Test de fumée
Un test de fumée est une vérification rapide de bout en bout permettant de s'assurer qu'une chaîne de traitement logicielle s'exécute sans planter sur des donné...
41 min de lecture
testing
technology
+4
Le test de fumée de la tête de défaut valide que le pipeline de détection des défauts structurels de TarmacView — backbone DINOv3 + tête MLP à 5 étiquettes pour fissure/éclatement/efflorescence/armature_exposée/corrosion — produit les sorties attendues sur les données de test. Il couvre les assertions de test (existence du checkpoint ; métriques AP ; colonnes de défauts de dalle/trame dans la sortie d’analyse) et ce que les tests de fumée vérifient par rapport à l’évaluation complète.
Le test de fumée de la tête de défaut est une procédure de vérification automatisée qui valide l’intégrité structurelle et les fonctionnalités de base d’un pipeline d’apprentissage automatique de détection de défauts. Il confirme que le pipeline — du prétraitement d’image d’entrée à travers le backbone de transformateur visuel DINOv3 jusqu’à la tête de classification MLP (Perceptron Multicouche) à 5 étiquettes — produit les sorties attendues sur des données synthétiques ou de petits ensembles de test statiques sans planter, sans produire d’erreurs numériques, ni générer des prédictions structurellement invalides. Le test de fumée est distinct d’une évaluation complète : il vérifie que le pipeline est correctement câblé et opérationnel, et non qu’il généralise à des données non vues avec une haute précision.
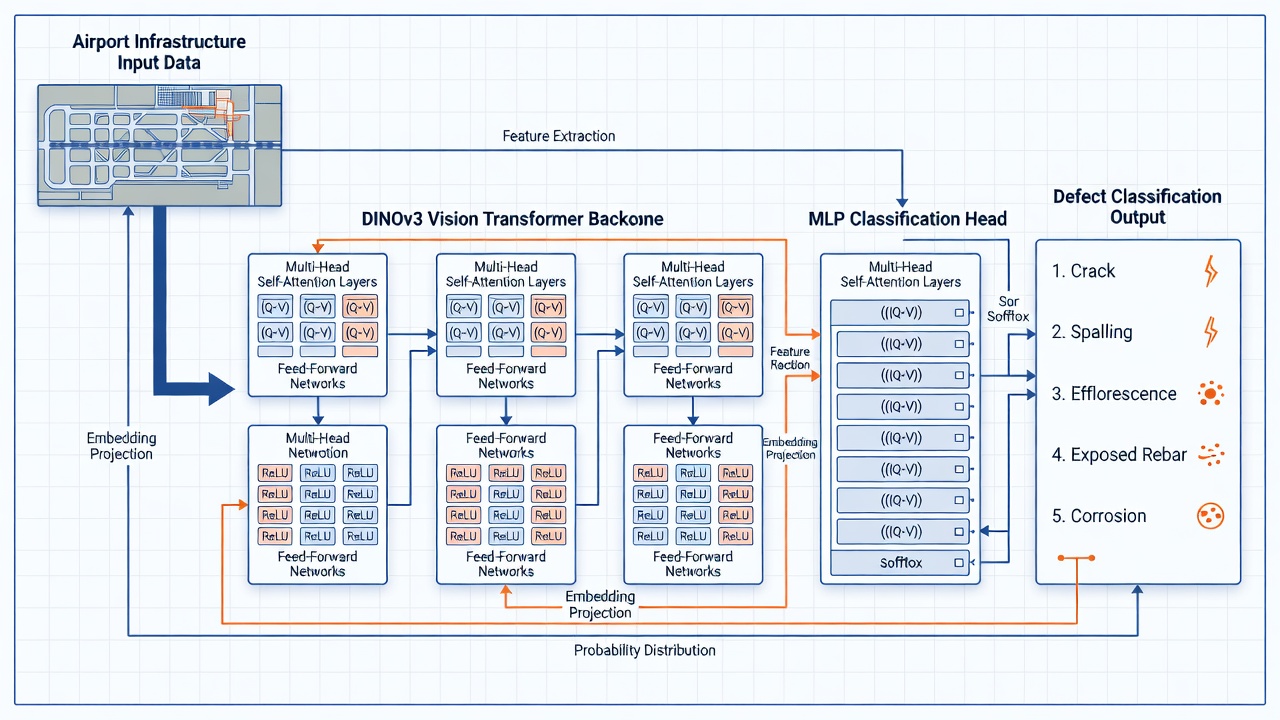
La tête de défaut est le composant final du pipeline de détection des défauts structurels de TarmacView, responsable de la mise en correspondance des représentations de caractéristiques riches extraites par le réseau backbone vers des prédictions de classes de défauts discrètes. Comprendre l’architecture à la fois du backbone et de la tête est essentiel pour concevoir des tests de fumée efficaces qui valident l’intégrité de chaque composant.
Le transformateur visuel DINOv3 (auto-DIstillation sans étiquettes, version 3), développé par Meta AI et publié en 2023, sert de backbone d’extraction de caractéristiques. DINOv3 a été entraîné en utilisant un paradigme d’apprentissage auto-supervisé sur un ensemble de données organisé de 142 millions d’images non étiquetées (LVD-142M), apprenant des représentations visuelles à usage général sans nécessiter d’annotations humaines. Cette approche produit des caractéristiques qui se transfèrent efficacement aux tâches en aval, y compris la classification, la segmentation et la détection de défauts — surpassant souvent l’apprentissage supervisé sur ImageNet-1K.
DINOv3 est disponible en plusieurs variantes de modèles avec différents profils de calcul :
| Variante | Paramètres | Dim. d’embedding | Taille de patch | Couches | Têtes |
|---|---|---|---|---|---|
| ViT-S/14 | 22 millions | 384 | 14×14 | 12 | 6 |
| ViT-B/14 | 86 millions | 768 | 14×14 | 12 | 12 |
| ViT-L/14 | 300 millions | 1024 | 14×14 | 24 | 16 |
| ViT-g/14 | 1,1 milliard | 1536 | 14×14 | 40 | 24 |
Pour le pipeline de détection des défauts de TarmacView, la variante ViT-B/14 est la configuration standard. Avec 86 millions de paramètres et un espace d’embedding de 768 dimensions, elle équilibre la capacité représentationnelle avec l’efficacité de calcul adaptée au traitement de grands volumes d’imagerie d’inspection de pistes. La taille de patch de 14×14 signifie qu’une image d’entrée de 224×224 pixels est divisée en 16×16 = 256 patches non chevauchants, chacun projeté dans l’espace d’embedding à 768 dimensions via une projection linéaire apprise.
La méthodologie d’entraînement de DINOv3 combine plusieurs techniques clés. L’auto-distillation avec architecture enseignant-élève garantit que le réseau élève apprend à correspondre aux représentations de l’enseignant, l’enseignant étant une moyenne mobile exponentielle de l’élève. iBOT (pré-entraînement BERT d’image avec Tokenizer en ligne) applique la modélisation d’image masquée, où des patches aléatoires sont masqués et le modèle doit prédire les représentations des patches masqués. Le centrage Sinkhorn-Knopp de la méthode SwAV empêche l’effondrement des représentations en imposant une distribution uniforme entre les échantillons du lot. Le régularisateur KoLeo encourage la diversité des caractéristiques apprises en pénalisant la similarité des caractéristiques entre les échantillons proches.
Pour le cas d’utilisation de la détection de défauts, DINOv3 est chargé avec des poids pré-entraînés et généralement figé pendant l’entraînement de la tête de défaut. Le backbone figé extrait des caractéristiques visuelles générales — bords, textures, gradients, motifs de surface — qui sont hautement pertinentes pour distinguer une chaussée intacte des cinq classes de défauts. Geler le backbone réduit le nombre de paramètres entraînables de 86 millions à environ 1 à 3 millions (selon la profondeur de la tête MLP), réduisant considérablement le temps d’entraînement, les besoins en mémoire GPU et le risque d’oubli catastrophique sur de petits ensembles de données spécifiques au domaine.
