FAISS (Facebook AI Similarity Search) es una biblioteca de código abierto para la búsqueda eficiente de similitud y agrupación de vectores densos, utilizada por TarmacView para almacenar y consultar aproximadamente 9000 embeddings de referencia etiquetados para la clasificación de calidad superficial por vecinos más cercanos. Cubre tipos de índice (Flat, IVF, HNSW), similitud coseno mediante producto interno en vectores normalizados, aceleración por GPU y su aplicación en la recuperación de imágenes de inspección.
FAISS – Búsqueda de Similitud de Alto Rendimiento en Embeddings Vectoriales
Definición y Capacidades
FAISS (Facebook AI Similarity Search) es una biblioteca de código abierto en C++ desarrollada por el equipo de Fundamental AI Research (FAIR) de Meta para la búsqueda eficiente de similitud y agrupación de vectores densos. Publicada por primera vez en 2017, FAISS ha crecido hasta más de 40 000 estrellas en GitHub y más de 5200 citas de su artículo de implementación en GPU. Los paquetes de FAISS se han descargado más de 6 millones de veces desde los repositorios de Conda. Las principales empresas de bases de datos vectoriales, incluyendo Zilliz (Milvus) y Pinecone, dependen de FAISS como su motor principal o han reimplementado los algoritmos de FAISS en sus sistemas de producción.
FAISS está diseñado específicamente para abordar el desafío computacional de encontrar vecinos más cercanos en espacios vectoriales de alta dimensionalidad. La operación central es la búsqueda de similitud: dado un vector de consulta q, FAISS identifica los vectores en el conjunto de referencia que están más próximos según una métrica de distancia especificada. Formalmente, para un conjunto de vectores de referencia {x₁, …, xₙ} en dimensión d, FAISS calcula eficientemente j = argminᵢ ||q - xᵢ|| donde ||·|| es la distancia euclidiana. La biblioteca también puede realizar búsqueda de producto interno máximo argmaxᵢ ⟨q, xᵢ⟩ y soporta métricas adicionales incluyendo distancias L1, Linf, Canberra, Bray-Curtis, Jensen-Shannon y Hamming a través de sus implementaciones IndexFlat e IndexHNSW. FAISS devuelve no solo el vecino más cercano único sino los k vecinos más cercanos, soporta procesamiento por lotes de múltiples consultas simultáneamente, y puede ejecutar búsquedas por rango devolviendo todos los elementos dentro de un radio dado.
La biblioteca opera sobre vectores densos — arreglos de longitud fija de números de punto flotante de 32 bits — que representan puntos de datos incrustados en un espacio vectorial continuo. Estos vectores son típicamente generados por redes neuronales profundas como Vision Transformers (ViT), Redes Neuronales Convolucionales (CNN) o grandes modelos de lenguaje. En los pipelines modernos de aprendizaje automático, los embeddings sirven como representaciones intermedias que mapean medios de entrada complejos en un espacio vectorial donde la localidad codifica la semántica. FAISS es el puente entre la extracción de embeddings y las tareas posteriores basadas en similitud: indexa los embeddings extraídos y permite operaciones rápidas de recuperación.
FAISS está extensamente optimizado para arquitecturas de hardware modernas. En CPU, aprovecha las bibliotecas BLAS (Basic Linear Algebra Subprograms) como Intel MKL, OpenBLAS o Apple Accelerate para realizar operaciones matriciales rápidas. Soporta vectorización SIMD (SSE, AVX2, AVX-512) en arquitecturas x86 e intrínsecos Neon en procesadores ARM. En GPU, FAISS proporciona implementaciones CUDA nativas que pueden ofrecer mejoras de rendimiento de 5 a 10 veces respecto a la ejecución en CPU para cargas de trabajo típicas. La implementación en GPU soporta múltiples GPUs en paralelo, permitiendo búsqueda distribuida a través de varios dispositivos simultáneamente.
FAISS no es una base de datos vectorial — es una biblioteca de búsqueda que puede integrarse directamente en las aplicaciones. A diferencia de los sistemas de base de datos completos (Pinecone, Milvus, Qdrant, Weaviate), FAISS no proporciona persistencia integrada, replicación, control de acceso, acceso concurrente de escritura, balanceo de carga, fragmentación, gestión de transacciones u optimización de consultas. En su lugar, expone una API limpia en C++ y Python para construir, consultar, guardar y cargar índices. Esta limitación intencional en su alcance permite a FAISS alcanzar el máximo rendimiento para la operación central de búsqueda de vecinos más cercanos. El alcance de la biblioteca está deliberadamente limitado a la implementación algorítmica de Búsqueda Aproximada de Vecinos Más Cercanos (ANNS), y como afirma el artículo original de FAISS: “Faiss no es una base de datos — no proporciona acceso concurrente de escritura, balanceo de carga, fragmentación, gestión de transacciones ni optimización de consultas.”
Tipos de Índice
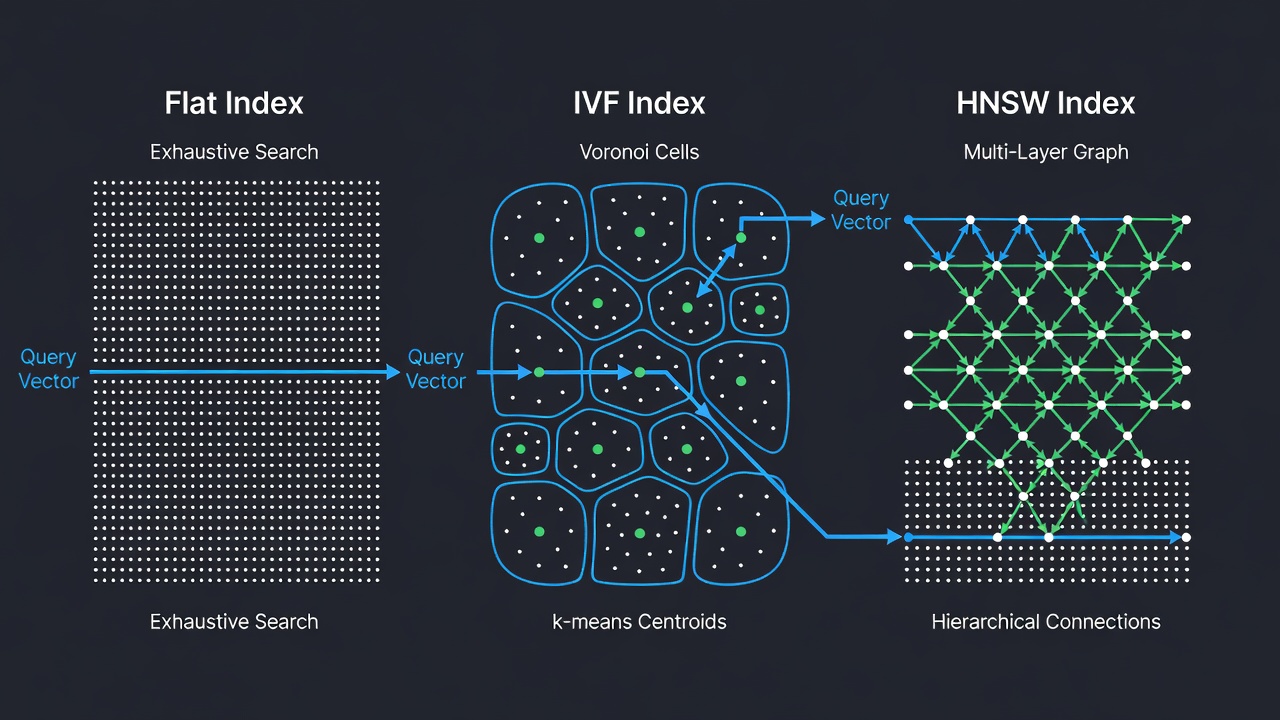
FAISS proporciona más de veinte tipos diferentes de índice, cada uno diseñado para una combinación específica de compensaciones entre precisión, velocidad y memoria. Los tres tipos de índice más fundamentales y ampliamente utilizados son IndexFlat (búsqueda exacta), IndexIVF (archivo invertido con agrupamiento k-means) e IndexHNSW (grafo jerárquico navegable de mundo pequeño). Cada tipo de índice está disponible con diferentes métricas de distancia y variantes codificadas (por ejemplo, FlatIP para producto interno, FlatL2 para distancia L2). Los índices de FAISS pueden componerse jerárquicamente — por ejemplo, usando HNSW como cuantizador grueso para un índice IVF, dando lugar a la estructura compuesta IndexIVFPQ que impulsa despliegues a escala de miles de millones.
