La vérification human-in-the-loop (HITL) dans l’inspection automatisée combine des modèles de détection de défauts basés sur l’IA avec un examen humain obligatoire des anomalies signalées. L’algorithme d’IA traite l’imagerie et attribue des scores de confiance aux défauts détectés, orientant les détections à faible confiance vers des inspecteurs qualifiés pour la décision finale. Ce flux de travail semi-automatisé constitue la meilleure pratique actuelle pour l’inspection d’infrastructures critiques telles que les ponts, les chaussées, les pistes et les installations aéroportuaires.
Vérification Human-in-the-Loop (HITL) dans l’inspection automatisée
Définition et justification
Le Human-in-the-loop (HITL) est un paradigme architectural pour les systèmes semi-automatisés dans lequel un modèle d’apprentissage automatique effectue un premier passage de traitement sur les données, et un opérateur humain examine, valide ou corrige ensuite les sorties du modèle avant qu’elles ne soient acceptées comme définitives. Dans le contexte de l’inspection des infrastructures, le HITL fait spécifiquement référence aux flux de travail où un algorithme de détection de défauts basé sur l’IA traite l’imagerie haute résolution de ponts, chaussées, pistes ou installations aéroportuaires, attribue des scores de confiance à chaque anomalie détectée, puis oriente les détections à faible confiance ou ambiguës vers un inspecteur qualifié pour décision manuelle.
La justification fondamentale du HITL dans l’inspection découle des limites inhérentes aux modèles de vision par ordinateur actuels lorsqu’ils sont déployés dans des environnements critiques pour la sécurité. Les modèles d’apprentissage profond, y compris les réseaux de neurones convolutifs (CNN) et les transformateurs de vision, atteignent une haute précision sur les ensembles de données de référence mais peuvent échouer de manière imprévisible sur des cas limites — conditions d’éclairage inhabituelles, morphologies de fissures nouvelles, contaminants de surface imitant des motifs de défauts, ou occlusions par la végétation ou les débris. Une étude de 2024 de l’Université d’État du Michigan évaluant sept grands modèles de langage multimodaux pour l’évaluation de l’état des chaussées a révélé que, bien que des modèles comme GPT-4o aient atteint de bonnes performances sur l’identification standard des dégradations, tous les modèles ont montré une variabilité dans la reconnaissance des motifs spatiaux et les tâches d’évaluation de la sévérité nécessitant une compréhension contextuelle. L’architecture HITL reconnaît que pour les actifs d’infrastructure dont la défaillance peut entraîner des conséquences catastrophiques, l’efficacité de la machine doit être subordonnée au jugement humain au point de décision finale.
L’approche HITL répond également au déficit de responsabilité qui survient lorsque les décisions sont entièrement prises par des algorithmes. Dans les secteurs réglementés — aviation, infrastructures routières, installations nucléaires — les rapports d’inspection doivent porter la signature d’un professionnel certifié qui assume la responsabilité légale des résultats. L’Agence européenne de la sécurité aérienne (AESA) a publié des directives dans le cadre de sa Feuille de route sur l’IA stipulant que les applications d’IA à haut risque dans la maintenance aéronautique doivent inclure une « supervision humaine significative » avec « la capacité d’annuler ou de renverser les décisions ». De même, les National Bridge Inspection Standards (NBIS) de la Federal Highway Administration (FHWA) américaine exigent que les évaluations de l’état des ponts soient attribuées par un chef d’équipe répondant à des critères de qualification spécifiques, une exigence qui ne peut être déléguée à un logiciel.
Un rapport de 2024 des National Academies sur les applications de l’IA pour l’évaluation automatique de l’état des chaussées a souligné que « la vérification humaine des résultats de détection automatisée des dégradations est essentielle pour maintenir la qualité des données et garantir que les décisions de maintenance sont basées sur des évaluations fiables ». Le rapport a documenté que les agences déployant une évaluation entièrement automatisée des chaussées sans examen humain ont connu des taux d’erreur de 15 à 25 % sur les fissures de sévérité modérée, contre 3 à 8 % lorsqu’un humain examinait les résultats de l’IA.
Architecture HITL : de la détection par IA au rapport final
L’architecture HITL standard pour l’inspection des infrastructures suit un pipeline structuré en cinq étapes qui transforme les données brutes des capteurs en une évaluation de l’état vérifiée. Chaque étape a des exigences techniques spécifiques et des points de contrôle qualité.
Étape 1 : Acquisition de données
L’imagerie haute résolution est capturée à l’aide de véhicules aériens sans pilote (UAV) , de véhicules d’inspection équipés de caméras à balayage linéaire, ou de caméras fixes montées sur des portiques. Pour l’inspection des ponts, une mission UAV typique collecte 5 000 à 10 000 images à des résolutions de 20 à 50 mégapixels, avec des distances d’échantillonnage au sol (GSD) de 0,5 à 2 mm par pixel. Pour les relevés de chaussées, des véhicules spécialisés capturent des images en continu à vitesse autoroutière à l’aide de plusieurs caméras synchronisées couvrant une largeur de voie de 4 mètres. La phase d’acquisition de données doit inclure un contrôle qualité rigoureux — détection de flou, validation de l’exposition et vérification du géoréférencement — car la performance en aval de l’IA est limitée par la qualité des données d’entrée.
