k-Najbliższych Sąsiadów (kNN)
k-Najbliższych Sąsiadów (kNN) klasyfikuje punkt zapytania poprzez głosowanie większościowe wśród jego k najbardziej podobnych punktów referencyjnych w przestrze...
36 min czytania
Machine Learning
Classification
+3
FAISS (Facebook AI Similarity Search) to biblioteka open-source do wydajnego wyszukiwania podobieństw i klastrowania gęstych wektorów, używana przez TarmacView do przechowywania i przeszukiwania około 9 000 oznaczonych referencyjnych embeddingów w celu klasyfikacji jakości powierzchni metodą najbliższych sąsiadów. Obejmuje typy indeksów (Flat, IVF, HNSW), podobieństwo cosinusowe przez iloczyn skalarny na znormalizowanych wektorach, akcelerację GPU oraz zastosowanie w odzyskiwaniu obrazów inspekcyjnych.
FAISS (Facebook AI Similarity Search) to otwartoźródłowa biblioteka C++ opracowana przez zespół Fundamental AI Research (FAIR) w Meta, przeznaczona do wydajnego wyszukiwania podobieństwa i grupowania gęstych wektorów. Wydana po raz pierwszy w 2017 roku, FAISS zdobyła ponad 40 000 gwiazdek na GitHubie oraz ponad 5 200 cytowań artykułu dotyczącego implementacji na GPU. Pakiety FAISS zostały pobrane ponad 6 milionów razy z repozytoriów Conda. Główne firmy zajmujące się bazami wektorowymi, w tym Zilliz (Milvus) i Pinecone, albo opierają się na FAISS jako swoim podstawowym silniku, albo zaimplementowały na nowo algorytmy FAISS w swoich systemach produkcyjnych.
FAISS został zaprojektowany specjalnie do rozwiązania problemu obliczeniowego znajdowania najbliższych sąsiadów w wysokowymiarowych przestrzeniach wektorowych. Podstawową operacją jest wyszukiwanie podobieństwa: mając wektor zapytania q, FAISS identyfikuje wektory w zbiorze referencyjnym, które są najbliższe według określonej metryki odległości. Formalnie, dla zbioru wektorów referencyjnych {x₁, …, xₙ} w wymiarze d, FAISS wydajnie oblicza j = argminᵢ ||q - xᵢ|| gdzie ||·|| jest odległością euklidesową. Biblioteka może również wykonywać wyszukiwanie maksymalnego iloczynu skalarnego argmaxᵢ ⟨q, xᵢ⟩ oraz obsługuje dodatkowe metryki, w tym odległości L1, Linf, Canberry, Braya–Curtisa, Jensena–Shannona i Hamminga poprzez swoje implementacje IndexFlat i IndexHNSW. FAISS zwraca nie tylko pojedynczego najbliższego sąsiada, ale k najbliższych sąsiadów, obsługuje przetwarzanie wsadowe wielu zapytań jednocześnie oraz może wykonywać wyszukiwanie zakresowe, zwracając wszystkie elementy w obrębie zadanego promienia.
Biblioteka operuje na gęstych wektorach — tablicach o stałej długości, zawierających 32-bitowe liczby zmiennoprzecinkowe — które reprezentują punkty danych osadzone w ciągłej przestrzeni wektorowej. Wektory te są zazwyczaj generowane przez głębokie sieci neuronowe, takie jak Vision Transformery (ViT), konwolucyjne sieci neuronowe (CNN) lub duże modele językowe. W nowoczesnych potokach uczenia maszynowego wektory osadzeń służą jako pośrednie reprezentacje, które mapują złożone dane wejściowe do przestrzeni wektorowej, gdzie bliskość koduje semantykę. FAISS jest pomostem między ekstrakcją wektorów osadzeń a zadaniami downstream opartymi na podobieństwie: indeksuje wyodrębnione wektory osadzeń i umożliwia szybkie operacje wyszukiwania.
FAISS jest szeroko zoptymalizowany pod kątem nowoczesnych architektur sprzętowych. Na CPU wykorzystuje biblioteki BLAS (Basic Linear Algebra Subprograms), takie jak Intel MKL, OpenBLAS czy Apple Accelerate, do wykonywania szybkich operacji na macierzach. Obsługuje wektoryzację SIMD (SSE, AVX2, AVX-512) na architekturach x86 oraz intrinsics Neon na procesorach ARM. Na GPU FAISS dostarcza natywne implementacje CUDA, które mogą zapewnić 5–10-krotną poprawę przepustowości w porównaniu do wykonywania na CPU dla typowych obciążeń. Implementacja GPU obsługuje wiele procesorów GPU równolegle, umożliwiając rozproszone wyszukiwanie na kilku urządzeniach jednocześnie.
FAISS nie jest bazą wektorową — jest biblioteką wyszukiwania, którą można osadzić bezpośrednio w aplikacjach. W przeciwieństwie do pełnych systemów bazodanowych (Pinecone, Milvus, Qdrant, Weaviate), FAISS nie zapewnia wbudowanej trwałości, replikacji, kontroli dostępu, współbieżnego dostępu do zapisu, równoważenia obciążenia, shardowania, zarządzania transakcjami ani optymalizacji zapytań. Zamiast tego udostępnia czyste API w językach C++ i Python do budowania, przeszukiwania, zapisywania i ładowania indeksów. To celowe ograniczenie zakresu pozwala FAISS osiągnąć maksymalną wydajność dla podstawowej operacji wyszukiwania najbliższych sąsiadów. Zakres biblioteki jest celowo ograniczony do implementacji algorytmicznej przybliżonego wyszukiwania najbliższych sąsiadów (ANNS) i, jak stwierdza oryginalny artykuł o FAISS: “Faiss nie jest bazą danych — nie zapewnia współbieżnego dostępu do zapisu, równoważenia obciążenia, shardowania, zarządzania transakcjami ani optymalizacji zapytań.”

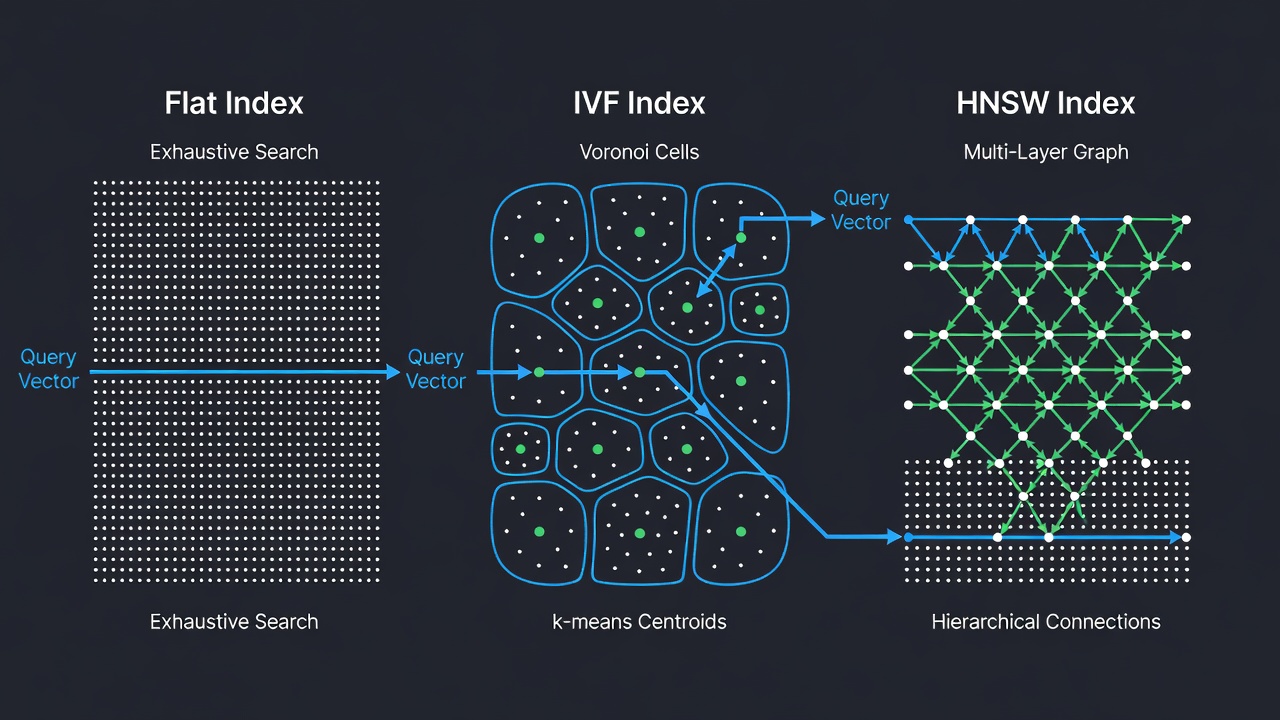
FAISS oferuje ponad dwadzieścia różnych typów indeksów, z których każdy został zaprojektowany dla określonej kombinacji kompromisów między dokładnością, szybkością a zużyciem pamięci. Trzy najbardziej podstawowe i szeroko stosowane typy indeksów to IndexFlat (wyszukiwanie dokładne), IndexIVF (odwrócony plik z grupowaniem k-średnich) oraz IndexHNSW (hierarchiczny nawigowalny graf małych światów). Każdy typ indeksu jest dostępny z różnymi metrykami odległości i wariantami kodowania (np. FlatIP dla iloczynu skalarnego, FlatL2 dla odległości L2). Indeksy FAISS mogą być komponowane hierarchicznie — na przykład używając HNSW jako grubego kwantyzatora dla indeksu IVF, co daje złożoną strukturę IndexIVFPQ, która napędza wdrożenia na miliardową skalę.
