Segmentation de fissures
La segmentation de fissures est une tâche de vision par ordinateur consistant à classer chaque pixel d'une image comme fissure ou non-fissure, produisant un mas...
41 min de lecture
Computer Vision
Deep Learning
+2
La détection d’objets localise et classifie les objets dans les images à l’aide de boîtes englobantes — pour l’inspection d’infrastructures, cela inclut les nids-de-poule, les réparations, les panneaux, les corps étrangers (FOD) et les défauts importants. YOLO, Faster R-CNN et DETR sont les architectures principales. Couvre les méthodes de détection d’objets, l’entraînement avec des annotations de boîtes englobantes (formats VOC, COCO), les métriques d’évaluation (mAP) et le déploiement pour l’inspection en temps réel.
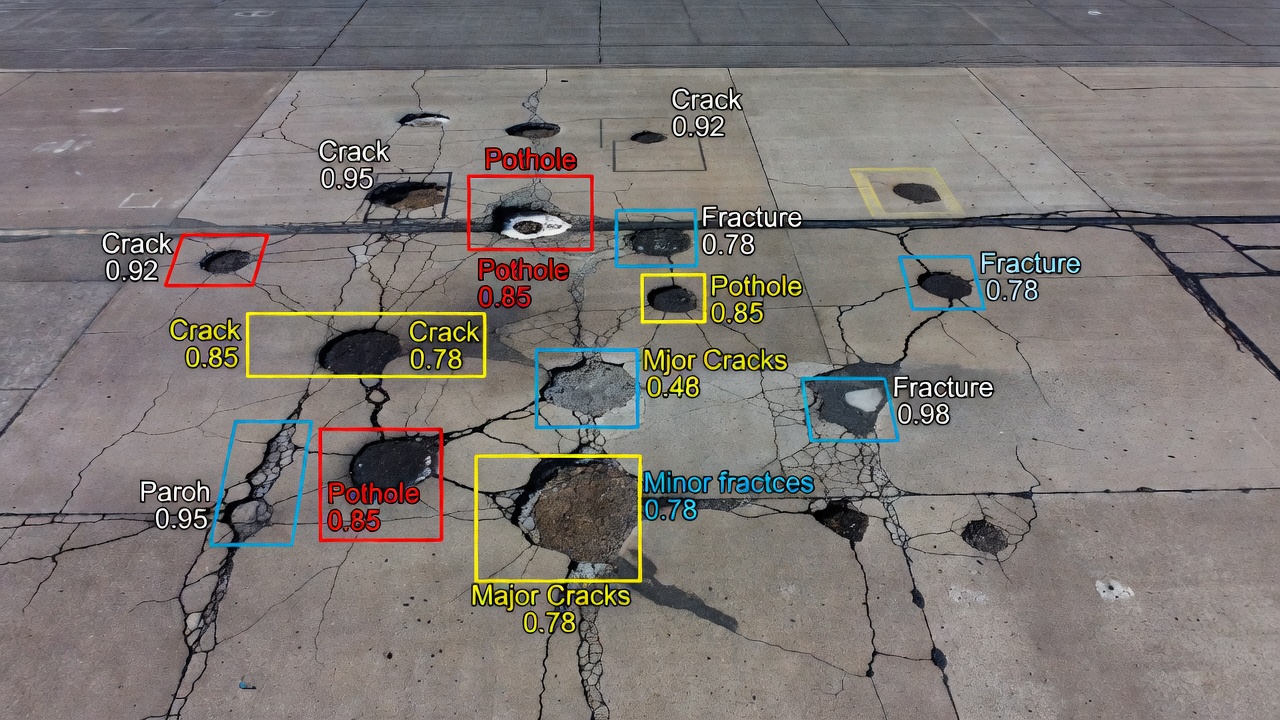
La détection d’objets est une tâche de vision par ordinateur qui identifie et localise les objets dans une image ou une image vidéo en traçant des rectangles alignés sur les axes — appelés boîtes englobantes — autour de chaque élément détecté et en attribuant une étiquette de classe avec un score de confiance. Contrairement à la classification d’images qui produit une seule étiquette pour l’image entière, la détection d’objets produit une liste de longueur variable de détections, une par instance d’objet présente dans la scène. Pour l’inspection d’infrastructures, ces objets détectés peuvent inclure des nids-de-poule, des éclats, des réparations, des joints de construction, des marquages de chaussée, de la signalisation de piste et des débris d’objets étrangers (FOD).
Le résultat d’un modèle de détection d’objets pour une seule image d’entrée est structuré comme une liste de N détections, où chaque détection contient trois composants. Le premier composant est la boîte englobante, généralement représentée soit par (x_min, y_min, x_max, y_max) en coordonnées pixel où (0,0) est le coin supérieur gauche, soit par (x_center, y_center, width, height) en coordonnées normalisées où toutes les valeurs vont de 0 à 1 par rapport aux dimensions de l’image. Le deuxième composant est l’étiquette de classe, qui est l’indice ou le nom de la catégorie d’objet attribué à la détection — par exemple, class_id=0 pour « nid-de-poule », class_id=1 pour « fissure », class_id=2 pour « FOD », et ainsi de suite. Le troisième composant est le score de confiance, une valeur à virgule flottante entre 0,0 et 1,0 représentant la probabilité estimée par le modèle qu’un objet de la classe prédite soit présent dans la boîte englobante à l’emplacement correct. Les scores de confiance égaux ou supérieurs à un seuil de détection défini (généralement 0,25 à 0,5 selon l’application) sont acceptés comme détections valides, tandis que les scores inférieurs au seuil sont rejetés.
Mathématiquement, un modèle de détection d’objets implémente une fonction de correspondance : f: I → {(b₁, c₁, s₁), (b₂, c₂, s₂), …, (b_N, c_N, s_N)}, où I est l’image d’entrée, b_i est le vecteur de la boîte englobante, c_i est l’indice de classe, et s_i est le score de confiance pour la détection i. Le nombre de détections N varie par image en fonction du nombre d’objets présents et de la sensibilité de détection du modèle.
La boîte englobante est définie par quatre coordonnées. Dans la convention COCO (utilisée par l’ensemble de données Microsoft COCO et la plupart des frameworks modernes), la boîte englobante est [x, y, width, height] où (x, y) est le coin supérieur gauche de la boîte en coordonnées pixel absolues. Dans la convention Pascal VOC, la boîte englobante est [x_min, y_min, x_max, y_max] — les coordonnées des coins supérieur gauche et inférieur droit. Dans le format YOLO, la boîte englobante est [x_center, y_center, width, height] en coordonnées normalisées (divisées par la largeur et la hauteur de l’image), rendant la représentation indépendante de la résolution. La conversion entre ces formats est explicite. À partir du format COCO ou VOC, la surface de la boîte englobante est calculée comme area = width × height, et l’intersection sur union (IoU) entre deux boîtes est définie comme la surface de leur chevauchement divisée par la surface de leur union — la métrique de correspondance fondamentale pour évaluer la qualité de détection.
Pour les applications d’inspection d’infrastructures régies par l’Annexe 14, Volume I de l’OACI (Conception et exploitation des aérodromes) et l’ASTM D5340 (Méthode d’essai standard pour les relevés d’indice de condition des chaussées aéroportuaires), la détection d’objets doit atteindre une précision de localisation suffisante pour le comptage des défauts et la classification de sévérité. Une détection de nid-de-poule sur une surface de piste, par exemple, doit avoir une boîte englobante qui enferme étroitement l’ouverture du défaut. Si la boîte englobante surestime significativement la zone du défaut (incluant trop de chaussée intacte), ou la sous-estime (coupant une partie du défaut), la classification de sévérité subséquente dérivée des mesures spatiales sera inexacte. L’étanchéité de l’ajustement de la boîte englobante autour des défauts d’infrastructure est mesurée par l’IoU par rapport à une boîte de vérité terrain annotée manuellement — des valeurs supérieures à 0,7 sont considérées comme bonnes pour la plupart des applications d’infrastructure.
