Crack Segmentation
Crack segmentation is the computer vision task of classifying every pixel in an image as either crack or non-crack, producing a binary mask that enables precise...
32 min read
Computer Vision
Deep Learning
+2
Semantic segmentation assigns a category label to every pixel in an image, enabling full-scene understanding for infrastructure inspection. Covers encoder-decoder architectures (U-Net, DeepLabV3+, SegFormer, PSPNet, Mask2Former), encoder backbones (ResNet, EfficientNet, ViT), loss functions (cross-entropy, Dice, focal, boundary), training with pixel-level labels, multi-class segmentation for road and airfield scenes, crack segmentation, surface type mapping, evaluation metrics (IoU, Dice, pixel accuracy), and deployment optimization for real-time inspection workflows.

Semantic segmentation is the computer vision task of assigning a predefined class label to every pixel in an input image, producing a complete pixel-wise classification map where each pixel is assigned to a category such as crack, non-crack pavement, pavement marking, vegetation, FOD, or surface type. The output is a dense prediction mask of the same spatial dimensions as the input image, where each pixel value corresponds to a class index.
This distinguishes semantic segmentation from three related but fundamentally different computer vision tasks:
Image classification assigns a single label to the entire image — for example, declaring “this image contains a crack” without specifying where the crack is located. Classification provides no spatial information about the object’s position, shape, or extent. It is the simplest computer vision task but also the least informative for infrastructure inspection, where knowing the location, geometry, and extent of defects is essential for condition assessment and maintenance planning.
Object detection identifies and locates objects by drawing axis-aligned bounding boxes around them, assigning each box a class label and confidence score. Detection answers “what objects are present and approximately where.” For crack detection, a bounding box might enclose a crack region but cannot delineate the crack’s precise shape, width, or connectivity — information critical for crack type classification (longitudinal, transverse, alligator, block) and severity assessment per ASTM D5340.
Instance segmentation goes a step further by detecting every individual object instance and producing a pixel-wise mask for each one, assigning unique instance IDs. For infrastructure inspection, this would distinguish individual cracks or potholes from one another. However, many surface defects — particularly cracking patterns like alligator cracking or block cracking — form interconnected networks that are difficult to decompose into discrete instances, making instance segmentation less suitable for general pavement condition assessment.
Panoptic segmentation unifies semantic and instance segmentation by assigning a semantic label to every pixel (including “stuff” classes like pavement, sky, vegetation) and simultaneously detecting and segmenting individual object instances (“thing” classes like specific potholes or FOD items). Panoptic segmentation is the most comprehensive approach but also the most computationally demanding and complex to train.
| Task | Output | Spatial Precision | Infrastructure Applicability |
|---|---|---|---|
| Image Classification | Single label per image | None | Crack presence detection only |
| Object Detection | Bounding boxes per object | Coarse | FOD detection, pothole localization |
| Semantic Segmentation | Pixel-wise class labels | Maximum (pixel level) | Crack mapping, surface type, PCI assessment |
| Instance Segmentation | Individual object masks | Maximum + instance ID | Discrete defect counting |
| Panoptic Segmentation | All-pixel labels + instances | Maximum + instance ID | Full scene understanding |
For infrastructure inspection applications — particularly airfield pavement condition assessment, crack mapping, and surface type classification — semantic segmentation is the most appropriate and widely adopted approach because it provides complete scene understanding at the pixel-level precision required for quantitative condition assessment, without requiring the decomposition of continuous defect networks into individual instances.
Architecturally, semantic segmentation models are typically fully convolutional networks (FCNs) or transformer-based models designed to accept an input image of arbitrary dimensions and produce an output segmentation map of the same spatial dimensions. The defining characteristic is the absence of fully connected layers that would fix the input size — instead, all layers are convolutional or attention-based, enabling the network to process images of varying resolutions during inference.
The output segmentation map has dimensions H × W × C, where H and W match the input spatial dimensions (or a fixed fraction thereof) and C is the number of classes. At each spatial location, the C-dimensional vector contains the predicted probability for each class, typically normalized through a softmax activation function so that probabilities sum to 1. The final class assignment is determined by taking the argmax across the channel dimension — the class with the highest probability at each pixel.

U-Net, introduced by Ronneberger, Fischer, and Brox in their 2015 paper “U-Net: Convolutional Networks for Biomedical Image Segmentation,” is the most influential semantic segmentation architecture and remains the de facto standard for infrastructure inspection tasks, particularly crack segmentation. The name derives from the symmetric U-shaped architecture comprising a contracting encoder path and an expansive decoder path interconnected by skip connections.
The encoder (contracting path) follows a typical convolutional network design: repeated application of two 3×3 convolutions (each followed by a rectified linear unit — ReLU) and a 2×2 max pooling operation with stride 2 for downsampling. At each downsampling step, the number of feature channels doubles: from 64 to 128 to 256 to 512 to 1024 at the deepest layer (the bottleneck). This progressive increase in channel depth compensates for the loss of spatial resolution, enabling the network to learn increasingly abstract and semantically meaningful features at coarser scales.
The decoder (expanding path) mirrors the encoder in reverse: each step begins with a 2×2 up-convolution (transposed convolution) that halves the number of feature channels and doubles the spatial dimensions. The upsampled feature map is then concatenated with the corresponding feature map from the encoder at the same resolution — this is the skip connection that defines U-Net. The concatenated feature map passes through two 3×3 convolutions with ReLU activation. The final layer is a 1×1 convolution that maps the feature representation to the desired number of output classes.
The skip connections are the architectural innovation that makes U-Net effective for precise localization. During encoding, spatial information about object boundaries, texture gradients, and fine details is progressively lost through downsampling and pooling operations. The skip connections bypass the bottleneck and directly deliver high-resolution feature maps from the encoder to the decoder at corresponding resolutions, enabling the decoder to access both the semantic context from deeper layers and the spatial precision from shallower layers. For crack segmentation, where crack widths of 0.5–3 mm must be resolved, preserving boundary precision through skip connections is essential.
