Az Apache Parquet egy oszloporientált, tömörített bináris tárolási formátum, amely nagy táblázatos adathalmazok elemzési lekérdezéseihez van optimalizálva. A TarmacView minden elemzési eredményt Parquet formátumban tárol a hatékony tárolás és gyors lekérdezés érdekében. A cikk bemutatja a Parquet előnyeit, sémáját, írási/olvasási műveleteit Pandas és Polars segítségével, valamint összehasonlítja a CSV-vel és JSON-nal az ellenőrzési adatok tekintetében.
Apache Parquet formátum az ellenőrzési adatokhoz
Definíció és oszlopos tárolási modell
Az Apache Parquet egy ingyenes, nyílt forráskódú, oszloporientált bináris fájlformátum, amelyet az alapoktól kezdve a hatékony adattárolásra és lekérdezésre terveztek elemzési munkaterhelésekhez. Eredetileg a Twitter és a Cloudera együttműködéséből született az Apache Hadoop ökoszisztémán belül, a Parquet azóta a de facto szabvánnyá vált az elemzési adattárolás területén a teljes adatmérnöki környezetben. Minden jelentős adatfeldolgozó motor – Apache Spark, DuckDB, ClickHouse, Presto, Trino, Snowflake, Google BigQuery, Amazon Redshift és Databricks – natív támogatást nyújt a Parquet fájlok olvasásához és írásához. A formátumot a sororientált formátumok alapvető teljesítménykorlátainak kezelésére tervezték az olyan elemzési lekérdezések feldolgozásakor, amelyek nagy mennyiségű adatot vizsgálnak, de csak az oszlopok vagy sorok egy részhalmazára hivatkoznak.
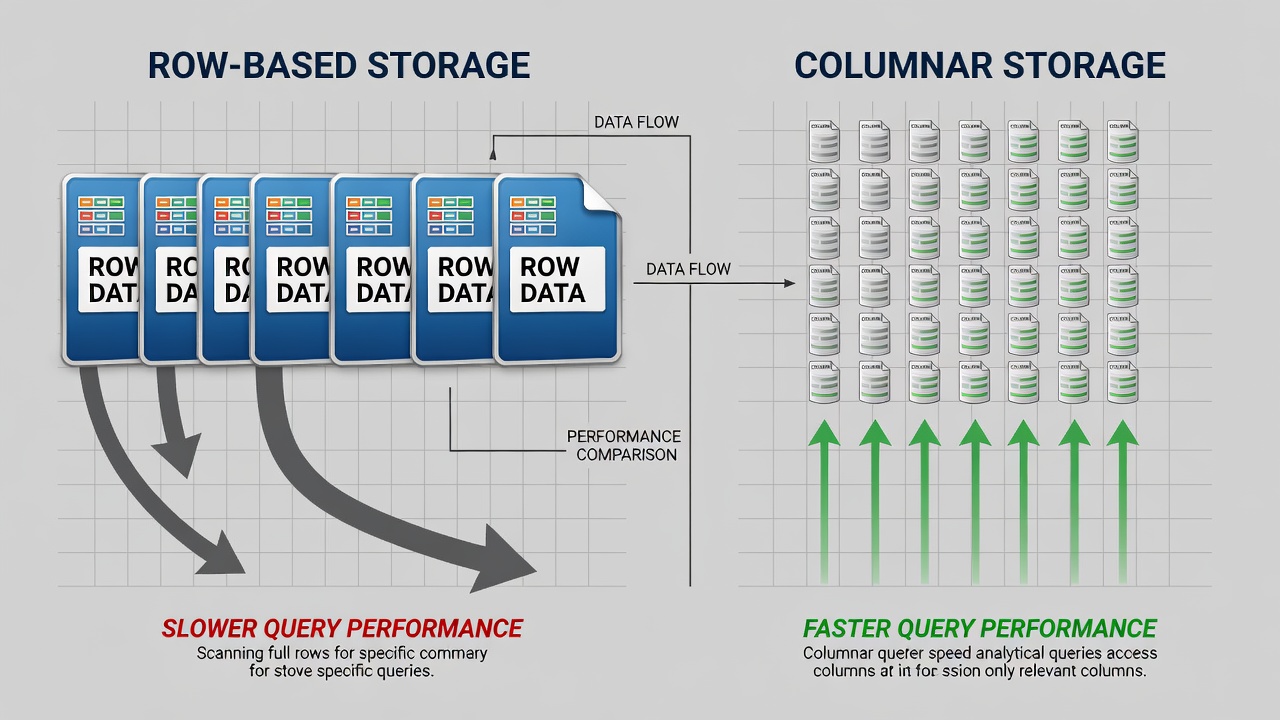
Oszlopos tárolás vs. sororientált tárolás. A Parquet meghatározó építészeti jellemzője az oszlopos tárolási modell. A hagyományos sororientált formátumban, mint a CSV vagy JSON, minden rekordhoz tartozó összes mező egymás után kerül tárolásra a lemezen. Egy 100 attribútumot tartalmazó burkolat-ellenőrzési adathalmaz esetén mért pontonként – koordináták, felületi állapotértékelések, károsodásmérések, képalkotási metaadatok – a CSV az 1. sor mind a 100 értékét tárolja, majd a 2. sor mind a 100 értékét, és így tovább. Amikor egy lekérdezés csak két attribútumot kér, például repedésszélességet és GPS-szélességet, a tárolómotornak minden egyes attribútumot be kell olvasnia minden egyes sorhoz a lemezről, elemeznie kell a teljes adathalmazt, ki kell bontania a két kért oszlopot, és el kell dobnia a maradék 98 oszlopot. Ez hatalmas I/O-veszteséget eredményez – a lemezről beolvasott adatok körülbelül 98%-a azonnal eldobásra kerül.
A Parquet teljesen megfordítja ezt a modellt. Minden egyes sorkészleten belül (az adathalmaz vízszintes partíciója, amely egy összefüggő sorblokkot tartalmaz) az adatok oszloponként tárolódnak, nem pedig soronként. A szélességi fok oszlop minden értéke egy oszlopdarabban, a repedésszélesség minden értéke egy másik oszlopdarabban, és így tovább. Egy lekérdezés, amely csak a szélességi fokot és a repedésszélességet kéri, csak ezt a két oszlopdarabot olvassa be a lemezről, ami ugyanazt a 98%-os I/O-csökkentést eredményezi, ami a sororientált formátumokban elpazarolódik. Ez az oszlopos elrendezés a Parquet teljesítményelőnyének alapja az elemzési lekérdezéseknél.
Belső fájlarchitektúra. A Parquet fájl szigorú hierarchikus struktúrát követ három egymásba ágyazott szervezési szinttel: sorkészletek, oszlopdarabok és oldalak. E hierarchia megértése elengedhetetlen a Parquet teljesítményének optimalizálásához az ellenőrzési adatcsővezetékekben.
A legkülső szint a sorkészlet, amely az adathalmazt vízszintesen, összefüggő sorblokkokra particionálja. Minden sorkészlet függetlenül olvasható és feldolgozható, lehetővé téve a párhuzamos végrehajtást több CPU-magon vagy elosztott fürtmunkavégzőn. Egy tipikus sorkészlet 64 000 és 1 000 000 sor között tartalmaz, a tömörítetlen méret pedig 64 MB és 1 GB között van, a munkaterheléstől függően. A TarmacView ellenőrzési adataihoz a körülbelül 256 MB tömörítetlen sorkészletek optimális egyensúlyt biztosítanak a párhuzamosítás granularitása és a metaadat-többletterhelés között. A nagyobb sorkészletek csökkentik a metaadat-bejegyzések számát a fájl láblécében, de korlátozzák a párhuzamosítást; a kisebb sorkészletek növelik a metaadat-többletterhelést, de finomabb adatkihagyást tesznek lehetővé.
Minden sorkészleten belül az adatok oszlopok szerint vannak felosztva oszlopdarabokra. Minden oszlopdarab egyetlen oszlop összes értékét tárolja az adott sorkészlet összes sorában. Mivel egy oszlopdarab minden értéke azonos adattípussal rendelkezik, és gyakran hasonló statisztikai tulajdonságokat mutat – például alacsony kardinalitást a kategorikus károsodásosztályozásoknál vagy monoton növekedést az időbélyegeknél – az oszlopdarabok sokkal hatékonyabban tömöríthetők és kódolhatók, mint a vegyes típusú soradatok. Az oszlopdarabok azok, ahol a Parquet statisztikai metaadatai számításra kerülnek: minden oszlopdarab opcionálisan tárolja a minimális értéket, a maximális értéket és a nullák számát az adott oszlopra az adott darabon belül. Ezek a statisztikák teszik lehetővé a predikátum lenyomást, ahol a lekérdező motorok kihagyják azokat az oszlopdarabokat, amelyek értéktartományai nem fedik át a szűrőfeltételeket.
Minden oszlopdarab oldalakra van felosztva, amelyek a tárolás legkisebb oszthatatlan egységei, és amelyek szintjén a tömörítés és kódolás alkalmazásra kerül. Az alapértelmezett oldalméret körülbelül 1 MB tömörítetlenül. Egy oszlopdarab jellemzően több adatoldalból áll, amelyek a kódolt oszlopértékeket tartalmazzák, opcionálisan egy szótároldallal kiegészítve, amely az egyedi értékeket egész indexekhez rendeli a szótári kódoláshoz. A Parquet több oldaltípust definiál, beleértve a DATA_PAGE (az eredeti v1 formátum), DATA_PAGE_V2 (egy továbbfejlesztett formátum, amely az ismétlési és definíciós szinteket tömörítetlenül tárolja a null és beágyazott értékek gyorsabb kihagyásához), és DICTIONARY_PAGE (a szótárleképezést tartalmazza a szótárkódolt oszlopokhoz).
Fájl lábléc és metaadatok. A fájllábléc minden Parquet fájl kritikus összetevője. A fájl végén található, és tartalmazza a teljes fájl metaadatokat, amelyek az Apache Thrift TCompactProtocol segítségével vannak szerializálva – egy kompakt bináris szerializációs formátum, amely a séma-olvasáskori munkaterhelésekhez van optimalizálva. A lábléc metaadatai tartalmazzák a fájl sémáját (oszlopnevek, adattípusok és beágyazott struktúra definíciók), a sorok számát, a fájl verzióját, a sorkészletek listáját az oszlopdarabok helyeivel és méreteivel, oszlopdarabonkénti statisztikákat (min, max, nullák száma), az egyes oszlopokhoz használt tömörítési kodeket, és opcionális kulcs-érték metaadatokat alkalmazásspecifikus információkhoz. Mivel a lábléc kicsi – jellemzően néhány kilobájt és néhány száz kilobájt között van a sok sorkészletet tartalmazó fájlok esetén – a lekérdező motorok gyorsan beolvashatják és megtervezhetik az adatelérési stratégiájukat, mielőtt bármilyen adatoldalt beolvasnának.
