Segmentación de Grietas
La segmentación de grietas es la tarea de visión por computadora que clasifica cada píxel de una imagen como grieta o no grieta, produciendo una máscara binaria...
40 min de lectura
Computer Vision
Deep Learning
+2
La segmentación de instancias identifica y delimita cada objeto individual o instancia de defecto a nivel de píxel, asignando una ID única a cada grieta, descascaramientos o bache. Esto permite el conteo, medición y seguimiento temporal por defecto. Cubre Mask R-CNN y otras arquitecturas de instancias, diferencia con la segmentación semántica y aplicación a defectos de infraestructura.
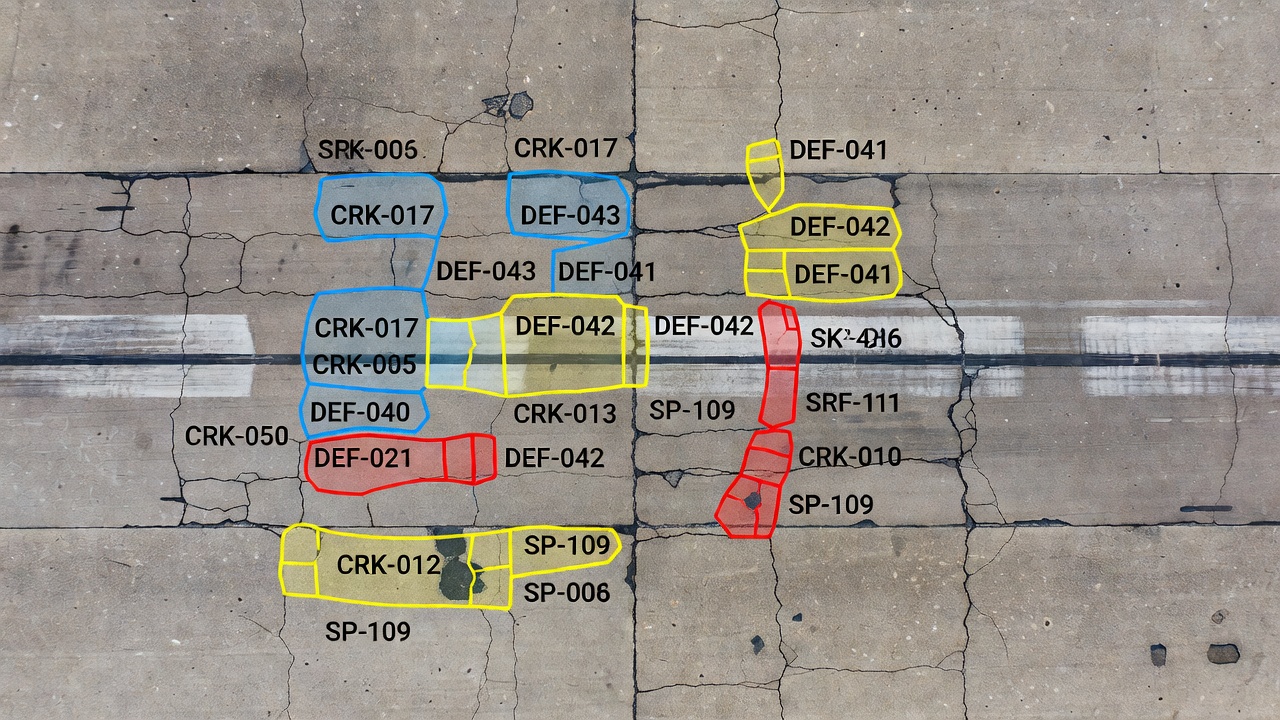
Segmentación de instancias es una tarea de visión artificial que identifica, clasifica y delimita cada objeto individual a nivel de píxel asignando un identificador de instancia único a cada objeto detectado. Para la inspección de infraestructura, la segmentación de instancias significa que cada grieta, descascaramientos, bache, falla de junta o deterioro superficial individual recibe su propia máscara perfecta a nivel de píxel con una ID distinta, lo que permite a los ingenieros contar, medir y rastrear cada defecto de forma independiente en lugar de tratar todos los defectos del mismo tipo como una masa única e indiferenciada.
La segmentación de instancias ocupa una posición distinta en la jerarquía de la visión artificial, situándose entre la detección de objetos (cuadros delimitadores con etiquetas de clase) y la segmentación semántica (etiquetas de clase a nivel de píxel sin distinción de instancias). Resuelve un problema que ninguna de estas tareas por sí sola puede abordar: la capacidad de clasificar cada píxel perteneciente a una categoría y distinguir qué píxeles pertenecen a qué objeto específico dentro de esa categoría.