Étape 2 : Moteur d’inférence IA
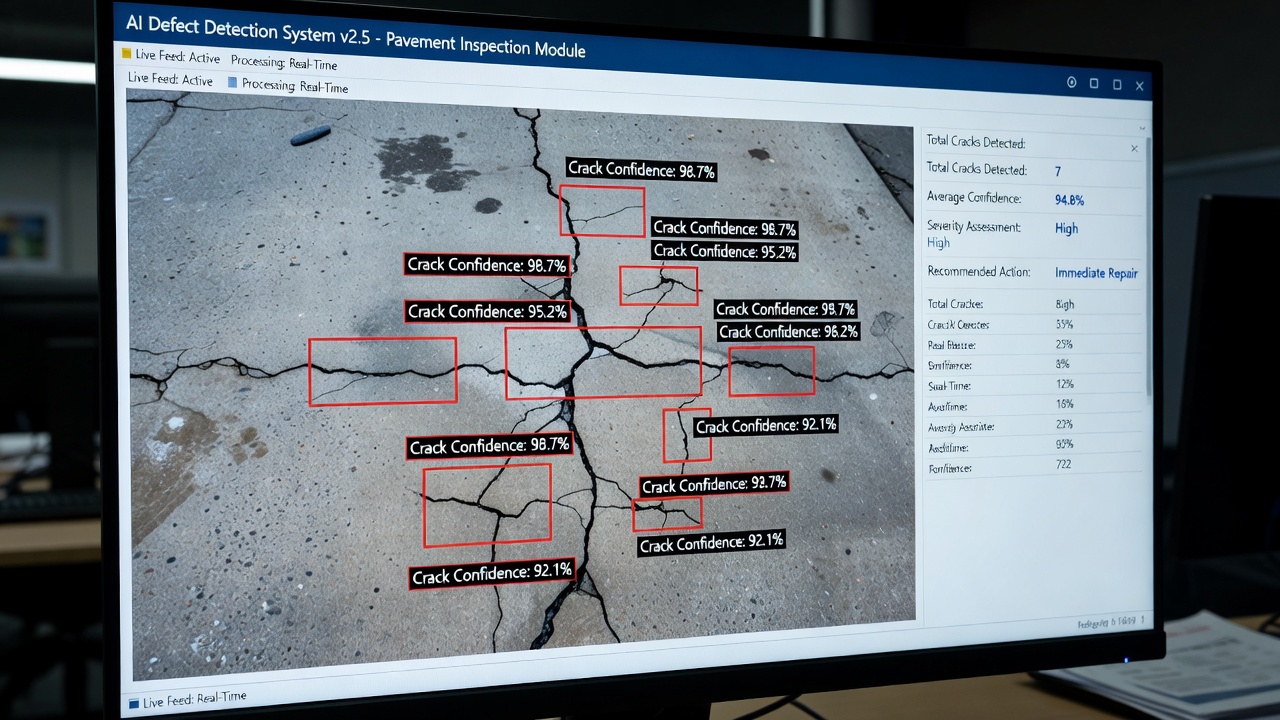
L’imagerie acquise est traitée par un moteur d’inférence d’apprentissage profond, généralement basé sur une architecture CNN telle que YOLOv8, Faster R-CNN ou une variante U-Net pour la segmentation sémantique. Le modèle effectue une détection au niveau du pixel ou par boîte englobante des classes de défauts prédéfinies. Pour l’inspection des ponts, ces classes incluent généralement les fissures (fissuration en carte, longitudinale, diagonale, transversale), les éclats, la délamination, les taches de corrosion, les armatures exposées et les dommages aux joints. Pour l’inspection des chaussées, les classes incluent la fissuration par fatigue, la fissuration en blocs, la fissuration de rive, l’orniérage, le désenrobage, les nids-de-poule et le rebouchage.
Chaque détection est accompagnée d’un score de confiance allant de 0,0 à 1,0, représentant l’estimation par le modèle de la probabilité que la détection soit un vrai positif. Le moteur d’inférence produit également des métadonnées incluant les coordonnées de détection dans l’espace image, les dimensions du défaut en pixels (ou en unités physiques si les données d’étalonnage sont disponibles) et l’étiquette de classification.
Étape 3 : Routage basé sur la confiance
Les sorties de l’IA sont traitées par un module de routage qui applique des seuils de confiance configurables pour trier les détections. La logique de routage utilise généralement un système à deux seuils :
Plage de confiance
Décision de routage
Justification
0,95 – 1,00
Acceptation automatique
Vrais positifs à haute confiance ; risque minimal de faux positifs
0,50 – 0,95
Orientation vers examen humain
Détections ambiguës nécessitant un jugement expert
0,00 – 0,50
Rejet automatique
Faux positifs à haute confiance ; filtrés comme bruit
Les valeurs des seuils sont spécifiques au site et ajustables. Une inspection de pont sur un élément critique en fracture (FCM) peut abaisser le seuil d’examen à 0,70 pour garantir que tous les défauts potentiellement significatifs soient examinés par un humain. Un relevé de chaussée sur une route rurale à faible volume peut relever le seuil à 0,90, acceptant un taux de faux négatifs légèrement plus élevé en échange d’une charge de travail d’examen réduite.
Étape 4 : Interface d’examen humain
Les détections signalées sont présentées à un inspecteur qualifié via une interface d’examen spécialisée. L’interface affiche généralement le défaut détecté avec la boîte englobante ou la superposition de segmentation générée par l’IA, le score de confiance, la classification du défaut et des informations contextuelles telles que l’identifiant de l’actif (numéro de pont, section de chaussée), les coordonnées de localisation et les données d’inspection historiques si disponibles.
