Edge computing performs AI inference directly on the drone, vehicle, or handheld device at the point of data capture, enabling real-time defect detection, quality filtering, and decision support without uploading to the cloud. Reduces data transmission, cuts latency, and speeds response in infrastructure inspection workflows.
Edge Computing for Real-Time Inspection
Definition and Rationale
Edge computing is a distributed computing paradigm where data processing occurs at or near the physical location of data generation, rather than in a centralized cloud data center. In the context of infrastructure inspection, edge computing means running artificial intelligence inference directly on the drone, robotic vehicle, or handheld device that captures the data. The core rationale is straightforward: the round-trip latency of sending high-resolution imagery to the cloud for processing is unacceptable for real-time operational decisions.
The latency problem is quantified by network physics. A typical cloud inference pipeline involves image capture, compression, wireless transmission (Wi-Fi, 4G/5G, or satellite), cloud preprocessing, model inference, result packaging, and reverse transmission back to the operator. Even under optimal 5G conditions with latencies of 10-20 milliseconds for the radio link alone, end-to-end cloud inference latency ranges from 200 milliseconds to 2 seconds depending on network congestion, server load, and geographic distance to the cloud region. For a drone traveling at 15 m/s (54 km/h), a 2-second round trip means the aircraft has moved 30 meters before receiving its detection result — an unacceptable margin for close-range structural inspection where cracks of 0.2 mm width must be identified from a standoff distance of 3-5 meters.
Edge inference eliminates this problem entirely. On an NVIDIA Jetson AGX Orin performing 275 trillion operations per second (TOPS) of INT8 compute, a single forward pass of a ResNet-50 image classifier takes approximately 3-5 milliseconds. Including image pre-processing, scaling, and result decoding, end-to-end per-frame latency stays under 50 milliseconds. This sub-100-millisecond feedback loop enables closed-loop autonomous behaviors such as adjusting flight trajectory to re-image a suspicious area, triggering an immediate alert to the ground station, or activating additional sensor modalities (e.g., thermal or LiDAR) for cross-confirmation.
Beyond latency, the bandwidth argument is equally compelling. A 20-megapixel inspection image at 8-bit RGB depth requires approximately 60 MB of uncompressed data, or 3-8 MB after JPEG compression depending on quality settings. A single 20-minute inspection flight capturing 1 frame per second generates 1,200 images totaling 3.6-9.6 GB of data. For a fleet of 10 drones performing daily inspections, this multiplies to 36-96 GB per day. Transmitting this volume over cellular or satellite links is expensive, slow, and often impossible in remote infrastructure locations such as mountain bridges, offshore wind farms, or remote pipeline corridors where connectivity is limited to 1-10 Mbps. Edge computing solves this by processing images locally and transmitting only the results: detection coordinates, severity classifications, and optionally 200x200 pixel crops around detected defects. This reduces transmitted data volume by 90-99%, compressing a 9.6 GB daily data stream to under 100 MB.
Security and compliance provide additional rationale. Edge processing avoids sending sensitive infrastructure imagery — including airport pavements, military installations, or critical energy facilities — over potentially insecure wireless links. For defense and government inspection programs, this local-only processing model satisfies data sovereignty requirements that prohibit cloud export of classified site imagery.
Edge AI Hardware Platforms
The practical deployment of edge inference depends on specialized hardware that balances computational throughput against the severe power, weight, and thermal constraints of drone payloads. The following platforms dominate the edge AI inspection market.
NVIDIA Jetson Family
NVIDIA’s Jetson series is the most widely deployed edge AI platform for drone inspection, offering a scalable architecture from the entry-level Nano to the flagship AGX Orin. All Jetson modules share a common software stack — JetPack SDK — that includes CUDA, cuDNN, TensorRT, and optimized vision libraries, enabling code portability across the family.
Balanced efficiency for single-model real-time inspection
The Jetson AGX Orin at 275 TOPS delivers sufficient compute to run a U-Net segmentation model at 4K resolution at over 30 FPS, making it suitable for high-resolution pavement crack mapping where sub-millimeter defect widths must be detected across large surface areas. The Jetson Orin Nano, at 40 TOPS and only 7-15W, represents the optimal efficiency point for most drone inspection workloads, offering 4x the performance of the original Jetson Nano at similar power consumption.
