Apache Parquet to kolumnowy, skompresowany binarny format przechowywania danych zoptymalizowany pod kątem zapytań analitycznych na dużych zbiorach tabelarycznych. TarmacView przechowuje wszystkie wyniki analiz w formacie Parquet dla wydajnego przechowywania i szybkiego zapytywania. Obejmuje zalety Parquet, schemat, odczytywanie/zapisywanie za pomocą Pandas i Polars oraz porównanie z CSV i JSON dla danych inspekcyjnych.
Format Apache Parquet dla Danych Inspekcyjnych
Definicja i Model Przechowywania Kolumnowego
Apache Parquet to darmowy, otwarty, kolumnowy binarny format plików zaprojektowany od podstaw do wydajnego przechowywania i wyszukiwania danych w obciążeniach analitycznych. Stworzony pierwotnie jako wspólny wysiłek Twittera i Cloudera w ekosystemie Apache Hadoop, Parquet stał się de facto standardem analitycznego przechowywania danych w całym krajobrazie inżynierii danych. Każdy główny silnik przetwarzania danych — Apache Spark, DuckDB, ClickHouse, Presto, Trino, Snowflake, Google BigQuery, Amazon Redshift i Databricks — zapewnia natywną obsługę odczytu i zapisu plików Parquet. Format został zaprojektowany, aby rozwiązać podstawowe ograniczenia wydajnościowe formatów zorientowanych wierszowo podczas przetwarzania zapytań analitycznych skanujących duże ilości danych, ale odnoszących się tylko do podzbioru kolumn lub wierszy.
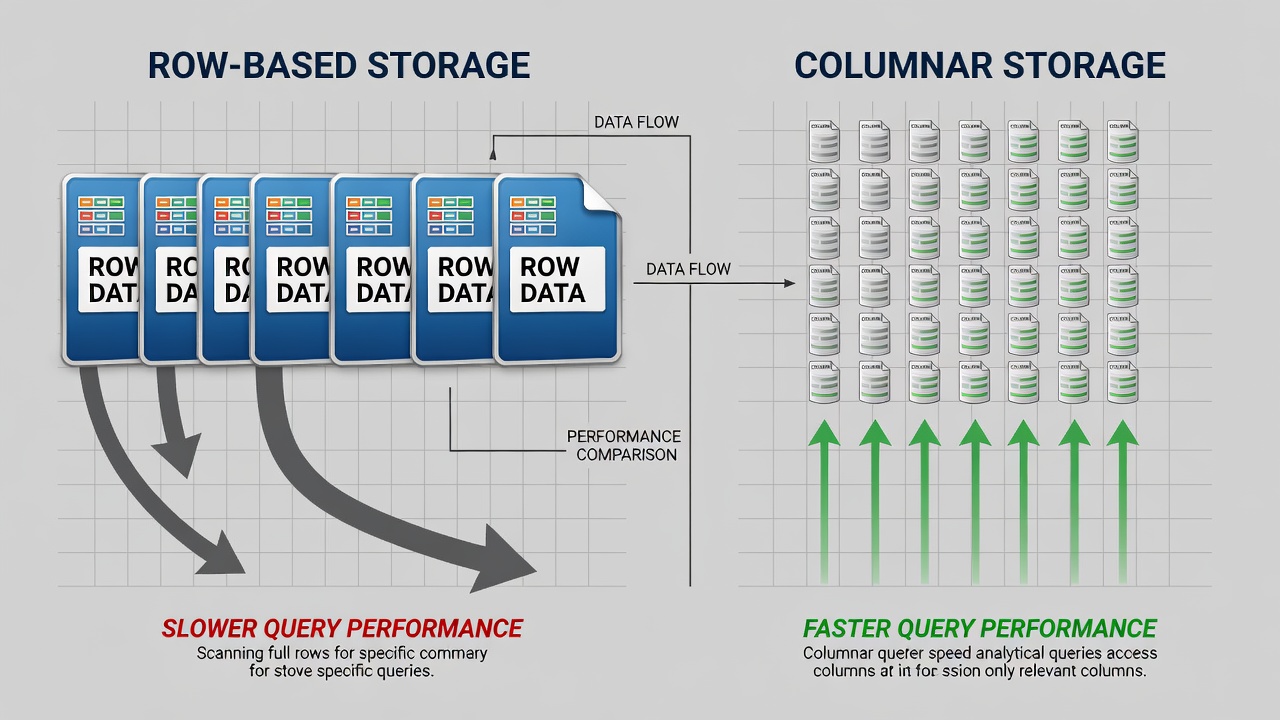
Przechowywanie kolumnowe a przechowywanie wierszowe. Definiującą cechą architektoniczną Parquet jest jego kolumnowy model przechowywania. W tradycyjnym formacie zorientowanym wierszowo, takim jak CSV czy JSON, wszystkie pola należące do każdego rekordu są przechowywane w sposób ciągły na dysku. Dla zbioru danych inspekcji nawierzchni ze 100 atrybutami na badany punkt — współrzędne, oceny stanu nawierzchni, pomiary uszkodzeń, metadane obrazów — CSV przechowuje wszystkie 100 wartości dla wiersza 1, następnie wszystkie 100 wartości dla wiersza 2 i tak dalej. Gdy zapytanie żąda tylko dwóch atrybutów, takich jak szerokość pęknięcia i szerokość geograficzna GPS, silnik przechowywania musi odczytać każdy atrybut dla każdego wiersza z dysku, przetworzyć cały zbiór danych, wyodrębnić dwie żądane kolumny i odrzucić pozostałe 98 kolumn. Skutkuje to ogromnym marnotrawstwem operacji wejścia/wyjścia — około 98% danych odczytanych z dysku jest natychmiast odrzucanych.
