Beágyazási tér
A beágyazási tér egy magas dimenziójú matematikai tér, amelyben objektumok – például képek, szövegek vagy érzékelőadatok – vektorokként vannak reprezentálva, le...
AI
Machine Learning
+2
A FAISS (Facebook AI Similarity Search) egy nyílt forráskódú könyvtár hatékony hasonlósági kereséshez és sűrű vektorok klaszterezéséhez, amelyet a TarmacView használ körülbelül 9 000 címkézett referencia-beágyazás tárolására és lekérdezésére a legközelebbi szomszéd alapú felületi minőség osztályozáshoz. Lefedi az indextípusokat (Flat, IVF, HNSW), a koszinusz hasonlóságot belső szorzaton keresztül normalizált vektorokon, a GPU-gyorsítást, valamint az alkalmazást ellenőrző képek visszakeresésére.
FAISS (Facebook AI Similarity Search) egy nyílt forráskódú C++ könyvtár, amelyet a Meta Fundamental AI Research (FAIR) csapata fejlesztett ki hatékony hasonlósági keresésre és sűrű vektorok klaszterezésére. A 2017-ben megjelent FAISS több mint 40 000 GitHub csillagot és GPU implementációjának cikkére több mint 5 200 hivatkozást gyűjtött. A FAISS csomagokat több mint 6 millió alkalommal töltötték le a Conda repozitóriumokból. A jelentős vektoradattábla-vállalatok, köztük a Zilliz (Milvus) és a Pinecone, vagy a FAISS-ra támaszkodnak alapmotorjukként, vagy újraimplementálták a FAISS algoritmusokat termelési rendszereikben.
A FAISS célzottan a nagy dimenziójú vektorterekben történő legközelebbi szomszédok megtalálásának számítási kihívására épül. Az alapszintű művelet a hasonlósági keresés: egy q lekérdezővektor adott esetén a FAISS azonosítja a referenciahalmaz azon vektorait, amelyek egy meghatározott távolságmetrika szerint a legközelebb vannak. Formálisan, egy {x₁, …, xₙ} referenciavektor-halmazra d dimenzióban, a FAISS hatékonyan számítja ki a j = argminᵢ ||q - xᵢ|| értéket, ahol ||·|| az euklideszi távolság. A könyvtár maximális belső szorzat keresést is végezhet: argmaxᵢ ⟨q, xᵢ⟩, és támogat további metrikákat, köztük az L1, Linf, Canberra, Bray-Curtis, Jensen-Shannon és Hamming távolságokat az IndexFlat és IndexHNSW implementációin keresztül. A FAISS nemcsak az egyetlen legközelebbi szomszédot adja vissza, hanem a k legközelebbi szomszédot, támogatja több lekérdezés párhuzamos kötegelt feldolgozását, és képes sugarú keresést (range search) végrehajtani, amely egy adott sugáron belüli összes elemet visszaadja.
A könyvtár sűrű vektorokkal — 32 bites lebegőpontos számok fix hosszúságú tömbjeivel — dolgozik, amelyek egy folytonos vektortérbe beágyazott adatpontokat reprezentálnak. Ezeket a vektorokat jellemzően mély neurális hálózatok állítják elő, mint amilyenek a Vision Transformer (ViT), a konvolúciós neurális hálózatok (CNN) vagy a nagy nyelvi modellek. A modern gépi tanulási folyamatokban a beágyazások (embeddings) közvetítő reprezentációként szolgálnak, amelyek komplex bemeneti médiát képeznek le egy vektortérbe, ahol a lokalitás szemantikát kódol. A FAISS híd a beágyazások kinyerése és a hasonlóságon alapuló downstream feladatok között: indexeli a kinyert beágyazásokat, és lehetővé teszi a gyors visszakeresési műveleteket.
A FAISS széles körben optimalizált a modern hardverarchitektúrákra. CPU-n BLAS (Basic Linear Algebra Subprograms) könyvtárakat használ, mint az Intel MKL, az OpenBLAS vagy az Apple Accelerate, a gyors mátrixműveletek végrehajtásához. Támogatja a SIMD vektorizációt (SSE, AVX2, AVX-512) x86 architektúrákon és a Neon utasításkészletet ARM processzorokon. GPU-n a FAISS natív CUDA implementációkat biztosít, amelyek tipikus feladatok esetén 5–10-szeres átbocsátóképesség-javulást érhetnek el a CPU végrehajtáshoz képest. A GPU implementáció támogatja több GPU párhuzamos használatát, lehetővé téve az elosztott keresést több eszközön egyidejűleg.
A FAISS nem egy vektoradattár – egy keresőkönyvtár, amely közvetlenül beágyazható alkalmazásokba. A teljes körű adatbázisrendszerekkel (Pinecone, Milvus, Qdrant, Weaviate) ellentétben a FAISS nem nyújt beépített perzisztenciát, replikációt, hozzáférés-vezérlést, egyidejű írási hozzáférést, terheléselosztást, sharding-ot, tranzakciókezelést vagy lekérdezésoptimalizálást. Ehelyett tiszta C++ és Python API-t biztosít indexek építéséhez, lekérdezéséhez, mentéséhez és betöltéséhez. Ez a szándékos határoltság lehetővé teszi a FAISS számára, hogy maximális teljesítményt érjen el a központi legközelebbi szomszéd keresési műveletben. A könyvtár hatóköre szándékosan az Approximate Nearest Neighbor Search (ANNS) algoritmikus implementációjára korlátozódik, és ahogy az eredeti FAISS cikk is megállapítja: “A Faiss nem adatbázis – nem biztosít egyidejű írási hozzáférést, terheléselosztást, sharding-ot, tranzakciókezelést vagy lekérdezésoptimalizálást.”

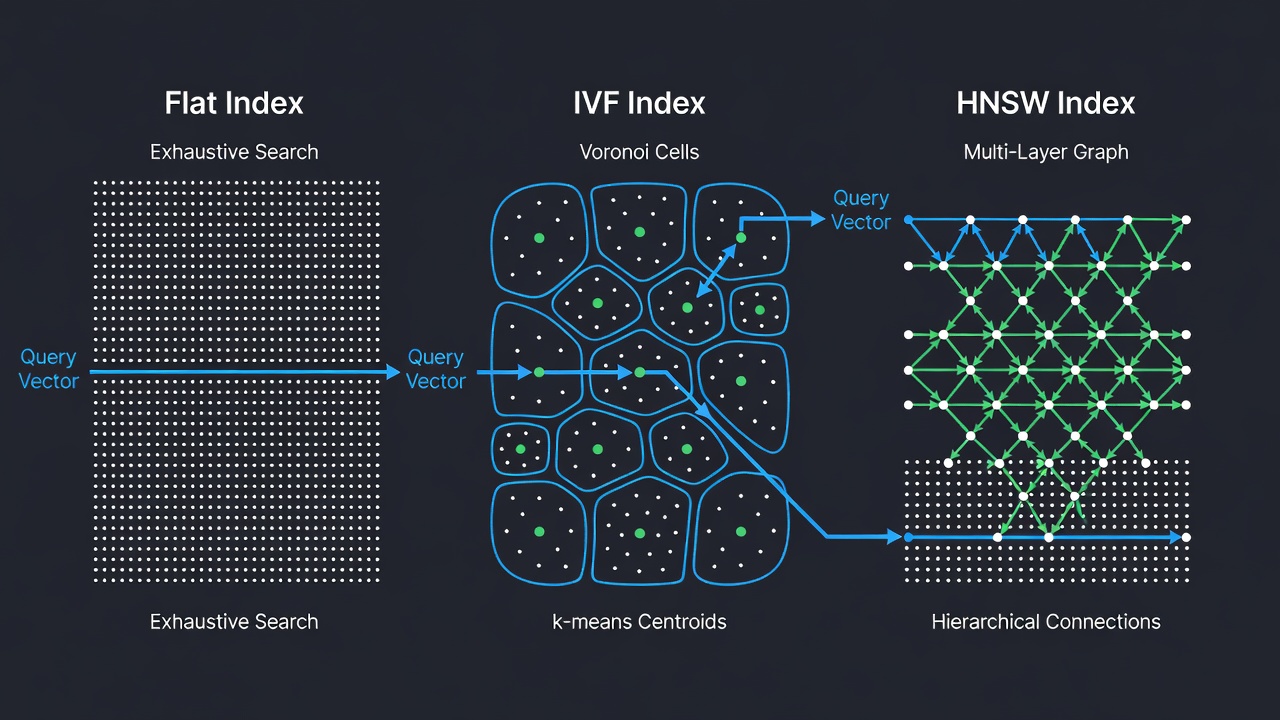
A FAISS több mint húsz különböző index típust kínál, amelyek mindegyike egy adott pontosság, sebesség és memória közötti kompromisszum-kombinációra lett tervezve. A három legalapvetőbb és legszélesebb körben használt index típus az IndexFlat (egzakt keresés), az IndexIVF (invertált fájl k-means klaszterezéssel) és az IndexHNSW (hierarchikus navigálható kicsi világ gráf). Minden index típus elérhető különböző távolságmetrikákkal és kódolt változatokkal (pl. FlatIP belső szorzathoz, FlatL2 L2 távolsághoz). A FAISS indexek hierarchikusan összeállíthatók – például a HNSW használata durva kvantálóként egy IVF indexhez, ami a milliárdos léptékű telepítéseket lehetővé tevő IndexIVFPQ összetett struktúrát eredményezi.