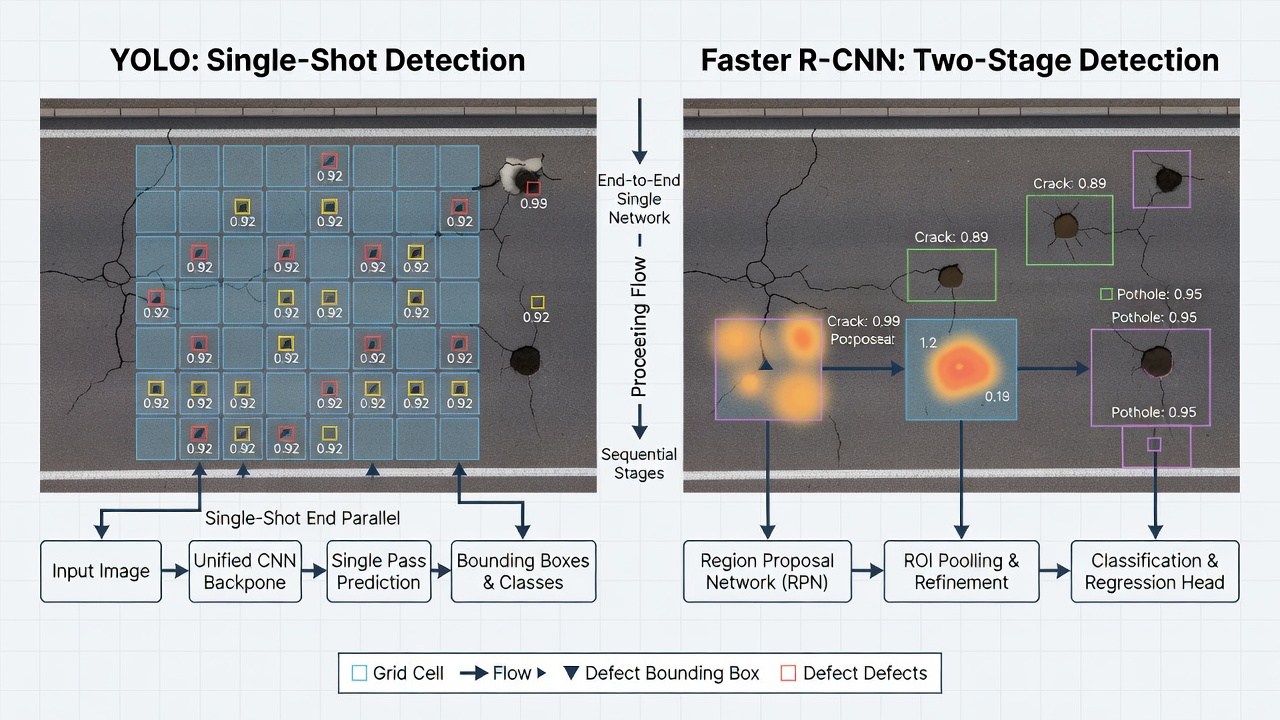
Les architectures de détection d’objets sont largement classées en trois familles : les détecteurs monocoups, les détecteurs à deux étapes et les détecteurs basés sur transformeurs. Chaque famille fait des compromis distincts entre la précision de détection, la vitesse d’inférence, le coût de calcul et la facilité d’entraînement.
YOLO (You Only Look Once), introduit par Joseph Redmon et al. à l’Université de Washington en 2016, a révolutionné la détection d’objets en la reformulant comme un problème de régression unique — directement des pixels de l’image aux coordonnées des boîtes englobantes et aux probabilités de classe en un seul passage avant d’un réseau neuronal. Au lieu d’exécuter un classifieur sur plusieurs régions de l’image comme le faisaient les méthodes précédentes, YOLO divise l’image d’entrée en une grille S×S (généralement 7×7 dans la version originale, mais des grilles plus fines dans les itérations ultérieures). Chaque cellule de la grille est responsable de la prédiction de B boîtes englobantes (généralement 2-3 dans les premières versions) et de C probabilités de classe, ainsi que d’un score de confiance pour chaque boîte indiquant à quel point le modèle est confiant que la boîte contient un objet et à quel point la boîte prédite est précise.
L’architecture YOLO originale utilise un réseau neuronal convolutif avec 24 couches convolutives suivies de 2 couches entièrement connectées, inspiré de l’architecture GoogLeNet mais avec moins de paramètres. Le réseau traite l’image entière en un seul coup, ce qui donne à YOLO son nom et son principal avantage : la vitesse. YOLO a atteint 45 FPS sur un GPU Titan X avec 63,4 mAP sur Pascal VOC 2007 — bien plus rapide que tout détecteur contemporain.
L’évolution de YOLO a été spectaculaire. YOLOv2 (YOLO9000, 2017) a introduit les boîtes ancres avec un clustering k-means des boîtes englobantes de l’ensemble de données pour de meilleurs a priori, la normalisation par lots et l’entraînement multi-échelles. YOLOv3 (2018) a remplacé le backbone par Darknet-53 incorporant des connexions résiduelles et des réseaux de pyramides de caractéristiques (FPN) pour détecter des objets à plusieurs échelles, atteignant 57,9 mAP@0,5 sur COCO. YOLOv4 (2020) a introduit le backbone CSPDarknet53, l’activation Mish, et les techniques d’entraînement Bag-of-Freebies (BoF) et Bag-of-Specials (BoS) incluant l’augmentation de données Mosaic, la régularisation DropBlock et la perte CIoU. YOLOv5, développé par Ultralytics, a introduit une implémentation basée sur PyTorch avec un cadre d’entraînement facile à utiliser qui est devenu le standard de l’industrie pour la détection d’objets appliquée.
YOLOv8 (2023) a apporté la détection sans ancres, des têtes de classification et de régression découplées, et un assignateur aligné sur les tâches pour l’appariement d’échantillons positifs/négatifs. YOLOv8x atteint 53,9 mAP sur COCO à 280 FPS sur un GPU T4. YOLO11 (Septembre 2024) a introduit une optimisation supplémentaire avec une conception améliorée du backbone et du cou, atteignant 54,7 mAP avec 26,4 millions de paramètres à 314 FPS. YOLO26 (Septembre 2025) est la dernière évolution, atteignant environ 56-57 mAP sur COCO avec des vitesses d’inférence dépassant 350 FPS sur les GPU modernes. Chaque génération a amélioré la frontière de Pareto vitesse-précision, faisant de YOLO l’architecture dominante pour l’inspection d’infrastructures en temps réel.
Le cadre d’entraînement Ultralytics YOLO (CLI yolo, paquet Python ultralytics) prend en charge les tâches de détection, segmentation, classification, estimation de pose et boîtes englobantes orientées (OBB) sous une API unifiée. Pour l’inspection d’infrastructures, les modèles de détection YOLO sont entraînés à l’aide de la commande yolo train data=dataset.yaml model=yolo11x.pt epochs=200 imgsz=640. Le cadre gère automatiquement le chargement des données, l’augmentation (Mosaic, MixUp, variation HSV, rotation, mise à l’échelle), la planification du taux d’apprentissage (décroissance cosinus) et la journalisation des métriques. L’exportation vers les formats ONNX, TensorRT, CoreML et OpenVINO pour le déploiement en périphérie est intégrée.
Faster R-CNN, introduit par Shaoqing Ren, Kaiming He, Ross Girshick et Jian Sun chez Microsoft Research (NIPS 2015), est le détecteur à deux étapes fondateur qui a établi le paradigme dominant pour la détection à haute précision avant l’essor des méthodes monocoups et basées sur transformeurs. Il reste largement utilisé pour les applications d’inspection d’infrastructures où la précision est priorisée par rapport à la vitesse.
