección es la detección de grietas en tiempo real en infraestructura de concreto y asfalto. Un estudio de referencia de 2024 publicado en Sensors (PMC11645055) demostró el pipeline completo: entrenamiento de redes neuronales convolucionales con aprendizaje por transferencia, despliegue en un NVIDIA Jetson Nano y validación en estructuras de concreto de laboratorio y campo.
El estudio entrenó seis arquitecturas CNN — ResNet18, ResNet50, GoogLeNet, MobileNetV2, MobileNetV3-Small y MobileNetV3-Large — utilizando aprendizaje por transferencia a partir de pesos preentrenados de ImageNet. El conjunto de datos comprendía 3.000 imágenes de superficies de concreto (agrietadas e intactas) aumentadas con ruido sal y pimienta y desenfoque de movimiento para mejorar la robustez en el mundo real. ResNet50 logró la mayor precisión de validación con un 96,0% y una puntuación F1 del 95,0% con un tamaño de lote de 16.
Desplegado en el Jetson Nano a 5-10W, el modelo ResNet50 clasificó una imagen de 224x224 en 38 milisegundos — permitiendo procesamiento en tiempo real a 26 cuadros por segundo. Este rendimiento es suficiente para un dron que vuela a 5 m/s con un 70% de superposición entre cuadros consecutivos, asegurando que cada centímetro cuadrado de superficie se clasifique múltiples veces.
Para una caracterización de defectos más detallada, los modelos de segmentación como U-Net y DeepLabV3+ proporcionan mapas de grietas a nivel de píxel. El estudio de inspección de puentes IJAMA logró una intersección sobre unión media (mIoU) de 0,86 para segmentación de grietas utilizando un U-Net con codificador MobileNetV2 en Jetson Orin Nano a 22 FPS y 7W. Esto permite cuantificar el ancho, largo y orientación de las grietas — métricas requeridas por estándares de inspección de puentes como AASHTO y los Estándares Nacionales de Inspección de Puentes (NBIS) de la Administración Federal de Carreteras.
La detección de grietas desplegada en el borde ha sido validada en campo en puentes operativos, incluyendo un puente de concreto de 50 metros de luz donde un dron DJI Matrice 300 RTK equipado con un Jetson Orin NX detectó 43 grietas (anchos de 0,3-3,2 mm) durante un vuelo de inspección automatizado de 12 minutos. La validación manual confirmó 41 verdaderos positivos (95,3% de recall) con 3 falsos positivos (92,8% de precisión).
Filtrado de Calidad en el Borde
Las imágenes de inspección en bruto contienen una alta proporción de cuadros no aptos para análisis debido a desenfoque de movimiento, exposición inadecuada, errores de enfoque o artefactos ambientales (gotas de lluvia en el lente, deslumbramiento solar, polvo). Sin filtrado, estas imágenes de baja calidad incrementan los costos de almacenamiento, transmisión y procesamiento posterior. El filtrado de calidad en el borde aborda esto ejecutando una red ligera de evaluación de calidad antes del modelo principal de detección de defectos.
El pipeline de filtrado de calidad típicamente consiste en:
Detección de desenfoque: Análisis de la varianza del Laplaciano de la imagen — una imagen borrosa produce valores de varianza bajos. Un umbral de 100 (en una imagen de 8 bits) típicamente separa los cuadros nítidos de los desenfocados por movimiento. En Jetson, esto toma menos de 1 milisegundo en CUDA.
Calidad de exposición: Análisis de histograma para detectar imágenes sobreexpuestas (más del 5% de píxeles saturados) o subexpuestas (luminancia media < 40). Las imágenes aceptables típicamente se encuentran en el rango de luminancia media de 40-200 para inspección.
Evaluación de contraste: Medición de contraste de raíz cuadrada media (RMS); las imágenes de bajo contraste (RMS < 0,3) se descartan ya que carecen de la información de gradiente necesaria para la detección de bordes de grietas.