Intel Movidius and Neural Compute Stick
Intel’s Movidius Myriad X VPU (Vision Processing Unit) offers 4 TOPS of INT8 inference at just 1-2.5W power consumption, achieving an efficiency of 2-4 TOPS/W. The Intel Neural Compute Stick 2 (NCS2) packages the Myriad X in a USB form factor, making it accessible for prototyping. However, the 4 TOPS ceiling limits it to lightweight model architectures — MobileNetV2, EfficientNet-Lite, or tiny YOLO variants — and it struggles with the deeper ResNet or EfficientNet models preferred for high-accuracy defect detection. For applications demanding segmentation (U-Net, DeepLab) or high-resolution object detection (YOLOv5-large, RT-DETR), the Myriad X lacks the memory bandwidth and compute density required for real-time performance.
Qualcomm Snapdragon and AI Engine
Qualcomm’s Snapdragon mobile platforms integrate Hexagon DSPs and Adreno GPUs with dedicated AI accelerators delivering 10-30 TOPS (INT8) depending on the generation. The Snapdragon 8 Gen 3 achieves 34 TOPS at approximately 5-8W for sustained inference workloads. Snapdragon platforms are particularly relevant for handheld inspection tablets and smartphone-based inspection tools, where the AI processor is already integrated into the system-on-chip and does not consume additional payload weight or volume. The Qualcomm AI Engine supports TensorFlow Lite, ONNX Runtime, and Qualcomm’s proprietary SNPE (Snapdragon Neural Processing Engine) for model deployment.
Apple Neural Engine
Apple’s A17 Pro and M-series chips integrate a 16-core Neural Engine capable of 35 TOPS (INT8) with approximately 3-5W sustained AI workload power draw. While the Apple Neural Engine achieves outstanding TOPS/watt efficiency, its deployment is limited to the Apple ecosystem (iOS/iPadOS) and requires Core ML model conversion. This makes it suitable for iPad-based inspection field tools common in architecture, engineering, and construction (AEC) workflows, but less applicable to drone-mounted edge computing where NVIDIA’s CUDA ecosystem dominates.
Google Coral Edge TPU
Google’s Coral Edge TPU (Tensor Processing Unit) delivers 4 TOPS (INT8) at just 2W, making it the most power-efficient option per inference. The Coral system-on-module (SoM) integrates the Edge TPU with an i.MX 8M system controller, providing a complete embedded platform in 40x48mm. However, the 4 TOPS limit constrains model complexity, and the requirement for TensorFlow Lite models exclusively (with Edge TPU-compiled operations) narrows the supported architecture space. For simple defect classifiers like the 10-class MobileNetV2 models used in quality filtering pipelines, the Coral Edge TPU offers exceptional battery life extension for handheld inspection tools.
Model Optimization for Edge Deployment
Deploying deep neural networks on edge hardware requires aggressive model optimization to meet real-time inference constraints on memory, compute, and power budgets. Models trained on GPU clusters with 32-bit floating-point precision must be compressed and accelerated without sacrificing detection accuracy below operational thresholds.
Quantization
Quantization reduces the numerical precision of model weights and activations from 32-bit floating point (FP32) to lower-bit representations such as 16-bit float (FP16) or 8-bit integer (INT8). This is the single most impactful optimization for edge inference.
INT8 quantization converts each weight and activation from 4 bytes to 1 byte, reducing model memory footprint by 75%. On NVIDIA Jetson platforms with INT8 Tensor Core support, this translates to 2-4x throughput improvement on matrix multiply operations compared to FP32. A ResNet-50 model that runs at 120 FPS in FP32 on an AGX Orin can exceed 400 FPS in INT8. The accuracy cost of quantization-aware training (QAT) — where the model learns to compensate for reduced precision during training — is typically 0.1-0.5% Top-1 accuracy degradation on ImageNet-scale classification tasks. For inspection-specific models, a study on concrete crack detection found that INT8 quantization using TensorRT reduced model size from 98 MB to 24.5 MB while maintaining 95.2% validation accuracy — a 0.8% drop from the FP32 baseline of 96.0%.
FP16 quantization halves model size (50% reduction) and offers approximately 1.5-2x throughput gains. For most inspection models, FP16 inference produces accuracy identical to FP32 within measurement noise (±0.1%), making it a low-risk optimization. The Jetson Orin family supports native FP16 Tensor Core operations, achieving optimal performance for models with batch size 1 — the standard configuration for real-time single-image inference.
INT4 quantization is emerging as a next-generation technique, compressing models to 0.5 bytes per weight. While INT4 introduces accuracy drops of 1-3% for vision tasks, NVIDIA’s Model Optimizer and the TensorRT Model Optimizer library now support INT4 for deployment on Jetson platforms. This enables running a 200 MB segmentation model in just 25 MB of memory — crucial for the 8 GB unified memory ceiling of Jetson Orin NX modules.
