La segmentation de fissures est une tâche de vision par ordinateur consistant à classer chaque pixel d’une image comme fissure ou non-fissure, produisant un masque binaire qui permet une mesure précise de la géométrie des fissures — surface, longueur, largeur et analyse des motifs. Les têtes de segmentation denses basées sur DINOv3 et les architectures U-Net sont à l’état de l’art pour l’inspection des infrastructures.
Segmentation de fissures au niveau pixel pour l’inspection des infrastructures
1. Définition et différence avec la classification de fissures
La segmentation de fissures est une tâche de prédiction dense de pixels en vision par ordinateur qui attribue une étiquette binaire (fissure ou non-fissure) à chaque pixel individuel d’une image d’entrée. La sortie est un masque de segmentation binaire de mêmes dimensions spatiales que l’entrée, où les pixels de fissure sont marqués comme premier plan (généralement blanc ou valeur 1) et les pixels non-fissure comme arrière-plan (noir ou valeur 0). Ce masque préserve la morphologie, la topologie et la géométrie exactes de chaque fissure présente dans la scène, y compris les branches, les fragments isolés et les fissures de largeur submillimétrique.
La classification de fissures opère au niveau de l’image — le modèle produit un scalaire unique indiquant si une fissure est présente quelque part dans l’image. Un modèle de classification pourrait prédire « fissure présente : confiance 93 % » mais ne peut pas localiser où se trouve la fissure, ni sa longueur, ni sa largeur. Cela est fondamentalement insuffisant pour l’inspection des infrastructures où des mesures précises guident la priorisation de la maintenance, l’estimation des coûts de réparation et l’évaluation de la sécurité structurelle.
La détection de fissures via la détection d’objets (Faster R-CNN, YOLO, SSD) produit des boîtes englobantes autour des régions de fissures. Bien que la détection fournisse une localisation, une boîte englobante autour d’une fissure fine et allongée contient principalement des pixels d’arrière-plan et ne transmet aucune information sur la largeur, la topologie ou la structure de ramification de la fissure. Une fissure qui serpente à travers une piste peut nécessiter des dizaines de boîtes englobantes qui se chevauchent sans relation sémantique entre elles.
La segmentation de fissures résout toutes ces limitations. Chaque pixel de fissure est identifié, permettant la mesure directe de :
La surface de la fissure en millimètres carrés (nombre de pixels × résolution spatiale)
La longueur de la fissure le long de la ligne centrale squelettisée en millimètres
La largeur de la fissure (profils de largeur moyenne, maximale et par pixel)
Les motifs de ramification (nombre de branches, points de jonction, dimension fractale)
Les statistiques par composante (nombre total de fissures distinctes, densité spatiale, connectivité)
L’Annexe 14 de l’Organisation de l’Aviation Civile Internationale (OACI) — Aérodromes, Volume I, spécifie que les surfaces des pistes doivent être régulièrement inspectées pour détecter la détérioration, y compris la fissuration. Le Doc 9157 de l’OACI, Partie 3 — Chaussées, fournit des orientations sur les méthodes d’évaluation des chaussées. L’inspection manuelle traditionnelle implique des inspecteurs marchant sur la piste, marquant les fissures à la craie ou à la peinture, et enregistrant les observations sur des formulaires papier — un processus subjectif, incohérent, dangereux (exposition aux opérations aéronautiques en direct) et impossible à réaliser avec une précision submillimétrique. La segmentation automatisée des fissures remplace l’estimation visuelle subjective par des mesures reproductibles, quantitatives et précises au pixel près qui peuvent être comparées entre inspections et entre aéroports.
Tâche
Sortie
Localisation des fissures
Géométrie des fissures
Précision de mesure
Classification
Étiquette unique (fissure/pas de fissure)
Aucune
Aucune
Niveau image
Détection
Boîtes englobantes
Boîte approximative
Aucune
Niveau boîte
Segmentation
Masque binaire
Précise au pixel près
Géométrie complète
Niveau pixel (sub-mm)
La transition de la classification à la segmentation représente un bond fondamental en capacité. La classification répond « y a-t-il une fissure ici ? » La segmentation répond « où se trouve exactement chaque fissure, quelle est sa taille, quelle forme a-t-elle et quelle est la gravité des dommages ? » Pour le crack_seg_head de TarmacView, cette capacité de prédiction dense de pixels est le fondement de la production de masques de fissures de haute précision qui alimentent directement les calculs d’indice de condition des chaussées, l’estimation des quantités de réparation et l’analyse de tendance longitudinale.
2. Architectures de segmentation
U-Net
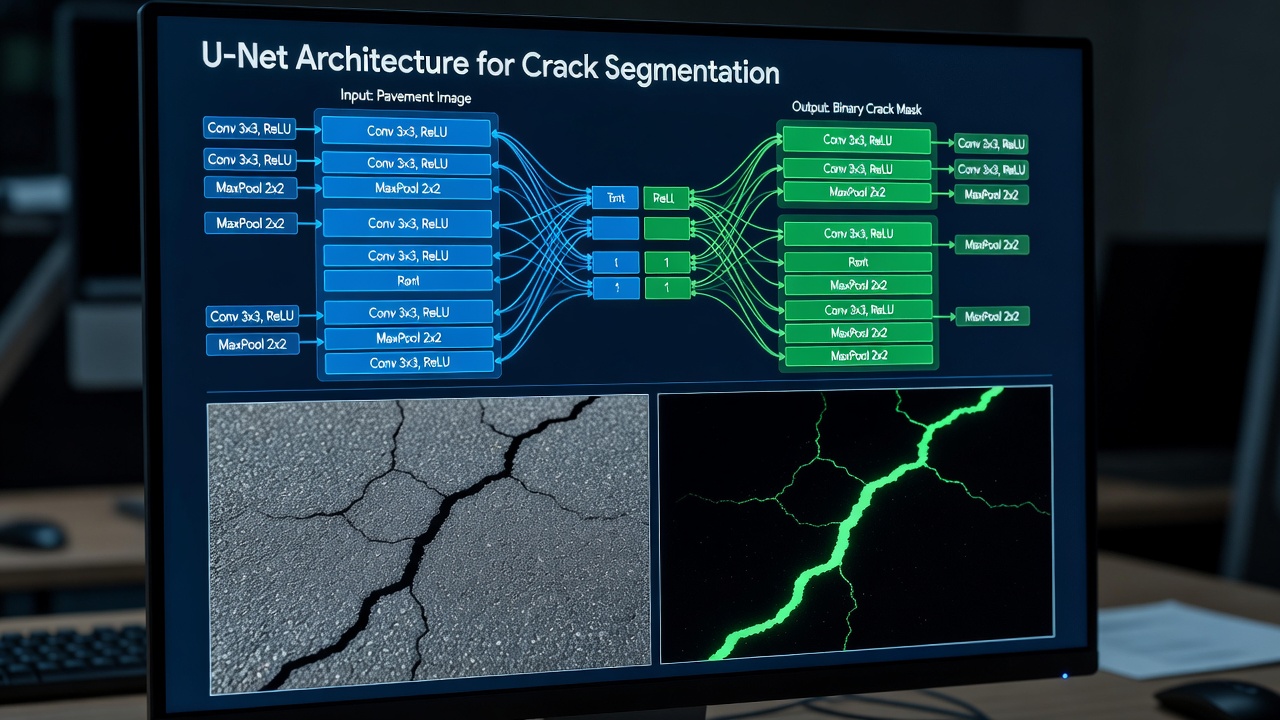
L’architecture U-Net, introduite par Ronneberger, Fischer et Brox en 2015 pour la segmentation d’images biomédicales, est devenue l’architecture la plus largement adoptée pour la segmentation de fissures dans les applications d’infrastructure. U-Net se compose d’une structure symétrique encodeur-décodeur avec quatre ou cinq niveaux de résolution connectés par des connexions de saut qui transmettent l’information spatiale haute résolution directement des couches de l’encodeur au décodeur.
