Segmentación de Grietas
La segmentación de grietas es la tarea de visión por computadora que clasifica cada píxel de una imagen como grieta o no grieta, produciendo una máscara binaria...
40 min de lectura
Computer Vision
Deep Learning
+2
La detección de objetos localiza y clasifica objetos en imágenes mediante cajas delimitadoras — para la inspección de infraestructura, esto incluye baches, parches, señales, FOD y defectos grandes. YOLO, Faster R-CNN y DETR son las arquitecturas líderes. Cubre métodos de detección de objetos, entrenamiento con anotaciones de cajas delimitadoras (formatos VOC, COCO), métricas de evaluación (mAP) y despliegue para inspección en tiempo real.
{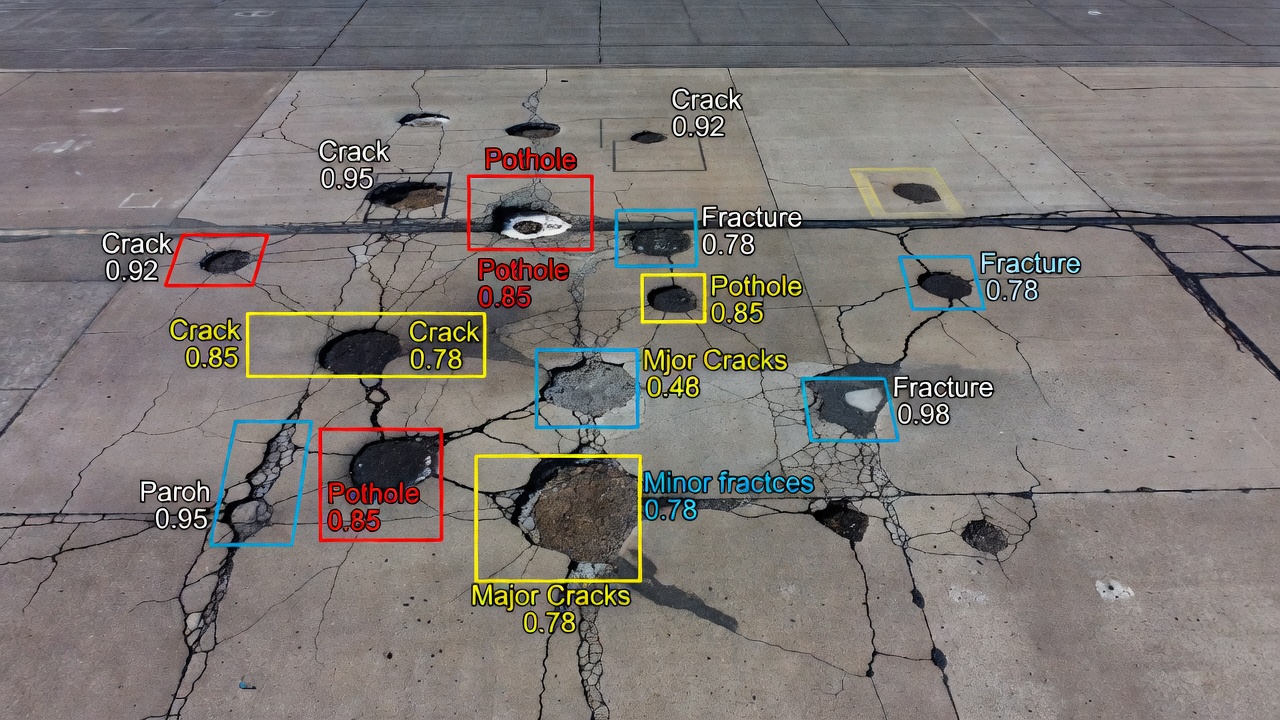
La detección de objetos es una tarea de visión por computadora que identifica y localiza objetos dentro de una imagen o fotograma de video dibujando rectángulos alineados con los ejes — llamados cajas delimitadoras — alrededor de cada elemento detectado y asignando una etiqueta de clase con un puntaje de confianza. A diferencia de la clasificación de imágenes, que produce una sola etiqueta para la imagen completa, la detección de objetos produce una lista de longitud variable de detecciones, una por instancia de objeto presente en la escena. Para la inspección de infraestructura, estos objetos detectados pueden incluir baches, descascaramientos, parches, juntas de construcción, marcas de pavimento, señalización de pistas y objetos extraños (FOD).
La salida de un modelo de detección de objetos para una sola imagen de entrada se estructura como una lista de N detecciones, donde cada detección contiene tres componentes. El primer componente es la caja delimitadora, típicamente representada como (x_min, y_min, x_max, y_max) en coordenadas de píxeles donde (0,0) es la esquina superior izquierda, o como (x_center, y_center, width, height) en coordenadas normalizadas donde todos los valores van de 0 a 1 en relación con las dimensiones de la imagen. El segundo componente es la etiqueta de clase, que es el índice o nombre de la categoría de objeto asignada a la detección — por ejemplo, class_id=0 para “bache”, class_id=1 para “grieta”, class_id=2 para “FOD”, y así sucesivamente. El tercer componente es el puntaje de confianza, un valor de punto flotante entre 0.0 y 1.0 que representa la probabilidad estimada por el modelo de que un objeto de la clase predicha esté presente dentro de la caja delimitadora en la ubicación correcta. Los puntajes de confianza iguales o superiores a un umbral de detección definido (típicamente 0.25 a 0.5 dependiendo de la aplicación) se aceptan como detecciones válidas, mientras que los puntajes por debajo del umbral se descartan.
Matemáticamente, un modelo de detección de objetos implementa una función de mapeo: f: I → {(b₁, c₁, s₁), (b₂, c₂, s₂), …, (b_N, c_N, s_N)}, donde I es la imagen de entrada, b_i es el vector de la caja delimitadora, c_i es el índice de clase y s_i es el puntaje de confianza para la detección i. El número de detecciones N varía por imagen dependiendo de la cantidad de objetos presentes y la sensibilidad de detección del modelo.
La caja delimitadora se define mediante cuatro coordenadas. En la convención COCO (utilizada por el conjunto de datos Microsoft COCO y la mayoría de los frameworks modernos), la caja delimitadora es [x, y, width, height] donde (x, y) es la esquina superior izquierda de la caja en coordenadas de píxeles absolutas. En la convención Pascal VOC, la caja delimitadora es [x_min, y_min, x_max, y_max] — las coordenadas de las esquinas superior izquierda e inferior derecha. En el formato YOLO, la caja delimitadora es [x_center, y_center, width, height] en coordenadas normalizadas (divididas por el ancho y alto de la imagen), lo que hace que la representación sea independiente de la resolución. La conversión entre estos formatos es explícita. A partir del formato COCO o VOC, el área de la caja delimitadora se calcula como area = width × height, y la intersección sobre unión (IoU) entre dos cajas se define como el área de su superposición dividida por el área de su unión — la métrica de emparejamiento fundamental para evaluar la calidad de la detección.
Para aplicaciones de inspección de infraestructura regidas por el Anexo 14, Volumen I de la OACI (Diseño y Operaciones de Aeródromos) y la ASTM D5340 (Método de Prueba Estándar para Estudios del Índice de Condición de Pavimentos de Aeropuertos), la detección de objetos debe alcanzar una precisión de localización adecuada para el conteo de defectos y la clasificación de severidad. Una detección de un bache en una superficie de pista, por ejemplo, debe tener una caja delimitadora que encierre ajustadamente la abertura del defecto. Si la caja delimitadora sobreestima significativamente el área del defecto (incluyendo demasiado pavimento intacto), o la subestima (cortando parte del defecto), la clasificación de severidad posterior derivada de las mediciones espaciales será inexacta. La ajustabilidad del ajuste de la caja delimitadora alrededor de los defectos de infraestructura se mide mediante IoU contra una caja de verdad de referencia (ground truth) anotada manualmente — valores por encima de 0.7 se consideran buenos para la mayoría de las aplicaciones de infraestructura.