The original U-Net implementation contains approximately 31 million parameters for a 2-class segmentation task. Modern implementations in frameworks like Segmentation Models PyTorch (smp) support configurable encoder depths (3–5 stages), pluggable encoder backbones (ResNet, EfficientNet, etc.), and decoder channel specifications, making U-Net highly adaptable to different accuracy-speed trade-offs. The architecture processes a 256×256 input image in approximately 15–30 milliseconds on a modern GPU, enabling real-time inference at 30–60 frames per second for tile-based processing of large area surveys.
DeepLabV3+, developed by Chen et al. at Google (2018), extends the DeepLab family of architectures (DeepLabV1, V2, V3) by adding an encoder-decoder structure to the Atrous Spatial Pyramid Pooling (ASPP) module introduced in DeepLabV3. The architecture was designed specifically to address the limitations of standard FCN-based segmentation: the loss of spatial resolution due to repeated downsampling, and the difficulty of segmenting objects at multiple scales.
The key innovation in DeepLabV3+ is atrous (dilated) convolution, which enables the network to control the resolution at which feature responses are computed without reducing spatial dimensions. Atrous convolution inserts zeros (holes) between filter weights, effectively expanding the receptive field without increasing the number of parameters. For a convolution with kernel size k and dilation rate r, the effective kernel size is k + (k-1)(r-1). DeepLabV3+ uses an output stride of 16 — meaning the final feature map resolution is 1/16 of the input — compared to 1/32 for standard ResNet backbones, preserving finer spatial detail.
The Atrous Spatial Pyramid Pooling (ASPP) module applies parallel atrous convolutions with different dilation rates to capture multi-scale context. The standard ASPP configuration uses four parallel branches with dilation rates of 1, 6, 12, and 18 when the output stride is 16 (or 1, 12, 24, 36 for output stride 8). Each branch processes the feature map through a 3×3 convolution at its specified dilation rate, followed by batch normalization and ReLU. The outputs are concatenated and passed through a 1×1 convolution to produce the final ASPP feature representation. An additional branch applies global average pooling to capture whole-image context, which is bilinearly upsampled and concatenated with the ASPP features.
The decoder module in DeepLabV3+ is a relatively lightweight component compared to U-Net’s full decoder. The encoder features (from ASPP) are bilinearly upsampled by a factor of 4. These upsampled features are concatenated with the corresponding low-level features from the encoder backbone (specifically, the feature map from the first convolutional block — typically at 1/4 resolution). The concatenated features pass through a 3×3 convolution and a second bilinear upsampling by a factor of 4 to restore the original input resolution.
DeepLabV3+ achieves state-of-the-art performance on benchmark datasets like Cityscapes (82.1% mIoU with ResNet-101 backbone) and PASCAL VOC 2012 (89.0% mIoU with Xception backbone). For infrastructure inspection, DeepLabV3+ excels at segmenting large, context-dependent surface features like pavement types and marking zones but may struggle with very thin features like hairline cracks (width < 1 mm) where the 1/16 output stride still loses critical spatial detail.
SegFormer, introduced by Xie et al. at NVIDIA (2021), represents a fundamental departure from convolutional architectures by using a purely transformer-based encoder with a lightweight multilayer perceptron (MLP) decoder. SegFormer was the first hierarchical transformer segmentation architecture to demonstrate that transformers could match or exceed convolutional architectures across the full range of model sizes — from lightweight (SegFormer-B0, 3.8 million parameters) to heavy (SegFormer-B5, 84.7 million parameters).
The Mix Transformer (MiT) encoder employs a hierarchical design that produces multi-scale feature maps at 1/4, 1/8, 1/16, and 1/32 of the input resolution, similar to the feature hierarchy in convolutional backbones like ResNet. Each stage applies overlapping patch embedding (rather than the non-overlapping patches in standard ViT), efficient self-attention with a reduced sequence length, and Mix-FFN feed-forward networks. The positional encoding in SegFormer is zero-initialized and learnable — the authors found that removing fixed positional encodings entirely and relying on the zero-initialized learnable variant improved performance on variable-resolution inference, which is critical for infrastructure imagery captured at varying altitudes and ground sampling distances.
The MLP decoder is remarkably simple compared to convolutional decoders: it aggregates the multi-scale features from the MiT encoder by bilinearly upsampling all feature maps to 1/4 resolution, concatenating them, passing through a 3×3 convolution fusion layer, and applying an MLP with two hidden layers to produce the final segmentation. The simplicity of the decoder contributes to SegFormer’s computational efficiency — the decoder contains only a few million parameters even for the largest model variants.
SegFormer’s key advantage for infrastructure inspection is its robustness to input resolution variation. The transformer encoder’s self-attention mechanism naturally adapts to different input sizes without the resolution-dependent behavior of convolutional kernels. For pavement inspection tasks where images may be captured at different flight altitudes or with different camera sensors, SegFormer maintains consistent segmentation quality without requiring resolution-specific fine-tuning.
Pyramid Scene Parsing Network (PSPNet), introduced by Zhao et al. (2017), addresses the challenge of global context understanding through pyramid pooling. The key insight is that many segmentation errors — particularly the misclassification of regions that are visually similar but semantically different (e.g., asphalt pavement vs. concrete pavement, or sealed crack vs. unsealed crack) — arise from insufficient global context.
The Pyramid Pooling Module (PPM) applies adaptive average pooling at four different scales: 1×1 (global), 2×2, 3×3, and 6×6. Each pooled feature map is passed through a 1×1 convolution to reduce channels to 1/N of the input (where N=4, the number of pyramid levels), then bilinearly upsampled back to the original feature map resolution. The upsampled features from all four levels are concatenated with the original feature map, producing a final representation that encodes both local details and global context at multiple scales.
For pavement segmentation, the pyramid pooling enables the network to distinguish between surface types based on context: a patch of asphalt in the center of a runway has different expected texture and condition than asphalt at the runway edge or on a taxiway. The global pooling at 1×1 captures the overall scene type (runway, taxiway, apron, road), while finer pooling scales capture local texture and condition patterns.
Mask2Former, introduced by Cheng et al. at Meta AI (2022), unifies semantic, instance, and panoptic segmentation within a single architecture by formulating all segmentation tasks as mask classification. Rather than producing pixel-wise classification maps directly, Mask2Former predicts a set of binary masks with associated class labels, similar to how object detection predicts bounding boxes with class labels.
