FAISS (Facebook AI Similarity Search) est une bibliothèque open-source de recherche de similarité efficace et de clustering de vecteurs denses, utilisée par TarmacView pour stocker et interroger environ 9 000 plongements de référence étiquetés pour la classification de qualité de surface par plus proches voisins. Couvre les types d’index (Flat, IVF, HNSW), la similarité cosinus via le produit scalaire sur des vecteurs normalisés, l’accélération GPU et l’application à la récupération d’images d’inspection.
FAISS – Recherche de Similarité Haute Performance dans les Plongements Vectoriels
Définition et Capacités
FAISS (Facebook AI Similarity Search) est une bibliothèque open-source en C++ développée par l’équipe Fundamental AI Research (FAIR) de Meta pour la recherche de similarité efficace et le clustering de vecteurs denses. Publiée pour la première fois en 2017, FAISS a accumulé plus de 40 000 étoiles GitHub et plus de 5 200 citations de son article sur l’implémentation GPU. Les packages FAISS ont été téléchargés plus de 6 millions de fois depuis les dépôts Conda. Les grandes sociétés de bases de données vectorielles, notamment Zilliz (Milvus) et Pinecone, s’appuient sur FAISS comme moteur principal ou ont réimplémenté les algorithmes de FAISS dans leurs systèmes de production.
FAISS est conçu spécifiquement pour relever le défi computationnel de la recherche de plus proches voisins dans des espaces vectoriels de haute dimension. L’opération centrale est la recherche de similarité : étant donné un vecteur de requête q, FAISS identifie les vecteurs de l’ensemble de référence les plus proches selon une métrique de distance spécifiée. Formellement, pour un ensemble de vecteurs de référence {x₁, …, xₙ} en dimension d, FAISS calcule efficacement j = argminᵢ ||q - xᵢ|| où ||·|| est la distance euclidienne. La bibliothèque peut également effectuer une recherche de produit scalaire maximum argmaxᵢ ⟨q, xᵢ⟩ et supporte des métriques supplémentaires incluant les distances L1, Linf, Canberra, Bray-Curtis, Jensen-Shannon et Hamming à travers ses implémentations IndexFlat et IndexHNSW. FAISS ne retourne pas seulement le plus proche voisin unique mais les k plus proches voisins, supporte le traitement par lots de multiples requêtes simultanément et peut exécuter des recherches par rayon retournant tous les éléments dans un rayon donné.
La bibliothèque opère sur des vecteurs denses — des tableaux de longueur fixe de nombres flottants 32 bits — qui représentent des points de données plongés dans un espace vectoriel continu. Ces vecteurs sont généralement générés par des réseaux de neurones profonds tels que les Vision Transformers (ViT), les réseaux de neurones convolutifs (CNN) ou les grands modèles de langage. Dans les pipelines modernes d’apprentissage automatique, les plongements servent de représentations intermédiaires qui projettent des données d’entrée complexes dans un espace vectoriel où la localité encode la sémantique. FAISS est le pont entre l’extraction de plongements et les tâches avales basées sur la similarité : il indexe les plongements extraits et permet des opérations de récupération rapides.
FAISS est largement optimisé pour les architectures matérielles modernes. Sur CPU, il exploite les bibliothèques BLAS (Basic Linear Algebra Subprograms) telles qu’Intel MKL, OpenBLAS ou Apple Accelerate pour effectuer des opérations matricielles rapides. Il supporte la vectorisation SIMD (SSE, AVX2, AVX-512) sur architectures x86 et les intrinsèques Neon sur processeurs ARM. Sur GPU, FAISS fournit des implémentations CUDA natives qui peuvent offrir des améliorations de débit de 5 à 10 fois par rapport à l’exécution sur CPU pour les charges de travail typiques. L’implémentation GPU supporte plusieurs GPU en parallèle, permettant une recherche distribuée sur plusieurs dispositifs simultanément.
FAISS n’est pas une base de données vectorielle — c’est une bibliothèque de recherche qui peut être intégrée directement dans les applications. Contrairement aux systèmes de base de données complets (Pinecone, Milvus, Qdrant, Weaviate), FAISS ne fournit pas de persistance intégrée, de réplication, de contrôle d’accès, d’accès concurrent en écriture, d’équilibrage de charge, de partitionnement, de gestion de transactions ou d’optimisation de requêtes. Il expose plutôt une API propre en C++ et Python pour construire, interroger, sauvegarder et charger des index. Cette limitation intentionnelle de son périmètre permet à FAISS d’atteindre des performances maximales pour l’opération centrale de recherche de plus proches voisins. Le périmètre de la bibliothèque est délibérément limité à l’implémentation algorithmique de la Recherche Approximative de Plus Proches Voisins (ANNS), et comme le stipule l’article original sur FAISS : « Faiss n’est pas une base de données — il ne fournit pas d’accès concurrent en écriture, d’équilibrage de charge, de partitionnement, de gestion de transactions ou d’optimisation de requêtes. »
Types d’Index
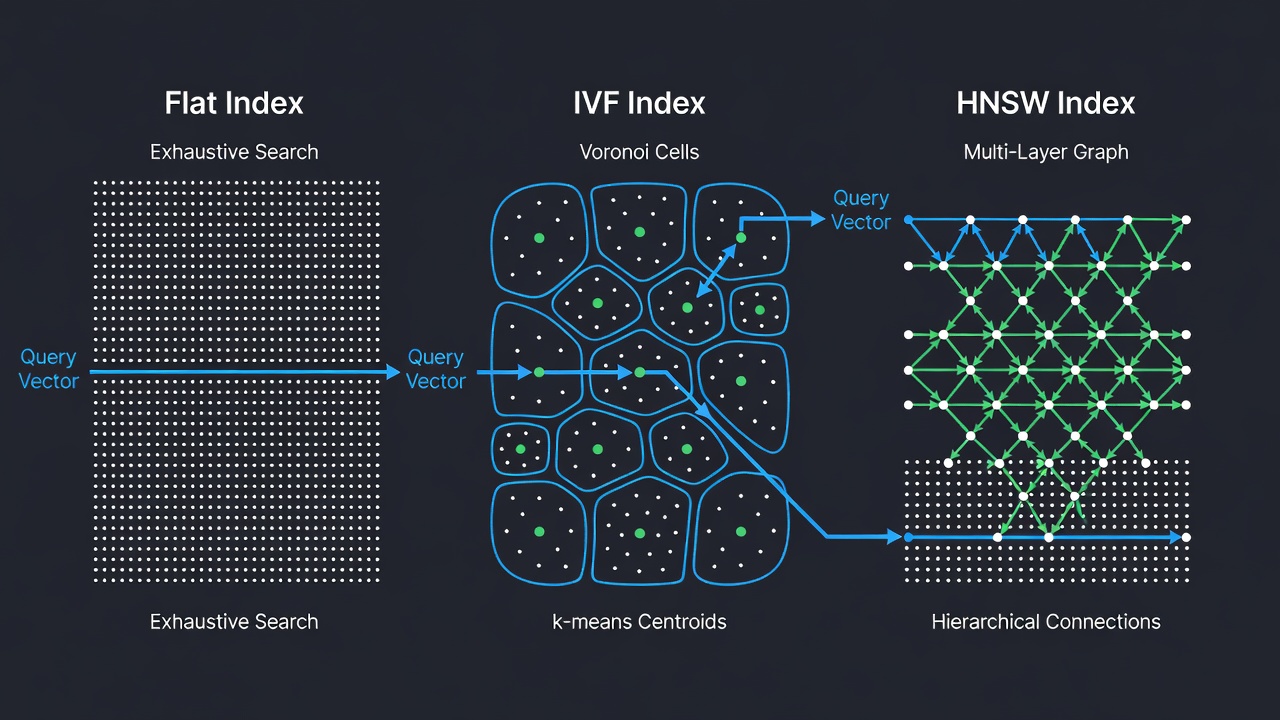
FAISS fournit plus de vingt types d’index différents, chacun conçu pour une combinaison spécifique de compromis entre précision, vitesse et mémoire. Les trois types d’index les plus fondamentaux et les plus utilisés sont IndexFlat (recherche exacte), IndexIVF (fichier inversé avec clustering k-means) et IndexHNSW (graphe hiérarchique navigable à petit monde). Chaque type d’index est disponible avec différentes métriques de distance et variantes encodées (par exemple, FlatIP pour le produit scalaire, FlatL2 pour la distance L2). Les index FAISS peuvent être composés hiérarchiquement — par exemple, en utilisant HNSW comme quantifieur grossier pour un index IVF, produisant la structure composée IndexIVFPQ qui alimente les déploiements à l’échelle du milliard.
