Qu’est-ce que la Segmentation Sémantique pour la Compréhension de Scènes d’Infrastructure ? Définition et Distinction des Tâches Connexes de Vision ...
23 min de lecture
Technology
Computer Vision
+3
La segmentation d’instance identifie et délimite chaque objet individuel ou défaut au niveau du pixel, en attribuant un identifiant unique à chaque fissure, éclat ou nid-de-poule. Cela permet le comptage, le dimensionnement et le suivi dans le temps de chaque défaut. Couvre Mask R-CNN et autres architectures d’instance, la différence avec la segmentation sémantique, et l’application aux défauts d’infrastructure.
La segmentation d’instance est une tâche de vision par ordinateur qui identifie, classifie et délimite chaque objet individuel au niveau du pixel en attribuant un identifiant d’instance unique à chaque objet détecté. Pour l’inspection d’infrastructures, la segmentation d’instance signifie que chaque fissure, éclat, nid-de-poule, défaut de joint ou détérioration de surface reçoit son propre masque pixel-parfait avec un identifiant distinct — permettant aux ingénieurs de compter, mesurer et suivre chaque défaut indépendamment plutôt que de traiter tous les défauts d’un même type comme une masse unique indifférenciée.
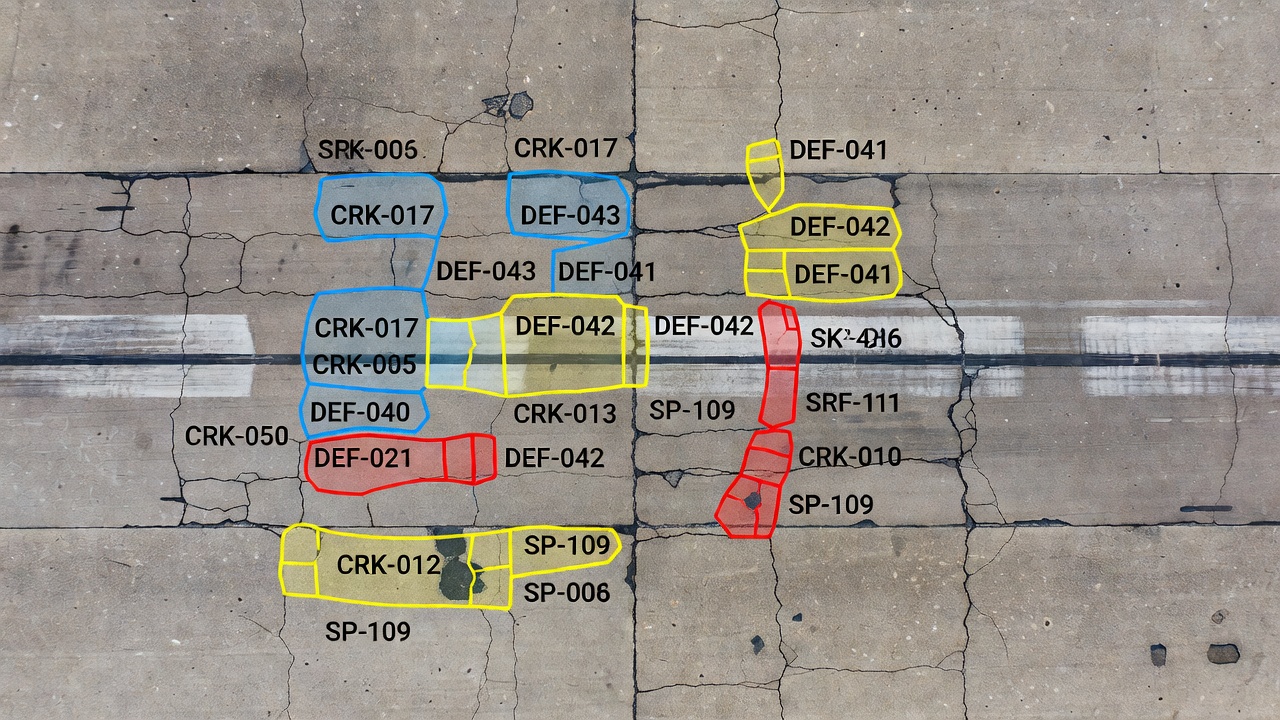
La segmentation d’instance occupe une position distincte dans la hiérarchie de la vision par ordinateur, située entre la détection d’objets (boîtes englobantes avec étiquettes de classe) et la segmentation sémantique (étiquettes de classe au niveau pixel sans distinction d’instance). Elle résout un problème qu’aucune de ces tâches ne peut traiter seule : la capacité à la fois de classifier chaque pixel appartenant à une catégorie et de distinguer quels pixels appartiennent à quel objet spécifique au sein de cette catégorie.
La segmentation sémantique étiquette chaque pixel d’une image selon la classe à laquelle il appartient. Sur une image de surface de piste d’aéroport contenant trois fissures longitudinales, un modèle de segmentation sémantique colorerait tous les pixels de fissure avec la même couleur de classe (par exemple, rouge). La sortie est un masque binaire ou multi-classe unique où toutes les fissures, quels que soient leur caractère distinct en tant que défauts physiques séparés, sont fusionnées en une seule région de classe continue. Cette approche fournit la surface totale des fissures en pixels mais n’offre aucune information sur le nombre de fissures individuelles existantes, leurs tailles individuelles ou leur distribution spatiale en tant que défauts discrets.
La détection d’objets place des boîtes englobantes autour de chaque objet détecté et attribue une étiquette de classe. Un détecteur sur la même image de piste tracerait trois boîtes rectangulaires autour des trois fissures. La sortie fournit le nombre de fissures et leur localisation approximative, mais les boîtes englobantes présentent une limitation fondamentale : elles incluent de la chaussée non défectueuse à l’intérieur du rectangle, rendant la mesure précise de surface impossible. Une boîte englobante autour d’une fissure sinueuse capture bien plus de pixels de non-fissure que de pixels de fissure.