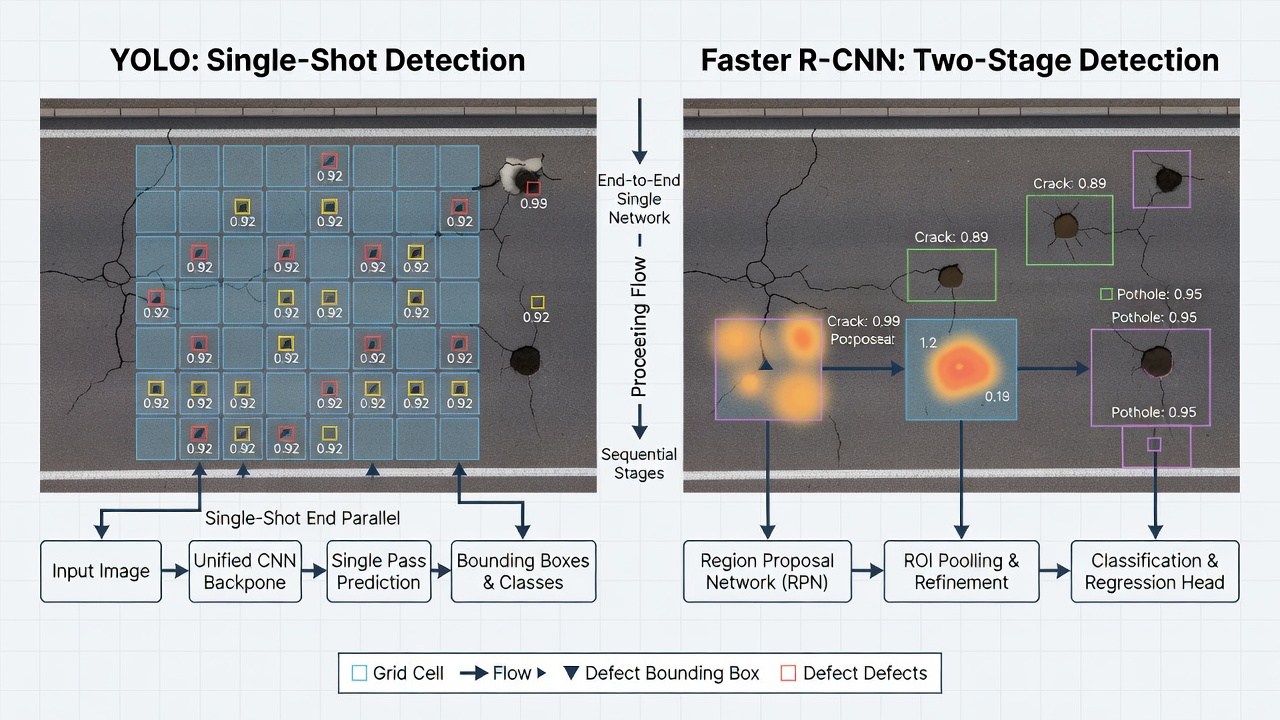
Las arquitecturas de detección de objetos se clasifican ampliamente en tres familias: detectores de una sola etapa, detectores de dos etapas y detectores basados en transformers. Cada familia establece compromisos distintos entre precisión de detección, velocidad de inferencia, costo computacional y facilidad de entrenamiento.
YOLO (You Only Look Once), presentado por Joseph Redmon et al. en la Universidad de Washington en 2016, revolucionó la detección de objetos al reformularla como un problema de regresión único — directamente desde los píxeles de la imagen hasta las coordenadas de las cajas delimitadoras y las probabilidades de clase en un solo paso hacia adelante de una red neuronal. En lugar de ejecutar un clasificador en múltiples regiones de la imagen como lo hacían los métodos anteriores, YOLO divide la imagen de entrada en una cuadrícula de S×S (típicamente 7×7 en la versión original, pero cuadrículas más finas en iteraciones posteriores). Cada celda de la cuadrícula es responsable de predecir B cajas delimitadoras (típicamente 2-3 en versiones tempranas) y C probabilidades de clase, junto con un puntaje de confianza para cada caja que indica cuán seguro está el modelo de que la caja contiene un objeto y cuán precisa es la caja predicha.
La arquitectura original de YOLO utiliza una red neuronal convolucional con 24 capas convolucionales seguidas de 2 capas totalmente conectadas, inspirada en la arquitectura GoogLeNet pero con menos parámetros. La red procesa la imagen completa en un solo paso, lo que le da a YOLO su nombre y su principal ventaja: la velocidad. YOLO alcanzó 45 FPS en una GPU Titan X con 63.4 mAP en Pascal VOC 2007 — mucho más rápido que cualquier detector contemporáneo.
La evolución de YOLO ha sido dramática. YOLOv2 (YOLO9000, 2017) introdujo las anchor boxes con agrupamiento k-means de las cajas delimitadoras del conjunto de datos para mejores prioris, normalización por lotes y entrenamiento multiescala. YOLOv3 (2018) reemplazó el backbone con Darknet-53 incorporando conexiones residuales y redes piramidales de características (FPN) para detectar objetos a múltiples escalas, alcanzando 57.9 mAP@0.5 en COCO. YOLOv4 (2020) introdujo el backbone CSPDarknet53, la activación Mish y las técnicas de entrenamiento Bag-of-Freebies (BoF) y Bag-of-Specials (BoS), incluyendo aumento de datos Mosaic, regularización DropBlock y pérdida CIoU. YOLOv5, desarrollado por Ultralytics, introdujo una implementación basada en PyTorch con un framework de entrenamiento fácil de usar que se convirtió en el estándar de la industria para la detección de objetos aplicada.
YOLOv8 (2023) trajo detección libre de anchor boxes, cabezales de clasificación y regresión desacoplados, y un asignador alineado con la tarea para el emparejamiento de muestras positivas/negativas. YOLOv8x alcanza 53.9 mAP en COCO a 280 FPS en una GPU T4. YOLO11 (septiembre de 2024) introdujo una optimización adicional con un diseño mejorado de backbone y cuello, alcanzando 54.7 mAP con 26.4 millones de parámetros a 314 FPS. YOLO26 (septiembre de 2025) es la evolución más reciente, alcanzando aproximadamente 56-57 mAP en COCO con velocidades de inferencia superiores a 350 FPS en GPUs modernas. Cada generación ha mejorado la frontera de Pareto velocidad-precisión, convirtiendo a YOLO en la arquitectura dominante para la inspección de infraestructura en tiempo real.
El framework de entrenamiento Ultralytics YOLO (CLI de yolo, paquete Python ultralytics) admite tareas de detección, segmentación, clasificación, estimación de poses y cajas delimitadoras orientadas (OBB) bajo una API unificada. Para la inspección de infraestructura, los modelos de detección YOLO se entrenan usando el comando yolo train data=dataset.yaml model=yolo11x.pt epochs=200 imgsz=640. El framework maneja automáticamente la carga de datos, el aumento (Mosaic, MixUp, variación HSV, rotación, escalado), la programación de la tasa de aprendizaje (decaimiento coseno) y el registro de métricas. La exportación a formatos ONNX, TensorRT, CoreML y OpenVINO para despliegue en el borde (edge) está integrada.
Faster R-CNN, presentado por Shaoqing Ren, Kaiming He, Ross Girshick y Jian Sun en Microsoft Research (NIPS 2015), es el detector de dos etapas fundamental que estableció el paradigma dominante para la detección de alta precisión antes del auge de los métodos de una sola etapa y basados en transformers. Sigue siendo ampliamente utilizado para aplicaciones de inspección de infraestructura donde la precisión tiene prioridad sobre la velocidad.