Parquet odwraca ten model całkowicie. W ramach każdej grupy wierszy (horyzontalnej partycji zbioru danych zawierającej ciągły blok wierszy), dane są przechowywane według kolumn, a nie według wierszy. Wszystkie wartości dla kolumny szerokości geograficznej są przechowywane w sposób ciągły w jednym fragmencie kolumny, wszystkie wartości dla szerokości pęknięcia w innym fragmencie kolumny i tak dalej. Zapytanie żądające tylko szerokości geograficznej i szerokości pęknięcia odczytuje tylko te dwa fragmenty kolumn z dysku, redukując wejście/wyjście o te same 98%, które są marnowane w formatach zorientowanych wierszowo. Ten kolumnowy układ jest podstawą przewagi wydajnościowej Parquet dla zapytań analitycznych.
Wewnętrzna Architektura Pliku. Plik Parquet ma ścisłą hierarchiczną strukturę z trzema zagnieżdżonymi poziomami organizacji: grupy wierszy, fragmenty kolumn i strony. Zrozumienie tej hierarchii jest niezbędne do optymalizacji wydajności Parquet w potokach danych inspekcyjnych.
Najbardziej zewnętrznym poziomem jest grupa wierszy, która partycjonuje zbiór danych horyzontalnie w ciągłe bloki wierszy. Każda grupa wierszy jest zaprojektowana jako niezależnie czytelna i przetwarzalna, umożliwiając równoległe wykonanie na wielu rdzeniach CPU lub rozproszonych węzłach klastra. Typowa grupa wierszy zawiera od 64 000 do 1 000 000 wierszy, z docelowym nieskompresowanym rozmiarem od 64 MB do 1 GB, w zależności od obciążenia. Dla danych inspekcyjnych TarmacView, grupy wierszy o rozmiarze około 256 MB nieskompresowane zapewniają optymalną równowagę między granularnością równoległości a narzutem metadanych. Większe grupy wierszy redukują liczbę wpisów metadanych w stopce pliku, ale ograniczają równoległość; mniejsze grupy wierszy zwiększają narzut metadanych, ale umożliwiają bardziej szczegółowe pomijanie danych.
W ramach każdej grupy wierszy dane są podzielone według kolumn na fragmenty kolumn. Każdy fragment kolumny przechowuje wszystkie wartości dla pojedynczej kolumny we wszystkich wierszach tej grupy wierszy. Ponieważ wszystkie wartości w fragmencie kolumny mają ten sam typ danych i często wykazują podobne właściwości statystyczne — takie jak niska kardynalność dla kategorycznych klasyfikacji uszkodzeń lub monotoniczne porządkowanie dla znaczników czasu — fragmenty kolumn mogą być kompresowane i kodowane znacznie wydajniej niż dane wierszowe mieszanego typu. Fragmenty kolumn to również miejsce, gdzie obliczane są statystyczne metadane Parquet: każdy fragment kolumny opcjonalnie przechowuje wartość minimalną, maksymalną i liczbę wartości null dla tej kolumny w ramach fragmentu. Te statystyki umożliwiają predykatowe pomijanie danych, gdzie silniki zapytań pomijają całe fragmenty kolumn, których zakresy wartości nie pokrywają się z warunkami filtru.
Każdy fragment kolumny jest podzielony na strony, najmniejszą niepodzielną jednostkę przechowywania i poziom, na którym stosowana jest kompresja i kodowanie. Domyślny rozmiar strony to około 1 MB nieskompresowany. Fragment kolumny zazwyczaj składa się z wielu stron danych zawierających zakodowane wartości kolumny, opcjonalnie poprzedzonych stroną słownika, która mapuje unikalne wartości na indeksy całkowite dla kodowania słownikowego. Parquet definiuje kilka typów stron, w tym DATA_PAGE (oryginalny format v1), DATA_PAGE_V2 (ulepszony format przechowujący poziomy powtórzeń i definicji nieskompresowane dla szybszego pomijania wartości null i zagnieżdżonych) oraz DICTIONARY_PAGE (zawierający mapowanie słownika dla kolumn kodowanych słownikowo).
Stopka Pliku i Metadane. Stopka pliku jest krytycznym komponentem każdego pliku Parquet. Znajdująca się na końcu pliku, stopka zawiera kompletne metadane pliku serializowane przy użyciu Apache Thrift TCompactProtocol — zwartego binarnego formatu serializacji zoptymalizowanego pod kątem obciążeń związanych z odczytem schematu. Metadane stopki obejmują schemat pliku (nazwy kolumn, typy danych i definicje struktur zagnieżdżonych), liczbę wierszy, wersję pliku, listę grup wierszy z lokalizacjami i rozmiarami fragmentów kolumn, statystyki na poziomie fragmentów kolumn (min, max, liczba null), kodek kompresji użyty dla każdej kolumny oraz opcjonalne metadane klucz-wartość dla informacji specyficznych dla aplikacji. Ponieważ stopka jest mała — zazwyczaj od kilku kilobajtów do kilkuset kilobajtów dla plików z wieloma grupami wierszy — silniki zapytań mogą ją szybko odczytać i zaplanować strategię dostępu do danych przed odczytaniem jakichkolwiek stron danych.
Bajty Magic i Identyfikacja Pliku. Każdy prawidłowy plik Parquet zaczyna się i kończy 4-bajtową magiczną liczbą PAR1 (szesnastkowo: 50 41 52 31). Bajty magiczne na początku identyfikują format pliku dla czytników, podczas gdy bajty magiczne na końcu potwierdzają integralność pliku i zapewniają punkt zaczepienia do lokalizacji metadanych stopki. Aby odczytać plik Parquet, silnik zapytań postępuje według następującego kanonicznego algorytmu: przejdź do końca pliku minus 8 bajtów, odczytaj 4 bajty magiczne, aby potwierdzić format PAR1, odczytaj poprzedzające 4 bajty jako 32-bitową liczbę całkowitą little-endian reprezentującą długość metadanych stopki, cofnij się o tę długość, odczytaj i zdeserializuj zakodowane w Thrift FileMetaData, przeanalizuj schemat, zlokalizuj żądane fragmenty kolumn według ich przesunięć w pliku i odczytaj tylko wymagane strony.
