Prueba de Humo
Una prueba de humo es una verificación rápida de extremo a extremo de que un pipeline de software se ejecuta sin fallos en datos representativos, produciendo lo...
40 min de lectura
testing
technology
+4
La prueba de smoke testing de la cabeza de defectos valida que el pipeline de detección de defectos estructurales de TarmacView — backbone DINOv3 + cabeza MLP de 5 etiquetas para grieta/descascarillamiento/eflorescencia/exposed_rebar/corrosión — produce resultados esperados en datos de prueba. Cubre aserciones de prueba (el checkpoint existe; métricas AP; columnas de defectos a nivel de baldosa/fotograma en el análisis de salida) y qué verifican las pruebas de smoke testing en comparación con la evaluación completa.
El smoke testing de la cabeza de defectos es un procedimiento de verificación automatizado que valida la integridad estructural y la funcionalidad básica de un pipeline de aprendizaje automático para la detección de defectos. Confirma que el pipeline — desde el preprocesamiento de imágenes de entrada a través del backbone de transformer de visión DINOv3 hasta la cabeza de clasificación de Perceptrón Multicapa (MLP) de 5 etiquetas — produce resultados esperados en datos sintéticos o conjuntos de datos estáticos pequeños sin fallos, errores numéricos o predicciones estructuralmente inválidas. El smoke test se distingue de una evaluación completa: verifica que el pipeline esté correctamente cableado y operativo, no que generalice a datos no vistos con alta precisión.
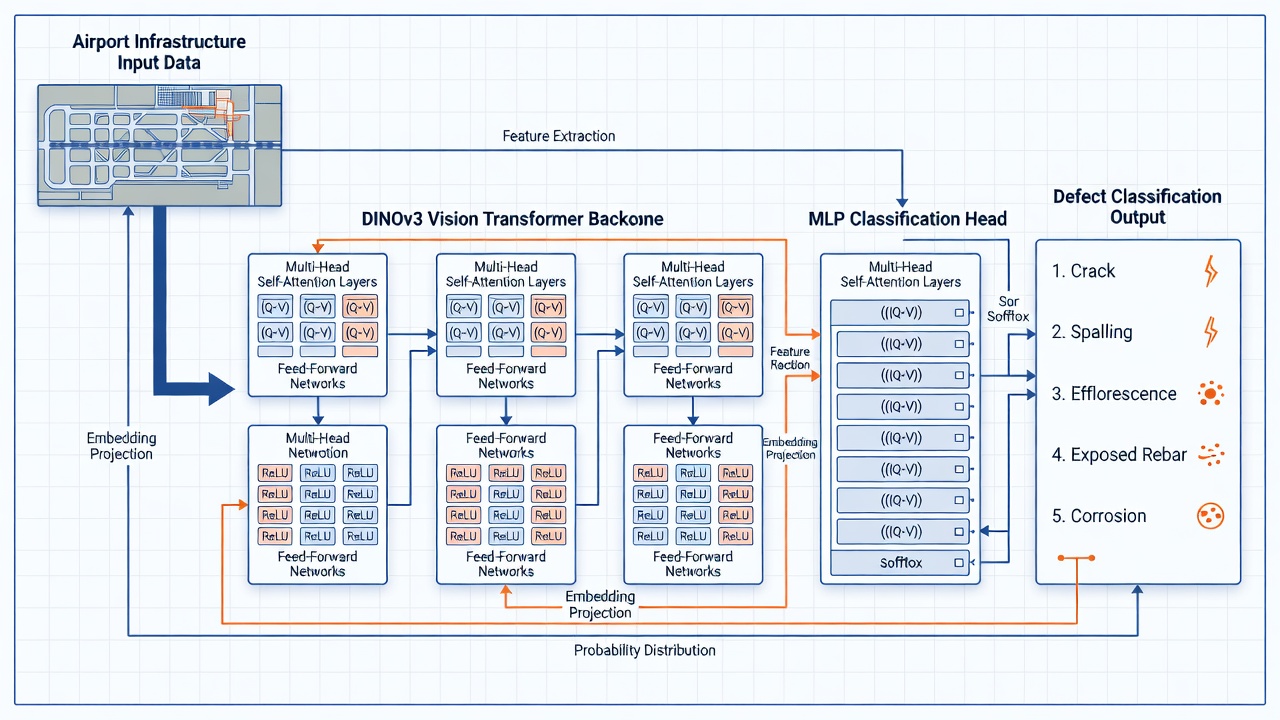
La cabeza de defectos es el componente final del pipeline de detección de defectos estructurales de TarmacView, responsable de mapear las ricas representaciones de características extraídas por la red backbone a predicciones discretas de clases de defectos. Comprender la arquitectura tanto del backbone como de la cabeza es esencial para diseñar smoke tests efectivos que validen la integridad de cada componente.
El DINOv3 (auto-DIstilización SIN etiquetas, versión 3) transformer de visión, desarrollado por Meta AI y lanzado en 2023, sirve como backbone de extracción de características. DINOv3 fue entrenado usando un paradigma de aprendizaje auto-supervisado en un conjunto de datos curado de 142 millones de imágenes no etiquetadas (LVD-142M), aprendiendo representaciones visuales de propósito general sin requerir anotaciones humanas. Este enfoque produce características que se transfieren efectivamente a tareas posteriores que incluyen clasificación, segmentación y detección de defectos — a menudo superando el preentrenamiento supervisado en ImageNet-1K.
DINOv3 está disponible en múltiples variantes de modelo con diferentes perfiles computacionales:
| Variante | Parámetros | Dim. de Incrustación | Tamaño de Parche | Capas | Cabezas |
|---|---|---|---|---|---|
| ViT-S/14 | 22 millones | 384 | 14×14 | 12 | 6 |
| ViT-B/14 | 86 millones | 768 | 14×14 | 12 | 12 |
| ViT-L/14 | 300 millones | 1024 | 14×14 | 24 | 16 |
| ViT-g/14 | 1.1 mil millones | 1536 | 14×14 | 40 | 24 |
Para el pipeline de detección de defectos de TarmacView, la variante ViT-B/14 es la configuración estándar. Con 86 millones de parámetros y un espacio de incrustación de 768 dimensiones, equilibra la capacidad representacional con la eficiencia computacional adecuada para procesar grandes volúmenes de imágenes de inspección de pistas. El tamaño de parche de 14×14 significa que una imagen de entrada de 224×224 píxeles se divide en 16×16 = 256 parches sin superposición, cada uno proyectado en el espacio de incrustación de 768 dimensiones a través de una proyección lineal aprendida.
La metodología de entrenamiento de DINOv3 combina varias técnicas clave. La auto-destilación con arquitectura profesor-alumno asegura que la red alumno aprenda a igualar las representaciones del profesor, siendo el profesor un promedio móvil exponencial del alumno. iBOT (Preentrenamiento de imagen BERT con Tokenizador en Línea) aplica modelado de imágenes enmascaradas, donde parches aleatorios se enmascaran y el modelo debe predecir las representaciones de los parches enmascarados. El centrado Sinkhorn-Knopp del método SwAV evita el colapso de representación al imponer una distribución uniforme entre las muestras del lote. El regularizador KoLeo fomenta la diversidad en las características aprendidas penalizando la similitud de características entre muestras cercanas.
