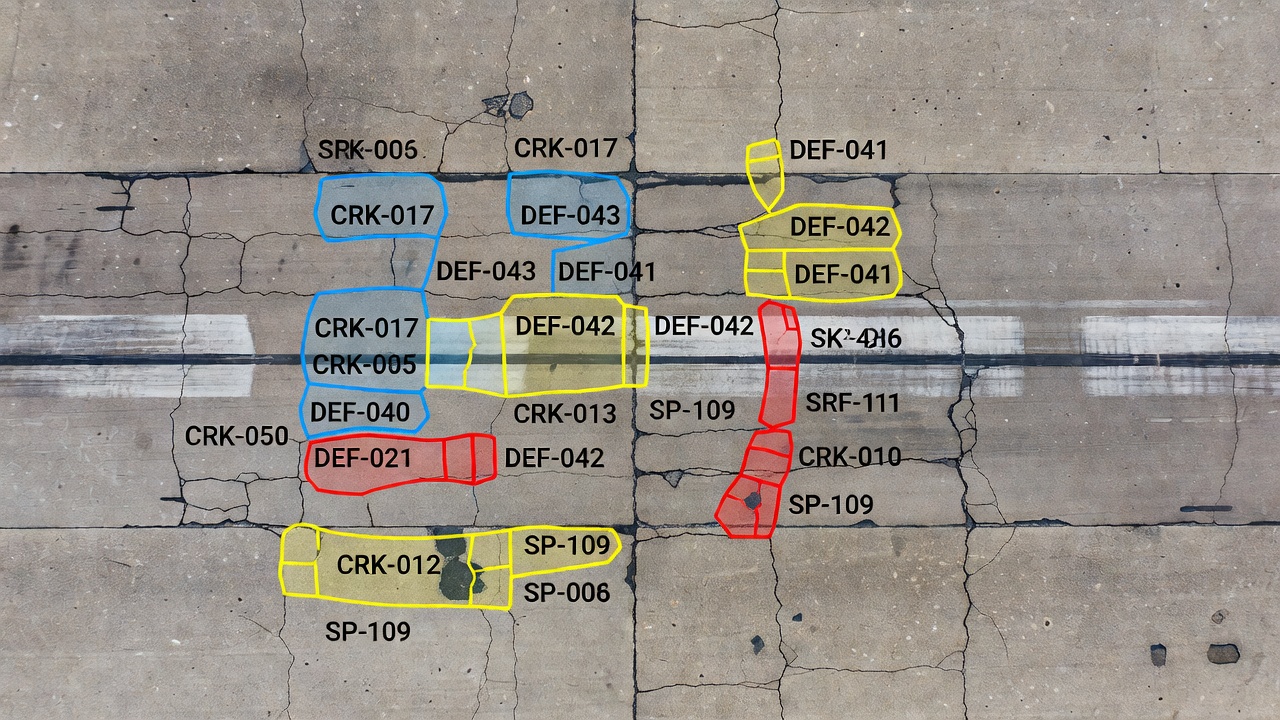
Segmentacja Instancji dla Identyfikacji Poszczególnych Uszkodzeń
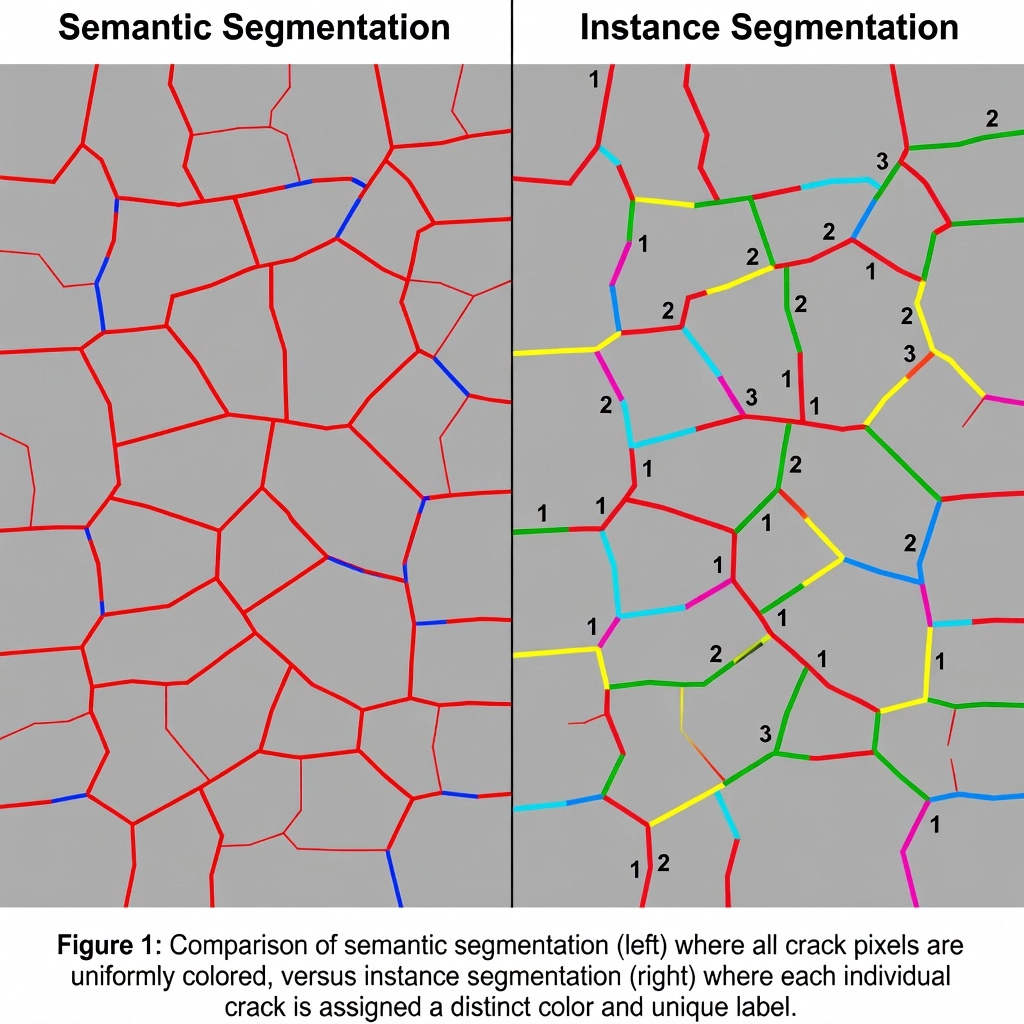
Segmentacja instancji identyfikuje i wyznacza granice każdego indywidualnego obiektu lub uszkodzenia na poziomie piksela, przypisując unikalny identyfikator każdej rysie, wykruszeniu lub wyrwie. Umożliwia to liczenie, pomiar i śledzenie uszkodzeń w czasie. Obejmuje Mask R-CNN oraz inne architektury instancyjne, różnicę w stosunku do segmentacji semantycznej i zastosowanie w uszkodzeniach infrastruktury.
Segmentacja instancji to zadanie wizji komputerowej, które identyfikuje, klasyfikuje i wyznacza granice każdego indywidualnego obiektu na poziomie piksela, przypisując unikalny identyfikator instancji każdemu wykrytemu obiektowi. Dla inspekcji infrastruktury segmentacja instancji oznacza, że każda pojedyncza rysa, wykruszenie, wyrwa, uszkodzenie spoiny lub powierzchniowe zniszczenie otrzymuje własną maskę na poziomie piksela z odrębnym ID — umożliwiając inżynierom samodzielne liczenie, pomiar i śledzenie każdego uszkodzenia, zamiast traktowania wszystkich uszkodzeń tego samego typu jako jednorodnej masy.
Definicja i Różnica w Stosunku do Segmentacji Semantycznej
Segmentacja instancji zajmuje odrębną pozycję w hierarchii wizji komputerowej, znajdując się pomiędzy wykrywaniem obiektów (ramki ograniczające z etykietami klas) a segmentacją semantyczną (etykiety klas na poziomie pikseli bez rozróżniania instancji). Rozwiązuje problem, którego żadne z tych zadań osobno nie może rozwiązać: zdolność zarówno do klasyfikowania każdego piksela należącego do kategorii, jak i rozróżniania, które piksele należą do którego konkretnego obiektu w obrębie tej kategorii.