IndexFlatIP – Recherche Exacte par Force Brute
IndexFlatIP est le plus simple des index FAISS. Il stocke tous les vecteurs dans un tableau plat et effectue une recherche exhaustive par force brute contre chaque vecteur de l’ensemble de données. Pour chaque requête, il calcule le produit scalaire entre la requête et chaque vecteur stocké, puis retourne les indices et les distances des k meilleurs résultats. Cet index est garanti de retourner les plus proches voisins exacts — aucune approximation, aucune dégradation du rappel. C’est le seul index FAISS qui offre cette garantie ; tous les autres index sont approximatifs et échangent une partie du rappel contre une meilleure vitesse ou une utilisation mémoire réduite.
La complexité computationnelle d’IndexFlatIP est de O(N × D) par requête, où N est le nombre de vecteurs de référence et D est la dimensionnalité. L’index utilise la routine BLAS gemm (multiplication matricielle générale) hautement optimisée pour calculer tous les produits scalaires en une seule multiplication matricielle. Pour un ensemble de données de 100 000 vecteurs en 768 dimensions (taille typique d’un plongement DINOv2 ViT), une seule requête sur CPU prend environ 5 à 15 millisecondes selon le matériel et l’optimisation BLAS. En mode batch avec 1 000 requêtes, l’index les traite toutes simultanément en utilisant une multiplication matrice-matrice, atteignant un débit nettement supérieur à 1 000 requêtes individuelles.
IndexFlatIP joue un rôle critique dans l’écosystème FAISS en tant qu’oracle de vérité terrain pour évaluer la précision des index approximatifs. Les praticiens construisent un index plat parallèlement à leur index approximatif, exécutent des requêtes identiques sur les deux et calculent des métriques de rappel. La suite de benchmarks standard de FAISS (faiss_benchmarks) utilise cette méthodologie pour quantifier la dégradation de précision des index IVF, HNSW et PQ. Dans TarmacView, IndexFlatIP est utilisé comme référence de base pour la validation du système, garantissant que les index approximatifs utilisés en production maintiennent un rappel acceptable.
L’index est construit avec un code minimal : index = faiss.IndexFlatIP(d) où d est la dimensionnalité des plongements. Les vecteurs sont ajoutés avec index.add(embeddings). La recherche est effectuée avec index.search(query, k), qui retourne deux tableaux float32 : les distances (forme [n_queries, k]) et les indices (forme [n_queries, k], dtype int64). Pour le produit scalaire, des valeurs de distance plus grandes indiquent une plus grande similarité. L’index ne nécessite pas d’étape d’entraînement, car il n’y a pas de paramètres à apprendre — les vecteurs sont stockés et comparés textuellement.
IndexIVFFlat – Fichier Inversé avec Clustering k-Means
IndexIVFFlat est un index approximatif de plus proches voisins qui partitionne l’espace vectoriel en cellules de Voronoï à l’aide du clustering k-means. L’architecture est dérivée de l’article fondateur « Video Google » de Sivic et Zisserman (ICCV 2003), qui a adapté les techniques de recherche textuelle à la correspondance d’objets visuels. Lors de l’indexation, l’ensemble de données est regroupé en nlist clusters via k-means, et chaque vecteur est assigné au centroïde de cluster le plus proche. Les centroïdes sont stockés dans un quantifieur grossier (typiquement IndexFlatL2). Lors de la recherche, seuls les vecteurs dans les nprobe clusters les plus proches de la requête sont examinés, réduisant considérablement le nombre de calculs de distance nécessaires.
L’accélération par rapport à IndexFlatIP est d’environ N / ((N / nlist) × nprobe) . Avec nlist=100 et nprobe=5, seulement 5 % de la base de données est parcourue — des requêtes qui prenaient 10 ms sur un index plat peuvent s’effectuer en 0,5 ms. Cependant, la contrepartie est une dégradation du rappel : certains véritables plus proches voisins peuvent se trouver en dehors des clusters parcourus et être manqués. L’étape d’entraînement k-means est critique pour la qualité du rappel — les centroïdes doivent représenter avec précision la distribution des données. FAISS exige que l’ensemble d’entraînement contienne au moins 30 × nlist vecteurs pour une estimation fiable des centroïdes.
Paramètres clés pour IndexIVFFlat :
Paramètre
Description
Plage Typique
Impact
nlist
Nombre de cellules de Voronoï (clusters)
10 – 100 000
Plus élevé = partitionnement plus fin, plus de mémoire pour les centroïdes, entraînement k-means plus lent
nprobe
Nombre de cellules parcourues lors de la requête
1 – 100+
Plus élevé = meilleur rappel (jusqu’à 99 %), recherche linéairement plus lente
metric
Métrique de distance (L2 ou IP)
L2 ou IP
Détermine comment les distances sont calculées entre les vecteurs et les centroïdes
Le paramètre nprobe est particulièrement important car il contrôle le compromis vitesse-précision au moment de la recherche sans nécessiter de reconstruction de l’index. Au moment de la requête, nprobe peut être ajusté dynamiquement : réglez-le sur une valeur élevée (par exemple, 20–50) lors des opérations critiques hors ligne où la précision est primordiale, et sur une valeur faible (par exemple, 1–5) lors des exécutions de production à haut débit où la vitesse est prioritaire. FAISS fournit un mécanisme d’auto-ajustement (AutoTune) qui explore les valeurs de nprobe pour trouver la configuration optimale pour un rappel cible.
La construction d’un IndexIVFFlat nécessite un pipeline en trois étapes : entraînement, ajout et recherche. Pendant l’entraînement, k-means s’exécute sur un échantillon représentatif pour apprendre les centroïdes des clusters. Pendant l’ajout, chaque vecteur de la base est assigné au centroïde le plus proche et ajouté à la liste inversée de ce centroïde. Pendant la recherche, la requête est comparée à tous les centroïdes, les nprobe plus proches sont sélectionnés, et seuls les vecteurs dans ces listes sélectionnées sont comparés exhaustivement. La chaîne de fabrication pour IndexIVFFlat avec produit scalaire est "IVF100,Flat" où 100 est la valeur nlist. En Python : index = faiss.index_factory(d, "IVF100,Flat", faiss.METRIC_INNER_PRODUCT).
Taille de l’ensemble
nlist recommandé
nprobe recommandé
Rappel attendu
Accélération vs Flat
10 000
10 – 100
1 – 5
95–98 %
5–20x
100 000
100 – 1 000
5 – 20
95–99 %
20–100x
1 000 000
1 000 – 10 000
10 – 50
95–99 %
100–500x
10 000 000
10 000 – 100 000
20 – 100
90–98 %
500–5000x
IndexHNSWFlat – Graphe Hiérarchique Navigable à Petit Monde
IndexHNSWFlat est un index approximatif de plus proches voisins basé sur un graphe qui construit un graphe hiérarchique multicouche connu sous le nom de Navigable Small World. L’algorithme, publié à l’origine par Malkov et Yashunin (2016), s’inspire de la structure de données de liste à saut. L’index organise les vecteurs en couches : la couche inférieure (couche 0) contient tous les vecteurs, et chaque couche successive contient un sous-ensemble progressivement plus petit généré par une assignation probabiliste de niveau. Lors de l’insertion, chaque vecteur se voit assigner un niveau l = floor(-ln(uniforme(0,1)) × mL) où mL = 1/ln(M). Le point d’entrée se trouve à la couche existante la plus élevée, garantissant une traversée logarithmique du graphe.
La recherche commence à la couche la plus haute (la plus grossière, avec le moins de nœuds) et descend à travers les couches, en affinant l’ensemble des candidats à chaque étape. À chaque couche, une recherche gloutonne traverse le graphe vers la requête en se déplaçant toujours vers le voisin qui minimise la distance. Après avoir trouvé le minimum local à la couche actuelle, l’algorithme descend à la couche suivante et répète le processus en utilisant le résultat de la couche supérieure comme point de départ. Cette structure hiérarchique permet une complexité de recherche logarithmique O(log N), faisant de HNSW l’un des algorithmes de recherche approximative de plus proches voisins les plus rapides disponibles pour les ensembles de données de taille moyenne à grande.
