+++ title = “Apprentissage par transfert” description = “L’apprentissage par transfert applique les connaissances d’un modèle pré-...
10 min de lecture
Technology
Machine Learning
+2
L’augmentation de données étend synthétiquement les ensembles d’entraînement en appliquant des transformations d’image — rotation, retournement, variation chromatique, flou, bruit, recadrage — pour améliorer la robustesse du modèle face aux variations d’éclairage, d’orientation et de qualité d’image. Pour l’inspection d’infrastructures, les augmentations spécifiques au domaine (transformations de perspective, simulation d’ombres, effets météorologiques) sont essentielles. Couvre les stratégies d’augmentation et leur impact sur la généralisation du modèle.
{
L’augmentation de données est une méthodologie d’entraînement qui étend synthétiquement la taille et la diversité d’un ensemble de données étiquetées en appliquant des transformations contrôlées et préservant les étiquettes aux échantillons de données existants. Dans les applications de vision par ordinateur, cela signifie prendre chaque image originale et générer plusieurs versions modifiées par déformation géométrique, manipulation d’espace chromatique, injection de bruit ou processus génératifs plus complexes. L’ensemble de données augmenté — images originales plus leurs variantes transformées — est ensuite utilisé pour entraîner des réseaux de neurones profonds, exposant le modèle à une gamme de conditions visuelles bien plus large que les seules données brutes de terrain.
L’objectif principal de l’augmentation de données est d’améliorer la généralisation du modèle — la capacité d’un modèle entraîné à effectuer des prédictions précises sur des données jamais vues auparavant. Un réseau de neurones convolutif profond (CNN) avec des millions de paramètres peut facilement mémoriser un ensemble d’entraînement de quelques milliers d’images, apprenant les textures spécifiques, les motifs d’éclairage et les artefacts d’arrière-plan de ces exemples plutôt que les signatures de défauts sous-jacentes. Ce phénomène, connu sous le nom de surapprentissage, entraîne une précision d’entraînement élevée mais de faibles performances de validation et de test. L’augmentation de données empêche le surapprentissage en garantissant que chaque époque d’entraînement présente au modèle des versions différemment transformées de chaque image, rendant la mémorisation pure impossible. Le modèle est forcé d’apprendre des caractéristiques invariantes — des motifs visuels qui persistent à travers les transformations.
Pour les modèles d’inspection d’infrastructures, l’augmentation de données n’est pas simplement bénéfique mais opérationnellement essentielle. Considérez les réalités de la collecte de données pour l’inspection des chaussées aéroportuaires : un seul relevé de piste utilisant une caméra montée sur UAV peut capturer 10 000 images haute résolution, mais moins de 200 de ces images peuvent contenir des défauts visibles. Les fissures, éclats, défaillances de joints d’étanchéité et l’altération météorologique de surface constituent ensemble moins de 1 pour cent de la surface totale de la chaussée à un moment donné. Collecter un ensemble de données équilibré et diversifié de défauts dans toutes les conditions d’inspection possibles — lumière directe du soleil, ciel couvert, aube, chaussée mouillée, chaussée sèche, différents angles d’inclinaison de caméra, différentes altitudes — serait prohibitif en termes de coût et de temps. L’augmentation de données comble cette lacune en simulant l’ensemble des conditions opérationnelles à partir d’un ensemble beaucoup plus restreint d’exemples collectés sur le terrain.
L’importance de l’augmentation est formellement reconnue dans les normes d’infrastructure aéronautique. L’Annexe 14 de l’OACI, Volume I (Conception et exploitation des aérodromes) exige que les surfaces de piste soient maintenues dans un état ne mettant pas en danger les opérations aériennes. Les systèmes d’inspection basés sur l’IA interprétés selon ces normes doivent démontrer des performances robustes sur l’ensemble des conditions d’éclairage et météorologiques opérationnelles spécifiées dans le manuel d’aérodrome. Sans augmentation complète, un modèle d’inspection entraîné exclusivement sur des captures sèches de midi échouerait à détecter les fissures obscurcies par les ombres, les flaques d’eau ou la lumière rasante — manquant potentiellement des défauts qui compromettent les performances de freinage des aéronefs et la sécurité opérationnelle.
L’augmentation de données opère au niveau des données plutôt qu’au niveau de l’architecture du modèle, la distinguant des techniques de régularisation comme l’abandon (dropout), la décroissance du poids (weight decay) ou la normalisation par lots (batch normalization). Alors que les régularisateurs au niveau du modèle limitent la capacité du réseau à surapprendre, l’augmentation élargit la distribution des données pour couvrir plus complètement l’espace d’entrée du monde réel. Les deux approches sont complémentaires : les pipelines d’inspection d’infrastructures de meilleure pratique combinent une augmentation agressive avec une régularisation architecturale pour une généralisation maximale.
Les augmentations géométriques modifient la disposition spatiale des pixels dans une image sans altérer leurs valeurs d’intensité. Ces transformations simulent les changements de position, d’orientation, de distance et de caractéristiques de l’objectif de la caméra qui se produisent lors de la collecte réelle de données d’inspection. Pour l’inspection d’infrastructures, les augmentations géométriques sont la catégorie la plus impactante car les plateformes d’inspection — UAV, véhicules terrestres, caméras portatives — capturent la même surface sous des perspectives très variées.
L’augmentation par rotation applique une rotation angulaire aléatoire à l’image d’entrée, allant typiquement de -180° à +180° ou limitée à des plages plus petites comme ±45° pour des applications spécifiques. L’image transformée est générée en faisant tourner chaque coordonnée de pixel (x, y) d’un angle θ autour du centre de l’image en utilisant la matrice de rotation standard :
x’ = x·cos(θ) - y·sin(θ)
y’ = x·sin(θ) + y·cos(θ)
Pour la détection de fissures sur les pistes d’aéroport et les chaussées autoroutières, l’augmentation par rotation est essentielle car l’orientation des fissures par rapport au cadre de la caméra est arbitraire. Une fissure longitudinale parallèle à l’axe de la piste peut apparaître horizontale dans une image et diagonale dans une autre, selon l’angle de lacet de la caméra par rapport à la direction d’atterrissage des aéronefs. Sans augmentation par rotation, un modèle peut apprendre à associer la présence de fissures à une orientation angulaire particulière, échouant à détecter les fissures qui apparaissent sous d’autres angles. Les recherches d’Alomar et al. (2023) démontrent que l’augmentation par rotation améliore systématiquement la précision de classification de 3 à 8 pour cent sur les ensembles de données de défauts structurels par rapport aux modèles entraînés sans rotation.