Segmentacja semantyczna oznacza każdy piksel obrazu według klasy, do której należy. Na obrazie powierzchni drogi startowej lotniska zawierającym trzy rysy podłużne, model segmentacji semantycznej pokolorowałby wszystkie piksele rys tym samym kolorem klasy (np. czerwonym). Wynikiem jest pojedyncza binarna lub wieloklasowa maska, w której wszystkie rysy, niezależnie od tego, że są oddzielnymi fizycznymi uszkodzeniami, są połączone w jeden ciągły region klasy. To podejście zapewnia całkowitą powierzchnię rys w pikselach, ale nie dostarcza informacji o liczbie poszczególnych rys, ich indywidualnych rozmiarach ani rozmieszczeniu przestrzennym jako odrębnych uszkodzeń.
Wykrywanie obiektów umieszcza ramki ograniczające wokół każdego wykrytego obiektu i przypisuje etykietę klasy. Detektor na tym samym obrazie drogi startowej narysowałby trzy prostokątne ramki wokół trzech rys. Wynik zapewnia liczbę rys i przybliżoną lokalizację, ale ramki ograniczające mają fundamentalne ograniczenie: obejmują również nawierzchnię bez uszkodzeń wewnątrz prostokąta, co uniemożliwia precyzyjny pomiar powierzchni. Ramka ograniczająca wokół wijącej się rysy obejmuje znacznie więcej pikseli niezawierających rys niż pikseli rysy.
Segmentacja instancji całkowicie usuwa te ograniczenia. Model generuje zestaw binarnych masek — po jednej na wykrytą instancję — każdą z parą etykietą klasy i unikalnym ID instancji. Dla trzech rys, wynikiem byłyby trzy odrębne maski binarne: Rysa-001, Rysa-002 i Rysa-003, każda pokazująca dokładnie piksele należące do tej konkretnej rysy i żadnych innych. Maski podążają za dokładnym konturem każdego uszkodzenia, oplatając każdą odnogę, zakręt i nieregularność. Zapewnia to geometrię na poziomie piksela dla każdej instancji, która wspiera precyzyjny pomiar powierzchni, analizę morfologii i indywidualne śledzenie uszkodzeń.
Krytyczna różnica operacyjna ujawnia się w wyniku inspekcji. Raport segmentacji semantycznej może stwierdzać: “Całkowita powierzchnia rys: 45 230 pikseli.” Raport segmentacji instancji stwierdza: “Wykryto trzy rysy. Rysa-001: 12 400 px², Rysa-002: 18 100 px², Rysa-003: 14 730 px².” To drugie jest znacznie bardziej użyteczne dla planowania utrzymania — informuje inżyniera nawierzchni o dokładnej liczbie uszkodzeń wymagających naprawy i ich indywidualnej dotkliwości.
To rozróżnienie na instancje jest sformalizowane w standardzie zbioru danych COCO (Common Objects in Context), który definiuje adnotacje segmentacji instancji jako listę obiektów, każdy zawierający wielokąt segmentacji (lista współrzędnych x,y tworzących kontur obiektu), ramkę ograniczającą, ID kategorii i ID obrazu. Metryki ewaluacji stosowane w COCO — szczególnie Średnia Precyzja (AP) — są de facto standardem porównywania modeli segmentacji instancji i mają bezpośrednie zastosowanie do modeli wykrywania uszkodzeń infrastruktury.
Architektury: Mask R-CNN, YOLACT, SOLO i Mask2Former
Opracowano wiele architektur głębokiego uczenia dla segmentacji instancji, każda z odrębnymi kompromisami między dokładnością, szybkością i złożonością architektoniczną.
Mask R-CNN: Dwuetapowy Benchmark
Mask R-CNN, wprowadzony przez He i in. w Facebook AI Research w 2017 roku, rozszerza Faster R-CNN poprzez dodanie gałęzi przewidywania maski równolegle do istniejących gałęzi regresji ramki ograniczającej i klasyfikacji. Architektura opiera się na dwuetapowym projekcie. W pierwszym etapie, Sieć Proponowania Regionów (RPN) skanuje mapy cech wyodrębnione przez szkieletową sieć CNN (zazwyczaj ResNet-50, ResNet-101 lub ResNeXt) i proponuje kandydackie regiony obiektów (RoI lub Regiony Zainteresowania). W drugim etapie, każdy RoI jest przetwarzany przez RoIAlign — kluczowy wkład Mask R-CNN, który wykorzystuje interpolację dwuliniową do obliczenia dokładnych wartości cech w każdym punkcie próbkowania, eliminując błędy kwantyzacji RoIPool — w celu wygenerowania map cech o stałym rozmiarze. Te mapy cech trafiają do trzech równoległych głowic: głowicy klasyfikacyjnej (predykcja klasy), głowicy regresji ramki ograniczającej (współrzędne ramki) i głowicy maski (w pełni splotowa sieć, która generuje maskę binarną dla każdej klasy dla każdego RoI).
Głowica maski generuje maskę o rozdzielczości 28×28 pikseli na RoI na klasę. Podczas treningu, funkcja straty łączy stratę klasyfikacji, stratę ramki ograniczającej i stratę maski (binarna entropia krzyżowa uśredniona po pikselach). Kluczowym spostrzeżeniem jest to, że przewidywanie maski i klasyfikacja są rozdzielone: głowica maski przewiduje maski dla wszystkich klas, ale tylko maska odpowiadająca rzeczywistej klasie przyczynia się do straty. To przewidywanie maski dla każdej klasy zmusza model do uczenia się cech kształtu specyficznych dla danej klasy.
Mask R-CNN osiąga 37-47 AP na segmentacji instancji COCO (w zależności od szkieletu), przy czym ResNet-50-FPN osiąga około 37,1 AP, a ResNeXt-101-FPN osiąga 39,4-47,1 AP. Szybkość wnioskowania wynosi od 5-10 FPS na nowoczesnym GPU. W zastosowaniach infrastrukturalnych, Mask R-CNN ze szkieletem ResNet-50-FPN jest najczęściej używaną konfiguracją, z raportowaną wydajnością 33,3 AP na zbiorach danych rys w nawierzchniach i 40-55 AP na zbiorach danych wyrw.
YOLACT: Segmentacja Instancji w Czasie Rzeczywistym
YOLACT (You Only Look At CoefficienTs) został wprowadzony przez Bolyę i in. w 2019 roku jako pierwsza metoda segmentacji instancji w czasie rzeczywistym zdolna do działania z szybkością 30+ FPS. W przeciwieństwie do dwuetapowego podejścia Mask R-CNN, YOLACT jest jednoetapową, w pełni splotową metodą, która dzieli segmentację instancji na dwa równoległe podzadania: generowanie zestawu prototypowych masek dla całego obrazu oraz przewidywanie współczynników kombinacji liniowej dla każdej instancji.
W pierwszym podzadaniu, szkieletowa sieć Piramidy Cech generuje zestaw prototypowych masek — k współczynników maski (zazwyczaj 32), które pokrywają cały obraz. Te prototypy przechwytują typowe wzorce kształtów (np. poziome, pionowe, zakrzywione, okrągłe). W drugim podzadaniu, głowica predykcyjna generuje wektor współczynników liniowych dla każdej wykrytej instancji. Końcowa maska dla każdej instancji jest obliczana jako liniowa kombinacja prototypów ważona wektorem współczynników instancji, a następnie poddawana aktywacji sigmoidalnej i przycinaniu z wykorzystaniem przewidywanej ramki ograniczającej.
YOLACT osiąga 29-31 AP na COCO przy 30-45 FPS na GPU Titan X. Szybszy wariant YOLACT-550 osiąga 28,2 AP przy 56 FPS. YOLACT++ poprawia jakość masek poprzez dodanie deformowalnych splotów i lepszego próbkowania prototypów, osiągając 34,1 AP przy 33,5 FPS. W inspekcji infrastruktury, YOLACT został z powodzeniem zastosowany do wykrywania rys w betonie w czasie rzeczywistym, osiągając konkurencyjne wyniki przy prędkościach odpowiednich do przetwarzania na pokładzie BSP. Kompromisem jest niższa precyzja granic masek w porównaniu do Mask R-CNN, co może wpływać na dokładny pomiar szerokości rys.