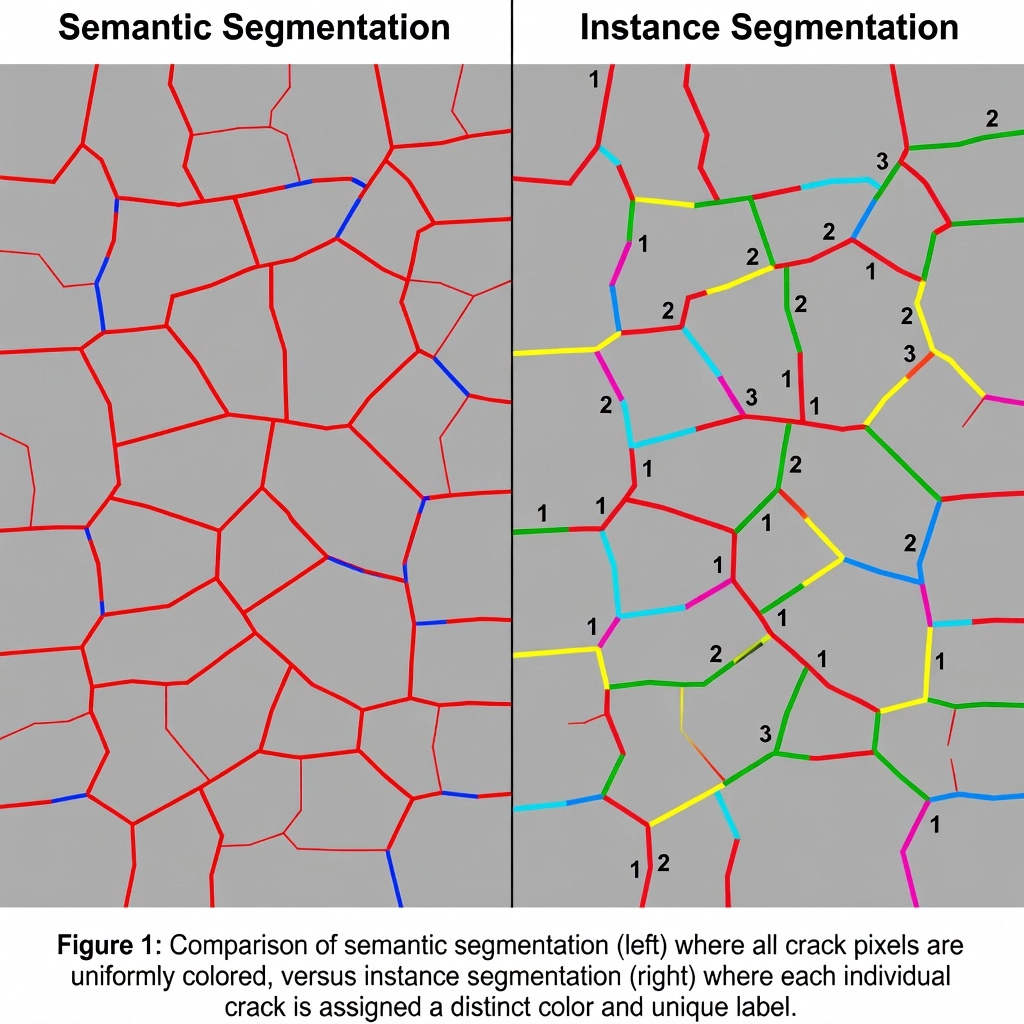
La segmentación semántica etiqueta cada píxel de una imagen según la clase a la que pertenece. En una imagen de la superficie de una pista de aeropuerto que contiene tres grietas longitudinales, un modelo de segmentación semántica colorearía todos los píxeles de grietas con el mismo color de clase (por ejemplo, rojo). La salida es una máscara binaria o multiclase única donde todas las grietas, independientemente de ser defectos físicos separados, se fusionan en una región de clase continua. Este enfoque proporciona el área total de grietas en píxeles, pero no ofrece información sobre cuántas grietas individuales existen, sus tamaños individuales o su distribución espacial como defectos discretos.
La detección de objetos coloca cuadros delimitadores alrededor de cada objeto detectado y asigna una etiqueta de clase. Un detector en la misma imagen de pista dibujaría tres cuadros rectangulares alrededor de las tres grietas. La salida proporciona el conteo de grietas y su ubicación aproximada, pero los cuadros delimitadores introducen una limitación fundamental: incluyen pavimento sin defectos dentro del rectángulo, lo que hace imposible la medición precisa del área. Un cuadro delimitador alrededor de una grieta sinuosa captura muchos más píxeles sin grieta que píxeles de grieta.
La segmentación de instancias resuelve estas limitaciones por completo. El modelo produce un conjunto de máscaras binarias, una por instancia detectada, cada una emparejada con una etiqueta de clase y una ID de instancia única. Para las tres grietas, la salida serían tres máscaras binarias distintas: Grieta-001, Grieta-002 y Grieta-003, cada una mostrando exactamente los píxeles que pertenecen a esa grieta específica y ninguno más. Las máscaras siguen el contorno exacto de cada defecto, rodeando cada ramificación, curva e irregularidad. Esto proporciona una geometría a nivel de píxel por instancia que admite la medición precisa de área, el análisis de morfología y el seguimiento individual de defectos.
La diferencia operativa crítica surge en el resultado de la inspección. Un informe de segmentación semántica podría indicar: “Área total de grietas: 45,230 píxeles.” Un informe de segmentación de instancias indica: “Tres grietas detectadas. Grieta-001: 12,400 px², Grieta-002: 18,100 px², Grieta-003: 14,730 px².” Esto último es mucho más procesable para la planificación de mantenimiento: le indica al ingeniero de pavimentos el número exacto de defectos que requieren reparación y su severidad individual.
Esta distinción por instancia se formaliza en el estándar del conjunto de datos COCO (Common Objects in Context), que define las anotaciones de segmentación de instancias como una lista de objetos, cada uno conteniendo un polígono de segmentación (lista de coordenadas x,y que forman el contorno del objeto), un cuadro delimitador, una ID de categoría y una ID de imagen. Las métricas de evaluación utilizadas en COCO, particularmente la Precisión Promedio (AP), son el estándar de facto para la comparación de modelos de segmentación de instancias y se aplican directamente a los modelos de detección de defectos en infraestructura.
Se han desarrollado múltiples arquitecturas de aprendizaje profundo para la segmentación de instancias, cada una con distintas compensaciones entre precisión, velocidad y complejidad arquitectónica.
Mask R-CNN, presentado por He et al. en Facebook AI Research en 2017, extiende Faster R-CNN añadiendo una rama de predicción de máscaras en paralelo con las ramas existentes de regresión de cuadros delimitadores y clasificación. La arquitectura sigue un diseño de dos etapas. En la primera etapa, una Red de Propuesta de Regiones (RPN) escanea los mapas de características extraídos por una CNN troncal (típicamente ResNet-50, ResNet-101 o ResNeXt) y propone regiones candidatas de objetos (RoI o Regiones de Interés). En la segunda etapa, cada RoI se procesa mediante RoIAlign — una contribución crítica de Mask R-CNN que utiliza interpolación bilineal para calcular valores de características exactos en cada punto de muestreo, eliminando los errores de cuantificación de RoIPool — para producir mapas de características de tamaño fijo. Estos mapas de características alimentan tres cabezales paralelos: un cabezal de clasificación (predicción de clase), un cabezal de regresión de cuadros delimitadores (coordenadas del cuadro) y un cabezal de máscaras (una red completamente convolucional que genera una máscara binaria para cada clase por cada RoI).