The architecture consists of three components: a backbone (typically a Swin Transformer or ResNet) that extracts multi-scale features, a transformer decoder with masked attention that iteratively refines mask predictions, and a pixel decoder that generates per-pixel embeddings. The masked attention mechanism restricts transformer self-attention to regions within each predicted mask, significantly reducing computational complexity (from O(N²) to O(NM) where M is the number of mask pixels) and focusing the model’s capacity on region-specific features.
For infrastructure inspection, Mask2Former’s advantage is its ability to naturally handle diverse object sizes — from large continuous regions (pavement types, vegetation zones) to small discrete objects (FOD items, individual spalls) — within a unified framework. However, the mask classification formulation can be less intuitive for continuous, amorphous defect patterns than direct pixel-wise classification, and Mask2Former typically requires more training data and computational resources than U-Net or DeepLabV3+.
ResNet, introduced by He et al. at Microsoft Research (2015), is the most widely used encoder backbone for semantic segmentation. The key innovation is the residual learning framework: instead of learning an unreferenced function H(x) = output, each layer (or stack of layers) learns the residual F(x) = H(x) − x. The original input x is added to the learned residual through a shortcut (skip) connection, giving the layer output H(x) = F(x) + x.
The residual block formalizes this: for a block with two 3×3 convolutional layers, the block output is σ(F(x) + x), where σ is the ReLU activation and F(x) is the composition of the two convolutions, batch normalization, and intermediate ReLU. If the dimensions of x and F(x) differ (e.g., when stride > 1 reduces spatial resolution), the shortcut connection uses a 1×1 convolution to match dimensions. The residual formulation enables training networks of unprecedented depth — ResNet-152 has 152 layers — by mitigating the vanishing gradient problem through direct gradient flow along the shortcut paths.
ResNet variants are designated by their depth: ResNet-18 (18 layers, 11.7 million parameters), ResNet-34 (34 layers, 21.8M), ResNet-50 (50 layers, 25.6M), ResNet-101 (101 layers, 44.5M), and ResNet-152 (152 layers, 60.2M). For infrastructure segmentation, ResNet-50 and ResNet-101 are the most common choices, balancing accuracy against memory and inference time.
For segmentation tasks, the standard ResNet backbone is modified to produce dilated (atrous) feature maps by removing striding in the last one or two blocks and replacing subsequent convolutions with dilated convolutions. This dilated ResNet variant maintains higher-resolution feature maps (1/8 or 1/16 of input resolution instead of 1/32) while preserving the receptive field size — a critical modification for dense prediction tasks.
EfficientNet, introduced by Tan and Le at Google (2019), achieves state-of-the-art accuracy with significantly fewer parameters and FLOPs than comparable architectures through compound scaling. The key insight is that scaling network depth, width, and input resolution should be performed jointly, not independently. EfficientNet uses a compound coefficient φ that simultaneously scales all three dimensions: depth α^φ, width β^φ, and resolution γ^φ, subject to the constraint α·β²·γ² ≈ 2 (ensuring total FLOPs scale by approximately 2^φ).
The building block of EfficientNet is the MBConv (Mobile Inverted Bottleneck Convolution) , originally introduced in MobileNetV2. Each MBConv block uses: a 1×1 expansion convolution (increasing channel count by a factor of 4–6), a depthwise 3×3 or 5×5 convolution (operating on each channel independently), squeeze-and-excitation (SE) channel attention (global average pooling → two FC layers → sigmoid activation → channel-wise scaling), and a 1×1 projection convolution (reducing channels back to the target dimension). SE attention enables EfficientNet to focus on informative channels — for pavement inspection, this means emphasizing texture channels that distinguish crack from non-crack while suppressing flat texture regions.
EfficientNet variants range from EfficientNet-B0 (5.3M parameters, 0.4 GFLOPs for 224×224 input) to EfficientNet-B7 (66M parameters, 37 GFLOPs). For edge deployment on inspection drones or embedded systems, EfficientNet-B0 to B3 offer excellent accuracy-to-compute ratios, achieving crack segmentation IoU within 2–3% of ResNet-50 while requiring 5–10× fewer FLOPs.
The Vision Transformer (ViT) , introduced by Dosovitskiy et al. at Google (2020), applies the transformer architecture — originally developed for natural language processing — directly to image patches. The input image is divided into fixed-size patches (typically 16×16 pixels), each patch is linearly projected to a token embedding, and these tokens are processed through a series of transformer encoder layers that apply multi-head self-attention and MLP blocks.
The self-attention mechanism computes pairwise attention weights between all pairs of tokens, enabling each patch representation to incorporate information from every other patch in the image. The attention weight between token i and token j is computed as: Attention(Q,K,V) = softmax(QK^T/√d_k)V, where Q (query), K (key), and V (value) are learned linear projections of the token embeddings, and d_k is the key dimension. This global receptive field — every output position integrated information from every input position — is ViT’s fundamental advantage over convolutional networks, which have limited receptive fields determined by kernel size and network depth.
For semantic segmentation, ViT backbones are used within hierarchical frameworks (like Swin Transformer, which applies self-attention within shifted windows for computational efficiency) or combined with convolutional decoders. The SegFormer architecture uses a hierarchical ViT variant specifically designed for segmentation, while SETR (Segmentation Transformer) uses a standard ViT with a progressive upsampling decoder.
ViT-based segmentation models generally achieve higher accuracy on large datasets (requiring >10 million training images for the backbone pre-training) but require substantially more training data and computational resources than convolutional backbones. For infrastructure inspection with limited annotated data, convolutional backbones like ResNet and EfficientNet remain more practical unless extensive pre-training on domain-relevant data is available.
Cross-entropy loss is the baseline loss function for semantic segmentation, directly derived from the principle of maximum likelihood estimation. For each pixel i, the predicted class probability distribution p_i(c) is compared to the ground-truth one-hot encoding y_i(c) (1 for the correct class, 0 for all others). The per-pixel loss is: L_i = −Σ_c y_i(c) · log(p_i(c)) = −log(p_i(ĉ)), where ĉ is the ground-truth class.
