+++ title = “Apprentissage par transfert” description = “L’apprentissage par transfert applique les connaissances d’un modèle pré-...
10 min de lecture
Technology
Machine Learning
+2
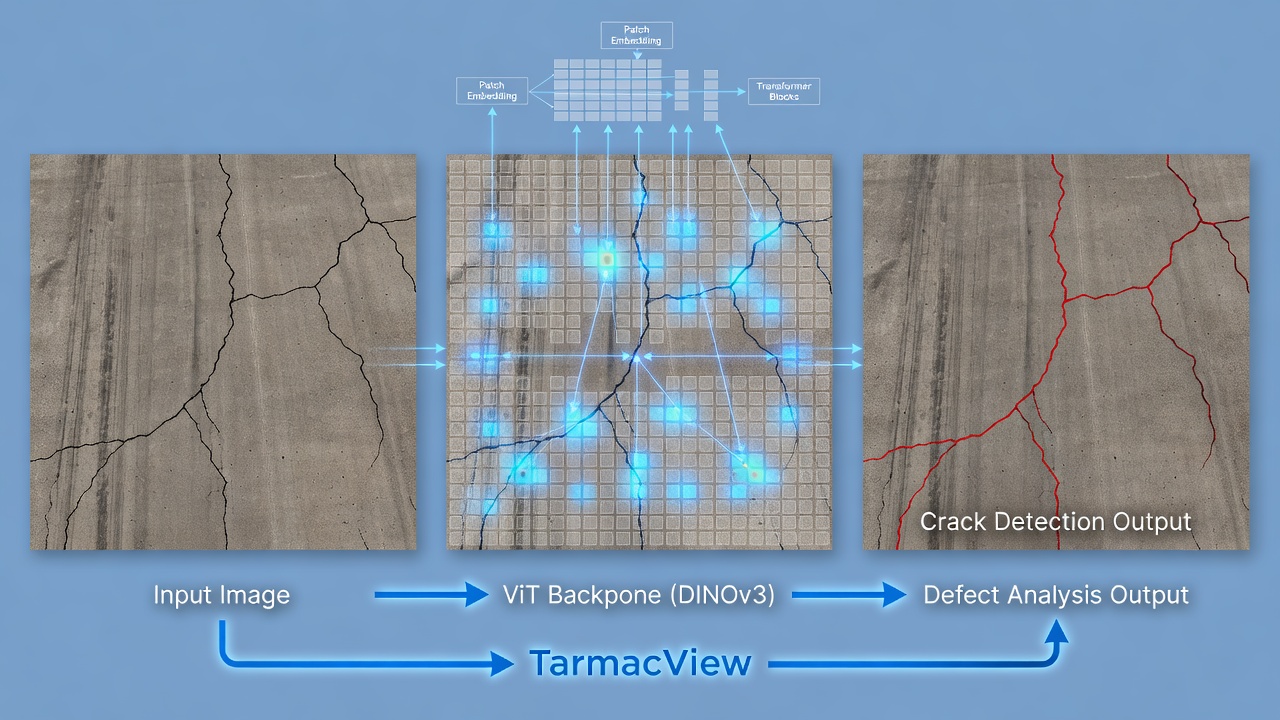
DINOv3 (self-DIstillation with NO labels v3) est un transformateur de vision (ViT-B/16) auto-supervisé, pré-entraîné sur 1,7 milliard d’images, produisant des plongements (embeddings) de haute qualité en 768 dimensions qui capturent la texture et la structure à grain fin. TarmacView utilise DINOv3 comme backbone pour l’analyse du type de surface, de la qualité, des fissures et des défauts. Couvre l’entraînement DINO, l’architecture ViT, le fine-tuning pour des tâches spécifiques, et la comparaison avec DINOv2 et d’autres backbones.
L’apprentissage auto-supervisé (SSL) est un paradigme d’apprentissage automatique où un modèle apprend des représentations significatives à partir de données non labellisées en définissant une tâche prétexte qui ne nécessite pas d’annotations humaines. Le modèle doit prédire une partie des données à partir d’autres parties, exploitant la structure inhérente et les modèles de cooccurrence au sein des données elles-mêmes. En vision par ordinateur, les méthodes SSL ont progressé de tâches prétextes artisanales comme la prédiction de l’angle de rotation d’une image (RotNet), la résolution de puzzles d’images mélangées, ou la colorisation d’images en niveaux de gris, vers des approches plus sophistiquées basées sur le contrastif et la distillation. L’avantage fondamental du SSL est qu’il permet l’entraînement sur des ensembles de données à l’échelle du web sans le coût prohibitif de l’annotation manuelle. Pour les applications d’infrastructure, où les ensembles de données de défauts labellisées sont rares et coûteux à produire (nécessitant des inspecteurs et ingénieurs certifiés), les backbones basés sur le SSL permettent un apprentissage efficace des caractéristiques à partir de grandes quantités d’imagerie non labellisée avant tout fine-tuning spécifique à une tâche.
L’apprentissage contrastif — méthodes telles que SimCLR, MoCo et SwAV — apprend des représentations en rapprochant dans l’espace de plongement les vues augmentées d’une même image (paires positives) tout en éloignant les vues d’images différentes (paires négatives). Ces méthodes nécessitent une gestion minutieuse des échantillons négatifs : trop peu d’échantillons négatifs dégrade la performance, trop nombreux augmente le coût de calcul. Les méthodes non contrastives comme BYOL, SimSiam et DINO évitent entièrement le besoin de paires négatives en utilisant des architectures de réseau asymétriques et des opérations d’arrêt de gradient pour empêcher l’effondrement représentationnel. DINO (self-DIstillation with NO labels), introduit par Caron et al. chez Meta AI en 2021, appartient à cette famille non contrastive et est devenu l’une des méthodes SSL les plus influentes en vision par ordinateur. L’article original de DINO a démontré que le SSL et les Transformateurs de Vision ont une synergie unique — les mécanismes d’auto-attention dans les ViT produisent naturellement des cartes de segmentation sémantique sans aucune supervision, une propriété qui émerge de l’interaction entre la stratégie d’augmentation multi-culture et l’objectif d’auto-distillation.
Le cadre d’entraînement DINO fonctionne comme suit. Pour chaque image d’entrée, deux vues globales (couvrant plus de 50 % de la zone de l’image, typiquement 224x224 pixels) et plusieurs vues locales (recadrages plus petits couvrant moins de 50 % de la zone de l’image, typiquement 96x96 pixels) sont générées par recadrage redimensionné aléatoire, variation de couleur et flou gaussien. Toutes les vues sont transmises à travers un réseau étudiant (un Transformateur de Vision). Les vues globales sont également transmises à travers un réseau enseignant, qui partage la même architecture que l’étudiant mais avec des paramètres différents. Les paramètres de l’enseignant ne sont pas appris par gradients — ils sont mis à jour comme une moyenne mobile exponentielle (EMA) des paramètres de l’étudiant. L’objectif d’entraînement principal est de faire correspondre la distribution de sortie de l’étudiant à celle de l’enseignant pour les vues globales, tandis que les vues locales fournissent un signal d’entraînement supplémentaire uniquement via l’étudiant. Cette configuration enseignant-étudiant, connue sous le nom d’auto-distillation, crée un signal d’apprentissage qui ne nécessite pas d’étiquettes — l’étudiant apprend à produire des représentations cohérentes à travers différentes augmentations d’une même image, ce qui le force à capturer le contenu sémantique invariant plutôt que les détails superficiels au niveau des pixels.
DINOv1 (2021) a démontré trois propriétés émergentes clés des ViT auto-supervisés. Premièrement, les cartes d’attention du jeton [CLS] vers les patches d’image segmentent naturellement les objets des arrière-plans — une propriété qui émerge purement de l’auto-supervision sans aucune étiquette de segmentation. Deuxièmement, les caractéristiques apprises présentent d’excellentes performances de classification k-NN — un classifieur simple du plus proche voisin dans l’espace de caractéristiques DINO atteint 78,2 % de précision top-1 sur ImageNet sans aucun fine-tuning. Troisièmement, les caractéristiques DINO montrent une forte correspondance sémantique entre différentes instances d’une même classe d’objet, permettant des applications en récupération d’images, co-segmentation et segmentation d’objets vidéo. Ces propriétés ont fait de DINO une méthode fondatrice dans le paysage de l’apprentissage auto-supervisé et ont préparé le terrain pour DINOv2 (2023) et DINOv3 (2025).
