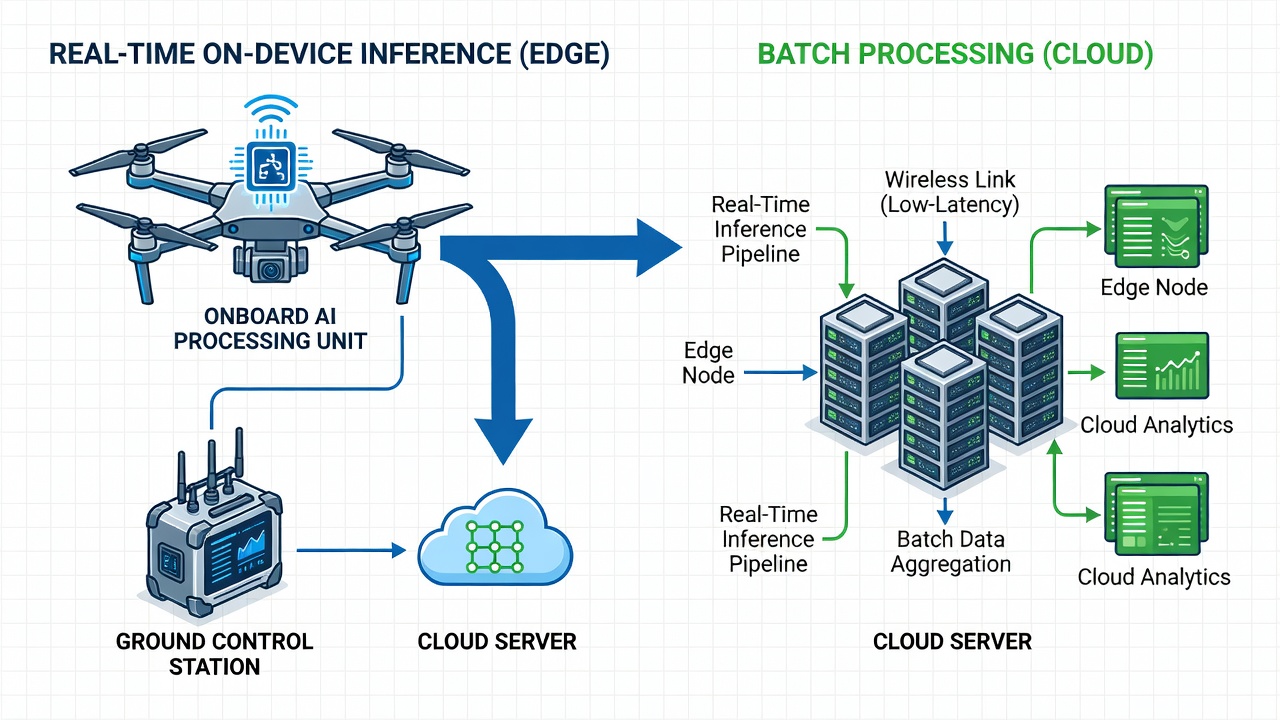
L’edge computing exécute l’inférence IA directement sur le drone, le véhicule ou l’appareil portable au point de capture des données, permettant la détection de défauts en temps réel, le filtrage de qualité et l’aide à la décision sans téléchargement vers le cloud. Réduit la transmission de données, diminue la latence et accélère la réponse dans les flux de travail d’inspection des infrastructures.
Edge Computing pour l’Inspection en Temps Réel
Définition et Justification
L’edge computing est un paradigme informatique distribué où le traitement des données s’effectue au niveau ou à proximité de l’emplacement physique de génération des données, plutôt que dans un centre de données cloud centralisé. Dans le contexte de l’inspection des infrastructures, l’edge computing signifie exécuter l’inférence d’intelligence artificielle directement sur le drone, le véhicule robotisé ou l’appareil portable qui capture les données. La justification fondamentale est simple : la latence aller-retour de l’envoi d’images haute résolution vers le cloud pour traitement est inacceptable pour les décisions opérationnelles en temps réel.
Le problème de latence est quantifié par la physique des réseaux. Un pipeline d’inférence cloud typique implique la capture d’image, la compression, la transmission sans fil (Wi-Fi, 4G/5G ou satellite), le prétraitement cloud, l’inférence du modèle, le conditionnement des résultats et la retransmission vers l’opérateur. Même dans des conditions 5G optimales avec des latences de 10 à 20 millisecondes pour la seule liaison radio, la latence d’inférence cloud de bout en bout varie de 200 millisecondes à 2 secondes selon la congestion du réseau, la charge du serveur et la distance géographique jusqu’à la région cloud. Pour un drone volant à 15 m/s (54 km/h), un aller-retour de 2 secondes signifie que l’aéronef s’est déplacé de 30 mètres avant de recevoir son résultat de détection — une marge inacceptable pour l’inspection rapprochée de structures où des fissures de 0,2 mm de largeur doivent être identifiées à une distance de 3 à 5 mètres.
L’inférence en périphérie élimine complètement ce problème. Sur un NVIDIA Jetson AGX Orin effectuant 275 billions d’opérations par seconde (TOPS) de calcul INT8, une passe avant unique d’un classificateur d’images ResNet-50 prend environ 3 à 5 millisecondes. En incluant le prétraitement d’image, la mise à l’échelle et le décodage des résultats, la latence de bout en bout par image reste inférieure à 50 millisecondes. Cette boucle de rétroaction de moins de 100 millisecondes permet des comportements autonomes en boucle fermée tels que l’ajustement de la trajectoire de vol pour ré-imager une zone suspecte, le déclenchement d’une alerte immédiate à la station au sol, ou l’activation de modalités de capteurs supplémentaires (thermique ou LiDAR) pour contre-vérification.