Para el caso de uso de detección de defectos, DINOv3 se carga con pesos preentrenados y típicamente se congela durante el entrenamiento de la cabeza de defectos. El backbone congelado extrae características visuales generales — bordes, texturas, gradientes, patrones de superficie — que son altamente relevantes para distinguir entre pavimento intacto y las cinco clases de defectos. Congelar el backbone reduce el número de parámetros entrenables de 86 millones a aproximadamente 1-3 millones (dependiendo de la profundidad de la cabeza MLP), reduciendo drásticamente el tiempo de entrenamiento, los requisitos de memoria de GPU y el riesgo de olvido catastrófico en conjuntos de datos pequeños y específicos del dominio.
La cabeza de defectos MLP (Perceptrón Multicapa) es una pequeña red neuronal feedforward que toma las incrustaciones congeladas de DINOv3 como entrada y produce una distribución de probabilidad de 5 dimensiones sobre las cinco clases de defectos: grieta, descascarillamiento, eflorescencia, exposed rebar y corrosión.
La arquitectura estándar consiste en:
Capa de entrada: Acepta la incrustación de DINOv3 — ya sea el token [CLS] (un vector de 768 dimensiones que representa el contenido global de la imagen) o una representación agrupada de todos los tokens de parche. El enfoque del token [CLS] es estándar porque DINOv3 está específicamente entrenado para producir información rica en el token [CLS] durante la auto-destilación.
Capas ocultas: Típicamente 1-2 capas completamente conectadas con funciones de activación ReLU o GELU. Una configuración de una sola capa oculta podría ser 768 → 256 → 5, mientras que una configuración más profunda podría ser 768 → 512 → 128 → 5. Cada capa oculta va seguida de normalización por lotes o normalización de capa para estabilizar el entrenamiento y reducir el cambio covariante interno. El abandono (dropout, tasa 0.2-0.5) se aplica entre capas ocultas durante el entrenamiento como regularizador para prevenir el sobreajuste, dado que los conjuntos de datos de defectos de infraestructura son típicamente pequeños (500-5000 imágenes).
Capa de salida: Una proyección lineal a 5 unidades correspondientes a las cinco clases de defectos, seguida de una activación softmax que convierte los logits en una distribución de probabilidad sobre las clases. La función softmax asegura que el vector de salida sume 1.0, con cada elemento representando la probabilidad predicha de que la imagen de entrada pertenezca a esa clase de defecto.
Procedimiento de entrenamiento: La cabeza MLP se entrena mediante ajuste fino supervisado mientras el backbone DINOv3 permanece congelado. La función de pérdida es entropía cruzada categórica, comparando la distribución de probabilidad predicha contra las etiquetas de verdad fundamental codificadas en one-hot. El entrenamiento utiliza típicamente el optimizador AdamW con una tasa de aprendizaje de 1e-3 a 1e-4, tamaño de lote de 32-128, y parada temprana basada en la pérdida de validación. La aumentación de datos (rotación aleatoria, volteo horizontal, variación de color, recorte aleatorio) se aplica durante el entrenamiento para mejorar la generalización.
Para la inferencia, el backbone DINOv3 procesa cada imagen de entrada en incrustaciones de parches y tokens [CLS] en un solo pase hacia adelante. La incrustación [CLS] se extrae y se pasa a través de la cabeza MLP. Las probabilidades softmax de salida se umbralizan (típicamente en 0.5 o se optimizan mediante análisis ROC) para producir una predicción binaria para cada clase de defecto. Debido a que las cinco clases de defectos no son mutuamente excluyentes — una misma área de pavimento puede presentar tanto grietas como descascarillamiento simultáneamente — las predicciones umbralizadas para cada clase son independientes, y la salida se interpreta correctamente como multietiqueta en lugar de predicción de clase única.
En el pipeline de análisis de TarmacView, la cabeza de defectos opera a dos niveles de granularidad.
Análisis a nivel de baldosa: La superficie de la pista se divide en una cuadrícula de baldosas de imagen (típicamente 224×224 o 512×512 píxeles a la resolución de inspección de 0.5-2.0 mm/píxel). Cada baldosa se procesa independientemente a través del backbone DINOv3 y la cabeza MLP de defectos, produciendo un vector de probabilidad de 5 elementos por baldosa. Las predicciones a nivel de baldosa se almacenan como columnas por baldosa en la salida del análisis: tile_crack_conf, tile_spalling_conf, tile_efflorescence_conf, tile_exposed_rebar_conf, tile_corrosion_conf.
Agregación a nivel de fotograma: Las predicciones individuales de baldosas dentro de un fotograma de cámara o sección de pista se agregan para producir evaluaciones de defectos a nivel de fotograma. Los métodos de agregación incluyen: max pooling (la confianza máxima entre todas las baldosas del fotograma), mean pooling (confianza promedio), votación top-k (la proporción de baldosas que superan un umbral), y densidad espacial (el recuento de baldosas con defectos por fotograma). Las columnas a nivel de fotograma en la salida incluyen frame_crack_flag, frame_spalling_flag, frame_defect_count y frame_max_defect_conf.
El esquema de salida del análisis es un componente crítico que los smoke tests deben validar. Si las columnas de confianza a nivel de baldosa o las columnas de agregación a nivel de fotograma faltan, se renombran o contienen valores inválidos (NaN, inf, probabilidades negativas), los cálculos descendentes del Índice de Condición del Pavimento (PCI) y los pipelines de generación de informes fallarán.
Las aserciones del smoke test son las verificaciones automatizadas específicas que confirman que el pipeline de la cabeza de defectos funciona correctamente. Cada aserción se dirige a un modo de fallo específico y produce un resultado claro de aprobado/fallado que puede integrarse en el control de acceso del pipeline CI/CD.
La primera categoría de aserciones del smoke test verifica que el checkpoint de la cabeza de defectos — el archivo de pesos del modelo guardado — sea válido y cargable. Las aserciones incluyen:
Existencia del archivo de checkpoint: La prueba verifica que el archivo de checkpoint existe en la ruta especificada. Esto detecta problemas donde una ejecución de entrenamiento falló, el checkpoint no se subió al registro del modelo, o la ruta del archivo fue configurada incorrectamente en el entorno de despliegue. La aserción es: assert os.path.exists(checkpoint_path), f"Checkpoint no encontrado en {checkpoint_path}".
Validación de tamaño de archivo y checksum: La prueba verifica que el archivo de checkpoint tenga un tamaño de archivo distinto de cero y opcionalmente valida su checksum MD5 o SHA256 contra una línea base almacenada. Un archivo de cero bytes o una descarga corrupta se detectarán aquí. La aserción es: assert os.path.getsize(checkpoint_path) > 0 y opcionalmente assert sha256(file) == expected_sha256.
Capacidad de carga con torch: La prueba carga el checkpoint usando torch.load() y verifica que la operación se complete sin lanzar una excepción. Esto detecta archivos corruptos, incompatibilidades de versión (por ejemplo, un checkpoint guardado con PyTorch 2.0 que intenta cargarse con PyTorch 1.8), y dependencias faltantes. La aserción envuelve la llamada de carga en un bloque try/except y falla ante cualquier excepción.
Estructura del diccionario de estado: Después de cargar, la prueba verifica que el checkpoint contenga las claves esperadas del diccionario de estado. Para el backbone DINOv3, las claves esperadas incluyen backbone.cls_token, backbone.patch_embed.proj.weight y los parámetros del bloque transformer. Para la cabeza MLP, las claves esperadas incluyen head.0.weight, head.0.bias, head.2.weight, head.2.bias (para un MLP de 2 capas). La prueba también verifica que todas las claves esperadas estén presentes y que no existan claves inesperadas, lo que podría indicar una discrepancia en la arquitectura del modelo.
La segunda categoría verifica que un pase hacia adelante a través del backbone y la cabeza combinados produzca salidas válidas.