La tête de défaut MLP (Perceptron Multicouche) est un petit réseau neuronal feedforward qui prend les embeddings DINOv3 figés en entrée et produit une distribution de probabilité à 5 dimensions sur les cinq classes de défauts : fissure, éclatement, efflorescence, armature exposée et corrosion.
L’architecture standard se compose de :
Couche d’entrée : Accepte l’embedding DINOv3 — soit le jeton [CLS] (un vecteur à 768 dimensions représentant le contenu global de l’image) soit une représentation regroupée de tous les jetons de patchs. L’approche du jeton [CLS] est standard car DINOv3 est spécifiquement entraîné à produire des informations riches dans le jeton [CLS] pendant l’auto-distillation.
Couches cachées : Généralement 1 à 2 couches entièrement connectées avec fonctions d’activation ReLU ou GELU. Une configuration à une seule couche cachée pourrait être 768 → 256 → 5, tandis qu’une configuration plus profonde pourrait être 768 → 512 → 128 → 5. Chaque couche cachée est suivie d’une normalisation par lot ou d’une normalisation de couche pour stabiliser l’entraînement et réduire le décalage de covariance interne. Le dropout (taux 0,2-0,5) est appliqué entre les couches cachées pendant l’entraînement comme régularisateur pour prévenir le surapprentissage, étant donné que les ensembles de données de défauts d’infrastructure sont généralement petits (500 à 5000 images).
Couche de sortie : Une projection linéaire vers 5 unités correspondant aux cinq classes de défauts, suivie d’une activation softmax qui convertit les logits en une distribution de probabilité sur les classes. La fonction softmax garantit que le vecteur de sortie totalise 1,0, chaque élément représentant la probabilité prédite que l’image d’entrée appartienne à cette classe de défaut.
Procédure d’entraînement : La tête MLP est entraînée via un ajustement supervisé tandis que le backbone DINOv3 reste figé. La fonction de perte est l’entropie croisée catégorielle, comparant la distribution de probabilité prédite aux étiquettes de vérité terrain encodées en one-hot. L’entraînement utilise généralement l’optimiseur AdamW avec un taux d’apprentissage de 1e-3 à 1e-4, une taille de lot de 32 à 128, et un arrêt précoce basé sur la perte de validation. L’augmentation des données (rotation aléatoire, retournement horizontal, variation de couleur, recadrage aléatoire) est appliquée pendant l’entraînement pour améliorer la généralisation.
Pour l’inférence, le backbone DINOv3 traite chaque image d’entrée en embeddings de patchs et de jeton [CLS] en un seul passage forward. L’embedding [CLS] est extrait et passé à travers la tête MLP. Les probabilités softmax de sortie sont seuillées (généralement à 0,5 ou optimisées via analyse ROC) pour produire une prédiction binaire pour chaque classe de défaut. Étant donné que les cinq classes de défauts ne sont pas mutuellement exclusives — une même zone de chaussée peut présenter à la fois des fissures et des éclats simultanément — les prédictions seuillées pour chaque classe sont indépendantes, et la sortie est correctement interprétée comme multi-étiquettes plutôt que comme une prédiction à classe unique.
Dans le pipeline d’analyse de TarmacView, la tête de défaut opère à deux niveaux de granularité.
Analyse au niveau dalle : La surface de la piste est divisée en une grille de dalles d’image (généralement 224×224 ou 512×512 pixels à la résolution d’inspection de 0,5 à 2,0 mm/pixel). Chaque dalle est traitée indépendamment à travers le backbone DINOv3 et la tête de défaut MLP, produisant un vecteur de probabilité à 5 éléments par dalle. Les prédictions au niveau dalle sont stockées sous forme de colonnes par dalle dans la sortie d’analyse : tile_crack_conf, tile_spalling_conf, tile_efflorescence_conf, tile_exposed_rebar_conf, tile_corrosion_conf.
Agrégation au niveau trame : Les prédictions individuelles des dalles au sein d’une trame de caméra ou d’une section de piste sont agrégées pour produire des évaluations de défauts au niveau trame. Les méthodes d’agrégation incluent : le max pooling (la confiance maximale parmi toutes les dalles de la trame), le mean pooling (confiance moyenne), le vote top-k (la proportion de dalles dépassant un seuil), et la densité spatiale (le nombre de dalles avec défaut par unité de surface). Les colonnes au niveau trame dans la sortie incluent frame_defect_count, frame_max_defect_conf, frame_defect_count, et frame_max_defect_conf.
Le schéma de sortie d’analyse est un composant critique que les tests de fumée doivent valider. Si les colonnes de confiance au niveau dalle ou les colonnes d’agrégation au niveau trame sont manquantes, renommées, ou contiennent des valeurs invalides (NaN, inf, probabilités négatives), les calculs d’indice de condition de chaussée (PCI) en aval et les pipelines de rapport échoueront.
Les assertions du test de fumée sont les vérifications automatisées spécifiques qui confirment que le pipeline de tête de défaut fonctionne correctement. Chaque assertion cible un mode de défaillance spécifique et produit un résultat clair de réussite/échec qui peut être intégré dans le contrôle du pipeline CI/CD.
La première catégorie d’assertions du test de fumée vérifie que le checkpoint de la tête de défaut — le fichier de poids du modèle sauvegardé — est valide et chargeable. Les assertions incluent :
Existence du fichier de checkpoint : Le test vérifie que le fichier de checkpoint existe au chemin spécifié. Cela détecte les problèmes où un entraînement a échoué, le checkpoint n’a pas été téléchargé dans le registre de modèles, ou le chemin du fichier a été mal configuré dans l’environnement de déploiement. L’assertion est : assert os.path.exists(checkpoint_path), f"Checkpoint introuvable à {checkpoint_path}".
Taille du fichier et validation de somme de contrôle : Le test vérifie que le fichier de checkpoint a une taille non nulle et valide optionnellement sa somme de contrôle MD5 ou SHA256 par rapport à une référence stockée. Un fichier de zéro octet ou un téléchargement corrompu seront détectés ici. L’assertion est : assert os.path.getsize(checkpoint_path) > 0 et optionnellement assert sha256(file) == expected_sha256.
Chargeabilité Torch : Le test charge le checkpoint en utilisant torch.load() et vérifie que l’opération se termine sans lever d’exception. Cela détecte les fichiers corrompus, les incompatibilités de version (par exemple, un checkpoint sauvegardé avec PyTorch 2.0 tentant de charger avec PyTorch 1.8) et les dépendances manquantes. L’assertion encapsule l’appel de chargement dans un bloc try/except et échoue sur toute exception.
Structure du dictionnaire d’état : Après le chargement, le test vérifie que le checkpoint contient les clés du dictionnaire d’état attendues. Pour le backbone DINOv3, les clés attendues incluent backbone.cls_token, backbone.patch_embed.proj.weight, et les paramètres des blocs de transformateur. Pour la tête MLP, les clés attendues incluent head.0.weight, head.0.bias, head.2.weight, head.2.bias (pour un MLP à 2 couches). Le test vérifie également que toutes les clés attendues sont présentes et qu’aucune clé inattendue n’existe, ce qui pourrait indiquer une incompatibilité d’architecture du modèle.
La deuxième catégorie vérifie qu’un passage forward à travers le backbone et la tête combinés produit des sorties valides.