L’encodeur (chemin de contraction) applique des convolutions 3×3 répétées suivies d’une activation ReLU et d’un max pooling 2×2, réduisant progressivement les dimensions spatiales tout en augmentant la profondeur des canaux de caractéristiques de 64 à 512 ou 1024 canaux. Chaque bloc de l’encodeur apprend des représentations de plus en plus abstraites — des simples détecteurs de contours dans la première couche aux détecteurs complexes de texture et de morphologie de fissures dans les couches les plus profondes. Pour la segmentation de fissures, l’encodeur doit apprendre à distinguer les vraies caractéristiques de fissures des textures ressemblant à des fissures, notamment les ombres d’agrégats, les marques de pneus, les joints de construction, les débris de surface et les traînées de produit d’étanchéité.
Le décodeur (chemin d’expansion) effectue l’opération miroir : la surconvolution 2×2 (convolution transposée) double la résolution spatiale tout en réduisant de moitié la profondeur des canaux, puis concatène la carte de caractéristiques correspondante de l’encodeur via la connexion de saut, suivie de deux convolutions 3×3 avec ReLU. La dernière couche utilise une convolution 1×1 avec activation sigmoïde pour produire le masque binaire de fissures.
Les connexions de saut sont l’innovation critique de U-Net. Dans les architectures encodeur-décodeur standard, tous les détails spatiaux sont perdus lors du sous-échantillonnage et doivent être réappris dans le décodeur. Les connexions de saut transfèrent directement l’information spatiale à grain fin — bords de fissures, lignes de fissures fines et limites précises — de l’encodeur au décodeur à chaque niveau de résolution. Cela est essentiel pour la segmentation de fissures car les fissures sont par nature des structures fines (souvent 1 à 10 pixels de large) qui seraient complètement perdues au niveau du goulot d’étranglement (sous-échantillonnées 32×).
Pour la segmentation de fissures spécifiquement, les variantes de U-Net incluent :
Attention U-Net : Ajoute des portes d’attention qui suppriment les caractéristiques d’arrière-plan non pertinentes tout en mettant en évidence les régions de fissures
Residual U-Net : Remplace les convolutions standard par des blocs résiduels, permettant des réseaux plus profonds sans gradients évanescents
Dense U-Net : Utilise des blocs denses (style DenseNet) pour une meilleure propagation des caractéristiques et du flux de gradient
U-Net++ : Ajoute des connexions de saut imbriquées avec des blocs convolutionnels denses, réduisant l’écart sémantique entre les caractéristiques de l’encodeur et du décodeur
U-Net atteint des performances à l’état de l’art sur les benchmarks de segmentation de fissures, notamment CRACK500 (IoU 0,65-0,72) et DeepCrack (IoU 0,70-0,78) lorsqu’il est entraîné avec des fonctions de perte et une augmentation de données appropriées.
DeepLabV3+
DeepLabV3+, développé par Google Research (Chen et al., 2018), étend la famille DeepLab avec une structure encodeur-décodeur augmentée par un Pooling Pyramidal Spatial Atrous (ASPP) . L’innovation centrale est l’utilisation de convolutions atrous (dilatées) avec plusieurs taux de dilatation appliqués en parallèle pour capturer des informations contextuelles multi-échelles sans réduire la résolution spatiale.
L’ASPP applique des convolutions 3×3 à différents taux de dilatation — généralement des taux de 6, 12 et 18 pour un pas de sortie de 16 — plus une convolution 1×1 et un pooling moyen global. Chaque taux de dilatation capture les caractéristiques de fissure à une échelle différente : le taux 6 capture les fissures fines et étroites (1-3 pixels de large), le taux 12 capture les fissures moyennes, et le taux 18 capture les fissures larges et les réseaux de fissures. Les branches parallèles sont concaténées et traitées par une convolution 1×1 pour produire la représentation de caractéristiques multi-échelles.
Pour la segmentation de fissures, DeepLabV3+ excelle dans la gestion de la variation d’échelle extrême dans l’apparence des fissures. Une seule image de piste peut contenir des fissures capillaires (0,5 mm de large, 1-2 pixels) aux côtés de fissures larges et écaillées (15+ mm de large, 30+ pixels). Le module ASPP traite toutes ces échelles simultanément. Le module décodeur suréchantillonne les caractéristiques ASPP d’un facteur 4, concatène avec les caractéristiques de l’encodeur d’une couche intermédiaire (avant le premier bloc atrous), et applique deux convolutions 3×3 suivies d’un suréchantillonnage bilinéaire à la résolution originale.
Les backbone DeepLabV3+ couramment utilisés pour la segmentation de fissures incluent ResNet-50, ResNet-101 et Xception. Plus récemment, les backbone EfficientNet et ConvNeXt ont été explorés, offrant de meilleurs ratios précision-paramètres. DeepLabV3+ avec backbone ResNet-101 atteint des scores IoU de 0,68-0,75 sur CRACK500 lorsqu’il est entraîné sur des ensembles de données spécifiques aux chaussées.
SegFormer
SegFormer (Xie et al., 2021) introduit un encodeur Transformeur hiérarchique avec un décodeur MLP (perceptron multi-couche) léger, représentant une rupture avec les architectures de segmentation basées sur CNN. L’encodeur utilise une série de blocs Mix Transformer (MiT) avec une résolution progressivement décroissante (de 1/4 à 1/32 de la taille d’entrée) et des dimensions de canaux croissantes. Chaque bloc MiT utilise une auto-attention efficace avec un taux de réduction spatiale réduit, le rendant réalisable sur le plan computationnel pour des images de fissures haute résolution.
L’avantage clé de SegFormer pour la segmentation de fissures est le champ récepteur global du transformeur dès la première couche. Contrairement aux CNN où chaque couche ne voit qu’un voisinage local (par exemple, convolution 3×3 = voisinage d'1 pixel après une couche), les Transformeurs calculent l’attention sur l’ensemble de la carte de caractéristiques. Cela permet à SegFormer de capturer les dépendances à longue portée — une fissure qui serpente à travers une tuile entière de 1024×1024 maintient les relations pixel à pixel via le mécanisme d’attention.
Le décodeur MLP de SegFormer est remarquablement simple comparé aux décodeurs U-Net ou DeepLabV3+. Il agrège les caractéristiques multi-niveaux des quatre étages de l’encodeur (en suréchantillonnant à la résolution 1/4 et en concaténant), applique une seule couche MLP pour le mélange des caractéristiques, puis un autre MLP pour produire la segmentation finale. Malgré sa simplicité, le décodeur MLP atteint de fortes performances car l’encodeur Transformeur hiérarchique produit déjà des caractéristiques bien structurées.
SegFormer-B3 atteint un IoU compétitif (0,66-0,74) sur les ensembles de données de segmentation de fissures tout en étant plus efficace en termes de paramètres que DeepLabV3+ avec ResNet-101. La famille de modèles B0-B5 offre un compromis entre vitesse et précision, B0 étant adapté au déploiement en temps réel sur des appareils embarqués et B5 pour une précision maximale sur du matériel serveur.
Têtes de prédiction dense DINOv2 et DINOv3
DINOv2 (Oquab et al., 2023) et DINOv3 représentent la dernière génération de modèles Vision Transformer (ViT) entraînés via apprentissage auto-supervisé sur des ensembles de données d’images organisés. Contrairement au pré-entraînement supervisé sur ImageNet-1K, DINO utilise une approche d’auto-distillation où un réseau étudiant apprend à correspondre à la sortie d’un réseau enseignant opérant sur différentes vues de la même image (vues locales recadrées vs vues globales).
L’avancée majeure de DINO pour la segmentation est que les caractéristiques ViT auto-supervisées — en particulier les têtes d’attention clé (K) et valeur (V) dans les dernières couches — encodent naturellement les limites des objets et l’information sémantique à grain fin sans aucun entraînement supervisé de segmentation. Un ensemble sparse de tokens de patches (par exemple, 0,05 % des patches) peut être sondé linéairement pour produire des cartes de segmentation qui rivalisent avec les modèles entièrement supervisés.