La arquitectura Faster R-CNN opera en dos etapas. En la primera etapa, una Red de Propuesta de Regiones (RPN) escanea los mapas de características producidos por una CNN backbone (típicamente ResNet-50, ResNet-101 o ResNeXt) y propone regiones candidatas de objetos llamadas Regiones de Interés (RoIs). La RPN es en sí misma una red completamente convolucional que desliza una pequeña ventana de red sobre el mapa de características convolucional, prediciendo k anchor boxes en cada ubicación espacial — típicamente k=9 anchor boxes de tres escalas (128², 256², 512²) y tres relaciones de aspecto (1:1, 1:2, 2:1). Para cada anchor, la RPN produce una puntuación de objetualidad (probabilidad de que el anchor contenga un objeto versus fondo) y desplazamientos de regresión de la caja delimitadora (4 valores que refinan la anchor box para ajustarse mejor al objeto). La RPN se entrena de extremo a extremo con la red de detección, compartiendo características convolucionales, que es la innovación clave de Faster R-CNN sobre el Fast R-CNN anterior, que utilizaba búsqueda selectiva externa para las propuestas de regiones.
En la segunda etapa, cada RoI de la RPN se procesa a través de una capa RoIPool que extrae un mapa de características de tamaño fijo (típicamente 7×7) de cada región. Estos mapas de características de tamaño fijo se introducen en capas totalmente conectadas — un cabezal de clasificación que predice probabilidades de clase (K clases de objetos + fondo) y un cabezal de regresión de caja delimitadora que produce coordenadas refinadas de la caja delimitadora para cada clase. La función de pérdida combina cuatro componentes: pérdida de clasificación de la RPN (entropía cruzada binaria para la objetualidad), pérdida de regresión de la RPN (L1 suave para los desplazamientos de la caja), pérdida de clasificación de detección (entropía cruzada para la clase) y pérdida de regresión de detección (L1 suave para las cajas refinadas).
Faster R-CNN con un backbone ResNet-101-FPN alcanza 59.1 AP en COCO test-dev (según el benchmark de Mask R-CNN). La velocidad de inferencia oscila entre 5-15 FPS dependiendo de la profundidad del backbone y la resolución de entrada. Para la detección de defectos en infraestructura, se ha demostrado que Faster R-CNN alcanza mayor precisión que YOLO para defectos pequeños (<32² píxeles en la imagen de entrada) debido a su diseño de dos etapas, que enfoca el clasificador de la segunda etapa específicamente en las regiones propuestas en lugar de en toda la cuadrícula de la imagen.
La principal desventaja de Faster R-CNN para la inspección de infraestructura es la velocidad de inferencia. A 5-15 FPS, no puede procesar flujos de video a velocidad completa (30 FPS) sin omitir fotogramas, lo que lo hace inadecuado para la inspección en tiempo real desde vehículos o UAVs en movimiento. Sin embargo, para el análisis fuera de línea de imágenes de inspección capturadas donde el tiempo de procesamiento no está limitado, Faster R-CNN sigue siendo una opción sólida para máxima precisión por imagen.
SSD (Single Shot MultiBox Detector), presentado por Wei Liu et al. en ECCV 2016, fue el primer detector de una sola etapa de alto rendimiento que rivalizó con la precisión de los detectores de dos etapas mientras mantenía velocidad en tiempo real. SSD opera prediciendo cajas delimitadoras y probabilidades de clase directamente desde mapas de características a múltiples escalas sin la etapa de propuesta de regiones.
La arquitectura SSD utiliza una red base (típicamente VGG-16 truncada en conv5_3, o MobileNet) seguida de una serie de capas convolucionales adicionales que reducen progresivamente la resolución espacial. Las detecciones se realizan desde mapas de características a 6 escalas diferentes — conv4_3 (38×38), conv7 (fc7, 19×19), conv8_2 (10×10), conv9_2 (5×5), conv10_2 (3×3) y conv11_2 (1×1). En cada ubicación del mapa de características, SSD predice desplazamientos para k cajas predeterminadas (similares a las anchor boxes) y puntajes de confianza por clase. Con 8732 cajas predeterminadas en todos los mapas de características, SSD proporciona una cobertura densa de la imagen a múltiples escalas.
El diseño multiescala es la contribución clave de SSD: los mapas de características más grandes (38×38) detectan objetos pequeños, mientras que los mapas de características más pequeños (1×1) detectan objetos grandes. Este mecanismo de detección jerárquico es conceptualmente similar a las Redes Piramidales de Características (FPN) que se convertirían en estándar en detectores posteriores.
SSD300 (entrada de 300×300) alcanza 77.2 mAP en Pascal VOC 2007 a 46 FPS en una Titan X, mientras que SSD512 (entrada de 512×512) alcanza 79.8 mAP a 19 FPS. En COCO, SSD512 alcanza 31.2 AP. Para la inspección de infraestructura, SSD se ha aplicado a la detección de defectos en carreteras desde vehículos, con un rendimiento reportado de 48-52 mAP@0.5 en conjuntos de datos de detección de baches.
DETR (Detection Transformer), presentado por Nicolas Carion, Francisco Massa y el equipo de Facebook AI Research en ECCV 2020, replantea fundamentalmente la detección de objetos al eliminar muchos componentes artesanales que dominaban las arquitecturas anteriores — anchor boxes, propuestas de regiones, supresión de no máximos (NMS) y emparejamiento basado en IoU. DETR en cambio trata la detección de objetos como un problema de predicción directa de conjuntos utilizando una arquitectura encoder-decoder transformer.
La arquitectura DETR tiene tres componentes. Una CNN backbone (típicamente ResNet-50 o ResNet-101) extrae un mapa de características de la imagen de entrada. Un encoder transformer procesa el mapa de características a través de capas de autoatención multi-cabeza, permitiendo que cada posición en el mapa de características atienda a todas las demás posiciones — construyendo una comprensión global del contexto de la imagen. Un decoder transformer toma un conjunto de N consultas de objeto aprendidas (típicamente N=100 vectores fijos) y las procesa a través de autoatención (consultas atendiendo a otras consultas) y atención cruzada (consultas atendiendo a la salida del encoder). Cada consulta aprende a predecir una instancia de objeto específica. El decoder produce N predicciones, cada una consistente en una etiqueta de clase (K clases + ∅ para ningún objeto) y una caja delimitadora. Durante el entrenamiento, una pérdida húngara empareja las N predicciones con los objetos de verdad de referencia (ground truth) usando emparejamiento bipartito — encontrando la asignación uno a uno óptima entre predicciones y objetos reales que minimiza la pérdida total.
La innovación central de DETR es que el marco de predicción de conjuntos elimina la necesidad de supresión de duplicados. Debido a que el emparejamiento húngaro impone una asignación uno a uno durante el entrenamiento, el modelo aprende naturalmente a producir detecciones únicas sin requerir post-procesamiento NMS. Esto simplifica el pipeline de detección y elimina un hiperparámetro (umbral de IoU de NMS) que necesita ajuste por aplicación.
DETR con backbone ResNet-50 alcanza 42.0 AP en COCO con 50 FPS en una GPU NVIDIA V100 con un tamaño de lote de 1. Deformable DETR (Zhu et al., ICLR 2021) mejoró la convergencia del entrenamiento (10× más rápida) y la detección de objetos pequeños al reemplazar la atención estándar con atención deformable que atiende solo a un conjunto disperso de puntos de muestreo clave cerca de cada consulta. DINO (Zhang et al., CVPR 2023) mejoró aún más DETR para alcanzar 63.2 AP en COCO — el primer detector en superar 63 AP — utilizando un enfoque de entrenamiento con eliminación de ruido contrastivo y una inicialización de consultas mejorada. RF-DETR (Roboflow, marzo de 2025) se convirtió en el primer detector en tiempo real en superar 60 AP (60.5 AP@0.50 :0.95 a 25 FPS en T4), específicamente optimizado para despliegue práctico.