The total loss is the average over all pixels: L_CE = (1/N) · Σ_i L_i, where N is the total number of pixels. Cross-entropy is differentiable, convex in the softmax logits, and guarantees that the global minimum corresponds to the true data distribution.
However, cross-entropy performs poorly on class-imbalanced data, which is the dominant characteristic of infrastructure inspection imagery. Crack pixels typically account for 0.1% to 3% of image pixels, pavement markings for 2–5%, and FOD for less than 0.01%. Cross-entropy treats all pixels equally, so the vast majority of the gradient signal comes from the dominant classes (non-crack pavement, vegetation), and the network learns to ignore minority classes. Weighted cross-entropy addresses this by assigning higher weight to minority classes: L_WCE = −(1/N) · Σ_i w(ĉ) · log(p_i(ĉ)), where w(c) is typically the inverse class frequency or a manually tuned weight.
Dice loss directly optimizes the Dice coefficient (F1 score), the overlap metric between predicted and ground-truth segmentation. For binary segmentation, the Dice coefficient is: Dice = 2|P ∩ G| / (|P| + |G|), where P is the set of predicted positive pixels and G is the set of ground-truth positive pixels. The Dice loss is: L_Dice = 1 − Dice = 1 − (2Σ_i p_i · y_i + ε) / (Σ_i p_i + Σ_i y_i + ε), where ε is a smoothing term (typically 1e-6) to prevent division by zero, p_i is the predicted probability, and y_i is the binary ground-truth label.
For multi-class segmentation, the generalized Dice loss computes the Dice coefficient for each class independently and averages them (potentially with class weights). Dice loss is more robust to class imbalance than cross-entropy because it treats the overlap region (true positives) as a proportion of the total prediction and ground-truth area, rather than counting pixels on a per-pixel basis.
A study on runway pavement crack segmentation at Zadar Airport demonstrated that using Dice loss improved the crack-class IoU by 5.9 percentage points compared to weighted cross-entropy, while combined Dice + Focal loss further improved boundary precision by 2–3%.
Focal loss, introduced by Lin et al. at Facebook AI Research (2017) for dense object detection, is designed specifically for extreme class imbalance. It modifies standard cross-entropy by adding a modulating factor (1 − p_t)^γ, where p_t is the predicted probability of the ground-truth class and γ ≥ 0 is the focusing parameter: L_Focal = −(1/N) · Σ_i (1 − p_t)^γ · log(p_t).
When γ = 0, focal loss reduces to cross-entropy. As γ increases, the modulating factor down-weights well-classified examples (high p_t) and focuses training on hard, misclassified examples (low p_t). For crack segmentation where γ is typically set to 2, a pixel with predicted probability 0.9 (well-classified background) contributes (1−0.9)^2 = 0.01 times the loss weight of standard cross-entropy, while a crack pixel with predicted probability 0.3 (hard example) contributes (1−0.3)^2 = 0.49 of the loss weight — effectively 49× more attention to the hard example relative to the easy one.
Focal loss is particularly effective for FOD detection in airfield imagery, where FOD items occupy 0.001–0.1% of pixels but are the safety-critical class. Combined Dice + Focal loss (L = α·L_Dice + β·L_Focal, with α and β typically set to 0.5–1.0) is the most common loss formulation in infrastructure inspection, combining Dice’s overlap optimization with Focal’s hard-example focus.
Boundary loss addresses a limitation of region-based losses (Dice, IoU): they optimize volumetric overlap but do not explicitly penalize boundary errors. For crack segmentation, where boundary precision determines crack width measurement accuracy, optimizing boundaries is critical.
Boundary loss computes a distance transform on the ground-truth segmentation boundary and multiplies the predicted probability map by the distance-weighted boundary map: L_Boundary = Σ_i D(i) · |p_i − y_i|, where D(i) is the distance from pixel i to the nearest ground-truth boundary pixel (typically truncated at a maximum distance, e.g., 5–10 pixels). Pixels near boundaries (small D) receive high weight, while interior pixels (large D) receive negligible weight.
The Hausdorff distance loss (HD loss) is a related formulation that minimizes the maximum distance between predicted and ground-truth boundaries, encouraging the predicted boundary to not deviate far from the true boundary at any point. Combined with Dice loss, boundary loss has been shown to improve crack width measurement accuracy by 15–25% compared to Dice loss alone, as measured by the mean absolute error between predicted and ground-truth crack width.
| Loss Function | Formula Form | Best For | Limitation |
|---|---|---|---|
| Cross-Entropy | −log(p_c) | Balanced classes, baseline | Poor imbalanced performance |
| Weighted Cross-Entropy | −w(c)·log(p_c) | Moderate imbalance | Fixed weights, no hard-example focus |
| Dice | 1 − 2 | P∩G | /( |
| Focal | −(1−p_t)^γ·log(p_t) | Extreme imbalance | Two hyperparameters (γ, α) |
| Dice + Focal | α·L_Dice + β·L_Focal | Infrastructure inspection (standard) | Requires tuning α, β |
| Boundary | Σ D(i)· | p_i−y_i |
Training semantic segmentation models requires pixel-level ground-truth annotations — every pixel in every training image must be assigned a class label. This is the most labor-intensive and expensive aspect of developing a segmentation model for infrastructure inspection. A single 1920×1080 image contains over 2 million pixels, each requiring annotation, and a typical training dataset for pavement crack segmentation contains 500–5,000 images.
Annotation tools for pixel-level segmentation include:
LabelMe (MIT CSAIL) is an open-source polygon-based annotation tool that runs in a web browser. Annotators draw polygons around objects of interest (cracks, potholes, markings), and the tool fills the polygon interior with the assigned class label. For crack annotation, where cracks are thin and branching, polygon drawing can be extremely time-consuming — a single 1,000-pixel-long crack might require 50–200 polygon vertices to trace accurately.
CVAT (Computer Vision Annotation Tool) , developed by Intel, supports both polygon and brush-based annotation. The smart brush (interactive segmentation tool based on the Deep Extreme Cut algorithm) allows annotators to place positive and negative clicks on an image to guide automatic segmentation, which can be manually refined. For pavement cracks, smart brush reduces annotation time by 40–60% compared to manual polygon drawing.