Au-delà de la latence, l’argument de la bande passante est tout aussi convaincant. Une image d’inspection de 20 mégapixels en profondeur RVB 8 bits nécessite environ 60 Mo de données non compressées, ou 3 à 8 Mo après compression JPEG selon les réglages de qualité. Un seul vol d’inspection de 20 minutes capturant 1 image par seconde génère 1 200 images totalisant 3,6 à 9,6 Go de données. Pour une flotte de 10 drones effectuant des inspections quotidiennes, cela se multiplie à 36-96 Go par jour. Transmettre ce volume via des liaisons cellulaires ou satellite est coûteux, lent et souvent impossible dans les infrastructures en zones reculées telles que les ponts de montagne, les parcs éoliens offshore ou les corridors de pipelines isolés où la connectivité est limitée à 1-10 Mbps. L’edge computing résout ce problème en traitant les images localement et en ne transmettant que les résultats : coordonnées de détection, classifications de sévérité et optionnellement des recadrages de 200x200 pixels autour des défauts détectés. Cela réduit le volume de données transmises de 90 à 99 %, compressant un flux quotidien de 9,6 Go à moins de 100 Mo.
La sécurité et la conformité fournissent une justification supplémentaire. Le traitement en périphérie évite d’envoyer des images sensibles d’infrastructures — y compris les pistes d’aéroport, les installations militaires ou les sites énergétiques critiques — via des liaisons sans fil potentiellement non sécurisées. Pour les programmes d’inspection de la défense et du gouvernement, ce modèle de traitement local uniquement satisfait aux exigences de souveraineté des données qui interdisent l’exportation cloud d’images classifiées de sites.
Plateformes Matérielles d’IA Embarquée
Le déploiement pratique de l’inférence en périphérie dépend de matériel spécialisé qui équilibre le débit de calcul contre les sévères contraintes de puissance, de poids et thermiques des charges utiles des drones. Les plateformes suivantes dominent le marché de l’IA embarquée pour l’inspection.
Famille NVIDIA Jetson
La série Jetson de NVIDIA est la plateforme d’IA embarquée la plus largement déployée pour l’inspection par drone, offrant une architecture évolutive du Nano d’entrée de gamme au AGX Orin haut de gamme. Tous les modules Jetson partagent une pile logicielle commune — JetPack SDK — qui inclut CUDA, cuDNN, TensorRT et des bibliothèques de vision optimisées, permettant la portabilité du code au sein de la famille.
Module
Performance IA
Architecture GPU
Puissance (TDP)
Facteur de forme
Cas d’usage typique en inspection
Jetson Nano
472 GFLOPS (FP16)
Maxwell 128 cœurs
5-10W
70x45mm
Classification légère fissure/non-fissure
Jetson TX2
1,3 TFLOPS (FP16)
Pascal 256 cœurs
7,5-15W
50x87mm
Détection d’objets en temps réel (modèles de type YOLO)
Efficacité équilibrée pour inspection temps réel mono-modèle
Le Jetson AGX Orin à 275 TOPS fournit une puissance de calcul suffisante pour exécuter un modèle de segmentation U-Net en résolution 4K à plus de 30 FPS, ce qui le rend adapté à la cartographie des fissures de chaussée à haute résolution où des largeurs de défauts inférieures au millimètre doivent être détectées sur de grandes surfaces. Le Jetson Orin Nano, à 40 TOPS et seulement 7-15W, représente le point d’efficacité optimal pour la plupart des charges de travail d’inspection par drone, offrant 4 fois les performances du Jetson Nano d’origine pour une consommation électrique similaire.
Intel Movidius et Neural Compute Stick
Le VPU (Vision Processing Unit) Intel Movidius Myriad X offre 4 TOPS d’inférence INT8 pour seulement 1-2,5 W de consommation électrique, atteignant une efficacité de 2-4 TOPS/W. L’Intel Neural Compute Stick 2 (NCS2) intègre le Myriad X dans un format USB, le rendant accessible pour le prototypage. Cependant, le plafond de 4 TOPS le limite aux architectures de modèles légers — MobileNetV2, EfficientNet-Lite ou les variantes tiny YOLO — et il peine avec les modèles ResNet ou EfficientNet plus profonds préférés pour la détection de défauts de haute précision. Pour les applications nécessitant de la segmentation (U-Net, DeepLab) ou de la détection d’objets haute résolution (YOLOv5-large, RT-DETR), le Myriad X manque de bande passante mémoire et de densité de calcul pour des performances temps réel.
Qualcomm Snapdragon et AI Engine
Les plateformes mobiles Snapdragon de Qualcomm intègrent des DSP Hexagon et des GPU Adreno avec des accélérateurs IA dédiés délivrant 10-30 TOPS (INT8) selon la génération. Le Snapdragon 8 Gen 3 atteint 34 TOPS à environ 5-8 W pour des charges de travail d’inférence soutenues. Les plateformes Snapdragon sont particulièrement pertinentes pour les tablettes d’inspection portables et les outils d’inspection basés sur smartphone, où le processeur IA est déjà intégré dans le système sur puce et ne consomme pas de poids ou de volume supplémentaire de charge utile. Le Qualcomm AI Engine supporte TensorFlow Lite, ONNX Runtime et le SNPE propriétaire de Qualcomm (Snapdragon Neural Processing Engine) pour le déploiement de modèles.
Apple Neural Engine
Les puces Apple A17 Pro et de la série M intègrent un Neural Engine à 16 cœurs capable de 35 TOPS (INT8) avec une consommation électrique soutenue d’environ 3-5 W pour les charges de travail IA. Bien que l’Apple Neural Engine atteigne une efficacité TOPS/watt exceptionnelle, son déploiement est limité à l’écosystème Apple (iOS/iPadOS) et nécessite une conversion de modèle Core ML. Cela le rend adapté aux outils de terrain d’inspection sur iPad courants dans les flux de travail d’architecture, d’ingénierie et de construction (AEC), mais moins applicable à l’edge computing monté sur drone où l’écosystème CUDA de NVIDIA domine.
Google Coral Edge TPU
Le Coral Edge TPU (Tensor Processing Unit) de Google délivre 4 TOPS (INT8) à seulement 2 W, ce qui en fait l’option la plus économe en énergie par inférence. Le système sur module (SoM) Coral intègre l’Edge TPU avec un contrôleur système i.MX 8M, fournissant une plateforme embarquée complète dans 40x48 mm. Cependant, la limite de 4 TOPS contraint la complexité du modèle, et l’exigence de modèles TensorFlow Lite exclusivement (avec des opérations compilées Edge TPU) réduit l’espace d’architecture supporté. Pour les classificateurs de défauts simples comme les modèles MobileNetV2 à 10 classes utilisés dans les pipelines de filtrage qualité, le Coral Edge TPU offre une extension exceptionnelle de l’autonomie de la batterie pour les outils d’inspection portables.