Pour la segmentation de fissures, une tête de prédiction dense est attachée au backbone DINO. L’approche typique extrait des caractéristiques multi-échelles des 4 à 6 dernières couches du ViT, les concatène, et applique un décodeur convolutionnel qui suréchantillonne à la résolution originale de l’image. Le décodeur peut être :
Une tête linéaire légère : Simplement une convolution 1×1 après suréchantillonnage des tokens de patches ViT (taille de patch 14×14 pour ViT-L/14)
Une tête Feature Pyramid Network (FPN) : Extraction de caractéristiques multi-échelles avec connexions latérales et chemin descendant
Une tête de type MaskFormer : Décodeur Transformeur qui applique une attention croisée aux caractéristiques DINO et produit des masques binaires
La segmentation de fissures basée sur DINOv3 atteint des scores IoU dépassant 0,78 sur CRACK500 et 0,82 sur DeepCrack lorsqu’il est fine-tuning de bout en bout avec des ensembles de données de masques de fissures. Le pré-entraînement auto-supervisé fournit des représentations de caractéristiques robustes qui généralisent mieux aux nouvelles surfaces et conditions d’éclairage comparé aux backbone supervisés ImageNet.
Architecture
Paramètres
IoU CRACK500
Vitesse d’inférence (MP/s)
Avantage clé
U-Net (ResNet-34)
24M
0,68
45
Efficacité avec peu de données
DeepLabV3+ (ResNet-101)
63M
0,72
28
ASPP multi-échelle
SegFormer-B3
47M
0,70
22
Attention globale
DINOv2-ViT-L/14 + tête dense
307M
0,78
8
Caractéristiques auto-supervisées
3. Ensembles de données de masques de vérité terrain
La qualité et la diversité des ensembles de données d’entraînement déterminent directement les performances du modèle de segmentation de fissures. Toutes les méthodes supervisées de segmentation de fissures nécessitent des masques de vérité terrain précis au pixel près — des images binaires où des annotateurs experts ont méticuleusement étiqueté chaque pixel de fissure. Les ensembles de données suivants représentent les benchmarks les plus utilisés dans la recherche en segmentation de fissures.
CRACK500
CRACK500 (Zhang et al., 2016) contient 500 images RVB de surfaces de chaussée capturées avec un appareil photo grand public à une distance d’échantillonnage au sol (GSD) d’environ 0,05 mm/pixel. Chaque image fait 2048×1536 pixels, fournissant une surface physique d’environ 100×75 mm. L’ensemble de données est divisé en 250 images d’entraînement, 50 de validation et 200 de test.
Les masques de vérité terrain ont été annotés manuellement par des inspecteurs formés et contre-vérifiés. Les fissures sont étiquetées avec une précision sub-pixel, y compris les fissures aussi étroites que 0,1-0,2 mm (2-4 pixels). L’ensemble de données présente principalement des chaussées en asphalte avec une variété de types de fissures : fissures transversales, fissures longitudinales, fissuration en peau de crocodile (fatigue), fissuration en blocs et fissuration de bord. L’arrière-plan inclut la texture des agrégats, un mélange de particules d’asphalte grossières et fines, des réparations par patch et des matériaux d’étanchéité.
CRACK500 est l’ensemble de données le plus fréquemment utilisé comme benchmark dans la littérature sur la segmentation de fissures en raison de sa qualité constante, de sa taille raisonnable et de sa disponibilité publique. Les modèles U-Net de base atteignent environ 0,65-0,68 IoU sur la partition de test, les modèles récents basés sur DINOv2 atteignant 0,78-0,80 IoU.
DeepCrack
DeepCrack (Zou et al., 2019) contient 537 images RVB de fissures sur des surfaces en béton et en maçonnerie à une résolution de 512×512 pixels. L’ensemble de données a été conçu spécifiquement pour la segmentation de fissures par apprentissage profond et inclut des types de surfaces variés que l’on ne trouve pas dans les ensembles de données de chaussées seulement : murs en béton, piliers de pont, revêtements de tunnels, façades de bâtiments et surfaces en pierre. Les annotations de vérité terrain ont été générées par plusieurs annotateurs et affinées par un processus de consensus.
Les images DeepCrack incluent des conditions difficiles : ombres, taches d’humidité, végétation envahissante, graffitis et rugosité de surface qui imite visuellement les caractéristiques des fissures. L’ensemble de données fournit des partitions officielles d’entraînement (400 images) et de test (137 images). DeepCrack est particulièrement utile pour évaluer la généralisation cross-surface — les modèles entraînés uniquement sur DeepCrack ont tendance à bien performer sur les nouvelles surfaces en béton mais peuvent avoir des difficultés sur l’asphalte.
Les modèles SOTA atteignent 0,70-0,78 IoU sur DeepCrack. La difficulté de base plus élevée de cet ensemble de données (comparé à CRACK500) provient de la plus grande complexité visuelle et de l’ambiguïté fissure-arrière-plan sur les surfaces en maçonnerie et en béton.
CrackForest (CFD)
CrackForest Dataset (CFD) (Shi et al., 2016) contient 118 images de chaussées routières en asphalte capturées à une résolution de 320×480 pixels. Malgré sa petite taille, CFD est largement utilisé pour la validation croisée en raison d’une annotation soignée et d’un type de surface cohérent. L’ensemble de données présente principalement des fissures transversales et longitudinales sur des routes à trafic moyen.
Les performances sur CFD sont proches de la saturation pour les modèles modernes — DINOv2 atteint 0,84-0,87 IoU — mais le petit ensemble d’évaluation signifie que la significativité statistique des différences est limitée. CFD est le plus couramment utilisé comme test de transfert d’apprentissage pour vérifier si les modèles entraînés sur des ensembles de données plus grands (CRACK500, DeepCrack) conservent leur précision sur ce domaine de capture distinct.
CrackAirport
CrackAirport est un ensemble de données spécialisé pour la segmentation de fissures dans les chaussées aéroportuaires, contenant des images de pistes, voies de circulation et aires de trafic capturées lors d’inspections aéroportuaires de routine. Les chaussées aéroportuaires présentent des défis uniques absents des ensembles de données routières : surfaces de pistes rainurées (rainures transversales espacées d’environ 30 mm conçues pour le drainage de l’eau), dépôts de caoutchouc provenant de l’atterrissage des aéronefs (réduisant le contraste fissure-chaussée), taches de carburant et de liquide hydraulique, et systèmes spécialisés de joints et de produits d’étanchéité.
L’ensemble de données inclut des images à plusieurs valeurs de GSD (0,1-0,5 mm/pixel) capturées depuis des caméras montées sur véhicule et des appareils portables. Les types de fissures spécifiques aux chaussées aéroportuaires — cassures de coin (chaussée rigide), pompage (perte de matière sous les joints) et éclats (perte d’agrégats) — sont annotés aux côtés des types de fissures standard. CrackAirport est essentiel pour entraîner des modèles qui doivent opérer sur de vraies surfaces aéroportuaires où un modèle entraîné sur des routes produirait des faux positifs inacceptables sur des textures rainurées ou des dépôts de caoutchouc.
Ensemble de données compilé CrackSeg9k
CrackSeg9k (Kulkarni et al., 2022) représente la plus grande compilation unifiée de segmentation de fissures, combinant des images de 9+ sous-ensembles de données : AigleRN (38 images), CFD (118), Crack500 (500), DeepCrack (537), CrackTree200 (200), GAPs384 (384), CrackLS315 (315), Stone331 (331) et des collections personnalisées supplémentaires totalisant plus de 9000 images après filtrage qualité. Les auteurs ont appliqué un affinement par traitement d’image pour unifier les annotations de vérité terrain inconsistantes — certains sous-ensembles utilisaient des annotations en lignes fines (lignes centrales de 1-3 pixels de large), d’autres utilisaient des annotations de régions pleine épaisseur.