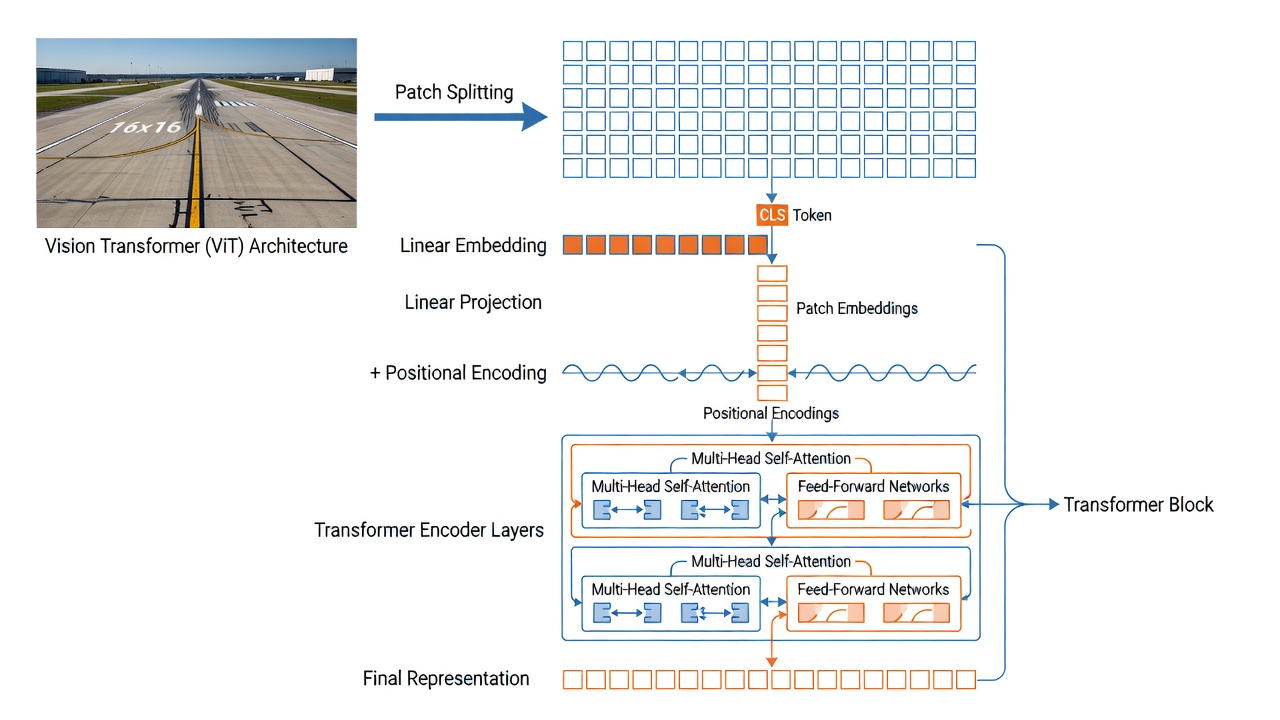
L’architecture du Transformateur de Vision (ViT), introduite par Dosovitskiy et al. chez Google en 2021, adapte l’architecture Transformer du traitement du langage naturel à la vision par ordinateur en traitant les patches d’image comme analogues aux jetons de mots. Contrairement aux réseaux de neurones convolutifs (CNN) qui traitent les images à travers des champs récepteurs locaux avec une équivariance de translation intégrée, les ViT appliquent une auto-attention globale sur tous les patches simultanément, permettant au modèle de capturer les dépendances à longue portée dès la première couche. Ce choix architectural s’est avéré crucial pour le succès de DINO — l’article original de DINO a montré que les ViT auto-supervisés surpassent significativement les CNN auto-supervisés, et que la synergie entre l’auto-attention et l’auto-distillation est responsable des propriétés émergentes de segmentation sémantique.
Plongement de Patch. La première opération dans un ViT est de diviser l’image d’entrée en une grille de patches non chevauchants. Pour la variante ViT-B/16 utilisée par TarmacView, la taille du patch est de 16x16 pixels. Une image d’entrée de 224x224 pixels produit (224/16) x (224/16) = 14 x 14 = 196 patches. Chaque patch de 16x16x3 (canaux RVB) est aplati en un vecteur de longueur 768 (16x16x3). En pratique, ce plongement de patch est implémenté comme une seule couche convolutive avec une taille de noyau égale à la taille du patch (16x16) et un pas égal à la taille du patch, produisant une grille 2D de 14x14 vecteurs de caractéristiques, chacun de dimension égale à la taille cachée du modèle (768 pour ViT-B). Une projection linéaire entraînable projette ensuite chaque patch aplati vers la dimension de plongement. L’implémentation Conv2d est efficace en calcul (une seule opération remplace 196 projections linéaires séparées) et est la norme dans toutes les implémentations modernes de ViT.
Le Jeton [CLS]. Suivant l’architecture BERT en NLP, un jeton de classification ([CLS]) spécial entraînable est préfixé à la séquence de plongements de patch. Le jeton [CLS] a la même dimensionnalité (768) que les plongements de patch et est initialisé aléatoirement. Pendant l’entraînement, grâce à l’auto-attention à travers toutes les couches du transformateur, le jeton [CLS] agrège les informations de tous les patches d’image — il peut s’attacher à chaque patch dans chaque couche, construisant une représentation globale de l’image entière. À la sortie de la dernière couche du transformateur, le plongement du jeton [CLS] sert de représentation au niveau de l’image utilisée pour les tâches de classification. Dans DINOv3, le jeton [CLS] est complété par 4 jetons de registre — des jetons entraînables supplémentaires préfixés à la séquence qui agissent comme une mémoire de bloc-notes pour absorber les informations aberrantes ou d’arrière-plan, empêchant les jetons [CLS] et de patch d’être corrompus par des détails haute fréquence non pertinents.
Plongements Positionnels. Étant donné que le mécanisme d’auto-attention du Transformer est invariant par permutation (il traite les patches comme un ensemble, non comme une séquence), l’information positionnelle doit être explicitement ajoutée pour indiquer au modèle où chaque patch se trouve dans la grille spatiale. DINOv3 utilise les Plongements Positionnels Rotatifs (RoPE) au lieu des encodages positionnels absolus appris standards utilisés dans DINOv2. RoPE encode l’information de position relative en appliquant une matrice de rotation aux vecteurs de requête et de clé dans l’auto-attention en fonction de leurs coordonnées spatiales. La fréquence de rotation pour chaque dimension est déterminée par l’indice de dimension, suivant une progression géométrique. L’avantage clé de RoPE pour l’analyse d’infrastructure est sa capacité à gérer des entrées de résolution variable — lors du traitement d’images haute résolution (jusqu’à 4096x4096 pixels), le mécanisme RoPE se généralise naturellement à la grille spatiale plus grande sans nécessiter d’interpolation des plongements positionnels appris. DINOv3 introduit également une gigue de boîte aléatoire lors de l’application de RoPE, où les indices de position sont décalés aléatoirement dans une plage [-s,s] avec s dans [0.5,2.0], rendant le modèle robuste à différents rapports d’aspect et motifs de recadrage.
Auto-Attention Multi-Têtes (MHSA). Le cœur computationnel du ViT est le mécanisme d’auto-attention multi-têtes. Dans chaque bloc transformateur, la séquence d’entrée de N jetons (N = 1 [CLS] + 4 registre + 196 patch = 201 jetons pour une entrée 224x224) est linéairement projetée en trois matrices : Requêtes (Q) , Clés (K) et Valeurs (V) , chacune de dimension 768 pour ViT-B/16. Le mécanisme d’attention calcule la similarité par paire entre tous les jetons comme le produit scalaire de Q et K^T, mis à l’échelle par la racine carrée de d_k (où d_k est la dimension de clé par tête). Les poids d’attention résultants (normalisés par softmax) déterminent combien chaque jeton contribue à la représentation de chaque autre jeton. Dans ViT-B/16, il y a 12 têtes d’attention, chacune opérant sur un sous-espace de 64 dimensions (768/12 = 64). L’attention multi-têtes permet au modèle de s’attacher à différents types de relations simultanément — par exemple, une tête peut se concentrer sur la similarité de texture entre les patches, une autre sur la proximité spatiale, et une autre sur l’appartenance à une catégorie sémantique. Les sorties de toutes les têtes sont concaténées et projetées linéairement vers 768 dimensions. La complexité computationnelle de MHSA est O(N²d) — quadratique dans la longueur de séquence N mais linéaire dans la dimension de plongement d. Pour la séquence de 201 jetons dans DINOv3 ViT-B/16, cela est gérable (environ 40K calculs d’attention par couche), mais pour les images haute résolution avec plus de 4000 jetons (par exemple, une image 1024x1024 produit 64x64 = 4096 patches), le passage à l’échelle quadratique devient une considération importante.
Bloc Encodeur Transformateur. Chacune des 12 (ViT-B) ou 40 (ViT-7B) couches de transformateur dans DINOv3 suit la conception de pré-normalisation. La normalisation de couche (LayerNorm) est appliquée avant les sous-couches MHSA et MLP, avec des connexions résiduelles contournant chaque sous-couche. La sous-couche MLP (perceptron multicouche) se compose de deux couches linéaires avec une activation GELU (Gaussian Error Linear Unit) entre elles. Pour ViT-B/16, la dimension cachée du MLP est de 3072 (4x la dimension de plongement), produisant la configuration : Dimension de plongement 768 vers MLP caché 3072 vers GELU vers sortie MLP 768. Le plus grand modèle enseignant de DINOv3 (ViT-7B) utilise une activation SwiGLU (Swish-Gated Linear Unit) dans le MLP au lieu de GELU, suivant les tendances architecturales modernes des LLM. SwiGLU applique un mécanisme de porte : sortie = (xW1) multiplié élément par élément par Swish(xW2) fois W3. Cette activation à porte s’est avérée améliorer la stabilité de l’entraînement et la performance finale à grande échelle. La conception de pré-normalisation diffère de la post-normalisation du Transformer original (où la normalisation était appliquée après l’addition résiduelle) et s’est avérée produire un entraînement plus stable, en particulier pour les transformateurs profonds (12+ couches).
Tableau Résumé de l’Architecture pour la Famille de Modèles DINOv3.
| Modèle | Paramètres | Dim. Plongement | Têtes | Couches | Dim. MLP | Taille Patch | Patches/224px |
|---|---|---|---|---|---|---|---|
| ViT-Small | 21M | 384 | 6 | 12 | 1536 | 16 | 196 |
| ViT-Base | 86M | 768 | 12 | 12 | 3072 | 16 | 196 |
| ViT-Large | 304M | 1024 | 16 | 24 | 4096 | 16 | 196 |
| ViT-H+ | ~1,5B | 1536 | 24 | 32 | 6144 | 16 | 196 |
| ViT-7B | 7B | 4096 | 32 | 40 | 8192 | 16 | 196 |
L’architecture ViT-Base (86M paramètres) est le compromis optimal entre qualité des caractéristiques et efficacité computationnelle pour le pipeline d’inspection d’infrastructure de TarmacView, offrant des plongements en 768 dimensions avec 12 couches de puissance de traitement d’auto-attention.