Similitud estructural: Para secuencias de video, el índice de similitud estructural (SSIM) entre cuadros consecutivos identifica imágenes casi duplicadas (SSIM > 0,95), conservando solo un cuadro representativo para maximizar la cobertura única por unidad de almacenamiento.
El clasificador ligero de calidad combinado — una red convolucional de 3 capas con 80.000 parámetros que se ejecuta en configuración MobileNetV2-lite — clasifica las imágenes como "aprobado" o "rechazado" en 2-4 milisegundos en dispositivos Jetson Orin. Datos de campo de operaciones de inspección de tuberías muestran que el filtrado de calidad en el borde rechaza el 60-75% de los cuadros en bruto, lo que significa que solo el 25-40% procede al modelo de detección de defectos más pesado. Esto reduce la carga total de cómputo de inferencia en 2,5-4x y los requisitos de almacenamiento proporcionalmente.
El resultado final: un vuelo de inspección de 20 minutos que genera 1.200 cuadros en bruto produce solo 300-480 imágenes filtradas por calidad. Después de la detección de defectos, solo se transmiten 30-80 imágenes con defectos detectados más sus metadatos georreferenciados (típicamente 2-5 KB por defecto mediante anotaciones GeoJSON). El volumen total de datos diarios por dron se reduce de 9,6 GB a menos de 200 MB — una reducción del 98%.
Arquitectura Híbrida de Borde y Nube
Si bien el edge computing maneja la inferencia en tiempo real, el procesamiento en la nube sigue siendo esencial para análisis de alta fidelidad, reentrenamiento de modelos, gestión de flotas y archivado de datos. La arquitectura óptima es un sistema híbrido de borde-nube donde cada nivel realiza las tareas para las que está mejor preparado.
Nivel de Borde (En el Punto de Captura)
Función
Detalles
Detección de defectos en tiempo real
Ejecutar modelos INT8 optimizados a 20-30 FPS para identificación inmediata
Filtrado de calidad
Rechazar cuadros borrosos/sobreexpuestos/duplicados antes del almacenamiento
Navegación autónoma
Detectar y evitar obstáculos, ajustar trayectoria de vuelo para reexaminar
Generación de alertas
Transmitir alertas de defectos georreferenciadas en tiempo real mediante enlace de telemetría de bajo ancho de banda
Almacenamiento local
Retener imágenes de resolución completa de defectos detectados en SSD a bordo (256GB-1TB)
Fusión de sensores
Combinar datos RGB, térmicos y LiDAR para inferencia multimodal
Nivel de Nube (Después de la Finalización del Vuelo)
Función
Detalles
Análisis de alta fidelidad
Ejecutar modelos ensemble FP32 o transformers de visión en imágenes de resolución completa para validación de segunda opinión
Integración con gemelo digital
Fusionar resultados de detección de borde en modelos BIM 3D para gestión de activos de infraestructura
Agregación a nivel de flota
Agregar resultados de detección de borde de todas las inspecciones para análisis de tendencias y programación de mantenimiento predictivo
Reentrenamiento de modelos
Usar falsos positivos y detecciones omitidas detectadas en el borde como muestras de aprendizaje activo para mejora del modelo
Generación de informes de cumplimiento
Generar informes de inspección conformes a normas OACI, FAA, ASTM o estándares nacionales de infraestructura
Archivado a largo plazo
Almacenar todos los datos de inspección (metadatos de borde + imágenes seleccionadas de resolución completa) para períodos de retención regulatoria (5-20 años)
El flujo de datos progresa a través de etapas definidas. Durante el vuelo, el pipeline de borde opera autónomamente — capturar, filtrar calidad, detectar, alertar. Después del aterrizaje, el dron se conecta a la estación terrestre o la nube mediante Wi-Fi local de alto ancho de banda o USB-C, y se produce la transferencia masiva de datos para imágenes no urgentes y telemetría del modelo. La nube procesa estos lotes de forma asíncrona, actualizando las bases de datos de defectos y los registros de modelos.