Para la inspección de infraestructura, los detectores de la familia DETR son prometedores porque el mecanismo de atención global del transformer puede capturar relaciones espaciales de largo alcance — una grieta en un extremo de la imagen puede ser parte de la misma red de defectos que otra grieta en el extremo opuesto, y la autoatención del transformer puede modelar esta dependencia. Sin embargo, la adopción práctica ha sido más lenta que YOLO debido a los mayores requisitos de memoria de GPU y la necesidad de infraestructura de entrenamiento especializada.
| Arquitectura | Tipo | COCO mAP@0.50 :0.95 | Velocidad (FPS) | Fortalezas para Infraestructura |
|---|---|---|---|---|
| YOLOv8x | CNN de una etapa | 53.9 | 280 | Inspección en tiempo real, despliegue en el borde, entrenamiento fácil |
| YOLO11x | CNN de una etapa | 54.7 | 314 | Mejor velocidad-precisión, ecosistema Ultralytics nativo |
| YOLO26x | CNN de una etapa | ~57 | 350+ | Última generación, detección de objetos pequeños mejorada |
| Faster R-CNN R101-FPN | CNN de dos etapas | 59.1 | 8-12 | Máxima precisión por imagen, análisis fuera de línea |
| SSD512 | CNN de una etapa | 31.2 | 19 | Ligero, bajos requisitos de memoria |
| Deformable DETR | Transformer | 46.2 | 10-15 | Sin NMS, conciencia del contexto global |
| DINO | Transformer | 63.2 | 8-10 | Precisión de última generación, benchmark de investigación |
| RF-DETR | Transformer | 60.5 | 25 | Detección transformer en tiempo real, despliegue práctico |
Entrenar modelos de detección de objetos requiere anotaciones de verdad de referencia (ground truth) — cajas delimitadoras etiquetadas manualmente y etiquetas de clase para cada instancia de objeto en las imágenes de entrenamiento. El formato en el que se almacenan estas anotaciones afecta la interoperabilidad del conjunto de datos, la sobrecarga de conversión y la compatibilidad con herramientas.
El formato Pascal VOC (Visual Object Classes), desarrollado para el desafío VOC anual (2005-2012), utiliza un archivo XML por imagen. Cada archivo XML contiene los metadatos de la imagen (nombre de archivo, tamaño) y una lista de anotaciones de objetos con cajas delimitadoras. El esquema es:
<annotation>
<folder>images</folder>
<filename>pothole_001.jpg</filename>
<source><database>RunwayDefects</database></source>
<size><width>1920</width><height>1080</height><depth>3</depth></size>
<object>
<name>pothole</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>342</xmin><ymin>156</ymin>
<xmax>521</xmax><ymax>378</ymax>
</bndbox>
</object>
<object>
<name>crack</name>
<bndbox>
<xmin>890</xmin><ymin>234</ymin>
<xmax>1245</xmax><ymax>256</ymax>
</bndbox>
</object>
</annotation>
Cada elemento <object> contiene: name — la cadena de la etiqueta de clase; pose — descriptor de pose aproximada (Frontal, Rear, Left, Right, Unspecified); truncated — indicador binario que señala si el objeto está cortado por el borde de la imagen (0=no, 1=sí); difficult — indicador binario para objetos considerados difíciles de reconocer incluso para humanos (a menudo excluidos durante la evaluación); y bndbox — la caja delimitadora en coordenadas de píxeles (xmin, ymin, xmax, ymax).
El formato VOC tiene la ventaja de ser legible por humanos y tener independencia por archivo (las anotaciones se pueden crear, copiar y modificar como archivos separados sin necesidad de analizar una base de datos monolítica). La desventaja es que los conjuntos de datos grandes con miles de imágenes requieren almacenar miles de archivos XML de anotaciones, lo que puede ralentizar la carga y el procesamiento en los pipelines de datos.
El formato VOC se utiliza predominantemente con implementaciones de Faster R-CNN y SSD en Detectron2 (Meta), mmdetection y pipelines antiguos de TensorFlow Object Detection API. La conversión del formato VOC a COCO JSON es compatible con todas las principales herramientas de gestión de datos, incluyendo Roboflow, CVAT y labelImg.
El formato COCO (Common Objects in Context) JSON, introducido por Microsoft con el conjunto de datos MS COCO (2015), es el formato de anotación más utilizado para modelos modernos de detección de objetos. Todas las anotaciones para todo el conjunto de datos se almacenan en un único archivo JSON con una estructura jerárquica que contiene cuatro arreglos de nivel superior.
El diccionario info contiene metadatos sobre el conjunto de datos — año, versión, descripción, colaborador, URL y fecha de creación. El arreglo licenses lista información de licencias de imágenes con id, name y URL para cada tipo de licencia. El arreglo categories define la taxonomía de clases, donde cada entrada tiene un id (entero, típicamente comenzando en 1), name (cadena de la etiqueta de clase) y supercategory (agrupación de nivel superior, por ejemplo, “defect” para “pothole”, “crack”, “spall”). El arreglo images lista cada imagen en el conjunto de datos con id (entero único), file_name (ruta relativa), height y width (en píxeles), y opcionalmente date_captured y license. El arreglo annotations es la estructura de datos central, donde cada entrada contiene: id (identificador de anotación único), image_id (referencia a la imagen padre), category_id (referencia a la categoría), bbox (caja delimitadora como [x, y, width, height] en coordenadas de píxeles — donde (x, y) es la esquina superior izquierda), area (calculada como width × height en píxeles), segmentation (formato polígono o RLE; arreglo vacío [] para conjuntos de datos solo de detección) y iscrowd (indicador: 0 para objetos individuales, 1 para grupos de objetos incontables).
La estructura de archivo único del formato COCO JSON hace que la carga del conjunto de datos sea rápida (una lectura de archivo frente a miles), permite un acceso aleatorio eficiente usando image_id como índice, y es el formato de entrada estándar para Detectron2, MMDetection y el pipeline de detección de referencia de torchvision. Todas las principales herramientas de anotación (CVAT, Labelbox, Supervisely, Roboflow, Scale AI) admiten la exportación a COCO JSON.
El servidor de evaluación COCO utiliza esta misma estructura JSON para enviar resultados de detección, garantizando la coherencia entre los datos de entrenamiento y los datos de evaluación.
El formato YOLO, desarrollado por el equipo de Ultralytics para su framework de entrenamiento YOLO, utiliza un archivo TXT de texto plano por imagen. Cada línea del archivo corresponde a una detección de objeto y sigue el formato:
<class_id> <x_center> <y_center> <width> <height>
Todos los valores son números de punto flotante normalizados al rango [0, 1] dividiendo por el ancho de la imagen (para x_center y width) y la altura (para y_center y height). Por ejemplo, un bache con una caja delimitadora absoluta (x_min=342, y_min=156, x_max=521, y_max=378) en una imagen de 1920×1080 se convierte a: x_center = (342+521)/2/1920 = 0.2247, y_center = (156+378)/2/1080 = 0.2472, width = (521-342)/1920 = 0.0932, height = (378-156)/1080 = 0.2056 — resultando en la línea de anotación: “0 0.2247 0.2472 0.0932 0.2056”.
Las ventajas del formato YOLO son su extrema simplicidad — una línea por objeto, sin sobrecarga de análisis XML/JSON, e independencia de resolución (las coordenadas normalizadas funcionan a cualquier resolución de imagen). Las desventajas son la necesidad de gestionar un archivo TXT por imagen (similar al enfoque de archivo por imagen de VOC) y la falta de metadatos estandarizados (las dimensiones de la imagen deben conocerse a partir de una especificación externa del conjunto de datos).
El formato YOLO es el formato nativo para el entrenamiento de Ultralytics YOLOv5 hasta YOLO26. La estructura del conjunto de datos es: dataset/images/train/, dataset/labels/train/, dataset/images/val/, dataset/labels/val/, con un archivo dataset.yaml que especifica los nombres de las clases y las rutas.