La plage de rotation optimale dépend de la symétrie de l’application. Pour les chaussées aéroportuaires où les fissures se développent dans les directions longitudinale et transversale par rapport au trafic aérien, une plage complète de ±180° est appropriée. Pour les inspections de poutres de pont où la caméra est toujours à peu près horizontale, une plage plus restreinte de ±15° peut suffire. La rotation introduit des zones de bord vides dans les coins de l’image, qui doivent être traitées par l’une des trois stratégies : (1) remplissage par zéros (remplissage des bords en noir), (2) remplissage par réflexion (miroir des pixels de bord), ou (3) remplissage par plus proche voisin. Le remplissage par réflexion est préféré pour l’inspection d’infrastructures car il évite d’introduire des bordures sombres artificielles que le modèle pourrait apprendre comme caractéristiques fallacieuses.
Le retournement horizontal (miroir gauche-droite) et le retournement vertical (miroir haut-bas) sont les augmentations géométriques les plus simples, nécessitant seulement une inversion de l’ordre des colonnes ou des lignes de pixels. Le retournement horizontal est appliqué avec une probabilité de 50 pour cent par défaut dans la plupart des pipelines d’augmentation et est universellement bénéfique car il double la taille effective de l’ensemble de données tout étant gratuit en calcul — il ne nécessite aucune interpolation.
Pour l’inspection d’infrastructures, le retournement horizontal préserve l’étiquette pour la plupart des types de défauts. Une fissure est une fissure qu’elle apparaisse du côté gauche ou droit de l’image. Cependant, certains défauts présentent une asymétrie directionnelle : le désenrobage (perte de granulats aux bords de la chaussée) a tendance à se produire préférentiellement le long du bord de la chaussée, et le faïençage (déplacement vertical à travers un joint) a une directionnalité liée au chargement du trafic. Pour ces défauts directionnels, le praticien doit vérifier que la version retournée reste un exemple d’entraînement valide.
Le retournement vertical est moins couramment utilisé pour l’inspection d’infrastructures terrestres car il inverse l’orientation cohérente avec la gravité de l’image. Une fissure sur un mur vertical en béton apparaît fondamentalement différente après retournement — bien que pour l’inspection de chaussée où la caméra regarde directement vers le bas, le retournement vertical préserve autant l’étiquette que le retournement horizontal. Pour l’imagerie d’inspection de ponts où la caméra capture des surfaces verticales (poutres, piles, culées), le retournement horizontal devrait être priorisé par rapport au retournement vertical.
Le recadrage aléatoire sélectionne une sous-région rectangulaire de l’image d’entrée et la redimensionne aux dimensions d’entrée attendues du réseau. Cela simule l’effet d’une caméra positionnée à différentes distances de la surface inspectée — les recadrages plus rapprochés correspondent à des vues de résolution plus élevée avec plus de détails, tandis que les recadrages plus larges montrent un contexte plus étendu.
L’augmentation par recadrage aléatoire standard échantillonne une région de recadrage avec une surface comprise entre min_scale et max_scale (typiquement 0,08 à 1,0 de la surface de l’image originale) et un rapport d’aspect entre min_ratio et max_ratio (typiquement 0,75 à 1,33). La région recadrée est ensuite redimensionnée à la taille d’entrée fixe du réseau, par exemple 512×512 pixels pour les modèles typiques de segmentation de fissures.
Pour l’inspection d’infrastructures, le recadrage aléatoire a un double objectif. Premièrement, il augmente la diversité positionnelle — un modèle entraîné uniquement sur des images en plein cadre peut apprendre à associer les défauts à leur position dans le cadre, échouant lorsque le même défaut apparaît dans une région de cadre différente. Deuxièmement, le recadrage avec redimensionnement simule différentes altitudes d’inspection et niveaux de zoom, ce qui est essentiel pour l’inspection par UAV où l’altitude de vol varie entre 10 mètres et 50 mètres selon les réglementations et les exigences de relevé. Le Doc 9137 de l’OACI, Partie 9 (Pratiques d’entretien des aéroports) et le Doc 9981 de l’OACI (PANS-Aérodromes) abordent les méthodes d’inspection qui peuvent impliquer une collecte de données montée sur véhicule ou portative, chacune introduisant différents champs de vision. Le recadrage aléatoire pendant l’entraînement garantit que le modèle généralise à travers ces modalités de capture.
Les transformations de perspective (également appelées déformations de perspective ou augmentations par homographie) appliquent un mapping projectif à l’image, simulant l’effet d’un plan de caméra incliné par rapport à la surface inspectée. Ceci est mathématiquement représenté par une matrice d’homographie 3×3 qui mappe des points d’un plan à un autre.
Pour l’inspection d’infrastructures, l’augmentation par perspective est particulièrement importante car l’imagerie d’inspection réelle est rarement capturée depuis un point de vue parfaitement orthogonal (nadir). Les caméras montées sur véhicule capturent la chaussée sous un léger angle avant. Les caméras UAV peuvent avoir des angles d’inclinaison de 5 à 20 degrés lorsque le drone manœuvre. Les caméras d’inspection portatives varient en inclinaison selon la taille de l’inspecteur et la position du bras. Une fissure qui semble linéaire et cohérente depuis une vue nadir devient raccourcie et géométriquement déformée depuis un angle oblique. L’augmentation par perspective entraîne le modèle à reconnaître les défauts quel que soit l’angle de capture.
Le degré de distorsion de perspective est contrôlé par le paramètre d’échelle de distorsion, généralement fixé entre 0,05 et 0,3 en coordonnées normalisées. Des valeurs plus élevées simulent des inclinaisons de caméra plus extrêmes. Pour l’inspection aéroportuaire, une échelle de perspective de 0,1 à 0,2 est recommandée, correspondant à des angles d’inclinaison de caméra d’environ 5 à 15 degrés par rapport au nadir.
