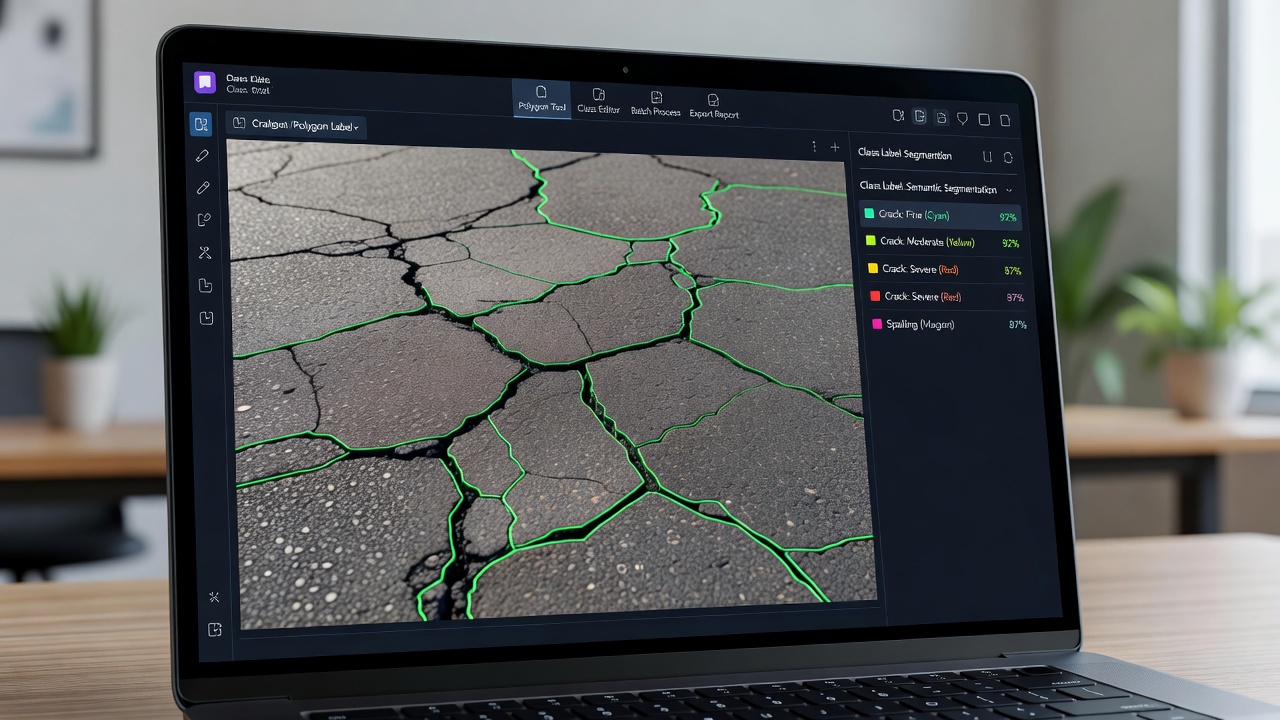
A szemantikai szegmentáció kategóriacímkét rendel minden pixelhez egy képben, lehetővé téve a teljes jelenet értelmezését infrastruktúra-ellenőrzés során. Lefedi a kódoló-dekódoló architektúrákat (U-Net, DeepLabV3+, SegFormer, PSPNet, Mask2Former), kódoló törzshálózatokat (ResNet, EfficientNet, ViT), veszteségfüggvényeket (cross-entropy, Dice, focal, boundary), pixelszintű címkékkel történő tanítást, többosztályos szegmentációt út- és repülőtéri jelenetekhez, repedésszegmentációt, felülettípus-térképezést, kiértékelési metrikákat (IoU, Dice, pixel accuracy), és telepítési optimalizálást valós idejű ellenőrzési munkafolyamatokhoz.
Mi a szemantikus szegmentálás az infrastruktúra-felderítés kontextusában?
Definíció és megkülönböztetés a kapcsolódó számítógépes látás feladatoktól
A szemantikus szegmentálás az a számítógépes látás feladat, amely egy előre meghatározott osztálycímkét rendel a bemeneti kép minden egyes pixeléhez, létrehozva egy teljes pixel szintű osztályozási térképet, ahol minden pixel egy kategóriába kerül besorolásra, mint például repedés, nem repedt burkolat, burkolati jelzés, növényzet, FOD vagy felülettípus. A kimenet egy sűrű előrejelzési maszk, amely megegyezik a bemeneti kép térbeli dimenzióival, ahol minden pixelérték egy osztályindexnek felel meg.
Ez különbözteti meg a szemantikus szegmentálást három kapcsolódó, de alapvetően eltérő számítógépes látás feladattól:
Képbesorolás (Image classification) egyetlen címkét rendel a teljes képhez — például kijelenti, hogy “ez a kép repedést tartalmaz”, anélkül, hogy meghatározná, hol található a repedés. A besorolás nem nyújt térbeli információt az objektum pozíciójáról, alakjáról vagy kiterjedéséről. Ez a legegyszerűbb számítógépes látás feladat, ugyanakkor a legkevésbé informatív az infrastruktúra-ellenőrzés szempontjából, ahol a hibák helyének, geometriájának és kiterjedésének ismerete elengedhetetlen az állapotfelméréshez és a karbantartástervezéshez.
Objektumdetekció (Object detection) azonosítja és lokalizálja az objektumokat tengelyekkel párhuzamos határolókeretek rajzolásával, minden kerethez osztálycímkét és konfidenciaszintet rendelve. A detekció arra ad választ, hogy “milyen objektumok vannak jelen, és megközelítőleg hol.” Repedésdetekció esetén egy határolókeret magába foglalhat egy repedési régiót, de nem képes lehatárolni a repedés pontos alakját, szélességét vagy összefüggőségét — ezek az információk kritikusak a repedéstípus besorolásához (hosszirányú, keresztirányú, hálós, tömbös) és a súlyosság értékeléséhez az ASTM D5340 szabvány szerint.
Példányszegmentálás (Instance segmentation) továbblép egy lépéssel azáltal, hogy detektál minden egyes objektumpéldányt, és mindegyikhez pixel szintű maszkot rendel egyedi példányazonosítókkal. Infrastruktúra-ellenőrzés esetén ez lehetővé tenné az egyedi repedések vagy kátyúk egymástól való megkülönböztetését. Azonban számos felületi hiba — különösen a hálós repedés vagy a tömbös repedés mintázatai — egymással összekapcsolódó hálózatokat alkotnak, amelyeket nehéz különálló példányokra bontani, így a példányszegmentálás kevésbé alkalmas általános burkolatállapot-felmérésre.
Pánoptikus szegmentálás (Panoptic segmentation) egyesíti a szemantikus és példányszegmentálást azáltal, hogy minden pixelhez szemantikus címkét rendel (beleértve a “dolog-szerű” osztályokat, mint a burkolat, égbolt, növényzet), és egyidejűleg detektálja és szegmentálja az egyes objektumpéldányokat (“dolog” osztályokat, mint konkrét kátyúk vagy FOD-tárgyak). A pánoptikus szegmentálás a legátfogóbb megközelítés, ugyanakkor a legnagyobb számítási igényű és legösszetettebb tanítási folyamatú.
Feladat
Kimenet
Térbeli pontosság
Infrastruktúra-alkalmazhatóság
Képbesorolás
Egyetlen címke képenként
Nincs
Csak repedés jelenlétének detektálása
Objektumdetekció
Határolókeretek objektumonként
Durva
FOD-detekció, kátyú lokalizálása
Szemantikus szegmentálás
Pixel szintű osztálycímkék
Maximális (pixel szintű)
Repedéstérképezés, felülettípus, PCI-értékelés
Példányszegmentálás
Egyedi objektummaszkok
Maximális + példányazonosító
Diszkrét hibák számlálása
Pánoptikus szegmentálás
Minden pixel címkék + példányok
Maximális + példányazonosító
Teljes felderítés
Infrastruktúra-ellenőrzési alkalmazások — különösen repülőtéri burkolat állapotfelmérése, repedéstérképezés és felülettípus-besorolás — esetén a szemantikus szegmentálás a legmegfelelőbb és legszélesebb körben alkalmazott megközelítés, mivel teljes képi felderítést biztosít a kvantitatív állapotértékeléshez szükséges pixel szintű pontossággal, anélkül hogy a folytonos hibahálózatokat egyedi példányokra kellene bontani.
Architekturális szempontból a szemantikus szegmentálási modellek jellemzően teljesen konvolúciós hálózatok (FCN) vagy transzformer-alapú modellek, amelyeket úgy terveztek, hogy tetszőleges dimenziójú bemeneti képet fogadjanak és azzal megegyező térbeli dimenziójú szegmentációs térképet állítsanak elő. A meghatározó jellemző a teljesen kapcsolt rétegek hiánya, amelyek rögzítenék a bemeneti méretet — ehelyett az összes réteg konvolúciós vagy figyelemalapú, lehetővé téve a hálózat számára, hogy változó felbontású képeket dolgozzon fel következtetés során.
A kimeneti szegmentációs térkép mérete H × W × C, ahol H és W megegyezik a bemenet térbeli dimenzióival (vagy azok rögzített hányadával), C pedig az osztályok száma. Minden térbeli pozícióban a C dimenziós vektor tartalmazza az egyes osztályokra vonatkozó előrejelzett valószínűségeket, amelyek jellemzően egy softmax aktivációs függvényen keresztül kerülnek normalizálásra, így a valószínűségek összege 1. A végső osztályhozzárendelés a argmax kiválasztásával történik a csatornadimenzió mentén — a legmagasabb valószínűségű osztály minden pixelnél.
Architektúrák szemantikus szegmentáláshoz
U-Net
Az U-Net-et Ronneberger, Fischer és Brox mutatták be 2015-ös “U-Net: Convolutional Networks for Biomedical Image Segmentation” című tanulmányukban. Ez a legbefolyásosabb szemantikus szegmentálási architektúra, és továbbra is a de facto szabvány az infrastruktúra-ellenőrzési feladatok, különösen a repedésszegmentálás terén. A név a szimmetrikus U-alakú architektúrából származik, amely egy szűkítő kódoló útból és egy tágító dekódoló útból áll, amelyeket skip kapcsolatok kötnek össze.
