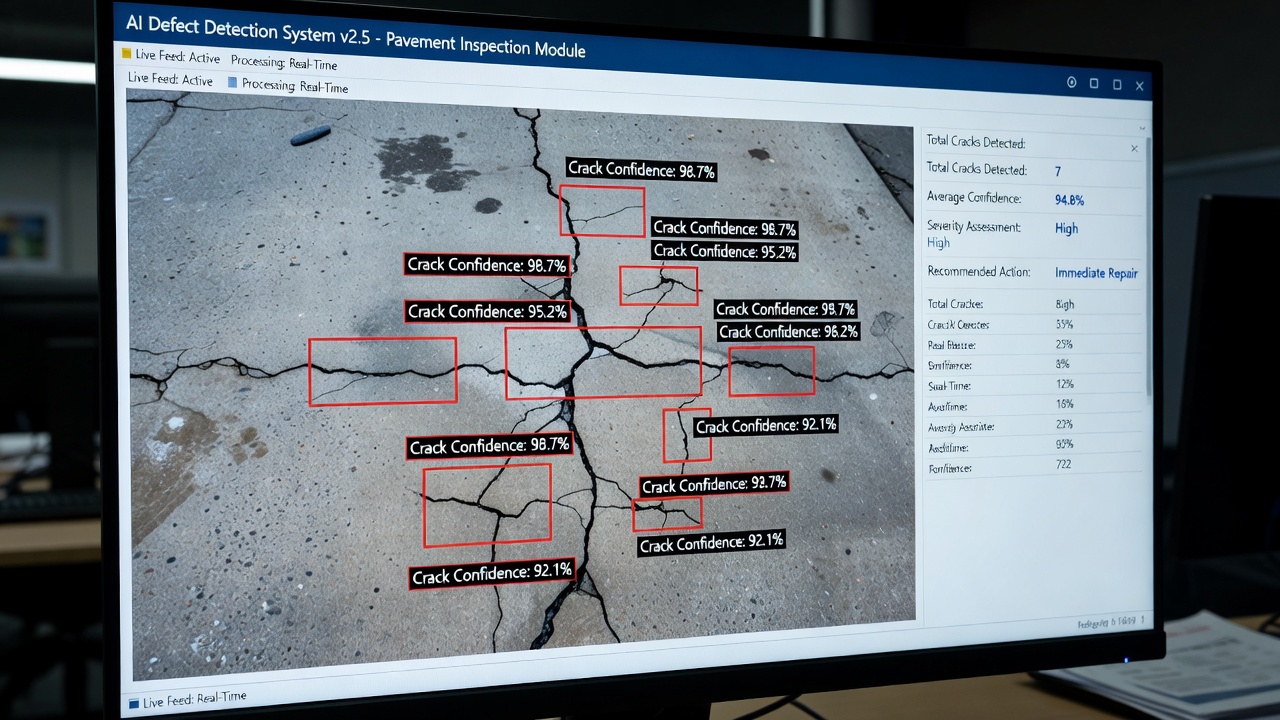
Human-in-the-loop (HITL) verification in automated inspection combines AI-based defect detection models with mandatory human review of flagged anomalies. The AI algorithm processes imagery and assigns confidence scores to detected defects, routing low-confidence detections to qualified inspectors for final adjudication. This semi-automated workflow is the current best practice for safety-critical infrastructure inspection of bridges, pavements, runways, and airport facilities.
Human-in-the-Loop (HITL) Verification in Automated Inspection
Definition and Rationale
Human-in-the-loop (HITL) is an architectural paradigm for semi-automated systems in which a machine learning model performs an initial processing pass over data, and a human operator subsequently reviews, validates, or corrects the model’s outputs before they are accepted as final. In the context of infrastructure inspection, HITL refers specifically to workflows where an AI-based defect detection algorithm processes high-resolution imagery of bridges, pavements, runways, or airport facilities, assigns confidence scores to each detected anomaly, and then routes low-confidence or ambiguous detections to a qualified inspector for manual adjudication.