L’inspecteur dispose de trois actions possibles pour chaque détection signalée :
Confirmer — Accepter la prédiction de l’IA comme correcte ; la détection fait partie du rapport final
Rejeter — Écarter la détection comme faux positif
Corriger — Modifier la prédiction de l’IA en ajustant la boîte englobante, en changeant la classification ou en mettant à jour l’évaluation de sévérité
Les interfaces d’examen modernes intègrent des raccourcis clavier et des opérations par lots pour accélérer le processus d’examen. Un inspecteur expérimenté peut examiner 200 à 500 défauts signalés par heure, selon la densité des défauts et la complexité des images. La session d’examen produit une piste d’audit documentant chaque action de l’inspecteur, ce qui est essentiel pour l’assurance qualité et la conformité réglementaire.
Étape 5 : Génération du rapport final
Le rapport d’état final intègre les détections à haute confiance automatiquement acceptées avec les détections signalées vérifiées par l’humain. Le rapport calcule des métriques agrégées telles que la densité de défauts (pourcentage de surface affectée par chaque type de défaut), l’indice de condition de chaussée (PCI) pour les aérodromes ou les routes, ou les évaluations de l’état des éléments pour les ponts selon le cadre d’inspection par éléments de l’AASHTO.
Seuils de confiance pour le signalement
Les seuils de confiance sont les paramètres de réglage critiques qui déterminent l’efficacité opérationnelle et la marge de sécurité de tout système d’inspection HITL. Définir des seuils trop agressifs (accepter des prédictions à faible confiance) augmente le risque de faux négatifs — des défauts manqués qui pourraient compromettre l’intégrité structurelle. Définir des seuils trop conservateurs (tout orienter vers l’examen humain) annule l’efficacité de l’automatisation.
La courbe ROC (Receiver Operating Characteristic) du modèle d’IA fournit la base analytique pour la sélection des seuils. La courbe ROC trace le taux de vrais positifs (sensibilité) par rapport au taux de faux positifs pour chaque valeur de seuil possible. L’aire sous la courbe ROC (AUC) résume la capacité discriminatoire globale du modèle. Un modèle avec une AUC de 0,95 ou plus sur des données de test représentatives est généralement considéré comme adapté au déploiement HITL.
Les bonnes pratiques industrielles recommandent de calibrer les seuils à l’aide d’une matrice de coûts qui attribue des pondérations monétaires ou basées sur le risque à chaque type d’erreur :
Type d’erreur
Conséquence
Coût relatif
Faux négatif (fissure critique manquée)
Défaillance structurelle potentielle, danger pour la sécurité
Le processus de calibrage des seuils implique généralement de faire fonctionner le modèle d’IA sur un ensemble de données de validation d’au moins 5 000 à 10 000 images qui ont été étiquetées indépendamment par des inspecteurs certifiés. Les détections du modèle sont comparées aux étiquettes de vérité terrain, et le seuil est ajusté pour atteindre un taux de faux négatifs cible — généralement 1 à 2 % pour les éléments de pont critiques en fracture et 5 à 8 % pour les relevés de chaussées généraux.
Le seuillage dynamique est une pratique émergente où les seuils sont ajustés en temps réel en fonction des conditions environnementales, des métriques de qualité d’image ou de la criticité de l’actif. Par exemple, si le véhicule d’inspection rencontre de fortes pluies ou des conditions de faible luminosité qui dégradent la qualité de l’image, le système abaisse automatiquement son seuil de confiance pour orienter davantage de détections vers l’examen humain, compensant ainsi l’incertitude plus élevée dans les prédictions du modèle.
Interfaces d’examen et flux de travail
L’interface d’examen humain est la pièce maîtresse opérationnelle d’un système d’inspection HITL. Sa conception impacte directement à la fois la rapidité et la précision du processus de vérification. Des interfaces mal conçues induisent la fatigue de l’opérateur, augmentent les taux d’erreur et créent des goulots d’étranglement qui annulent les gains de productivité de l’automatisation par IA.
Les interfaces d’examen efficaces intègrent plusieurs principes de conception clés :
Affichage parallèle de la sortie IA et de l’image source. L’interface doit superposer la détection de l’IA (boîte englobante, masque de segmentation ou carte de chaleur) sur l’image originale, avec des commandes pour activer ou désactiver la superposition. Cela permet à l’inspecteur de voir précisément ce que le modèle a détecté tout en conservant la possibilité d’inspecter l’image brute pour les défauts manqués.
Aides à la navigation contextuelle. L’interface doit fournir un système de navigation au niveau du défaut (précédent/suivant parmi les détections signalées) intégré à une navigation au niveau de l’actif (par exemple, sélecteur d’élément de pont ou carte de section de chaussée). La plateforme Twinsight Twinspect, démontrée dans une preuve de concept de 2025 avec Die Autobahn GmbH sur des ponts autoroutiers allemands, a implémenté une vue consolidée où les dommages apparaissant dans plusieurs images sont fusionnés en enregistrements de défauts uniques, réduisant la redondance et accélérant l’examen par l’inspecteur de plus de 600 anomalies détectées par IA.
Visualisation du score de confiance. Chaque détection doit afficher son score de confiance numériquement et visuellement — généralement sous forme de badge coloré (vert pour confiance élevée, jaune pour moyenne, rouge pour faible). Cela aide l’inspecteur à prioriser l’attention sur les détections les plus incertaines en premier, un flux de travail connu sous le nom d’examen guidé par l’incertitude.