Este enfoque híbrido combina la capacidad de respuesta de menos de 50 ms de la inferencia en el borde con la profundidad analítica del procesamiento en la nube, logrando tanto velocidad operativa como precisión analítica. Los despliegues de campo que utilizan esta arquitectura reportan un 97% de concordancia entre las detecciones iniciales de borde y los hallazgos validados en la nube en una muestra de 10.000 imágenes de inspección.
Edge Computing para Operaciones BVLOS
Las operaciones Más Allá de la Línea Visual (BVLOS) — donde el dron opera más allá del rango visual sin ayuda del piloto — imponen requisitos estrictos de autonomía a bordo, y el edge computing es la tecnología habilitadora. El marco regulatorio de la OACI para sistemas UAS y la elaboración de normas de la FAA Parte 108 para operaciones BVLOS identifican el procesamiento de datos a bordo en tiempo real como un requisito previo para el vuelo seguro más allá de la línea visual.
Bajo las normas BVLOS, el dron debe mantener una separación segura del terreno, obstáculos y otras aeronaves sin supervisión visual directa del piloto. Esto requiere sistemas de Detectar y Evitar (DAA) que procesen datos de sensores a bordo y ejecuten maniobras evasivas en 100-200 milisegundos — muy por debajo de la latencia de ida y vuelta de las arquitecturas dependientes de la nube. El edge computing permite DAA ejecutando modelos de detección de objetos (YOLOv8, RT-DETR) en datos de cámaras a bordo y radar en tiempo real, detectando tráfico cooperativo y no cooperativo a distancias de 200-1000 metros dependiendo del conjunto de sensores.
El edge computing también permite operaciones con enlace degradado. Cuando el enlace C2 experimenta pérdida de paquetes o degradación de señal — común en terreno montañoso, cañones urbanos o sobre agua — el dron debe continuar su misión de forma segura. Los sistemas de borde almacenan el plan de vuelo localmente, ejecutan navegación por puntos de ruta usando fusión GPS y IMU a bordo, y continúan el procesamiento de datos de inspección hasta que el enlace se restablece. La fusión de sensores entre la odometría visual procesada en el borde y la navegación por estimación inercial mantiene la precisión posicional dentro de 1-5 metros durante cortes de C2 de hasta 60 segundos.
El Kit de Herramientas UAS de la OACI y el marco regulatorio de EASA para operaciones UAS en las categorías Específica y Certificada requieren que los drones equipados con BVLOS demuestren la capacidad de completar una terminación segura del vuelo o regreso a casa sin depender de conectividad continua del enlace de datos. El edge computing cumple con esto alojando todas las funciones de navegación, evitación de obstáculos y gestión de misiones a bordo.
Para la inspección de infraestructura lineal de largo alcance — tuberías, líneas de transmisión eléctrica, corredores ferroviarios — las operaciones BVLOS con edge computing permiten la cobertura de 50-100 km en un solo vuelo. El dron procesa los datos de inspección en tiempo real durante el vuelo de 45-90 minutos, luego carga en masa los resultados y las imágenes de resolución completa de los defectos detectados a la nube después del aterrizaje. Sin el procesamiento en el borde, los costos de almacenamiento y ancho de banda de capturar 60-120 GB por vuelo serían prohibitivos.
Restricciones de Energía y Térmicas
El hardware de edge computing en drones opera bajo los presupuestos de energía y térmicos más restrictivos de la industria informática. A diferencia de las GPUs de centros de datos con presupuestos de energía de 300-700W y refrigeración líquida, las cargas útiles de drones deben operar dentro de 10-60W de potencia total del sistema mientras soportan temperaturas ambiente que van desde -20°C hasta +50°C, cambios rápidos de velocidad del aire e irradiación solar.