The fundamental rationale for HITL in inspection stems from the inherent limitations of current computer vision models when deployed in safety-critical environments. Deep learning models, including convolutional neural networks (CNNs) and vision transformers, achieve high accuracy on benchmark datasets but can fail unpredictably on edge cases — unusual lighting conditions, novel crack morphologies, surface contaminants that mimic defect patterns, or occlusions from vegetation or debris. A 2024 study from Michigan State University evaluating seven multimodal large language models for pavement condition assessment found that while models like GPT-4o achieved strong performance on standard distress identification, all models exhibited variability in spatial pattern recognition and severity evaluation tasks that require contextual understanding. The HITL architecture acknowledges that for infrastructure assets where failure can lead to catastrophic consequences, machine efficiency must be subordinated to human judgment at the point of final decision.
The HITL approach also addresses the accountability gap that arises when decisions are made entirely by algorithms. In regulated industries — aviation, highway infrastructure, nuclear facilities — inspection reports must carry the signature of a certified professional who bears legal responsibility for the findings. The European Union Aviation Safety Agency (EASA) has issued guidance under its AI Roadmap stating that high-risk AI applications in aviation maintenance must include “meaningful human oversight” with “the ability to override or reverse decisions.” Similarly, the U.S. Federal Highway Administration (FHWA) National Bridge Inspection Standards (NBIS) require that bridge condition ratings be assigned by a team leader meeting specific qualification criteria, a requirement that cannot be delegated to software.
A 2024 National Academies report on AI applications for automatic pavement condition evaluation emphasized that “human verification of automated distress detection outputs is essential for maintaining data quality and ensuring that maintenance decisions are based on reliable assessments.” The report documented that agencies deploying fully automated pavement evaluation without human review experienced error rates of 15–25% on moderate-severity cracks, compared to 3–8% when a human reviewed AI outputs.
HITL Architecture: AI Detection to Final Report
The standard HITL architecture for infrastructure inspection follows a structured five-stage pipeline that transforms raw sensor data into a verified condition assessment. Each stage has specific technical requirements and quality control checkpoints.
Stage 1: Data Acquisition
High-resolution imagery is captured using unmanned aerial vehicles (UAVs), inspection vehicles equipped with line-scan cameras, or fixed-position cameras mounted on gantries. For bridge inspections, a typical UAV mission collects 5,000–10,000 images at resolutions of 20–50 megapixels, with ground sampling distances (GSD) of 0.5–2 mm per pixel. For pavement surveys, specialized vehicles capture continuous imagery at highway speeds using multiple synchronized cameras covering a 4-meter lane width. The data acquisition phase must include rigorous quality control — blur detection, exposure validation, and geospatial tagging verification — because downstream AI performance is bounded by input quality.
Stage 2: AI Inference Engine
The acquired imagery is processed by a deep learning inference engine, typically based on a CNN architecture such as YOLOv8, Faster R-CNN, or a U-Net variant for semantic segmentation. The model performs pixel-level or bounding-box detection of predefined defect classes. For bridge inspection, these classes typically include cracks (transverse, longitudinal, diagonal, map cracking), spalls, delamination, corrosion staining, exposed rebar, and joint damage. For pavement inspection, the classes include fatigue cracking, block cracking, edge cracking, rutting, raveling, potholes, and patching.
Each detection is accompanied by a confidence score ranging from 0.0 to 1.0, representing the model’s estimate of the probability that the detection is a true positive. The inference engine also outputs metadata including detection coordinates in image space, defect dimensions in pixels (or in physical units if calibration data is available), and the classification label.
Stage 3: Confidence-Based Routing
The AI outputs are processed by a routing module that applies configurable confidence thresholds to triage detections. The routing logic typically uses a two-threshold system:
High-confidence false positives; filtered out as noise
The threshold values are site-specific and adjustable. A bridge inspection on a fracture-critical member (FCM) may lower the review threshold to 0.70 to ensure all potentially significant defects are human-reviewed. A pavement survey on a low-volume rural road may raise the threshold to 0.90, accepting a slightly higher false-negative rate in exchange for reduced review workload.
Stage 4: Human Review Interface
Flagged detections are presented to a qualified inspector through a specialized review interface. The interface typically displays the detected defect with the AI-generated bounding box or segmentation overlay, the confidence score, the defect classification, and contextual information such as the asset identifier (bridge number, pavement section), location coordinates, and historical inspection data if available.
The inspector has three possible actions for each flagged detection:
Confirm — Accept the AI prediction as correct; the detection becomes part of the final report
Reject — Dismiss the detection as a false positive
Correct — Modify the AI prediction by adjusting the bounding box, changing the classification, or updating the severity rating
Modern review interfaces incorporate keyboard shortcuts and batch operations to accelerate the review process. An experienced inspector can review 200–500 flagged defects per hour, depending on defect density and image complexity. The review session produces an audit trail documenting every inspector action, which is critical for quality assurance and regulatory compliance.
