Fuzja danych
Fuzja danych to systematyczny proces integrowania informacji z wielu źródeł—takich jak czujniki, bazy danych i logi—w celu uzyskania bogatszych, dokładniejszych...
6 min czytania
Data Management
Aviation
+3
Augmentacja danych w syntetyczny sposób rozszerza zbiory treningowe poprzez stosowanie transformacji obrazów — obracanie, odbijanie, zmiana nasycenia kolorów, rozmywanie, szum, przycinanie — w celu poprawy odporności modelu na różnice w oświetleniu, orientacji i jakości obrazu. W przypadku inspekcji infrastruktury kluczowe są augmentacje specyficzne dla domeny (transformacje perspektywy, symulacja cieni, efekty pogodowe). Obejmuje strategie augmentacji i ich wpływ na generalizację modelu.
{
Augmentacja danych to metodologia treningowa, która w syntetyczny sposób zwiększa rozmiar i różnorodność oznakowanego zbioru danych poprzez stosowanie kontrolowanych, zachowujących etykiety transformacji do istniejących próbek danych. W aplikacjach wizji komputerowej oznacza to pobranie każdego oryginalnego obrazu i wygenerowanie wielu zmodyfikowanych wersji poprzez geometryczne przekształcenia, manipulacje przestrzenią kolorów, dodawanie szumu lub bardziej złożone procesy generatywne. Rozszerzony zbiór danych — oryginalne obrazy plus ich przekształcone warianty — jest następnie używany do trenowania głębokich sieci neuronowych, wystawiając model na znacznie szerszy zakres warunków wizualnych niż surowe dane terenowe mogłyby zapewnić.
Podstawowym celem augmentacji danych jest poprawa generalizacji modelu — zdolności wytrenowanego modelu do dokładnego działania na danych, których nigdy wcześniej nie widział. Głęboka konwolucyjna sieć neuronowa (CNN) z milionami parametrów może łatwo zapamiętać zbiór treningowy składający się z kilku tysięcy obrazów, ucząc się konkretnych tekstur, wzorców oświetlenia i artefaktów tła tych przykładów, zamiast leżących u ich podstaw sygnatur defektów. To zjawisko, znane jako nadmierne dopasowanie (overfitting), skutkuje wysoką dokładnością treningową, ale słabą wydajnością walidacyjną i testową. Augmentacja danych zapobiega nadmiernemu dopasowaniu, zapewniając, że każda epoka treningowa przedstawia modelowi różnie przekształcone wersje każdego obrazu, uniemożliwiając czyste zapamiętywanie. Model jest zmuszony do uczenia się cech niezmienniczych — wzorców wizualnych, które utrzymują się pomimo transformacji.
Dla modeli inspekcji infrastruktury augmentacja danych jest nie tylko korzystna, ale operacyjnie niezbędna. Rozważmy realia zbierania danych do inspekcji nawierzchni lotniskowych: pojedynczy przegląd pasa startowego przy użyciu kamery zamontowanej na UAV może uchwycić 10 000 obrazów w wysokiej rozdzielczości, ale mniej niż 200 z tych obrazów może zawierać widoczne defekty. Pęknięcia, ubytki, uszkodzenia uszczelnień spoin i wietrzenie powierzchni stanowią łącznie mniej niż 1 procent całkowitej powierzchni nawierzchni w danym momencie. Zebranie zrównoważonego, różnorodnego zbioru defektów we wszystkich możliwych warunkach inspekcji — bezpośrednie światło słoneczne, zachmurzenie, świt, mokra nawierzchnia, sucha nawierzchnia, różne kąty nachylenia kamery, różne wysokości — byłoby zbyt kosztowne i czasochłonne. Augmentacja danych wypełnia tę lukę poprzez symulację pełnego zakresu warunków operacyjnych na podstawie znacznie mniejszego zestawu przykładów zebranych w terenie.
Znaczenie augmentacji jest formalnie uznawane w standardach infrastruktury lotniczej. ICAO Annex 14, Volume I (Projektowanie i eksploatacja lotnisk) wymaga, aby nawierzchnie pasów startowych były utrzymywane w stanie niezagrażającym bezpieczeństwu operacji lotniczych. Systemy inspekcyjne oparte na AI interpretowane zgodnie z tymi standardami muszą wykazywać solidną wydajność w pełnym zakresie operacyjnych warunków oświetleniowych i pogodowych określonych w instrukcji lotniska. Bez kompleksowej augmentacji model inspekcyjny trenowany wyłącznie na suchych, południowych ujęciach nie wykryłby pęknięć zasłoniętych przez cienie, mokre plamy lub nisko padające światło słoneczne — potencjalnie pomijając defekty, które zagrażają skuteczności hamowania i bezpieczeństwu operacyjnemu.
Augmentacja danych działa na poziomie danych, a nie na poziomie architektury modelu, odróżniając się od technik regularyzacyjnych, takich jak dropout, waga decay czy normalizacja batch. Podczas gdy regulatory na poziomie modelu ograniczają zdolność sieci do nadmiernego dopasowania, augmentacja rozszerza dystrybucję danych, aby pełniej pokryć rzeczywistą przestrzeń wejściową. Te dwa podejścia są komplementarne: najlepsze praktyki w potokach inspekcji infrastruktury łączą agresywną augmentację z regularyzacją architektoniczną dla maksymalnej generalizacji.
Augmentacje geometryczne modyfikują przestrzenne rozmieszczenie pikseli w obrazie bez zmiany ich wartości intensywności. Te transformacje symulują zmiany położenia kamery, orientacji, odległości i charakterystyki obiektywu, które występują podczas rzeczywistego zbierania danych inspekcyjnych. Dla inspekcji infrastruktury augmentacje geometryczne są najbardziej wpływową kategorią, ponieważ platformy inspekcyjne — UAV, pojazdy naziemne, ręczne kamery — rejestrują tę samą powierzchnię z bardzo różnych perspektyw.
Augmentacja przez obrót stosuje losowy obrót kątowy do obrazu wejściowego, zazwyczaj w zakresie od -180° do +180° lub ograniczonym do mniejszych zakresów, takich jak ±45° dla konkretnych aplikacji. Przekształcony obraz jest generowany poprzez obrót każdej współrzędnej piksela (x, y) o kąt θ wokół środka obrazu przy użyciu standardowej macierzy obrotu:
x’ = x·cos(θ) - y·sin(θ)
y’ = x·sin(θ) + y·cos(θ)
Dla wykrywania pęknięć na pasach startowych lotnisk i nawierzchniach autostrad augmentacja przez obrót jest kluczowa, ponieważ orientacja pęknięć względem kadru kamery jest dowolna. Podłużne pęknięcie równoległe do osi pasa startowego może wydawać się poziome w jednym fragmencie obrazu i ukośne w innym, w zależności od kąta odchylenia kamery względem kierunku lądowania samolotu. Bez augmentacji przez obrót model może nauczyć się kojarzyć obecność pęknięcia z określoną orientacją kątową, nie wykrywając pęknięć pojawiających się pod innymi kątami. Badania Alomar i in. (2023) pokazują, że augmentacja przez obrót konsekwentnie poprawia dokładność klasyfikacji o 3-8 procent w zbiorach danych defektów konstrukcyjnych w porównaniu do modeli trenowanych bez obrotu.