La segmentation d’instance résout entièrement ces limitations. Le modèle produit un ensemble de masques binaires — un par instance détectée — chacun associé à une étiquette de classe et un identifiant d’instance unique. Pour les trois fissures, la sortie serait trois masques binaires distincts : Fissure-001, Fissure-002 et Fissure-003, montrant chacun exactement les pixels appartenant à cette fissure spécifique et aucun autre. Les masques suivent le contour exact de chaque défaut, épousant chaque embranchement, courbe et irrégularité. Cela fournit une géométrie au niveau pixel par instance qui permet une mesure précise de surface, une analyse morphologique et un suivi individuel des défauts.
La différence opérationnelle cruciale apparaît dans le rapport d’inspection. Un rapport de segmentation sémantique pourrait indiquer : « Surface totale de fissures : 45 230 pixels. » Un rapport de segmentation d’instance indique : « Trois fissures détectées. Fissure-001 : 12 400 px², Fissure-002 : 18 100 px², Fissure-003 : 14 730 px². » Ce dernier est bien plus exploitable pour la planification de maintenance — il indique à l’ingénieur de chaussée le nombre exact de défauts nécessitant une réparation et leur sévérité individuelle.
Cette distinction par instance est formalisée dans la norme du jeu de données COCO (Common Objects in Context), qui définit les annotations de segmentation d’instance comme une liste d’objets, chacun contenant un polygone de segmentation (liste de coordonnées x,y formant le contour de l’objet), une boîte englobante, un identifiant de catégorie et un identifiant d’image. Les métriques d’évaluation utilisées dans COCO — en particulier la Précision Moyenne (AP) — sont la norme de facto pour la comparaison des modèles de segmentation d’instance et s’appliquent directement aux modèles de détection de défauts d’infrastructure.
De multiples architectures d’apprentissage profond ont été développées pour la segmentation d’instance, chacune présentant des compromis distincts entre précision, vitesse et complexité architecturale.
Mask R-CNN, introduit par He et al. chez Facebook AI Research en 2017, étend Faster R-CNN en ajoutant une branche de prédiction de masque en parallèle des branches existantes de régression de boîte englobante et de classification. L’architecture suit une conception en deux étapes. Dans la première étape, un Réseau de Proposition de Régions (RPN) parcourt les cartes de caractéristiques extraites par un réseau dorsal CNN (généralement ResNet-50, ResNet-101 ou ResNeXt) et propose des régions candidates d’objets (RoI ou Régions d’Intérêt). Dans la deuxième étape, chaque RoI est traitée via RoIAlign — une contribution critique de Mask R-CNN qui utilise l’interpolation bilinéaire pour calculer les valeurs exactes des caractéristiques à chaque point d’échantillonnage, éliminant les erreurs de quantification de RoIPool — pour produire des cartes de caractéristiques de taille fixe. Ces cartes de caractéristiques alimentent trois têtes parallèles : une tête de classification (prédiction de classe), une tête de régression de boîte englobante (coordonnées de la boîte) et une tête de masque (un réseau entièrement convolutionnel qui produit un masque binaire pour chaque classe pour chaque RoI).
La tête de masque produit un masque de résolution 28×28 pixels par RoI et par classe. Pendant l’entraînement, la fonction de perte combine la perte de classification, la perte de boîte englobante et la perte de masque (entropie croisée binaire moyennée sur les pixels). L’idée clé est que la prédiction de masque et la classification sont découplées : la tête de masque prédit des masques pour toutes les classes, mais seul le masque correspondant à la classe de vérité terrain contribue à la perte. Cette prédiction de masque par classe force le modèle à apprendre des caractéristiques de forme spécifiques à chaque classe.
Mask R-CNN atteint 37-47 AP sur la segmentation d’instance COCO (selon le réseau dorsal), avec ResNet-50-FPN atteignant environ 37,1 AP et ResNeXt-101-FPN atteignant 39,4-47,1 AP. La vitesse d’inférence varie de 5 à 10 FPS sur un GPU moderne. Pour les applications d’infrastructure, un Mask R-CNN avec un réseau dorsal ResNet-50-FPN est la configuration la plus couramment utilisée, avec des performances rapportées de 33,3 AP sur les jeux de données de fissures de chaussée et de 40-55 AP sur les jeux de données de nids-de-poule.
YOLACT (You Only Look At CoefficienTs) a été introduit par Bolya et al. en 2019 comme la première méthode de segmentation d’instance en temps réel capable de fonctionner à 30+ FPS. Contrairement à l’approche en deux étapes de Mask R-CNN, YOLACT est une méthode entièrement convolutionnelle en une étape qui divise la segmentation d’instance en deux sous-tâches parallèles : générer un ensemble de masques prototypes pour l’image entière, et prédire des coefficients de combinaison linéaire par instance.
Dans la première sous-tâche, un réseau dorsal à pyramide de caractéristiques produit un ensemble de masques prototypes — k coefficients de masque (généralement 32) qui couvrent l’image entière. Ces prototypes capturent des motifs de forme courants (par exemple, horizontaux, verticaux, courbes, circulaires). Dans la deuxième sous-tâche, la tête de prédiction produit un vecteur de coefficients linéaires pour chaque instance détectée. Le masque final pour chaque instance est calculé comme une combinaison linéaire des prototypes pondérés par le vecteur de coefficients de l’instance, suivie d’une activation sigmoïde et d’un recadrage utilisant la boîte englobante prédite.
YOLACT atteint 29-31 AP sur COCO à 30-45 FPS sur un GPU Titan X. La variante plus rapide YOLACT-550 atteint 28,2 AP à 56 FPS. YOLACT++ améliore la qualité des masques en ajoutant des convolutions déformables et un meilleur sur-échantillonnage des prototypes, atteignant 34,1 AP à 33,5 FPS. Pour l’inspection d’infrastructures, YOLACT a été appliqué avec succès à la détection en temps réel de fissures dans le béton, obtenant des résultats compétitifs tout en fonctionnant à des vitesses adaptées au traitement embarqué sur drone. Le compromis est une précision de contour de masque inférieure à celle de Mask R-CNN, ce qui peut affecter la mesure précise de la largeur des fissures.