Az IndexFlatIP a legegyszerűbb FAISS index. Az összes vektort egy lapos tömbben tárolja, és kimerítő nyers erőn alapuló keresést végez az adathalmaz összes vektora ellen. Minden lekérdezéshez kiszámítja a belső szorzatot a lekérdezés és az összes tárolt vektor között, majd visszaadja a top-k találat indexeit és távolságait. Ez az index garantáltan az egzakt legközelebbi szomszédokat adja vissza – nincs közelítés, nincs visszahívási romlás. Ez az egyetlen FAISS index, amely ezt a garanciát nyújtja; az összes többi index közelítő jellegű, és a visszahívás egy részét a jobb sebesség vagy kisebb memóriahasználat érdekében adja fel.
Az IndexFlatIP számítási komplexitása O(N × D) lekérdezésenként, ahol N a referenciavektorok száma, D pedig a dimenziószám. Az index a nagymértékben optimalizált BLAS gemm (általános mátrixszorzás) rutint használja az összes belső szorzat egyetlen mátrixszorzásban történő kiszámításához. Egy 100 000 vektorból álló, 768 dimenziós adathalmaz esetén (egy tipikus DINOv2 ViT beágyazási méret) egyetlen lekérdezés CPU-n körülbelül 5–15 ezredmásodpercet vesz igénybe a hardvertől és a BLAS optimalizálástól függően. Kötegelt módban 1000 lekérdezéssel az index mindegyiket egyszerre dolgozza fel mátrix-mátrix szorzás segítségével, ami lényegesen nagyobb átbocsátóképességet ér el, mint 1000 egyedi lekérdezés.
Az IndexFlatIP kritikus szerepet játszik a FAISS ökoszisztémájában a közelítő indexek pontosságának kiértékelésére szolgáló referencia igazságforrásként (ground-truth oracle). A szakemberek egy lapos indexet építenek a közelítő index mellé, azonos lekérdezéseket futtatnak mindkettőn, és kiszámítják a visszahívási mérőszámokat. A szabványos FAISS benchmark csomag (faiss_benchmarks) ezt a módszertant használja az IVF, HNSW és PQ indexek pontosságromlásának számszerűsítésére. A TarmacView-ban az IndexFlatIP alapvonali referenciaként szolgál a rendszer validálásához, biztosítva, hogy a termelésben használt közelítő indexek elfogadható visszahívást tartsanak fenn.
Az index minimális kóddal építhető fel: index = faiss.IndexFlatIP(d), ahol d a beágyazások dimenziószáma. Vektorokat az index.add(embeddings) paranccsal adhatunk hozzá. A keresést az index.search(query, k) végzi, amely két float32 tömböt ad vissza: távolságokat (alakja [n_queries, k]) és indexeket (alakja [n_queries, k], dtype int64). Belső szorzat esetén a nagyobb távolságértékek nagyobb hasonlóságot jeleznek. Az index nem igényel tanítási lépést, mivel nincsenek tanulandó paraméterei – a vektorokat szó szerint tárolja és hasonlítja össze.
Az IndexIVFFlat egy közelítő legközelebbi szomszéd index, amely Voronoi-cellákra osztja fel a vektorteret k-means klaszterezés segítségével. Az architektúra a Sivic és Zisserman (ICCV 2003) által jegyzett úttörő “Video Google” cikkből származik, amely a szöveges visszakeresési technikákat adaptálta vizuális objektumok egyeztetéséhez. Az indexelés során az adathalmaz nlist klaszterre van osztva k-means segítségével, és minden vektor a hozzá legközelebbi klasztercentroidhoz van rendelve. A centroidok egy durva kvantálóban (jellemzően IndexFlatL2) vannak tárolva. A keresés során csak a lekérdezéshez legközelebbi nprobe klaszterben lévő vektorokat vizsgálja meg a rendszer, ami drámaian csökkenti a szükséges távolságszámítások számát.
A sebességnövekedés az IndexFlatIP-hez képest körülbelül N / ((N / nlist) × nprobe) . nlist=100 és nprobe=5 esetén csak az adatbázis 5%-át keresi meg – a lekérdezések, amelyek 10 ms-ot vettek igénybe egy lapos indexen, akár 0,5 ms alatt is befejeződhetnek. A kompromisszum azonban a visszahívás romlása: egyes valódi legközelebbi szomszédok a keresett klasztereken kívül eshetnek, és így elveszhetnek. A k-means tanítási lépés kritikus fontosságú a visszahívás minősége szempontjából – a centroidoknak pontosan kell reprezentálniuk az adateloszlást. A FAISS megköveteli, hogy a tanítóhalmaz legalább 30 × nlist vektort tartalmazzon a megbízható centroid-becsléshez.
Az IndexIVFFlat kulcsparaméterei:
| Paraméter | Leírás | Tipikus tartomány | Hatás |
|---|---|---|---|
| nlist | Voronoi-cellák (klaszterek) száma | 10 – 100 000 | Magasabb = finomabb felosztás, több memória a centroidoknak, lassabb k-means tanítás |
| nprobe | Lekérdezéskor megvizsgált cellák száma | 1 – 100+ | Magasabb = jobb visszahívás (akár 99%), lineárisan lassabb keresés |
| metric | Távolságmetrika (L2 vagy IP) | L2 vagy IP | Meghatározza, hogyan számítódnak a távolságok vektorok és centroidok között |
Az nprobe paraméter különösen fontos, mert a keresési idő és pontosság közötti kompromisszumot szabályozza anélkül, hogy az index rekonstrukciójára lenne szükség. Lekérdezési időben az nprobe dinamikusan állítható: állítsuk magas értékre (pl. 20–50) offline, minőségkritikus műveleteknél, ahol a pontosság a legfontosabb, és alacsony értékre (pl. 1–5) nagy áteresztőképességű termelési futtatásoknál, ahol a sebesség élvez elsőbbséget. A FAISS automatikus hangoló mechanizmust (AutoTune) biztosít, amely végigkeresi az nprobe értékeket a célzott visszahíváshoz optimális konfiguráció megtalálásához.
