FAISS
FAISS (Facebook AI Similarity Search) to biblioteka open-source do wydajnego wyszukiwania podobieństw i klastrowania gęstych wektorów, używana przez TarmacView ...
29 min czytania
Vector Search
Similarity Search
+6
k-Najbliższych Sąsiadów (kNN) klasyfikuje punkt zapytania poprzez głosowanie większościowe wśród jego k najbardziej podobnych punktów referencyjnych w przestrzeni osadzeń. TarmacView używa kNN (k=10) z podobieństwem cosinusowym na osadzeniach referencyjnych indeksowanych przez FAISS do przewidywania typu nawierzchni i klasy jakości. Omówiono algorytm, metryki odległości, wybór k, ważone głosowanie oraz zalety dla inspekcyjnej, interpretowalnej klasyfikacji.
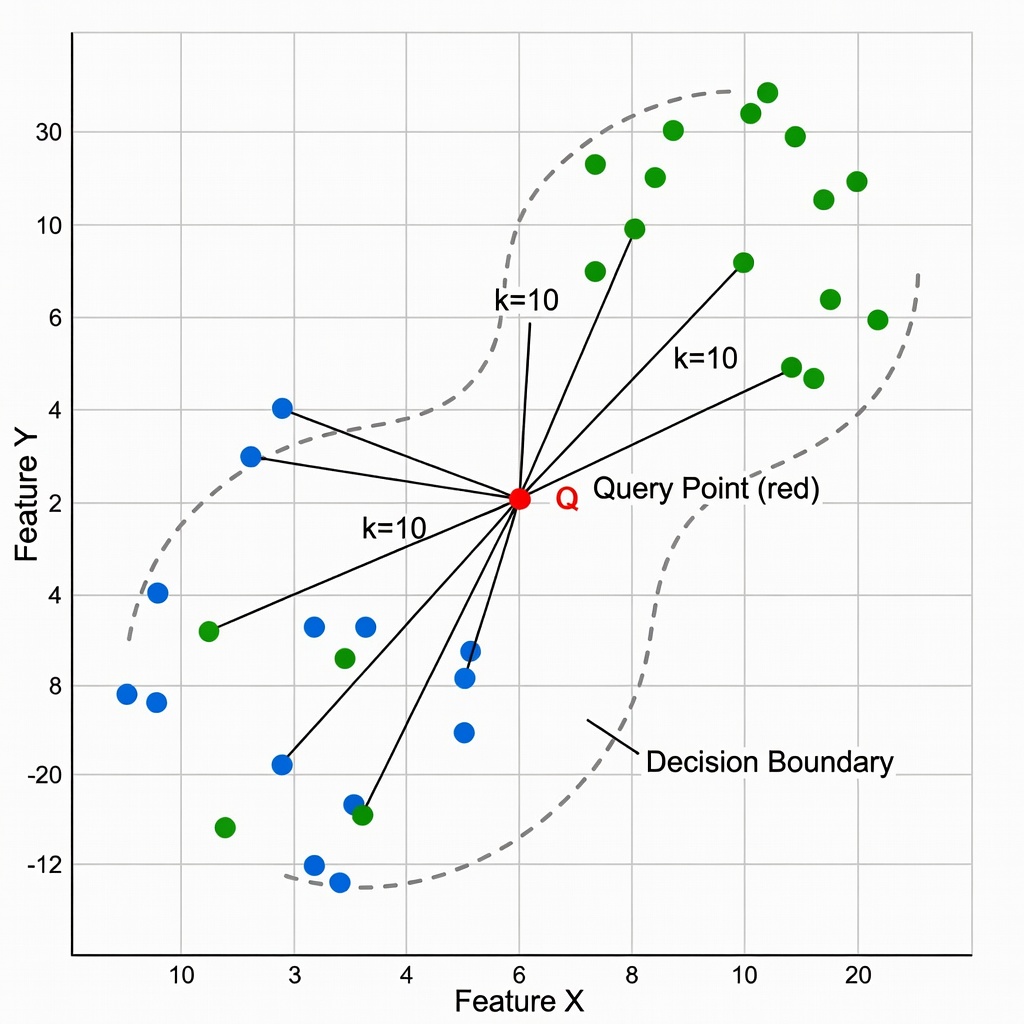
Algorytm k-Najbliższych Sąsiadów (kNN) to nieparametryczna, instancyjna metoda uczenia nadzorowanego, po raz pierwszy formalnie opisana przez Evelyn Fix i Josepha Hodgesa w 1951 roku podczas badań prowadzonych dla United States Air Force School of Aviation Medicine. Ich raport techniczny „Discriminatory Analysis — Nonparametric Discrimination: Consistency Properties" ustanowił podstawy teorii nieparametrycznego estymacji gęstości i klasyfikacji. W 1967 roku Thomas Cover i Peter Hart opublikowali przełomową pracę „Nearest Neighbor Pattern Classification" w IEEE Transactions on Information Theory, w której udowodnili, że asymptotyczny poziom błędów klasyfikatora 1-najbliższego sąsiada jest ograniczony od góry przez dwukrotność optymalnego poziomu błędów Bayesa. To teoretyczne zapewnienie — że prosty algorytm operujący na przechowywanych danych treningowych może osiągnąć poziom błędów w granicach dwukrotności teoretycznie optymalnego klasyfikatora — ustanowiło kNN jako fundamentalną metodę w statystycznym rozpoznawaniu wzorców.
Algorytm działa na prostej zasadzie geometrycznej: punkty znajdujące się blisko siebie w przestrzeni cech lub osadzeń prawdopodobnie należą do tej samej klasy. Dla danego punktu zapytania q w d-wymiarowej przestrzeni osadzeń, algorytm oblicza odległość od q do każdego punktu referencyjnego w bazie treningowej według wybranej metryki odległości, wybiera k punktów referencyjnych o najmniejszych odległościach i przypisuje q etykietę klasy, która pojawia się najczęściej wśród tych k sąsiadów. Dla zadań regresji algorytm zwraca średnią lub ważoną średnią wartości docelowych k sąsiadów zamiast głosowania większościowego.
kNN jest klasyfikowany jako leniwy uczeń, ponieważ nie wykonuje jawnej generalizacji ani abstrakcji podczas fazy trenowania. Zamiast uczyć się parametrycznej granicy decyzyjnej (jak regresja logistyczna, maszyny wektorów nośnych czy sieci neuronowe), kNN zapamiętuje cały zbiór treningowy i odkłada wszystkie obliczenia do czasu inferencji. Faza trenowania jest natychmiastowa — po prostu przechowuje dane referencyjne w pamięci lub w strukturze indeksu. Praktyczną konsekwencją jest to, że kNN jest trywialnie równoległy i nie wymaga optymalizacji hiperparametrów poza wyborem k i metryki odległości. Jednak faza inferencji wymaga wyszukiwania najbliższego sąsiada w bazie referencyjnej dla każdego zapytania, co przy brute-force ma złożoność obliczeniową O(N × d), gdzie N to liczba punktów referencyjnych, a d to wymiarowość osadzenia. Dla biblioteki referencyjnej TarmacView zawierającej dziesiątki tysięcy fragmentów nawierzchni zakodowanych w 128-wymiarowe wektory osadzeń, wyszukiwanie brute-force jest wykonalne przy umiarkowanej skali, ale staje się niepraktyczne w miarę wzrostu biblioteki. Indeksowanie FAISS redukuje złożoność inferencji do około O(log N × d) dla wyszukiwania przybliżonego.
Podstawy teoretyczne kNN opierają się na założeniu gładkości: funkcja mapująca wejścia na etykiety jest lokalnie stała — punkty w małym sąsiedztwie wokół q mają tę samą etykietę co q. To założenie jest słuszne, gdy przestrzeń osadzeń jest tak zorganizowana, że semantycznie podobne wejścia mapują się na pobliskie wektory. Jakość klasyfikacji kNN zależy zatem krytycznie od jakości przestrzeni osadzeń. Jeśli enkoder tworzy przestrzeń osadzeń, w której punkty tej samej klasy są ściśle skupione, a punkty różnych klas dobrze rozdzielone — właściwość zwana separowalnością klas — wówczas kNN osiągnie wysoką dokładność przy małym k. Jeśli przestrzeń osadzeń jest słabo zorganizowana, kNN degraduje się do losowej wydajności niezależnie od wartości k. Przestrzeń osadzeń TarmacView jest tworzona przez cel nadzorowanego uczenia kontrastywnego, który explicitnie optymalizuje separowalność klas: cel treningowy zbliża do siebie fragmenty nawierzchni tej samej klasy (np. asfalt PCI 70-80) w przestrzeni osadzeń, jednocześnie oddalając fragmenty różnych klas. Tworzy to wysoce ustrukturyzowaną przestrzeń osadzeń, w której kNN z k=10 osiąga 96-98% dokładności klasyfikacji.