L’architecture Faster R-CNN fonctionne en deux étapes. Dans la première étape, un réseau de proposition de régions (RPN) parcourt les cartes de caractéristiques produites par un CNN backbone (généralement ResNet-50, ResNet-101 ou ResNeXt) et propose des régions candidates d’objets appelées régions d’intérêt (RoI). Le RPN est lui-même un réseau entièrement convolutif qui fait glisser une petite fenêtre de réseau sur la carte de caractéristiques convolutionnelles, prédisant k boîtes ancres à chaque emplacement spatial — généralement k=9 boîtes ancres de trois échelles (128², 256², 512²) et trois proportions (1:1, 1:2, 2:1). Pour chaque ancre, le RPN produit un score d’objectness (probabilité que l’ancre contienne un objet plutôt que du fond) et des décalages de régression de boîte englobante (4 valeurs affinant la boîte ancre pour mieux correspondre à l’objet). Le RPN est entraîné de bout en bout avec le réseau de détection, partageant les caractéristiques convolutionnelles, ce qui est l’innovation clé de Faster R-CNN par rapport au Fast R-CNN précédent qui utilisait la recherche sélective externe pour les propositions de régions.
Dans la deuxième étape, chaque RoI du RPN est traitée par une couche RoIPool qui extrait une carte de caractéristiques de taille fixe (généralement 7×7) de chaque région. Ces cartes de caractéristiques de taille fixe sont alimentées dans des couches entièrement connectées — une tête de classification qui prédit les probabilités de classe (K classes d’objets + fond) et une tête de régression de boîte englobante qui produit les coordonnées de boîte englobante affinées pour chaque classe. La fonction de perte combine quatre composants : la perte de classification RPN (entropie croisée binaire pour l’objectness), la perte de régression RPN (L1 lisse pour les décalages de boîte), la perte de classification de détection (entropie croisée pour la classe) et la perte de régression de détection (L1 lisse pour les boîtes affinées).
Faster R-CNN avec un backbone ResNet-101-FPN atteint 59,1 AP sur COCO test-dev (selon le benchmark Mask R-CNN). La vitesse d’inférence varie de 5 à 15 FPS selon la profondeur du backbone et la résolution d’entrée. Pour la détection de défauts d’infrastructure, il a été démontré que Faster R-CNN atteint une précision supérieure à YOLO pour les petits défauts (<32² pixels dans l’image d’entrée) en raison de sa conception en deux étapes qui concentre le classifieur de la deuxième étape spécifiquement sur les régions proposées plutôt que sur la grille d’image entière.
Le principal inconvénient de Faster R-CNN pour l’inspection d’infrastructures est la vitesse d’inférence. À 5-15 FPS, il ne peut pas traiter les flux vidéo à pleine cadence (30 FPS) sans saut d’images, ce qui le rend inadapté à l’inspection en temps réel depuis des véhicules rapides ou des drones. Cependant, pour l’analyse hors ligne d’images d’inspection capturées où le temps de traitement n’est pas contraint, Faster R-CNN reste un choix solide pour une précision maximale par image.
SSD (Single Shot MultiBox Detector), introduit par Wei Liu et al. à l’ECCV 2016, a été le premier détecteur monocoup haute performance à rivaliser avec la précision des détecteurs à deux étapes tout en maintenant une vitesse temps réel. SSD fonctionne en prédisant les boîtes englobantes et les probabilités de classe directement à partir des cartes de caractéristiques à plusieurs échelles sans l’étape de proposition de régions.
L’architecture SSD utilise un réseau de base (généralement VGG-16 tronqué à conv5_3, ou MobileNet) suivi d’une série de couches convolutionnelles supplémentaires qui réduisent progressivement la résolution spatiale. Les détections sont effectuées à partir de cartes de caractéristiques à 6 échelles différentes — conv4_3 (38×38), conv7 (fc7, 19×19), conv8_2 (10×10), conv9_2 (5×5), conv10_2 (3×3) et conv11_2 (1×1). À chaque emplacement de carte de caractéristiques, SSD prédit des décalages pour k boîtes par défaut (similaires aux boîtes ancres) et des scores de confiance par classe. Avec 8732 boîtes par défaut sur toutes les cartes de caractéristiques, SSD fournit une couverture dense de l’image à plusieurs échelles.
La conception multi-échelles est la contribution clé de SSD : les cartes de caractéristiques plus grandes (38×38) détectent les petits objets tandis que les cartes de caractéristiques plus petites (1×1) détectent les grands objets. Ce mécanisme de détection hiérarchique est conceptuellement similaire aux réseaux de pyramides de caractéristiques (FPN) qui deviendront standard dans les détecteurs ultérieurs.
SSD300 (entrée 300×300) atteint 77,2 mAP sur Pascal VOC 2007 à 46 FPS sur un Titan X, tandis que SSD512 (entrée 512×512) atteint 79,8 mAP à 19 FPS. Sur COCO, SSD512 atteint 31,2 AP. Pour l’inspection d’infrastructures, SSD a été appliqué à la détection de défauts routiers embarquée avec des performances rapportées de 48-52 mAP@0,5 sur des ensembles de données de détection de nids-de-poule.
DETR (Detection Transformer), introduit par Nicolas Carion, Francisco Massa et l’équipe Facebook AI Research à l’ECCV 2020, repense fondamentalement la détection d’objets en éliminant de nombreux composants artisanaux qui dominaient les architectures précédentes — boîtes ancres, propositions de régions, suppression non maximale (NMS) et appariement basé sur l’IoU. DETR traite plutôt la détection d’objets comme un problème de prédiction d’ensemble direct en utilisant une architecture encodeur-décodeur de transformeur.
L’architecture DETR comporte trois composants. Un CNN backbone (généralement ResNet-50 ou ResNet-101) extrait une carte de caractéristiques de l’image d’entrée. Un encodeur transformeur traite la carte de caractéristiques à travers des couches d’auto-attention multi-têtes, permettant à chaque position de la carte de caractéristiques d’assister à toutes les autres positions — construisant une compréhension globale du contexte de l’image. Un décodeur transformeur prend un ensemble de N requêtes d’objets apprises (généralement N=100 vecteurs fixes) et les traite à travers l’auto-attention (requêtes assistant à d’autres requêtes) et l’attention croisée (requêtes assistant à la sortie de l’encodeur). Chaque requête apprend à prédire une instance d’objet spécifique. Le décodeur produit N prédictions, chacune consistant en une étiquette de classe (K classes + ∅ pour aucun objet) et une boîte englobante. Pendant l’entraînement, une perte hongroise fait correspondre les N prédictions aux objets de vérité terrain en utilisant l’appariement bipartite — trouvant l’assignation un-à-un optimale entre les prédictions et les objets réels qui minimise la perte totale.
L’innovation centrale de DETR est que le cadre de prédiction d’ensemble élimine le besoin de suppression des doublons. Parce que l’appariement hongrois impose une assignation un-à-un pendant l’entraînement, le modèle apprend naturellement à produire des détections uniques sans nécessiter de post-traitement NMS. Cela simplifie le pipeline de détection et supprime un hyperparamètre (seuil IoU NMS) qui nécessite un réglage par application.
DETR avec backbone ResNet-50 atteint 42,0 AP sur COCO avec 50 FPS sur un GPU NVIDIA V100 avec une taille de lot de 1. Deformable DETR (Zhu et al., ICLR 2021) a amélioré la convergence d’entraînement (10× plus rapide) et la détection des petits objets en remplaçant l’attention standard par une attention déformable qui assiste uniquement à un ensemble clairsemé de points d’échantillonnage clés près de chaque requête. DINO (Zhang et al., CVPR 2023) a encore amélioré DETR pour atteindre 63,2 AP sur COCO — le premier détecteur à dépasser 63 AP — en utilisant une approche d’entraînement par débruitage contrastif et une initialisation de requête améliorée. RF-DETR (Roboflow, Mars 2025) est devenu le premier détecteur temps réel à dépasser 60 AP (60,5 AP@0,50:0,95 à 25 FPS sur T4), spécifiquement optimisé pour le déploiement pratique.