Az IndexIVFFlat felépítése háromlépcsős folyamatot igényel: tanítás, hozzáadás és keresés. Tanítás során a k-means egy reprezentatív mintán fut a klasztercentroidok megtanulásához. Hozzáadás során minden adatbázisvektor a hozzá legközelebbi centroidhoz van rendelve és hozzáfűzve a centroid invertált listájához. Keresés során a lekérdezés összehasonlításra kerül az összes centroiddal, a kiválasztott nprobe legközelebbi centroid kerül kiválasztásra, és csak az ezekben a kiválasztott listákban lévő vektorok hasonlítandók össze kimerítő jelleggel. Az IndexIVFFlat gyári sztringje belső szorzathoz: "IVF100,Flat", ahol 100 az nlist érték. Pythonban: index = faiss.index_factory(d, "IVF100,Flat", faiss.METRIC_INNER_PRODUCT).
| Adathalmaz mérete | Ajánlott nlist | Ajánlott nprobe | Várható visszahívás | Sebességnövekedés a Flat-hez képest |
|---|---|---|---|---|
| 10 000 | 10 – 100 | 1 – 5 | 95–98% | 5–20x |
| 100 000 | 100 – 1 000 | 5 – 20 | 95–99% | 20–100x |
| 1 000 000 | 1 000 – 10 000 | 10 – 50 | 95–99% | 100–500x |
| 10 000 000 | 10 000 – 100 000 | 20 – 100 | 90–98% | 500–5000x |
Az IndexHNSWFlat egy gráf-alapú közelítő legközelebbi szomszéd index, amely egy többrétegű hierarchikus gráfot épít, amelyet Navigálható Kicsi Világként (Navigable Small World) ismernek. Az algoritmust, amelyet eredetileg Malkov és Yashunin publikált (2016), a skip-list adatszerkezet inspirálta. Az index rétegekbe szervezi a vektorokat: az alsó réteg (0. réteg) tartalmazza az összes vektort, és minden következő réteg egy progresszíven kisebb részhalmazt tartalmaz, amelyet valószínűségi szint-hozzárendelés generál. Beszúráskor minden vektorhoz egy l = floor(-ln(uniform(0,1)) × mL) szint kerül hozzárendelésre, ahol mL = 1/ln(M). A belépési pont a legmagasabb létező rétegben van, biztosítva a logaritmikus gráfbejárást.
A keresés a legfelső rétegben (legdurvább, legkevesebb csomóponttal) kezdődik, és lefelé halad a rétegeken keresztül, minden lépésben finomítva a jelölthalmazt. Minden rétegben egy mohó keresés járja be a gráfot a lekérdezés felé azáltal, hogy mindig a távolságot minimalizáló szomszédhoz lép. Miután megtalálta a lokális minimumot az aktuális rétegben, az algoritmus lelép a következő rétegre, és megismétli a folyamatot a felső réteg eredményét használva kiindulópontként. Ez a hierarchikus struktúra logaritmikus keresési komplexitást tesz lehetővé: O(log N), ami a HNSW-t az egyik leggyorsabb közelítő legközelebbi szomszéd algoritmussá teszi közepes és nagy adathalmazokra.
A HNSW index három kritikus paraméterrel rendelkezik:
| Paraméter | Leírás | Tipikus tartomány | Hatás |
|---|---|---|---|
| M | Maximális kétirányú kapcsolatok száma csomópontonként | 8 – 64 (alapértelmezett 32) | Magasabb M = sűrűbben összekapcsolt gráf, jobb visszahívás, több memória |
| efConstruction | Dinamikus jelölthalmaz mérete a gráf építése során | 40 – 200 (alapértelmezett 40) | Magasabb = alaposabb keresés az építés során, jobb minőségű gráf, lassabb építés |
| efSearch | Dinamikus jelölthalmaz mérete a keresés során | 10 – 200 (lekérdezéskor állítható) | Magasabb = jobb visszahívás, lassabb keresés (újjáépítés nélkül hangolható) |
Az M paraméter közvetlenül szabályozza a gráf összekapcsoltságát. Minden vektor legfeljebb M kétirányú éllel rendelkezik a legközelebbi szomszédaihoz. A gráf diverzitást erősítő heurisztikát használ a szomszéd kiválasztása során: amikor egy új csomópont kerül hozzáadásra, a szomszéd jelöltek ritkításra kerülnek a változatos összekapcsoltság biztosítása érdekében, elkerülve, hogy hub csomópontok dominálják a gráf struktúrát. Magasabb M értékek robusztusabb útválasztást eredményeznek, de növelik a memóriafogyasztást: körülbelül 4d + M × 2 × 4 bájt vektoronként a gráf struktúra plusz a vektortárolás számára.
Az efConstruction paraméter a keresés alaposságát szabályozza az index építése során. Nagyobb értékek jobb minőségű gráfot eredményeznek, de lineárisan növelik az építési időt. Általános szabályként az efConstruction ≈ M × 2 jó egyensúlyt biztosít a legtöbb feladathoz. Az efSearch paraméter analóg az IVF indexek nprobe paraméterével – a keresés alaposságát szabályozza lekérdezési időben, és az index újjáépítése nélkül dinamikusan állítható.
A HNSW indexek számos előnyt kínálnak az IVF indexekkel szemben. Jellemzően magasabb visszahívást érnek el azonos keresési sebesség mellett, különösen nagy dimenziójú adatokon (d > 256). Nem igényelnek külön tanítási lépést (ellentétben az IVF-fel, amely k-means klaszterezést igényel, így a HNSW alkalmas dinamikus adathalmazokhoz, ahol a vektorok növekményesen érkeznek). Elegáns visszahívás-romlást mutatnak az efSearch csökkenésével – a visszahívás simán, éles küszöbértékek nélkül javul. A HNSW indexek azonban több memóriát használnak vektoronként (a gráf szomszédsági listái többletköltséget jelentenek), és lassabb az építésük, mint az IVF indexeké. A HNSW natív módon nem támogatja a vektorok törlését, mivel csomópontok eltávolítása a gráf szerkezetből sértené az összekapcsoltságot.
A TarmacView körülbelül 9 000 beágyazásból álló referenciahalmazához egy IndexHNSWFlat M=32 és efSearch=64 paraméterekkel >99%-os visszahívást ér el 200 mikroszekundum alatti lekérdezési időkkel CPU-n – ami 50-szeres sebességnövekedés az IndexFlatIP-hez képest elhanyagolható pontosságveszteség mellett. A "HNSW32,Flat" gyári sztring építi fel ezt az indexet. Pythonban: index = faiss.index_factory(d, "HNSW32,Flat", faiss.METRIC_INNER_PRODUCT).
A koszinusz hasonlóság két nem nulla vektor közötti szög koszinuszát méri – azt számszerűsíti, hogy két vektor mennyire hasonló, függetlenül a nagyságuktól. Az a és b vektorok közötti koszinusz hasonlóság definíciója: cos(θ) = (a · b) / (||a|| × ||b||) , ahol a · b a pontszorzat, ||a|| pedig a L2 normája. Az eredmény -1 (ellentétes irány) és +1 (azonos irány) közé esik, ahol a 0 ortogonalitást jelez.
A FAISS nem biztosít dedikált koszinusz hasonlóság metrikát. Ehelyett a koszinusz hasonlóság egy kétlépéses transzformáción keresztül valósul meg, amelyet a FAISS fejlesztőcsapata kanonikusnak tekint. Először is, az összes vektor L2-normalizálásra kerül egységnyi hosszúságúra – minden vektort elosztunk az L2 normájával, így ||a|| = 1 és ||b|| = 1. Másodszor, a METRIC_INNER_PRODUCT kerül használatra távolságmetrikaként. Egységnyi hosszúságúra normalizált vektorok esetén a belső szorzat egyenlő a koszinusz hasonlósággal: a · b = cos(θ). Ez az egyenértékűség közvetlenül következik a koszinusz képletből: ha a nevező egyenlő 1-gyel, a képlet a pontszorzatra redukálódik.
Ez a normalizációs technika szabványos a vektoros keresőrendszerekben, mivel a belső szorzat hatékonyan számítható nagymértékben optimalizált BLAS mátrixszorzó rutinokkal. Az index összes vektorának normalizálásának számítási költsége egy egyszeri O(N × D) művelet az indexépítéskor, és minden lekérdezés normalizálása O(D) – elhanyagolható a keresés saját költségéhez képest. Az L2 normalizálást a vektorok indexhez adása előtt kell alkalmazni, valamint a lekérdezések benyújtása előtt, biztosítva, hogy minden összehasonlítás a koszinusz hasonlósági térben történjen.