Istnieje krytyczne rozróżnienie algorytmiczne między głosowaniem większościowym a głosowaniem pluralistycznym w kNN. Głosowanie większościowe wymaga, aby jedna klasa otrzymała więcej niż 50% głosów — jest to naturalny mechanizm dla klasyfikacji binarnej (dwie klasy). Głosowanie pluralistyczne, które jest standardowym mechanizmem dla problemów wieloklasowych z trzema lub więcej klasami, przypisuje etykietę z najwyższym udziałem głosów, niezależnie od tego, czy przekracza on 50%. W klasyfikacji 10 typów nawierzchni z k=10, klasa otrzymująca 4 głosy wygrywa przez pluralizm, mimo że 60% sąsiadów głosowało na inne klasy. To rozróżnienie ma znaczenie dla interpretacji pewności: zwycięstwo pluralistyczne z 40% zgodnością oznacza, że 60% sąsiadów było przeciwnego zdania, co wskazuje na znaczną niepewność, mimo że predykcja została wygenerowana.
Metryka odległości jest pojedynczym najważniejszym wyborem algorytmicznym w klasyfikacji kNN, ponieważ definiuje, co znaczy „najbliższy" w przestrzeni osadzeń. Metryka określa geometrię sąsiedztw — kontroluje kształt i orientację granic decyzyjnych oraz bezpośrednio decyduje, które punkty referencyjne wpływają na każde zapytanie. Wybór metryki powinien być kierowany strukturą przestrzeni osadzeń i niezmiennikami wymaganymi przez domenę aplikacji.
Podobieństwo cosinusowe mierzy cosinus kąta między dwoma wektorami w przestrzeni osadzeń. Jest zdefiniowane jako:
cos(θ) = (A · B) / (‖A‖ × ‖B‖)
gdzie A · B to iloczyn skalarny wektorów A i B, a ‖A‖ to norma L2 (długość euklidesowa). Podobieństwo cosinusowe przyjmuje wartości od -1 (wektory skierowane w dokładnie przeciwnych kierunkach) do +1 (wektory skierowane w identycznych kierunkach). Wartość 0 oznacza wektory ortogonalne, bez korelacji. Odpowiadająca mu odległość cosinusowa, używana jako metryka odległości w wyszukiwaniu kNN, jest zdefiniowana jako:
d_cos(A, B) = 1 − cos(θ)
Odległość cosinusowa przyjmuje wartości od 0 (identyczny kierunek) do 2 (dokładnie przeciwny). Podobieństwo cosinusowe jest niezmiennicze względem wielkości wektora — dwa wektory o identycznym kierunku, ale różnych długościach, są uznawane za idealnie podobne. Jest to metryka używana przez TarmacView do wszystkich klasyfikacji nawierzchni kNN.
Kluczową właściwością podobieństwa cosinusowego jest niezmienniczość względem wielkości. Cechy wyglądu nawierzchni, takie jak tekstura powierzchni, gęstość wzoru spękań i ekspozycja kruszywa, są uchwycone głównie w kierunku wektora osadzenia, a nie w jego wielkości. Dobrze oświetlone zdjęcie nawierzchni drogi startowej i słabo oświetlone zdjęcie tej samej nawierzchni powinny dawać osadzenia o podobnej treści kierunkowej, ale potencjalnie różnych wielkościach. Podobieństwo cosinusowe naturalnie zapewnia tę niezmienniczość oświetleniową. Co więcej, gdy sieć enkodera produkuje znormalizowane wektory jednostkowe L2 (standardowa praktyka w uczeniu kontrastywnym), podobieństwo cosinusowe redukuje się do prostego iloczynu skalarnego: cos(θ) = A · B. Pozwala to FAISS na używanie zoptymalizowanych procedur wyszukiwania iloczynu skalarnego (IP), które korzystają z implementacji iloczynu skalarnego na poziomie BLAS zarówno na architekturach CPU, jak i GPU.
W przestrzeni osadzeń TarmacView wszystkie osadzenia referencyjne i zapytań są znormalizowane do długości jednostkowej. Indeks FAISS jest skonfigurowany z METRIC_INNER_PRODUCT, a ponieważ wszystkie wektory są znormalizowane jednostkowo, ranking według iloczynu skalarnego jest identyczny z rankingiem według podobieństwa cosinusowego. Ta konfiguracja umożliwia FAISS używanie wydajnych obliczeń iloczynu skalarnego z akceleracją SIMD.
Odległość euklidesowa (zwana również odległością L2) mierzy odległość w linii prostej między dwoma punktami w przestrzeni osadzeń:
d_euk(A, B) = sqrt(∑_(i=1)^d (A_i − B_i)²)
Odległość euklidesowa jest najczęstszą metryką odległości we wszystkich zastosowaniach uczenia maszynowego. Jest wrażliwa zarówno na kierunek, jak i wielkość wektorów osadzeń — dwa zdjęcia o tej samej teksturze powierzchni, ale różnym poziomie jasności, mogą dawać osadzenia o tym samym kierunku, ale różnych wielkościach, co skutkuje dużą odległością euklidesową, mimo że treść semantyczna jest identyczna. W domenach aplikacji, gdzie wielkość koduje istotną informację — na przykład, gdzie nasilenie deterioracji powierzchni proporcjonalnie zwiększa wielkość cechy — odległość euklidesowa może być odpowiednim wyborem.
Dla znormalizowanych jednostkowo osadzeń (konfiguracja TarmacView), odległość euklidesowa i podobieństwo cosinusowe są matematycznie powiązane tożsamością:
‖A − B‖² = ‖A‖² + ‖B‖² − 2(A · B) = 2 − 2cos(θ)
Gdy oba wektory są znormalizowane do długości jednostkowej (‖A‖ = ‖B‖ = 1), ranking według odległości euklidesowej daje takie samo uporządkowanie najbliższych sąsiadów jak ranking według podobieństwa cosinusowego, ponieważ zależność jest monotoniczna: mniejsza odległość euklidesowa odpowiada większemu podobieństwu cosinusowemu. W tym szczególnym przypadku wybór między tymi dwiema metrykami jest obliczeniowo nieistotny. Jeśli jednak osadzenia nie są znormalizowane, obie metryki dają znacząco różne sąsiedztwa, a wybór musi być podyktowany wymaganiami domeny.
Przekleństwo wymiarowości w nieproporcjonalnym stopniu dotyka odległość euklidesową. Wraz ze wzrostem wymiarowości osadzenia d, stosunek odległości między najbliższymi i najdalszymi punktami dąży do 1 dla danych niezależnych i identycznie rozłożonych — zasadniczo wszystkie punkty stają się równoodległe, a wyszukiwanie najbliższego sąsiada traci moc dyskryminacyjną. Dla d=128 (wymiarowość osadzenia TarmacView), ten efekt jest obecny, ale złagodzony przez fakt, że osadzenia nie są niezależne: uczenie kontrastywne explicitnie strukturuje przestrzeń, aby wytworzyć znaczące różnice odległości wzdłuż semantycznie istotnych wymiarów.
Odległość Manhattan (zwana również odległością L1 lub geometrią taksówkową) sumuje bezwzględne różnice wzdłuż każdego wymiaru:
d_man(A, B) = ∑_(i=1)^d |A_i − B_i|
W przeciwieństwie do odległości euklidesowej, która podnosi różnice do kwadratu przed sumowaniem (nadając nieproporcjonalną wagę dużym różnicom w pojedynczym wymiarze), odległość Manhattan traktuje każdy wymiar równo. Czyni ją to bardziej odporną na wymiary odstające i na przekleństwo wymiarowości — w przestrzeniach wysokowymiarowych metryki L1 lepiej zachowują dyskryminowalność odległości niż metryki L2, ponieważ nie amplifikują wyrazów kwadratowych.
Odległość Manhattan jest szczególnie odpowiednia dla rzadkich lub binarnych wektorów cech, gdzie większość wymiarów wynosi zero, a znacząca informacja leży w tym, które wymiary są niezerowe, a nie w ich dokładnych wartościach. W kontekście kNN na osadzeniach obrazów do inspekcji nawierzchni, odległość Manhattan jest rzadko używana, ponieważ cel uczenia kontrastywnego strukturujący przestrzeń osadzeń jest zazwyczaj optymalizowany dla geometrii euklidesowej (L2). Użycie odległości L1 na przestrzeni osadzeń zorganizowanej według L2 pogarsza wydajność, ponieważ geometria sąsiedztwa nie jest już zgodna z celem treningowym.
Odległość Minkowskiego uogólnia zarówno odległość euklidesową, jak i Manhattan poprzez pojedynczy parametr p:
d_mink(A, B) = (∑_(i=1)^d |A_i − B_i|^p)^(1/p)
Gdy p = 1, Minkowski redukuje się do odległości Manhattan (L1). Gdy p = 2, redukuje się do odległości euklidesowej (L2). Gdy p dąży do nieskończoności, odległość zbiega do odległości Czebyszewa (L∞), zdefiniowanej jako maksymalna bezwzględna różnica we wszystkich wymiarach: d_∞(A, B) = max_i |A_i − B_i|. Odległość Minkowskiego z p między 1 a 2 (normy ułamkowe) jest czasami używana dla wysokowymiarowego kNN, ponieważ interpoluje między wrażliwością L2 na wartości odstające a właściwością równej wagi L1, ale w praktyce oferuje ograniczoną przewagę nad wyborem bezpośrednio L1 lub L2.