IndexFlatIP — Búsqueda Exacta por Fuerza Bruta
IndexFlatIP es el índice más simple de FAISS. Almacena todos los vectores en un arreglo plano y realiza una búsqueda exhaustiva por fuerza bruta contra todos los vectores del conjunto de datos. Para cada consulta, calcula el producto interno entre la consulta y cada vector almacenado, y luego devuelve los índices y distancias de los k resultados principales. Este índice está garantizado para devolver los vecinos más cercanos exactos — sin aproximaciones, sin degradación del recall. Es el único índice de FAISS que ofrece esta garantía; todos los demás índices son aproximados y sacrifican algo de recall a cambio de mayor velocidad o menor uso de memoria.
La complejidad computacional de IndexFlatIP es O(N × D) por consulta, donde N es el número de vectores de referencia y D es la dimensionalidad. El índice utiliza la rutina BLAS gemm (multiplicación general de matrices) altamente optimizada para calcular todos los productos internos en una sola multiplicación de matrices. Para un conjunto de datos de 100 000 vectores de 768 dimensiones (un tamaño de embedding típico de DINOv2 ViT), una sola consulta en CPU toma aproximadamente de 5 a 15 milisegundos, dependiendo del hardware y la optimización de BLAS. En modo por lotes con 1000 consultas, el índice las procesa todas simultáneamente usando multiplicación matriz-matriz, logrando un rendimiento significativamente mayor que 1000 consultas individuales.
IndexFlatIP cumple un rol crítico en el ecosistema de FAISS como el oráculo de verdad fundamental para evaluar la precisión de los índices aproximados. Los profesionales construyen un índice plano junto a su índice aproximado, ejecutan consultas idénticas contra ambos y calculan métricas de recall. El conjunto de benchmarking estándar de FAISS (faiss_benchmarks) utiliza esta metodología para cuantificar la degradación de precisión de los índices IVF, HNSW y PQ. En TarmacView, IndexFlatIP se utiliza como la referencia base para la validación del sistema, asegurando que los índices aproximados utilizados en producción mantengan un recall aceptable.
El índice se construye con código mínimo: index = faiss.IndexFlatIP(d) donde d es la dimensionalidad del embedding. Los vectores se añaden con index.add(embeddings). La búsqueda se realiza con index.search(query, k), que devuelve dos arreglos float32: distancias (forma [n_queries, k]) e índices (forma [n_queries, k], dtype int64). Para el producto interno, valores de distancia mayores indican mayor similitud. El índice no requiere paso de entrenamiento, ya que no hay parámetros que aprender — los vectores se almacenan y comparan textualmente.
IndexIVFFlat — Archivo Invertido con Agrupamiento k-Means
IndexIVFFlat es un índice de vecinos más cercanos aproximado que divide el espacio vectorial en celdas de Voronoi utilizando agrupamiento k-means. La arquitectura se deriva del artículo seminal “Video Google” de Sivic y Zisserman (ICCV 2003), que adaptó técnicas de recuperación de texto a la correspondencia de objetos visuales. Durante la indexación, el conjunto de datos se agrupa en nlist grupos mediante k-means, y cada vector se asigna a su centroide de grupo más cercano. Los centroides se almacenan en un cuantizador grueso (típicamente IndexFlatL2). Durante la búsqueda, solo se examinan los vectores en los nprobe grupos más cercanos a la consulta, reduciendo drásticamente el número de cálculos de distancia necesarios.
La aceleración respecto a IndexFlatIP es aproximadamente N / ((N / nlist) × nprobe) . Con nlist=100 y nprobe=5, solo se busca el 5% de la base de datos — las consultas que tomaban 10 ms en un índice plano pueden completarse en 0.5 ms. Sin embargo, la compensación es la degradación del recall: algunos verdaderos vecinos más cercanos pueden quedar fuera de los grupos buscados y pasar desapercibidos. El paso de entrenamiento k-means es crítico para la calidad del recall — los centroides deben representar con precisión la distribución de los datos. FAISS requiere que el conjunto de entrenamiento contenga al menos 30 × nlist vectores para una estimación fiable de los centroides.
Parámetros clave para IndexIVFFlat:
Parámetro
Descripción
Rango Típico
Impacto
nlist
Número de celdas de Voronoi (grupos)
10 – 100 000
Mayor = particionado más fino, más memoria para centroides, entrenamiento k-means más lento
nprobe
Número de celdas buscadas al consultar
1 – 100+
Mayor = mejor recall (hasta 99%), búsqueda linealmente más lenta
metric
Métrica de distancia (L2 o IP)
L2 o IP
Determina cómo se calculan las distancias entre vectores y centroides
El parámetro nprobe es especialmente importante porque controla la compensación velocidad-precisión en tiempo de búsqueda sin requerir reconstrucción del índice. En tiempo de consulta, nprobe puede ajustarse dinámicamente: establézcase en un valor alto (p. ej., 20–50) durante operaciones offline críticas en calidad donde la precisión es primordial, y en un valor bajo (p. ej., 1–5) durante ejecuciones de producción de alto rendimiento donde se prioriza la velocidad. FAISS proporciona un mecanismo de autoajuste (AutoTune) que busca entre valores de nprobe para encontrar la configuración óptima para un recall objetivo.
Construir un IndexIVFFlat requiere un pipeline de tres etapas: entrenamiento, adición y búsqueda. Durante el entrenamiento, k-means se ejecuta sobre una muestra representativa para aprender los centroides de los grupos. Durante la adición, cada vector de la base de datos se asigna a su centroide más cercano y se añade a la lista invertida de ese centroide. Durante la búsqueda, la consulta se compara con todos los centroides, se seleccionan los nprobe más cercanos, y solo los vectores en esas listas seleccionadas se comparan exhaustivamente. La cadena de fábrica para IndexIVFFlat con producto interno es "IVF100,Flat" donde 100 es el valor de nlist. En Python: index = faiss.index_factory(d, "IVF100,Flat", faiss.METRIC_INNER_PRODUCT).
Tamaño del dataset
nlist recomendado
nprobe recomendado
Recall esperado
Aceleración vs Flat
10 000
10 – 100
1 – 5
95–98%
5–20x
100 000
100 – 1000
5 – 20
95–99%
20–100x
1 000 000
1000 – 10 000
10 – 50
95–99%
100–500x
10 000 000
10 000 – 100 000
20 – 100
90–98%
500–5000x
IndexHNSWFlat — Grafo Jerárquico Navegable de Mundo Pequeño
IndexHNSWFlat es un índice de vecinos más cercanos aproximado basado en grafos que construye un grafo jerárquico multicapa conocido como Navigable Small World. El algoritmo, publicado originalmente por Malkov y Yashunin (2016), está inspirado en la estructura de datos skip list. El índice organiza los vectores en capas: la capa inferior (capa 0) contiene todos los vectores, y cada capa subsiguiente contiene un subconjunto progresivamente más pequeño generado por una asignación probabilística de nivel. En la inserción, a cada vector se le asigna un nivel l = floor(-ln(uniform(0,1)) × mL) donde mL = 1/ln(M). El punto de entrada está en la capa más alta existente, asegurando un recorrido logarítmico del grafo.
La búsqueda comienza en la capa superior (la más gruesa, con menos nodos) y desciende a través de las capas, refinando el conjunto de candidatos en cada paso. En cada capa, una búsqueda voraz recorre el grafo hacia la consulta moviéndose siempre al vecino que minimiza la distancia. Después de encontrar el mínimo local en la capa actual, el algoritmo desciende a la siguiente capa y repite el proceso usando el resultado de la capa superior como punto de partida. Esta estructura jerárquica permite una complejidad de búsqueda logarítmica O(log N), convirtiendo a HNSW en uno de los algoritmos de vecinos más cercanos aproximados más rápidos disponibles para conjuntos de datos medianos a grandes.