Les transformations affines combinent la mise à l’échelle, le cisaillement, la rotation et la translation en une seule opération matricielle 2×3. Contrairement aux transformations de perspective, les transformations affines préservent le parallélisme — les lignes parallèles restent parallèles après transformation. L’opération peut être exprimée comme suit :
[x’, y’]² = A · [x, y]² + b
où A est une matrice 2×2 contrôlant la rotation, la mise à l’échelle et le cisaillement, et b est un vecteur de translation.
Pour l’inspection d’infrastructures, une configuration d’augmentation affine courante inclut : translation (±10 pour cent des dimensions de l’image, simulant un désalignement du cadre), mise à l’échelle (0,8x à 1,2x, simulant une variation d’altitude), cisaillement (±10 degrés, simulant l’inclinaison de la caméra), et rotation (±15 degrés). L’effet combiné produit des images qui simulent de manière réaliste la variabilité de position et d’orientation de la collecte de données d’inspection sans nécessiter de distorsions extrêmes qui pourraient introduire des artefacts irréalistes.
| Type d’augmentation | Plage typique | Application pour l’infrastructure |
|---|---|---|
| Rotation | ±45° à ±180° | Simule différents angles de lacet de caméra par rapport à l’orientation des fissures |
| Retournement horizontal | Probabilité 50% | Double l’ensemble de données ; invariant pour la plupart des défauts |
| Retournement vertical | Probabilité 50% | Utile pour l’imagerie de chaussée au nadir |
| Recadrage aléatoire | Échelle 0,08-1,0, rapport d’aspect 0,75-1,33 | Simule différentes altitudes d’inspection et niveaux de zoom |
| Perspective | Échelle de distorsion 0,05-0,3 | Simule les angles d’inclinaison de caméra non nadir |
| Affine (échelle) | 0,8x-1,2x | Simule la variation d’altitude des plateformes UAV |
| Affine (cisaillement) | ±5° à ±15° | Simule le roulis et le tangage de la caméra |
| Affine (translation) | ±5% à ±15% | Simule la variation de position du cadre |
| Affine (rotation) | ±10° à ±30° | Combiné avec d’autres paramètres affines |
{
Les augmentations chromatiques et photométriques modifient les valeurs d’intensité des pixels d’une image sans changer la disposition spatiale des objets. Ces transformations simulent les variations des conditions d’éclairage — la source la plus significative de variabilité du monde réel dans l’imagerie d’inspection d’infrastructures.
L’augmentation de luminosité décale linéairement toutes les valeurs de pixels en ajoutant un offset constant : I’ = I + δ, où δ est échantillonné uniformément dans une plage telle que [-30, +30] sur une échelle de 0-255. Cela simule la différence entre la lumière solaire de midi (luminosité élevée) et le ciel couvert ou les conditions d’inspection matinales (faible luminosité). L’augmentation de contraste met à l’échelle les valeurs des pixels autour de l’intensité moyenne : I’ = α(I - μ) + μ, où α est échantillonné dans une plage telle que [0,7, 1,3]. Des valeurs de contraste plus faibles simulent des conditions brumeuses ou de brouillard ; des valeurs plus élevées simulent la lumière solaire directe et dure qui produit des ombres prononcées.
Pour l’inspection d’infrastructures, la plage de luminosité recommandée est de ±40 pour cent pour couvrir tout le spectre des conditions d’éclairage opérationnel spécifiées dans les plans d’éclairage d’aérodrome selon l’Annexe 14 de l’OACI, Chapitre 5 (Aides visuelles pour la navigation). L’éclairage de bord de piste, l’éclairage d’approche et l’éclairage de l’aire de trafic créent tous différents niveaux d’illumination ambiante que le modèle d’inspection doit gérer.
Le décalage de teinte fait pivoter toutes les couleurs des pixels dans l’espace colorimétrique TSV (Teinte, Saturation, Valeur) d’un angle aléatoire, typiquement ±30° sur un cercle chromatique de 360°. L’ajustement de saturation multiplie le canal de saturation par un facteur aléatoire (typiquement 0,5 à 1,5). Ces augmentations simulent l’effet de différentes conditions de surface de chaussée — l’asphalte sec a une saturation plus faible que l’asphalte mouillé, le béton vieilli diffère en teinte du béton neuf, et les dépôts de pneus en caoutchouc créent des artefacts de couleur distincts sur les zones de toucher des pistes.
Pour la détection de fissures sur les chaussées asphaltiques, l’augmentation de teinte est particulièrement utile car le contraste entre une fissure sombre et la chaussée environnante varie avec l’humidité de surface. Une fissure capillaire sèche peut avoir un contraste chromatique minimal avec l’asphalte sec, tandis que la même fissure remplie d’eau après la pluie apparaît comme une ligne sombre clairement définie. Les modèles entraînés avec l’augmentation de teinte et de saturation apprennent à détecter les fissures dans cette gamme de contraste liée à l’humidité.
La variation chromatique est une augmentation composite qui ajuste aléatoirement la luminosité, le contraste, la saturation et la teinte simultanément. L’implémentation standard échantillonne chaque paramètre indépendamment : facteur de luminosité dans [1-δ_b, 1+δ_b], facteur de contraste dans [1-δ_c, 1+δ_c], facteur de saturation dans [1-δ_s, 1+δ_s], et rotation de teinte dans [-δ_h, +δ_h]. Pour l’inspection d’infrastructures, les plages recommandées sont δ_b=0,3, δ_c=0,3, δ_s=0,2 et δ_h=0,1.
La variation chromatique est un régularisateur très efficace pour les modèles de détection de défauts. La recherche sur la classification des fissures de chaussée montre que les modèles entraînés avec une variation chromatique complète améliorent la précision de validation de 5 à 12 pour cent par rapport aux modèles entraînés avec seulement des augmentations géométriques. L’effet est plus prononcé pour les fissures fines (< 2 mm de largeur) où le contraste fissure-chaussée est déjà faible et où la variation d’éclairage supplémentaire pendant l’entraînement force le modèle à apprendre des caractéristiques basées sur les contours plutôt que sur les couleurs.