Supervisely provides AI-assisted annotation with pre-trained segmentation models that can be fine-tuned interactively. Annotators can apply a rough scribble or bounding box, and the model generates an initial segmentation that is refined through iterative corrections. For crack datasets, this approach reduces annotation time to 30–90 seconds per image for experienced annotators, compared to 5–15 minutes for manual polygon annotation.
Annotation challenges for infrastructure imagery include:
Data augmentation is essential for training robust segmentation models, particularly when working with limited annotated datasets (a common constraint in infrastructure inspection where labeling is expensive). Augmentation increases effective dataset size and improves generalization to variations in lighting, surface texture, camera angle, and pavement condition.
Geometric augmentations transform the spatial layout of the image and segmentation mask together:
Photometric augmentations modify pixel intensities without changing spatial structure:
Specialized augmentations for pavement inspection include:
The number of training images required for effective semantic segmentation depends on task complexity, class distribution, and the availability of pre-trained encoder weights. For pavement crack segmentation using transfer learning from ImageNet-pretrained encoders (ResNet-50, EfficientNet-B3):
For multi-class segmentation (crack, marking, pavement type, FOD, vegetation), the required dataset size increases by approximately 2–3× per additional class, as the model must learn to discriminate between visually similar surface features.
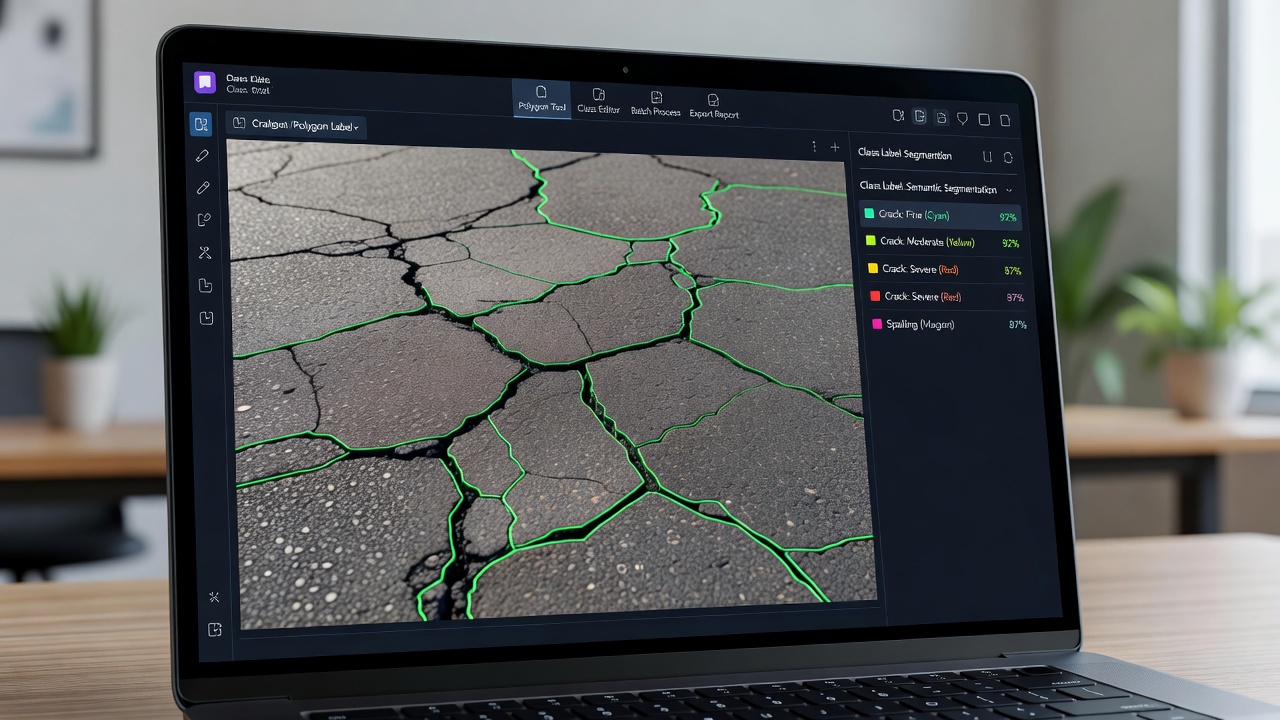
Multi-class semantic segmentation for airfield and road pavement scenes requires defining a class taxonomy that captures all surface features relevant to condition assessment, safety evaluation, and maintenance planning. Based on ASTM D5340 (Standard Test Method for Airport Pavement Condition Index Surveys), ICAO Annex 14 requirements, and practical inspection workflows, a comprehensive taxonomy for airfield pavement segmentation includes:
| Class | Description | Typical Pixel Fraction | PCI Relevance |
|---|---|---|---|
| Non-Crack Pavement | Sound pavement surface without defects | 75–92% | Baseline (no deduct) |
| Longitudinal Crack | Cracks parallel to pavement centerline | 0.5–3% | Severity-dependent deduct |
| Transverse Crack | Cracks perpendicular to centerline | 0.3–2% | Severity-dependent deduct |
| Alligator/Block Crack | Interconnected cracking forming polygons | 1–8% | High deduct values |
| Edge Crack | Cracks within 0.6m of pavement edge | 0.1–0.5% | Moderate deduct |
| Joint Spall (Concrete) | Fracture at concrete pavement joints | 0.5–2% | High deduct |
| Corner Break (Concrete) | Diagonal break at slab corner | 0.1–0.5% | High deduct |
| Raveling | Aggregate loss from asphalt surface | 1–5% | Moderate deduct |
| Patching | Repaired pavement area | 1–10% | Low-moderate deduct |
| Pavement Marking | Paint, thermoplastic, or tape markings | 3–8% | Not direct PCI deduct |
| Rubber Deposit | Tire rubber accumulation in touchdown zone | 1–5% | Friction-related |
| Vegetation | Grass, weeds growing through cracks/edges | 0.5–3% | Edge drain issue |
| FOD | Foreign object debris on surface | 0.001–0.1% | Safety-critical |
| Sealed Crack | Crack previously filled with sealant | 0.3–2% | Depends on sealant condition |
| Pothole | Localized pavement surface depression | 0.01–0.5% | High deduct, safety-critical |
The class distribution is extremely imbalanced: non-crack pavement dominates at 75–92% of pixels, while FOD occupies less than 0.1%. This imbalance necessitates specialized loss functions (Dice + Focal) and training strategies like class-aware sampling (oversampling minibatches containing minority classes) or online hard example mining (selecting training samples with the highest loss for gradient updates).