La conversión entre formatos se realiza mediante herramientas como Roboflow (basada en web, convertidor de formato universal), CVAT (herramienta de anotación web con exportación en todos los formatos), labelImg (herramienta de anotación de escritorio con exportación a Pascal VOC y YOLO) y FiftyOne (gestión de conjuntos de datos de código abierto con conversión de formatos). Las librerías de Python para conversión de formatos incluyen pycocotools (COCO JSON), xml.etree.ElementTree (Pascal VOC XML) y el paquete ultralytics (formato YOLO).
| Formato | Estructura de Archivos | Representación de la Caja Delimitadora | Uso Principal |
|---|---|---|---|
| Pascal VOC XML | 1 archivo XML por imagen | (xmin, ymin, xmax, ymax) en píxeles | Detectron2, MMDetection, pipelines heredados |
| COCO JSON | 1 archivo JSON por conjunto de datos | [x, y, width, height] en píxeles | Pipelines de entrenamiento modernos, servidor de evaluación |
| YOLO TXT | 1 archivo TXT por imagen | [x_center, y_center, w, h] normalizado [0,1] | Framework Ultralytics YOLO |
La elección entre detección de objetos (cajas delimitadoras) y segmentación (máscaras a nivel de píxel) para la inspección de infraestructura está determinada por el tipo de medición requerida, el costo de anotación y las restricciones computacionales.
Cuándo usar detección de objetos — La detección con cajas delimitadoras es preferible cuando los objetivos principales son el conteo de objetos, la localización aproximada y la clasificación. Contar el número de baches en una sección de pista, determinar sus posiciones aproximadas para el despliegue de cuadrillas de reparación y clasificar el tipo de defecto (bache vs. descascaramiento vs. parche) se puede lograr con cajas delimitadoras. El costo de anotación para cajas delimitadoras es drásticamente menor que para segmentación — una caja delimitadora requiere 4 valores de coordenadas (unos segundos por objeto), mientras que un polígono de segmentación requiere 20-100+ vértices (30 segundos a varios minutos por objeto dependiendo de la complejidad de la forma). Para un conjunto de datos típico de inspección de infraestructura de 10,000 imágenes con 5-20 objetos por imagen, la anotación con cajas delimitadoras podría requerir 100-500 horas-persona, mientras que la segmentación con polígonos podría requerir 1,000-5,000 horas-persona. La velocidad de inferencia para los modelos de detección de objetos también es mayor: los modelos YOLO alcanzan 300+ FPS, mientras que los modelos de segmentación de instancias más rápidos (YOLACT, YOLOv8-seg) alcanzan 30-60 FPS.
Cuándo usar segmentación — La detección a nivel de píxel es necesaria cuando se requiere una medición precisa del área del defecto, cálculo del perímetro y análisis de la forma. El cálculo del PCI de aeropuertos según ASTM D5340 requiere la longitud, anchura y profundidad del descascaramiento — las cajas delimitadoras no pueden proporcionar longitud y anchura precisas para descascaramientos de forma irregular. Un descascaramiento en forma de media luna en la esquina de una junta de pavimento encerrado por una caja delimitadora sobreestimará el área del descascaramiento en un 30-60%, lo que lleva a una clasificación de severidad incorrecta. La medición del ancho de grietas — el parámetro principal para la clasificación de severidad de grietas según ASTM D5340 — requiere una delineación exacta a nivel de píxel que las cajas delimitadoras no pueden proporcionar. Para contratos de mantenimiento basados en el rendimiento donde el pago al contratista depende del área medida del defecto, la segmentación es esencial para evitar disputas de medición.
El problema de la sobrecarga de la caja delimitadora se cuantifica mediante la métrica de eficiencia de la caja delimitadora: BBE = píxeles_del_objeto / píxeles_de_la_caja. Un bache con 5,000 píxeles de defecto dentro de una caja delimitadora de 7,000 píxeles tiene BBE = 71% — la caja delimitadora sobreestima el área en un 29%. Una grieta sinuosa con 3,000 píxeles de grieta dentro de una caja delimitadora de 25,000 píxeles tiene BBE = 12% — la caja delimitadora sobreestima el área en un 88%, lo que la hace inútil para la medición de área. Para la inspección de infraestructura, los valores de BBE:
Compromiso práctico — Una tendencia creciente en la inspección de infraestructura es la detección con caja delimitadora orientada (OBB), compatible con YOLOv8-OBB y YOLO11-OBB. OBB utiliza rectángulos rotados en lugar de alineados con los ejes, mejorando significativamente el ajuste para defectos alargados como grietas longitudinales. Una grieta orientada a 30 grados respecto al eje de la imagen encerrada por una caja delimitadora alineada con los ejes puede tener un BBE del 15%, mientras que la misma grieta encerrada por una caja delimitadora rotada con la misma orientación alcanza un BBE del 50-60%. OBB proporciona un punto intermedio entre la simplicidad de anotación de la detección alineada con los ejes y la precisión de medición de la segmentación.
La detección de baches es la aplicación más madura y comercialmente exitosa de la detección de objetos en la inspección de infraestructura. Los baches son adecuados para la detección con cajas delimitadoras porque son objetos discretos, localizados y compactos con límites visuales claros — a diferencia de las grietas, que son alargadas y ramificadas.
Características de detección — Los baches en superficies de asfalto y concreto se presentan como depresiones oscuras en forma de cuenco con bordes de alto contraste contra el pavimento circundante. En superficies de asfalto, un bache aparece como un agujero oscuro (exponiendo las capas base) con una relación diámetro-profundidad típicamente entre 3:1 y 10:1. En pavimentos de concreto, los baches (denominados más precisamente descascaramientos cuando están en juntas) aparecen como áreas astilladas con agregado expuesto y bordes de fractura nítidos. La firma visual incluye una región interior oscura (sombra de la profundidad de la depresión), un borde que a menudo tiene un anillo de color más claro (agregado expuesto) y ocasionalmente escombros sueltos dentro o alrededor del agujero.
Rendimiento del modelo — La detección de baches basada en YOLO ha sido ampliamente estudiada. ECC-YOLO (2025), basado en YOLOv11n con módulos Enhanced Context Capture, alcanza 82.12% mAP@0.5 en el conjunto de datos NHA Pothole Dataset (NPD) y 80.19% mAP@0.5 en el conjunto de datos Road Pothole Detection (RPD). YOLOv8 estándar alcanza aproximadamente 78-80% mAP@0.5 en estos benchmarks. Para baches pequeños (diámetro <15 cm a una distancia de muestreo en terreno de 2 mm/píxel), el rendimiento del modelo cae a 55-70% mAP@0.5 , lo que indica que los baches pequeños cerca del límite perceptual siguen siendo un desafío. Faster R-CNN alcanza una precisión marginalmente mayor (aproximadamente 81-83% mAP@0.5 en benchmarks de baches) pero a 5-15 FPS en comparación con los 100-300 FPS de YOLOv8.
Estimación de tamaño — Las dimensiones de la caja delimitadora en píxeles se convierten a dimensiones físicas utilizando la distancia de muestreo en terreno (GSD) conocida de la cámara de inspección. Para una cámara montada en UAV a 30 m de altitud con un lente de 24 mm y un sensor de 20 MP, la GSD es de aproximadamente 2.5 mm/píxel. Una caja delimitadora de bache de 200×180 píxeles corresponde a 0.5 m × 0.45 m = 0.225 m². Esta estimación de área (a partir de la caja delimitadora) es típicamente 20-40% mayor que el área real del bache debido a la sobreestimación discutida anteriormente. Para la clasificación de severidad ASTM D5340 — donde la severidad del bache depende de la profundidad y el diámetro — la estimación del diámetro mediante la caja delimitadora es suficientemente precisa para la clasificación de baja (diámetro <30 cm, profundidad <25 mm) vs. media (30-60 cm, 25-50 mm) vs. alta (>60 cm, >50 mm), siempre que el bache sea aproximadamente circular.
Consideraciones de despliegue — La detección de baches en tiempo real desde cámaras montadas en vehículos que operan a 80 km/h requiere modelos que procesen fotogramas a 30+ FPS con latencia mínima. Un despliegue típico utiliza un modelo YOLOv8s o YOLO11s (variante pequeña) en un dispositivo edge NVIDIA Jetson Orin, alcanzando 60-90 FPS con resolución de entrada de 640×640. Las detecciones se georreferencian utilizando metadatos GPS del dispositivo de captura (datos GPS/IMU registrados en los EXIF de la imagen). Las ubicaciones de los baches se cargan en una base de datos del sistema de gestión de pavimentos (PMS) para la generación de órdenes de trabajo.