El cabezal de máscaras produce una máscara de resolución 28×28 píxeles por RoI por clase. Durante el entrenamiento, la función de pérdida combina la pérdida de clasificación, la pérdida del cuadro delimitador y la pérdida de máscara (entropía cruzada binaria promediada sobre píxeles). La idea clave es que la predicción de máscaras y la clasificación están desacopladas: el cabezal de máscaras predice máscaras para todas las clases, pero solo la máscara correspondiente a la clase real contribuye a la pérdida. Esta predicción de máscaras por clase fuerza al modelo a aprender características de forma específicas de cada clase.
Mask R-CNN logra 37-47 AP en segmentación de instancias de COCO (dependiendo del troncal), con ResNet-50-FPN alcanzando aproximadamente 37.1 AP y ResNeXt-101-FPN alcanzando 39.4-47.1 AP. La velocidad de inferencia oscila entre 5-10 FPS en una GPU moderna. Para aplicaciones de infraestructura, la configuración más utilizada es Mask R-CNN con troncal ResNet-50-FPN, con un rendimiento reportado de 33.3 AP en conjuntos de datos de grietas en pavimentos y 40-55 AP en conjuntos de datos de baches.
YOLACT (You Only Look At CoefficienTs) fue presentado por Bolya et al. en 2019 como el primer método de segmentación de instancias en tiempo real capaz de funcionar a 30+ FPS. A diferencia del enfoque de dos etapas de Mask R-CNN, YOLACT es un método completamente convolucional de una sola etapa que divide la segmentación de instancias en dos subtareas paralelas: generar un conjunto de máscaras prototipo para toda la imagen y predecir coeficientes de combinación lineal por instancia.
En la primera subtarea, un troncal de Red de Pirámide de Características produce un conjunto de máscaras prototipo: k coeficientes de máscara (típicamente 32) que cubren toda la imagen. Estos prototipos capturan patrones de forma comunes (por ejemplo, horizontal, vertical, curva, circular). En la segunda subtarea, el cabezal de predicción genera un vector de coeficientes lineales para cada instancia detectada. La máscara final para cada instancia se calcula como una combinación lineal de los prototipos ponderada por el vector de coeficientes de la instancia, seguida de una activación sigmoide y un recorte utilizando el cuadro delimitador predicho.
YOLACT alcanza 29-31 AP en COCO a 30-45 FPS en una GPU Titan X. La variante más rápida YOLACT-550 logra 28.2 AP a 56 FPS. YOLACT++ mejora la calidad de las máscaras añadiendo convoluciones deformables y mejor sobremuestreo de prototipos, alcanzando 34.1 AP a 33.5 FPS. Para la inspección de infraestructura, YOLACT se ha aplicado con éxito a la detección de grietas en concreto en tiempo real, logrando resultados competitivos mientras opera a velocidades adecuadas para procesamiento a bordo de UAV. La compensación es una menor precisión en los bordes de las máscaras en comparación con Mask R-CNN, lo que puede afectar la medición precisa del ancho de grietas.
SOLO (Segmenting Objects by LOcations), presentado por Wang et al. en 2020, adopta un enfoque fundamentalmente diferente: elimina por completo la rama de detección y predice máscaras de instancias directamente utilizando una arquitectura completamente convolucional. La idea central es que cada instancia puede identificarse de manera única por su ubicación central y tamaño del objeto. SOLO divide la imagen de entrada en una cuadrícula S×S. Cada celda de la cuadrícula es responsable de predecir la máscara binaria de cualquier instancia cuyo centro caiga dentro de esa celda. Cada celda de la cuadrícula predice máscaras de C canales (uno por clase) más probabilidades de clase.
La arquitectura de SOLO consta de un troncal (ResNet-FPN), una rama de categoría que predice probabilidades de clase para cada celda de la cuadrícula, y una rama de máscaras que predice S² máscaras binarias por imagen (una por posición de la cuadrícula). Durante la inferencia, la predicción de clase por celda y la predicción de máscara se combinan: para cada celda de la cuadrícula, la clase predicha con confianza superior al umbral selecciona el canal de máscara correspondiente. SOLOv2 mejora el original introduciendo predicción de núcleos de máscara y correlación de características de máscara, logrando 37.8 AP en COCO a una velocidad comparable a Mask R-CNN.
El paradigma basado en la ubicación de SOLO es particularmente interesante para defectos de infraestructura porque asigna naturalmente cada defecto a su posición espacial sin depender de propuestas de cuadros delimitadores, que pueden ser problemáticas para defectos altamente alargados como las grietas que se extienden a través de grandes porciones de la imagen.
Mask2Former, presentado por Cheng et al. en Facebook AI Research (CVPR 2022), representa el estado del arte en segmentación basada en transformadores. Mask2Former unifica la segmentación semántica, de instancias y panóptica dentro de una sola arquitectura tratando todas las tareas de segmentación como clasificación de máscaras. La arquitectura tiene tres componentes: un troncal (Swin Transformer o ResNet) que extrae características multiescala, un decodificador de píxeles que sobremuestrea las características a incrustaciones por píxel de alta resolución, y un decodificador de transformadores con atención enmascarada que predice un conjunto de N consultas (típicamente 100), cada una produciendo una máscara binaria y una etiqueta de clase.
La innovación clave es la atención enmascarada — un mecanismo donde cada consulta del decodificador de transformadores solo atiende a la región de máscara predicha de la capa del decodificador anterior, en lugar de atender a todo el mapa de características. Esto reduce el cómputo en 3× en comparación con los modelos de transformadores estándar y obliga a cada consulta a especializarse en una región específica, mejorando la velocidad de convergencia y la calidad de las máscaras.