Zalety Parquet dla Danych Inspekcyjnych
Współczynniki Kompresji. Kolumnowy model przechowywania Parquet samoistnie produkuje znacznie mniejsze rozmiary plików niż formaty wierszowe, nawet przed zastosowaniem kodeka kompresji. To zmniejszenie rozmiaru pochodzi z dwóch źródeł: technik kodowania kolumnowego wykorzystujących charakterystyki danych w poszczególnych kolumnach oraz opcjonalnych kodeków kompresji stosowanych na poziomie strony. Badania benchmarkowe na rzeczywistych zbiorach danych konsekwentnie pokazują, że nieskompresowany Parquet ma około 25% do 32% rozmiaru równoważnych plików CSV. Dodanie kodeka kompresji, takiego jak Snappy czy Zstd, redukuje rozmiar pliku dalej do 8% do 18% rozmiaru CSV, co stanowi 5- do 12-krotną redukcję przechowywania.
Dla danych inspekcyjnych ta kompresja jest szczególnie korzystna, ponieważ zbiory danych łączą wysokoprecyzyjne współrzędne zmiennoprzecinkowe (które doskonale poddają się kodowaniu delta), kategoryczne klasyfikacje uszkodzeń (które korzystają z kodowania słownikowego) oraz znaczniki czasu (które kompresują się wydajnie poprzez kodowanie delta). Kompletny pomiar pasa startowego generujący 50 milionów punktów danych z 80 atrybutami na punkt zajmuje około 40 GB jako surowy CSV. Te same dane przechowywane jako Parquet z kompresją Zstd zajmują około 3 GB do 5 GB — redukcja przechowywania od 8 do 12 razy. Dla operatorów lotnisk przeprowadzających kwartalne pomiary na wielu pasach startowych, drogach kołowania i płytach postojowych, przekłada się to bezpośrednio na zmniejszone koszty infrastruktury przechowywania, szybszy transfer danych i bardziej efektywne wykorzystanie przechowywania w chmurze.
Predykatowe Pomijanie Danych. Predykatowe pomijanie danych to pojedyncza najbardziej wpływowa optymalizacja wydajności umożliwiona przez kolumnowe przechowywanie i statystyki na poziomie fragmentów w Parquet. Gdy zapytanie zawiera klauzulę WHERE — taką jak WHERE pci < 40 AND survey_date >= '2024-01-01' — silnik zapytań najpierw odczytuje stopkę pliku zawierającą statystyki na poziomie fragmentów kolumn dla filtrowanych kolumn. Dla każdej grupy wierszy silnik porównuje warunek filtru z przechowywanymi wartościami minimalnymi i maksymalnymi. Grupy wierszy, których zakres statystyk nie pokrywa się z warunkiem filtru, są całkowicie pomijane, nie zużywając żadnych operacji wejścia/wyjścia.
Rozważmy archiwum inspekcji TarmacView zawierające pięć lat kwartalnych pomiarów pasów startowych, zorganizowane w 200 grup wierszy na rok, co daje łącznie 1000 grup wierszy. Zapytanie filtrujące dla survey_date >= '2024-06-01' porównuje datę filtru z przechowywanymi minimalnymi i maksymalnymi znacznikami czasu dla każdej grupy wierszy. Tylko grupy wierszy odpowiadające pomiarom z połowy 2024 i później pokrywają się z filtrem — około 50 do 100 grup wierszy z 1000, czyli 5% do 10% wszystkich danych. Pozostałe 900 do 950 grup wierszy jest pomijanych bez odczytu. Zapytanie odczytuje tylko 5% do 10% danych pliku, zapewniając 10- do 20-krotną poprawę wydajności w porównaniu do pełnego skanowania. W połączeniu z przycinaniem kolumn, efektywne oszczędności wejścia/wyjścia mogą przekroczyć 100-krotność dla selektywnych zapytań na szerokich zbiorach danych.
Ewolucja Schematu. Parquet obsługuje ewolucję schematu — możliwość dodawania, usuwania lub modyfikowania kolumn w czasie bez przepisywania istniejących plików. Jest to krytyczne dla długoterminowych programów inspekcji, gdzie wymagania dotyczące zbierania danych ewoluują. Program inspekcji pasa startowego, który początkowo rejestruje tylko oceny uszkodzeń powierzchni, może później dodać klasyfikację pęknięć, pomiary tekstury lub metadane obrazów w miarę dojrzewania programu. Dzięki ewolucji schematu, nowe pliki Parquet zapisane z rozszerzonym schematem współistnieją bezproblemowo ze starszymi plikami używającymi oryginalnego schematu. Silniki zapytań odczytujące zbiór danych widzą scalony schemat z wartościami null wypełnionymi dla kolumn, które nie istniały w starszych plikach. Parquet obsługuje również dodawanie kolumn z wartościami domyślnymi, zmianę nazw kolumn poprzez metadane aliasów kolumn oraz wstecznie zgodne promocje typów, takie jak int32 na int64.
Przycinanie Kolumn (Projekcyjne Pomijanie Danych). Przycinanie kolumn to praktyka odczytywania z dysku tylko kolumn, do których odwołuje się zapytanie. Ponieważ Parquet przechowuje kolumny w oddzielnych fragmentach kolumn w ramach każdej grupy wierszy, silnik zapytań odczytuje tylko fragmenty kolumn dla kolumn występujących w klauzuli SELECT. Dla pliku inspekcji TarmacView ze 100 atrybutami, zapytanie wybierające latitude, longitude, pci odczytuje tylko trzy fragmenty kolumn — około 3% wszystkich danych pliku. W przypadku formatów zorientowanych wierszowo, to samo zapytanie musi odczytać 100% danych i odrzucić 97% w pamięci. Przycinanie kolumn jest automatyczne we wszystkich silnikach zapytań kompatybilnych z Parquet i nie wymaga jawnej konfiguracji. Korzyść wydajnościowa skaluje się liniowo z liczbą kolumn w zbiorze danych: im więcej atrybutów zebranych na badany punkt, tym większe oszczędności z przycinania kolumn.