Pour l’inspection d’infrastructures, les détecteurs de la famille DETR sont prometteurs car le mécanisme d’attention globale du transformeur peut capturer les relations spatiales à longue portée — une fissure à une extrémité de l’image peut faire partie du même réseau de défauts qu’une autre fissure à l’extrémité opposée, et l’auto-attention du transformeur peut modéliser cette dépendance. Cependant, l’adoption pratique a été plus lente que YOLO en raison des besoins plus élevés en mémoire GPU et de la nécessité d’une infrastructure d’entraînement spécialisée.
| Architecture | Type | COCO mAP@0,50:0,95 | Vitesse (FPS) | Atouts pour l’infrastructure |
|---|---|---|---|---|
| YOLOv8x | CNN monocoup | 53,9 | 280 | Inspection temps réel, déploiement périphérique, entraînement facile |
| YOLO11x | CNN monocoup | 54,7 | 314 | Meilleur vitesse-précision, écosystème Ultralytics natif |
| YOLO26x | CNN monocoup | ~57 | 350+ | Dernière génération, détection améliorée des petits objets |
| Faster R-CNN R101-FPN | CNN deux étapes | 59,1 | 8-12 | Précision par image la plus élevée, analyse hors ligne |
| SSD512 | CNN monocoup | 31,2 | 19 | Léger, faibles besoins en mémoire |
| Deformable DETR | Transformeur | 46,2 | 10-15 | Pas de NMS, conscience du contexte global |
| DINO | Transformeur | 63,2 | 8-10 | Précision de pointe, référence de recherche |
| RF-DETR | Transformeur | 60,5 | 25 | Détection par transformeur temps réel, déploiement pratique |
L’entraînement des modèles de détection d’objets nécessite des annotations de vérité terrain — des boîtes englobantes et des étiquettes de classe étiquetées manuellement pour chaque instance d’objet dans les images d’entraînement. Le format dans lequel ces annotations sont stockées affecte l’interopérabilité des ensembles de données, la surcharge de conversion et la compatibilité des outils.
Le format Pascal VOC (Visual Object Classes), développé pour le défi VOC annuel (2005-2012), utilise un fichier XML par image. Chaque fichier XML contient les métadonnées de l’image (nom de fichier, taille) et une liste d’annotations d’objets avec des boîtes englobantes. Le schéma est :
<annotation>
<folder>images</folder>
<filename>pothole_001.jpg</filename>
<source><database>RunwayDefects</database></source>
<size><width>1920</width><height>1080</height><depth>3</depth></size>
<object>
<name>pothole</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>342</xmin><ymin>156</ymin>
<xmax>521</xmax><ymax>378</ymax>
</bndbox>
</object>
<object>
<name>crack</name>
<bndbox>
<xmin>890</xmin><ymin>234</ymin>
<xmax>1245</xmax><ymax>256</ymax>
</bndbox>
</object>
</annotation>
Chaque élément <object> contient : name — la chaîne de l’étiquette de classe ; pose — descripteur de pose approximative (Frontal, Arrière, Gauche, Droite, Non spécifié) ; truncated — indicateur binaire indiquant si l’objet est coupé par le bord de l’image (0=non, 1=oui) ; difficult — indicateur binaire pour les objets considérés comme difficiles à reconnaître même pour les humains (souvent exclus lors de l’évaluation) ; et bndbox — la boîte englobante en coordonnées pixels (xmin, ymin, xmax, ymax).
Le format VOC a l’avantage d’être lisible par l’homme et indépendant par fichier (les annotations peuvent être créées, copiées et modifiées en tant que fichiers séparés sans analyser une base de données monolithique). L’inconvénient est que les grands ensembles de données avec des milliers d’images nécessitent le stockage de milliers de fichiers d’annotation XML, ce qui peut ralentir le chargement et le traitement dans les pipelines de données.
Le format VOC est principalement utilisé avec les implémentations Faster R-CNN et SSD dans Detectron2 (Meta), mmdetection et les anciens pipelines de l’API TensorFlow Object Detection. La conversion du format VOC vers le format JSON COCO est prise en charge par tous les principaux outils de gestion de données, y compris Roboflow, CVAT et labelImg.
Le format JSON COCO (Common Objects in Context), introduit par Microsoft avec l’ensemble de données MS COCO (2015), est le format d’annotation le plus largement utilisé pour les modèles modernes de détection d’objets. Toutes les annotations pour l’ensemble de données entier sont stockées dans un seul fichier JSON avec une structure hiérarchique contenant quatre tableaux de premier niveau.
Le dictionnaire info contient les métadonnées de l’ensemble de données — année, version, description, contributeur, URL et date_created. Le tableau licenses liste les informations de licence d’image avec id, name et URL pour chaque type de licence. Le tableau categories définit la taxonomie des classes, où chaque entrée a un id (entier, commençant généralement à 1), un name (chaîne d’étiquette de classe) et un supercategory (regroupement de niveau supérieur, ex. « défaut » pour « nid-de-poule », « fissure », « éclat »). Le tableau images liste chaque image de l’ensemble de données avec id (entier unique), file_name (chemin relatif), height et width (en pixels), et éventuellement date_captured et license. Le tableau annotations est la structure de données centrale, où chaque entrée contient : id (identifiant d’annotation unique), image_id (référence à l’image parente), category_id (référence à la catégorie), bbox (boîte englobante comme [x, y, width, height] en coordonnées pixels — où (x, y) est le coin supérieur gauche), area (calculée comme width × height en pixels), segmentation (format polygone ou RLE ; tableau vide [] pour les ensembles de données de détection uniquement), et iscrowd (indicateur : 0 pour les objets individuels, 1 pour les groupes d’objets non dénombrables).
La structure en un seul fichier du format JSON COCO rend le chargement de l’ensemble de données rapide (une lecture de fichier contre des milliers), permet un accès aléatoire efficace en utilisant image_id comme index, et est le format d’entrée standard pour Detectron2, MMDetection et le pipeline de détection de référence de torchvision. Tous les principaux outils d’annotation (CVAT, Labelbox, Supervisely, Roboflow, Scale AI) prennent en charge l’exportation JSON COCO.
Le serveur d’évaluation COCO utilise cette même structure JSON pour soumettre les résultats de détection, garantissant la cohérence entre les données d’entraînement et les données d’évaluation.
Le format YOLO, développé par l’équipe Ultralytics pour leur cadre d’entraînement YOLO, utilise un fichier TXT en texte brut par image. Chaque ligne du fichier correspond à une détection d’objet et suit le format :
<class_id> <x_center> <y_center> <width> <height>
Toutes les valeurs sont des nombres à virgule flottante normalisés dans l’intervalle [0, 1] en divisant par la largeur de l’image (pour x_center et width) et la hauteur (pour y_center et height). Par exemple, un nid-de-poule avec une boîte englobante absolue (x_min=342, y_min=156, x_max=521, y_max=378) dans une image de 1920×1080 se convertit en : x_center = (342+521)/2/1920 = 0,2247, y_center = (156+378)/2/1080 = 0,2472, width = (521-342)/1920 = 0,0932, height = (378-156)/1080 = 0,2056 — résultant en la ligne d’annotation : « 0 0,2247 0,2472 0,0932 0,2056 ».
Les avantages du format YOLO sont une extrême simplicité — une ligne par objet, pas de surcharge d’analyse XML/JSON, et une indépendance de résolution (les coordonnées normalisées fonctionnent à n’importe quelle résolution d’image). Les inconvénients sont la nécessité de gérer un fichier TXT par image (similaire à l’approche par fichier de VOC) et l’absence de métadonnées standardisées (les dimensions de l’image doivent être connues à partir d’une spécification externe de l’ensemble de données).
Le format YOLO est le format natif pour l’entraînement Ultralytics YOLOv5 à YOLO26. La structure de l’ensemble de données est : dataset/images/train/, dataset/labels/train/, dataset/images/val/, dataset/labels/val/, avec un fichier dataset.yaml spécifiant les noms et chemins des classes.