Validación de forma del tensor: La prueba crea un tensor de entrada sintético de la forma esperada (típicamente [batch_size, 3, height, width] con batch_size=1-4, height=width=224 para ViT-B/14), lo pasa a través del modelo, y verifica que la forma del tensor de salida sea [batch_size, 5] — exactamente 5 logits correspondientes a las 5 clases de defectos. La aserción es: assert output.shape == (batch_size, 5), f"Se esperaba forma (batch_size, 5), se obtuvo {output.shape}".
Validación de estabilidad numérica: La prueba verifica que ningún valor de salida sea NaN (No es un Número), infinito o infinito negativo. Los valores NaN pueden surgir de inestabilidad numérica en el backbone transformer (por ejemplo, desbordamiento de logits de atención), división por cero en capas de normalización, o pesos corruptos. La aserción es: assert not torch.isnan(output).any(), "La salida contiene valores NaN" y assert not torch.isinf(output).any(), "La salida contiene valores inf".
Validación de probabilidad softmax: La prueba aplica softmax a los logits brutos y verifica que las probabilidades resultantes sumen 1.0 para cada muestra en el lote (dentro de la tolerancia de coma flotante, típicamente 1e-5). Esto confirma que la capa de salida está configurada correctamente y que ningún paso de posprocesamiento está corrompiendo la distribución de probabilidad. La aserción es: assert torch.allclose(probs.sum(dim=1), torch.ones(batch_size), atol=1e-5).
La tercera categoría verifica que el modelo produzca distribuciones de predicción razonables en lugar de salidas degeneradas.
Verificación de distribución no uniforme: La prueba verifica que las probabilidades predichas no sean uniformes en todas las clases (lo que indicaría un modelo que no ha aprendido características discriminativas). La entropía de la distribución predicha se calcula y se compara contra un umbral mínimo. Una distribución completamente uniforme tiene entropía máxima (log(5) ≈ 1.61 nats para 5 clases), mientras que una predicción segura tiene baja entropía. La aserción es: assert entropy < 1.5, "Las predicciones son casi uniformes, el modelo puede no estar entrenado".
Verificación de cobertura de clases: La prueba ejecuta inferencia en un pequeño conjunto de imágenes de entrada diversas y verifica que cada una de las 5 clases de defectos sea la predicción de mayor confianza para al menos una entrada. Esto verifica que ninguna clase sea suprimida sistemáticamente — por ejemplo, un modelo que nunca predice “eflorescencia” indicaría un desbalance en los datos de entrenamiento o un problema de configuración de la cabeza. La aserción es: assert set(predicted_classes) == set(range(5)), f"Las clases {missing} nunca se predijeron".
Manejo de clase de fondo: Si el modelo incluye una clase de fondo o “sin defecto” implícita, el smoke test verifica que una imagen de pavimento intacto — libre de cualquier defecto — produzca una predicción de fondo con confianza por encima de un umbral (típicamente 0.8). Esto confirma que el modelo puede rechazar correctamente ejemplos negativos, lo cual es crítico para evitar falsas alarmas positivas en inspecciones de producción.
La validación del checkpoint es un componente fundamental del smoke test que confirma que el artefacto del modelo — los pesos de la red neuronal guardados — está intacto, es cargable y es estructuralmente consistente con la arquitectura esperada. En sistemas de ML de producción, la corrupción del checkpoint o la discrepancia de versión es uno de los modos de fallo más comunes, y detectarlo temprano en CI/CD evita fallos en cascada posteriores.
Los checkpoints de la cabeza de defectos de TarmacView se almacenan en el registro del modelo — un almacén de artefactos centralizado con versionado, metadatos y seguimiento de linaje (MLflow Model Registry o DVC). Cada checkpoint se identifica por una combinación única de nombre de modelo, número de versión e ID de ejecución. El archivo de checkpoint en sí es un diccionario de estado de PyTorch serializado (típicamente model.pt o checkpoint.pt) que contiene los parámetros aprendidos tanto del backbone DINOv3 (si se ajustó finamente) como de la cabeza MLP.
El smoke test primero resuelve la ruta del checkpoint desde el registro del modelo, manejando los siguientes casos:
defect-head:v3), y la prueba carga esa versión exacta.El backbone DINOv3 es un modelo grande con 86 millones de parámetros para la variante ViT-B/14. El smoke test verifica que el backbone cargado coincida con la arquitectura esperada comprobando:
Formas de los tensores de peso: Cada tensor de parámetros en el diccionario de estado cargado se verifica contra la forma esperada. Por ejemplo, el tensor backbone.patch_embed.proj.weight debería tener forma (768, 3, 14, 14) para un ViT-B/14 con 3 canales de entrada, 768 canales de salida y un kernel de parche de 14×14. Una discrepancia de forma indicaría que el checkpoint fue entrenado con una configuración diferente (diferente tamaño de parche, diferente dimensión de incrustación, diferentes canales de entrada).
Verificación de rango numérico: La prueba verifica que los valores de los pesos se encuentren dentro de rangos numéricos esperados. Los pesos de atención del transformer deberían tener valores distribuidos aproximadamente como N(0, σ²) con σ dependiendo del esquema de inicialización. Valores extremos (|w| > 10) en todas las capas indicarían divergencia de entrenamiento o corrupción del checkpoint. La verificación calcula la media y la desviación estándar de cada tensor de parámetros y señala los valores atípicos.
Consistencia de la incrustación de salida: La prueba ejecuta una entrada sintética fija a través del backbone y compara la distribución de la incrustación de salida contra una línea base almacenada. La línea base se genera durante la primera ejecución exitosa del smoke test y se almacena como referencia. La aserción verifica que la media y la varianza de la incrustación no se desvíen más allá de una tolerancia (típicamente ±5%). Esto detecta degradación silenciosa del modelo que no produce valores NaN o inf pero aún así genera incrustaciones anómalas.
La cabeza MLP es más pequeña que el backbone pero igualmente crítica. El smoke test verifica:
Número de capas: La cabeza debe tener exactamente el número esperado de capas. Para un MLP de 2 capas con dimensión oculta 256, las claves esperadas incluyen head.0.weight (768×256), head.0.bias (256), head.2.weight (256×5), head.2.bias (5). La numeración de capas considera la función de activación (capa 1) entre las capas lineales.
Dimensión de salida: La dimensión de salida de la última capa lineal debe ser exactamente 5, correspondiente a las 5 clases de defectos. Esto se verifica comprobando head.2.weight.shape[0] == 5.
Consistencia de la inicialización de pesos: La prueba verifica que los pesos no estén congelados en valores de inicialización (todos ceros o todos unos). Una cabeza con pesos todos cero produciría logits uniformes independientemente de la entrada, indicando un fallo de entrenamiento. La verificación comprueba que head.2.weight.std() > 0.001.
Si bien el smoke test trata principalmente sobre la integridad del pipeline más que sobre la calidad del modelo, incluir el cálculo ligero de métricas en el smoke test proporciona una alerta temprana de regresión significativa del modelo. El smoke test calcula métricas de eficacia en datos sintéticos o conjuntos de datos estáticos pequeños, comparándolos con líneas base almacenadas de ejecuciones validadas anteriores.
La Precisión Promedio (AP) es el área bajo la curva de precisión-recall, calculada a través de umbrales de confianza de 0 a 1. El smoke test calcula la AP para cada una de las 5 clases de defectos utilizando la evaluación estilo COCO:
Las aserciones de AP del smoke test incluyen:
AP@0.50 (métrica PASCAL VOC): AP en el umbral IoU de 0.50. La aserción es que AP@0.50 para cada clase supere un umbral mínimo. Para datos de prueba sintéticos con patrones de defectos limpios y conocidos, un umbral típico es AP@0.50 > 0.85 para las 5 clases. Si el modelo alcanza AP@0.50 por debajo de este umbral en datos sintéticos triviales, indica una regresión grave.