Optymalny zakres obrotu zależy od symetrii aplikacji. Dla nawierzchni lotniskowych, gdzie pęknięcia rozwijają się zarówno w kierunku podłużnym, jak i poprzecznym względem ruchu samolotów, odpowiedni jest pełny zakres ±180°. Dla inspekcji dźwigarów mostowych, gdzie kamera jest zawsze mniej więcej pozioma, wystarczający może być węższy zakres ±15°. Obrót wprowadza puste obszary brzegowe w rogach obrazu, które muszą być obsłużone jedną z trzech strategii: (1) wypełnianie zerami (wypełnianie brzegów czernią), (2) wypełnianie przez odbicie (odbijanie pikseli krawędziowych) lub (3) wypełnianie najbliższym sąsiadem. Wypełnianie przez odbicie jest preferowane w inspekcji infrastruktury, ponieważ unika wprowadzania sztucznych ciemnych krawędzi, które model mógłby nauczyć się traktować jako cechy pozorne.
Odbicie poziome (lustrzane odbicie lewo-prawo) i odbicie pionowe (lustrzane odbicie góra-dół) to najprostsze augmentacje geometryczne, wymagające jedynie odwrócenia kolejności kolumn lub wierszy pikseli. Odbicie poziome jest stosowane z 50-procentowym prawdopodobieństwem jako domyślne w większości potoków augmentacji i jest uniwersalnie korzystne, ponieważ podwaja efektywny rozmiar zbioru danych, będąc jednocześnie darmowe obliczeniowo — nie wymaga interpolacji.
Dla inspekcji infrastruktury odbicie poziome zachowuje etykietę dla większości typów defektów. Pęknięcie jest pęknięciem niezależnie od tego, czy pojawia się po lewej, czy po prawej stronie obrazu. Jednak niektóre defekty mają asymetrię kierunkową: wykruszanie (utrata kruszywa na krawędziach nawierzchni) występuje preferencyjnie wzdłuż krawędzi nawierzchni, a uskoki (pionowe przemieszczenie w poprzek spoiny) mają kierunkowość związaną z obciążeniem ruchem. W przypadku tych kierunkowych defektów praktyk musi zweryfikować, czy odbita wersja pozostaje ważnym przykładem treningowym.
Odbicie pionowe jest rzadziej używane do inspekcji infrastruktury naziemnej, ponieważ odwraca zgodną z grawitacją orientację obrazu. Pęknięcie na pionowej betonowej ścianie wygląda zasadniczo inaczej po odwróceniu — jednak w przypadku inspekcji nawierzchni, gdzie kamera skierowana jest prosto w dół, odbicie pionowe jest tak samo zachowujące etykietę jak odbicie poziome. W przypadku obrazów z inspekcji mostów, gdzie kamera rejestruje powierzchnie pionowe (dźwigary, filary, przyczółki), należy priorytetowo traktować odbicie poziome nad pionowym.
Losowe przycinanie wybiera prostokątny podobszar obrazu wejściowego i skaluje go do oczekiwanych wymiarów wejściowych sieci. Symuluje to efekt umieszczenia kamery w różnych odległościach od inspekcjonowanej powierzchni — bliższe przycięcia odpowiadają widokom o wyższej rozdzielczości z większą ilością szczegółów, podczas gdy szersze przycięcia pokazują szerszy kontekst.
Standardowa augmentacja losowego przycinania próbkuje obszar przycięcia o powierzchni między min_scale a max_scale (zazwyczaj 0,08 do 1,0 oryginalnej powierzchni obrazu) i proporcjach między min_ratio a max_ratio (zazwyczaj 0,75 do 1,33). Przycięty obszar jest następnie skalowany do stałego rozmiaru wejściowego sieci, na przykład 512×512 pikseli dla typowych modeli segmentacji pęknięć.
Dla inspekcji infrastruktury losowe przycinanie służy podwójnemu celowi. Po pierwsze, zwiększa różnorodność pozycyjną — model trenowany tylko na pełnoklatkowych obrazach może nauczyć się kojarzyć defekty z ich pozycją w kadrze, zawodząc, gdy ten sam defekt pojawi się w innym obszarze kadru. Po drugie, przycinanie ze skalowaniem symuluje różne wysokości i poziomy zoomu inspekcji, co jest kluczowe dla inspekcji opartej na UAV, gdzie wysokość lotu waha się między 10 a 50 metrów w zależności od przepisów i wymogów przeglądu. ICAO Doc 9137, Part 9 (Praktyki utrzymania lotnisk) oraz ICAO Doc 9981 (PANS-Aerodromes) odnoszą się do metod inspekcji, które mogą obejmować zbieranie danych z pojazdów lub ręczne, każde z różnymi polami widzenia. Losowe przycinanie podczas treningu zapewnia generalizację modelu w różnych tych modalnościach rejestracji.
Transformacje perspektywy (zwane również przekształceniami perspektywicznymi lub augmentacją homograficzną) stosują odwzorowanie projekcyjne do obrazu, symulując efekt pochylenia płaszczyzny kamery względem inspekcjonowanej powierzchni. Jest to matematycznie reprezentowane przez macierz homografii 3×3, która mapuje punkty z jednej płaszczyzny na drugą.
Dla inspekcji infrastruktury augmentacja perspektywy jest wyjątkowo ważna, ponieważ rzeczywiste obrazy inspekcyjne rzadko są rejestrowane z idealnie ortogonalnego (nadir) punktu widzenia. Kamery zamontowane na pojazdach rejestrują nawierzchnię pod niewielkim kątem do przodu. Kamery UAV mogą mieć kąty nachylenia 5-20 stopni podczas manewrów drona. Ręczne kamery inspekcyjne różnią się nachyleniem w zależności od wzrostu inspektora i pozycji ramienia. Pęknięcie, które wydaje się liniowe i spójne z widoku nadiru, ulega skróceniu perspektywicznemu i zniekształceniu geometrycznemu pod kątem skośnym. Augmentacja perspektywy trenuje model do rozpoznawania defektów niezależnie od kąta rejestracji.