Odległość Hamminga zlicza liczbę pozycji, na których dwa binarne wektory o równej długości różnią się. Dla dwóch binarnych ciągów x i y o długości d:
d_ham(x, y) = ∑_(i=1)^d [x_i ≠ y_i]
Odległość Hamminga jest używana dla kNN na cechach binarnych, kodach hash lub reprezentacjach skwantowanych. W kontekście FAISS, kwantyzacja produktowa (PQ) kompresuje wysokowymiarowe osadzenia do krótkich kodów binarnych, a odległość Hamminga umożliwia niezwykle szybkie przybliżone wyszukiwanie najbliższego sąsiada poprzez bitowe operacje XOR (instrukcje POPCNT na nowoczesnych procesorach). Chociaż TarmacView nie używa osadzeń binarnych do końcowej klasyfikacji, indeks FAISS wewnętrznie może używać PQ do stratnej kompresji bazy referencyjnej w celu zmniejszenia śladu pamięciowego, z asymetrycznym obliczaniem odległości (ADC) używanym do obliczania odległości bez pełnej dekompresji przechowywanych wektorów.
| Metryka | Wzór | Zakres | Niezmiennicza względem | Najlepsza dla |
|---|---|---|---|---|
| Cosinusowa | 1 − cos(θ) | [0, 2] | Wielkości | Tekstu, znormalizowanych osadzeń, cech kierunkowych |
| Euklidesowa (L2) | √∑(A_i−B_i)² | [0, ∞) | Obrótu (nie wielkości) | Cech ciągłych, surowej przestrzeni pikseli |
| Manhattan (L1) | ∑ | A_i−B_i | [0, ∞) | |
| Hamminga | ∑[A_i≠B_i] | [0, d] | — | Kodów binarnych, wyszukiwania hash, wyszukiwania PQ |
| Czebyszewa (L∞) | max | A_i−B_i | [0, ∞) |
Wybór metryki odległości powinien być walidowany empirycznie poprzez walidację krzyżową na docelowym zbiorze danych. Dla TarmacView, wybór podobieństwa cosinusowego został zweryfikowany poprzez porównanie dokładności klasyfikacji kNN dla wszystkich pięciu metryk na wstrzymanym zbiorze walidacyjnym 2000 fragmentów nawierzchni. Podobieństwo cosinusowe dało najwyższą średnią dokładność (97,2%), następnie euklidesowe (96,8%), Manhattan (93,4%), Czebyszewa (89,1%) i Hamminga (72,3%). Różnica w wydajności między cosinusowym a euklidesowym była niewielka, ponieważ osadzenia są znormalizowane L2, ale cosinusowe zostało wybrane jako podstawowa metryka ze względu na jego teoretyczne dopasowanie do celu uczenia kontrastywnego (który używa podobieństwa cosinusowego w swojej funkcji straty) i jego zgodność z wyszukiwaniem iloczynu skalarnego FAISS.
Parametr k — liczba najbliższych sąsiadów konsultowanych podczas głosowania — jest najważniejszym hiperparametrem w klasyfikacji kNN. Bezpośrednio kontroluje kompromis między obciążeniem a wariancją: małe k daje niskie obciążenie (model może uchwycić drobnoziarnistą strukturę klas), ale wysoką wariancję (model jest wrażliwy na szum i pojedyncze punkty referencyjne). Duże k daje niską wariancję (predykcje są stabilne i uśrednione po wielu punktach), ale wysokie obciążenie (model wygładza ważną strukturę klas). Optymalne k równoważy te konkurencyjne naciski.
Małe wartości k (1–5) dają bardzo elastyczne, lokalnie adaptacyjne granice decyzyjne. Przy k=1 (klasyfikator 1-NN), granica decyzyjna jest teselacją Woronoja punktów treningowych — każdy punkt w przestrzeni jest przypisany do klasy swojego pojedynczego najbliższego punktu referencyjnego. Ta granica interpoluje idealnie każdy punkt treningowy (zerowy błąd treningowy), ale może być wysoce nieregularna, tworząc izolowane wyspy decyzyjne odzwierciedlające szum w etykietach treningowych. Teoretyczne gwarancje Covera i Harta (1967) mówią, że asymptotyczny poziom błędów klasyfikatora 1-NN spełnia:
R_1NN ≤ 2R_Bayes (1 − R_Bayes) ≤ 2R_Bayes
gdzie R_Bayes to optymalny poziom błędów Bayesa (minimalny osiągalny błąd przy prawdziwym rozkładzie danych). Oznacza to, że klasyfikator 1-NN nigdy nie może osiągnąć lepszego niż dwukrotność optymalnego poziomu błędów, ale dla problemów, gdzie R_Bayes jest małe (łatwe problemy), klasyfikator 1-NN zbliża się do optymalnego poziomu błędów. Małe wartości k są odpowiednie, gdy granice klas są wysoce nieliniowe, a dane referencyjne są czyste — na przykład cienkie spękania w nawierzchni asfaltowej mogą wymagać lokalnie adaptacyjnych granic, które może zapewnić klasyfikator z małym k.
Duże wartości k (20+) wygładzają granicę decyzyjną poprzez uśrednianie po wielu sąsiadach. Zmniejsza to wpływ pojedynczych, zaszumionych etykiet i daje bardziej stabilne, generalizowalne predykcje. Granica decyzyjna staje się wypukła i zbliża się do separatora liniowego w miarę wzrostu k, ponieważ uśrednianie po dużym regionie skutecznie oblicza lokalne porównanie centroidów. Jednak gdy k przekracza typowy rozmiar klastra klas, sąsiedztwo zaczyna obejmować punkty z innych klas, zwiększając obciążenie. W granicy k = N (gdzie N to całkowity rozmiar zbioru treningowego), każde zapytanie jest przypisywane do globalnej klasy większościowej — model zapada się do stałego predyktora ignorującego całą lokalną strukturę. Duże wartości k są odpowiednie, gdy dane referencyjne są zaszumione, ale klasy są dobrze rozdzielone na poziomie globalnym — na przykład klasyfikacja asfaltu kontra betonu, gdzie separacja globalna jest duża.
Wybór nieparzystych wartości k jest praktyczną konwencją w klasyfikacji binarnej, aby uniknąć remisów. Przy k=4, podział 2-2 między dwiema klasami daje remis bez wyraźnej większości. Przy k=5, podział 3-2 zawsze daje większość. Dla klasyfikacji wieloklasowej z więcej niż dwiema klasami, nieparzyste k nie gwarantuje wyraźnej większości — podział 3-2-2 między trzema klasami nadal daje zwycięzcę przez pluralizm (3 głosy), mimo że udział większościowy wynosi tylko 43%. Strategie łamania remisów dla parzystego k obejmują: wybór klasy z mniejszą całkowitą odległością do punktu zapytania (ważony tie-break oparty na skumulowanej bliskości), losowy wybór spośród remisujących klas lub użycie klasy z najmniejszą średnią odległością.
Walidacja krzyżowa jest standardową empiryczną metodą wyboru k. Zbiór danych treningowych jest dzielony na v fałd (zazwyczaj v=5 lub v=10, przy czym 10-krotna walidacja krzyżowa jest najczęstsza dla selekcji modeli). Dla każdej kandydackiej wartości k w zakresie (np. k = 1, 3, 5, …, 51), model jest trenowany na v−1 fałdach i oceniany na wstrzymanej fałdzie. Proces jest powtarzany dla wszystkich v fałd, a średnia dokładność między fałdami jest rejestrowana. Wybierane jest k z najwyższą dokładnością walidacji krzyżowej jako wartość optymalna. Metoda łokcia wykreśla dokładność jako funkcję k: dokładność rośnie gwałtownie dla małych k, osiąga plateau w optymalnym zakresie, a następnie stopniowo spada, gdy k staje się zbyt duże i dominuje obciążenie. Optymalne k znajduje się przy lub w pobliżu łokcia — punktu, w którym dokładność nasyca się przed spadkiem.
Prosta heurystyka do wstępnego wyboru k to k = √N, gdzie N to liczba próbek treningowych. Ta heurystyka zapewnia, że rozmiar sąsiedztwa rośnie proporcjonalnie do gęstości przestrzeni osadzeń — większe bazy danych mogą obsługiwać większe sąsiedztwa, ponieważ jest więcej punktów referencyjnych na jednostkę objętości przestrzeni osadzeń. Dla biblioteki referencyjnej TarmacView zawierającej około 10 000 fragmentów nawierzchni, √10 000 = 100 byłoby punktem wyjścia do przeszukiwania siatki. Jednak optymalne k zależy od efektywnej liczby próbek na klasę i struktury osadzeń. TarmacView używa k=10 na podstawie walidacji krzyżowej specyficznej dla domeny: przy maksymalnie 10 typach nawierzchni i w przybliżeniu zrównoważonym rozkładzie klas, k=10 zapewnia wystarczające sąsiedztwo dla stabilnego głosowania bez wykraczania poza lokalny klaster klas. Walidacja krzyżowa na wstrzymanych sekcjach dróg startowych potwierdziła, że k=10 minimalizuje RMSE predykcji PCI na poziomie 4,8 punktów, jednocześnie maksymalizując dokładność klasyfikacji typu nawierzchni na poziomie 97,2%.