IndexFlatIP to najprostszy indeks FAISS. Przechowuje wszystkie wektory w płaskiej tablicy i wykonuje wyczerpujące wyszukiwanie brute-force względem każdego wektora w zbiorze danych. Dla każdego zapytania oblicza iloczyn skalarny między zapytaniem a każdym przechowywanym wektorem, a następnie zwraca indeksy i odległości dla k najlepszych wyników. Ten indeks gwarantuje zwrócenie dokładnych najbliższych sąsiadów — bez przybliżeń, bez degradacji recall. Jest to jedyny indeks FAISS dający taką gwarancję; wszystkie pozostałe indeksy są przybliżone i poświęcają część recallu na rzecz większej szybkości lub mniejszego zużycia pamięci.
Złożoność obliczeniowa IndexFlatIP wynosi O(N × D) na zapytanie, gdzie N to liczba wektorów referencyjnych, a D to wymiarowość. Indeks wykorzystuje wysoce zoptymalizowaną rutynę BLAS gemm (ogólne mnożenie macierzy) do obliczenia wszystkich iloczynów skalarnych w jednym mnożeniu macierzy. Dla zbioru danych składającego się ze 100 000 wektorów o 768 wymiarach (typowy rozmiar wektora osadzeń z DINOv2 ViT), pojedyncze zapytanie na CPU zajmuje około 5–15 milisekund, w zależności od sprzętu i optymalizacji BLAS. W trybie wsadowym z 1000 zapytań indeks przetwarza je wszystkie jednocześnie przy użyciu mnożenia macierz-macierz, osiągając znacznie wyższą przepustowość niż 1000 pojedynczych zapytań.
IndexFlatIP pełni kluczową rolę w ekosystemie FAISS jako oracle ground-truth do oceny dokładności przybliżonych indeksów. Praktycy budują płaski indeks obok swojego przybliżonego indeksu, wykonują identyczne zapytania względem obu i obliczają metryki recall. Standardowy zestaw narzędzi do benchmarkowania FAISS (faiss_benchmarks) wykorzystuje tę metodologię do określenia ilościowego spadku dokładności indeksów IVF, HNSW i PQ. W TarmacView IndexFlatIP jest używany jako odniesienie bazowe do walidacji systemu, zapewniając, że przybliżone indeksy używane w produkcji utrzymują akceptowalny poziom recall.
Indeks jest konstruowany za pomocą minimalnej ilości kodu: index = faiss.IndexFlatIP(d) gdzie d to wymiarowość wektora osadzeń. Wektory dodaje się przez index.add(embeddings). Wyszukiwanie wykonuje się przez index.search(query, k), które zwraca dwie tablice float32: odległości (kształt [n_queries, k]) oraz indeksy (kształt [n_queries, k], dtype int64). Dla iloczynu skalarnego większe wartości odległości oznaczają większe podobieństwo. Indeks nie wymaga kroku uczenia, ponieważ nie ma parametrów do nauczenia — wektory są przechowywane i porównywane w niezmienionej postaci.
IndexIVFFlat to przybliżony indeks najbliższych sąsiadów, który dzieli przestrzeń wektorową na komórki Woronoja przy użyciu klasteryzacji k-średnich. Architektura wywodzi się z przełomowej pracy “Video Google” autorstwa Sivica i Zissermana (ICCV 2003), która zaadaptowała techniki wyszukiwania tekstowego do dopasowywania obiektów wizualnych. Podczas indeksowania zbiór danych jest grupowany w nlist klastrów za pomocą k-średnich, a każdy wektor jest przypisywany do najbliższego centroidu klastra. Centroidy są przechowywane w kwantyzatorze zgrubnym (zazwyczaj IndexFlatL2). Podczas wyszukiwania analizowane są tylko wektory w nprobe najbliższych klastrach względem zapytania, co radykalnie redukuje liczbę wymaganych obliczeń odległości.
Przyspieszenie względem IndexFlatIP wynosi w przybliżeniu N / ((N / nlist) × nprobe) . Przy nlist=100 i nprobe=5 przeszukiwane jest tylko 5% bazy danych — zapytania, które zajmowały 10ms na indeksie płaskim, mogą zostać wykonane w 0,5ms. Ceną za to jest jednak degradacja kompletności (recall): niektóre prawdziwie najbliższe sąsiady mogą znajdować się poza przeszukiwanymi klastrami i zostać pominięte. Etap uczenia k-średnich jest kluczowy dla jakości kompletności — centroidy muszą dokładnie odzwierciedlać rozkład danych. FAISS wymaga, aby zbiór uczący zawierał co najmniej 30 × nlist wektorów dla wiarygodnego oszacowania centroidów.
Kluczowe parametry IndexIVFFlat:
| Parametr | Opis | Typowy zakres | Wpływ |
|---|---|---|---|
| nlist | Liczba komórek Woronoja (klastrów) | 10 – 100 000 | Wyższa = drobniejszy podział, więcej pamięci dla centroidów, wolniejsze uczenie k-średnich |
| nprobe | Liczba komórek przeszukiwanych podczas zapytania | 1 – 100+ | Wyższa = lepsza kompletność (do 99%), liniowo wolniejsze wyszukiwanie |
| metric | Metryka odległości (L2 lub IP) | L2 lub IP | Określa sposób obliczania odległości między wektorami a centroidami |
Parametr nprobe jest szczególnie ważny, ponieważ kontroluje kompromis między szybkością a dokładnością podczas wyszukiwania bez konieczności przebudowy indeksu. W czasie zapytania nprobe można dostosowywać dynamicznie: ustawić wysoką wartość (np. 20–50) podczas krytycznych operacji offline, gdzie najważniejsza jest dokładność, oraz niską wartość (np. 1–5) podczas produkcyjnych przebiegów o wysokiej przepustowości, gdzie priorytetem jest szybkość. FAISS udostępnia mechanizm auto-tuning (AutoTune), który przeszukuje wartości nprobe w celu znalezienia optymalnej konfiguracji dla docelowej kompletności.