A kódoló (szűkítő út) egy tipikus konvolúciós hálózati felépítést követ: két 3×3-as konvolúció ismételt alkalmazása (mindegyiket egy egyenirányított lineáris egység — ReLU követ), majd egy 2×2-es max pooling művelet stride 2-vel a mintavételezés csökkentésére. Minden egyes mintavételezési lépésnél a jellemzőcsatornák száma megduplázódik: 64-ről 128-ra, majd 256-ra, 512-re, végül 1024-re a legmélyebb rétegnél (a szűk keresztmetszetnél). Ez a progresszív csatornamélység-növekedés kompenzálja a térbeli felbontás csökkenését, lehetővé téve a hálózat számára, hogy egyre absztraktabb és szemantikailag jelentősebb jellemzőket tanuljon durvább skálákon.
A dekódoló (tágító út) fordított sorrendben tükrözi a kódolót: minden lépés egy 2×2-es felfelé konvolúcióval (transzponált konvolúció) kezdődik, amely a jellemzőcsatornák számát megfelezi és a térbeli dimenziókat megduplázza. A felskálázott jellemzőtérkép ezután összefűzésre kerül a kódoló megfelelő jellemzőtérképével azonos felbontáson — ez az U-Netet meghatározó skip kapcsolat. Az összefűzött jellemzőtérkép két 3×3-as konvolúción megy keresztül ReLU aktiválással. A végső réteg egy 1×1-es konvolúció, amely a jellemzőreprezentációt a kívánt számú kimeneti osztályra képezi le.
A skip kapcsolatok jelentik azt az architekturális újítást, amely hatékonnyá teszi az U-Netet a precíz lokalizációhoz. A kódolás során az objektumhatárokra, textúragradiensekre és finom részletekre vonatkozó térbeli információ fokozatosan elvész a mintavételezés csökkentése és a pooling műveletek révén. A skip kapcsolatok megkerülik a szűk keresztmetszetet, és közvetlenül juttatják el a nagy felbontású jellemzőtérképeket a kódolóból a dekódolóba a megfelelő felbontásokon, lehetővé téve a dekódoló számára, hogy hozzáférjen mind a mélyebb rétegekből származó szemantikus kontextushoz, mind a sekélyebb rétegekből származó térbeli pontossághoz. Repedésszegmentálás esetén, ahol a 0,5–3 mm széles repedéseket kell feloldani, a határpontosság megőrzése a skip kapcsolatokon keresztül elengedhetetlen.
Az eredeti U-Net implementáció körülbelül 31 millió paramétert tartalmaz egy 2 osztályos szegmentálási feladathoz. A modern implementációk, mint a Segmentation Models PyTorch (smp), támogatják a konfigurálható kódolómélységeket (3–5 szint), a csatlakoztatható kódoló törzshálózatokat (ResNet, EfficientNet, stb.) és a dekódoló csatornaspecifikációkat, így az U-Net rendkívül adaptálható a különböző pontosság-sebesség kompromisszumokhoz. Az architektúra egy 256×256-os bemeneti képet körülbelül 15–30 ezredmásodperc alatt dolgoz fel egy modern GPU-n, lehetővé téve a valós idejű következtetést 30–60 képkocka/másodperc sebességgel csempézett feldolgozás esetén nagyméretű területi felméréseknél.
DeepLabV3+
A DeepLabV3+-t Chen és munkatársai fejlesztették ki a Google-nál (2018). Továbbfejleszti a DeepLab architektúracsaládot (DeepLabV1, V2, V3) azáltal, hogy egy kódoló-dekódoló szerkezetet ad a DeepLabV3-ban bevezetett Atrous Spatial Pyramid Pooling (ASPP) modulhoz. Az architektúrát kifejezetten a szabványos FCN-alapú szegmentálás korlátainak kezelésére tervezték: a térbeli felbontás csökkenése az ismételt mintavételezés miatt, valamint a többszintű objektumok szegmentálásának nehézsége.
A DeepLabV3+ kulcsfontosságú újítása az atrous (dilatált) konvolúció, amely lehetővé teszi a hálózat számára, hogy szabályozza a jellemzőválaszok számítási felbontását anélkül, hogy csökkentené a térbeli dimenziókat. Az atrous konvolúció nullákat (lyukakat) szúr be a szűrősúlyok közé, hatékonyan növelve a receptív mezőt a paraméterek számának növelése nélkül. Egy k méretű kernelű és r dilatációs rátájú konvolúció esetén az effektív kernelméret k + (k-1)(r-1). A DeepLabV3+ egy output stride értéket használ — ami azt jelenti, hogy a végső jellemzőtérkép felbontása a bemenet 1/16-a — szemben a szabványos ResNet törzshálózatok 1/32-ével, megőrizve ezzel a finomabb térbeli részleteket.
Az Atrous Spatial Pyramid Pooling (ASPP) modul párhuzamos atrous konvolúciókat alkalmaz különböző dilatációs rátákkal a többszintű kontextus rögzítésére. A szabványos ASPP konfiguráció négy párhuzamos ágat használ 1, 6, 12 és 18 dilatációs rátákkal, ha az output stride 16 (vagy 1, 12, 24, 36 ha az output stride 8). Minden ág egy 3×3-as konvolúcióval dolgozza fel a jellemzőtérképet a megadott dilatációs rátával, majd batch normalizáció és ReLU következik. A kimenetek összefűzésre kerülnek, és egy 1×1-es konvolúción mennek keresztül, hogy létrehozzák a végső ASPP jellemzőreprezentációt. Egy további ág globális átlagpoolingot alkalmaz a teljes kép kontextusának rögzítésére, amely bilineárisan felskálázásra és összefűzésre kerül az ASPP jellemzőkkel.
A DeepLabV3+ dekódoló modulja viszonylag könnyű súlyú komponens az U-Net teljes dekódolójához képest. A kódoló jellemzői (az ASPP-ből) bilineárisan felskálázásra kerülnek 4-es tényezővel. Ezek a felskálázott jellemzők összefűzésre kerülnek a kódoló törzshálózat megfelelő alacsony szintű jellemzőivel (pontosabban az első konvolúciós blokk jellemzőtérképével — jellemzően 1/4 felbontáson). Az összefűzött jellemzők egy 3×3-as konvolúción mennek keresztül, majd egy második bilineáris felskálázás következik 4-es tényezővel, hogy visszaállítsák az eredeti bemeneti felbontást.
A DeepLabV3+ a legmodernebb teljesítményt éri el referencia adatkészleteken, mint a Cityscapes (82,1% mIoU ResNet-101 törzshálózattal) és a PASCAL VOC 2012 (89,0% mIoU Xception törzshálózattal). Infrastruktúra-ellenőrzés esetén a DeepLabV3+ kiválóan teljesít nagy, kontextusfüggő felületi jellemzők, például burkolattípusok és jelzési zónák szegmentálásában, de nehézségekbe ütközhet nagyon vékony jellemzőkkel, mint a hajszálvékony repedések (szélesség < 1 mm), ahol az 1/16-os output stride még mindig elveszíti a kritikus térbeli részleteket.
SegFormer
A SegFormer-t Xie és munkatársai mutatták be az NVIDIA-nál (2021). Alapvető eltérést jelent a konvolúciós architektúráktól azáltal, hogy tisztán transzformer-alapú kódolót használ könnyű súlyú MLP (multilayer perceptron) dekódolóval. A SegFormer volt az első hierarchikus transzformer szegmentálási architektúra, amely demonstrálta, hogy a transzformerek képesek felülmúlni vagy elérni a konvolúciós architektúrák teljesítményét a modellméretek teljes skáláján — a könnyű súlyútól (SegFormer-B0, 3,8 millió paraméter) a nehézig (SegFormer-B5, 84,7 millió paraméter).
A Mix Transformer (MiT) kódoló hierarchikus felépítést alkalmaz, amely többszintű jellemzőtérképeket hoz létre a bemeneti felbontás 1/4, 1/8, 1/16 és 1/32 részénél, hasonlóan a konvolúciós törzshálózatok, mint a ResNet jellemzőhierarchiájához. Minden szint átfedő patch beágyazást alkalmaz (a szabványos ViT nem átfedő patch-ei helyett), hatékony önfigyelmet csökkentett szekvenciahosszal, és Mix-FFN előrecsatolt hálózatokat. A SegFormer pozíciós kódolása nullával inicializált és tanulható — a szerzők megállapították, hogy a rögzített pozíciós kódolások teljes elhagyása és a nullával inicializált, tanulható változatra támaszkodás javította a teljesítményt változó felbontású következtetés esetén, ami kritikus fontosságú a különböző magasságokból és talajmintavételi távolságokkal rögzített infrastruktúra-felvételeknél.
Az MLP dekódoló figyelemre méltóan egyszerű a konvolúciós dekódolókhoz képest: összegyűjti a MiT kódoló többszintű jellemzőit az összes jellemzőtérkép 1/4 felbontásra történő bilineáris felskálázásával, összefűzi azokat, átvezeti egy 3×3-as konvolúciós fúziós rétegen, majd egy két rejtett réteggel rendelkező MLP-t alkalmaz a végső szegmentáció előállításához. A dekódoló egyszerűsége hozzájárul a SegFormer számítási hatékonyságához — a dekódoló csak néhány millió paramétert tartalmaz még a legnagyobb modellváltozatok esetében is.
A SegFormer kulcsfontosságú előnye az infrastruktúra-ellenőrzés számára a bemeneti felbontás változásával szembeni robusztussága. A transzformer kódoló önfigyelem mechanizmusa természetesen alkalmazkodik a különböző bemeneti méretekhez, anélkül hogy a konvolúciós kernelek felbontásfüggő viselkedését mutatná. Olyan burkolat-ellenőrzési feladatoknál, ahol a képek különböző repülési magasságokból vagy eltérő kamerák segítségével készülhetnek, a SegFormer konzisztens szegmentálási minőséget tart fenn anélkül, hogy felbontásspecifikus finomhangolásra lenne szükség.
PSPNet
A Pyramid Scene Parsing Network (PSPNet)-et Zhao és munkatársai mutatták be (2017). A globális kontextus megértésének kihívását kezeli piramispooling segítségével. A kulcsfontosságú felismerés az, hogy számos szegmentációs hiba — különösen a vizuálisan hasonló, de szemantikailag eltérő régiók (pl. aszfaltburkolat vs. betonburkolat, vagy tömített repedés vs. tömítetlen repedés) téves besorolása — az elégtelen globális kontextusból ered.