SOLO: W Pełni Splotowa Bez Wykrywania
SOLO (Segmenting Objects by LOcations), wprowadzony przez Wanga i in. w 2020 roku, przyjmuje fundamentalnie inne podejście: całkowicie eliminuje gałąź wykrywania i przewiduje maski instancji bezpośrednio przy użyciu w pełni splotowej architektury. Podstawową ideą jest to, że każda instancja może być jednoznacznie zidentyfikowana przez położenie jej środka i rozmiar obiektu. SOLO dzieli obraz wejściowy na siatkę S×S. Każda komórka siatki jest odpowiedzialna za przewidywanie binarnej maski dowolnej instancji, której środek znajduje się w tej komórce. Każda komórka siatki przewiduje maski C-kanałowe (po jednej na klasę) plus prawdopodobieństwa klas.
Architektura SOLO składa się ze szkieletu (ResNet-FPN), gałęzi kategorii przewidującej prawdopodobieństwa klas dla każdej komórki siatki oraz gałęzi maski przewidującej S² binarnych masek na obraz (po jednej na pozycję siatki). Podczas wnioskowania, przewidywanie klasy dla komórki i przewidywanie maski są łączone: dla każdej komórki siatki, przewidywana klasa z pewnością powyżej progu wybiera odpowiedni kanał maski. SOLOv2 ulepsza oryginał poprzez wprowadzenie predykcji jądra maski i korelacji cech maski, osiągając 37,8 AP na COCO przy porównywalnej szybkości do Mask R-CNN.
Paradygmat SOLO oparty na lokalizacji jest szczególnie interesujący dla uszkodzeń infrastruktury, ponieważ naturalnie przypisuje każde uszkodzenie do jego pozycji przestrzennej bez polegania na propozycjach ramek ograniczających, co może być problematyczne dla bardzo wydłużonych uszkodzeń, takich jak rysy rozciągające się na duże części obrazu.
Mask2Former, wprowadzony przez Chenga i in. w Facebook AI Research (CVPR 2022), reprezentuje najnowocześniejszy poziom w segmentacji opartej na transformerach. Mask2Former łączy segmentację semantyczną, instancyjną i panoptyczną w ramach jednej architektury, traktując wszystkie zadania segmentacji jako klasyfikację masek. Architektura składa się z trzech komponentów: szkieletu (Swin Transformer lub ResNet) ekstrahującego cechy wieloskalowe, dekodera pikseli próbkującego cechy do wysokorozdzielczych osadzeń na piksel oraz dekodera transformerowego z maskowaną uwagą, który przewiduje zestaw N zapytań (zazwyczaj 100), z których każde generuje binarną maskę i etykietę klasy.
Kluczową innowacją jest maskowana uwaga — mechanizm, w którym każde zapytanie dekodera transformerowego skupia się tylko na przewidywanym regionie maski z poprzedniej warstwy dekodera, zamiast skupiać się na całej mapie cech. Zmniejsza to obliczenia 3× w porównaniu do standardowych modeli transformerowych i zmusza każde zapytanie do specjalizacji w konkretnym regionie, poprawiając szybkość zbieżności i jakość maski.
Mask2Former osiąga 50,1 AP na segmentacji instancji COCO ze szkieletem Swin-L oraz 57,8 PQ na segmentacji panoptycznej COCO. Jego trening jest 3× szybszy w zbieżności niż poprzednie podejścia oparte na transformerach (np. MaskFormer, DETR). W zastosowaniach infrastrukturalnych, zdolność Mask2Former do obsługi nakładających się i sąsiadujących instancji uszkodzeń poprzez uczenie oparte na zapytaniach sprawia, że jest on szczególnie skuteczny w przypadku gęstych pól uszkodzeń, takich jak spękania siatkowe lub mapowe.
Architektura
Typ
COCO AP
FPS
Zalety
Zastosowanie w Infrastrukturze
Mask R-CNN
Dwuetapowa CNN
37-47
5-10
Wysoka dokładność masek, ugruntowana
Offline analiza uszkodzeń
YOLACT
Jednoetapowa CNN
29-34
30-56
Szybkość czasu rzeczywistego
Przetwarzanie na pokładzie BSP
SOLOv2
CNN bez wykrywania
37,8
~10
Brak zależności od kotwic/propozycji
Wydłużone instancje uszkodzeń
Mask2Former
Transformer
50,1
~15
Najwyższa dokładność, ujednolicona struktura
Gęste pola uszkodzeń
Segmentacja Instancji a Segmentacja Semantyczna dla Rys
Wybór między segmentacją instancji a semantyczną do wykrywania rys zależy od konkretnych wymagań analitycznych programu inspekcji, a te dwa podejścia generują fundamentalnie różne wyniki.
Segmentacja semantyczna dla rys traktuje całą sieć rys jako pojedynczą klasę pierwszego planu. Model uczy się klasyfikować każdy piksel jako “rysę” lub “tło”. Wynikiem jest binarna maska, w której wszystkie piksele rys są białe, a wszystkie piksele niebędące rysami są czarne. To podejście ma kilka dobrze udokumentowanych zalet: naturalnie obsługuje połączone sieci rys (rozgałęziona rysa jest pojedynczym połączonym komponentem), wymaga prostszych adnotacji (pociągnięcia pędzlem na poziomie piksela zamiast wielokątów dla każdej instancji), a złożoność treningu jest mniejsza przy mniejszej liczbie kanałów wyjściowych. Najnowocześniejsze modele segmentacji semantycznej dla rys — takie jak DeepCrack (93% F1 na CrackTree260), CrackU-Net (97,5% F1 na CRACK500) i SwinUNETR (90,5% F1 na wieloczasowych zbiorach danych rys) — osiągają doskonałą dokładność na poziomie piksela.
Jednak segmentacja semantyczna ma kluczowe ograniczenie dla oceny stanu infrastruktury: nie może liczyć poszczególnych rys. Kiedy segmentacja semantyczna raportuje 5000 pikseli rys, nie dostarcza informacji, czy te piksele należą do jednej rysy o powierzchni 5000 pikseli, czy do pięćdziesięciu rys po 100 pikseli. To rozróżnienie jest kluczowe dla obliczeń Wskaźnika Stanu Nawierzchni (PCI), gdzie gęstość rys (liczba rys na jednostkę powierzchni) i dotkliwość poszczególnych rys są oddzielnymi parametrami oceny zgodnie z protokołami inspekcji ASTM D5340 i ICAO Annex 14.
Segmentacja instancji dla rys przypisuje unikalny ID każdej indywidualnej instancji rysy. Dla obrazu nawierzchni pokazującego wiele rys, wynik składa się z N binarnych masek, każda odpowiadającej jednej rysie, z powiązaną etykietą klasy i ID instancji. Metoda segmentacji instancji augmentowana CrackMover zaproponowana przez Zhao i in. (2024) osiąga 33,3 AP w wykrywaniu rys, przewyższając standardowy Mask R-CNN o 8,6% dzięki specjalistycznej augmentacji danych dla wydłużonych kształtów rys.
Segmentacja instancji dla rys stwarza unikalne wyzwania. Rysy są bardzo wydłużone, cienkie i często rozgałęzione — a nie zwartymi plamami jak wyrwy. Standardowe architektury segmentacji instancji zaprojektowane dla obiektów COCO (zwarte, dobrze zdefiniowane kształty) mogą dzielić pojedynczą rozgałęzioną rysę na wiele instancji lub nie rozdzielać sąsiadujących równoległych rys. Specjalistyczne techniki obejmują modyfikację rozdzielczości RoIAlign dla ekstrakcji wydłużonych cech, stosowanie splotów atrous w głowicy maski do wieloskalowego przechwytywania rys oraz zastosowanie kaskadowego ulepszania (Cascade Mask R-CNN), które iteracyjnie poprawia propozycje niskiej jakości.