Ważony kNN (zwany również odległościowo ważonym kNN) rozszerza standardowy schemat głosowania, przypisując każdemu sąsiadowi wagę głosu proporcjonalną do jego bliskości względem punktu zapytania. W standardowym (jednorodnym) kNN, wszyscy k sąsiedzi mają równą siłę głosu — najdalszy sąsiad ma dokładnie taki sam wpływ na predykcję jak najbliższy sąsiad. Tworzy to nieciągłość na granicy sąsiedztwa: punkt referencyjny tuż wewnątrz k-tej granicy ma pełną siłę głosu, podczas gdy punkt tuż na zewnątrz (k+1-szy sąsiad) ma zerowy wpływ, niezależnie od tego, jak blisko jest. Ważony kNN usuwa ten efekt graniczny, płynnie zmniejszając wagę odległych sąsiadów, tworząc miękkie sąsiedztwo, gdzie wpływ zanika w sposób ciągły wraz z odległością.
Najczęstszą funkcją wagową jest ważenie odwrotnością odległości:
w_i = 1 / (d(q, x_i) + ε)
gdzie d(q, x_i) to odległość (lub odległość cosinusowa) między zapytaniem q a sąsiadem x_i, a ε to mała stała (typowo 1e−8), która zapobiega dzieleniu przez zero, gdy zapytanie dokładnie pasuje do punktu referencyjnego (d = 0). W tym schemacie najbliższy sąsiad otrzymuje największą wagę głosu, a wagi maleją hiperbolicznie wraz ze wzrostem odległości. Predykcja klasy staje się:
ŷ = argmax_c ∑_(i=1)^k w_i × 1[y_i = c]
gdzie suma jest po k najbliższych sąsiadach, w_i to waga, a 1[y_i = c] to funkcja wskaźnikowa (1, jeśli sąsiad i ma klasę c, 0 w przeciwnym razie). Dla zadań regresji, ważona predykcja to:
ŷ = (∑(i=1)^k w_i × y_i) / (∑(i=1)^k w_i)
co jest estymatorem regresji jądrowej Nadaraya-Watsona w przestrzeni osadzeń — lokalnie ważoną średnią, która zbiega do prawdziwej warunkowej wartości oczekiwanej E[Y | X = q] wraz ze wzrostem liczby punktów referencyjnych.
Alternatywne schematy ważenia obejmują:
Ważony kNN zmniejsza wrażliwość modelu na konkretny wybór k. Nawet przy umiarkowanie dużym k, dalsi sąsiedzi wnoszą minimalny wkład do głosowania (ich wagi są bliskie zera), więc efektywny rozmiar sąsiedztwa jest samoograniczający. Dla predykcji klasy jakości TarmacView — zadania regresji, gdzie PCI jest ciągłą wartością standaryzowaną przez ASTM D5340 — ważony kNN z ważeniem odwrotnością odległości daje gładszą i dokładniejszą powierzchnię predykcji niż jednorodne głosowanie. Przewidywane PCI dla fragmentu zapytania wynosi:
PCÎ = (∑(i=1)^k w_i × PCI_i) / (∑(i=1)^k w_i)
gdzie w_i = 1 / (odległość_cosinusowa(q, x_i) + ε). Ten estymator jest regresją jądrową Nadaraya-Watsona w przestrzeni osadzeń. Walidacja krzyżowa na wstrzymanych danych inspekcyjnych pokazuje, że ważony kNN redukuje RMSE estymacji PCI z 5,6 punktów (jednorodne głosowanie) do 4,8 punktów (ważenie odwrotnością odległości), co stanowi 14% poprawę.
W systemie TarmacView klasyfikacja typu nawierzchni jest pierwszym etapem analizy nawierzchni. System musi określić, czy fragment zdjęcia inspekcyjnego przedstawia asfalt (nawierzchnię podatną), beton (nawierzchnię sztywną), kompozyt (podłoże betonowe z nakładką asfaltową) lub powierzchnie niebędące nawierzchnią, takie jak trawa, żwir, gleba lub oznakowania malowane. Jest to problem klasyfikacji wieloklasowej z kategorycznymi, wzajemnie wykluczającymi się etykietami. Klasyfikacja musi być dokładna w różnych warunkach oświetleniowych, stanach wilgotności powierzchni i stopniach deterioracji nawierzchni.
Klasyfikator typu nawierzchni działa na fragmentach zdjęć wyodrębnionych z ortofotomap dróg startowych i kołowania wykonanych z drona. Każdy fragment ma wymiary 224×224 pikseli przy naziemnej odległości próbkowania (GSD) 2–5 mm, co oznacza, że każdy piksel reprezentuje 2–5 milimetrów rzeczywistej powierzchni nawierzchni. Przy tej rozdzielczości tekstura wizualna nawierzchni — rozmiar i kształt kruszywa dla asfaltu, wzory spoin i ekspozycja kruszywa dla betonu — jest wyraźnie widoczna. Każdy fragment przechodzi przez konwolucyjną sieć enkodera (szkielet ResNet-50 trenowany z nadzorowanym uczeniem kontrastywnym), aby wyprodukować 128-wymiarowy wektor osadzenia znormalizowany L2 do długości jednostkowej.
Biblioteka referencyjna zawiera dziesiątki tysięcy par osadzenie-etykieta zebranych z wcześniej inspekcjonowanych nawierzchni lotniskowych. Każdy fragment referencyjny został ręcznie oznaczony przez certyfikowanego inspektora nawierzchni zgodnie z ASTM D5340 Standard Test Method for Airport Pavement Condition Index Surveys. Biblioteka referencyjna obejmuje pełny zakres typów nawierzchni, regionów klimatycznych i wieków nawierzchni, zapewniając gęste pokrycie przestrzeni osadzeń w całej domenie operacyjnej.
W czasie inferencji system przetwarza każdy nowy fragment przez ten sam enkoder, aby wyprodukować osadzenie zapytania, a następnie wykonuje wyszukiwanie kNN oparte na FAISS z k=10 przy użyciu odległości cosinusowej. Pobieranych jest 10 najbliższych osadzeń referencyjnych wraz z ich etykietami typu nawierzchni. Głosowanie pluralistyczne określa przewidywany typ nawierzchni: system zlicza, ile spośród 10 sąsiadów należy do każdej klasy typu nawierzchni, a klasa z najwyższą liczbą wygrywa. Wynik pewności jest obliczany jako:
pewność = (liczba sąsiadów głosujących na zwycięską klasę) / k
Dla k=10, wartości pewności mieszczą się w przyrostach co 0,1 od 0,1 (pojedynczy sąsiad wspiera predykcję) do 1,0 (wszyscy 10 sąsiadów zgodnych). Próg pewności 0,6 (6 z 10 sąsiadów zgodnych) jest używany do filtrowania predykcji do automatycznego raportowania.
Konfiguracja k=10 zapewnia praktyczną równowagę dla klasyfikacji typu nawierzchni. Przy 4 podstawowych typach nawierzchni w typowej bibliotece referencyjnej, k=10 zapewnia, że nawet w pobliżu granic decyzyjnych, wiele próbek z każdej klasy uczestniczy w głosowaniu. Gdyby k było zbyt małe (np. k=3), pojedyncze anomalne osadzenie referencyjne w pobliżu granicy decyzyjnej mogłoby odwrócić predykcję. Gdyby k było zbyt duże (np. k=50), sąsiedztwo wykraczałoby poza lokalny klaster typu nawierzchni do sąsiednich klas, rozwadniając głosowanie i zwiększając obciążenie.
Mechanizm odrzucania obsługuje niejednoznaczne przypadki poprzez próg pewności. Jeśli wynik pewności spada poniżej 0,6 (lub, równoważnie, jeśli 10 sąsiadów jest podzielonych w stosunku większym niż 6:4 między dwiema najlepszymi klasami), fragment jest oznaczany do przeglądu ludzkiego, zamiast być automatycznie etykietowanym. Ten mechanizm jest szczególnie ważny dla stref przejściowych, gdzie zmienia się typ nawierzchni — takich jak interfejsy asfalt-beton na końcach dróg startowych lub nawierzchnie kompozytowe, gdzie górna warstwa asfaltu częściowo zasłania leżący pod spodem beton. Strefy te dają fragmenty, które są z natury wizualnie niejednoznaczne, a system poprawnie identyfikuje je jako wymagające ludzkiego osądu.
Dokładność klasyfikacji typu nawierzchni na wstrzymanych danych testowych przekracza 98% dla standardowych nawierzchni asfaltowych i betonowych. Główne tryby awarii występują dla nawierzchni kompozytowych (gdzie cienka nakładka asfaltowa częściowo ujawnia podłoże betonowe poprzez spękania odbite, dezorientując klasyfikator tekstury) oraz dla mocno zdegradowanych nawierzchni, gdzie rozległe sieci spękań i łatanie zaciemniają podstawowe wskazówki teksturowe nawierzchni. Te przypadki awarii są zazwyczaj wychwytywane przez próg pewności (zgodność spada poniżej 0,6) i kierowane do recenzentów ludzkich.