Stopień zniekształcenia perspektywy jest kontrolowany przez parametr skali zniekształcenia, zazwyczaj ustawiany między 0,05 a 0,3 we współrzędnych znormalizowanych. Wyższe wartości symulują bardziej ekstremalne nachylenia kamery. Dla inspekcji lotniskowej zalecana jest skala perspektywy 0,1-0,2, co odpowiada kątom nachylenia kamery około 5-15 stopni od nadiru.
Transformacje afiniczne łączą skalowanie, ścinanie, obrót i translację w jedną operację macierzy 2×3. W przeciwieństwie do transformacji perspektywy, transformacje afiniczne zachowują równoległość — linie równoległe pozostają równoległe po transformacji. Operację można wyrazić jako:
[x’, y’]² = A · [x, y]² + b
gdzie A to macierz 2×2 kontrolująca obrót, skalowanie i ścinanie, a b to wektor translacji.
Dla inspekcji infrastruktury typowa konfiguracja augmentacji afinicznej obejmuje: translację (±10 procent wymiarów obrazu, symulującą nieprawidłowe ustawienie kadru), skalowanie (0,8x do 1,2x, symulujące zmianę wysokości), ścinanie (±10 stopni, symulujące pochylenie kamery) oraz obrót (±15 stopni). Łączny efekt daje obrazy, które realistycznie symulują zmienność pozycji i orientacji zbierania danych inspekcyjnych, bez konieczności ekstremalnych zniekształceń, które mogłyby wprowadzać nierealistyczne artefakty.
| Typ augmentacji | Typowy zakres | Zastosowanie w infrastrukturze |
|---|---|---|
| Obrót | ±45° do ±180° | Symuluje różne kąty odchylenia kamery względem orientacji pęknięcia |
| Odbicie poziome | 50% prawdopodobieństwa | Podwaja zbiór danych; niezmiennicze dla większości defektów |
| Odbicie pionowe | 50% prawdopodobieństwa | Przydatne dla obrazów nawierzchni z widoku nadiru |
| Losowe przycięcie | skala 0,08-1,0, proporcje 0,75-1,33 | Symuluje różne wysokości i poziomy zoomu inspekcji |
| Perspektywa | skala zniekształcenia 0,05-0,3 | Symuluje nie-nadirowe kąty nachylenia kamery |
| Afiniczne (skala) | 0,8x-1,2x | Symuluje zmiany wysokości platform UAV |
| Afiniczne (ścinanie) | ±5° do ±15° | Symuluje przechylenie i pochylenie kamery |
| Afiniczne (translacja) | ±5% do ±15% | Symuluje zmiany pozycji kadru |
| Afiniczne (obrót) | ±10° do ±30° | Łączone z innymi parametrami afinicznymi |
{
Augmentacje kolorów i fotometryczne modyfikują wartości intensywności pikseli obrazu bez zmiany przestrzennego rozmieszczenia obiektów. Te transformacje symulują różnice w warunkach oświetleniowych — najważniejszym źródle rzeczywistej zmienności w obrazach inspekcji infrastruktury.
Augmentacja jasności liniowo przesuwa wszystkie wartości pikseli poprzez dodanie stałego przesunięcia: I’ = I + δ, gdzie δ jest próbkowane jednolicie z zakresu, np. [-30, +30] w skali 0-255. Symuluje to różnicę między południowym światłem słonecznym (wysoka jasność) a zachmurzonym niebem lub warunkami inspekcji o poranku (niska jasność). Augmentacja kontrastu skaluje wartości pikseli wokół średniej intensywności: I’ = α(I - μ) + μ, gdzie α jest próbkowane z zakresu, np. [0,7, 1,3]. Niższe wartości kontrastu symulują warunki zamglone lub mgliste; wyższe wartości symulują ostre, bezpośrednie światło słoneczne, które tworzy silne cienie.
Dla inspekcji infrastruktury zalecany zakres jasności to ±40 procent, aby pokryć pełne spektrum operacyjnych warunków oświetleniowych określonych w planach oświetlenia lotnisk zgodnie z ICAO Annex 14, Chapter 5 (Pomoce wzrokowe do nawigacji). Oświetlenie krawędzi pasa startowego, oświetlenie podejścia i oświetlenie płyty postojowej tworzą różne poziomy oświetlenia otoczenia, z którymi model inspekcyjny musi sobie radzić.
Przesunięcie odcienia obraca wszystkie kolory pikseli w przestrzeni kolorów HSV (Hue, Saturation, Value) o losowy kąt, typowo ±30° w 360-stopniowym kole kolorów. Regulacja nasycenia mnoży kanał nasycenia przez losowy współczynnik (zazwyczaj 0,5 do 1,5). Te augmentacje symulują efekt różnych stanów powierzchni nawierzchni — suchy asfalt ma niższe nasycenie niż mokry asfalt, starzejący się beton różni się odcieniem od nowego betonu, a osady z gumowych opon tworzą charakterystyczne artefakty kolorystyczne w strefach przyziemienia pasa startowego.
Dla wykrywania pęknięć na nawierzchniach asfaltowych augmentacja odcienia jest szczególnie pomocna, ponieważ kontrast między ciemnym pęknięciem a otaczającą nawierzchnią zmienia się wraz z wilgotnością powierzchni. Suche, włoskowate pęknięcie może mieć minimalny kontrast kolorystyczny z suchym asfaltem, podczas gdy to samo pęknięcie wypełnione wodą po deszczu pojawia się jako wyraźnie zarysowana ciemna linia. Modele trenowane z augmentacją odcienia i nasycenia uczą się wykrywać pęknięcia w tym zakresie kontrastu zależnym od wilgotności.
Color jitter to złożona augmentacja, która jednocześnie losowo reguluje jasność, kontrast, nasycenie i odcień. Standardowa implementacja próbkuje każdy parametr niezależnie: współczynnik jasności w [1-δ_b, 1+δ_b], współczynnik kontrastu w [1-δ_c, 1+δ_c], współczynnik nasycenia w [1-δ_s, 1+δ_s] i obrót odcienia w [-δ_h, +δ_h]. Dla inspekcji infrastruktury zalecane zakresy to δ_b=0,3, δ_c=0,3, δ_s=0,2 i δ_h=0,1.
Color jitter jest wysoce skutecznym regularyzatorem dla modeli wykrywania defektów. Badania nad klasyfikacją pęknięć nawierzchni pokazują, że modele trenowane z kompleksowym color jitter poprawiają dokładność walidacji o 5-12 procent w porównaniu do modeli trenowanych tylko z augmentacjami geometrycznymi. Efekt jest najbardziej wyraźny w przypadku drobnych pęknięć (< 2 mm szerokości), gdzie kontrast pęknięcie-nawierzchnia jest już niski, a dodatkowa zmienność oświetlenia w treningu zmusza model do uczenia się cech opartych na krawędziach, a nie na kolorze.