Enregistrement de la piste d’audit. Chaque action entreprise par l’inspecteur — confirmer, rejeter, corriger, passer — doit être horodatée, identifiée par utilisateur et enregistrée dans une piste d’audit immuable. Ce n’est pas facultatif ; c’est une exigence réglementaire pour toute donnée d’inspection qui alimente les systèmes de gestion de la sécurité ou les rapports de conformité.
Confirmation par lots pour l’examen à grand volume. Pour les inspections avec des milliers de détections signalées, l’interface doit prendre en charge la sélection par lots et la confirmation groupée de détections similaires à faible risque. Un inspecteur examinant des fissures de chaussée sur une section d’autoroute de 10 km peut rencontrer des centaines de fissures transversales identiques ; le regroupement de celles-ci en une seule action de confirmation réduit considérablement le temps d’examen.
La séquence du flux de travail d’examen suit généralement cet ordre :
L’inspecteur se connecte à la plateforme HITL et charge la mission d’inspection
Le système affiche un tableau de bord montrant le total des détections signalées pour examen, réparties par type de défaut et bande de confiance
L’inspecteur commence à examiner les détections, en commençant par les éléments à la plus faible confiance
Pour chaque détection, l’inspecteur examine la superposition IA par rapport à l’image brute et prend une décision de confirmation/rejet/correction
Le système passe automatiquement à la détection suivante
À la fin, le système génère un résumé de vérification montrant le ratio des détections confirmées, rejetées et corrigées
Les détections vérifiées sont fusionnées avec les détections automatiquement acceptées dans le rapport final
Correction humaine des prédictions de l’IA
La correction humaine des prédictions de l’IA est l’une des fonctions les plus précieuses d’un système HITL. Lorsqu’un inspecteur corrige une sortie de l’IA — en ajustant une boîte englobante mal placée, en reclassifiant un type de défaut mal identifié ou en mettant à jour une évaluation de sévérité — le système capture non seulement la sortie corrigée, mais aussi la différence entre la prédiction de l’IA et la vérité terrain humaine. Cette différence est le signal qui pilote l’amélioration du modèle grâce à l’apprentissage actif.
Les types de correction courants dans l’inspection des infrastructures incluent :
Ajustement de la boîte englobante. L’IA peut correctement identifier qu’un défaut existe mais placer la boîte englobante de manière inexacte — soit trop serrée (coupant une partie de la fissure) soit trop lâche (incluant une surface non défectueuse). L’inspecteur ajuste la boîte pour enfermer précisément le défaut, et le système enregistre l’IoU (Intersection over Union) entre la prédiction de l’IA et la correction humaine. Des scores IoU faibles et répétés sur des classes de défauts spécifiques signalent la nécessité de réentraîner le modèle avec de meilleurs exemples de localisation.
Correction de classification. L’IA peut détecter une fissure mais la classer comme « transversale » alors qu’elle est en réalité « longitudinale ». Cette erreur de classification a des conséquences sur l’évaluation de l’état, car différents types de fissures correspondent à différentes matrices de sévérité dans les systèmes de gestion des chaussées (par exemple, ASTM D6433 pour le calcul du PCI). L’inspecteur corrige l’étiquette, et le système enregistre l’entrée de la matrice de confusion, constituant un ensemble de cas de classification difficiles.
Reclassification de sévérité. De nombreux protocoles d’évaluation de l’état exigent des évaluations de sévérité (faible, moyenne, élevée, ou une échelle numérique) basées sur les dimensions du défaut. L’IA peut correctement identifier et localiser une fissure mais mal estimer sa largeur ou sa longueur, conduisant à une attribution de sévérité incorrecte. L’inspecteur corrige la sévérité, et le système enregistre l’écart de mesure.
Rejet de faux positif. L’action la plus courante de l’inspecteur pour les détections à faible confiance est le rejet — l’IA a signalé une caractéristique de surface (tache d’huile, ombre, marque de pneu, joint) qui n’est pas un défaut. Chaque rejet est un exemple de faux positif étiqueté qui améliore la capacité de discrimination du modèle.
Une étude de preuve de concept de 2025 menée par Twinsight en coopération avec Die Autobahn GmbH a démontré l’impact pratique de la correction humaine. Le modèle d’IA a initialement détecté 600 anomalies sur un pont autoroutier allemand, dont 176 étaient des fissures confirmées par des ingénieurs en structures. Grâce au processus d’examen HITL, les inspecteurs ont corrigé les classifications de l’IA, affiné les boîtes englobantes et rejeté les faux positifs. Le nombre final vérifié de 156 fissures confirmées a donné un taux de précision de 88,6 %, qui est passé à plus de 95 % après que les données de correction ont été utilisées pour le réglage fin du modèle.
Apprentissage actif à partir du retour humain
L’intégration du HITL avec l’apprentissage actif crée un cycle d’amélioration continue qui réduit progressivement la charge d’examen humain au fil du temps. L’apprentissage actif est une stratégie d’apprentissage automatique où l’algorithme identifie quels points de données non étiquetés seraient les plus informatifs pour améliorer les performances du modèle et demande des étiquettes pour ces points spécifiques à un annotateur humain.