Skonstruowanie IndexIVFFlat wymaga trzyetapowego procesu: uczenie, dodawanie i wyszukiwanie. Podczas uczenia k-średnie są uruchamiane na reprezentatywnej próbce w celu poznania centroidów klastrów. Podczas dodawania każdy wektor z bazy jest przypisywany do najbliższego centroidu i dołączany do listy odwróconej tego centroidu. Podczas wyszukiwania zapytanie jest porównywane ze wszystkimi centroidami, wybieranych jest nprobe najbliższych, a tylko wektory z tych wybranych list są porównywane wyczerpująco. Ciąg znaków fabryki (factory string) dla IndexIVFFlat z iloczynem skalarnym to "IVF100,Flat", gdzie 100 to wartość nlist. W Pythonie: index = faiss.index_factory(d, "IVF100,Flat", faiss.METRIC_INNER_PRODUCT).
| Rozmiar zbioru | Zalecane nlist | Zalecane nprobe | Oczekiwana kompletność | Przyspieszenie vs Flat |
|---|---|---|---|---|
| 10 000 | 10 – 100 | 1 – 5 | 95–98% | 5–20× |
| 100 000 | 100 – 1 000 | 5 – 20 | 95–99% | 20–100× |
| 1 000 000 | 1 000 – 10 000 | 10 – 50 | 95–99% | 100–500× |
| 10 000 000 | 10 000 – 100 000 | 20 – 100 | 90–98% | 500–5000× |
IndexHNSWFlat to grafowy przybliżony indeks najbliższych sąsiadów, który konstruuje wielowarstwowy graf hierarchiczny znany jako Nawigowalny Mały Świat. Algorytm, opublikowany pierwotnie przez Malkova i Yashunina (2016), jest inspirowany strukturą danych skip-listy. Indeks organizuje wektory w warstwy: dolna warstwa (warstwa 0) zawiera wszystkie wektory, a każda kolejna warstwa zawiera progresywnie mniejszy podzbiór generowany przez probabilistyczne przypisanie poziomu. Podczas wstawiania każdemu wektorowi przypisywany jest poziom l = floor(-ln(uniform(0,1)) × mL), gdzie mL = 1/ln(M). Punkt wejścia znajduje się na najwyższej istniejącej warstwie, co zapewnia logarytmiczne przechodzenie grafu.
Wyszukiwanie rozpoczyna się od górnej warstwy (najbardziej zgrubnej, z najmniejszą liczbą węzłów) i schodzi w dół przez kolejne warstwy, udoskonalając zbiór kandydatów na każdym etapie. Na każdej warstwie zachłanne wyszukiwanie przechodzi przez graf w kierunku zapytania, zawsze przechodząc do sąsiada, który minimalizuje odległość. Po znalezieniu lokalnego minimum w bieżącej warstwie algorytm schodzi do następnej warstwy i powtarza proces, używając wyniku z warstwy powyżej jako punktu startowego. Ta hierarchiczna struktura umożliwia logarytmiczną złożoność wyszukiwania O(log N), czyniąc HNSW jednym z najszybszych algorytmów przybliżonego wyszukiwania najbliższych sąsiadów dla średnich i dużych zbiorów danych.
Indeks HNSW ma trzy kluczowe parametry:
| Parametr | Opis | Typowy zakres | Wpływ |
|---|---|---|---|
| M | Maksymalna liczba dwukierunkowych połączeń na węzeł | 8 – 64 (domyślnie 32) | Wyższe M = gęściej połączony graf, lepsza kompletność, więcej pamięci |
| efConstruction | Rozmiar dynamicznej listy kandydatów podczas budowy grafu | 40 – 200 (domyślnie 40) | Wyższa = dokładniejsze wyszukiwanie podczas budowy, lepszej jakości graf, wolniejsza budowa |
| efSearch | Rozmiar dynamicznej listy kandydatów podczas wyszukiwania | 10 – 200 (ustawiany w czasie zapytania) | Wyższa = lepsza kompletność, wolniejsze wyszukiwanie (można dostroić bez przebudowy) |
Parametr M bezpośrednio kontroluje łączność grafu. Każdy wektor utrzymuje do M dwukierunkowych krawędzi do swoich najbliższych sąsiadów. Graf stosuje heurystykę wymuszającą różnorodność podczas wyboru sąsiadów: gdy dodawany jest nowy węzeł, jego kandydaci na sąsiadów są przycinani, aby zapewnić różnorodną łączność zapobiegającą dominacji węzłów-hubów w strukturze grafu. Wyższe wartości M zapewniają bardziej niezawodne routowanie, ale zwiększają zużycie pamięci: około 4d + M × 2 × 4 bajty na wektor dla struktury grafu plus przechowywanie wektora.
Parametr efConstruction kontroluje dokładność wyszukiwania podczas budowy indeksu. Większe wartości tworzą lepszej jakości grafy, ale liniowo wydłużają czas budowy. Z praktycznego punktu widzenia efConstruction ≈ M × 2 zapewnia dobry balans dla większości zastosowań. Parametr efSearch jest analogiczny do nprobe w indeksach IVF — kontroluje dokładność wyszukiwania w czasie zapytania i może być dostosowywany dynamicznie bez przebudowy indeksu.
Indeksy HNSW oferują kilka zalet w porównaniu z indeksami IVF. Zazwyczaj osiągają wyższą kompletność przy równoważnej szybkości wyszukiwania, szczególnie na danych o wysokiej wymiarowości (d > 256). Nie wymagają osobnego etapu uczenia (w przeciwieństwie do IVF, który potrzebuje klasteryzacji k-średnich, co czyni HNSW odpowiednim dla dynamicznych zbiorów danych, gdzie wektory są dodawane stopniowo). Wykazują łagodną degradację kompletności wraz ze spadkiem efSearch — kompletność poprawia się płynnie, bez ostrych progów. Jednak indeksy HNSW zużywają więcej pamięci na wektor (listy sąsiedztwa grafu dodają narzut) i są wolniejsze w budowie niż indeksy IVF. HNSW nie obsługuje również natywnie usuwania wektorów, ponieważ usuwanie węzłów ze struktury grafu naruszałoby łączność.
Dla zbioru referencyjnego TarmacView składającego się z około 9 000 embeddingów, IndexHNSWFlat z M=32 i efSearch=64 osiąga >99% kompletności przy czasie zapytania poniżej 200 mikrosekund na CPU — 50-krotne przyspieszenie względem IndexFlatIP przy znikomej utracie dokładności. Ciąg znaków fabryki "HNSW32,Flat" konstruuje ten indeks. W Pythonie: index = faiss.index_factory(d, "HNSW32,Flat", faiss.METRIC_INNER_PRODUCT).
Podobieństwo cosinusowe mierzy cosinus kąta między dwoma niezerowymi wektorami — określa, jak bardzo dwa wektory są podobne, niezależnie od ich długości. Podobieństwo cosinusowe między wektorami a i b definiuje się jako cos(θ) = (a · b) / (||a|| × ||b||), gdzie a · b to iloczyn skalarny, a ||a|| to norma L2 wektora a. Wynik zawiera się w przedziale od -1 (kierunki całkowicie przeciwne) do +1 (kierunki identyczne), przy czym 0 oznacza ortogonalność.
FAISS nie udostępnia dedykowanej metryki podobieństwa cosinusowego. Zamiast tego podobieństwo cosinusowe jest implementowane poprzez dwuetapową transformację, którą zespół programistów FAISS uważa za kanoniczną. Po pierwsze, wszystkie wektory są normalizowane L2 do jednostkowej długości — każdy wektor jest dzielony przez swoją normę L2, tak aby ||a|| = 1 i ||b|| = 1. Po drugie, jako metrykę odległości stosuje się METRIC_INNER_PRODUCT. Dla wektorów znormalizowanych do jednostki, iloczyn skalarny jest równy podobieństwu cosinusowemu: a · b = cos(θ). Ta równoważność wynika bezpośrednio ze wzoru na cosinus: gdy mianownik jest równy 1, wzór sprowadza się do iloczynu skalarnego.
Ta technika normalizacji jest standardem w systemach wyszukiwania wektorowego, ponieważ iloczyn skalarny może być wydajnie obliczany przez wysoko zoptymalizowane procedury mnożenia macierzy BLAS. Koszt obliczeniowy normalizacji wszystkich wektorów w indeksie to jednorazowa operacja O(N × D) podczas budowania indeksu, a normalizacja każdego zapytania to O(D) — wartość pomijalna w porównaniu z kosztem samego wyszukiwania. Normalizacja L2 jest stosowana przed dodaniem wektorów do indeksu i przed przesłaniem zapytań, co zapewnia, że wszystkie porównania odbywają się w przestrzeni podobieństwa cosinusowego.
