Semantic Segmentation for Infrastructure Scene Understanding
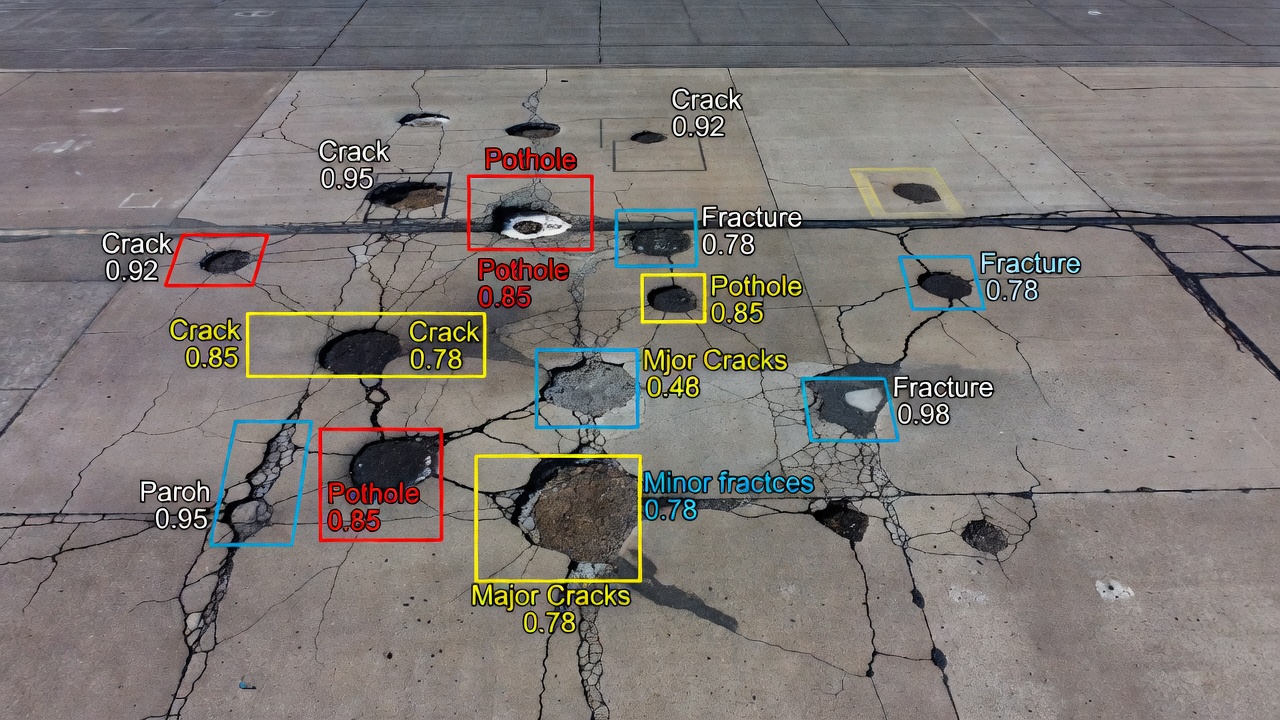
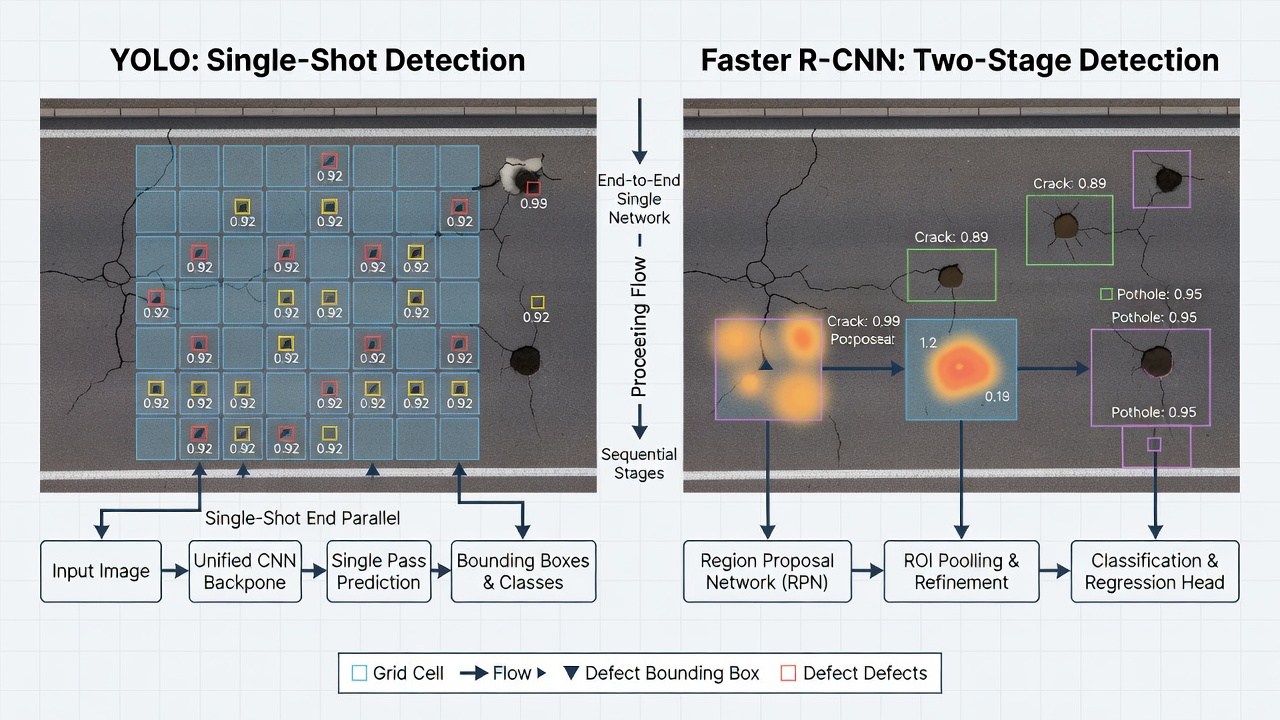