Asignación del Presupuesto de Energía
Un dron de inspección típico (ej. DJI Matrice 350 RTX) tiene un presupuesto total de energía para la carga útil de 25-50W del sistema de baterías del dron, compartido entre:
Componente
Consumo Típico de Energía
Módulo de Cómputo de IA de Borde
7-25W
Cámara RGB (operación continua)
3-8W
Cámara Térmica (si está equipada)
2-5W
LiDAR o telémetro
5-15W
Radios de comunicación (C2 + telemetría)
2-5W
Estabilización de cardán del sensor
2-4W
El módulo de borde debe operar dentro de su presupuesto de energía térmica. La experiencia práctica muestra que desplegar un Jetson AGX Orin a su máximo rendimiento de 60W rara vez es factible en drones de menos de 25 kg debido a los límites de capacidad de la batería — una carga de cómputo de 60W consumiría el 30% de una batería de dron de 200 Wh durante un vuelo de 60 minutos, dejando energía insuficiente para motores y sensores. El Jetson Orin Nano a 7-15W es la opción más práctica para vuelos de inspección sostenidos que exceden los 30 minutos.
Potencia de Diseño Térmico (TDP) y Refrigeración
Módulo de Borde
TDP
Refrigeración Requerida
Ambiente Máx. (Pasivo)
Ambiente Máx. (Activo)
Google Coral Edge TPU
2W
Pasiva (solo difusor)
70°C
N/A
Jetson Nano
5-10W
Disipador pasivo
50°C
70°C con ventilador
Jetson Orin Nano
7-15W
Disipador + ventilador opcional
45°C
65°C con ventilador
Intel Movidius NCS2
2,5W
Pasiva
60°C
N/A
Jetson Orin NX
10-25W
Ventilador activo requerido
N/A
55°C
Jetson AGX Orin
15-60W
Ventilador activo requerido
N/A
50°C
La estrangulación térmica es una preocupación operativa crítica. Cuando la temperatura interna del módulo Jetson excede su límite térmico (típicamente 80-85°C de temperatura de unión para módulos Orin), el controlador reduce progresivamente las frecuencias del reloj de la GPU. Al 50% de estrangulación térmica, el rendimiento de inferencia disminuye aproximadamente un 40-50%. Con luz solar directa a 35°C ambiente, un Jetson Orin Nano con refrigeración pasiva ejecutando inferencia sostenida puede alcanzar 82°C después de 8-12 minutos. La refrigeración activa utilizando un ventilador de 40x40x10 mm aumenta la masa en 15 gramos y el consumo de energía en 0,8W pero mantiene la temperatura de unión por debajo de 70°C indefinidamente.
La escala dinámica de frecuencia y voltaje (DVFS) es la estrategia de mitigación estándar. El módulo Jetson ajusta su frecuencia de operación en 5-7 estados de rendimiento, intercambiando rendimiento de inferencia por seguridad térmica. Un perfil de vuelo típico podría ejecutarse al máximo rendimiento (15W, 40 TOPS) durante la inspección activa sobre un segmento de puente, luego reducir a 7W (15 TOPS) durante el tránsito entre objetivos — manteniendo margen térmico mientras optimiza el consumo de batería.
Edge Computing en el Contexto de TarmacView
La plataforma de inspección de infraestructura de TarmacView integra edge computing como la capa de procesamiento central entre la carga útil de sensores del dron y la plataforma de análisis en la nube. La arquitectura sigue el modelo híbrido de borde-nube: la inferencia de IA a bordo maneja la detección de defectos en tiempo real y el filtrado de calidad durante el vuelo, mientras que la plataforma en la nube de TarmacView proporciona análisis posterior al vuelo, integración con gemelo digital y gestión de activos a nivel de flota.
En el flujo de trabajo de TarmacView, el dron lleva un módulo NVIDIA Jetson Orin NX (100 TOPS INT8, 10-25W) conectado a la cámara de carga útil mediante interfaz USB 3.0 o GigE Vision. El stack de software a bordo incluye:
Filtro de calidad: Un clasificador MobileNetV3-Small (entrenado en el conjunto de datos propietario de TarmacView de 50.000 imágenes de pistas y calles de rodaje) que rechaza cuadros desenfocados por movimiento, sobreexpuestos o duplicados en menos de 3 ms por imagen.