L’index HNSW a trois paramètres critiques :
Paramètre
Description
Plage Typique
Impact
M
Nombre maximum de connexions bidirectionnelles par nœud
8 – 64 (défaut 32)
M plus élevé = graphe plus densément connecté, meilleur rappel, plus de mémoire
efConstruction
Taille de la liste dynamique de candidats lors de la construction du graphe
40 – 200 (défaut 40)
Plus élevé = recherche plus approfondie lors de la construction, graphe de meilleure qualité, construction plus lente
efSearch
Taille de la liste dynamique de candidats lors de la recherche
10 – 200 (défini au moment de la requête)
Plus élevé = meilleur rappel, recherche plus lente (réglable sans reconstruction)
Le paramètre M contrôle directement la connectivité du graphe. Chaque vecteur maintient jusqu’à M arêtes bidirectionnelles vers ses plus proches voisins. Le graphe utilise une heuristique favorisant la diversité lors de la sélection des voisins : lorsqu’un nouveau nœud est ajouté, ses candidats voisins sont élagués pour garantir une connectivité diversifiée qui évite que des nœuds pivots ne dominent la structure du graphe. Des valeurs de M plus élevées produisent un routage plus robuste mais augmentent la consommation mémoire : environ 4d + M × 2 × 4 octets par vecteur pour la structure du graphe plus le stockage des vecteurs.
Le paramètre efConstruction contrôle la rigueur de la recherche lors de la construction de l’index. Des valeurs plus grandes produisent des graphes de meilleure qualité mais augmentent le temps de construction de manière linéaire. En règle générale, efConstruction ≈ M × 2 offre un bon équilibre pour la plupart des charges de travail. Le paramètre efSearch est analogue à nprobe dans les index IVF — il contrôle la rigueur de la recherche au moment de la requête et peut être ajusté dynamiquement sans reconstruction de l’index.
Les index HNSW offrent plusieurs avantages par rapport aux index IVF. Ils atteignent généralement un rappel plus élevé à vitesse de recherche équivalente, en particulier sur des données de haute dimension (d > 256). Ils ne nécessitent pas d’étape d’entraînement séparée (contrairement à IVF qui nécessite un clustering k-means, rendant HNSW adapté aux ensembles de données dynamiques où les vecteurs arrivent de manière incrémentale). Ils présentent une dégradation progressive du rappel à mesure que efSearch diminue — le rappel s’améliore de manière fluide sans seuils brusques. Cependant, les index HNSW utilisent plus de mémoire par vecteur (les listes d’adjacence du graphe ajoutent une surcharge) et sont plus lents à construire que les index IVF. HNSW ne supporte pas non plus nativement la suppression de vecteurs, car retirer des nœuds de la structure du graphe compromettrait la connectivité.
Pour l’ensemble de référence de TarmacView d’environ 9 000 plongements, un IndexHNSWFlat avec M=32 et efSearch=64 atteint >99 % de rappel avec des temps de requête inférieurs à 200 microsecondes sur CPU — une accélération de 50x par rapport à IndexFlatIP avec une perte de précision négligeable. La chaîne de fabrication "HNSW32,Flat" construit cet index. En Python : index = faiss.index_factory(d, "HNSW32,Flat", faiss.METRIC_INNER_PRODUCT).
Similarité Cosinus via le Produit Scalaire sur des Vecteurs Normalisés
La similarité cosinus mesure le cosinus de l’angle entre deux vecteurs non nuls — elle quantifie à quel point deux vecteurs sont similaires indépendamment de leur magnitude. La similarité cosinus entre les vecteurs a et b est définie comme cos(θ) = (a · b) / (||a|| × ||b||) où a · b est le produit scalaire et ||a|| est la norme L2 de a. Le résultat varie de -1 (direction complètement opposée) à +1 (direction identique), 0 indiquant l’orthogonalité.
FAISS ne fournit pas de métrique de similarité cosinus dédiée. Au lieu de cela, la similarité cosinus est implémentée via une transformation en deux étapes que l’équipe de développement de FAISS considère comme canonique. Premièrement, tous les vecteurs sont normalisés L2 à longueur unitaire — chaque vecteur est divisé par sa norme L2 de sorte que ||a|| = 1 et ||b|| = 1. Deuxièmement, METRIC_INNER_PRODUCT est utilisé comme métrique de distance. Pour des vecteurs normalisés, le produit scalaire est égal à la similarité cosinus : a · b = cos(θ). Cette équivalence découle directement de la formule du cosinus : lorsque le dénominateur est égal à 1, la formule se réduit au produit scalaire.
Cette technique de normalisation est standard dans les systèmes de recherche vectorielle car le produit scalaire est calculable efficacement par des routines de multiplication matricielle BLAS hautement optimisées. Le coût computationnel de la normalisation de tous les vecteurs de l’index est une opération unique O(N × D) au moment de la construction de l’index, et la normalisation de chaque requête est O(D) — négligeable par rapport au coût de la recherche elle-même. La normalisation L2 est appliquée avant que les vecteurs ne soient ajoutés à l’index et avant que les requêtes ne soient soumises, garantissant que toutes les comparaisons se font dans l’espace de similarité cosinus.
Dans FAISS, la normalisation est implémentée à l’aide de l’enveloppe IndexPreTransform combinée à une NormalizationTransform (en Python, faiss.NormalizationTransform). Le motif de construction est :
import faiss
import numpy as np
dimension =768# Crée l'index de produit scalairebase_index = faiss.IndexFlatIP(dimension)
# Enveloppe avec normalisation L2index = faiss.IndexPreTransform(
faiss.NormalizationTransform(dimension),
base_index
)
# Les vecteurs ajoutés ici sont automatiquement normalisés L2index.add(reference_embeddings)
# Les requêtes soumises ici sont automatiquement normalisées L2distances, indices = index.search(query_embeddings, k)
Les approches alternatives incluent la normalisation manuelle des vecteurs avec faiss.normalize_L2() avant l’ajout et la requête, ou la construction de l’index via index_factory qui supporte la normalisation intégrée via l’étape de prétraitement "L2norm". Avec la méthode factory : index = faiss.index_factory(d, "L2norm,HNSW32,Flat") crée un index qui normalise automatiquement les vecteurs à longueur unitaire avant de construire le graphe HNSW.
Pour TarmacView, cette approche est essentielle car les plongements DINOv2, comme la plupart des sorties de Vision Transformers, varient en magnitude selon les images. Les variations d’exposition, de conditions d’éclairage et de réglages de l’appareil photo lors de l’inspection des chaussées aéroportuaires produisent des plongements de magnitudes différentes même lors de la capture de textures de surface identiques. La normalisation supprime la composante de magnitude et concentre la comparaison de similarité sur l’alignement directionnel — deux images de surface qui capturent la même texture de chaussée mais à des niveaux d’exposition différents seront considérées comme très similaires car leurs plongements normalisés pointent dans la même direction, même si leurs magnitudes brutes diffèrent considérablement.
La FAQ de FAISS aborde explicitement ce point : « La similarité cosinus entre les vecteurs x et y est définie par cos(x, y) = ⟨x, y⟩ / (|x| × |y|). En normalisant au préalable les vecteurs de requête et de la base, le problème peut être ramené à une recherche de produit scalaire maximum. » FAISS note également que l’utilisation du produit scalaire sur des vecteurs normalisés est mathématiquement équivalente à l’utilisation de la distance L2 sur des vecteurs normalisés, avec la relation ||x - y||² = 2 - 2 × ⟨x, y⟩ pour des vecteurs normalisés.
Construction et Interrogation d’un Index FAISS
Le cycle de vie d’un index FAISS en production comprend cinq étapes distinctes : configuration, entraînement, peuplement, sérialisation et interrogation. Chaque étape a des appels API spécifiques, des considérations de performance et des bonnes pratiques.