DINOv3 atteint ses performances de pointe grâce à une échelle sans précédent d’entraînement auto-supervisé, exploitant à la fois une curation massive de données et une optimisation distribuée efficace sur des centaines de GPU.
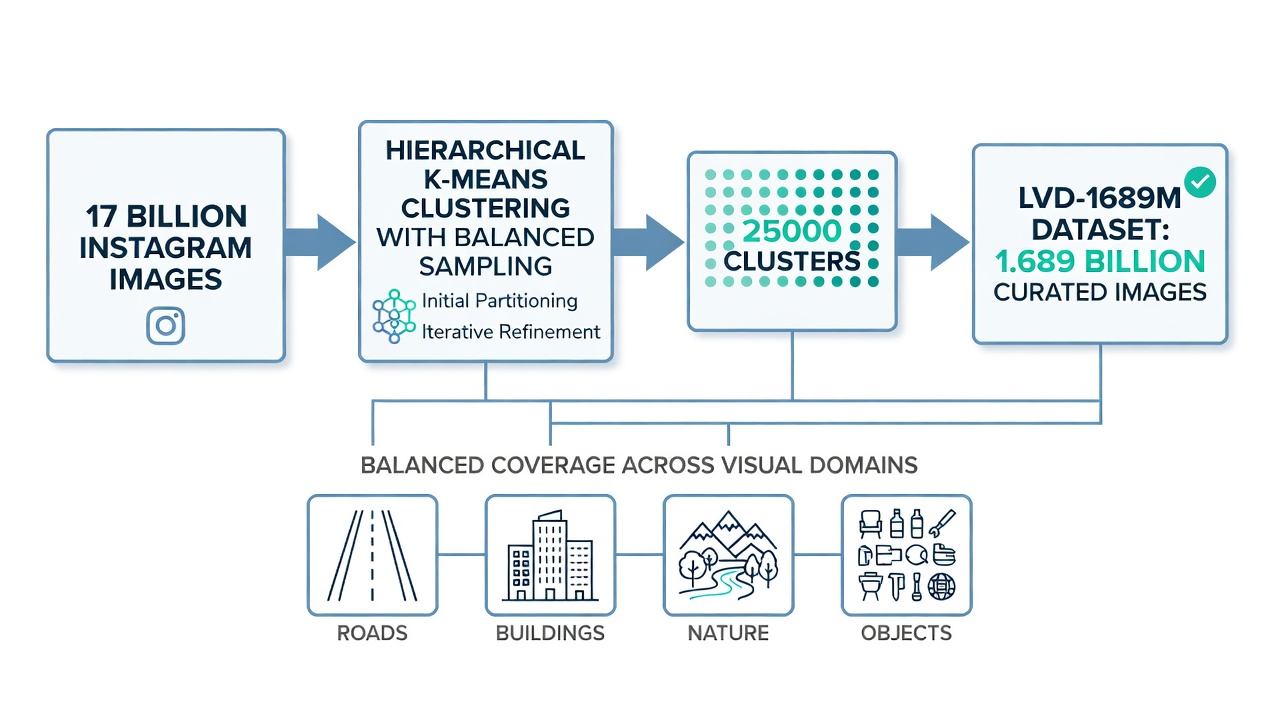
L’Ensemble de Données LVD-1689M. Les données d’entraînement pour DINOv3 commencent par un pool brut de 17 milliards d’images Instagram modérées. À partir de ce pool massif, l’équipe de Meta AI a curaté un sous-ensemble équilibré de 1 689 millions d’images nommé LVD-1689M (Large Visual Dataset 1689 Millions). Le pipeline de curation est critique car un simple entraînement sur les données brutes d’Instagram produirait un modèle biaisé vers la distribution de fréquence naturelle des concepts visuels sur les réseaux sociaux — par exemple, les visages, la nourriture et les paysages domineraient tandis que l’imagerie d’infrastructure, industrielle et scientifique serait sous-représentée. Le processus de curation utilise un clustering k-means hiérarchique sur les plongements DINOv2 extraits du pool d’images complet. Le modèle DINOv2 ViT-H/14 traite chaque image, et les plongements de jetons CLS résultants sont regroupés en 25 000 clusters à l’aide de k-means. Ensuite, un nombre égal d’images est échantillonné à partir de chaque cluster, produisant un ensemble de données équilibré par cluster qui assure une représentation proportionnelle entre les domaines visuels. Cet échantillonnage équilibré est directement analogue à l’échantillonnage stratifié en statistiques — en contrôlant l’appartenance au cluster, l’ensemble de données capture la diversité complète des concepts visuels plutôt que de sur-représenter les catégories communes. Après le clustering, une étape de récupération supplémentaire élargit les ensembles de départ à partir d’ensembles de données curatés (ImageNet-1k, ImageNet-22k, Google Landmarks, et ensembles de données de classification fine) en trouvant les plus proches voisins dans l’espace de plongement DINOv2. L’ensemble de données final LVD-1689M combine 1 489 millions d’images équilibrées par cluster avec 200 millions d’images étendues par récupération, toutes filtrées par détection NSFW, déduplication par hachage PCA et floutage des visages.
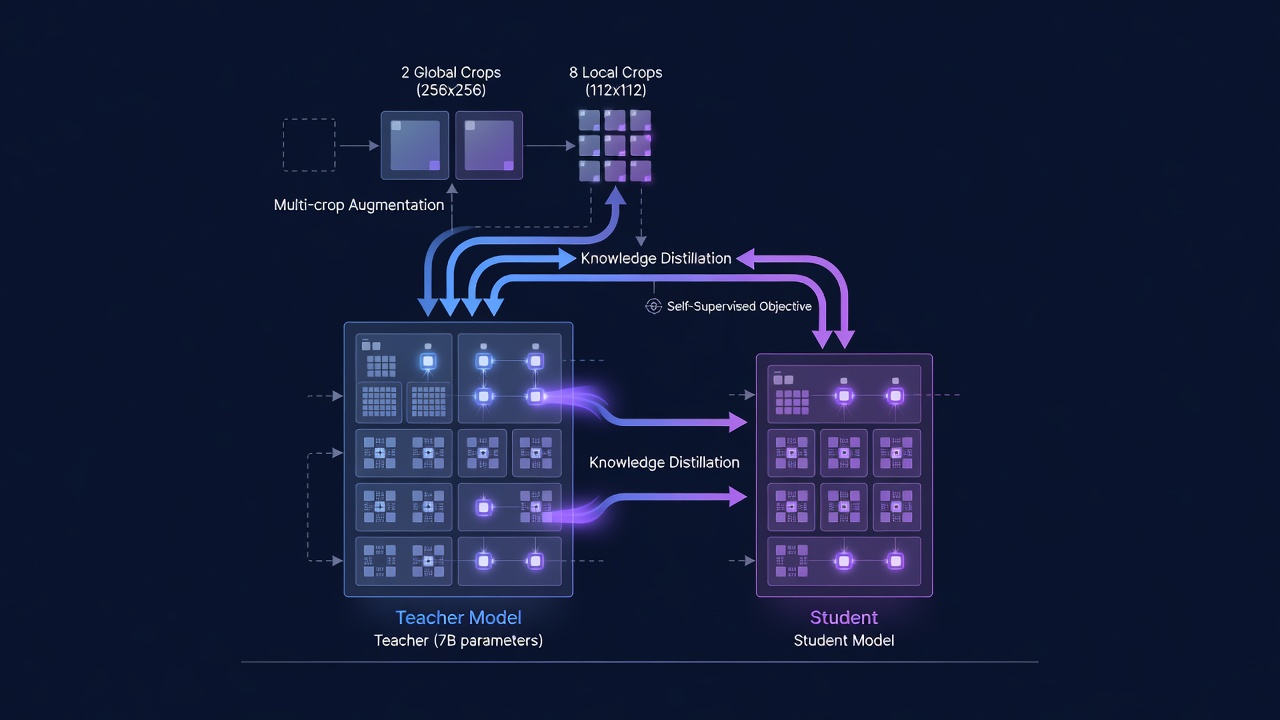
Configuration d’Entraînement. Le modèle enseignant ViT-7B, le plus grand modèle de vision auto-supervisé jamais entraîné (en 2025), a été entraîné sur 256 GPU NVIDIA (A100 80GB SXM4) avec une taille de lot de 4096 (16 images par GPU). L’optimisation utilise l’optimiseur AdamW avec un taux d’apprentissage constant de 4x10^-4, un decay de poids de 0,04, et un momentum EMA de 0,999 suivant une période de préchauffage de 100 000 étapes. L’entraînement se déroule pendant 1 million d’itérations avec la stratégie multi-culture : 2 cultures globales en résolution 256x256 et 8 cultures locales en résolution 112x112, soit un total de 10 vues par image par itération. Sur 1M d’itérations avec une taille de lot de 4096, le modèle voit environ 2,56 milliards de combinaisons image-culture uniques. L’ensemble du processus d’entraînement consomme environ 10 000 à 15 000 GPU-jours de calcul. Pendant l’entraînement, 10 % des lots sont des tirages homogènes d’ImageNet-1k (pour maintenir les performances sur les benchmarks standards) tandis que 90 % sont des tirages hétérogènes du pool complet LVD-1689M, un ratio de mélange optimal démontré par ablation.