Mágikus bájtok és fájlazonosítás. Minden érvényes Parquet fájl a PAR1 4 bájtos mágikus számmal kezdődik és végződik (hexadecimális: 50 41 52 31). A kezdő mágikus bájtok azonosítják a fájlformátumot az olvasók számára, míg a záró mágikus bájtok megerősítik a fájl integritását és horgonyt biztosítanak a lábléc metaadatainak megtalálásához. Egy Parquet fájl olvasásához a lekérdező motor a következő kanonikus algoritmust követi: ugorjon a fájl végéhez mínusz 8 bájt, olvassa be a 4 bájtos mágikus számot a PAR1 formátum megerősítéséhez, olvassa be az előző 4 bájtot kis-endian 32 bites egészként, amely a lábléc metaadatainak hosszát jelenti, ugorjon vissza ezzel a hosszal, olvassa be és deszerializálja a Thrift-kódolt FileMetaData-t, elemezze a sémát, keresse meg a kívánt oszlopdarabokat a fájl eltolásaik alapján, és olvassa be csak a szükséges oldalakat.
A Parquet előnyei az ellenőrzési adatokhoz
Tömörítési arányok. A Parquet oszlopos tárolási modellje eleve drámaian kisebb fájlméreteket eredményez, mint a sororientált formátumok, még a tömörítési kodek alkalmazása előtt is. Ez a méretcsökkentés két forrásból származik: az oszloponkénti adatjellemzőket kihasználó oszlopos kódolási technikákból, valamint az oldalszinten alkalmazott opcionális tömörítési kodekekből. Valós adathalmazokon végzett benchmark tanulmányok következetesen azt mutatják, hogy a tömörítetlen Parquet körülbelül 25%-32%-a a megfelelő CSV fájlok méretének. Egy tömörítési kodek, például Snappy vagy Zstd hozzáadása tovább csökkenti a fájlméretet a CSV méretének 8%-18%-ára, ami 5x-12x tároláscsökkentést jelent.
Az ellenőrzési adatok esetében ez a tömörítés különösen előnyös, mert az adathalmazok nagy pontosságú lebegőpontos koordinátákat (amelyek delta-kódolással rendkívül jól tömöríthetők), kategorikus károsodásosztályozásokat (amelyek a szótári kódolásból profitálnak) és időbélyegeket (amelyek delta-kódolással hatékonyan tömöríthetők) kombinálnak. Egy teljes futópálya-burkolat felmérés, amely 50 millió adatpontot generál pontonként 80 attribútummal, körülbelül 40 GB-ot tesz ki nyers CSV formátumban. Ugyanez az adat Parquet-ben tárolva Zstd tömörítéssel körülbelül 3 GB-5 GB-ot foglal – ez 8x-12x tároláscsökkentés. A negyedéves felméréseket végző repülőtér-üzemeltetők számára, több futópályán, gurulóúton és előtér-területen, ez közvetlenül csökkentett tárolási infrastruktúra-költségeket, gyorsabb adatátviteli időket és hatékonyabb felhőalapú tároláshasználatot jelent.
Predikátum lenyomás. A predikátum lenyomás a legjelentősebb teljesítményoptimalizálás, amelyet a Parquet oszlopos tárolása és darabonkénti statisztikái tesznek lehetővé. Amikor egy lekérdezés WHERE záradékot tartalmaz – például WHERE pci < 40 AND survey_date >= '2024-01-01' – a lekérdező motor először beolvassa a fájlláblécet, amely a szűrt oszlopok oszlopdarabonkénti statisztikáit tartalmazza. Minden sorkészlet esetében a motor összehasonlítja a szűrőfeltételt a tárolt minimális és maximális értékekkel. Azokat a sorkészleteket, amelyek statisztikai tartománya nem fedi át a szűrőfeltételt, teljesen kihagyja a rendszer, nulla I/O-felhasználással.
Tekintsünk egy TarmacView ellenőrzési archívumot, amely öt év negyedéves futópálya-felméréseit tartalmazza, évente 200 sorkészletre szervezve, összesen 1000 sorkészlettel. Egy survey_date >= '2024-06-01' szűrőfeltételű lekérdezés összehasonlítja a szűrési dátumot az egyes sorkészletek tárolt min és max időbélyegeivel. Csak a 2024 közepétől készült felméréseknek megfelelő sorkészletek fedik át a szűrőt – körülbelül 50-100 sorkészlet az 1000-ből, azaz az adatok 5%-10%-a. A maradék 900-950 sorkészlet kihagyásra kerül anélkül, hogy beolvasásra kerülne. A lekérdezés a fájladatok csak 5%-10%-át olvassa be, ami 10x-20x teljesítményjavulást eredményez a teljes beolvasáshoz képest. Oszlopritkítással kombinálva a hatékony I/O-megtakarítás meghaladhatja a 100x-ot a szelektív lekérdezéseknél széles adathalmazokon.
Sémafejlődés. A Parquet támogatja a sémafejlődést – az oszlopok hozzáadásának, eltávolításának vagy módosításának képességét az idő múlásával anélkül, hogy a meglévő fájlokat újra kellene írni. Ez kritikus fontosságú a hosszú távú ellenőrzési programoknál, ahol az adatgyűjtési követelmények változnak. Egy futópálya-ellenőrzési program, amely kezdetben csak felületi károsodási értékeléseket rögzít, később repedésosztályozást, textúraméréseket vagy képalkotási metaadatokat adhat hozzá, ahogy a program érik. A sémafejlődéssel a kibővített sémával írt új Parquet fájlok zökkenőmentesen együttélnek a régebbi, eredeti sémát használó fájlokkal. Az adathalmazt olvasó lekérdező motorok egy egyesített sémát látnak, ahol a null értékekkel vannak kitöltve azok az oszlopok, amelyek a régebbi fájlokban nem léteztek. A Parquet támogatja továbbá az oszlopok hozzáadását alapértelmezett értékekkel, az oszlopok átnevezését oszlopalias-metaadatokon keresztül, valamint a visszafelé kompatibilis típuspromóciókat, például int32-ről int64-re.
Oszlopritkítás (projekció lenyomás). Az oszlopritkítás az a gyakorlat, hogy csak a lekérdezésben hivatkozott oszlopokat olvassuk be a lemezről. Mivel a Parquet az oszlopokat külön oszlopdarabokban tárolja az egyes sorkészleteken belül, a lekérdező motor csak azokat az oszlopdarabokat olvassa be, amelyek a SELECT záradékban szereplő oszlopokhoz tartoznak. Egy 100 attribútumot tartalmazó TarmacView ellenőrzési fájl esetén egy latitude, longitude, pci mezőket kiválasztó lekérdezés csak három oszlopdarabot olvas be – a teljes fájladat körülbelül 3%-át. A sororientált formátumokkal ugyanez a lekérdezés az adatok 100%-át kénytelen beolvasni, és 97%-át a memóriában eldobni. Az oszlopritkítás automatikus minden Parquet-kompatibilis lekérdező motorban, és nem igényel explicit konfigurációt. A teljesítményelőny lineárisan skálázódik az adathalmaz oszlopainak számával: minél több attribútumot gyűjtenek mért pontonként, annál nagyobb a megtakarítás az oszlopritkításból.
Önleíró formátum. A Parquet fájlok teljes mértékben önleíróak – a séma, a tömörítési kodek, a kódolás, a statisztikák és az alkalmazás metaadatai mind magában a fájlban vannak beágyazva. Nincs szükség külső séma-regiszterre, adatszótárra vagy konfigurációs fájlra a Parquet fájl olvasásához. Ez a tulajdonság leegyszerűsíti az adatmegosztást, archiválást és hosszú távú megőrzést. Egy öt évvel ezelőtt, ismeretlen sémával írt Parquet fájlt a modern szoftverek képesek olvasni külső dokumentáció nélkül. Az önleíró jelleg lehetővé teszi a séma érvényesítését olvasáskor is, kiszűrve az adattípus-eltéréseket és strukturális inkonzisztenciákat, mielőtt azok továbbterjednének az elemzési csővezetékeken.
Felosztható és párhuzamos olvasásra alkalmas. A Parquet sorkészletek függetlenül olvashatók, lehetővé téve a párhuzamos feldolgozást több CPU-magon, elosztott fürtcsomópontokon vagy egyidejű felhőtárolási kapcsolatokon keresztül. Egyetlen nagy Parquet fájl felosztható az alkotó sorkészleteire és egyidejűleg feldolgozható, minden munkavégző a sorkészletek egy részhalmazát kezelve. Ez a tulajdonság elengedhetetlen az elosztott feldolgozó keretrendszerekhez, mint az Apache Spark, amely különböző sorkészleteket rendel különböző végrehajtó feladatokhoz, valamint a többszálú elemzési könyvtárakhoz, mint a Polars, amely több sorkészletet olvas párhuzamosan egyetlen folyamaton belül. A TarmacView ellenőrzési adatcsővezetékei számára, amelyek terabájtnyi felmérési adatot dolgoznak fel, a párhuzamos sorkészlet-olvasás a feldolgozási időt óráról percre csökkenti.
Parquet vs. CSV és JSON az ellenőrzési adatokhoz
Az adatformátum megválasztása alapvetően befolyásolja az ellenőrzési adatcsővezeték minden aspektusát: tárolási költségeket, lekérdezési teljesítményt, adatintegritást és hosszú távú karbantarthatóságot. A Parquet, CSV és JSON mindegyike eltérő jellemzőkkel rendelkezik, amelyek különböző felhasználási esetekre teszik őket alkalmassá az ellenőrzési adatok ökoszisztémáján belül.
Tárolási hatékonyság. A CSV fájlok az adatokat egyszerű szövegként tárolják vesszőelválasztókkal, tömörítés nélkül. Egyetlen lebegőpontos szám, mint a 14,732859, 9 bájt ASCII szövegként tárolódik, függetlenül a pontossági követelményektől. A JSON még bőbeszédűbb, strukturális karaktereket – kapcsos zárójeleket, szögletes zárójeleket, idézőjeleket és kettőspontokat – adva hozzá, amelyek megduplázhatják vagy megháromszorozhatják a fájlméretet a CSV-hez képest ugyanazon adat esetén. A Parquet ugyanazt az értéket 4 vagy 8 bájt bináris adatként tárolja, attól függően, hogy 32 bites vagy 64 bites pontosságot használunk. Ha ezt kombináljuk a kategorikus oszlopok szótári kódolásával – amely az ismétlődő sztringértékeket kompakt egész indexekkel helyettesíti – a Parquet 5x-20x tároláscsökkentést ér el a CSV-hez és 8x-30x-ot a JSON-hoz képest.
Jellemző
Parquet
CSV
JSON
Tárolási modell
Oszlopos bináris
Sororientált szöveg
Sororientált szöveg (beágyazott)
Fájlméret (1M ellenőrzési sor, 80 oszlop)
50–200 MB
500 MB–2 GB
800 MB–3 GB
Beépített tömörítés
Igen (kódolás + kodek)
Nincs (csak külső)
Nincs (csak külső)
Olvasás: 80 oszlopból 2
~2,5% fájl I/O
100% fájl I/O
100% fájl I/O
Séma
Önleíró, típusos
Nincs (következtetett)
Implicit, nem típusos
Ember által olvasható
Nem (bináris)
Igen
Igen
Beágyazott adatok támogatása
Natív (struct, list, map)
Nem támogatott
Natív
Lekérdezési sebesség (analitika)
10x–100x gyorsabb, mint a CSV
Alapvonal
Lassabb, mint a CSV
Írási sebesség
Lassabb (kódolási többletterhelés)
Gyors
Gyors
Ökoszisztéma-támogatás
Spark, DuckDB, BigQuery, Snowflake
Minden eszköz
Minden eszköz
Lekérdezési teljesítmény. A Parquet és a sororientált formátumok közötti teljesítménykülönbség egyre hangsúlyosabbá válik az adathalmaz méretének és a lekérdezés összetettségének növekedésével. Egyszerű számláló lekérdezéseknél kis adathalmazokon (kevesebb mint 100 000 sor) a CSV versenyképes lehet a Parquet-val, ha optimalizált CSV-olvasókat használunk. Azonban a tipikus ellenőrzési adat munkaterhelésekhez, amelyek szűrést, aggregációt és több oszlopos elemzést igényelnek millióktól milliárdokig terjedő adathalmazokon, a Parquet 10x-100x-szor jobb teljesítményt nyújt a CSV-nél. A teljesítményelőny három forrásból származik: csökkentett I/O az oszlopritkításon keresztül (csak a szükséges oszlopok olvasása), csökkentett I/O a predikátum lenyomáson keresztül (irreleváns sorkészletek kihagyása), valamint a tömörített bináris adatok gyorsabb kitömörítése és dekódolása az egyszerű szöveg elemzéséhez képest.