La conversion entre les formats est effectuée par des outils tels que Roboflow (basé sur le web, convertisseur de format universel), CVAT (outil d’annotation web avec exportation dans tous les formats), labelImg (outil d’annotation desktop avec exportation Pascal VOC et YOLO) et FiftyOne (gestion d’ensembles de données open source avec conversion de format). Les bibliothèques Python pour la conversion de format incluent pycocotools (JSON COCO), xml.etree.ElementTree (XML Pascal VOC) et le paquet ultralytics (format YOLO).
| Format | Structure de fichier | Représentation de la boîte englobante | Utilisation principale |
|---|---|---|---|
| Pascal VOC XML | 1 fichier XML par image | (xmin, ymin, xmax, ymax) en pixels | Detectron2, MMDetection, pipelines hérités |
| COCO JSON | 1 fichier JSON par ensemble de données | [x, y, width, height] en pixels | Pipelines d’entraînement modernes, serveur d’évaluation |
| YOLO TXT | 1 fichier TXT par image | [x_center, y_center, w, h] normalisé [0,1] | Cadre Ultralytics YOLO |
Le choix entre la détection d’objets (boîtes englobantes) et la segmentation (masques au niveau pixel) pour l’inspection d’infrastructures est déterminé par le type de mesure requis, le coût d’annotation et les contraintes de calcul.
Quand utiliser la détection d’objets — La détection par boîte englobante est préférée lorsque les objectifs principaux sont le comptage d’objets, la localisation approximative et la classification. Compter le nombre de nids-de-poule sur une section de piste, déterminer leurs positions approximatives pour le déploiement des équipes de réparation et classifier le type de défaut (nid-de-poule vs éclat vs réparation) peuvent tous être accomplis avec des boîtes englobantes. Le coût d’annotation pour les boîtes englobantes est considérablement inférieur à celui de la segmentation — une boîte englobante nécessite 4 valeurs de coordonnées (quelques secondes par objet), tandis qu’un polygone de segmentation nécessite 20 à 100+ sommets (30 secondes à plusieurs minutes par objet selon la complexité de la forme). Pour un ensemble de données d’inspection d’infrastructures typique de 10 000 images avec 5 à 20 objets par image, l’annotation par boîte englobante pourrait nécessiter 100 à 500 heures-personnes tandis que la segmentation par polygone pourrait nécessiter 1 000 à 5 000 heures-personnes. La vitesse d’inférence des modèles de détection d’objets est également plus élevée : les modèles YOLO atteignent 300+ FPS, tandis que les modèles de segmentation d’instances les plus rapides (YOLACT, YOLOv8-seg) atteignent 30 à 60 FPS.
Quand utiliser la segmentation — La détection au niveau pixel est nécessaire lorsque la mesure précise de la surface du défaut, le calcul du périmètre et l’analyse de forme sont nécessaires. Le calcul PCI aéroportuaire selon l’ASTM D5340 nécessite la longueur, la largeur et la profondeur des éclats — les boîtes englobantes ne peuvent pas fournir une longueur et une largeur précises pour les éclats de forme irrégulière. Un éclat en forme de croissant au coin d’un joint de chaussée enfermé dans une boîte englobante surestimera la surface de l’éclat de 30 à 60 %, conduisant à une classification de sévérité incorrecte. La mesure de la largeur de fissure — le paramètre principal pour la classification de sévérité des fissures selon ASTM D5340 — nécessite une délimitation exacte au niveau pixel que les boîtes englobantes ne peuvent pas fournir. Pour les contrats de maintenance basés sur la performance où le paiement de l’entrepreneur dépend de la surface de défaut mesurée, la segmentation est essentielle pour éviter les litiges de mesure.
Le problème de la surcharge de la boîte englobante est quantifié par la métrique d’efficacité de la boîte englobante : BBE = pixels_objet / pixels_boîte. Un nid-de-poule avec 5 000 pixels de défaut à l’intérieur d’une boîte englobante de 7 000 pixels a un BBE = 71 % — la boîte englobante surestime la surface de 29 %. Une fissure sinueuse avec 3 000 pixels de fissure à l’intérieur d’une boîte englobante de 25 000 pixels a un BBE = 12 % — la boîte englobante surestime la surface de 88 %, la rendant inutile pour la mesure de surface. Pour l’inspection d’infrastructures, les valeurs de BBE :
Compromis pratique — Une tendance croissante dans l’inspection d’infrastructures est la détection par boîte englobante orientée (OBB), prise en charge par YOLOv8-OBB et YOLO11-OBB. L’OBB utilise des rectangles pivotés plutôt qu’alignés sur les axes, améliorant considérablement l’ajustement pour les défauts allongés comme les fissures longitudinales. Une fissure orientée à 30 degrés par rapport à l’axe de l’image enfermée dans une boîte englobante alignée sur les axes peut avoir un BBE de 15 %, tandis que la même fissure enfermée dans une boîte englobante pivotée de la même orientation atteint un BBE de 50 à 60 %. L’OBB offre un juste milieu entre la simplicité d’annotation de la détection alignée sur les axes et la précision de mesure de la segmentation.
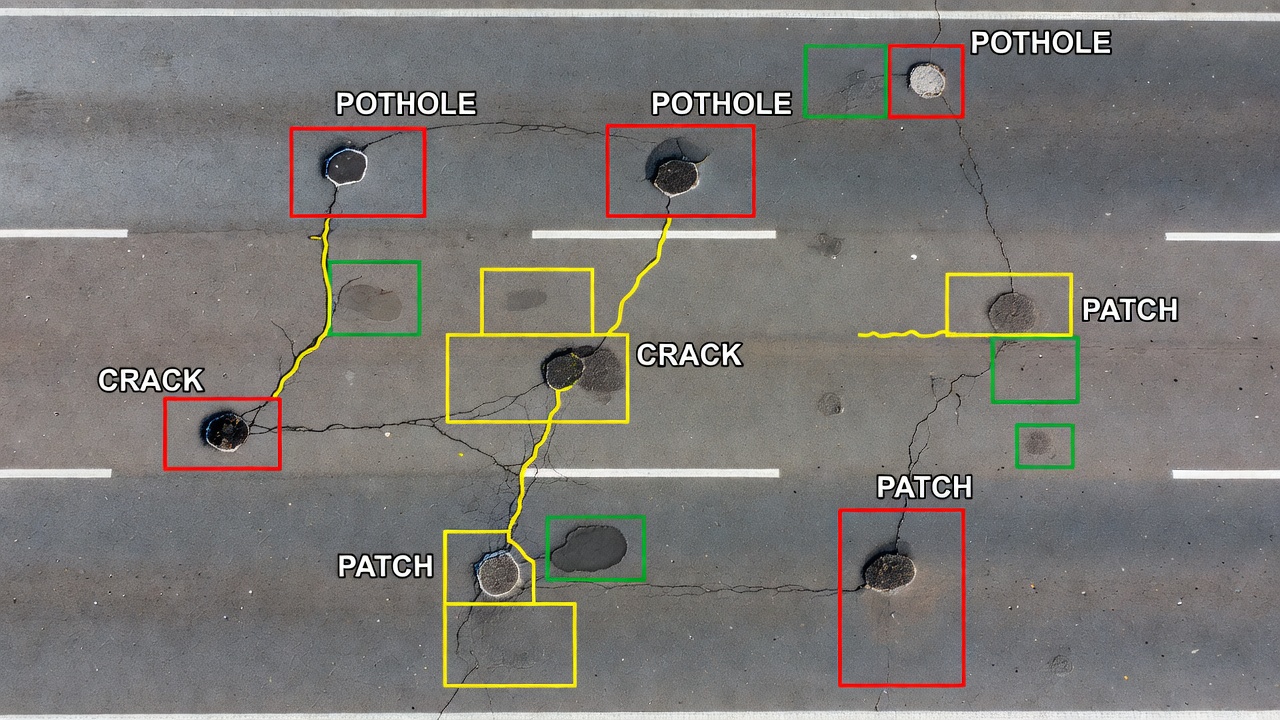
La détection des nids-de-poule est l’application la plus mature et la plus réussie commercialement de la détection d’objets dans l’inspection d’infrastructures. Les nids-de-poule sont bien adaptés à la détection par boîte englobante car ce sont des objets discrets, localisés et compacts avec des limites visuelles claires — contrairement aux fissures qui sont allongées et ramifiées.