Drugim zastosowaniem kNN w TarmacView jest klasyfikacja klasy jakości — przewidywanie Wskaźnika Stanu Nawierzchni (PCI) na podstawie fragmentów zdjęć. PCI to numeryczna ocena od 0 (niesprawna) do 100 (doskonała), standaryzowana przez ASTM D5340 dla nawierzchni lotniskowych i przez ASTM D6433 dla dróg i parkingów. Metodologia PCI, opracowana przez United States Army Corps of Engineers, a następnie przyjęta przez FAA i ICAO, jest międzynarodowym standardem do kwantyfikacji stanu nawierzchni. PCI jest określany poprzez inspekcję wizualną, podczas której inspektor identyfikuje typ, nasilenie i gęstość każdego rodzaju uszkodzenia (spękania, koleiny, wykruszanie, złuszczenia, łatanie itp.) w jednostce próbnej, a następnie stosuje procedurę wartości odliczeniowych, aby obliczyć złożony wskaźnik.
W praktyce, ciągła skala PCI 0-100 jest agregowana w przedziały klas do raportowania i podejmowania decyzji:
| Przedział klasy | Zakres PCI | Opis | Typowe działanie utrzymaniowe |
|---|---|---|---|
| Dobry | 71–100 | Niewielkie lub brak uszkodzeń | Utrzymanie rutynowe |
| Zadowalający | 56–70 | Umiarkowane uszkodzenia | Utrzymanie zapobiegawcze |
| Dostateczny | 41–55 | Znaczące uszkodzenia | Poważna rehabilitacja |
| Słaby | 26–40 | Rozległe uszkodzenia | Rozważenie przebudowy |
| Bardzo słaby | 11–25 | Poważne uszkodzenia | Konieczna przebudowa |
| Niesprawny | 0–10 | Całkowita degradacja | Przebudowa awaryjna |
kNN może wykonywać zarówno regresję (przewidywanie ciągłej wartości PCI w skali 0-100), jak i klasyfikację (przewidywanie przedziału klasy jako etykiety kategorycznej). TarmacView obsługuje oba tryby w zależności od wymogów raportowania.
Dla regresji PCI, ważony kNN oblicza ważoną odległością średnią wartości PCI z k najbliższych sąsiadów. Dla danego osadzenia zapytania q, system pobiera k=10 najbliższych fragmentów referencyjnych z ich powiązanymi wynikami PCI (wartości prawdziwe z inspekcji ludzkich zgodnych z ASTM). Przewidywane PCI wynosi:
PCÎ = (∑(i=1)^k w_i × PCI_i) / ∑(i=1)^k w_i
gdzie w_i = 1 / (odległość_cosinusowa(q, x_i) + ε). Ten estymator regresji jądrowej Nadaraya-Watsona daje gładką powierzchnię predykcji w przestrzeni osadzeń. Fragmenty o podobnej jakości wizualnej grupują się razem, ponieważ cel uczenia kontrastywnego organizuje przestrzeń według podobieństwa wizualnego, które silnie koreluje z PCI. Fragment wykazujący rozległe spękania siatkowe, spękania podłużne i koleiny zostanie osadzony w pobliżu innych zdegradowanych fragmentów asfaltowych z niskimi wartościami PCI, dając poprawnie niskie przewidywane PCI. Odwrotnie, fragment przedstawiający nienaruszoną, dobrze utrzymaną powierzchnię zostanie osadzony w pobliżu innych fragmentów referencyjnych z wysokim PCI.
Dla klasyfikacji przedziałów klas, standardowe głosowanie pluralistyczne z k=10 przypisuje fragment do jednego z sześciu przedziałów klas PCI. To zdyskretyzowane podejście jest bardziej odporne, gdy biblioteka referencyjna ma rzadkie pokrycie dla dokładnych wartości PCI (np. kilka fragmentów referencyjnych z PCI dokładnie 47), ale gęste pokrycie w obrębie przedziałów (np. wiele fragmentów z PCI 40-55). Podejście przedziałów klas jest zgodne z konwencjami raportowania ASTM D5340 stosowanymi w systemach zarządzania nawierzchniami lotniskowymi (APMS), gdzie stan jest zazwyczaj raportowany według kategorii, a nie dokładnego wskaźnika liczbowego.
Dokładność estymacji PCI zależy od gęstości i jakości biblioteki referencyjnej. Przy bibliotece referencyjnej obejmującej pełny zakres PCI zarówno dla nawierzchni asfaltowych, jak i betonowych, estymator kNN osiąga błąd średniokwadratowy (RMSE) około ±5 punktów PCI na wstrzymanych danych testowych. Wypada to korzystnie w porównaniu z ±10 punktami PCI zmienności międzyosobowej między certyfikowanymi inspektorami ludzkimi według ASTM D5340 Sekcja 4.2 — co oznacza, że estymator kNN jest bardziej spójny niż ludzcy eksperci. Głównym trybem awarii jest estymacja PCI dla rzadkich warunków nawierzchni — takich jak nowo wykonana droga startowa z nowatorską mieszanką asfaltu modyfikowanego polimerem, która nie ma porównywalnych próbek referencyjnych — gdzie estymator cofa się do najbliższego dostępnego stanu w przestrzeni osadzeń, potencjalnie przeszacowując lub niedoszacowując prawdziwe PCI. Filtrowanie pewnością (zgodność < 0,6) wychwytuje większość tych przypadków.
Jedną z najcenniejszych właściwości kNN dla aplikacji inspekcyjnych jest naturalna metryka pewności pochodząca ze zgodności sąsiadów. W przeciwieństwie do klasyfikatorów sieci neuronowych, które wyprowadzają prawdopodobieństwa softmax — które są notorycznie słabo skalibrowane (systematycznie zbyt pewne na danych spoza rozkładu i zbyt niepewne na danych z rozkładu, co udokumentowali Guo i in., 2017 w „On Calibration of Modern Neural Networks") — pewność kNN ma proste, interpretowalne i empirycznie dobrze skalibrowane znaczenie.
Dla punktu zapytania q z k najbliższymi sąsiadami, wynik zgodności to:
zgodność = (liczba sąsiadów głosujących na przewidywaną klasę) / k
Ten wynik zgodności waha się od 1/k (minimalna możliwa zgodność — każdy sąsiad głosuje na inną klasę) do 1,0 (jednomyślna — wszyscy k sąsiedzi głosują na tę samą klasę). Zgodność 1,0 oznacza, że zapytanie leży głęboko w jednorodnym regionie przestrzeni osadzeń otoczonym punktami referencyjnymi tej samej klasy — predykcja jest wysoce wiarygodna. Zgodność 1/k oznacza, że sąsiedzi są maksymalnie podzieleni — zapytanie leży na granicy decyzyjnej lub w jej pobliżu, a predykcja jest zasadniczo niepewna. W praktyce, dla k=10, zgodność waha się od 0,1 (10 sąsiadów, 10 różnych klas — niezwykle mało prawdopodobne w dobrze ustrukturyzowanej przestrzeni osadzeń) do 1,0.
TarmacView używa wyniku zgodności do implementacji filtrowania pewnością — produkcyjnego mechanizmu kontroli jakości. Fragmenty ze zgodnością poniżej progu (typowo 0,6, czyli 6 z 10 sąsiadów zgodnych) są oznaczane do ręcznego przeglądu, zamiast być uwzględniane w automatycznych raportach inspekcyjnych. To filtrowanie wychwytuje trzy kategorie problematycznych wejść:
Przypadki graniczne: fragmenty ze stref przejściowych między typami nawierzchni lub między klasami jakości, gdzie cechy wizualne rzeczywiście wspierają wiele etykiet. Fragment uchwycający interfejs między nakładką asfaltową a podłożem betonowym — pokazujący obie tekstury powierzchni — będzie miał sąsiadów podzielonych między etykiety „asfalt" i „kompozyt", dając zgodność poniżej 0,6 i poprawnie uruchamiając przegląd.
Wejścia spoza rozkładu (OOD): fragmenty pokazujące nowatorskie zabiegi powierzchniowe, treści niebędące nawierzchnią lub artefakty obrazowania niereprezentowane w bibliotece referencyjnej. Te fragmenty osadzają się w regionach o niskiej gęstości przestrzeni osadzeń, gdzie nawet najbliższe punkty referencyjne są stosunkowo odległe. Zgodność jest niska, ponieważ sąsiedzi są rozproszeni po wielu klasach — żadna pojedyncza klasa nie ma większości. Ta właściwość — niska zgodność kNN dla wejść OOD — jest dobrze udokumentowanym zjawiskiem w analizie najbliższych sąsiadów i zapewnia wbudowany mechanizm detekcji OOD bez potrzeby oddzielnego klasyfikatora.
Powierzchnie anomalne: fragmenty pokazujące rzadkie tryby uszkodzeń słabo reprezentowane w danych treningowych, takie jak reakcja alkaliczno-krzemianowa (ASR) w nawierzchniach betonowych lub wycieki paliwa na asfalcie. Te warunki dają tekstury wizualne odmienne od standardowej biblioteki referencyjnej, powodując, że osadzenie zapytania znajduje się między klastrami klas, a nie wewnątrz jednego z nich.