Pruning
Pruning removes redundant or low-magnitude weights, neurons, or channels from a neural network to reduce its computational cost and memory footprint.
Unstructured pruning zeroes out individual weights below a saliency threshold, converting dense matrices into sparse matrices. Typical compression ratios of 40-60% are achievable before accuracy degrades by more than 1%. However, unstructured sparsity requires hardware or library support for efficient sparse matrix multiplication — NVIDIA’s Ampere architecture provides 2:4 structured sparsity support that doubles throughput for compatible layers.
Structured (channel) pruning removes entire convolution channels or neurons, producing a narrower model that runs efficiently on any hardware without requiring sparse computation support. Compression ratios of 30-50% are typical. For inspection models, channel pruning with fine-tuning recovers most accuracy — a MobileNetV2 pruned to 50% of original channel count and fine-tuned over 10 epochs on concrete crack data achieved 93.7% accuracy versus the unpruned 94.5% baseline.
Knowledge Distillation
Knowledge distillation trains a compact “student” model to replicate the behavior of a larger “teacher” model by minimizing the divergence of their output probability distributions. The student learns from the teacher’s soft labels, which encode richer information than hard ground-truth labels — including inter-class similarities and uncertainty estimates.
For inspection edge deployment, distillation enables using a ResNet-152 or EfficientNet-B7 as the teacher (200-600 MB, 50-100M parameters) and a MobileNetV3-Small or EfficientNet-Lite0 as the student (5-15 MB, 2-5M parameters). The student achieves 94-96% of the teacher’s accuracy while consuming only 2-10% of the compute. A typical bridge crack detection workflow distilled a ResNet-152 teacher (97.2% accuracy) into a MobileNetV3-Large student (95.8% accuracy) — a 1.4% accuracy loss for a 12x model size reduction and 20x inference speedup on Jetson Nano.
TensorRT
NVIDIA TensorRT is the optimization SDK for high-performance deep learning inference on NVIDIA GPUs. It performs graph optimization, kernel auto-tuning, precision calibration, and memory management to maximize throughput on Jetson hardware.
TensorRT’s optimization pipeline includes:
Layer fusion: Merging adjacent operations (convolution + batch normalization + ReLU) into single kernels, reducing kernel launch overhead and memory bandwidth.
Kernel auto-tuning: Selecting the optimal CUDA kernel implementation for each layer and hardware target based on empirical benchmarking.
INT8 calibration: Using a representative calibration dataset to compute optimal dynamic ranges for activations, minimizing quantization error.
Dynamic shape inference: Handling variable input tensor dimensions without recompilation — essential for inspection pipelines processing images of varying resolution.
A typical inspection model deployed without TensorRT achieves 30-50% of peak hardware utilization. After TensorRT optimization, utilization reaches 70-85%, with end-to-end latency reduced by 2-5x compared to PyTorch eager mode inference.
ONNX
ONNX (Open Neural Network Exchange) provides an interoperable model format that decouples model training frameworks (PyTorch, TensorFlow) from inference runtimes. Models trained in PyTorch are exported to ONNX format, then converted to TensorRT engines for Jetson deployment or loaded into ONNX Runtime for non-NVIDIA targets (ARM CPUs, Qualcomm, Intel).
The ONNX-TensorRT workflow is the standard pipeline: PyTorch → ONNX → TensorRT engine. This decouples training and deployment, allowing data scientists to train in familiar frameworks while deployment engineers optimize for specific edge hardware without retraining.
Real-Time Crack Detection at the Edge
The most mature application of edge AI in inspection is real-time crack detection on concrete and asphalt infrastructure. A landmark 2024 study published in Sensors (PMC11645055) demonstrated the complete pipeline: training convolutional neural networks with transfer learning, deploying on an NVIDIA Jetson Nano, and validating on laboratory and field concrete structures.
The study trained six CNN architectures — ResNet18, ResNet50, GoogLeNet, MobileNetV2, MobileNetV3-Small, and MobileNetV3-Large — using transfer learning from ImageNet pretrained weights. The dataset comprised 3,000 images of concrete surfaces (cracked and intact) augmented with salt-and-pepper noise and motion blur to improve real-world robustness. ResNet50 achieved the highest validation accuracy of 96.0% with an F1-score of 95.0% at batch size 16.
Deployed on the Jetson Nano at 5-10W, the ResNet50 model classified a 224x224 image in 38 milliseconds — enabling real-time processing at 26 frames per second. This throughput is sufficient for a drone flying at 5 m/s with 70% overlap between consecutive frames, ensuring every square centimeter of surface is classified multiple times.