Augmentacja w skali szarości konwertuje losowy podzbiór obrazów treningowych do jednokanałowej luminancji, usuwając wszystkie informacje o kolorze. Stosuje się ją z niskim prawdopodobieństwem (zwykle 5-10 procent), aby zapewnić, że model nie stanie się nadmiernie zależny od wskazówek kolorystycznych, które mogą nie być obecne we wszystkich warunkach inspekcji. Dla inspekcji infrastruktury konwersja do skali szarości jest szczególnie cenna dla termicznych i bliskiej podczerwieni modalności inspekcyjnych, gdzie obrazy kolorowe nie są dostępne.
Podczas wnioskowania model trenowany z okazjonalnymi obrazami w skali szarości podczas treningu może z łatwością obsługiwać monochromatyczne lub prawie monochromatyczne dane wejściowe bez konieczności replikacji kanałów lub wstępnego przetwarzania. Jest to ważne dla interoperacyjności ze starszymi systemami kamer inspekcyjnych, które mogą rejestrować w trybie skali szarości, lub do analizy historycznych obrazów inspekcyjnych zebranych przed upowszechnieniem się cyfrowych kamer kolorowych.
Augmentacje szumu i rozmycia symulują degradację jakości obrazu, która występuje w rzeczywistym zbieraniu danych inspekcyjnych z powodu ograniczeń czujników, ruchu, błędów ostrości i niekorzystnych warunków środowiskowych.
Augmentacja szumu gaussowskiego dodaje losowe perturbacje wartości pikseli próbkowane z rozkładu normalnego N(0, σ²) do każdego piksela niezależnie. Odchylenie standardowe szumu σ jest zazwyczaj ustawiane między 0,01 a 0,05 dla znormalizowanych wartości pikseli (zakres 0-1). Symuluje to szum śrutowy obecny we wszystkich czujnikach kamer cyfrowych, który wzrasta przy wyższych ustawieniach ISO stosowanych w warunkach inspekcji przy słabym oświetleniu.
Dodawanie szumu gaussowskiego podczas treningu zmusza filtry konwolucyjne modelu do reagowania na leżący u podstaw wzór strukturalny defektu, a nie na wysokoczęstotliwościowe artefakty na poziomie pikseli, które nie są powtarzalne między rejestracjami. Modele trenowane z augmentacją szumu są bardziej odporne na różnice jakości czujników między kamerami inspekcyjnymi — ten sam defekt zarejestrowany kamerą telefonu 12 megapikseli i lustrzanką 50 megapikseli będzie wyglądał inaczej dla modelu nietrenowanego na obrazach zaszumionych.
Augmentacja rozmycia gaussowskiego wykonuje konwolucję obrazu z jądrem Gaussa o rozmiarze k×k i odchyleniu standardowym σ. Symuluje to kilka rzeczywistych warunków: nieostrą rejestrację (kamera nie ustawiła idealnej ostrości na powierzchni nawierzchni), rozmycie ruchowe (pojazd inspekcyjny poruszał się podczas rejestracji obrazów), zamglenie atmosferyczne (para wodna lub cząstki stałe w powietrzu rozpraszają światło i zmniejszają ostrość obrazu) oraz niedoskonałości obiektywu (kurz lub kondensacja na soczewce kamery).
Dla inspekcji infrastruktury zalecane parametry rozmycia gaussowskiego to k ∈ {3, 5, 7} i σ ∈ {0.5, 1.0, 2.0} stosowane z 20-30 procentowym prawdopodobieństwem. Ten zakres obejmuje umiarkowane do znaczącego rozmycie bez czynienia obrazu nierozpoznawalnym. Rozmycie ruchowe można alternatywnie symulować przy użyciu kierunkowego jądra rozmycia, które rozmazuje piksele w określonym kierunku — jest to bardziej realistyczne dla kamer zamontowanych na pojazdach, gdzie kierunek rozmycia jest zgodny z trajektorią pojazdu.
Znaczenie augmentacji rozmycia staje się jasne, gdy weźmie się pod uwagę prędkość inspekcji. Pojazd inspekcyjny poruszający się z prędkością 50 km/h rejestruje obrazy z około 3-5 pikselami rozmycia ruchowego przy typowych czasach otwarcia migawki. Dron inspekcyjny poruszający się z prędkością 10 m/s z kamerą stabilizowaną żyroskopowo może mieć 1-3 piksele rozmycia. Trening z augmentacją rozmycia zapewnia niezawodne działanie modelu w tych różnych prędkościach rejestracji, bez konieczności zwalniania przez operatora inspekcji dla dokładności modelu.
Random Erasing i Cutout to augmentacje skoncentrowane na regularyzacji, które losowo zasłaniają prostokątne obszary obrazu wejściowego. W Cutout, kwadratowa łatka o boku s (zazwyczaj 16-64 piksele dla obrazów 256×256) jest losowo pozycjonowana i wypełniana stałą wartością (zwykle zero lub średnia wartość piksela zbioru danych). Random Erasing zmienia proporcje i wartość wypełnienia zasłoniętego obszaru.
Dla inspekcji infrastruktury te augmentacje symulują zasłonięcie przez ciała obce (FOD) na nawierzchniach lotniskowych — krytyczny problem bezpieczeństwa zgodnie ze standardami ICAO Annex 14. FOD obejmuje luźne kamienie, fragmenty opon, przywieszki bagażowe, narzędzia i inne zanieczyszczenia, które częściowo zasłaniają powierzchnię nawierzchni. Model trenowany z augmentacją Cutout uczy się wykrywać defekty nawet wtedy, gdy części defektu lub otaczającej nawierzchni są ukryte przez zasłaniające obiekty. To bezpośrednio poprawia zdolność modelu do identyfikacji pęknięć i defektów widocznych w szczelinach między zanieczyszczeniami a śladami opon na powierzchniach pasów startowych.
Augmentacje specyficzne dla domeny to transformacje dostosowane do unikalnych cech wizualnych obrazów inspekcji infrastruktury. Te augmentacje wykraczają poza ogólne transformacje wizji komputerowej, aby symulować specyficzne warunki środowiskowe i operacyjne, z którymi spotykają się kamery inspekcyjne.
Cienie na powierzchniach infrastruktury są rzucane przez szeroki zakres obiektów: konstrukcje mostów, bramownice znaków, hangary, budynki terminali, sąsiednie samoloty, ogrodzenia peryferyjne, a nawet sam pojazd inspekcyjny lub UAV. Cienie powodują gwałtowne lokalne zmniejszenie oświetlenia, które może zasłaniać pęknięcia, zmieniać pozorną fakturę nawierzchni i powodować fałszywie pozytywne detekcje krawędzi na granicach cieni.