A FAISS-ban a normalizálás az IndexPreTransform csomagolóosztály és egy NormalizationTransform kombinációjával valósítható meg (Pythonban faiss.NormalizationTransform). A felépítési minta:
import faiss
import numpy as np
dimension = 768
# Belső szorzat index létrehozása
base_index = faiss.IndexFlatIP(dimension)
# Csomagolás L2 normalizálással
index = faiss.IndexPreTransform(
faiss.NormalizationTransform(dimension),
base_index
)
# Az itt hozzáadott vektorok automatikusan L2-normalizálásra kerülnek
index.add(reference_embeddings)
# Az itt benyújtott lekérdezések automatikusan L2-normalizálásra kerülnek
distances, indices = index.search(query_embeddings, k)
Alternatív megközelítések közé tartozik a vektorok kézi normalizálása a faiss.normalize_L2() segítségével a hozzáadás és lekérdezés előtt, vagy az index felépítése az index_factory-n keresztül, amely beépített normalizálást támogat az "L2norm" előfeldolgozási lépés segítségével. A gyári módszerrel: index = faiss.index_factory(d, "L2norm,HNSW32,Flat") létrehoz egy indexet, amely automatikusan egységnyi hosszúságúra normalizálja a vektorokat a HNSW gráf felépítése előtt.
A TarmacView számára ez a megközelítés azért elengedhetetlen, mert a DINOv2 beágyazások – mint a legtöbb Vision Transformer kimenet – nagysága különböző képek esetén változó. A repülőtéri burkolatvizsgálat során az expozíció, a megvilágítási viszonyok és a kamerabeállítások eltérései eltérő nagyságú beágyazásokat eredményeznek akkor is, amikor azonos felületi textúrákat rögzítenek. A normalizálás eltávolítja a nagyságkomponenst, és a hasonlósági összehasonlítást az irány szerinti egyezésre összpontosítja – két olyan felületi kép, amely ugyanazt a burkolati textúrát rögzíti, de eltérő expozíciós szinteken, magas hasonlóságot fog mutatni, mert a normalizált beágyazásaik ugyanabba az irányba mutatnak, még akkor is, ha a nyers nagyságuk jelentősen eltér.
A FAISS GYIK kifejezetten foglalkozik ezzel: “A koszinusz hasonlóság az x és y vektorok között a következőképpen definiált: cos(x, y) = ⟨x, y⟩ / (|x| × |y|). A lekérdező és adatbázisvektorok előzetes normalizálásával a probléma visszavezethető egy maximális belső szorzat keresésre.” A FAISS azt is megjegyzi, hogy a belső szorzat használata normalizált vektorokon matematikailag egyenértékű az L2 távolság használatával normalizált vektorokon, a ||x - y||² = 2 - 2 × ⟨x, y⟩ összefüggéssel egységnyi hosszúságúra normalizált vektorok esetén.
Egy FAISS index életciklusa termelésben öt különálló szakaszból áll: konfiguráció, tanítás, feltöltés, szerializáció és lekérdezés. Minden szakasznak meghatározott API hívásai, teljesítménybeli szempontjai és bevált gyakorlatai vannak.
Konfiguráció az index típusának és távolságmetrikájának kiválasztásával kezdődik. A FAISS a gyári sztring mechanizmust biztosítja – egy tömör sztring specifikációt, amely összetett indexeket épít fel. A gyári minta az ajánlott megközelítés, mert elvonatkoztat a konkrét osztályhierarchiától és automatikusan kiválasztja az optimális implementációt:
| Gyári sztring | Index típus | Memória vektoronként (d=768) | Használati eset |
|---|---|---|---|
"Flat" | IndexFlat (egzakt L2 keresés) | 3 072 bájt | Kis referenciahalmazok, alaptény (ground truth) |
"IVF100,Flat" | IndexIVFFlat 100 centroiddal | ~3 100 bájt | Közepes halmazok, gyors közelítő keresés |
"HNSW32,Flat" | IndexHNSWFlat M=32-vel | ~3 328 bájt | Gyors közelítő keresés, dinamikus adat |
"IVF100,PQ16" | IndexIVFPQ, 16 alvektor | ~80 bájt | Nagyméretű, memóriakorlátozott |
"IVF100,SQ8" | IndexIVF skalár kvantálással | ~784 bájt | Kiegyensúlyozott, kiváló sebesség |
Tanítás csak azoknál az indexeknél szükséges, amelyek megtanulják az adatok eloszlását (IVF, PQ, SQ stb.). A tanítás során az index k-means klaszterezést futtat a vektorok egy reprezentatív mintáján. A k-means algoritmushoz a FAISS több véletlen inicializálást használ, és kiválasztja azt, amelyik a legalacsonyabb torzítást eredményezi. A tanítóhalmaznak reprezentatívnak kell lennie a indexelni kívánt adatokra – általános gyakorlat a teljes adathalmaz 1–10%-ának véletlenszerű részhalmazát használni. A FAISS megköveteli, hogy a tanítóvektorok dimenziószáma megegyezzen az indexelendő adatok dimenziószámával. Az index.is_trained jelző mutatja, hogy a tanítás befejeződött-e. A tanítás hívása: index.train(training_vectors). Olyan adathalmazok esetén, ahol az index már tanítva van (pl. előre tanított centroidok betöltése fájlból), a train újrahívása szükségtelen, és felülírja a megtanult paramétereket.
Feltöltés vektorokat ad a tanított indexhez: index.add(reference_vectors). Az ntotal tulajdonság nyomon követi a hozzáadott vektorok számát. IVF indexek esetén minden vektor a hozzá legközelebbi klasztercentroidhoz van rendelve, és a centroid invertált listájához fűzve a hozzáadási művelet során. HNSW indexek esetén a gráf növekményesen épül: minden új vektorhoz egy rétegszint kerül hozzárendelésre, és élek jönnek létre a hozzá legközelebbi M szomszédhoz minden rétegben az efConstruction paraméter használatával. A vektorok hozzáadása jellemzően lassabb, mint a lekérdezés, különösen HNSW esetén, ahol a gráfot frissíteni kell.
Szerializáció elmenti az indexet a lemezre: faiss.write_index(index, "index.faissindex"). Az index visszatöltése: index = faiss.read_index("index.faissindex") paranccsal történik. A szerializáció megőrzi a teljes index állapotát, beleértve a tanított centroidokat, a gráf szerkezetét, az összes tárolt vektort, a távolságmetrika konfigurációját és a belső paramétereket. A szabványos fájlkiterjesztés .faissindex. A szerializáció mérete az index típusától és a vektorok számától függ – IndexFlat esetén N darab D dimenziós vektorral a méret körülbelül N × D × 4 bájt, plusz kis többletköltség.
Lekérdezés visszaadja a k legközelebbi szomszédot: distances, indices = index.search(query_vectors, k). A distances tömb a metrikától függően hasonlósági vagy távolságértékeket tartalmaz. Az indices tömb az egyeztető referenciavektorok pozícióit tartalmazza a hozzáadás sorrendjében (0-tól indexelve). Kötegelt lekérdezések esetén a FAISS hatékonyan dolgoz fel több lekérdezést egyszerre a mátrix-mátrix szorzás segítségével, ami lényegesen jobb átbocsátóképességet ér el, mint az egyes lekérdezések egyenkénti hívása. Az index objektumok szálbiztosak különálló indexpéldányokon végzett keresési műveletekhez, lehetővé téve a párhuzamos lekérdezés-kiszolgálást termelési környezetekben.
A FAISS-t gyakran használják a k-legközelebbi szomszéd (kNN) osztályozás megvalósítására — ez egy nem-paraméteres gépi tanulási módszer, amely egy lekérdezési pontot a referenciahalmazban lévő k legközelebbi szomszédja többségi címkéje alapján osztályoz. Ez a megközelítés különösen vonzó, ha: (1) a referenciahalmazt rendszeresen frissítik új címkézett mintákkal, (2) a beágyazási tér értelmes szemantikai kapcsolatokat rögzít az adatpontok között, és (3) az értelmezhető, példa-alapú döntések előnyben részesülnek a fekete-doboz neurális osztályozókkal szemben.