Optimisation de Modèle pour le Déploiement en Périphérie
Déployer des réseaux de neurones profonds sur du matériel embarqué nécessite une optimisation agressive des modèles pour respecter les contraintes d’inférence en temps réel sur la mémoire, le calcul et le budget énergétique. Les modèles entraînés sur des clusters GPU avec une précision en virgule flottante 32 bits doivent être compressés et accélérés sans sacrifier la précision de détection en dessous des seuils opérationnels.
Quantification
La quantification réduit la précision numérique des poids et activations du modèle, passant d’une virgule flottante 32 bits (FP32) à des représentations à plus faible nombre de bits telles que les flottants 16 bits (FP16) ou les entiers 8 bits (INT8). Il s’agit de l’optimisation la plus impactante pour l’inférence en périphérie.
La quantification INT8 convertit chaque poids et activation de 4 octets à 1 octet, réduisant l’empreinte mémoire du modèle de 75 %. Sur les plateformes NVIDIA Jetson avec support INT8 Tensor Core, cela se traduit par une amélioration du débit de 2 à 4x sur les opérations de multiplication matricielle par rapport au FP32. Un modèle ResNet-50 qui fonctionne à 120 FPS en FP32 sur un AGX Orin peut dépasser 400 FPS en INT8. Le coût en précision de l’entraînement tenant compte de la quantification (QAT) — où le modèle apprend à compenser la précision réduite pendant l’entraînement — est typiquement de 0,1 à 0,5 % de dégradation de précision Top-1 sur les tâches de classification de type ImageNet. Pour les modèles spécifiques à l’inspection, une étude sur la détection de fissures dans le béton a montré que la quantification INT8 utilisant TensorRT réduisait la taille du modèle de 98 Mo à 24,5 Mo tout en maintenant une précision de validation de 95,2 % — une baisse de 0,8 % par rapport à la référence FP32 de 96,0 %.
La quantification FP16 réduit de moitié la taille du modèle (réduction de 50 %) et offre des gains de débit d’environ 1,5 à 2x. Pour la plupart des modèles d’inspection, l’inférence FP16 produit une précision identique au FP32 dans les limites du bruit de mesure (±0,1 %), ce qui en fait une optimisation à faible risque. La famille Jetson Orin prend en charge les opérations Tensor Core FP16 natives, atteignant des performances optimales pour les modèles avec une taille de lot de 1 — la configuration standard pour l’inférence temps réel sur image unique.
La quantification INT4 émerge comme une technique de nouvelle génération, compressant les modèles à 0,5 octet par poids. Bien que INT4 introduise des baisses de précision de 1 à 3 % pour les tâches de vision, l’Optimizer de Modèle NVIDIA et la bibliothèque TensorRT Model Optimizer supportent désormais INT4 pour le déploiement sur les plateformes Jetson. Cela permet d’exécuter un modèle de segmentation de 200 Mo dans seulement 25 Mo de mémoire — crucial pour le plafond de mémoire unifiée de 8 Go des modules Jetson Orin NX.
Élagage
L’élagage supprime les poids, neurones ou canaux redondants ou de faible amplitude d’un réseau de neurones pour réduire son coût de calcul et son empreinte mémoire.
L’élagage non structuré met à zéro les poids individuels en dessous d’un seuil de saillance, convertissant les matrices denses en matrices creuses. Des taux de compression typiques de 40 à 60 % sont atteignables avant que la précision ne se dégrade de plus de 1 %. Cependant, la parcimonie non structurée nécessite un support matériel ou logiciel pour une multiplication efficace de matrices creuses — l’architecture Ampere de NVIDIA offre un support de parcimonie structurée 2:4 qui double le débit pour les couches compatibles.
L’élagage structuré (de canaux) supprime des canaux de convolution ou des neurones entiers, produisant un modèle plus étroit qui fonctionne efficacement sur n’importe quel matériel sans nécessiter de support de calcul creux. Des taux de compression de 30 à 50 % sont typiques. Pour les modèles d’inspection, l’élagage de canaux avec ajustement fin récupère la plupart de la précision — un MobileNetV2 élagué à 50 % du nombre de canaux d’origine et ajusté finement sur 10 époques sur des données de fissures de béton a atteint 93,7 % de précision contre la référence non élaguée de 94,5 %.
Distillation de Connaissances
La distillation de connaissances entraîne un modèle « étudiant » compact à reproduire le comportement d’un modèle « enseignant » plus grand en minimisant la divergence de leurs distributions de probabilités de sortie. L’étudiant apprend à partir des étiquettes douces de l’enseignant, qui encodent des informations plus riches que les étiquettes de vérité terrain strictes — y compris les similarités inter-classes et les estimations d’incertitude.
Pour le déploiement en périphérie d’inspection, la distillation permet d’utiliser un ResNet-152 ou EfficientNet-B7 comme enseignant (200-600 Mo, 50-100 M paramètres) et un MobileNetV3-Small ou EfficientNet-Lite0 comme étudiant (5-15 Mo, 2-5 M paramètres). L’étudiant atteint 94 à 96 % de la précision de l’enseignant tout en ne consommant que 2 à 10 % du calcul. Un flux typique de détection de fissures de pont a distillé un enseignant ResNet-152 (97,2 % de précision) en un étudiant MobileNetV3-Large (95,8 % de précision) — une perte de précision de 1,4 % pour une réduction de taille de modèle de 12x et une accélération de l’inférence de 20x sur Jetson Nano.
TensorRT
NVIDIA TensorRT est le SDK d’optimisation pour l’inférence d’apprentissage profond haute performance sur les GPU NVIDIA. Il effectue l’optimisation de graphe, l’auto-ajustement des noyaux, l’étalonnage de précision et la gestion de la mémoire pour maximiser le débit sur le matériel Jetson.