La configuration commence par la sélection d’un type d’index et d’une métrique de distance. FAISS fournit le mécanisme de chaîne de fabrication — une spécification sous forme de chaîne compacte qui construit des index complexes. Le motif factory est l’approche recommandée car il abstrait la hiérarchie de classes spécifique et sélectionne automatiquement l’implémentation optimale :
Chaîne de Fabrication
Type d’Index
Mémoire par Vecteur (d=768)
Cas d’Usage
"Flat"
IndexFlat (recherche exacte L2)
3 072 octets
Petits ensembles de référence, vérité terrain
"IVF100,Flat"
IndexIVFFlat avec 100 centroïdes
~3 100 octets
Ensembles moyens, recherche approximative rapide
"HNSW32,Flat"
IndexHNSWFlat avec M=32
~3 328 octets
Recherche approx. rapide, données dynamiques
"IVF100,PQ16"
IndexIVFPQ, 16 sous-vecteurs
~80 octets
Grande échelle, mémoire limitée
"IVF100,SQ8"
IndexIVF avec quantification scalaire
~784 octets
Équilibré, excellente vitesse
L’entraînement n’est requis que pour les index qui apprennent une distribution de données (IVF, PQ, SQ, etc.). Pendant l’entraînement, l’index exécute un clustering k-means sur un échantillon représentatif de vecteurs. Pour l’algorithme k-means, FAISS utilise plusieurs initialisations aléatoires et sélectionne celle avec la plus faible distortion. L’ensemble d’entraînement doit être représentatif des données qui seront indexées — l’utilisation d’un sous-ensemble aléatoire de 1 à 10 % de l’ensemble complet est une pratique courante. FAISS exige que les vecteurs d’entraînement aient la même dimensionnalité que les données qui seront indexées. Le drapeau index.is_trained indique si l’entraînement est terminé. L’appel d’entraînement est : index.train(training_vectors). Pour les ensembles de données où l’index a déjà été entraîné (par exemple, des centroïdes pré-entraînés sont chargés depuis un fichier), appeler à nouveau train est inutile et écrasera les paramètres appris.
Le peuplement ajoute des vecteurs à l’index entraîné : index.add(reference_vectors). La propriété ntotal suit le nombre de vecteurs ajoutés. Pour les index IVF, chaque vecteur est assigné au centroïde de cluster le plus proche et ajouté à la liste inversée de ce centroïde lors de l’opération d’ajout. Pour les index HNSW, le graphe est construit de manière incrémentale : chaque nouveau vecteur se voit assigner un niveau de couche, et des arêtes sont établies vers ses M plus proches voisins à chaque couche en utilisant le paramètre efConstruction. L’ajout de vecteurs est généralement plus lent que l’interrogation, en particulier pour HNSW où le graphe doit être mis à jour.
La sérialisation sauvegarde l’index sur disque : faiss.write_index(index, "index.faissindex"). L’index est rechargé avec index = faiss.read_index("index.faissindex"). La sérialisation préserve l’état complet de l’index incluant les centroïdes entraînés, la structure du graphe, tous les vecteurs stockés, la configuration de la métrique de distance et les paramètres internes. L’extension de fichier standard est .faissindex. La taille de sérialisation dépend du type d’index et du nombre de vecteurs — pour IndexFlat avec N vecteurs de dimensionnalité D, la taille est d’environ N × D × 4 octets plus une faible surcharge.
L’interrogation récupère les k plus proches voisins : distances, indices = index.search(query_vectors, k). Le tableau distances contient les valeurs de similarité ou de distance selon la métrique. Le tableau indices contient les positions des vecteurs de référence correspondants tels qu’ils ont été ajoutés (indexés à partir de 0). Pour les requêtes par lots, FAISS traite efficacement plusieurs requêtes simultanément en utilisant la multiplication matrice-matrice, atteignant un débit nettement supérieur à celui des appels requête par requête. Les objets index sont thread-safe pour les opérations de recherche sur des instances d’index séparées, permettant un service de requêtes parallèles dans les déploiements de production.
FAISS pour la Classification kNN
FAISS est fréquemment utilisé pour implémenter la classification par k-plus proches voisins (kNN) — une méthode d’apprentissage automatique non paramétrique qui classifie un point de requête en fonction de l’étiquette majoritaire parmi ses k plus proches voisins dans l’ensemble de référence. Cette approche est particulièrement attractive lorsque : (1) l’ensemble de référence est régulièrement mis à jour avec de nouveaux échantillons étiquetés, (2) l’espace de plongements capture des relations sémantiques significatives entre les points de données, et (3) des décisions interprétables et basées sur des instances sont préférées aux classifieurs neuronaux en boîte noire.
Le pipeline de classification utilisant FAISS suit cinq étapes :
Construire un ensemble de référence étiqueté : Chaque vecteur de référence est associé à une étiquette de vérité terrain (par exemple, « asphalte – bon état », « béton – surface fissurée », « tarmac – réparé »). Les étiquettes sont stockées dans un tableau séparé aligné sur l’ordre de l’index FAISS. TarmacView maintient environ 9 000 plongements de référence étiquetés couvrant plusieurs types de surface et états de qualité.
Indexer les vecteurs de référence : Tous les plongements de référence sont ajoutés à un index FAISS. Pour une recherche exacte avec un rappel parfait, IndexFlatIP est utilisé. Pour une recherche approximative à grande échelle, IndexHNSWFlat ou IndexIVFFlat offrent des temps de requête inférieurs à la milliseconde avec >99 % de rappel lorsqu’ils sont correctement paramétrés.
Soumettre les plongements de requête : Pour chaque nouvelle image à classifier, extraire son plongement en utilisant le même modèle de plongement (DINOv2 avec sortie de 768 dimensions) et normaliser à longueur unitaire pour la similarité cosinus.
Récupérer les k plus proches voisins : FAISS retourne les indices et les distances des k vecteurs de référence les plus similaires. Le paramètre k contrôle le compromis biais-variance. Un k plus petit (par exemple, 3–5) produit des frontières de décision sensibles à la structure locale mais sujettes au surapprentissage du bruit. Un k plus grand (par exemple, 15–20) produit des frontières plus lisses avec une meilleure généralisation mais peut perdre des distinctions fines. TarmacView utilise k=10, équilibrant la robustesse contre les valeurs aberrantes et la sensibilité aux variations subtiles de qualité de surface.
Effectuer un vote majoritaire : Compter les étiquettes parmi les k voisins et sélectionner l’étiquette la plus fréquente comme résultat de classification. Optionnellement, le vote pondéré par la distance donne plus de poids aux voisins plus proches : poids = 1,0 / (distance + ε) où ε est une petite constante pour éviter la division par zéro. Le vote pondéré est particulièrement bénéfique lorsque l’ensemble de référence a des distributions de classes inégales ou lorsque la densité de voisins varie dans l’espace de plongements.
Valeur k
Biais
Variance
Idéal pour
1 – 3
Faible
Élevé
Grands ensembles de référence propres, frontières fines
5 – 10
Modéré
Modéré
Classification équilibrée, usage général
15 – 30
Plus élevé
Plus faible
Étiquettes bruitées, frontières de décision lisses
Les scores de distance retournés par FAISS informent également l’estimation de confiance. Si les k meilleurs voisins partagent tous la même étiquette et ont des scores de similarité élevés (similarité cosinus > 0,95), la classification est hautement fiable. Si le vote est partagé (par exemple, 6 sur 10 pour l’étiquette gagnante) ou que les scores de similarité sont faibles (< 0,70), le système peut signaler le résultat pour révision humaine. Cette architecture consciente de la confiance est critique pour les applications où la sécurité est primordiale, comme l’inspection des chaussées aéroportuaires, où une erreur de classification pourrait affecter la priorisation de la maintenance et la sécurité opérationnelle.
Le contrat de plongement entre le modèle DINOv2 et l’index FAISS est fondamental pour la précision de la classification. L’extracteur de plongements est entraîné via un apprentissage auto-supervisé pour que les distances entre plongements reflètent la similarité visuelle entre les images de surface de chaussée. L’index FAISS récupère fidèlement les plus proches voisins selon la métrique de similarité cosinus. Lorsque ce contrat est respecté — lorsque des conditions de surface visuellement similaires produisent des plongements proches — la classification kNN atteint une haute précision avec l’interprétabilité inhérente de montrer exactement quelles images de référence ont éclairé chaque décision de classification.
Accélération GPU
Le support GPU de FAISS est une fonctionnalité de première classe qui offre des améliorations de performance substantielles tant pour la construction d’index que pour la recherche. L’implémentation GPU, décrite dans l’article « Billion-scale similarity search with GPUs » (Johnson, Douze, Jégou, 2017), est écrite en CUDA C++ et exploite les architectures GPU NVIDIA de Kepler (Compute Capability 3.5) jusqu’à Hopper (Compute Capability 9.0+) et au-delà.