Az FAISS-t használó osztályozási pipeline öt lépésből áll:
Címkézett referenciahalmaz építése: Minden referenciavektor párosításra kerül egy valós címkével (pl. “aszfalt – jó állapot”, “beton – repedezett felület”, “bitumen – javított”). A címkéket egy külön tömbben tároljuk, a FAISS index sorrendjéhez igazítva. A TarmacView körülbelül 9 000 ilyen címkézett referenciabeágyazást tart karban, amelyek több felülettípust és minőségi állapotot fednek le.
Referenciavektorok indexelése: Az összes referenciabeágyazást hozzáadjuk egy FAISS indexhez. Egzakt kereséshez tökéletes visszahívással az IndexFlatIP-t használjuk. Közelítő kereséshez nagy méretben az IndexHNSWFlat vagy IndexIVFFlat ezredmásodperc alatti lekérdezési időket biztosít >99%-os visszahívással, megfelelő hangolás mellett.
Lekérdezési beágyazások beküldése: Minden új osztályozandó képhez kinyerjük a beágyazást ugyanazzal a beágyazó modellel (DINOv2 768-dimenziós kimenettel), és egységnyi hosszra normalizáljuk a koszinusz hasonlósághoz.
k legközelebbi szomszéd lekérése: A FAISS visszaadja a k leghasonlóbb referenciavektor indexeit és távolságait. A k paraméter szabályozza a torzítás-variancia átváltást. Kisebb k (pl. 3–5) olyan döntési határokat eredményez, amelyek érzékenyek a lokális struktúrára, de hajlamosak a zaj túlillesztésére. Nagyobb k (pl. 15–20) simább határokat ad jobb általánosítással, de elveszítheti a finom részleteket. A TarmacView k=10-et használ, egyensúlyt teremtve a kiugró értékekkel szembeni robusztusság és a felületi minőség finom eltéréseire való érzékenység között.
Többségi szavazás végrehajtása: Megszámláljuk a címkéket a k szomszéd között, és kiválasztjuk a leggyakoribb címkét osztályozási eredményként. Opcionálisan a távolság-súlyozott szavazás nagyobb súlyt ad a közelebbi szomszédoknak: súly = 1,0 / (távolság + ε) ahol ε egy kis konstans a nullával osztás elkerülésére. A súlyozott szavazás különösen előnyös, ha a referenciahalmaz egyenlőtlen osztályeloszlású, vagy ha a szomszédsűrűség változó a beágyazási térben.
| k érték | Torzítás | Variancia | Legjobb használat |
|---|---|---|---|
| 1 – 3 | Alacsony | Magas | Nagy, tiszta referenciahalmazok, finom határok |
| 5 – 10 | Közepes | Közepes | Kiegyensúlyozott, általános célú osztályozás |
| 15 – 30 | Magasabb | Alacsonyabb | Zajos címkék, sima döntési határok |
A FAISS által visszaadott távolságértékek a konfidencia becslésében is segítenek. Ha a top-k szomszédok mindannyian ugyanazt a címkét osztják, és magas hasonlósági pontszámmal rendelkeznek (koszinusz hasonlóság > 0,95), az osztályozás nagy biztonságú. Ha a szavazás megosztott (pl. 6 a 10-ből a nyertes címkére), vagy a hasonlósági pontszámok alacsonyak (< 0,70), a rendszer emberi felülvizsgálatra jelölheti az eredményt. Ez a konfidencia-tudatos architektúra kritikus fontosságú a biztonság szempontjából kritikus alkalmazásokban, mint például a repülőtéri burkolatvizsgálat, ahol a téves osztályozás befolyásolhatja a karbantartási prioritásokat és az üzembiztonságot.
A beágyazási szerződés a DINOv2 modell és a FAISS index között alapvető fontosságú az osztályozási pontosság szempontjából. A beágyazó-kinyerő önfelügyelt tanulással van betanítva, így a beágyazások közötti távolságok a burkolati felületképek vizuális hasonlóságát tükrözik. A FAISS index hűen visszakeresi a legközelebbi szomszédokat a koszinusz hasonlósági metrika alapján. Amikor ez a szerződés érvényes — amikor a vizuálisan hasonló felületi állapotok közeli beágyazásokat eredményeznek — a kNN osztályozás nagy pontosságot ér el azzal a velejáró értelmezhetőséggel, hogy pontosan látható, mely referencia-képek befolyásolták az egyes osztályozási döntéseket.
A FAISS GPU-támogatása első osztályú funkció, amely jelentős teljesítménybeli javulást biztosít mind az indexépítés, mind a keresés terén. A GPU-megvalósítás, amelyet a “Billion-scale similarity search with GPUs” című cikk (Johnson, Douze, Jégou, 2017) ír le, CUDA C++ nyelven íródott, és az NVIDIA GPU architektúrákat használja a Kepler (Compute Capability 3.5) architektúrától a Hopper (Compute Capability 9.0+) architektúrán túl.
A FAISS GPU-gyorsítása mérhető teljesítményjavulást nyújt: 5–10-szeres keresési átbocsátóképesség-növekedés a CPU-hoz képest tipikus IVF és HNSW indexek esetében; akár 12-szer gyorsabb indexépítés IVF indexeknél, mivel a k-means klaszterezés jól párhuzamosítható; 8-szor alacsonyabb késleltetés HNSW lekérdezéseknél GPU-n optimalizált gráfbejárási kernelek segítségével; valamint natív támogatás a kötegelt lekérdezésekhez, ahol a GPU-k kiválóan teljesítenek száz vagy ezer lekérdezés egyidejű feldolgozásában mátrix-mátrix műveletekkel.
A GPU-megvalósítás a leggyakrabban használt index típusokat dedikált CUDA osztályokon keresztül fedi le:
| GPU Index Osztály | CPU Megfelelő | Használt CUDA Funkciók |
|---|---|---|
| GpuIndexFlat | IndexFlat | BLAS gemm GPU-n, megosztott memória tile-olás |
| GpuIndexIVFFlat | IndexIVFFlat | Párhuzamos távolságszámítás, warp-szintű redukciók |
| GpuIndexIVFPQ | IndexIVFPQ | PQ keresőtáblák GPU-n, gyors kód-hozzárendelés |
| GpuIndexIVFScalarQuantizer | IndexIVFScalarQuantizer | float16 támogatás Pascal+ GPU-kon |
A GPU-megvalósítás warp shuffle (Compute Capability 3.0+-on elérhető) és csak olvasható textúra gyorsítótár (ld.nc / __ldg segítségével, Compute Capability 3.5+) használ. A k-kiválasztási algoritmus — a top-k érték megtalálása egy nagy távolságtömbből — az elméleti GPU-csúcsteljesítmény akár 55%-án működik, lehetővé téve egy olyan legközelebbi szomszéd megvalósítást, amely a 2017-es cikk szerint 8,5-szer gyorsabb, mint a korábbi GPU-k legjobb megoldásai. GPU memóriakezeléshez egy StandardGpuResources objektum allokál scratch területet a GPU-n: körülbelül 512 MiB-ot ≤4 GiB memóriájú GPU-kon, és körülbelül 1 536 MiB-ot nagyobb GPU-kon. Ez a scratch terület elkerüli az ismételt cudaMalloc / cudaFree hívásokat a keresés során.