W FAISS normalizacja jest implementowana za pomocą otoczki IndexPreTransform w połączeniu z NormalizationTransform (w Pythonie faiss.NormalizationTransform). Wzorzec konstrukcji jest następujący:
import faiss
import numpy as np
dimension = 768
# Create the inner product index
base_index = faiss.IndexFlatIP(dimension)
# Wrap with L2 normalization
index = faiss.IndexPreTransform(
faiss.NormalizationTransform(dimension),
base_index
)
# Vectors added here are automatically L2-normalized
index.add(reference_embeddings)
# Queries submitted here are automatically L2-normalized
distances, indices = index.search(query_embeddings, k)
Alternatywne podejścia obejmują ręczną normalizację wektorów za pomocą faiss.normalize_L2() przed dodaniem i zapytaniem, lub konstrukcję indeksu przez index_factory, który obsługuje wbudowaną normalizację poprzez krok przetwarzania wstępnego "L2norm". Metodą fabryki: index = faiss.index_factory(d, "L2norm,HNSW32,Flat") tworzy indeks, który automatycznie normalizuje wektory do jednostkowej długości przed zbudowaniem grafu HNSW.
Dla TarmacView to podejście jest kluczowe, ponieważ embeddings DINOv2, podobnie jak większość wyników transformerów wizyjnych, różnią się długością w zależności od obrazu. Różnice w ekspozycji, warunkach oświetleniowych i ustawieniach kamery podczas inspekcji nawierzchni lotniskowych generują embeddings o różnych długościach, nawet gdy rejestrują identyczne tekstury powierzchni. Normalizacja usuwa składową długości i koncentruje porównanie podobieństwa na zgodności kierunkowej — dwa obrazy powierzchni rejestrujące tę samą teksturę nawierzchni, ale przy różnych poziomach ekspozycji, zostaną uznane za bardzo podobne, ponieważ ich znormalizowane embeddings wskazują ten sam kierunek, nawet jeśli ich surowe długości znacząco się różnią.
FAQ FAISS wprost wyjaśnia tę kwestię: „Podobieństwo cosinusowe między wektorami x i y definiuje się jako cos(x, y) = ⟨x, y⟩ / (|x| × |y|). Poprzez wcześniejszą normalizację wektorów zapytania i bazy danych, problem można sprowadzić z powrotem do problemu maksymalnego wyszukiwania iloczynu skalarnego." FAISS zauważa również, że użycie iloczynu skalarnego na znormalizowanych wektorach jest matematycznie równoważne użyciu odległości L2 na znormalizowanych wektorach, z zależnością ||x - y||² = 2 - 2 × ⟨x, y⟩ dla wektorów o jednostkowej normie.
Cykl życia indeksu FAISS w produkcji obejmuje pięć odrębnych etapów: konfigurację, uczenie, zapełnianie, serializację i przeszukiwanie. Każdy etap ma określone wywołania API, kwestie wydajnościowe i najlepsze praktyki.
Konfiguracja rozpoczyna się od wyboru typu indeksu i metryki odległości. FAISS udostępnia mechanizm ciągu fabrycznego — zwięzłej specyfikacji tekstowej, która konstruuje złożone indeksy. Wzorzec fabryki jest zalecanym podejściem, ponieważ abstrahuje od konkretnej hierarchii klas i automatycznie wybiera optymalną implementację:
| Factory String | Index Type | Memory per Vector (d=768) | Use Case |
|---|---|---|---|
"Flat" | IndexFlat (dokładne wyszukiwanie L2) | 3,072 bajty | Małe zbiory referencyjne, ground truth |
"IVF100,Flat" | IndexIVFFlat ze 100 centroidami | ~3 100 bajtów | Średnie zbiory, szybkie przybliżone wyszukiwanie |
"HNSW32,Flat" | IndexHNSWFlat z M=32 | ~3 328 bajtów | Szybkie przybliżone wyszukiwanie, dane dynamiczne |
"IVF100,PQ16" | IndexIVFPQ, 16 podwektorów | ~80 bajtów | Duża skala, ograniczona pamięć |
"IVF100,SQ8" | IndexIVF z kwantyzacją skalarną | ~784 bajty | Zrównoważony, doskonała szybkość |
Uczenie jest wymagane tylko dla indeksów, które uczą się rozkładu danych (IVF, PQ, SQ itp.). Podczas uczenia indeks wykonuje grupowanie k-średnich na reprezentatywnej próbce wektorów. W algorytmie k-średnich FAISS używa wielu losowych inicjalizacji i wybiera tę z najmniejszym zniekształceniem. Zbiór uczący powinien być reprezentatywny dla danych, które będą indeksowane — powszechną praktyką jest użycie losowej podpróbki stanowiącej 1–10% całego zestawu danych. FAISS wymaga, aby wektory uczące miały ten sam wymiar co dane, które będą indeksowane. Flaga index.is_trained wskazuje, czy uczenie zostało zakończone. Wywołanie uczące ma postać: index.train(training_vectors). W przypadku zestawów danych, gdzie indeks został już wcześniej wytrenowany (np. wstępnie wytrenowane centroidy są wczytywane z pliku), ponowne wywołanie train jest niepotrzebne i nadpisze wyuczone parametry.
Zapełnianie dodaje wektory do wytrenowanego indeksu: index.add(reference_vectors). Właściwość ntotal śledzi liczbę dodanych wektorów. W przypadku indeksów IVF, każdy wektor jest przypisywany do najbliższego centroidu klastra i dołączany do listy odwróconej tego centroidu podczas operacji dodawania. W przypadku indeksów HNSW graf jest budowany przyrostowo: każdy nowy wektor otrzymuje poziom warstwy, a krawędzie są ustanawiane do jego M najbliższych sąsiadów na każdej warstwie z użyciem parametru efConstruction. Dodawanie wektorów jest zazwyczaj wolniejsze niż przeszukiwanie, szczególnie w przypadku HNSW, gdzie graf musi być aktualizowany.
Serializacja zapisuje indeks na dysk: faiss.write_index(index, "index.faissindex"). Indeks jest wczytywany z powrotem za pomocą index = faiss.read_index("index.faissindex"). Serializacja zachowuje pełny stan indeksu, w tym wytrenowane centroidy, strukturę grafu, wszystkie przechowywane wektory, konfigurację metryki odległości oraz parametry wewnętrzne. Standardowe rozszerzenie pliku to .faissindex. Rozmiar serializacji zależy od typu indeksu i liczby wektorów — dla IndexFlat z N wektorami o wymiarze D, rozmiar wynosi w przybliżeniu N × D × 4 bajty plus niewielki narzut.
Zapytania pobierają k najbliższych sąsiadów: distances, indices = index.search(query_vectors, k). Tablica distances zawiera wartości podobieństwa lub odległości w zależności od metryki. Tablica indices zawiera pozycje pasujących wektorów referencyjnych w kolejności ich dodawania (indeksowane od 0). W przypadku zapytań wsadowych FAISS efektywnie przetwarza wiele zapytań jednocześnie, wykorzystując mnożenie macierz-macierz, osiągając znacząco wyższą przepustowość niż w przypadku pojedynczych zapytań wykonywanych jedno po drugim. Obiekty indeksów są bezpieczne wątkowo dla operacji wyszukiwania na oddzielnych instancjach indeksów, co umożliwia równoległą obsługę zapytań w środowiskach produkcyjnych.
FAISS jest często używany do implementacji klasyfikacji k-Najbliższych Sąsiadów (kNN) — nieparametrycznej metody uczenia maszynowego, która klasyfikuje punkt zapytania na podstawie etykiety większościowej wśród jego k najbliższych sąsiadów w zbiorze referencyjnym. To podejście jest szczególnie atrakcyjne, gdy: (1) zbiór referencyjny jest regularnie aktualizowany o nowe oznaczone próbki, (2) przestrzeń osadzeń (embeddingów) oddaje znaczące semantyczne relacje między punktami danych oraz (3) preferowane są interpretowalne decyzje oparte na przykładach zamiast czarnoskrzynkowych klasyfikatorów neuronowych.