L’augmentation en niveaux de gris convertit un sous-ensemble aléatoire d’images d’entraînement en luminance monocanal, supprimant toutes les informations de couleur. Ceci est appliqué avec une faible probabilité (typiquement 5-10 pour cent) pour garantir que le modèle ne devienne pas trop dépendant des indices de couleur qui pourraient ne pas être présents dans toutes les conditions d’inspection. Pour l’inspection d’infrastructures, la conversion en niveaux de gris est particulièrement précieuse pour les modalités d’inspection thermique et infrarouge où l’imagerie couleur n’est pas disponible.
Au moment de l’inférence, un modèle entraîné avec des images en niveaux de gris occasionnelles pendant l’entraînement peut traiter élégamment les entrées monochromes ou quasi-monochromes sans nécessiter de réplication de canaux ou de prétraitement. Ceci est important pour l’interopérabilité avec les systèmes de caméra d’inspection plus anciens qui peuvent capturer en mode niveaux de gris ou pour l’analyse d’imagerie d’inspection historique collectée avant que les caméras couleur numériques ne deviennent standard.
Les augmentations par bruit et flou simulent la dégradation de la qualité d’image qui se produit dans la collecte de données d’inspection réelle en raison des limitations du capteur, du mouvement, des erreurs de mise au point et des conditions environnementales défavorables.
L’augmentation par bruit gaussien ajoute des perturbations aléatoires des valeurs de pixels échantillonnées à partir d’une distribution normale N(0, σ²) à chaque pixel indépendamment. L’écart type du bruit σ est généralement fixé entre 0,01 et 0,05 pour les valeurs de pixels normalisées (plage 0-1). Cela simule le bruit de grenaille présent dans tous les capteurs d’appareils photo numériques, qui augmente à des réglages ISO plus élevés utilisés dans des conditions d’inspection à faible luminosité.
L’ajout de bruit gaussien pendant l’entraînement force les filtres convolutionnels du modèle à répondre au motif structurel sous-jacent du défaut plutôt qu’aux artefacts de pixels haute fréquence qui ne sont pas reproductibles d’une capture à l’autre. Les modèles entraînés avec augmentation par bruit sont plus robustes aux différences de qualité de capteur entre les caméras d’inspection — le même défaut imagé avec un appareil photo de téléphone de 12 mégapixels et un reflex numérique de 50 mégapixels apparaîtra différemment à un modèle non entraîné sur des images bruitées.
L’augmentation par flou gaussien convolue l’image avec un noyau gaussien de taille k×k et d’écart type σ. Cela simule plusieurs conditions réelles : capture hors foyer (la caméra n’a pas fait la mise au point parfaite sur la surface de la chaussée), flou de mouvement (le véhicule d’inspection se déplaçait pendant la capture), brume atmosphérique (la vapeur d’eau ou les particules en suspension dans l’air diffusent la lumière et réduisent la netteté de l’image), et imperfections de l’objectif (poussière ou condensation sur l’objectif de la caméra).
Pour l’inspection d’infrastructures, les paramètres de flou gaussien recommandés sont k ∈ {3, 5, 7} et σ ∈ {0,5, 1,0, 2,0} appliqués avec une probabilité de 20-30 pour cent. Cette plage couvre un flou modéré à significatif sans rendre l’image méconnaissable. Le flou de mouvement peut alternativement être simulé en utilisant un noyau de flou directionnel qui étale les pixels dans une direction spécifique — ceci est plus réaliste pour les caméras montées sur véhicule où la direction du flou est alignée avec la trajectoire du véhicule.
L’importance de l’augmentation par flou devient évidente lorsqu’on considère la vitesse d’inspection. Un véhicule d’inspection circulant à 50 km/h capture des images avec environ 3 à 5 pixels de flou de mouvement à des vitesses d’obturation typiques. Un drone d’inspection se déplaçant à 10 m/s avec une caméra stabilisée par cardan peut avoir 1 à 3 pixels de flou. L’entraînement avec augmentation par flou garantit que le modèle fonctionne de manière fiable à travers ces vitesses de capture sans obliger l’opérateur d’inspection à ralentir pour la précision du modèle.
L’effacement aléatoire (Random Erasing) et le Cutout sont des augmentations axées sur la régularisation qui occluent aléatoirement des régions rectangulaires de l’image d’entrée. Dans Cutout, un patch carré de côté s (typiquement 16-64 pixels pour des images 256×256) est positionné aléatoirement et rempli d’une valeur constante (généralement zéro ou la valeur moyenne des pixels de l’ensemble de données). L’effacement aléatoire fait varier le rapport d’aspect et la valeur de remplissage de la région occluse.
Pour l’inspection d’infrastructures, ces augmentations simulent l’occlusion par des débris d’objets étrangers (FOD) sur les chaussées aéroportuaires — une préoccupation de sécurité critique selon les normes de l’Annexe 14 de l’OACI. Les FOD incluent des pierres détachées, des fragments de pneus, des étiquettes de bagages, des outils et autres débris qui obscurcissent partiellement la surface de la chaussée. Un modèle entraîné avec l’augmentation Cutout apprend à détecter les défauts même lorsque des parties du défaut ou de la chaussée environnante sont cachées par des objets occlusifs. Cela améliore directement la capacité du modèle à identifier les fissures et défauts visibles dans les espaces entre les débris ou les marques de pneus sur les surfaces de piste.
Les augmentations spécifiques au domaine sont des transformations adaptées aux caractéristiques visuelles uniques de l’imagerie d’inspection d’infrastructures. Ces augmentations vont au-delà des transformations génériques de vision par ordinateur pour simuler les conditions environnementales et opérationnelles spécifiques que rencontrent les caméras d’inspection.
Les ombres sur les surfaces d’infrastructures sont projetées par une large gamme d’objets : superstructures de ponts, portiques de signalisation, hangars, bâtiments terminaux, aéronefs adjacents, clôtures périmétriques, et même le véhicule d’inspection ou l’UAV lui-même. Les ombres créent des réductions locales et brusques de l’illumination qui peuvent obscurcir les fissures, altérer la texture apparente de la chaussée et produire des détections de faux positifs aux limites des ombres.