Validation de la forme du tenseur : Le test crée un tenseur d’entrée synthétique de la forme attendue (généralement [batch_size, 3, height, width] avec batch_size=1-4, height=width=224 pour ViT-B/14), le passe à travers le modèle, et vérifie que la forme du tenseur de sortie est [batch_size, 5] — exactement 5 logits correspondant aux 5 classes de défauts. L’assertion est : assert output.shape == (batch_size, 5), f"Forme attendue (batch_size, 5), obtenue {output.shape}".
Validation de la stabilité numérique : Le test vérifie qu’aucune valeur de sortie n’est NaN (Pas un Nombre), infini ou infini négatif. Les valeurs NaN peuvent provenir d’une instabilité numérique dans le backbone du transformateur (par exemple, débordement de logit d’attention), d’une division par zéro dans les couches de normalisation, ou de poids corrompus. L’assertion est : assert not torch.isnan(output).any(), "La sortie contient des valeurs NaN" et assert not torch.isinf(output).any(), "La sortie contient des valeurs inf".
Validation des probabilités softmax : Le test applique softmax aux logits bruts et vérifie que les probabilités résultantes totalisent 1,0 pour chaque échantillon du lot (avec une tolérance en virgule flottante, généralement 1e-5). Cela confirme que la couche de sortie est correctement configurée et qu’aucune étape de post-traitement ne corrompt la distribution de probabilité. L’assertion est : assert torch.allclose(probs.sum(dim=1), torch.ones(batch_size), atol=1e-5).
La troisième catégorie vérifie que le modèle produit des distributions de prédictions raisonnables plutôt que des sorties dégénérées.
Vérification de distribution non uniforme : Le test vérifie que les probabilités prédites ne sont pas uniformes entre toutes les classes (ce qui indiquerait un modèle qui n’a appris aucune caractéristique discriminante). L’entropie de la distribution prédite est calculée et comparée à un seuil minimum. Une distribution complètement uniforme a une entropie maximale (log(5) ≈ 1,61 nats pour 5 classes), tandis qu’une prédiction confiante a une faible entropie. L’assertion est : assert entropy < 1.5, "Les prédictions sont quasi-uniformes, le modèle n'est peut-être pas entraîné".
Vérification de la couverture des classes : Le test exécute une inférence sur un petit ensemble d’images d’entrée diverses et vérifie que chacune des 5 classes de défauts est la prédiction la plus confiante pour au moins une entrée. Cela vérifie qu’aucune classe n’est systématiquement supprimée — par exemple, un modèle qui ne prédit jamais « efflorescence » indiquerait un déséquilibre des données d’entraînement ou un problème de configuration de la tête. L’assertion est : assert set(predicted_classes) == set(range(5)), f"Classes {missing} jamais prédites".
Gestion de la classe d’arrière-plan : Si le modèle inclut une classe implicite d’arrière-plan ou « sans défaut », le test de fumée vérifie qu’une image de chaussée intacte — sans aucun défaut — produit une prédiction d’arrière-plan avec une confiance supérieure à un seuil (généralement 0,8). Cela confirme que le modèle peut correctement rejeter les exemples négatifs, ce qui est essentiel pour éviter les fausses alarmes dans les inspections de production.
La validation du checkpoint est un composant fondamental du test de fumée qui confirme que l’artefact du modèle — les poids du réseau neuronal sauvegardés — est intact, chargeable et structurellement cohérent avec l’architecture attendue. Dans les systèmes de ML de production, la corruption du checkpoint ou l’incompatibilité de version est l’un des modes de défaillance les plus courants, et le détecter tôt dans le CI/CD empêche les défaillances en cascade en aval.
Les checkpoints de tête de défaut de TarmacView sont stockés dans le registre de modèles — un stockage centralisé d’artefacts avec gestion de versions, métadonnées et suivi de lignée (MLflow Model Registry ou DVC). Chaque checkpoint est identifié par une combinaison unique de nom de modèle, numéro de version et ID d’exécution. Le fichier de checkpoint lui-même est un dictionnaire d’état PyTorch sérialisé (généralement model.pt ou checkpoint.pt) contenant les paramètres appris à la fois du backbone DINOv3 (si ajusté) et de la tête MLP.
Le test de fumée résout d’abord le chemin du checkpoint à partir du registre de modèles, en traitant les cas suivants :
defect-head:v3), et le test charge cette version exacte.Le backbone DINOv3 est un grand modèle avec 86 millions de paramètres pour la variante ViT-B/14. Le test de fumée vérifie que le backbone chargé correspond à l’architecture attendue en contrôlant :
Formes des tenseurs de poids : Chaque tenseur de paramètre dans le dictionnaire d’état chargé est vérifié par rapport à la forme attendue. Par exemple, le tenseur backbone.patch_embed.proj.weight devrait avoir la forme (768, 3, 14, 14) pour un ViT-B/14 avec 3 canaux d’entrée, 768 canaux de sortie et un noyau de patch de 14×14. Une incompatibilité de forme indiquerait que le checkpoint a été entraîné avec une configuration différente (taille de patch différente, dimension d’embedding différente, canaux d’entrée différents).
Plage numérique raisonnable : Le test vérifie que les valeurs des poids se situent dans des plages numériques attendues. Les poids d’attention du transformateur devraient avoir des valeurs distribuées approximativement comme N(0, σ²) avec σ dépendant du schéma d’initialisation. Des valeurs extrêmes (|w| > 10) à travers toutes les couches indiqueraient une divergence d’entraînement ou une corruption du checkpoint. La vérification calcule la moyenne et l’écart type de chaque tenseur de paramètre et signale les valeurs aberrantes.
Cohérence de l’embedding de sortie : Le test exécute une entrée synthétique fixe à travers le backbone et compare la distribution de l’embedding de sortie à une référence stockée. La référence est générée lors de la première exécution réussie du test de fumée et stockée comme point de référence. L’assertion vérifie que la moyenne et la variance de l’embedding ne dérivent pas au-delà d’une tolérance (généralement ±5%). Cela détecte la dégradation silencieuse du modèle qui ne produit pas de valeurs NaN ou inf mais produit néanmoins des embeddings anormaux.
La tête MLP est plus petite que le backbone mais tout aussi critique. Le test de fumée vérifie :
Nombre de couches : La tête doit avoir exactement le nombre attendu de couches. Pour un MLP à 2 couches avec dimension cachée 256, les clés attendues incluent head.0.weight (768×256), head.0.bias (256), head.2.weight (256×5), head.2.bias (5). La numérotation des couches tient compte de la fonction d’activation (couche 1) entre les couches linéaires.
Dimension de sortie : La dimension de sortie de la dernière couche linéaire doit être exactement 5, correspondant aux 5 classes de défauts. Cela est vérifié en contrôlant head.2.weight.shape[0] == 5.
Cohérence de l’initialisation des poids : Le test vérifie que les poids ne sont pas figés aux valeurs d’initialisation (tous nuls ou tous à un). Une tête avec des poids tous nuls produirait des logits uniformes quelle que soit l’entrée, indiquant un échec d’entraînement. La vérification confirme que head.2.weight.std() > 0.001.
Bien que le test de fumée porte principalement sur l’intégrité du pipeline plutôt que sur la qualité du modèle, inclure un calcul léger de métriques dans le test de fumée fournit un avertissement précoce d’une régression significative du modèle. Le test de fumée calcule des métriques d’efficacité sur des données synthétiques ou de petits ensembles de test statiques, en les comparant aux références stockées lors d’exécutions validées précédentes.
La Précision Moyenne (AP) est l’aire sous la courbe précision-rappel, calculée à travers des seuils de confiance de 0 à 1. Le test de fumée calcule l’AP pour chacune des 5 classes de défauts en utilisant l’évaluation de style COCO :
Les assertions AP du test de fumée incluent :
AP@0,50 (métrique PASCAL VOC) : AP au seuil IoU de 0,50. L’assertion est que l’AP@0,50 pour chaque classe dépasse un seuil minimum. Pour des données de test synthétiques avec des motifs de défauts connus et propres, un seuil typique est AP@0,50 > 0,85 pour les 5 classes. Si le modèle atteint une AP@0,50 inférieure à ce seuil sur des données synthétiques triviales, cela indique une régression sévère.