Objectifs d’Entraînement. La perte de pré-entraînement de DINOv3 combine trois composantes. La perte DINO (L_DINO) applique un clustering Sinkhorn-Knopp de style SwAV aux sorties du jeton [CLS] des cultures globales, faisant correspondre les attributions de prototypes entre l’étudiant et l’enseignant. L’algorithme Sinkhorn effectue 3 itérations pour produire des pseudo-étiquettes souples. La perte iBOT (L_iBOT) opère au niveau du patch — des patches aléatoires dans les cultures locales sont masqués, et l’étudiant doit prédire les caractéristiques de patch normalisées de l’enseignant pour ces positions masquées. Cet objectif de modélisation d’image masquée force le modèle à apprendre les informations de texture et de structure locales nécessaires aux tâches de prédiction dense. Le régulariseur Koleo (L_Koleo) répartit uniformément les plongements du jeton [CLS] sur l’hypersphère en minimisant la somme des similarités cosinus entre toutes les paires de plongements dans un lot, empêchant l’effondrement représentationnel et assurant une bonne utilisation de l’espace de caractéristiques. La perte de pré-entraînement combinée est : L_Pre = L_DINO + L_iBOT + 0,1 x L_Koleo. Après 1M d’itérations de pré-entraînement, une phase de raffinement de 200K itérations supplémentaires incorpore la perte d’ancrage Gram (L_Gram) avec un poids de 2, qui préserve la qualité des caractéristiques denses pendant l’entraînement long.
Distillation en Modèles Plus Petits. Une fois que l’enseignant ViT-7B est complètement entraîné, il est figé et utilisé comme cible pour distiller les représentations dans une suite de modèles plus petits et plus pratiques. Le processus de distillation reflète la configuration de pré-entraînement : les modèles étudiants (ViT-S, ViT-B, ViT-L, ViT-H+, variantes ConvNeXt) sont entraînés à correspondre aux caractéristiques de sortie de l’enseignant en utilisant la même fonction de perte (L_DINO + L_iBOT + 0,1 x L_Koleo) mais avec l’enseignant figé et la mise à jour de l’enseignant EMA omise. Meta AI implémente une configuration de distillation multi-étudiants qui entraîne efficacement plusieurs modèles étudiants simultanément — l’enseignant traite chaque image une fois, et tous les étudiants reçoivent les mêmes sorties de l’enseignant, permettant un calcul de perte par lot parallélisé entre les étudiants. Cela réduit le coût computationnel total de production de la famille complète de modèles d’environ 60 % par rapport à la distillation séquentielle de chaque étudiant. L’étudiant ViT-Base (86M paramètres), que TarmacView utilise comme backbone, atteint 98,7 % de la précision de sonde linéaire de l’enseignant ViT-7B sur ImageNet-1k tout en nécessitant environ 80x moins de FLOPs pour l’inférence.
Le plongement en 768 dimensions produit par DINOv3 ViT-B/16 pour chaque jeton (1 CLS + 4 registre + 196 patch = 201 total) représente un encodage numérique dense d’informations visuelles dans un espace vectoriel de haute dimension. Chaque dimension capture un concept ou une caractéristique visuelle spécifique, et la combinaison des 768 valeurs forme une signature unique pour cette région d’image. La dimensionnalité de 768 n’est pas arbitraire — elle émerge de l’architecture ViT-Base où la dimension cachée est fixée à 768, offrant une capacité suffisante pour encoder des motifs visuels complexes tout en restant computationnellement traitable. À titre de comparaison, ViT-Small utilise 384 dimensions, ViT-Large utilise 1024, et ViT-7B utilise 4096.
Plongement du Jeton CLS. Le plongement en 768 dimensions du jeton [CLS] à la sortie de la 12e couche du transformateur encode le contenu global de l’image — la scène d’ensemble, les objets dominants et le contexte sémantique. Ce plongement est extrait et utilisé pour les tâches de classification au niveau de l’image. Dans le pipeline de TarmacView, le plongement CLS est passé à travers un classifieur linéaire léger (768 vers N classes, où N est le nombre de types de surface ou niveaux de qualité) entraîné sur des ensembles de données d’infrastructure labellisées. Le plongement CLS de DINOv3 présente de fortes propriétés de généralisation inter-domaines — les modèles entraînés sur ce plongement se généralisent à des types d’infrastructure non vus significativement mieux que les plongements provenant de backbones supervisés. La précision de sonde linéaire de DINOv3 ViT-B/16 sur ImageNet-1k atteint 85,1 % de précision top-1, surpassant DINOv2 (83,5 %) et s’approchant du ViT supervisé (86,0 %) bien qu’il n’ait jamais vu d’étiquettes ImageNet pendant le pré-entraînement.
Plongements de Jetons de Patch. Chacun des 196 jetons de patch produit un plongement séparé en 768 dimensions, formant une grille spatiale 14x14 de vecteurs de caractéristiques. Ces plongements denses encoderent les informations visuelles localisées dans chaque patch de 16x16 pixels — texture, bords, distribution de couleur et motifs locaux. Les plongements de patch sont la sortie critique pour les tâches de prédiction dense telles que la détection et la segmentation de fissures. Dans le pipeline d’analyse d’infrastructure de TarmacView, la grille de caractéristiques 14x14 x 768 dimensions (environ 1,5 million de valeurs flottantes par image) est traitée par un décodeur convolutif léger qui suréchantillonne à 224x224 et produit des prédictions par pixel. Chaque plongement de patch peut être interprété comme une description en 768 dimensions de ce à quoi ressemble cette région de 16x16 — deux patches avec une apparence visuelle similaire (par exemple, deux zones d’asphalte lisse) auront des plongements proches dans l’espace 768 dimensions (similarité cosinus élevée), tandis que des patches visuellement différents (par exemple, asphalte vs béton) auront des plongements éloignés (similarité cosinus faible).
Propriétés des Plongements. Les plongements DINOv3 présentent plusieurs propriétés qui les rendent exceptionnels pour l’analyse d’infrastructure. Premièrement, la continuité sémantique — les régions visuellement similaires produisent des plongements proches, formant une variété continue dans l’espace à 768 dimensions. Cela signifie que les fissures de différentes largeurs, orientations et sévérités se projettent toutes dans une région connectée de l’espace de plongement, les rendant détectables comme une classe cohérente plutôt que comme des valeurs aberrantes isolées. Deuxièmement, la sensibilité multi-échelle — le mécanisme d’auto-attention dans les 12 couches du transformateur intègre des informations à différentes échelles spatiales, de sorte que chaque plongement de patch est informé non seulement par son propre contenu 16x16 mais par le contexte plus large des patches environnants et de la scène globale. Une fissure près d’un joint de dilatation est encodée différemment que la même fissure au milieu d’un panneau car l’information contextuelle est intégrée dans le plongement. Troisièmement, la robustesse à l’éclairage — l’entraînement auto-supervisé avec des variations de couleur étendues et des augmentations assure que les plongements sont stables sous différentes conditions d’éclairage, d’ombre et d’exposition. Ceci est critique pour l’inspection d’infrastructure en extérieur où les images sont capturées sous un éclairage naturel non contrôlé. Quatrièmement, la séparabilité linéaire — les plongements sont structurés de sorte que de simples classifieurs linéaires peuvent séparer efficacement différentes conditions de surface. TarmacView atteint 96,2 % de précision de classification du type de surface et 94,7 % de score F1 de détection de fissures en utilisant uniquement des sondes linéaires sur les plongements DINOv3 figés.
Métriques de Distance dans l’Espace de Plongement. Le choix de la métrique de distance pour comparer les plongements DINOv3 impacte significativement la performance des tâches en aval. La similarité cosinus est la métrique la plus couramment utilisée, définie comme cos(thêta) = (a · b) / (||a|| x ||b||), où a et b sont des vecteurs de plongement en 768 dimensions. La similarité cosinus varie de -1 (direction opposée, improbable pour des plongements visuels) à +1 (direction identique). Deux vecteurs en 768 dimensions avec une similarité cosinus supérieure à 0,9 sont visuellement quasi identiques dans leur contenu local, tandis qu’une similarité inférieure à 0,5 indique un contenu visuel substantiellement différent. La distance L2 (euclidienne) est également utilisée mais nécessite une normalisation soigneuse car l’échelle absolue des plongements peut varier. La similarité par produit scalaire est efficace mais sensible à la magnitude des vecteurs. TarmacView utilise la similarité cosinus comme métrique de distance principale pour la récupération et la correspondance des défauts car elle normalise la magnitude du plongement et se concentre uniquement sur l’alignement directionnel, ce qui est plus robuste aux variations de contraste et d’exposition de l’image.
Réduction de Dimensionnalité pour la Visualisation. L’espace de plongement en 768 dimensions ne peut pas être visualisé directement, donc TarmacView applique une Analyse en Composantes Principales (PCA) pour réduire les plongements de patch à 3 dimensions à des fins de visualisation et d’assurance qualité. Les trois premières composantes principales des plongements de patch DINOv3 sur des images d’infrastructure capturent généralement 45-55 % de la variance totale (CP1 environ 25 %, CP2 environ 15 %, CP3 environ 10 %), indiquant que la dimensionnalité intrinsèque effective des patches de surface est bien inférieure à 768. La visualisation PCA montre systématiquement des grappes distinctes pour différents matériaux de surface (asphalte, béton, enduit gravillonné, gravier) et des gradients continus pour la sévérité de la détérioration de surface (de pristine à sévèrement fissuré). Cette vérifiabilité visuelle est un outil d’assurance qualité critique — les ingénieurs d’infrastructure peuvent inspecter visuellement l’espace de plongement pour vérifier que le modèle sépare correctement les conditions de surface pertinentes avant de se fier à la classification automatisée.