Format Samoopisujący się. Pliki Parquet są w pełni samoopisujące się — schemat, kodek kompresji, kodowanie, statystyki i metadane aplikacji są osadzone w samym pliku. Żaden zewnętrzny rejestr schematów, słownik danych ani plik konfiguracyjny nie jest potrzebny do odczytu pliku Parquet. Ta właściwość upraszcza udostępnianie danych, archiwizację i długoterminowe przechowywanie. Plik Parquet zapisany pięć lat temu z nieznanym schematem może być odczytany przez nowoczesne oprogramowanie bez zewnętrznej dokumentacji. Samoopisujący się charakter umożliwia również walidację schematu w czasie odczytu, wychwytując niezgodności typów danych i niespójności strukturalne, zanim rozprzestrzenią się przez potoki analityczne.
Możliwość Dzielenia i Równoległego Odczytu. Grupy wierszy Parquet są niezależnie czytelne, umożliwiając równoległe przetwarzanie na wielu rdzeniach CPU, rozproszonych węzłach klastra lub równoczesnych połączeniach do przechowywania w chmurze. Pojedynczy duży plik Parquet może zostać podzielony na swoje składowe grupy wierszy i przetwarzany równocześnie, gdzie każdy pracownik obsługuje podzbiór grup wierszy. Ta właściwość jest niezbędna dla rozproszonych frameworków przetwarzania, takich jak Apache Spark, który przypisuje różne grupy wierszy do różnych zadań wykonawców, oraz dla wielowątkowych bibliotek analitycznych, takich jak Polars, który odczytuje wiele grup wierszy równolegle w ramach jednego procesu. Dla potoków danych inspekcyjnych TarmacView przetwarzających terabajty danych pomiarowych, równoległy odczyt grup wierszy redukuje czas przetwarzania z godzin do minut.
Parquet vs. CSV i JSON dla Danych Inspekcyjnych
Wybór formatu danych fundamentalnie wpływa na każdy aspekt potoku danych inspekcyjnych: koszty przechowywania, wydajność zapytań, integralność danych i długoterminową utrzymywalność. Parquet, CSV i JSON mają różne charakterystyki, które czynią je odpowiednimi dla różnych przypadków użycia w ekosystemie danych inspekcyjnych.
Efektywność Przechowywania. Pliki CSV przechowują dane jako zwykły tekst z separatorami przecinkowymi i bez kompresji. Pojedyncza liczba zmiennoprzecinkowa, taka jak 14.732859, jest przechowywana jako 9 bajtów tekstu ASCII niezależnie od wymagań dotyczących precyzji. JSON jest jeszcze bardziej rozwlekły, dodając znaki strukturalne, takie jak nawiasy klamrowe, kwadratowe, cudzysłowy i dwukropki, które mogą podwoić lub potroić rozmiar pliku w porównaniu do CSV dla tych samych danych. Parquet przechowuje tę samą wartość jako 4 lub 8 bajtów danych binarnych, w zależności od tego, czy używana jest precyzja 32-bitowa czy 64-bitowa. W połączeniu z kodowaniem słownikowym dla kolumn kategorycznych — które zastępuje powtarzające się wartości ciągów zwartymi indeksami całkowitymi — Parquet osiąga redukcję przechowywania od 5 do 20 razy w porównaniu do CSV i od 8 do 30 razy w porównaniu do JSON.
Cecha
Parquet
CSV
JSON
Model przechowywania
Kolumnowy binarny
Wierszowy tekstowy
Wierszowy tekstowy (zagnieżdżony)
Rozmiar pliku (1M wierszy inspekcji, 80 kolumn)
50–200 MB
500 MB–2 GB
800 MB–3 GB
Wbudowana kompresja
Tak (kodowanie + kodek)
Brak (tylko zewnętrzna)
Brak (tylko zewnętrzna)
Odczyt: 2 kolumny z 80
~2.5% wejścia/wyjścia pliku
100% wejścia/wyjścia pliku
100% wejścia/wyjścia pliku
Schemat
Samoopisujący się, typowany
Brak (wnioskowany)
Niejawny, nietypowy
Czytelny dla człowieka
Nie (binarny)
Tak
Tak
Obsługa danych zagnieżdżonych
Natywna (struct, list, map)
Nieobsługiwana
Natywna
Szybkość zapytań (analityka)
10–100x szybciej niż CSV
Bazowa
Wolniejsza niż CSV
Szybkość zapisu
Wolniejsza (narzut kodowania)
Szybka
Szybka
Wsparcie ekosystemu
Spark, DuckDB, BigQuery, Snowflake
Wszystkie narzędzia
Wszystkie narzędzia
Wydajność Zapytań. Różnica w wydajności między Parquet a formatami wierszowymi staje się bardziej wyraźna wraz ze wzrostem rozmiaru zbioru danych i złożoności zapytań. Dla prostych zapytań zliczających na małych zbiorach danych (poniżej 100 000 wierszy), CSV może konkurować z Parquet przy użyciu zoptymalizowanych czytników CSV. Jednak dla typowych obciążeń danych inspekcyjnych obejmujących filtrowanie, agregację i analizę wielokolumnową na zbiorach danych od milionów do miliardów wierszy, Parquet przewyższa CSV od 10 do 100 razy. Przewaga wydajnościowa pochodzi z trzech źródeł: zmniejszonego wejścia/wyjścia poprzez przycinanie kolumn (odczytywanie tylko potrzebnych kolumn), zmniejszonego wejścia/wyjścia poprzez predykatowe pomijanie danych (pomijanie nieistotnych grup wierszy) oraz szybszej dekompresji i dekodowania skompresowanych danych binarnych w porównaniu do przetwarzania zwykłego tekstu.