SOLO (Segmenting Objects by LOcations), introduit par Wang et al. en 2020, adopte une approche fondamentalement différente : il élimine complètement la branche de détection et prédit directement les masques d’instance à l’aide d’une architecture entièrement convolutionnelle. L’idée centrale est que chaque instance peut être identifiée de manière unique par son emplacement central et sa taille d’objet. SOLO divise l’image d’entrée en une grille S×S. Chaque cellule de grille est chargée de prédire le masque binaire de toute instance dont le centre tombe dans cette cellule. Chaque cellule de grille prédit des masques à C canaux (un par classe) ainsi que des probabilités de classe.
L’architecture de SOLO comprend un réseau dorsal (ResNet-FPN), une branche de catégorie qui prédit les probabilités de classe pour chaque cellule de grille, et une branche de masque qui prédit S² masques binaires par image (un par position de grille). Pendant l’inférence, la prédiction de classe par cellule et la prédiction de masque sont combinées : pour chaque cellule de grille, la classe prédite dont la confiance dépasse le seuil sélectionne le canal de masque correspondant. SOLOv2 améliore l’original en introduisant la prédiction de noyau de masque et la corrélation de caractéristiques de masque, atteignant 37,8 AP sur COCO à une vitesse comparable à Mask R-CNN.
Le paradigme basé sur la localisation de SOLO est particulièrement intéressant pour les défauts d’infrastructure car il attribue naturellement chaque défaut à sa position spatiale sans dépendre de propositions de boîtes englobantes, ce qui peut être problématique pour les défauts très allongés comme les fissures qui s’étendent sur de grandes portions de l’image.
Mask2Former, introduit par Cheng et al. chez Facebook AI Research (CVPR 2022), représente l’état de l’art en matière de segmentation basée sur les transformeurs. Mask2Former unifie la segmentation sémantique, d’instance et panoptique au sein d’une architecture unique en traitant toutes les tâches de segmentation comme une classification de masques. L’architecture comprend trois composants : un réseau dorsal (Swin Transformer ou ResNet) qui extrait des caractéristiques multi-échelles, un décodeur de pixels qui sur-échantillonne les caractéristiques en embeddings par pixel haute résolution, et un décodeur à transformeurs avec attention masquée qui prédit un ensemble de N requêtes (généralement 100), chacune produisant un masque binaire et une étiquette de classe.
L’innovation clé est l’attention masquée — un mécanisme où chaque requête du décodeur à transformeurs ne prête attention qu’à la région de masque prédite par la couche de décodeur précédente, plutôt qu’à l’ensemble de la carte de caractéristiques. Cela réduit le calcul de 3× par rapport aux modèles à transformeurs standards et force chaque requête à se spécialiser sur une région spécifique, améliorant la vitesse de convergence et la qualité des masques.
Mask2Former atteint 50,1 AP sur la segmentation d’instance COCO avec un réseau dorsal Swin-L et 57,8 PQ sur la segmentation panoptique COCO. Son entraînement converge 3× plus vite que les approches précédentes basées sur les transformeurs (par exemple, MaskFormer, DETR). Pour les applications d’infrastructure, la capacité de Mask2Former à traiter des instances de défauts chevauchantes et adjacentes grâce à la prédiction de masques basée sur des requêtes apprises le rend particulièrement efficace pour les champs de défauts denses tels que les fissures en faïençage ou les fissurations maillées.
| Architecture | Type | AP COCO | FPS | Points forts | Utilisation infrastructure |
|---|---|---|---|---|---|
| Mask R-CNN | CNN en deux étapes | 37-47 | 5-10 | Haute précision de masque, bien établi | Analyse de défauts hors ligne |
| YOLACT | CNN en une étape | 29-34 | 30-56 | Vitesse temps réel | Traitement embarqué sur drone |
| SOLOv2 | CNN sans détection | 37,8 | ~10 | Indépendance des ancres/propositions | Instances de défauts allongés |
| Mask2Former | Transformeur | 50,1 | ~15 | Précision SOTA, cadre unifié | Champs de défauts denses |
Le choix entre la segmentation d’instance et la segmentation sémantique pour la détection de fissures dépend des exigences analytiques spécifiques du programme d’inspection, et les deux approches produisent des résultats fondamentalement différents.
La segmentation sémantique pour les fissures traite l’ensemble du réseau de fissures comme une seule classe de premier plan. Le modèle apprend à classifier chaque pixel comme « fissure » ou « arrière-plan ». La sortie est un masque binaire où tous les pixels de fissure sont blancs et tous les pixels non-fissure sont noirs. Cette approche présente plusieurs points forts bien documentés : elle gère naturellement les réseaux de fissures connectés (une fissure ramifiée est un seul composant connecté), elle nécessite des annotations plus simples (traits au niveau pixel plutôt que des polygones par instance), et la complexité d’entraînement est moindre avec moins de canaux de sortie. Les modèles de segmentation sémantique de pointe pour les fissures — tels que DeepCrack (93% F1 sur CrackTree260), CrackU-Net (97,5% F1 sur CRACK500) et SwinUNETR (90,5% F1 sur des jeux de données de fissures multi-temporels) — atteignent une excellente précision au niveau pixel.
Cependant, la segmentation sémantique présente une limitation critique pour l’évaluation de l’état des infrastructures : elle ne peut pas compter les fissures individuelles. Lorsque la segmentation sémantique rapporte 5 000 pixels de fissure, elle ne fournit aucune information sur le fait que ces pixels appartiennent à une fissure de 5 000 pixels ou à cinquante fissures de 100 pixels. Cette distinction est cruciale pour les calculs d’indice de condition de chaussée (PCI), où la densité de fissures (nombre de fissures par unité de surface) et la sévérité individuelle des fissures sont des paramètres d’évaluation distincts selon les protocoles d’inspection ASTM D5340 et OACI Annexe 14.
La segmentation d’instance pour les fissures attribue un identifiant unique à chaque instance de fissure individuelle. Pour une image de chaussée montrant plusieurs fissures, la sortie consiste en N masques binaires, chacun correspondant à une fissure, avec une étiquette de classe et un identifiant d’instance associés. La méthode de segmentation d’instance augmentée par CrackMover proposée par Zhao et al. (2024) atteint 33,3 AP sur la détection de fissures, surpassant le Mask R-CNN standard de 8,6% grâce à une augmentation de données spécialisée pour les formes de fissures allongées.