Augmentacja cieni symuluje to poprzez przyciemnienie losowego obszaru obrazu za pomocą miękkiej maski. Maska jest zazwyczaj wielokątem z rozmytymi krawędziami (rozmycie gaussowskie na masce z σ=10-30 pikseli), który płynnie przechodzi od pełnego oświetlenia do poziomu ciemności cienia. Współczynnik ciemności cienia jest próbkowany między 0,2 a 0,6 (gdzie 0,0 to czerń, a 1,0 to brak zmian). Pozycja, kształt i orientacja cienia są losowane, aby zapobiec kojarzeniu przez model wzorców cieni z konkretnymi obszarami obrazu.
Dla inspekcji mostów w szczególności symulacja cieni jest kluczowa, ponieważ dźwigary mostowe, poprzecznice i zwisy pomostów tworzą złożone wzory cieni, które zmieniają się wraz z kątem padania słońca w ciągu dnia. Standardy inspekcji mostów FHWA wymagają, aby oceny stanu były spójne niezależnie od tego, kiedy inspekcja jest przeprowadzana. Modele z augmentacją cieni utrzymują tę spójność, dostarczając dokładne wykrywanie defektów niezależnie od tego, czy most jest inspekcjonowany o 9:00 (długie cienie) czy o 12:00 (minimalne cienie).
Mokra nawierzchnia dramatycznie zmienia wizualny wygląd defektów powierzchni. Woda wypełnia pęknięcia i puste przestrzenie, przyciemniając je i zwiększając ich kontrast wizualny z otaczającą nawierzchnią. Jednocześnie woda tworzy odbicia spekularne, które wprowadzają jasne refleksy, szczególnie na gładkich powierzchniach asfaltowych. Kałuże i stojąca woda mogą całkowicie zasłonić leżące pod nimi defekty.
Augmentacja deszczu symuluje te efekty poprzez kilka mechanizmów:
Nakładka filmu wodnego — Dodanie półprzezroczystej niebiesko-szarej nakładki do losowych obszarów obrazu z przezroczystością 0,1-0,3, aby symulować cienkie warstwy wody. Generowanie refleksów spekularnych — Dodawanie jasnych eliptycznych lub nieregularnych plam z wysokimi wartościami luminancji (200-250 w skali 0-255), aby symulować światło słoneczne odbijające się od powierzchni wody. Nakładka smug deszczu — Dodawanie kierunkowych wzorów smug, aby symulować deszcz padający podczas rejestracji. Gęstość smug, długość (10-50 pikseli) i kąt (zazwyczaj 0-30° od pionu, w zależności od wiatru) są losowane.
Dla inspekcji nawierzchni lotniskowych augmentacja mokrej nawierzchni jest wymagana przez realizm operacyjny. ICAO Annex 14 oraz FAA AC 150/5320-5D wymagają, aby ocena stanu nawierzchni pasa startowego uwzględniała wpływ wody na tarcie i widoczność defektów. Model inspekcyjny wdrożony w regionie z 100+ dni deszczowych w roku musi działać dokładnie w mokrych warunkach. Trening z augmentacjami deszczu i filmu wodnego zapewnia tę zdolność.
Faktura powierzchni nawierzchni różni się znacząco w zależności od:
Augmentacja zmiany faktury powierzchni stosuje lokalne wzmocnienie kontrastu, lokalną wyrównanie i syntezę tekstury, aby symulować te różnice. Zaawansowane implementacje wykorzystują transfer stylu lub adaptację domeny opartą na CycleGAN do transformacji obrazów między domenami tekstur — na przykład, pobranie obrazu pęknięcia z nowego asfaltu i wygenerowanie wersji, która wygląda jak stary, zwietrzały asfalt.
Badania Krestenitisa i in. (2026) nad inspekcją pasów startowych przy użyciu obrazów z UAV pokazują, że modele augmentowane zmianą faktury powierzchni osiągają 15-20 procent wyższe IoU segmentacji (Intersection over Union) na zróżnicowanych teksturowo zestawach testowych w porównaniu do modeli trenowanych wyłącznie na oryginalnej domenie tekstury. Jest to szczególnie ważne dla sieci nawierzchni lotniskowych, które mogą obejmować pasy startowe, drogi kołowania i płyty postojowe zbudowane z różnych materiałów i w różnym czasie.
{
Polityka augmentacji określa, które transformacje są stosowane, w jakiej kolejności, z jakim prawdopodobieństwem i z jaką wielkością podczas treningu. Wybór polityki znacząco wpływa na wydajność modelu. Istnieją trzy główne kategorie: polityki ręczne, wyszukiwane i losowe.
Polityki ręczne są tworzone ręcznie przez praktyków w oparciu o wiedzę domenową i testy empiryczne. Dla inspekcji infrastruktury typowa ręczna polityka może stosować następującą sekwencję na każdym kroku treningowym:
Polityki ręczne są przejrzyste, interpretowalne i szybkie obliczeniowo — nie wymagają wyszukiwania ani walidacji. Wadą jest to, że mogą nie być optymalne i mogą pomijać korzystne kombinacje augmentacji.
AutoAugment, wprowadzony przez Cubuka i in. (2019) w Google Brain, wykorzystuje uczenie przez wzmacnianie do wyszukiwania optymalnych polityk augmentacji. Proces wyszukiwania działa następująco:
Kontroler RNN proponuje polityki augmentacji, każda składająca się z K podpolityk (zazwyczaj K=5), gdzie każda podpolityka określa 2 operacje z ich wielkościami i prawdopodobieństwami. Polityka jest stosowana do zbioru treningowego, a model potomny jest trenowany i oceniany na zbiorze walidacyjnym. Dokładność walidacji służy jako sygnał nagrody dla kontrolera RNN, który jest aktualizowany przy użyciu Proximal Policy Optimization (PPO) w celu generowania lepszych polityk. Wyszukiwanie zazwyczaj wymaga od 15 000 do 20 000 godzin GPU dla zbiorów danych skali ImageNet.
AutoAugment odkrywa nieintuicyjne polityki, które często przewyższają ręczne projekty. Na przykład polityka ImageNet odkryła, że ShearX/Y i Rotate z wysokim prawdopodobieństwem i umiarkowaną wielkością są wysoce skuteczne, podczas gdy Equalize i Solarize (odwracanie wartości pikseli powyżej progu) poprawiają odporność kolorystyczną. Odkryte polityki przenoszą się między zbiorami danych o podobnych domenach wizualnych — polityka znaleziona na ogólnym zbiorze danych nawierzchni może być zastosowana do konkretnego zbioru danych pasa startowego z dobrymi wynikami.