A Pyramid Pooling Module (PPM) adaptív átlagpoolingot alkalmaz négy különböző skálán: 1×1 (globális), 2×2, 3×3 és 6×6. Minden egyes poolozott jellemzőtérkép egy 1×1-es konvolúción megy keresztül, hogy a csatornák számát a bemenet 1/N-ére csökkentse (ahol N=4, a piramisszintek száma), majd bilineárisan felskálázásra kerül vissza az eredeti jellemzőtérkép felbontására. A négy szintről származó felskálázott jellemzők összefűzésre kerülnek az eredeti jellemzőtérképpel, létrehozva egy végső reprezentációt, amely mind a lokális részleteket, mind a globális kontextust több skálán kódolja.
Burkolatszegmentálás esetén a piramispooling lehetővé teszi a hálózat számára, hogy a felülettípusokat kontextus alapján különböztesse meg: egy aszfaltfoltnak a kifutópálya közepén más a várható textúrája és állapota, mint a kifutópálya szélén vagy egy gurulóúton. A globális 1×1-es pooling rögzíti a teljes jelenet típusát (kifutópálya, gurulóút, előtér, út), míg a finomabb pooling skálák a lokális textúra- és állapotmintázatokat rögzítik.
Mask2Former
A Mask2Former-t Cheng és munkatársai mutatták be a Meta AI-nál (2022). Egyesíti a szemantikus, példány- és pánoptikus szegmentálást egyetlen architektúrán belül azáltal, hogy az összes szegmentálási feladatot maszkbesorolásként fogalmazza meg. Ahelyett, hogy közvetlenül pixel szintű besorolási térképeket állítana elő, a Mask2Former bináris maszkok egy halmazát becsüli meg kapcsolódó osztálycímkékkel, hasonlóan ahhoz, ahogy az objektumdetekció határolókereteket becsül osztálycímkékkel.
Az architektúra három komponensből áll: egy törzshálózatból (jellemzően Swin Transformer vagy ResNet), amely többszintű jellemzőket von ki; egy transzformer dekódolóból maszkolt figyelemmel, amely iteratívan finomítja a maszkbecsléseket; és egy pixel dekódolóból, amely pixelenkénti beágyazásokat generál. A maszkolt figyelem mechanizmus a transzformer önfigyelmét az egyes becsült maszkokon belüli régiókra korlátozza, jelentősen csökkentve a számítási komplexitást (O(N²)-ről O(NM)-re, ahol M a maszkpixelek száma), és a modell kapacitását a régióspecifikus jellemzőkre összpontosítva.
Infrastruktúra-ellenőrzés esetén a Mask2Former előnye, hogy természetesen képes kezelni a változatos objektumméreteket — a nagy folytonos régióktól (burkolattípusok, növényzeti zónák) a kis diszkrét objektumokig (FOD-tárgyak, egyedi kagylósodások) — egy egységes keretrendszeren belül. Azonban a maszkbesorolási megközelítés kevésbé intuitív lehet a folytonos, amorf hibamintázatok esetén, mint a közvetlen pixel szintű besorolás, és a Mask2Former jellemzően több tanítási adatot és számítási erőforrást igényel, mint az U-Net vagy a DeepLabV3+.
Kódoló törzshálózatok
ResNet (Residual Network)
A ResNet-et He és munkatársai mutatták be a Microsoft Research-nél (2015). Ez a legszélesebb körben használt kódoló törzshálózat a szemantikus szegmentáláshoz. A kulcsfontosságú újítás a reziduális tanítási keretrendszer: ahelyett, hogy egy nem referenciált H(x) = kimenet függvényt tanulna, minden réteg (vagy réteghalmaz) a reziduális F(x) = H(x) − x értéket tanulja. Az eredeti x bemenet hozzáadódik a tanult reziduálishoz egy gyorsítótávon (skip kapcsolaton) keresztül, így a réteg kimenete H(x) = F(x) + x.
A reziduális blokk ezt formalizálja: egy két 3×3-as konvolúciós rétegből álló blokk esetén a blokk kimenete σ(F(x) + x), ahol σ a ReLU aktiváció és F(x) a két konvolúció, a batch normalizáció és a köztes ReLU kompozíciója. Ha x és F(x) dimenziói eltérnek (pl. amikor a stride > 1 csökkenti a térbeli felbontást), a gyorsítótáv egy 1×1-es konvolúciót használ a dimenziók összehangolására. A reziduális megfogalmazás lehetővé teszi példátlan mélységű hálózatok tanítását — a ResNet-152 152 réteggel rendelkezik — mivel mérsékli az eltűnő gradiens problémát a gradiensek közvetlen áramlásán keresztül a gyorsítótávok mentén.
A ResNet változatokat mélységük alapján jelölik: ResNet-18 (18 réteg, 11,7 millió paraméter), ResNet-34 (34 réteg, 21,8M), ResNet-50 (50 réteg, 25,6M), ResNet-101 (101 réteg, 44,5M) és ResNet-152 (152 réteg, 60,2M). Infrastruktúra-szegmentáláshoz a ResNet-50 és ResNet-101 a leggyakoribb választás, egyensúlyt teremtve a pontosság és a memória- és következtetési idő között.
Szegmentálási feladatokhoz a szabványos ResNet törzshálózat módosításra kerül, hogy dilatált (atrous) jellemzőtérképeket állítson elő, eltávolítva a stride-ot az utolsó egy vagy két blokkból, és a későbbi konvolúciókat dilatált konvolúciókkal helyettesítve. Ez a dilatált ResNet változat nagyobb felbontású jellemzőtérképeket tart fenn (a bemeneti felbontás 1/8-a vagy 1/16-a az 1/32 helyett), miközben megőrzi a receptív mező méretét — ez a kritikus módosítás a sűrű becslési feladatokhoz.
EfficientNet
Az EfficientNet-et Tan és Le mutatták be a Google-nál (2019). A legmodernebb pontosságot éri el jelentősen kevesebb paraméterrel és FLOP-pal a hasonló architektúrákhoz képest a kompaund skálázás révén. A kulcsfontosságú felismerés az, hogy a hálózat mélységének, szélességének és bemeneti felbontásának skálázását együttesen, nem pedig egymástól függetlenül kell végezni. Az EfficientNet egy φ kompaund együtthatót használ, amely egyidejűleg skálázza mindhárom dimenziót: mélység α^φ, szélesség β^φ és felbontás γ^φ, az α·β²·γ² ≈ 2 korlátozás mellett (biztosítva, hogy a teljes FLOP körülbelül 2^φ-vel skálázódjon).
Az EfficientNet építőeleme az MBConv (Mobile Inverted Bottleneck Convolution), amelyet eredetileg a MobileNetV2-ben vezettek be. Minden MBConv blokk a következőket használja: egy 1×1-es expanziós konvolúció (a csatornák számának 4–6-szoros növelése), egy mélységi (depthwise) 3×3-as vagy 5×5-ös konvolúció (minden csatornán függetlenül működve), squeeze-and-excitation (SE) csatornafigyelem (globális átlagpooling → két FC réteg → sigmoid aktiválás → csatornánkénti skálázás), és egy 1×1-es projekciós konvolúció (a csatornák visszacsökkentése a cél dimenzióra). Az SE figyelem lehetővé teszi az EfficientNet számára, hogy az informatív csatornákra összpontosítson — burkolat-ellenőrzés esetén ez azt jelenti, hogy hangsúlyozza a repedést a nem repedéstől megkülönböztető textúracsatornákat, miközben elnyomja a lapos textúrájú régiókat.
Az EfficientNet változatok EfficientNet-B0 (5,3M paraméter, 0,4 GFLOP 224×224-es bemenet esetén) és EfficientNet-B7 (66M paraméter, 37 GFLOP) között mozognak. Peremszámítógépes telepítéshez ellenőrző drónokon vagy beágyazott rendszereken az EfficientNet-B0-tól B3-ig terjedő változatok kiváló pontosság-számítási arányt kínálnak, elérve a ResNet-50 repedésszegmentálási IoU értékének 2–3%-án belüli teljesítményt, miközben 5–10× kevesebb FLOP-ot igényelnek.
Vision Transformer (ViT)
A Vision Transformer (ViT) -t Dosovitskiy és munkatársai mutatták be a Google-nál (2020). A transzformer architektúrát — amelyet eredetileg a természetes nyelvi feldolgozáshoz fejlesztettek ki — közvetlenül alkalmazza képrészletekre. A bemeneti kép rögzített méretű részekre van osztva (jellemzően 16×16 pixel), minden részt lineárisan egy token beágyazásba vetítenek, és ezeket a tokeneket egy sor transzformer kódoló réteg dolgozza fel, amelyek többszintű önfigyelmet és MLP blokkokat alkalmaznak.
Az önfigyelem mechanizmus páronkénti figyelemsúlyokat számít ki az összes tokenpár között, lehetővé téve, hogy minden részreprezentáció információt építsen be a kép minden más részéből. Az i token és j token közötti figyelemsúly a következőképpen számítódik: Attention(Q,K,V) = softmax(QK^T/√d_k)V, ahol Q (lekérdezés), K (kulcs) és V (érték) a token beágyazások tanult lineáris vetületei, d_k pedig a kulcsdimenzió. Ez a globális receptív mező — minden kimeneti pozíció információt integrál minden bemeneti pozícióból — a ViT alapvető előnye a konvolúciós hálózatokkal szemben, amelyek korlátozott receptív mezővel rendelkeznek, amelyet a kernelméret és a hálózati mélység határoz meg.
Szemantikus szegmentáláshoz a ViT törzshálózatokat hierarchikus keretrendszereken belül használják (mint a Swin Transformer, amely eltolt ablakokon belül alkalmaz önfigyelmet a számítási hatékonyság érdekében), vagy konvolúciós dekódolókkal kombinálják. A SegFormer architektúra egy kifejezetten szegmentáláshoz tervezett hierarchikus ViT változatot használ, míg a SETR (Segmentation Transformer) egy szabványos ViT-t használ progresszív felskálázó dekódolóval.
A ViT-alapú szegmentálási modellek általában magasabb pontosságot érnek el nagy adatkészleteken (a törzshálózat előtanításához >10 millió tanítási kép szükséges), de lényegesen több tanítási adatot és számítási erőforrást igényelnek, mint a konvolúciós törzshálózatok. Korlátozott annotált adatokkal rendelkező infrastruktúra-ellenőrzés esetén a konvolúciós törzshálózatok, mint a ResNet és az EfficientNet, továbbra is praktikusabbak maradnak, kivéve ha kiterjedt előtanítás áll rendelkezésre domain-releváns adatokon.