El índice HNSW tiene tres parámetros críticos:
Parámetro
Descripción
Rango Típico
Impacto
M
Número máximo de conexiones bidireccionales por nodo
8 – 64 (por defecto 32)
Mayor M = grafo más densamente conectado, mejor recall, más memoria
efConstruction
Tamaño de la lista dinámica de candidatos durante la construcción del grafo
40 – 200 (por defecto 40)
Mayor = búsqueda más exhaustiva durante la construcción, mejor calidad del grafo, construcción más lenta
efSearch
Tamaño de la lista dinámica de candidatos durante la búsqueda
10 – 200 (se establece en tiempo de consulta)
Mayor = mejor recall, búsqueda más lenta (se puede ajustar sin reconstruir)
El parámetro M controla directamente la conectividad del grafo. Cada vector mantiene hasta M aristas bidireccionales hacia sus vecinos más cercanos. El grafo utiliza una heurística de fomento de la diversidad durante la selección de vecinos: cuando se añade un nuevo nodo, sus candidatos a vecinos se podan para asegurar una conectividad diversa que evite que los nodos hub dominen la estructura del grafo. Valores más altos de M producen un enrutamiento más robusto pero aumentan el consumo de memoria: aproximadamente 4d + M × 2 × 4 bytes por vector para la estructura del grafo más el almacenamiento del vector.
El parámetro efConstruction controla la exhaustividad de la búsqueda durante la construcción del índice. Valores mayores producen grafos de mejor calidad pero aumentan el tiempo de construcción linealmente. Como regla general, efConstruction ≈ M × 2 proporciona un buen equilibrio para la mayoría de las cargas de trabajo. El parámetro efSearch es análogo a nprobe en los índices IVF — controla la exhaustividad de la búsqueda en tiempo de consulta y puede ajustarse dinámicamente sin reconstrucción del índice.
Los índices HNSW ofrecen varias ventajas sobre los índices IVF. Típicamente logran un recall más alto a velocidad de búsqueda equivalente, especialmente en datos de alta dimensionalidad (d > 256). No requieren un paso de entrenamiento separado (a diferencia de IVF que necesita agrupamiento k-means, lo que hace a HNSW adecuado para conjuntos de datos dinámicos donde los vectores llegan incrementalmente). Exhiben una degradación gradual del recall a medida que efSearch disminuye — el recall mejora suavemente sin umbrales abruptos. Sin embargo, los índices HNSW usan más memoria por vector (las listas de adyacencia del grafo añaden sobrecarga) y son más lentos de construir que los índices IVF. HNSW tampoco soporta de forma nativa la eliminación de vectores, ya que eliminar nodos de la estructura del grafo comprometería la conectividad.
Para el conjunto de referencia de TarmacView de aproximadamente 9000 embeddings, un IndexHNSWFlat con M=32 y efSearch=64 logra >99% de recall con tiempos de consulta inferiores a 200 microsegundos en CPU — una aceleración de 50x respecto a IndexFlatIP con una pérdida de precisión insignificante. La cadena de fábrica "HNSW32,Flat" construye este índice. En Python: index = faiss.index_factory(d, "HNSW32,Flat", faiss.METRIC_INNER_PRODUCT).
Similitud Coseno mediante Producto Interno en Vectores Normalizados
La similitud coseno mide el coseno del ángulo entre dos vectores no nulos — cuantifica cuán similares son dos vectores independientemente de su magnitud. La similitud coseno entre los vectores a y b se define como cos(θ) = (a · b) / (||a|| × ||b||) donde a · b es el producto punto y ||a|| es la norma L2 de a. El resultado varía de -1 (dirección completamente opuesta) a +1 (dirección idéntica), donde 0 indica ortogonalidad.
FAISS no proporciona una métrica de similitud coseno dedicada. En su lugar, la similitud coseno se implementa mediante una transformación de dos pasos que el equipo de desarrollo de FAISS considera canónica. Primero, todos los vectores se normalizan mediante L2 a longitud unitaria — cada vector se divide por su norma L2 de modo que ||a|| = 1 y ||b|| = 1. Segundo, se utiliza METRIC_INNER_PRODUCT como métrica de distancia. Para vectores normalizados a unidad, el producto interno es igual a la similitud coseno: a · b = cos(θ). Esta equivalencia se deriva directamente de la fórmula del coseno: cuando el denominador es igual a 1, la fórmula se reduce al producto punto.
Esta técnica de normalización es estándar en los sistemas de búsqueda vectorial porque el producto interno es computable eficientemente mediante rutinas de multiplicación de matrices BLAS altamente optimizadas. El costo computacional de normalizar todos los vectores en el índice es una operación única de O(N × D) en el momento de construcción del índice, y normalizar cada consulta es O(D) — insignificante en comparación con el costo de la búsqueda misma. La normalización L2 se aplica antes de que los vectores se añadan al índice y antes de que se envíen las consultas, asegurando que todas las comparaciones estén en el espacio de similitud coseno.
En FAISS, la normalización se implementa usando el envoltorio IndexPreTransform combinado con un NormalizationTransform (en Python, faiss.NormalizationTransform). El patrón de construcción es:
import faiss
import numpy as np
dimension =768# Crear el índice de producto internobase_index = faiss.IndexFlatIP(dimension)
# Envolver con normalización L2index = faiss.IndexPreTransform(
faiss.NormalizationTransform(dimension),
base_index
)
# Los vectores añadidos aquí se normalizan automáticamente con L2index.add(reference_embeddings)
# Las consultas enviadas aquí se normalizan automáticamente con L2distances, indices = index.search(query_embeddings, k)
Los enfoques alternativos incluyen normalizar manualmente los vectores con faiss.normalize_L2() antes de añadirlos y consultarlos, o construir el índice mediante index_factory que soporta normalización integrada a través del paso de preprocesamiento "L2norm". Con el método de fábrica: index = faiss.index_factory(d, "L2norm,HNSW32,Flat") crea un índice que normaliza automáticamente los vectores a longitud unitaria antes de construir el grafo HNSW.
Para TarmacView, este enfoque es esencial porque los embeddings de DINOv2, como la mayoría de las salidas de Vision Transformers, varían en magnitud entre diferentes imágenes. Las variaciones en exposición, condiciones de iluminación y configuración de la cámara durante la inspección de pavimentos aeroportuarios producen embeddings de diferentes magnitudes incluso cuando capturan texturas de superficie idénticas. La normalización elimina el componente de magnitud y enfoca la comparación de similitud en la alineación direccional — dos imágenes de superficie que capturan la misma textura de pavimento pero con diferentes niveles de exposición se registrarán como altamente similares porque sus embeddings normalizados apuntan en la misma dirección, incluso si sus magnitudes brutas difieren significativamente.
Las FAQ de FAISS abordan esto explícitamente: “La similitud coseno entre los vectores x e y se define por cos(x, y) = ⟨x, y⟩ / (|x| × |y|). Normalizando previamente los vectores de consulta y de la base de datos, el problema puede mapearse de nuevo a una búsqueda de producto interno máximo.” FAISS también señala que usar producto interno en vectores normalizados es matemáticamente equivalente a usar distancia L2 en vectores normalizados, con la relación ||x - y||² = 2 - 2 × ⟨x, y⟩ para vectores normalizados a unidad.
Construcción y Consulta de un Índice FAISS
El ciclo de vida de un índice FAISS en producción involucra cinco etapas distintas: configuración, entrenamiento, población, serialización y consulta. Cada etapa tiene llamadas API específicas, consideraciones de rendimiento y mejores prácticas.