Potok klasyfikacji z użyciem FAISS składa się z pięciu kroków:
Zbuduj oznaczony zbiór referencyjny: Każdy wektor referencyjny jest sparowany z etykietą (np. “asfalt – dobry stan”, “beton – spękana powierzchnia”, “mieszanka bitumiczna – łatana”). Etykiety są przechowywane w osobnej tablicy zgodnej z kolejnością indeksu FAISS. TarmacView utrzymuje około 9 000 takich oznaczonych osadzeń referencyjnych obejmujących wiele typów nawierzchni i stanów jakości.
Indeksuj wektory referencyjne: Wszystkie osadzenia referencyjne są dodawane do indeksu FAISS. Dla wyszukiwania dokładnego z perfekcyjnym przywołaniem używany jest IndexFlatIP. Dla wyszukiwania przybliżonego na dużą skalę, IndexHNSWFlat lub IndexIVFFlat zapewniają czas zapytania poniżej milisekundy z przywołaniem >99% przy odpowiednim dostrojeniu.
Prześlij osadzenia zapytań: Dla każdego nowego obrazu do klasyfikacji wyodrębnij jego osadzenie przy użyciu tego samego modelu osadzeń (DINOv2 z 768-wymiarowym wyjściem) i znormalizuj do długości jednostkowej dla podobieństwa cosinusowego.
Pobierz k najbliższych sąsiadów: FAISS zwraca indeksy i odległości k najbardziej podobnych wektorów referencyjnych. Parametr k kontroluje kompromis między obciążeniem a wariancją. Mniejsze k (np. 3–5) tworzy granice decyzyjne wrażliwe na lokalną strukturę, ale podatne na nadmierne dopasowanie do szumu. Większe k (np. 15–20) tworzy gładsze granice z lepszą generalizacją, ale może tracić subtelne rozróżnienia. TarmacView używa k=10, równoważąc odporność na wartości odstające z wrażliwością na subtelne zmiany jakości nawierzchni.
Przeprowadź głosowanie większościowe: Policz etykiety wśród k sąsiadów i wybierz najczęściej występującą etykietę jako wynik klasyfikacji. Opcjonalnie, głosowanie ważone odległością przypisuje wyższą wagę bliższym sąsiadom: waga = 1.0 / (odległość + ε) gdzie ε jest małą stałą zapobiegającą dzieleniu przez zero. Głosowanie ważone jest szczególnie korzystne, gdy zbiór referencyjny ma nierównomierny rozkład klas lub gdy gęstość sąsiadów zmienia się w przestrzeni osadzeń.
| k | Obciążenie | Wariancja | Najlepsze dla |
|---|---|---|---|
| 1 – 3 | Niskie | Wysoka | Duże, czyste zbiory referencyjne, szczegółowe granice |
| 5 – 10 | Umiarkowane | Umiarkowana | Zrównoważona, ogólnego przeznaczenia klasyfikacja |
| 15 – 30 | Wyższe | Niższa | Zaszumione etykiety, gładkie granice decyzyjne |
Wyniki odległości zwracane przez FAISS służą również do szacowania pewności. Jeśli k najbliższych sąsiadów ma tę samą etykietę i wysokie wyniki podobieństwa (podobieństwo cosinusowe > 0,95), klasyfikacja jest wysoce pewna. Jeśli głos jest podzielony (np. 6 na 10 dla zwycięskiej etykiety) lub wyniki podobieństwa są niskie (< 0,70), system może oznaczyć wynik do przeglądu przez człowieka. Ta architektura świadoma pewności jest kluczowa dla aplikacji krytycznych dla bezpieczeństwa, takich jak inspekcja nawierzchni lotniskowych, gdzie błędna klasyfikacja mogłaby wpłynąć na priorytetyzację konserwacji i bezpieczeństwo operacyjne.
Kontrakt osadzeń pomiędzy modelem DINOv2 a indeksem FAISS jest fundamentalny dla dokładności klasyfikacji. Ekstraktor osadzeń jest trenowany poprzez uczenie samonadzorowane, tak aby odległości między osadzeniami odzwierciedlały podobieństwo wizualne między obrazami nawierzchni. Indeks FAISS wiernie wyszukuje najbliższych sąsiadów zgodnie z metryką podobieństwa cosinusowego. Gdy ten kontrakt jest spełniony — gdy wizualnie podobne stany nawierzchni tworzą bliskie osadzenia — klasyfikacja kNN osiąga wysoką dokładność z nieodłączną interpretowalnością, pokazując dokładnie, które obrazy referencyjne wpłynęły na każdą decyzję klasyfikacyjną.
Wsparcie GPU w FAISS jest funkcją pierwszoplanową, zapewniającą znaczącą poprawę wydajności zarówno przy budowie indeksu, jak i wyszukiwaniu. Implementacja GPU, opisana w artykule “Billion-scale similarity search with GPUs” (Johnson, Douze, Jégou, 2017), jest napisana w CUDA C++ i wykorzystuje architektury GPU NVIDIA od Kepler (Compute Capability 3.5) przez Hopper (Compute Capability 9.0+) i nowsze.
Akceleracja GPU w FAISS zapewnia mierzalne poprawy wydajności: 5–10x wzrost przepustowości wyszukiwania w porównaniu do CPU dla typowych indeksów IVF i HNSW; do 12x szybsze budowanie indeksów IVF, ponieważ grupowanie k-średnich jest wysoce zrównoleglone; 8x niższe opóźnienie dla zapytań HNSW na GPU przy użyciu zoptymalizowanych jąder przechodzenia przez graf; oraz natywne wsparcie dla zapytań wsadowych, gdzie GPU doskonale radzi sobie z przetwarzaniem setek lub tysięcy zapytań jednocześnie poprzez operacje macierz-macierz.
Implementacja GPU obejmuje najczęściej używane typy indeksów poprzez dedykowane klasy CUDA:
| Klasa indeksu GPU | Odpowiednik CPU | Użyte funkcje CUDA |
|---|---|---|
| GpuIndexFlat | IndexFlat | BLAS gemm na GPU, dzielenie pamięci współdzielonej (shared memory tiling) |
| GpuIndexIVFFlat | IndexIVFFlat | Równoległe obliczanie odległości, redukcje na poziomie wątków (warp-level) |
| GpuIndexIVFPQ | IndexIVFPQ | Tablice lookup PQ na GPU, szybkie przypisywanie kodów |
| GpuIndexIVFScalarQuantizer | IndexIVFScalarQuantizer | Wsparcie float16 na GPU Pascal+ |
Implementacja GPU wykorzystuje mieszania wątków (warp shuffles) (dostępne od Compute Capability 3.0+) oraz buforowanie tekstur tylko do odczytu poprzez ld.nc / __ldg (Compute Capability 3.5+). Algorytm k-selekcji — znajdowania k największych wartości z dużej tablicy odległości — działa z wydajnością do 55% teoretycznego szczytu wydajności GPU, umożliwiając implementację najbliższych sąsiadów 8,5x szybszą niż wcześniejszy stan wiedzy na GPU, zgodnie z artykułem z 2017 roku. Dla zarządzania pamięcią GPU, obiekt StandardGpuResources alokuje pamięć tymczasową na GPU: około 512 MiB na GPU z pamięcią ≤4 GiB i około 1 536 MiB na większych GPU. Ta pamięć tymczasowa pozwala uniknąć wielokrotnych wywołań cudaMalloc / cudaFree podczas wyszukiwania.