Stage 5: Final Report Generation
The final condition report integrates auto-accepted high-confidence detections with human-verified flagged detections. The report computes aggregate metrics such as defect density (percentage of surface area affected by each defect type), Pavement Condition Index (PCI) for airfields or roads, or element-level condition ratings for bridges following the AASHTO element-level inspection framework.
Confidence Thresholds for Flagging
Confidence thresholds are the critical tuning parameters that determine the operational efficiency and safety margin of any HITL inspection system. Setting thresholds too aggressively (accepting low-confidence predictions) increases the risk of false negatives — missed defects that could compromise structural integrity. Setting thresholds too conservatively (routing everything to human review) defeats the efficiency purpose of automation.
The Receiver Operating Characteristic (ROC) curve of the AI model provides the analytical basis for threshold selection. The ROC curve plots the true positive rate (sensitivity) against the false positive rate for every possible threshold value. The area under the ROC curve (AUC) summarizes the model’s overall discriminative ability. A model with AUC of 0.95 or higher on representative test data is generally considered suitable for HITL deployment.
Industry best practices recommend calibrating thresholds using a cost matrix that assigns monetary or risk-based weights to each error type:
Error Type
Consequence
Relative Cost
False negative (missed critical crack)
Potential structural failure, safety hazard
Very high
False negative (missed cosmetic defect)
Delayed maintenance, increased lifecycle cost
Medium
False positive (flagging non-defect)
Wasted inspector review time
Low
Misclassification (correct box, wrong class)
Incorrect condition rating
Medium
The threshold calibration process typically involves running the AI model against a validation dataset of at least 5,000–10,000 images that have been independently labeled by certified inspectors. The model’s detections are compared against the ground truth labels, and the threshold is adjusted to achieve a target false-negative rate — commonly 1–2% for fracture-critical bridge elements and 5–8% for general pavement surveys.
Dynamic thresholding is an emerging practice where thresholds are adjusted in real time based on environmental conditions, image quality metrics, or asset criticality. For example, if the inspection vehicle encounters heavy rain or low-light conditions that degrade image quality, the system automatically lowers its confidence threshold to route more detections to human review, compensating for the higher uncertainty in the model’s predictions.
Review Interfaces and Workflows
The human review interface is the operational centerpiece of a HITL inspection system. Its design directly impacts both the speed and accuracy of the verification process. Poorly designed interfaces induce operator fatigue, increase error rates, and create bottlenecks that negate the productivity gains from AI automation.
Effective review interfaces incorporate several key design principles:
Parallel display of AI output and source imagery. The interface should overlay the AI detection (bounding box, segmentation mask, or heatmap) on the original image, with controls to toggle the overlay on and off. This allows the inspector to see precisely what the model detected while retaining the ability to inspect the raw imagery for missed defects.
Contextual navigation aids. The interface should provide a defect-level navigation system (forward/back through flagged detections) integrated with asset-level navigation (e.g., bridge element selector or pavement section map). The Twinsity Twinspect platform, demonstrated in a 2025 proof of concept with Die Autobahn GmbH on German highway bridges, implemented a consolidated view where damages appearing in multiple images are merged into unique defect records, reducing redundancy and accelerating inspector review of over 600 AI-detected anomalies.
Confidence score visualization. Each detection should display its confidence score numerically and visually — typically as a color-coded badge (green for high confidence, yellow for medium, red for low). This helps the inspector prioritize attention on the most uncertain detections first, a workflow known as uncertainty-guided review.
Audit trail recording. Every action taken by the inspector — confirm, reject, correct, skip — must be timestamped, user-identified, and logged in an immutable audit trail. This is not optional; it is a regulatory requirement for any inspection data that feeds into safety management systems or compliance reporting.
Batch confirmation for high-volume review. For inspections with thousands of flagged detections, the interface should support batch selection and bulk confirmation of similar low-risk detections. An inspector reviewing pavement cracks on a 10-km highway section may encounter hundreds of identical transverse cracks; batching these into a single confirmation action dramatically reduces review time.