Wynik zgodności jest bardziej interpretowalny niż entropia softmax, pewność oparta na marginesie lub inne parametryczne miary pewności, ponieważ ma bezpośrednie wyjaśnienie instancyjne: „6 z 10 najbardziej podobnych próbek referencyjnych zgadza się co do asfaltu, 3 mówią beton, a 1 mówi kompozyt." Inspektor przeglądający oznaczony fragment może zbadać konkretnych najbliższych sąsiadów — ich obrazy, etykiety i odległości — i zrozumieć, dlaczego model jest niepewny, a następnie podjąć świadomą decyzję. Ta możliwość śledzenia jest niemożliwa w przypadku wyników softmax.
Kalibracja wyniku zgodności — jak dobrze odpowiada on prawdziwemu prawdopodobieństwu poprawności klasyfikacji — poprawia się wraz z większym k, ale podlega malejącym korzyściom. Walidacja krzyżowa na bibliotece referencyjnej TarmacView ustala następującą krzywą kalibracji dla k=10:
| Zakres zgodności | Średnia rzeczywista dokładność | Interpretacja |
|---|---|---|
| 0,9 – 1,0 | 98,7% | Wysoce pewna, głęboko w klastrze klas |
| 0,7 – 0,8 | 94,2% | Pewna, blisko centrum klastra |
| 0,6 | 86,5% | Umiarkowanie pewna, blisko granicy klastra |
| 0,5 | 78,3% | Niepewna, na granicy decyzyjnej |
| ≤ 0,4 | 62,1% | Niska pewność, prawdopodobnie OOD lub przypadek graniczny |
Ta monotoniczna zależność między zgodnością a dokładnością potwierdza podejście filtrowania pewnością. Próg 0,6 wychwytuje około 92% błędnych klasyfikacji, oznaczając do przeglądu tylko 8% poprawnych predykcji — korzystny kompromis precyzji i czułości dla produkcyjnej inspekcji.
Wybór między kNN, sondą liniową a klasyfikatorem sieci neuronowej jako głowicą klasyfikacyjną na wyuczonych osadzeniach wiąże się z fundamentalnymi kompromisami między interpretowalnością, generalizacją, szybkością inferencji i adaptowalnością do nowych danych. Wszystkie trzy metody operują na tej samej przestrzeni osadzeń wytworzonej przez enkoder, ale uczą się lub odpytywują różne typy granic decyzyjnych o różnych właściwościach.
Sonda liniowa to pojedyncza w pełni połączona warstwa (gęsta warstwa bez aktywacji, analogiczna do wielomianowej regresji logistycznej) trenowana na zamrożonych osadzeniach. Uczy się macierzy wag W o kształcie (wymiar_osadzenia × liczba_klas), która mapuje osadzenia na logity klas: logity = x·W + b. Granica decyzyjna w przestrzeni osadzeń to zbiór liniowych hiperpłaszczyzn — jedna na parę klas — zdefiniowanych równaniem granicy decyzyjnej (W_j − W_i)·x + (b_j − b_i) = 0. Sondy liniowe zakładają, że przestrzeń osadzeń jest liniowo separowalna, co jest generalnie prawdą, gdy enkoder jest trenowany z kontrastywnym celem lub celem klasyfikacji softmax.
Zalety sond liniowych obejmują szybkość inferencji (pojedyncze mnożenie macierzy o złożoności O(d × C), gdzie d to wymiar osadzenia, a C to liczba klas), mały rozmiar modelu (d × C + C parametrów — dla d=128 i C=10 to tylko 1290 parametrów) oraz umiarkowaną interpretowalność (wielkości wag na wymiar mogą być interpretowane jako ważność cechy dla każdej klasy, choć wymaga to, aby wymiary osadzeń były semantycznie znaczące — właściwość, której wyuczone osadzenia generalnie nie mają). Podstawowym ograniczeniem jest założenie liniowości: jeśli przestrzeń osadzeń ma nieliniową strukturę klas (np. jedna klasa zajmuje dwa niepołączone regiony w przestrzeni osadzeń — co narusza założenie liniowej separowalności), sonda liniowa nie może uchwycić tej struktury i narysuje prostoliniową granicę przecinającą oba klastry, błędnie klasyfikując połowę każdego klastra.
Klasyfikator sieci neuronowej (jedna lub więcej warstw ukrytych na wyjściu z enkodera) może uczyć się dowolnie złożonych, nieliniowych granic decyzyjnych. Dwuwarstwowy MLP z wymiarem ukrytym 64 i aktywacją ReLU, a następnie warstwą wyjściową softmax, może podzielić przestrzeń osadzeń na nieliniowe regiony owijające się wokół klastrów, tworząc rozłączne regiony decyzyjne, których sonda liniowa nie może reprezentować. Zapewnia to najwyższy potencjał teoretycznej dokładności, gdy przestrzeń osadzeń ma nietrywialną strukturę klas.
Wady są znaczące: parametry MLP wymagają trenowania z gradientowym zejściem (dodatkowy koszt obliczeniowy, strojenie hiperparametrów dla szybkości uczenia, rozmiaru batcha, liczby warstw, wymiarów ukrytych, regularyzacji L2, współczynnika dropout i wyboru optymalizatora), model jest nieinterpretowalny (nie można prześledzić predykcji do żadnej konkretnej próbki referencyjnej — predykcja jest funkcją całej macierzy wag i wzorca aktywacji), a dodawanie nowych klas wymaga ponownego trenowania całej głowicy klasyfikatora. Dla inspekcji nawierzchni lotniskowych, gdzie biblioteki referencyjne rosną przyrostowo z każdą nową inspekcją lotniska, wymóg ponownego trenowania wprowadza znaczące tarcie operacyjne — każdy nowy typ nawierzchni lub referencja klasy jakości wymaga pełnego cyklu ponownego trenowania.
kNN znajduje się na przeciwległym końcu spektrum w stosunku do klasyfikatorów parametrycznych. Nie wymaga żadnego trenowania, żadnego gradientowego zejścia, żadnych aktualizacji wag i żadnej optymalizacji hiperparametrów poza wyborem k i metryki odległości. Dodawanie nowych próbek referencyjnych do indeksu FAISS natychmiast zmienia granice decyzyjne — skutecznie, model „trenuje" przyrostowo przy każdym dodaniu danych z zerowym kosztem obliczeniowym. kNN zapewnia doskonałą interpretowalność, ponieważ każdej predykcji towarzyszą jej dowody potwierdzające: tożsamości, etykiety i odległości k najbliższych sąsiadów.
Kompromisem jest szybkość inferencji. Sonda liniowa wymaga O(d × C) operacji na zapytanie — pojedynczego mnożenia macierzy niezależnego od rozmiaru bazy N. kNN z wyszukiwaniem brute-force wymaga O(N × d) operacji na zapytanie — liniowo względem rozmiaru bazy. Jednak z indeksowaniem FAISS (indeksy IVF, HNSW lub PQ), inferencja kNN redukuje się do około O(log N × d) dla przybliżonego wyszukiwania najbliższego sąsiada, co dla N=10 000 i d=128 daje czasy zapytań poniżej 10 milisekund — porównywalne z sondą liniową, ale z wszystkimi zaletami interpretowalności i adaptowalności.
| Właściwość | Sonda liniowa | Klasyfikator MLP | kNN (FAISS) |
|---|---|---|---|
| Wymagane trenowanie | Gradientowe zejście (minuty) | Gradientowe zejście (godziny) | Brak (natychmiast) |
| Złożoność inferencji | O(d × C) | O(d × H + H × C) | O(log N × d) indeksowany |
| Interpretowalność | Niska (analiza wag) | Brak (czarna skrzynka) | Wysoka (dowody instancyjne) |
| Adaptacja do nowych klas | Pełne ponowne trenowanie | Pełne ponowne trenowanie | Natychmiastowa (dodanie do indeksu) |
| Typ granicy decyzyjnej | Liniowe hiperpłaszczyzny | Nieliniowa, dowolna | Dowolna (oparta na Woronoju) |
| Przechowywanie danych treningowych | Nie (tylko wagi) | Nie (tylko wagi) | Tak (indeks referencyjny) |
| Kalibracja pewności | Softmax (słaba) | Softmax (słaba) | Zgodność (dobrze skalibrowana) |
| Pamięć dla inferencji | d × C parametrów | d×H + H×C parametrów | N × d osadzeń |
| Detekcja OOD | Wymaga osobnego klasyfikatora | Wymaga osobnego klasyfikatora | Wbudowana (niska zgodność) |
Do produkcyjnej inspekcji nawierzchni, TarmacView używa kNN jako podstawowego klasyfikatora na bibliotece referencyjnej indeksowanej przez FAISS. Sonda liniowa jest zachowana jako klasyfikator zapasowy dla zapytań, gdzie wyszukiwanie FAISS daje niską zgodność — sonda zapewnia drugą opinię poprzez zastosowanie globalnie wyuczonego separatora liniowego. Jeśli oba klasyfikatory są zgodne, predykcja jest akceptowana z wysoką pewnością. Jeśli się różnią, fragment jest oznaczany do przeglądu ludzkiego. To podejście ensemble łączy interpretowalność i adaptowalność kNN z deterministyczną globalną strukturą sondy liniowej, dając bardziej odporne predykcje niż każda z metod osobno.