Configuración comienza con la selección de un tipo de índice y una métrica de distancia. FAISS proporciona el mecanismo de cadena de fábrica — una especificación compacta en forma de cadena de texto que construye índices complejos. El patrón de fábrica es el enfoque recomendado porque abstrae la jerarquía de clases específica y selecciona automáticamente la implementación óptima:
Cadena de Fábrica
Tipo de Índice
Memoria por Vector (d=768)
Caso de Uso
"Flat"
IndexFlat (búsqueda L2 exacta)
3072 bytes
Conjuntos de referencia pequeños, verdad fundamental
"IVF100,Flat"
IndexIVFFlat con 100 centroides
~3100 bytes
Conjuntos medianos, búsqueda aproximada rápida
"HNSW32,Flat"
IndexHNSWFlat con M=32
~3328 bytes
Búsqueda aproximada rápida, datos dinámicos
"IVF100,PQ16"
IndexIVFPQ, 16 subvectores
~80 bytes
Gran escala, memoria limitada
"IVF100,SQ8"
IndexIVF con cuantización escalar
~784 bytes
Equilibrado, velocidad excelente
Entrenamiento es necesario solo para los índices que aprenden una distribución de datos (IVF, PQ, SQ, etc.). Durante el entrenamiento, el índice ejecuta agrupamiento k-means sobre una muestra representativa de vectores. Para el algoritmo k-means, FAISS utiliza múltiples inicializaciones aleatorias y selecciona la que tiene la menor distorsión. El conjunto de entrenamiento debe ser representativo de los datos que se indexarán — usar un subconjunto aleatorio del 1 al 10% del conjunto de datos completo es una práctica común. FAISS requiere que los vectores de entrenamiento tengan la misma dimensionalidad que los datos que se indexarán. El indicador index.is_trained señala si el entrenamiento se ha completado. La llamada de entrenamiento es: index.train(training_vectors). Para conjuntos de datos donde el índice ya ha sido entrenado (por ejemplo, centroides preentrenados cargados desde un archivo), llamar a train nuevamente es innecesario y sobrescribirá los parámetros aprendidos.
Población añade vectores al índice entrenado: index.add(reference_vectors). La propiedad ntotal rastrea el número de vectores añadidos. Para índices IVF, cada vector se asigna a su centroide de grupo más cercano y se añade a la lista invertida de ese centroide durante la operación de adición. Para índices HNSW, el grafo se construye incrementalmente: a cada nuevo vector se le asigna un nivel de capa, y se establecen aristas hacia sus M vecinos más cercanos en cada capa utilizando el parámetro efConstruction. Añadir vectores es típicamente más lento que consultar, especialmente para HNSW donde el grafo debe actualizarse.
Serialización guarda el índice en disco: faiss.write_index(index, "index.faissindex"). El índice se carga de vuelta con index = faiss.read_index("index.faissindex"). La serialización preserva el estado completo del índice incluyendo centroides entrenados, estructura del grafo, todos los vectores almacenados, configuración de la métrica de distancia y parámetros internos. La extensión de archivo estándar es .faissindex. El tamaño de la serialización depende del tipo de índice y la cantidad de vectores — para IndexFlat con N vectores de dimensionalidad D, el tamaño es aproximadamente N × D × 4 bytes más una pequeña sobrecarga.
Consulta recupera los k vecinos más cercanos: distances, indices = index.search(query_vectors, k). El arreglo distances contiene valores de similitud o distancia dependiendo de la métrica. El arreglo indices contiene las posiciones de los vectores de referencia coincidentes tal como fueron añadidos (indexado desde 0). Para consultas por lotes, FAISS procesa eficientemente múltiples consultas simultáneamente usando multiplicación matriz-matriz, logrando un rendimiento significativamente mejor que las llamadas individuales de consulta por vez. Los objetos de índice son thread-safe para operaciones de búsqueda en instancias de índice separadas, permitiendo el servicio paralelo de consultas en despliegues de producción.
FAISS para Clasificación kNN
FAISS se utiliza con frecuencia para implementar la clasificación k-Nearest Neighbors (kNN) — un método de aprendizaje automático no paramétrico que clasifica un punto de consulta basándose en la etiqueta mayoritaria entre sus k vecinos más cercanos en el conjunto de referencia. Este enfoque es particularmente atractivo cuando: (1) el conjunto de referencia se actualiza regularmente con nuevas muestras etiquetadas, (2) el espacio de embeddings captura relaciones semánticas significativas entre los puntos de datos, y (3) se prefieren decisiones interpretables basadas en instancias sobre clasificadores neuronales de caja negra.
El pipeline de clasificación usando FAISS sigue cinco pasos:
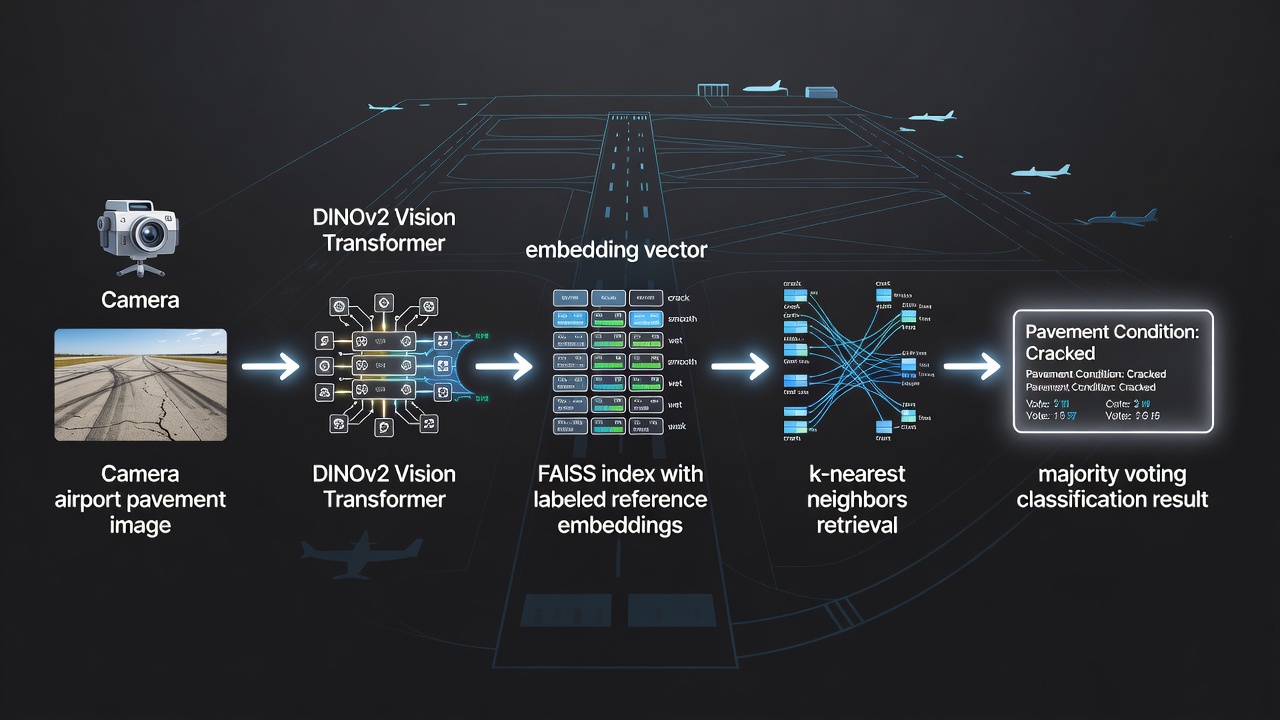
Construir un conjunto de referencia etiquetado: Cada vector de referencia se empareja con una etiqueta de verdad fundamental (por ejemplo, “asfalto - buen estado”, “hormigón - superficie agrietada”, “tarmac - parcheado”). Las etiquetas se almacenan en un arreglo separado alineado con el orden del índice FAISS. TarmacView mantiene aproximadamente 9000 de estos embeddings de referencia etiquetados que abarcan múltiples tipos de superficie y condiciones de calidad.
Indexar los vectores de referencia: Todos los embeddings de referencia se añaden a un índice FAISS. Para búsqueda exacta con recall perfecto, se usa IndexFlatIP. Para búsqueda aproximada a escala, IndexHNSWFlat o IndexIVFFlat proporcionan tiempos de consulta de sub-milisegundo con >99% de recall cuando se ajustan adecuadamente.
Enviar embeddings de consulta: Para cada nueva imagen a clasificar, extraer su embedding usando el mismo modelo de embeddings (DINOv2 con salida de 768 dimensiones) y normalizar a longitud unitaria para similitud coseno.
Recuperar k vecinos más cercanos: FAISS devuelve los índices y distancias de los k vectores de referencia más similares. El parámetro k controla la compensación entre sesgo y varianza. Un k más pequeño (por ejemplo, 3–5) produce fronteras de decisión sensibles a la estructura local pero propensas a sobreajustar el ruido. Un k más grande (por ejemplo, 15–20) produce fronteras más suaves con mejor generalización pero puede perder distinciones de grano fino. TarmacView utiliza k=10, equilibrando robustez frente a valores atípicos con sensibilidad a variaciones sutiles de calidad superficial.