L’accélération GPU de FAISS offre des améliorations de performance mesurables : une amélioration du débit de recherche de 5 à 10 fois par rapport au CPU pour les index IVF et HNSW typiques ; une construction d’index jusqu’à 12 fois plus rapide pour les index IVF car le clustering k-means est hautement parallélisable ; une latence 8 fois plus faible pour les requêtes HNSW sur GPU grâce à des noyaux optimisés de traversée de graphe ; et un support natif pour les requêtes par lots où les GPU excellent dans le traitement de centaines ou milliers de requêtes simultanément via des opérations matrice-matrice.
L’implémentation GPU couvre les types d’index les plus couramment utilisés via des classes CUDA dédiées :
Classe d’Index GPU
Équivalent CPU
Fonctionnalités CUDA Utilisées
GpuIndexFlat
IndexFlat
BLAS gemm sur GPU, tuilage en mémoire partagée
GpuIndexIVFFlat
IndexIVFFlat
Calcul parallèle de distance, réductions au niveau warp
GpuIndexIVFPQ
IndexIVFPQ
Tables de correspondance PQ sur GPU, assignation rapide de codes
GpuIndexIVFScalarQuantizer
IndexIVFScalarQuantizer
Support float16 sur GPU Pascal+
L’implémentation GPU utilise les warp shuffles (disponibles sur Compute Capability 3.0+) et la mise en cache de texture en lecture seule via ld.nc / __ldg (Compute Capability 3.5+). L’algorithme de sélection-k — trouvant les k meilleures valeurs dans un grand tableau de distances — fonctionne jusqu’à 55 % de la performance GPU théorique de pointe, permettant une implémentation de plus proches voisins 8,5 fois plus rapide que l’état de l’art GPU antérieur selon l’article de 2017. Pour la gestion de la mémoire GPU, un objet StandardGpuResources alloue de l’espace de travail sur GPU : environ 512 Mio sur les GPU avec ≤4 Gio de mémoire, et environ 1 536 Mio sur les GPU plus grands. Cet espace de travail évite les appels répétés cudaMalloc / cudaFree lors de la recherche.
FAISS fournit une interopérabilité transparente CPU-GPU via deux fonctions clés : faiss.index_cpu_to_gpu(cpu_index, device_id) transfère un index CPU vers un dispositif GPU spécifié, et faiss.index_gpu_to_cpu(gpu_index) transfère un index GPU vers la mémoire CPU. Pour les déploiements multi-GPU, faiss.index_cpu_to_gpu_multiple_py(resources, cpu_index) distribue un index sur tous les dispositifs GPU disponibles, et les requêtes sont automatiquement équilibrées en charge. L’approche multi-GPU peut passer à l’échelle pour des index contenant des centaines de millions de vecteurs en partitionnant l’index entre les espaces mémoire GPU.
Scénario
CPU
GPU (1x)
GPU (8x)
Recherche IndexFlat (100K x 768d), batch=8192
50 ms
5 ms
<1 ms
Entraînement k-means IVF (1M x 128d), nlist=1000
120 s
10 s
5 s
Construction HNSW (100K x 128d), M=32
30 s
8 s
—
Graphe k-NN à l’échelle du milliard
jours
12 heures
4 heures
Pour TarmacView, l’accélération GPU est précieuse pendant la phase de construction de l’index lorsque de nouvelles images de référence sont ajoutées périodiquement. La construction d’un index IVF avec k-means sur 9 000 vecteurs de 768 dimensions s’effectue en environ 1 à 2 secondes sur un GPU moderne (NVIDIA A100 ou RTX 4090) contre 30 à 60 secondes sur CPU. Pendant l’inférence, l’index reste sur CPU pour un déploiement économique — la latence des requêtes sur CPU avec IndexHNSWFlat est déjà inférieure à 200 microsecondes pour l’ensemble de référence de 9K, et le passage au GPU ajouterait une surcharge de transfert PCIe sans bénéfice significatif en latence.
Utilisation de FAISS par TarmacView
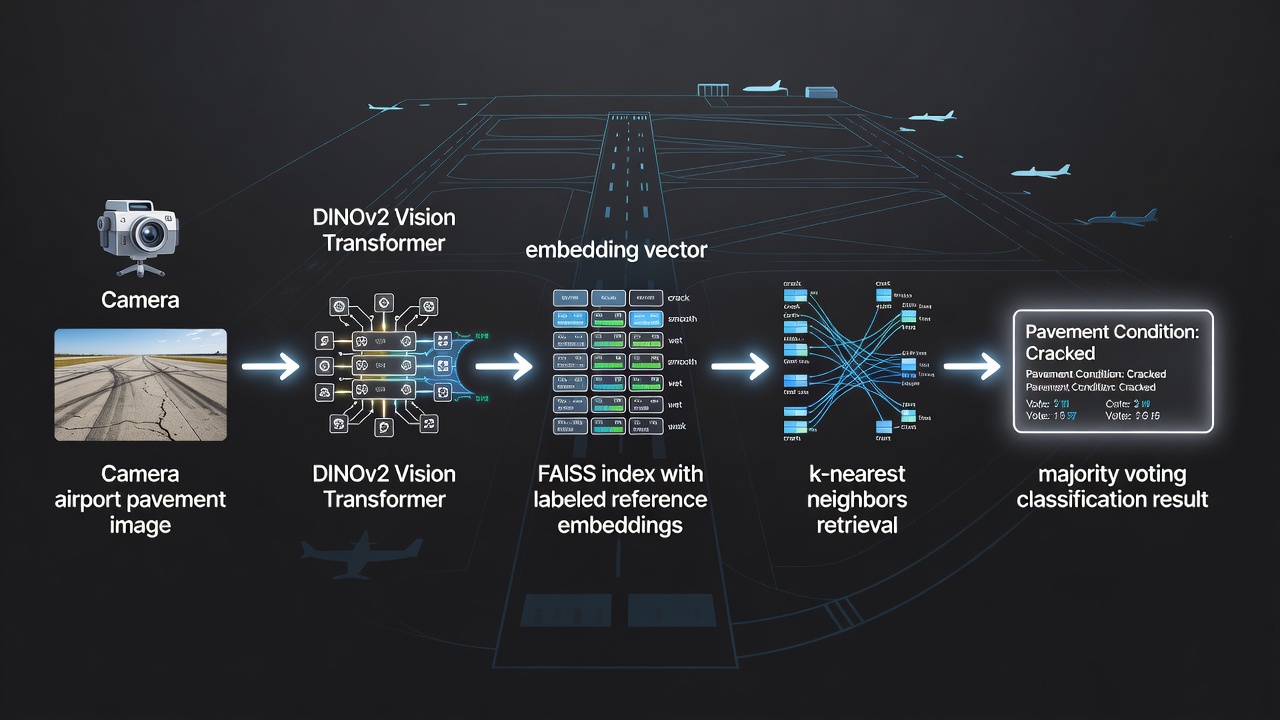
TarmacView intègre FAISS comme moteur central de recherche de similarité pour son système automatisé de classification de la qualité de surface des chaussées aéroportuaires. Le système classifie les types de surface de chaussée (asphalte, béton, tarmac) et les états de qualité de surface (bon, moyen, mauvais, dégradé, fissuré, réparé) en comparant les images d’inspection à un ensemble de référence organisé d’environ 9 000 plongements étiquetés.
Construction de l’ensemble de référence : Chaque plongement de référence est extrait d’une image de chaussée haute résolution à l’aide d’un modèle Vision Transformer DINOv2 (ViT-B/14 ou équivalent), qui produit un vecteur de 768 dimensions capturant des caractéristiques visuelles telles que les motifs de texture, la distribution des couleurs, la morphologie des fissures, l’exposition des granulats, l’usure de surface et les traces de réparation. Chaque plongement est annoté avec des étiquettes de vérité terrain établies par des inspecteurs de chaussée certifiés lors d’une phase initiale d’entraînement du système. L’ensemble de référence couvre plusieurs aéroports, zones climatiques et âges de chaussée pour garantir une classification robuste dans des conditions diverses.
Sélection de l’index : TarmacView choisit le type d’index en fonction des exigences de déploiement :
Scénario de Déploiement
Type d’Index
Temps de Requête
Rappel
Mémoire
QA / validation hors ligne
IndexFlatIP
~2 ms
100 %
~28 Mo
Déploiement terrain temps réel
IndexHNSWFlat (M=32, efSearch=64)
<200 μs
>99 %
~30 Mo
Dispositif embarqué (RAM limitée)
IndexIVFFlat (nlist=100, nprobe=10)
~300 μs
~97 %
~28 Mo
Flux de travail de classification :
Une caméra montée sur drone (par exemple, série DJI Matrice avec charge utile haute résolution) ou un dispositif d’inspection portable capture des images de chaussée lors des inspections de routine des aires aéroportuaires, conformément aux directives de l’Annexe 14 de l’OACI et de la FAA AC 150/5380-7B pour l’évaluation de l’état des chaussées.