Séma integritás. A CSV-nek nincs beépített sémája. Egy oszlop, amely az egyik fájlban egész értékeket tartalmaz, másik fájlban sztring értékeket vagy üres mezőket tartalmazhat, anélkül hogy lenne mechanizmus az inkonzisztencia észlelésére vagy jelentésére. Az adattípus-következtetés a CSV-olvasókban heurisztikus és hibás eredményeket produkálhat – például egy 02134-es irányítószámot a 2134 egész számként értelmezve a vezető nulla eltávolítása után. A JSON rendelkezik implicit sémával, de nincs típuskényszerítése; ugyanaz a mező lehet sztring az egyik rekordban és szám a következőben. A Parquet szigorú, explicit sémát kényszerít ki fájlszinten. Minden értéknek egy oszlopban meg kell felelnie a deklarált adattípusnak, és a séma érvényesítése íráskor történik. Ez a típusbiztonság kritikus fontosságú az ellenőrzési adatoknál, ahol az adatintegritás elsődleges fontosságú a biztonságkritikus infrastruktúra-döntéseknél.
Mikor használjuk az egyes formátumokat. A CSV továbbra is hasznos kis adathalmazokhoz, amelyeknek ember által olvashatónak kell lenniük, a Parquet támogatással nem rendelkező rendszerek közötti adatcseréhez, valamint olyan munkafolyamatokhoz, ahol a generálás egyszerűsége fontosabb, mint a lekérdezési teljesítmény. A JSON alkalmas félig strukturált adatokhoz változó sémával, API-adatcsomagokhoz és naplókhoz, ahol a beágyazott struktúra elengedhetetlen. A Parquet a helyes választás minden körülbelül 100 MB-ot meghaladó ellenőrzési adathalmazhoz, minden elemzési lekérdezési munkaterheléshez, hosszú távú adatarchiváláshoz, valamint minden olyan csővezetékhez, ahol a lekérdezési teljesítmény és a tárolási hatékonyság prioritás. A TarmacView architektúrában a nyers felmérési adatok kezdetben JSON vagy CSV formátumban érkezhetnek az érzékelőrendszerektől, de minden elemzési adattermék – eredmények, csempék, értékelések – kizárólag Parquet-ben tárolódik.
Parquet olvasása és írása Pythonban
A Python három elsődleges könyvtárat biztosít a Parquet feldolgozásához – PyArrow, Pandas és Polars –, mindegyik eltérő erősségekkel az ellenőrzési adatok elemzéséhez. A könyvtár kiválasztása a munkafolyamat konkrét követelményeitől függ: csővezeték-átbocsátóképesség, interaktív elemzési sebesség, memóriakorlátok és a meglévő eszközökkel való integráció.
PyArrow. A PyArrow az Apache Arrow C++ könyvtár Python kötése, és a legteljesebb, alacsony szintű API-t biztosítja a Parquet műveletekhez. Finomhangolási lehetőséget kínál az összes Parquet paraméterhez, beleértve a sorkészletméretet, oldalméretet, tömörítési kodeket, szótári kódolási küszöbértékeket és statisztikagyűjtést. A pyarrow.parquet modul read_table() és write_table() függvényeket biztosít az alapvető műveletekhez.
A columns paraméter lehetővé teszi az explicit oszlopritkítást, csak a megadott oszlopokat olvasva be a fájlból. A filters paraméter lehetővé teszi a predikátum lenyomást, elfogadva a szűrőkifejezések listáját DNF (diszjunktív normálforma) formátumban. A PyArrow ezeket a szűrőket a darabonkénti statisztikák alapján értékeli ki, mielőtt bármilyen adatoldalt beolvasna. Particionált adathalmazokhoz – ami gyakori a TarmacView-ban, ahol az adatok felmérési dátum és futópálya-szakasz szerint vannak rendezve – a pq.ParquetDataset() automatikus partíció-felfedezést biztosít mind a partíciószűrők, mind az oszlopstatisztikák lenyomásával.
Pandas. A Pandas egyszerűbb, magasabb szintű API-t biztosít a Parquet műveletekhez a pd.read_parquet() és df.to_parquet() függvényeken keresztül. A könyvtár a mögöttes Parquet implementációt a PyArrow-ra (az újabb Pandas verziók alapértelmezettje) vagy a fastparquet-ra bízza. A Pandas ideális interaktív elemzéshez, Jupyter notebook munkafolyamatokhoz és gyors adatfelderítéshez, ahol az egyszerűség értékesebb, mint a finomhangolási lehetőségek.
A Pandas a teljes Parquet fájlt egy DataFrame-be olvassa a memóriában. Ez alkalmas olyan adathalmazokhoz, amelyek elférnek a rendelkezésre álló RAM-ban – körülbelül 10 GB-50 GB között, a hardvertől függően. Nagyobb adathalmazokhoz a Pandas darabolt olvasást vagy memórián kívüli feldolgozási stratégiákat igényelhet. Az engine paraméter alapértelmezés szerint a PyArrow a legújabb Pandas verziókban, de beállítható fastparquet-ra is a kisebb függőségi lábnyom érdekében.
Polars. A Polars egy Apache Arrow-ra épülő DataFrame könyvtár, Rust-alapú motorral, amely a leggyorsabb Parquet olvasási teljesítményt nyújtja a Python könyvtárak között – jellemzően 3x-10x gyorsabb, mint a Pandas. A Polars ezt agresszív többszálúsítással, gyorsítótár-hatékony adatelrendezésekkel és lusta lekérdezés-optimalizálással éri el, amely elhalasztja a végrehajtást addig, amíg a teljes lekérdezési terv ismertté válik.
A scan_parquet() metódus egy lusta számítási gráfot hoz létre, amely rögzíti a teljes lekérdezési tervet – szűrőket, kiválasztásokat, aggregációkat – mielőtt bármilyen adatot beolvasna a lemezről. Amikor a collect() meghívásra kerül, a Polars az összes alkalmazható szűrőt lenyomja a Parquet olvasóba, kihagyva a teljes sorkészleteket a statisztikák alapján, és csak a szükséges oszlopokat olvasva be a fennmaradó sorkészletekből. Ez a lusta optimalizálás 95%-kal vagy még jobban csökkentheti az adatolvasást a teljes fájl mohó beolvasásához és a memóriában történő szűréséhez képest.
Teljesítmény-összehasonlítás. Valós adatfeldolgozási munkaterhelésekből származó benchmark eredmények mutatják a három könyvtár relatív teljesítményét:
Művelet
Pandas (pyarrow motor)
Polars
PyArrow
10 GB Parquet olvasása, teljes beolvasás
~60 mp
~15–20 mp
~25 mp
Szűrés + aggregáció 10 GB-on
~45 mp
~8–12 mp
~15 mp
10 GB Parquet írása Zstd-vel
~80 mp
~30 mp
~40 mp
Oszlopritkítás + szűrő lenyomás
~50 mp
~3–5 mp
~10 mp
A Polars a legerősebb előnyt a szelektív lekérdezéseknél mutatja, amelyek oszlopritkítást és predikátum lenyomást használnak, mert a lusta optimalizálója kiküszöböli a szükségtelen I/O-t a végrehajtás megkezdése előtt. Az írás-intenzív műveletekhez adatcsővezeték-kontextusban a PyArrow nyújtja a legmegbízhatóbb teljesítményt a legszélesebb funkciókészlettel.
TarmacView Parquet séma
A TarmacView az ellenőrzési elemzési eredményeket Parquet fájlok egy családjába szervezi, mindegyik dedikált sémával, optimalizálva bizonyos lekérdezési mintákhoz és felhasználási esetekhez. Ez a séma-tervezés követi a Parquet bevált gyakorlatait, beleértve a megfelelő adattípus kiválasztást, az oszlopstatisztikákat a predikátum lenyomáshoz, valamint a partíciószervezést az időtartomány- és térbeli lekérdezésekhez.
results.parquet. Az elsődleges ellenőrzési kimeneti fájl soronként egy mért pozíciót tárol a futópálya vagy burkolatfelület mentén. A séma tartalmazza a pontos GPS-koordinátákat méter alatti pontossággal a WGS84 dátum használatával, a felmérés időbélyegét időzóna-információval az időjárási és üzemeltetési adatokkal való összefüggéshez, valamint átfogó burkolatállapot-méréseket. Az egyedi károsodási oszlopok tárolják a repedésszélességet milliméterben, a repedéshosszt méterben, a kipattogzási területet négyzetméterben, a felületi mállás súlyosságát kategorikus skálán, valamint a felületi textúra mérőszámait, beleértve az átlagos profilmélységet. A PCI-számítási mezők tárolják a számított Burkolatállapot-index értéket az ASTM D5340 módszertan szerint, az egyes károsodástípusokra vonatkozó levonási értékeket, valamint a végső PCI-besorolási osztályozást. A minőség-ellenőrzési oszlopok rögzítik a GPS-pontosság becslését méterben, a feldolgozási megbízhatósági pontszámot és a minőségi jelzőket, amelyek lehetséges adatrendellenességekre utalnak. Minden sor egyedi azonosítással rendelkezik egy felmérési futásazonosító és egy sorszámozott pontindex segítségével, lehetővé téve minden mérés pontos térbeli és időbeli hivatkozását.
tiles.parquet. A csempe-alapú elemzési fájl a burkolatfelületet egy szabályos rácsra particionálja, konfigurálható csempemérettel, alapértelmezés szerint 1 méter x 1 méter a részletes felmérésekhez és 5 méter x 5 méter a gyors értékelésekhez. Minden sor egyetlen csempét képvisel a geotérbeli befoglaló téglalap koordinátáival, a csempe középpontjának szélességi és hosszúsági fokával, valamint az összesített statisztikákkal, amelyek a csempén belüli összes felmérési pontból számítódnak. Az összesített mezők tartalmazzák az átlagos, medián, minimális és maximális PCI-értékeket a csempén belül, a domináns károsodástípust a legmagasabb levonási érték alapján, a károsodási sűrűséget a csempe területének százalékában kifejezve, valamint az adatpontok számát, amelyek hozzájárulnak a csempe statisztikáihoz. A csempe séma tárolja a csempe szintű PCI-besorolási osztályozást és egy ajánlott karbantartási intézkedést küszöbérték-elemzés alapján. A csempe-alapú tárolás lehetővé teszi a gyors térbeli lekérdezéseket és vizualizációs munkafolyamatokat, ahol az egyes felmérési pontok megjelenítése szükségtelen és számításilag költséges lenne.