Mask2Former alcanza 50.1 AP en segmentación de instancias de COCO con un troncal Swin-L y 57.8 PQ en segmentación panóptica de COCO. Su entrenamiento converge 3× más rápido que los enfoques anteriores basados en transformadores (por ejemplo, MaskFormer, DETR). Para aplicaciones de infraestructura, la capacidad de Mask2Former para manejar instancias de defectos superpuestas y adyacentes mediante la predicción de máscaras basada en consultas aprendidas lo hace particularmente efectivo para campos densos de defectos como el agrietamiento en piel de cocodrilo o patrones de agrietamiento en mapa.
| Arquitectura | Tipo | AP COCO | FPS | Fortalezas | Uso en Infraestructura |
|---|---|---|---|---|---|
| Mask R-CNN | CNN de dos etapas | 37-47 | 5-10 | Alta precisión de máscara, bien establecida | Análisis de defectos fuera de línea |
| YOLACT | CNN de una etapa | 29-34 | 30-56 | Velocidad en tiempo real | Procesamiento a bordo de UAV |
| SOLOv2 | CNN sin detección | 37.8 | ~10 | Sin dependencia de anclas/propuestas | Instancias de defectos alargados |
| Mask2Former | Transformador | 50.1 | ~15 | Precisión SOTA, marco unificado | Campos densos de defectos |
La elección entre segmentación de instancias y semántica para la detección de grietas depende de los requisitos analíticos específicos del programa de inspección, y los dos enfoques producen resultados fundamentalmente diferentes.
La segmentación semántica para grietas trata toda la red de grietas como una sola clase de primer plano. El modelo aprende a clasificar cada píxel como “grieta” o “fondo”. La salida es una máscara binaria donde todos los píxeles de grietas son blancos y todos los píxeles sin grietas son negros. Este enfoque tiene varias fortalezas bien documentadas: maneja redes de grietas conectadas de forma natural (una grieta ramificada es un solo componente conectado), requiere anotaciones más simples (trazos a nivel de píxel en lugar de polígonos por instancia), y la complejidad del entrenamiento es menor con menos canales de salida. Los modelos de segmentación semántica de última generación para grietas — como DeepCrack (93% F1 en CrackTree260), CrackU-Net (97.5% F1 en CRACK500) y SwinUNETR (90.5% F1 en conjuntos de datos de grietas multitemporales) — logran una excelente precisión a nivel de píxel.
Sin embargo, la segmentación semántica tiene una limitación crítica para la evaluación de condición de infraestructura: no puede contar grietas individuales. Cuando la segmentación semántica reporta 5,000 píxeles de grietas, no proporciona información sobre si esos píxeles pertenecen a una grieta de 5,000 píxeles o a cincuenta grietas de 100 píxeles. Esta distinción es crítica para los cálculos del Índice de Condición de Pavimento (PCI), donde la densidad de grietas (número de grietas por unidad de área) y la severidad individual de las grietas son parámetros de evaluación separados según los protocolos de inspección ASTM D5340 y Anexo 14 de la OACI.
La segmentación de instancias para grietas asigna una ID única a cada instancia de grieta individual. Para una imagen de pavimento que muestra múltiples grietas, la salida consiste en N máscaras binarias, cada una correspondiente a una grieta, con una etiqueta de clase y una ID de instancia asociadas. El método de segmentación de instancias aumentado con CrackMover propuesto por Zhao et al. (2024) logra 33.3 AP en detección de grietas, superando a Mask R-CNN estándar en un 8.6% mediante aumentación de datos especializada para formas de grietas alargadas.
La segmentación de instancias para grietas presenta desafíos únicos. Las grietas son objetos muy alargados, delgados y a menudo ramificados — no son masas compactas como los baches. Las arquitecturas estándar de segmentación de instancias diseñadas para objetos COCO (formas compactas y bien definidas) pueden dividir una sola grieta ramificada en múltiples instancias o no lograr separar grietas paralelas adyacentes. Las técnicas especializadas incluyen modificar la resolución de RoIAlign para la extracción de características alargadas, usar convoluciones atrosas en el cabezal de máscaras para la captura multiescala de grietas, y aplicar refinamiento en cascada (Cascade Mask R-CNN) que mejora iterativamente las propuestas de baja calidad.
La decisión práctica depende de la pregunta de mantenimiento que se esté planteando. Para la cuantificación del área total de grietas (por ejemplo, medir el porcentaje de agrietamiento por sección de pista), la segmentación semántica puede ser suficiente y es computacionalmente más eficiente. Para el conteo de grietas, seguimiento del ancho de grietas individuales y clasificación de severidad por grieta (por ejemplo, severidad de grietas según ASTM D5340 donde la severidad depende del ancho individual de la grieta), la segmentación de instancias es necesaria. Una tendencia creciente en la inspección de infraestructura es la segmentación panóptica — combinar segmentación semántica y de instancias para clasificar semánticamente regiones no contables (por ejemplo, superficie de pavimento, césped, marcas) mientras se segmentan por instancia los defectos contables (grietas, descascaramientos, baches).
Los descascaramientos y baches son fundamentalmente diferentes de las grietas en términos de geometría: son defectos discretos, delimitados y compactos con extensión espacial clara, bordes bien definidos y volumen medible. Esto los hace naturalmente adecuados para la segmentación de instancias, y las arquitecturas que funcionan bien en instancias COCO (que en su mayoría son objetos compactos) se transfieren de manera efectiva a la detección de descascaramientos y baches.
Un bache es una depresión en forma de tazón en la superficie del pavimento que típicamente se forma cuando el agrietamiento superficial permite la infiltración de agua, lo que lleva a la degradación de la capa base y la pérdida de material. Los baches son instancias discretas por definición — cada bache es un vacío físico separado. La segmentación de instancias captura el perímetro exacto de cada bache, lo cual es crítico para la estimación precisa del volumen de reparación. Un enfoque de cuadro delimitador (detección de objetos) podría encerrar un 30-50% de área sin defecto dependiendo de la irregularidad de la forma del bache, mientras que la segmentación de instancias proporciona el área real del defecto.