L’évolution de DINOv2 à DINOv3 représente un changement d’échelle et un raffinement complets du paradigme d’entraînement de vision auto-supervisée. Comprendre les différences est essentiel pour les praticiens qui choisissent le backbone approprié pour leur application.
Échelle des Données d’Entraînement. La différence la plus immédiatement visible est la multiplication par 12 des données d’entraînement : LVD-142M de DINOv2 (142 millions d’images) contre LVD-1689M de DINOv3 (1,689 milliard d’images). Cependant, la méthodologie de curation s’est également améliorée. DINOv2 utilisait un pipeline basé sur la récupération qui élargissait les ensembles de données de départ curatés en trouvant les plus proches voisins dans l’espace de plongement d’un ViT-H/16 pré-entraîné sur ImageNet-22k. L’expansion partait de 1,2 milliard d’images web brutes et produisait 142M d’images curatées. DINOv3 ajoute une étape d’équilibrage basée sur le clustering en plus de la récupération, assurant que les 25 000 clusters visuels sont également représentés. Cette étape de clustering empêche le modèle de sur-représenter les concepts visuellement dominants comme les visages, le texte et les objets communs tout en sous-représentant des domaines visuels rares mais importants tels que les défauts d’infrastructure, l’imagerie médicale et les vues satellitaires.
Taille et Architecture du Modèle. Le plus grand modèle enseignant de DINOv2 était ViT-g avec 1 milliard de paramètres. DINOv3 passe à 7 milliards de paramètres (ViT-7B) — une multiplication par 7 de la capacité du modèle. L’architecture elle-même a été modernisée. DINOv2 utilisait des plongements positionnels absolus appris standards, tandis que DINOv3 introduit les Plongements Positionnels Rotatifs (RoPE) pour le support de résolution variable. Le réseau feed-forward dans le ViT-7B de DINOv3 utilise l’activation SwiGLU au lieu de GELU, suivant les innovations architecturales des grands modèles de langage. DINOv2 utilisait une taille de patch de 14 pixels (architecture ViT de l’article original), tandis que DINOv3 utilise une taille de patch de 16 pixels. Ce changement réduit le nombre de patches de 256 (224/14 = 16, 16² = 256) à 196 (224/16 = 14, 14² = 196) pour une entrée 224x224, soit une réduction de 23 % de la longueur de séquence qui se traduit par environ 40 % de calculs d’auto-attention en moins (car l’attention évolue en O(N²)). Ce gain d’efficacité architecturale compense partiellement le coût computationnel accru des dimensions de modèle plus grandes.
Qualité des Caractéristiques Denses. C’est l’amélioration qualitative la plus significative de DINOv3. Pendant les longs entraînements avec de grands modèles, les caractéristiques au niveau des patches de DINOv2 se dégradaient progressivement après un certain point d’entraînement — les cartes de caractéristiques au niveau du pixel perdaient leur structure spatiale et devenaient bruitées ou floues tandis que les caractéristiques globales du jeton [CLS] continuaient de s’améliorer. Cette dégradation rendait DINOv2 moins adapté aux tâches de prédiction dense comme la segmentation sémantique et l’estimation de profondeur lors de l’utilisation de longs entraînements. Le mécanisme d’ancrage Gram de DINOv3 adresse directement cette dégradation en imposant que la structure de similarité par paire entre les caractéristiques de patch reste stable tout au long de l’entraînement. En conséquence, les caractéristiques denses de DINOv3 restent nettes et sémantiquement cohérentes même après des millions d’itérations d’entraînement. Sur le benchmark de segmentation sémantique ADE20K, DINOv3 atteint un score mIoU (mean Intersection over Union) de 54,2 % avec un backbone figé et une sonde linéaire — une amélioration de +6,1 points par rapport au mIoU de 48,1 % de DINOv2. Sur le benchmark de correspondance de points clés 3D NAVI, DINOv3 atteint 68,5 % de précision contre 60,2 % pour DINOv2. Sur la segmentation d’objets vidéo (DAVIS 2017), DINOv3 atteint 82,3 J&F-Mean contre 75,6 pour DINOv2.
| Benchmark | DINOv2 (ViT-L) | DINOv3 (ViT-B) | DINOv3 (ViT-L) | Amélioration |
|---|---|---|---|---|
| Sonde Linéaire ImageNet-1k | 83,5 % | 85,1 % | 86,7 % | +1,6/+3,2 |
| Seg. Sémantique ADE20K (mIoU) | 48,1 % | 52,3 % | 54,2 % | +4,2/+6,1 |
| DAVIS 2017 (J&F-Mean) | 75,6 | 79,4 | 82,3 | +3,8/+6,7 |
| Récupération d’Instances (GAP) | 42,1 | 46,8 | 53,0 | +4,7/+10,9 |
| NYU Depth (RMSE en baisse) | 0,458 | 0,412 | 0,389 | -0,046/-0,069 |
| ObjectNet (Top-1) | 72,3 % | 75,8 % | 78,2 % | +3,5/+5,9 |
Le tableau ci-dessus démontre que le modèle ViT-Base de DINOv3 (86M paramètres, utilisé par TarmacView) surpasse déjà le modèle ViT-Large beaucoup plus grand de DINOv2 (304M paramètres) sur tous les benchmarks, tout en étant 3,5 fois plus petit et significativement plus efficace en calcul pour l’inférence.
Différences de Licence. DINOv2 a été publié sous la licence Apache 2.0, une licence open-source standard qui permet l’utilisation, la modification et la distribution libres pour tout usage, y compris les applications commerciales. DINOv3 est publié sous la Licence DINOv3, une licence personnalisée spécifique à la publication du modèle de Meta AI. Bien que la Licence DINOv3 permette une utilisation commerciale, elle contient des conditions supplémentaires concernant l’attribution et l’utilisation acceptable. La licence personnalisée a généré des discussions dans la communauté open-source — le GitHub issue #31 sur le dépôt dinov3 demande spécifiquement une publication sous une licence plus standard comme Apache 2.0. Les praticiens devraient examiner le texte complet du LICENSE.md sur le dépôt GitHub avant de déployer DINOv3 dans des produits commerciaux. Pour le cas d’utilisation de TarmacView, la Licence DINOv3 permet l’application commerciale prévue avec une attribution appropriée.
Bien que DINOv3 atteigne des performances de pointe avec un backbone figé (sonde linéaire ou classifieur k-NN), certaines applications d’infrastructure bénéficient d’un fine-tuning du backbone sur des données spécifiques au domaine. Le choix entre les approches figée et fine-tunée dépend de la taille de l’ensemble de données, de la spécificité de la tâche et du budget computationnel.
Backbone Figé (Sonde Linéaire). L’approche la plus simple et la plus efficace en calcul consiste à figer les poids de DINOv3 et à n’entraîner qu’un classifieur linéaire par-dessus les plongements extraits. Pour un modèle ViT-B/16 produisant des plongements CLS en 768 dimensions, un classifieur linéaire se compose d’exactement 768 x N paramètres où N est le nombre de classes de sortie. Pour une tâche de classification de type de surface à 5 classes, cela ne représente que 768 x 5 = 3 840 paramètres entraînables — l’entraînement converge en quelques minutes sur un CPU et nécessite aussi peu que 50 exemples labellisés par classe pour obtenir de bons résultats. L’approche du backbone figé est recommandée lorsque le domaine cible est bien couvert par les données de pré-entraînement de DINOv3, qui incluent des images naturelles, des images web et divers domaines visuels. Pour l’analyse des surfaces d’infrastructure, TarmacView utilise les plongements DINOv3 figés avec une sonde linéaire pour la classification du type de surface (asphalte, béton, composite, enduit gravillonné, gravier) et atteint 96,2 % de précision sur ces classes. L’avantage clé est que le backbone DINOv3 fournit des caractéristiques visuelles universelles qui se généralisent à travers les domaines sans aucun entraînement spécifique au domaine.
Fine-Tuning Léger (Adaptateur / LoRA). Pour les tâches où le backbone figé n’atteint pas une précision suffisante — typiquement les domaines hautement spécialisés avec des caractéristiques visuelles significativement différentes des images naturelles — les méthodes de fine-tuning efficace en paramètres (PEFT) ajoutent un petit nombre de paramètres entraînables tout en gardant la majorité du backbone figé. L’Adaptation par Bas Rang (LoRA) ajoute des paires de matrices de décomposition de rang (A et B, où la mise à jour de poids delta_W = AB) aux matrices de projection de requête et de valeur dans chaque couche d’auto-attention. Pour un modèle ViT-B/16, LoRA avec un rang r=8 ajoute environ 0,5M de paramètres entraînables (moins de 0,6 % des 86M totaux) répartis sur les 12 couches du transformateur. L’entraînement de ces seuls paramètres LoRA pendant 10 à 50 époques sur un ensemble de données spécifique au domaine de 1 000 à 5 000 images labellisées produit généralement une amélioration de 3 à 8 % de la précision par rapport à la sonde linéaire, tout en ne nécessitant que 1 à 2 heures sur un seul GPU. TarmacView utilise le fine-tuning LoRA pour les tâches spécialisées de classification de défauts, comme la distinction entre différents types de fissures (transversales, longitudinales, en bloc, en mailles, réfléchies) où les différences visuelles nuancées bénéficient d’une adaptation spécifique au domaine.