assessment.parquet. A végső állapotértékelési fájl a szakaszszintű értékelést tárolja, soronként egy homogén burkolati szakasszal felmérési kampányonként. Minden szakaszt a futópálya vagy gurulóút azonosítója, a kezdő és végállomás koordinátái, valamint a szakaszhossz határozza meg. Az értékelési séma tartalmazza a számított szakasz PCI-t az ASTM D5340 módszertan szerint az összes levonási érték számításával, az ICAO Annex 14 felületi állapotbesorolást a nemzetközi megfelelőségi jelentéskészítéshez, az egyes károsodástípusok sűrűségét a szakaszterület százalékában kifejezve, a korrigált levonási értékeket minden károsodáshoz, valamint a végső PCI-t. A karbantartási ajánlás mezők tárolják a számított prioritási sorrendet a PCI küszöbértékek alapján, az ajánlott kezelési típust, például repedés-tömítést, burkolat-erősítést vagy rekonstrukciót, valamint a becsült kezelési sürgősséget. Az értékelési fájl a felmérés metaadatait is rögzíti, beleértve a felmérő jármű azonosítóját, az érzékelő konfigurációját, az elemző szoftver verzióját és az adatfeldolgozási csővezeték verzióját a teljes nyomonkövethetőség érdekében.
telemetry.parquet. A felmérő jármű telemetriai adatfolyam fájlja az ellenőrzési futás során gyűjtött idősoros érzékelőadatokat rögzíti. Minden sor egy telemetriai leolvasást képvisel egy adott időbélyegnél, beleértve a GPS-időt, a jármű sebességét kilométer per órában, az irányt fokban a valódi északtól, a hossz- és keresztirányú gyorsulást méter per szekundum négyzetben, a magasságot GPS-ből, valamint a GPS-helymeghatározáshoz használt műholdak számát. Az érzékelő-specifikus oszlopok rögzítik az egyes képalkotó és mérőérzékelők állapotát, beleértve a kamera képkockasebességét, a lézervonal-szkenner állapotát és a tehetetlenségi mérőegység orientációs szögeit. A telemetriai fájl lehetővé teszi a feldolgozás utáni minőségelemzést, például a túl nagy sebességgel végzett felmérési futások észlelését, amelyek veszélyeztethetik az adatminőséget, azon területek azonosítását, ahol a felmérő jármű eltért az előírt útvonaltól, valamint a burkolatállapot-mérések és a járműdinamika összefüggésbe hozását kutatási és optimalizálási célokra.
Fájlparticionálás és szervezés. A TarmacView Parquet fájljai felmérési dátum és futópálya-szakasz szerint vannak particionálva az időtartomány- és térbeli lekérdezések optimalizálásához. A partíció könyvtárstruktúrája a survey_date=ÉÉÉÉ-HH-NN/runway_id=RWY09/section=SECTION_A/ mintát követi. A partícióritkítás lehetővé teszi, hogy a felmérési dátumra vagy futópálya-szakaszra szűrő lekérdezések csak a releváns könyvtárakat olvassák be, kihagyva az összes többi partíciót. Az egyes partíciókon belül a Parquet sorkészletek körülbelül 256 MB tömörítetlen méretűek, egyensúlyt teremtve a párhuzamosítás granularitása és a metaadat-többletterhelés között. Minden fájl Zstd tömörítést használ 3-as szinten, a szótári kódolás engedélyezve van a kategorikus oszlopokhoz, a delta-kódolás pedig a monoton mezőkhöz, például az állomáskoordinátákhoz.
Parquet nagy videós felmérési adatokhoz
A repülőtéri burkolat-ellenőrzési felmérések kivételesen nagy adathalmazokat hoznak létre, amelyek a hagyományos adattárolási megközelítések határait feszegetik. Egyetlen futópálya-felmérés 1 mm-es felbontással, járműre szerelt kamerarendszer használatával 500 GB-tól 2 TB-ig terjedő nyers képalkotási adatot generálhat kilométerenként, a lézerprofilerekből, tehetetlenségi érzékelőkből és GPS-vevőkből származó megfelelő mérési adatok további strukturált adatfolyamokat termelve. A Parquet központi szerepet játszik ezen adatok strukturált mérési összetevőjének kezelésében – a nagy dimenziójú, többváltozós táblázatos adatokban, amelyek a burkolat állapotát írják le minden egyes mért pontnál.
Nagydimenziós ellenőrzési adatok kezelése. A modern burkolat-ellenőrzési rendszerek tucatnyitól több százig terjedő attribútumot gyűjtenek mért pontonként. Egy tipikus felmérő jármű érzékelőparkja több nagy felbontású kamerát foglal magában, amelyek vizuális képalkotást biztosítanak milliméter alatti felbontásban, lézervonal-szkennereket, amelyek 3D felületi profilokat készítenek mikronszintű függőleges pontossággal, infravörös termográfiai érzékelőket a felületi hőmérséklet mérésére delamináció észleléséhez, talajradart a felszín alatti rétegek értékeléséhez, tehetetlenségi mérőegységeket a pontos helymeghatározáshoz és tájoláshoz, valamint GPS-vevőket az abszolút georeferáláshoz. Minden érzékelő strukturált méréseket produkál, amelyek térben és időben korreláltak. A kombinált adathalmaz egyetlen, nagy nemzetközi repülőtérre kiterjedő felmérési kampány esetén meghaladhatja a 100 milliárd adatpontot, ha az összes érzékelőcsatornát teljes mintavételezési frekvencián vesszük figyelembe.
A Parquet lehetővé teszi ezen nagydimenziós adathalmazok hatékony tárolását és lekérdezését az oszlopos tárolás (sűrű attribútumkészletekhez), a szótári kódolás (ismétlődő kategorikus mezőkhöz), a delta-kódolás (monoton növekvő időbélyegekhez és állomáskoordinátákhoz) és a futáshossz-kódolás (azonos értékek sorozataihoz, amelyek gyakoriak a károsodásosztályozási mezőkben) kombinációja révén. Egy tipikus, 80 attribútummal rendelkező felmérési pontrekord körülbelül 70 bájtot foglal el a Parquet-ben Zstd tömörítéssel, szemben a körülbelül 400 bájttal tömörítetlen CSV-ben és a körülbelül 800 bájttal JSON-ban. 100 milliárd felmérési pont esetén ez 7 TB-os tárolási különbséget jelent a Parquet javára a 40 TB-os CSV-vel és a 80 TB-os JSON-nal szemben.
Időbeli és térbeli lekérdezési minták. Az ellenőrzési adatok lekérdezései jellegzetes mintákat követnek, amelyeket a Parquet architektúrája jól szolgál ki. Az időtartomány-lekérdezések, mint például “Mutasd az összes felmérési adatot 2024 márciusa és szeptembere között”, profitálnak a Parquet partícióritkításából, ha a fájlok felmérési dátum szerint vannak rendezve, valamint az időbélyeg oszlopon belüli predikátum lenyomásából. A térbeli lekérdezések, mint például “Keress meg minden károsodást a futópálya küszöbétől számított 100 méteren belül”, profitálnak a delta-kódolt állomáskoordinátákból, amelyek hatékonyan tömöríthetők és lehetővé teszik az összefüggő térbeli kiterjedések gyors szekvenciális beolvasását. A több attribútumos lekérdezések, mint például “Keresd meg a 40 alatti PCI-vel és 3 mm-t meghaladó repedésszélességgel rendelkező területeket”, profitálnak az oszlopritkításból, amely csak a három releváns oszlopot – PCI, repedésszélesség és koordináták – olvassa be a teljes attribútumkészletből.
Streamelt és inkrementális feldolgozás. A nagy videós felmérési adatok gyakran inkrementális feldolgozást igényelnek, ahol a nyers érzékelőadatokat szakaszosan töltik be, dolgozzák fel és írják Parquet-be. A Parquet támogatja a streamelt írást a sorkészlet-architektúráján keresztül: az adatok a memóriában halmozhatók fel, amíg egy sorkészlet el nem éri a célméretet, majd kiírásra kerülnek a lemezre. Ez lehetővé teszi olyan feldolgozó csővezetékeket, amelyek valós idejű érzékelőadatokat fogyasztanak a felmérési futások során, és inkrementálisan hoznak létre Parquet fájlokat anélkül, hogy a teljes adathalmazt a memóriában kellene tartani. A TarmacView feldolgozó csővezetéke ezt a mintát valósítja meg, a felmérési eredményeket közel valós időben írva Parquet-be, ahogy a felmérő jármű halad a futópályán.
Parquet lekérdezése szűrő lenyomással és oszlopritkítással
A szűrő lenyomás és az oszlopritkítás kombinációja az elsődleges mechanizmus, amellyel a Parquet eléri teljesítményelőnyét a sororientált formátumokkal szemben. Ezen optimalizálások működésének megértése lehetővé teszi az ellenőrzési adatelemzők és csővezeték-fejlesztők számára, hogy a lekérdezéseket a maximális hatékonyság érdekében strukturálják.
Szűrő lenyomás mechanizmusa. Amikor egy lekérdező motor beolvas egy Parquet fájlt, első művelete a fájllábléc beolvasása, amely tartalmazza a séma definícióját és a sorkészletek listáját az oszlopdarabonkénti statisztikáikkal. Minden olyan oszlop esetében, amelyre a WHERE záradék hivatkozik, a motor kinyeri a tárolt minimális és maximális értékeket minden oszlopdarab statisztikájából. A motor ezután kiértékeli az egyes szűrőfeltételeket minden oszlopdarab min-max tartományára a következő logika alapján: ha a szűrőfeltétel X-nél nagyobb értékeket igényel, és az oszlopdarab maximális értéke kisebb vagy egyenlő X-nél, akkor a darab nem tartalmaz egyező sorokat, és teljesen kihagyható. Hasonlóan, ha a szűrőfeltétel Y-nál kisebb értékeket igényel, és az oszlopdarab minimális értéke nagyobb vagy egyenlő Y-nál, a darab kihagyható. A motor párhuzamosan iterál az összes oszlopdarabon, létrehozva egy maszkot a beolvasandó és a kihagyható sorkészletekről.
Tekintsünk egy konkrét példát a TarmacView ellenőrzési adataiból. Egy elemző lekérdezi: “Keresse meg az összes 40 alatti PCI-vel rendelkező szakaszt, amelyet 2024. június 1. után mértek fel.” A motor beolvassa a láblécet, és megvizsgálja a pci és survey_date oszlopdarabok statisztikáit az összes sorkészletben. Egy sorkészlet, amely 2024 januárjától márciusáig terjedő felmérési dátumokat fed le, survey_date maximuma 2024. március 31. – ez alatta van a 2024. június 1-jei szűrési küszöbértéknek, így a teljes sorkészlet kihagyásra kerül. Egy másik sorkészlet, amely 45-től 95-ig terjedő PCI-értékeket fed le, pci minimuma 45 – ez a 40-es szűrési küszöb felett van, így ez a sorkészlet is kihagyásra kerül. Az összes sorkészlet kiértékelése után a motor azonosítja, hogy csak azok a sorkészletek tartalmazhatnak egyező sorokat, amelyek min-max tartományai átfedik a szűrőfeltételeket – jellemzően a teljes adatmennyiség 1%-10%-a a szelektív lekérdezéseknél nagy archívumokban.