Realizar votación por mayoría: Contar las etiquetas entre los k vecinos y seleccionar la etiqueta más frecuente como resultado de la clasificación. Opcionalmente, la votación ponderada por distancia asigna mayor peso a los vecinos más cercanos: weight = 1.0 / (distance + ε) donde ε es una pequeña constante para evitar la división por cero. La votación ponderada es particularmente beneficiosa cuando el conjunto de referencia tiene distribuciones de clase desiguales o cuando la densidad de vecinos varía en el espacio de embeddings.
Valor de k
Sesgo
Varianza
Mejor para
1 – 3
Bajo
Alta
Conjuntos de referencia grandes y limpios, fronteras de grano fino
5 – 10
Moderado
Moderada
Clasificación equilibrada de propósito general
15 – 30
Mayor
Menor
Etiquetas ruidosas, fronteras de decisión suaves
Las puntuaciones de distancia devueltas por FAISS también informan la estimación de confianza. Si los k vecinos principales comparten todos la misma etiqueta y tienen puntuaciones de similitud altas (similitud coseno > 0.95), la clasificación es altamente confiable. Si la votación está dividida (por ejemplo, 6 de cada 10 para la etiqueta ganadora) o las puntuaciones de similitud son bajas (< 0.70), el sistema puede marcar el resultado para revisión humana. Esta arquitectura consciente de la confianza es crítica para aplicaciones de seguridad crítica como la inspección de pavimentos aeroportuarios, donde una clasificación errónea podría afectar la priorización de mantenimiento y la seguridad operacional.
El contrato de embedding entre el modelo DINOv2 y el índice FAISS es fundamental para la precisión de la clasificación. El extractor de embeddings se entrena mediante aprendizaje autosupervisado para que las distancias entre embeddings reflejen la similitud visual entre las imágenes de superficie de pavimento. El índice FAISS recupera fielmente los vecinos más cercanos según la métrica de similitud coseno. Cuando este contrato se cumple — cuando condiciones de superficie visualmente similares producen embeddings cercanos — la clasificación kNN alcanza una alta precisión con la interpretabilidad inherente de mostrar exactamente qué imágenes de referencia fundamentaron cada decisión de clasificación.
Aceleración por GPU
El soporte de GPU en FAISS es una característica de primera clase que proporciona mejoras sustanciales de rendimiento tanto para la construcción de índices como para la búsqueda. La implementación en GPU, descrita en el artículo “Billion-scale similarity search with GPUs” (Johnson, Douze, Jégou, 2017), está escrita en CUDA C++ y aprovecha las arquitecturas de GPU NVIDIA desde Kepler (Compute Capability 3.5) hasta Hopper (Compute Capability 9.0+) y posteriores.
La aceleración por GPU de FAISS ofrece mejoras de rendimiento medibles: mejora de 5 a 10 veces en el rendimiento de búsqueda respecto a la CPU para índices IVF y HNSW típicos; hasta 12 veces más rápido en la construcción de índices IVF ya que el agrupamiento k-means es altamente paralelizable; 8 veces menor latencia para consultas HNSW en GPU usando núcleos optimizados de recorrido de grafos; y soporte nativo para consultas por lotes donde las GPUs sobresalen procesando cientos o miles de consultas simultáneamente mediante operaciones matriz-matriz.
La implementación en GPU cubre los tipos de índice más utilizados a través de clases CUDA dedicadas:
Clase de Índice en GPU
Equivalente en CPU
Características CUDA Utilizadas
GpuIndexFlat
IndexFlat
BLAS gemm en GPU, tileado de memoria compartida
GpuIndexIVFFlat
IndexIVFFlat
Cálculo de distancia paralelo, reducciones a nivel de warp
GpuIndexIVFPQ
IndexIVFPQ
Tablas de búsqueda PQ en GPU, asignación rápida de códigos
GpuIndexIVFScalarQuantizer
IndexIVFScalarQuantizer
Soporte float16 en GPUs Pascal+
La implementación en GPU utiliza warp shuffles (disponibles desde Compute Capability 3.0+) y caché de textura de solo lectura mediante ld.nc / __ldg (Compute Capability 3.5+). El algoritmo de k-selección — encontrar los k valores principales de un gran arreglo de distancias — opera hasta al 55% del rendimiento pico teórico de la GPU, permitiendo una implementación de vecinos más cercanos 8.5 veces más rápida que el estado del arte previo en GPU, según el artículo de 2017. Para la gestión de memoria de la GPU, un objeto StandardGpuResources asigna espacio temporal en GPU: aproximadamente 512 MiB en GPUs con ≤4 GiB de memoria, y aproximadamente 1536 MiB en GPUs más grandes. Este espacio temporal evita llamadas repetidas a cudaMalloc / cudaFree durante la búsqueda.
FAISS proporciona interoperabilidad fluida entre CPU y GPU mediante dos funciones clave: faiss.index_cpu_to_gpu(cpu_index, device_id) transfiere un índice de CPU a un dispositivo GPU especificado, y faiss.index_gpu_to_cpu(gpu_index) transfiere un índice de GPU de vuelta a la memoria de la CPU. Para despliegues con múltiples GPUs, faiss.index_cpu_to_gpu_multiple_py(resources, cpu_index) distribuye un índice entre todos los dispositivos GPU disponibles, y las consultas se balancean automáticamente. El enfoque multi-GPU puede escalar a índices que contienen cientos de millones de vectores mediante la partición entre espacios de memoria de GPU.
Escenario
CPU
GPU (1x)
GPU (8x)
Búsqueda IndexFlat (100K x 768d), lote=8192
50 ms
5 ms
<1 ms
Entrenamiento k-means IVF (1M x 128d), nlist=1000
120 s
10 s
5 s
Construcción HNSW (100K x 128d), M=32
30 s
8 s
—
Grafo k-NN a escala de mil millones
días
12 horas
4 horas
Para TarmacView, la aceleración por GPU es valiosa durante la fase de construcción del índice cuando se añaden periódicamente nuevas imágenes de referencia. Construir un índice IVF con k-means sobre 9000 vectores de 768 dimensiones se completa en aproximadamente 1–2 segundos en una GPU moderna (NVIDIA A100 o RTX 4090) frente a 30–60 segundos en CPU. Durante la inferencia, el índice permanece en CPU para un despliegue rentable — la latencia de consulta en CPU con IndexHNSWFlat ya es inferior a 200 microsegundos para el conjunto de referencia de 9K, y convertir a GPU añadiría sobrecarga de transferencia PCIe sin beneficios significativos de latencia.
Uso de FAISS en TarmacView
TarmacView integra FAISS como el motor central de búsqueda de similitud para su sistema automatizado de clasificación de calidad superficial de pavimentos aeroportuarios. El sistema clasifica tipos de superficie de pavimento (asfalto, hormigón, tarmac) y condiciones de calidad superficial (bueno, regular, pobre, deteriorado, agrietado, parcheado) comparando imágenes de inspección contra un conjunto de referencia curado de aproximadamente 9000 embeddings etiquetados.
Construcción del Conjunto de Referencia: Cada embedding de referencia se extrae de una imagen de pavimento de alta resolución utilizando un modelo DINOv2 Vision Transformer (ViT-B/14 o equivalente), que produce un vector de 768 dimensiones que captura características visuales como patrones de textura, distribución de color, morfología de grietas, exposición de agregados, desgaste superficial y evidencia de reparaciones. Cada embedding se anota con etiquetas de verdad fundamental establecidas por inspectores de pavimento certificados durante una fase inicial de entrenamiento del sistema. El conjunto de referencia abarca múltiples aeropuertos, zonas climáticas y edades de pavimento para asegurar una clasificación robusta en diversas condiciones.
Selección del Índice: TarmacView elige el tipo de índice según los requisitos del despliegue:
Escenario de Despliegue
Tipo de Índice
Tiempo de Consulta
Recall
Memoria
QA / validación offline
IndexFlatIP
~2 ms
100%
~28 MB
Despliegue de campo en tiempo real
IndexHNSWFlat (M=32, efSearch=64)
<200 μs
>99%
~30 MB
Dispositivo periférico (RAM limitada)
IndexIVFFlat (nlist=100, nprobe=10)
~300 μs
~97%
~28 MB
Flujo de Trabajo de Clasificación:
Una cámara montada en dron (por ejemplo, serie DJI Matrice con carga útil de alta resolución) o un dispositivo de inspección manual captura imágenes de pavimento durante las inspecciones rutinarias de campos de aviación, siguiendo las directrices del Anexo 14 de la OACI y la AC 150/5380-7B de la FAA para la evaluación del estado del pavimento.