Detección de defectos: Un modelo YOLOv5nano optimizado (entrada de 640x640, < 10 MB después de cuantización INT8) que detecta grietas, desconchados, desprendimientos, defectos de juntas y objetos extraños (FOD) a 30 FPS usando TensorRT en el Orin NX.
Clasificador de severidad: Cada región de defecto detectada se recorta y se pasa a un clasificador de severidad ResNet18 (menor / moderado / severo) basado en umbrales de ancho de grieta de la Circular de Asesoramiento FAA 150/5380-6B y el Manual de Diseño de Aeródromos de la OACI Parte 3.
Georreferenciación: La información de posición del GPS RTK del dron (precisión de 2-5 cm) se fusiona con cada cuadro delimitador de detección, produciendo anotaciones de inspección compatibles con GeoJSON almacenadas localmente y transmitidas mediante telemetría.
El módulo de borde almacena imágenes de resolución completa de los defectos detectados en un SSD NVMe de 256 GB. Durante el vuelo, solo se transmiten resúmenes de detección en JSON (tipo de defecto, coordenadas GPS, severidad, marca de tiempo, puntuación de confianza — típicamente 500 bytes por detección) a través del enlace de telemetría C2. Después del aterrizaje, el dron se conecta a la estación terrestre de TarmacView mediante Wi-Fi de 5 GHz para la transferencia masiva de recortes de imágenes de defectos y mosaicos ortomosaico de resolución completa a 1-2 Gbps.
La capa de nube procesa los datos por lotes de forma asíncrona: cotejando las detecciones de borde con datos históricos de inspección, generando puntuaciones del Índice de Condición del Pavimento (PCI) según las directrices de la OACI y actualizando el gemelo digital de infraestructura para la planificación de mantenimiento. La nube también monitorea el rendimiento del modelo de borde en toda la flota, señalando deriva o detecciones omitidas sistemáticas para reentrenamiento.
Futuro de la Inspección en el Borde
El edge computing para inspección está evolucionando a lo largo de varios vectores tecnológicos que expandirán fundamentalmente lo que es posible en el punto de captura.
Computación Neuromórfica
Los procesadores neuromórficos — como el Loihi 2 de Intel y el Speck de SynSense — emulan redes neuronales biológicas utilizando redes neuronales de picos (SNN) que consumen órdenes de magnitud menos energía que los aceleradores de aprendizaje profundo convencionales. Loihi 2 logra 10-100x mejor TOPS/watt para tareas de visión específicas en comparación con GPUs de clase Jetson. Para inspección, las cámaras de eventos neuromórficas emiten solo los píxeles que cambian (eventos de movimiento) en lugar de cuadros completos, reduciendo el ancho de banda de datos en un 90-99% mientras logran velocidades de cuadro efectivas que exceden los 10.000 Hz. Un procesador de borde neuromórfico acoplado con una cámara de eventos podría detectar una grieta que aparece en una probeta de concreto bajo carga con latencia submilisegundo, con un consumo de energía inferior a 100 mW — permitiendo monitoreo continuo de salud estructural desde sensores alimentados por batería durante meses en lugar de horas.
Procesamiento en el Sensor
Los sensores con procesamiento integrado — como el sensor de visión inteligente IMX500 de Sony — realizan inferencia CNN dentro del propio sensor de imagen, emitiendo metadatos (cuadros delimitadores, etiquetas de clase, recuentos) en lugar de datos de píxeles. El IMX500 ofrece hasta 30 FPS de clasificación a 0,5W de potencia total para el paquete de sensor más procesador, eliminando la necesidad de un módulo de cómputo de borde separado para tareas de detección simples. Para la inspección con drones ultraligeros, el procesamiento en el sensor permite la detección en plataformas de dron de menos de 250 g que no pueden transportar un módulo Jetson.