Caractéristiques de détection — Les nids-de-poule sur les surfaces asphaltées et en béton se présentent comme des dépressions sombres en forme de bol avec des bords de contraste marqués par rapport à la chaussée environnante. Sur les surfaces asphaltées, un nid-de-poule apparaît comme un trou sombre (exposant les couches de base) avec un rapport diamètre/profondeur généralement compris entre 3:1 et 10:1. Sur les chaussées en béton, les nids-de-poule (plus précisément appelés éclats lorsqu’ils sont aux joints) apparaissent comme des zones écaillées avec des granulats exposés et des limites de fracture nettes. La signature visuelle comprend une région intérieure sombre (ombre de la profondeur de la dépression), un bord limite qui a souvent un anneau de couleur plus claire (granulats exposés) et parfois des débris meubles à l’intérieur ou autour du trou.
Performance du modèle — La détection de nids-de-poule basée sur YOLO a été largement étudiée. ECC-YOLO (2025), basé sur YOLOv11n avec des modules de capture de contexte améliorés, atteint 82,12 % mAP@0,5 sur l’ensemble de données NHA Pothole (NPD) et 80,19 % mAP@0,5 sur l’ensemble de données Road Pothole Detection (RPD). Le YOLOv8 standard atteint environ 78-80 % mAP@0,5 sur ces références. Pour les petits nids-de-poule (diamètre <15 cm à une distance d’échantillonnage au sol de 2 mm/pixel), la performance du modèle chute à 55-70 % mAP@0,5, indiquant que les petits nids-de-poule près de la limite perceptuelle restent difficiles. Faster R-CNN atteint une précision marginalement plus élevée (environ 81-83 % mAP@0,5 sur les références de nids-de-poule) mais à 5-15 FPS contre 100-300 FPS pour YOLOv8.
Estimation de la taille — Les dimensions de la boîte englobante en pixels sont converties en dimensions physiques en utilisant la distance d’échantillonnage au sol (GSD) connue de la caméra d’inspection. Pour une caméra montée sur drone à 30 m d’altitude avec un objectif de 24 mm et un capteur de 20 MP, la GSD est d’environ 2,5 mm/pixel. Une boîte englobante de nid-de-poule de 200×180 pixels correspond à 0,5 m × 0,45 m = 0,225 m². Cette estimation de surface (à partir de la boîte englobante) est généralement 20 à 40 % plus grande que la vraie surface du nid-de-poule en raison de la surestimation discutée ci-dessus. Pour la classification de sévérité selon l’ASTM D5340 — où la sévérité du nid-de-poule dépend de la profondeur et du diamètre — l’estimation du diamètre par la boîte englobante est suffisamment précise pour la classification faible (diamètre <30 cm, profondeur <25 mm) vs moyenne (30-60 cm, 25-50 mm) vs élevée (>60 cm, >50 mm), à condition que le nid-de-poule soit approximativement circulaire.
Considérations de déploiement — La détection en temps réel de nids-de-poule à partir de caméras embarquées sur véhicule roulant à 80 km/h nécessite des modèles qui traitent les images à 30+ FPS avec une latence minimale. Un déploiement typique utilise un modèle YOLOv8s ou YOLO11s (variante petite) sur un dispositif périphérique NVIDIA Jetson Orin, atteignant 60-90 FPS avec une résolution d’entrée de 640×640. Les détections sont géolocalisées à l’aide des métadonnées GPS du dispositif de capture (données GPS/IMU enregistrées dans les EXIF de l’image). Les emplacements des nids-de-poule sont téléchargés dans une base de données du système de gestion de chaussée (PMS) pour la génération d’ordres de travail.
La détection de débris d’objets étrangers (FOD) est une application de sécurité critique régie par l’Annexe 14, Volume I, Chapitre 9 de l’OACI et la Circulaire consultative FAA 150/5220-24 (Norme pour les systèmes de détection de débris d’objets étrangers). Les FOD incluent tout objet sur une surface de piste d’aéroport qui pourrait endommager un aéronef — fragments métalliques, outils, boulons, rivets, caoutchouc de pneus, fragments de chaussée, pierres, pièces de bagages, animaux, et même les flaques d’eau ou plaques de glace.
Exigences réglementaires — Selon la FAA AC 150/5220-24, un système opérationnel de détection FOD doit répondre à des normes de performance minimales : détecter des objets aussi petits que 2-3 cm (environ ¾-1 pouce) dans n’importe quelle dimension, atteindre un taux de détection d’au moins 90 % pour les objets au-dessus du seuil de taille minimal, minimiser les fausses alarmes (pour éviter les fermetures inutiles de piste), fournir des alertes en temps réel avec géolocalisation à 1-3 mètres près, et fonctionner dans toutes les conditions opérationnelles (jour/nuit, pluie, brouillard, neige). La circulaire distingue les FOD primaires (objets pouvant causer des dommages par impact ou ingestion) et les FOD secondaires (débris de chaussée générés par les opérations aériennes comme les dépôts de caoutchouc de pneus ou les éclats de chaussée).
Approche de détection d’objets — La détection FOD par vision par ordinateur a été largement étudiée comme complément ou alternative aux systèmes radar (comme le système de détection FOD Tarsier déployé dans les grands aéroports). La détection FOD basée sur YOLO a été évaluée sur plusieurs ensembles de données, notamment l’ensemble de données FOD-A (2 500 images de 14 types de FOD sur surfaces de piste) et le benchmark Runway FOD (4 200 images de débris courants). Un modèle léger de détection FOD basé sur YOLOv8n atteint environ 93,5 % mAP@0,5 sur l’ensemble de données FOD-A avec une vitesse d’inférence de 180+ FPS sur un Jetson Orin NX, répondant à l’exigence de temps réel.
Défis pour la détection FOD — Les objets FOD présentent des conditions particulièrement difficiles pour la détection d’objets. Ils sont extrêmement petits par rapport à l’image — un boulon de 3 cm à une GSD typique d’inspection de piste de 0,5-1,0 mm/pixel n’occupe que 30 à 60 pixels de diamètre, ce qui en fait un petit objet selon la définition COCO (<32² pixels). La détection de petits objets nécessite des images d’entrée à haute résolution (au moins 1920×1080) et des architectures spécialisées comme les réseaux de pyramides de caractéristiques (FPN) qui préservent la résolution spatiale dans les cartes de caractéristiques peu profondes. Les objets FOD présentent une grande diversité de classes avec des catégories visuellement similaires — un boulon métallique peut ressembler presque identiquement à une petite rondelle métallique, et une pierre peut ressembler à un morceau de caoutchouc de pneu sous certains angles. Les modèles de détection FOD doivent distinguer les FOD des caractéristiques de chaussée visuellement similaires — les marques de pneus (dépôts de caoutchouc sombres), l’eau stagnante (reflets sombres), les marquages de peinture (lignes blanches) et les variations de texture de surface sont toutes des sources courantes de faux positifs. Les vrais objets FOD ont une composante 3D (ils se trouvent au-dessus de la surface de la chaussée), créant une petite ombre que les inspecteurs humains utilisent comme indice de profondeur. Certains systèmes de détection FOD intègrent cela en analysant les motifs de contraste local et les indices d’ombre pour distinguer les vrais débris 3D des marquages de chaussée 2D.
Architecture de déploiement — Les systèmes de détection FOD conformes à la FAA utilisent généralement un réseau multi-caméras monté sur le véhicule de balayage de piste ou sur des portiques fixes aux extrémités de la piste. Le modèle de détection d’objets fonctionne sur un dispositif de calcul en périphérie (NVIDIA Jetson AGX Orin, Intel Movidius ou FPGA dédié) avec une sortie en temps réel vers le cockpit/centre de contrôle. Les détections sont affichées sur une carte de piste avec superposition de boîtes englobantes, coordonnées GPS, étiquette de classe et score de confiance. Le système enregistre toutes les détections pour la conformité de la piste d’audit avec les exigences de documentation de la FAA AC 150/5220-24.
Les marquages de chaussée et la signalisation aéroportuaire sont des caractéristiques d’infrastructure essentielles qui doivent être maintenues selon des normes spécifiées pour la sécurité aérienne. La détection d’objets automatise l’évaluation de l’état des marquages et des panneaux, remplaçant les inspections visuelles à forte intensité de main-d’œuvre.