AP@0,50:0,95 (métrique primaire COCO) : La moyenne des valeurs AP calculées aux seuils IoU 0,50, 0,55, …, 0,95. Le seuil d’assertion est plus bas — généralement AP@0,50:0,95 > 0,50 — car les seuils IoU stricts sont plus difficiles même sur des données synthétiques.
Cohérence AP par classe : La variance de l’AP entre les 5 classes est vérifiée. Un écart type dépassant 0,15 indiquerait qu’une classe a régressé de manière significative par rapport aux autres, suggérant un problème spécifique à ce type de défaut (par exemple, exemples d’entraînement insuffisants pour l’efflorescence).
L’ensemble de données de test synthétique est soigneusement construit pour garantir la stabilité des métriques. Chaque image synthétique contient exactement un type de défaut superposé sur une texture de fond ressemblant à une chaussée. Les défauts sont générés à l’aide de techniques procédurales : fissures sous forme de fines lignes noires ramifiées avec flou gaussien pour le réalisme ; éclats sous forme de régions circulaires/ovales irrégulières avec rugosité de bord ; efflorescence sous forme de taches blanches amorphes avec opacité variable ; armature exposée sous forme de motifs circulaires sombres périodiques ; corrosion sous forme de taches irrégulières de couleur rouille. L’ensemble de données synthétique est versionné et vérifié dans le référentiel pour garantir des résultats de test de fumée déterministes et reproductibles.
Le score F1 est la moyenne harmonique de la précision et du rappel, fournissant une mesure unique et équilibrée de la performance du modèle. Le test de fumée calcule le F1 à un seuil de confiance fixe (généralement 0,5) pour chaque classe de défaut.
Les assertions F1 incluent :
F1 minimum par classe : Chaque classe doit atteindre F1 > 0,80 sur l’ensemble de test synthétique. La nature multi-étiquettes de la tâche de prédiction de défauts signifie que le F1 est calculé indépendamment par classe.
F1 macro-moyenné : La moyenne non pondérée du F1 sur les 5 classes est calculée. Le seuil d’assertion est macro-F1 > 0,85. La macro-moyenne traite toutes les classes de manière égale, donc une régression sur une classe rare (par exemple, armature exposée) est immédiatement visible.
Équilibre précision-rappel : Le rapport de la précision au rappel est vérifié pour chaque classe. Un rapport supérieur à 1,5 ou inférieur à 0,67 indique un déséquilibre — le modèle est soit trop conservateur (haute précision, faible rappel, manquant de nombreux défauts) soit trop agressif (rappel élevé, faible précision, générant de nombreux faux positifs). L’assertion signale toute classe où le rapport est en dehors de [0,67, 1,5].
| Métrique | Seuil de Test Synthétique | Objectif |
|---|---|---|
| AP@0,50 | > 0,85 | Capacité de détection de base par classe |
| AP@0,50:0,95 | > 0,50 | Qualité de détection complète |
| Écart type AP par classe | < 0,15 | Vérification de l’équilibre des classes |
| F1 par classe | > 0,80 | Équilibre précision-rappel par classe |
| F1 macro-moyenné | > 0,85 | Qualité globale du modèle |
| Rapport Précision/Rappel | [0,67, 1,5] | Équilibre précision-rappel par classe |
Le test de fumée stocke les références métriques de la dernière exécution validée et compare les métriques actuelles à ces références. Une baisse significative (>5% de diminution relative) de toute métrique déclenche un échec du test de fumée, même si la valeur métrique absolue est au-dessus du seuil minimum. Cela détecte la dégradation graduelle — les modèles qui passent les seuils absolus mais dont les performances diminuent constamment au fil des entraînements successifs ou des mises à jour de données.
Les historiques métriques sont enregistrés dans une base de données de séries temporelles (MLflow, Weights & Biases, ou un simple fichier CSV dans le référentiel). Le test de fumée lit les 10 dernières valeurs métriques validées et ajuste une tendance linéaire. Si la pente est négative et statistiquement significative (p < 0,05), le test produit un avertissement mais n’échoue pas — seul l’échec basé sur le seuil est utilisé pour le contrôle CI/CD afin d’éviter des interruptions bruyantes du pipeline dues à des fluctuations métriques mineures.
Un test de fumée critique valide que la sortie d’analyse — les données structurées produites en exécutant la tête de défaut sur l’imagerie d’inspection — contient toutes les colonnes attendues avec les types de données corrects et des valeurs valides. Cela comble le fossé entre l’inférence du modèle et le calcul de l’indice de condition de chaussée (PCI) en aval, la création de rapports et l’intégration SIG.
La sortie d’analyse de TarmacView est un format tabulaire (Parquet, CSV ou table de base de données) avec des colonnes organisées en niveaux :
Colonnes de confiance de défaut au niveau dalle — une colonne flottante par classe de défaut, représentant la confiance softmax de la tête MLP que la dalle contient ce défaut :
| Nom de Colonne | Type de Données | Plage Valide | Description |
|---|---|---|---|
tile_crack_conf | Float32 | [0,0, 1,0] | Probabilité de présence de fissure |
tile_spalling_conf | Float32 | [0,0, 1,0] | Probabilité de présence d’éclatement |
tile_efflorescence_conf | Float32 | [0,0, 1,0] | Probabilité de présence d’efflorescence |
tile_exposed_rebar_conf | Float32 | [0,0, 1,0] | Probabilité de présence d’armature exposée |
tile_corrosion_conf | Float32 | [0,0, 1,0] | Probabilité de présence de corrosion |
Colonnes d’agrégation au niveau trame — résumant la présence de défauts sur toutes les dalles d’une trame de caméra ou d’une section de piste :
| Nom de Colonne | Type de Données | Plage Valide | Description |
|---|---|---|---|
frame_defect_count | Int32 | [0, max_dalles] | Nombre de dalles avec un défaut au-dessus du seuil |
frame_max_defect_conf | Float32 | [0,0, 1,0] | Confiance maximale parmi tous les défauts et dalles |
frame_crack_flag | Booléen | {0, 1} | Une dalle a crack_conf > seuil |
frame_spalling_flag | Booléen | {0, 1} | Une dalle a spalling_conf > seuil |
frame_efflorescence_flag | Booléen | {0, 1} | Une dalle a efflorescence_conf > seuil |
frame_exposed_rebar_flag | Booléen | {0, 1} | Une dalle a exposed_rebar_conf > seuil |
frame_corrosion_flag | Booléen | {0, 1} | Une dalle a corrosion_conf > seuil |
Colonnes de métadonnées — identifiant le contexte spatial et temporel de chaque enregistrement d’analyse :
| Nom de Colonne | Type de Données | Description |
|---|---|---|
image_id | Chaîne | Identifiant unique de l’image source |
tile_x | Int32 | Index de colonne de la dalle dans la grille de la piste |
tile_y | Int32 | Index de ligne de la dalle dans la grille de la piste |
frame_timestamp | DateTime | Heure de capture de la trame source |
gps_lat | Float64 | Latitude GPS du centre de la dalle |
gps_lon | Float64 | Longitude GPS du centre de la dalle |
Le test de fumée charge la sortie d’analyse et vérifie que chaque colonne attendue existe en utilisant une correspondance simple de nom de colonne :
expected_tile_cols = ["tile_crack_conf", "tile_spalling_conf",
"tile_efflorescence_conf", "tile_exposed_rebar_conf",
"tile_corrosion_conf"]
expected_frame_cols = ["frame_defect_count", "frame_max_defect_conf",
"frame_crack_flag", "frame_spalling_flag",
"frame_efflorescence_flag", "frame_exposed_rebar_flag",
"frame_corrosion_flag"]
expected_meta_cols = ["image_id", "tile_x", "tile_y",
"frame_timestamp", "gps_lat", "gps_lon"]
actual_cols = set(df.columns)
assert expected_cols.issubset(actual_cols), f"Colonnes manquantes : {expected_cols - actual_cols}"
Pour chaque colonne de confiance de défaut, le test de fumée vérifie :
Type flottant : Le type de données de la colonne est float32 ou float64. Des types inattendus (int, string, object) indiquent une erreur de sérialisation ou de pipeline. L’assertion utilise assert df[col].dtype in [np.float32, np.float64].