RandAugment, wprowadzony przez Cubuka i in. (2020), rozwiązuje problem kosztu obliczeniowego AutoAugment poprzez całkowite wyeliminowanie procesu wyszukiwania. Polityka jest zdefiniowana za pomocą zaledwie dwóch parametrów: N (liczba transformacji stosowanych na obraz) i M (globalny parametr wielkości dla wszystkich transformacji).
Na każdym kroku treningowym RandAugment losowo wybiera N transformacji ze stałej puli K operacji (zazwyczaj K=14-17, obejmujących rotate, shear, translate, contrast, brightness, sharpness, solarize, equalize, autocontrast, posterize, color i identity). Wybrane operacje są stosowane sekwencyjnie z wielkością M. Prostota tego podejścia oznacza brak wyszukiwania, brak zbioru walidacyjnego podczas treningu i minimalne dostrajanie hiperparametrów.
Dla inspekcji infrastruktury RandAugment z N=2 i M=10 (w skali wielkości 0-30) służy jako doskonała domyślna konfiguracja. Wyższe wartości N (3-4) i M (15-20) zapewniają silniejszą regularyzację dla większych modeli lub mniejszych zbiorów danych. Badania nad benchmarkami klasyfikacji pęknięć nawierzchni pokazują, że RandAugment osiąga porównywalną lub lepszą wydajność niż AutoAugment, jednocześnie redukując przestrzeń wyszukiwania hiperparametrów z tysięcy godzin GPU do pojedynczego 2D przeszukiwania siatki po N i M.
| Polityka | Koszt wyszukiwania | Parametry | Przydatność dla infrastruktury |
|---|---|---|---|
| Ręczna | Zero | Pełna kontrola na operację | Dobra dla potrzeb specyficznych dla domeny |
| AutoAugment | 15 000+ godzin GPU | Polityka znaleziona przez RL | Doskonała wydajność, wysoki koszt |
| RandAugment | Pomijalny | N (int), M (float) | Doskonała, praktyczna wartość domyślna |
| TrivialAugment | Pomijalny | Pojedynczy parametr siły | Bardzo prosta, konkurencyjna |
| Fast AutoAugment | ~100 godzin GPU | Dopasowanie gęstości | Dobry kompromis |
Wykrywanie pęknięć — zadanie identyfikacji i lokalizacji pęknięć w powierzchniach infrastruktury — jest najlepiej zbadanym zastosowaniem augmentacji danych w domenie inspekcji infrastruktury. Pęknięcia stwarzają unikalne wyzwania, które sprawiają, że augmentacja jest szczególnie wpływowa.
Pęknięcia w powierzchniach betonowych i asfaltowych wykazują następujące właściwości istotne dla projektowania augmentacji:
Wysoki współczynnik kształtu — Pęknięcia są długie i wąskie, ze stosunkiem szerokości do długości często przekraczającym 1:100. Oznacza to, że augmentacje geometryczne, które silnie zniekształcają proporcje (ekstremalne ścinanie, niekwadratowe przycięcia), mogą uczynić pęknięcia nierozpoznawalnymi. Zachowanie liniowości — Większość pęknięć konstrukcyjnych podąża za w przybliżeniu liniowymi lub łagodnie zakrzywionymi ścieżkami, chociaż pękniacja siatkowa tworzy połączone sieci wielokątne. Augmentacje, które przerywają ciągłość liniową (losowe wymazywanie środka pęknięcia, agresywna kompresja JPEG), mogą zniszczyć sygnaturę pęknięcia. Niski kontrast — Drobne pęknięcia (włoskowate poniżej 0,3 mm szerokości) mają minimalny kontrast z otaczającą nawierzchnią — często tylko 5-15 różnic poziomów szarości w 8-bitowym obrazie. Augmentacje kolorów muszą być stosowane ostrożnie, aby nie zatrzeć tego już słabego sygnału. Zależność od tekstury — Pęknięcia są wykrywane jako anomalie względem tekstury tła nawierzchni. Augmentacje, które homogenizują teksturę (nadmierne rozmycie, silna wyrównanie), mogą sprawić, że pęknięcia staną się nieodróżnialne od nienaruszonej nawierzchni.
W oparciu o opublikowane badania i testy empiryczne na zbiorach danych nawierzchni lotniskowych, zalecany jest następujący potok dla modeli wykrywania pęknięć:
Etap 1 — Rdzeń geometryczny: Odbicie poziome (50%), losowy obrót ±45° (30%), losowe przycięcie do 80-95% ze skalowaniem (zawsze). Te augmentacje są zawsze stosowane, ponieważ orientacja i pozycja pęknięcia są zmiennymi zakłócającymi.
Etap 2 — Symulacja oświetlenia: Color jitter z jasnością ±0,3, kontrastem ±0,3, nasyceniem ±0,2, odcieniem ±0,1 (50% prawdopodobieństwa). Symuluje to pełen zakres operacyjnych warunków oświetleniowych.
Etap 3 — Symulacja jakości: Rozmycie gaussowskie σ=0,5-2,0 (25% prawdopodobieństwa), szum gaussowski σ=0,01-0,03 (15% prawdopodobieństwa). Symuluje to zmienność jakości rejestracji.
Etap 4 — Symulacja domenowa: Nakładka cienia z losową maską wielokąta (20% prawdopodobieństwa), symulacja mokrej powierzchni ze zwiększonym nasyceniem i refleksami spekularnymi (15% prawdopodobieństwa). Symuluje to warunki terenowe.
Etap 5 — Regularyzacja: Cutout z rozmiarem łatki 16-32 piksele (10% prawdopodobieństwa). Zapobiega to nadmiernemu dopasowaniu do konkretnych obszarów obrazu.
Ten potok utrzymuje ważność etykiety — pęknięcie pozostaje pęknięciem po wszystkich transformacjach — jednocześnie wystawiając model na ekstremalną zmienność wyglądu.
Klasyfikacja defektów — przypisywanie etykiety kategorycznej do fragmentu obrazu (np. „pęknięcie", „ubytek", „wietrzenie", „nienaruszony") — ma inne wymagania dotyczące augmentacji niż segmentacja na poziomie pikseli.
Zbiory danych defektów infrastruktury są z natury silnie niezrównoważone. Nienaruszona nawierzchnia dominuje w każdym zbiorze danych, podczas gdy poszczególne klasy defektów mogą mieć tylko setki przykładów. Augmentacja danych rozwiązuje ten problem nierównowagi poprzez augmentację świadomą klas: stosowanie bardziej agresywnych lub liczniejszych transformacji do niedoreprezentowanych klas, aby zwiększyć ich efektywną reprezentację w każdej partii treningowej.