Oszlopritkítás a gyakorlatban. Az oszlopritkítás ugyanazon a szinten működik, mint a szűrő lenyomás, de az I/O-csökkentés egy másik dimenzióját kezeli. Míg a szűrő lenyomás a beolvasott sorok számát csökkenti a teljes sorkészletek kihagyásával, addig az oszlopritkítás a beolvasott oszlopok számát csökkenti azáltal, hogy csak a hivatkozott oszlopok oszlopdarabjait választja ki. A két optimalizálás összeadódik: a szűrő lenyomás kiküszöböli az irreleváns sorkészleteket, az oszlopritkítás pedig csak a szükséges oszlopokat olvassa be a fennmaradó sorkészletekből.
Egy SELECT latitude, longitude, pci FROM assessment WHERE pci < 40 lekérdezés a szűrő lenyomás után csak azokat a sorkészleteket olvasná be, amelyek 40 alatti PCI-értékeket tartalmaznak. Ezekből a sorkészletekből az oszlopritkítás csak a latitude, longitude és pci oszlopdarabokat olvassa be – három oszlopot a teljes sémából. Ha a teljes séma 80 oszlopot tartalmaz, és a szűrő lenyomás kiküszöböli a sorkészletek 95%-át, a hatékony I/O-megtakarítás 99,8% a tömörítetlen fájl teljes beolvasásához képest.
Motorspecifikus lenyomási képességek. A különböző lekérdező motorok eltérő szintű kifinomultsággal implementálják a szűrő lenyomást és az oszlopritkítást. A DuckDB teljes sorkészlet-szintű lenyomást biztosít oldalszintű indexkihagyással a v2 oldalfejlécekkel írt Parquet fájlokhoz. Az Apache Spark a DataSource v2 API-ján keresztül implementálja a lenyomást, kombinálva a partícióritkítást, a sorkészletenkénti min-max szűrést és opcionális Bloom-szűrő kihagyást. A Presto és a Trino támogatja az oszlopritkítást és a sorkészlet min-max szűrést konfigurálható predikátum lenyomási viselkedéssel. A PyArrow explicit szűrő lenyomást biztosít a filters paraméteren keresztül a read_table() függvényben, valamint automatikus oszlopritkítást a columns paraméteren keresztül. A Polars automatikus lusta lenyomást biztosít a scan_parquet() metódusán keresztül, explicit konfiguráció nélkül.
Parquet és GIS integráció GeoPandasszal
A térbeli elemzés alapvető fontosságú a burkolat-ellenőrzési munkafolyamatokban, és a Parquet integrációja a geotérbeli eszközökkel a GeoParquet specifikáción keresztül lehetővé teszi az analitikai teljesítmény és a térbeli lekérdezési képességek zökkenőmentes kombinálását.
GeoParquet szabvány. A GeoParquet egy OGC (Open Geospatial Consortium) szabvány, amely interoperábilis geotérbeli típusokat ad a Parquet formátumhoz. Az 1.0-s verzió, amelyet 2022-ben tettek közzé, meghatározza, hogy a geometria oszlopok hogyan tárolódnak Well-Known Binary (WKB) formátumban a Parquet bináris oszlopában, kiegészítő metaadatokkal a fájl láblécében, amelyek leírják a koordináta-referenciarendszert (CRS), az egyes oszlopokban jelen lévő geometriatípusokat és az adathalmaz teljes befoglaló téglalapját. Az 1.1-es verzió, amelyet 2024-ben tettek közzé, támogatást adott a natív geometriatípusokhoz sorkészletenként tárolt befoglaló téglalap statisztikákkal, lehetővé téve a térbeli predikátum lenyomást – a Parquet szabványos predikátum lenyomásának geotérbeli megfelelőjét. A térbeli predikátum lenyomással az olyan térbeli szűrőket használó lekérdezések, mint a ST_Intersects(geometry, query_polygon), kihagyhatják azokat a sorkészleteket, amelyek befoglaló téglalapjai nem fedik át a lekérdezési régiót.
GeoPandas integráció. A GeoPandas kiterjeszti a Pandas DataFrame-et geotérbeli műveletekkel, és közvetlenül olvassa a GeoParquet fájlokat a read_parquet() metódusán keresztül. Az integráció átlátható: a GeoParquet fájlok GeoDataFrame-ként olvashatók be egy geometria oszloppal, amely támogatja a Shapely térbeli műveletek teljes skáláját, beleértve a metszetet, tartalmazást, pufferelést és távolságszámításokat.
Amikor a GeoPandas beolvas egy GeoParquet fájlt, amely sorkészlet-szintű befoglaló téglalap statisztikákkal lett létrehozva, a mögöttes PyArrow olvasó kiértékeli a térbeli szűrőt a sorkészletenkénti befoglaló téglalapokra, mielőtt bármilyen geometriaadatot betöltene. Azok a sorkészletek, amelyek befoglaló téglalapjai nem metszik a lekérdezési régiót, teljesen kihagyásra kerülnek. Egy országos ellenőrzési adathalmaz esetén, amely több ezer sorkészletet tartalmaz, egyetlen futópályára célzó térbeli lekérdezés a teljes sorkészletek kevesebb mint 1%-át olvashatja be.
Integráció QGIS-szel és más GIS eszközökkel. A GeoParquet natív támogatással rendelkezik a QGIS-ben (3.28-as verziótól kezdődően), lehetővé téve a Parquet ellenőrzési adatok közvetlen betöltését és vizualizációját a vezető nyílt forráskódú GIS alkalmazásban. Ez az integráció azt jelenti, hogy a TarmacView Parquet fájlok közvetlenül megnyithatók a QGIS-ben tematikus térképezéshez, szimbólumosztályozáshoz és nyomtatási elrendezés készítéséhez anélkül, hogy közbeeső adatkonverzióra lenne szükség. Az Apache Sedona elosztott térbeli SQL-t biztosít a GeoParquet-en az Apache Spark segítségével, lehetővé téve a térbeli lekérdezéseket terabájt méretű ellenőrzési adathalmazokon több csomópontos fürtökön keresztül. A Google BigQuery támogatja a GeoParquet külső táblák közvetlen lekérdezését térbeli függvényekkel, lehetővé téve a felhőalapú elemzést anélkül, hogy az adatokat adatbázisba kellene tölteni. Az Overture Maps Foundation a teljes globális térkép adathalmazát GeoParquet formátumban terjeszti, bizonyítva a formátum életképességét a nagy léptékű geotérbeli adatmegosztás számára.
Parquet tömörítési kodekek
A Parquet több tömörítési kodeket támogat, amelyek mindegyike eltérő kompromisszumokat kínál a tömörítési arány, az írási sebesség és az olvasási sebesség között. A kodek kiválasztása jelentősen befolyásolja mind a tárolási költségeket, mind a lekérdezési teljesítményt az ellenőrzési adatok munkaterheléseihez.
Kodek összehasonlítás. A következő táblázat összefoglalja a leggyakrabban használt Parquet tömörítési kodekek jellemzőit, valós adathalmazokon – beleértve a NYC Taxi utazási adatokat (20 millió sor) és a publikált tanulmányokból származó autópálya-burkolat ellenőrzési adatokat – végzett benchmarkok alapján:
Kodek
Írási sebesség (relatív)
Olvasási sebesség (relatív)
Tömörítési arány a CSV-hez képest
Legjobb használat
Nincs (tömörítetlen)
Leggyorsabb
Leggyorsabb
~25–32% of CSV
Köztes adat, gyors helyi I/O
Snappy
Közel tömörítetlen
Közel tömörítetlen
~12–18% of CSV
Alapértelmezett egyensúly a legtöbb rendszerhez
LZ4_RAW
Összességében leggyorsabb
Összességében leggyorsabb
~12–18% of CSV
Írás-intenzív csővezetékek, streamelt betöltés
Zstd (3. szint)
~10%-kal lassabb, mint Snappy
Közel Snappy
~8–14% of CSV
Legjobb általános a legtöbb munkaterheléshez
Gzip (6. szint)
~50%-kal lassabb
~10–20%-kal lassabb
~8–15% of CSV
Archiválás, hideg adatok
Brotli
Leglassabb írás
Mérsékelt
~7–12% of CSV
Maximális tömörítés hidegtároláshoz
Snappy az alapértelmezett tömörítési kodek az Apache Sparkban, az Apache Hive-ban és számos más Hadoop ökoszisztéma eszközben. Kiváló egyensúlyt biztosít a tömörítési arány (4x-6x csökkentés a CSV-hez képest) és az írási/olvasási sebesség között, az írási többletterhelés körülbelül 3-5% a tömörítetlen Parquet-hoz képest. A Snappy fő korlátja, hogy nem támogatja a konfigurálható tömörítési szinteket, míg a Zstd hangolható akár sebességre, akár arányra.
Zstandard (Zstd) az ajánlott alapértelmezett kodek a legtöbb ellenőrzési adat munkaterheléshez. A 3-as szinten a Zstd 10%-30%-kal jobb tömörítést ér el, mint a Snappy, miközben közel azonos olvasási sebességet tart fenn, és csak 10%-os írási sebesség büntetést jelent. Magasabb szinteken (9-22) a Zstd megközelíti a Gzip szintű tömörítési arányokat, miközben jelentősen gyorsabb marad a kitömörítésben. A tömörítési szint hangolhatósága sokoldalúvá teszi a Zstd-t a munkaterhelés-típusok között: 1-es szint az írás-intenzív streamelt csővezetékekhez, 3-as szint a kiegyensúlyozott általános célú használathoz, és 9-22 szintek az archiválási tároláshoz.
LZ4_RAW biztosítja a leggyorsabb tömörítési és kitömörítési sebességet az összes Parquet kodek közül, marginálisan gyorsabb, mint a Snappy. Az LZ4 az optimális választás azokhoz a betöltési csővezetékekhez, amelyek az írási áteresztőképességet részesítik előnyben, mint például a valós idejű felmérési adatfolyamok, ahol a Parquet fájlok a teljes adatgyűjtési sebességgel íródnak. A tömörítési arány hasonló a Snappy-hoz, így a kompromisszum az írási sebesség a kissé nagyobb fájlok árán.
Gzip és Brotli a legmagasabb tömörítési arányokat érik el, de jelentős írási sebesség büntetéssel – a Gzip körülbelül 50%-kal lassabban ír, mint a Snappy, a Brotli pedig 100-200%-kal lassabb lehet a szinttől függően. Ezek a kodekek a hidegtároláshoz és archiválási felhasználási esetekhez alkalmasak, ahol az adatok egyszer kerülnek kiírásra, és ritkán vagy soha nem íródnak felül, és ahol az elsődleges cél a tárolási költségek minimalizálása. Egy 40 TB-os CSV ellenőrzési archívum esetén a Gzip-tömörített Parquet használata körülbelül 3 TB-5 TB-ra csökkenti a tárolást, szemben az 5 TB-7 TB-tal a Snappy esetében, ami jelentős költségmegtakarítást jelent a havonta gigabájtonként számlázott felhőtárolás esetén.