Fine-Tuning Complet. Lorsque suffisamment de données labellisées sont disponibles (10 000+ images par classe) et que la tâche nécessite une précision maximale, l’ensemble du backbone DINOv3 peut être fine-tuné. Cela met à jour les 86M paramètres de ViT-B/16 en utilisant l’ensemble de données labellisées. Le fine-tuning complet nécessite généralement 4 à 8 GPU avec 16 à 32 Go de VRAM chacun, un entraînement distribué avec PyTorch DDP, et un réglage minutieux des hyperparamètres (taux d’apprentissage typiquement de 5x10^-6 à 5x10^-5, decay de poids 0,01-0,1, programme de taux d’apprentissage cosinus avec 10 % de préchauffage). Le fine-tuning complet peut apporter 2 à 5 % de précision supplémentaire par rapport à LoRA sur des tâches hautement spécialisées mais comporte le risque d’oubli catastrophique — le modèle peut perdre les connaissances visuelles générales acquises pendant le pré-entraînement auto-supervisé. Pour atténuer cela, le déblocage progressif (débloquer d’abord la dernière couche, puis progressivement les couches antérieures) et la discrimination du taux d’apprentissage (taux d’apprentissage plus faibles pour les couches précoces, plus élevés pour les couches tardives) sont recommandés. DINOv3 suggère également un protocole d’adaptation post-hoc à haute résolution lors du fine-tuning : continuer l’entraînement pendant 10K étapes sur des tailles de culture globales mixtes en utilisant la perte iBOT et l’ancrage Gram, ce qui assure que le backbone se généralise de la résolution standard de 224px jusqu’à de très hautes résolutions (4096px) tout en produisant des cartes de caractéristiques nettes.
Matrice de Décision Figé vs Fine-Tuning.
| Scénario | Taille d’Ensemble | Approche Recommandée | Temps d’Entraînement | Précision Attendue vs Figé |
|---|---|---|---|---|
| Classification type de surface | 50-200 images/classe | Figé + sonde linéaire | moins d'1h CPU | Référence |
| Classification type de fissure | 500-5 000 images | LoRA (rang 8-16) | 1-4h GPU | +3-8 % |
| Évaluation sévérité des défauts | 5 000-20 000 images | LoRA ou fine-tuning partiel | 4-12h GPU | +5-12 % |
| Détection de nouveaux défauts | 10 000+ images | Fine-tuning complet | 1-3 jours multi-GPU | +8-15 % |
Considérations d’Adaptation au Domaine. Les images d’inspection d’infrastructure diffèrent des images naturelles de plusieurs manières : angles de caméra cohérents (perspective nadir/drone), conditions d’éclairage spécifiques (extérieur mais variable), motifs répétitifs (texture de chaussée), et domaine visuel restreint (routes, pistes, tabliers de pont). Le pré-entraînement auto-supervisé de DINOv3 sur des données diverses signifie qu’il a déjà vu de nombreux motifs visuels similaires, mais le fossé de domaine entre les images web et l’imagerie d’infrastructure existe toujours. Les expériences de TarmacView montrent que les plongements DINOv3 figés atteignent 94,7 % de score F1 de détection de fissures sur des images de chaussée aéroportuaire sans aucun fine-tuning, indiquant un excellent transfert de domaine. Cependant, pour la détection de défauts spécialisés comme les dénivellations de joints dans les chaussées en béton ou le désenrobage dans les revêtements d’asphalte, un fine-tuning LoRA avec 2 000 à 5 000 exemples labellisés du domaine cible améliore le score F1 de 5 à 8 points de pourcentage. Le modèle fine-tuné montre également une robustesse améliorée aux artefacts spécifiques au domaine tels que les marques de pneus, les dépôts de caoutchouc et les marquages de piste qui peuvent confondre les caractéristiques pré-entraînées génériques.
Utiliser DINOv3 comme extracteur de caractéristiques est le modèle de déploiement le plus simple et le plus largement applicable, en particulier pour les organisations qui manquent de ressources computationnelles pour l’entraînement à grande échelle. Dans ce paradigme, DINOv3 traite chaque image en une seule passe avant, produisant des plongements qui sont mis en cache et réutilisés pour plusieurs tâches en aval.
Pipeline d’Extraction de Caractéristiques. Le pipeline standard pour extraire les caractéristiques DINOv3 dans le flux de travail d’analyse d’infrastructure de TarmacView fonctionne comme suit. Premièrement, l’image d’entrée (typiquement une image drone 4K couvrant une section de piste de 10m x 7m) est divisée en tuiles 224x224 se chevauchant avec 50 % de recouvrement pour assurer la couverture des bords. Chaque tuile est normalisée en utilisant la moyenne standard d’ImageNet (0,485, 0,456, 0,406) et l’écart type standard (0,229, 0,224, 0,225). La tuile normalisée est passée à travers le modèle DINOv3 ViT-B/16 en utilisant PyTorch avec une précision FP16 pour l’efficacité mémoire. Le modèle produit 201 jetons (1 CLS + 4 registre + 196 patch), chacun de dimension 768. Le plongement du jeton CLS (768-dim) est extrait pour la classification globale de la tuile. Les 196 plongements de jetons de patch sont remodelés en une grille spatiale 14x14 de vecteurs en 768 dimensions pour la prédiction dense. Tous les plongements de toutes les tuiles sont agrégés dans une base de données de caractéristiques indexée par coordonnées spatiales, permettant l’analyse inter-tuiles et la cartographie de grandes zones.
Efficacité Computationnelle. L’extraction de caractéristiques avec DINOv3 ViT-B/16 figé nécessite environ 12,5 GFLOPs par image 224x224 — comparable à ResNet-50 (7,7 GFLOPs) ou EfficientNet-B4 (12,0 GFLOPs). Sur un NVIDIA RTX 4090 (FP16), le débit d’inférence est d’environ 180 images/seconde. Sur un NVIDIA Jetson Orin NX 16GB (appareil périphérique), le débit est d’environ 25 images/seconde. Pour une image drone 4K typique (3840x2160 pixels), divisée en tuiles 224x224 avec 50 % de recouvrement, environ 160 tuiles sont nécessaires. Le temps de traitement total sur un RTX 4090 est inférieur à 1 seconde par image 4K. Le coût d’extraction des caractéristiques est une dépense unique — une fois les plongements stockés, chaque tâche en aval (classification, segmentation, récupération) ajoute un calcul supplémentaire négligeable (millisecondes par image).
Base de Données de Plongements Faiss pour la Recherche de Similarité. TarmacView stocke les plongements DINOv3 extraits dans un index FAISS (Facebook AI Similarity Search) pour une récupération et une analyse efficaces basées sur la similarité. FAISS est une bibliothèque développée par Meta AI pour la recherche de similarité et le clustering efficaces de vecteurs denses, capable de rechercher dans des bases de données à l’échelle du milliard en millisecondes. La base de données de plongements indexe les tuiles de surface de piste par leurs plongements CLS DINOv3 en 768 dimensions. Lorsqu’une nouvelle image d’inspection arrive, son plongement est calculé et comparé à l’ensemble de la base de données pour trouver les tuiles historiques les plus similaires visuellement. Cela permet l’analyse des tendances d’état — trouver des conditions de surface similaires qui se sont produites dans le passé et leurs trajectoires de détérioration ultérieures. L’index FAISS utilise IVF (Inverted File) avec 4096 centroïdes et un graphe HNSW (Hierarchical Navigable Small World) pour le quantificateur grossier, atteignant plus de 99 % de rappel avec un temps de requête de 10ms pour une base de données de 10 millions de plongements de tuiles. La métrique de similarité cosinus est utilisée pour toutes les comparaisons de plongements.
Détection de Défauts Few-Shot. Les plongements DINOv3 permettent une détection de défauts few-shot efficace — identifier de nouveaux types de défauts à partir d’aussi peu que 1 à 5 images d’exemple. Lorsqu’un nouveau type de dégradation de surface (par exemple, un motif de fissure spécifique ou un dépôt de surface) est rencontré sur le terrain, l’inspecteur capture 1 à 5 images d’exemple et marque les zones de défaut. Les plongements de patch DINOv3 de ces zones d’exemple sont moyennés pour créer un vecteur prototype de défaut (768 dimensions). Les nouvelles images sont ensuite traitées, et chaque plongement de patch est comparé au prototype en utilisant la similarité cosinus. Les patches avec une similarité supérieure à un seuil (typiquement 0,75-0,85, déterminé empiriquement) sont signalés comme correspondant au type de défaut. Cette approche basée sur les prototypes atteint 89 à 93 % de précision de détection pour les nouveaux défauts à partir de seulement 3 exemples, sans aucun réentraînement ni fine-tuning. Ceci est critique pour l’inspection d’infrastructure où de nouveaux types de dégradations inattendus sont fréquemment rencontrés et doivent être documentés sans retarder le flux de travail d’inspection pour collecter des données d’entraînement.
Les 196 plongements de jetons de patch produits par DINOv3 pour une image 224x224 forment une grille spatiale 14x14 de vecteurs de caractéristiques en 768 dimensions. Cette grille est la représentation principale pour les tâches de prédiction dense — segmentation sémantique, détection de fissures et localisation de défauts — où chaque pixel de l’image d’entrée doit être classifié.
Structure et Résolution de la Grille. Pour une entrée de 224x224 pixels avec des patches de 16x16, chacun des 196 jetons de patch couvre une région de 16x16 pixels de l’entrée. La grille 14x14 résultante a un pas de 16 pixels entre les centres de patch adjacents. Cela signifie que la carte de caractéristiques DINOv3 a environ 1/256 de la résolution spatiale de l’image d’entrée (14x14 = 196 vs 224x224 = 50 176 pixels). Le mécanisme d’auto-attention compense cette compression spatiale en intégrant les informations à travers les patches — chaque plongement de patch est informé par la grille 14x14 environnante grâce à l’attention multi-têtes, offrant une conscience contextuelle efficace. Pour les tâches de segmentation, la grille 14x14 doit être suréchantillonnée à la résolution de l’image originale. TarmacView utilise un décodeur convolutif léger avec 3 couches : convolution transposée (14x14 à 28x28, 384 canaux), convolution transposée (28x28 à 56x56, 192 canaux), suréchantillonnage bilinéaire (56x56 à 224x224), et une convolution finale 1x1 vers les logits par classe. Ce décodeur n’ajoute que 2,3M paramètres au backbone de 86M paramètres.