Le pipeline d’optimisation de TensorRT comprend :
Fusion de couches : Fusion des opérations adjacentes (convolution + normalisation par lot + ReLU) en noyaux uniques, réduisant les frais généraux de lancement de noyaux et la bande passante mémoire.
Auto-ajustement des noyaux : Sélection de l’implémentation de noyau CUDA optimale pour chaque couche et cible matérielle basée sur des benchmarks empiriques.
Étalonnage INT8 : Utilisation d’un ensemble de données d’étalonnage représentatif pour calculer les plages dynamiques optimales des activations, minimisant l’erreur de quantification.
Inférence de forme dynamique : Gestion des dimensions variables des tenseurs d’entrée sans recompilation — essentiel pour les pipelines d’inspection traitant des images de résolution variable.
Un modèle d’inspection typique déployé sans TensorRT atteint 30 à 50 % de l’utilisation matérielle maximale. Après optimisation TensorRT, l’utilisation atteint 70 à 85 %, avec une latence de bout en bout réduite de 2 à 5x par rapport à l’inférence en mode eager de PyTorch.
ONNX
ONNX (Open Neural Network Exchange) fournit un format de modèle interopérable qui découple les frameworks d’entraînement de modèles (PyTorch, TensorFlow) des environnements d’exécution d’inférence. Les modèles entraînés dans PyTorch sont exportés au format ONNX, puis convertis en moteurs TensorRT pour le déploiement Jetson ou chargés dans ONNX Runtime pour les cibles non-NVIDIA (CPU ARM, Qualcomm, Intel).
Le flux de travail ONNX-TensorRT est le pipeline standard : PyTorch → ONNX → moteur TensorRT. Cela découple l’entraînement et le déploiement, permettant aux data scientists de s’entraîner dans des frameworks familiers tandis que les ingénieurs de déploiement optimisent pour un matériel embarqué spécifique sans réentraînement.
Détection de Fissures en Temps Réel en Périphérie
L’application la plus mature de l’IA embarquée dans l’inspection est la détection de fissures en temps réel sur les infrastructures en béton et en asphalte. Une étude marquante de 2024 publiée dans Sensors (PMC11645055) a démontré le pipeline complet : entraînement de réseaux de neurones convolutifs avec apprentissage par transfert, déploiement sur un NVIDIA Jetson Nano, et validation sur des structures en béton en laboratoire et sur le terrain.
L’étude a entraîné six architectures CNN — ResNet18, ResNet50, GoogLeNet, MobileNetV2, MobileNetV3-Small et MobileNetV3-Large — en utilisant l’apprentissage par transfert à partir de poids pré-entraînés sur ImageNet. L’ensemble de données comprenait 3 000 images de surfaces en béton (fissurées et intactes) augmentées avec du bruit sel et poivre et du flou de mouvement pour améliorer la robustesse en conditions réelles. ResNet50 a atteint la précision de validation la plus élevée, soit 96,0 % avec un score F1 de 95,0 % pour une taille de lot de 16.
Déployé sur le Jetson Nano à 5-10W, le modèle ResNet50 a classé une image 224x224 en 38 millisecondes — permettant un traitement en temps réel à 26 images par seconde. Ce débit est suffisant pour un drone volant à 5 m/s avec un chevauchement de 70 % entre les images consécutives, garantissant que chaque centimètre carré de surface est classifié plusieurs fois.
Pour une caractérisation plus fine des défauts, les modèles de segmentation comme U-Net et DeepLabV3+ fournissent des cartes de fissures au niveau du pixel. L’étude d’inspection de ponts IJAMA a atteint une intersection sur union moyenne (mIoU) de 0,86 pour la segmentation des fissures en utilisant un U-Net avec encodeur MobileNetV2 sur Jetson Orin Nano à 22 FPS et 7W. Cela permet la quantification de la largeur, de la longueur et de l’orientation des fissures — des mesures requises par les normes d’inspection des ponts telles que l’AASHTO et les National Bridge Inspection Standards (NBIS) de la Federal Highway Administration.
La détection de fissures en périphérie a été validée sur le terrain sur des ponts opérationnels, notamment un pont en béton de 50 mètres de portée où un drone DJI Matrice 300 RTK équipé d’un Jetson Orin NX a détecté 43 fissures (largeurs de 0,3 à 3,2 mm) lors d’un vol d’inspection automatisé de 12 minutes. La validation manuelle a confirmé 41 vrais positifs (rappel de 95,3 %) avec 3 faux positifs (précision de 92,8 %).
Filtrage de Qualité en Périphérie
Les images brutes d’inspection contiennent une forte proportion d’images inadaptées à l’analyse en raison du flou de mouvement, d’une exposition incorrecte, d’erreurs de mise au point ou d’artefacts environnementaux (gouttes de pluie sur l’objectif, reflets du soleil, poussière). Sans filtrage, ces images de faible qualité gonflent les coûts de stockage, de transmission et de traitement en aval. Le filtrage de qualité en périphérie répond à ce problème en exécutant un réseau d’évaluation de qualité léger avant le modèle principal de détection de défauts.
Le pipeline de filtrage de qualité comprend généralement :
Détection de flou : Analyse de la variance du Laplacien de l’image — une image floue produit de faibles valeurs de variance. Un seuil de 100 (sur une image 8 bits) sépare généralement les images nettes des images floues par mouvement. Sur Jetson, cela prend moins d’une milliseconde en CUDA.
Qualité d’exposition : Analyse d’histogramme pour détecter les images surexposées (saturées > 5 % des pixels) ou sous-exposées (luminance moyenne < 40). Les images acceptables se situent généralement dans la plage de luminance moyenne de 40 à 200 pour l’inspection.
Évaluation du contraste : Mesure du contraste RMS (root-mean-square) ; les images à faible contraste (RMS < 0,3) sont écartées car elles manquent des informations de gradient nécessaires à la détection des bords de fissures.
Similarité structurelle : Pour les séquences vidéo, l’indice de similarité structurelle (SSIM) entre les images consécutives identifie les images quasi-dupliquées (SSIM > 0,95), ne conservant qu’une seule image représentative pour maximiser la couverture unique par unité de stockage.