The review workflow sequence typically follows this order:
Inspector logs into the HITL platform and loads the inspection assignment
System displays a dashboard showing total detections flagged for review, broken down by defect type and confidence band
Inspector begins reviewing detections, starting with the lowest-confidence items first
For each detection, inspector examines the AI overlay against the raw image and makes a confirm/reject/correct decision
System automatically advances to the next detection
At completion, the system generates a verification summary showing the ratio of confirmed, rejected, and corrected detections
The verified detections are merged with auto-accepted detections into the final report
Human Correction of AI Predictions
Human correction of AI predictions is one of the most valuable functions in a HITL system. When an inspector corrects an AI output — by adjusting a poorly placed bounding box, reclassifying a misidentified defect type, or updating a severity rating — the system captures not just the corrected output but also the difference between the AI prediction and the human ground truth. This difference is the signal that drives model improvement through active learning.
Common correction types in infrastructure inspection include:
Bounding box adjustment. The AI may correctly identify that a defect exists but place the bounding box inaccurately — either too tight (cutting off part of the crack) or too loose (including non-defect surface area). The inspector adjusts the box to precisely enclose the defect, and the system records the IoU (Intersection over Union) between the AI prediction and the human correction. Repeated low IoU scores on specific defect classes signal the need for model retraining with better localization examples.
Classification correction. The AI may detect a crack but classify it as “transverse” when it is actually “longitudinal.” This misclassification has consequences for condition rating, because different crack types map to different severity matrices in pavement management systems (e.g., ASTM D6433 for PCI calculation). The inspector corrects the label, and the system records the confusion matrix entry, building a dataset of hard classification cases.
Severity re-rating. Many condition assessment protocols require severity ratings (low, medium, high, or a numeric scale) based on defect dimensions. The AI may correctly identify and localize a crack but misestimate its width or length, leading to an incorrect severity assignment. The inspector corrects the severity, and the system logs the measurement discrepancy.
False positive dismissal. The most common inspector action for low-confidence detections is rejection — the AI flagged a surface feature (oil stain, shadow, tire mark, joint) that is not a defect. Each rejection is a labeled false positive example that improves the model’s discrimination ability.
A 2025 proof-of-concept study conducted by Twinsity in cooperation with Die Autobahn GmbH demonstrated the practical impact of human correction. The AI model initially detected 600 anomalies on a German highway bridge, of which 176 were cracks confirmed by structural engineers. Through the HITL review process, inspectors corrected the AI’s classifications, refined bounding boxes, and rejected false positives. The final verified count of 156 confirmed cracks yielded an 88.6% accuracy rate, which increased to over 95% after the correction data was used for model fine-tuning.
Active Learning from Human Feedback
The integration of HITL with active learning creates a continuous improvement cycle that progressively reduces the human review burden over time. Active learning is a machine learning strategy where the algorithm identifies which unlabeled data points would be most informative for improving model performance and requests labels for those specific points from a human annotator.
In the HITL inspection context, active learning operates as follows:
The AI model processes new inspection imagery and generates predictions with confidence scores
The system identifies detections with the highest uncertainty — those closest to the decision boundary between true positive and false positive
These uncertain detections are routed to the human inspector for verification
The inspector’s confirmed or corrected labels become training data for the next model update
The model is retrained or fine-tuned on the expanded dataset, improving its accuracy on the previously uncertain cases
Over successive inspection cycles, the number of detections requiring human review decreases
The query strategy for selecting which detections to route for human labeling is critical. Common strategies include:
Least confidence sampling: Route detections with confidence scores closest to the decision threshold (e.g., 0.45–0.55)
Margin sampling: Route detections where the difference between the top two class probabilities is smallest
Entropy sampling: Route detections with the highest prediction entropy, indicating the model is most uncertain about the classification
A study published in Automation in Construction evaluating automation-enabled HITL systems for infrastructure visual inspection found that active learning reduced the human labeling workload by 60–75% compared to random sampling while maintaining equivalent model accuracy. The study documented that after five active learning cycles on a crack detection dataset, the model achieved 94.7% accuracy with only 30% of the training data requiring human review.
Implementing active learning in production HITL systems requires versioned model management. Each retraining cycle produces a new model version that must be validated against a held-out test set before deployment. The system must also support A/B testing — running the new model in shadow mode alongside the current production model to verify that performance improvements generalize to new inspection data before committing to the update.