Integralność Schematu. CSV nie ma wbudowanego schematu. Kolumna zawierająca wartości całkowite w jednym pliku może zawierać wartości ciągów lub puste pola w innym, bez mechanizmu wykrywania lub raportowania niespójności. Wnioskowanie typów danych w czytnikach CSV jest heurystyczne i może dawać nieprawidłowe wyniki — na przykład interpretując kod pocztowy, taki jak 02134, jako liczbę całkowitą 2134 po usunięciu wiodącego zera. JSON ma niejawny schemat, ale nie wymusza typów; to samo pole może być ciągiem w jednym rekordzie i liczbą w następnym. Parquet wymusza ścisły, jawny schemat na poziomie pliku. Każda wartość w kolumnie musi odpowiadać zadeklarowanemu typowi danych, a walidacja schematu następuje w czasie zapisu. To bezpieczeństwo typów jest kluczowe dla danych inspekcyjnych, gdzie integralność danych jest najważniejsza dla decyzji infrastrukturalnych krytycznych dla bezpieczeństwa.
Kiedy Używać Każdego Formatu. CSV pozostaje użyteczny dla małych zbiorów danych, które muszą być czytelne dla człowieka, do wymiany danych między systemami, które nie obsługują Parquet, oraz dla przepływów pracy, gdzie prostota generowania jest ważniejsza niż wydajność zapytań. JSON jest odpowiedni dla danych półstrukturalnych o zmiennym schemacie, dla ładunków API oraz dla logów, gdzie niezbędna jest zagnieżdżona struktura. Parquet jest właściwym wyborem dla każdego zbioru danych inspekcyjnych przekraczającego około 100 MB, dla wszystkich analitycznych obciążeń zapytań, dla długoterminowej archiwizacji danych oraz dla każdego potoku, gdzie wydajność zapytań i efektywność przechowywania są priorytetami. W architekturze TarmacView, surowe dane pomiarowe mogą być początkowo pozyskiwane jako JSON lub CSV z systemów czujników, ale wszystkie analityczne produkty danych — wyniki, kafelki, oceny — są przechowywane wyłącznie w formacie Parquet.
Odczytywanie i Zapisywanie Parquet w Pythonie
Python oferuje trzy główne biblioteki do przetwarzania Parquet — PyArrow, Pandas i Polars — każda z odrębnymi mocnymi stronami do analizy danych inspekcyjnych. Wybór biblioteki zależy od konkretnych wymagań przepływu pracy: przepustowości potoku, szybkości analizy interaktywnej, ograniczeń pamięciowych i integracji z istniejącymi narzędziami.
PyArrow. PyArrow to wiązanie Python dla biblioteki Apache Arrow C++ i zapewnia najbardziej kompletne, niskopoziomowe API do operacji Parquet. Oferuje szczegółową kontrolę nad wszystkimi parametrami Parquet, w tym rozmiarem grup wierszy, rozmiarem strony, kodekiem kompresji, progami kodowania słownikowego i zbieraniem statystyk. Moduł pyarrow.parquet udostępnia funkcje read_table() i write_table() do podstawowych operacji.
import pyarrow.parquet as pq
import pyarrow as pa
# Odczyt z przycinaniem kolumn i predykatowym pomijaniem danychtable = pq.read_table(
'survey_results.parquet',
columns=['latitude', 'longitude', 'pci', 'crack_width'],
filters=[('pci', '<', 40), ('survey_date', '>=', '2024-01-01')]
)
# Zapis ze szczegółową kontroląpq.write_table(
table,
'filtered_results.parquet',
row_group_size=100000,
compression='zstd',
compression_level=3,
use_dictionary=True,
write_statistics=True,
data_page_size=1048576# 1 MB domyślny rozmiar strony)
Parametr columns umożliwia jawne przycinanie kolumn, odczytując tylko określone kolumny z pliku. Parametr filters umożliwia predykatowe pomijanie danych, akceptując listę wyrażeń filtrujących w formacie DNF (Disjunctive Normal Form). PyArrow ocenia te filtry względem statystyk na poziomie fragmentów przed odczytaniem jakichkolwiek stron danych. Dla partycjonowanych zbiorów danych — typowych w TarmacView, gdzie dane są organizowane według daty pomiaru i odcinka pasa startowego — pq.ParquetDataset() zapewnia automatyczne wykrywanie partycji z pomijaniem zarówno filtrów partycji, jak i statystyk kolumn.
Pandas. Pandas zapewnia prostsze, wyższego poziomu API do operacji Parquet poprzez pd.read_parquet() i df.to_parquet(). Biblioteka deleguje podstawową implementację Parquet do PyArrow (domyślnie w nowszych wersjach Pandas) lub fastparquet. Pandas jest idealny do analizy interaktywnej, przepływów pracy w Jupyter notebook i szybkiej eksploracji danych, gdzie ceniona jest prostota ponad szczegółową kontrolę.
Pandas odczytuje cały plik Parquet do DataFrame w pamięci. Jest to odpowiednie dla zbiorów danych mieszczących się w dostępnej pamięci RAM — do około 10 GB do 50 GB w zależności od sprzętu. Dla większych zbiorów danych Pandas może wymagać odczytu fragmentami lub strategii przetwarzania poza pamięcią. Parametr engine domyślnie ustawiony jest na PyArrow w najnowszych wersjach Pandas, ale można go ustawić na fastparquet dla lżejszego zestawu zależności.