FAISS zapewnia bezproblemową interoperacyjność CPU-GPU poprzez dwie kluczowe funkcje: faiss.index_cpu_to_gpu(cpu_index, device_id) przenosi indeks CPU na określone urządzenie GPU, a faiss.index_gpu_to_cpu(gpu_index) przenosi indeks GPU z powrotem do pamięci CPU. We wdrożeniach wielo-GPU, faiss.index_cpu_to_gpu_multiple_py(resources, cpu_index) dystrybuuje indeks na wszystkie dostępne urządzenia GPU, a zapytania są automatycznie równoważone. Podejście wielo-GPU może skalować się do indeksów zawierających setki milionów wektorów poprzez partycjonowanie między przestrzeniami pamięci GPU.
| Scenariusz | CPU | GPU (1x) | GPU (8x) |
|---|---|---|---|
| Wyszukiwanie IndexFlat (100K x 768d), batch=8192 | 50 ms | 5 ms | <1 ms |
| Trenowanie k-średnich dla IVF (1M x 128d), nlist=1000 | 120 s | 10 s | 5 s |
| Budowa HNSW (100K x 128d), M=32 | 30 s | 8 s | — |
| Wykres k-NN w skali miliardowej | dni | 12 godzin | 4 godziny |
Dla TarmacView, akceleracja GPU jest wartościowa podczas fazy budowy indeksu, gdy okresowo dodawane są nowe obrazy referencyjne. Budowanie indeksu IVF z grupowaniem k-średnich na 9 000 768-wymiarowych wektorów zajmuje około 1–2 sekund na nowoczesnym GPU (NVIDIA A100 lub RTX 4090) w porównaniu do 30–60 sekund na CPU. Podczas wnioskowania indeks pozostaje na CPU dla opłacalnego wdrożenia — opóźnienie zapytania na CPU z IndexHNSWFlat wynosi już poniżej 200 mikrosekund dla zbioru referencyjnego 9K, a przeniesienie na GPU dodałoby narzut związany z transferem PCIe bez znaczących korzyści w zakresie opóźnień.

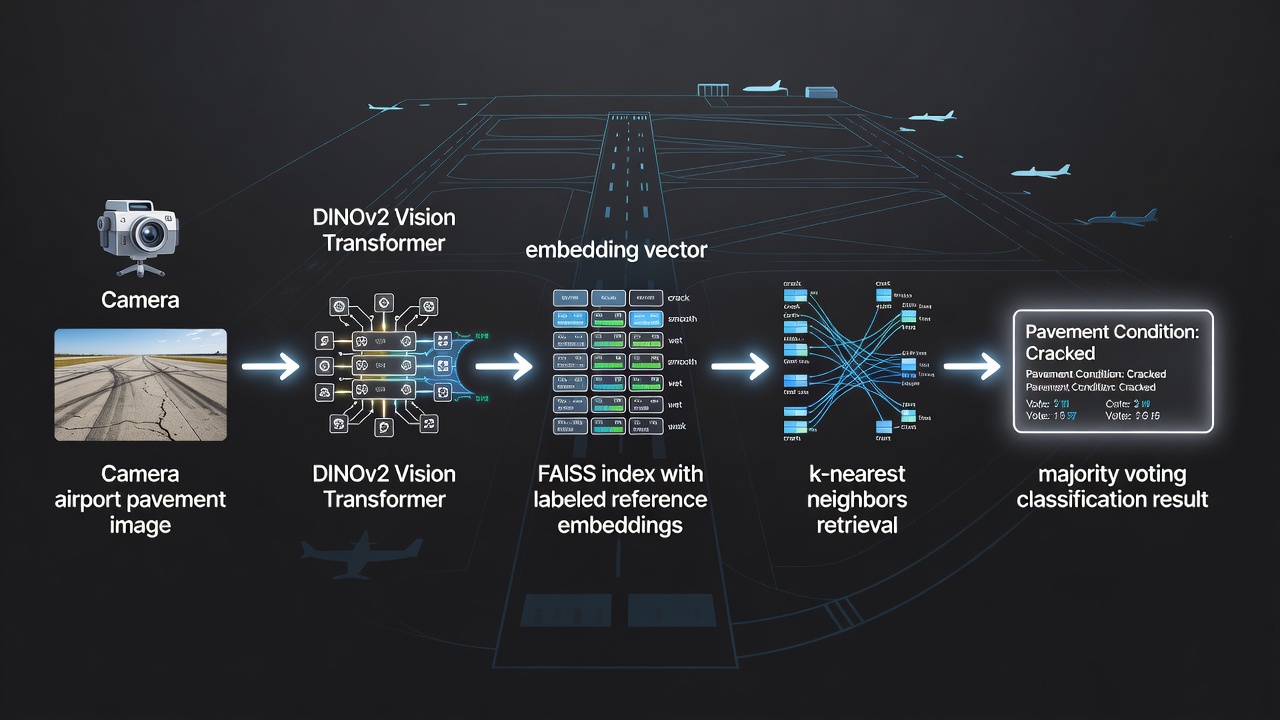
TarmacView integruje FAISS jako podstawowy silnik wyszukiwania podobieństw dla swojego zautomatyzowanego systemu klasyfikacji jakości nawierzchni lotniskowych. System klasyfikuje typy nawierzchni (asfalt, beton, tarmac) oraz stany jakości nawierzchni (dobry, dostateczny, słaby, zniszczony, popękany, połatany) poprzez porównywanie zdjęć inspekcyjnych z kuratorskim zestawem referencyjnym składającym się z około 9 000 oznakowanych embeddingów.
Budowa zestawu referencyjnego: Każdy embedding referencyjny jest ekstrahowany ze zdjęcia nawierzchni w wysokiej rozdzielczości przy użyciu modelu DINOv2 Vision Transformer (ViT-B/14 lub równoważnego), który generuje wektor o wymiarze 768, przechwytujący cechy wizualne takie jak wzory tekstury, rozkład kolorów, morfologia pęknięć, ekspozycja kruszywa, zużycie powierzchni oraz ślady napraw. Każdy embedding jest opatrzony etykietami referencyjnymi ustalonymi przez certyfikowanych inspektorów nawierzchni podczas początkowej fazy treningu systemu. Zestaw referencyjny obejmuje wiele lotnisk, stref klimatycznych i wieków nawierzchni, aby zapewnić solidną klasyfikację w różnych warunkach.
Wybór indeksu: TarmacView wybiera typ indeksu na podstawie wymagań wdrożeniowych:
| Deployment Scenario | Index Type | Query Time | Recall | Memory |
|---|---|---|---|---|
| Offline QA / validation | IndexFlatIP | ~2 ms | 100% | ~28 MB |
| Real-time field deployment | IndexHNSWFlat (M=32, efSearch=64) | <200 μs | >99% | ~30 MB |
| Edge device (limited RAM) | IndexIVFFlat (nlist=100, nprobe=10) | ~300 μs | ~97% | ~28 MB |
Przebieg klasyfikacji:
Kamera zamontowana na dronie (np. seria DJI Matrice z wysokorozdzielczym payloadem) lub ręczne urządzenie inspekcyjne wykonuje zdjęcia nawierzchni podczas rutynowych inspekcji lotniskowych, zgodnie z wytycznymi ICAO Annex 14 oraz FAA AC 150/5380-7B dotyczącymi oceny stanu nawierzchni.
Każde zdjęcie jest wstępnie przetwarzane (kadrowane w celu usunięcia obszarów poza nawierzchnią, normalizowane do standardowej rozdzielczości) i przekazywane przez model embeddingowy DINOv2 uruchomiony na akceleratorze wnioskowania brzegowego (NVIDIA Jetson lub równoważnym).
Wynikowy embedding o wymiarze 768 jest normalizowany L2 do jednostkowej długości w celu obliczenia podobieństwa cosinusowego. Normalizacja zapewnia, że różnice w ekspozycji między lotami inspekcyjnymi nie wpływają na ranking podobieństwa.
FAISS przeszukuje indeks IndexHNSWFlat z k=10, zwracając 10 najbliższych indeksów embeddingów referencyjnych oraz ich wyniki podobieństwa iloczynu skalarnego (równoważne podobieństwu cosinusowemu dla wektorów znormalizowanych).
System przeprowadza głosowanie większościowe na etykietach 10 sąsiadów. Jeśli zwycięska etykieta uzyska co najmniej 6 z 10 głosów (konsensus 60%), klasyfikacja jest akceptowana z wynikiem ufności obliczonym jako stosunek głosów zwycięskich do wszystkich głosów.