Veszteségfüggvények szemantikus szegmentációhoz
Kereszt-entrópia veszteség
A kereszt-entrópia veszteség az alapvető veszteségfüggvény a szemantikus szegmentációhoz, amely közvetlenül a maximum likelihood becslés elvéből származik. Minden i pixel esetében a p_i(c) prediktált osztályvalószínűség-eloszlást összehasonlítjuk a y_i(c) valós one-hot kódolással (1 a helyes osztályra, 0 az összes többire). A pixelenkénti veszteség: L_i = −Σ_c y_i(c) · log(p_i(c)) = −log(p_i(ĉ)), ahol ĉ a valós osztály.
A teljes veszteség az összes pixel átlaga: L_CE = (1/N) · Σ_i L_i, ahol N a pixelek teljes száma. A kereszt-entrópia differenciálható, konvex a softmax logitekben, és garantálja, hogy a globális minimum megfelel a valódi adateloszlásnak.
A kereszt-entrópia azonban gyengén teljesít osztályegyensúlyhiányos adatokon, ami az infrastruktúra-ellenőrzési felvételek domináns jellemzője. A repedéspixelek jellemzően a képpixelek 0,1%-ától 3%-áig terjednek, az útburkolati jelek 2–5%-ot, a FOD pedig kevesebb mint 0,01%-ot tesz ki. A kereszt-entrópia minden pixelt egyformán kezel, így a gradiensjel túlnyomó része a domináns osztályokból (repedésmentes burkolat, növényzet) származik, és a hálózat megtanulja figyelmen kívül hagyni a kisebbségi osztályokat. A súlyozott kereszt-entrópia ezt úgy kezeli, hogy nagyobb súlyt rendel a kisebbségi osztályokhoz: L_WCE = −(1/N) · Σ_i w(ĉ) · log(p_i(ĉ)), ahol w(c) jellemzően az inverz osztálygyakoriság vagy egy manuálisan hangolt súly.
Dice veszteség
A Dice veszteség közvetlenül optimalizálja a Dice koefficienst (F1 pontszám), a prediktált és valós szegmentáció közötti átfedési mérőszámot. Bináris szegmentáció esetén a Dice koefficiens: Dice = 2|P ∩ G| / (|P| + |G|), ahol P a prediktált pozitív pixelek halmaza, G pedig a valós pozitív pixelek halmaza. A Dice veszteség: L_Dice = 1 − Dice = 1 − (2Σ_i p_i · y_i + ε) / (Σ_i p_i + Σ_i y_i + ε), ahol ε egy simító tag (jellemzően 1e-6) a nullával osztás elkerülésére, p_i a prediktált valószínűség, és y_i a bináris valós címke.
Többosztályos szegmentáció esetén az általánosított Dice veszteség minden osztályra függetlenül kiszámítja a Dice koefficienst, és átlagolja őket (potenciálisan osztálysúlyokkal). A Dice veszteség robusztusabb az osztályegyensúlyhiánnyal szemben, mint a kereszt-entrópia, mert az átfedési régiót (valós pozitívok) a teljes predikció és valós terület arányaként kezeli, nem pedig pixelenként számolva.
Egy, a zadari repülőtéri futópálya repedés-szegmentációjával foglalkozó tanulmány kimutatta, hogy a Dice veszteség használata 5,9 százalékponttal javította a repedésosztály IoU-ját a súlyozott kereszt-entrópiához képest, míg a kombinált Dice + Focal veszteség további 2–3%-kal javította a határpontosságot.
Focal veszteség
A Focal veszteséget, amelyet Lin és munkatársai vezettek be a Facebook AI Research-nél (2017) sűrű objektumdetekcióhoz, kifejezetten szélsőséges osztályegyensúlyhiányra tervezték. A standard kereszt-entrópiát egy (1 − p_t)^γ modulációs tényező hozzáadásával módosítja, ahol p_t a valós osztály prediktált valószínűsége, γ ≥ 0 pedig a fókuszálási paraméter: L_Focal = −(1/N) · Σ_i (1 − p_t)^γ · log(p_t).
Ha γ = 0, a Focal veszteség kereszt-entrópiává redukálódik. A γ növekedésével a modulációs tényező csökkenti a jól osztályozott példák (magas p_t) súlyát, és a képzést a nehéz, rosszul osztályozott példákra (alacsony p_t) fókuszálja. Repedés-szegmentációhoz, ahol γ jellemzően 2-re van állítva, egy 0,9 prediktált valószínűségű pixel (jól osztályozott háttér) (1−0,9)^2 = 0,01-szeres veszteségsúlyt ad a standard kereszt-entrópiához képest, míg egy 0,3 prediktált valószínűségű repedéspixel (nehéz példa) (1−0,3)^2 = 0,49 veszteségsúlyt ad — ami 49× nagyobb figyelmet jelent a nehéz példára a könnyűhöz képest.
A Focal veszteség különösen hatékony a FOD-detekcióban repülőtéri felvételeken, ahol a FOD-tárgyak a pixelek 0,001–0,1%-át foglalják el, de biztonságkritikus osztályt képviselnek. A kombinált Dice + Focal veszteség (L = α·L_Dice + β·L_Focal, α és β jellemzően 0,5–1,0 között) a leggyakoribb veszteségformuláció az infrastruktúra-ellenőrzésben, egyesítve a Dice átfedés-optimalizálását a Focal nehézpélda-fókuszálásával.
Boundary veszteség
A Boundary veszteség a régió-alapú veszteségek (Dice, IoU) egy korlátját kezeli: optimalizálják a térfogati átfedést, de nem büntetik kifejezetten a határhibákat. Repedés-szegmentáció esetén, ahol a határpontosság határozza meg a repedésszélesség-mérés pontosságát, a határok optimalizálása kritikus.
A Boundary veszteség egy távolságtranszformációt számít a valós szegmentációs határon, és megszorozza a prediktált valószínűségi térképet a távolsággal súlyozott határtérképpel: L_Boundary = Σ_i D(i) · |p_i − y_i|, ahol D(i) az i pixel távolsága a legközelebbi valós határpixeltől (jellemzően egy maximális távolságra csonkítva, pl. 5–10 pixel). A határokhoz közeli pixelek (kis D) magas súlyt kapnak, míg a belső pixelek (nagy D) elhanyagolható súlyt kapnak.
A Hausdorff-távolság veszteség (HD loss) egy rokon formuláció, amely minimalizálja a prediktált és valós határok közötti maximális távolságot, arra ösztönözve a prediktált határt, hogy egyetlen ponton se térjen el messze a valódi határtól. A Dice veszteséggel kombinálva a Boundary veszteségről kimutatták, hogy 15–25%-kal javítja a repedésszélesség-mérés pontosságát a Dice veszteséghez képest, a prediktált és valós repedésszélesség közötti átlagos abszolút hiba alapján mérve.
Veszteségfüggvény
Képletforma
Legjobb használat
Korlát
Kereszt-entrópia
−log(p_c)
Kiegyensúlyozott osztályok, alapvonal
Gyenge kiegyensúlyozatlan teljesítmény
Súlyozott kereszt-entrópia
−w(c)·log(p_c)
Mérsékelt egyensúlyhiány
Rögzített súlyok, nincs nehézpélda-fókusz
Dice
1 − 2
P∩G
/(
Focal
−(1−p_t)^γ·log(p_t)
Szélsőséges egyensúlyhiány
Két hiperparaméter (γ, α)
Dice + Focal
α·L_Dice + β·L_Focal
Infrastruktúra-ellenőrzés (szabvány)
α, β hangolást igényel
Boundary
Σ D(i)·
p_i−y_i
Tréningadatok szemantikus szegmentációhoz
Pixel-szintű annotációs követelmények
A szemantikus szegmentációs modellek betanításához pixel-szintű valós annotációk szükségesek — minden pixelnek minden egyes tréningképen osztálycímkével kell rendelkeznie. Ez a legmunkaigényesebb és legköltségesebb aspektusa a szegmentációs modell fejlesztésének az infrastruktúra-ellenőrzésben. Egyetlen 1920×1080-as kép több mint 2 millió pixelt tartalmaz, amelyek mindegyike annotációt igényel, és egy tipikus tréningadatkészlet a burkolatrepedés-szegmentációhoz 500–5000 képet tartalmaz.
Annotációs eszközök pixel-szintű szegmentációhoz:
A LabelMe (MIT CSAIL) egy nyílt forráskódú, sokszög-alapú annotációs eszköz, amely webböngészőben fut. Az annotátorok sokszögeket rajzolnak a kívánt objektumok (repedések, kátyúk, jelzések) köré, és az eszköz kitölti a sokszög belsejét a hozzárendelt osztálycímkével. Repedések annotálásához, ahol a repedések vékonyak és elágazóak, a sokszög rajzolás rendkívül időigényes lehet — egyetlen 1000 pixel hosszúságú repedés akár 50–200 sokszögcsúcsot is igényelhet a pontos nyomon követéshez.
A CVAT (Computer Vision Annotation Tool), amelyet az Intel fejlesztett, támogatja mind a sokszög, mind az ecset-alapú annotációt. Az intelligens ecset (interaktív szegmentációs eszköz a Deep Extreme Cut algoritmus alapján) lehetővé teszi az annotátorok számára, hogy pozitív és negatív kattintásokat helyezzenek el egy képen az automatikus szegmentáció irányításához, amely manuálisan finomítható. Burkolatrepedések esetén az intelligens ecset 40–60%-kal csökkenti az annotációs időt a kézi sokszög rajzoláshoz képest.
A Supervisely AI-asszisztált annotációt biztosít előre betanított szegmentációs modellekkel, amelyek interaktívan finomhangolhatók. Az annotátorok egy durva karcolást vagy határolókeretet alkalmazhatnak, és a modell generál egy kezdeti szegmentációt, amely iteratív korrekciókkal finomítható. Repedés adatkészletek esetén ez a megközelítés 30–90 másodpercre csökkenti az annotációs időt képenként tapasztalt annotátorok számára, szemben a kézi sokszög-annotáció 5–15 percével.