Polars. Polars to biblioteka DataFrame zbudowana natywnie na Apache Arrow z silnikiem opartym na Rust, która zapewnia najszybszą wydajność odczytu Parquet wśród bibliotek Python — zazwyczaj 3 do 10 razy szybciej niż Pandas. Polars osiąga to poprzez agresywną wielowątkowość, wydajne układy danych w pamięci podręcznej oraz leniwą optymalizację zapytań, która opóźnia wykonanie do momentu poznania pełnego planu zapytania.
import polars as pl
# Leniwe czytanie z automatycznym predykatowym pomijaniem danych i przycinaniem kolumnlazy_df = pl.scan_parquet('survey_results.parquet')
# Zbuduj plan zapytaniaquery = (lazy_df
.filter(pl.col('pci') <40)
.filter(pl.col('survey_date') >= pl.date(2024, 1, 1))
.select(['latitude', 'longitude', 'pci', 'crack_width'])
.group_by('runway_section')
.agg(pl.mean('pci'))
)
# Wykonaj zapytanieresult = query.collect()
# Zapisz Parquetpl.DataFrame(result).write_parquet('section_summary.parquet', compression='zstd')
Metoda scan_parquet() tworzy leniwy graf obliczeniowy, który przechwytuje pełny plan zapytania — filtry, selekcje, agregacje — przed odczytaniem jakichkolwiek danych z dysku. Gdy wywoływane jest collect(), Polars przekazuje wszystkie odpowiednie filtry do czytnika Parquet, pomijając całe grupy wierszy poprzez statystyki i odczytując tylko wymagane kolumny z pozostałych grup wierszy. Ta leniwa optymalizacja może zmniejszyć odczyt danych o 95% lub więcej w porównaniu do niecierpliwego odczytu całego pliku, a następnie filtrowania w pamięci.
Porównanie Wydajności. Wyniki benchmarków z rzeczywistych obciążeń przetwarzania danych pokazują względną wydajność trzech bibliotek:
Operacja
Pandas (silnik pyarrow)
Polars
PyArrow
Odczyt 10 GB Parquet, pełne skanowanie
~60 s
~15–20 s
~25 s
Filtrowanie + agregacja na 10 GB
~45 s
~8–12 s
~15 s
Zapis 10 GB Parquet z Zstd
~80 s
~30 s
~40 s
Przycinanie kolumn + pomijanie filtrów
~50 s
~3–5 s
~10 s
Polars wykazuje największą przewagę dla selektywnych zapytań obejmujących przycinanie kolumn i predykatowe pomijanie danych, ponieważ jego leniwy optymalizator eliminuje niepotrzebne wejście/wyjście przed rozpoczęciem wykonania. Dla operacji intensywnie zapisujących w kontekście potoków danych, PyArrow zapewnia najbardziej niezawodną wydajność z najszerszym zestawem funkcji.
Schemat Parquet w TarmacView
TarmacView organizuje wyniki analiz inspekcyjnych w rodzinę plików Parquet, każdy z dedykowanym schematem zoptymalizowanym pod kątem konkretnych wzorców zapytań i przypadków użycia. Ten projekt schematu podąża za najlepszymi praktykami Parquet, w tym odpowiednim doborem typów danych, statystykami kolumn dla predykatowego pomijania danych oraz organizacją partycji dla zapytań zakresów czasu i przestrzeni.
results.parquet. Podstawowy plik wyjściowy inspekcji przechowuje jeden wiersz na badaną pozycję wzdłuż pasa startowego lub powierzchni nawierzchni. Schemat obejmuje dokładne współrzędne GPS z precyzją poniżej metra przy użyciu układu WGS84, znacznik czasu pomiaru z informacją o strefie czasowej dla korelacji z danymi pogodowymi i operacyjnymi oraz kompleksowe pomiary stanu nawierzchni. Poszczególne kolumny uszkodzeń przechowują szerokość pęknięcia w milimetrach, długość pęknięcia w metrach, obszar spękań w metrach kwadratowych, stopień ravelingu w skali kategorycznej oraz metryki tekstury powierzchni, w tym średnią głębokość profilu. Pola obliczeń PCI przechowują obliczoną wartość wskaźnika stanu nawierzchni zgodnie z metodyką ASTM D5340, wartości potrąceń dla każdego typu uszkodzenia oraz końcową klasyfikację PCI. Kolumny kontroli jakości rejestrują szacunkową dokładność GPS w metrach, wynik ufności przetwarzania oraz flagi jakości wskazujące potencjalne anomalie danych. Każdy wiersz jest jednoznacznie identyfikowany przez identyfikator przejazdu pomiarowego i sekwencyjny indeks punktu, umożliwiając precyzyjne przestrzenne i czasowe odnoszenie każdego pomiaru.
tiles.parquet. Plik analizy opartej na kafelkach dzieli powierzchnię nawierzchni na regularną siatkę z konfigurowalnym rozmiarem kafelka, domyślnie 1 metr na 1 metr dla szczegółowych pomiarów i 5 metrów na 5 metrów dla szybkich ocen. Każdy wiersz reprezentuje pojedynczy kafelek ze współrzędnymi jego geoprzestrzennego prostokąta otaczającego, środkową szerokością i długością geograficzną kafelka oraz zagregowanymi statystykami obliczonymi ze wszystkich punktów pomiarowych znajdujących się w kafelku. Zagregowane pola obejmują średnią, medianę, minimalną i maksymalną wartość PCI w kafelku, dominujący typ uszkodzenia określony przez najwyższą wartość potrącenia, gęstość uszkodzeń jako procent powierzchni kafelka dotkniętej uszkodzeniem oraz liczbę punktów danych przyczyniających się do statystyk kafelka. Schemat kafelka przechowuje również klasyfikację PCI na poziomie kafelka oraz rekomendowane działanie naprawcze oparte na analizie progowej. Przechowywanie oparte na kafelkach umożliwia szybkie zapytania przestrzenne i przepływy pracy wizualizacyjne, gdzie wyświetlanie każdego indywidualnego punktu pomiarowego jest niepotrzebne i kosztowne obliczeniowo.