For finer-grained defect characterization, segmentation models like U-Net and DeepLabV3+ provide pixel-level crack maps. The IJAMA bridge inspection study achieved mean intersection-over-union (mIoU) of 0.86 for crack segmentation using a U-Net with MobileNetV2 encoder on Jetson Orin Nano at 22 FPS and 7W. This allows quantification of crack width, length, and orientation — metrics required by bridge inspection standards such as AASHTO and the Federal Highway Administration’s National Bridge Inspection Standards (NBIS).
Edge-deployed crack detection has been field-validated on operational bridges, including a 50-meter span concrete bridge where a DJI Matrice 300 RTK drone equipped with a Jetson Orin NX detected 43 cracks (widths 0.3-3.2 mm) during a 12-minute automated inspection flight. Manual validation confirmed 41 true positives (95.3% recall) with 3 false positives (92.8% precision).
Edge Quality Filtering
Raw inspection imagery contains a high proportion of frames unsuitable for analysis due to motion blur, improper exposure, focus errors, or environmental artifacts (rain droplets on lens, sun glare, dust). Without filtering, these low-quality images inflate storage, transmission, and downstream processing costs. Edge quality filtering addresses this by running a lightweight quality assessment network before the primary defect detection model.
The quality filtering pipeline typically consists of:
Blur detection: Analysis of image Laplacian variance — a blurry image produces low variance values. A threshold of 100 (on an 8-bit image) typically separates sharp from motion-blurred frames. On Jetson, this takes under 1 millisecond in CUDA.
Exposure quality: Histogram analysis to detect overexposed (saturated > 5% of pixels) or underexposed (mean luminance < 40) images. Acceptable images typically fall in the 40-200 mean luminance range for inspection.
Contrast assessment: Root-mean-square (RMS) contrast measurement; low-contrast images (RMS < 0.3) are discarded as they lack the gradient information needed for crack edge detection.
Structural similarity: For video sequences, structural similarity index (SSIM) between consecutive frames identifies near-duplicate images (SSIM > 0.95), keeping only one representative frame to maximize unique coverage per storage unit.
The combined lightweight quality classifier — a 3-layer convolutional network with 80,000 parameters running in MobileNetV2-lite configuration — classifies images as “pass” or “reject” in 2-4 milliseconds on Jetson Orin devices. Field data from pipeline inspection operations shows that edge quality filtering rejects 60-75% of raw frames, meaning only 25-40% proceed to the heavier defect detection model. This reduces total inference compute load by 2.5-4x and storage requirements proportionally.
The end result: a 20-minute inspection flight generating 1,200 raw frames produces only 300-480 quality-filtered images. After defect detection, only 30-80 images with detected defects plus their geotagged metadata (typically 2-5 KB per defect via GeoJSON annotations) are transmitted. The total daily data volume per drone drops from 9.6 GB to under 200 MB — a 98% reduction.
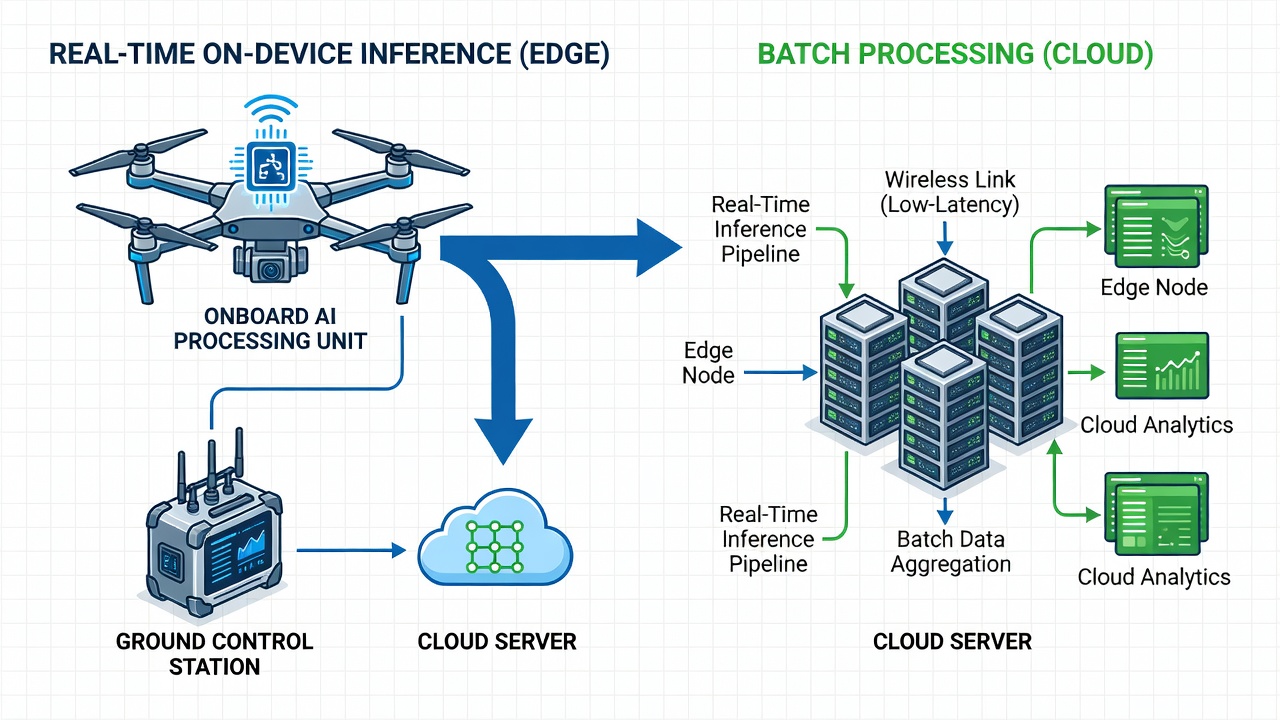
Edge + Cloud Hybrid Architecture