Plage de valeurs : Toutes les valeurs sont dans [0,0, 1,0]. Des valeurs en dehors de cette plage indiquent un échec de softmax ou de normalisation. L’assertion utilise assert df[col].between(0.0, 1.0).all().
Vérification des valeurs manquantes : Aucune valeur n’est NaN ou None. Des valeurs NaN dans les colonnes de confiance indiquent que le pipeline d’inférence n’a produit aucune sortie pour certaines dalles — un échec grave. L’assertion utilise assert df[col].notna().all().
Les colonnes au niveau trame doivent être cohérentes avec les données au niveau dalle dont elles sont dérivées. Le test de fumée valide :
frame_defect_count égal au nombre de dalles où la confiance maximale dépasse le seuil : Pour chaque groupe de trames, le test recalcule le nombre de défauts à partir des données au niveau dalle et vérifie qu’il correspond à la valeur de trame stockée. Cela détecte les erreurs de logique d’agrégation dans le pipeline.
frame_max_defect_conf égal au maximum de toutes les valeurs de confiance des dalles : Le test recalcule le maximum à partir des données au niveau dalle et vérifie la correspondance.
frame_flag cohérent avec tile_conf : Pour chaque trame, le drapeau doit être 1 si une dalle a la confiance correspondante au-dessus du seuil, et 0 sinon. Le test vérifie cela pour les 5 types de défauts.
Ces vérifications de cohérence fonctionnent sur le principe que les colonnes au niveau trame devraient être déterminées de manière déterministe à partir des colonnes au niveau dalle. Si la logique d’agrégation est correcte, les vérifications devraient toujours réussir. Un échec indique un bogue dans l’étape de post-traitement du pipeline d’analyse, pas dans le modèle lui-même.
Le test de fumée compare l’ensemble de colonnes attendues à l’ensemble de colonnes réelles et génère des avertissements pour :
tile_moisture_conf), le test avertit mais n’échoue pas, car cela peut indiquer une amélioration du pipeline nécessitant des mises à jour d’intégration en aval.tile_crack_conf → tile_cracking_conf), le test échoue, empêchant les ruptures silencieuses en aval lorsque les tableaux de bord, API ou bases de données font référence aux anciens noms de colonnes.La logique de contrôle détermine si la tête de défaut réussit ou échoue le test de fumée dans son ensemble, basée sur une combinaison pondérée des résultats d’assertion individuels. Le contrôle est le mécanisme qui empêche le déploiement en production d’un modèle défaillant.
Toutes les assertions du test de fumée ne sont pas également critiques. Le système de contrôle attribue à chaque assertion un niveau de gravité :
| Niveau | Poids | Effet sur le Contrôle | Exemples |
|---|---|---|---|
| Fatal | 1,0 | Bloque immédiatement | Échec de chargement du checkpoint, NaN dans les sorties |
| Critique | 0,8 | Bloque si >1 échec | Colonnes manquantes, incompatibilité de forme de sortie |
| Avertissement | 0,4 | Bloque si >3 échecs | AP par classe sous le seuil |
| Info | 0,0 | Journalisation uniquement, pas de blocage | Avertissements de tendance métrique, avis d’obsolescence de colonne |
Les assertions Fatales sont celles où aucune exécution valide du pipeline n’est possible — le checkpoint est corrompu, le modèle ne peut pas se charger, ou l’inférence produit des valeurs numériques invalides. Un seul échec fatal bloque le déploiement.
Les assertions Critiques indiquent que le pipeline produit des résultats structurellement valides mais potentiellement incorrects — des colonnes manquantes entraîneraient des échecs de rapport en aval, une incompatibilité de forme de sortie indique une discordance d’architecture du modèle avec l’infrastructure de service.
Les assertions de type Avertissement indiquent que les métriques du modèle sont en dessous des seuils nominaux mais que le pipeline est structurellement sain. Elles sont agrégées : si plus de 3 avertissements se déclenchent lors d’une même exécution, le contrôle s’active.
Les assertions Info sont purement observationnelles — elles enregistrent les tendances de dérive métrique, les avis d’obsolescence de colonnes et les comparaisons de performances avec les exécutions précédentes — mais ne bloquent jamais le déploiement.
Le résultat global du test de fumée est calculé comme suit :
gate_score = max(fatal_failures,
critical_failures > 1 ? 1.0 : 0.0,
warning_failures > 3 ? 1.0 : 0.0)
Si gate_score >= 1.0, le test de fumée échoue et le déploiement est bloqué. Si gate_score < 1.0, le test de fumée réussit et le pipeline passe à l’évaluation complète ou au déploiement.
Le message composite de réussite/échec résume le résultat :
TEST DE FUMÉE : ÉCHEC
- Fatal : 1 [checkpoint_load_failure]
- Critique : 0
- Avertissement : 2 [class_crack_ap_below_threshold, class_efflorescence_f1_below_threshold]
- Info : 1 [metric_class_crack_ap a chuté de 3,2% depuis la dernière exécution]
Le contrôle du test de fumée s’intègre au pipeline de déploiement via :
Hook post-commit : Le test de fumée s’exécute à chaque commit de pull request. Si le contrôle échoue, le système CI/CD bloque la fusion (règle de protection de branche GitHub, échec de pipeline de merge request GitLab).
Contrôle pré-déploiement : Avant qu’un modèle ne soit promu de la préproduction à la production, le test de fumée s’exécute à nouveau sur l’artefact exact du candidat au déploiement. Cela détecte les problèmes qui peuvent ne pas avoir été présents pendant le développement — par exemple, un environnement de développement avec une version CUDA différente de celle de l’environnement de production.
Déclencheur de retour arrière : Si le test de fumée réussit le déploiement mais qu’un incident de production ultérieur est attribué à la tête de défaut, la logique de contrôle du test de fumée est auditée. Si une assertion de niveau avertissement aurait dû être une assertion critique, la configuration du contrôle est mise à jour pour éviter la récurrence.
Les tests d’applicabilité au domaine étendent le test de fumée de base pour vérifier que la tête de défaut fonctionne correctement dans les conditions opérationnelles spécifiques que TarmacView rencontre dans l’inspection des chaussées aéroportuaires et des infrastructures. Ces tests garantissent que le pipeline est non seulement fonctionnel mais aussi adapté à son objectif dans le domaine cible.
La tête de défaut doit fonctionner de manière cohérente sur les différents types de chaussées rencontrés sur les surfaces aéroportuaires :
Chaussées bitumineuses (flexibles) : Pistes, voies de circulation et aires de trafic construites avec de l’enrobé bitumineux à chaud (HMA). Les défauts sur le bitume incluent la fissuration par fatigue (motif en peau de crocodile), la fissuration longitudinale, la fissuration transversale, l’orniérage et le désenrobage. Le test de fumée inclut des images synthétiques avec des textures semblables au bitume (gris foncé, granulat visible, rugosité de surface variable) et vérifie que la détection des fissures et des éclats maintient des niveaux de confiance nominaux.