assessment.parquet. Końcowy plik oceny stanu przechowuje ewaluację na poziomie odcinka z jednym wierszem na jednorodny odcinek nawierzchni na kampanię pomiarową. Każdy odcinek jest zdefiniowany przez identyfikator pasa startowego lub drogi kołowania, współrzędne początkowe i końcowe stacji oraz długość odcinka. Schemat oceny obejmuje obliczone PCI odcinka zgodnie z metodyką ASTM D5340 ze wszystkimi obliczeniami wartości potrąceń, ocenę stanu powierzchni ICAO Annex 14 do raportowania zgodności międzynarodowej, gęstości poszczególnych typów uszkodzeń wyrażone jako procent powierzchni odcinka, skorygowane wartości potrąceń dla każdego uszkodzenia oraz końcowe PCI. Pola rekomendacji konserwacyjnych przechowują obliczony ranking priorytetów oparty na progach PCI, rekomendowany rodzaj naprawy, taki jak uszczelnianie pęknięć, nakładka lub przebudowa, oraz szacowaną pilność naprawy. Plik oceny rejestruje również metadane dotyczące pomiaru, w tym identyfikator pojazdu pomiarowego, konfigurację czujników, wersję oprogramowania analitycznego i wersję potoku przetwarzania danych dla pełnej identyfikowalności.
telemetry.parquet. Plik strumienia telemetrii pojazdu pomiarowego rejestruje szeregowe dane czujników zebrane podczas przejazdu inspekcyjnego. Każdy wiersz reprezentuje odczyt telemetrii w określonym znaczniku czasu, w tym czas GPS, prędkość pojazdu w kilometrach na godzinę, kurs w stopniach od północy geograficznej, przyspieszenie wzdłużne i boczne w metrach na sekundę kwadratową, wysokość z GPS oraz liczbę satelitów użytych do ustalenia pozycji GPS. Kolumny specyficzne dla czujników rejestrują status każdego czujnika obrazowania i pomiarowego, w tym liczbę klatek na sekundę kamery, status skanera linii laserowej i kąty orientacji jednostki bezwładnościowej. Plik telemetrii umożliwia analizę jakości po przetwarzaniu, taką jak wykrywanie przejazdów pomiarowych przeprowadzonych z nadmierną prędkością, które mogą pogorszyć jakość danych, identyfikację obszarów, gdzie pojazd pomiarowy odbiegł od wyznaczonej ścieżki, oraz korelację pomiarów stanu nawierzchni z dynamiką pojazdu do celów badawczych i optymalizacyjnych.
Partycjonowanie i Organizacja Plików. Pliki Parquet TarmacView są partycjonowane według daty pomiaru i odcinka pasa startowego, aby zoptymalizować zapytania zakresów czasu i przestrzeni. Struktura katalogów partycji podąża za wzorcem survey_date=YYYY-MM-DD/runway_id=RWY09/section=SECTION_A/. Przycinanie partycji pozwala zapytaniom filtrującym według daty pomiaru lub odcinka pasa startowego na odczyt tylko odpowiednich katalogów, pomijając wszystkie inne partycje. W ramach każdej partycji grupy wierszy Parquet mają rozmiar około 256 MB nieskompresowane, balansując granularność równoległości z narzutem metadanych. Wszystkie pliki używają kompresji Zstd na poziomie 3 z włączonym kodowaniem słownikowym dla kolumn kategorycznych i kodowaniem delta dla pól monotonicznych, takich jak współrzędne stacji.
Parquet dla Dużych Danych z Pomiarów Wideo
Inspekcje nawierzchni lotniskowych produkują wyjątkowo duże zbiory danych, które przesuwają granice tradycyjnych podejść do przechowywania danych. Pojedynczy pomiar pasa startowego w rozdzielczości 1 mm przy użyciu systemu kamer zamontowanych na pojeździe może wygenerować 500 GB do 2 TB surowych danych obrazowych na kilometr nawierzchni, z odpowiadającymi danymi pomiarowymi z profilerów laserowych, czujników bezwładnościowych i odbiorników GPS produkującymi dodatkowe ustrukturyzowane strumienie danych. Parquet odgrywa centralną rolę w zarządzaniu ustrukturyzowanym komponentem pomiarowym tych danych — wielowymiarowymi, wieloatrybutowymi danymi tabelarycznymi opisującymi stan nawierzchni w każdym badanym punkcie.
Zarządzanie Wielowymiarowymi Danymi Inspekcyjnymi. Nowoczesne systemy inspekcji nawierzchni zbierają dziesiątki do setek atrybutów na badany punkt. Typowy zestaw czujników pojazdu pomiarowego obejmuje wiele kamer wysokiej rozdzielczości zapewniających obrazy wizualne w rozdzielczości submilimetrowej, skanery linii laserowej produkujące trójwymiarowe profile powierzchni z dokładnością pionową na poziomie mikronów, czujniki termografii podczerwonej mierzące temperaturę powierzchni do wykrywania delaminacji, georadar do oceny podpowierzchniowych warstw, jednostki bezwładnościowe do precyzyjnego pozycjonowania i orientacji oraz odbiorniki GPS do absolutnego georeferencjonowania. Każdy czujnik produkuje ustrukturyzowane pomiary, które są skorelowane przestrzennie i czasowo. Połączony zbiór danych dla pojedynczej kampanii pomiarowej na dużym międzynarodowym lotnisku może przekroczyć 100 miliardów punktów danych, biorąc pod uwagę wszystkie kanały czujników przy pełnej częstotliwości próbkowania.
Parquet umożliwia wydajne przechowywanie i zapytywanie tych wielowymiarowych zbiorów danych poprzez połączenie przechowywania kolumnowego dla gęstych zestawów atrybutów, kodowania słownikowego dla powtarzalnych pól kategorycznych, kodowania delta dla monotonicznie rosnących znaczników czasu i współrzędnych stacji oraz kodowania długości serii dla sekwencji identycznych wartości typowych w polach klasyfikacji uszkodzeń. Typowy rekord punktu pomiarowego z 80 atrybutami zajmuje około 70 bajtów w Parquet z kompresją Zstd, w porównaniu do około 400 bajtów jako nieskompresowany CSV i około 800 bajtów jako JSON. Dla 100 miliardów punktów pomiarowych stanowi to różnicę w przechowywaniu 7 TB dla Parquet w porównaniu do 40 TB dla CSV i 80 TB dla JSON.