L’augmentation d’ombre simule cela en assombrissant une région aléatoire de l’image à l’aide d’un masque doux. Le masque est typiquement un polygone avec des bords flous (flou gaussien sur le masque avec σ=10-30 pixels) qui passe en douceur de la pleine illumination au niveau d’obscurité de l’ombre. Le facteur d’obscurité de l’ombre est échantillonné entre 0,2 et 0,6 (où 0,0 est noir et 1,0 est inchangé). La position, la forme et l’angle de l’ombre sont randomisés pour empêcher le modèle d’associer des motifs d’ombre à des régions spécifiques de l’image.
Pour l’inspection de ponts spécifiquement, la simulation d’ombres est essentielle car les poutres de pont, les diaphragmes et les porte-à-faux de tablier créent des motifs d’ombre complexes qui varient avec l’angle du soleil tout au long de la journée. Les normes d’inspection de ponts de la FHWA exigent que les évaluations de condition soient cohérentes indépendamment du moment où l’inspection a lieu. Les modèles augmentés d’ombres maintiennent cette cohérence, fournissant une détection précise des défauts que le pont soit inspecté à 9h00 (ombres longues) ou à 12h00 (ombres minimales).
La chaussée mouillée change radicalement l’apparence visuelle des défauts de surface. L’eau remplit les fissures et les vides, les assombrissant et augmentant leur contraste visuel par rapport à la chaussée environnante. En même temps, l’eau crée des réflexions spéculaires qui introduisent des reflets lumineux, particulièrement sur les surfaces d’asphalte lisses. Les flaques et l’eau stagnante peuvent complètement obscurcir les défauts sous-jacents.
L’augmentation de pluie simule ces effets à travers plusieurs mécanismes : Superposition de film d’eau — Ajout d’une superposition semi-transparente bleu-gris à des régions d’image aléatoires avec une opacité de 0,1-0,3 pour simuler de minces films d’eau. Génération de reflets spéculaires — Ajout de taches elliptiques ou irrégulières brillantes avec des valeurs de luminance élevées (200-250 sur une échelle de 0-255) pour simuler la lumière solaire se reflétant sur les surfaces d’eau. Superposition de traînées de pluie — Ajout de motifs de traînées directionnelles pour simuler la pluie tombant pendant la capture. La densité, la longueur (10-50 pixels) et l’angle des traînées (typiquement 0-30° par rapport à la verticale, selon le vent) sont randomisés.
Pour l’inspection des chaussées aéroportuaires, l’augmentation de chaussée mouillée est imposée par le réalisme opérationnel. L’Annexe 14 de l’OACI et la Circulaire FAA AC 150/5320-5D exigent que l’évaluation de l’état de la surface de piste tienne compte des effets de l’eau sur la friction et la visibilité des défauts. Un modèle d’inspection déployé dans une région avec plus de 100 jours de précipitations annuelles doit fonctionner avec précision dans des conditions humides. L’entraînement avec des augmentations de pluie et de film d’eau garantit cette capacité.
La texture de surface de la chaussée varie significativement selon :
L’augmentation par variation de texture de surface applique un rehaussement de contraste local, une égalisation locale et une synthèse de texture pour simuler ces variations. Les implémentations avancées utilisent le transfert de style ou l’adaptation de domaine basée sur CycleGAN pour transformer les images entre les domaines de texture — par exemple, prendre une image de fissure sur de l’asphalte neuf et générer une version qui apparaît comme de l’asphalte vieilli et altéré par les intempéries.
Les recherches de Krestenitis et al. (2026) sur l’inspection de pistes utilisant l’imagerie par UAV démontrent que les modèles augmentés avec variation de texture de surface atteignent 15 à 20 pour cent d’IoU de segmentation plus élevé (Intersection over Union) sur des ensembles de test à texture diversifiée par rapport aux modèles entraînés exclusivement sur le domaine de texture original. Ceci est particulièrement important pour les réseaux de chaussées aéroportuaires qui peuvent inclure des pistes, des voies de circulation et des aires de trafic construites avec différents matériaux et à différentes époques.
{
Une politique d’augmentation définit quelles transformations sont appliquées, dans quel ordre, avec quelle probabilité et à quelle magnitude pendant l’entraînement. Le choix de la politique impacte significativement les performances du modèle. Trois grandes catégories existent : les politiques manuelles, les politiques recherchées et les politiques aléatoires.
Les politiques manuelles sont conçues artisanalement par les praticiens sur la base de connaissances du domaine et de tests empiriques. Pour l’inspection d’infrastructures, une politique manuelle typique pourrait appliquer la séquence suivante à chaque étape d’entraînement :
Les politiques manuelles sont transparentes, interprétables et rapides en calcul — elles ne nécessitent ni recherche ni validation. L’inconvénient est qu’elles peuvent ne pas être optimales et peuvent manquer des combinaisons d’augmentation bénéfiques.
AutoAugment, introduit par Cubuk et al. (2019) chez Google Brain, utilise l’apprentissage par renforcement pour rechercher des politiques d’augmentation optimales. Le processus de recherche fonctionne comme suit :
Un RNN contrôleur propose des politiques d’augmentation, chacune consistant en K sous-politiques (typiquement K=5), où chaque sous-politique spécifie 2 opérations avec leurs magnitudes et probabilités. La politique est appliquée à l’ensemble d’entraînement, et un modèle enfant est entraîné et évalué sur l’ensemble de validation. La précision de validation sert de signal de récompense pour le RNN contrôleur, qui est mis à jour en utilisant l’optimisation de politique proximale (PPO) pour générer de meilleures politiques. La recherche nécessite typiquement 15 000 à 20 000 heures-GPU pour des ensembles de données à l’échelle d’ImageNet.
AutoAugment découvre des politiques non intuitives qui surpassent souvent les conceptions manuelles. Par exemple, la politique ImageNet a découvert que ShearX/Y et Rotate avec une probabilité élevée et une magnitude modérée sont très efficaces, tandis que Equalize et Solarize (inversion des valeurs de pixels au-dessus d’un seuil) améliorent la robustesse chromatique. Les politiques découvertes se transfèrent entre des ensembles de données de domaines visuels similaires — une politique trouvée sur un ensemble de données de chaussée général peut être appliquée à un ensemble de données spécifique de piste aéroportuaire avec de bons résultats.