Interpretowalność — zdolność człowieka do zrozumienia, dlaczego model podjął konkretną predykcję — nie jest jedynie wygodą w inspekcji nawierzchni lotniskowych. Jest to wymóg regulacyjny i operacyjny wynikający z wielu norm. ASTM D5340 Standard Test Method for Airport Pavement Condition Index Surveys (Sekcja 5.3) wymaga, aby oceny stanu były możliwe do prześledzenia do obserwowalnych fizycznych dowodów uszkodzeń. ICAO Aerodrome Design and Operations Manual (Doc 9157, Part 3) określa, że metody oceny nawierzchni muszą być przejrzyste i poddawane audytowi przez wykwalifikowanych inspektorów. FAA Advisory Circular 150/5380-6C nakazuje, aby systemy zarządzania nawierzchniami utrzymywały ślad audytowy łączący oceny stanu z danymi inspekcyjnymi. kNN zapewnia nieodłączną, wbudowaną interpretowalność, która spełnia te wymogi możliwości śledzenia — klasyfikatory parametryczne zasadniczo nie są w stanie tego zapewnić, ponieważ ich predykcje są funkcjami wyuczonych macierzy wag, a nie konkretnych przykładów referencyjnych.
Interpretowalność kNN wynika z jego rozumowania instancyjnego. Każda predykcja jest oparta na konkretnych przykładach referencyjnych, które mogą być sprawdzone przez człowieka:
Ta możliwość śledzenia umożliwia interfejs wyjaśniania przez przykład TarmacView. Gdy system klasyfikuje fragment nawierzchni, automatycznie pobiera i wyświetla k najbliższych fragmentów referencyjnych wraz z ich etykietami typu nawierzchni, wynikami PCI i odległościami cosinusowymi. Inspektor przeglądający wynik może przeprowadzić weryfikację wizualną — porównując fragment zapytania z jego najbliższymi sąsiadami i potwierdzając, że podobieństwo wizualne wspiera przewidywaną etykietę. To wizualne sprawdzenie krzyżowe wykorzystuje wiedzę dziedzinową inspektora i zapewnia naturalny mechanizm kontroli jakości.
Co więcej, podejście wyjaśniania przez przykład umożliwia inspektorom identyfikację i korektę problemów z jakością referencji. Jeśli referencyjny sąsiad wydaje się błędnie oznaczony (np. fragment betonowy oznaczony jako asfalt przez poprzedniego inspektora), błąd propaguje się do przyszłych predykcji. Inspektor może poprawić etykietę referencyjną w bazie danych, a korekta zaczyna obowiązywać natychmiast dla wszystkich kolejnych zapytań — bez potrzeby ponownego trenowania. Tworzy to pętlę ciągłego ulepszania, w której system staje się dokładniejszy z czasem, gdy biblioteka referencyjna jest kuratorowana przez ekspertów dziedzinowych.
Inspektorzy mogą również zrozumieć przypadki brzegowe poprzez wyjaśnienie kNN. Fragment w pobliżu granicy klas pokazuje sąsiadów z wielu klas, co czyni niejednoznaczność przejrzystą, a nie ukrytą wewnątrz wektora softmax. Jeśli klasyfikator sieci neuronowej błędnie sklasyfikuje fragment graniczny, inspektor widzi tylko przewidywaną etykietę i wynik pewności — nie ma możliwości stwierdzenia, czy fragment był rzeczywiście niejednoznaczny, czy model popełnił błąd algorytmiczny. Dzięki kNN inspektor może zobaczyć dokładny rozkład głosów i podjąć świadomą decyzję, czy niepewność jest uzasadniona.
Ślad audytowy zapewniany przez kNN jest znaczącą zaletą operacyjną. Każda predykcja może być prześledzona do k próbek referencyjnych, które ją wygenerowały. Jeśli sekcja drogi startowej jest raportowana jako PCI 65, a później okazuje się PCI 55, inżynier lotniskowy może przeprowadzić audyt predykcji, badając, które fragmenty referencyjne wpłynęły na estymację PCI 65, określając, czy te referencje były odpowiednimi analogami, i oceniając, czy błąd był rozsądny, czy stanowił systematyczną awarię. Ta możliwość audytu jest niemożliwa w przypadku klasyfikatorów parametrycznych.
Produkcyjny system TarmacView implementuje klasyfikację kNN z określoną konfiguracją zoptymalizowaną do inspekcji nawierzchni lotniskowych poprzez rozległą walidację empiryczną. Parametry konfiguracji — k=10, metryka odległości cosinusowej i indeks FAISS IVF z nprobe=10 — są wynikiem systematycznej walidacji krzyżowej na zbiorach danych inspekcyjnych z wielu lotnisk obejmujących różne strefy klimatyczne i wieki nawierzchni.
Wybór k=10 został określony przez 10-krotną stratyfikowaną walidację krzyżową na wstrzymanym zbiorze walidacyjnym 2000 fragmentów nawierzchni zebranych z 5 różnych lotnisk (3 międzynarodowe, 2 regionalne). Stratyfikacja zapewniła, że każda fałda utrzymywała ten sam rozkład klas co pełny zbiór danych. Kandydackie wartości k od 1 do 50 zostały ocenione na dwóch podstawowych metrykach: dokładności klasyfikacji typu nawierzchni (ważony wynik F1 dla 4 typów nawierzchni) i błędzie średniokwadratowym (RMSE) estymacji PCI.
Dla k=1 do k=5, dokładność klasyfikacji na czystych (wysoka pewność, zgodność > 0,8) fragmentach była powyżej 98%, ale ogólna dokładność na pełnym zbiorze walidacyjnym była niższa (93-95%), ponieważ fragmenty graniczne były często błędnie klasyfikowane z powodu szumu od pojedynczych sąsiadów. RMSE PCI wynosił 6,2-5,8 punktów — stosunkowo wysoki, ponieważ wartość PCI pojedynczego sąsiada silnie wpływała na estymację.
Dla k=10 do k=20, ogólna dokładność klasyfikacji osiągnęła plateau na poziomie 96-97%, przy czym k=10 zapewniało najlepszy kompromis między dokładnością a szybkością inferencji. RMSE estymacji PCI był minimalny przy k=10 z ważonym głosowaniem (RMSE = 4,8 punktów PCI), co stanowi punkt optymalny, w którym sąsiedztwo jest wystarczająco duże, aby uśrednić szum etykiet, ale wystarczająco małe, aby pozostać lokalnym. Ważony wynik F1 dla klasyfikacji typu nawierzchni wynosił 0,972 przy k=10.
Dla k=30 i powyżej, ogólna dokładność spadała stopniowo do 93%, gdy sąsiedztwa zaczynały obejmować punkty z odległych klas — kompromis obciążenie-wariancja przesunął się w kierunku obciążenia, a granica decyzyjna stała się nadmiernie wygładzona. RMSE PCI wzrósł do 5,5 punktów, gdy sąsiedztwo uśredniało po coraz bardziej odmiennych powierzchniach.
Właściwość parzystego k (k=10 jest parzyste, a nie nieparzyste) jest obsługiwana przez dwa mechanizmy. Po pierwsze, TarmacView klasyfikuje do 10 typów nawierzchni, co sprawia, że remisy między wszystkimi klasami są niezwykle mało prawdopodobne — prawdopodobieństwo dokładnego remisu 5-5 między dwiema klasami przy 10 typach nawierzchni jest niskie. Po drugie, gdy remisy występują (podział 5-5 między dwiema klasami), system stosuje łamanie remisów ważone odległością: wygrywa klasa z niższą skumulowaną odległością cosinusową (suma odległości dla sąsiadów tej klasy). Zapewnia to deterministyczne zachowanie nawet dla k=10.
Odległość cosinusowa jest wybraną metryką, ponieważ przestrzeń osadzeń jest znormalizowana L2. Sieć enkodera wyprowadza 128-wymiarowe wektory, które są normalizowane do długości jednostkowej przed indeksowaniem i wyszukiwaniem. Ten wybór projektowy został zweryfikowany poprzez trzy rozważania:
Niezmienniczość oświetleniowa: Fragmenty nawierzchni rejestrowane w zmiennych warunkach oświetleniowych — bezpośrednie słońce w południe, zachmurzone niebo, oświetlenie o niskim kącie o świcie/zmierzchu, cień od oświetlenia krawędzi drogi startowej — muszą dawać osadzenia o podobnej treści kierunkowej dla tego samego stanu nawierzchni. Odległość cosinusowa zapewnia tę niezmienniczość, ponieważ zależy tylko od kąta między wektorami, a nie od ich wielkości. Podczas walidacji krzyżowej, odległość cosinusowa osiągnęła 97,2% dokładności w porównaniu do 96,8% dla odległości euklidesowej na zbiorze testowym z celowo zróżnicowanymi warunkami oświetleniowymi — mała, ale statystycznie znacząca poprawa.
Spójność skali: Normalizacja zapewnia, że wszystkie osadzenia leżą na jednostkowej hipersferze (sferze o promieniu 1 w 128-wymiarowej przestrzeni), co czyni porównania odległości spójnymi między fragmentami. Bez normalizacji, fragmenty o wysokim kontraście teksturalnym (świeży asfalt z wyraźną teksturą kruszywa) dawałyby dłuższe wektory osadzeń niż fragmenty o niskim kontraście (zdegradowana, jednolicie ciemna powierzchnia), co obciążałoby wyszukiwanie kNN w kierunku fragmentów o wysokim kontraście niezależnie od podobieństwa — znaczące źródło systematycznego błędu.