Jeśli głosowanie nie osiąga konsensusu 60%, embedding obrazu oraz 10 najlepszych obrazów referencyjnych są oznaczane do przeglądu przez człowieka — certyfikowanego inspektora nawierzchni — za pośrednictwem interfejsu webowego TarmacView.
Klasyfikacje są rejestrowane w bazie danych TarmacView wraz ze znacznikami czasu, współrzędnymi GPS, typem nawierzchni, stanem jakości, wynikiem ufności oraz linkami do powiązanych obrazów referencyjnych. Tworzy to w pełni audytowalny ślad inspekcyjny dla zgodności regulacyjnej.
Ten potok klasyfikacji oparty na FAISS umożliwia TarmacView przetwarzanie tysięcy zdjęć nawierzchni dziennie z spójną, obiektywną oceną jakości — redukując zależność od subiektywnej ludzkiej inspekcji wzrokowej i umożliwiając skalowalne monitorowanie stanu nawierzchni lotniskowych w całych sieciach lotnisk.
FAISS zajmuje wyraźną niszę w ekosystemie wyszukiwania wektorowego. Jest biblioteką, a nie bazą danych, a to rozróżnienie ma istotne implikacje dla architektury, wdrożenia i charakterystyki operacyjnej. Biblioteka FAISS zapewnia czystą funkcjonalność wyszukiwania najbliższych sąsiadów bez narzutu związanego z pełnym systemem zarządzania bazą danych.
| Feature | FAISS | Pinecone | Milvus | Qdrant | Weaviate |
|---|---|---|---|---|---|
| Type | Library | Managed service | Database | Database | Database |
| Deployment | Embedded | Cloud / SaaS | Self-hosted / Cloud | Self-hosted / Cloud | Self-hosted / Cloud |
| Persistence | Manual save/load | Automatic | Automatic | Automatic | Automatic |
| CRUD | Not built-in | Full CRUD | Full CRUD | Full CRUD | Full CRUD |
| Metadata filtering | ID-based only | Rich filters | Attribute + scalar | Payload filtering | Graph-based |
| Scaling | Manual sharding | Auto-scaling | Distributed Raft/Paxos | Distributed | Distributed |
| GPU support | Native CUDA | No | Limited (CUDA) | No | No |
| Query latency | 10 μs – 1 ms | 2 – 10 ms | 1 – 10 ms | 1 – 5 ms | 1 – 10 ms |
| License | MIT | Proprietary | Apache 2.0 | Apache 2.0 | BSD-3 |
Kluczową zaletą FAISS w porównaniu do pełnych systemów bazodanowych jest wydajność i prostota. Zapytania FAISS są zazwyczaj 10–100 razy szybsze niż równoważne zapytania w systemach bazodanowych, ponieważ: biblioteka działa w procesie bez podróży sieciowych; nie ma narzutu na parsowanie zapytań, uwierzytelnianie ani autoryzację; nie ma pośrednictwa silnika składowania ani zarządzania buforami; a indeksy FAISS to zoptymalizowane struktury danych algebry liniowej bez narzutu transakcyjnego. FAISS operuje bezpośrednio na strukturach danych w pamięci przy użyciu zoptymalizowanych procedur BLAS, bez komunikacji międzyprocesowej.
Kluczową zaletą systemów bazodanowych nad FAISS jest wygoda operacyjna. Zapewniają one automatyczną trwałość danych z logowaniem z wyprzedzeniem i replikacją, obsługują bogate filtrowanie metadanych (np. „znajdź podobne obrazy wykonane po styczniu 2025, które przedstawiają nawierzchnię betonową w południowo-zachodnim regionie USA"), oferują interfejsy REST lub gRPC dla dostępu niezależnego od języka, zawierają pulpity monitorujące i alerty oraz obsługują kopie zapasowe i odtwarzanie po awarii. Obsługują one współbieżne operacje odczytu i zapisu z gwarancjami transakcyjnymi oraz ewolucję schematu.
Dla TarmacView użycie bezpośrednio FAISS zamiast bazy wektorowej jest właściwym wyborem architektonicznym z czterech powodów: (1) zestaw referencyjny jest mały (~9 tys. wektorów, około 28 MB) i mieści się w całości w pamięci; (2) wymagania dotyczące czasu odpowiedzi są rygorystyczne (klasyfikacja poniżej 200 mikrosekund jest osiągalna z HNSW na CPU); (3) system działa we wdrożeniach brzegowych na lotniskach, gdzie dostęp sieciowy do serwera bazy danych może być niepraktyczny lub wprowadzać niedopuszczalne opóźnienia; oraz (4) indeks jest odbudowywany rzadko (co tydzień lub co miesiąc, gdy dodawane są nowe obrazy referencyjne po walidacji przez inspektora), co sprawia, że ręczna serializacja i kontrola wersji są łatwe w zarządzaniu.
Serializacja indeksu FAISS przekształca obiekt indeksu w pamięci na reprezentację binarną, która może być zapisana na dysku, przesłana przez sieć lub załadowana do innego procesu lub maszyny. Serializacja zachowuje pełny stan indeksu, w tym wszystkie przechowywane wektory, wytrenowane centroidy (dla indeksów IVF i PQ), strukturę grafu (dla HNSW), konfigurację metryki odległości (L2 vs IP vs inne) oraz wszystkie parametry wewnętrzne (efConstruction, M, ustawienia normalizacji itp.).
Podstawowe funkcje serializacji to:
| Function | Description | Output | Use Case |
|---|---|---|---|
| write_index(index, filename) | Writes index to file | .faissindex file | Persistent disk storage |
| read_index(filename) | Loads index from file | Index object | Load for serving |
| serialize_index(index) | Writes index to bytes | Python bytes object | Database storage, message queues |
| deserialize_index(data) | Loads index from bytes | Index object | Load from memory buffer |
Rozmiar serializacji zależy od typu indeksu i liczby wektorów. Dla IndexFlatIP z N wektorami o wymiarze D, rozmiar pliku wynosi w przybliżeniu N × D × 4 bajty (przechowywanie 32-bitowych liczb zmiennoprzecinkowych) plus narzut na nagłówek i metadane. Dla IndexIVFFlat, dodatkowe miejsce jest zajmowane przez centroidy klastrów: nlist × D × 4 bajty. Dla IndexHNSWFlat, struktura grafu dodaje N × M × 2 × 4 bajty na listy sąsiedztwa (zakładając 32-bitowe indeksy sąsiadów przechowywane dwukierunkowo). Dla indeksu HNSW TarmacView z 9 000 wektorów o wymiarze 768 i M=32, zserializowany plik ma około 25 MB: 9 000 × 768 × 4 = 27,6 MB dla wektorów plus 9 000 × 32 × 2 × 4 = 2,3 MB dla struktury grafu, pomniejszone o fakt, że HNSW przechowuje wektory wewnętrznie w płaskim indeksie.
Serializacja obsługuje transfer między kontekstami: indeks zbudowany na GPU może być zapisany na dysku i załadowany na CPU. Zalecanym wzorcem jest zawsze przenoszenie indeksów GPU na CPU przed serializacją:
cpu_index = faiss.index_gpu_to_cpu(gpu_index) # transfer to CPU
faiss.write_index(cpu_index, "production_index.faissindex") # save to disk
# On a different machine (or later):
deployed_index = faiss.read_index("production_index.faissindex")
deployed_index.hnsw.efSearch = 64 # set search-time parameters
D, I = deployed_index.search(queries, k)
W przypadku wdrożeń produkcyjnych zserializowany indeks może być kontrolowany wersjami wraz z kodem aplikacji. TarmacView przechowuje wersjonowane pliki indeksów FAISS w swoich artefaktach wdrożeniowych, zapewniając, że każde wdrożenie brzegowe używa identycznego zestawu referencyjnego dla powtarzalnych wyników klasyfikacji. Gdy dodawane i walidowane są nowe obrazy referencyjne, trenowany jest nowy indeks, jego dokładność jest porównywana z poprzednim indeksem przy użyciu referencyjnego IndexFlatIP, a nowy indeks jest wdrażany przez standardowy potok CI/CD.