Le pipeline d’affinement incluait :
Révision manuelle et réétiquetage des images incorrectement annotées
Dilatation morphologique pour étendre les annotations en lignes fines afin qu’elles correspondent aux standards de vérité terrain pleine épaisseur
Suppression du bruit (amas de pixels isolés de moins de 5 pixels supprimés)
Alignement des masques par registration d’image pour corriger le décalage spatial entre l’image et l’annotation
CrackSeg9k catégorise les fissures en classes morphologiques linéaire (simple, non ramifiée), ramifiée (divisions en Y ou T) et réticulée (en réseau, type peau de crocodile). Cette catégorisation permet d’entraîner des têtes de segmentation spécifiques à chaque classe qui peuvent mieux capturer la variabilité morphologique. Les modèles entraînés sur CrackSeg9k démontrent une généralisation cross-surface significativement améliorée par rapport aux modèles entraînés sur un seul ensemble de données.
Tableau comparatif des ensembles de données
Ensemble de données
Images
Résolution
Type de surface
Types de fissures
GSD (mm/pixel)
Public
CRACK500
500
2048×1536
Chaussée asphaltée
Tous types
0,05
Oui
DeepCrack
537
512×512
Béton, maçonnerie
Linéaire, ramifiée
0,1-0,3
Oui
CrackForest
118
320×480
Route asphaltée
Transversale, longitudinale
0,15
Oui
CrackAirport
~300
Variable
Piste/voie de circulation
Spécifique aéroport
0,1-0,5
Limitée
CrackSeg9k
9000+
Mixte
Toutes surfaces
Tous types
Mixte
Oui
4. Fonctions de perte pour la segmentation de fissures
La segmentation de fissures est fondamentalement un problème de segmentation binaire avec déséquilibre de classe. Dans une image de piste typique, les pixels de fissure constituent 0,1 % à 5 % du total des pixels. Une fonction de perte naïve qui traite tous les pixels de manière égale produirait un modèle qui prédit simplement « arrière-plan » pour chaque pixel et atteindrait une précision de 95 %+ tout en ne détectant aucune fissure. Des fonctions de perte spécialisées sont essentielles pour forcer le modèle à apprendre la classe minoritaire des fissures.
Perte d’entropie croisée binaire (BCE)
La perte BCE (également appelée perte logistique) calcule l’entropie croisée binaire pixel par pixel entre la carte de probabilités prédite et le masque de vérité terrain :
où (y_i) est l’étiquette de vérité terrain (0 ou 1) pour le pixel (i), (p_i) est la probabilité prédite pour le pixel (i), et (N) est le nombre total de pixels.
La BCE standard pondère chaque pixel de manière égale. Pour la segmentation de fissures, une variante BCE pondérée est couramment utilisée :
où (w_+) (poids de la classe positive) est défini à (N / (2 \cdot N_{fissure})) et (w_-) (poids de la classe négative) est défini à (N / (2 \cdot N_{fond})). Cela pondère inversement les classes selon leur fréquence — si les fissures représentent 1 % des pixels, chaque pixel de fissure reçoit 50× le poids d’un pixel d’arrière-plan.
La perte BCE traite chaque pixel indépendamment et n’optimise pas explicitement le chevauchement entre prédiction et vérité terrain. Elle se comporte bien pour l’optimisation par gradient mais tend à produire des prédictions légèrement floues aux bords des fissures.
Perte Dice
La perte Dice optimise directement le coefficient Dice (score F1) — le chevauchement entre les régions de fissures prédites et de vérité terrain :
où (\epsilon) est une constante de lissage (généralement 1×10⁻⁶) pour éviter la division par zéro.
La propriété critique de la perte Dice est qu’elle est basée sur la région plutôt que sur le pixel. Elle mesure le chevauchement entre la région de fissure prédite et la région de fissure de vérité terrain dans son ensemble, gérant naturellement le déséquilibre de classe car les deux termes du dénominateur portent sur l’image entière. La perte Dice est particulièrement efficace pour la segmentation de fissures car :
Elle optimise directement la métrique d’évaluation (Dice/IoU) utilisée pour l’évaluation finale du modèle
Elle gère le déséquilibre de classe extrême sans pondération (les fissures peuvent représenter 0,1 % des pixels et Dice fonctionne toujours)
Elle produit des limites de prédiction nettes car le chevauchement de région est maximisé
Le gradient de la perte Dice est bien défini mais peut être instable lorsque le masque de prédiction et la vérité terrain n’ont aucun chevauchement (numérateur et dénominateur proches de zéro). Le terme de lissage (\epsilon) atténue ce problème.
Perte Focal
La perte Focal (Lin et al., 2017) a été introduite pour la détection dense d’objets (RetinaNet) et adapte la BCE en sous-pondérant les pixels bien classés et en se concentrant sur les exemples difficiles :
où (p_t = p_i) si (y_i = 1) et (p_t = 1-p_i) si (y_i = 0), (\alpha_t) est un poids d’équilibrage de classe, et (\gamma) est le paramètre de focalisation (généralement 2,0).
Le facteur modulateur ((1-p_t)^\gamma) réduit la contribution des exemples faciles (où (p_t) est proche de 1) et concentre l’entraînement sur les exemples difficiles (où (p_t) est proche de 0,5). Pour la segmentation de fissures, cela signifie que le modèle concentre son apprentissage sur :
Les pixels de bord de fissure (là où la fissure rencontre l’arrière-plan et où les prédictions sont incertaines)
Les fissures très fines que le modèle pourrait autrement ignorer
Les pixels de fissure dans des arrière-plans difficiles (ombres, taches, textures rugueuses)
La perte Focal avec (\gamma = 2,0) et (\alpha = 0,25) (poids de la fissure) atteint de bons résultats sur les benchmarks de segmentation de fissures, améliorant typiquement l’IoU de 3 à 5 % par rapport à la BCE seule.
Perte Combo
La perte Combo (également appelée perte hybride) combine plusieurs fonctions de perte pour tirer parti de leurs forces complémentaires. Les formulations les plus courantes pour la segmentation de fissures sont :
avec (\lambda) typiquement réglé à 0,5-0,7. La perte Dice fournit une optimisation du chevauchement au niveau région ; la BCE fournit une stabilité du gradient au niveau pixel et une information de bord à grain fin.
Cette combinaison s’est avérée la plus efficace pour la segmentation de fissures dans plusieurs études (F. Zhao et al., 2023), atteignant une amélioration de 2 à 4 % de l’IoU par rapport à Dice seul. Le terme Dice assure le chevauchement de la région de fissure, tandis que le terme Focal force le modèle à se concentrer sur les pixels de fissure difficiles — fissures fines, points de ramification, fissures à faible contraste.
La perte Tversky est une généralisation de la perte Dice qui ajoute une pondération séparée pour les faux positifs et les faux négatifs :
où (\beta) contrôle la pénalité des faux positifs. Pour la segmentation de fissures, (\beta = 0,7) (pénalité plus élevée sur les faux négatifs — fissures manquées) est courant car une fissure non détectée qui s’agrandit avec le temps présente un risque de sécurité plus grand qu’une caractéristique non-fissure signalée par erreur.
Fonction de perte
Déséquilibre de classe
Netteté des bords
Concentration sur exemples difficiles
IoU typique
BCE
Faible (nécessite pondération)
Faible
Non
0,55-0,62
BCE pondérée
Bonne
Moyenne
Non
0,62-0,68
Dice
Excellente
Élevée
Faible
0,65-0,72
Focal
Bonne
Moyenne
Forte
0,64-0,70
Combo Dice + Focal
Excellente
Élevée
Forte
0,68-0,76
Tversky ((\beta=0,7))
Excellente
Élevée
Axée FN
0,67-0,74
5. Post-traitement des sorties de segmentation
Les prédictions brutes du modèle produisent une carte de probabilités (valeurs flottantes entre 0,0 et 1,0) qui doit être convertie en un masque binaire propre par une séquence d’opérations de post-traitement. La qualité de ces opérations affecte directement la précision des mesures de géométrie en aval.
Seuillage
La première étape de post-traitement convertit la carte de probabilités continue en un masque binaire. Le seuillage global applique un seuil fixe (T) (généralement 0,3-0,5) à chaque pixel. Le seuil optimal est déterminé en évaluant l’IoU sur l’ensemble de validation pour une gamme de valeurs de seuil (par exemple, 0,1 à 0,9 par incréments de 0,05). Les modèles entraînés avec la perte Dice fonctionnent généralement mieux avec des seuils de 0,3-0,4 ; les modèles entraînés avec BCE nécessitent des seuils plus élevés de 0,4-0,5.