Oszloponkénti tömörítési konfiguráció. A Parquet lehetővé teszi a tömörítés oszloponkénti független konfigurálását, lehetővé téve az optimalizálást az egyes oszlopok adatjellemzői alapján. Az ellenőrzési adatok esetében a lebegőpontos koordinátaoszlopok profitálnak a delta-kódolásból, amelyet Zstd tömörítés követ. A kategorikus oszlopok, mint a károsodástípus és a burkolatbesorolás, profitálnak a szótári kódolásból, amely megfelelően tömöríthet további kodekkompresszió nélkül. Az időbélyeg oszlopok profitálnak a delta-kódolásból, amely a szekvenciális időbélyegeket átlagosan 3-5 bájtra tömöríti értékenként, függetlenül az eredeti időbélyeg-reprezentációtól. Az oszloponkénti tömörítési konfiguráció elérhető a PyArrow write_table() függvényén keresztül és a legtöbb lekérdező motor táblalétrehozási szintaxisában.
Parquet az ellenőrzési adatcsővezetékben
A Parquet központi adatformátumként szolgál a TarmacView ellenőrzési adatarchitektúrájában, lehetővé téve egy olyan csővezetéket, amely a nyers érzékelőadatok betöltésétől az analitikai lekérdezésen át a vizualizációig és jelentéskészítésig terjed. A csővezeték architektúrája bemutatja a Parquet gyakorlati előnyeit az egyes feldolgozási szakaszokban.
Csővezeték architektúra áttekintése. A TarmacView ellenőrzési csővezeték egy többlépcsős architektúrát követ, hasonlóan az adat-tóház mintához. A felmérő járművekből származó nyers érzékelőadatok – kameraképek, lézerprofilok, GPS-nyomvonalak és telemetria – kezdetben betöltésre kerülnek és objektumtárolóban tárolódnak nyers adatrétegként. A képfeldolgozó és számítógépes látás algoritmusok elemzik a képeket a burkolati károsodások észleléséhez és osztályozásához, strukturált mérési adatokat hozva létre, amelyek Parquet-be íródnak finomított adatrétegként. Az analitikai és aggregációs feladatok kiszámítják a csempe- és szakaszszintű állapotértékeléseket, az eredményeket Parquet-be írva analitikai rétegként. Végül a vizualizációs eszközök és jelentéskészítő rendszerek lekérdezik az analitikai réteg Parquet fájljait az interaktív irányítópultok kiszolgálásához és a megfelelőségi jelentések elkészítéséhez.
Nyers réteg: Érzékelőadatok betöltése. A nyers rétegben a felmérési adatok heterogén formátumú keverékként érkeznek. A GPS-adatok NMEA mondatok vagy bináris naplók formájában érkeznek. A lézerprofil-adatok bináris fájlokként érkeznek saját formátumban. A nagy felbontású képek szekvenciális képfájlként érkeznek EXIF metaadatokkal. Egy előfeldolgozó csővezeték normalizálja ezeket a különböző formátumokat egy közös sémába, és a strukturált részt – koordinátákat, időbélyegeket, érzékelőleolvasásokat és mérési értékeket – Parquet-be írja. Maguk a képek natív formátumukban maradnak (GeoTIFF vagy JPEG2000), a Parquet metaadatokban tárolt hivatkozásokkal a keresztreferencia számára. Ez a hibrid megközelítés kombinálja a Parquet analitikai teljesítményét a strukturált adatokhoz a raszteres tárolásra optimalizált speciális képformátumokkal.
Finomított réteg: Károsodásészlelés és osztályozás. A számítógépes látás feldolgozási szakasz beolvassa a nyers képeket, és gépi tanulási modelleket alkalmaz a burkolati károsodások észlelésére és osztályozására, beleértve a hosszirányú repedéseket, keresztirányú repedéseket, hálós repedezést, foltozást, mállást és kátyúkat. A modell kimenetei Parquet-be íródnak finomított adatrétegként, minden észlelt károsodás egy sorban rögzítve, amely tartalmazza a károsodástípus osztályozást, a megbízhatósági pontszámot, a befoglaló poligon koordinátáit, a mért méreteket (hossz, szélesség, terület) és a súlyossági besorolást. A finomított réteg Parquet fájljai jellemzően a legnagyobbak a csővezetékben, több milliótól több milliárdig terjedő károsodási rekordot tartalmazva repülőtéri felmérésenként. Az oszlopritkítás itt elengedhetetlen: a minőségbiztosítási munkafolyamatok, amelyek csak a magas megbízhatóságú észleléseket igénylik, először a megbízhatósági oszlopot olvassák, majd szelektíven olvassák a geometria oszlopokat a minősítő rekordokhoz.
Analitikai réteg: Állapotértékelés és PCI számítás. Az analitikai réteg összesíti a finomított károsodási adatokat burkolati állapotértékelésekké az ASTM D5340 módszertan szerint. Minden meghatározott burkolati szakaszhoz az aggregációs motor kiszámítja a károsodási sűrűségeket, az alkalmazható levonási értékeket és a végső PCI-t. Az eredmények Parquet-be íródnak szakaszszintű értékelési fájlokként. Ez a réteg kiszámítja a csempe szintű aggregációkat is a vizualizációhoz, előre kiszámítva azokat a statisztikákat, amelyeket drága lenne menet közben kiszámítani az interaktív irányítópultokban. Az analitikai réteg Parquet fájljai viszonylag kicsik a finomított réteghez képest – jellemzően néhány száz megabájt egy nagy repülőtér esetében – és gyors interaktív lekérdezésre vannak optimalizálva, 64 MB-128 MB sorkészletmérettel.
Tóház architektúra és táblaformátumok. A Parquet alapul szolgáló fájlformátumként is szolgál azokhoz a táblaformátumokhoz, amelyek ACID tranzakciókat, időutazást és sémafejlődést biztosítanak a Parquet fájlok tetején. Az Apache Iceberg, a Delta Lake és az Apache Hudi mind a Parquet-t használják alapértelmezett vagy elsődleges tárolási formátumként, tranzakciós naplókat, pillanatkép-kezelést és optimalizálási segédprogramokat hozzáadva. Az egyidejű olvasást és írást igénylő TarmacView telepítésekhez – például egyidejű felmérési adatbetöltés és elemzői lekérdezés – az Iceberg vagy Delta Lake rétegek a Parquet tetején biztosítják a szükséges elkülönítési garanciákat. A táblaformátum kezeli az egyidejű írási ütközéseket, konzisztens pillanatkép-nézeteket biztosít az olvasók számára, és kezeli a metaadatokat a partíciófejlődéshez és a fájltömörítéshez.
Építészeti előnyök összefoglalása. A Parquet-alapú csővezeték architektúra számos konkrét előnyt kínál az ellenőrzési adatkezeléshez. Egy példány, több motor: Ugyanazokat a Parquet fájlokat lekérdezheti a DuckDB interaktív elemzéshez, az Apache Spark kötegelt feldolgozáshoz, a Polars alkalmi szkripteléshez és a QGIS geotérbeli vizualizációhoz, mindezt adatduplikáció vagy formátumkonverzió nélkül. Költséghatékony tárolás: A Parquet tömörítés 5x-10x-re csökkenti az objektumtárolási költségeket a CSV-hez képest, és 10x-20x-re a JSON-hoz képest, közvetlen költségmegtakarítással a mennyiség alapján számlázott felhőtárolás esetén. Számítás és tárolás szétválasztása: A lekérdező motorok közvetlenül az objektumtárolóból olvassák a Parquet-t anélkül, hogy betöltési lépésre lenne szükség, lehetővé téve a rugalmas számítási skálázást, ahol az elemzési erőforrások függetlenül fel- és leskálázhatók az állandó adattárolótól. Hosszú távú adatmegőrzés: A Parquet önleíró sémája és nyílt szabványa biztosítja, hogy az ellenőrzési adatok olvashatók maradjanak a jövőbeli szoftverek számára anélkül, hogy függnének a saját API-któl vagy elavult könyvtáraktól.
Jó gyakorlatok a Parquet használatához ellenőrzési munkafolyamatokban
Sorkészletméret kiválasztása. Az optimális sorkészletméret az adott ellenőrzési munkaterhelés hozzáférési mintáitól függ. Interaktív lekérdezésekhez kis- és közepes méretű adathalmazokon – például egyetlen felmérési kampány felfedezése utófeldolgozási áttekintés során – a 64 MB-128 MB sorkészletek gyors metaadat-olvasást és gyors sorkészlet-kihagyást biztosítanak. Kötegelt feldolgozáshoz nagy archívumokban – például az éves trendek kiszámítása öt év negyedéves felméréseiből – a 256 MB-512 MB sorkészletek jobb tömörítési arányokat biztosítanak, és csökkentik a metaadat-bejegyzések számát a láblécben, javítva a lábléc olvasási sebességét. Általános szabályként célozzon olyan sorkészletméreteket, hogy minden sorkészlet kényelmesen elférjen az objektumtároló rendszer oldalcache-ében, miközben elegendő granularitást biztosít a párhuzamos olvasáshoz a rendelkezésre álló CPU-magok között.
Particionálási stratégia. Particionálja az ellenőrzési adatokat a szűrőfeltételekben leggyakrabban használt oszlopok szerint. A TarmacView munkaterhelésekhez az elsődleges partíciós dimenziók a felmérés dátuma (nap vagy hónap szerint) és a futópálya azonosítója. A partícióritkítás biztosítja, hogy az ezekre a dimenziókra szűrő lekérdezések csak a releváns könyvtárakat olvassák, kihagyva az összes többi partíciót. Kerülje a túlzott particionálást, ami nagyszámú kis fájlt hoz létre magas metaadat-többletterheléssel és csökkent lekérdezési teljesítménnyel. Egy partíció legalább 100 MB-500 MB adatot tartalmazzon, hogy indokolja a további könyvtárszint metaadat-többletterhelését.
Statisztika konfiguráció. Engedélyezze az oszloponkénti statisztikákat a szűrőfeltételekben használt oszlopokhoz a predikátum lenyomás lehetővé tételéhez. A PyArrow és más Parquet-olvasók alapértelmezés szerint engedélyezik a statisztikákat, de a statisztikák letilthatók a lábléc méretének csökkentéséhez nagyon szűk sémájú vagy kiszámítható hozzáférési mintájú fájlok esetében. Az ellenőrzési adatokhoz engedélyezze a statisztikákat a PCI-értékek, felmérési dátumok, károsodási súlyossági besorolások és térbeli befoglaló koordináták oszlopain – ezek mind gyakran használt lekérdezési szűrők. A nagy kardinalitású oszlopok, mint az egyedi pontazonosítók, statisztikái minimális lenyomási előnyt biztosítanak, és növelik a lábléc metaadatainak méretét.
Tömörítés kiválasztása. Használja a Zstd-t 3-as szinten alapértelmezett tömörítési kodekként az ellenőrzési adatokhoz. Ez biztosítja a legjobb egyensúlyt a tömörítési arány, az írási sebesség és az olvasási sebesség között a tipikus munkaterhelések során. Streamelt betöltési csővezetékekhez, ahol az írási áteresztőképesség a szűk keresztmetszet, váltson Snappy vagy LZ4_RAW kodekre. Hidegtárolási archívumokhoz, ahol a tárolási költség az elsődleges szempont, használja a Zstd-t 9-22 szinten vagy a Gzip-et 6-9 szinten. Konfiguráljon oszloponkénti tömörítést, ha az oszlopok jelentősen eltérő tömörítési jellemzőkkel rendelkeznek – például használjon szótári kódolást további kodek nélkül a kategorikus oszlopokhoz, és delta-kódolást Zstd-vel a monoton koordináta- és időbélyeg-oszlopokhoz.