Chaussées en béton (rigides) : Pistes et aires de trafic construites avec du béton de ciment Portland (PCC). Les défauts incluent l’éclatement des joints, les cassures d’angle, la fissuration linéaire, l’efflorescence (dépôts de calcium blancs aux joints), l’armature exposée (dans les zones éclatées) et les taches de corrosion. Le test de fumée vérifie que le modèle identifie correctement l’efflorescence et l’armature exposée — des défauts bien plus fréquents sur le béton que sur les surfaces bitumineuses.
Chaussées composites : Revêtements bitumineux sur béton existant. Les défauts incluent la fissuration par réflexion (fissures bitumineuses suivant le motif des joints de béton sous-jacents) et la délamination. Le test vérifie que le modèle peut détecter les fissures sur les surfaces composites sans confusion due au motif de joints sous-jacent.
Couches de friction poreuses (PFC) : Bitume à haute perméabilité utilisé sur les pistes pour un meilleur drainage et une meilleure friction. Le PFC a une texture ouverte distincte qui apparaît visuellement différente du HMA à granulométrie dense. Le test vérifie que le modèle ne produit pas de taux de faux positifs élevés sur les surfaces PFC, où la texture rugueuse pourrait être confondue avec des fissures ou des éclats.
L’Annexe 14 de l’OACI et la FAA AC 150/5320-5D spécifient que les évaluations de l’état des surfaces de pistes doivent être valides dans des conditions opérationnelles. Le test de fumée d’applicabilité au domaine vérifie que la tête de défaut maintient ses performances dans les conditions suivantes :
Lumière directe du soleil : Contraste élevé, ombres fortes. Le test vérifie que les valeurs de confiance ne sont pas systématiquement plus faibles dans des conditions de contraste élevé en raison de faux positifs induits par les ombres.
Lumière diffuse/ciel couvert : Faible contraste, pas d’ombres. Le test vérifie que les fissures fines (étroites, faible contraste par rapport à la chaussée) sont toujours détectables à des niveaux de confiance réduits.
Chaussée humide : L’eau dans les fissures augmente la visibilité des fissures mais introduit des réflexions spéculaires. Le test vérifie que les dalles de surface humide ne produisent pas de faux positifs élevés en raison de reflets spéculaires confondus avec de l’efflorescence (les deux apparaissent comme des régions brillantes).
Aube/crépuscule : Faibles niveaux de lumière, ombres longues. Le test vérifie que le modèle produit des sorties dans des plages de confiance attendues même à des niveaux d’éclairement réduits.
Le test de fumée simule ces conditions en appliquant des transformations photométriques contrôlées aux images de test synthétiques : mise à l’échelle de la luminosité pour la simulation d’éclairage, flou gaussien pour la simulation de brume/brouillard, et ajustement de la saturation pour la simulation de surface humide.
L’imagerie d’inspection varie en distance d’échantillonnage au sol (GSD) selon la plateforme de capture :
| Plateforme | Altitude Typique | GSD (mm/pixel) | Couverture de Dalle |
|---|---|---|---|
| UAV (haute résolution) | 15-20 m | 0,5-1,0 | 0,1-0,5 m² |
| UAV (standard) | 30-50 m | 1,0-2,0 | 0,5-2,0 m² |
| Monté sur véhicule | 2-3 m | 0,3-0,8 | 0,05-0,2 m² |
| Appareil portable | 1-1,5 m | 0,2-0,5 | 0,02-0,08 m² |
Le test de fumée vérifie que la tête de défaut produit des sorties cohérentes sur une plage de résolutions d’entrée. Les images de test synthétiques sont générées à plusieurs échelles (0,5×, 1,0×, 2,0× la GSD nominale) et passées à travers le modèle. Le test vérifie que la distribution des classes prédites ne change pas de plus de 10% entre les résolutions, garantissant que le modèle est approximativement invariant à l’échelle dans la plage opérationnelle.
L’ASTM D5340 définit trois niveaux de gravité (Faible, Moyen, Élevé) pour chaque type de défaut. Le test de fumée vérifie que les scores de confiance de la tête de défaut sont corrélés à la gravité du défaut :
Gravité faible : Fissures capillaires (<1mm de largeur), petits éclats (<150mm de longueur), efflorescence légère, taches de corrosion minimales. Le test vérifie que ces éléments produisent des scores de confiance au-dessus du seuil de détection (>0,5) mais pas à la confiance maximale (<0,8).
Gravité moyenne : Fissures (1-3mm de largeur), éclats (150-600mm de longueur), dépôts d’efflorescence modérés, armature exposée visible avec corrosion légère. Le test vérifie que les scores de confiance sont élevés (>0,7).
Gravité élevée : Fissures larges (>3mm de largeur), grands éclats (>600mm de longueur), efflorescence abondante avec perturbation de surface, armature exposée avec corrosion importante et perte de section. Le test vérifie que les scores de confiance sont très élevés (>0,9).
La vérification de la corrélation de gravité est une assertion de niveau avertissement dans le système de contrôle — le modèle peut encore fonctionner correctement même si la corrélation de gravité est imparfaite, mais le test la signale comme un domaine d’amélioration du modèle.
Comprendre la distinction entre le test de fumée et l’évaluation complète est essentiel pour concevoir une stratégie d’assurance qualité ML efficace. Les deux approches servent des objectifs fondamentalement différents et opèrent à différents moments du cycle de développement et de déploiement.
| Dimension | Test de Fumée | Évaluation Complète |
|---|---|---|
| Objectif | Vérifier l’intégrité du pipeline | Mesurer la qualité du modèle |
| Question posée | « Le pipeline fonctionne-t-il correctement ? » | « Le modèle est-il suffisamment précis ? » |
| Données | Synthétiques / petit ensemble statique (10-100 images) | Grand ensemble de validation exclus (500-5000+ images) |
| Durée | Secondes à minutes | Minutes à heures |
| Calcul | CPU ou GPU minimal | GPU complet (souvent multi-GPU) |
| Fréquence | Chaque commit / PR | Quotidienne, hebdomadaire ou par version |
| Seuils métriques | Généreux (AP > 0,50) | Stricts (AP > 0,75) |
| Couverture | Intégrité structurelle uniquement | Généralisation statistique |
| Action en cas d’échec | Bloquer la fusion/le déploiement | Signaler pour révision |
Le test de fumée est conçu pour détecter les erreurs de pipeline — la classe de bogues qui font échouer l’ensemble du système ou produisent des sorties dénuées de sens. Cela inclut la corruption du checkpoint, l’incompatibilité de version, les ruptures de pipeline de prétraitement, les colonnes manquantes, les sorties NaN et les incompatibilités de forme. Les données de l’industrie provenant d’équipes d’ingénierie ML montrent que les erreurs de pipeline représentent 60 à 70% des échecs d’entraînement et 40% des retours arrière de déploiement. Les tests de fumée détectent ces erreurs en quelques secondes, avant que des évaluations complètes coûteuses ne soient lancées.
L’évaluation complète est conçue pour mesurer la qualité du modèle — la précision statistique, la justesse, le rappel et la généralisation des prédictions du modèle. Elle utilise de grands ensembles de données de validation diversifiés et représentatifs, calcule des métriques rigoureuses (AP@0,50:0,95, F1 par classe, matrices de confusion, courbes précision-rappel à plusieurs seuils) et compare les résultats à la fois à des seuils absolus et à des références relatives provenant des versions précédentes du modèle. Les exécutions d’évaluation complète sont coûteuses en calcul et en temps, ce qui les rend inadaptées à une exécution par commit.
Les données du test de fumée sont générées synthétiquement pour être simples, propres et déterministes. Chaque image synthétique contient exactement un type de défaut sur un fond uniforme, sans occlusion, sans chevauchement de défauts et sans conditions d’éclairage difficiles. Cela minimise la variabilité et garantit que toute fluctuation métrique dans le test de fumée est attribuable au modèle, et non à la variabilité des données.