Cada imagen se preprocesa (recortada para eliminar áreas sin pavimento, normalizada a resolución estándar) y se pasa a través del modelo de embeddings DINOv2 alojado en un acelerador de inferencia periférico (NVIDIA Jetson o equivalente).
El embedding resultante de 768 dimensiones se normaliza mediante L2 a longitud unitaria para el cálculo de similitud coseno. La normalización asegura que las variaciones de exposición entre vuelos de inspección no afecten la clasificación por similitud.
FAISS consulta el índice IndexHNSWFlat con k=10, devolviendo los 10 índices de embeddings de referencia más cercanos y sus puntuaciones de similitud de producto interno (equivalentes a similitud coseno para vectores normalizados).
El sistema realiza votación por mayoría sobre las etiquetas de los 10 vecinos. Si la etiqueta ganadora tiene al menos 6 de cada 10 votos (60% de consenso), la clasificación se acepta con una puntuación de confianza calculada como la relación entre votos ganadores y votos totales.
Si la votación está dividida por debajo del 60% de consenso, el embedding de la imagen y las 10 imágenes de referencia principales se marcan para revisión humana por parte de un inspector de pavimento certificado a través de la interfaz web de TarmacView.
Las clasificaciones se registran en la base de datos de TarmacView con marcas de tiempo, coordenadas GPS, tipo de superficie, condición de calidad, puntuación de confianza y enlaces a las imágenes de referencia de soporte. Esto crea un rastro de inspección completamente auditable para el cumplimiento normativo.
Este pipeline de clasificación impulsado por FAISS permite a TarmacView procesar miles de imágenes de pavimento por día con una evaluación de calidad consistente y objetiva — reduciendo la dependencia de la inspección visual humana subjetiva y permitiendo la monitorización escalable del estado de los campos de aviación en redes aeroportuarias completas.
FAISS vs Otras Bases de Datos Vectoriales
FAISS ocupa un nicho distintivo en el ecosistema de búsqueda vectorial. Es una biblioteca, no una base de datos, y esta distinción tiene implicaciones significativas para la arquitectura, el despliegue y las características operativas. La biblioteca FAISS proporciona funcionalidad pura de búsqueda de vecinos más cercanos sin la sobrecarga de un sistema de gestión de base de datos completo.
Característica
FAISS
Pinecone
Milvus
Qdrant
Weaviate
Tipo
Biblioteca
Servicio gestionado
Base de datos
Base de datos
Base de datos
Despliegue
Incrustado
Cloud / SaaS
Autogestionado / Cloud
Autogestionado / Cloud
Autogestionado / Cloud
Persistencia
Guardado/carga manual
Automática
Automática
Automática
Automática
CRUD
No integrado
CRUD completo
CRUD completo
CRUD completo
CRUD completo
Filtrado de metadatos
Solo por ID
Filtros enriquecidos
Atributo + escalar
Filtrado por payload
Basado en grafos
Escalado
Fragmentación manual
Autoescalado
Raft/Paxos distribuido
Distribuido
Distribuido
Soporte GPU
CUDA nativo
No
Limitado (CUDA)
No
No
Latencia de consulta
10 μs – 1 ms
2 – 10 ms
1 – 10 ms
1 – 5 ms
1 – 10 ms
Licencia
MIT
Propietaria
Apache 2.0
Apache 2.0
BSD-3
La ventaja clave de FAISS sobre los sistemas de base de datos completos es el rendimiento y la simplicidad. Las consultas con FAISS son típicamente de 10 a 100 veces más rápidas que las consultas equivalentes en sistemas de base de datos porque: la biblioteca se ejecuta en-proceso sin viajes de ida y vuelta por red; no hay sobrecarga de análisis de consultas, autenticación o autorización; no hay indirección del motor de almacenamiento ni gestión del pool de búferes; y los índices de FAISS son estructuras de datos de álgebra lineal optimizadas sin sobrecarga transaccional. FAISS opera directamente sobre estructuras de datos en memoria utilizando rutinas BLAS optimizadas, sin comunicación entre procesos.
La ventaja clave de los sistemas de base de datos sobre FAISS es la conveniencia operativa. Proporcionan durabilidad automática de datos con registro de escritura anticipada y replicación, soportan filtrado rico de metadatos (por ejemplo, “encontrar imágenes similares capturadas después de enero de 2025 que muestren pavimento de hormigón en la región suroeste de EE. UU.”), ofrecen APIs REST o gRPC para acceso independiente del lenguaje, incluyen paneles de monitorización y alertas, y manejan copias de seguridad y recuperación ante desastres. Soportan operaciones concurrentes de lectura y escritura con garantías transaccionales y evolución de esquemas.
Para TarmacView, usar FAISS directamente en lugar de una base de datos vectorial es la elección arquitectónica correcta por cuatro razones: (1) el conjunto de referencia es pequeño (~9K vectores, aproximadamente 28 MB) y cabe completamente en memoria; (2) los requisitos de latencia de consulta son exigentes (la clasificación en menos de 200 microsegundos es alcanzable con HNSW en CPU); (3) el sistema se ejecuta en despliegues periféricos en aeropuertos donde el acceso de red a un servidor de base de datos puede ser impracticable o introducir latencia inaceptable; y (4) el índice se reconstruye con poca frecuencia (semanal o mensualmente a medida que se añaden nuevas imágenes de referencia después de la validación del inspector), lo que hace que la serialización manual y el control de versiones sean manejables.
Serialización de Índices
La serialización de índices de FAISS convierte un objeto de índice en memoria en una representación binaria que puede guardarse en disco, transferirse a través de una red o cargarse en un proceso o máquina diferente. La serialización preserva el estado completo del índice incluyendo todos los vectores almacenados, centroides entrenados (para índices IVF y PQ), estructura del grafo (para HNSW), configuración de la métrica de distancia (L2 vs IP vs otras) y todos los parámetros internos (efConstruction, M, configuraciones de normalización, etc.).
Las funciones de serialización principales son:
Función
Descripción
Salida
Caso de Uso
write_index(index, filename)
Escribe el índice en un archivo
Archivo .faissindex
Almacenamiento persistente en disco
read_index(filename)
Carga el índice desde un archivo
Objeto Index
Carga para servicio
serialize_index(index)
Escribe el índice a bytes
Objeto bytes de Python
Almacenamiento en base de datos, colas de mensajes
deserialize_index(data)
Carga el índice desde bytes
Objeto Index
Carga desde búfer de memoria
El tamaño de la serialización depende del tipo de índice y la cantidad de vectores. Para IndexFlatIP con N vectores de dimensión D, el tamaño del archivo es aproximadamente N × D × 4 bytes (almacenamiento float32 de 32 bits) más sobrecarga para la cabecera y metadatos. Para IndexIVFFlat, se consume almacenamiento adicional por los centroides de los grupos: nlist × D × 4 bytes. Para IndexHNSWFlat, la estructura del grafo añade N × M × 2 × 4 bytes para las listas de adyacencia (asumiendo índices de vecinos de 32 bits almacenados bidireccionalmente). Para el índice HNSW de TarmacView con 9000 vectores de 768 dimensiones y M=32, el archivo serializado es de aproximadamente 25 MB: 9000 × 768 × 4 = 27.6 MB para vectores más 9000 × 32 × 2 × 4 = 2.3 MB para la estructura del grafo, menos el hecho de que HNSW almacena los vectores internamente en un índice plano.
La serialización soporta transferencia entre contextos: un índice construido en GPU puede guardarse en disco y cargarse en CPU. El patrón recomendado es transferir siempre los índices de GPU a CPU antes de la serialización:
cpu_index = faiss.index_gpu_to_cpu(gpu_index) # transferir a CPUfaiss.write_index(cpu_index, "production_index.faissindex") # guardar en disco# En una máquina diferente (o más tarde):deployed_index = faiss.read_index("production_index.faissindex")
deployed_index.hnsw.efSearch =64# establecer parámetros de tiempo de búsquedaD, I = deployed_index.search(queries, k)
Para despliegues en producción, el índice serializado puede controlarse por versiones junto con el código de la aplicación. TarmacView mantiene archivos de índice FAISS versionados en sus artefactos de despliegue, asegurando que cada despliegue periférico utilice un conjunto de referencia idéntico para resultados de clasificación reproducibles. Cuando se añaden y validan nuevas imágenes de referencia, se entrena un nuevo índice, se compara su precisión con el índice anterior usando el IndexFlatIP de verdad fundamental, y el nuevo índice se despliega a través del pipeline CI/CD estándar.