Repedés összefüggősége: A vékony, elágazó repedések folyamatos jellemzőkként történő annotálása hézagok vagy megszakítások nélkül, amelyek megzavarnák a szegmentációs modellt a repedés topológiájában
Határpontosság: A repedésélek szub-pixel pontosságú (±1–2 pixel) annotálása, hogy a modell pontos repedésszélesség-méréseket produkáljon
Osztály kétértelműség: A repedés és nem-repedés felületi jellemzők megkülönböztetése — a tömített repedések (tömítőanyaggal kitöltve) vizuálisan hasonlíthatnak a környező burkolatra, az árnyékélek összetéveszthetők repedésekkel, és az építési hézagok betonban lehetnek hibák vagy nem
Annotátorok közötti egyetértés: Különböző annotátorok eltérő szegmentációs maszkokat készítenek ugyanarra a képre; Cohen-féle kappa vagy IoU méréssel az annotátorok között, a repedés-szegmentáció tipikus egyetértése IoU = 0,65–0,80 között van, ami a modellel elérhető teljesítmény felső határát jelenti
Adatbővítés szegmentációhoz
Az adatbővítés elengedhetetlen a robusztus szegmentációs modellek betanításához, különösen korlátozott annotált adatkészletek esetén (gyakori korlát az infrastruktúra-ellenőrzésben, ahol a címkézés költséges). A bővítés növeli az effektív adatkészlet méretét és javítja az általánosítást a megvilágítás, felületi textúra, kameraszög és burkolatállapot változásaira.
Geometriai bővítések megváltoztatják a kép és a szegmentációs maszk térbeli elrendezését együtt:
Véletlenszerű forgatás (−180° és +180° között): A repedéseknek nincs kanonikus orientációja a burkolatfelületeken, ezért a forgatási invariancia kritikus
Véletlenszerű vízszintes/függőleges tükrözés: Megduplázza az effektív adatkészlet méretét
Véletlenszerű skálázás (0,5× és 2,0× között): Különböző repülési magasságokat és talaj-mintavételi távolságokat szimulál
Véletlenszerű kivágás: Részleteket nyer ki nagyobb képekből, lehetővé téve a modell számára a lokális textúramintákból való tanulást
Rugalmas deformáció: Ellenőrzött véletlen elmozdulási mezőket alkalmaz a képre és a maszkra egyidejűleg, szimulálva a burkolatfelületek hőtágulásból és forgalmi terhelésből eredő nem merev deformációit
Fotometriai bővítések a pixelintenzitásokat módosítják a térbeli szerkezet megváltoztatása nélkül:
Fényerő és kontraszt beállítás (±20%): Különböző megvilágítási körülményeket szimulál a borús égbolttól a közvetlen napfényig
Gauss-zaj hozzáadása (σ = 0,01–0,03): Érzékelőzajt szimulál magasabb ISO-beállításoknál vagy alacsonyabb minőségű kameráknál
Gauss-életlenítés (σ = 0,5–1,5 pixel): Különböző kameratávolságokból eredő defókuszt vagy mozgáséletlenítést szimulál
Szín vibrálás: Enyhe eltérések a színárnyalatban, telítettségben és értékben, amelyek nem változtatják meg a szemantikus tartalmat
Speciális bővítések burkolat-ellenőrzéshez:
Árnyékszintézis: Szintetikus árnyékminták hozzáadása a repülőgépekből, épületekből vagy világítási infrastruktúrából származó árnyékok szimulálására, amelyek részben eltakarhatják a repedéseket
Víz/olajfolt szimuláció: Lokális színváltoztatások hozzáadása a felületi szennyeződés szimulálására, amely megváltoztatja a burkolat megjelenését anélkül, hogy megváltoztatná a hiba állapotát
JPEG tömörítés szimulációja: A képátviteli rendszerekből származó tömörítési műtermékek szimulálása, amelyek ronthatják a repedésél láthatóságát
Adatkészlet méretkövetelmények
A hatékony szemantikus szegmentációhoz szükséges tréningképek száma a feladat összetettségétől, az osztályeloszlástól és az előre betanított kódoló súlyok elérhetőségétől függ. Burkolatrepedés-szegmentációhoz ImageNet-en előre betanított kódolókkal (ResNet-50, EfficientNet-B3) történő transzfer tanulás esetén:
500–1000 annotált kép: IoU = 0,65–0,75 repedésre, alkalmas kvalitatív repedéstérképezéshez és PCI súlyosságbecsléshez
1000–3000 annotált kép: IoU = 0,75–0,82 repedésre, alkalmas automatizált repedésszélesség-méréshez és rutinszerű állapotfelméréshez
3000–10 000 annotált kép: IoU = 0,82–0,88 repedésre, szükséges szabályozási szintű jelentéskészítéshez és szub-pixel repedésszélesség-becsléshez
10 000+ annotált kép: IoU = 0,88+ repedésre, szükséges az emberi ellenőrzés nélküli autonóm ellenőrzéshez
Többosztályos szegmentáció esetén (repedés, jelzés, burkolattípus, FOD, növényzet) a szükséges adatkészlet mérete osztályonként körülbelül 2–3×-esére nő, mivel a modellnek meg kell tanulnia megkülönböztetni a vizuálisan hasonló felületi jellemzőket.
Többosztályos szegmentáció út- és repülőtéri jelenetekhez
Osztálytaxonómia repülőtéri burkolatokhoz
A többosztályos szemantikus szegmentáció repülőtéri és úti burkolatjelenetekhez megköveteli egy olyan osztálytaxonómia meghatározását, amely lefedi az állapotfelmérés, biztonsági értékelés és karbantartási tervezés szempontjából releváns összes felületi jellemzőt. Az ASTM D5340 (Standard vizsgálati módszer repülőtéri burkolatállapot-index felmérésekhez), az ICAO Annex 14 követelményei és a gyakorlati ellenőrzési munkafolyamatok alapján egy átfogó taxonómia a repülőtéri burkolat szegmentációjához a következőket tartalmazza:
Osztály
Leírás
Tipikus pixeltört
PCI relevancia
Nem repedt burkolat
Hibamentes burkolatfelület
75–92%
Alapérték (nincs levonás)
Hosszirányú repedés
Burkolat középvonalával párhuzamos repedések
0,5–3%
Súlyosságfüggő levonás
Keresztirányú repedés
Középvonalra merőleges repedések
0,3–2%
Súlyosságfüggő levonás
Hálózatos/tömb repedés
Összefüggő, sokszögeket alkotó repedések
1–8%
Magas levonási értékek
Szélrepedés
Repedések a burkolat szélétől 0,6 m-en belül
0,1–0,5%
Közepes levonás
Fugakipergés (beton)
Törés a betonburkolat fugáinál
0,5–2%
Magas levonás
Saroktörés (beton)
Átlós törés a födémsaroknál
0,1–0,5%
Magas levonás
Kipergés
Aszfaltfelületből való anyagvesztés
1–5%
Közepes levonás
Foltozás
Javított burkolati terület
1–10%
Alacsony-közepes levonás
Burkolati jelzés
Festék, hőre lágyuló vagy szalag jelzések
3–8%
Nem közvetlen PCI levonás
Gumi lerakódás
Gumiabroncs gumifelhalmozódás a leszállási zónában
1–5%
Súrlódással kapcsolatos
Növényzet
Fű, gyomok repedéseken/széleken áttörve
0,5–3%
Szélvízelvezetési probléma
FOD
Idegen tárgyak a felületen
0,001–0,1%
Biztonságkritikus
Tömített repedés
Korábban tömítőanyaggal kitöltött repedés
0,3–2%
Tömítés állapotától függ
Kátyú
Lokalizált burkolatfelületi bemélyedés
0,01–0,5%
Magas levonás, biztonságkritikus
Az osztályeloszlás rendkívül kiegyensúlyozatlan: a nem repedt burkolat dominál a pixelek 75–92%-ával, míg a FOD kevesebb mint 0,1%-ot foglal el. Ez az egyensúlyhiány speciális veszteségfüggvényeket (Dice + Focal) és olyan tréningstratégiákat tesz szükségessé, mint az osztálytudatos mintavételezés (a kisebbségi osztályokat tartalmazó minicsomagok túlmintavételezése) vagy az online nehéz példa bányászat (a legmagasabb veszteségű tréningminták kiválasztása gradiens frissítésekhez).
Osztályegyensúlyhiány mérséklése
A veszteségfüggvény választáson túl számos tréningstratégia mérsékli az osztályegyensúlyhiányt a többosztályos burkolat-szegmentációban:
Osztálysúlyozott mintavételezés beállítja az egyes tréningrészletek kiválasztásának valószínűségét, hogy a kisebbségi osztályok egy minimális gyakorisággal legyenek képviselve. A repedés, FOD vagy kátyú pixeleket tartalmazó részletek 3–10×-esen túlmintavételezettek a csak nem repedt burkolatot tartalmazó részletekhez képest. A megvalósítás jellemzően egy prioritási sort tart fenn a tréningrészletekből, a kisebbségi osztályok jelenléte alapján rangsorolva.
Fokális moduláció a veszteségfüggvényben osztály-specifikus fókuszálási paramétereket alkalmaz: magasabb γ értékeket a többségi osztályokhoz és alacsonyabb γ-t a kisebbségi osztályokhoz, biztosítva, hogy a modell több tanulási kapacitást fordítson a ritka, de kritikus hibás osztályokra.
Kétlépcsős tréning először egy osztályban kiegyensúlyozott részhalmazon tanítja a modellt, ahol a kisebbségi osztályok a teljes pixelek 20–30%-ára vannak túlmintavételezve, majd finomhangolja a teljes adatkészleten az eredeti osztályeloszlással. Ez a megközelítés megakadályozza, hogy a modell egy triviális megoldáshoz konvergáljon, ahol minden pixelt háttérként osztályoz.
Repedés szemantikus szegmentáció
Speciális megközelítések repedésdetekcióhoz
A repedés szemantikus szegmentáció olyan egyedi kihívásokat vet fel, amelyek megkülönböztetik az általános célú szegmentációtól: a repedések a képpixelek nagyon kis hányadát foglalják el (0,1–3%), magas oldalarányúak, szélsőséges megnyúlással (szélesség-hossz arány 1:100 és 1:1000 között), alacsony kontraszttal rendelkeznek a környező burkolatfelülethez képest, és vizuálisan hasonlítanak nem-repedés jellemzőkre, mint az árnyékok, építési hézagok és felületi textúra-változatok.