Un descascaramiento es un área astillada o rota en el borde de una junta o grieta, típicamente en pavimentos de concreto. Los descascaramientos también son instancias discretas delimitadas por la línea de la junta o grieta. La segmentación de instancias para descascaramientos debe manejar sus restricciones geométricas: los descascaramientos siempre se originan en una discontinuidad estructural (junta, borde de grieta), tienen un lado delimitado por la junta y se extienden hacia la cara de la losa. Los modelos especializados de segmentación de instancias para descascaramientos incorporan mecanismos de atención enfocados en las regiones de las juntas.
La investigación demuestra la efectividad de estos enfoques. Utilizando Mask R-CNN para la detección de baches en conjuntos de datos de carreteras, Nhat-Duc et al. (2020) reportaron AP@0.50 de 55.2 y AP@0.75 de 42.8. YOLACT aplicado a la detección de baches alcanzó una velocidad de inferencia de 33 FPS con AP@0.50 de 48.7, lo que permite el conteo de baches en tiempo real desde cámaras montadas en vehículos. Para descascaramientos en concreto, Cascade Mask R-CNN con un troncal ResNeXt-101 logró 44.6 AP en un conjunto de datos de descascaramientos en tableros de puentes de 2,400 imágenes anotadas.
El estándar ASTM D5340 para el Índice de Condición de Pavimento aeroportuario define requisitos de medición específicos para descascaramientos y baches:
La segmentación de instancias respalda directamente todas estas mediciones. La máscara a nivel de píxel proporciona dimensiones precisas de largo y ancho (cuando se combina con una resolución espacial conocida, por ejemplo, 1mm/píxel a partir de imágenes UAV calibradas). La ID de instancia única permite el conteo por defecto para los cálculos de densidad. Cuando se combina con datos de profundidad estereoscópicos o de estructura a partir de movimiento (SfM), las máscaras de instancias pueden extrusionarse a 3D para la medición de volumen.
La ventaja clave sobre la segmentación semántica para descascaramientos y baches es el conteo de defectos. Considere una sección de pista con 15 descascaramientos individuales. La segmentación semántica reporta “área de descascaramiento: 0.85 m²” — sin proporcionar indicación del número de defectos. La segmentación de instancias reporta “15 descascaramientos detectados: Desc-001 (0.12 m²), Desc-002 (0.04 m²), …, Desc-015 (0.03 m²)” — informando al ingeniero que se necesitan 15 tratamientos de reparación individuales y cuáles son los más severos.
Una vez que cada instancia de defecto está aislada por su máscara única, se puede extraer un conjunto completo de mediciones por instancia para la evaluación de condición y la planificación de mantenimiento.
La medición de área es la métrica más fundamental por defecto. El recuento de píxeles dentro de cada máscara de instancia se convierte a área física utilizando calibración espacial. Para imágenes adquiridas por UAV con una distancia de muestreo en suelo (GSD) conocida — típicamente 0.5-2.0 mm/píxel para inspecciones de pistas — el recuento de píxeles de la máscara multiplicado por (GSD)² da el área física en mm² o m². Para grietas, la medición de área permite el cálculo del ancho de grieta: ancho medio de grieta = área de la máscara / longitud del esqueleto. Para baches y descascaramientos, el área alimenta directamente los umbrales de clasificación de severidad.
La medición de ubicación asigna coordenadas geográficas a cada instancia de defecto. El centroide de la máscara de la instancia (media x,y de los píxeles de la máscara) o el punto central inferior (para ubicación consciente de la orientación) se transforma de coordenadas de imagen a coordenadas del mundo real utilizando los parámetros de georreferenciación de la cámara (de metadatos GPS/IMU o de puntos de control en tierra fotogramétricos). Los datos de ubicación permiten: análisis de agrupamiento espacial para identificar zonas de alta densidad de defectos, correlación con características estructurales (juntas, esquinas de paneles, drenajes), y vinculación con bases de datos SIG del sistema de gestión de pavimentos (PMS) para la generación de órdenes de trabajo de mantenimiento.
La medición de morfología caracteriza las propiedades geométricas de cada instancia de defecto más allá del área simple. Los descriptores morfológicos clave incluyen:
Estas mediciones se calculan eficientemente utilizando las funciones de análisis de contornos de OpenCV (cv2.findContours, cv2.moments, cv2.convexHull) o las operaciones morfológicas de scikit-image (skimage.measure.regionprops, skimage.morphology.skeletonize). Para un conjunto de datos típico de inspección de pistas de 10,000 imágenes con 50,000+ instancias de defectos, la extracción de características por defecto se completa en minutos en una estación de trabajo estándar.
La segmentación de instancias permite el conteo automatizado de defectos que es simplemente imposible con la segmentación semántica por sí sola. El conteo de defectos — el número de defectos individuales discretos por unidad de área — es una entrada fundamental para los índices de condición de infraestructura, incluyendo el PCI (ASTM D5340), el Índice de Condición Estructural (SCI) y el Índice de Condición de Pista (RCI).
El conteo por defecto procede de la siguiente manera: el modelo de segmentación de instancias produce máscaras de instancias con ID únicas (típicamente números enteros a partir de 1). El número de ID de instancia únicas en cada imagen o área de inspección da directamente el conteo de defectos. Para una pista de 3,000 metros inspeccionada a 1mm GSD, generando aproximadamente 3,000 mosaicos de imágenes de 2000×2000 píxeles cada uno, un modelo de segmentación de instancias podría detectar 200-500 grietas individuales, 50-100 descascaramientos y 10-20 baches — cada uno contado y registrado individualmente.