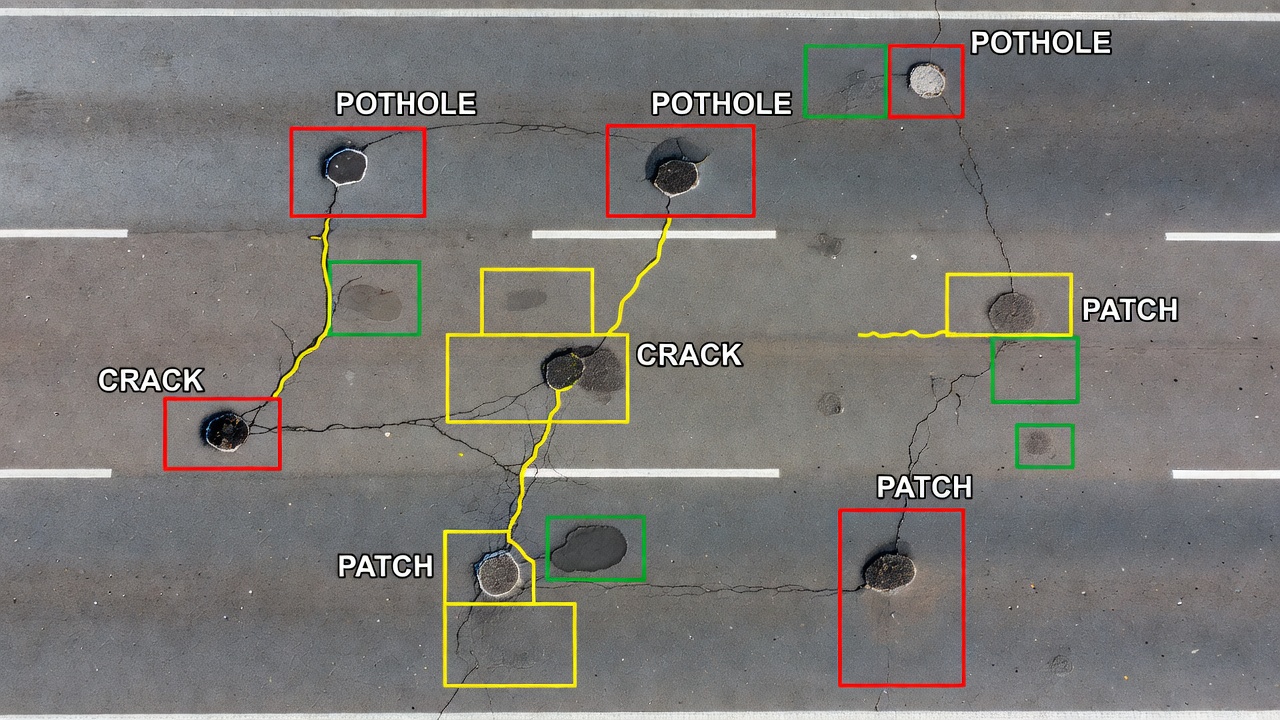
La detección de Objetos Extraños (FOD) es una aplicación crítica de seguridad regida por el Anexo 14, Volumen I, Capítulo 9 de la OACI y la Circular de Asesoramiento 150/5220-24 de la FAA (Estándar para Sistemas de Detección de Objetos Extraños). FOD incluye cualquier objeto en la superficie de una pista de aeropuerto que pueda dañar aeronaves — fragmentos metálicos, herramientas, pernos, remaches, caucho de neumáticos, fragmentos de pavimento, piedras, piezas de equipaje, fauna silvestre e incluso charcos de agua o parches de hielo.
Requisitos reglamentarios — Según la FAA AC 150/5220-24, un sistema operativo de detección de FOD debe cumplir estándares mínimos de rendimiento: detectar objetos tan pequeños como 2-3 cm (aproximadamente ¾-1 pulgada) en cualquier dimensión, alcanzar una tasa de detección de al menos el 90% para objetos por encima del umbral de tamaño mínimo, minimizar las falsas alarmas (para evitar cierres innecesarios de pistas), proporcionar alertas en tiempo real con geolocalización dentro de 1-3 metros y operar en todas las condiciones operativas (día/noche, lluvia, niebla, nieve). La AC distingue entre FOD primario (objetos que podrían causar daños por impacto o ingestión) y FOD secundario (desechos de pavimento generados por operaciones de aeronaves, como depósitos de caucho de neumáticos o descascaramientos de pavimento).
Enfoque de detección de objetos — La detección de FOD mediante visión por computadora ha sido ampliamente investigada como complemento o alternativa a los sistemas basados en radar (como el sistema de detección de FOD Tarsier desplegado en aeropuertos importantes). La detección de FOD basada en YOLO ha sido evaluada en múltiples conjuntos de datos, incluyendo el FOD-A dataset (2,500 imágenes de 14 tipos de FOD en superficies de pista) y el Runway FOD benchmark (4,200 imágenes de desechos comunes). Un modelo ligero de detección de FOD basado en YOLOv8n alcanza aproximadamente 93.5% mAP@0.5 en el conjunto de datos FOD-A con una velocidad de inferencia de 180+ FPS en una Jetson Orin NX, cumpliendo con el requisito de tiempo real.
Desafíos para la detección de FOD — Los objetos FOD presentan condiciones particularmente difíciles para la detección de objetos. Son extremadamente pequeños en relación con la imagen — un perno de 3 cm a una GSD típica de inspección de pista de 0.5-1.0 mm/píxel ocupa solo 30-60 píxeles de ancho, lo que lo convierte en un objeto pequeño según la definición de COCO (<32² píxeles). La detección de objetos pequeños requiere imágenes de entrada de alta resolución (al menos 1920×1080) y arquitecturas especializadas como redes piramidales de características (FPN) que preservan la resolución espacial en los mapas de características superficiales. Los objetos FOD tienen una alta diversidad de clases con categorías visualmente similares — un perno metálico puede verse casi idéntico a una arandela metálica pequeña, y una piedra puede parecerse a un trozo de caucho de neumático desde ciertos ángulos. Los modelos de detección de FOD deben distinguir entre FOD y elementos de pavimento visualmente similares — marcas de neumáticos (depósitos oscuros de caucho), agua estancada (reflejos oscuros), marcas de pintura (líneas blancas) y variaciones de textura de superficie son fuentes comunes de falsos positivos. Los objetos FOD verdaderos tienen un componente 3D (se sitúan sobre la superficie del pavimento), creando una pequeña sombra que los inspectores humanos utilizan como indicio de profundidad. Algunos sistemas de detección de FOD incorporan esto analizando patrones de contraste local e indicios de sombra para distinguir desechos 3D reales de marcas de pavimento 2D.
Arquitectura de despliegue — Los sistemas de detección de FOD conformes con la FAA utilizan típicamente un conjunto de múltiples cámaras montadas en el vehículo barredor de pistas o en pórticos fijos en los extremos de la pista. El modelo de detección de objetos se ejecuta en un dispositivo de computación en el borde (NVIDIA Jetson AGX Orin, Intel Movidius o FPGA dedicado) con salida en tiempo real a la cabina/centro de control. Las detecciones se muestran en un mapa de la pista con superposición de cajas delimitadoras, coordenadas GPS, etiqueta de clase y puntaje de confianza. El sistema registra todas las detecciones para cumplir con los requisitos de documentación de la pista de auditoría según la FAA AC 150/5220-24.
Las marcas de pavimento y la señalización de aeródromos son elementos esenciales de infraestructura que deben mantenerse según estándares específicos para la seguridad de la aviación. La detección de objetos automatiza la evaluación del estado de las marcas y señales, reemplazando las inspecciones visuales que requieren mucho trabajo.