A DeepCrack (Zou et al., 2019) volt az egyik első mélytanuló architektúra, amelyet kifejezetten repedés-szegmentációra terveztek. Módosított SegNet kódoló-dekódolót használ többléptékű jellemzőfúzióval és oldalkimeneti rétegekkel, amelyek több dekódolási szakaszban produkálnak predikciókat. A végső predikció az összes oldalsó réteg kimeneteinek fúziójával jön létre, lehetővé téve a hálózat számára, hogy a repedéseket egyszerre több léptékben ragadja meg — vékony hajszálrepedéseket a korai dekódoló szakaszokból és szélesebb szerkezeti repedéseket a későbbi szakaszokból.
A CrackU-Net (Liu et al., 2021) a standard U-Net-et a következőkkel bővíti: (1) figyelmi kapuk az ugró kapcsolatokban, amelyek súlyozzák a jellemzőtérképeket a repedésrégiók térbeli relevanciája alapján, elnyomva a háttérjellemzőket és erősítve a repedésjellemzőket; (2) mély felügyelet, amely veszteségszámítást alkalmaz több dekódoló szakaszban, gradiensjeleket biztosítva több léptékben; és (3) tágított konvolúció a szűk keresztmetszetben a receptív mező kiterjesztésére felbontásvesztés nélkül. A CrackU-Net 0,78–0,84 közötti repedés IoU-t ér el benchmark burkolati adatkészleteken.
A CrackTransformer (Chen et al., 2022) hibrid CNN-transzformer architektúrát alkalmaz kifejezetten repedés-szegmentációhoz. Egy ResNet-50 kódoló kinyeri a kezdeti jellemzőtérképeket, amelyeket aztán egy transzformer kódoló dolgoz fel 8 önfigyelmi fejjel, amely a repedésszegmensek közötti hosszú távú függőségeket modellezi. A vizuálisan szétkapcsolt (megvilágítási változatosság vagy felületi szennyeződés miatt), de ugyanahhoz a fizikai repedéshez tartozó repedések az önfigyelmen keresztül összekapcsolhatók, javítva a kapcsolódási teljességet — egy mérőszámot, amely azt méri, hogy a valós repedéspixelek mekkora hányada a kapcsolódó komponensekben helyesen van prediktálva.
Vékony repedések kihívásai
A 2–3 pixelnél keskenyebb repedések alapvető kihívást jelentenek a konvolúciós neurális hálózatokon alapuló szemantikus szegmentáció számára, amelyek lesamplinget alkalmaznak. Egy szabványos, 5 lesampling szinttel és 1/32 kimeneti léptékkel rendelkező kódoló a 3 pixel szélességű vagy annál keskenyebb repedéseket egyetlen pixelként vagy annál kisebbként ábrázolja a legmélyebb jellemzőtérképeken — ami elégtelen a megbízható detektáláshoz.
Megoldások vékony repedések szegmentálására:
Minimális talajmintavételi távolság (GSD) korlátozás: A bemeneti felvételek GSD-jének teljesítenie kell a GSD ≤ W_min / 3 feltételt, ahol W_min a minimálisan detektálható repedésszélesség. 0,3 mm-es hajszálrepedések detektálásához a felvételeket ≤0,1 mm/pixel GSD mellett kell rögzíteni, ami tipikus nagy felbontású kamerákkal 3–8 m repülési magasságot igényel. Üzemszerű 1 mm-es repedésvizsgálathoz GSD ≤ 0,33 mm/pixel szükséges.
Szubpixeles repedésdetektálás a folytonos repedésvalószínűségi térképet használja (a 0,5-ös küszöbölés előtt) a repedés szubpixeles felbontású jelenlétének becslésére. A repedés középvonala szubpixeles szinten kerül kinyerésre Gauss- vagy kvadratikus függvény illesztésével a repedésirányra merőleges valószínűségi profilra, 0,1–0,3 pixel pontossággal meghatározva a repedés pozícióját.
Többléptékű bemenet a képet több felbontáson dolgozza fel (pl. 0,5×, 1×, 1,5×), és egyesíti az előrejelzéseket. A nagy felbontású ág megőrzi a vékony repedések részleteit, míg a kis felbontású ág kontextust biztosít és csökkenti a zajt. Az U-Net-be integrált Feature Pyramid Networks (FPN) ezt a többléptékű viselkedést egyetlen előrecsatoló feldolgozás során biztosítja.
Kapcsolódás megőrzése
A repedések kapcsolódása — az a topológiai tulajdonság, hogy a repedéspixelek folytonos hálózatokat alkotnak elszigetelt pontok helyett — kritikus fontosságú a repedéstípusok osztályozásához (hosszanti, keresztirányú, alligátor) és a súlyosság értékeléséhez. A szabványos szegmentációs veszteségfüggvények nem kényszerítik ki explicit módon a kapcsolódást, ami gyakran szétkapcsolt repedéstöredékeket eredményez.
Vázalapú veszteség kiszámítja a valós repedésmaszk vázát (medialis tengelyt), és magasabb veszteségi súlyt alkalmaz a vázpixelekre, ösztönözve a modellt a repedés középvonalának helyes előrejelzésére. A váz a repedéspixelek 5–10%-át foglalja el, de a topológiai információ 50%-át hordozza.
Topológiai veszteség perzisztens homológián alapulva a Betti-számok (β₀: kapcsolódó komponensek száma, β₁: lyukak száma) különbségeit bünteti az előrejelzett és a valós repedésmaszkok között. A topológiai veszteséggel tanított modell 30–60%-kal kevesebb szétkapcsolt repedéstöredéket produkál a Dice veszteséghez képest.
Feltételes véletlen mező (CRF) utófeldolgozás egy teljesen kapcsolt CRF-et alkalmaz végső finomítási lépésként. A CRF ösztönzi a hasonló színű és intenzitású szomszédos pixeleket, hogy ugyanazt az osztálycímkét kapják, kitöltve a repedésmaszkok hézagait és simítva a szaggatott határvonalakat. A DenseCRF implementáció (Krähenbühl & Koltun, 2011) általánosan használt utófeldolgozási lépés, amely 5–10%-kal javítja a repedések kapcsolódását, képként 50–200 ms többlet következtetési idő árán.
Repedésszélesség becslése
A szemantikus szegmentáció biztosítja azt a térbeli maszkot, amelyből a repedésszélesség becsülhető. A szélességmérés elengedhetetlen a PCI súlyossági értékeléshez: az ASTM D5340 az átlagos szélesség alapján határozza meg a repedés súlyossági kategóriáit (pl. alacsony súlyosság: <3 mm, közepes súlyosság: 3–6 mm, magas súlyosság: >6 mm aszfalt hosszanti repedések esetén).
A szabványos szélességbecslési folyamat: (1) a repedés középvonalának kinyerése skeletonizációval (iteratív vékonyító algoritmusok, mint Zhang-Suen vagy Medial Axis Transform); (2) minden középvonali pixelre a legközelebbi háttérpixelhez mért euklideszi távolság kiszámítása (távolságtranszformáció); (3) a repedés szélessége az adott pontban a távolságtranszformációs érték 2×-ese. A lokális szélességmérés lehetővé teszi az átlagos szélesség, a maximális szélesség és a szélességeloszlás jelentését minden repedésszakaszra.
Szubpixel pontosságú szélességméréshez a folytonos előrejelzett valószínűségi térképet (a binarizálás előtt) használjuk a bináris maszk helyett. A repedésre merőleges valószínűségi profilra Gauss-függvényt illesztünk, és a szélességet az illesztett Gauss-függvény félértékszélességeként (FWHM) definiáljuk. Ez a megközelítés 0,1–0,3 pixel szélességmérési pontosságot ér el, lehetővé téve a megbízható súlyossági osztályozást akár 0,3 mm-es repedések esetén is 1 mm/pixel felbontású felvételeken.
Felületi típusok szegmentálása
Burkolati anyagok megkülönböztetése
A felületi típus szegmentálása — aszfalt, beton, kavics, tarmac, burkolt és burkolatlan felületek megkülönböztetése ugyanazon a képen belül — egy különálló feladat a hibák szegmentálásától. A felületi típusok jellegzetes spektrális reflexiós, textúra- és térbeli eloszlási mintázatokkal rendelkeznek, amelyeket a szegmentációs modellek megtanulhatnak.
Aszfalt vs. beton megkülönböztetése spektrális és texturális jegyeken alapul:
Aszfaltburkolatok viszonylag egységes sötétszürke megjelenést mutatnak alacsony spektrális varianciával, finomszemcsés textúrával (0,5–5 mm-es adalékanyag), valamint gyakori repedésmintázatokkal és foltozásokkal
Betonburkolatok világosabb szürke színűek, magasabb spektrális varianciával, látható durva adalékanyaggal (10–30 mm), rendszeres időközönként (jellemzően 5–8 m) elhelyezkedő keresztirányú dilatációs hézagokkal és eltérő károsodási mintázatokkal (kirepedezés, vetődés, saroktörés)
Kavicsos felületek magas spektrális varianciát mutatnak a szemcse méretében (2–20 mm), nincsenek repedésmintázatok (kötetlen felület), és laza szemcsés megjelenésűek
Spektrális jellemzők multispektrális felvételekből (RGB + közeli infravörös) javítják a felületi típusok megkülönböztetését. Az aszfalt több NIR sugárzást nyel el, mint a beton (NIR reflexió: aszfalt 5–10%, beton 20–40%), ami egyértelmű spektrális elkülönítést biztosít. A Normalizált Differenciált Vegetációs Index (NDVI) megkülönbözteti a növényzetet (NDVI > 0,3) a burkolati felületektől (NDVI < 0,1). A rövidhullámú infravörös (SWIR) sávok megkülönböztetik az aszfalttípusokat és detektálják a tömítőanyagokat.
Textúra-jellemzők a Szürkeárnyalatos Együttes Előfordulási Mátrix (GLCM) statisztikáiból (kontraszt, dissimilaritás, homogenitás, energia, korreláció), Lokális Bináris Mintázatokból (LBP) és Gabor-szűrő válaszokból számítva kvantitatív textúramértékeket biztosítanak, amelyek javítják a felületi típusok osztályozását. Egy ResNet-50 vagy EfficientNet-B4 hátterű, burkolati felületképeken tanított modell, amely egy további bemeneti csatornát használ az entrópia számára (lokális intenzitásvarianciából számítva), 3–5% mIoU-val javítja a felületi típus osztályozás pontosságát.