Le classificateur de qualité léger combiné — un réseau convolutif à 3 couches avec 80 000 paramètres fonctionnant en configuration MobileNetV2-lite — classe les images comme « acceptées » ou « rejetées » en 2 à 4 millisecondes sur les appareils Jetson Orin. Les données terrain des opérations d’inspection de pipelines montrent que le filtrage de qualité en périphérie rejette 60 à 75 % des images brutes, ce qui signifie que seulement 25 à 40 % sont transmises au modèle de détection de défauts plus lourd. Cela réduit la charge de calcul d’inférence totale de 2,5 à 4x et les besoins de stockage proportionnellement.
Le résultat final : un vol d’inspection de 20 minutes générant 1 200 images brutes ne produit que 300 à 480 images filtrées par qualité. Après détection des défauts, seulement 30 à 80 images avec défauts détectés plus leurs métadonnées géolocalisées (typiquement 2 à 5 Ko par défaut via des annotations GeoJSON) sont transmises. Le volume quotidien total de données par drone passe de 9,6 Go à moins de 200 Mo — une réduction de 98 %.
Architecture Hybride Edge + Cloud
Bien que l’edge computing gère l’inférence en temps réel, le traitement cloud reste essentiel pour l’analyse haute fidélité, le réentraînement des modèles, la gestion de flotte et l’archivage des données. L’architecture optimale est un système hybride edge-cloud où chaque niveau effectue les tâches pour lesquelles il est le mieux adapté.
Niveau Périphérique (Au Point de Capture)
Fonction
Détails
Détection de défauts en temps réel
Exécuter des modèles INT8 optimisés à 20-30 FPS pour une identification immédiate
Filtrage de qualité
Rejeter les images floues/surexposées/dupliquées avant stockage
Navigation autonome
Détecter et éviter les obstacles, ajuster la trajectoire de vol pour ré-imager
Génération d’alertes
Transmettre des alertes de défauts géolocalisées en temps réel via liaison télémétrique à faible bande passante
Stockage local
Conserver les images pleine résolution des défauts détectés sur SSD embarqué (256 Go - 1 To)
Fusion de capteurs
Combiner les données RVB, thermiques et LiDAR pour une inférence multi-modale
Niveau Cloud (Après le Vol)
Fonction
Détails
Analyse haute fidélité
Exécuter des modèles d’ensemble FP32 ou des transformeurs de vision sur des images pleine résolution pour une validation de second avis
Intégration au jumeau numérique
Fusionner les résultats de détection périphérique dans les modèles BIM 3D pour la gestion des actifs d’infrastructure
Agrégation à l’échelle de la flotte
Compiler les statistiques de détection de toutes les inspections pour l’analyse des tendances et la planification de la maintenance prédictive
Réentraînement de modèles
Utiliser les faux positifs et les détections manquées de la périphérie comme échantillons d’apprentissage actif pour l’amélioration du modèle
Rapports de conformité
Générer des rapports d’inspection conformes aux normes OACI, FAA, ASTM ou aux normes nationales d’infrastructure
Archivage à long terme
Stocker toutes les données d’inspection (métadonnées de périphérie + images pleine résolution sélectionnées) pour les périodes de conservation réglementaires (5-20 ans)
Le flux de données progresse à travers des étapes définies. Pendant le vol, le pipeline périphérique fonctionne de manière autonome — capture, filtre qualité, détecte, alerte. Après l’atterrissage, le drone se connecte à la station au sol ou au cloud via Wi-Fi local haute bande passante ou USB-C, et le transfert de données en masse a lieu pour les images non urgentes et la télémétrie du modèle. Le cloud traite ces lots de manière asynchrone, mettant à jour les bases de données de défauts et les registres de modèles.
Cette approche hybride combine la réactivité inférieure à 50 ms de l’inférence en périphérie avec la profondeur analytique du traitement cloud, atteignant à la fois la vitesse opérationnelle et la précision analytique. Les déploiements terrain utilisant cette architecture rapportent un accord de 97 % entre les détections initiales en périphérie et les résultats validés par le cloud sur un échantillon de 10 000 images d’inspection.
Edge Computing pour les Opérations BVLOS
Les opérations hors visibilité directe (BVLOS) — où le drone opère au-delà de la portée visuelle non assistée du pilote — imposent des exigences strictes en matière d’autonomie embarquée, et l’edge computing est la technologie habilitante. Le cadre réglementaire de l’OACI pour les systèmes d’aéronefs sans pilote et l’élaboration de règles de la FAA Part 108 pour les opérations BVLOS identifient tous deux le traitement embarqué de données en temps réel comme une condition préalable au vol sécurisé hors visibilité directe.
Selon les règles BVLOS, le drone doit maintenir une séparation sécurisée du terrain, des obstacles et des autres aéronefs sans surveillance visuelle directe du pilote. Cela nécessite des systèmes de détection et d’évitement (DAA) qui traitent les données des capteurs à bord et exécutent des manœuvres d’évitement en 100 à 200 millisecondes — bien en dessous de la latence aller-retour des architectures dépendantes du cloud. L’edge computing permet le DAA en exécutant des modèles de détection d’objets (YOLOv8, RT-DETR) sur les caméras embarquées et les données radar en temps réel, détectant le trafic coopératif et non coopératif à des distances de 200 à 1 000 mètres selon l’équipement de capteurs.
L’edge computing permet également les opérations en liaison dégradée. Lorsque la liaison C2 subit des pertes de paquets ou une dégradation du signal — courant en terrain montagneux, dans les canyons urbains ou au-dessus de l’eau — le drone doit poursuivre sa mission en toute sécurité. Les systèmes embarqués stockent le plan de vol localement, exécutent la navigation par points de cheminement à l’aide de la fusion GPS et IMU embarquée, et continuent le traitement des données d’inspection jusqu’à ce que la liaison soit rétablie. La fusion de capteurs entre l’odométrie visuelle traitée en périphérie et la navigation à l’estime par IMU maintient une précision de position de 1 à 5 mètres pendant les interruptions C2 allant jusqu’à 60 secondes.