Les données de l’évaluation complète sont des images d’inspection réelles avec les caractéristiques suivantes : types et âges de chaussées diversifiés, toutes les conditions d’éclairage opérationnelles, niveaux de gravité de défauts variables, défauts chevauchants et adjacents, occlusions réelles (débris, marques de pneus, eau), et annotations de vérité terrain polygonales précises. Ces données représentent la véritable distribution que le modèle rencontre en production et fournissent une estimation fiable des performances de déploiement.
La prévention des fuites de données est essentielle pour l’évaluation complète mais non pertinente pour les tests de fumée — puisque le test de fumée utilise des données synthétiques, il n’y a aucun risque de fuite de données de test réelles dans l’entraînement. L’ensemble de données d’évaluation complète est soigneusement partitionné : les ensembles d’entraînement, de validation et de test sont divisés au niveau de la trame ou de la piste (pas au niveau de la dalle) pour empêcher les fuites d’autocorrélation spatiale, où des dalles adjacentes de la même piste apparaîtraient à la fois dans les ensembles d’entraînement et de test.
Une exécution typique du test de fumée pour le pipeline de tête de défaut :
Une exécution typique d’évaluation complète :
Le test de fumée est 10 à 100 fois plus rapide que l’évaluation complète, permettant une exécution par commit. L’évaluation complète s’exécute à une cadence plus lente (par nuit, par version, par promotion en production).
| Mode de Défaillance | Détecté Par |
|---|---|
| Fichier de checkpoint corrompu | Test de fumée (fatal) |
| NaN/inf dans les sorties du modèle | Test de fumée (fatal) |
| Colonnes de sortie manquantes | Test de fumée (critique) |
| Forme de tenseur de sortie incorrecte | Test de fumée (critique) |
| Incompatibilité de normalisation du prétraitement | Test de fumée (fatal) |
| Prédictions dégénérées (toutes la même classe) | Test de fumée (avertissement) |
| Baisse de 10% de l’AP sur de nouvelles données | Évaluation complète |
| Surapprentissage d’un type de chaussée spécifique | Évaluation complète |
| Dérive de calibration | Évaluation complète |
| Bruit d’étiquettes dans les données d’entraînement | Évaluation complète |
La matrice de couverture démontre que les tests de fumée et les évaluations complètes sont complémentaires — chacun détecte des modes de défaillance que l’autre manque. Une stratégie de test ML complète nécessite les deux.
L’intégration du test de fumée de tête de défaut dans les pipelines d’intégration continue (CI) est essentielle pour détecter les régressions tôt et garantir que chaque modification de code est validée avant d’affecter les systèmes de production.
Le pipeline CI pour le système de détection de défauts de TarmacView est organisé en étapes séquentielles :
Étape 1 — Qualité du Code : Linting (flake8, pylint), vérification de types (mypy), tests unitaires (pytest pour les utilitaires de chargement de données, fonctions de prétraitement et fonctions de calcul métrique). Cette étape s’exécute sur CPU et se termine en 1 à 3 minutes. L’échec bloque toutes les étapes en aval.
Étape 2 — Validation des Données : Validation du schéma des ensembles de données d’entraînement et d’évaluation en utilisant Great Expectations ou TensorFlow Data Validation. Vérifie la présence des colonnes, les types de données, les plages de valeurs et les statistiques de distribution par rapport aux attentes définies dans le contrat de données. Cette étape s’exécute sur CPU et se termine en 2 à 5 minutes.
Étape 3 — Test de Fumée de la Tête de Défaut : La suite complète de tests de fumée telle que décrite dans cet article. S’exécute sur CPU (ou GPU minimal si disponible) et se termine en 15 à 60 secondes. L’échec bloque la fusion dans main.
Étape 4 — Tests Unitaires pour l’Évaluation : Tests de calcul métrique à petite échelle qui vérifient que le calcul AP, le calcul F1 et la génération de matrice de confusion produisent des sorties correctes sur de petits ensembles de données étiquetés manuellement (5 à 10 images avec vérité terrain connue). S’exécute sur CPU, se termine en 30 secondes.
Étape 5 — Entraînement (à la demande) : Déclenché uniquement lorsque les poids du modèle sont censés changer (nouvelles données d’entraînement, changements d’architecture, réglage des hyperparamètres). Pas automatiquement déclenché à chaque commit. S’exécute sur GPU et prend 1 à 8 heures selon la taille de l’ensemble de données.
Étape 6 — Évaluation Complète (lors de la fusion dans main) : Déclenchée lorsque le code est fusionné dans la branche main. Exécute la suite d’évaluation complète sur l’ensemble de validation exclus, calcule toutes les métriques, compare aux références et publie les résultats dans le registre de modèles. S’exécute sur GPU et prend 20 à 40 minutes.
Le test de fumée est déclenché sur :
Les artefacts CI du test de fumée sont stockés et versionnés :
Ces artefacts sont stockés dans le registre de modèles aux côtés de l’artefact du modèle lui-même, fournissant une piste d’audit complète : « Cette version du modèle a réussi le test de fumée avec les données synthétiques v3.2 sur l’exécution CI n°4827 avec le commit a3f2c1. »
Lorsque le test de fumée échoue, des notifications sont envoyées via plusieurs canaux :
La notification inclut un rapport d’erreur structuré :
Sujet : [ÉCHEC FUMÉE] pipeline tête-de-défaut - main - exécution #4827
Corps :
Commit : a3f2c1 (fusionné à 12:34 UTC)
Checkpoint : defect-head:v3 (candidat-production)
Résultat : ÉCHEC (gate_score=1.0)
Fatal (1) :
- [output_nan] Le tenseur de sortie contient des valeurs NaN
Le passage forward du backbone a produit NaN à la normalisation de couche 8
Critique (0) :
Avertissement (2) :
- [class_efflorescence_ap] AP@0,50 = 0,42 sous le seuil de 0,50
- [class_efflorescence_f1] F1 = 0,55 sous le seuil de 0,60
Action requise : Enquêter sur le NaN dans la normalisation de couche 8 du backbone.
Causes possibles : checkpoint corrompu, incompatibilité de version CUDA,
ou instabilité numérique dans le calcul d'attention.
L’interprétation correcte des sorties du test de fumée est essentielle pour diagnostiquer les problèmes de pipeline et déterminer les actions correctives appropriées.
Le test de fumée génère un rapport JSON complet structuré comme suit :
{
"pipeline_id": "defect-head-smoke",
"run_id": "2026-06-16-4827",
"timestamp": "2026-06-16T12:34:56Z",
"commit_sha": "a3f2c1d4e5b6...",
"checkpoint_version": "defect-head:v3",
"synthetic_data_version": "v3.2",
"gate_result": "ÉCHEC",
"gate_score": 1.0,
"assertions": {
"checkpoint_file_exists": {"status": "RÉUSSI", "detail": "checkpoint.pt (842MB)"},
"checkpoint_loadable": {"status": "RÉUSSI", "detail": "Dictionnaire d'état chargé avec succès"},
"forward_pass_shape": {"status": "RÉUSSI", "detail": "Forme de sortie (8, 5)"},
"output_no_nan": {"status": "ÉCHEC", "detail": "NaN trouvé dans 1 des 8 échantillons du lot"},
"output_no_inf": {"status": "RÉUSSI", "detail": "Aucune valeur inf"},
"softmax_sum": {"status": "RÉUSSI", "detail": "Toutes les sommes à 1e-5 près de 1,0"},
"tile_columns_exist": {"status": "RÉUSSI", "detail": "Les 5 colonnes de dalle présentes"},
"frame_columns_exist": {"status": "RÉUSSI", "detail": "Les 7 colonnes de trame présentes"},
"column_value_ranges": {"status": "RÉUSSI", "detail": "Toutes les valeurs dans [0,0, 1,0]"},
"class_crack_ap50": {"status": "RÉUSSI", "detail": "AP@0,50 = 0,92"},
"class_spalling_ap50": {"status": "RÉUSSI", "detail": "AP@0,50 = 0,88"},
"class_efflorescence_ap50": {"status": "AVERTISSEMENT", "detail": "AP@0,50 = 0,42"},
"class_exposed_rebar_ap50": {"status": "RÉUSSI", "detail": "AP@0,50 = 0,91"},
"class_corrosion_ap50": {"status": "RÉUSSI", "detail": "AP@0,50 = 0,90"}
}
}
Le rapport doit être lu de haut en bas, en traitant d’abord les échecs fatals (car ils invalident tous les résultats en aval), puis les échecs critiques (problèmes structurels qui entraîneraient des échecs de production), et enfin les échecs d’avertissement (régressions de qualité qui peuvent nécessiter une enquête).