AP@0.50 :0.95 (métrica principal COCO): El promedio de los valores de AP calculados en los umbrales IoU 0.50, 0.55, …, 0.95. El umbral de aserción es más bajo — típicamente AP@0.50 :0.95 > 0.50 — porque los umbrales IoU estrictos son más desafiantes incluso en datos sintéticos.
Consistencia de AP por clase: Se verifica la varianza de la AP entre las 5 clases. Una desviación estándar que exceda 0.15 indicaría que una clase ha regresado significativamente en relación con las demás, sugiriendo un problema específico de ese tipo de defecto (por ejemplo, ejemplos de entrenamiento insuficientes para eflorescencia).
El conjunto de datos de prueba sintético se construye cuidadosamente para garantizar la estabilidad de las métricas. Cada imagen sintética contiene exactamente un tipo de defecto superpuesto sobre una textura de fondo similar al pavimento. Los defectos se generan mediante técnicas procedimentales: grietas como líneas negras delgadas y ramificadas con desenfoque gaussiano para realismo; descascarillamientos como regiones circulares/ovaladas irregulares con rugosidad en los bordes; eflorescencia como parches blancos amorfos con opacidad variable; exposed rebar como patrones circulares oscuros periódicos; corrosión como manchas irregulares de color óxido. El conjunto de datos sintético tiene versión y se registra en el repositorio para garantizar resultados de smoke test deterministas y reproducibles.
La puntuación F1 es la media armónica de precisión y recall, proporcionando una medida equilibrada única del rendimiento del modelo. El smoke test calcula F1 en un umbral de confianza fijo (típicamente 0.5) para cada clase de defecto.
Las aserciones F1 incluyen:
F1 mínimo por clase: Cada clase debe alcanzar F1 > 0.80 en el conjunto de prueba sintético. La naturaleza multi-etiqueta de la tarea de predicción de defectos significa que F1 se calcula de forma independiente por clase.
F1 macro-promediado: El promedio no ponderado de F1 en las 5 clases se calcula. El umbral de aserción es macro-F1 > 0.85. El macro-promedio trata a todas las clases por igual, por lo que la regresión en una clase rara (por ejemplo, exposed rebar) es inmediatamente visible.
Equilibrio precisión-recall: La relación entre precisión y recall se verifica para cada clase. Una relación por encima de 1.5 o por debajo de 0.67 indica desequilibrio — el modelo es demasiado conservador (alta precisión, bajo recall, omitiendo muchos defectos) o demasiado agresivo (alto recall, baja precisión, generando muchos falsos positivos). La aserción señala cualquier clase donde la relación esté fuera de [0.67, 1.5].
| Métrica | Umbral de Prueba Sintética | Propósito |
|---|---|---|
| AP@0.50 | > 0.85 | Capacidad básica de detección por clase |
| AP@0.50 :0.95 | > 0.50 | Calidad integral de detección |
| Desviación estándar de AP por clase | < 0.15 | Verificación de equilibrio entre clases |
| F1 por clase | > 0.80 | Precisión-recall equilibrada por clase |
| F1 macro-promediado | > 0.85 | Calidad general del modelo |
| Relación Precisión/Recall | [0.67, 1.5] | Equilibrio precisión-recall por clase |
El smoke test almacena líneas base de métricas de la última ejecución validada y compara las métricas actuales contra estas líneas base. Una caída significativa (>5% de disminución relativa) en cualquier métrica provoca un fallo del smoke test, incluso si el valor absoluto de la métrica está por encima del umbral mínimo. Esto detecta la degradación gradual — modelos que superan los umbrales absolutos pero están disminuyendo consistentemente en rendimiento a lo largo de ejecuciones de entrenamiento sucesivas o actualizaciones de datos.
Los historiales de métricas se registran en una base de datos de series temporales (MLflow, Weights & Biases, o un archivo CSV simple en el repositorio). El smoke test lee los últimos 10 valores de métricas validadas y ajusta una tendencia lineal. Si la pendiente es negativa y estadísticamente significativa (p < 0.05), la prueba genera una advertencia pero no falla — el fallo basado solo en umbral se usa para el control de acceso CI/CD para evitar interrupciones ruidosas del pipeline debido a fluctuaciones métricas menores.
Un smoke test crítico valida que la salida del análisis — los datos estructurados producidos al ejecutar la cabeza de defectos en imágenes de inspección — contenga todas las columnas esperadas con tipos de datos correctos y valores válidos. Esto cierra la brecha entre la inferencia del modelo y el cálculo descendente del Índice de Condición del Pavimento (PCI), la generación de informes y la integración con SIG.
La salida del análisis de TarmacView es un formato tabular (Parquet, CSV o tabla de base de datos) con columnas organizadas en niveles:
Columnas de confianza de defectos a nivel de baldosa — una columna flotante por clase de defecto, que representa la confianza softmax de la cabeza MLP de que la baldosa contiene ese defecto:
| Nombre de Columna | Tipo de Dato | Rango Válido | Descripción |
|---|---|---|---|
tile_crack_conf | Float32 | [0.0, 1.0] | Probabilidad de presencia de grieta |
tile_spalling_conf | Float32 | [0.0, 1.0] | Probabilidad de presencia de descascarillamiento |
tile_efflorescence_conf | Float32 | [0.0, 1.0] | Probabilidad de presencia de eflorescencia |
tile_exposed_rebar_conf | Float32 | [0.0, 1.0] | Probabilidad de presencia de exposed rebar |
tile_corrosion_conf | Float32 | [0.0, 1.0] | Probabilidad de presencia de corrosión |
Columnas de agregación a nivel de fotograma — resumiendo la presencia de defectos en todas las baldosas de un fotograma de cámara o sección de pista:
| Nombre de Columna | Tipo de Dato | Rango Válido | Descripción |
|---|---|---|---|
frame_defect_count | Int32 | [0, max_tiles] | Número de baldosas con algún defecto por encima del umbral |
frame_max_defect_conf | Float32 | [0.0, 1.0] | Confianza máxima entre todos los defectos y baldosas |
frame_crack_flag | Booleano | {0, 1} | Alguna baldosa tiene crack_conf > umbral |
frame_spalling_flag | Booleano | {0, 1} | Alguna baldosa tiene spalling_conf > umbral |
frame_efflorescence_flag | Booleano | {0, 1} | Alguna baldosa tiene efflorescence_conf > umbral |
frame_exposed_rebar_flag | Booleano | {0, 1} | Alguna baldosa tiene exposed_rebar_conf > umbral |
frame_corrosion_flag | Booleano | {0, 1} | Alguna baldosa tiene corrosion_conf > umbral |
Columnas de metadatos — identificando el contexto espacial y temporal de cada registro de análisis:
| Nombre de Columna | Tipo de Dato | Descripción |
|---|---|---|
image_id | String | Identificador único de la imagen de origen |
tile_x | Int32 | Índice de columna de baldosa en la cuadrícula de la pista |
tile_y | Int32 | Índice de fila de baldosa en la cuadrícula de la pista |
frame_timestamp | DateTime | Hora de captura del fotograma de origen |
gps_lat | Float64 | Latitud GPS del centro de la baldosa |
gps_lon | Float64 | Longitud GPS del centro de la baldosa |
El smoke test carga la salida del análisis y verifica que cada columna esperada exista usando una simple coincidencia de nombres de columna:
expected_tile_cols = ["tile_crack_conf", "tile_spalling_conf",
"tile_efflorescence_conf", "tile_exposed_rebar_conf",
"tile_corrosion_conf"]
expected_frame_cols = ["frame_defect_count", "frame_max_defect_conf",
"frame_crack_flag", "frame_spalling_flag",
"frame_efflorescence_flag", "frame_exposed_rebar_flag",
"frame_corrosion_flag"]
expected_meta_cols = ["image_id", "tile_x", "tile_y",
"frame_timestamp", "gps_lat", "gps_lon"]
actual_cols = set(df.columns)
assert expected_cols.issubset(actual_cols), f"Columnas faltantes: {expected_cols - actual_cols}"
Para cada columna de confianza de defectos, el smoke test verifica:
Tipo flotante: El tipo de dato de la columna es float32 o float64. Tipos inesperados (int, string, object) indican un error de serialización o del pipeline. La aserción usa assert df[col].dtype in [np.float32, np.float64].