HITL for Bridge Inspection
Bridge inspection is the most safety-critical application of HITL technology in infrastructure. The United States has over 617,000 bridges, of which approximately 42% are over 50 years old and 7.5% are classified as structurally deficient according to the 2024 American Society of Civil Engineers (ASCE) Infrastructure Report Card. The National Bridge Inspection Standards (NBIS) codified in 23 CFR 650 require that all bridges on public roads be inspected at intervals not exceeding 24 months by qualified team leaders.
FHWA documentation emphasizes that human verification is non-negotiable for condition ratings assigned under the NBIS framework. The condition rating scales for bridge elements (0–9 for decks, superstructure, and substructure per the National Bridge Inventory coding guide) require the inspector to synthesize multiple observable conditions into a single numeric rating — a task that current AI systems cannot perform reliably because it requires understanding of structural load paths, material behavior, and deterioration mechanisms.
The HITL bridge inspection workflow integrates multiple data sources:
UAV imagery provides high-resolution visual data of all accessible bridge surfaces — deck, soffit, girders, piers, abutments, bearings, and joints. A typical UAV bridge inspection collects 3,000–8,000 images per structure, depending on bridge size and complexity. The AI inference engine processes these images to detect cracks, spalls, corrosion, and other visible defects.
Ground-penetrating radar (GPR) data is used alongside visual imagery for deck delamination detection and rebar corrosion assessment. While the GPR signal interpretation requires specialized expertise, AI models can flag anomalous signal patterns for human review.
The inspector’s role in the HITL system is not merely to confirm or reject AI predictions but to add structural engineering judgment that the AI cannot provide. The inspector reviews flagged detections in the context of the bridge’s known load rating, traffic volume, environmental exposure, and inspection history. A hairline crack in the web of a prestressed concrete girder may be immediately flagged for urgent repair, while an identical crack in a secondary diaphragm member may be rated as a minor observation — a distinction that depends on structural engineering knowledge, not pixel-level pattern recognition.
The FHWA’s recommended framework for a bridge inspection QC/QA program, updated in 2024, explicitly addresses the integration of automated inspection technologies. The framework requires that any automated crack detection system be validated against manual inspection on at least 10% of bridge elements, with the validation results documented and reviewed by the inspection team leader. This dual-validation approach is a formalized HITL process that ensures automation serves as a decision-support tool rather than a replacement for professional judgment.
HITL for Pavement Inspection
Pavement condition assessment has been an early adopter of automated inspection technology because of the high data volumes involved — a single highway agency may manage 10,000–50,000 lane-km of pavement, with inspection intervals of 1–3 years. Manual visual surveys at this scale are prohibitively expensive, requiring 30–50 person-days per 100 lane-km. AI-assisted methods can process the same network in 5–10 hours of compute time, but the results must be verified by human inspectors before they can be used for maintenance programming decisions.
The HITL workflow for pavement inspection typically uses line-scan cameras mounted on survey vehicles traveling at highway speeds (80–100 km/h), capturing continuous 360-degree imagery of the pavement surface. The images are georeferenced using GPS/IMU systems accurate to 10–50 cm. The AI model segments the pavement surface into defect categories and computes distress density metrics.
The American Association of State Highway and Transportation Officials (AASHTO) guidelines for pavement condition data collection recognize the role of automated systems while maintaining human verification requirements. The AASHTO PP 89-21 standard for automated pavement distress data collection specifies quality assurance procedures including:
Field verification: A minimum of 5% of survey sections must be ground-truthed by manual inspection within 30 days of the automated survey
Repeatability testing: The automated system must demonstrate repeatability of ±5% on distress quantities when re-surveying the same section within 24 hours
Human review of edge cases: All sections with distress quantities exceeding predefined thresholds (e.g., >20% cracking area) must be manually reviewed
The HITL review interface for pavement inspection typically presents a strip chart view showing the pavement surface with AI-detected defects color-coded by type and severity. The inspector scrolls through the continuous pavement imagery, reviewing flagged sections and verifying the AI’s condition assessment. For agencies using the Pavement Condition Index (PCI) methodology per ASTM D6433, the HITL system computes PCI values from the verified defect data, with the inspector accepting or overriding the calculated value based on their field knowledge.
A 2025 study from the National Academies on AI applications for automatic pavement condition evaluation found that HITL systems achieved 92–96% agreement with manual inspection on distress identification, compared to 78–85% for fully automated systems without human review. The study also found that HITL reduced inspection time by 55–70% compared to purely manual methods while maintaining compliance with AASHTO data quality standards.