A FAISS zökkenőmentes CPU-GPU együttműködést biztosít két kulcsfontosságú függvényen keresztül: a faiss.index_cpu_to_gpu(cpu_index, device_id) áthelyez egy CPU-indexet egy megadott GPU eszközre, a faiss.index_gpu_to_cpu(gpu_index) pedig egy GPU-indexet helyez vissza CPU memóriába. Több GPU-s telepítésekhez a faiss.index_cpu_to_gpu_multiple_py(resources, cpu_index) elosztja az indexet az összes elérhető GPU eszköz között, a lekérdezések pedig automatikusan terheléselosztásra kerülnek. A több GPU-s megközelítés akár több százmillió vektort tartalmazó indexekre is skálázható a GPU memóriaterek particionálásával.
| Forgatókönyv | CPU | GPU (1x) | GPU (8x) |
|---|---|---|---|
| IndexFlat keresés (100K x 768d), batch=8192 | 50 ms | 5 ms | <1 ms |
| IVF k-means tanítás (1M x 128d), nlist=1000 | 120 s | 10 s | 5 s |
| HNSW építés (100K x 128d), M=32 | 30 s | 8 s | — |
| Milliárd méretű k-NN gráf | napok | 12 óra | 4 óra |
A TarmacView számára a GPU-gyorsítás az indexépítési fázisban értékes, amikor új referencia-képek kerülnek hozzáadásra időszakonként. Egy IVF index felépítése k-means-szal 9 000 darab 768-dimenziós vektoron körülbelül 1–2 másodpercet vesz igénybe egy modern GPU-n (NVIDIA A100 vagy RTX 4090), szemben a CPU-n mért 30–60 másodperccel. Kiértékelés során az index a CPU-n marad a költséghatékony telepítés érdekében — a lekérdezési késleltetés CPU-n IndexHNSWFlat-tal már így is 200 mikroszekundum alatt van a 9K referenciahalmaz esetén, és GPU-ra váltva PCIe átviteli többletköltség keletkezne anélkül, hogy érdemi késleltetésbeli előny jelentkezne.

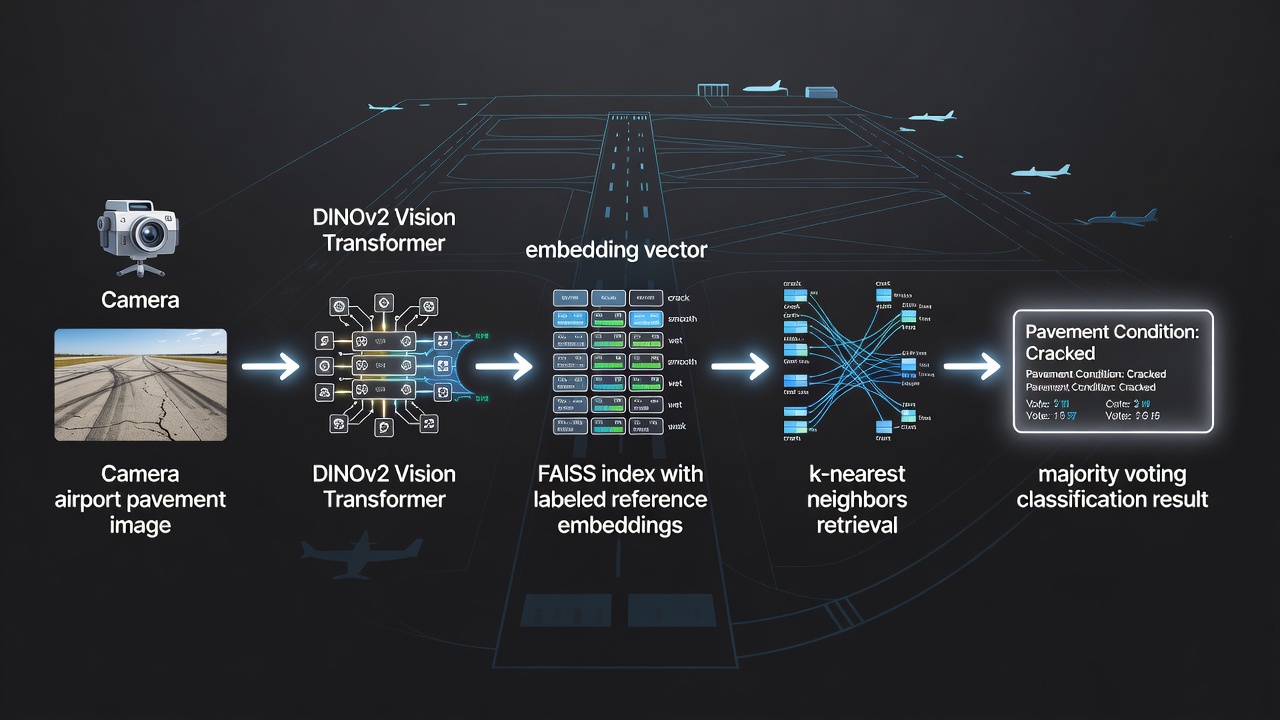
A TarmacView a FAISS-t integrálja kulcsfontosságú hasonlósági keresőmotorjaként automatikus repülőtéri burkolati felületminőség-osztályozó rendszeréhez. A rendszer burkolati felülettípusokat (aszfalt, beton, bitumen) és felületminőségi állapotokat (jó, megfelelő, gyenge, leromlott, repedezett, javított) osztályoz úgy, hogy a vizsgálati képeket egy körülbelül 9 000 címkézett beágyazásból álló, gondozott referenciahalmazzal hasonlítja össze.
Referenciahalmaz felépítése: Minden referenciabeágyazás egy nagy felbontású burkolati képből kerül kinyerésre egy DINOv2 Vision Transformer modell segítségével (ViT-B/14 vagy azzal egyenértékű), amely egy 768-dimenziós vektort állít elő, ami olyan vizuális jellemzőket ragad meg, mint a textúramintázatok, színeloszlás, repedésmorfológia, aggregátum-kitettség, felületi kopás és javítási nyomok. Minden beágyazás ellátásra kerül a valós címkékkel, amelyeket minősített burkolatvizsgálók állapítottak meg a rendszer kezdeti tanítási fázisában. A referenciahalmaz több repülőteret, klímazónát és burkolati kort fed le a robusztus osztályozás biztosítása érdekében változatos körülmények között.
Index kiválasztása: A TarmacView a telepítési követelmények alapján választja meg az index típusát:
| Telepítési forgatókönyv | Index típusa | Lekérdezési idő | Visszahívás | Memória |
|---|---|---|---|---|
| Offline QA / validáció | IndexFlatIP | ~2 ms | 100% | ~28 MB |
| Valós idejű terepi telepítés | IndexHNSWFlat (M=32, efSearch=64) | <200 μs | >99% | ~30 MB |
| Edge eszköz (korlátozott RAM) | IndexIVFFlat (nlist=100, nprobe=10) | ~300 μs | ~97% | ~28 MB |
Osztályozási munkafolyamat:
Egy drónra szerelt kamera (pl. DJI Matrice sorozat nagy felbontású szenzorral) vagy kézi vizsgálati eszköz burkolati képeket rögzít a rutin repülőtéri ellenőrzések során, követve az ICAO Annex 14 és az FAA AC 150/5380-7B irányelveket a burkolatállapot-értékeléshez.
Minden kép előfeldolgozásra kerül (levágás a nem burkolati területek eltávolításához, normalizálás standard felbontásra), és átmegy a DINOv2 beágyazó modellen, amely egy edge inferencia gyorsítón fut (NVIDIA Jetson vagy azzal egyenértékű).
Az eredményül kapott 768-dimenziós beágyazás L2-normalizálásra kerül egységnyi hosszra a koszinusz hasonlóság számításához. A normalizálás biztosítja, hogy a vizsgálati repülések közötti expozíciós eltérések ne befolyásolják a hasonlósági rangsorolást.
A FAISS lekérdezi az IndexHNSWFlat indexet k=10 paraméterrel, visszaadva a 10 legközelebbi referenciabeágyazás indexét és azok belső szorzat hasonlósági pontszámait (ami megegyezik a koszinusz hasonlósággal normalizált vektorok esetén).
A rendszer többségi szavazást végez a 10 szomszéd címkéin. Ha a nyertes címke legalább 6 szavazatot kap a 10-ből (60%-os konszenzus), az osztályozás elfogadásra kerül egy konfidenciapontszámmal, amely a nyertes szavazatok és az összes szavazat aránya.
Ha a szavazás 60%-os konszenzus alatt megosztott, a kép beágyazása és a top-10 referencia-kép emberi felülvizsgálatra kerül kijelölésre egy minősített burkolatvizsgáló számára a TarmacView webes felületén keresztül.