Spektrális és Texturális Jellemzők Integrációja
A felületi típust és hibadetektálást kombináló többosztályos szegmentációhoz két architekturális megközelítés elterjedt:
Egylépcsős többosztályos modell C osztályt ad ki, amelyek mind a felületi típusokat, mind a hibákat lefedik (pl. 5 felületi típus × 10 hibatípus = 15 kimeneti osztály). Ez a megközelítés előnyt kovácsol a megosztott jellemzőtanulásból — ugyanazok a jellemzők, amelyek megkülönböztetik az aszfaltot a betontól, segítenek a repedések megjelenésének differenciálásában is ezeken a felületeken. Az osztályhierarchia lehet lapított (minden kombináció külön osztály) vagy hierarchikus (a felületi típus durva léptékben kerül előrejelzésre, a hibák finom léptékben az egyes felületi típusú régiókon belül).
Kétlépcsős folyamat két külön szegmentációs modellt futtat: egy felületi típus osztályozót (gyors, könnyű), amelyet egy adott felületi típusra szakosodott hibaszegmentációs modell követ (pontos, specializált). A felületi típus modell alacsonyabb felbontáson dolgozza fel a teljes képet, azonosítva a burkolati típusú régiókat. Ezután minden régiót a megfelelő, kifejezetten arra a felületi típusra tanított hibamodell dolgoz fel. Ez a megközelítés magasabb típusonkénti pontosságot ér el, de több számítást igényel a következtetéshez (N felületi típus × hibamodell következtetés).
Értékelési Metrikák a Szegmentációhoz
Intersection over Union (IoU)
Az Intersection over Union (IoU), más néven Jaccard Index, a szemantikus szegmentáció elsődleges értékelési metrikája. Egy adott c osztályra az IoU a következőképpen számítható: IoU_c = TP_c / (TP_c + FP_c + FN_c), ahol TP_c a c osztályként helyesen előrejelzett pixelek száma (valós pozitív), FP_c a c osztályként helytelenül előrejelzett pixelek száma (hamis pozitív), FN_c pedig a c osztályba tartozó, de más osztályként előrejelzett pixelek száma (hamis negatív).
A mean IoU (mIoU) átlagolja az IoU-t az összes osztályra. Kiegyensúlyozatlan infrastruktúra-adathalmazok esetén a súlyozatlan mIoU a szabványos jelentési metrika, mert minden osztály egyformán járul hozzá a pixelszámtól függetlenül — egy olyan modell, amely figyelmen kívül hagyja a repedéseket, de helyesen osztályozza az összes nem repedés burkolatot, magas pixelpontosságot (99%), de alacsony mIoU-t (50% egy 2 osztályos modell esetén) érne el.
Dice Együttható (F1 Pontszám)
A Dice együttható megegyezik az F1 pontszámmal, és szorosan kapcsolódik az IoU-hoz: Dice = 2TP / (2TP + FP + FN) = 2TP / (Összes előrejelzett pozitív + Összes valós pozitív). A Dice együttható és az IoU monoton kapcsolatban állnak: Dice = 2IoU / (1 + IoU).
IoU
Dice (F1)
Értelmezés
0,90
0,947
Kiváló — majdnem tökéletes szegmentáció
0,80
0,889
Nagyon jó — megfelelő automatizált PCI-hez
0,70
0,824
Jó — alkalmas támogatott vizsgálatra
0,60
0,750
Mérsékelt — kézi ellenőrzést igényel
0,50
0,667
Elfogadható — csak kvalitatív használatra
0,40
0,571
Gyenge — magas hamis pozitív/negatív arány
Repedésszegmentáció esetén a repedésosztályra vonatkozó 0,70–0,80 Dice megfelelőnek tekinthető automatizált repedéstérképezéshez, míg a Dice > 0,85 szükséges automatizált szélességméréshez és súlyossági osztályozáshoz emberi ellenőrzés nélkül.
Pixelpontosság
A Pixel Accuracy a helyesen osztályozott pixelek arányát méri: PA = Σ TP_c / Σ (TP_c + FP_c). Súlyosan kiegyensúlyozatlan adatok esetén — ahol a nem repedés burkolat a pixelek 95%-át teszi ki — egy olyan modell, amely minden pixelt nem repedésként osztályoz, 95%-os pixelpontosságot ér el 0%-os repedésdetektálás mellett. A pixelpontosság ezért nem ajánlott elsődleges metrikaként infrastruktúra-szegmentációhoz. Csak osztályonkénti metrikák (IoU, Dice, precízió, recall) mellett szabad jelenteni.
Precízió, Recall és Osztályonkénti Metrikák
A Precízió = TP / (TP + FP) a helyes pozitív előrejelzések arányát méri — fontos a vizsgálati erőforrásokat pazarló hamis riasztások minimalizálásához. A Recall = TP / (TP + FN) a tényleges pozitív pixelek helyesen azonosított arányát méri — fontos a biztonságot veszélyeztető nem észlelt hibák minimalizálásához.
A precízió-recall kapcsolatot az előrejelzési küszöbérték szabályozza (jellemzően 0,5 a softmax kimenethez). Infrastruktúra-vizsgálat esetén:
Magas precíziós cél (0,90+): Automatizált PCI jelentéshez használatos, ahol a hamis pozitívok túlbecsülnék a romlást. A küszöb 0,75–0,85-re emelve a bizonytalan előrejelzések kiszűrésére.
Magas recall cél (0,90+): Biztonságkritikus FOD detektáláshoz használatos, ahol a nem észlelt törmelék elfogadhatatlan. A küszöb 0,3–0,4-re csökkentve a marginális detektálások rögzítésére, az összes riasztás utólagos emberi ellenőrzésével.
Határvonal-Értékelés
A határvonal-értékelési metrikák a szegmentáció minőségét az objektumok éleinél értékelik — a legnagyobb kihívást jelentő területen az infrastruktúra-hibák esetén:
Boundary F1 (BF) a precíziót és recall-t számítja ki egy keskeny sávon belül (jellemzően 2–5 pixel) a valós szegmentációs határvonal körül. A magas BF pontszám (0,80+) azt jelzi, hogy az előrejelzett repedéshatárok szorosan illeszkednek a valódi repedésélekhez, ami elengedhetetlen a pontos repedésszélesség-méréshez.
Hausdorff-távolság (HD) a maximális távolságot méri az előrejelzett és a valós határvonalak között: HD = max(max_p min_g d(p,g), max_g min_p d(g,p)), ahol p és g az előrejelzett, illetve a valós határvonalak pontjai. A 95. percentilis Hausdorff-távolság (HD95) robusztusabb a kiugró értékekkel szemben, és általában ezt jelentik repedésszegmentációhoz. A HD95 < 3 pixel egy 1 mm/pixel felbontású képen 3 mm-nél kisebb határvonal lokalizációs hibának felel meg.
Metrika
Képlet
Repedésszegmentáció tipikus értéke
Értelmezés
Repedés IoU
TP/(TP+FP+FN)
0,65–0,85
Pixel-átfedés a valósággal
Repedés Dice
2TP/(2TP+FP+FN)
0,79–0,92
F1 átfedés a valósággal
Pixel Accuracy
Helyes pixelek / Összes pixel
0,95–0,99
Általános helyesség (félrevezető)
Precízió
TP/(TP+FP)
0,75–0,90
Pozitív előrejelzések helyessége
Recall
TP/(TP+FN)
0,70–0,90
Hibák feltárásának teljessége
Boundary F1
BF 2 pixeles sávban
0,60–0,80
Él lokalizáció minősége
HD95 (pixel)
HD 95. percentilis
2–8 pixel
Maximális határvonal-hiba
Üzembe helyezés és Következtetési Sebesség
Modell Optimalizálás Peremhálózati Üzembe Helyezéshez
A szemantikus szegmentációs modellek üzemszerű infrastruktúra-vizsgálathoz történő telepítése megköveteli a pontosság egyensúlyba hozását a következtetési sebességgel és a memóriakorlátozásokkal. A vizsgálati drónok és peremeszközök (NVIDIA Jetson, Google Coral, Intel Neural Compute Stick) korlátozott számítási erőforrásokkal rendelkeznek a felhőalapú GPU-khoz képest.
Modell ritkítás (pruning) eltávolítja a redundáns súlyokat vagy csatornákat a tanított hálózatból. A strukturálatlan ritkítás egyedi súlyokat nulláz ki (50–80% ritkaság elérése <2% pontosságvesztéssel), míg a strukturált ritkítás teljes csatornákat vagy szűrőket távolít el (30–50% csatornacsökkentés). A strukturált ritkítás előnyösebb hardveres telepítéshez, mert közvetlenül csökkenti a számítási műveleteket és a memóriatranszfereket.
Kvantálás csökkenti a súlyok és aktivációk numerikus pontosságát 32-bites lebegőpontosról (FP32) 16-bitesre (FP16) vagy 8-bites egészre (INT8). Az utóképzési kvantálás (PTQ) kalibrálja a modell aktivációs tartományait egy kis kalibrációs adathalmaz segítségével, és INT8-ra konvertál átképzés nélkül — jellemzően 2–3× gyorsulást ér el 1–3% pontosságromlással. A kvantálás-tudatos képzés (QAT) szimulálja a kvantálást a képzés során, lehetővé téve a modell számára, hogy alkalmazkodjon a csökkentett pontossághoz, és a pontosságveszteséget <1%-ra korlátozza.
ONNX Runtime hardveresen optimalizált következtetést biztosít CPU, GPU és NPU háttérrendszereken keresztül. A PyTorch-ból vagy TensorFlow-ból ONNX (Open Neural Network Exchange) formátumba exportált modellek profitálnak a gráfoptimalizálásból (operátorfúzió, konstans összevonás) és a cél-specifikus végrehajtási szolgáltatókból (CUDA NVIDIA GPU-khoz, TensorRT Jetson platformokhoz, OpenVINO Intel hardverekhez).
TensorRT (NVIDIA) további optimalizálást alkalmaz NVIDIA GPU-khoz: kernel automatikus hangolás (a leggyorsabb kernel implementáció kiválasztása minden réteghez), rétegfúzió (szomszédos rétegek egyesítése egyetlen kernellé), precíziós kalibrálás (automatikus FP16/INT8 optimalizálás) és dinamikus tenzor memóriakezelés. Egy PyTorch-ból TensorRT-re FP16 következtetéssel konvertált U-Net modell 3–5× gyorsulást ér el Jetson Orin hardveren.