La segmentation d’instance pour les fissures présente des défis uniques. Les fissures sont des objets très allongés, fins et souvent ramifiés — pas des amas compacts comme les nids-de-poule. Les architectures de segmentation d’instance standard conçues pour les objets COCO (formes compactes et bien définies) peuvent diviser une fissure ramifiée unique en plusieurs instances ou ne pas parvenir à séparer des fissures parallèles adjacentes. Les techniques spécialisées incluent la modification de la résolution RoIAlign pour l’extraction de caractéristiques allongées, l’utilisation de convolutions atreuses dans la tête de masque pour la capture multi-échelle des fissures, et l’application d’un raffinement en cascade (Cascade Mask R-CNN) qui améliore itérativement les propositions de faible qualité.
La décision pratique dépend de la question de maintenance posée. Pour la quantification de la surface totale de fissures (par exemple, mesurer le pourcentage de fissuration par section de piste), la segmentation sémantique peut suffire et est plus efficace sur le plan computationnel. Pour le comptage de fissures, le suivi individuel de la largeur des fissures et la classification de sévérité par fissure (par exemple, la sévérité des fissures selon ASTM D5340 où la sévérité dépend de la largeur individuelle de la fissure), la segmentation d’instance est nécessaire. Une tendance croissante dans l’inspection d’infrastructures est la segmentation panoptique — combinant la segmentation sémantique et d’instance pour classifier sémantiquement les régions non dénombrables (par exemple, surface de chaussée, herbe, marquages) tout en segmentant par instance les défauts dénombrables (fissures, éclats, nids-de-poule).
Les éclats et les nids-de-poule sont fondamentalement différents des fissures en termes de géométrie : ce sont des défauts discrets, délimités et compacts avec une étendue spatiale claire, des bords bien définis et un volume mesurable. Cela les rend naturellement adaptés à la segmentation d’instance, et les architectures qui performent bien sur les instances COCO (qui sont principalement des objets compacts) se transfèrent efficacement à la détection des éclats et des nids-de-poule.
Un nid-de-poule est une dépression en forme de bol dans la surface de la chaussée qui se forme généralement lorsque la fissuration de surface permet l’infiltration d’eau, entraînant une dégradation de la couche de base et une perte de matériau. Les nids-de-poule sont des instances discrètes par définition — chaque nid-de-poule est un vide physique distinct. La segmentation d’instance capture le périmètre exact de chaque nid-de-poule, ce qui est essentiel pour une estimation précise du volume de réparation. Une approche par boîte englobante (détection d’objets) pourrait englober 30-50% de surface non défectueuse selon l’irrégularité de forme du nid-de-poule, tandis que la segmentation d’instance fournit la surface réelle du défaut.
Un éclat est une zone écaillée ou cassée au bord d’un joint ou d’une fissure, typiquement dans les chaussées en béton. Les éclats sont également des instances discrètes délimitées par la ligne de joint ou de fissure. La segmentation d’instance pour les éclats doit gérer leurs contraintes géométriques : les éclats prennent toujours naissance à une discontinuité structurelle (joint, bord de fissure), ont un côté délimité par le joint et s’étendent dans la face de la dalle. Les modèles spécialisés de segmentation d’instance pour éclats intègrent des mécanismes d’attention focalisés sur les zones de joints.
La recherche démontre l’efficacité de ces approches. En utilisant Mask R-CNN pour la détection de nids-de-poule sur des jeux de données routiers, Nhat-Duc et al. (2020) ont rapporté un AP@0,50 de 55,2 et un AP@0,75 de 42,8. YOLACT appliqué à la détection de nids-de-poule a atteint une vitesse d’inférence de 33 FPS avec un AP@0,50 de 48,7, permettant le comptage en temps réel des nids-de-poule à partir de caméras embarquées. Pour les éclats de béton, Cascade Mask R-CNN avec un réseau dorsal ResNeXt-101 a atteint 44,6 AP sur un jeu de données d’éclats de tablier de pont comprenant 2 400 images annotées.
La norme ASTM D5340 pour l’indice de condition de chaussée aéroportuaire définit des exigences de mesure spécifiques pour les éclats et les nids-de-poule :
La segmentation d’instance prend directement en charge toutes ces mesures. Le masque au niveau pixel fournit des dimensions précises de longueur et de largeur (lorsqu’il est combiné avec une résolution spatiale connue, par exemple 1mm/pixel à partir d’images de drone calibrées). L’identifiant d’instance unique permet le comptage par défaut pour les calculs de densité. Lorsqu’elle est combinée avec des données de profondeur stéréoscopiques ou de structure par le mouvement (SfM), les masques d’instance peuvent être extrudés en 3D pour la mesure de volume.
L’avantage clé par rapport à la segmentation sémantique pour les éclats et les nids-de-poule est le comptage des défauts. Considérons une section de piste avec 15 éclats individuels. La segmentation sémantique rapporte « surface d’éclats : 0,85 m² » — ne fournissant aucune indication sur le nombre de défauts. La segmentation d’instance rapporte « 15 éclats détectés : Éclat-001 (0,12 m²), Éclat-002 (0,04 m²), …, Éclat-015 (0,03 m²) » — informant l’ingénieur que 15 traitements de réparation individuels sont nécessaires et lesquels sont les plus sévères.
Une fois chaque instance de défaut isolée par son masque unique, un ensemble complet de mesures par instance peut être extrait pour l’évaluation de l’état et la planification de la maintenance.
La mesure de surface est la métrique par défaut la plus fondamentale. Le nombre de pixels dans chaque masque d’instance est converti en surface physique à l’aide d’un calibrage spatial. Pour les images acquises par drone à une distance d’échantillonnage au sol (GSD) connue — typiquement 0,5-2,0 mm/pixel pour les inspections de pistes — le nombre de pixels du masque multiplié par (GSD)² donne la surface physique en mm² ou m². Pour les fissures, la mesure de surface permet le calcul de la largeur de fissure : largeur moyenne de fissure = surface du masque / longueur du squelette. Pour les nids-de-poule et les éclats, la surface alimente directement les seuils de classification de sévérité.