Chaque image est prétraitée (recadrée pour supprimer les zones non pavées, normalisée à une résolution standard) et transmise au modèle de plongement DINOv2 hébergé sur un accélérateur d’inférence embarqué (NVIDIA Jetson ou équivalent).
Le plongement résultant de 768 dimensions est normalisé L2 à longueur unitaire pour le calcul de similarité cosinus. La normalisation garantit que les variations d’exposition entre les vols d’inspection n’affectent pas le classement de similarité.
FAISS interroge l’index IndexHNSWFlat avec k=10, retournant les 10 indices de plongements de référence les plus proches et leurs scores de similarité par produit scalaire (équivalents à la similarité cosinus pour des vecteurs normalisés).
Le système effectue un vote majoritaire sur les étiquettes des 10 voisins. Si l’étiquette gagnante obtient au moins 6 votes sur 10 (consensus de 60 %), la classification est acceptée avec un score de confiance calculé comme le rapport des votes gagnants sur le total des votes.
Si le vote est inférieur à 60 % de consensus, le plongement de l’image et les 10 images de référence les plus proches sont signalés pour révision humaine par un inspecteur de chaussée certifié via l’interface web de TarmacView.
Les classifications sont enregistrées dans la base de données TarmacView avec les horodatages, les coordonnées GPS, le type de surface, l’état de qualité, le score de confiance et les liens vers les images de référence associées. Cela crée une piste d’inspection entièrement vérifiable pour la conformité réglementaire.
Ce pipeline de classification alimenté par FAISS permet à TarmacView de traiter des milliers d’images de chaussée par jour avec une évaluation de qualité objective et cohérente — réduisant la dépendance à l’inspection visuelle humaine subjective et permettant une surveillance scalable de l’état des aires aéroportuaires sur l’ensemble des réseaux d’aéroports.
FAISS vs Autres Bases de Données Vectorielles
FAISS occupe une niche distincte dans l’écosystème de la recherche vectorielle. C’est une bibliothèque, pas une base de données, et cette distinction a des implications significatives sur l’architecture, le déploiement et les caractéristiques opérationnelles. La bibliothèque FAISS fournit des fonctionnalités pures de recherche de plus proches voisins sans la surcharge d’un système complet de gestion de base de données.
Fonctionnalité
FAISS
Pinecone
Milvus
Qdrant
Weaviate
Type
Bibliothèque
Service géré
Base de données
Base de données
Base de données
Déploiement
Intégré
Cloud / SaaS
Auto-hébergé / Cloud
Auto-hébergé / Cloud
Auto-hébergé / Cloud
Persistance
Sauvegarde/chargement manuel
Automatique
Automatique
Automatique
Automatique
CRUD
Non intégré
CRUD complet
CRUD complet
CRUD complet
CRUD complet
Filtrage par métadonnées
Basé uniquement sur les ID
Filtres riches
Attribut + scalaire
Filtrage de charge utile
Basé sur graphe
Passage à l’échelle
Partitionnement manuel
Auto-scaling
Distribué Raft/Paxos
Distribué
Distribué
Support GPU
CUDA natif
Non
Limitée (CUDA)
Non
Non
Latence de requête
10 μs – 1 ms
2 – 10 ms
1 – 10 ms
1 – 5 ms
1 – 10 ms
Licence
MIT
Propriétaire
Apache 2.0
Apache 2.0
BSD-3
Le principal avantage de FAISS par rapport aux systèmes de base de données complets est la performance et la simplicité. Les requêtes FAISS sont typiquement 10 à 100 fois plus rapides que les requêtes équivalentes sur des systèmes de base de données car : la bibliothèque s’exécute en processus sans allers-retours réseau ; il n’y a pas d’analyse de requête, d’authentification ou de surcharge d’autorisation ; il n’y a pas d’indirection de moteur de stockage ni de gestion de pool de buffers ; et les index FAISS sont des structures de données d’algèbre linéaire optimisées sans surcharge transactionnelle. FAISS opère directement sur des structures de données en mémoire en utilisant des routines BLAS optimisées, sans communication inter-processus.
Le principal avantage des systèmes de base de données par rapport à FAISS est la commodité opérationnelle. Ils fournissent une durabilité automatique des données avec journalisation par anticipation et réplication, supportent un filtrage riche par métadonnées (par exemple, « trouver des images similaires capturées après janvier 2025 qui montrent une chaussée en béton dans la région du Sud-Ouest des États-Unis »), offrent des API REST ou gRPC pour un accès indépendant du langage, incluent des tableaux de bord de surveillance et des alertes, et gèrent la sauvegarde et la reprise après sinistre. Ils supportent les opérations de lecture et d’écriture concurrentes avec garanties de transaction et évolution de schéma.
Pour TarmacView, l’utilisation directe de FAISS plutôt qu’une base de données vectorielle est le choix architectural correct pour quatre raisons : (1) l’ensemble de référence est petit (~9K vecteurs, environ 28 Mo) et tient entièrement en mémoire ; (2) les exigences de latence des requêtes sont agressives (une classification inférieure à 200 microsecondes est réalisable avec HNSW sur CPU) ; (3) le système s’exécute dans des déploiements en périphérie dans les aéroports où l’accès réseau à un serveur de base de données peut être impraticable ou introduire une latence inacceptable ; et (4) l’index est reconstruit peu fréquemment (hebdomadairement ou mensuellement à mesure que de nouvelles images de référence sont ajoutées après validation par l’inspecteur), rendant la sérialisation manuelle et le contrôle de version gérables.
Sérialisation d’Index
La sérialisation d’index FAISS convertit un objet index en mémoire en une représentation binaire qui peut être sauvegardée sur disque, transférée sur un réseau ou chargée dans un autre processus ou machine. La sérialisation préserve l’état complet de l’index incluant tous les vecteurs stockés, les centroïdes entraînés (pour les index IVF et PQ), la structure du graphe (pour HNSW), la configuration de la métrique de distance (L2 vs IP vs autres) et tous les paramètres internes (efConstruction, M, paramètres de normalisation, etc.).
Les fonctions de sérialisation principales sont :
Fonction
Description
Sortie
Cas d’Usage
write_index(index, filename)
Écrit l’index dans un fichier
Fichier .faissindex
Stockage persistant sur disque
read_index(filename)
Charge l’index depuis un fichier
Objet Index
Chargement pour service
serialize_index(index)
Écrit l’index en octets
Objet Python bytes
Stockage en base de données, files de messages
deserialize_index(data)
Charge l’index depuis des octets
Objet Index
Chargement depuis tampon mémoire
La taille de sérialisation dépend du type d’index et du nombre de vecteurs. Pour IndexFlatIP avec N vecteurs de dimension D, la taille du fichier est d’environ N × D × 4 octets (stockage flottant 32 bits) plus la surcharge pour l’en-tête et les métadonnées. Pour IndexIVFFlat, un stockage supplémentaire est consommé par les centroïdes des clusters : nlist × D × 4 octets. Pour IndexHNSWFlat, la structure du graphe ajoute N × M × 2 × 4 octets pour les listes d’adjacence (en supposant des indices de voisins 32 bits stockés de manière bidirectionnelle). Pour l’index HNSW de TarmacView avec 9 000 vecteurs en 768 dimensions et M=32, le fichier sérialisé fait environ 25 Mo : 9 000 × 768 × 4 = 27,6 Mo pour les vecteurs plus 9 000 × 32 × 2 × 4 = 2,3 Mo pour la structure du graphe, moins le fait que HNSW stocke les vecteurs dans un index plat en interne.