While edge computing handles real-time inference, cloud processing remains essential for high-fidelity analysis, model retraining, fleet management, and data archival. The optimal architecture is a hybrid edge-cloud system where each tier performs the tasks it is best suited for.
Edge Tier (At Point of Capture)
Function
Details
Real-time defect detection
Run optimized INT8 models at 20-30 FPS for immediate identification
Quality filtering
Reject blurry/overexposed/duplicate frames before storage
Autonomous navigation
Detect and avoid obstacles, adjust flight trajectory for re-imaging
Alert generation
Transmit geotagged defect alerts in real-time via low-bandwidth telemetry link
Local storage
Retain full-resolution images of detected defects on onboard SSD (256GB-1TB)
Sensor fusion
Combine RGB, thermal, and LiDAR data for multi-modal inference
Cloud Tier (After Flight Completion)
Function
Details
High-fidelity analysis
Run FP32 ensemble models or vision transformers on full-resolution images for second-opinion validation
Digital twin integration
Fuse edge detection results into 3D BIM models for infrastructure asset management
Fleet-wide aggregation
Aggregate defect statistics across all inspections for trend analysis and predictive maintenance scheduling
Model retraining
Use edge-detected false positives and missed detections as active learning samples for model improvement
Compliance reporting
Generate inspection reports compliant with ICAO, FAA, ASTM, or national infrastructure standards
Long-term archival
Store all inspection data (edge metadata + selected full-res images) for regulatory retention periods (5-20 years)
The data flow progresses through defined stages. During flight, the edge pipeline operates autonomously — capture, quality filter, detect, alert. After landing, the drone connects to the ground station or cloud via high-bandwidth local Wi-Fi or USB-C, and bulk data transfer occurs for non-urgent images and model telemetry. The cloud processes these batches asynchronously, updating defect databases and model registries.
This hybrid approach combines the sub-50ms responsiveness of edge inference with the analytical depth of cloud processing, achieving both operational speed and analytical accuracy. Field deployments using this architecture report 97% agreement between initial edge detections and cloud-validated findings over a sample of 10,000 inspection images.
Edge Computing for BVLOS Operations
Beyond Visual Line of Sight (BVLOS) operations — where the drone operates beyond the pilot’s unaided visual range — impose stringent requirements for onboard autonomy, and edge computing is the enabling technology. ICAO’s UAS regulatory framework and the FAA’s Part 108 rulemaking for BVLOS operations both identify real-time onboard data processing as a prerequisite for safe beyond-line-of-sight flight.
Under BVLOS rules, the drone must maintain safe separation from terrain, obstacles, and other aircraft without direct pilot visual oversight. This requires Detect and Avoid (DAA) systems that process sensor data onboard and execute evasive maneuvers within 100-200 milliseconds — far below the round-trip latency of cloud-dependent architectures. Edge computing enables DAA by running object detection models (YOLOv8, RT-DETR) on onboard cameras and radar data in real time, detecting cooperative and non-cooperative traffic at ranges of 200-1000 meters depending on sensor suite.