Dans le contexte de l’inspection HITL, l’apprentissage actif fonctionne comme suit :
Le modèle d’IA traite de nouvelles images d’inspection et génère des prédictions avec des scores de confiance
Le système identifie les détections présentant la plus grande incertitude — celles les plus proches de la frontière de décision entre vrai positif et faux positif
Ces détections incertaines sont orientées vers l’inspecteur humain pour vérification
Les étiquettes confirmées ou corrigées par l’inspecteur deviennent des données d’entraînement pour la prochaine mise à jour du modèle
Le modèle est réentraîné ou affiné sur l’ensemble de données élargi, améliorant sa précision sur les cas auparavant incertains
Au fil des cycles d’inspection, le nombre de détections nécessitant un examen humain diminue
La stratégie de requête pour sélectionner les détections à orienter vers l’étiquetage humain est essentielle. Les stratégies courantes incluent :
Échantillonnage par moindre confiance : Orienter les détections dont les scores de confiance sont les plus proches du seuil de décision (par exemple, 0,45–0,55)
Échantillonnage par marge : Orienter les détections où la différence entre les deux probabilités de classe les plus élevées est la plus faible
Échantillonnage par entropie : Orienter les détections avec l’entropie de prédiction la plus élevée, indiquant que le modèle est le plus incertain quant à la classification
Une étude publiée dans Automation in Construction évaluant les systèmes HITL activés par l’automatisation pour l’inspection visuelle des infrastructures a révélé que l’apprentissage actif réduisait la charge de travail d’étiquetage humain de 60 à 75 % par rapport à l’échantillonnage aléatoire tout en maintenant une précision équivalente du modèle. L’étude a documenté qu’après cinq cycles d’apprentissage actif sur un ensemble de données de détection de fissures, le modèle a atteint une précision de 94,7 % avec seulement 30 % des données d’entraînement nécessitant un examen humain.
La mise en œuvre de l’apprentissage actif dans les systèmes HITL de production nécessite une gestion versionnée des modèles. Chaque cycle de réentraînement produit une nouvelle version du modèle qui doit être validée sur un ensemble de test réservé avant le déploiement. Le système doit également prendre en charge les tests A/B — exécuter le nouveau modèle en mode furtif parallèlement au modèle de production actuel pour vérifier que les améliorations de performance se généralisent aux nouvelles données d’inspection avant de valider la mise à jour.
HITL pour l’inspection des ponts
L’inspection des ponts est l’application la plus critique pour la sécurité de la technologie HITL dans les infrastructures. Les États-Unis comptent plus de 617 000 ponts, dont environ 42 % ont plus de 50 ans et 7,5 % sont classés comme structurellement déficients selon le bulletin 2024 de l’American Society of Civil Engineers (ASCE) sur l’état des infrastructures. Les National Bridge Inspection Standards (NBIS) codifiées dans le 23 CFR 650 exigent que tous les ponts sur les voies publiques soient inspectés à des intervalles ne dépassant pas 24 mois par des chefs d’équipe qualifiés.
La documentation de la FHWA souligne que la vérification humaine est non négociable pour les évaluations de l’état attribuées dans le cadre des NBIS. Les échelles d’évaluation de l’état des éléments de pont (0–9 pour le tablier, la superstructure et l’infrastructure selon le guide de codage du National Bridge Inventory) exigent que l’inspecteur synthétise plusieurs conditions observables en une seule évaluation numérique — une tâche que les systèmes d’IA actuels ne peuvent pas effectuer de manière fiable car elle nécessite une compréhension des chemins de charge structurels, du comportement des matériaux et des mécanismes de détérioration.
Le flux de travail HITL pour l’inspection des ponts intègre plusieurs sources de données :
L’imagerie UAV fournit des données visuelles haute résolution de toutes les surfaces accessibles du pont — tablier, intrados, poutres, piles, culées, appareils d’appui et joints. Une inspection UAV typique de pont collecte 3 000 à 8 000 images par structure, selon la taille et la complexité du pont. Le moteur d’inférence IA traite ces images pour détecter les fissures, les éclats, la corrosion et autres défauts visibles.
Les données de radar à pénétration de sol (GPR) sont utilisées parallèlement à l’imagerie visuelle pour la détection de délamination du tablier et l’évaluation de la corrosion des armatures. Bien que l’interprétation du signal GPR nécessite une expertise spécialisée, les modèles d’IA peuvent signaler des motifs de signal anormaux pour examen humain.
Le rôle de l’inspecteur dans le système HITL n’est pas simplement de confirmer ou de rejeter les prédictions de l’IA, mais d’ajouter un jugement d’ingénierie structurelle que l’IA ne peut pas fournir. L’inspecteur examine les détections signalées dans le contexte de la charge nominale connue du pont, du volume de trafic, de l’exposition environnementale et de l’historique d’inspection. Une fissure capillaire dans l’âme d’une poutre en béton précontraint peut être immédiatement signalée pour réparation urgente, tandis qu’une fissure identique dans un élément de diaphragme secondaire peut être évaluée comme une observation mineure — une distinction qui dépend des connaissances en ingénierie structurelle, et non de la reconnaissance de motifs au niveau du pixel.
Le cadre recommandé par la FHWA pour un programme d’assurance qualité/contrôle qualité de l’inspection des ponts, mis à jour en 2024, aborde explicitement l’intégration des technologies d’inspection automatisées. Le cadre exige que tout système automatisé de détection de fissures soit validé par rapport à une inspection manuelle sur au moins 10 % des éléments du pont, les résultats de validation étant documentés et examinés par le chef d’équipe d’inspection. Cette approche de double validation est un processus HITL formalisé qui garantit que l’automatisation sert d’outil d’aide à la décision plutôt que de remplacement du jugement professionnel.