Podczas gdy obecny zestaw referencyjny TarmacView wynoszący około 9 000 wektorów jest skromny, FAISS jest zaprojektowany do skalowania do miliardów wektorów na pojedynczym serwerze. Biblioteka zapewnia kompleksowy zestaw narzędzi do obsługi wielkoskalowych wdrożeń poprzez trzy uzupełniające się techniki: kompresję wektorów, wyszukiwanie niewyczerpujące oraz indeksowanie rozproszone.
Kwantyzacja produktowa (PQ) to stratna technika kompresji, która drastycznie zmniejsza pamięciowe zapotrzebowanie na wektor. PQ dzieli każdy wektor o wymiarze D na m podwektorów równej wielkości (każdy o wymiarze D/m). Każdy podwektor jest kwantyzowany niezależnie przy użyciu książki kodowej zawierającej 256 wpisów (8 bitów) wyuczonej za pomocą k-średnich. Oryginalny wektor float32 (4 × D bajtów) jest kompresowany do m bajtów indeksów kodowych plus mała książka kodowa. Współczynniki kompresji PQ rzędu 4x do 16x są powszechne, umożliwiając indeksowanie setek milionów wektorów w pamięci głównej na pojedynczej maszynie. FAISS IndexIVFPQ łączy IVF z PQ, używając centroidów klastrów jako grubego kwantyzatora i kodów PQ do kompresji reszt. Obliczanie odległości wykorzystuje Asymetryczne Obliczanie Odległości (ADC): zapytanie pozostaje nieskompresowane, a odległości do skompresowanych wektorów w bazie są obliczane za pomocą wstępnie obliczonych tablic odnośników, unikając narzutu dekompresji.
| PQ Configuration | Bytes/vector (d=768) | Memory, N=100M | Recall vs uncompressed |
|---|---|---|---|
| PQ32 (m=32, 8-bit) | 40 | 3.7 GB | ~90-95% |
| PQ64 (m=64, 8-bit) | 72 | 6.7 GB | ~95-98% |
| PQ96 (m=96, 8-bit) | 104 | 9.7 GB | ~97-99% |
Kwantyzacja skalarna (SQ) konwertuje każdy składnik float32 na 8-bitową lub 4-bitową liczbę całkowitą bez znaku, redukując pamięć 4-krotnie (SQ8) lub 8-krotnie (SQ4) przy minimalnej utracie dokładności. Ciąg fabryczny "IVF100,SQ8" tworzy indeks IVF z kwantyzacją skalarną. SQ jest szybsza niż PQ w czasie zapytania, ponieważ obliczenia odległości są wykonywane bezpośrednio na skwantyzowanych wartościach bez wstępnego obliczania tablic odnośników. SQ8 przechowuje jeden bajt na wymiar; SQ4 przechowuje dwa wymiary na bajt.
Dla zbiorów danych na skalę miliardów zalecana konfiguracja FAISS łączy HNSW jako gruby kwantyzator z IVFPQ do kompresji wektorów: quantizer = IndexHNSWFlat(d, hnsw_m); index = IndexIVFPQ(quantizer, d, nlist, M, nbits). Kwantyzator HNSW przyspiesza wyszukiwanie centroidów w porównaniu do płaskiego przeszukiwania w czasie zapytania, a PQ kompresuje wektory bazy danych do ułamka ich pierwotnego rozmiaru. Oryginalna praca o FAISS (2017) mierzyła budowę grafu k-NN na 95 milionach obrazów (z zbioru YFCC100M) w 35 minut na GPU oraz graf k-NN na 1 miliardzie wektorów w mniej niż 12 godzin na 4 GPU Maxwell Titan X.
FAISS IndexShards dzieli duży zbiór danych na wiele podindeksów, każdy potencjalnie na innej maszynie lub GPU. Każdy fragment otrzymuje podzbiór wektorów i przetwarza zapytania niezależnie. Wyniki są łączone poprzez scalanie k-wierzchołkowe najlepszych k wyników z każdego fragmentu. To podejście zapewnia liniowe skalowanie wraz z liczbą dostępnych serwerów: podwojenie liczby fragmentów zmniejsza o połowę czas wyszukiwania dla ustalonego rozmiaru zbioru danych.
Dla zbiorów danych przekraczających dostępną pamięć RAM, FAISS zapewnia indeksy dyskowe, które przechowują strukturę indeksu (listy odwrócone lub graf) w pamięci, ale dane wektorów na dysku SSD. Klasa IndexOnDisk i powiązane narzędzia przezroczyście ładują dane wektorów z dysku podczas wyszukiwania, używając plików mapowanych w pamięci lub jawnych operacji wejścia/wyjścia. Dzięki nowoczesnym dyskom NVMe SSD zapewniającym prędkość odczytu sekwencyjnego 3–7 GB/s, wyszukiwanie dyskowe może zbliżyć się do wydajności pamięciowej w wielu zastosowaniach, zwłaszcza gdy zachowana jest lokalność przestrzenna (sąsiednie wektory przechowywane w sposób ciągły na dysku).
Dla TarmacView obecny zestaw referencyjny 9K wektorów znajduje się dobrze w optymalnym zakresie FAISS dla dokładnego wyszukiwania z IndexFlatIP. Jednak w miarę rozszerzania się systemu o obrazy referencyjne z setek lotnisk i wielu kampanii inspekcyjnych — potencjalnie do milionów oznakowanych embeddingów — mechanizmy skalowania FAISS (IVF dla wyszukiwania niewyczerpującego, PQ dla kompresji, przechowywanie dyskowe dla zbiorów danych nie mieszczących się w RAM) zapewniają jasną ścieżkę uaktualnienia bez konieczności fundamentalnie innej architektury. Typ indeksu może być uaktualniany z IndexFlatIP → IndexIVFFlat → IndexIVFPQ → IndexShards(IndexIVFPQ) w miarę wzrostu zestawu referencyjnego, przy czym każdy krok wymienia minimalną dokładność na poprawę szybkości wyszukiwania i efektywności pamięciowej o rzędy wielkości.
Literatura dotycząca FAISS (w tym kompleksowa praca z 2024 roku na arXiv “The Faiss Library” autorstwa Douze, Guzhva, Deng, Johnson, Szilvasy, Mazaré, Lomeli, Hosseini i Jégou) zawiera szczegółowe wskazówki dotyczące wyboru indeksu: “Istnieje wybór między kilkunastoma typami indeksów, a optymalny zazwyczaj zależy od ograniczeń danego problemu.” FAISS zawiera również kompleksowy zestaw narzędzi do testowania wydajności (faiss_benchmarks), który mierzy skuteczność i przepustowość dla różnych konfiguracji indeksów, uruchamiając wyszukiwania z wynikami referencyjnymi z IndexFlat w celu określenia dokładności. Praktycy są zachęcani do testowania wydajności na swojej konkretnej dystrybucji danych — optymalny indeks dla danego zbioru danych zależy od wymiarowości wektorów, rozmiaru zbioru danych, docelowej skuteczności, budżetu opóźnienia i dostępnej pamięci.
Wykorzystaj FAISS do wydajnego wyszukiwania podobieństw na danych embeddingów obrazów. Skontaktuj się z nami, aby dowiedzieć się, jak TarmacView integruje FAISS do klasyfikacji jakości powierzchni w czasie rzeczywistym i odzyskiwania obrazów inspekcyjnych.
k-Najbliższych Sąsiadów (kNN) klasyfikuje punkt zapytania poprzez głosowanie większościowe wśród jego k najbardziej podobnych punktów referencyjnych w przestrze...
Test dymny głowicy defektów weryfikuje, czy potok detekcji defektów strukturalnych TarmacView — szkielet DINOv3 + 5-etykietowa głowica MLP dla pęknięć/odprysków...
Pomiar fazy to kluczowa technika w geodezji, telekomunikacji i aparaturze pomiarowej, służąca do określania względnego czasu lub położenia sygnałów okresowych. ...