La mesure de localisation attribue des coordonnées géographiques à chaque instance de défaut. Le centroïde du masque d’instance (moyenne x,y des pixels du masque) ou le point inférieur central (pour une localisation sensible à l’orientation) est transformé des coordonnées image vers des coordonnées du monde réel à l’aide des paramètres de géoréférencement de la caméra (provenant des métadonnées GPS/IMU ou des points de contrôle photogrammétriques). Les données de localisation permettent : l’analyse de regroupement spatial pour identifier les zones à haute densité de défauts, la corrélation avec les caractéristiques structurelles (joints, coins de dalles, chemins de drainage), et le lien avec les bases de données SIG des systèmes de gestion de chaussée (PMS) pour la génération d’ordres de travail de maintenance.
La mesure morphologique caractérise les propriétés géométriques de chaque instance de défaut au-delà de la simple surface. Les principaux descripteurs morphologiques comprennent :
Ces mesures sont calculées efficacement à l’aide des fonctions d’analyse de contours d’OpenCV (cv2.findContours, cv2.moments, cv2.convexHull) ou des opérations morphologiques de scikit-image (skimage.measure.regionprops, skimage.morphology.skeletonize). Pour un ensemble de données d’inspection de piste typique de 10 000 images avec 50 000+ instances de défauts, l’extraction de caractéristiques par défaut s’effectue en quelques minutes sur une station de travail standard.
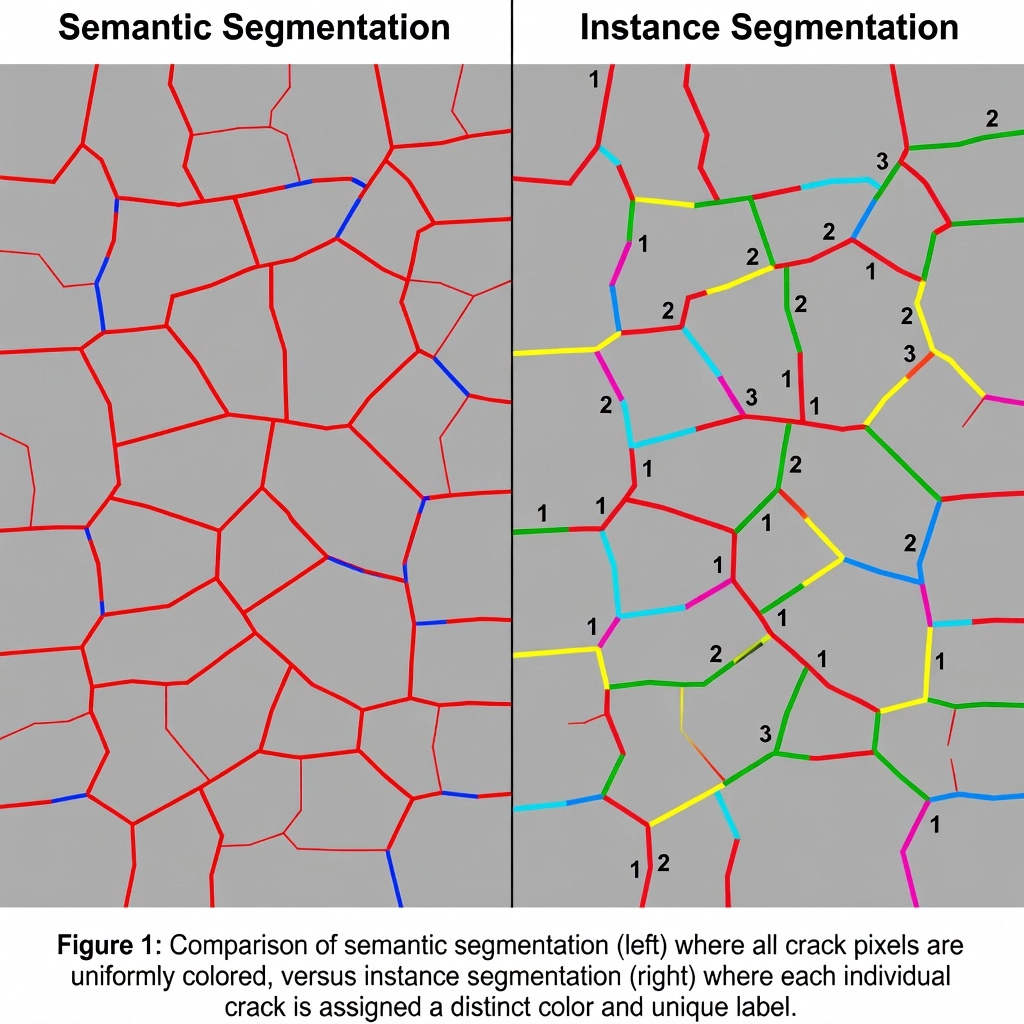
La segmentation d’instance permet un comptage automatisé des défauts qui est tout simplement impossible avec la seule segmentation sémantique. Le nombre de défauts — le nombre de défauts individuels discrets par unité de surface — est une donnée fondamentale pour les indices de condition d’infrastructure, notamment le PCI (ASTM D5340), l’indice de condition structurelle (SCI) et l’indice de condition de piste (RCI).
Le comptage par défaut se déroule comme suit : le modèle de segmentation d’instance produit des masques d’instance avec des identifiants uniques (généralement des entiers commençant à 1). Le nombre d’identifiants d’instance uniques dans chaque image ou zone d’inspection donne directement le nombre de défauts. Pour une piste de 3 000 mètres inspectée à 1mm de GSD, générant environ 3 000 tuiles d’image de 2 000×2 000 pixels chacune, un modèle de segmentation d’instance pourrait détecter 200 à 500 fissures individuelles, 50 à 100 éclats et 10 à 20 nids-de-poule — chacun compté et enregistré individuellement.