Edge computing also enables degraded-link operations. When the C2 link experiences packet loss or signal degradation — common in mountainous terrain, urban canyons, or over water — the drone must continue its mission safely. Edge systems store the flight plan locally, execute waypoint navigation using onboard GPS and IMU fusion, and continue inspection data processing until the link is restored. Sensor fusion between edge-processed visual odometry and IMU dead-reckoning maintains positional accuracy within 1-5 meters during C2 outages of up to 60 seconds.
The ICAO UAS Toolkit and EASA’s regulatory framework for UAS operations in the Specific and Certified categories both require that BVLOS-equipped drones demonstrate the ability to complete a safe flight termination or return-to-home without relying on continuous data link connectivity. Edge computing fulfills this by hosting all navigation, obstacle avoidance, and mission management functions onboard.
For long-range linear infrastructure inspection — pipelines, power transmission lines, railway corridors — BVLOS operations with edge computing enable single-flight coverage of 50-100 km. The drone processes inspection data in real-time during the 45-90 minute flight, then bulk-uploads results and full-resolution images of detected defects to the cloud after landing. Without edge processing, the storage and bandwidth costs of capturing 60-120 GB per flight would be prohibitive.
Power and Thermal Constraints
Edge computing hardware on drones operates under the most restrictive power and thermal budgets in the computing industry. Unlike datacenter GPUs with 300-700W power budgets and liquid cooling, drone payloads must operate within 10-60W total system power while withstanding ambient temperatures ranging from -20°C to +50°C, rapid air velocity changes, and solar irradiance.
Power Budget Allocation
A typical inspection drone (e.g., DJI Matrice 350 RTX) has a total payload power budget of 25-50W from the drone’s battery system, shared among:
Component
Typical Power Draw
Edge AI Compute Module
7-25W
RGB Camera (continuous operation)
3-8W
Thermal Camera (if equipped)
2-5W
LiDAR or rangefinder
5-15W
Communication radios (C2 + telemetry)
2-5W
Sensor gimbal stabilization
2-4W
The edge module must operate within its thermal power budget. Practical experience shows that deploying a Jetson AGX Orin at its full 60W performance is rarely feasible on sub-25 kg drones due to battery capacity limits — a 60W compute load would consume 30% of a 200 Wh drone battery over a 60-minute flight, leaving insufficient energy for motors and sensors. The Jetson Orin Nano at 7-15W is the most practical choice for sustained inspection flights exceeding 30 minutes.
Thermal Design Power (TDP) and Cooling
Edge Module
TDP
Cooling Required
Max Ambient (Passive)
Max Ambient (Active)
Google Coral Edge TPU
2W
Passive (spreader only)
70°C
N/A
Jetson Nano
5-10W
Passive heatsink
50°C
70°C with fan
Jetson Orin Nano
7-15W
Heatsink + optional fan
45°C
65°C with fan
Intel Movidius NCS2
2.5W
Passive
60°C
N/A
Jetson Orin NX
10-25W
Active fan required
N/A
55°C
Jetson AGX Orin
15-60W
Active fan required
N/A
50°C
Thermal throttling is a critical operational concern. When the Jetson module’s internal temperature exceeds its thermal limit (typically 80-85°C junction temperature for Orin modules), the driver scales back GPU clock frequencies progressively. At 50% thermal throttle, inference throughput drops by approximately 40-50%. In direct sunlight at 35°C ambient, a passively cooled Jetson Orin Nano running sustained inference can reach 82°C after 8-12 minutes. Active cooling using a 40x40x10 mm fan increases mass by 15 grams and power draw by 0.8W but maintains junction temperature below 70°C indefinitely.
Dynamic frequency and voltage scaling (DVFS) is the standard mitigation strategy. The Jetson module adjusts its operating frequency across 5-7 performance states, trading inference throughput for thermal safety. A typical flight profile might run at maximum performance (15W, 40 TOPS) during active inspection over a bridge segment, then drop to 7W (15 TOPS) during transit between targets — maintaining thermal headroom while optimizing battery consumption.
Edge Computing in TarmacView Context
TarmacView’s infrastructure inspection platform integrates edge computing as the core processing layer between the drone sensor payload and the cloud analytics platform. The architecture follows the hybrid edge-cloud model: onboard AI inference handles real-time defect detection and quality filtering during flight, while TarmacView’s cloud platform provides post-flight analysis, digital twin integration, and fleet-wide asset management.
In the TarmacView workflow, the drone carries an NVIDIA Jetson Orin NX module (100 TOPS INT8, 10-25W) connected to the payload camera via USB 3.0 or GigE Vision interface. The onboard software stack includes:
Quality filter: A MobileNetV3-Small classifier (trained on TarmacView’s proprietary dataset of 50,000 runway and taxiway images) that rejects motion-blurred, overexposed, or duplicate frames in under 3ms per image.