RandAugment, introduit par Cubuk et al. (2020), répond au coût de calcul d’AutoAugment en éliminant complètement le processus de recherche. La politique est définie par seulement deux paramètres : N (nombre de transformations à appliquer par image) et M (paramètre de magnitude global pour toutes les transformations).
À chaque étape d’entraînement, RandAugment sélectionne aléatoirement N transformations dans un pool fixe de K opérations (typiquement K=14-17, incluant rotation, cisaillement, translation, contraste, luminosité, netteté, solarisation, égalisation, auto-contraste, posterisation, couleur et identité). Les opérations sélectionnées sont appliquées séquentiellement avec la magnitude M. La simplicité de cette approche signifie qu’il n’y a pas de recherche, pas d’ensemble de validation pendant l’entraînement et un minimum de réglage d’hyperparamètres.
Pour l’inspection d’infrastructures, RandAugment avec N=2 et M=10 (sur une échelle de magnitude 0-30) sert d’excellente configuration par défaut. Des valeurs N plus élevées (3-4) et M plus élevées (15-20) fournissent une régularisation plus forte pour des modèles plus grands ou des ensembles de données plus petits. La recherche sur les benchmarks de classification de fissures de chaussée montre que RandAugment atteint des performances comparables ou supérieures à AutoAugment tout en réduisant l’espace de recherche d’hyperparamètres de milliers d’heures-GPU à une simple recherche de grille 2D sur N et M.
| Politique | Coût de recherche | Paramètres | Adéquation infrastructure |
|---|---|---|---|
| Manuelle | Zéro | Contrôle total par opération | Bonne pour les besoins spécifiques au domaine |
| AutoAugment | 15 000+ heures-GPU | Politique trouvée par RL | Performance supérieure, coût élevé |
| RandAugment | Négligeable | N (int), M (float) | Excellence, valeur par défaut pratique |
| TrivialAugment | Négligeable | Paramètre de force unique | Très simple, compétitif |
| Fast AutoAugment | ~100 heures-GPU | Appariement de densité | Bon compromis |
La détection de fissures — la tâche d’identifier et de localiser les fissures dans les surfaces d’infrastructures — est l’application la plus étudiée de l’augmentation de données dans le domaine de l’inspection d’infrastructures. Les fissures présentent des défis uniques qui rendent l’augmentation particulièrement impactante.
Les fissures dans les surfaces en béton et en asphalte présentent les propriétés suivantes pertinentes pour la conception de l’augmentation :
Rapport d’aspect élevé — Les fissures sont longues et étroites, avec des rapports largeur/longueur dépassant souvent 1:100. Cela signifie que les augmentations géométriques qui déforment fortement les rapports d’aspect (cisaillement extrême, recadrages non carrés) peuvent rendre les fissures méconnaissables. Préservation de la linéarité — La plupart des fissures structurelles suivent des trajectoires approximativement linéaires ou légèrement courbes, bien que le faïençage forme des réseaux polygonaux interconnectés. Les augmentations qui brisent la continuité linéaire (effacement aléatoire du centre de la fissure, compression JPEG agressive) peuvent détruire la signature de la fissure. Faible contraste — Les fissures fines (fissures capillaires de moins de 0,3 mm de largeur) ont un contraste minimal avec la chaussée environnante — souvent seulement 5 à 15 différences de niveaux de gris sur une image 8 bits. Les augmentations chromatiques doivent être appliquées avec précaution pour éviter d’effacer ce signal déjà faible. Dépendance à la texture — Les fissures sont détectées comme des anomalies par rapport à la texture de fond de la chaussée. Les augmentations qui homogénéisent la texture (flou excessif, égalisation forte) peuvent rendre les fissures indistinguables de la chaussée intacte.
Sur la base de recherches publiées et de tests empiriques sur des ensembles de données de chaussées aéroportuaires, le pipeline suivant est recommandé pour les modèles de détection de fissures :
Étape 1 — Noyau géométrique : Retournement horizontal (50%), rotation aléatoire ±45° (30%), recadrage aléatoire à 80-95% avec redimensionnement (toujours). Ces augmentations sont toujours appliquées car l’orientation et la position des fissures sont des variables parasites.
Étape 2 — Simulation d’éclairage : Variation chromatique avec luminosité ±0,3, contraste ±0,3, saturation ±0,2, teinte ±0,1 (probabilité 50%). Cela simule toute la gamme des conditions d’éclairage opérationnel.
Étape 3 — Simulation de qualité : Flou gaussien σ=0,5-2,0 (probabilité 25%), bruit gaussien σ=0,01-0,03 (probabilité 15%). Cela simule la variation de qualité de capture.
Étape 4 — Simulation de domaine : Superposition d’ombre avec masque polygonal aléatoire (probabilité 20%), simulation de surface mouillée avec saturation accrue et reflets spéculaires (probabilité 15%). Cela simule les conditions de terrain.
Étape 5 — Régularisation : Cutout avec taille de patch 16-32 pixels (probabilité 10%). Cela empêche le surapprentissage à des régions d’image spécifiques.
Ce pipeline maintient la validité des étiquettes — la fissure reste une fissure après toutes les transformations — tout en exposant le modèle à une variabilité extrême d’apparence.
La classification des défauts — attribution d’une étiquette catégorielle à une zone d’image (par exemple, « fissure », « éclat », « altération météorologique », « intact ») — a des exigences d’augmentation différentes de la segmentation au niveau pixel.
Les ensembles de données de défauts d’infrastructures sont sévèrement déséquilibrés par nature. La chaussée intacte domine chaque ensemble de données, tandis que les classes de défauts individuelles peuvent n’avoir que des centaines d’exemples. L’augmentation de données répond à ce déséquilibre grâce à l’augmentation tenant compte des classes : appliquer des transformations plus agressives ou plus nombreuses aux classes sous-représentées pour augmenter leur représentation effective dans chaque lot d’entraînement.
Par exemple, si l’ensemble d’entraînement contient 10 000 images intactes, 500 images de fissures et 200 images d’éclats, le pipeline d’augmentation peut être configuré pour appliquer 5 augmentations échantillonnées aléatoirement à chaque image d’éclat (générant 5×200 = 1 000 exemples d’éclats effectifs par époque) tout en appliquant seulement 1 augmentation à chaque image intacte. Cette stratégie d’augmentation tenant compte des classes améliore la sensibilité du classifieur aux types de défauts rares sans nécessiter de collecte de données supplémentaire.