La stratification des comptages regroupe les défauts par type et par sévérité. Les identifiants d’instance uniques sont d’abord regroupés par classe prédite (fissure, éclat, nid-de-poule, défaut de joint, désagrégation). Au sein de chaque classe, les instances peuvent être davantage stratifiées par sévérité sur la base de seuils de surface ou de caractéristiques morphologiques :
La cartographie de distribution spatiale agrège les comptages par défaut dans des cases spatiales. La piste est divisée en unités d’échantillonnage selon les spécifications OACI/ASTM : généralement 20 dalles contiguës pour les chaussées en béton (chaque dalle ~5m × 5m = 25 m²) ou des unités rectangulaires de 25m × 25m = 625 m² pour les chaussées en enrobé. Le centroïde de chaque instance de défaut est projeté dans l’unité d’échantillonnage qui le contient. La densité de défauts par unité est calculée comme suit : nombre de défauts dans l’unité / surface de l’unité. Cette densité alimente directement les tables de calcul du PCI.
Les cartes de distribution révèlent les motifs de regroupement des défauts. Une piste avec 500 fissures individuelles réparties sur 120 unités d’échantillonnage pourrait montrer 85% des unités avec 0-5 fissures et 5% des unités avec 20+ fissures. Les unités regroupées indiquent des zones nécessitant une maintenance ciblée — généralement associées à des problèmes structurels sous-jacents (défaillance de la plate-forme, mauvais drainage, joints de construction) plutôt qu’à une usure de surface uniforme.
L’analyse de motifs ponctuels spatiaux (fonction K de Ripley, estimation par noyau de densité) peut quantifier davantage l’intensité du regroupement et identifier les points chauds de défauts statistiquement significatifs. Lorsqu’elle est combinée avec une analyse SIG de superposition, les regroupements de défauts peuvent être corrélés avec les emplacements des joints de construction, les zones d’âge de la chaussée, les motifs de drainage et les zones d’eau stagnante, les emplacements des travaux de maintenance et de réparation antérieurs, et la distribution du trafic (zones de concentration des passages de roues).
La capacité unique de la segmentation d’instance à attribuer des identifiants persistants à des défauts individuels permet le suivi temporel — la quantification de l’évolution de chaque défaut entre les inspections. C’est le fondement de la maintenance prédictive et de la gestion d’actifs basée sur l’état.
Le pipeline de suivi temporel comprend quatre étapes. Premièrement, la piste est ré-inspectée à une cadence régulière (trimestrielle, semestrielle ou annuelle, selon la pratique recommandée par l’OACI pour les inspections de chaussées aéroportuaires). Deuxièmement, la segmentation d’instance est appliquée indépendamment à chaque ensemble de données d’inspection, générant des masques par défaut avec des identifiants d’instance pour chaque point temporel. Troisièmement, un algorithme d’association d’instances fait correspondre les instances de défauts entre les inspections consécutives sur la base de la proximité spatiale (distance entre centroïdes < seuil), du chevauchement des masques (IoU ≥ 0,3-0,5) et de la similarité morphologique (changement de surface <50%, changement d’orientation <15°). Quatrièmement, les instances appariées reçoivent un identifiant global persistant qui les relie à travers toutes les époques d’inspection, créant une série temporelle pour chaque défaut.
Les algorithmes d’association doivent gérer plusieurs défis. Les défauts peuvent fusionner ou se diviser entre les inspections (une fissure qui bifurque, un éclat qui se dilate et rejoint un éclat voisin). Les défauts peuvent apparaître ou disparaître (formation de nouvelle fissure, défauts réparés). L’algorithme hongrois (affectation de Munkres) résout le problème d’affectation linéaire pour l’appariement un-à-un entre les instances d’inspections consécutives à un coût computationnel O(n³). Pour les cas complexes avec divisions et fusions, le suivi basé sur graphe (flux à coût minimum sur un graphe spatio-temporel) fournit un appariement plus robuste à un coût computationnel plus élevé.
Les métriques de changement par défaut calculées à partir de la série temporelle appariée comprennent :
La précision du suivi temporel dépend de la précision du recalage des inspections. Les inspections répétées doivent être géoréférencées dans le même système de coordonnées avec une précision sub-centimétrique. Ceci est réalisé grâce à des points de contrôle au sol (GCP) installés en permanence le long de la piste et relevés avec un GPS RTK (±2cm de précision), ou grâce à un co-recalage basé sur l’image utilisant l’appariement de caractéristiques (caractéristiques SIFT/SuperPoint) entre les ensembles de données d’inspection pour calculer les transformations d’homographie.
La maintenance prédictive utilise les séries temporelles par défaut pour prévoir quand un défaut atteindra une sévérité critique. Un modèle de régression linéaire ajusté à la série temporelle de largeur ou de surface de chaque défaut prédit le moment où le défaut dépassera le seuil de sévérité (par exemple, largeur de fissure >3mm pour une sévérité Élevée selon ASTM D5340). Cela génère une file d’attente de maintenance priorisée : les défauts qui devraient atteindre une sévérité critique dans le prochain cycle d’inspection sont signalés pour réparation immédiate.
L’entraînement de modèles de segmentation d’instance pour les défauts d’infrastructure présente des défis uniques par rapport aux jeux de données d’objets naturels, principalement en raison des exigences d’annotation et des caractéristiques des données.
Format d’annotation : La segmentation d’instance nécessite des annotations au niveau polygone — chaque défaut individuel doit être délimité par un polygone fermé de sommets. C’est considérablement plus intensif en main-d’œuvre que les annotations de segmentation sémantique (qui utilisent des outils de coup de pinceau ou de remplissage par inondation) ou les annotations de détection d’objets (qui utilisent des rectangles alignés sur les axes). Une annotation typique de fissure nécessite 20 à 100 sommets de polygone pour tracer précisément le chemin de la fissure, selon la complexité et la longueur de la fissure. Une annotation d’éclat nécessite généralement 8 à 30 sommets. Les outils d’annotation standard de l’industrie (CVAT, Labelbox, Supervisely, Scale AI) prennent en charge l’annotation par polygone avec des outils semi-automatisés (par exemple, segmentation interactive avec SAM — Segment Anything Model — pour réduire le temps de placement manuel des sommets).