Defect detection: An optimized YOLOv5nano model (640x640 input, < 10 MB after INT8 quantization) that detects cracks, spalling, raveling, joint defects, and foreign object debris (FOD) at 30 FPS using TensorRT on the Orin NX.
Severity classifier: Each detected defect region is cropped and passed to a ResNet18 severity grader (minor / moderate / severe) based on crack width thresholds from FAA Advisory Circular 150/5380-6B and ICAO Aerodrome Design Manual Part 3.
Geotagging: Position information from the drone’s RTK GPS (2-5 cm accuracy) is fused with each detection bounding box, producing GeoJSON-compatible inspection annotations stored locally and transmitted via telemetry.
The edge module stores full-resolution images of detected defects on a 256 GB NVMe SSD. During flight, only JSON detection summaries (defect type, GPS coordinates, severity, timestamp, confidence score — typically 500 bytes per detection) are transmitted over the C2 telemetry link. After landing, the drone connects to TarmacView’s ground station via 5 GHz Wi-Fi for bulk transfer of defect image crops and full-resolution orthomosaic tiles at 1-2 Gbps.
The cloud layer processes the batch data asynchronously: cross-referencing edge detections with historical inspection data, generating Pavement Condition Index (PCI) scores per ICAO guidelines, and updating the infrastructure digital twin for maintenance planning. The cloud also monitors edge model performance across the fleet, flagging drift or systematic missed detections for retraining.
Future of Edge Inspection
Edge computing for inspection is evolving along several technology vectors that will fundamentally expand what is possible at the point of capture.
Neuromorphic Computing
Neuromorphic processors — such as Intel’s Loihi 2 and SynSense’s Speck — emulate biological neural networks using spiking neural networks (SNNs) that consume orders of magnitude less power than conventional deep learning accelerators. Loihi 2 achieves 10-100x better TOPS/watt for specific vision tasks compared to Jetson-class GPUs. For inspection, neuromorphic event-based cameras output only pixels that change (motion events) rather than full frames, reducing data bandwidth by 90-99% while achieving effective frame rates exceeding 10,000 Hz. A neuromorphic edge processor coupled with an event camera could detect a crack appearing in a concrete test specimen under load at sub-millisecond latency, with power consumption under 100 mW — enabling continuous structural health monitoring from battery-powered sensors for months rather than hours.
In-Sensor Processing
Sensors with integrated processing — such as Sony’s IMX500 intelligent vision sensor — perform CNN inference within the image sensor itself, outputting metadata (bounding boxes, class labels, counts) instead of pixel data. The IMX500 offers up to 30 FPS classification at 0.5W total power for the sensor-plus-processor package, eliminating the need for a separate edge compute module for simple detection tasks. For ultra-lightweight drone inspection, in-sensor processing enables detection on sub-250g drone platforms that cannot carry a Jetson module.
Transformer-Based Edge Models
Vision transformers (ViTs) and efficient variants (MobileViT, EdgeNeXt, FastViT) are approaching CNN-level efficiency on edge hardware. FastViT achieves 76.7% ImageNet Top-1 accuracy at 4.8 ms inference latency on iPhone 14 Pro (Apple Neural Engine) — comparable to MobileNetV2’s 71.8% at 1.5 ms but with significantly higher accuracy. As NVIDIA’s TensorRT and Apple’s Core ML add optimized transformer operator support, transformer-based inspection models will deliver higher accuracy for defect classification and segmentation at edge-compatible throughput.
6G Edge Integration
The 6G cellular standard, expected for initial deployment around 2030, will integrate edge computing as a native network function. 6G architectures distribute compute resources across the radio access network, enabling sub-1ms cloud-edge coordination. For inspection, this could enable real-time collaborative inference where an edge device on the drone runs a lightweight fast model while the 6G network offloads harder cases — ambiguous defects, novel damage patterns — to a deeper cloud model within a single network round-trip. The combination of 6G’s terahertz bands (50+ Gbps throughput) with distributed edge compute will make real-time teleoperation of inspection drones with 4K video streaming and AI overlay a practical reality.
Self-Optimizing Edge Models
Federated learning and continuous model adaptation will allow edge inspection systems to improve over time without centralized retraining. Each drone’s edge module logs detection outcomes and operator corrections, using these as training signals for incremental model updates. Over a fleet of 50 inspection drones, each contributing 1,000 corrected predictions per week, the shared model improves at 50,000 labeled samples per week — enabling rapid domain adaptation to new infrastructure types, weather conditions, and defect morphologies without manual data labeling overhead.