HITL pour l’inspection des chaussées
L’évaluation de l’état des chaussées a été une adoptrice précoce de la technologie d’inspection automatisée en raison des volumes de données élevés impliqués — une seule agence autoroutière peut gérer 10 000 à 50 000 km-voies de chaussée, avec des intervalles d’inspection de 1 à 3 ans. Les relevés visuels manuels à cette échelle sont prohibitifs en termes de coût, nécessitant 30 à 50 jours-personne pour 100 km-voies. Les méthodes assistées par IA peuvent traiter le même réseau en 5 à 10 heures de temps de calcul, mais les résultats doivent être vérifiés par des inspecteurs humains avant de pouvoir être utilisés pour les décisions de programmation de maintenance.
Le flux de travail HITL pour l’inspection des chaussées utilise généralement des caméras à balayage linéaire montées sur des véhicules de relevé circulant à vitesse autoroutière (80–100 km/h), capturant une imagerie continue à 360 degrés de la surface de la chaussée. Les images sont géoréférencées à l’aide de systèmes GPS/IMU d’une précision de 10 à 50 cm. Le modèle d’IA segmente la surface de la chaussée en catégories de défauts et calcule des métriques de densité de dégradation.
Les directives de l’American Association of State Highway and Transportation Officials (AASHTO) pour la collecte de données sur l’état des chaussées reconnaissent le rôle des systèmes automatisés tout en maintenant des exigences de vérification humaine. La norme AASHTO PP 89-21 pour la collecte automatisée de données sur les dégradations des chaussées spécifie des procédures d’assurance qualité incluant :
Vérification sur le terrain : Un minimum de 5 % des sections de relevé doit être vérifié par inspection manuelle dans les 30 jours suivant le relevé automatisé
Test de répétabilité : Le système automatisé doit démontrer une répétabilité de ±5 % sur les quantités de dégradation lors du resurveyage de la même section dans les 24 heures
Examen humain des cas limites : Toutes les sections avec des quantités de dégradation dépassant des seuils prédéfinis (par exemple, >20 % de surface fissurée) doivent être examinées manuellement
L’interface d’examen HITL pour l’inspection des chaussées présente généralement une vue en bande continue montrant la surface de la chaussée avec les défauts détectés par l’IA, codés par couleur selon le type et la sévérité. L’inspecteur parcourt l’imagerie continue de la chaussée, examinant les sections signalées et vérifiant l’évaluation de l’état par l’IA. Pour les agences utilisant la méthodologie de l’indice de condition de chaussée (PCI) selon ASTM D6433, le système HITL calcule les valeurs PCI à partir des données de défauts vérifiées, l’inspecteur acceptant ou annulant la valeur calculée en fonction de sa connaissance du terrain.
Une étude de 2025 des National Academies sur les applications de l’IA pour l’évaluation automatique de l’état des chaussées a révélé que les systèmes HITL atteignaient un taux de concordance de 92 à 96 % avec l’inspection manuelle sur l’identification des dégradations, contre 78 à 85 % pour les systèmes entièrement automatisés sans examen humain. L’étude a également constaté que le HITL réduisait le temps d’inspection de 55 à 70 % par rapport aux méthodes purement manuelles tout en maintenant la conformité aux normes de qualité des données de l’AASHTO.
Acceptation réglementaire du HITL
Le paysage réglementaire pour l’IA dans l’inspection des infrastructures évolue rapidement, mais le thème constant dans tous les grands cadres est que la supervision humaine est obligatoire pour les décisions liées à la sécurité.
Organisation de l’aviation civile internationale (OACI) — Selon l’Annexe 14 de l’OACI, Volume I (Conception et exploitation des aérodromes), l’exploitant d’aérodrome est responsable de veiller à ce que les pistes, les voies de circulation et les surfaces d’aires de trafic soient maintenues dans un état acceptable pour les opérations aériennes. Bien que l’OACI n’interdise pas explicitement l’inspection automatisée, l’exigence selon laquelle « l’exploitant d’aérodrome doit établir un programme d’inspection » qui soit « acceptable pour l’État » implique implicitement que les évaluations de l’état doivent être effectuées ou vérifiées par du personnel compétent. Le Document OACI 9157 (Manuel de conception des aérodromes) fait référence à la méthodologie de l’indice de condition de chaussée (PCI), qui nécessite une inspection visuelle par des évaluateurs formés, sauf si l’État approuve une procédure alternative.
Agence européenne de la sécurité aérienne (AESA) — La Feuille de route IA 2.0 de l’AESA, publiée en 2024, établit une approche par niveaux pour l’IA dans l’aviation. Sous le Niveau 2 (« Collaboration Humain-IA »), qui couvre l’inspection assistée par IA, l’agence exige : (a) que l’humain conserve l’autorité décisionnelle finale, (b) que le système d’IA fournisse des explications pour ses sorties, et (c) que le système puisse être annulé ou désengagé à tout moment par l’opérateur humain. Ces exigences correspondent directement à l’architecture HITL.