Les échecs fatals indiquent que le pipeline est complètement non fonctionnel. Les causes profondes et les correctifs les plus courants :
Fichier de checkpoint introuvable : Le chemin du checkpoint spécifié dans la configuration du pipeline ne pointe pas vers un fichier existant. Correctif : vérifier le chemin du registre de modèles, s’assurer que l’entraînement s’est terminé et a téléchargé l’artefact, ou mettre à jour la configuration avec le chemin correct.
Échec de chargement du checkpoint : torch.load() a levé une exception. Causes courantes : corruption du fichier (relancer l’entraînement ou restaurer à partir d’une sauvegarde), incompatibilité de version PyTorch (vérifier que l’environnement de déploiement a la même version PyTorch que l’environnement d’entraînement — torch.save() avec PyTorch 2.0 produit des fichiers qui se chargent différemment sur PyTorch 1.x), ou incompatibilité CUDA/non-CUDA (un checkpoint sauvegardé avec des tenseurs CUDA peut échouer à se charger sur un environnement CPU uniquement sans map_location='cpu').
NaN dans les sorties : L’échec fatal le plus techniquement difficile. Causes courantes : instabilité numérique dans le mécanisme d’attention de DINOv3 (débordement de normalisation de couche avec des valeurs d’entrée extrêmes), poids corrompus dans une couche spécifique (vérifier quelle couche produit le NaN en exécutant avec torch.autograd.set_detect_anomaly(True)), ou prétraitement qui produit des entrées hors plage (par exemple, valeurs de pixels au-delà de [0,1] après normalisation).
Incompatibilité de forme de sortie : Le tenseur de sortie a une forme différente de celle attendue. Causes courantes : la tête MLP a été remplacée par une architecture différente (nombre différent de classes de sortie), la dimension d’embedding du backbone a changé (checkpoint d’une variante DINOv3 différente), ou la dimension du lot a été compressée/décompressée incorrectement dans le code de post-traitement.
Les échecs critiques indiquent des problèmes structurels qui entraîneraient un comportement de production incorrect.
Colonnes manquantes : Le DataFrame de sortie d’analyse manque de colonnes attendues. Causes courantes : la convention de nommage des colonnes a été modifiée sans mettre à jour les consommateurs en aval, la logique d’agrégation a été modifiée pour renommer les colonnes, ou la sortie de la tête de défaut a été changée (par exemple, de 5 classes à 4 classes).
Violations de plage de valeurs : Valeurs de confiance en dehors de [0,0, 1,0]. Cela indique presque toujours un dysfonctionnement du softmax — soit le softmax n’a pas été appliqué aux logits, soit le mauvais axe a été utilisé pour la normalisation softmax. Vérifier que F.softmax(logits, dim=1) est utilisé (dimension de classe, pas dimension de lot).
NaN dans les colonnes de sortie : Similaire au NaN fatal dans les sorties du modèle mais se produisant dans l’étape d’agrégation de post-traitement. Vérifier la division par zéro dans l’agrégation dalle-à-trame (par exemple, division par le nombre de dalles quand la trame a zéro dalle), ou la propagation de valeurs manquantes à partir des sorties NaN du modèle qui n’ont pas été détectées au niveau du modèle.
Les échecs d’avertissement indiquent une dégradation de la qualité qui peut ne pas nécessiter un blocage immédiat du déploiement mais devrait être étudiée.
AP spécifique à une classe sous le seuil : Une seule classe de défaut montre des performances significativement inférieures aux autres. Causes courantes : exemples d’entraînement synthétiques insuffisants pour cette classe (le générateur de données synthétiques peut produire des exemples peu réalistes pour certaines classes), déséquilibre de classe dans les données d’entraînement réelles affectant la capacité discriminative de la tête pour les classes rares, ou les caractéristiques du backbone étant moins informatives pour certains types de défauts (par exemple, l’efflorescence est caractérisée par la couleur (dépôts blancs) plus que par la texture, tandis que les caractéristiques DINOv3 peuvent mettre l’accent sur la texture plutôt que sur la couleur).
Déséquilibre précision-rappel : Le modèle est trop conservateur ou trop agressif pour des classes spécifiques. Causes courantes : le seuil de confiance a été optimisé pour la performance globale mais est sous-optimal pour des classes individuelles, ou les données d’entraînement ont un bruit asymétrique (plus de faux négatifs que de faux positifs pour une classe spécifique).
Dérive métrique par rapport à la référence : Les métriques ont changé de plus de 5% par rapport à la dernière exécution validée sans changement de code ou de données. Cela peut indiquer : un non-déterminisme dans le modèle (couches de dropout ou de normalisation par lot se comportant différemment en mode entraînement vs évaluation — s’assurer que model.eval() est appelé avant l’inférence), une dérive numérique due à des différences matérielles (ordre d’accumulation en virgule flottante CPU vs GPU), ou des modifications du générateur de données synthétiques produisant des échantillons de test différents.
La sortie du test de fumée inclut des suggestions de correction pour les modes de défaillance courants :
| Échec | Suggestion de Correction |
|---|---|
| Checkpoint introuvable | Vérifier le chemin du registre de modèles ; exécuter l’entraînement pour générer le checkpoint |
| NaN dans le backbone | Passer à la précision float32 si float16 est utilisé ; ajouter un clipping de gradient |
| Colonne manquante | Mettre à jour les noms de colonnes dans la logique d’agrégation pour correspondre au schéma |
| AP faible sur une classe spécifique | Ajouter plus d’exemples d’entraînement synthétiques pour cette classe ; vérifier l’équilibre des classes |
| Dérive métrique | Exécuter l’inférence avec torch.inference_mode() et model.eval() ; vérifier les opérations non déterministes |
Ces suggestions sont générées par un système basé sur des règles qui fait correspondre les modèles d’échec d’assertion à des actions correctives connues, réduisant le temps moyen de résolution (MTTR) pour les modes de défaillance courants.

TarmacView met en œuvre des pipelines rigoureux de tests de fumée et d'évaluation pour la détection automatisée des défauts structurels sur les chaussées aéroportuaires et les infrastructures en béton. Planifiez une démo pour voir comment les tests automatisés assurent la fiabilité du déploiement.
Un test de fumée est une vérification rapide de bout en bout permettant de s'assurer qu'une chaîne de traitement logicielle s'exécute sans planter sur des donné...
DINOv3 (self-DIstillation with NO labels v3) est un transformateur de vision (ViT-B/16) auto-supervisé, pré-entraîné sur 1,7 milliard d'images, produisant des p...
Le filtrage contextuel des défauts est une stratégie d'inférence qui filtre les étiquettes de défauts prédites par type de surface et domaine structurel afin de...