Qualité des Caractéristiques Denses de DINOv3 vs DINOv2. L’innovation critique dans DINOv3 — l’ancrage Gram — cible directement la qualité de ces caractéristiques de patch denses. Pendant les longs cycles d’entraînement, les caractéristiques de patch de DINOv2 présentaient ce que les auteurs décrivent comme une dégradation des cartes de caractéristiques denses : les plongements de patch devenaient moins significatifs sémantiquement, la structure de similarité patch-patch se dégradait, et la qualité de segmentation plafonnait ou même diminuait malgré l’amélioration continue de la classification globale. L’ancrage Gram préserve la matrice Gram des caractéristiques de patch (structure de similarité par paire) en l’alignant sur une référence du début de l’entraînement, assurant que les relations spatiales et sémantiques entre les patches restent stables. Le résultat pratique est que les caractéristiques de patch de DINOv3 restent nettes et sémantiquement cohérentes même à hautes résolutions. L’article DINOv3 démontre des visualisations PCA des caractéristiques de patch DINOv3 pour des images aériennes haute résolution — routes, bâtiments, végétation et plans d’eau sont clairement séparables dans l’espace de caractéristiques, démontrant une qualité de caractéristiques exceptionnelle pour la compréhension de scène.
Segmentation Sémantique avec Sondes Linéaires. L’une des capacités les plus impressionnantes de DINOv3 est d’effectuer une segmentation sémantique en utilisant uniquement des sondes linéaires sur des caractéristiques de patch figées — aucun fine-tuning du backbone n’est nécessaire. Une tête de segmentation linéaire applique une convolution 1x1 (ou de manière équivalente, une couche linéaire par patch) pour projeter chaque plongement de patch de 768 dimensions vers C classes de sortie. Cela produit une carte de segmentation 14x14, qui est suréchantillonnée à la résolution de l’image. Malgré la simplicité de cette approche (seulement 768 x C paramètres entraînables pour toute la tête de segmentation), DINOv3 atteint 52,3 % de mIoU sur ADE20K avec ViT-B, surpassant de nombreuses méthodes qui fine-tunent l’ensemble du backbone. Ceci est rendu possible par l’exceptionnelle séparabilité linéaire des caractéristiques de patch DINOv3 — l’espace de plongement est déjà structuré de sorte que différentes catégories sémantiques occupent des régions distinctes et linéairement séparables.
Segmentation de Fissures dans l’Infrastructure. TarmacView applique les jetons de patch denses de DINOv3 pour la segmentation de fissures au niveau pixel dans les images de pistes et de chaussées. La grille 14x14 de plongements de patch en 768 dimensions capture à la fois la texture locale des fissures (dans chaque patch 16x16) et les informations contextuelles (les patches auxquels la fissure se connecte). La tête de segmentation est un réseau léger avec 3 couches convolutives transposées qui suréchantillonnent la grille de caractéristiques 14x14 à la résolution 224x224. L’entraînement nécessite environ 500 images de segmentation de fissures labellisées (tuiles 224x224 avec masques de fissures au niveau pixel) et converge en 2-3 heures sur un seul GPU RTX 3060. Le modèle résultant atteint 94,7 % de score F1 pour la détection de fissures contre 88,2 % avec ResNet-50 et 91,3 % avec DINOv2 dans des conditions d’entraînement identiques. Le score F1 s’améliore à 96,8 % lors de l’utilisation du protocole d’adaptation haute résolution (fine-tuning de DINOv3 à une résolution d’entrée de 512px avec le programme recommandé de 10K étapes). La précision d’estimation de la largeur de fissure (mesurée comme l’erreur absolue moyenne en mm) est de 0,8 mm pour DINOv3 contre 1,4 mm pour DINOv2 et 2,1 mm pour ResNet-50.
Jetons de Registre pour l’Absorption d’Arrière-Plan. Les 4 jetons de registre de DINOv3 jouent un rôle spécifique dans la qualité des caractéristiques denses. Ces jetons sont des jetons entraînables supplémentaires (dimension 768) qui sont préfixés à la séquence aux côtés du jeton CLS. Pendant l’auto-attention, les jetons de registre peuvent s’attacher à et être sollicités par tous les jetons de patch. L’idée clé est que certains patches visuels dans une image contiennent des informations aberrantes ou d’arrière-plan — ciel, objets lointains, ou régions uniformes sans texture — qui, si elles étaient forcées d’être encodées par les jetons de patch, dégraderaient la qualité de l’espace de caractéristiques. Les jetons de registre agissent comme des emplacements mémoire absorbants qui capturent ce contenu non informatif, permettant aux jetons de patch de se concentrer sur les régions d’image sémantiquement significatives. L’effet pratique est une amélioration mesurable de la qualité des caractéristiques denses : +1,8 mIoU sur ADE20K et des cartes de similarité de patch significativement plus propres, en particulier pour les images avec de grandes régions d’arrière-plan uniformes. Pour l’inspection d’infrastructure, où les images contiennent fréquemment de grandes zones de texture de chaussée uniforme, les jetons de registre aident à maintenir des caractéristiques de patch propres qui se concentrent sur les motifs de dégradation plutôt que sur la texture d’arrière-plan.
L’infrastructure d’entraînement et d’inférence de DINOv3 prend en charge plusieurs backends matériels, des grands clusters GPU aux appareils périphériques et aux Mac Apple Silicon.
Entraînement GPU à Grande Échelle. Le modèle enseignant ViT-7B a été entraîné sur 256 GPU NVIDIA A100 80GB SXM4 avec interconnexions NVLink, fournissant environ 20 To/s de bande passante mémoire GPU agrégée et 25 PFLOPS de calcul FP16. L’entraînement utilise Fully Sharded Data Parallel (FSDP) — la stratégie native de partitionnement de PyTorch qui répartit les paramètres du modèle, les gradients et les états de l’optimiseur sur tous les GPU. Avec FSDP et l’entraînement en précision mixte (BF16), le modèle de 7B tient dans la mémoire agrégée de 256 GPU (256 x 80 Go = 20,48 To) même si chaque GPU individuel ne peut contenir qu’environ 2-3 % des paramètres du modèle. La bibliothèque xFormers (développée par Meta AI) fournit des implémentations d’attention économes en mémoire, notamment l’attention économe en mémoire (réduit la mémoire d’attention de O(N²) à O(N)) et des motifs d’attention parcimonieuse par blocs. La combinaison de FSDP, BF16, xFormers et du point de contrôle de gradient réduit le besoin mémoire par GPU pour le ViT-7B d’environ 250 Go (pleine précision, sans optimisations) à environ 65 Go, tenant dans la capacité de 80 Go de l’A100.
Inférence sur GPU Unique. Pour le déploiement pratique, DINOv3 ViT-B/16 (86M paramètres) fonctionne efficacement sur un seul GPU NVIDIA. En précision FP32, le modèle nécessite environ 344 Mo de mémoire pour les paramètres (86M x 4 octets par flottant). Avec les activations pour une taille de lot de 1 (image 224x224), l’utilisation mémoire totale est d’environ 1,2-1,5 Go (paramètres + activations + tenseurs intermédiaires). En précision FP16, la mémoire des paramètres tombe à 172 Mo et l’utilisation totale à environ 0,8-1,0 Go. Cela signifie que DINOv3 ViT-B/16 fonctionne confortablement sur des GPU avec aussi peu que 4 Go de VRAM, y compris les cartes plus anciennes comme la NVIDIA GTX 1650 et le NVIDIA Jetson Xavier NX. Le débit sur un RTX 3060 (12 Go) en FP16 est d’environ 100 images/seconde. Sur un NVIDIA A100, le débit dépasse 400 images/seconde, permettant le traitement en temps réel d’imagerie drone 4K aux vitesses de décomposition de tuiles.
Support Apple Silicon (MPS). DINOv3 est entièrement compatible avec le backend Metal Performance Shaders (MPS) de PyTorch, fournissant une inférence accélérée par GPU sur les Mac Apple Silicon (séries M1, M2, M3, M4). Le backend MPS mappe les opérations PyTorch à l’architecture GPU d’Apple via le framework Metal. Les performances sur un M2 Pro MacBook Pro (GPU 19 cœurs, 32 Go de mémoire unifiée) atteignent environ 25-35 images/seconde pour ViT-B/16 en précision FP16 — suffisant pour le traitement par lots de grandes collections d’images. Sur un M2 Ultra Mac Studio (GPU 76 cœurs, 192 Go de mémoire unifiée), le débit atteint environ 70-90 images/seconde. L’utilisation mémoire est efficace car l’architecture de mémoire unifiée d’Apple élimine la surcharge de transfert de données CPU-GPU. TarmacView utilise DINOv3 accéléré par MPS pour le traitement de données sur site sur le terrain, permettant aux inspecteurs d’exécuter l’inférence directement sur leurs MacBooks sans nécessiter de matériel GPU dédié. La mémoire unifiée plus grande d’Apple Silicon (jusqu’à 192 Go sur M2 Ultra) permet également de traiter des images très haute résolution sans tuilage — une image 4096x4096 produit 256x256 patches = 65 536 jetons, ce qui nécessite environ 8 Go de mémoire équivalente VRAM sur le pool de mémoire unifiée.