Praktyczna decyzja zależy od pytania dotyczącego utrzymania. Dla ilościowego określenia całkowitej powierzchni rys (np. pomiaru procentowego udziału spękań na sekcję drogi startowej), segmentacja semantyczna może być wystarczająca i jest bardziej wydajna obliczeniowo. Dla liczenia rys, śledzenia indywidualnej szerokości rys i klasyfikacji dotkliwości poszczególnych rys (np. ASTM D5340, gdzie dotkliwość zależy od indywidualnej szerokości rysy), segmentacja instancji jest niezbędna. Rosnącym trendem w inspekcji infrastruktury jest segmentacja panoptyczna — łącząca segmentację semantyczną i instancyjną w celu semantycznej klasyfikacji regionów niezliczalnych (np. powierzchnia nawierzchni, trawa, oznakowanie) przy jednoczesnym segmentowaniu policzalnych uszkodzeń (rysy, wykruszenia, wyrwy) według instancji.
Segmentacja Instancji dla Wykruszeń i Wyrw
Wykruszenia i wyrwy różnią się fundamentalnie od rys pod względem geometrii: są to odrębne, ograniczone, zwarte uszkodzenia o wyraźnym zasięgu przestrzennym, dobrze zdefiniowanych krawędziach i mierzalnej objętości. To czyni je naturalnie odpowiednimi dla segmentacji instancji, a architektury, które dobrze radzą sobie z instancjami COCO (które są głównie zwartymi obiektami), skutecznie przenoszą się na wykrywanie wykruszeń i wyrw.
Wyrwa to zagłębienie w kształcie misy w powierzchni nawierzchni, które zazwyczaj powstaje, gdy spękania powierzchniowe umożliwiają infiltrację wody, prowadząc do degradacji warstwy podłoża i utraty materiału. Wyrwy są z definicji odrębnymi instancjami — każda wyrwa jest oddzielną fizyczną pustką. Segmentacja instancji przechwytuje dokładny obwód każdej wyrwy, co jest kluczowe dla dokładnego oszacowania objętości naprawy. Podejście z ramką ograniczającą (wykrywanie obiektów) może obejmować 30-50% powierzchni bez uszkodzenia, w zależności od nieregularności kształtu wyrwy, podczas gdy segmentacja instancji zapewnia rzeczywistą powierzchnię uszkodzenia.
Wykruszenie to wyszczerbiony lub połamany obszar na krawędzi spoiny lub rysy, występujący zazwyczaj w nawierzchniach betonowych. Wykruszenia są również odrębnymi instancjami ograniczonymi linią spoiny lub rysy. Segmentacja instancji dla wykruszeń musi uwzględniać ich ograniczenia geometryczne: wykruszenia zawsze zaczynają się przy nieciągłości strukturalnej (spoina, krawędź rysy), mają jedną stronę ograniczoną przez spoinę i rozciągają się na powierzchnię płyty. Specjalistyczne modele segmentacji instancji wykruszeń wykorzystują mechanizmy uwagi skupione na obszarach spoin.
Badania potwierdzają skuteczność tych podejść. Używając Mask R-CNN do wykrywania wyrw na zbiorach danych drogowych, Nhat-Duc i in. (2020) odnotowali AP@0,50 na poziomie 55,2 i AP@0,75 na poziomie 42,8. YOLACT zastosowany do wykrywania wyrw osiągnął szybkość wnioskowania 33 FPS z AP@0,50 na poziomie 48,7, umożliwiając liczenie wyrw w czasie rzeczywistym z kamer zamontowanych w pojeździe. W przypadku wykruszeń betonu, Cascade Mask R-CNN ze szkieletem ResNeXt-101 osiągnął 44,6 AP na zbiorze danych wykruszeń pomostów mostowych składającym się z 2400 oznaczonych obrazów.
Norma ASTM D5340 dla Wskaźnika Stanu Nawierzchni Lotnisk definiuje specyficzne wymagania pomiarowe dla wykruszeń i wyrw:
Pomiar wykruszeń: Rejestruj długość, szerokość i głębokość każdego wykruszenia; klasyfikuj dotkliwość na podstawie wymiarów (Niska: <25mm głębokości, Średnia: 25-50mm głębokości, Wysoka: >50mm głębokości)
Pomiar wyrw: Rejestruj średnicę i głębokość każdej wyrwy; klasyfikuj dotkliwość podobnie
Obliczanie gęstości: Liczba wykruszeń/wyrw na jednostkę próbki, skalowana do maksymalnej gęstości
Segmentacja instancji bezpośrednio wspiera wszystkie te pomiary. Maska na poziomie piksela zapewnia dokładne wymiary długości i szerokości (w połączeniu ze znaną rozdzielczością przestrzenną, np. 1mm/piksel ze skalibrowanych zdjęć z BSP). Unikalny ID instancji umożliwia liczenie uszkodzeń dla obliczeń gęstości. W połączeniu z danymi głębi ze stereoskopii lub struktury z ruchu (SfM), maski instancji mogą być ekstrudowane do 3D w celu pomiaru objętości.
Kluczową zaletą nad segmentacją semantyczną dla wykruszeń i wyrw jest liczenie uszkodzeń. Rozważmy sekcję drogi startowej z 15 indywidualnymi wykruszeniami. Segmentacja semantyczna raportuje “powierzchnia wykruszeń: 0,85 m²” — nie dostarczając informacji o liczbie uszkodzeń. Segmentacja instancji raportuje “wykryto 15 wykruszeń: Wykruszenie-001 (0,12 m²), Wykruszenie-002 (0,04 m²), …, Wykruszenie-015 (0,03 m²)” — informując inżyniera, że potrzebnych jest 15 indywidualnych zabiegów naprawczych i które z nich są najbardziej dotkliwe.
Pomiary Poszczególnych Uszkodzeń: Powierzchnia, Lokalizacja i Morfologia
Po wyizolowaniu każdej instancji uszkodzenia przez jej unikalną maskę, można wyodrębnić kompleksowy zestaw pomiarów dla każdej instancji w celu oceny stanu i planowania utrzymania.
Pomiar powierzchni jest najbardziej podstawową metryką dla każdego uszkodzenia. Liczba pikseli w masce każdej instancji jest przeliczana na fizyczną powierzchnię przy użyciu kalibracji przestrzennej. Dla obrazów pozyskanych z BSP przy znanej odległości próbkowania terenu (GSD) — zazwyczaj 0,5-2,0 mm/piksel dla inspekcji dróg startowych — liczba pikseli maski pomnożona przez (GSD)² daje fizyczną powierzchnię w mm² lub m². Dla rys, pomiar powierzchni umożliwia obliczenie szerokości rysy: średnia szerokość rysy = powierzchnia maski / długość szkieletu. Dla wyrw i wykruszeń, powierzchnia bezpośrednio zasila progi klasyfikacji dotkliwości.
Pomiar lokalizacji przypisuje współrzędne geograficzne każdej instancji uszkodzenia. Środek ciężkości maski instancji (średnia x,y pikseli maski) lub punkt środka-dolny (dla lokalizacji świadomej orientacji) jest przekształcany ze współrzędnych obrazu na współrzędne świata rzeczywistego przy użyciu parametrów georeferencyjnych kamery (z metadanych GPS/IMU lub z fotogrametrycznych punktów kontroli naziemnej). Dane lokalizacji umożliwiają: analizę grupowania przestrzennego w celu identyfikacji stref o wysokiej gęstości uszkodzeń, korelację z cechami strukturalnymi (spoiny, narożniki paneli, ścieżki odwadniające) oraz łączenie z bazami GIS systemu zarządzania nawierzchnią (PMS) w celu generowania zleceń robót utrzymaniowych.
Pomiar morfologii charakteryzuje właściwości geometryczne każdej instancji uszkodzenia wykraczające poza prostą powierzchnię. Kluczowe deskryptory morfologiczne obejmują:
Powierzchnia Otoczki Wypukłej: Powierzchnia najmniejszego wypukłego wielokąta zawierającego uszkodzenie. Stosunek powierzchni uszkodzenia do powierzchni otoczki wypukłej (solidność) wskazuje na wklęsłość kształtu. Niska solidność (<0,5) wskazuje na wysoce nieregularne lub rozgałęzione rysy.