Federal Aviation Administration (FAA) — La Circulaire consultative AC 150/5380-6C de la FAA sur les « Lignes directrices pour les programmes de gestion des chaussées » stipule que les méthodes automatisées de collecte de données sont acceptables à condition que « l’équipement de collecte de données soit certifié et que les données soient validées par un ingénieur expérimenté en évaluation des chaussées ». Cette double exigence — certification de l’équipement plus validation humaine — est un mandat HITL formel.
Federal Highway Administration (FHWA) — Les NBIS de la FHWA (23 CFR 650 Sous-partie C) exigent que toutes les inspections de ponts soient effectuées par ou sous la direction d’un chef d’équipe répondant à des exigences de qualification spécifiques (ingénieur professionnel ou inspecteur de ponts certifié avec des seuils d’expérience minimaux). Bien que la collecte automatisée de données soit autorisée, l’évaluation de l’état doit être déterminée par le chef d’équipe. Les directives 2024 de la FHWA sur le processus d’examen des NBIS confirment que « les technologies d’inspection automatisées complètent mais ne remplacent pas le jugement professionnel du chef d’équipe ».
ISO 55001 (Gestion d’actifs) — La norme internationale pour la gestion d’actifs exige que les données sur l’état utilisées pour la prise de décision soient fiables, reproductibles et vérifiables. Les flux de travail HITL satisfont à ces exigences en maintenant la vérification humaine comme dernier contrôle qualité.
L’implication pratique de cet environnement réglementaire est que le HITL n’est pas simplement une préférence technique pour l’inspection des infrastructures — c’est une exigence de conformité. Toute organisation déployant l’IA pour l’inspection d’actifs aéronautiques, routiers ou structurels doit mettre en œuvre un processus d’examen humain pour satisfaire aux obligations réglementaires. L’architecture exacte peut varier — certaines agences exigent un examen humain à 100 % de toutes les détections, tandis que d’autres acceptent un échantillonnage statistique — mais le principe de la vérification humaine est universel.
Entièrement automatisé vs HITL
La distinction entre l’inspection entièrement automatisée et l’inspection human-in-the-loop est fondamentale pour comprendre les décisions de déploiement dans la gestion des actifs d’infrastructure. Chaque approche a des caractéristiques, avantages et limitations distincts :
Dimension
Entièrement automatisé
Human-in-the-Loop
Autorité décisionnelle
Modèle d’IA
Inspecteur humain
Débit
Très élevé (100 000+ images/heure)
Modéré (200–500 éléments signalés/heure)
Gestion des cas limites
Médiocre — le modèle échoue sur les nouveaux motifs
Bonne — l’humain s’adapte aux situations nouvelles
Responsabilité
Diffuse — aucune entité responsable unique
Claire — l’inspecteur certifié assume la responsabilité
Conformité réglementaire
Limitée — la plupart des normes exigent une approbation humaine
Établie — satisfait aux cadres réglementaires existants
Amélioration continue
Nécessite un pipeline de données séparé
Intégrée via l’apprentissage actif
Coût par inspection
Faible après déploiement initial
Plus élevé en raison du travail humain
Taux de faux négatifs
10–25 % sur les défauts ambigus
2–5 % après examen humain
Adapté pour
Actifs à faible risque, tri initial, grand volume
Actifs critiques pour la sécurité, évaluation finale d’état, réglementé
La décision entre un déploiement entièrement automatisé et HITL dépend de la catégorie de risque de l’actif inspecté. Les actifs à faible risque — comme les routes secondaires, les éléments de construction non structurels et les conditions de surface esthétiques — peuvent être candidats à une inspection entièrement automatisée où le coût des faux négatifs est acceptable. Les actifs critiques pour la sécurité — ponts, pistes, tunnels, barrages et autoroutes à fort trafic — nécessitent le HITL car la conséquence d’un défaut critique manqué est inacceptable.
Une enquête de 2024 auprès de 47 Départements des Transports d’États américains a révélé que 93 % des agences utilisant la collecte automatisée de données sur les chaussées employaient une forme de vérification humaine, allant de l’échantillonnage aléatoire (10 % des sections) à l’examen complet de toutes les sections signalées comme déficientes. Seulement 7 % acceptaient les données automatisées sans aucune vérification humaine, et ces agences limitaient l’acceptation entièrement automatisée aux routes locales à faible volume en bon état. Pour l’inspection des ponts, la même enquête a révélé que 100 % des agences maintenaient des exigences de vérification humaine, l’approche la plus courante étant l’examen humain de toutes les anomalies détectées par l’IA combiné à une vérification ponctuelle aléatoire de 15 à 20 % des images classées comme sans défaut.
La tendance opérationnelle est vers des modèles hybrides qui ajustent le degré d’automatisation en fonction de l’état de l’actif. Un pont en bon état (évaluation NBI 7–9) peut être traité avec des seuils d’acceptation automatique à haute confiance et un examen humain minimal, tandis qu’un pont en mauvais état (évaluation NBI 3–4) peut voir toutes ses détections orientées vers un examen humain, quel que soit le score de confiance. Cette approche HITL adaptative au risque optimise l’effort de l’inspecteur en allouant l’attention aux actifs où elle apporte le plus grand bénéfice en matière de sécurité.
Conclusion
La vérification human-in-the-loop représente l’état de l’art actuel dans l’inspection automatisée des infrastructures. L’architecture HITL — combinant la détection initiale basée sur l’IA avec un routage basé sur la confiance et un examen humain obligatoire — offre les avantages de productivité de l’automatisation tout en maintenant la responsabilité sécuritaire et le jugement professionnel exigés par les normes réglementaires. Le calibrage des seuils, la conception de l’interface d’examen, les flux de travail de correction humaine et l’intégration de l’apprentissage actif sont les éléments techniques qui déterminent si un système HITL fonctionne efficacement en pratique.