Beyond loss function selection, several training strategies mitigate class imbalance in multi-class pavement segmentation:
Class-weighted sampling adjusts the probability of selecting each training patch to ensure that minority classes are represented at a minimum frequency. Patches containing crack, FOD, or pothole pixels are oversampled by 3–10× compared to patches containing only non-crack pavement. Implementation typically maintains a priority queue of training patches ranked by the presence of minority classes.
Focal modulation in the loss function applies class-specific focusing parameters: higher γ values for majority classes and lower γ for minority classes, ensuring that the model allocates more learning capacity to rare but critical defect classes.
Two-stage training first trains the model on a class-balanced subset where minority classes are oversampled to 20–30% of total pixels, then fine-tunes on the full dataset with the original class distribution. This approach prevents the model from converging to a trivial solution that classifies all pixels as background.
Crack semantic segmentation presents unique challenges that distinguish it from general-purpose segmentation: cracks occupy a very small fraction of image pixels (0.1–3%), have high aspect ratios with extreme elongation (width-to-length ratios of 1:100 to 1:1000), exhibit low contrast against the surrounding pavement surface, and are visually similar to non-crack features like shadows, construction joints, and surface texture variations.
DeepCrack (Zou et al., 2019) was one of the first deep learning architectures specifically designed for crack segmentation. It uses a modified SegNet encoder-decoder with multi-scale feature fusion and side-output layers that produce predictions at multiple decoder stages. The final prediction is generated by fusing outputs from all side layers, enabling the network to capture cracks at multiple scales simultaneously — thin hairline cracks from early decoder stages and wider structural cracks from later stages.
CrackU-Net (Liu et al., 2021) extends standard U-Net with: (1) attention gates in skip connections that weight feature maps based on spatial relevance to crack regions, suppressing background features and amplifying crack features; (2) deep supervision that applies loss computation at multiple decoder stages, providing gradient signals at multiple scales; and (3) dilated convolution in the bottleneck to expand receptive field without resolution loss. CrackU-Net achieves crack IoU of 0.78–0.84 on benchmark pavement datasets.
CrackTransformer (Chen et al., 2022) applies a hybrid CNN-transformer architecture specifically for crack segmentation. A ResNet-50 encoder extracts initial feature maps, which are then processed through a transformer encoder with 8 self-attention heads that models long-range dependencies between crack segments. Cracks that are visually disconnected (due to lighting variations or surface contamination) but belong to the same physical crack can be linked through self-attention, improving connectivity completeness — a metric measuring what fraction of ground-truth crack pixels in connected components are correctly predicted.
Cracks narrower than 2–3 pixels in width present a fundamental challenge for semantic segmentation based on convolutional neural networks with downsampling. A standard encoder with 5 downsampling stages and 1/32 output stride represents cracks of 3 pixels width or less as a single pixel or less in the deepest feature maps — insufficient for reliable detection.
Solutions for thin crack segmentation include:
Minimum ground sampling distance (GSD) constraint: The GSD of the input imagery must satisfy GSD ≤ W_min / 3, where W_min is the minimum detectable crack width. For detecting 0.3 mm hairline cracks, imagery must be captured at ≤0.1 mm/pixel GSD, requiring flight altitudes of 3–8 m with typical high-resolution cameras. For operational inspection of 1 mm cracks, GSD ≤ 0.33 mm/pixel is required.
Sub-pixel crack detection uses the continuous crack probability map (before thresholding at 0.5) to estimate crack presence at sub-pixel resolution. The crack centerline is extracted at the sub-pixel level by fitting a Gaussian or quadratic function to the probability profile perpendicular to the crack direction, determining the crack position with precision of 0.1–0.3 pixels.
Multi-scale input processes the image at multiple resolutions (e.g., 0.5×, 1×, 1.5×) and fuses the predictions. The high-resolution branch preserves thin crack detail, while the low-resolution branch provides context and suppresses noise. Feature pyramid networks (FPN) integrated with U-Net provide this multi-scale behavior within a single forward pass.
Crack connectivity — the topological property that crack pixels form continuous networks rather than isolated dots — is critical for crack type classification (longitudinal, transverse, alligator) and severity assessment. Standard segmentation losses do not explicitly enforce connectivity, often producing disconnected crack fragments.
Skeleton-aware loss computes the skeleton (medial axis) of the ground-truth crack mask and applies higher loss weight to skeleton pixels, encouraging the model to correctly predict the crack centerline. The skeleton occupies 5–10% of crack pixels but carries 50% of the topological information.
Topological loss based on persistent homology penalizes differences in the Betti numbers (β₀: number of connected components, β₁: number of holes) between predicted and ground-truth crack masks. A model trained with topological loss produces 30–60% fewer disconnected crack fragments compared to Dice loss alone.
Conditional random field (CRF) post-processing applies a fully connected CRF as a final refinement step. The CRF encourages adjacent pixels with similar color and intensity to share the same class label, filling gaps in predicted crack masks and smoothing jagged boundaries. The DenseCRF implementation (Krähenbühl & Koltun, 2011) is commonly applied as a post-processing step, improving crack connectivity by 5–10% at the cost of 50–200 ms additional inference time per image.
Semantic segmentation provides the spatial mask from which crack width can be estimated. Width measurement is essential for PCI severity assessment: ASTM D5340 defines crack severity categories based on mean width (e.g., low severity: <3 mm, medium severity: 3–6 mm, high severity: >6 mm for asphalt longitudinal cracks).
The standard width estimation pipeline: (1) extract the crack centerline through skeletonization (iterative thinning algorithms like Zhang-Suen or Medial Axis Transform); (2) for each centerline pixel, compute the Euclidean distance to the nearest background pixel (the distance transform); (3) the crack width at that point is 2× the distance transform value. The local width measurement enables reporting of mean width, maximum width, and width distribution for each crack segment.