Pour la classification, il est essentiel que les augmentations préservent l’étiquette — l’image transformée doit toujours appartenir à la classe originale. Certaines transformations peuvent changer l’étiquette :
Pour la classification, la magnitude de l’augmentation doit être calibrée à la taille minimale de caractéristique détectable de chaque classe de défaut. Pour les fissures capillaires (largeur minimale ~0,2 mm à la résolution de capture), le flou dépassant σ=2,0 et les rotations au-delà de ±60° doivent être appliqués avec une probabilité réduite ou exclus.
Les surfaces d’infrastructures présentent souvent plusieurs types de défauts simultanés — une zone éclatée peut contenir des fissures, ou une zone altérée peut avoir une défaillance de joint d’étanchéité. Pour la classification multi-étiquettes, l’augmentation doit être cohérente pour toutes les étiquettes d’une image donnée. La même transformation géométrique appliquée à l’image s’applique à toutes les étiquettes simultanément. Les transformations de couleur et de bruit sont intrinsèquement préservatrices d’étiquettes pour la classification multi-étiquettes car elles ne changent pas la présence ou l’absence d’aucun type de défaut.
La relation entre l’augmentation de données et le surapprentissage est fondamentale pour comprendre le rôle de l’augmentation dans l’apprentissage profond.
Le surapprentissage se produit lorsqu’un modèle à haute capacité (nombreux paramètres entraînables) est entraîné sur un ensemble de données de taille ou de diversité insuffisante. Le modèle apprend non pas les motifs généraux de la classe de défauts, mais les arrangements spécifiques de pixels, les textures et les artefacts des exemples d’entraînement. Mathématiquement, le surapprentissage se manifeste par le modèle apprenant un mapping dégénéré de l’entrée à la sortie qui minimise la perte d’entraînement mais échoue à minimiser la perte attendue sur la véritable distribution des données.
Pour les modèles d’inspection d’infrastructures, le surapprentissage apparaît typiquement après 50 à 100 époques d’entraînement. La précision d’entraînement continue d’augmenter vers 100 pour cent tandis que la précision de validation plafonne puis décline. L’écart entre la précision d’entraînement et de validation — l’écart de généralisation — s’élargit progressivement. Sans augmentation, un ResNet-50 entraîné sur 2 000 images de fissures présentera typiquement un écart de généralisation de 15 à 25 pour cent. Avec une augmentation complète, cet écart peut être réduit à 3-5 pour cent ou moins.
Le mécanisme clé par lequel l’augmentation prévient le surapprentissage est l’augmentation de la taille effective de l’ensemble d’entraînement. Avec l’augmentation appliquée à la volée pendant l’entraînement, chaque image est transformée différemment à chaque époque. Un ensemble d’entraînement de 5 000 images avec une politique d’augmentation qui applique 3 transformations aléatoires à partir d’un pool de 10 opérations, chacune avec 5 magnitudes possibles, génère 5 000 × 10³ × 5³ ≈ 6,25 millions d’exemples d’entraînement distincts sur 100 époques.
Cette expansion effective de l’ensemble de données est particulièrement précieuse pour l’inspection d’infrastructures car :
L’augmentation de données fonctionne comme un régularisateur au sens de l’apprentissage statistique. En élargissant la distribution d’entraînement, l’augmentation réduit la capacité du modèle à s’ajuster au bruit dans l’ensemble de données original. La variance des paramètres appris diminue car le modèle doit satisfaire des contraintes provenant de beaucoup plus d’exemples d’entraînement effectivement indépendants.
La force de régularisation de l’augmentation est contrôlée par :
Pour les modèles d’inspection d’infrastructures, l’équilibre optimal entre régularisation et augmentation est trouvé en surveillant la trajectoire de la perte de validation. Si la perte de validation augmente tandis que la perte d’entraînement continue de diminuer (surapprentissage), la magnitude ou la probabilité d’augmentation doit être augmentée. Si les pertes d’entraînement et de validation sont élevées (sous-apprentissage), l’augmentation doit être réduite pour permettre au modèle d’apprendre davantage des données d’entraînement brutes.
L’implémentation de l’augmentation de données dans un pipeline d’entraînement de production nécessite des décisions architecturales minutieuses sur quand, où et comment les augmentations sont appliquées.
L’augmentation hors ligne pré-génère des images augmentées et les sauvegarde sur disque avant le début de l’entraînement. L’ensemble de données augmenté peut contenir 50 000 images dérivées de 5 000 originales via 10 augmentations fixes par image. L’entraînement se déroule ensuite sur cet ensemble de données augmenté fixe.
L’augmentation en ligne applique les transformations à la volée pendant l’entraînement, chaque image étant chargée depuis le disque, augmentée aléatoirement et transmise immédiatement au modèle. Aucune image augmentée n’est stockée de manière permanente.
L’augmentation en ligne est l’approche standard pour les pipelines de production d’inspection d’infrastructures car :
Le coût de calcul de l’augmentation en ligne est minimal — les bibliothèques d’augmentation accélérées par GPU modernes (NVIDIA DALI, Kornia, ou torchvision de PyTorch) appliquent les transformations en microsecondes par image, représentant typiquement moins de 5 pour cent du temps d’entraînement total lorsque le chargement des données est mis en pipeline avec l’exécution GPU.
Le choix de la bibliothèque d’augmentation impacte les performances, la flexibilité et la maintenabilité du pipeline :
Albumentations est la bibliothèque la plus utilisée pour l’inspection d’infrastructures en raison de sa vitesse (backend C++ optimisé via OpenCV), de son ensemble complet d’opérations (70+ transformations) et de son support natif de l’augmentation à double canal pour les masques de segmentation. Albumentations garantit que toute transformation géométrique appliquée à l’image est identiquement appliquée au masque, maintenant l’alignement au niveau pixel entre l’entrée et la vérité terrain.