La sérialisation supporte le transfert entre contextes : un index construit sur GPU peut être sauvegardé sur disque et chargé sur CPU. Le motif recommandé est de toujours transférer les index GPU vers le CPU avant la sérialisation :
cpu_index = faiss.index_gpu_to_cpu(gpu_index) # transfert vers CPUfaiss.write_index(cpu_index, "production_index.faissindex") # sauvegarde sur disque# Sur une autre machine (ou plus tard) :deployed_index = faiss.read_index("production_index.faissindex")
deployed_index.hnsw.efSearch =64# réglage des paramètres de rechercheD, I = deployed_index.search(queries, k)
Pour les déploiements de production, l’index sérialisé peut être versionné parallèlement au code de l’application. TarmacView maintient des fichiers d’index FAISS versionnés dans ses artefacts de déploiement, garantissant que chaque déploiement en périphérie utilise un ensemble de référence identique pour des résultats de classification reproductibles. Lorsque de nouvelles images de référence sont ajoutées et validées, un nouvel index est entraîné, sa précision est évaluée par rapport à l’index précédent en utilisant le IndexFlatIP de vérité terrain, et le nouvel index est déployé via le pipeline CI/CD standard.
Passage à l’Échelle de FAISS pour de Grands Ensembles de Référence
Bien que l’ensemble de référence actuel de TarmacView d’environ 9 000 vecteurs soit modeste, FAISS est conçu pour passer à l’échelle jusqu’à des milliards de vecteurs sur un seul serveur. La bibliothèque fournit une boîte à outils complète pour gérer les déploiements à grande échelle via trois techniques complémentaires : la compression vectorielle, la recherche non exhaustive et l’indexation distribuée.
Quantification Produit
La quantification produit (PQ) est une technique de compression avec pertes qui réduit considérablement l’empreinte mémoire par vecteur. PQ divise chaque vecteur de dimension D en m sous-vecteurs de taille égale (dimensions D/m chacun). Chaque sous-vecteur est quantifié indépendamment à l’aide d’un dictionnaire de 256 entrées (8 bits) appris par clustering k-means. Le vecteur float32 original (4 × D octets) est compressé en m octets d’indices de code plus un petit dictionnaire. Les taux de compression PQ de 4x à 16x sont courants, permettant à une seule machine d’indexer des centaines de millions de vecteurs en mémoire principale. L’IndexIVFPQ de FAISS combine IVF avec PQ, utilisant les centroïdes des clusters comme quantifieur grossier et les codes PQ pour la compression résiduelle. Le calcul de distance utilise le calcul de distance asymétrique (ADC) : la requête reste non compressée, et les distances aux vecteurs de la base compressés par PQ sont calculées via des tables de correspondance précalculées, évitant la surcharge de décompression.
Configuration PQ
Octets/vecteur (d=768)
Mémoire, N=100M
Rappel vs non compressé
PQ32 (m=32, 8 bits)
40
3,7 Go
~90-95 %
PQ64 (m=64, 8 bits)
72
6,7 Go
~95-98 %
PQ96 (m=96, 8 bits)
104
9,7 Go
~97-99 %
Quantification Scalaire
La quantification scalaire (SQ) convertit chaque composante float32 en un entier non signé de 8 bits ou 4 bits, réduisant le stockage par 4x (SQ8) ou 8x (SQ4) avec une perte de précision minimale. La chaîne de fabrication "IVF100,SQ8" crée un index IVF avec quantification scalaire. SQ est plus rapide que PQ au moment de la requête car les calculs de distance sont effectués directement sur les valeurs quantifiées sans précalcul de table de correspondance. SQ8 stocke un octet par dimension ; SQ4 stocke deux dimensions par octet.
Indexation à l’Échelle du Milliard
Pour les ensembles de données à l’échelle du milliard, la configuration FAISS recommandée combine HNSW comme quantifieur grossier avec IVFPQ pour la compression vectorielle : quantizer = IndexHNSWFlat(d, hnsw_m); index = IndexIVFPQ(quantizer, d, nlist, M, nbits). Le quantifieur HNSW accélère la recherche de centroïdes par rapport à la recherche plate lors de l’interrogation, et PQ compresse les vecteurs de la base à une fraction de leur taille originale. L’article original sur FAISS (2017) a évalué la construction d’un graphe k-NN sur 95 millions d’images (provenant de l’ensemble de données YFCC100M) en 35 minutes sur GPU, et un graphe k-NN sur 1 milliard de vecteurs en moins de 12 heures sur 4 GPU Maxwell Titan X.
Recherche Distribuée avec IndexShards
FAISS IndexShards divise un grand ensemble de données entre plusieurs sous-index, chacun sur potentiellement différentes machines ou GPU. Chaque partition reçoit un sous-ensemble des vecteurs et traite les requêtes indépendamment. Les résultats sont fusionnés via un merge k-way des meilleurs résultats de chaque partition. Cette approche offre un passage à l’échelle linéaire avec le nombre de serveurs disponibles : doubler le nombre de partitions réduit de moitié le temps de recherche pour une taille d’ensemble de données fixe.
Index sur Disque
Pour les ensembles de données dépassant la RAM disponible, FAISS fournit des index sur disque qui maintiennent la structure de l’index (listes inversées ou graphe) en mémoire mais stockent les données vectorielles sur SSD. La classe IndexOnDisk et les utilitaires associés chargent de manière transparente les données vectorielles depuis le disque lors de la recherche, en utilisant des fichiers mappés en mémoire ou des opérations d’E/S explicites. Avec les SSD NVMe modernes offrant des vitesses de lecture séquentielle de 3 à 7 Go/s, la recherche sur disque peut approcher les performances en mémoire pour de nombreuses charges de travail, en particulier lorsque la localité spatiale (vecteurs voisins stockés de manière contiguë sur le disque) est maintenue.
Pour TarmacView, l’ensemble de référence actuel de 9K vecteurs est bien dans la plage optimale de FAISS pour la recherche exacte avec IndexFlatIP. Cependant, à mesure que le système s’étend pour inclure des images de référence de centaines d’aéroports et de multiples campagnes d’inspection — potentiellement jusqu’à des millions de plongements étiquetés — les mécanismes de passage à l’échelle de FAISS (IVF pour la recherche non exhaustive, PQ pour la compression, stockage sur disque pour les ensembles de données hors RAM) offrent une voie de mise à niveau claire sans nécessiter une architecture fondamentalement différente. Le type d’index peut être mis à niveau de IndexFlatIP → IndexIVFFlat → IndexIVFPQ → IndexShards(IndexIVFPQ) à mesure que l’ensemble de référence grandit, chaque étape échangeant une précision minimale contre des améliorations d’ordre de grandeur en vitesse de recherche et en efficacité mémoire.
La littérature FAISS (incluant l’article arXiv complet de 2024 « The Faiss Library » par Douze, Guzhva, Deng, Johnson, Szilvasy, Mazaré, Lomeli, Hosseini et Jégou) fournit des conseils détaillés sur la sélection d’index : « Il existe un choix entre une douzaine de types d’index, et le type optimal dépend généralement des contraintes du problème. » FAISS inclut également une suite de benchmarks complète (faiss_benchmarks) qui mesure le rappel et le débit à travers différentes configurations d’index, exécutant des recherches avec des résultats de vérité terrain provenant d’IndexFlat pour quantifier la précision. Les praticiens sont encouragés à évaluer leur propre distribution de données — l’index optimal pour un ensemble de données donné dépend de la dimensionnalité des vecteurs, de la taille de l’ensemble de données, du rappel cible, du budget de latence et de la mémoire disponible.
Questions Fréquemment Posées
FAISS (Facebook AI Similarity Search) est une bibliothèque open-source développée par l'équipe Fundamental AI Research (FAIR) de Meta pour la recherche de similarité efficace et le clustering de vecteurs denses. Elle fournit des implémentations de pointe d'algorithmes de recherche de plus proches voisins, incluant la recherche exhaustive exacte (IndexFlat), l'index à fichier inversé avec clustering k-means (IndexIVF), les graphes hiérarchiques navigables à petit monde (IndexHNSW) et la quantification produit (IndexIVFPQ), avec un support natif pour l'exécution sur CPU et GPU. La bibliothèque a été initialement rendue open-source en 2017 et a accumulé plus de 40 000 étoiles sur GitHub.
FAISS est une bibliothèque, pas un système de base de données complet. Il se concentre exclusivement sur la recherche vectorielle rapide sans stockage distribué intégré, réplication, opérations CRUD ou langages de requête. Les bases de données vectorielles comme Pinecone, Milvus, Qdrant et Weaviate s'appuient sur FAISS ou des moteurs similaires mais ajoutent la persistance, la scalabilité, le filtrage par métadonnées et des fonctionnalités de gestion. Les requêtes FAISS sont typiquement 10 à 100 fois plus rapides que les requêtes équivalentes sur base de données car il n'y a pas de surcharge réseau ni d'analyse de requête, ce qui le rend idéal lorsqu'on a besoin d'un composant de recherche léger et intégrable dans une application.