Le format JSON COCO est le schéma d’annotation standard pour la segmentation d’instance. Chaque entrée d’annotation contient id (identifiant d’annotation unique), image_id (référence à l’image source), category_id (étiquette de classe telle que 1=fissure, 2=éclat, 3=nid-de-poule), segmentation (polygone représenté comme une liste aplatie de coordonnées x,y), area (surface du polygone en pixels), bbox (boîte englobante sous forme [x, y, width, height]), et iscrowd (0 pour les instances de défauts individuelles).
Exigences de taille d’ensemble de données : Les modèles de segmentation d’instance nécessitent généralement 500 à 2 000+ images annotées par catégorie de défaut pour des performances acceptables (AP >35). Les petits ensembles de données (<200 images) risquent le surajustement et une mauvaise généralisation à de nouveaux types de chaussée, conditions d’éclairage et variantes de défauts. L’apprentissage par transfert à partir de grands réseaux dorsaux pré-entraînés (ImageNet-1K, COCO) réduit considérablement la taille d’ensemble de données requise — un Mask R-CNN initialisé avec des poids pré-entraînés sur COCO et affiné sur 500 images de fissures atteint des performances comparables à un modèle entraîné de zéro sur 2 000 images.
L’augmentation de données est cruciale pour les ensembles de données de défauts d’infrastructure, qui sont généralement plus petits que les ensembles de données de vision par ordinateur générale. Les augmentations efficaces comprennent la rotation aléatoire (±180°), le retournement horizontal/vertical, la mise à l’échelle aléatoire (0,5×-2,0×), les ajustements de luminosité/contraste (±20%), le recadrage aléatoire, les transformations élastiques (champ de déplacement gaussien) et l’augmentation par mosaïque (combinaison de 4 images en une seule). CrackMover, une augmentation spécialisée pour la segmentation d’instance de fissures, rééchantillonne des instances de fissures d’une image et les colle dans de nouvelles images d’arrière-plan avec un mélange réaliste, augmentant artificiellement à la fois le nombre d’instances de fissures et la diversité des arrière-plans.
La génération de données synthétiques répond au problème fondamental de rareté des annotations dans l’inspection d’infrastructures. Le cadre d’inspection de chaussées aéroportuaires par drone (Alonso et al., 2024) démontre que l’entraînement sur des ensembles de données mixtes réels et synthétiques améliore le F1 de segmentation des fissures de 8 à 12% par rapport à l’entraînement sur des données réelles seules. Des environnements virtuels hyperréalistes construits dans Unreal Engine ou Unity peuvent générer des images annotées illimitées avec des masques de vérité terrain parfaits, des conditions d’éclairage variées et des géométries de défauts diverses. La randomisation de domaine — faisant varier aléatoirement les textures, les couleurs et l’éclairage dans les scènes synthétiques — améliore le transfert sim-vers-réel en forçant le modèle à apprendre la géométrie plutôt que les motifs de texture.
Les modèles de segmentation d’instance sont évalués à l’aide de métriques héritées à la fois de la détection d’objets et de la segmentation sémantique, avec le protocole d’évaluation COCO comme référence standard.
La Précision Moyenne (AP) est la métrique principale. L’AP est calculée à plusieurs seuils d’Intersection sur Union (IoU) entre les masques prédits et les masques de vérité terrain. Pour chaque seuil IoU t (allant de 0,50 à 0,95 par incréments de 0,05), les courbes de précision-rappel sont calculées pour chaque classe, et l’AP est l’aire sous la courbe précision-rappel. La métrique principale COCO AP (ou mAP) fait la moyenne sur tous les seuils IoU et toutes les classes.
Les principales variantes d’AP utilisées dans la détection de défauts comprennent AP@IoU=0,50 (seuil indulgent considéré comme le seuil de détection ; un masque prédit chevauchant 50% ou plus de la vérité terrain est considéré comme correct), AP@IoU=0,75 (seuil strict exigeant des masques de haute qualité, important pour les applications nécessitant une délimitation précise des contours de défauts comme la mesure de largeur de fissure), et AP@petit, AP@moyen, AP@grand (métriques par taille définies par la surface de vérité terrain : petit <32² pixels, moyen 32²-96² pixels, grand >96² pixels).
Le Rappel Moyen (AR) mesure la proportion d’instances de vérité terrain qui ont une correspondance prédite à chaque seuil IoU. L’AR est généralement rapporté comme AR@max=100 (maximum de 100 détections par image). Un rappel élevé est essentiel pour l’inspection d’infrastructures critique pour la sécurité, où des défauts manqués pourraient conduire à une détérioration non détectée.
L’IoU des masques est le critère d’appariement central. Pour un masque prédit P et un masque de vérité terrain G, IoU = |P ∩ G| / |P ∪ G|. Une prédiction est considérée comme un Vrai Positif (TP) si IoU ≥ seuil ET la classe prédite correspond à la classe de vérité terrain. Les Faux Positifs (FP) se produisent lorsque les prédictions ont un IoU < seuil avec tout masque de vérité terrain de la même classe, ou prédisent la mauvaise classe. Les Faux Négatifs (FN) sont des masques de vérité terrain qui ne correspondent à aucune prédiction.
L’algorithme d’appariement COCO gère les détections en double : si plusieurs prédictions correspondent à une seule vérité terrain, seule la prédiction avec la plus haute confiance est comptée comme TP ; les autres sont FP. Cela récompense la précision et pénalise la sur-segmentation — important pour la détection de défauts où de multiples prédictions chevauchantes sur la même fissure indiqueraient une instabilité du modèle.
L’évaluation spécifique aux infrastructures ajoute souvent l’AP par classe ventilée par type de défaut. Un modèle de détection de fissures pourrait rapporter AP_fissure=32,1, AP_éclat=44,6, AP_nid-de-poule=51,3. L’AP significativement plus faible pour les fissures reflète la difficulté de la segmentation d’instance pour les objets fins et allongés (l’IoU des masques est très sensible aux petites erreurs d’alignement pour les structures fines).
Le score F1 à un seuil IoU spécifique (généralement 0,50) est également couramment rapporté dans la littérature sur les infrastructures : F1 = 2 × (Précision × Rappel) / (Précision + Rappel). F1 fournit une mesure équilibrée unique des compromis entre précision et rappel.