Le Kit d’outils UAS de l’OACI et le cadre réglementaire de l’AESA pour les opérations UAS dans les catégories Spécifique et Certifiée exigent tous deux que les drones équipés BVLOS démontrent la capacité d’effectuer une terminaison de vol sécurisée ou un retour au bercail sans dépendre d’une connectivité de liaison de données continue. L’edge computing répond à cette exigence en hébergeant toutes les fonctions de navigation, d’évitement d’obstacles et de gestion de mission à bord.
Pour l’inspection d’infrastructures linéaires longue distance — pipelines, lignes de transport d’électricité, corridors ferroviaires — les opérations BVLOS avec edge computing permettent une couverture de 50 à 100 km en un seul vol. Le drone traite les données d’inspection en temps réel pendant le vol de 45 à 90 minutes, puis télécharge en masse les résultats et les images pleine résolution des défauts détectés vers le cloud après l’atterrissage. Sans traitement en périphérie, les coûts de stockage et de bande passante de la capture de 60 à 120 Go par vol seraient prohibitifs.
Contraintes de Puissance et Thermiques
Le matériel d’edge computing sur drone fonctionne sous les budgets de puissance et thermiques les plus restrictifs de l’industrie informatique. Contrairement aux GPU de centre de données avec des budgets de 300-700 W et un refroidissement liquide, les charges utiles des drones doivent fonctionner dans une limite de 10 à 60 W de puissance système totale tout en résistant à des températures ambiantes allant de -20 °C à +50 °C, à des changements rapides de vitesse d’air et au rayonnement solaire.
Allocation du Budget Énergétique
Un drone d’inspection typique (ex. DJI Matrice 350 RTX) dispose d’un budget énergétique total pour la charge utile de 25 à 50 W provenant du système de batterie du drone, partagé entre :
Composant
Consommation Électrique Typique
Module de Calcul IA Embarqué
7-25W
Caméra RVB (fonctionnement continu)
3-8W
Caméra Thermique (si équipée)
2-5W
LiDAR ou télémètre
5-15W
Radios de communication (C2 + télémétrie)
2-5W
Stabilisation de la nacelle de capteurs
2-4W
Le module périphérique doit fonctionner dans les limites de son budget thermique. L’expérience pratique montre que déployer un Jetson AGX Orin à ses pleines performances de 60 W est rarement réalisable sur des drones de moins de 25 kg en raison des limites de capacité de la batterie — une charge de calcul de 60 W consommerait 30 % d’une batterie de drone de 200 Wh sur un vol de 60 minutes, ne laissant pas assez d’énergie pour les moteurs et les capteurs. Le Jetson Orin Nano à 7-15 W est le choix le plus pratique pour les vols d’inspection soutenus dépassant 30 minutes.
Puissance Thermique de Conception (TDP) et Refroidissement
Module Périphérique
TDP
Refroidissement Nécessaire
Température Ambiante Max (Passif)
Température Ambiante Max (Actif)
Google Coral Edge TPU
2W
Passif (dissipateur uniquement)
70 °C
N/A
Jetson Nano
5-10W
Dissipateur passif
50 °C
70 °C avec ventilateur
Jetson Orin Nano
7-15W
Dissipateur + ventilateur optionnel
45 °C
65 °C avec ventilateur
Intel Movidius NCS2
2,5W
Passif
60 °C
N/A
Jetson Orin NX
10-25W
Ventilateur actif requis
N/A
55 °C
Jetson AGX Orin
15-60W
Ventilateur actif requis
N/A
50 °C
Le throttling thermique est une préoccupation opérationnelle critique. Lorsque la température interne du module Jetson dépasse sa limite thermique (généralement 80-85 °C de température de jonction pour les modules Orin), le pilote réduit progressivement les fréquences d’horloge du GPU. À 50 % de throttling thermique, le débit d’inférence chute d’environ 40 à 50 %. En plein soleil à 35 °C ambiant, un Jetson Orin Nano refroidi passivement et exécutant une inférence soutenue peut atteindre 82 °C après 8 à 12 minutes. Le refroidissement actif utilisant un ventilateur de 40x40x10 mm augmente la masse de 15 grammes et la consommation électrique de 0,8 W mais maintient la température de jonction en dessous de 70 °C indéfiniment.
La gestion dynamique de la fréquence et de la tension (DVFS) est la stratégie d’atténuation standard. Le module Jetson ajuste sa fréquence de fonctionnement sur 5 à 7 états de performance, échangeant le débit d’inférence contre la sécurité thermique. Un profil de vol typique peut fonctionner à performance maximale (15W, 40 TOPS) pendant l’inspection active d’un segment de pont, puis descendre à 7W (15 TOPS) pendant le transit entre les cibles — maintenant une marge thermique tout en optimisant la consommation de la batterie.
Edge Computing dans le Contexte de TarmacView
La plateforme d’inspection d’infrastructures de TarmacView intègre l’edge computing comme couche de traitement centrale entre la charge utile de capteurs du drone et la plateforme d’analyse cloud. L’architecture suit le modèle hybride edge-cloud : l’inférence IA embarquée gère la détection de défauts en temps réel et le filtrage de qualité pendant le vol, tandis que la plateforme cloud de TarmacView fournit l’analyse post-vol, l’intégration au jumeau numérique et la gestion des actifs à l’échelle de la flotte.
Dans le flux de travail de TarmacView, le drone transporte un module NVIDIA Jetson Orin NX (100 TOPS INT8, 10-25W) connecté à la caméra de charge utile via USB 3.0 ou interface GigE Vision. La pile logicielle embarquée comprend :
Filtre de qualité : Un classificateur MobileNetV3-Small (entraîné sur l’ensemble de données propriétaire de TarmacView de 50 000 images de pistes et de voies de circulation) qui rejette les images floues, surexposées ou dupliquées en moins de 3 ms par image.
Détection de défauts : Un modèle YOLOv5nano optimisé (entrée 640x640, < 10 Mo après quantification INT8) qui détecte les fissures, l’écaillage, le désenrobage, les défauts de joints et les débris d’objets étrangers (FOD) à 30 FPS en utilisant TensorRT sur l’Orin NX.