Détection des marquages de chaussée — Les marquages de piste et de voie de circulation — lignes axiales, lignes de bord, barres de seuil, marquages de zone de toucher des roues et marquages axiaux de voie de circulation — sont détectés à l’aide de modèles de détection d’objets entraînés sur des images aériennes ou embarquées. La tâche consiste à détecter les segments de marquage et à les classifier par type, couleur (blanc ou jaune) et état (bon, délavé, usé). La détection de marquages basée sur YOLO atteint environ 85-92 % mAP@0,5 sur les références de marquages de piste. Les marquages sévèrement délavés ou usés deviennent des objets à faible contraste qui défient la détection — les performances chutent à 60-75 % pour les marquages avec une rétroréflexivité inférieure à 100 mcd/m²/lx.
Évaluation de la rétroréflexivité — La détection d’objets seule ne peut pas mesurer la rétroréflexivité (la capacité des marquages à réfléchir la lumière vers la source, mesurée en millicandelas par lux par mètre carré). Cependant, la détection par boîte englobante fournit l’étendue spatiale de chaque segment de marquage, qui est ensuite utilisée pour échantillonner les valeurs d’intensité des pixels à l’intérieur de la boîte à partir d’images de chaussée nocturnes capturées sous éclairage de phares. Le rapport entre l’intensité des pixels du marquage et l’intensité de la chaussée adjacente est corrélé à la rétroréflexivité. Cette approche combinée — détection pour la localisation, analyse d’intensité pour l’état — est implémentée dans plusieurs systèmes commerciaux d’évaluation des marquages de chaussée.
Détection de la signalisation aéroportuaire — Les panneaux de piste et de voie de circulation (panneaux d’instruction obligatoire — fond rouge, texte blanc ; panneaux de localisation — fond noir, texte jaune ; panneaux de direction — fond jaune, texte noir) sont détectés à l’aide de modèles de détection d’objets. La boîte englobante enferme le panneau, et l’étiquette de classe identifie le type de panneau. La reconnaissance de texte (OCR) est ensuite appliquée dans la région de la boîte englobante pour extraire le contenu du panneau — par exemple, le désignateur de piste « 09/27 » ou l’identifiant de voie de circulation « A ». Le pipeline combiné détection + OCR atteint une précision de classification du type de panneau de 90-95 % et une précision de lecture de texte de 85-90 % dans des conditions d’éclairage diurne. Les performances nocturnes chutent à 70-80 % en raison de l’éblouissement rétroréfléchissant et de l’éclairage non uniforme des phares de véhicules.
Conformité à l’Annexe 14 de l’OACI — La détection de panneaux alimente directement la vérification de conformité selon l’Annexe 14, Volume I, Chapitre 5 de l’OACI (Aides visuelles pour la navigation), qui spécifie les dimensions, couleurs, luminance et exigences de positionnement des panneaux. La détection automatisée des panneaux et l’évaluation de leur état permettent aux exploitants d’aéroport de vérifier que tous les panneaux d’instruction obligatoire sont présents, lisibles et correctement positionnés avant les inspections côté piste.
Les modèles de détection d’objets sont évalués à l’aide d’un ensemble complet de métriques qui évaluent à la fois la précision de localisation et l’exactitude de la classification. Le cadre d’évaluation standard est défini par le protocole d’évaluation COCO et est implémenté dans tous les principaux frameworks de détection.
La métrique d’intersection sur union (IoU) mesure le chevauchement entre une boîte englobante prédite et sa boîte englobante de vérité terrain correspondante. Pour deux boîtes A (prédite) et B (vérité terrain), l’IoU est calculée comme :
IoU = Surface(A ∩ B) / Surface(A ∪ B)
La valeur d’IoU va de 0,0 (aucun chevauchement) à 1,0 (alignement parfait). Une détection est classifiée comme vrai positif (TP) si IoU ≥ seuil ET la classe prédite correspond à la classe de vérité terrain. Les seuils d’IoU courants sont 0,50 (indulgent, utilisé dans l’évaluation PASCAL VOC) et 0,75 (strict, utilisé dans l’évaluation COCO). L’évaluation COCO fait la moyenne de l’AP sur 10 seuils d’IoU de 0,50 à 0,95 par incréments de 0,05, fournissant une évaluation complète de la qualité de localisation à plusieurs niveaux de sévérité.
La précision mesure combien des détections positives du modèle sont correctes : P = TP / (TP + FP). Une précision élevée signifie que le modèle a peu de fausses alarmes. Le rappel mesure combien des objets de vérité terrain le modèle a trouvés : R = TP / (TP + FN). Un rappel élevé signifie que le modèle a peu de détections manquées.
Pour une classe et un seuil d’IoU donnés, la variation du seuil de confiance (le score de confiance minimal pour qu’une détection soit acceptée) produit une courbe précision-rappel. Lorsque le seuil de confiance diminue : le rappel augmente (plus d’objets détectés) mais la précision diminue (plus de faux positifs). La courbe précision-rappel montre ce compromis sur toute la plage des seuils de confiance.
La précision moyenne (AP) calcule l’aire sous la courbe précision-rappel, fournissant un nombre unique qui résume la performance du modèle sur tous les seuils de confiance pour une classe et un seuil d’IoU donnés. Dans le protocole d’évaluation COCO, l’AP est calculée en utilisant l’interpolation à 101 points :
AP = (1/101) × Σ P_interp(r) pour r ∈ {0, 0,01, 0,02, …, 1,0}
où P_interp(r) = max P(r’) pour r’ ≥ r. Cette interpolation garantit une courbe précision-rappel monotone décroissante pour un calcul stable de l’AP.
La moyenne de la précision moyenne (mAP) fait la moyenne de l’AP sur toutes les classes et/ou seuils d’IoU. Les métriques COCO clés sont :
Pour l’inspection d’infrastructures, l’AP par classe est la métrique la plus diagnostique. Un modèle de détection de nids-de-poule pourrait rapporter :
Cette répartition par classe indique au praticien quels types de défauts le modèle traite bien et lesquels nécessitent des données d’entraînement supplémentaires, des changements architecturaux ou une approche complètement différente.
Le déploiement de modèles de détection d’objets pour le traitement vidéo en temps réel dans l’inspection d’infrastructures nécessite une conception minutieuse du pipeline pour équilibrer le débit, la latence et la précision.
Pipeline de traitement d’images — Le flux vidéo est traité comme une séquence d’images individuelles. Chaque image est capturée depuis la caméra, éventuellement prétraitée (redimensionnement à la taille d’entrée du modèle, normalisation, conversion d’espace colorimétrique), passée à travers le modèle de détection d’objets, et les sorties sont post-traitées (seuillage de confiance, suppression non maximale) pour produire les détections finales. Le pipeline doit terminer le traitement de chaque image avant l’arrivée de l’image suivante pour maintenir un fonctionnement en temps réel — pour une caméra à 30 FPS, cela signifie un maximum de 33,3 ms par image (incluant la capture, le prétraitement, l’inférence et le post-traitement).
Saut d’images — Lorsque le modèle de détection d’objets est plus lent que la cadence de la caméra, des images sélectionnées sont supprimées (sautées) pour maintenir le débit du pipeline. Par exemple, avec un modèle fonctionnant à 15 FPS et une caméra à 30 FPS, une image sur deux est sautée, traitant les images 0, 2, 4, 6, … Ceci est acceptable pour l’inspection d’infrastructures car les défauts ne se déplacent pas entre les images — un nid-de-poule visible dans l’image 0 est toujours visible dans l’image 2 (67 ms plus tard) tandis que le véhicule ne se déplace que de 1 à 2 mètres à 80 km/h.
Suppression non maximale (NMS) — Les modèles de détection d’objets génèrent généralement de multiples détections qui se chevauchent pour le même objet (en particulier YOLO et SSD avec une couverture dense d’ancres). La NMS est l’algorithme de post-traitement qui supprime les détections en double. L’algorithme trie toutes les détections par score de confiance, sélectionne la détection ayant le score le plus élevé et supprime toutes les détections restantes avec IoU ≥ seuil_NMS (généralement 0,5-0,7) avec la détection sélectionnée. Ce processus est répété jusqu’à ce qu’il ne reste plus de détections. La NMS garantit que chaque objet est signalé exactement une fois. La Soft-NMS (Bodla et al., 2017) diminue les scores de confiance des détections qui se chevauchent plutôt que de les supprimer complètement, améliorant la détection des objets fortement chevauchants.