Na przykład, jeśli zbiór treningowy zawiera 10 000 obrazów nienaruszonej nawierzchni, 500 obrazów pęknięć i 200 obrazów ubytków, potok augmentacji może być skonfigurowany do stosowania 5 losowo próbkowanych augmentacji do każdego obrazu ubytku (generując 5×200 = 1000 efektywnych przykładów ubytków na epokę), podczas gdy stosuje tylko 1 augmentację do każdego obrazu nienaruszonej nawierzchni. Ta strategia augmentacji świadomej klas poprawia czułość klasyfikatora na rzadkie typy defektów bez konieczności dodatkowego zbierania danych.
Dla klasyfikacji kluczowe jest, aby augmentacje były zachowujące etykietę — przekształcony obraz musi nadal należeć do oryginalnej klasy. Niektóre transformacje mogą zmienić etykietę:
Dla klasyfikacji wielkość augmentacji musi być skalibrowana do minimalnego wykrywalnego rozmiaru cechy każdej klasy defektów. Dla włoskowatych pęknięć (minimalna szerokość ~0,2 mm przy rozdzielczości rejestracji) rozmycie przekraczające σ=2,0 i obroty powyżej ±60° powinny być stosowane ze zmniejszonym prawdopodobieństwem lub wykluczone.
Powierzchnie infrastruktury często wykazują wiele współistniejących typów defektów — obszar z ubytkiem może zawierać pęknięcia, a zwietrzały fragment może mieć uszkodzone uszczelnienie spoiny. Dla klasyfikacji wieloetykietowej augmentacja musi być spójna dla wszystkich etykiet danego obrazu. Ta sama transformacja geometryczna zastosowana do obrazu odnosi się do wszystkich etykiet jednocześnie. Transformacje kolorów i szumu są z natury zachowujące etykietę dla klasyfikacji wieloetykietowej, ponieważ nie zmieniają obecności ani braku żadnego typu defektu.
Związek między augmentacją danych a nadmiernym dopasowaniem jest fundamentalny dla zrozumienia roli augmentacji w głębokim uczeniu.
Nadmierne dopasowanie występuje, gdy model o wysokiej pojemności (wielu parametrach trenowalnych) jest trenowany na zbiorze danych o niewystarczającym rozmiarze lub różnorodności. Model uczy się nie ogólnych wzorców klasy defektów, ale konkretnych układów pikseli, tekstur i artefaktów przykładów treningowych. Matematycznie nadmierne dopasowanie objawia się jako uczenie się przez model zdegenerowanego odwzorowania z wejścia na wyjście, które minimalizuje stratę treningową, ale nie minimalizuje oczekiwanej straty na prawdziwym rozkładzie danych.
Dla modeli inspekcji infrastruktury nadmierne dopasowanie pojawia się typowo po 50-100 epokach treningowych. Dokładność treningowa nadal rośnie w kierunku 100 procent, podczas gdy dokładność walidacyjna osiąga plateau, a następnie spada. Różnica między dokładnością treningową a walidacyjną — luka generalizacji — systematycznie się powiększa. Bez augmentacji ResNet-50 trenowany na 2000 obrazów pęknięć będzie typowo wykazywał lukę generalizacji 15-25 procent. Z kompleksową augmentacją ta luka może być zredukowana do 3-5 procent lub mniej.
Kluczowym mechanizmem, przez który augmentacja zapobiega nadmiernemu dopasowaniu, jest zwiększenie efektywnego rozmiaru zbioru treningowego. Dzięki augmentacji stosowanej w czasie rzeczywistym podczas treningu, każdy obraz jest przekształcany inaczej w każdej epoce. Zbiór treningowy 5000 obrazów z polityką augmentacji, która stosuje 3 losowe transformacje z puli 10 operacji, każda z 5 możliwymi wielkościami, generuje 5000 × 10³ × 5³ ≈ 6,25 miliona odrębnych przykładów treningowych w ciągu 100 epok.
Ta efektywna ekspansja zbioru danych jest szczególnie cenna dla inspekcji infrastruktury, ponieważ:
Augmentacja danych działa jako regularyzator w sensie statystycznego uczenia się. Poprzez rozszerzenie dystrybucji treningowej, augmentacja zmniejsza zdolność modelu do dopasowania szumu w oryginalnym zbiorze danych. Wariancja nauczonych parametrów maleje, ponieważ model musi spełniać ograniczenia z wielu bardziej efektywnie niezależnych przykładów treningowych.
Siła regularyzacji augmentacji jest kontrolowana przez:
Dla modeli inspekcji infrastruktury optymalną równowagę regularyzacji-augmentacji znajduje się poprzez monitorowanie trajektorii straty walidacyjnej. Jeśli strata walidacyjna wzrasta, podczas gdy strata treningowa nadal maleje (nadmierne dopasowanie), wielkość lub prawdopodobieństwo augmentacji powinny zostać zwiększone. Jeśli zarówno strata treningowa, jak i walidacyjna są wysokie (niedostateczne dopasowanie), augmentacja powinna zostać zmniejszona, aby pozwolić modelowi nauczyć się więcej z surowych danych treningowych.
Wdrożenie augmentacji danych w produkcyjnym potoku treningowym wymaga starannych decyzji architektonicznych dotyczących tego, kiedy, gdzie i jak augmentacje są stosowane.
Augmentacja offline wstępnie generuje augmentowane obrazy i zapisuje je na dysku przed rozpoczęciem treningu. Rozszerzony zbiór danych może zawierać 50 000 obrazów pochodzących z 5000 oryginałów poprzez 10 stałych augmentacji na obraz. Trening odbywa się następnie na tym stałym, augmentowanym zbiorze danych.
Augmentacja online stosuje transformacje w czasie rzeczywistym podczas treningu, gdzie każdy obraz jest ładowany z dysku, losowo augmentowany i natychmiast podawany do modelu. Żadne augmentowane obrazy nie są trwale przechowywane.
Augmentacja online jest standardowym podejściem dla produkcyjnych potoków inspekcji infrastruktury, ponieważ:
Koszt obliczeniowy augmentacji online jest minimalny — nowoczesne biblioteki augmentacji z akceleracją GPU (NVIDIA DALI, Kornia lub torchvision PyTorch) stosują transformacje w mikrosekundach na obraz, typowo stanowiąc mniej niż 5 procent całkowitego czasu treningu, gdy ładowanie danych jest potokowane z wykonaniem GPU.
Wybór biblioteki augmentacji wpływa na wydajność, elastyczność i łatwość utrzymania potoku:
Albumentations jest najczęściej używaną biblioteką do inspekcji infrastruktury ze względu na szybkość (zoptymalizowane zaplecze C++ przez OpenCV), kompleksowy zestaw operacji (70+ transformacji) i natywne wsparcie augmentacji dwukanałowej dla masek segmentacji. Albumentations zapewnia, że każda transformacja geometryczna zastosowana do obrazu jest identycznie stosowana do maski, utrzymując zgodność na poziomie pikseli między wejściem a prawdą podstawową.