Rango de valores: Todos los valores están en [0.0, 1.0]. Los valores fuera de este rango indican un fallo de softmax o normalización. La aserción usa assert df[col].between(0.0, 1.0).all().
Verificación de valores faltantes: Ningún valor es NaN o None. Los valores NaN en columnas de confianza indican que el pipeline de inferencia no produjo salida para algunas baldosas — un fallo grave. La aserción usa assert df[col].notna().all().
Las columnas a nivel de fotograma deben ser consistentes con los datos a nivel de baldosa de los que se derivan. El smoke test valida:
frame_defect_count es igual al recuento de baldosas donde la confianza máxima supera el umbral: Para cada grupo de fotograma, la prueba recalcula el recuento de defectos a partir de los datos a nivel de baldosa y verifica que coincida con el valor de fotograma almacenado. Esto detecta errores de lógica de agregación en el pipeline.
frame_max_defect_conf es igual al máximo de todos los valores de confianza de baldosas: La prueba recalcula el máximo a partir de los datos a nivel de baldosa y verifica la coincidencia.
frame_flag es consistente con tile_conf: Para cada fotograma, el indicador debe ser 1 si alguna baldosa tiene la confianza correspondiente por encima del umbral, y 0 en caso contrario. La prueba verifica esto para los 5 tipos de defectos.
Estas verificaciones de consistencia operan bajo el principio de que las columnas a nivel de fotograma deberían ser derivables de forma determinista a partir de las columnas a nivel de baldosa. Si la lógica de agregación es correcta, las verificaciones deberían pasar siempre. Un fallo indica un error en el paso de posprocesamiento del pipeline de análisis, no en el modelo en sí.
El smoke test compara el conjunto de columnas esperado contra el conjunto de columnas real y genera advertencias para:
tile_moisture_conf), la prueba advierte pero no falla, ya que esto puede indicar una mejora del pipeline que requiere actualizaciones de integración posteriores.tile_crack_conf → tile_cracking_conf), la prueba falla, evitando roturas silenciosas posteriores cuando los paneles de informes, APIs o bases de datos referencian los nombres de columna antiguos.La lógica de control de acceso determina si la cabeza de defectos pasa o falla el smoke test en su conjunto, basándose en una combinación ponderada de los resultados de aserciones individuales. El control de acceso es el mecanismo que impide que un modelo defectuoso sea desplegado en producción.
No todas las aserciones del smoke test son igualmente críticas. El sistema de control de acceso asigna cada aserción a un nivel de gravedad:
| Nivel | Peso | Efecto en el Control | Ejemplos |
|---|---|---|---|
| Fatal | 1.0 | Bloquea inmediatamente | Fallo de carga del checkpoint, NaN en salidas |
| Crítico | 0.8 | Bloquea si >1 fallo | Columnas faltantes, discrepancia de forma de salida |
| Advertencia | 0.4 | Bloquea si >3 fallos | AP por clase por debajo del umbral |
| Informativo | 0.0 | Solo registra, no bloquea | Advertencias de tendencia de métricas, avisos de obsolescencia de columnas |
Las aserciones Fatales son aquellas donde no es posible una ejecución válida del pipeline — el checkpoint está corrupto, el modelo no puede cargarse, o la inferencia produce valores numéricos inválidos. Un solo fallo fatal bloquea el despliegue.
Las aserciones Críticas indican que el pipeline produce resultados estructuralmente válidos pero potencialmente incorrectos — las columnas faltantes causarían fallos en los informes posteriores, la discrepancia de forma de salida indica una falta de coincidencia entre la arquitectura del modelo y la infraestructura de servicio.
Las aserciones de Advertencia indican que las métricas del modelo están por debajo de los umbrales nominales pero el pipeline es estructuralmente sólido. Estas se agregan: si más de 3 advertencias se activan en una sola ejecución, el control se activa.
Las aserciones Informativas son puramente observacionales — registran tendencias de deriva de métricas, avisos de obsolescencia de columnas y comparaciones de rendimiento contra ejecuciones anteriores — pero nunca bloquean el despliegue.
El resultado general del smoke test se calcula como:
gate_score = max(fatal_failures,
critical_failures > 1 ? 1.0 : 0.0,
warning_failures > 3 ? 1.0 : 0.0)
Si gate_score >= 1.0, el smoke test falla y el despliegue se bloquea. Si gate_score < 1.0, el smoke test pasa y el pipeline procede a la evaluación completa o al despliegue.
El mensaje compuesto de aprobado/fallado resume el resultado:
SMOKE TEST: FALLÓ
- Fatal: 1 [checkpoint_load_failure]
- Crítico: 0
- Advertencia: 2 [class_crack_ap_below_threshold, class_efflorescence_f1_below_threshold]
- Informativo: 1 [metric_class_crack_ap cayó 3.2% desde la última ejecución]
El control de acceso del smoke test se integra con el pipeline de despliegue a través de:
Hook post-commit: El smoke test se ejecuta en cada commit de pull request. Si el control falla, el sistema CI/CD bloquea la fusión (regla de protección de rama de GitHub, fallo del pipeline de merge request de GitLab).
Control previo al despliegue: Antes de que un modelo sea promocionado de staging a producción, el smoke test se ejecuta nuevamente en el artefacto candidato al despliegue exacto. Esto detecta problemas que pueden no haber estado presentes durante el desarrollo — por ejemplo, un entorno de desarrollo con una versión de CUDA diferente a la del entorno de servicio de producción.
Disparador de reversión: Si el smoke test pasa el despliegue pero un incidente de producción posterior se atribuye a la cabeza de defectos, la lógica de control del smoke test se audita. Si una aserción de nivel de advertencia debería haber sido una aserción crítica, la configuración del control se actualiza para prevenir recurrencia.
Las pruebas de aplicabilidad del dominio extienden el smoke test básico para verificar que la cabeza de defectos funcione correctamente en las condiciones operativas específicas que TarmacView encuentra en la inspección de pavimentos de aeródromos e infraestructura. Estas pruebas aseguran que el pipeline no solo sea funcional, sino que sea adecuado para su propósito en el dominio objetivo.
La cabeza de defectos debe funcionar de manera consistente en diferentes tipos de pavimento encontrados en superficies aeroportuarias:
Pavimentos asfálticos (flexibles): Pistas, calles de rodaje y plataformas construidas con mezcla asfáltica en caliente (HMA). Los defectos en asfalto incluyen agrietamiento por fatiga (patrón de piel de cocodrilo), agrietamiento longitudinal, agrietamiento transversal, ahuellamiento y desprendimiento. El smoke test incluye imágenes sintéticas con texturas similares al asfalto (gris oscuro, agregado visible, rugosidad superficial variable) y verifica que la detección de grietas y descascarillamiento mantenga niveles de confianza nominales.