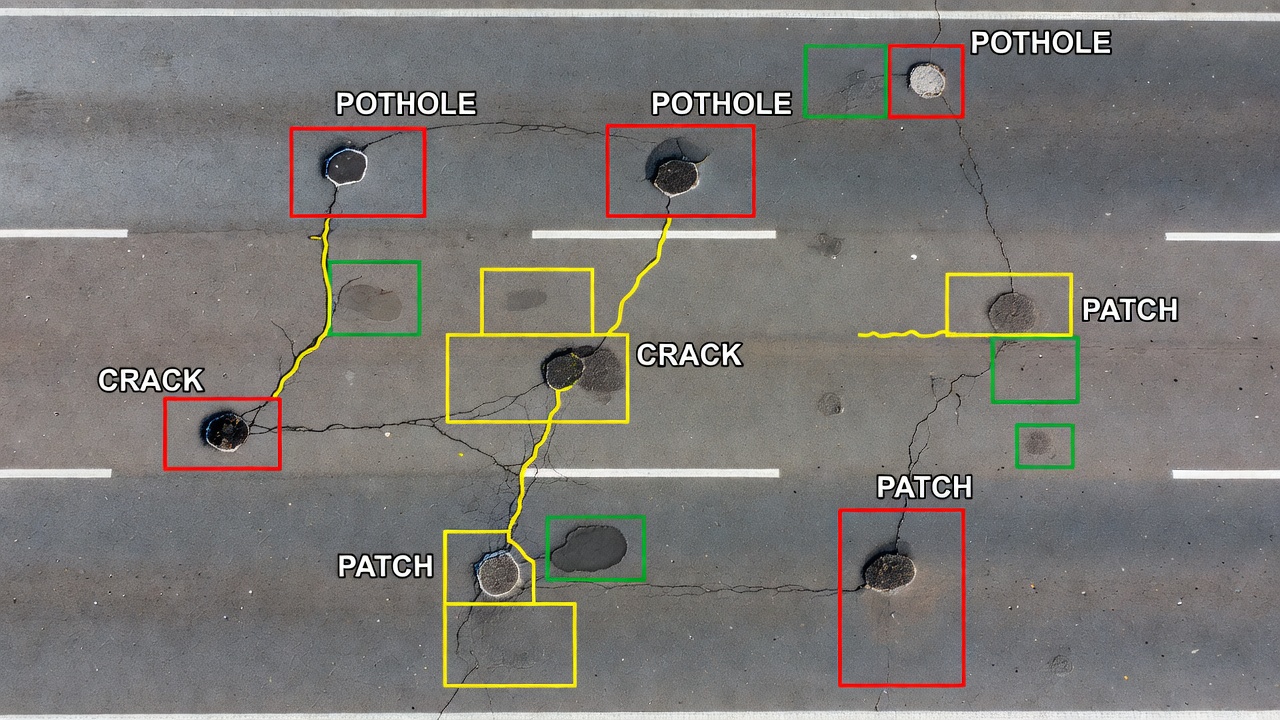
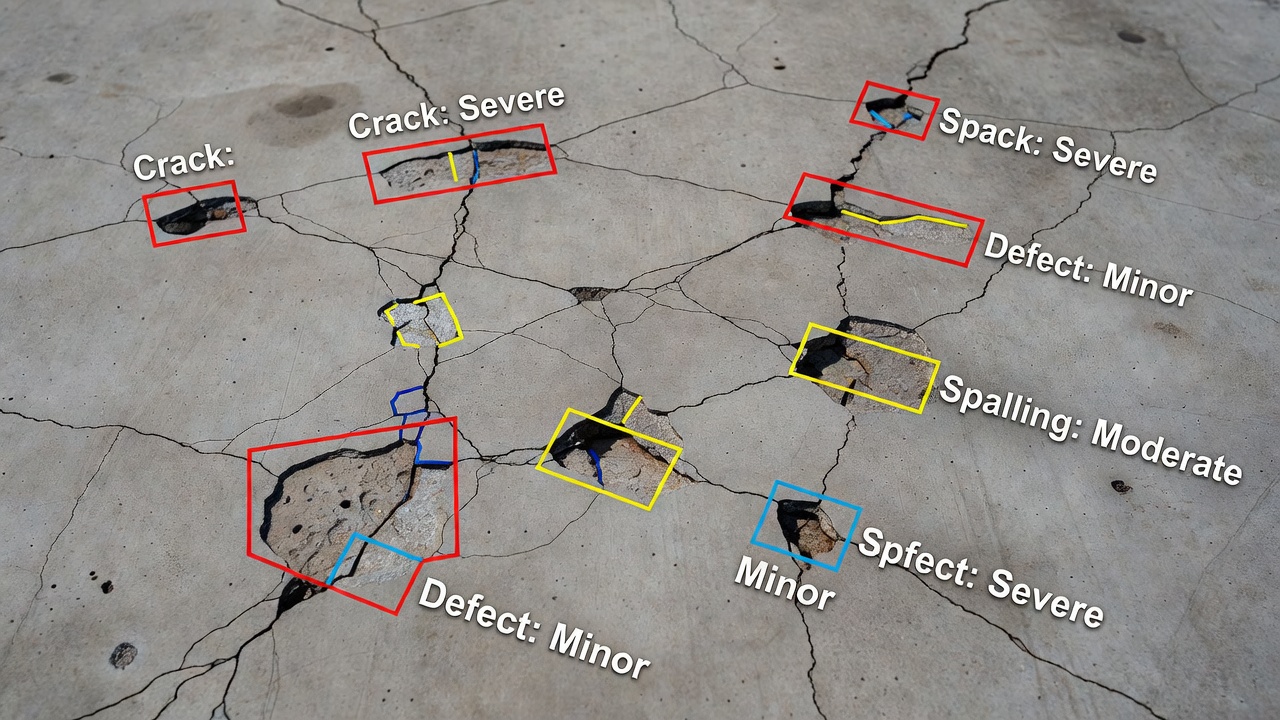
Semantic segmentation assigns a category label to every pixel in an image, enabling full-scene understanding for infrastructure inspection. Covers encoder-decod...
37 min read
Technology
Computer Vision
+3