Orientacja: Kąt osi głównej uszkodzenia (z momentów obrazu lub PCA pikseli maski). Orientacja rysy względem osi drogi startowej jest kluczowa dla oceny znaczenia strukturalnego: rysy poprzeczne (prostopadłe do ruchu) są zazwyczaj bardziej istotne strukturalnie niż rysy podłużne.
Ekscentryczność: Stosunek długości osi głównej do długości osi pobocznej. Wysoka ekscentryczność (>10) wskazuje na wydłużone uszkodzenia (rysy); niska ekscentryczność (<3) wskazuje na zwarte uszkodzenia (wyrwy, wykruszenia).
Obwód i Wymiar Fraktalny: Długość obwodu maski i wymiar fraktalny (zależność log(obwód) / log(powierzchnia)). Wyższy wymiar fraktalny wskazuje na bardziej nieregularne, złożone granice uszkodzenia — charakterystyczne dla zdegradowanych wykruszeń i spękań krokodylowych.
Szkielet i Punkty Rozgałęzień: Dla rys, szkieletoryzacja morfologiczna wyodrębnia sieć linii środkowej rysy. Punkty rozgałęzień (skrzyżowania, gdzie ścieżki rys się przecinają) są liczone i klasyfikowane. Liczba punktów rozgałęzień na instancję rysy jest kluczowym wskaźnikiem dotkliwości dla spękań blokowych i zmęczeniowych (D 5340).
Pomiary te są wydajnie obliczane przy użyciu funkcji analizy konturów OpenCV (cv2.findContours, cv2.moments, cv2.convexHull) lub operacji morfologicznych scikit-image (skimage.measure.regionprops, skimage.morphology.skeletonize). Dla typowego zbioru danych inspekcji drogi startowej składającego się z 10 000 obrazów z 50 000+ instancjami uszkodzeń, ekstrakcja cech dla poszczególnych uszkodzeń jest wykonywana w minutach na standardowej stacji roboczej.
Liczenie Uszkodzeń i Mapowanie Rozkładu Przestrzennego
Segmentacja instancji umożliwia automatyczne liczenie uszkodzeń, które jest po prostu niemożliwe przy użyciu samej segmentacji semantycznej. Liczba uszkodzeń — liczba odrębnych indywidualnych uszkodzeń na jednostkę powierzchni — jest podstawowym wkładem do wskaźników stanu infrastruktury, w tym PCI (ASTM D5340), Wskaźnika Stanu Konstrukcyjnego (SCI) i Wskaźnika Stanu Drogi Startowej (RCI).
Liczenie poszczególnych uszkodzeń przebiega następująco: model segmentacji instancji generuje maski instancji z unikalnymi ID (zazwyczaj liczby całkowite zaczynające się od 1). Liczba unikalnych ID instancji na każdym obrazie lub obszarze inspekcji daje bezpośrednio liczbę uszkodzeń. Dla 3000-metrowej drogi startowej badanej przy GSD 1mm, generującej około 3000 kafelków obrazu o rozmiarze 2000×2000 pikseli każdy, model segmentacji instancji może wykryć 200-500 indywidualnych rys, 50-100 wykruszeń i 10-20 wyrw — każda liczona i rejestrowana indywidualnie.
Stratyfikacja liczby grupuje uszkodzenia według typu i dotkliwości. Unikalne ID instancji są najpierw grupowane według przewidywanej klasy (rysa, wykruszenie, wyrwa, uszkodzenie spoiny, wietrzenie). W obrębie każdej klasy instancje można dalej stratyfikować według dotkliwości w oparciu o progi powierzchni lub cechy morfologiczne:
Rysy według dotkliwości: Rysy włoskowate (<1mm szerokości), Rysy średnie (1-3mm), Rysy szerokie (>3mm) — szerokość pochodzi ze stosunku powierzchni do długości szkieletu
Wykruszenia według dotkliwości: Niskie (<25mm głębokości, <150mm długości), Średnie (25-50mm głębokości, 150-600mm długości), Wysokie (>50mm głębokości, >600mm długości) — według ASTM D5340
Wyrwy według dotkliwości: Małe (<0,1 m²), Średnie (0,1-0,5 m²), Duże (>0,5 m²)
Mapowanie rozkładu przestrzennego agreguje liczby uszkodzeń na komórki przestrzenne. Droga startowa jest dzielona na jednostki próbkowe zgodnie ze specyfikacjami ICAO/ASTM: zazwyczaj 20 sąsiednich płyt dla nawierzchni betonowych (każda płyta ~5m × 5m = 25 m²) lub jednostki prostokątne 25m × 25m = 625 m² dla nawierzchni asfaltowych. Środek ciężkości każdej instancji uszkodzenia jest mapowany do zawierającej go jednostki próbkowej. Gęstość uszkodzeń na jednostkę jest obliczana jako: liczba uszkodzeń w jednostce / powierzchnia jednostki. Ta gęstość jest bezpośrednio wykorzystywana w tabelach obliczeniowych PCI.
Mapy rozkładu ujawniają wzorce grupowania się uszkodzeń. Droga startowa z 500 indywidualnymi rysami rozłożonymi na 120 jednostek próbkowych może wykazywać 85% jednostek z 0-5 rysami i 5% jednostek z 20+ rysami. Zgrupowane jednostki wskazują obszary wymagające ukierunkowanego utrzymania — zazwyczaj związane z podstawowymi problemami strukturalnymi (awaria podłoża, słaby drenaż, złącza konstrukcyjne), a nie z równomiernym zużyciem powierzchni.
Przestrzenna analiza wzorców punktowych (funkcja K Ripleya, estymacja gęstości jądrowej) może dalej ilościowo określić intensywność grupowania i zidentyfikować statystycznie istotne gorące punkty uszkodzeń. W połączeniu z analizą nakładania GIS, skupiska uszkodzeń mogą być korelowane z lokalizacjami złączy konstrukcyjnych, strefami wieku nawierzchni, wzorcami drenażu i obszarami stojącej wody, poprzednimi lokalizacjami utrzymania i napraw oraz rozkładem ruchu (strefy koncentracji ścieżek kół).
Śledzenie Instancji w Czasie
Unikalna zdolność segmentacji instancji do przypisywania trwałych identyfikatorów poszczególnym uszkodzeniom umożliwia śledzenie czasowe — ilościowe określenie, jak każde uszkodzenie ewoluuje między inspekcjami. Jest to podstawa predykcyjnego utrzymania i zarządzania aktywami opartego na stanie.
Proces śledzenia czasowego obejmuje cztery etapy. Po pierwsze, droga startowa jest ponownie badana w regularnym cyklu (kwartalnie, półrocznie lub rocznie, zgodnie z zalecaną praktyką ICAO dla przeglądów stanu nawierzchni lotnisk). Po drugie, segmentacja instancji jest stosowana niezależnie do każdego zbioru danych z przeglądu, generując maski dla poszczególnych uszkodzeń z ID instancji dla każdego punktu w czasie. Po trzecie, algorytm kojarzenia instancji dopasowuje instancje uszkodzeń między kolejnymi przeglądami na podstawie bliskości przestrzennej (odległość między środkami ciężkości < próg), nakładania się masek (IoU ≥ 0,3-0,5) i podobieństwa morfologicznego (zmiana powierzchni <50%, zmiana orientacji <15°). Po czwarte, dopasowane instancje otrzymują trwały globalny ID, który łączy je we wszystkich epokach przeglądów, tworząc szereg czasowy dla każdego uszkodzenia.
Algorytmy kojarzenia muszą radzić sobie z kilkoma wyzwaniami. Uszkodzenia mogą łączyć się lub dzielić między przeglądami (rysa, która się rozwidla, wykruszenie, które rozszerza się i łączy z sąsiednim wykruszeniem). Uszkodzenia mogą pojawiać się lub znikać (powstawanie nowych rys, naprawione uszkodzenia). Algorytm węgierski (przypisanie Munkresa) rozwiązuje problem przypisania liniowego dla dopasowania jeden-do-jednego między instancjami w kolejnych przeglądach przy koszcie obliczeniowym O(n³). W przypadku złożonych sytuacji z podziałami i połączeniami, śledzenie oparte na grafach (przepływ o minimalnym koszcie na grafie czasoprzestrzennym) zapewnia bardziej niezawodne dopasowanie przy wyższym koszcie obliczeniowym.