Pavimentos de hormigón (rígidos): Pistas y plataformas construidas con hormigón de cemento Portland (PCC). Los defectos incluyen descascarillamiento en juntas, roturas en esquinas, agrietamiento lineal, eflorescencia (depósitos blancos de calcio en las juntas), exposed rebar (en áreas descascarilladas) y manchas de corrosión. El smoke test verifica que el modelo identifique correctamente la eflorescencia y el exposed rebar — defectos que son mucho más prevalentes en superficies de hormigón que en asfalto.
Pavimentos compuestos: Capas de asfalto sobre hormigón existente. Los defectos incluyen agrietamiento reflejado (grietas de asfalto que siguen el patrón de junta de hormigón subyacente) y delaminación. La prueba verifica que el modelo pueda detectar grietas en superficies compuestas sin confundirse con el patrón de junta subyacente.
Capas de fricción porosas (PFC): Asfalto de alta permeabilidad utilizado en pistas para mejorar el drenaje y la fricción. El PFC tiene una textura abierta distintiva que se ve visualmente diferente del HMA de gradación densa. La prueba verifica que el modelo no produzca tasas elevadas de falsos positivos en superficies PFC, donde la textura rugosa podría confundirse con agrietamiento o descascarillamiento.
El Anexo 14 de la OACI y la AC 150/5320-5D de la FAA especifican que las evaluaciones de la condición de la superficie de la pista deben ser válidas en condiciones operativas. El smoke test de aplicabilidad del dominio verifica que la cabeza de defectos mantenga el rendimiento en:
Luz solar directa: Alto contraste, sombras fuertes. La prueba verifica que los valores de confianza no sean sistemáticamente más bajos en condiciones de alto contraste debido a falsos positivos inducidos por sombras.
Luz nublada/difusa: Bajo contraste, sin sombras. La prueba verifica que las grietas finas (estrechas, de bajo contraste contra el pavimento) sigan siendo detectables con niveles de confianza reducidos.
Pavimento mojado: El agua en las grietas aumenta la visibilidad de las mismas pero introduce reflejos especulares. La prueba verifica que las baldosas de superficie mojada no produzcan falsos positivos elevados debido a que los reflejos especulares se confundan con eflorescencia (ambos aparecen como regiones brillantes).
Amanecer/anochecer: Niveles de luz bajos, sombras largas. La prueba verifica que el modelo produzca salidas dentro de rangos de confianza esperados incluso con niveles de iluminación reducidos.
El smoke test simula estas condiciones aplicando transformaciones fotométricas controladas a las imágenes de prueba sintéticas: escalado de brillo para simulación de iluminación, desenfoque gaussiano para simulación de niebla/bruma, y ajuste de saturación para simulación de superficie mojada.
Las imágenes de inspección varían en distancia de muestreo en el suelo (GSD) dependiendo de la plataforma de captura:
| Plataforma | Altitud Típica | GSD (mm/píxel) | Cobertura por Baldosa |
|---|---|---|---|
| UAV (alta resolución) | 15-20 m | 0.5-1.0 | 0.1-0.5 m² |
| UAV (estándar) | 30-50 m | 1.0-2.0 | 0.5-2.0 m² |
| Montado en vehículo | 2-3 m | 0.3-0.8 | 0.05-0.2 m² |
| Cámara manual | 1-1.5 m | 0.2-0.5 | 0.02-0.08 m² |
El smoke test verifica que la cabeza de defectos produzca salidas consistentes en un rango de resoluciones de entrada. Las imágenes de prueba sintéticas se generan a múltiples escalas (0.5×, 1.0×, 2.0× de la GSD nominal) y se pasan a través del modelo. La prueba verifica que la distribución de clases predicha no varíe más del 10% entre resoluciones, asegurando que el modelo sea aproximadamente invariante a la escala dentro del rango operativo.
La norma ASTM D5340 define tres niveles de severidad (Bajo, Medio, Alto) para cada tipo de defecto. El smoke test verifica que las puntuaciones de confianza de la cabeza de defectos se correlacionen con la severidad del defecto:
Severidad baja: Grietas capilares (<1mm de ancho), descascarillamientos pequeños (<150mm de longitud), eflorescencia ligera, manchas de corrosión mínimas. La prueba verifica que estos produzcan puntuaciones de confianza por encima del umbral de detección (>0.5) pero no con confianza máxima (<0.8).
Severidad media: Grietas (1-3mm de ancho), descascarillamientos (150-600mm de longitud), depósitos de eflorescencia moderados, exposed rebar visible con corrosión ligera. La prueba verifica que las puntuaciones de confianza sean altas (>0.7).
Severidad alta: Grietas anchas (>3mm de ancho), descascarillamientos grandes (>600mm de longitud), eflorescencia intensa con alteración de la superficie, exposed rebar con corrosión intensa y pérdida de sección. La prueba verifica que las puntuaciones de confianza sean muy altas (>0.9).
La verificación de correlación de severidad es una aserción de nivel de advertencia en el sistema de control — el modelo puede seguir funcionando correctamente incluso si la correlación de severidad es imperfecta, pero la prueba lo señala como un área de mejora del modelo.
Comprender la distinción entre el smoke testing y la evaluación completa es crítico para diseñar una estrategia efectiva de aseguramiento de calidad de ML. Los dos enfoques sirven propósitos fundamentalmente diferentes y operan en diferentes puntos del ciclo de vida de desarrollo y despliegue.
| Dimensión | Smoke Test | Evaluación Completa |
|---|---|---|
| Objetivo | Verificar la integridad del pipeline | Medir la calidad del modelo |
| Pregunta respondida | “¿El pipeline funciona correctamente?” | “¿Es el modelo suficientemente preciso?” |
| Datos | Sintéticos / conjunto estático pequeño (10-100 imágenes) | Conjunto de validación grande reservado (500-5000+ imágenes) |
| Duración | Segundos a minutos | Minutos a horas |
| Cómputo | CPU o GPU mínima | GPU completa (a menudo multi-GPU) |
| Frecuencia | Cada commit / PR | Diaria, semanal o por lanzamiento |
| Umbrales de métricas | Generosos (AP > 0.50) | Exigentes (AP > 0.75) |
| Cobertura | Solo integridad estructural | Generalización estadística |
| Acción ante fallo | Bloquear fusión/despliegue | Señalar para revisión |
El smoke test está diseñado para detectar errores del pipeline — la clase de bugs que causan que todo el sistema falle o produzca salidas sin sentido. Estos incluyen corrupción del checkpoint, incompatibilidad de versiones, roturas en el pipeline de preprocesamiento, columnas faltantes, salidas NaN y discrepancias de forma. Los datos de la industria de equipos de ingeniería de ML muestran que los errores del pipeline representan el 60-70% de las ejecuciones de entrenamiento fallidas y el 40% de las reversiones de despliegue. Los smoke tests detectan estos errores en segundos, antes de que se inicien costosas ejecuciones de evaluación completa.
La evaluación completa está diseñada para medir la calidad del modelo — la precisión estadística, la precisión, el recall y la generalización de las predicciones del modelo. Utiliza conjuntos de datos de validación grandes, diversos y representativos, calcula métricas rigurosas (AP@0.50 :0.95, F1 por clase, matrices de confusión, curvas de precisión-recall en múltiples umbrales) y compara los resultados tanto contra umbrales absolutos como contra líneas base relativas de versiones anteriores del modelo. Las ejecuciones de evaluación completa son computacionalmente costosas y consumen mucho tiempo, lo que las hace inadecuadas para la ejecución por commit.