La estratificación del conteo agrupa los defectos por tipo y por severidad. Las ID de instancia únicas se agrupan primero por clase predicha (grieta, descascaramiento, bache, falla de junta, desgaste). Dentro de cada clase, las instancias se pueden estratificar aún más por severidad basándose en umbrales de área o características morfológicas:
El mapeo de distribución espacial agrega los conteos por defecto en contenedores espaciales. La pista se divide en unidades de muestreo según las especificaciones OACI/ASTM: típicamente 20 losas contiguas para pavimentos de concreto (cada losa ~5m × 5m = 25 m²) o unidades rectangulares de 25m × 25m = 625 m² para pavimentos asfálticos. El centroide de cada instancia de defecto se mapea a su unidad de muestreo correspondiente. La densidad de defectos por unidad se calcula como: número de defectos en la unidad / área de la unidad. Esta densidad alimenta directamente las tablas de cálculo del PCI.
Los mapas de distribución revelan patrones de agrupamiento de defectos. Una pista con 500 grietas individuales distribuidas en 120 unidades de muestreo podría mostrar el 85% de las unidades con 0-5 grietas y el 5% de las unidades con 20+ grietas. Las unidades agrupadas indican áreas que requieren mantenimiento específico — típicamente asociadas con problemas estructurales subyacentes (falla de la subrasante, mal drenaje, juntas de construcción) en lugar de desgaste superficial uniforme.
El análisis de patrón de puntos espacial (función K de Ripley, estimación de densidad de núcleo) puede cuantificar aún más la intensidad del agrupamiento e identificar puntos críticos de defectos estadísticamente significativos. Cuando se combina con análisis de superposición SIG, los grupos de defectos pueden correlacionarse con ubicaciones de juntas de construcción, zonas de edad del pavimento, patrones de drenaje y áreas de agua estancada, ubicaciones de mantenimiento y reparación anteriores, y distribución del tráfico (zonas de concentración de la trayectoria de las ruedas).
La capacidad única de la segmentación de instancias para asignar ID persistentes a defectos individuales permite el seguimiento temporal — la cuantificación de cómo evoluciona cada defecto entre inspecciones. Esta es la base del mantenimiento predictivo y la gestión de activos basada en la condición.
El proceso de seguimiento temporal involucra cuatro etapas. Primero, la pista se vuelve a inspeccionar con una cadencia regular (trimestral, semestral o anual, según la práctica recomendada por la OACI para inspecciones de condición de pavimentos aeroportuarios). Segundo, la segmentación de instancias se aplica de forma independiente a cada conjunto de datos de inspección, generando máscaras por defecto con ID de instancia para cada punto temporal. Tercero, un algoritmo de asociación de instancias empareja las instancias de defectos entre inspecciones consecutivas basándose en la proximidad espacial (distancia entre centroides < umbral), superposición de máscaras (IoU ≥ 0.3-0.5) y similitud morfológica (cambio de área <50%, cambio de orientación <15°). Cuarto, las instancias emparejadas reciben una ID global persistente que las vincula a través de todos los periodos de inspección, creando una serie temporal para cada defecto.
Los algoritmos de asociación deben manejar varios desafíos. Los defectos pueden fusionarse o dividirse entre inspecciones (una grieta que se bifurca, un descascaramiento que se expande y se une a un descascaramiento vecino). Los defectos pueden aparecer o desaparecer (nueva formación de grietas, defectos reparados). El algoritmo húngaro (asignación de Munkres) resuelve el problema de asignación lineal para el emparejamiento uno a uno entre instancias en inspecciones consecutivas con un costo computacional O(n³). Para casos complejos con divisiones y fusiones, el seguimiento basado en grafos (flujo de costo mínimo en un grafo espacio-temporal) proporciona un emparejamiento más robusto a un mayor costo computacional.
Las métricas de cambio por defecto calculadas a partir de la serie temporal emparejada incluyen:
La precisión del seguimiento temporal depende de la precisión del registro de la inspección. Las inspecciones repetidas deben estar georreferenciadas al mismo sistema de coordenadas con precisión subcentimétrica. Esto se logra mediante puntos de control en tierra (GCP) instalados permanentemente a lo largo de la pista y levantados con GPS RTK (±2cm de precisión), o mediante correregistro basado en imágenes utilizando emparejamiento de características (características SIFT/SuperPoint) entre conjuntos de datos de inspección para calcular transformaciones de homografía.
El mantenimiento predictivo utiliza series temporales por defecto para pronosticar cuándo un defecto alcanzará la severidad crítica. Un modelo de regresión lineal ajustado a la serie temporal de ancho o área de cada defecto predice la fecha en que el defecto superará el umbral de severidad (por ejemplo, ancho de grieta >3mm para severidad Alta según ASTM D5340). Esto genera una cola de mantenimiento priorizada: los defectos que se proyecta que alcanzarán la severidad crítica dentro del próximo ciclo de inspección se marcan para reparación inmediata.
El entrenamiento de modelos de segmentación de instancias para defectos de infraestructura presenta desafíos únicos en comparación con conjuntos de datos de objetos naturales, debido principalmente a los requisitos de anotación y las características de los datos.
Formato de anotación: La segmentación de instancias requiere anotaciones a nivel de polígono — cada defecto individual debe ser delineado por un polígono cerrado de vértices. Esto es sustancialmente más laborioso que las anotaciones de segmentación semántica (que utilizan trazos de pincel o herramientas de relleno por inundación) o las anotaciones de detección de objetos (que utilizan rectángulos alineados con los ejes). Una anotación típica de grieta requiere 20-100 vértices de polígono para trazar con precisión el recorrido de la grieta, dependiendo de la complejidad y longitud de la misma. Una anotación de descascaramiento típicamente requiere 8-30 vértices. Las herramientas de anotación estándar de la industria (CVAT, Labelbox, Supervisely, Scale AI) admiten anotación de polígonos con herramientas semiautomatizadas (por ejemplo, segmentación interactiva con SAM — Segment Anything Model — para reducir el tiempo de colocación manual de vértices).