Valós Idejű Következtetési Követelmények
Üzembe helyezési forgatókönyv
Szükséges átviteli sebesség
Elfogadható késleltetés
Tipikus hardver
Repülés utáni kötegelt feldolgozás
1–10 kép/mp
Percek felmérésenként
Felhő GPU (A10, A100)
Drón peremeszköz következtetés
10–30 kép/mp
<100ms képként
Jetson Orin NX/Nano
Valós idejű FOD detektálás
30+ kép/mp
<30ms képként
Jetson AGX Orin
Okostelefonos vizsgálat
1–5 kép/mp
<500ms képként
Snapdragon/Apple Neural Engine
Sebesség-Pontosság Kompromisszumok
A modellméret, a következtetési sebesség és a szegmentációs pontosság közötti kapcsolat megalapozott skálázási törvényeket követ. Repedésszegmentációhoz 1 mm/pixel felbontású felvételeken:
Modell változat
Háttérhálózat
Paraméterek
Repedés IoU
Következtetés (256² mozaik)
Platform
U-Net tiny
EfficientNet-B0
3,8M
0,72
3 ms
Jetson Nano
U-Net small
ResNet-18
14,3M
0,76
8 ms
Jetson Orin NX
U-Net medium
ResNet-50
34,5M
0,80
18 ms
Jetson Orin NX
U-Net large
ResNet-101
57,4M
0,83
35 ms
Jetson AGX Orin
DeepLabV3+
ResNet-50
40,1M
0,82
22 ms
Jetson AGX Orin
DeepLabV3+
ResNet-101
63,6M
0,84
42 ms
Jetson AGX Orin
SegFormer-B2
MiT-B2
24,5M
0,81
28 ms
Jetson AGX Orin
SegFormer-B3
MiT-B3
44,1M
0,84
45 ms
Jetson AGX Orin
Üzemszerű telepítés esetén egy repülőtéren, amely egy 3 000 m × 45 m-es kifutópályát dolgoz fel 1 mm/pixel GSD mellett (körülbelül 135 000 2048×2048 méretű mozaik), egy U-Net medium modell Jetson Orin NX-en körülbelül 40 perc alatt végzi el a teljes kifutópálya következtetését — ami kompatibilis az éjszakai feldolgozással a másnapi karbantartási döntésekhez. Ugyanez a modell felhő GPU-n 5–8 percre csökkenti a feldolgozási időt.
Mozaikolás és Összeillesztés Nagyméretű Felvételekhez
Az infrastruktúra-vizsgálati felvételek — különösen a drónfelvételekből készült ortomozzikok — általában túl nagyok az egylépéses modell következtetéshez (10 000–500 000 pixel dimenziónként). A mozaikolás (tiling) a képet átfedő foltokra (jellemzően 512×512–2048×2048 pixel) osztja, amelyeket egymástól függetlenül dolgoz fel. Az átfedési régiók (a mozaik méretének 10–25%-a) biztosítják, hogy a mozaikhatárokat keresztező hibák konzisztensen legyenek szegmentálva — az átfedési régiókban az előrejelzések átlagolásra vagy súlyozott keveréssel egyesítésre kerülnek.
Az összeillesztés (stitching) visszaállítja a mozaik előrejelzéseket egy teljes felbontású szegmentációs térképpé. A lineáris átmenetekkel történő sima keverés az átfedési régiókban megszünteti a látható mozaikhatárokat. Az összeillesztett térkép 1 mm/pixel GSD mellett egy 45 m széles kifutópálya esetén 45 000 pixel széles — gondos memóriakezelést igényelve a vizualizációhoz és a downstream elemzéshez.
A TarmacView platformja 0,3–3 mm/pixel GSD közötti mozaikolt szegmentációs előrejelzéseket dolgoz fel, automatikus mozaikméret-választással a rendelkezésre álló GPU memória és modellarchitektúra alapján, zökkenőmentes teljes kifutópálya szegmentációs térképeket előállítva szubpixeles repedéslokalizációs pontossággal.
Gyakran Ismételt Kérdések
A szemantikai szegmentáció egyetlen osztálycímkét rendel minden pixelhez anélkül, hogy különbséget tenne az egyes objektumpéldányok között ugyanazon osztályon belül – minden repedés 'repedés' címkét kap, minden burkolat 'burkolat' címkét. A példányszegmentáció észleli és körülhatárolja az egyes objektumpéldányokat külön-külön, egyedi azonosítókat rendelve minden objektumhoz – repedés #1, repedés #2. A pánoptikus szegmentáció egyesíti mindkét megközelítést: szemantikai címkét rendel minden pixelhez (anyagosztályok, mint burkolat, égbolt, növényzet), és egyidejűleg azonosítja és szegmentálja az egyes objektumpéldányokat (dologosztályok, mint konkrét repedések, kátyúk vagy FOD elemek). Infrastruktúra-ellenőrzés esetén a szemantikai szegmentáció a leggyakrabban használt megközelítés, mivel sok felületi hiba folyamatos, összekapcsolódó régiókat alkot, amelyek nem rendelkeznek jól meghatározott egyedi példányokkal.
Az U-Net egy teljesen konvolúciós kódoló-dekódoló architektúra, amelyet Ronneberger és munkatársai mutattak be 2015-ben biomedikai képek szegmentálására. A kódoló (összehúzó ág) hierarchikus jellemzőket von ki egymást követő konvolúciós és pooling műveletekkel, fokozatosan csökkentve a térbeli felbontást, miközben növeli a csatornamélységet. A dekódoló (kiterjesztő ág) a jellemzőtérképeket visszaméretezi az eredeti bemeneti felbontásra transzponált konvolúciók vagy bilineáris interpoláció segítségével. A legfontosabb újítás a kihagyásos kapcsolatok (skip connections), amelyek a kódoló jellemzőtérképeit közvetlenül összekapcsolják a megfelelő dekódoló réteggel azonos felbontáson, lehetővé téve a dekódoló számára, hogy hozzáférjen a mintavételezés során elvesztett finom térbeli részletekhez. Az U-Net körülbelül 31 millió paramétert tartalmaz egy szabványos implementációban, és továbbra is széles körben használják infrastrukturális repedésszegmentációra kiváló lokalizációs pontossága miatt, korlátozott tanítóadatokkal is.
Az elsődleges kiértékelési metrikák az Intersection over Union (IoU), más néven Jaccard-index, és a Dice-együttható (F1 pontszám). Az IoU a prediktált és a valóság szerinti szegmentációs maszkok átfedésének és uniójának hányadosa: TP / (TP + FP + FN). A Dice-együttható megegyezik az F1 pontszámmal: 2TP / (2TP + FP + FN). A pixelpontosság a helyesen osztályozott pixelek arányát méri, de félrevezető kiegyensúlyozatlan adathalmazok esetén, ahol a nem repedés pixelek dominálnak. Repedésszegmentációnál, ahol a repedés pixelek jellemzően a kép kevesebb mint 1%-át teszik ki, az osztályonkénti IoU és különösen a repedésosztály IoU a legértelmesebb jelentési metrikák. A Boundary F1 pontszám és a Hausdorff-távolság további információt nyújt a szegmentációs határok minőségéről.
A kereszt-entrópia veszteség (cross-entropy loss) a helyes osztály előrejelzett valószínűségének negatív log-likelihoodját számítja ki minden pixelre, átlagolva az összes pixelen. Ez az alap veszteségfüggvény, de rosszul teljesít osztályokban kiegyensúlyozatlan adatokon. A Dice veszteség minimalizálja az 1 - Dice-együtthatót, közvetlenül optimalizálva az átfedési metrikát, és jól kezeli a mérsékelt osztályegyensúlytalanságot. A fokális veszteség (focal loss) egy moduláló tényezőt (1-pᵗ)ᵞ ad a kereszt-entrópiához, csökkentve a könnyű példák súlyát és a nehéz pixelekre összpontosítva a tanítást; hatékony extrém osztályegyensúlytalanság esetén, ahol a repedések a pixelek kevesebb mint 1%-át foglalják el. A határveszteség (boundary loss) távolságtranszformációkat használ a szegmentációs határokon előforduló hibák büntetésére. Hibrid veszteségfüggvényeket (pl. Dice + Focal) gyakran használnak infrastruktúra-ellenőrzésben a több formuláció előnyeinek kombinálására.
A ResNet (Residual Network) a legszélesebb körben használt törzshálózat, elérhető ResNet-18, ResNet-34, ResNet-50, ResNet-101 és ResNet-152 változatokban, a szám a rétegmélységet jelzi. A maradék kapcsolatok (residual connections) kihagyásos kapcsolatokkal lehetővé teszik nagyon mély hálózatok tanítását. Az EfficientNet összetett skálázást (mélység, szélesség, felbontás) használ MBConv blokkokkal, amelyek squeeze-and-excitation (SE) figyelmet tartalmaznak a számítási hatékonyság érdekében. A Vision Transformer (ViT) transzformer önfigyelmet alkalmaz képfoltokra, globális kontextust rögzítve magasabb számítási igények árán. A választás a pontosság-sebesség kompromisszumtól függ: a könnyűsúlyú törzshálózatok (ResNet-18, EfficientNet-B0) alkalmasak valós idejű szélső telepítésre, míg a nehéz törzshálózatok (ResNet-101, ViT-Base) maximalizálják a pontosságot offline elemzéshez.
Automatizálja infrastruktúrája ellenőrzését
Használja a szemantikai szegmentációt pixeltökéletes burkolatállapot-felméréshez, repedésészleléshez és felülettípus-térképezéshez. Platformunk automatizált elemzést biztosít drónfelvételekből, szubmilliméteres repedésméréssel és PCI-kompatibilis jelentésekkel.
Példányalapú Szegmentálás Egyedi Hibák Azonosításához
A példányalapú szegmentálás azonosítja és körülhatárolja az egyes objektum- vagy hibapéldányokat pixeles szinten, egyedi azonosítót rendelve minden repedéshez, ...
A számítógépes látás mesterséges intelligencián alapuló technológia, amely lehetővé teszi a gépek számára, hogy értelmezzék és feldolgozzák a vizuális adatokat....
11 perc olvasás
Artificial Intelligence
Aviation Technology
+3
Sütik Hozzájárulás A sütiket használjuk, hogy javítsuk a böngészési élményt és elemezzük a forgalmunkat. See our privacy policy.