Classificateur de sévérité : Chaque région de défaut détectée est recadrée et transmise à un classeur de sévérité ResNet18 (mineur / modéré / sévère) basé sur les seuils de largeur de fissure de la Circulaire Consultative FAA 150/5380-6B et du Manuel de Conception des Aérodromes de l’OACI Partie 3.
Géolocalisation : Les informations de position du GPS RTK du drone (précision de 2 à 5 cm) sont fusionnées avec chaque boîte englobante de détection, produisant des annotations d’inspection compatibles GeoJSON stockées localement et transmises via télémétrie.
Le module périphérique stocke les images pleine résolution des défauts détectés sur un SSD NVMe de 256 Go. Pendant le vol, seuls les résumés de détection JSON (type de défaut, coordonnées GPS, sévérité, horodatage, score de confiance — typiquement 500 octets par détection) sont transmis via la liaison télémétrique C2. Après l’atterrissage, le drone se connecte à la station au sol de TarmacView via Wi-Fi 5 GHz pour le transfert en masse des recadrages d’images de défauts et des tuiles d’orthomosaïque pleine résolution à 1-2 Gbps.
La couche cloud traite les données par lots de manière asynchrone : croisement des détections périphériques avec les données d’inspection historiques, génération des scores d’indice de condition de chaussée (PCI) selon les directives de l’OACI, et mise à jour du jumeau numérique d’infrastructure pour la planification de la maintenance. Le cloud surveille également les performances des modèles périphériques sur l’ensemble de la flotte, signalant les dérives ou les détections manquées systématiques pour réentraînement.
Futur de l’Inspection en Périphérie
L’edge computing pour l’inspection évolue selon plusieurs axes technologiques qui élargiront fondamentalement ce qui est possible au point de capture.
Calcul Neuromorphique
Les processeurs neuromorphiques — tels que Loihi 2 d’Intel et Speck de SynSense — émulent les réseaux de neurones biologiques à l’aide de réseaux de neurones impulsionnels (SNN) qui consomment des ordres de grandeur de moins d’énergie que les accélérateurs d’apprentissage profond conventionnels. Loihi 2 atteint un rapport TOPS/watt 10 à 100 fois meilleur pour des tâches de vision spécifiques par rapport aux GPU de classe Jetson. Pour l’inspection, les caméras événementielles neuromorphiques ne produisent en sortie que les pixels qui changent (événements de mouvement) plutôt que des images complètes, réduisant la bande passante de données de 90 à 99 % tout en atteignant des fréquences d’images effectives dépassant 10 000 Hz. Un processeur périphérique neuromorphique couplé à une caméra événementielle pourrait détecter une fissure apparaissant dans un spécimen de béton sous charge avec une latence inférieure à la milliseconde, pour une consommation électrique inférieure à 100 mW — permettant une surveillance continue de l’intégrité structurelle à partir de capteurs sur batterie pendant des mois plutôt que des heures.
Traitement Intégré au Capteur
Les capteurs avec traitement intégré — tels que le capteur de vision intelligent IMX500 de Sony — effectuent l’inférence CNN au sein même du capteur d’image, produisant des métadonnées (boîtes englobantes, étiquettes de classe, comptages) au lieu de données de pixels. L’IMX500 offre jusqu’à 30 FPS de classification pour une puissance totale de 0,5 W pour l’ensemble capteur-plus-processeur, éliminant le besoin d’un module de calcul périphérique séparé pour les tâches de détection simples. Pour l’inspection par drone ultra-léger, le traitement intégré au capteur permet la détection sur des plateformes drone de moins de 250 g qui ne peuvent pas transporter un module Jetson.
Modèles Périphériques Basés sur les Transformeurs
Les transformeurs de vision (ViT) et leurs variantes efficaces (MobileViT, EdgeNeXt, FastViT) approchent l’efficacité des CNN sur le matériel embarqué. FastViT atteint une précision Top-1 ImageNet de 76,7 % avec une latence d’inférence de 4,8 ms sur iPhone 14 Pro (Apple Neural Engine) — comparable au 71,8 % de MobileNetV2 à 1,5 ms mais avec une précision significativement plus élevée. À mesure que TensorRT de NVIDIA et Core ML d’Apple ajoutent un support optimisé des opérateurs de transformeurs, les modèles d’inspection basés sur les transformeurs offriront une précision plus élevée pour la classification et la segmentation des défauts avec un débit compatible avec la périphérie.
Intégration 6G en Périphérie
La norme cellulaire 6G, dont le déploiement initial est attendu vers 2030, intégrera l’edge computing comme fonction réseau native. Les architectures 6G distribuent les ressources de calcul sur le réseau d’accès radio, permettant une coordination cloud-périphérie inférieure à 1 ms. Pour l’inspection, cela pourrait permettre une inférence collaborative en temps réel où un dispositif périphérique sur le drone exécute un modèle rapide et léger tandis que le réseau 6G délègue les cas plus difficiles — défauts ambigus, motifs de dommages inédits — à un modèle cloud plus profond en un seul aller-retour réseau. La combinaison des bandes térahertz de la 6G (débit de 50+ Gbps) avec le calcul distribué en périphérie fera de la téléopération en temps réel des drones d’inspection avec streaming vidéo 4K et superposition IA une réalité pratique.
Modèles Périphériques Auto-Optimisants
L’apprentissage fédéré et l’adaptation continue des modèles permettront aux systèmes d’inspection en périphérie de s’améliorer au fil du temps sans réentraînement centralisé. Chaque module périphérique du drone enregistre les résultats de détection et les corrections de l’opérateur, les utilisant comme signaux d’entraînement pour des mises à jour incrémentielles du modèle. Sur une flotte de 50 drones d’inspection, chacun contribuant 1 000 prédictions corrigées par semaine, le modèle partagé s’améliore à raison de 50 000 échantillons étiquetés par semaine — permettant une adaptation rapide du domaine à de nouveaux types d’infrastructures, conditions météorologiques et morphologies de défauts sans surcharge d’étiquetage manuel des données.