El formato JSON COCO es el esquema de anotación estándar para segmentación de instancias. Cada entrada de anotación contiene id (identificador único de anotación), image_id (referencia a la imagen de origen), category_id (etiqueta de clase como 1=grieta, 2=descascaramiento, 3=bache), segmentation (polígono representado como una lista plana de coordenadas x,y), area (área del polígono en píxeles), bbox (cuadro delimitador como [x, y, ancho, alto]) y iscrowd (0 para instancias de defectos individuales).
Requisitos de tamaño del conjunto de datos: Los modelos de segmentación de instancias típicamente requieren 500-2,000+ imágenes anotadas por categoría de defecto para un rendimiento aceptable (AP >35). Los conjuntos de datos pequeños (<200 imágenes) corren el riesgo de sobreajuste y mala generalización a nuevos tipos de pavimento, condiciones de iluminación y variantes de defectos. El aprendizaje por transferencia desde troncales preentrenados grandes (ImageNet-1K, COCO) reduce significativamente el tamaño requerido del conjunto de datos — un Mask R-CNN inicializado con pesos preentrenados de COCO y ajustado en 500 imágenes de grietas logra un rendimiento comparable a un modelo entrenado desde cero en 2,000 imágenes.
La aumentación de datos es crítica para los conjuntos de datos de defectos de infraestructura, que típicamente son más pequeños que los conjuntos de datos generales de visión artificial. Las aumentaciones efectivas incluyen rotación aleatoria (±180°), volteo horizontal/vertical, escalado aleatorio (0.5×-2.0×), ajustes de brillo/contraste (±20%), recorte aleatorio, transformaciones elásticas (campo de desplazamiento gaussiano) y aumentación de mosaico (combinando 4 imágenes en una). CrackMover, una aumentación especializada para la segmentación de instancias de grietas, remuestrea instancias de grietas de una imagen y las pega en nuevas imágenes de fondo con mezcla realista, aumentando artificialmente tanto el número de instancias de grietas como la diversidad de fondos.
La generación de datos sintéticos aborda el problema fundamental de escasez de anotaciones en la inspección de infraestructura. El marco de inspección de pavimentos aeroportuarios basado en UAV (Alonso et al., 2024) demuestra que el entrenamiento con conjuntos de datos mixtos reales y sintéticos mejora el F1 de segmentación de grietas en un 8-12% en comparación con el entrenamiento solo con datos reales. Los entornos virtuales hiperrealistas construidos en Unreal Engine o Unity pueden generar imágenes anotadas ilimitadas con máscaras de verdad absoluta perfectas, condiciones de iluminación variadas y geometrías de defectos diversas. La aleatorización de dominio — variando aleatoriamente texturas, colores e iluminación en escenas sintéticas — mejora la transferencia de simulación a realidad al forzar al modelo a aprender geometría en lugar de patrones de textura.
Los modelos de segmentación de instancias se evalúan utilizando métricas heredadas tanto de la detección de objetos como de la segmentación semántica, con el protocolo de evaluación COCO como punto de referencia estándar.
La Precisión Promedio (AP) es la métrica principal. La AP se calcula en múltiples umbrales de Intersección sobre Unión (IoU) entre máscaras predichas y máscaras de verdad absoluta. Para cada umbral IoU t (que va de 0.50 a 0.95 en incrementos de 0.05), se calculan curvas de precisión-recuperación para cada clase, y la AP es el área bajo la curva de precisión-recuperación. La métrica principal de COCO AP (o mAP) promedia sobre todos los umbrales IoU y clases.
Las variantes clave de AP utilizadas en la detección de defectos incluyen AP@IoU=0.50 (umbral indulgente considerado el umbral de detección; una máscara predicha que se superpone al 50% o más con la verdad absoluta cuenta como correcta), AP@IoU=0.75 (umbral estricto que requiere máscaras de alta calidad, importante para aplicaciones que requieren delineación precisa de los bordes del defecto, como la medición del ancho de grietas), y AP@pequeña, AP@mediana, AP@grande (métricas por tamaño definidas por el área de verdad absoluta: pequeña <32² píxeles, mediana 32²-96² píxeles, grande >96² píxeles).
La Recuperación Promedio (AR) mide la proporción de instancias de verdad absoluta que tienen una coincidencia predicha en cada umbral IoU. La AR típicamente se reporta como AR@max=100 (máximo de 100 detecciones por imagen). Una alta recuperación es crítica para la inspección de infraestructura crítica para la seguridad, donde los defectos pasados por alto podrían llevar a un deterioro no detectado.
La IoU de máscara es el criterio de emparejamiento central. Para una máscara predicha P y una máscara de verdad absoluta G, IoU = |P ∩ G| / |P ∪ G|. Una predicción se considera un Verdadero Positivo (TP) si IoU ≥ umbral Y la clase predicha coincide con la clase de verdad absoluta. Los Falsos Positivos (FP) ocurren cuando las predicciones tienen IoU < umbral con cualquier máscara de verdad absoluta de la misma clase, o predicen la clase incorrecta. Los Falsos Negativos (FN) son máscaras de verdad absoluta que no logran coincidir con ninguna predicción.
El algoritmo de emparejamiento COCO maneja detecciones duplicadas: si múltiples predicciones coinciden con una sola verdad absoluta, solo la predicción de mayor confianza se cuenta como TP; el resto son FP. Esto recompensa la precisión y penaliza la sobresegmentación — importante para la detección de defectos donde múltiples predicciones superpuestas sobre la misma grieta indicarían inestabilidad del modelo.
La evaluación específica de infraestructura a menudo añade AP por clase desglosada por tipo de defecto. Un modelo de detección de grietas podría reportar AP_grieta=32.1, AP_descascaramiento=44.6, AP_bache=51.3. La AP significativamente más baja para grietas refleja la dificultad de la segmentación de instancias para objetos delgados y alargados (la IoU de máscara es altamente sensible a pequeños errores de alineación para estructuras delgadas).
La puntuación F1 en un umbral IoU específico (típicamente 0.50) también se reporta comúnmente en la literatura de infraestructura: F1 = 2 × (Precisión × Recuperación) / (Precisión + Recuperación). F1 proporciona una medida balanceada única de las compensaciones entre precisión y recuperación.