Optymalizacja FAISS: Wyszukiwanie iloczynu skalarnego FAISS na wektorach jednostkowych jest matematycznie równoważne wyszukiwaniu podobieństwa cosinusowego (ponieważ A·B = cos(θ) gdy ‖A‖ = ‖B‖ = 1) i korzysta z wysoko zoptymalizowanych implementacji iloczynu skalarnego na poziomie BLAS zarówno na CPU (Intel MKL, OpenBLAS), jak i GPU (cuBLAS). Zapewnia to około 3-krotne przyspieszenie w porównaniu z jawnym obliczaniem odległości cosinusowej, które byłoby wymagane dla wektorów nieznormalizowanych.
FAISS (Facebook AI Similarity Search) to silnik indeksowania wektorów opracowany przez Meta AI (pierwotnie Facebook Research), który umożliwia wyszukiwanie kNN w czasie rzeczywistym w bibliotece referencyjnej. FAISS jest wydany na licencji MIT i jest standardem branżowym dla wyszukiwania podobieństw w skali miliardów, używanym przez firmy takie jak Facebook, Spotify, Pinterest i Uber.
TarmacView używa indeksu IVF (Inverted File) ze 100 centroidami trenowanymi poprzez grupowanie k-średnich na osadzeniach referencyjnych. Indeks IVF dzieli przestrzeń osadzeń na 100 komórek Woronoja poprzez grupowanie k-średnich. W czasie zapytania przeszukiwana jest tylko komórka zawierająca punkt zapytania plus konfigurowalna liczba sąsiednich komórek, zamiast całej bazy referencyjnej. Redukuje to złożoność wyszukiwania z O(N × d) do około O((N / nlist) × nprobe × d).
Konfiguracja indeksu:
| Parametr | Wartość | Uzasadnienie |
|---|---|---|
| Typ indeksu | IndexIVFFlat | Kodowanie płaskie (dokładne, nieskompresowane); brak utraty dokładności przez kwantyzację |
| Liczba centroidów (nlist) | 100 | Około √N dla N=10 000 — heurystyka dla zrównoważonego partycjonowania |
| Liczba sond (nprobe) | 10 | Przeszukiwanie 10 ze 100 komórek — 90% odwołania przy 10-krotnym przyspieszeniu |
| Metryka | METRIC_INNER_PRODUCT | Podobieństwo cosinusowe przez iloczyn skalarny na wektorach jednostkowych |
| Minimum danych treningowych | 1000 | Minimalna liczba próbek dla stabilnej inicjalizacji k-średnich |
| Typ wektora | float32 | Standardowa 32-bitowa zmiennoprzecinkowa — 512 bajtów na 128-wymiarowe osadzenie |
Ta konfiguracja redukuje złożoność zapytania z O(10 000 × 128) ≈ 1,28 miliona operacji do około O((10 000/100) × 10 × 128) ≈ 128 000 operacji — 10-krotne przyspieszenie przy utrzymaniu 90% odwołania prawdziwych najbliższych sąsiadów. Dla wdrożeń produkcyjnych z większymi bibliotekami referencyjnymi (100 000+ fragmentów referencyjnych), parametr nlist jest skalowany proporcjonalnie (nlist = 1000), a nprobe jest zwiększane w celu utrzymania odwołania, co daje 100-krotne przyspieszenie w porównaniu z wyszukiwaniem brute-force.
Indeks jest aktualizowany przyrostowo w miarę dodawania fragmentów referencyjnych z każdej nowej inspekcji lotniska. Nowe osadzenia są dodawane przez index.add_with_ids(), co dołącza do list odwróconego pliku bez przebudowy centroidów k-średnich. Umożliwia to aktualizacje w czasie rzeczywistym z zerowym przestojem — nowe dane referencyjne są natychmiast dostępne dla zapytań kNN. Okresowe pełne przebudowy indeksu są planowane po każdych 1000 nowych osadzeniach lub po 10 wdrożeniach inspekcyjnych, w zależności od tego, co nastąpi wcześniej. Przebudowa ponownie grupuje centroidy przy użyciu pełnego zaktualizowanego zestawu danych, zapewniając optymalne partycjonowanie w miarę ewolucji rozkładu referencji.
Kompletny potok inferencji kNN TarmacView przetwarza pojedynczy fragment inspekcyjny przez osiem etapów:
Akwijzycja obrazu: 224×224 pikselowy fragment RGB wyodrębniony z ortofotomapy z drona przy naziemnej odległości próbkowania 2-5 mm/px. Rozmiar fragmentu odpowiada około 0,5-1,1 metra rzeczywistej powierzchni nawierzchni na fragment, zapewniając wystarczający kontekst do identyfikacji uszkodzeń przy jednoczesnej izolacji lokalnych warunków powierzchni.
Kodowanie: Fragment przechodzi przez konwolucyjny szkielet enkodera ResNet-50 (trenowany z nadzorowanym uczeniem kontrastywnym na około 50 000 fragmentów nawierzchni), aby wyprodukować 128-wymiarowy wektor cech. Wektor jest normalizowany L2 do długości jednostkowej, umieszczając go na jednostkowej hipersferze dla wyszukiwania podobieństwa cosinusowego.
Wyszukiwanie FAISS: index.search(query_embedding.reshape(1, -1).astype('float32'), k=10) zwraca dwie tablice: odległości (odległości cosinusowe do 10 najbliższych sąsiadów) i ID (całkowite identyfikatory referencyjne mapujące do 10 sąsiadów). Wyszukiwanie jest zazwyczaj wykonywane w czasie poniżej 10 milisekund na CPU (jednowątkowo).
Pobieranie etykiet: Identyfikatory referencyjne są mapowane na przechowywane metadane — etykietę typu nawierzchni (ciąg: „asphalt", „concrete", „composite", „non-pavement") i wynik PCI (liczba zmiennoprzecinkowa: 0,0 do 100,0). Te metadane są przechowywane w oddzielnym magazynie klucz-wartość (FAISS IDMap) wraz z indeksem.
Głosowanie: Głosowanie pluralistyczne określa typ nawierzchni (klasa z najwyższą liczbą sąsiadów wygrywa). Uśrednianie ważone odległością określa regresję PCI (estymator Nadaraya-Watsona z wagami odwrotności odległości).
Obliczanie pewności: zgodność = maks_liczba_głosów / k. Dla k=10, zgodność jest wielokrotnością 0,1. Wynik zgodności jest podstawową miarą pewności.
Filtrowanie pewnością: Jeśli zgodność < 0,6 (próg produkcyjny), fragment jest oznaczany do ręcznego przeglądu przez certyfikowanego inspektora nawierzchni. Oznaczone fragmenty są wykluczane z automatycznego raportowania PCI, ale zachowywane w zbiorze danych inspekcyjnych do analizy kontroli jakości.
Raportowanie: Przewidywane etykiety, wyniki pewności i identyfikatory najbliższych sąsiadów są rejestrowane w raporcie inspekcyjnym wraz z obrazem fragmentu i współrzędnymi GPS. Raport jest formatowany do wprowadzenia do systemu zarządzania nawierzchnią (PMS) lotniska zgodnie z wymogami FAA Advisory Circular 150/5380-6C.
Kompleksowy potok przetwarza około 50 fragmentów na sekundę na pojedynczym GPU NVIDIA T4 do kodowania (rozmiar batcha 64) z wyszukiwaniem FAISS na CPU działającym asynchronicznie. Dla 3000-metrowej drogi startowej z 5-metrowymi pasami próbkowania po obu stronach, pełna inspekcja generuje około 10 000 fragmentów. Kompletny raport inferencji — od pobrania ortofotomapy do sfinalizowanego raportu inspekcyjnego — jest generowany w poniżej 5 minut, w porównaniu do 4-8 godzin dla ręcznej inspekcji wizualnej przez certyfikowany zespół inspekcyjny. System oparty na kNN osiąga porównywalną lub lepszą dokładność niż ludzcy inspektorzy (RMSE ±5 punktów PCI wobec ±10 punktów PCI zmienności międzyosobowej), jednocześnie redukując czas inspekcji o dwa rzędy wielkości i zapewniając pełną możliwość śledzenia każdej predykcji do jej dowodów potwierdzających.

TarmacView wykorzystuje klasyfikację kNN na wyuczonych osadzeniach do szybkiego i interpretowalnego przewidywania typu nawierzchni lotniskowej i klasy jakości. Skontaktuj się z nami, aby zobaczyć, jak klasyfikacja najbliższych sąsiadów napędza zautomatyzowane inspekcje lotnisk.
FAISS (Facebook AI Similarity Search) to biblioteka open-source do wydajnego wyszukiwania podobieństw i klastrowania gęstych wektorów, używana przez TarmacView ...
System oceny jakości nawierzchni TarmacView przypisuje ocenę porządkową 1–5 (1=Znakomita, 5=Bardzo Zła) na podstawie większościowego głosowania cosine kNN wzglę...
+++ title = “Macierz pomyłek” description = “Macierz pomyłek zestawia przewidywania modelu z wartościami rzeczywistymi: wiersze to rzeczywiste...