Detección de marcas de pavimento — Las marcas de pistas y calles de rodaje — líneas centrales, líneas de borde, barras de umbral, marcas de zona de toma de contacto y marcas de línea central de calles de rodaje — se detectan utilizando modelos de detección de objetos entrenados con imágenes aéreas o montadas en vehículos. La tarea implica detectar segmentos de marcas y clasificarlos por tipo, color (blanco o amarillo) y condición (buena, descolorida, desgastada). La detección de marcas basada en YOLO alcanza aproximadamente 85-92% mAP@0.5 en benchmarks de marcas de pista. Las marcas severamente descoloridas o desgastadas se convierten en objetos de bajo contraste que desafían la detección — el rendimiento cae a 60-75% para marcas con retrorreflectividad por debajo de 100 mcd/m²/lx.
Evaluación de retrorreflectividad — La detección de objetos por sí sola no puede medir la retrorreflectividad (la capacidad de las marcas para reflejar la luz de vuelta hacia la fuente, medida en milicandelas por lux por metro cuadrado). Sin embargo, la detección con cajas delimitadoras proporciona la extensión espacial de cada segmento de marca, que luego se utiliza para muestrear los valores de intensidad de píxel dentro de la caja a partir de imágenes de pavimento nocturnas capturadas bajo iluminación de faros. La relación entre la intensidad de píxel de la marca y la del pavimento adyacente se correlaciona con la retrorreflectividad. Este enfoque combinado — detección para localización, análisis de intensidad para condición — está implementado en varios sistemas comerciales de evaluación de marcas de pavimento.
Detección de señales de aeródromo — Las señales de pistas y calles de rodaje (señales de instrucción obligatoria — fondo rojo, texto blanco; señales de ubicación — fondo negro, texto amarillo; señales de dirección — fondo amarillo, texto negro) se detectan utilizando modelos de detección de objetos. La caja delimitadora encierra el panel de la señal, y la etiqueta de clase identifica el tipo de señal. Luego se aplica reconocimiento de texto (OCR) dentro de la región de la caja delimitadora para extraer el contenido de la señal — por ejemplo, el designador de pista “09/27” o el identificador de calle de rodaje “A”. El pipeline combinado de detección + OCR alcanza una precisión de clasificación del tipo de señal del 90-95% y una precisión de lectura de texto del 85-90% en condiciones de luz diurna. El rendimiento nocturno cae al 70-80% debido al deslumbramiento retrorreflectante y la iluminación no uniforme de los faros de los vehículos.
Cumplimiento del Anexo 14 de la OACI — La detección de señales alimenta directamente la verificación de cumplimiento según el Anexo 14, Volumen I, Capítulo 5 de la OACI (Ayudas Visuales para la Navegación), que especifica requisitos de dimensiones, colores, luminancia y posicionamiento de las señales. La detección automatizada de señales y la evaluación de su estado permite a los operadores de aeropuertos verificar que todas las señales de instrucción obligatoria estén presentes, legibles y correctamente posicionadas antes de las inspecciones en el lado aire.
Los modelos de detección de objetos se evalúan utilizando un conjunto completo de métricas que evalúan tanto la precisión de localización como la corrección de la clasificación. El marco de evaluación estándar está definido por el protocolo de evaluación COCO y está implementado en todos los frameworks de detección principales.
La métrica de Intersección sobre Unión (IoU) mide la superposición entre una caja delimitadora predicha y su correspondiente caja delimitadora de verdad de referencia (ground truth). Para dos cajas A (predicha) y B (verdad de referencia), la IoU se calcula como:
IoU = Área(A ∩ B) / Área(A ∪ B)
El valor de IoU varía de 0.0 (sin superposición) a 1.0 (alineación perfecta). Una detección se clasifica como Verdadero Positivo (TP) si IoU ≥ umbral Y la clase predicha coincide con la clase de verdad de referencia. Los umbrales de IoU comunes son 0.50 (indulgente, utilizado en la evaluación PASCAL VOC) y 0.75 (estricto, utilizado en la evaluación COCO). La evaluación COCO promedia AP en 10 umbrales de IoU desde 0.50 hasta 0.95 en incrementos de 0.05, proporcionando una evaluación integral de la calidad de localización en múltiples niveles de exigencia.
Precisión (Precision) mide cuántas de las detecciones positivas del modelo son correctas: P = TP / (TP + FP). Una precisión alta significa que el modelo tiene pocas falsas alarmas. Recall (Exhaustividad) mide cuántos de los objetos de verdad de referencia encontró el modelo: R = TP / (TP + FN). Un recall alto significa que el modelo tiene pocas detecciones omitidas.
Para una clase y un umbral de IoU dados, variar el umbral de confianza (el puntaje de confianza mínimo para que una detección sea aceptada) produce una curva de precisión-recall. A medida que el umbral de confianza disminuye: el recall aumenta (se detectan más objetos) pero la precisión disminuye (más falsos positivos). La curva de precisión-recall muestra este compromiso en todo el rango de umbrales de confianza.
La Precisión Promedio (AP) calcula el área bajo la curva de precisión-recall, proporcionando un número único que resume el rendimiento del modelo en todos los umbrales de confianza para una clase y un umbral de IoU dados. En el protocolo de evaluación COCO, la AP se calcula mediante interpolación de 101 puntos:
AP = (1/101) × Σ P_interp(r) para r ∈ {0, 0.01, 0.02, …, 1.0}
donde P_interp(r) = max P(r’) para r’ ≥ r. Esta interpolación garantiza una curva de precisión-recall monótonamente decreciente para un cálculo de AP estable.
La Precisión Promedio Media (mAP) promedia la AP en todas las clases y/o umbrales de IoU. Las métricas clave de COCO son:
Para la inspección de infraestructura, la AP por clase es la métrica más diagnóstica. Un modelo de detección de baches podría reportar:
Este desglose por clase indica al profesional qué tipos de defectos maneja bien el modelo y cuáles requieren datos de entrenamiento adicionales, cambios arquitectónicos o un enfoque completamente diferente.
Desplegar modelos de detección de objetos para el procesamiento de video en tiempo real en la inspección de infraestructura requiere un diseño cuidadoso del pipeline para equilibrar el rendimiento, la latencia y la precisión.
Pipeline de procesamiento de fotogramas — El flujo de video se procesa como una secuencia de fotogramas individuales. Cada fotograma se captura de la cámara, opcionalmente se preprocesa (redimensionar al tamaño de entrada del modelo, normalización, conversión de espacio de color), se pasa a través del modelo de detección de objetos, y las salidas se post-procesan (umbralizado de confianza, supresión de no máximos) para producir las detecciones finales. El pipeline debe completar el procesamiento de cada fotograma antes de que llegue el siguiente fotograma para mantener la operación en tiempo real — para una cámara de 30 FPS, esto significa un máximo de 33.3 ms por fotograma (incluyendo captura, preprocesamiento, inferencia y post-procesamiento).
Salto de fotogramas — Cuando el modelo de detección de objetos es más lento que la velocidad de fotogramas de la cámara, se descartan (saltan) fotogramas seleccionados para mantener el rendimiento del pipeline. Por ejemplo, con un modelo que funciona a 15 FPS y una cámara de 30 FPS, se salta un fotograma de cada dos, procesando los fotogramas 0, 2, 4, 6, … Esto es aceptable para la inspección de infraestructura porque los defectos no se mueven entre fotogramas — un bache visible en el fotograma 0 sigue siendo visible en el fotograma 2 (67 ms después) mientras el vehículo se mueve solo 1-2 metros a 80 km/h.
Supresión de No Máximos (NMS) — Los modelos de detección de objetos típicamente generan múltiples detecciones superpuestas para el mismo objeto (especialmente YOLO y SSD con cobertura densa de anchors). NMS es el algoritmo de post-procesamiento que elimina las detecciones duplicadas. El algoritmo ordena todas las detecciones por puntaje de confianza, selecciona la detección con mayor puntuación y elimina todas las detecciones restantes con IoU ≥ umbral_NMS (típicamente 0.5-0.7) con la detección seleccionada. Este proceso se repite hasta que no quedan detecciones. NMS asegura que cada objeto se reporte exactamente una vez. Soft-NMS (Bodla et al., 2017) reduce los puntajes de confianza de las detecciones superpuestas en lugar de eliminarlas por completo, mejorando la detección de objetos muy superpuestos.