La segmentación de instancias transforma la inspección de infraestructura de un proceso subjetivo e intensivo en mano de obra a un flujo de trabajo digital objetivo, cuantitativo y escalable. La tecnología se está desplegando en múltiples dominios de infraestructura con mejoras documentadas en precisión, consistencia y rendimiento de la inspección.
La inspección de pistas de aeropuertos representa la aplicación más exigente. Las inspecciones calificadas de pistas según el Anexo 14 de la OACI requieren estudios de condición de pavimento cada 1-3 años utilizando procedimientos estandarizados (ASTM D5340, ASTM D6433, Manual de Diseño de Aeródromos de la OACI Parte 3). La segmentación de instancias respalda directamente estos estándares automatizando el conteo y la medición de defectos. El marco de inspección automatizada de pistas basado en UAV (Krestenitis et al., 2026) demuestra el despliegue de extremo a extremo: estudio UAV → adquisición de imágenes → inferencia de aprendizaje profundo (EfficientNet + FPN de segmentación semántica superpuesta con posprocesamiento de instancias) → agregación basada en SIG → cálculo de PCI. El sistema logra una precisión de detección del 95%+ para defectos de >3mm de ancho en la extensión completa de la pista, con una finalización del estudio en 45 minutos frente a 4-6 horas para la inspección manual tradicional que requiere cierre de la pista.
La inspección de pavimentos de carreteras y autopistas utiliza sistemas de cámaras montados en vehículos que operan a velocidades de autopista (60-100 km/h). Los modelos de segmentación de instancias (YOLACT, YOLOv8-seg) procesan flujos de video a 15-30 FPS, detectando grietas, baches y parches por milla-carril. El estudio automatizado de deterioro de pavimentos del Nevada DOT utiliza un sistema de segmentación de instancias basado en YOLOv8 que logra un 88% F1 para detección de grietas y un 93% F1 para detección de baches en más de 5,000 millas-carril, con una precisión de medición por defecto dentro del 5% de las mediciones de referencia manuales.
La inspección de tableros de puentes aplica segmentación de instancias a descascaramientos, delaminaciones y fallas de juntas en concreto. Los tableros de puentes presentan desafíos únicos: iluminación variable bajo el voladizo del puente, texturas de fondo complejas (juntas de expansión, entradas de drenaje, marcas de tráfico) y la necesidad de resolución de grietas submillimétrica para la medición del ancho. Cascade Mask R-CNN ajustado en un conjunto de datos de tableros de puentes logra un 82% mAP@50 para la detección de descascaramientos, lo que permite el cálculo automatizado de la calificación de condición SNBI (Specification for National Bridge Inspection) para tableros de puentes de concreto.
La inspección de infraestructura ferroviaria utiliza segmentación de instancias para defectos superficiales de rieles (head checks, squats, shelling) y anomalías de la vía. Los sistemas de cámaras montadas en rieles capturan imágenes de alta resolución a 100+ km/h; los modelos YOLACT que se ejecutan en GPU integradas detectan y clasifican defectos de rieles individuales a la velocidad de la línea. El Ferrocarril Alemán (Deutsche Bahn) reportó una tasa de detección del 96% para grietas superficiales >1mm utilizando un proceso de segmentación de instancias desplegado en 30 trenes de inspección, con una precisión de ubicación por defecto de ±5mm utilizando odometría de rueda codificadora.
La inspección de revestimientos de túneles despliega segmentación de instancias en imágenes capturadas desde matrices de múltiples cámaras montadas en vehículos de inspección que viajan a 30-50 km/h. Los revestimientos de túneles de concreto desarrollan grietas, descascaramientos y manchas de filtraciones que requieren análisis a nivel de instancia. El desafío clave es distinguir entre grietas estructurales (que requieren reparación) y grietas superficiales no estructurales (contracción, térmicas). La segmentación de instancias combinada con la medición del ancho de grieta (a partir del análisis de máscara por instancia) proporciona los datos cuantitativos necesarios para esta clasificación. El sistema de inspección de túneles de los Ferrocarriles Federales Austriacos (ÖBB) utiliza Mask R-CNN con una cuadrícula de calibración basada en marcadores Aruco para lograr una precisión de medición del ancho de grieta de ±0.1mm a una resolución de 0.5mm/píxel.
Los beneficios sobre la inspección tradicional están bien documentados en todos los tipos de infraestructura. Un estudio comparativo en 12 agencias de transporte encontró que la inspección automatizada de segmentación de instancias redujo el tiempo de inspección en un 60-80%, eliminó la variabilidad entre evaluadores (el coeficiente kappa mejoró de 0.45-0.55 para la inspección manual a 0.88-0.94 para la automatizada) y aumentó la sensibilidad de detección de defectos en un 25-40% (particularmente para defectos de baja severidad que los inspectores humanos frecuentemente pasan por alto debido a la fatiga). La capacidad de medición por defecto permite un cambio del mantenimiento basado en índices de condición (tratar áreas por encima de un umbral de severidad) al mantenimiento basado en defectos individuales (priorizar reparaciones por criticidad del defecto), reduciendo los costos totales de mantenimiento en un estimado del 15-30% mediante reparación específica en lugar de tratamiento de área amplia.

TarmacView utiliza modelos de segmentación de instancias de última generación para detectar, contar y rastrear cada defecto individual en pavimentos aeroportuarios, puentes e infraestructura de concreto. Programe una demostración para ver cómo el análisis por defecto puede transformar su planificación de mantenimiento.
La segmentación de grietas es la tarea de visión por computadora que clasifica cada píxel de una imagen como grieta o no grieta, produciendo una máscara binaria...
La detección de grietas basada en IA utiliza visión por computadora — redes neuronales convolucionales, transformadores de visión y modelos de segmentación semá...
La detección de objetos localiza y clasifica objetos en imágenes mediante cajas delimitadoras — para la inspección de infraestructura, esto incluye baches, parc...