Escalando FAISS a Conjuntos de Referencia Grandes
Si bien el conjunto de referencia actual de TarmacView de aproximadamente 9000 vectores es modesto, FAISS está diseñado para escalar a miles de millones de vectores en un solo servidor. La biblioteca proporciona un conjunto completo de herramientas para manejar despliegues a gran escala mediante tres técnicas complementarias: compresión de vectores, búsqueda no exhaustiva e indexación distribuida.
Cuantización de Producto
La Cuantización de Producto (PQ) es una técnica de compresión con pérdida que reduce drásticamente la huella de memoria por vector. PQ divide cada vector D-dimensional en m subvectores de igual tamaño (dimensiones D/m cada uno). Cada subvector se cuantiza de forma independiente utilizando un codebook de 256 entradas (8 bits) aprendido mediante agrupamiento k-means. El vector float32 original (4 × D bytes) se comprime a m bytes de índices de código más un pequeño codebook. Las relaciones de compresión PQ de 4x a 16x son comunes, permitiendo que una sola máquina indexe cientos de millones de vectores en memoria principal. FAISS IndexIVFPQ combina IVF con PQ, utilizando los centroides de los grupos como un cuantizador grueso y códigos PQ para la compresión residual. El cálculo de distancia utiliza Cálculo de Distancia Asimétrica (ADC): la consulta permanece sin comprimir, y las distancias a los vectores de la base de datos comprimidos con PQ se calculan mediante tablas de búsqueda precalculadas, evitando la sobrecarga de descompresión.
Configuración PQ
Bytes/vector (d=768)
Memoria, N=100M
Recall vs sin comprimir
PQ32 (m=32, 8-bit)
40
3.7 GB
~90-95%
PQ64 (m=64, 8-bit)
72
6.7 GB
~95-98%
PQ96 (m=96, 8-bit)
104
9.7 GB
~97-99%
Cuantización Escalar
La Cuantización Escalar (SQ) convierte cada componente float32 en un entero sin signo de 8 o 4 bits, reduciendo el almacenamiento en 4x (SQ8) u 8x (SQ4) con una pérdida mínima de precisión. La cadena de fábrica "IVF100,SQ8" crea un índice IVF con cuantización escalar. SQ es más rápido que PQ en tiempo de consulta porque los cálculos de distancia se realizan directamente sobre los valores cuantizados sin necesidad de precomputar tablas de búsqueda. SQ8 almacena un byte por dimensión; SQ4 almacena dos dimensiones por byte.
Indexación a Escala de Miles de Millones
Para conjuntos de datos de miles de millones, la configuración recomendada de FAISS combina HNSW como cuantizador grueso con IVFPQ para compresión de vectores: quantizer = IndexHNSWFlat(d, hnsw_m); index = IndexIVFPQ(quantizer, d, nlist, M, nbits). El cuantizador HNSW acelera la búsqueda de centroides en comparación con la búsqueda plana durante el tiempo de consulta, y PQ comprime los vectores de la base de datos a una fracción de su tamaño original. El artículo original de FAISS (2017) evaluó la construcción de un grafo k-NN sobre 95 millones de imágenes (del conjunto de datos YFCC100M) en 35 minutos en GPUs, y un grafo k-NN sobre 1 mil millones de vectores en menos de 12 horas en 4 GPUs Maxwell Titan X.
Búsqueda Distribuida con IndexShards
FAISS IndexShards divide un conjunto de datos grande entre múltiples subíndices, cada uno potencialmente en máquinas o GPUs diferentes. Cada fragmento recibe un subconjunto de los vectores y procesa consultas de forma independiente. Los resultados se fusionan mediante una fusión k-way de los k resultados principales de cada fragmento. Este enfoque proporciona escalado lineal con el número de servidores disponibles: duplicar el número de fragmentos reduce a la mitad el tiempo de búsqueda para un tamaño de conjunto de datos fijo.
Índices en Disco
Para conjuntos de datos que exceden la RAM disponible, FAISS proporciona índices en disco que mantienen la estructura del índice (listas invertidas o grafo) en memoria pero almacenan los datos vectoriales en SSD. La clase IndexOnDisk y las utilidades relacionadas cargan de forma transparente los datos vectoriales desde el disco durante la búsqueda, utilizando archivos mapeados en memoria u operaciones de E/S explícitas. Con los NVMe SSD modernos que proporcionan velocidades de lectura secuencial de 3 a 7 GB/s, la búsqueda en disco puede acercarse al rendimiento en memoria para muchas cargas de trabajo, especialmente cuando se mantiene la localidad espacial (vectores vecinos almacenados de forma contigua en disco).
Para TarmacView, el conjunto de referencia actual de 9K está dentro del rango óptimo de FAISS para búsqueda exacta con IndexFlatIP. Sin embargo, a medida que el sistema se expanda para incluir imágenes de referencia de cientos de aeropuertos y múltiples campañas de inspección — potencialmente creciendo a millones de embeddings etiquetados — los mecanismos de escalado de FAISS (IVF para búsqueda no exhaustiva, PQ para compresión, almacenamiento en disco para conjuntos de datos fuera de RAM) proporcionan una ruta de actualización clara sin requerir una arquitectura fundamentalmente diferente. El tipo de índice puede actualizarse de IndexFlatIP → IndexIVFFlat → IndexIVFPQ → IndexShards(IndexIVFPQ) a medida que el conjunto de referencia crece, intercambiando cada paso una precisión mínima por mejoras de orden de magnitud en velocidad de búsqueda y eficiencia de memoria.
La literatura de FAISS (incluyendo el completo artículo de 2024 en arXiv “The Faiss Library” de Douze, Guzhva, Deng, Johnson, Szilvasy, Mazaré, Lomeli, y Jégou) proporciona una guía detallada sobre la selección de índices: “Existe una elección entre una docena de tipos de índice, y el óptimo generalmente depende de las restricciones del problema.” FAISS también incluye un conjunto completo de benchmarking (faiss_benchmarks) que mide el recall y el rendimiento a través de diferentes configuraciones de índice, ejecutando búsquedas con resultados de verdad fundamental de IndexFlat para cuantificar la precisión. Se anima a los profesionales a realizar benchmarking con su distribución de datos específica — el índice óptimo para un conjunto de datos dado depende de la dimensionalidad del vector, el tamaño del conjunto de datos, el recall objetivo, el presupuesto de latencia y la memoria disponible.
Preguntas Frecuentes
FAISS (Facebook AI Similarity Search) es una biblioteca de código abierto desarrollada por el equipo de Fundamental AI Research (FAIR) de Meta para la búsqueda eficiente de similitud y agrupación de vectores densos. Proporciona implementaciones de vanguardia de algoritmos de búsqueda de vecinos más cercanos, incluyendo búsqueda exacta por fuerza bruta (IndexFlat), índice de archivo invertido con agrupamiento k-means (IndexIVF), grafos jerárquicos navegables de mundo pequeño (IndexHNSW) y cuantización de producto (IndexIVFPQ), con soporte nativo para ejecución tanto en CPU como en GPU. La biblioteca se publicó como código abierto por primera vez en 2017 y ha obtenido más de 40 000 estrellas en GitHub.
FAISS es una biblioteca, no un sistema de base de datos completo. Se centra exclusivamente en la búsqueda rápida de vectores sin almacenamiento distribuido integrado, replicación, operaciones CRUD ni lenguajes de consulta. Las bases de datos vectoriales como Pinecone, Milvus, Qdrant y Weaviate se basan en FAISS o motores similares, pero añaden persistencia, escalabilidad, filtrado de metadatos y funciones de gestión. Las consultas con FAISS suelen ser entre 10 y 100 veces más rápidas que las consultas equivalentes en bases de datos porque no hay sobrecarga de red ni análisis de consultas, lo que lo hace ideal cuando se necesita un componente de búsqueda ligero e incrustable dentro de una aplicación.