Seguimiento entre fotogramas — Para contar objetos únicos a lo largo de un estudio de video, las detecciones deben asociarse entre fotogramas para evitar contar el mismo defecto múltiples veces. El algoritmo SORT (Simple Online and Realtime Tracking) utiliza el filtro de Kalman para predecir la posición de cada objeto en el siguiente fotograma y el algoritmo húngaro para asociar detecciones a trayectorias. DeepSORT añade extracción de características de apariencia para re-identificar objetos después de una oclusión. Para la inspección de infraestructura donde la cámara se mueve (vehículo o UAV), el modelo de seguimiento debe compensar el movimiento propio de la cámara utilizando datos GPS/IMU u odometría visual.
Despliegue en el borde (Edge) — La detección en tiempo real en vehículos de inspección o UAVs requiere optimización del modelo para hardware de borde. Las técnicas incluyen cuantización del modelo (reducir la precisión de los pesos de FP32 a INT8, logrando una aceleración de 2-4× con una pérdida de precisión del 1-2%), optimización TensorRT (optimización de grafos y ajuste automático de kernels de NVIDIA, logrando una aceleración de 2-5× para modelos compatibles), optimización OpenVINO (kit de herramientas de optimización de inferencia de Intel, principalmente para despliegue en CPU y GPU integrada) y poda del modelo (eliminar pesos de baja magnitud para reducir el tamaño del modelo con un impacto mínimo en la precisión).
Entrenar un modelo de detección de objetos para la inspección de infraestructura sigue un pipeline sistemático que transforma los datos anotados en bruto en un modelo desplegable.
Paso 1 — Recolección de datos — Las imágenes se capturan de estudios de inspección que cubren toda la gama de condiciones operativas: diferentes iluminaciones (amanecer, mediodía, atardecer), condiciones de superficie (seca, mojada, cubierta de nieve), ángulos de cámara (nadir, oblicuo) y altitudes (10-50 m para UAV, 0.5-3 m para montado en vehículo). Para la inspección de pavimentos de aeródromos según los estándares de la OACI, las imágenes deben cubrir todos los tipos de pavimento presentes (asfalto, concreto, compuesto) y todas las clases de defectos definidas en ASTM D5340. Se recomienda un mínimo de 1,000-2,000 imágenes por clase de defecto para un rendimiento aceptable del modelo (mAP > 40).
Paso 2 — Anotación — Cada imagen es anotada manualmente por inspectores capacitados utilizando herramientas de cajas delimitadoras. Cada instancia de defecto recibe una caja delimitadora que encierra ajustadamente el defecto y una etiqueta de clase de la taxonomía de defectos predefinida (por ejemplo, bache, grieta, descascaramiento, parche, falla de junta, meteorización). El control de calidad de la anotación incluye verificaciones de concordancia entre anotadores (al menos el 10% de las imágenes anotadas por dos anotadores independientes, la IoU entre sus cajas debe superar 0.7) y revisión de expertos en casos ambiguos.
Paso 3 — División del conjunto de datos — El conjunto de datos anotado se divide en conjuntos de entrenamiento (70%), validación (15%) y prueba (15%). La división se estratifica por clase de defecto y (importante) por ubicación — todas las imágenes de la misma sección de pista deben ir a la misma división para evitar la fuga de datos, donde el modelo ve textura de pavimento similar tanto en los conjuntos de entrenamiento como de prueba.
Paso 4 — Aumento de datos — El aumento sobre la marcha durante el entrenamiento incluye Mosaic (combinar 4 imágenes en una, específico de YOLO), volteo horizontal aleatorio (probabilidad del 50%), rotación aleatoria (±45°), variación HSV (tono ±0.015, saturación ±0.7, valor ±0.4), escalado (±50%), traslación (±20%) y probabilidad de mosaico (1.0). Estos aumentos simulan la variabilidad de las condiciones reales de inspección.
Paso 5 — Configuración del modelo — La arquitectura del modelo se selecciona según los requisitos de velocidad-precisión. Para inspección en tiempo real: YOLO11m o YOLO11l (que equilibran velocidad y precisión). Para máxima precisión: YOLO11x, Faster R-CNN con ResNet-101-FPN o DINO. El tamaño de imagen de entrada es típicamente 640×640 para modelos YOLO (equilibrando resolución y velocidad) o 800-1333 para Faster R-CNN/DETR. Los pesos del backbone se inicializan a partir de un preentrenamiento en COCO o ImageNet.
Paso 6 — Entrenamiento — El modelo se entrena durante 200-300 épocas usando el optimizador SGD o AdamW. La tasa de aprendizaje comienza en 0.01 (SGD) o 0.001 (AdamW) con un programa de recocido coseno. El tamaño de lote se maximiza para la memoria GPU disponible (típicamente 16-64 para imágenes de 640×640 en una sola GPU A100). Los componentes de pérdida incluyen pérdida de clasificación (BCE o entropía cruzada), pérdida de regresión de caja (pérdida CIoU o GIoU) y opcionalmente pérdida de objetualidad (para YOLO). El entrenamiento típicamente toma de 8 a 48 horas en una sola GPU dependiendo del tamaño del modelo y del conjunto de datos.
Paso 7 — Evaluación — Después de cada época, el modelo se evalúa en el conjunto de validación. La métrica principal es mAP@0.50 y mAP@0.50 :0.95. Se examina la AP por clase para identificar clases de defectos débiles. El sobreajuste se detecta cuando el mAP de validación se estabiliza o disminuye mientras la pérdida de entrenamiento continúa decreciendo. El checkpoint con mejor rendimiento (mAP de validación más alto) se guarda.
Paso 8 — Ajuste de hiperparámetros — Usando el conjunto de validación, se optimizan los hiperparámetros: tasa de aprendizaje, tamaño de lote, optimizador, magnitudes de aumento, umbral de confianza (para inferencia), umbral de IoU de NMS (para inferencia). Optuna o Ray Tune pueden automatizar esta búsqueda con optimización bayesiana sobre un espacio de parámetros definido.
Paso 9 — Evaluación en prueba — El modelo final se evalúa una vez en el conjunto de prueba reservado para obtener las métricas de rendimiento finales. Esta evaluación en el conjunto de prueba es el rendimiento reportado para la aprobación del despliegue.
Paso 10 — Despliegue — El modelo entrenado se exporta al formato de despliegue (ONNX, TensorRT, CoreML u OpenVINO) utilizando la API de exportación del framework. Para modelos YOLO: yolo export model=best.pt format=onnx imgsz=640. El modelo exportado se integra en el pipeline de inspección — se carga en el dispositivo edge (Jetson, laptop o servidor en la nube), se conecta al flujo de video y se configura con los umbrales de confianza y NMS óptimos determinados durante el ajuste de hiperparámetros. El pipeline de despliegue registra todas las detecciones con marcas de tiempo, coordenadas GPS, coordenadas de cajas delimitadoras, etiquetas de clase y puntajes de confianza en una base de datos para su posterior análisis basado en GIS y cálculo de PCI según ASTM D5340.
TarmacView utiliza modelos de detección de objetos de última generación para identificar, contar y localizar baches, grietas, FOD y elementos de infraestructura en pavimentos de aeródromos, puentes y carreteras. Solicite una demostración para ver cómo la detección de objetos en tiempo real puede optimizar su flujo de trabajo de inspección.
La segmentación de grietas es la tarea de visión por computadora que clasifica cada píxel de una imagen como grieta o no grieta, produciendo una máscara binaria...
La detección de grietas basada en IA utiliza visión por computadora — redes neuronales convolucionales, transformadores de visión y modelos de segmentación semá...
La segmentación de instancias identifica y delimita cada objeto individual o instancia de defecto a nivel de píxel, asignando una ID única a cada grieta, descas...