Termes Associés
Inférence : Le processus d’exécution d’un modèle d’apprentissage automatique entraîné sur de nouvelles données pour produire des prédictions.
Traitement Cloud : Analyse centralisée des données effectuée dans des centres de données distants avec une capacité de calcul élevée mais une latence plus élevée.
Systèmes Temps Réel : Systèmes informatiques qui garantissent une réponse dans des contraintes temporelles strictes.
Automatisation : L’utilisation de la technologie pour effectuer des tâches avec une intervention humaine réduite.
Apprentissage Profond : Un sous-ensemble de l’apprentissage automatique utilisant des réseaux de neurones multicouches pour la reconnaissance de formes.
Drone (UAV) : Un véhicule aérien sans pilote qui sert de plateforme d’inspection.
GPU Mobile : Une unité de traitement graphique conçue pour les applications mobiles et embarquées à contrainte énergétique.
Optimisation de Modèle : Techniques pour réduire la taille du modèle et augmenter le débit d’inférence pour le déploiement.
Quantification : Réduction de la précision numérique dans les poids et activations des réseaux de neurones.
Questions Fréquemment Posées
L'edge computing dans l'inspection par drone signifie exécuter l'inférence IA directement sur l'ordinateur embarqué du drone plutôt que de diffuser toutes les données vers le cloud pour traitement. Le drone capture des images haute résolution et les traite localement à l'aide de réseaux de neurones optimisés, détectant les défauts comme les fissures, la corrosion ou le délaminage en temps réel pendant le vol. Seuls les résultats de détection, les alertes géolocalisées et les recadrages d'images sélectionnés sont transmis à la station au sol, réduisant le transfert de données de 90 à 99 % par rapport au téléchargement cloud en pleine résolution.
La famille NVIDIA Jetson est la plateforme la plus largement adoptée pour l'IA embarquée sur drone, allant du Jetson Nano (472 GFLOPS, 10W) pour la classification légère au Jetson AGX Orin (275 TOPS, 60W) pour l'inférence multi-modèles. D'autres options incluent le Google Coral Edge TPU (4 TOPS, 2W) pour les applications à très faible consommation, les VPU Intel Movidius pour les tâches de vision spécifiques, et les plateformes Qualcomm Snapdragon avec moteurs IA intégrés pour l'inspection par smartphone. Le choix dépend du budget énergétique, de la complexité du modèle et des exigences temps réel.
Les techniques d'optimisation de modèle compressent les réseaux de neurones profonds pour fonctionner efficacement sur du matériel embarqué aux ressources limitées. La quantification convertit les poids du modèle de nombres flottants 32 bits en entiers 8 bits (INT8), réduisant la taille du modèle de 75 % et augmentant le débit d'inférence de 2 à 4x avec une perte de précision minimale (généralement < 1 %). L'élagage supprime les poids ou neurones redondants, permettant une compression de 40 à 60 %. La distillation de connaissances entraîne un modèle étudiant plus petit pour imiter un modèle enseignant plus grand. TensorRT est le SDK d'optimisation de NVIDIA qui fusionne les couches, sélectionne les noyaux optimisés et applique une quantification spécifique à la cible.
La détection de fissures en temps réel en périphérie utilise des réseaux de neurones convolutifs (CNN) déployés sur des dispositifs embarqués comme le NVIDIA Jetson Nano pour classer les images de surfaces en béton comme fissurées ou intactes pendant le vol. Une étude de l'Université du Queensland du Sud a atteint une précision de validation de 96 % en utilisant ResNet50 par apprentissage par transfert sur un Jetson Nano, avec des latences d'inférence inférieures à 50 ms par image 224x224. Des modèles de segmentation plus avancés comme U-Net atteignent jusqu'à 0,86 mIoU à 22 FPS sur le Jetson Orin Nano avec seulement 7W de consommation électrique.
Les opérations hors visibilité directe (BVLOS) exigent que le drone maintienne un vol sûr sans surveillance visuelle humaine continue. L'edge computing permet cela en traitant la détection d'obstacles, la cartographie du terrain et les décisions de navigation à bord en temps réel — même si la liaison de commande et de contrôle (C2) est dégradée ou temporairement perdue. Les réglementations de l'OACI et de la FAA pour le BVLOS soulignent la nécessité de capacités autonomes de détection et d'évitement (DAA), qui dépendent de l'IA embarquée à faible latence. Les systèmes embarqués réduisent également la bande passante de communication nécessaire au pilotage à distance en ne transmettant que des résumés télémétriques et des alertes.
L'edge computing sur drone fonctionne sous des contraintes de puissance sévères. Un drone d'inspection classique (ex. DJI Matrice 300/350) dispose d'un budget énergétique total pour la charge utile de 25 à 50 W, dont le module d'IA embarquée peut consommer 7 à 25 W. Le NVIDIA Jetson Orin Nano fonctionne à 7-15 W TDP, le Jetson AGX Orin à 15-60 W, et le Google Coral à seulement 2 W. La gestion thermique est tout aussi critique : le refroidissement passif suffit pour les modules sous 10 W, mais les modules plus performants nécessitent un refroidissement actif (ventilateurs ou dissipateurs) qui ajoute du poids et consomme de l'énergie supplémentaire. Au-dessus de 40 °C de température ambiante, le throttling thermique peut réduire le débit d'inférence de 30 à 50 %.
Déployez l'IA Embarquée en Temps Réel pour Vos Inspections
TarmacView intègre l'edge computing à l'inspection par drone pour fournir une détection instantanée des défauts, un filtrage de qualité et une aide à la décision au point de capture. Contactez-nous pour découvrir comment l'inférence en périphérie peut transformer vos flux de travail d'inspection des infrastructures.
Détection de fissures par IA pour l'inspection des infrastructures
La détection de fissures par IA utilise la vision par ordinateur — réseaux de neurones convolutifs, vision transformers et modèles de segmentation sémantique — ...
Détection d'objets pour les défauts et caractéristiques d'infrastructure
La détection d'objets localise et classifie les objets dans les images à l'aide de boîtes englobantes — pour l'inspection d'infrastructures, cela inclut les nid...
40 min de lecture
technology
machine-learning
+6
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.