Suivi entre les images — Pour compter les objets uniques dans une enquête vidéo, les détections doivent être associées entre les images pour éviter de compter deux fois le même défaut. L’algorithme SORT (Simple Online and Realtime Tracking) utilise le filtrage de Kalman pour prédire la position de chaque objet dans l’image suivante et l’algorithme hongrois pour associer les détections aux pistes. DeepSORT ajoute l’extraction de caractéristiques d’apparence pour ré-identifier les objets après occlusion. Pour l’inspection d’infrastructures où la caméra est en mouvement (véhicule ou drone), le modèle de suivi doit compenser l’égomouvement de la caméra en utilisant les données GPS/IMU ou l’odométrie visuelle.
Déploiement en périphérie — La détection en temps réel sur véhicules d’inspection ou drones nécessite une optimisation du modèle pour le matériel périphérique. Les techniques incluent la quantification du modèle (réduction de la précision des poids de FP32 à INT8, permettant un gain de vitesse de 2-4× avec une perte de précision de 1-2 %), l’optimisation TensorRT (optimisation de graphe et auto-ajustement du noyau de NVIDIA, permettant un gain de vitesse de 2-5× pour les modèles compatibles), l’optimisation OpenVINO (boîte à outils d’optimisation d’inférence d’Intel, principalement pour le déploiement sur CPU et GPU intégré) et l’élagage de modèle (suppression des poids de faible amplitude pour réduire la taille du modèle avec un impact minimal sur la précision).
L’entraînement d’un modèle de détection d’objets pour l’inspection d’infrastructures suit un pipeline systématique qui transforme des données annotées brutes en un modèle déployable.
Étape 1 — Collecte de données — Les images sont capturées lors d’inspections couvrant toute la gamme des conditions opérationnelles : différents éclairages (aube, midi, crépuscule), conditions de surface (sèche, humide, enneigée), angles de caméra (nadir, oblique) et altitudes (10-50 m pour drone, 0,5-3 m pour véhicule). Pour l’inspection des chaussées aéroportuaires selon les normes de l’OACI, les images doivent couvrir tous les types de chaussée présents (asphalte, béton, composite) et toutes les classes de défauts définies dans l’ASTM D5340. Un minimum de 1 000 à 2 000 images par classe de défaut est recommandé pour une performance acceptable du modèle (mAP > 40).
Étape 2 — Annotation — Chaque image est annotée manuellement par des inspecteurs formés à l’aide d’outils de boîte englobante. Chaque instance de défaut reçoit une boîte englobante qui enferme étroitement le défaut et une étiquette de classe provenant de la taxonomie de défauts prédéfinie (ex. : nid-de-poule, fissure, éclat, réparation, défaut de joint, weathering). Le contrôle qualité de l’annotation comprend des vérifications de concordance entre annotateurs (au moins 10 % des images annotées par deux annotateurs indépendants, l’IoU entre leurs boîtes doit dépasser 0,7) et un examen expert des cas ambigus.
Étape 3 — Division de l’ensemble de données — L’ensemble de données annoté est divisé en ensembles d’entraînement (70 %), de validation (15 %) et de test (15 %). La division est stratifiée par classe de défaut et (important) par emplacement — toutes les images de la même section de piste doivent aller dans la même division pour éviter la fuite de données où le modèle voit une texture de chaussée similaire dans les ensembles d’entraînement et de test.
Étape 4 — Augmentation de données — L’augmentation à la volée pendant l’entraînement inclut Mosaic (combinaison de 4 images en une, spécifique à YOLO), retournement horizontal aléatoire (probabilité 50 %), rotation aléatoire (±45°), variation HSV (teinte ±0,015, saturation ±0,7, valeur ±0,4), mise à l’échelle (±50 %), translation (±20 %) et probabilité de mosaïque (1,0). Ces augmentations simulent la variabilité des conditions d’inspection réelles.
Étape 5 — Configuration du modèle — L’architecture du modèle est sélectionnée en fonction des exigences de vitesse et de précision. Pour l’inspection en temps réel : YOLO11m ou YOLO11l (qui équilibre vitesse et précision). Pour une précision maximale : YOLO11x, Faster R-CNN avec ResNet-101-FPN, ou DINO. La taille d’image d’entrée est typiquement de 640×640 pour les modèles YOLO (équilibrant résolution et vitesse) ou de 800-1333 pour Faster R-CNN/DETR. Les poids du backbone sont initialisés à partir d’un pré-entraînement sur COCO ou ImageNet.
Étape 6 — Entraînement — Le modèle est entraîné pendant 200 à 300 époques en utilisant l’optimiseur SGD ou AdamW. Le taux d’apprentissage commence à 0,01 (SGD) ou 0,001 (AdamW) avec un programme de décroissance cosinus. La taille du lot est maximisée pour la mémoire GPU disponible (généralement 16-64 pour des images 640×640 sur un seul GPU A100). Les composants de perte incluent la perte de classification (BCE ou entropie croisée), la perte de régression de boîte (CIoU ou GIoU) et éventuellement la perte d’objectness (pour YOLO). L’entraînement prend typiquement 8 à 48 heures sur un seul GPU selon la taille du modèle et la taille de l’ensemble de données.
Étape 7 — Évaluation — Après chaque époque, le modèle est évalué sur l’ensemble de validation. Les métriques principales sont mAP@0,50 et mAP@0,50:0,95. L’AP par classe est examinée pour identifier les classes de défauts faibles. Le surapprentissage est détecté lorsque la mAP de validation plafonne ou diminue tandis que la perte d’entraînement continue de diminuer. Le point de contrôle avec les meilleures performances (mAP de validation la plus élevée) est sauvegardé.
Étape 8 — Réglage des hyperparamètres — À l’aide de l’ensemble de validation, les hyperparamètres sont optimisés : taux d’apprentissage, taille de lot, optimiseur, amplitudes d’augmentation, seuil de confiance (pour l’inférence), seuil IoU NMS (pour l’inférence). Optuna ou Ray Tune peuvent automatiser cette recherche avec une optimisation bayésienne sur un espace de paramètres défini.
Étape 9 — Évaluation sur le test — Le modèle final est évalué une fois sur l’ensemble de test mis de côté pour obtenir les métriques de performance finales. Cette évaluation sur l’ensemble de test est la performance rapportée pour l’approbation du déploiement.
Étape 10 — Déploiement — Le modèle entraîné est exporté vers le format de déploiement (ONNX, TensorRT, CoreML ou OpenVINO) à l’aide de l’API d’exportation du framework. Pour les modèles YOLO : yolo export model=best.pt format=onnx imgsz=640. Le modèle exporté est intégré dans le pipeline d’inspection — chargé sur le dispositif périphérique (Jetson, ordinateur portable ou serveur cloud), connecté au flux vidéo et configuré avec les seuils de confiance et NMS optimaux déterminés lors du réglage des hyperparamètres. Le pipeline de déploiement enregistre toutes les détections avec les horodatages, les coordonnées GPS, les coordonnées des boîtes englobantes, les étiquettes de classe et les scores de confiance dans une base de données pour une analyse SIG ultérieure et un calcul PCI selon l’ASTM D5340.
TarmacView utilise des modèles de détection d'objets de pointe pour identifier, compter et localiser les nids-de-poule, les fissures, les FOD et les caractéristiques d'infrastructure sur les chaussées aéroportuaires, les ponts et les routes. Planifiez une démonstration pour voir comment la détection d'objets en temps réel peut rationaliser votre flux d'inspection.
La segmentation de fissures est une tâche de vision par ordinateur consistant à classer chaque pixel d'une image comme fissure ou non-fissure, produisant un mas...
Qu’est-ce que la Segmentation Sémantique pour la Compréhension de Scènes d’Infrastructure ? Définition et Distinction des Tâches Connexes de Vision ...
La détection de fissures par IA utilise la vision par ordinateur — réseaux de neurones convolutifs, vision transformers et modèles de segmentation sémantique — ...