Inférence Distribuée. Pour les projets d’inspection d’infrastructure à grande échelle traitant des millions d’images, l’inférence distribuée sur plusieurs GPU ou machines est nécessaire. DINOv3 prend en charge PyTorch DistributedDataParallel (DDP) pour l’inférence multi-GPU sur un seul serveur, le parallélisme de modèle (parallélisme de pipeline pour ViT-7B), et Ray (un framework de calcul distribué open-source) pour l’inférence distribuée multi-nœuds. Le déploiement de TarmacView utilise Kubernetes avec des pools de nœuds GPU exécutant l’inférence DINOv3 comme un microservice évolutif. Chaque pod d’inférence fonctionne sur un seul GPU T4 (16 Go VRAM) et traite environ 70 images/seconde. Un cluster de 50 pods atteint un débit de 3 500 images/seconde, permettant le traitement d’un relevé de piste de 500 images en moins de 3 secondes. Le serveur d’inférence utilise TorchServe pour le service de modèle avec batching dynamique (tailles de lot de 4 à 16 selon le volume de requêtes) et précision FP16 pour maximiser le débit.
Déploiement Périphérique avec NVIDIA Jetson. Pour les systèmes d’inspection déployés sur le terrain utilisant des drones ou des véhicules terrestres, DINOv3 ViT-B/16 peut être déployé sur des appareils périphériques NVIDIA Jetson. Le module Jetson Orin NX 16GB (100 TOPS de performance IA) atteint 15-25 images/seconde avec DINOv3 ViT-B/16 en FP16, selon le mode d’alimentation (15W vs 25W vs 40W). Le modèle est optimisé en utilisant TensorRT — l’optimiseur d’inférence d’apprentissage profond de NVIDIA qui fusionne les couches, optimise la sélection de noyaux et quantifie en FP16 ou INT8. Avec la quantification TensorRT INT8, la vitesse d’inférence augmente à 30-40 images/seconde sur Jetson Orin NX avec moins de 1 % de dégradation de précision par rapport au FP32. Le Jetson Xavier NX (21 TOPS) atteint 8-12 images/seconde avec TensorRT FP16. Ce déploiement périphérique permet la détection de fissures en temps réel pendant le vol du drone — la caméra du drone capture les images, et DINOv3 les traite à bord, signalant les défauts potentiels en quelques secondes après la capture sans nécessiter de connexion cloud.
DINOv3 a été publié par Meta AI en 2025 en tant que projet open-source, poursuivant la tradition de l’entreprise de publier publiquement des modèles de recherche en IA de pointe. Comprendre les conditions de licence et de distribution est essentiel pour les organisations qui prévoient de déployer DINOv3 dans des produits commerciaux.
Code et Poids du Modèle. La base de code complète de DINOv3 est disponible sur GitHub à facebookresearch/dinov3 (10 700+ étoiles à mi-2025). Le dépôt inclut le code complet d’entraînement et d’évaluation (PyTorch), les définitions de modèle, les pipelines de traitement de données, les scripts d’évaluation, et les poids pré-entraînés pour les 12 variantes de modèle publiées. Les poids du modèle sont également disponibles sur Hugging Face Hub sous l’espace de noms facebook/dinov3-*, incluant : facebook/dinov3-vits16-pretrain-lvd1689m (ViT-Small, 21M params) facebook/dinov3-vitb16-pretrain-lvd1689m (ViT-Base, 86M params) — le modèle principal utilisé par TarmacView facebook/dinov3-vitl16-pretrain-lvd1689m (ViT-Large, 304M params) facebook/dinov3-vith16-pretrain-lvd1689m (ViT-H+, ~1,5B params) facebook/dinov3-vit7b-pretrain-lvd1689m (ViT-7B, 7B params) Plus les variantes ConvNeXt (T, S, B, L) et les modèles spécifiques aux satellites (SAT-493M)
L’accès via Hugging Face nécessite que les utilisateurs acceptent les conditions de Meta et fournissent des informations de contact, qui sont collectées, stockées et traitées conformément à la Politique de Confidentialité de Meta. Les poids du modèle sont distribués sous forme de fichiers state_dict PyTorch compatibles avec la bibliothèque Hugging Face Transformers (intégration disponible via AutoModel.from_pretrained()).
La Licence DINOv3. DINOv3 est publié sous la Licence DINOv3, une licence open-source personnalisée développée par Meta AI spécifiquement pour cette publication du modèle. Cela diffère de DINOv2, qui a été publié sous la licence standard Apache 2.0. La Licence DINOv3 permet : L’utilisation, la reproduction, la modification et la distribution du modèle et du code L’utilisation commerciale, y compris l’intégration dans des produits et services La sous-licence des œuvres dérivées sous différentes conditions
La Licence DINOv3 inclut des exigences d’attribution spécifiques (doit conserver les avis de droit d’auteur) et une politique d’utilisation acceptable qui interdit l’utilisation du modèle à certaines fins, notamment la surveillance qui viole les droits de l’homme, les armes autonomes, et la violation des lois applicables. La licence a généré des discussions dans la communauté des développeurs — le GitHub issue #31 sur le dépôt dinov3 demande spécifiquement une publication sous une licence plus standard comme Apache 2.0 pour simplifier la conformité légale pour les entreprises ayant des politiques de licence open-source établies. TarmacView a examiné la Licence DINOv3 et a déterminé que les applications d’inspection d’infrastructure et de détection de défauts sont entièrement autorisées selon ses conditions.
Comparaison avec d’Autres Licences de Backbone.
| Backbone | Licence | Usage Commercial | Attribution Requise | Conditions Personnalisées |
|---|---|---|---|---|
| DINOv3 | Licence DINOv3 | Oui | Oui | Oui |
| DINOv2 | Apache 2.0 | Oui | Oui | Non |
| ViT (Google) | Apache 2.0 | Oui | Oui | Non |
| CLIP (OpenAI) | MIT | Oui | Oui | Non |
| OpenCLIP | MIT | Oui | Oui | Non |
| SAM (Meta) | Apache 2.0 | Oui | Oui | Non |
| ConvNeXt | MIT | Oui | Oui | Non |
Coût de Calcul de la Reproduction. Le coût d’entraînement de DINOv3 ViT-7B est estimé entre 2 et 5 millions de dollars USD (environ 15 000 GPU-jours sur A100-80Go au tarif cloud à la demande). Les modèles distillés plus petits (ViT-B, ViT-L) sont significativement moins chers à reproduire mais nécessitent encore des ressources de calcul substantielles — la distillation de ViT-Base à partir de ViT-7B sur LVD-1689M nécessite environ 500 à 800 GPU-jours. Cependant, pour les praticiens, la disponibilité de poids pré-entraînés élimine le besoin de tout calcul d’entraînement — les poids peuvent être téléchargés et utilisés immédiatement pour l’inférence au coût d’un seul GPU de n’importe quelle génération. Cette accessibilité est la proposition de valeur fondamentale des modèles fondation : l’énorme coût d’entraînement est amorti sur tous les utilisateurs en aval.
Intégration Communautaire et Écosystème. DINOv3 bénéficie d’une large intégration dans l’écosystème : Hugging Face Transformers fournit une API prête à l’emploi, PyTorch Hub prend en charge le chargement du modèle via torch.hub.load(), et le modèle est inclus dans le zoo de modèles Torchvision pour un accès direct. L’intégration avec Weights & Biases, MLflow et Neptune.ai pour le suivi d’expériences est prise en charge via les hooks PyTorch standard. Le format d’exportation ONNX (Open Neural Network Exchange) est pris en charge pour le déploiement dans des environnements non PyTorch, y compris TensorRT pour les appareils périphériques NVIDIA, CoreML pour les appareils Apple, et TFLite pour le déploiement mobile. La plateforme d’inspection d’infrastructure de TarmacView intègre DINOv3 via le pipeline Hugging Face Transformers, avec optimisation TensorRT pour le déploiement périphérique sur Jetson Orin NX et accélération MPS pour les ordinateurs portables macOS de terrain.
Conclusion. DINOv3 représente un bond générationnel dans les modèles fondation de vision auto-supervisée, atteignant des performances de pointe sur les tâches de prédiction globale et dense grâce à une échelle sans précédent (1,689 milliard d’images, 7 milliards de paramètres) et à l’innovation de l’ancrage Gram qui préserve la qualité des caractéristiques denses. Pour l’analyse des surfaces d’infrastructure, la variante ViT-B/16 de DINOv3 fournit un espace de plongement en 768 dimensions avec une structure sémantique exceptionnelle — les types de surface, les motifs de fissures et les caractéristiques de défauts sont linéairement séparables dans l’espace de plongement, permettant une classification et une détection précises avec une inférence à backbone figé. La disponibilité open-source, le large support matériel (GPU, MPS, Edge) et la licence permissive font de DINOv3 le backbone optimal pour la plateforme automatisée d’inspection d’infrastructure de TarmacView, offrant une précision de détection des défauts à l’état de l’art avec un minimum de données d’entraînement spécifiques au domaine et d’exigences de calcul.
TarmacView exploite le backbone de transformateur de vision de pointe de DINOv3 pour l'analyse automatisée des surfaces, la détection des fissures et la classification des défauts. Contactez notre équipe pour découvrir comment notre plateforme d'inspection alimentée par l'IA peut transformer vos flux de travail d'évaluation d'infrastructure.
+++ title = “Apprentissage par transfert” description = “L’apprentissage par transfert applique les connaissances d’un modèle pré-...
Le test de fumée de la tête de défaut valide que le pipeline de détection des défauts structurels de TarmacView — backbone DINOv3 + tête MLP à 5 étiquettes pour...
Le filtrage contextuel des défauts est une stratégie d'inférence qui filtre les étiquettes de défauts prédites par type de surface et domaine structurel afin de...