Fájlméret kezelés. Kerülje a nagyon kis Parquet fájlok létrehozását, amelyek körülbelül 10 MB-nál kisebbek. A kis fájlok aránytalanul nagy metaadat-többletterheléssel rendelkeznek az adattartalomhoz képest – egy 5 MB-os Parquet fájl tartalmazhat 1 MB lábléc metaadatot és csak 4 MB tényleges adatot. A kis fájlok csökkentik a párhuzamosítást is, mert minden fájlt függetlenül kell megnyitni, olvasni és bezárni, fájlonkénti többletterhelést okozva az objektumtároló rendszerekben. Az ETL csővezetékekben, amelyek sok kis Parquet fájlt hoznak létre, adjon hozzá egy tömörítési vagy összevonási lépést a feldolgozás után a kis fájlok nagyobbakká egyesítéséhez. A 64 MB-512 MB célnagyság fájlonként megfelelő a legtöbb ellenőrzési adat munkaterheléshez.
Séma tervezés. Válasszon megfelelő adattípusokat minden oszlophoz. Használjon 32 bites egészeket azokhoz az oszlopokhoz, amelyek értékei beleférnek az előjeles 32 bites tartományba (körülbelül ±2,1 milliárd), mint például a sorszámozott pontindexek egy felmérési futáson belül. Használjon 64 bites egészeket nagyobb azonosítókhoz, mint például a globális egyedi pontazonosítók. Használjon 32 bites lebegőpontos típust a koordinátaoszlopokhoz, ahol a méter alatti pontosság elegendő, fenntartva a 64 bites dupla pontosságot a milliméteres pontosságot igénylő tudományos mérésekhez. Használja a date32 vagy időbélyeg adattípusokat a dátum és idő oszlopokhoz, ahelyett, hogy sztringként tárolná őket – ez lehetővé teszi a delta-kódolást és a predikátum lenyomást az időbeli oszlopokon. Használjon szótári kódolást az alacsony kardinalitású kategorikus oszlopokhoz, mint a károsodástípus osztályozások és a burkolati felület típusok.
Összehasonlítás más oszlopos formátumokkal
A Parquet nem az egyetlen oszlopos tárolási formátum, amely elérhető az elemzési munkaterhelésekhez. A más formátumokhoz való viszonyának megértése segít a megalapozott építészeti döntések meghozatalában az ellenőrzési adatcsővezetékekhez.
ORC (Optimized Row Columnar). Az Apache ORC az elsődleges alternatív oszlopos formátum a Hadoop ökoszisztémán belül, amelyet eredetileg a Hortonworks fejlesztett ki a korábbi RCFile formátum továbbfejlesztéseként. Az ORC és a Parquet számos jellemzőben osztozik: mindkettő oszlopos, mindkettő támogatja a predikátum lenyomást beágyazott statisztikákon keresztül, mindkettő kínál tömörítési kodek választást, és mindkettő önleíró. Az ORC kissé jobb tömörítési arányokat biztosít bizonyos adattípusokhoz, különösen a sztring oszlopokhoz, és robusztusabb beépített indexeléssel rendelkezik, beleértve a Bloom-szűrőket és min-max indexeket. A Parquet azonban szélesebb ökoszisztéma-támogatással rendelkezik – minden jelentős lekérdező motor és felhőalapú adattárház támogatja a Parquet-t, míg az ORC támogatás az Apache Hive és Spark ökoszisztémákra koncentrálódik. Azokhoz az ellenőrzési adatcsővezetékekhez, amelyek maximális hordozhatóságot igényelnek a lekérdező motorok és felhőplatformok között, a Parquet a biztonságosabb választás.
Arrow IPC formátum. Az Apache Arrow egy memóriabeli oszlopos formátumot definiál, amely szorosan kapcsolódik a Parquet-hoz, de nulla másolásos adatmegosztásra van optimalizálva egy folyamaton belül, nem pedig állandó tárolásra. Az Arrow IPC (Inter-Process Communication) fájlok gyorsabb olvasási és írási műveletekre lettek tervezve minimális szerializációs többletterheléssel, nagyobb fájlméret és a beépített tömörítés vagy predikátum lenyomási metaadatok hiányának árán. A Parquet és az Arrow kiegészítik egymást: az Arrow-t memóriabeli adatfeldolgozásra és folyamatok közötti adatcserére használják, míg a Parquet-t állandó tárolásra és hosszú távú archiválásra. A PyArrow, a Polars és a DuckDB mind natívan az Arrow memórián működnek, miközben Parquet fájlokat olvasnak és írnak, biztosítva mindkét formátum előnyeit.
CSV oszlopos elrendezéssel (Parquet-szerű). Egyes rendszerek oszlopos olvasást implementálnak a CSV fájlokon az adatok memóriában történő átrendezésével olvasás után, de ez a megközelítés nem érheti el a Parquet lemezszintű oszlopos elrendezését. Az oszlopos CSV olvasás továbbra is megköveteli a fájladatok 100%-ának lemezről történő beolvasását, az összes érték elemzését minden sorból, majd az oszlopokba rendezést – az oszlopritkítás I/O-megtakarítása lemezszinten nem érhető el, mert a CSV sorok szerint tárolja az adatokat. A Parquet lemezen lévő oszlopos elrendezése az az alapvető építészeti előny, amely nem reprodukálható szoftveresen egy sororientált formátum tetején.
Következtetés
Az Apache Parquet az alapvető tárolási formátum a modern analitikai adatfeldolgozásban, és jellemzői különösen alkalmassá teszik a repülőtéri burkolat-ellenőrzési adatok igényes követelményeihez. Az oszlopos tárolási modell 5x-20x tömörítést biztosít a sororientált formátumokhoz képest, csökkentve a tárolási költségeket és lehetővé téve a gyorsabb adatátvitelt. A predikátum lenyomás és az oszlopritkítás együtt 10x-100x lekérdezési teljesítményjavulást eredményez a szelektív lekérdezéseknél széles ellenőrzési adathalmazokon, lehetővé téve a terabájt méretű felmérési archívumok interaktív felfedezését. A sémafejlődés támogatja az ellenőrzési programok természetes fejlődését, ahogy az adatgyűjtési követelmények idővel bővülnek. Az önleíró formátum biztosítja a hosszú távú adatmegőrzést anélkül, hogy külső séma-regiszterektől vagy saját szoftverektől függne. A széles ökoszisztéma-támogatás – amely átível a Python adattudományi könyvtáraitól az elosztott feldolgozó keretrendszereken, geotérbeli elemző eszközökön és felhőalapú adattárházakon keresztül – lehetővé teszi, hogy az ellenőrzési adatok zökkenőmentesen áramoljanak a teljes elemzési csővezetéken keresztül a nyers érzékelőgyűjtéstől a végső jelentéskészítésig. A TarmacView és a tágabb burkolat-ellenőrzési iparág számára a Parquet biztosítja azt a tárolási hatékonyságot, lekérdezési teljesítményt és ökoszisztéma-kompatibilitást, amely szükséges az infrastruktúra-állapot adatok növekvő mennyiségének és kifinomultságának kezeléséhez.
Gyakran Ismételt Kérdések
Az Apache Parquet alapvetően különbözik a CSV-től és JSON-tól, mert oszlopos tárolási modellt használ a sororientált tárolás helyett. CSV-ben és JSON-ban minden sor összes mezője egymás után kerül tárolásra a lemezen. A Parquet-ben az egyes oszlopok összes értéke folytonosan, külön oszlopdarabokban kerül tárolásra sorkészleteken belül. Ez az építészeti különbség drámai gyakorlati előnyöket eredményez az elemzési munkaterhelésekhez. Sok attribútumot tartalmazó ellenőrzési adatok esetén – mint repedéstípus, súlyosság, helykoordináták, felületi állapotértékelések és időbélyegek – egy olyan lekérdezés, amely csak a repedéskoordinátákat és a súlyosságot igényli egy 50 oszlopos adathalmazból, csak ezt a két oszlopot olvassa ki a lemezről, ami körülbelül 96%-os I/O-csökkentést eredményez. A CSV és JSON minden sort minden oszlopával együtt be kell olvasson, mielőtt a felesleges adatokat eldobhatná. A Parquet oszlopos elrendezése kiváló tömörítést is lehetővé tesz, mert egyetlen oszlopon belüli értékek azonos adattípusúak, és gyakran alacsony kardinalitásúak vagy ismétlődő mintázatúak. Egy 10 GB-os CSV fájl burkolat-ellenőrzési adatokkal jellemzően 500 MB és 1,5 GB közé tömöríthető Parquet-ben, ami 7x-20x tároláscsökkentést jelent. Emellett a Parquet egy bináris formátum beágyazott metaadatokkal, amelyek leírják a sémát, a kódolást és a tömörítést, szemben a CSV-vel, amely nem rendelkezik beépített sémával, és a JSON-nal, amely minden sorban redundánsan tartalmazza a séma információkat. Több ezer repülőtéri futópálya-állapot rekordot feldolgozó ellenőrzési adatcsővezetékek esetén a Parquet 10x-100x gyorsabb elemzési lekérdezési teljesítményt nyújt a CSV-hez vagy JSON-hoz képest.
A predikátum lenyomás egy lekérdezésoptimalizálási technika, amely kihasználja a Parquet oszlopdarabonkénti statisztikáit – konkrétan a fájl lábléc metaadataiban tárolt minimumértéket, maximumértéket és nullák számát – hogy teljes sorkészleteket kihagyjon az adatvizsgálat során anélkül, hogy beolvasná azokat. Amikor egy lekérdezés szűrőfeltételt tartalmaz, például WHERE severity = 'HIGH' VAGY WHERE timestamp > '2024-06-01', a lekérdező motor először beolvassa a könnyű fájlláblécet, majd megvizsgálja az egyes sorkészletek tárolt min/max statisztikáit. Azokat a sorkészleteket, amelyek statisztikai tartománya nem fedi át a szűrőfeltételt, teljesen kihagyja a rendszer, ami nulla I/O-t jelent az adott sorkészletre. Több felmérési kampány során gyűjtött ellenőrzési adathalmazok esetén egy adott dátumtartományra szűrő lekérdezés a sorkészletek 90%-99%-át kihagyhatja. Ez kritikus fontosságú a repülőtéri burkolat-ellenőrzési adatoknál, mert a felmérések nagy mennyiségű, nagy felbontású adatot termelnek – egyetlen futópálya-felmérés 1 mm-es felbontással kilométerenként több millió adatpontot generál. Predikátum lenyomás nélkül minden lekérdezés az összes gyűjtött adat teljes beolvasását igényelné. A Parquet statisztika-alapú kihagyásával a gyakori műveleti lekérdezések, mint például 'Keresd meg az összes 40 alatti PCI-vel rendelkező területet 2024-ben' vagy 'Töltsd le a 09/27 futópálya repedéstérképeit az utolsó két ellenőrzésből' másodpercek alatt végrehajthatók percek helyett, akár terabájt méretű adathalmazokon is. Az eredmény interaktív lekérdezési teljesítmény hatalmas ellenőrzési archívumokon.