Los datos del smoke test se generan sintéticamente para ser simples, limpios y deterministas. Cada imagen sintética contiene exactamente un tipo de defecto sobre un fondo uniforme, sin oclusión, sin defectos superpuestos y sin condiciones de iluminación desafiantes. Esto minimiza la variabilidad y asegura que cualquier fluctuación de métrica en el smoke test sea atribuible al modelo, no a la variabilidad de los datos.
Los datos de la evaluación completa son imágenes de inspección del mundo real con las siguientes características: diversos tipos y edades de pavimento, todas las condiciones de iluminación operativas, niveles variables de severidad de defectos, defectos superpuestos y adyacentes, oclusiones del mundo real (escombros, marcas de neumáticos, agua) y anotaciones precisas de verdad fundamental a nivel de polígono. Estos datos representan la distribución real que el modelo encuentra en producción y proporcionan una estimación fiable del rendimiento del despliegue.
La prevención de fuga de datos es crítica para la evaluación completa pero irrelevante para los smoke tests — dado que el smoke test utiliza datos sintéticos, no hay riesgo de filtrar datos reales de prueba en el entrenamiento. El conjunto de datos de evaluación completa se particiona cuidadosamente: los conjuntos de entrenamiento, validación y prueba se dividen a nivel de fotograma o pista (no a nivel de baldosa) para evitar la fuga por autocorrelación espacial, donde baldosas adyacentes de la misma pista aparecen tanto en los conjuntos de entrenamiento como de prueba.
Una ejecución típica de smoke test para el pipeline de la cabeza de defectos:
Una ejecución típica de evaluación completa:
El smoke test es 10-100× más rápido que la evaluación completa, permitiendo la ejecución por commit. La evaluación completa se ejecuta en una cadencia más lenta (por noche, por lanzamiento, por promoción a producción).
| Modo de Fallo | Detectado Por |
|---|---|
| Archivo de checkpoint corrupto | Smoke test (fatal) |
| NaN/inf en salidas del modelo | Smoke test (fatal) |
| Columnas de salida faltantes | Smoke test (crítico) |
| Forma incorrecta del tensor de salida | Smoke test (crítico) |
| Discrepancia de normalización en preprocesamiento | Smoke test (fatal) |
| Predicciones degeneradas (todas la misma clase) | Smoke test (advertencia) |
| Caída del 10% de AP en nuevos datos | Evaluación completa |
| Sobreajuste a un tipo específico de pavimento | Evaluación completa |
| Deriva de calibración | Evaluación completa |
| Ruido en etiquetas de datos de entrenamiento | Evaluación completa |
La matriz de cobertura demuestra que los smoke tests y las evaluaciones completas son complementarios — cada uno detecta modos de fallo que el otro no detecta. Una estrategia integral de pruebas de ML requiere ambos.
La integración del smoke test de la cabeza de defectos en los pipelines de integración continua (CI) es esencial para detectar regresiones tempranamente y asegurar que cada cambio de código sea validado antes de afectar los sistemas de producción.
El pipeline CI para el sistema de detección de defectos de TarmacView está organizado en etapas secuenciales:
Etapa 1 — Calidad del Código: Linting (flake8, pylint), verificación de tipos (mypy), pruebas unitarias (pytest para utilidades de carga de datos, funciones de preprocesamiento y funciones de cálculo de métricas). Esta etapa se ejecuta en CPU y se completa en 1-3 minutos. El fallo bloquea todas las etapas posteriores.
Etapa 2 — Validación de Datos: Validación de esquema de los conjuntos de datos de entrenamiento y evaluación utilizando Great Expectations o TensorFlow Data Validation. Verifica la presencia de columnas, tipos de datos, rangos de valores y estadísticas de distribución contra las expectativas definidas en el contrato de datos. Esta etapa se ejecuta en CPU y se completa en 2-5 minutos.
Etapa 3 — Smoke Test de la Cabeza de Defectos: El conjunto completo de pruebas de smoke testing descrito en este artículo. Se ejecuta en CPU (o GPU mínima si está disponible) y se completa en 15-60 segundos. El fallo bloquea la fusión a main.
Etapa 4 — Pruebas Unitarias para Evaluación: Pruebas de cálculo de métricas a pequeña escala que verifican que el cálculo de AP, el cálculo de F1 y la generación de matrices de confusión produzcan salidas correctas en conjuntos de datos pequeños etiquetados manualmente (5-10 imágenes con verdad fundamental conocida). Se ejecuta en CPU, se completa en 30 segundos.
Etapa 5 — Entrenamiento (bajo demanda): Se activa solo cuando se espera que los pesos del modelo cambien (nuevos datos de entrenamiento, cambios de arquitectura, ajuste de hiperparámetros). No se activa automáticamente en cada commit. Se ejecuta en GPU y toma de 1 a 8 horas dependiendo del tamaño del conjunto de datos.
Etapa 6 — Evaluación Completa (al fusionar en main): Se activa cuando el código se fusiona en la rama principal. Ejecuta el conjunto completo de evaluación en el conjunto de validación reservado, calcula todas las métricas, compara contra líneas base y publica los resultados en el registro del modelo. Se ejecuta en GPU y toma de 20 a 40 minutos.
El smoke test se activa en:
Los artefactos CI del smoke test se almacenan y versionan:
Estos artefactos se almacenan en el registro del modelo junto al artefacto del modelo en sí, proporcionando una pista de auditoría completa: “Esta versión del modelo pasó el smoke test con datos sintéticos v3.2 en la ejecución CI #4827 con el commit a3f2c1.”
Cuando el smoke test falla, se envían notificaciones a través de múltiples canales:
La notificación incluye un informe de error estructurado:
Asunto: [SMOKE FALLÓ] pipeline defect-head - main - ejecución #4827
Cuerpo:
Commit: a3f2c1 (fusionado 12:34 UTC)
Checkpoint: defect-head:v3 (candidato-producción)
Resultado: FALLÓ (gate_score=1.0)
Fatal (1):
- [output_nan] El tensor de salida contiene valores NaN
El pase hacia adelante del backbone produjo NaN en la normalización de capa 8
Crítico (0):
Advertencia (2):
- [class_efflorescence_ap] AP@0.50 = 0.42 por debajo del umbral 0.50
- [class_efflorescence_f1] F1 = 0.55 por debajo del umbral 0.60
Acción requerida: Investigar NaN en la normalización de capa 8 del backbone.
Causas posibles: checkpoint corrupto, discrepancia de versión de CUDA,
o inestabilidad numérica en el cálculo de atención.
La interpretación correcta de las salidas del smoke test es esencial para diagnosticar problemas del pipeline y determinar las acciones de remediación apropiadas.