Le seuillage d’Otsu détermine automatiquement le seuil optimal en maximisant la variance inter-classes dans l’histogramme des probabilités. Pour la segmentation de fissures, la méthode d’Otsu tend à fixer le seuil à 0,4-0,6 selon le rapport fissure/arrière-plan dans l’image. Elle est particulièrement utile lorsque la distribution des probabilités varie d’une image à l’autre (par exemple, différentes conditions d’éclairage lors d’un levé de piste).
Nettoyage morphologique
Après le seuillage, le masque binaire contient du bruit de type sel et poivre : des pixels de premier plan isolés (bruit de taches) où le modèle a classé par erreur l’arrière-plan comme fissure, et de petits trous dans les régions de premier plan où le modèle a manqué des pixels de fissure.
L’ouverture (érosion suivie de dilatation) supprime le bruit de premier plan de petite taille :
Érosion : Pour chaque pixel de premier plan, vérifier si tous ses voisins 4-connectés ou 8-connectés sont aussi du premier plan ; sinon, le marquer comme arrière-plan. Cela supprime les pixels de fissure isolés.
Dilatation : Pour chaque pixel d’arrière-plan adjacent au premier plan, le marquer comme premier plan. Cela restaure les pixels de fissure restants à leur épaisseur d’origine.
Un élément structurant (généralement un noyau en forme de croix 3×3 ou 5×5) contrôle l’opération. Pour la segmentation de fissures, un noyau 3×3 supprime les taches de pixels individuelles sans rétrécir significativement les lignes de fissure réelles.
La fermeture (dilatation suivie d’érosion) comble les petits trous et les lacunes dans les régions de fissures :
Dilater : Étendre les limites des fissures de 1-2 pixels pour combler les lacunes étroites (interruptions de fissures de 1-3 pixels causées par l’incertitude du modèle)
Éroder : Restaurer les limites des fissures à une largeur approximativement originale
L’opération de fermeture est cruciale pour les fissures de chaussées aéroportuaires où les dépôts de caoutchouc de pneus ou les particules d’agrégats peuvent amener le modèle à fragmenter une fissure continue en plusieurs segments. Un seul passage de fermeture avec un noyau 5×5 peut combler des lacunes allant jusqu’à 3 pixels et restaurer la continuité de la fissure.
Analyse en composantes connexes
L’analyse en composantes connexes (CCA) étiquette chaque région de fissure distincte dans le masque binaire avec un identifiant unique. La CCA standard utilise soit la 4-connexité (voisins du pixel uniquement haut/bas/gauche/droite) soit la 8-connexité (inclut les diagonales). Pour la segmentation de fissures, la 8-connexité est préférée car les fissures peuvent se connecter en diagonale à travers l’image.
Après étiquetage, le filtrage par surface supprime les composantes plus petites qu’un seuil de surface minimal (généralement 10-100 pixels selon le GSD). Pour une image de piste à 0,1 mm/pixel, une surface minimale de 50 pixels correspond à une surface de fissure physique de 0,5 mm² — bien en dessous des tailles de fissure actionnables mais supprimant efficacement le bruit de taches. Les composantes en dessous de ce seuil sont presque toujours des faux positifs provenant de la texture des agrégats ou des débris de surface.
Les statistiques au niveau composante calculées lors de la CCA incluent :
Surface de la composante en pixels (convertir en mm² en utilisant le GSD)
Coordonnées de la boîte englobante (pour la localisation)
Coordonnées du centroïde (pour la cartographie)
Excentricité (mesure d’allongement ; les composantes de type fissure ont une excentricité > 0,9)
Convexité (rapport du périmètre au périmètre de l’enveloppe convexe ; les fissures sont non convexes)
Squelettisation
La squelettisation (également appelée amincissement) réduit chaque composante de fissure à une ligne centrale d’un pixel de large tout en préservant la structure topologique de la fissure — connectivité, ramifications et points d’extrémité. Le squelette est essentiel pour la mesure de la longueur et le calcul du profil de largeur.
L’algorithme d’amincissement de Zhang-Suen (1984) est le plus largement utilisé pour la squelettisation des fissures. Il fonctionne de manière itérative :
Sous-itération 1 : Marquer les pixels de bord (pixels de premier plan avec au moins un voisin d’arrière-plan) pour suppression s’ils satisfont :
2 ≤ B(P1) ≤ 6 (nombre de voisins de premier plan entre 2 et 6)
A(P1) = 1 (nombre de connectivité — exactement une transition arrière-plan-vers-premier-plan connectée)
P2 × P4 × P6 = 0
P4 × P6 × P8 = 0
Sous-itération 2 : Mêmes conditions mais avec des vérifications de voisinage différentes :
P2 × P4 × P8 = 0
P2 × P6 × P8 = 0
Répéter jusqu’à ce qu’aucun pixel ne soit supprimé (squelette stable atteint)
L’algorithme de Guo-Hall produit un squelette plus centré pour les fissures épaisses (>10 pixels de large) en utilisant des sous-itérations parallèles qui suppriment les pixels des deux côtés simultanément. Il est préféré pour les fissures fortement écaillées ou en peau de crocodile où la région de fissure est suffisamment large pour avoir une zone intérieure.
Après squelettisation, l’analyse des branches et jonctions identifie :
Les points d’extrémité : Pixels du squelette avec exactement 1 voisin (terminaisons de fissures)
Les points de jonction : Pixels du squelette avec 3 voisins ou plus (points de ramification des fissures)
Les segments de branche : Chemins entre points d’extrémité et jonctions
Cette analyse produit la structure du graphe de fissure — une représentation mathématique de la topologie des fissures sous forme d’un ensemble de sommets (points d’extrémité, jonctions) et d’arêtes (segments de fissure entre eux).
6. Extraction de la géométrie des fissures à partir des masques binaires
Le masque de fissure au niveau pixel combiné à la squelettisation permet l’extraction quantitative de la géométrie des fissures. Ces mesures sont essentielles pour l’évaluation de l’état des chaussées selon les normes de l’OACI et de la FAA, où la sévérité des fissures est classée selon des gammes de largeur (capillaire : <3 mm, moyenne : 3-6 mm, sévère : >6 mm pour les chaussées de piste).
Surface de la fissure
La surface de la fissure est la mesure la plus directe :
[
A_{fissure} = N_{fissure} \times GSD^2
]
où (N_{fissure}) est le nombre total de pixels de fissure dans le masque binaire et (GSD) est la distance d’échantillonnage au sol (mm/pixel) déterminée par calibrage de la caméra ou des marqueurs de référence dans l’image.
Pour le crack_seg_head de TarmacView, le GSD est calculé à partir des paramètres intrinsèques du système de caméra (distance focale, pas de pixel du capteur) et de l’altitude de capture ou de la distance à la cible. Une caméra avec une distance focale de 20 mm, un pas de pixel de 3,45 µm, capturée à 2 mètres de la surface de la chaussée produit un GSD d’environ 0,069 mm/pixel (3,45 µm × 2000 mm / 20 mm).
La surface par composante permet le calcul de la densité de fissuration :
exprimée en pourcentage. Pour les chaussées de pistes, les seuils de densité de fissuration recommandés par l’OACI déclenchent des actions de maintenance.
Longueur de la fissure
La longueur totale de la fissure est mesurée le long de la ligne centrale squelettisée :
où (E) est l’ensemble des arêtes du squelette (segments de branche), et ((x_i, y_i)) sont les coordonnées de pixels consécutives le long de chaque arête. Les pas diagonaux (d’un coin à l’autre) sont multipliés par (\sqrt{2}) par rapport aux pas orthogonaux, rendant la mesure de longueur précise au sous-pixel près.
La longueur peut être calculée par composante, par angle de branche, ou comme un total sur la surface. La densité de longueur de fissuration ((L_{total} / A_{surface}), en mm/mm² ou m/m²) est une métrique d’état de chaussée couramment utilisée.