La segmentation d’instance transforme l’inspection d’infrastructures d’un processus subjectif et intensif en main-d’œuvre en un flux de travail numérique objectif, quantitatif et évolutif. La technologie est déployée dans de multiples domaines d’infrastructure avec des améliorations documentées de la précision, de la cohérence et du débit d’inspection.
L’inspection des pistes aéroportuaires représente l’application la plus exigeante. Les inspections qualifiées de pistes selon l’OACI Annexe 14 exigent des relevés de chaussée tous les 1 à 3 ans selon des procédures standardisées (ASTM D5340, ASTM D6433, Manuel de conception des aérodromes OACI Partie 3). La segmentation d’instance soutient directement ces normes en automatisant le comptage et la mesure des défauts. Le cadre d’inspection automatisée de piste par drone (Krestenitis et al., 2026) démontre un déploiement de bout en bout : relevé par drone → acquisition d’images → inférence par apprentissage profond (EfficientNet + FPN segmentation sémantique superposée avec post-traitement d’instance) → agrégation SIG → calcul du PCI. Le système atteint une précision de détection de 95%+ pour les défauts de largeur >3mm sur toute l’étendue de la piste, avec un relevé complet en 45 minutes contre 4 à 6 heures pour l’inspection manuelle traditionnelle nécessitant la fermeture de la piste.
L’inspection des chaussées routières et autoroutières utilise des systèmes de caméras embarqués fonctionnant à vitesse autoroutière (60-100 km/h). Les modèles de segmentation d’instance (YOLACT, YOLOv8-seg) traitent les flux vidéo à 15-30 FPS, détectant fissures, nids-de-poule et réparations par mile-voie. Le relevé automatisé des dégradations de chaussée du Nevada DOT utilise un système de segmentation d’instance basé sur YOLOv8 atteignant 88% F1 pour la détection de fissures et 93% F1 pour la détection de nids-de-poule sur plus de 5 000 miles-voies, avec une précision de mesure par défaut à moins de 5% des mesures manuelles de référence.
L’inspection des tabliers de pont applique la segmentation d’instance aux éclats de béton, délaminations et défaillances de joints. Les tabliers de pont présentent des défis uniques : éclairage variable sous l’intrados du pont, textures d’arrière-plan complexes (joints de dilatation, avaloirs, marquages de circulation), et la nécessité d’une résolution sub-millimétrique des fissures pour la mesure de largeur. Cascade Mask R-CNN affiné sur un ensemble de données de tablier de pont atteint 82% mAP@50 pour la détection des éclats, permettant le calcul automatisé de la notation d’état SNBI (Specification for National Bridge Inspection) pour les tabliers de pont en béton.
L’inspection des infrastructures ferroviaires utilise la segmentation d’instance pour les défauts de surface du rail (fissures de tête de rail, bavures, écaillage) et les anomalies de la plateforme. Les systèmes de caméras montés sur rail capturent des images haute résolution à 100+ km/h ; les modèles YOLACT fonctionnant sur des GPU embarqués détectent et classifient les défauts individuels du rail à la cadence de la ligne. La Deutsche Bahn (chemins de fer allemands) a rapporté un taux de détection de 96% pour les fissures de surface >1mm en utilisant un pipeline de segmentation d’instance déployé sur 30 trains d’inspection, avec une précision de localisation par défaut de ±5mm grâce à l’odométrie par encodeur de roue.
L’inspection des revêtements de tunnels déploie la segmentation d’instance sur des images capturées par des réseaux de caméras multiples montés sur des véhicules d’inspection se déplaçant à 30-50 km/h. Les revêtements de tunnels en béton développent des fissures, des éclats et des taches d’infiltration qui nécessitent une analyse au niveau instance. Le défi clé est de distinguer les fissures structurelles (nécessitant réparation) des fissures de surface non structurelles (retrait, thermiques). La segmentation d’instance combinée à la mesure de largeur de fissure (à partir de l’analyse du masque par instance) fournit les données quantitatives nécessaires à cette classification. Le système d’inspection de tunnels des chemins de fer fédéraux autrichiens (ÖBB) utilise Mask R-CNN avec une grille de calibration basée sur des marqueurs Aruco pour atteindre une précision de mesure de largeur de fissure de ±0,1mm à une résolution de 0,5mm/pixel.
Les avantages par rapport à l’inspection traditionnelle sont bien documentés dans tous les types d’infrastructure. Une étude comparative portant sur 12 types d’infrastructure a montré que l’inspection automatisée par segmentation d’instance réduisait le temps d’inspection de 60 à 80%, éliminait la variabilité inter-évaluateurs (coefficient kappa amélioré de 0,45-0,55 pour l’inspection manuelle à 0,88-0,94 pour l’automatisée) et augmentait la sensibilité de détection des défauts de 25 à 40% (en particulier pour les défauts de faible sévérité que les inspecteurs humains manquent fréquemment en raison de la fatigue). La capacité de mesure par défaut permet de passer d’une maintenance basée sur l’indice de condition (traitement des zones dépassant un seuil de sévérité) à une maintenance basée sur les défauts individuels (priorisation des réparations par criticité individuelle du défaut), réduisant les coûts globaux de maintenance de 15 à 30% estimés grâce à une réparation ciblée plutôt qu’à un traitement à l’échelle de la zone.

TarmacView utilise des modèles de segmentation d'instance de pointe pour détecter, compter et suivre chaque défaut individuel sur les chaussées aéroportuaires, les ponts et les infrastructures en béton. Planifiez une démonstration pour voir comment l'analyse par défaut peut transformer votre planification de maintenance.
Qu’est-ce que la Segmentation Sémantique pour la Compréhension de Scènes d’Infrastructure ? Définition et Distinction des Tâches Connexes de Vision ...
La segmentation de fissures est une tâche de vision par ordinateur consistant à classer chaque pixel d'une image comme fissure ou non-fissure, produisant un mas...
La détection de fissures par IA utilise la vision par ordinateur — réseaux de neurones convolutifs, vision transformers et modèles de segmentation sémantique — ...