Metryki zmian dla poszczególnych uszkodzeń obliczane z dopasowanego szeregu czasowego obejmują:
Tempo wzrostu szerokości rysy: (szerokość_t2 - szerokość_t1) / dni. Wzrost >0,1mm/miesiąc zazwyczaj wskazuje na aktywną degradację strukturalną.
Tempo ekspansji powierzchni wykruszenia: (powierzchnia_t2 - powierzchnia_t1) / dni. Tempo ekspansji przekraczające 10-20 cm²/miesiąc wymaga zbadania.
Wzrost objętości wyrwy: W połączeniu z danymi głębokości, tempo wzrostu objętości w cm³/miesiąc.
Tempo powstawania nowych uszkodzeń: Liczba niedopasowanych instancji niepowiązanych z żadną poprzednią instancją z przeglądu na jednostkę powierzchni na jednostkę czasu.
Kierunek propagacji uszkodzenia: Wektor od centroid_t1 do centroid_t2 wskazuje kierunek propagacji deterioracji.
Dokładność śledzenia czasowego zależy od precyzji rejestracji przeglądów. Powtarzane przeglądy muszą być georeferencjonowane w tym samym układzie współrzędnych z dokładnością poniżej centymetra. Osiąga się to poprzez punkty kontroli naziemnej (GCP) trwale zainstalowane wzdłuż drogi startowej i mierzone za pomocą GPS RTK (±2cm dokładności) lub poprzez współrejestrację opartą na obrazie z wykorzystaniem dopasowania cech (cechy SIFT/SuperPoint) między zbiorami danych z przeglądów w celu obliczenia transformacji homograficznych.
Predykcyjne utrzymanie wykorzystuje szeregi czasowe poszczególnych uszkodzeń do prognozowania, kiedy uszkodzenie osiągnie krytyczną dotkliwość. Model regresji liniowej dopasowany do szeregu czasowego szerokości lub powierzchni każdego uszkodzenia przewiduje datę, w której uszkodzenie przekroczy próg dotkliwości (np. szerokość rysy >3mm dla Wysokiej dotkliwości według ASTM D5340). Generuje to priorytetową kolejkę utrzymania: uszkodzenia, które mają osiągnąć krytyczną dotkliwość w następnym cyklu inspekcji, są oznaczane do natychmiastowej naprawy.
Wymagania Szkoleniowe dla Etykiet na Poziomie Instancji
Trenowanie modeli segmentacji instancji dla uszkodzeń infrastruktury stwarza unikalne wyzwania w porównaniu do zbiorów danych obiektów naturalnych, głównie ze względu na wymagania dotyczące adnotacji i charakterystykę danych.
Format adnotacji: Segmentacja instancji wymaga adnotacji na poziomie wielokątów — każda indywidualne uszkodzenie musi być obrysowane zamkniętym wielokątem wierzchołków. Jest to znacznie bardziej pracochłonne niż adnotacje segmentacji semantycznej (które używają pociągnięć pędzlem lub narzędzi wypełniania zalewowego) lub adnotacje wykrywania obiektów (które używają prostokątów wyrównanych do osi). Typowa adnotacja rysy wymaga 20-100 wierzchołków wielokąta, aby dokładnie prześledzić ścieżkę rysy, w zależności od złożoności i długości rysy. Adnotacja wykruszenia zazwyczaj wymaga 8-30 wierzchołków. Standardowe narzędzia do adnotacji (CVAT, Labelbox, Supervisely, Scale AI) obsługują adnotacje wielokątów z półautomatycznymi narzędziami (np. interaktywna segmentacja z SAM — Segment Anything Model — w celu skrócenia czasu ręcznego umieszczania wierzchołków).
Format JSON COCO jest standardowym schematem adnotacji segmentacji instancji. Każdy wpis adnotacji zawiera id (unikalny identyfikator adnotacji), image_id (odniesienie do obrazu źródłowego), category_id (etykieta klasy, np. 1=rysa, 2=wykruszenie, 3=wyrwa), segmentation (wielokąt przedstawiony jako spłaszczona lista współrzędnych x,y), area (powierzchnia wielokąta w pikselach), bbox (ramka ograniczająca jako [x, y, width, height]) i iscrowd (0 dla pojedynczych instancji uszkodzeń).
Wymagania dotyczące rozmiaru zbioru danych: Modele segmentacji instancji zazwyczaj wymagają 500-2000+ oznaczonych obrazów na kategorię uszkodzeń dla akceptowalnej wydajności (AP >35). Małe zbiory danych (<200 obrazów) są narażone na nadmierne dopasowanie i słabą generalizację na nowe typy nawierzchni, warunki oświetleniowe i warianty uszkodzeń. Uczenie transferowe z dużych wstępnie wytrenowanych szkieletów (ImageNet-1K, COCO) znacznie zmniejsza wymagany rozmiar zbioru danych — Mask R-CNN zainicjowany wagami wstępnie wytrenowanymi na COCO i dostrojony na 500 obrazach rys osiąga porównywalną wydajność do modelu trenowanego od podstaw na 2000 obrazach.
Augmentacja danych jest kluczowa dla zbiorów danych uszkodzeń infrastruktury, które są zazwyczaj mniejsze niż ogólne zbiory danych wizji komputerowej. Skuteczne augmentacje obejmują losowy obrót (±180°), odwracanie poziome/pionowe, losowe skalowanie (0,5×-2,0×), regulację jasności/kontrastu (±20%), losowe przycinanie, transformacje elastyczne (pole przemieszczenia Gaussa) i augmentację mozaikową (łączenie 4 obrazów w jeden). CrackMover, specjalistyczna augmentacja do segmentacji instancji rys, pobiera instancje rys z jednego obrazu i wkleja je do nowych obrazów tła z realistycznym mieszaniem, sztucznie zwiększając zarówno liczbę instancji rys, jak i różnorodność tła.
Generowanie danych syntetycznych rozwiązuje podstawowy problem niedoboru adnotacji w inspekcji infrastruktury. Oparta na BSP struktura inspekcji nawierzchni lotnisk (Alonso i in., 2024) pokazuje, że trenowanie na mieszanych rzeczywistych i syntetycznych zbiorach danych poprawia F1 segmentacji rys o 8-12% w porównaniu do trenowania wyłącznie na rzeczywistych danych. Hiperrealistyczne wirtualne środowiska zbudowane w Unreal Engine lub Unity mogą generować nieograniczone oznakowane obrazy z idealnymi maskami prawdy podstawowej, zróżnicowanymi warunkami oświetleniowymi i różnorodnymi geometriami uszkodzeń. Randomizacja domeny — losowe zmienianie tekstur, kolorów i oświetlenia w scenach syntetycznych — poprawia transfer symulacja-rzeczywistość, zmuszając model do uczenia się geometrii, a nie wzorców tekstur.
Ewaluacja Segmentacji Instancji
Modele segmentacji instancji są oceniane przy użyciu metryk odziedziczonych zarówno z wykrywania obiektów, jak i segmentacji semantycznej, z protokołem ewaluacji COCO jako standardowym benchmarkiem.
Średnia Precyzja (AP) jest podstawową metryką. AP jest obliczana przy wielu progach Intersection over Union (IoU) między przewidywanymi maskami a maskami prawdy podstawowej. Dla każdego progu IoU t (w zakresie od 0,50 do 0,95 w krokach co 0,05), krzywe precyzji-swoistości są obliczane dla każdej klasy, a AP to pole pod krzywą precyzji-swoistości. Podstawowa metryka COCO AP (lub mAP) uśrednia wszystkie progi IoU i klasy.
Kluczowe warianty AP stosowane w wykrywaniu uszkodzeń obejmują AP@IoU=0,50 (łagodny próg uważany za próg wykrycia; przewidywana maska pokrywająca 50% lub więcej z maską prawdy podstawowej jest uznawana za poprawną), AP@IoU=0,75 (ścisły próg wymagający wysokiej jakości masek, ważny dla aplikacji wymagających precyzyjnego wyznaczania granic uszkodzeń, takich jak pomiar szerokości rys) oraz AP@small, AP@medium, AP@large (metryki według rozmiaru zdefiniowane przez powierzchnię prawdy podstawowej: mała <32² pikseli, średnia 32²-96² pikseli, duża >96² pikseli).