For sub-pixel width accuracy, the continuous predicted probability map (before binarization) is used instead of the binary mask. The probability profile perpendicular to the crack is fitted with a Gaussian function, and the width is defined as the full width at half maximum (FWHM) of the fitted Gaussian. This approach achieves width measurement precision of 0.1–0.3 pixels, enabling reliable severity classification for cracks as narrow as 0.3 mm in 1 mm/pixel imagery.
Surface type segmentation — differentiating asphalt, concrete, gravel, tarmac, sealed, and unsealed surfaces within the same image — is a distinct task from defect segmentation. Surface types have characteristic spectral reflectance, texture, and spatial distribution patterns that can be learned by segmentation models.
Asphalt vs. concrete discrimination relies on spectral and textural cues:
Spectral features from multispectral imagery (RGB + near-infrared) improve surface type discrimination. Asphalt absorbs more NIR radiation than concrete (NIR reflectance: asphalt 5–10%, concrete 20–40%), providing a clear spectral separation. The Normalized Difference Vegetation Index (NDVI) distinguishes vegetation (NDVI > 0.3) from pavement surfaces (NDVI < 0.1). Short-wave infrared (SWIR) bands differentiate asphalt types and detect sealant materials.
Textural features computed from Gray-Level Co-occurrence Matrix (GLCM) statistics (contrast, dissimilarity, homogeneity, energy, correlation), Local Binary Patterns (LBP), and Gabor filter responses provide quantitative texture measures that enhance surface type classification. A ResNet-50 or EfficientNet-B4 backbone trained on pavement surface images with an additional input channel for entropy (computed from local intensity variance) improves surface type classification accuracy by 3–5% mIoU.
For multi-class segmentation combining surface type and defect detection, two architectural approaches are common:
Single-stage multi-class model outputs C classes covering both surface types and defects (e.g., 5 surface types × 10 defect types = 15 output classes). This approach benefits from shared feature learning — the same features that distinguish asphalt from concrete also help differentiate crack appearance on these surfaces. The class hierarchy can be flattened (each combination is a separate class) or hierarchical (surface type predicted at a coarse scale, defects at a fine scale within each surface type region).
Two-stage pipeline runs two separate segmentation models: a surface type classifier (fast, lightweight) followed by a defect segmentation model specific to each surface type (accurate, specialized). The surface type model processes the full image at lower resolution, identifying pavement type regions. Each region is then processed by the corresponding defect model trained specifically on that surface type. This approach achieves higher per-type accuracy but requires more computation for inference (N surface types × defect model inference).
Intersection over Union (IoU) , also known as the Jaccard Index, is the primary evaluation metric for semantic segmentation. For a given class c, IoU is calculated as: IoU_c = TP_c / (TP_c + FP_c + FN_c), where TP_c is the number of pixels correctly predicted as class c (true positives), FP_c is the number of pixels incorrectly predicted as class c (false positives), and FN_c is the number of pixels of class c incorrectly predicted as another class (false negatives).
The mean IoU (mIoU) averages IoU over all classes. For imbalanced infrastructure datasets, the unweighted mIoU is the standard reporting metric because each class contributes equally regardless of pixel count — a model that ignores cracks but correctly classifies all non-crack pavement would achieve high pixel accuracy (99%) but low mIoU (50% for a 2-class model).
The Dice coefficient is equivalent to the F1 score and is closely related to IoU: Dice = 2TP / (2TP + FP + FN) = 2TP / (Total predicted positives + Total ground-truth positives). The Dice coefficient and IoU are monotonically related: Dice = 2IoU / (1 + IoU).
| IoU | Dice (F1) | Interpretation |
|---|---|---|
| 0.90 | 0.947 | Excellent — near-perfect segmentation |
| 0.80 | 0.889 | Very good — adequate for automated PCI |
| 0.70 | 0.824 | Good — suitable for assisted inspection |
| 0.60 | 0.750 | Moderate — requires manual verification |
| 0.50 | 0.667 | Fair — limited to qualitative use |
| 0.40 | 0.571 | Poor — high false positive/negative rate |
For crack segmentation, a crack-class Dice of 0.70–0.80 is considered adequate for automated crack mapping, while Dice > 0.85 is required for automated width measurement and severity classification without human verification.
Pixel Accuracy measures the fraction of correctly classified pixels: PA = Σ TP_c / Σ (TP_c + FP_c). For severely imbalanced data — non-crack pavement at 95% of pixels — a model that classifies every pixel as non-crack achieves 95% pixel accuracy with 0% crack detection. Pixel accuracy is therefore not recommended as the primary metric for infrastructure segmentation. It should only be reported alongside per-class metrics (IoU, Dice, precision, recall).
Precision = TP / (TP + FP) measures the proportion of positive predictions that are correct — important for minimizing false alarms that waste inspection resources. Recall = TP / (TP + FN) measures the proportion of actual positive pixels correctly identified — important for minimizing missed defects that compromise safety.
The precision-recall trade-off is controlled by the prediction threshold (typically 0.5 for softmax output). For infrastructure inspection:
Boundary evaluation metrics assess segmentation quality at object edges — the most challenging region for infrastructure defects:
Boundary F1 (BF) computes precision and recall within a narrow band (typically 2–5 pixels) around the ground-truth segmentation boundary. High BF score (0.80+) indicates that the predicted crack boundaries closely match true crack edges, which is essential for accurate crack width measurement.