NVIDIA DALI fournit des pipelines de chargement de données et d’augmentation accélérés par GPU qui peuvent traiter les images entièrement sur le GPU, évitant les goulots d’étranglement du transfert CPU-GPU. DALI est recommandé pour les très grands ensembles de données d’entraînement (10 000+ images) où le temps de chargement des données domine le temps d’entraînement.
torchvision.transforms (PyTorch) et tf.image (TensorFlow) fournissent des capacités d’augmentation intégrées avec une bonne intégration avec leurs frameworks respectifs mais ont moins de transformations spécifiques au domaine (simulation d’ombres, perspective, effacement aléatoire) qu’Albumentations.
Dans un pipeline d’entraînement de production, l’augmentation est intégrée comme suit :
[Chargeur d'images] → [Échantillonneur aléatoire] → [Séquence d'augmentation] → [Normalisation] → [Échantillonneur de lots aléatoires] → [Passage avant du modèle]
L’échantillonneur aléatoire sélectionne si chaque augmentation de la politique est appliquée (basé sur son paramètre de probabilité) et la magnitude à chaque fois. La séquence d’augmentation applique les transformations dans un ordre fixe : typiquement d’abord les transformations géométriques (recadrage, retournement, rotation, perspective), puis photométriques (variation chromatique, luminosité, contraste), puis bruit et flou (bruit gaussien, flou gaussien), puis spécifiques au domaine (ombre, pluie), et enfin la régularisation (Cutout).
Pendant la validation et l’inférence, l’augmentation est réduite aux transformations minimales nécessaires : typiquement seulement le recadrage central (ou le redimensionnement) et la normalisation. Aucune transformation aléatoire n’est appliquée pendant l’évaluation pour garantir des résultats déterministes et reproductibles.
Les pipelines d’entraînement de production doivent journaliser les statistiques d’augmentation pour surveiller leur effet sur la dynamique d’entraînement :
Ces métriques de surveillance garantissent que l’augmentation atteint son effet prévu — élargir la distribution d’entraînement sans introduire d’artefacts ou de biais qui dégradent les performances dans le monde réel.
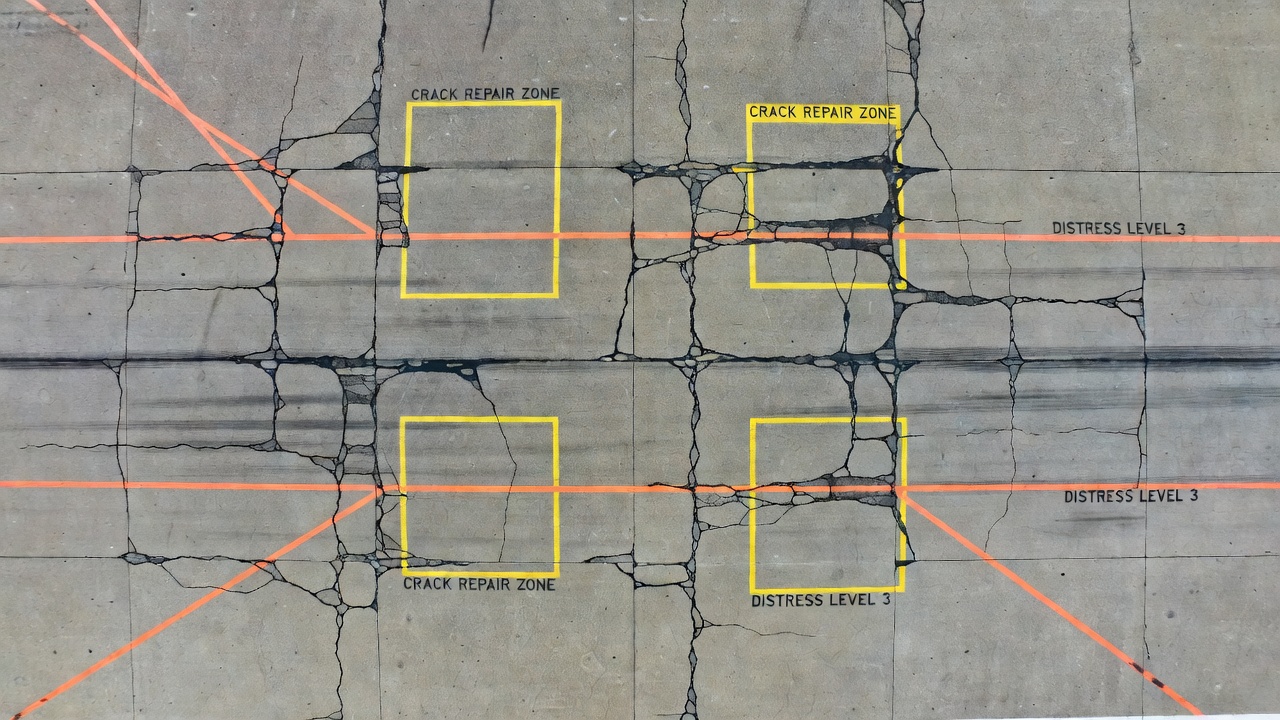
L’image de la grille d’augmentations de fissures de béton illustre le résultat pratique d’un pipeline d’augmentation : la même image originale de fissure est transformée en 12+ exemples d’entraînement distincts par rotation, retournement, recadrage, ajustement chromatique et flou. Chaque version augmentée préserve l’étiquette de fissure tout en la présentant dans un contexte visuellement différent, apprenant au modèle à détecter les fissures indépendamment de l’orientation, de l’éclairage ou de la qualité d’image.
{
TarmacView exploite des pipelines d'augmentation de données avancés pour former des modèles d'inspection d'infrastructures qui généralisent à travers les conditions d'éclairage, météorologiques et de surface. Optimisez l'entraînement de votre modèle de détection de défauts avec des stratégies d'augmentation spécifiques au domaine adaptées aux chaussées aéroportuaires et aux structures en béton.
+++ title = “Apprentissage par transfert” description = “L’apprentissage par transfert applique les connaissances d’un modèle pré-...
La vision par ordinateur est la technologie basée sur l'IA qui permet aux machines d'interpréter et d'agir sur des données visuelles, alimentant des application...
La détection de fissures par IA utilise la vision par ordinateur — réseaux de neurones convolutifs, vision transformers et modèles de segmentation sémantique — ...