Średnia Swoistość (AR) mierzy proporcję instancji prawdy podstawowej, które mają przewidywane dopasowanie przy każdym progu IoU. AR jest zazwyczaj raportowane jako AR@max=100 (maksimum 100 detekcji na obraz). Wysoka swoistość jest kluczowa dla inspekcji infrastruktury krytycznej dla bezpieczeństwa, gdzie pominięte uszkodzenia mogą prowadzić do niewykrytej deterioracji.
Mask IoU jest podstawowym kryterium dopasowania. Dla przewidywanej maski P i maski prawdy podstawowej G, IoU = |P ∩ G| / |P ∪ G|. Przewidywanie jest uważane za Prawdziwie Pozytywne (TP), jeśli IoU ≥ próg ORAZ przewidywana klasa zgadza się z klasą prawdy podstawowej. Fałszywie Pozytywne (FP) występują, gdy przewidywania mają IoU < próg z jakąkolwiek maską prawdy podstawowej tej samej klasy lub przewidują złą klasę. Fałszywie Negatywne (FN) to maski prawdy podstawowej, które nie pasują do żadnego przewidywania.
Algorytm dopasowania COCO obsługuje zduplikowane detekcje: jeśli wiele przewidywań pasuje do pojedynczej prawdy podstawowej, tylko przewidywanie o najwyższej pewności jest liczone jako TP; reszta to FP. Nagradza to precyzję i karze nadmierną segmentację — ważne dla wykrywania uszkodzeń, gdzie wiele nakładających się przewidywań na tej samej rysie wskazywałoby na niestabilność modelu.
Ewaluacja specyficzna dla infrastruktury często dodaje AP na klasę podzieloną według typu uszkodzenia. Model wykrywania rys może raportować AP_rysa=32,1, AP_wykruszenie=44,6, AP_wyrwa=51,3. Znacznie niższe AP dla rys odzwierciedla trudność segmentacji instancji dla cienkich, wydłużonych obiektów (mask IoU jest bardzo wrażliwy na małe błędy wyrównania dla cienkich struktur).
Wynik F1 przy konkretnym progu IoU (zazwyczaj 0,50) jest również często raportowany w literaturze infrastrukturalnej: F1 = 2 × (Precyzja × Swoistość) / (Precyzja + Swoistość). F1 zapewnia pojedynczą zrównoważoną miarę kompromisu między precyzją a swoistością.
Zastosowanie w Inspekcji Infrastruktury
Segmentacja instancji przekształca inspekcję infrastruktury z subiektywnego, pracochłonnego procesu w obiektywny, ilościowy i skalowalny cyfrowy przepływ pracy. Technologia jest wdrażana w wielu domenach infrastrukturalnych z udokumentowanymi poprawami dokładności, spójności i przepustowości inspekcji.
Inspekcja dróg startowych lotnisk stanowi najbardziej wymagające zastosowanie. Kwalifikowane inspekcje dróg startowych zgodnie z ICAO Annex 14 wymagają przeglądów stanu nawierzchni co 1-3 lata przy użyciu standaryzowanych procedur (ASTM D5340, ASTM D6433, ICAO Aerodrome Design Manual Part 3). Segmentacja instancji bezpośrednio wspiera te standardy poprzez automatyzację liczenia i pomiaru uszkodzeń. Oparta na BSP zautomatyzowana struktura inspekcji dróg startowych (Krestenitis i in., 2026) demonstruje wdrożenie od końca do końca: przegląd BSP → pozyskanie obrazów → wnioskowanie głębokiego uczenia (EfficientNet + FPN segmentacja semantyczna z nakładanym przetwarzaniem końcowym instancji) → agregacja w GIS → obliczenie PCI. System osiąga 95%+ dokładności wykrywania dla uszkodzeń >3mm szerokości na całej długości dróg startowych, z zakończeniem przeglądu w 45 minut vs 4-6 godzin dla tradycyjnej inspekcji ręcznej wymagającej zamknięcia drogi startowej.
Inspekcja nawierzchni autostrad i dróg wykorzystuje systemy kamer montowane w pojazdach poruszających się z prędkościami autostradowymi (60-100 km/h). Modele segmentacji instancji (YOLACT, YOLOv8-seg) przetwarzają strumienie wideo z szybkością 15-30 FPS, wykrywając rysy, wyrwy i łaty na milę pasa ruchu. Zautomatyzowany przegląd uszkodzeń nawierzchni Nevada DOT wykorzystuje system segmentacji instancji oparty na YOLOv8, osiągając 88% F1 dla wykrywania rys i 93% F1 dla wykrywania wyrw na ponad 5000 mil pasów ruchu, z dokładnością pomiaru poszczególnych uszkodzeń w granicach 5% ręcznych pomiarów referencyjnych.
Inspekcja pomostów mostowych stosuje segmentację instancji do wykruszeń betonu, rozwarstwień i uszkodzeń spoin. Pomosty mostów stwarzają unikalne wyzwania: zmienne oświetlenie pod spodem mostu, złożone tekstury tła (dylatacje, wpusty odwadniające, oznakowanie drogowe) oraz potrzeba submilimetrowej rozdzielczości dla rys do pomiaru szerokości. Cascade Mask R-CNN dostrojony na zbiorze danych pomostów mostowych osiąga 82% mAP@50 dla wykrywania wykruszeń, umożliwiając zautomatyzowane obliczanie ratingu stanu SNBI (Specyfikacja Krajowej Inspekcji Mostów) dla betonowych pomostów mostów.
Inspekcja infrastruktury kolejowej wykorzystuje segmentację instancji do uszkodzeń powierzchni szyn (pęknięcia główkowe, wygniecenia, łuszczenie) i anomalii podtorza. Systemy kamer montowane na szynach rejestrują obrazy o wysokiej rozdzielczości przy prędkości 100+ km/h; modele YOLACT działające na wbudowanych GPU wykrywają i klasyfikują poszczególne uszkodzenia szyn z prędkością liniową. Koleje Niemieckie (Deutsche Bahn) zgłosiły 96% współczynnik wykrywalności dla rys powierzchniowych >1mm przy użyciu potoku segmentacji instancji wdrożonego na 30 pociągach inspekcyjnych, z dokładnością lokalizacji poszczególnych uszkodzeń ±5mm przy użyciu odometrii z koła enkodera.
Inspekcja obudów tuneli wdraża segmentację instancji na obrazach przechwyconych z zestawów wielu kamer zamontowanych na pojazdach inspekcyjnych poruszających się z prędkością 30-50 km/h. Betonowe obudowy tuneli rozwijają rysy, wykruszenia i plamy przesiąków, które wymagają analizy na poziomie instancji. Kluczowym wyzwaniem jest rozróżnienie między rysami konstrukcyjnymi (wymagającymi naprawy) a niekonstrukcyjnymi rysami powierzchniowymi (skurczowymi, termicznymi). Segmentacja instancji w połączeniu z pomiarem szerokości rysy (z analizy maski dla każdej instancji) dostarcza danych ilościowych potrzebnych do tej klasyfikacji. System inspekcji tuneli Kolei Austriackich (ÖBB) wykorzystuje Mask R-CNN z siatką kalibracyjną opartą na markerach Aruco, aby osiągnąć dokładność pomiaru szerokości rysy ±0,1mm przy rozdzielczości 0,5mm/piksel.
Korzyści w stosunku do tradycyjnej inspekcji są dobrze udokumentowane we wszystkich typach infrastruktury. Badanie porównawcze przeprowadzone w 12 agencjach transportowych wykazało, że zautomatyzowana inspekcja z segmentacją instancji skróciła czas inspekcji o 60-80%, wyeliminowała zmienność między oceniającymi (współczynnik kappa poprawił się z 0,45-0,55 dla inspekcji ręcznej do 0,88-0,94 dla zautomatyzowanej) oraz zwiększyła czułość wykrywania uszkodzeń o 25-40% (szczególnie w przypadku uszkodzeń o niskiej dotkliwości, które są często pomijane przez inspektorów z powodu zmęczenia). Możliwość pomiaru poszczególnych uszkodzeń umożliwia przejście od utrzymania opartego na wskaźniku stanu (leczenie obszarów powyżej progu dotkliwości) do utrzymania opartego na poszczególnych uszkodzeniach (priorytetyzacja napraw według krytyczności poszczególnych uszkodzeń), zmniejszając całkowite koszty utrzymania o szacowane 15-30% poprzez ukierunkowaną naprawę zamiast leczenia całych obszarów.