Pour l’inspection des ponts, l’évaluation de l’état des chaussées, l’évaluation des pistes aéroportuaires et la conformité de maintenance des aérodromes, le HITL n’est pas une approche transitoire sur la voie de la pleine autonomie — c’est la meilleure pratique démontrée qui équilibre les forces complémentaires des machines et des humains. À mesure que la précision des modèles d’IA continue de s’améliorer, la charge d’examen humain diminuera grâce à l’apprentissage actif, mais le principe de la vérification humaine pour les décisions critiques pour la sécurité restera une exigence réglementaire et éthique.
Questions Fréquemment Posées
Le human-in-the-loop (HITL) dans l'inspection automatisée est un flux de travail semi-automatisé où un modèle d'IA effectue une détection initiale des défauts sur l'imagerie d'inspection et attribue des scores de confiance à chaque détection. Les anomalies se situant en dessous d'un seuil de confiance prédéfini sont orientées vers un inspecteur humain qualifié pour examen, vérification et décision finale. Cette approche combine la rapidité de traitement et la cohérence de la vision machine avec le jugement contextuel, la responsabilité sécuritaire et la conformité réglementaire que seuls les inspecteurs humains certifiés peuvent fournir.
Les seuils de confiance dans les systèmes HITL définissent la frontière entre l'acceptation automatisée et l'examen humain. Les détections avec des scores de confiance supérieurs à un seuil élevé (par exemple >0,95) sont automatiquement acceptées comme vrais positifs. Les détections en dessous d'un seuil bas (par exemple <0,50) sont automatiquement rejetées comme bruit. Les détections dans la bande intermédiaire sont signalées pour examen humain. Les valeurs des seuils sont calibrées en fonction de la criticité de l'actif, des exigences réglementaires et du coût des faux négatifs par rapport aux faux positifs.
L'architecture HITL pour l'inspection des infrastructures suit un pipeline en cinq étapes : (1) acquisition de données via drones, véhicules d'inspection ou caméras fixes, (2) inférence IA où les modèles de vision par ordinateur détectent et classifient les défauts avec des scores de confiance, (3) routage basé sur la confiance qui sépare les détections à haute confiance des détections ambiguës, (4) interface d'examen humain où les inspecteurs examinent les images signalées et confirment, rejettent ou corrigent les prédictions de l'IA, et (5) génération du rapport final qui intègre à la fois les résultats automatisés et ceux vérifiés par l'humain.
L'inspection entièrement automatisée repose entièrement sur l'IA pour détecter, classifier et signaler les défauts sans intervention humaine. L'inspection HITL utilise l'IA pour le tri initial mais exige qu'un inspecteur humain vérifie et tranche les résultats avant qu'ils ne fassent partie du dossier officiel. Le HITL est préféré pour les infrastructures critiques car il préserve la responsabilité humaine, gère les cas limites que l'IA pourrait mal classifier et satisfait aux exigences réglementaires imposant la signature d'un inspecteur certifié sur les rapports d'inspection.
Selon l'Annexe 14 de l'OACI et les cadres de certification des aérodromes associés, les rapports d'inspection des infrastructures aéroportuaires critiques pour la sécurité doivent être approuvés par du personnel qualifié. Bien que les outils assistés par IA soient autorisés pour la collecte de données et l'analyse préliminaire, l'évaluation finale de l'état et la classification des défauts doivent impliquer une vérification humaine. L'Agence européenne de la sécurité aérienne (AESA) et la Federal Aviation Administration (FAA) ont publié des directives sur l'utilisation de l'IA dans la maintenance aéronautique qui exigent une supervision humaine significative pour les décisions liées à la sécurité.
L'apprentissage actif dans les systèmes HITL sélectionne les détections les plus incertaines de l'IA pour examen humain, puis utilise les étiquettes confirmées ou corrigées par l'inspecteur comme données d'entraînement pour améliorer le modèle. Au fil des cycles d'inspection successifs, cela réduit le nombre de détections nécessitant un examen humain. Des études ont montré que l'apprentissage actif réduit la charge de travail d'étiquetage humain de 60 à 75 % tout en maintenant une précision équivalente du modèle.
Améliorez vos flux d'inspection avec le HITL
Mettez en œuvre des processus de vérification human-in-the-loop qui combinent la rapidité de la détection de défauts par IA avec la responsabilité de l'examen par un inspecteur certifié. Contactez-nous pour découvrir comment nos solutions s'intègrent dans les flux de travail HITL pour l'inspection des ponts, des chaussées et des aérodromes.
Détection de fissures par IA pour l'inspection des infrastructures
La détection de fissures par IA utilise la vision par ordinateur — réseaux de neurones convolutifs, vision transformers et modèles de segmentation sémantique — ...
Détection d'objets pour les défauts et caractéristiques d'infrastructure
La détection d'objets localise et classifie les objets dans les images à l'aide de boîtes englobantes — pour l'inspection d'infrastructures, cela inclut les nid...
40 min de lecture
technology
machine-learning
+6
+++ title = “Apprentissage par transfert” description = “L’apprentissage par transfert applique les connaissances d’un modèle pré-...
10 min de lecture
Technology
Machine Learning
+2
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.