Modelos de Borde Basados en Transformers
Los transformers de visión (ViT) y sus variantes eficientes (MobileViT, EdgeNeXt, FastViT) se están acercando a la eficiencia de nivel CNN en hardware de borde. FastViT alcanza un 76,7% de precisión Top-1 en ImageNet con una latencia de inferencia de 4,8 ms en iPhone 14 Pro (Apple Neural Engine) — comparable al 71,8% de MobileNetV2 a 1,5 ms pero con una precisión significativamente mayor. A medida que NVIDIA TensorRT y Apple Core ML añadan soporte optimizado para operadores de transformers, los modelos de inspección basados en transformers ofrecerán mayor precisión para clasificación y segmentación de defectos con un rendimiento compatible con el borde.
Integración de Borde 6G
El estándar celular 6G, cuyo despliegue inicial se espera alrededor de 2030, integrará el edge computing como una función de red nativa. Las arquitecturas 6G distribuyen recursos de cómputo a través de la red de acceso de radio, permitiendo coordinación de borde-nube en menos de 1 ms. Para inspección, esto podría permitir inferencia colaborativa en tiempo real donde un dispositivo de borde en el dron ejecuta un modelo rápido y ligero mientras la red 6G descarga los casos más difíciles — defectos ambiguos, patrones de daño novedosos — a un modelo de nube más profundo dentro de un único viaje redondo de red. La combinación de las bandas de terahercios del 6G (rendimiento de 50+ Gbps) con cómputo de borde distribuido hará de la teleoperación en tiempo real de drones de inspección con transmisión de video 4K y superposición de IA una realidad práctica.
Modelos de Borde Autootimizables
El aprendizaje federado y la adaptación continua de modelos permitirán que los sistemas de inspección de borde mejoren con el tiempo sin reentrenamiento centralizado. Cada módulo de borde del dron registra los resultados de detección y las correcciones del operador, utilizando estas como señales de entrenamiento para actualizaciones incrementales del modelo. En una flota de 50 drones de inspección, cada uno contribuyendo con 1.000 predicciones corregidas por semana, el modelo compartido mejora a razón de 50.000 muestras etiquetadas por semana — permitiendo una adaptación rápida del dominio a nuevos tipos de infraestructura, condiciones climáticas y morfologías de defectos sin la sobrecarga del etiquetado manual de datos.
Términos Relacionados
Inferencia: El proceso de ejecutar un modelo de aprendizaje automático entrenado sobre nuevos datos para producir predicciones.
Procesamiento en la Nube: Análisis de datos centralizado realizado en centros de datos remotos con alta capacidad de cómputo pero mayor latencia.
Sistemas en Tiempo Real: Sistemas informáticos que garantizan respuesta dentro de restricciones de tiempo estrictas.
Automatización: El uso de tecnología para realizar tareas con intervención humana reducida.
Aprendizaje Profundo: Un subconjunto del aprendizaje automático que utiliza redes neuronales multicapa para reconocimiento de patrones.
Dron (UAV): Un vehículo aéreo no tripulado que sirve como plataforma de inspección.
GPU Móvil: Una unidad de procesamiento gráfico diseñada para aplicaciones móviles y embebidas con restricciones de energía.
Optimización de Modelos: Técnicas para reducir el tamaño del modelo y aumentar la velocidad de inferencia para su despliegue.
Cuantización: Reducción de la precisión numérica en pesos y activaciones de redes neuronales.
Preguntas Frecuentes
El edge computing en la inspección con drones significa ejecutar inferencia de IA directamente en el ordenador de a bordo del dron en lugar de transmitir todos los datos a la nube para su procesamiento. El dron captura imágenes de alta resolución y las procesa localmente utilizando redes neuronales optimizadas, detectando defectos como grietas, corrosión o delaminación en tiempo real durante el vuelo. Solo los resultados de detección, alertas georreferenciadas y recortes de imágenes seleccionados se transmiten a la estación terrestre, reduciendo la transferencia de datos en un 90-99% en comparación con la carga a la nube a resolución completa.