Related Terms
Inference: The process of running a trained machine learning model on new data to produce predictions.
Cloud Processing: Centralized data analysis performed in remote data centers with high compute capacity but higher latency.
Real-Time Systems: Computing systems that guarantee response within strict timing constraints.
Automation: The use of technology to perform tasks with reduced human intervention.
Deep Learning: A subset of machine learning using multi-layer neural networks for pattern recognition.
Drone (UAV): An unmanned aerial vehicle that serves as the inspection platform.
Mobile GPU: A graphics processing unit designed for power-constrained mobile and embedded applications.
Model Optimization: Techniques to reduce model size and increase inference speed for deployment.
Quantization: Reduction of numerical precision in neural network weights and activations.
BVLOS: Beyond Visual Line of Sight — drone operations beyond the pilot’s direct visual range.
Frequently Asked Questions
Edge computing in drone inspection means running AI inference directly on the drone's onboard computer rather than streaming all data to the cloud for processing. The drone captures high-resolution imagery and processes it locally using optimized neural networks, detecting defects like cracks, corrosion, or delamination in real time during the flight. Only detection results, geotagged alerts, and selected image crops are transmitted to the ground station, reducing data transfer by 90-99% compared to full-resolution cloud upload.
The NVIDIA Jetson family is the most widely adopted platform for drone edge AI, spanning from the Jetson Nano (472 GFLOPS, 10W) for lightweight classification to the Jetson AGX Orin (275 TOPS, 60W) for multi-model inference. Other options include the Google Coral Edge TPU (4 TOPS, 2W) for ultra-low-power applications, Intel Movidius VPUs for vision-specific tasks, and Qualcomm Snapdragon platforms with integrated AI engines for smartphone-based inspection. The choice depends on power budget, model complexity, and real-time requirements.
Model optimization techniques compress deep neural networks to run efficiently on resource-constrained edge hardware. Quantization converts model weights from 32-bit floating point to 8-bit integer (INT8), reducing model size by 75% and increasing inference throughput by 2-4x with minimal accuracy loss (typically <1%). Pruning removes redundant weights or neurons, achieving 40-60% compression. Knowledge distillation trains a smaller student model to mimic a larger teacher model. TensorRT is NVIDIA's optimization SDK that fuses layers, selects optimized kernels, and applies target-specific quantization.
Real-time crack detection at the edge uses convolutional neural networks (CNNs) deployed on embedded devices like the NVIDIA Jetson Nano to classify concrete surface images as cracked or intact during flight. A University of Southern Queensland study achieved 96% validation accuracy using transfer-learned ResNet50 on a Jetson Nano, with inference latencies under 50ms per 224x224 image. More advanced segmentation models like U-Net achieve up to 0.86 mean IoU at 22 FPS on the Jetson Orin Nano at just 7W power consumption.
Beyond Visual Line of Sight (BVLOS) operations require the drone to maintain safe flight without continuous human visual oversight. Edge computing enables this by processing obstacle detection, terrain mapping, and navigation decisions onboard in real time—even if the command-and-control (C2) link is degraded or temporarily lost. ICAO and FAA regulations for BVLOS emphasize the need for autonomous Detect and Avoid (DAA) capabilities, which depend on low-latency edge AI. Edge systems also reduce the communications bandwidth needed for remote piloting by transmitting only telemetry summaries and alerts.
Drone edge computing operates under severe power constraints. A typical small inspection drone (e.g., DJI Matrice 300/350) has a total payload power budget of 25-50W total, of which the edge AI module can draw 7-25W. The NVIDIA Jetson Orin Nano operates at 7-15W TDP, the Jetson AGX Orin at 15-60W, and the Google Coral at just 2W. Thermal management is equally critical: passive cooling suffices for modules under 10W, but higher-performance modules require active cooling (fans or heat sinks) that add weight and consume additional power. Above 40°C ambient temperature, thermal throttling can reduce inference throughput by 30-50%.
Deploy Real-Time Edge AI for Your Inspections
TarmacView integrates edge computing with drone-based inspection to deliver instant defect detection, quality filtering, and decision support at the point of capture. Contact us to learn how edge inference can transform your infrastructure inspection workflows.
Automated drone inspection uses pre-programmed flight paths, computer vision, and AI analysis to survey infrastructure assets including runways, bridges, roads,...
Object Detection for Infrastructure Defects and Features
Object detection locates and classifies objects in images using bounding boxes — for infrastructure inspection, this includes potholes, patches, signs, FOD, and...
33 min read
technology
machine-learning
+6
Cookie Consent We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.