Az osztályozások rögzítésre kerülnek a TarmacView adatbázisában időbélyegekkel, GPS koordinátákkal, felülettípussal, minőségi állapottal, konfidenciapontszámmal és a kapcsolódó referencia-képek hivatkozásaival. Ez teljesen ellenőrizhető vizsgálati nyomvonalat hoz létre a szabályozási megfeleléshez.
Ez a FAISS-alapú osztályozási pipeline lehetővé teszi a TarmacView számára, hogy naponta több ezer burkolati képet dolgozzon fel konzisztens, objektív minőségértékeléssel — csökkentve a szubjektív emberi vizuális vizsgálatra való támaszkodást, és lehetővé téve a skálázható repülőtéri burkolatállapot-figyelést teljes repülőtéri hálózatokon.
A FAISS egy sajátos rést foglal el a vektoros keresés ökoszisztémájában. Ez egy könyvtár, nem adatbázis, és ennek a megkülönböztetésnek jelentős kihatásai vannak az architektúrára, a telepítésre és az üzemeltetési jellemzőkre. A FAISS könyvtár tiszta legközelebbi-szomszéd keresési funkciót nyújt egy teljes értékű adatbázis-kezelő rendszer többletterhelése nélkül.
| Jellemző | FAISS | Pinecone | Milvus | Qdrant | Weaviate |
|---|---|---|---|---|---|
| Típus | Könyvtár | Menedzselt szolgáltatás | Adatbázis | Adatbázis | Adatbázis |
| Telepítés | Beágyazott | Cloud / SaaS | Saját üzemeltetésű / Cloud | Saját üzemeltetésű / Cloud | Saját üzemeltetésű / Cloud |
| Perzisztencia | Kézi mentés/betöltés | Automatikus | Automatikus | Automatikus | Automatikus |
| CRUD | Nincs beépítve | Teljes CRUD | Teljes CRUD | Teljes CRUD | Teljes CRUD |
| Metaadat szűrés | Csak ID-alapú | Gazdag szűrők | Attribútum + skalár | Payload szűrés | Gráf-alapú |
| Skálázás | Kézi sharding | Auto-skálázás | Elosztott Raft/Paxos | Elosztott | Elosztott |
| GPU támogatás | Natív CUDA | Nem | Korlátozott (CUDA) | Nem | Nem |
| Lekérdezési késleltetés | 10 μs – 1 ms | 2 – 10 ms | 1 – 10 ms | 1 – 5 ms | 1 – 10 ms |
| Licenc | MIT | Saját | Apache 2.0 | Apache 2.0 | BSD-3 |
A FAISS kulcsfontosságú előnye a teljes adatbázis-rendszerekkel szemben a teljesítmény és egyszerűség. A FAISS lekérdezések jellemzően 10–100-szor gyorsabbak, mint az adatbázis-rendszereken végzett egyenértékű lekérdezések, mert: a könyvtár folyamaton belül fut hálózati körözés nélkül; nincs lekérdezés-elemzési, hitelesítési vagy engedélyezési többletterhelés; nincs tárolómotor-indirekció vagy buffer pool menedzsment; és a FAISS indexek optimalizált lineáris algebrai adatszerkezetek tranzakciós többletterhelés nélkül. A FAISS közvetlenül a memóriabeli adatszerkezeteken dolgozik optimalizált BLAS rutinokat használva, folyamatok közötti kommunikáció nélkül.
Az adatbázis-rendszerek kulcsfontosságú előnye a FAISS-szal szemben az üzemeltetési kényelem. Automatikus adattartósságot biztosítanak write-ahead naplózással és replikációval, támogatják a gazdag metaadat-szűrést (pl. “keress hasonló képeket, amelyek 2025 januárja után készültek és beton burkolatot mutatnak az USA délnyugati régiójában”), REST vagy gRPC API-kat kínálnak nyelvfüggetlen hozzáféréshez, tartalmaznak monitoring irányítópultokat és riasztásokat, valamint kezelik a biztonsági mentést és a katasztrófa-helyreállítást. Támogatják az egyidejű olvasási és írási műveleteket tranzakciós garanciákkal és sémafejlesztéssel.
A TarmacView számára a FAISS közvetlen használata vektoradatbázis helyett a helyes architekturális választás négy okból: (1) a referenciahalmaz kicsi (~9K vektor, körülbelül 28 MB) és teljes egészében elfér a memóriában; (2) a lekérdezési késleltetési követelmények szigorúak (200 mikroszekundum alatti osztályozás elérhető HNSW-vel CPU-n); (3) a rendszer edge telepítésekben fut repülőtereken, ahol a hálózati hozzáférés egy adatbázis-szerverhez nem praktikus vagy elfogadhatatlan késleltetést okozhat; és (4) az index ritkán épül újra (hetente vagy havonta, ahogy új referencia-képek kerülnek hozzáadásra a vizsgálói validálást követően), így a kézi szerializáció és verziókezelés kezelhető.
A FAISS index szerializáció egy memóriabeli index objektumot bináris reprezentációvá alakít, amely lemezre menthető, hálózaton átvihető, vagy betölthető egy másik folyamatba vagy gépre. A szerializáció megőrzi a teljes index állapotát, beleértve az összes tárolt vektort, a betanított centroidokat (IVF és PQ indexekhez), a gráfszerkezetet (HNSW esetén), a távolságmetrika konfigurációját (L2 vs IP vs egyéb), valamint az összes belső paramétert (efConstruction, M, normalizálási beállítások stb.).
Az elsődleges szerializációs függvények:
| Függvény | Leírás | Kimenet | Használati eset |
|---|---|---|---|
| write_index(index, filename) | Index írása fájlba | .faissindex fájl | Tartós lemeztárolás |
| read_index(filename) | Index betöltése fájlból | Index objektum | Betöltés kiszolgáláshoz |
| serialize_index(index) | Index írása bájtokba | Python bytes objektum | Adatbázis tárolás, üzenetsorok |
| deserialize_index(data) | Index betöltése bájtokból | Index objektum | Betöltés memória pufferből |
A szerializáció mérete az index típusától és a vektorok számától függ. IndexFlatIP esetén N darab D dimenziójú vektorral a fájlméret körülbelül N × D × 4 bájt (32 bites lebegőpontos tárolás) plusz a fejléc és metaadatok többlete. IndexIVFFlat esetén további tárhelyet foglalnak a klasztercentroidok: nlist × D × 4 bájt. IndexHNSWFlat esetén a gráfszerkezet további N × M × 2 × 4 bájtot igényel a szomszédsági listák számára (32 bites szomszédindexeket feltételezve, kétirányú tárolással). A TarmacView HNSW indexéhez, amely 9 000 vektort tartalmaz 768 dimenzióval és M=32 paraméterrel, a szerializált fájl körülbelül 25 MB: 9 000 × 768 × 4 = 27,6 MB a vektoroknak plusz 9 000 × 32 × 2 × 4 = 2,3 MB a gráfszerkezetnek, levonva azt a tényt, hogy a HNSW a vektorokat belsőleg egy lapos indexben tárolja.
A szerializáció támogatja a kontextusok közötti átvitelt: egy GPU-n épített index lemezre menthető és CPU-n betölthető. Az ajánlott minta szerint a GPU indexeket mindig át kell helyezni CPU-ra szerializáció előtt:
cpu_index = faiss.index_gpu_to_cpu(gpu_index) # transfer to CPU
faiss.write_index(cpu_index, "production_index.faissindex") # save to disk
# On a different machine (or later):
deployed_index = faiss.read_index("production_index.faissindex")
deployed_index.hnsw.efSearch = 64 # set search-time parameters
D, I = deployed_index.search(queries, k)
Éles telepítésekhez a szerializált index verziókezelhető az alkalmazáskód mellett. A TarmacView verziózott FAISS indexfájlokat tart fenn a telepítési artefaktumai között, biztosítva, hogy minden edge telepítés azonos referenciahalmazt használjon a reprodukálható osztályozási eredményekhez. Amikor új referencia-képek kerülnek hozzáadásra és validálásra, egy új index kerül betanításra, annak pontosságát összevetik az előző indexszel a valós IndexFlatIP segítségével, majd az új index telepítésre kerül a standard CI/CD pipeline-on keresztül.