La familia NVIDIA Jetson es la plataforma más adoptada para IA de borde en drones, abarcando desde el Jetson Nano (472 GFLOPS, 10W) para clasificación ligera hasta el Jetson AGX Orin (275 TOPS, 60W) para inferencia multimodelo. Otras opciones incluyen el Google Coral Edge TPU (4 TOPS, 2W) para aplicaciones de ultra bajo consumo, Intel Movidius VPU para tareas específicas de visión, y las plataformas Qualcomm Snapdragon con motores de IA integrados para inspección basada en smartphones. La elección depende del presupuesto de energía, la complejidad del modelo y los requisitos de tiempo real.
Las técnicas de optimización de modelos comprimen redes neuronales profundas para ejecutarse eficientemente en hardware de borde con recursos limitados. La cuantización convierte los pesos del modelo de punto flotante de 32 bits a entero de 8 bits (INT8), reduciendo el tamaño del modelo en un 75% y aumentando el rendimiento de inferencia en 2-4x con una pérdida mínima de precisión (típicamente <1%). El podado elimina pesos o neuronas redundantes, logrando una compresión del 40-60%. La destilación de conocimiento entrena un modelo "estudiante" más pequeño para imitar a un modelo "maestro" más grande. TensorRT es el SDK de optimización de NVIDIA que fusiona capas, selecciona kernels optimizados y aplica cuantización específica para el objetivo.
La detección de grietas en tiempo real en el borde utiliza redes neuronales convolucionales (CNN) desplegadas en dispositivos integrados como el NVIDIA Jetson Nano para clasificar imágenes de superficies de concreto como agrietadas o intactas durante el vuelo. Un estudio de la Universidad del Sur de Queensland logró un 96% de precisión de validación utilizando ResNet50 con aprendizaje por transferencia en un Jetson Nano, con latencias de inferencia inferiores a 50 ms por imagen de 224x224. Modelos de segmentación más avanzados como U-Net alcanzan hasta 0.86 de IoU medio a 22 FPS en el Jetson Orin Nano con solo 7W de consumo de energía.
Las operaciones Más Allá de la Línea Visual (BVLOS) requieren que el dron mantenga un vuelo seguro sin supervisión visual humana continua. El edge computing lo permite procesando la detección de obstáculos, el mapeo del terreno y las decisiones de navegación a bordo en tiempo real, incluso si el enlace de comando y control (C2) está degradado o temporalmente perdido. Las regulaciones de la OACI y la FAA para BVLOS enfatizan la necesidad de capacidades autónomas de Detectar y Evitar (DAA), que dependen de la IA de borde de baja latencia. Los sistemas de borde también reducen el ancho de banda de comunicaciones necesario para el pilotaje remoto al transmitir solo resúmenes de telemetría y alertas.
El edge computing en drones opera bajo severas restricciones de energía. Un dron de inspección pequeño típico (ej. DJI Matrice 300/350) tiene un presupuesto total de energía para la carga útil de 25-50W en total, del cual el módulo de IA de borde puede consumir 7-25W. El NVIDIA Jetson Orin Nano opera con un TDP de 7-15W, el Jetson AGX Orin de 15-60W y el Google Coral con solo 2W. La gestión térmica es igualmente crítica: la refrigeración pasiva es suficiente para módulos de menos de 10W, pero los módulos de mayor rendimiento requieren refrigeración activa (ventiladores o disipadores) que añaden peso y consumen energía adicional. Por encima de 40°C de temperatura ambiente, la estrangulación térmica puede reducir el rendimiento de inferencia en un 30-50%.
Despliegue IA de Borde en Tiempo Real para sus Inspecciones
TarmacView integra edge computing con inspección basada en drones para ofrecer detección instantánea de defectos, filtrado de calidad y soporte de decisiones en el punto de captura. Contáctenos para saber cómo la inferencia en el borde puede transformar sus flujos de trabajo de inspección de infraestructura.
Inspección automatizada de infraestructura con drones
La inspección automatizada con drones utiliza rutas de vuelo preprogramadas, visión artificial y análisis de IA para inspeccionar activos de infraestructura, in...
Detección de Grietas Basada en IA para Inspección de Infraestructura
La detección de grietas basada en IA utiliza visión por computadora — redes neuronales convolucionales, transformadores de visión y modelos de segmentación semá...