NVIDIA DALI zapewnia przyspieszone GPU ładowanie danych i potoki augmentacji, które mogą przetwarzać obrazy w całości na GPU, unikając wąskich gardeł transferu CPU-GPU. DALI jest zalecane dla bardzo dużych zbiorów treningowych (10 000+ obrazów), gdzie czas ładowania danych dominuje nad czasem treningu.
torchvision.transforms (PyTorch) i tf.image (TensorFlow) zapewniają wbudowane możliwości augmentacji z dobrą integracją z odpowiednimi frameworkami, ale mają mniej transformacji specyficznych dla domeny (symulacja cieni, perspektywa, losowe wymazywanie) niż Albumentations.
W produkcyjnym potoku treningowym augmentacja jest zintegrowana w następujący sposób:
[Ładowarka obrazów] → [Losowy próbnik] → [Sekwencja augmentacji] → [Normalizacja] → [Losowy próbnik partii] → [Przejście w przód modelu]
Losowy próbnik decyduje, czy każda augmentacja w polityce jest stosowana (na podstawie jej parametru prawdopodobieństwa) i z jaką wielkością za każdym razem. Sekwencja augmentacji stosuje transformacje w ustalonej kolejności: typowo najpierw geometryczne (przycięcie, odbicie, obrót, perspektywa), następnie fotometryczne (color jitter, jasność, kontrast), następnie szum i rozmycie (szum gaussowski, rozmycie gaussowskie), następnie specyficzne dla domeny (cień, deszcz), a na końcu regularyzacja (Cutout).
Podczas walidacji i wnioskowania augmentacja jest redukowana do minimalnych niezbędnych transformacji: typowo tylko przycięcie do środka (lub skalowanie) i normalizacja. Żadne losowe transformacje nie są stosowane podczas oceny, aby zapewnić deterministyczne, powtarzalne wyniki.
Produkcyjne potoki treningowe powinny rejestrować statystyki augmentacji, aby monitorować ich wpływ na dynamikę treningu:
Te metryki monitorowania zapewniają, że augmentacja osiąga zamierzony efekt — rozszerzenie dystrybucji treningowej bez wprowadzania artefaktów lub uprzedzeń, które pogarszają wydajność w rzeczywistych warunkach.
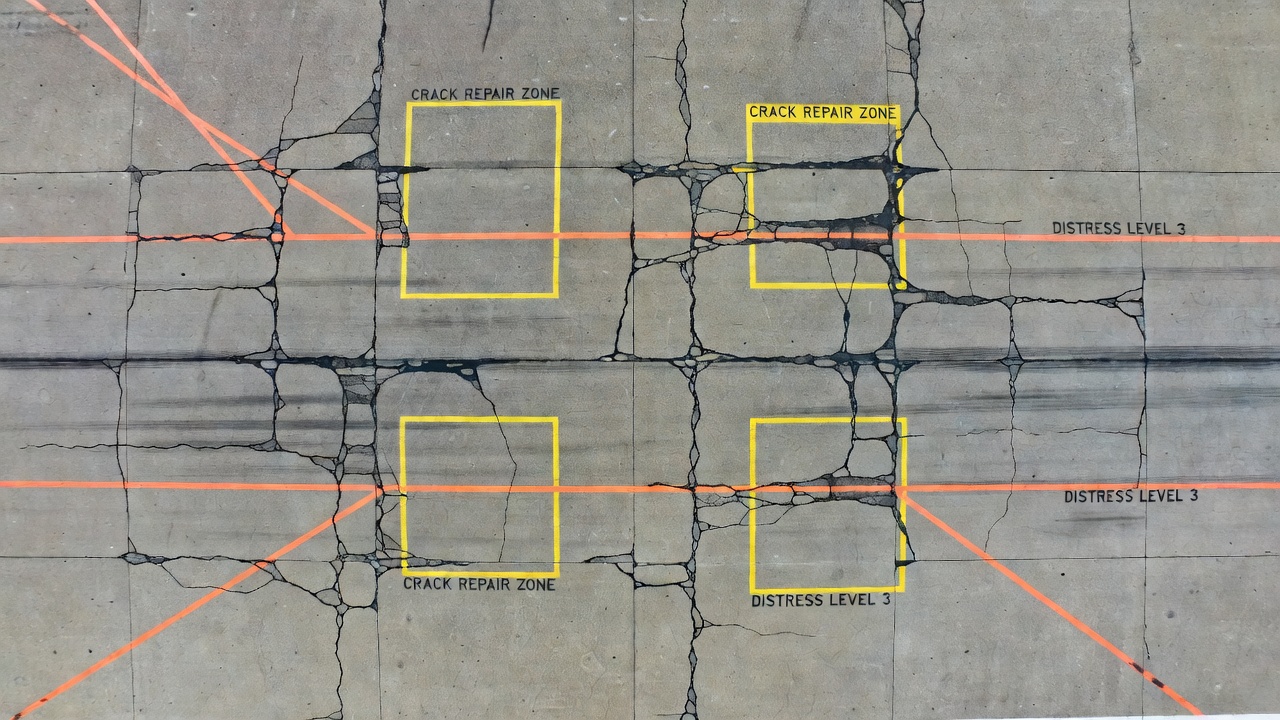
Obraz siatki augmentacji pęknięć betonu pokazuje praktyczne rezultaty działania potoku augmentacji: ten sam oryginalny obraz pęknięcia jest przekształcany w 12+ odrębnych przykładów treningowych poprzez obrót, odbicie, przycięcie, regulację kolorów i rozmycie. Każda augmentowana wersja zachowuje etykietę pęknięcia, prezentując je w wizualnie innym kontekście, ucząc model wykrywania pęknięć niezależnie od orientacji, oświetlenia czy jakości obrazu.
{
TarmacView wykorzystuje zaawansowane potoki augmentacji danych do trenowania modeli inspekcji infrastruktury, które generalizują się na różne warunki oświetleniowe, pogodowe i stanu nawierzchni. Zoptymalizuj trening modeli wykrywania defektów dzięki strategiom augmentacji specyficznym dla domeny, dostosowanym do nawierzchni lotniskowych i konstrukcji betonowych.
Fuzja danych to systematyczny proces integrowania informacji z wielu źródeł—takich jak czujniki, bazy danych i logi—w celu uzyskania bogatszych, dokładniejszych...
Edge computing wykonuje wnioskowanie AI bezpośrednio na dronie, pojeździe lub urządzeniu przenośnym w miejscu przechwytywania danych, umożliwiając wykrywanie de...
Integracja danych łączy dane z różnych źródeł w jeden, spójny i dostępny format do analiz, operacji oraz raportowania. Jest to kluczowe w lotnictwie dla zapewni...