Bár a TarmacView jelenlegi referenciahalmaza, körülbelül 9 000 vektor, szerény méretű, a FAISS-t úgy tervezték, hogy több milliárd vektorig skálázódjon egyetlen szerveren. A könyvtár átfogó eszközkészletet biztosít a nagyméretű telepítések kezeléséhez három kiegészítő technikán keresztül: vektor-kompresszió, nem-teljes körű keresés és elosztott indexelés.
A Product Quantization (PQ) egy veszteséges tömörítési technika, amely drámaian csökkenti az egy vektorra jutó memóriafogyasztást. A PQ minden D-dimenziós vektort m darab egyenlő méretű alvektorra bont (D/m dimenzió alvenként). Minden alvektor önállóan kvantálásra kerül egy 256 bejegyzésből (8 bit) álló kódkönyv segítségével, amelyet k-means klaszterezéssel tanítunk. Az eredeti float32 vektor (4 × D bájt) m bájtra van tömörítve kódindexek formájában, plusz egy kis kódkönyv. A PQ tömörítési arányok jellemzően 4x és 16x között mozognak, lehetővé téve, hogy egyetlen gép több százmillió vektort indexeljen a főmemóriában. A FAISS IndexIVFPQ kombinálja az IVF-et PQ-val, a klasztercentroidokat durva kvantálóként és a PQ kódokat reziduális tömörítéshez használva. A távolságszámítás Aszimmetrikus Távolságszámítást (ADC) használ: a lekérdezés tömörítetlen marad, és a PQ-val tömörített adatbázisvektoroktól való távolságokat előre kiszámított keresőtáblák segítségével számítjuk, elkerülve a kitömörítési többletköltséget.
| PQ Konfiguráció | Bájt/vektor (d=768) | Memória, N=100M | Visszahívás a tömörítetlenhez képest |
|---|---|---|---|
| PQ32 (m=32, 8-bit) | 40 | 3,7 GB | ~90-95% |
| PQ64 (m=64, 8-bit) | 72 | 6,7 GB | ~95-98% |
| PQ96 (m=96, 8-bit) | 104 | 9,7 GB | ~97-99% |
A Skaláris Kvantálás (SQ) minden float32 komponenst 8 bites vagy 4 bites előjel nélküli egész számmá alakít, négyszeres (SQ8) vagy nyolcszoros (SQ4) tároláscsökkentést érve el minimális pontosságvesztéssel. A "IVF100,SQ8" gyári sztring egy IVF indexet hoz létre skaláris kvantálással. Az SQ gyorsabb, mint a PQ lekérdezési időben, mert a távolságszámítások közvetlenül a kvantált értékeken történnek, keresőtábla előzetes számítása nélkül. Az SQ8 egy bájtot tárol dimenziónként; az SQ4 két dimenziót tárol bájtonként.
Milliárd méretű adathalmazokhoz az ajánlott FAISS konfiguráció a HNSW-t durva kvantálóként kombinálja az IVFPQ-val vektor-tömörítéshez: quantizer = IndexHNSWFlat(d, hnsw_m); index = IndexIVFPQ(quantizer, d, nlist, M, nbits). A HNSW kvantáló felgyorsítja a centroid-keresést a lapos kereséshez képest lekérdezési időben, a PQ pedig az adatbázisvektorokat az eredeti méretük töredékére tömöríti. Az eredeti FAISS cikk (2017) egy k-NN gráf felépítését mérte 95 millió képen (az YFCC100M adathalmazból) 35 perc alatt GPU-kon, és egy k-NN gráfot 1 milliárd vektoron kevesebb mint 12 óra alatt 4x Maxwell Titan X GPU-n.
A FAISS IndexShards egy nagy adathalmazt több al-indexre bont, amelyek potenciálisan különböző gépeken vagy GPU-kon lehetnek. Minden shard a vektorok egy részhalmazát kapja, és a lekérdezéseket egymástól függetlenül dolgozza fel. Az eredmények egy k-utas egyesítéssel kerülnek összefésülésre az egyes shardok top-k eredményeiből. Ez a megközelítés lineáris skálázást biztosít az elérhető szerverek számával: a shardok számának megduplázása felére csökkenti a keresési időt egy adott adathalmazméret esetén.
Az elérhető RAM-ot meghaladó adathalmazokhoz a FAISS lemez-alapú indexeket biztosít, amelyek az index szerkezetét (invertált listák vagy gráf) a memóriában tartják, de a vektoradatokat SSD-n tárolják. Az IndexOnDisk osztály és kapcsolódó segédprogramok transzparensen töltik be a vektoradatokat a lemezről keresés során, memóriába-leképezett fájlok vagy explicit I/O műveletek segítségével. A modern NVMe SSD-k 3–7 GB/s szekvenciális olvasási sebességet biztosítanak, így a lemez-alapú keresés megközelítheti a memóriabeli teljesítményt számos munkaterhelés esetén, különösen ha a térbeli lokalitás (szomszédos vektorok egymás mellett tárolva a lemezen) fennmarad.
A TarmacView jelenlegi 9K referenciahalmaza jól beleesik a FAISS optimális tartományába az egzakt kereséshez IndexFlatIP-vel. Ahogy azonban a rendszer bővül, hogy több száz repülőtérről és több vizsgálati kampányból származó referencia-képeket tartalmazzon — potenciálisan milliós nagyságrendű címkézett beágyazásra nőve — a FAISS skálázási mechanizmusai (IVF a nem-teljes körű kereséshez, PQ a tömörítéshez, lemez-alapú tárolás a RAM-on túli adathalmazokhoz) egyértelmű frissítési utat biztosítanak anélkül, hogy alapvetően eltérő architektúrára lenne szükség. Az index típusa frissíthető IndexFlatIP → IndexIVFFlat → IndexIVFPQ → IndexShards(IndexIVFPQ) irányban a referenciahalmaz növekedésével, minden lépésben minimális pontosságot áldozva fel nagyságrendi javulásokért a keresési sebességben és memóriahatékonyságban.
A FAISS szakirodalom (beleértve a 2024-es átfogó arXiv cikket “The Faiss Library” címmel, Douze, Guzhva, Deng, Johnson, Szilvasy, Mazaré, Lomeli, Hosseini és Jégou tollából) részletes útmutatást nyújt az index kiválasztásához: “Tucatnyi indextípus közül lehet választani, és az optimális általában a probléma korlátaitól függ.” A FAISS emellett tartalmaz egy átfogó benchmarking csomagot (faiss_benchmarks), amely a visszahívást és az átbocsátóképességet méri különböző index konfigurációkon, az IndexFlat valós eredményeivel összehasonlítva a pontosság számszerűsítéséhez. A gyakorlati szakemberek számára ajánlott a saját adateloszlásukon benchmarkolni — az adott adathalmazhoz optimális index a vektorok dimenziójától, az adathalmaz méretétől, a cél-visszahívástól, a késleltetési kerettől és a rendelkezésre álló memóriától függ.
Használja a FAISS-t a nagy teljesítményű hasonlósági kereséshez a képbeágyazási adatain. Lépjen kapcsolatba velünk, hogy megtudja, hogyan integrálja a TarmacView a FAISS-t valós idejű felületi minőség osztályozáshoz és ellenőrző képek visszakereséséhez.
A beágyazási tér egy magas dimenziójú matematikai tér, amelyben objektumok – például képek, szövegek vagy érzékelőadatok – vektorokként vannak reprezentálva, le...
Az AI-alapú repedésfelismerés számítógépes látást – konvolúciós neurális hálózatokat, víziótranszformátorokat és szemantikus szegmentációs modelleket – használ ...
A Forgalmi Információs Szolgáltatás (TIS) növeli a repülésbiztonságot azáltal, hogy valós idejű forgalmi adatokat nyújt a pilótáknak, támogatva a helyzetismeret...