El smoke test genera un informe JSON completo estructurado de la siguiente manera:
{
"pipeline_id": "defect-head-smoke",
"run_id": "2026-06-16-4827",
"timestamp": "2026-06-16T12:34:56Z",
"commit_sha": "a3f2c1d4e5b6...",
"checkpoint_version": "defect-head:v3",
"synthetic_data_version": "v3.2",
"gate_result": "FAIL",
"gate_score": 1.0,
"assertions": {
"checkpoint_file_exists": {"status": "PASS", "detail": "checkpoint.pt (842MB)"},
"checkpoint_loadable": {"status": "PASS", "detail": "Diccionario de estado cargado exitosamente"},
"forward_pass_shape": {"status": "PASS", "detail": "Forma de salida (8, 5)"},
"output_no_nan": {"status": "FAIL", "detail": "NaN encontrado en 1 de 8 muestras del lote"},
"output_no_inf": {"status": "PASS", "detail": "Sin valores inf"},
"softmax_sum": {"status": "PASS", "detail": "Todas las sumas dentro de 1e-5 de 1.0"},
"tile_columns_exist": {"status": "PASS", "detail": "Las 5 columnas de baldosa presentes"},
"frame_columns_exist": {"status": "PASS", "detail": "Las 7 columnas de fotograma presentes"},
"column_value_ranges": {"status": "PASS", "detail": "Todos los valores en [0.0, 1.0]"},
"class_crack_ap50": {"status": "PASS", "detail": "AP@0.50 = 0.92"},
"class_spalling_ap50": {"status": "PASS", "detail": "AP@0.50 = 0.88"},
"class_efflorescence_ap50": {"status": "WARN", "detail": "AP@0.50 = 0.42"},
"class_exposed_rebar_ap50": {"status": "PASS", "detail": "AP@0.50 = 0.91"},
"class_corrosion_ap50": {"status": "PASS", "detail": "AP@0.50 = 0.90"}
}
}
El informe debe leerse de arriba a abajo, abordando primero los fallos fatales (ya que invalidan todos los resultados posteriores), luego los fallos críticos (problemas estructurales que causarían fallos en producción) y finalmente los fallos de advertencia (regresiones de calidad que pueden requerir investigación).
Los fallos fatales indican que el pipeline es completamente no funcional. Las causas raíz más comunes y su remediación:
Archivo de checkpoint no encontrado: La ruta del checkpoint especificada en la configuración del pipeline no apunta a un archivo existente. Remedio: verificar la ruta del registro del modelo, comprobar que la ejecución de entrenamiento se completó y subió el artefacto, o actualizar la configuración con la ruta correcta.
Fallo de carga del checkpoint: torch.load() lanzó una excepción. Las causas comunes incluyen: corrupción del archivo (re-ejecutar entrenamiento o restaurar desde copia de seguridad), discrepancia de versión de PyTorch (verificar que el entorno de despliegue tenga la misma versión de PyTorch que el entorno de entrenamiento — torch.save() con PyTorch 2.0 produce archivos que se cargan de manera diferente en PyTorch 1.x), o discrepancia CUDA/no-CUDA (un checkpoint guardado con tensores CUDA puede fallar al cargarse en un entorno solo con CPU sin map_location='cpu').
NaN en las salidas: El fallo fatal más desafiante técnicamente. Las causas comunes incluyen: inestabilidad numérica en el mecanismo de atención de DINOv3 (desbordamiento de la normalización de capa con valores de entrada extremos), pesos corruptos en una capa específica (verificar qué capa produce el NaN ejecutando con torch.autograd.set_detect_anomaly(True)), o preprocesamiento que produce entradas fuera de rango (por ejemplo, valores de píxel más allá de [0,1] después de la normalización).
Discrepancia de forma de salida: El tensor de salida tiene una forma diferente a la esperada. Las causas comunes incluyen: la cabeza MLP fue reemplazada por una arquitectura diferente (diferente número de clases de salida), la dimensión de incrustación del backbone cambió (checkpoint de una variante diferente de DINOv3), o la dimensión del lote fue comprimida/expandida incorrectamente en el código de posprocesamiento.
Los fallos críticos indican problemas estructurales que causarían un comportamiento incorrecto en producción.
Columnas faltantes: El DataFrame de salida del análisis carece de columnas esperadas. Causas comunes: la convención de nombres de columnas se cambió sin actualizar los consumidores posteriores, la lógica de agregación se modificó para renombrar columnas, o la salida de la cabeza de defectos se cambió (por ejemplo, de 5 clases a 4 clases).
Violaciones de rango de valores: Valores de confianza fuera de [0.0, 1.0]. Esto casi siempre indica un mal funcionamiento de softmax — ya sea que no se aplicó softmax a los logits, o que se utilizó el eje incorrecto para la normalización softmax. Verificar que se esté usando F.softmax(logits, dim=1) (dimensión de clase, no dimensión de lote).
NaN en columnas de salida: Similar al NaN fatal en las salidas del modelo, pero ocurriendo en el paso de agregación de posprocesamiento. Verificar división por cero en la agregación de baldosa a fotograma (por ejemplo, dividiendo por el número de baldosas cuando el fotograma tiene cero baldosas), o propagación de valores faltantes desde salidas NaN del modelo que no fueron detectadas a nivel del modelo.
Los fallos de advertencia indican degradación de la calidad que puede no requerir bloqueo inmediato del despliegue pero debe ser investigada.
AP específica de clase por debajo del umbral: Una sola clase de defecto muestra un rendimiento significativamente menor que las demás. Causas comunes: ejemplos de entrenamiento sintéticos insuficientes para esa clase (el generador de datos sintéticos puede producir ejemplos poco realistas para algunas clases), desbalance de clases en los datos de entrenamiento reales que afecta la capacidad discriminativa de la cabeza para clases raras, o que las características del backbone sean menos informativas para ciertos tipos de defectos (por ejemplo, la eflorescencia se caracteriza por el color (depósitos blancos) más que por la textura, mientras que las características de DINOv3 pueden enfatizar la textura sobre el color).
Desequilibrio precisión-recall: El modelo es demasiado conservador o demasiado agresivo para clases específicas. Causas comunes: el umbral de confianza se optimizó para el rendimiento general pero es subóptimo para clases individuales, o los datos de entrenamiento tienen ruido asimétrico (más falsos negativos que falsos positivos para una clase específica).
Deriva de métricas respecto a la línea base: Las métricas han cambiado más del 5% desde la última ejecución validada sin cambios de código o datos. Esto puede indicar: no determinismo en el modelo (capas de dropout o normalización por lotes que se comportan de manera diferente en modo train vs eval — asegurar que se llame model.eval() antes de la inferencia), deriva numérica debido a diferencias de hardware (orden de acumulación de coma flotante entre CPU y GPU), o cambios en el generador de datos sintéticos que producen muestras de prueba diferentes.
La salida del smoke test incluye sugerencias de remediación para modos de fallo comunes:
| Fallo | Sugerencia de Remediación |
|---|---|
| Checkpoint no encontrado | Verificar la ruta del registro del modelo; ejecutar entrenamiento para generar el checkpoint |
| NaN en el backbone | Cambiar a precisión float32 si se usa float16; añadir recorte de gradiente |
| Columna faltante | Actualizar nombres de columna en la lógica de agregación para que coincidan con el esquema |
| AP baja en clase específica | Añadir más ejemplos de entrenamiento sintéticos para esa clase; verificar el balance de clases |
| Deriva de métricas | Ejecutar inferencia con torch.inference_mode() y model.eval(); verificar operaciones no deterministas |
Estas sugerencias son generadas por un sistema basado en reglas que mapea patrones de fallo de aserciones a acciones de remediación conocidas, reduciendo el tiempo medio de resolución (MTTR) para modos de fallo comunes.

TarmacView implementa rigurosos pipelines de smoke testing y evaluación para la detección de defectos estructurales basada en IA en pavimentos de aeródromos e infraestructura de hormigón. Solicita una demostración para ver cómo las pruebas automatizadas garantizan la fiabilidad del despliegue.
Una prueba de humo es una verificación rápida de extremo a extremo de que un pipeline de software se ejecuta sin fallos en datos representativos, produciendo lo...
DINOv3 (self-DIstillation with NO labels v3) es un vision transformer (ViT-B/16) autosupervisado, preentrenado con 1.7 mil millones de imágenes, que produce emb...
La segmentación de grietas es la tarea de visión por computadora que clasifica cada píxel de una imagen como grieta o no grieta, produciendo una máscara binaria...