IndexFlatIP effectue une recherche exhaustive exacte avec le produit scalaire comme métrique de distance — il calcule les distances avec chaque vecteur de l'index, garantissant les plus proches voisins exacts avec une complexité O(N×D) par requête. IndexIVFFlat utilise le clustering k-means pour partitionner l'espace vectoriel en nlist cellules de Voronoï et ne recherche que les nprobe cellules les plus proches, échangeant un peu de précision (généralement 90–99 % de rappel) contre des gains de vitesse significatifs proportionnels à nlist/nprobe. IndexHNSWFlat construit un graphe hiérarchique multicouche inspiré des listes à saut qui permet une recherche en temps logarithmique O(log N), offrant d'excellents compromis vitesse-précision. HNSW atteint généralement un rappel plus élevé à vitesse de recherche équivalente par rapport à IVF sur des données de haute dimension.
FAISS ne possède pas de métrique cosinus native. À la place, la similarité cosinus est calculée en normalisant L2 tous les vecteurs à longueur unitaire, puis en utilisant le produit scalaire (METRIC_INNER_PRODUCT). Pour des vecteurs normalisés où ||a|| = ||b|| = 1, le produit scalaire est égal à la similarité cosinus : a·b = cos(θ). Cette approche est implémentée en enveloppant les vecteurs dans un IndexPreTransform qui applique une NormalizationTransform avant de les passer à un index utilisant le produit scalaire. La normalisation garantit que les comparaisons de similarité se concentrent sur l'alignement directionnel plutôt que sur la magnitude des vecteurs.
Oui. FAISS est couramment utilisé pour implémenter la classification par k-plus proches voisins (kNN) — une méthode non paramétrique qui classifie un point de requête en fonction de l'étiquette majoritaire parmi ses k plus proches voisins dans l'ensemble de référence. Le pipeline consiste à construire un ensemble de référence étiqueté, indexer les vecteurs de référence dans FAISS, soumettre les plongements de requête, récupérer les k plus proches voisins et effectuer un vote majoritaire (ou un vote pondéré par la distance) sur les étiquettes. Cette approche est utilisée par TarmacView pour la classification de la qualité de surface avec k=10 et un ensemble de référence d'environ 9 000 plongements étiquetés.
L'accélération GPU de FAISS exploite NVIDIA CUDA pour exécuter les opérations de construction d'index et de recherche sur GPU avec des implémentations natives pour IndexFlat, IndexIVF, IndexIVFPQ et les index à quantification scalaire. Elle offre une amélioration du débit de recherche de 5 à 10 fois par rapport au CPU pour les index IVF et HNSW typiques, une construction d'index jusqu'à 12 fois plus rapide pour les index IVF (le clustering k-means est hautement parallélisable) et un support natif pour les requêtes par lots. FAISS assure une interopérabilité transparente CPU-GPU via les fonctions index_cpu_to_gpu et index_gpu_to_cpu, permettant des workflows hybrides où les index sont construits sur GPU et déployés sur CPU.
Les index FAISS sont sérialisés à l'aide de write_index(index, filename) qui sauvegarde l'état complet de l'index, incluant tous les vecteurs, les centroïdes entraînés, la structure du graphe, la configuration de la métrique de distance et les paramètres internes dans un fichier binaire. La fonction read_index(filename) restaure l'index à son état pré-sérialisé, prêt pour une recherche immédiate sans entraînement supplémentaire. FAISS fournit également les fonctions serialize_index et deserialize_index pour la sérialisation en mémoire tampon. Les index GPU ne peuvent pas être sauvegardés directement sur disque — ils doivent d'abord être transférés vers le CPU via index_gpu_to_cpu.
TarmacView utilise FAISS pour stocker environ 9 000 plongements de référence étiquetés extraits d'un modèle Vision Transformer DINOv2. Chaque plongement de référence de 768 dimensions représente un type de surface connu ou un état de qualité de surface sur les chaussées aéroportuaires. Lorsqu'une nouvelle image d'inspection est collectée, son plongement est normalisé à longueur unitaire et interrogé dans l'index FAISS. Le système récupère les k=10 plus proches voisins en utilisant IndexHNSWFlat avec M=32 et efSearch=64 (>99 % de rappel en moins d'une milliseconde), puis effectue un vote majoritaire pour classer la qualité de surface. Si l'étiquette gagnante atteint moins de 60 % de consensus, l'image est signalée pour révision humaine.
FAISS supporte plus de vingt types d'index. Les plus utilisés sont IndexIVF (fichier inversé avec clustering k-means, paramétré par nlist et nprobe), IndexHNSW (graphe hiérarchique navigable à petit monde, paramétré par M, efConstruction et efSearch), IndexIVFPQ (fichier inversé avec quantification produit pour un stockage économique en mémoire à grande échelle), IndexIVFScalarQuantizer (quantification scalaire sur entiers 8 bits ou 4 bits), IndexLSH (hachage sensible à la localité pour données de faible dimension) et IndexBinary (pour la recherche vectorielle binaire). Des index composites combinant plusieurs techniques sont également disponibles.
La quantification produit (PQ) est une technique de compression avec pertes pour les vecteurs de haute dimension qui divise chaque vecteur en m sous-vecteurs et quantifie chaque sous-vecteur indépendamment à l'aide d'un dictionnaire appris par k-means. FAISS IndexIVFPQ combine IVF avec PQ, compressant chaque vecteur en m octets (avec des sous-quantifieurs 8 bits). Pour un vecteur de 128 dimensions, PQ avec m=64 réduit le stockage de 512 octets (float32) à 72 octets, frais généraux inclus — une réduction d'un facteur 7. PQ permet d'indexer des centaines de millions à des milliards de vecteurs sur un seul serveur, avec un calcul de distance effectué dans le domaine compressé grâce au calcul de distance asymétrique (ADC).
FAISS gère l'indexation à l'échelle du milliard grâce à une combinaison de compression vectorielle (quantification produit, quantification scalaire) et de recherche non exhaustive (IVF, HNSW, ou les deux combinés). La pile recommandée pour le milliard utilise HNSW comme quantifieur grossier pour un index IVFPQ : quantizer=IndexHNSWFlat, index=IndexIVFPQ(quantizer, d, nlist, M, nbits). Cette combinaison atteint des temps de recherche inférieurs à la seconde sur des ensembles de données à l'échelle du milliard. L'article original sur FAISS GPU (2017) a démontré un graphe k-NN sur 95 millions d'images construit en 35 minutes, et un graphe k-NN sur 1 milliard de vecteurs construit en moins de 12 heures sur 4 GPU Titan X.
Le contrat de plongement est l'accord implicite entre l'extracteur de plongements (généralement un réseau de neurones) et l'algorithme de recherche vectorielle. L'extracteur de plongements est entraîné pour que les distances entre plongements reflètent la similarité sémantique entre les entrées. L'index vectoriel effectue une recherche de voisins parmi les plongements aussi précisément que possible par rapport à la métrique de distance convenue (L2 ou produit scalaire/cosinus). Lors de l'utilisation de FAISS avec les plongements DINOv2 pour la classification de la qualité de surface, le contrat exige que les plongements de surfaces de chaussée visuellement similaires soient proches dans l'espace vectoriel, permettant à la recherche de plus proches voisins de fonctionner comme un mécanisme de classification fiable.
Optimisez Votre Infrastructure de Recherche Vectorielle
Tirez parti de FAISS pour une recherche de similarité haute performance sur vos données de plongements d'images. Contactez-nous pour découvrir comment TarmacView intègre FAISS pour la classification en temps réel de la qualité de surface et la récupération d'images d'inspection.
Transformateur de Vision DINOv3 pour l'Analyse des Surfaces d'Infrastructure
DINOv3 (self-DIstillation with NO labels v3) est un transformateur de vision (ViT-B/16) auto-supervisé, pré-entraîné sur 1,7 milliard d'images, produisant des p...
Détection de fissures par IA pour l'inspection des infrastructures
La détection de fissures par IA utilise la vision par ordinateur — réseaux de neurones convolutifs, vision transformers et modèles de segmentation sémantique — ...
Le test de fumée de la tête de défaut valide que le pipeline de détection des défauts structurels de TarmacView — backbone DINOv3 + tête MLP à 5 étiquettes pour...
44 min de lecture
testing
defect
+4
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.