Regulatory Acceptance of HITL
The regulatory landscape for AI in infrastructure inspection is evolving rapidly, but the consistent theme across all major frameworks is that human oversight is mandatory for safety-related decisions.
International Civil Aviation Organization (ICAO) — Under ICAO Annex 14, Volume I (Aerodrome Design and Operations), the aerodrome operator is responsible for ensuring that runways, taxiways, and apron surfaces are maintained in a condition acceptable for aircraft operations. While ICAO does not explicitly prohibit automated inspection, the requirement that the “aerodrome operator shall establish an inspection program” that is “acceptable to the State” implicitly requires that condition assessments be performed by or verified by competent personnel. ICAO Document 9157 (Aerodrome Design Manual) references the Pavement Condition Index (PCI) methodology, which requires visual inspection by trained raters unless the State approves an alternative procedure.
European Union Aviation Safety Agency (EASA) — EASA’s AI Roadmap 2.0, published in 2024, establishes a tiered approach to AI in aviation. Under Level 2 (“Human-AI Collaboration”), which covers AI-assisted inspection, the agency requires: (a) the human retains final decision authority, (b) the AI system provides explanations for its outputs, and (c) the system can be overridden or disengaged at any time by the human operator. These requirements map directly to HITL architecture.
Federal Aviation Administration (FAA) — The FAA’s Advisory Circular AC 150/5380-6C on “Guidelines for Pavement Management Programs” states that automated data collection methods are acceptable provided that “the data collection equipment is certified and the data is validated by an engineer experienced in pavement evaluation.” This dual requirement — equipment certification plus human validation — is a formal HITL mandate.
Federal Highway Administration (FHWA) — The FHWA NBIS (23 CFR 650 Subpart C) requires that all bridge inspections be performed by or under the direction of a team leader who meets specific qualification requirements (Professional Engineer or certified bridge inspector with minimum experience thresholds). While automated data collection is permitted, the condition rating must be determined by the team leader. The FHWA’s 2024 NBIS review process guidance confirms that “automated inspection technologies supplement but do not replace the team leader’s professional judgment.”
ISO 55001 (Asset Management) — The international standard for asset management requires that condition data used for decision-making be reliable, repeatable, and verifiable. HITL workflows satisfy these requirements by maintaining human verification as the final quality gate.
The practical implication of this regulatory environment is that HITL is not merely a technical preference for infrastructure inspection — it is a compliance requirement. Any organization deploying AI for inspection of aviation, highway, or structural assets must implement a human review process to satisfy regulatory obligations. The exact architecture may vary — some agencies require 100% human review of all detections, while others accept statistical sampling — but the principle of human verification is universal.
Fully Automated vs HITL
The distinction between fully automated inspection and human-in-the-loop inspection is fundamental to understanding deployment decisions in infrastructure asset management. Each approach has distinct characteristics, benefits, and limitations:
Dimension
Fully Automated
Human-in-the-Loop
Decision authority
AI model
Human inspector
Throughput
Very high (100,000+ images/hour)
Moderate (200–500 flagged items/hour)
Edge case handling
Poor — model fails on novel patterns
Good — human adapts to novel situations
Accountability
Diffuse — no single responsible entity
Clear — certified inspector bears responsibility
Regulatory compliance
Limited — most standards require human sign-off
Established — satisfies existing regulatory frameworks
Continuous improvement
Requires separate data pipeline
Built-in through active learning
Cost per inspection
Low after initial deployment
Higher due to human labor
False negative rate
10–25% on ambiguous defects
2–5% after human review
Suitable for
Low-risk assets, initial screening, high-volume
Safety-critical assets, final condition assessment, regulated
The decision between fully automated and HITL deployment depends on the risk category of the asset being inspected. Low-risk assets — such as secondary roads, non-structural building elements, and cosmetic surface conditions — may be candidates for fully automated inspection where the cost of false negatives is acceptable. Safety-critical assets — bridges, runways, tunnels, dams, and high-traffic highways — require HITL because the consequence of a missed critical defect is unacceptable.
A 2024 survey of 47 U.S. state Departments of Transportation found that 93% of agencies using automated pavement data collection employ some form of human verification, ranging from random sampling (10% of sections) to comprehensive review of all sections flagged as deficient. Only 7% accepted automated data without any human verification, and those agencies limited automated-only acceptance to low-volume local roads in good condition. For bridge inspection, the same survey found that 100% of agencies maintained human verification requirements, with the most common approach being human review of all AI-detected anomalies combined with random spot-checking of 15–20% of images classified as defect-free.