Largeur de la fissure
La mesure de la largeur de la fissure nécessite le calcul de la distance de chaque pixel du squelette au pixel d’arrière-plan le plus proche dans le masque binaire original. Ceci est réalisé via la Transformée de Distance Euclidienne (EDT) :
Calculer l’EDT sur le masque binaire : pour chaque pixel de premier plan (fissure), calculer sa distance euclidienne au pixel d’arrière-plan le plus proche
Échantillonner les valeurs EDT à chaque pixel du squelette : la valeur EDT à un pixel du squelette est égale à la moitié de la largeur locale de la fissure (distance du squelette au bord le plus proche)
Multiplier par 2 pour la largeur totale, puis multiplier par le GSD pour les unités physiques
La largeur locale de la fissure au pixel du squelette (i) est :
[
w_i = 2 \times EDT(skel_i) \times GSD
]
Les résumés statistiques incluent :
Largeur moyenne de la fissure : (\bar{w} = \frac{1}{N_{skel}} \sum_{i=1}^{N_{skel}} w_i)
Largeur maximale de la fissure : (w_{max} = \max(w_i)) — typiquement dans les zones écaillées ou en peau de crocodile
Profil de largeur : largeur en fonction de la position le long du squelette (pour le classement de sévérité des fissures longitudinales)
Histogramme de largeur : distribution des valeurs de largeur indiquant le type de fissure (largeur uniforme ≈ fissure transversale ; largeur variable ≈ fissure en peau de crocodile)
Selon le rapport sur l’état de la surface des pistes de l’OACI, les fissures dépassant 6 mm de largeur sur les surfaces asphaltées ou 3 mm sur les surfaces en béton sont classées comme « détérioration sévère » nécessitant une intervention de maintenance immédiate.
Statistiques au niveau composante
Pour chaque composante connexe (fissure individuelle), le pipeline d’extraction de géométrie calcule :
Métrique
Unité
Calcul
Objectif
Surface
mm²
Nombre de pixels × GSD²
Étendue totale des dommages
Longueur
mm
Longueur du squelette × GSD
Étendue de la propagation de la fissure
Largeur moyenne
mm
EDT moyenne au squelette × GSD
Classification de sévérité
Largeur max
mm
EDT max au squelette × GSD
Échelle de détérioration maximale
Excentricité
sans unité
(Rapport d’aspect de la composante)
Classification de forme de fissure
Largeur
mm
Largeur max de la composante
Classification de sévérité
Orientation
degrés
Angle de l’axe majeur du squelette
Type de fissure (transversale/longitudinale)
7. Métriques d’évaluation
Les modèles de segmentation de fissures sont évalués à l’aide de métriques au niveau pixel qui comparent le masque binaire prédit au masque de vérité terrain. Ces métriques doivent gérer le déséquilibre de classe extrême inhérent à la segmentation de fissures.
Intersection sur Union (IoU / Indice de Jaccard)
L’IoU est la métrique principale pour l’évaluation de la segmentation de fissures :
où (P) est l’ensemble des pixels de fissure prédits, (T) est l’ensemble des vrais pixels de fissure, (TP) = vrais positifs (pixels de fissure correctement segmentés), (FP) = faux positifs (arrière-plan classé comme fissure), (FN) = faux négatifs (fissure classée comme arrière-plan).
L’IoU va de 0,0 (aucun chevauchement) à 1,0 (chevauchement parfait). Pour la segmentation de fissures, les valeurs typiques d’IoU vont de 0,65 (correct, seuil pour une utilisation pratique) à 0,85 (état de l’art). L’IoU est la métrique de choix car elle pénalise à la fois les faux positifs et les faux négatifs de manière égale — un modèle qui prédit agressivement des fissures partout (rappel élevé, faible précision) reçoit un IoU faible.
Coefficient Dice (Score F1)
Le coefficient Dice (également appelé Sørensen-Dice ou score F1 au niveau pixel) :
Dice est mathématiquement lié à IoU : (Dice = 2 \times IoU / (1 + IoU)). Un IoU de 0,75 correspond à un Dice de 0,857. Dice met l’accent sur les vrais positifs, les pondérant doublement par rapport à IoU. Pour la segmentation de fissures, Dice est la deuxième métrique la plus rapportée et fournit une vision légèrement plus optimiste que IoU.
Précision et Rappel au niveau pixel
La précision au niveau pixel mesure la fraction des pixels de fissure prédits qui sont effectivement des fissures :
[
Précision = \frac{TP}{TP + FP}
]
Une précision élevée signifie peu de faux positifs — le modèle ne confond pas la texture des agrégats, les ombres ou les débris de surface avec des fissures. Les faux positifs dans l’inspection des pistes sont coûteux car ils gaspillent les ressources de maintenance sur des dommages inexistants.
Le rappel au niveau pixel (sensibilité) mesure la fraction des vrais pixels de fissure que le modèle a identifiés avec succès :
[
Rappel = \frac{TP}{TP + FN}
]
Un rappel élevé signifie peu de fissures manquées — le modèle détecte la majeure partie de la surface réelle des fissures. Les faux négatifs dans l’inspection des pistes sont critiques pour la sécurité car une fissure non détectée peut se propager sous le chargement des aéronefs et conduire à une défaillance structurelle.
Le compromis précision-rappel est contrôlé par le seuil (T). Un seuil bas (par exemple 0,2) maximise le rappel au détriment de la précision ; un seuil élevé (par exemple 0,7) maximise la précision mais manque de vraies fissures. Le seuil optimal est généralement celui où la précision et le rappel sont approximativement égaux — le point d’équilibrage F1.
Exactitude pixel
L’exactitude pixel est la métrique la plus simple mais très trompeuse pour la segmentation de fissures :
Si les fissures occupent 1 % des pixels, un modèle qui prédit tout arrière-plan atteint 99 % d’exactitude tout en ne détectant aucune fissure. L’exactitude n’est rapportée que comme métrique secondaire dans la littérature sur la segmentation de fissures et ne devrait jamais être utilisée comme critère d’évaluation principal.
Métriques composites
Le score F-beta généralise F1 avec un poids ajustable sur le rappel :
Pour la segmentation de fissures sur pistes, (F_2) (rappel pondéré 2× la précision) est parfois utilisé car manquer une fissure est plus dangereux que d’en signaler une par erreur. (\beta = 2) signifie que le rappel est deux fois plus important que la précision.
Le F1 de bordure (BF1) évalue la qualité de segmentation spécifiquement aux bords des fissures, calculant la précision et le rappel dans une bande étroite (par exemple 2-3 pixels) autour des limites de fissure de la vérité terrain. BF1 est une métrique plus stricte pour les applications où la précision des bords de fissure est importante pour la mesure de la largeur.
8. Segmentation plein cadre vs par tuiles
La segmentation de fissures sur les surfaces de pistes présente un défi computationnel fondamental : les pistes se mesurent en milliers de mètres linéaires (une piste de code E mesure 45 mètres de large × 3000+ mètres de long), mais les modèles de segmentation acceptent des tenseurs d’entrée typiquement de 512×512 à 1536×1536 pixels en raison des contraintes de mémoire GPU. Deux approches permettent de gérer ce décalage d’échelle.
Segmentation plein cadre
La segmentation plein cadre traite l’image entière de la piste en une seule passe avant dans le modèle. En pratique, une véritable approche plein cadre n’est réalisable que pour de petites surfaces (images de médias sociaux, photos de smartphone en gros plan) ou sur du matériel à mémoire extrêmement élevée (GPU A100 de 80 Go avec des tailles d’image allant jusqu’à 4000×4000 pixels).
Pour l’inspection aéroportuaire, une seule image de levé de piste capturée à 0,2 mm/pixel de GSD couvre environ 1×1 mètre à 5000×5000 pixels — nécessitant 100 Mo de stockage en virgule flottante 32 bits par image. Exécuter U-Net sur une image de 5000×5000 nécessite environ 200 Go de mémoire GPU pour les cartes de caractéristiques intermédiaires — 40× plus que ce qui est disponible sur un A100 (80 Go).