IndexFlatIP realiza una búsqueda exacta por fuerza bruta con producto interno como métrica de distancia: calcula distancias contra todos los vectores del índice, garantizando los vecinos más cercanos exactos con complejidad O(NxD) por consulta. IndexIVFFlat utiliza agrupamiento k-means para dividir el espacio vectorial en nlist celdas de Voronoi y solo busca en las nprobe celdas más cercanas, intercambiando algo de precisión (típicamente 90-99% de recall) por ganancias significativas de velocidad proporcionales a nlist/nprobe. IndexHNSWFlat construye un grafo jerárquico multicapa inspirado en las skip lists que permite búsqueda en tiempo logarítmico O(log N), ofreciendo excelentes compensaciones entre velocidad y precisión. HNSW generalmente logra un recall más alto a velocidad de búsqueda equivalente en comparación con IVF en datos de alta dimensionalidad.
FAISS no tiene una métrica de coseno nativa. En su lugar, la similitud coseno se calcula normalizando todos los vectores mediante L2 para que tengan longitud unitaria y luego utilizando el producto interno (METRIC_INNER_PRODUCT). Para vectores normalizados a unidad donde ||a|| = ||b|| = 1, el producto interno es igual a la similitud coseno: a·b = cos(θ). Este enfoque se implementa envolviendo los vectores en un IndexPreTransform que aplica un NormalizationTransform antes de pasarlos a un índice que utiliza producto interno. La normalización asegura que las comparaciones de similitud se centren en la alineación direccional en lugar de la magnitud del vector.
Sí. FAISS se utiliza comúnmente para implementar clasificación k-Nearest Neighbors (kNN), un método no paramétrico que clasifica un punto de consulta basándose en la etiqueta mayoritaria entre sus k vecinos más cercanos en el conjunto de referencia. El proceso implica construir un conjunto de referencia etiquetado, indexar los vectores de referencia en FAISS, enviar los embeddings de consulta, recuperar los k vecinos más cercanos y realizar votación por mayoría (o votación ponderada por distancia) sobre las etiquetas. Este enfoque es utilizado por TarmacView para la clasificación de calidad superficial con k=10 y un conjunto de referencia de aproximadamente 9000 embeddings etiquetados.
La aceleración por GPU en FAISS aprovecha NVIDIA CUDA para ejecutar operaciones de construcción de índices y búsqueda en GPUs con implementaciones nativas para IndexFlat, IndexIVF, IndexIVFPQ e índices con cuantización escalar. Ofrece una mejora de 5 a 10 veces en el rendimiento de búsqueda respecto a la CPU para índices IVF y HNSW típicos, hasta 12 veces más rápido en la construcción de índices IVF (el agrupamiento k-means es altamente paralelizable) y soporte nativo para consultas por lotes. FAISS proporciona interoperabilidad fluida entre CPU y GPU mediante las funciones index_cpu_to_gpu e index_gpu_to_cpu, lo que permite flujos de trabajo híbridos donde los índices se construyen en GPU y se despliegan en CPU.
Los índices de FAISS se serializan usando write_index(index, filename), que guarda el estado completo del índice, incluyendo todos los vectores, centroides entrenados, estructura del grafo, configuración de la métrica de distancia y parámetros internos en un archivo binario. La función read_index(filename) restaura el índice a su estado previo a la serialización, listo para búsqueda inmediata sin entrenamiento adicional. FAISS también proporciona las funciones serialize_index y deserialize_index para la serialización en búfer de bytes en memoria. Los índices de GPU no se pueden guardar directamente en disco; primero deben transferirse a CPU mediante index_gpu_to_cpu.
TarmacView utiliza FAISS para almacenar aproximadamente 9000 embeddings de referencia etiquetados extraídos de un modelo DINOv2 Vision Transformer. Cada embedding de referencia de 768 dimensiones representa un tipo de superficie conocido o una condición de calidad superficial en pavimentos aeroportuarios. Cuando se recoge una nueva imagen de inspección, su embedding se normaliza a longitud unitaria y se consulta contra el índice FAISS. El sistema recupera los k=10 vecinos más cercanos usando IndexHNSWFlat con M=32 y efSearch=64 (>99% de recall con tiempos de consulta de sub-milisegundos), y luego realiza votación por mayoría para clasificar la calidad superficial. Si la etiqueta ganadora alcanza menos del 60% de consenso, la imagen se marca para revisión humana.
FAISS soporta más de veinte tipos de índice. Los más utilizados son IndexIVF (archivo invertido con agrupamiento k-means, parametrizado por nlist y nprobe), IndexHNSW (grafo jerárquico navegable de mundo pequeño, parametrizado por M, efConstruction y efSearch), IndexIVFPQ (archivo invertido con cuantización de producto para almacenamiento eficiente en memoria a gran escala), IndexIVFScalarQuantizer (cuantización escalar a enteros de 8 o 4 bits), IndexLSH (hashing sensible a localidad para datos de baja dimensionalidad) e IndexBinary (para búsqueda de vectores binarios). También están disponibles índices compuestos que combinan múltiples técnicas.
La Cuantización de Producto (PQ) es una técnica de compresión con pérdida para vectores de alta dimensionalidad que divide cada vector en m subvectores y cuantiza cada subvector de forma independiente utilizando un codebook aprendido mediante k-means. FAISS IndexIVFPQ combina IVF con PQ, comprimiendo cada vector a m bytes (con subcuantizadores de 8 bits). Para un vector de 128 dimensiones, PQ con m=64 reduce el almacenamiento de 512 bytes (float32) a 72 bytes incluyendo sobrecarga, una reducción de 7 veces. PQ permite indexar cientos de millones a miles de millones de vectores en un solo servidor, con el cálculo de distancias realizado en el dominio comprimido mediante Cálculo de Distancia Asimétrica (ADC).
FAISS maneja la indexación a escala de miles de millones mediante una combinación de compresión de vectores (cuantización de producto, cuantización escalar) y búsqueda no exhaustiva (IVF, HNSW, o ambos combinados). La pila recomendada para escala de mil millones utiliza HNSW como cuantizador grueso para un índice IVFPQ: quantizer=IndexHNSWFlat, index=IndexIVFPQ(quantizer, d, nlist, M, nbits). Esta combinación logra tiempos de búsqueda de subsegundos en conjuntos de datos de miles de millones. El artículo original de FAISS GPU (2017) demostró un grafo k-NN sobre 95 millones de imágenes construido en 35 minutos, y un grafo k-NN de 1 mil millones de vectores construido en menos de 12 horas en 4 GPUs Titan X.
El contrato de embedding es el acuerdo implícito entre el extractor de embeddings (típicamente una red neuronal) y el algoritmo de búsqueda vectorial. El extractor de embeddings se entrena para que las distancias entre embeddings reflejen la similitud semántica entre las entradas. El índice vectorial realiza la búsqueda de vecinos entre embeddings con la mayor precisión posible respecto a la métrica de distancia acordada (L2 o producto interno/coseno). Al usar FAISS con embeddings de DINOv2 para la clasificación de calidad superficial, el contrato requiere que los embeddings de superficies de pavimento visualmente similares estén cerca en el espacio vectorial, permitiendo que la recuperación de vecinos más cercanos funcione como un mecanismo de clasificación fiable.
Potencie su Infraestructura de Búsqueda Vectorial
Aproveche FAISS para la búsqueda de similitud de alto rendimiento en sus datos de embeddings de imágenes. Contáctenos para saber cómo TarmacView integra FAISS para la clasificación de calidad superficial y recuperación de imágenes de inspección en tiempo real.
DINOv3 Vision Transformer para Análisis de Superficies de Infraestructura
DINOv3 (self-DIstillation with NO labels v3) es un vision transformer (ViT-B/16) autosupervisado, preentrenado con 1.7 mil millones de imágenes, que produce emb...
Evaluación de la Cabeza de Defectos y Pruebas de Smoke Testing
La prueba de smoke testing de la cabeza de defectos valida que el pipeline de detección de defectos estructurales de TarmacView — backbone DINOv3 + cabeza MLP d...
El Fijo de Aproximación Final (FAF) es un punto crítico en los procedimientos de aproximación por instrumentos, que marca el inicio del segmento de aproximación...
8 min de lectura
Instrument Approach
Aviation Glossary
+2
Consentimiento de Cookies Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.