The operational trend is toward hybrid models that adjust the degree of automation based on asset condition. A bridge in good condition (NBI rating 7–9) may be processed with high-confidence auto-acceptance thresholds and minimal human review, while a bridge in poor condition (NBI rating 3–4) may have all detections routed for human review regardless of confidence score. This risk-adaptive HITL approach optimizes inspector effort by allocating attention to the assets where it provides the greatest safety benefit.
Conclusion
Human-in-the-loop verification represents the current state of the art in automated infrastructure inspection. The HITL architecture — combining AI-based initial detection with confidence-based routing and mandatory human review — delivers the productivity benefits of automation while maintaining the safety accountability and professional judgment that regulatory standards demand. The threshold calibration, review interface design, human correction workflows, and active learning integration are the technical elements that determine whether a HITL system operates effectively in practice.
For bridge inspection, pavement condition assessment, airport runway evaluation, and aerodrome maintenance compliance, HITL is not a transitional approach on the path to full autonomy — it is the demonstrated best practice that balances the complementary strengths of machines and humans. As AI model accuracy continues to improve, the human review burden will decrease through active learning, but the principle of human verification for safety-critical decisions will remain a regulatory and ethical requirement.
Frequently Asked Questions
Human-in-the-loop (HITL) in automated inspection is a semi-automated workflow where an AI model performs initial defect detection on inspection imagery and assigns confidence scores to each detection. Anomalies falling below a predefined confidence threshold are routed to a qualified human inspector for review, verification, and final adjudication. This approach combines the processing speed and consistency of machine vision with the contextual judgment, safety accountability, and regulatory compliance that only certified human inspectors can provide.
Confidence thresholds in HITL systems define the boundary between automated acceptance and human review. Detections with confidence scores above a high threshold (e.g., >0.95) are automatically accepted as true positives. Detections below a low threshold (e.g., <0.50) are automatically rejected as noise. Detections in the middle band are flagged for human review. The threshold values are calibrated based on the criticality of the asset, regulatory requirements, and the cost of false negatives versus false positives.
The HITL architecture for infrastructure inspection follows a five-stage pipeline: (1) data acquisition via drones, inspection vehicles, or stationary cameras, (2) AI inference where computer vision models detect and classify defects with confidence scores, (3) confidence-based routing that separates high-confidence detections from ambiguous ones, (4) human review interface where inspectors examine flagged imagery and either confirm, reject, or correct AI predictions, and (5) final report generation that integrates both automated and human-verified findings.
Fully automated inspection relies entirely on AI to detect, classify, and report defects without human involvement. HITL inspection uses AI for initial screening but requires a human inspector to verify and adjudicate findings before they become part of the official record. HITL is preferred for safety-critical infrastructure because it preserves human accountability, handles edge cases that AI may misclassify, and satisfies regulatory requirements that mandate certified inspector sign-off on inspection reports.
Under ICAO Annex 14 and associated aerodrome certification frameworks, inspection reports for safety-critical airfield infrastructure must be signed off by qualified personnel. While AI-assisted tools are permitted for data collection and preliminary analysis, the final condition assessment and defect classification must involve human verification. The European Union Aviation Safety Agency (EASA) and the Federal Aviation Administration (FAA) have issued guidance on the use of AI in aviation maintenance that requires meaningful human oversight for safety-related decisions.
Active learning in HITL systems selects the most uncertain AI detections for human review, then uses the inspector's confirmed or corrected labels as training data to improve the model. Over successive inspection cycles, this reduces the number of detections requiring human review. Studies have shown active learning reduces human labeling workload by 60-75% while maintaining equivalent model accuracy.
Enhance Your Inspection Workflows with HITL
Implement human-in-the-loop verification processes that combine the speed of AI-powered defect detection with the accountability of certified inspector review. Contact us to learn how our solutions integrate into HITL workflows for bridge, pavement, and airfield inspections.
Automated drone inspection uses pre-programmed flight paths, computer vision, and AI analysis to survey infrastructure assets including runways, bridges, roads,...
Edge computing performs AI inference directly on the drone, vehicle, or handheld device at the point of data capture, enabling real-time defect detection, quali...
22 min read
Technology
AI
+5
Cookie Consent We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.