La segmentation plein cadre évite les artefacts de bordure de tuile — pas de coutures, pas de prédictions qui se chevauchent, pas de mélange — fournissant les résultats de la plus haute qualité pour la région qu’elle peut traiter. Cependant, les contraintes de mémoire empêchent un véritable traitement plein cadre de surfaces de pistes réalistes.
Segmentation par tuiles (fenêtre glissante)
La segmentation par tuiles divise l’image d’entrée en tuiles plus petites (typiquement 512×512 ou 1024×1024 pixels), exécute l’inférence indépendamment sur chaque tuile, et assemble les résultats en un masque pleine résolution. C’est l’approche standard pour la segmentation de fissures à l’échelle aéroportuaire.
Chevauchement et mélange : Les tuiles adjacentes se chevauchent de 10 à 25 % pour éviter que les fissures ne soient coupées aux limites des tuiles. La région de chevauchement reçoit les prédictions des deux tuiles, qui sont combinées en utilisant :
Moyenne pondérée : Les pixels près des bords des tuiles reçoivent un poids plus faible ; les pixels près du centre de la tuile reçoivent un poids complet
Assemblage sans couture : Les prédictions sont mélangées en utilisant une transformée de distance — plus on est loin de la couture, plus le poids de la prédiction de cette tuile est élevé
Mélange médian : Pour chaque pixel dans la région de chevauchement, prendre la médiane de toutes les prédictions couvrant ce pixel
La sélection de la taille des tuiles implique un compromis :
Tuiles 512×512 : Inférence rapide, faible mémoire GPU (4-8 Go), mais plus d’artefacts de bordure ; adapté au déploiement temps réel sur périphériques embarqués
Tuiles 1024×1024 : Meilleur contexte pour les grandes fissures, moins de coutures, mais mémoire plus élevée (16-32 Go) et traitement plus lent
Pour le crack_seg_head de TarmacView, une taille de tuile de 1024×1024 avec 15 % de chevauchement offre l’équilibre optimal pour les surfaces de pistes. Une section de piste de 45 m × 45 m à 0,2 mm/pixel (225 000 × 225 000 pixels) nécessite environ 45 000 tuiles dans cette configuration — 37 minutes d’inférence sur un RTX 4090 (20 tuiles/seconde).
Les tuiles multi-échelles améliorent la détection des fissures à différentes largeurs. La même région d’image est traitée à plusieurs échelles (0,5×, 1,0×, 2,0×) et les résultats sont fusionnés. Les petites tuiles au zoom 2,0× capturent les fissures fines ; les grandes tuiles à 0,5× capturent les réseaux de fissures larges.
9. Défis de la segmentation plein cadre des pistes
La segmentation des pistes aéroportuaires impose des défis uniques au-delà de ceux de la segmentation des chaussées routières :
Rainurage de surface : La plupart des pistes principales ont des rainures transversales (3-6 mm de profondeur, espacement de 25-35 mm) découpées dans la surface pour le drainage de l’eau et l’amélioration de la friction. Ces rainures apparaissent dans l’imagerie comme des lignes sombres parallèles qui ressemblent visuellement à des fissures. Les modèles doivent apprendre à distinguer les rainures (espacement régulier, largeur uniforme, orientation parallèle sur toute la largeur de la piste) des fissures (irrégulières, largeur variable, non parallèles). Un modèle entraîné sur des routes produit typiquement 10-30 % de faux positifs sur les pistes rainurées.
Dépôts de caoutchouc : Les zones de touché des pneus d’aéronefs accumulent des couches de caoutchouc — des dépôts de polymère qui apparaissent comme des taches sombres et irrégulières dans l’imagerie. Les dépôts de caoutchouc peuvent obscurcir les fissures sous-jacentes (réduisant le rappel) et produire des caractéristiques de bordure ressemblant à des fissures le long des limites des dépôts (augmentant les faux positifs). Le pré-traitement avec estimation du caoutchouc (utilisant l’imagerie multispectrale — le caoutchouc a une signature spectrale distincte dans les bandes NIR) et masquage améliore la précision de la segmentation de fissures dans les zones de touché de 5 à 15 %.
Confusion joints/produit d’étanchéité : Les chaussées en béton des pistes ont des joints de contraction tous les 4 à 6 mètres, remplis de produit d’étanchéité (généralement un polymère flexible sombre). Les joints apparaissent dans la sortie de segmentation comme des caractéristiques de type fissure. Cependant, les joints sont intentionnels, attendus et structurellement nécessaires — ils ne doivent pas être classés comme fissures. La détection des joints utilisant des a priori géométriques (espacement régulier, orientation linéaire perpendiculaire à l’axe de la piste) permet le masquage des joints avant la mesure des fissures.
Variation d’éclairage : Les images de levés de pistes entières couvrent des centaines de mètres avec un éclairage variable. Une extrémité de l’image de la piste peut être en plein soleil (contraste élevé, ombres de fissures marquées) tandis que l’autre est à l’ombre (faible contraste, pas d’ombres). Les modèles doivent être invariants à l’éclairage. L’augmentation de données incluant des changements aléatoires de luminosité/contraste, l’égalisation d’histogramme et la génération synthétique d’ombres pendant l’entraînement améliore la robustesse dans diverses conditions d’éclairage.
Variabilité des chaussées : Les pistes ont plusieurs types de chaussée (arrêts en asphalte, piste principale en béton, voies de circulation en asphalte) avec différentes textures, couleurs et morphologies de fissures. Un seul vol d’inspection capture tous les types de chaussée, ce qui oblige le modèle de segmentation à généraliser sur ces surfaces sans modèles séparés par type de chaussée.
10. Généralisation à de nouvelles surfaces
Les modèles de segmentation de fissures sont vulnérables au décalage de domaine — la dégradation des performances lorsqu’ils sont appliqués à des surfaces, des caméras ou des conditions non représentées dans les données d’entraînement. Un modèle entraîné exclusivement sur CRACK500 (asphalte capturé à 0,05 mm/pixel, éclairage de type intérieur, proximité) déployé sur une piste en béton (texture différente, GSD 0,2 mm/pixel, éclairage extérieur, distance variable) peut voir son IoU chuter de 0,72 à 0,35-0,45.
Sources de décalage de domaine
Texture de surface : L’asphalte a une texture d’agrégats sombre, rugueuse et irrégulière ; le béton a une texture plus claire, plus lisse, plus uniforme avec des agrégats fins visibles. Les modèles entraînés sur la texture de l’asphalte apprennent à ignorer les variations de texture sombres et haute fréquence — les surfaces en béton violent cette invariance apprise.
Résolution : L’apparence des fissures change avec le GSD. À 0,05 mm/pixel, une fissure de 2 mm de large fait 40 pixels de large avec des bords nets et bien définis. À 0,2 mm/pixel, la même fissure fait 10 pixels de large avec des bords plus doux. Les modèles entraînés à haute résolution produisent des prédictions floues et incertaines à plus basse résolution.
Éclairage : Les images de pistes extérieures ont un ensoleillement directionnel créant des ombres de fissures (améliorant la visibilité des fissures mais produisant des artefacts d’ombres), tandis que les images intérieures ou nuageuses ont un éclairage diffus (moins d’ombres, contraste plus faible). Les ombres de fissures peuvent améliorer le rappel dans des conditions ensoleillées mais causer des faux positifs sur des éléments non fissurés (marches thermiques, changements d’élévation de surface).
Système de caméra : Différentes caméras ont différentes réponses spectrales de capteur, pas de pixel, distorsion d’objectif et caractéristiques de bruit. Un modèle entraîné sur un reflex numérique 20 MP (faible bruit, faible distorsion) peut se dégrader sur une caméra de drone 12 MP (bruit plus élevé, obturateur roulant, aberration chromatique d’objectif).
Amélioration de la généralisation
Randomisation de domaine : Pendant l’entraînement, appliquer des augmentations aléatoires qui couvrent le domaine de déploiement attendu : GSD aléatoire (redimensionner les images à 0,5×-2,0×), éclairage aléatoire (luminosité ±30 %, contraste ±30 %, gamma ±0,3), bruit aléatoire (bruit gaussien avec σ=5-25), flou aléatoire (flou gaussien avec noyau de 1-5 pixels), changements de couleur aléatoires (décalage HSV teinte ±15, saturation ±30, valeur ±30). Les modèles entraînés avec une randomisation de domaine suffisante maintiennent un IoU à moins de 5-10 % de leurs performances sur le domaine d’entraînement lorsqu’ils sont déployés sur de nouvelles surfaces.