Najczęściej Zadawane Pytania
Segmentacja semantyczna oznacza każdy piksel obrazu według klasy, ale nie rozróżnia poszczególnych obiektów tej samej klasy. Segmentacja instancji idzie dalej, przypisując unikalny identyfikator każdemu indywidualnemu obiektowi. Na przykład na powierzchni drogi startowej z trzema rysami segmentacja semantyczna pokolorowałaby wszystkie piksele rys tym samym kolorem, podczas gdy segmentacja instancji nadałaby każdej z trzech rys inny kolor i unikalny identyfikator (Rysa-001, Rysa-002, Rysa-003). To rozróżnienie jest kluczowe dla liczenia uszkodzeń i pomiaru poszczególnych uszkodzeń.
Najlepsza architektura zależy od zastosowania. Mask R-CNN oferuje wysoką dokładność (37-47 AP na COCO), ale jest wolniejszy przy 5-10 FPS, co czyni go idealnym do analizy offline. YOLACT działa z szybkością 30+ FPS i nadaje się do inspekcji dronami w czasie rzeczywistym. Mask2Former osiąga najwyższą wydajność z 50,1 AP na segmentacji instancji COCO, wykorzystując transformerową uwagę maskowaną, i jest 3 razy szybszy w zbieżności niż tradycyjne modele transformerowe. Do inspekcji infrastruktury Mask2Former i Cascade Mask R-CNN zazwyczaj zapewniają najlepszą dokładność dla złożonych kształtów uszkodzeń.
Segmentacja instancji przypisuje unikalny numeryczny identyfikator każdej wykrytej instancji uszkodzenia w czasie wnioskowania. Etap przetwarzania końcowego zlicza wszystkie unikalne identyfikatory instancji obecne na obrazie lub w obszarze inspekcji, dając całkowitą liczbę uszkodzeń. Liczba ta może być stratyfikowana według typu uszkodzenia (rysa vs wykruszenie vs wyrwa), klasy dotkliwości lub regionu przestrzennego. W przeciwieństwie do segmentacji semantycznej, która podaje tylko całkowitą powierzchnię pikseli na klasę, segmentacja instancji dostarcza dokładną liczbę odrębnych instancji uszkodzeń, niezbędną do obliczeń Wskaźnika Stanu Nawierzchni (PCI) i priorytetyzacji utrzymania.
Segmentacja instancji wymaga adnotacji na poziomie wielokątów (nie tylko pikseli), gdzie każda indywidualna instancja uszkodzenia jest obrysowana zamkniętym wielokątem. Każdy wielokąt musi mieć przypisaną etykietę klasy i być traktowany jako oddzielny element adnotacji. Typowe zestawy danych infrastrukturalnych wymagają 500-2000+ oznaczonych obrazów na kategorię uszkodzenia. Standardem jest format adnotacji JSON w stylu COCO z wielokątami segmentacji i ramkami ograniczającymi. Augmentacja danych (obrót, skalowanie, transformacje elastyczne) i generowanie danych syntetycznych (np. CrackMover) są powszechnie stosowane w celu uzupełnienia ograniczonej ilości rzeczywistych oznaczonych danych.
Tak, segmentacja instancji umożliwia czasowe śledzenie uszkodzeń poprzez kojarzenie instancji w kolejnych przeglądach. Każda instancja uszkodzenia wykryta w Przeglądzie 1 (Czas T1) otrzymuje trwały identyfikator instancji. Gdy przeprowadzany jest Przegląd 2 (Czas T2), model ponownie wykrywa instancje. Algorytm kojarzenia dopasowuje instancje między przeglądami na podstawie lokalizacji przestrzennej (współrzędne GPS), nakładania się masek (IoU) i podobieństwa morfologicznego. Umożliwia to ilościowe określenie wzrostu szerokości rys, powiększania się powierzchni wykruszeń i tempa powstawania nowych uszkodzeń — kluczowe dla modeli predykcyjnego utrzymania.
Segmentacja instancji jest oceniana przy użyciu metryk Średniej Precyzji (AP) w stylu COCO. AP@IoU=0,50 mierzy wykrywanie przy łagodnym progu nakładania, podczas gdy AP@IoU=0,75 wymaga wysokiej dokładności. Podstawowa metryka AP (uśredniona dla progów IoU od 0,50 do 0,95 w krokach co 0,05) zapewnia kompleksową ocenę. Mask IoU (Intersection over Union między przewidywaną a rzeczywistą maską) jest podstawowym kryterium dopasowania. Raportowane są również AP na klasę, AR (Średnia Swoistość) i wynik F1. W przypadku oceny specyficznej dla infrastruktury powszechnie stosuje się AP na uszkodzenie przy progach IoU 0,50 i 0,75.
Mask R-CNN to dwuetapowy detektor, który najpierw proponuje kandydackie regiony (RPN), a następnie przewiduje maski dla każdego regionu. YOLACT to jednoetapowa metoda czasu rzeczywistego, która jednocześnie generuje prototypowe maski i współczynniki liniowe. W przypadku segmentacji rys, Mask R-CNN zazwyczaj osiąga wyższą dokładność masek (33,3 AP vs ~28-30 AP dla YOLACT na zbiorach danych rys), ale działa z szybkością 5-10 FPS. YOLACT osiąga 30+ FPS, co czyni go odpowiednim do inspekcji BSP w czasie rzeczywistym. Oba zostały z powodzeniem zastosowane do wykrywania rys w nawierzchniach drogowych w badaniach naukowych.
Segmentacja instancji jest szczególnie skuteczna w przypadku wyrw i wykruszeń, ponieważ te uszkodzenia są odrębnymi, ograniczonymi obiektami o wyraźnym zasięgu przestrzennym. Każda instancja wyrwy otrzymuje unikalną maskę, pomiar powierzchni (w pikselach lub mm²), ramkę ograniczającą i położenie środka ciężkości. Umożliwia to klasyfikację dotkliwości według powierzchni i głębokości dla każdej wyrwy, liczenie wyrw na sekcję drogi startowej oraz śledzenie ekspansji wyrw w czasie. Badania wykorzystujące Mask R-CNN i YOLACT do wykrywania wyrw podają wartości AP na poziomie 40-55 na zbiorach danych drogowych, przy czym maski na poziomie instancji zapewniają bardziej precyzyjne pomiary niż same ramki ograniczające.
Zautomatyzuj swoją Inspekcję Uszkodzeń Infrastruktury
TarmacView wykorzystuje najnowocześniejsze modele segmentacji instancji do wykrywania, liczenia i śledzenia każdego indywidualnego uszkodzenia na nawierzchniach lotniskowych, mostach i infrastrukturze betonowej. Umów się na demo, aby zobaczyć, jak analiza poszczególnych uszkodzeń może przekształcić Twoje planowanie utrzymania.
Segmentacja Semantyczna dla Rozumienia Scen Infrastrukturalnych
Segmentacja semantyczna przypisuje etykietę kategorii do każdego piksela obrazu, umożliwiając pełne zrozumienie sceny do inspekcji infrastruktury. Obejmuje arch...
Wykrywanie pęknięć za pomocą AI w inspekcji infrastruktury
Wykrywanie pęknięć oparte na AI wykorzystuje widzenie komputerowe — konwolucyjne sieci neuronowe, transformery wizyjne i modele segmentacji semantycznej — do au...
Wykrywanie zmian porównuje współzarejestrowane obrazy lub chmury punktów tej samej struktury wykonane w różnych momentach, aby zidentyfikować nowe, pogłębiające...
37 min czytania
Technology
Inspection
+2
Zgoda na Pliki Cookie Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.