Az optimális Parquet tömörítési kodek a konkrét munkaterhelési jellemzőktől és a tömörítési arány, valamint az írási/olvasási sebesség közötti kompromisszumtól függ. Az ellenőrzési adatok munkaterheléseihez a Zstandard (Zstd) 3-as tömörítési szinten az ajánlott alapértelmezett választás, mert a Snappy-hoz közeli olvasási sebességet nyújt, miközben jelentősen jobb tömörítési arányt ér el. Valós adathalmazokon végzett benchmarkok szerint a Parquet Zstd tömörítéssel a CSV fájlméretet körülbelül 8%-14%-ára csökkenti, szemben a Snappy 12%-18%-ával és a tömörítetlen Parquet 25%-ával. Az írás-intenzív csővezetékekhez, ahol a betöltési sebesség a legfontosabb – például valós idejű ellenőrzési adatfolyam felmérő járművekből – az LZ4_RAW vagy Snappy biztosítja a leggyorsabb írási teljesítményt elhanyagolható CPU-többletterheléssel, miközben továbbra is 5x-8x tömörítést ér el a CSV-hez képest. A hidegtároláshoz és a történeti ellenőrzési adatok archiválásához, ahol a tömörítési arány a legfontosabb, a Zstd 9-22 szinten vagy a Gzip 9-es szinten a tárolási költségeket az eredeti CSV méretének akár 5%-8%-ára csökkenti. A kompromisszum az, hogy a maximális tömörítés 30%-60%-kal növeli az írási CPU-időt a Snappy-hoz képest. A tipikus TarmacView ellenőrzési adat munkafolyamatokhoz, amelyek egyensúlyt teremtenek a tárolási hatékonyság és a lekérdezési teljesítmény között, a Zstd 3-as szint kínálja a legjobb általános értéket. Az olyan ellenőrzési adatoszlopok, mint a burkolatállapot-index értékek, repedésosztályozások és felmérési időbélyegek különösen jól profitálnak a szótári kódolás és a Zstd tömörítés kombinációjából, mert ezek az oszlopok viszonylag alacsony kardinalitásúak, ami azt jelenti, hogy a szótár a legtöbb egyedi értéket kis számú bejegyzésben rögzíti.
Az oszlopritkítás, más néven projekció lenyomás, az a technika, amelynek során csak a lekérdezésben hivatkozott oszlopokat olvassuk ki a lemezről, miközben az összes többi oszlopot teljesen kihagyjuk. A Parquet oszlopos tárolási modelljében minden oszlop adatai külön oszlopdarabokban tárolódnak az egyes sorkészleteken belül, így a lekérdező motor szelektíven csak a kért oszlopok oszlopdarabjait olvashatja be. Ellenőrzési adatok esetén, ahol egyetlen fájl 50-100 vagy több attribútumot tartalmazhat mért pontonként – beleértve a koordinátákat, több károsodástípust, súlyossági besorolásokat, felületi textúra mérőszámokat, képalkotási metaadatokat és minőségi jelzőket – az oszlopritkítás hatalmas teljesítménybeli előnyöket biztosít. Egy lekérdezés, amely csak a földrajzi koordinátákat és a repedésszélesség-méréseket igényli egy 100 attribútumos adathalmazból, a teljes fájladat körülbelül 2%-át olvassa be. A sororientált formátumokkal, mint a CSV vagy JSON, ugyanez a lekérdezés az adatok 100%-ának beolvasását és elemzését igényli, majd a 98% eldobását a memóriában. A gyakorlatban az oszlopritkítás a Parquet tömörítésével kombinálva 50x-100x I/O-csökkentést eredményezhet a szelektív lekérdezéseknél széles ellenőrzési adathalmazokon. Ez különösen értékes a TarmacView munkafolyamatokban, ahol elemzők interaktívan fedezik fel a burkolatállapot-adatokat, váltogatva a különböző károsodási mérőszámok, történeti összehasonlítások és térbeli részhalmazok között. A modern lekérdező motorok, beleértve a DuckDB-t, a Polars-t és a PyArrow-t, mind automatikus oszlopritkítást alkalmaznak a Parquet fájlok olvasásakor, amihez nincs szükség külön konfigurációra az elemző részéről.
Igen, a Parquet natívan kezeli a geotérbeli adatokat a GeoParquet specifikáción keresztül, amely egy OGC (Open Geospatial Consortium) szabvány, ami interoperábilis geotérbeli típusokat ad a Parquet formátumhoz. A GeoParquet a geometria oszlopokat Well-Known Binary (WKB) formátumban tárolja a Parquet bináris oszlopában, kiegészítő metaadatokkal a fájl láblécében, amelyek leírják a koordináta-referenciarendszert (CRS), a jelen lévő geometria típusokat és a teljes befoglaló téglalapot. Ez lehetővé teszi a térbeli predikátum lenyomást, ahol a térbeli szűrőket (például ST_Intersects vagy ST_Within) használó lekérdezések kihagyhatják azokat a sorkészleteket, amelyek befoglaló téglalapjai nem fedik át a lekérdezési régiót. A kilométereken átívelő burkolatfelületet lefedő futópálya-ellenőrzési adatok esetén a térbeli szűrés elengedhetetlen bizonyos szakaszok, kereszteződések vagy nagy kopású zónák elkülönítéséhez. A GeoPandas, QGIS, Apache Sedona, Google BigQuery és Snowflake mind támogatják a GeoParquet fájlok közvetlen olvasását, ami lehetővé teszi a TarmacView ellenőrzési eredmények zökkenőmentes integrációját tágabb geotérbeli elemzési munkafolyamatokba. A TarmacView-ben a Parquet fájlok az ellenőrzési eredményeket pontos GPS-koordinátákkal tárolják minden mért ponthoz vagy károsodási poligonhoz, lehetővé téve a térbeli illesztéseket futópálya-geometriával, gurulóút-középvonalakkal és előtér-határokkal. A Parquet elemzési teljesítményének és geotérbeli képességeinek kombinációja ideális formátummá teszi nagy léptékű burkolatállapot-felmérésekhez, ahol mind a térbeli elhelyezkedést, mind a többváltozós attribútumokat hatékonyan kell lekérdezni.
A Python három elsődleges könyvtárat kínál a Parquet fájlok olvasásához és írásához, amelyek mindegyike eltérő erősségekkel rendelkezik az ellenőrzési adatok elemzéséhez. A PyArrow (az Apache Arrow C++ Python kötései) a legteljesebb funkciókészletű könyvtár, amely finomhangolási lehetőségeket biztosít a sorkészletméret, tömörítés, kódolás és statisztikák terén. Támogatja az explicit oszlopritkítást a columns paraméteren, a predikátum lenyomást a filters paraméteren, valamint a particionált adathalmazokat a ParquetDataset segítségével. A TarmacView ellenőrzési adat munkafolyamataihoz a PyArrow az ajánlott motor a programozott adatfeldolgozási csővezetékekhez. A Pandas egyszerűbb, magasabb szintű API-t biztosít a pd.read_parquet és df.to_parquet függvényeken keresztül, a mögöttes Parquet implementációt a PyArrow-ra vagy fastparquet-ra bízva. A Pandas ideális interaktív elemzéshez és feltáró munkához Jupyter notebookokban, bár a teljes adathalmazt a memóriába olvassa. A Polars egy Apache Arrow-ra épülő DataFrame könyvtár, amely a legyorsabb Parquet olvasási teljesítményt nyújt – jellemzően 3x-10x gyorsabb, mint a Pandas – a többszálas, Rust-alapú motorjának köszönhetően. A Polars lusta API-t kínál a pl.scan_parquet függvényen keresztül, amely teljes predikátum lenyomást és oszlopritkítást végez, mielőtt bármilyen adat betöltődne. Nagy, a rendelkezésre álló memóriát meghaladó ellenőrzési adathalmazokhoz a Polars támogatja a streamelt olvasást. Geotérbeli Parquet adatokhoz a GeoPandas kiterjeszti a Pandas-t geotérbeli műveletekkel, és közvetlenül olvashat GeoParquet fájlokat a gpd.read_parquet függvényen keresztül. A könyvtár kiválasztása a konkrét munkafolyamattól függ: PyArrow csővezeték-fejlesztéshez, Pandas és GeoPandas interaktív elemzéshez, és Polars a maximális teljesítményhez nagy ellenőrzési adathalmazokon.
A TarmacView az ellenőrzési elemzési eredményeket több különálló Parquet fájlba szervezi, amelyek mindegyike dedikált sémával rendelkezik, optimalizálva bizonyos lekérdezési mintákhoz. A results.parquet fájl tárolja az elsődleges ellenőrzési kimenetet, soronként egy mért pozícióval, beleértve a GPS-koordináták (szélesség, hosszúság, magasság), a felmérés időbélyege, burkolatállapot-index (PCI) értékek, egyedi károsodásmérések (repedésszélesség, repedéshossz, kipattogzási terület, felületi mállás súlyossága), felületi textúra mérőszámok és minőség-ellenőrzési jelzők oszlopait. A tiles.parquet fájl a csempe-alapú elemzési eredményeket tárolja, ahol a burkolatfelület egy szabályos rácsra van osztva (jellemzően 1 m x 1 m vagy 5 m x 5 m csempék, a felmérés felbontásától függően), minden sor egy adott csempe összesített állapotértékelését képviseli, beleértve az átlagos PCI-t, a domináns károsodástípust és a mérések statisztikai eloszlását. Az assessment.parquet fájl tárolja a végső állapotértékelést burkolati szakaszonként, beleértve a számított PCI-értékeket az ASTM D5340 és ICAO Annex 14 módszertan szerint, a szakaszszintű károsodási sűrűségeket, az ajánlott karbantartási intézkedéseket és a prioritási sorrendet. A telemetry.parquet fájl rögzíti a felmérő jármű telemetriai adatfolyamát, beleértve a sebességet, gyorsulást, irányt és érzékelő állapotokat rendszeres időközönként az adatgyűjtési futás során. Minden Parquet fájl Zstd tömörítést használ 3-as szinten, körülbelül 256 MB tömörítetlen sorkészletmérettel, és oszloponkénti statisztikákat engedélyez az optimális predikátum lenyomási teljesítmény érdekében. A fájlok felmérési dátum és futópálya-szakasz szerint vannak particionálva a hatékony időtartomány- és térbeli lekérdezések érdekében. Ez a struktúra lehetővé teszi az elemzők számára, hogy meghatározott szakaszokat, időszakokat vagy károsodástípusokat kérdezzenek le anélkül, hogy a teljes felmérési archívumot be kellene olvasniuk.
Hatékony adattárolásra van szüksége az ellenőrzési analitikához?
A TarmacView Apache Parquet formátumot használ a repülőtéri burkolat-ellenőrzési adatok gyors, hatékony és lekérdezhető tárolásához. Vegye fel a kapcsolatot csapatunkkal, hogy megtudja, hogyan gyorsíthatja fel oszlopos adatarchitektúránk az infrastruktúra-elemzési munkafolyamatait.
Az adatformátum és az adatreprezentáció szerkezete a technológiában
Az adatformátum azt határozza meg, hogyan tároljuk és továbbítjuk az információkat, míg az adatreprezentáció szerkezete az adatok belső kódolására vonatkozik. M...
Az adatátvitel, vagy adatmozgatás, az a folyamat, amely során adatokat helyeznek át, másolnak vagy továbbítanak digitális környezetek között—támogatva a migráci...
6 perc olvasás
Data management
Cloud computing
+3
Sütik Hozzájárulás A sütiket használjuk, hogy javítsuk a böngészési élményt és elemezzük a forgalmunkat. See our privacy policy.