Génération synthétique de fissures : Composer des fissures synthétiques sur des images de surface sans fissures en utilisant des modèles de fissures basés sur la physique ou la génération de fissures par GAN. La base de données de surfaces sans fissures (capturées dans le domaine cible) combinée à des fissures synthétiques fournit des données d’entraînement appariées où le modèle apprend à détecter les caractéristiques des fissures tout en ignorant la texture de surface spécifique. Cette approche a démontré des améliorations d’IoU de 8 à 12 % lors du transfert de l’asphalte routier au béton de piste.
Adaptation de domaine non supervisée (UDA) : Des techniques telles que CycleGAN, CUT et AdaIN transfèrent les images du domaine source vers l’apparence du domaine cible tout en préservant les annotations de fissures. Les caractéristiques de fissures d’un modèle entraîné sur CRACK500 sont extraites d’images qui ont été stylisées pour ressembler à la surface de piste cible. Les méthodes UDA améliorent l’IoU du domaine cible de 10 à 18 % sans nécessiter d’annotation du domaine cible.
Fine-tuning few-shot : Collecter 5 à 20 images annotées de la nouvelle surface, et fine-tuner le modèle pré-entraîné avec un faible taux d’apprentissage (1×10⁻⁵ à 5×10⁻⁵) et un petit nombre d’époques (10-30). Cette approche de fine-tuning supervisé récupère typiquement l’IoU à moins de 2-4 % d’un modèle entièrement supervisé entraîné sur des centaines d’images du domaine cible. C’est l’approche pratique la plus fiable pour le déploiement aéroportuaire où la collecte d’un petit nombre d’images annotées est opérationnellement réalisable.
Le crack_seg_head de TarmacView implémente un pipeline de généralisation qui inclut un pré-entraînement à domaine randomisé sur CrackSeg9k, une sélection de tuiles spécifiques au domaine cible, un fine-tuning few-shot optionnel avec jusqu’à 20 images annotées fournies par l’utilisateur depuis la surface cible, et une détection automatique d’anomalie de domaine (la confiance du modèle en dessous d’un seuil déclenche une alerte pour révision manuelle).
Questions Fréquemment Posées
La segmentation de fissures attribue une étiquette fissure ou non-fissure à chaque pixel d'une image, produisant un masque binaire qui préserve la forme exacte, la topologie et la géométrie des fissures. La classification de fissures prédit uniquement si une image contient une fissure (étiquette au niveau image). La segmentation permet une mesure précise de la surface, de la longueur, de la largeur et des motifs de ramification des fissures, tandis que la classification ne fournit qu'une réponse binaire oui/non.
Les architectures les plus courantes incluent U-Net (encodeur-décodeur avec connexions de saut), DeepLabV3+ (avec pooling pyramidal spatial atrous), SegFormer (encodeur Transformeur hiérarchique avec décodeur MLP) et les backbone Vision Transformer comme DINOv2/v3 avec des têtes de prédiction dense. U-Net reste la plus largement adoptée en raison de son efficacité avec des données limitées et de ses performances solides sur les structures de fissures fines et allongées.
Les ensembles de données clés incluent CRACK500 (500 images de chaussée, 0,05 mm/pixel), DeepCrack (537 images RVB de diverses surfaces), CrackForest (118 images routières), CrackAirport (chaussée spécifique aux aéroports), Crack500, CrackTree200, CFD (Crack Forest Dataset), AEL et GAPs384. La compilation CrackSeg9k a unifié plus de 9000 images provenant de multiples sources avec des masques de vérité terrain affinés.
L'extraction de la géométrie des fissures commence par la squelettisation (amincissement itératif jusqu'à une ligne centrale d'un pixel de large), suivie d'un étiquetage des composantes connexes pour isoler les fissures individuelles. La longueur de la fissure est mesurée le long du chemin squelettisé. La largeur de la fissure est calculée via la transformée de distance euclidienne perpendiculairement au squelette. La surface de la fissure correspond au nombre total de pixels de fissure multiplié par la résolution spatiale en mm²/pixel. Les valeurs de largeur moyenne et maximale sont rapportées par composante.
Les métriques d'évaluation standard incluent l'Intersection sur Union (IoU/Indice de Jaccard), le coefficient Dice (score F1 au niveau pixel), la précision pixel, le rappel pixel et l'exactitude pixel. L'IoU est l'intersection des pixels de fissure prédits et de vérité terrain divisée par leur union. Le Dice est 2×IoU/(1+IoU). Pour la segmentation de fissures, la précision (fraction des pixels de fissure prédits qui sont de vraies fissures) et le rappel (fraction des vrais pixels de fissure détectés) sont tous deux critiques, car les faux positifs gaspillent les ressources de maintenance tandis que les faux négatifs laissent passer des défauts dangereux.
La segmentation plein cadre traite l'image entière de la piste en une seule passe, ce qui est limité par la mémoire pour les surfaces haute résolution (les pistes peuvent dépasser 50 mégapixels). La segmentation par tuiles divise l'image en patches avec chevauchement (par exemple 512×512 ou 1024×1024 pixels), exécute l'inférence sur chaque tuile et assemble les résultats. Les zones de chevauchement utilisent une moyenne pondérée ou un mélange sans couture pour éviter les artefacts de bordure. Les approches par tuiles permettent de traiter des surfaces arbitrairement grandes mais nécessitent une gestion soigneuse des fissures qui traversent les limites des tuiles.
La généralisation entre différents types de surfaces (asphalte vs béton, chaussée neuve vs usée, conditions d'éclairage différentes) reste un défi majeur. Le décalage de domaine — différences de texture, couleur, apparence des fissures et rugosité de surface — peut significativement dégrader les performances. Les techniques pour améliorer la généralisation incluent la randomisation de domaine pendant l'entraînement, l'augmentation de données synthétiques, l'adaptation non supervisée de domaine (CycleGAN, transfert de style) et le fine-tuning supervisé avec un petit nombre d'images du domaine cible. Des ensembles de données d'entraînement diversifiés et bien organisés comme CrackSeg9k améliorent la robustesse cross-surface.
L'Annexe 14 de l'OACI et le Doc 9157 de l'OACI spécifient que l'évaluation de l'état de la surface des pistes doit identifier et mesurer les fissures, la détérioration et les défauts qui pourraient affecter la sécurité des aéronefs. La segmentation automatisée des fissures s'aligne sur l'accent mis par l'OACI sur des méthodes d'inspection objectives, reproductibles et documentées. Le Format de Rapport Mondial (GRF) de l'OACI exige un reporting standardisé des conditions de surface des pistes, et la segmentation automatisée fournit des données quantifiables sur l'étendue, la densité et la sévérité des fissures qui peuvent alimenter directement les cadres de rapport de condition.
Améliorez votre inspection d'infrastructures
Implémentez la segmentation de fissures au niveau pixel pour une évaluation précise et automatisée de l'état des chaussées. Notre segmentation de fissures basée sur l'IA offre une précision submillimétrique pour les pistes, les voies de circulation et les aires de trafic.
Détection de fissures par IA pour l'inspection des infrastructures
La détection de fissures par IA utilise la vision par ordinateur — réseaux de neurones convolutifs, vision transformers et modèles de segmentation sémantique — ...
46 min de lecture
Computer Vision
Deep Learning
+8
Qu’est-ce que la Segmentation Sémantique pour la Compréhension de Scènes d’Infrastructure ? Définition et Distinction des Tâches Connexes de Vision ...
Segmentation d'instance pour l'identification individuelle des défauts
La segmentation d'instance identifie et délimite chaque objet individuel ou défaut au niveau du pixel, en attribuant un identifiant unique à chaque fissure, écl...
33 min de lecture
technology
machine-learning
+6
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.