Hausdorff Distance (HD) measures the maximum distance between predicted and ground-truth boundaries: HD = max(max_p min_g d(p,g), max_g min_p d(g,p)), where p and g are points on the predicted and ground-truth boundaries. The 95th percentile Hausdorff distance (HD95) is more robust to outliers and is typically reported for crack segmentation. HD95 < 3 pixels for a 1 mm/pixel image corresponds to boundary localization error < 3 mm.
| Metric | Formula | Crack Segmentation Typical Value | Interpretation |
|---|---|---|---|
| Crack IoU | TP/(TP+FP+FN) | 0.65–0.85 | Pixel overlap with ground truth |
| Crack Dice | 2TP/(2TP+FP+FN) | 0.79–0.92 | F1 overlap with ground truth |
| Pixel Accuracy | Correct pixels / Total pixels | 0.95–0.99 | Overall correctness (misleading) |
| Precision | TP/(TP+FP) | 0.75–0.90 | Correctness of positive predictions |
| Recall | TP/(TP+FN) | 0.70–0.90 | Completeness of defect capture |
| Boundary F1 | BF in 2-pixel band | 0.60–0.80 | Edge localization quality |
| HD95 (pixels) | 95th % Hausdorff dist. | 2–8 pixels | Maximum boundary error |
Deploying semantic segmentation models for operational infrastructure inspection requires balancing accuracy against inference speed and memory constraints. Inspection drones and edge devices (NVIDIA Jetson, Google Coral, Intel Neural Compute Stick) have limited computational resources compared to cloud GPUs.
Model pruning removes redundant weights or channels from the trained network. Unstructured pruning sets individual weights to zero (achieving 50–80% sparsity with <2% accuracy loss), while structured pruning removes entire channels or filters (achieving 30–50% channel reduction). Structured pruning is preferred for hardware deployment because it directly reduces computational operations and memory transfers.
Quantization reduces numerical precision of weights and activations from 32-bit floating point (FP32) to 16-bit (FP16) or 8-bit integer (INT8). Post-training quantization (PTQ) calibrates the model’s activation ranges using a small calibration dataset and converts to INT8 without retraining — typically achieving 2–3× speedup with 1–3% accuracy degradation. Quantization-aware training (QAT) simulates quantization during training, enabling the model to adapt to reduced precision and limiting accuracy loss to <1%.
ONNX Runtime provides hardware-optimized inference across CPU, GPU, and NPU backends. Models exported from PyTorch or TensorFlow to the ONNX (Open Neural Network Exchange) format benefit from graph optimization (operator fusion, constant folding) and target-specific execution providers (CUDA for NVIDIA GPUs, TensorRT for Jetson platforms, OpenVINO for Intel hardware).
TensorRT (NVIDIA) applies additional optimization for NVIDIA GPUs: kernel auto-tuning (selecting the fastest kernel implementation for each layer), layer fusion (combining adjacent layers into single kernels), precision calibration (automatic FP16/INT8 optimization), and dynamic tensor memory management. A U-Net model converted from PyTorch to TensorRT with FP16 inference achieves 3–5× speedup on Jetson Orin hardware.
| Deployment Scenario | Required Throughput | Acceptable Latency | Typical Hardware |
|---|---|---|---|
| Post-flight batch processing | 1–10 images/sec | Minutes per survey | Cloud GPU (A10, A100) |
| Drone edge inference | 10–30 images/sec | <100ms per image | Jetson Orin NX/Nano |
| Real-time FOD detection | 30+ images/sec | <30ms per image | Jetson AGX Orin |
| Smartphone inspection | 1–5 images/sec | <500ms per image | Snapdragon/Apple Neural Engine |
The relationship between model size, inference speed, and segmentation accuracy follows established scaling laws. For crack segmentation on 1 mm/pixel imagery:
| Model Variant | Backbone | Parameters | Crack IoU | Inference (256² tile) | Platform |
|---|---|---|---|---|---|
| U-Net tiny | EfficientNet-B0 | 3.8M | 0.72 | 3 ms | Jetson Nano |
| U-Net small | ResNet-18 | 14.3M | 0.76 | 8 ms | Jetson Orin NX |
| U-Net medium | ResNet-50 | 34.5M | 0.80 | 18 ms | Jetson Orin NX |
| U-Net large | ResNet-101 | 57.4M | 0.83 | 35 ms | Jetson AGX Orin |
| DeepLabV3+ | ResNet-50 | 40.1M | 0.82 | 22 ms | Jetson AGX Orin |
| DeepLabV3+ | ResNet-101 | 63.6M | 0.84 | 42 ms | Jetson AGX Orin |
| SegFormer-B2 | MiT-B2 | 24.5M | 0.81 | 28 ms | Jetson AGX Orin |
| SegFormer-B3 | MiT-B3 | 44.1M | 0.84 | 45 ms | Jetson AGX Orin |
For operational deployment at an airport processing a 3,000 m × 45 m runway at 1 mm/pixel GSD (approximately 135,000 2048×2048 tiles), a U-Net medium model on Jetson Orin NX completes full-runway inference in approximately 40 minutes — compatible with overnight processing for next-day maintenance decisions. The same model on a cloud GPU reduces processing to 5–8 minutes.
Infrastructure inspection imagery — particularly orthomosaics from drone surveys — is typically too large for single-pass model inference (10,000–500,000 pixels per dimension). Tiling divides the image into overlapping patches (typically 512×512 to 2048×2048 pixels) that are processed independently. Overlap regions (10–25% of tile dimension) ensure that defects crossing tile boundaries are consistently segmented — predictions in overlap regions are averaged or merged using weighted blending.
Stitching reassembles the tile predictions into a full-resolution segmentation map. Smooth blending with linear ramps in overlap regions eliminates visible tile boundaries. The stitched map at 1 mm/pixel GSD for a 45 m wide runway is 45,000 pixels wide — requiring careful memory management for visualization and downstream analysis.
TarmacView’s platform processes tiled segmentation predictions at GSDs from 0.3 to 3 mm/pixel, with automatic tile size selection based on available GPU memory and model architecture, producing seamless full-runway segmentation maps with sub-pixel crack localization accuracy.
Leverage semantic segmentation for pixel-perfect pavement condition assessment, crack detection, and surface type mapping. Our platform delivers automated analysis from drone imagery with sub-millimeter crack measurement and PCI-compliant reporting.
Crack segmentation is the computer vision task of classifying every pixel in an image as either crack or non-crack, producing a binary mask that enables precise...
Instance segmentation identifies and delineates each individual object or defect instance at the pixel level, assigning a unique ID to each crack, spall, or pot...
AI-based crack detection uses computer vision — convolutional neural networks, vision transformers, and semantic segmentation models — to automatically identify...