Wzorce Zapytań Czasowych i Przestrzennych. Zapytania dotyczące danych inspekcyjnych podążają za charakterystycznymi wzorcami, którym dobrze służy architektura Parquet. Zapytania zakresu czasu, takie jak “Pokaż wszystkie dane pomiarowe między marcem a wrześniem 2024”, korzystają z przycinania partycji Parquet, gdy pliki są zorganizowane według daty pomiaru, oraz z predykatowego pomijania danych na kolumnie znacznika czasu w plikach. Zapytania przestrzenne, takie jak “Znajdź wszystkie uszkodzenia w promieniu 100 metrów od progu pasa startowego”, korzystają z zakodowanych delta współrzędnych stacji, które kompresują się wydajnie i umożliwiają szybkie sekwencyjne skanowanie ciągłych zakresów przestrzennych. Zapytania wieloatrybutowe, takie jak “Zlokalizuj obszary z PCI poniżej 40 i szerokością pęknięcia przekraczającą 3 mm”, korzystają z przycinania kolumn, które odczytuje tylko trzy odpowiednie kolumny — PCI, szerokość pęknięcia i współrzędne — z pełnego zestawu atrybutów.
Przetwarzanie Strumieniowe i Przyrostowe. Duże dane z pomiarów wideo często wymagają przyrostowego przetwarzania, gdzie surowe dane czujników są pozyskiwane, przetwarzane i zapisywane do Parquet etapami. Parquet obsługuje zapis strumieniowy poprzez swoją architekturę grup wierszy: dane mogą być gromadzone w pamięci, aż grupa wierszy osiągnie docelowy rozmiar, a następnie opróżniane na dysk. Umożliwia to potoki przetwarzania, które konsumują na żywo strumienie czujników podczas przejazdów pomiarowych i produkują pliki Parquet przyrostowo, bez konieczności przechowywania całego zbioru danych w pamięci. Potok przetwarzania TarmacView implementuje ten wzorzec, zapisując wyniki pomiarów do Parquet w czasie zbliżonym do rzeczywistego, gdy pojazd pomiarowy porusza się po pasie startowym.
Zapytania Parquet z Pomijaniem Filtrów i Przycinaniem Kolumn
Połączenie pomijania filtrów i przycinania kolumn jest podstawowym mechanizmem, dzięki któremu Parquet osiąga przewagę wydajnościową nad formatami wierszowymi. Zrozumienie, jak działają te optymalizacje, umożliwia analitykom danych inspekcyjnych i programistom potoków strukturyzowanie zapytań dla maksymalnej wydajności.
Mechanizm Pomijania Filtrów. Gdy silnik zapytań odczytuje plik Parquet, jego pierwszą operacją jest odczytanie stopki pliku zawierającej definicję schematu i listę grup wierszy z ich statystykami na poziomie fragmentów kolumn. Dla każdej kolumny, do której odwołują się klauzule WHERE, silnik wyodrębnia przechowywane wartości minimalne i maksymalne ze statystyk każdego fragmentu kolumny. Silnik następnie ocenia każdy warunek filtru względem zakresu min-max każdego fragmentu kolumny, używając następującej logiki: jeśli warunek filtru wymaga wartości większych niż X, a maksymalna wartość fragmentu kolumny jest mniejsza lub równa X, wówczas fragment nie zawiera pasujących wierszy i może być całkowicie pominięty. Podobnie, jeśli warunek filtru wymaga wartości mniejszych niż Y, a minimalna wartość fragmentu kolumny jest większa lub równa Y, fragment może być pominięty. Silnik iteruje przez wszystkie fragmenty kolumn równolegle, budując maskę grup wierszy, które muszą być odczytane i grup wierszy, które mogą być pominięte.
Rozważmy konkretny przykład z danych inspekcyjnych TarmacView. Analityk zapytuje: “Znajdź wszystkie odcinki z PCI poniżej 40 badane po 1 czerwca 2024.” Silnik odczytuje stopkę i bada statystyki dla fragmentów kolumn pci i survey_date we wszystkich grupach wierszy. Grupa wierszy obejmująca daty pomiarów od stycznia do marca 2024 ma maksymalną wartość survey_date na 31 marca 2024 — jest to poniżej progu filtru 1 czerwca 2024, więc cała grupa wierszy jest pomijana. Inna grupa wierszy obejmująca wartości PCI od 45 do 95 ma minimalną wartość pci 45 — jest to powyżej progu filtru 40, więc ta grupa wierszy również jest pomijana. Po ocenie wszystkich grup wierszy, silnik identyfikuje, że tylko grupy wierszy z nakładającymi się zakresami min-max zawierają potencjalnie pasujące wiersze — zazwyczaj 1% do 10% całkowitej objętości danych dla selektywnych zapytań na dużych archiwach.
Przycinanie Kolumn w Praktyce. Przycinanie kolumn działa na tym samym poziomie co pomijanie filtrów, ale dotyczy innego wymiaru redukcji wejścia/wyjścia. Podczas gdy pomijanie filtrów zmniejsza liczbę odczytywanych wierszy przez pomijanie całych grup wierszy, przycinanie kolumn zmniejsza liczbę odczytywanych kolumn przez wybieranie tylko fragmentów kolumn dla referencjonowanych kolumn. Te dwie optymalizacje kumulują się: pomijanie filtrów eliminuje nieistotne grupy wierszy całkowicie, a przycinanie kolumn odczytuje tylko potrzebne kolumny z pozostałych grup wierszy.
Zapytanie takie jak SELECT latitude, longitude, pci FROM assessment WHERE pci < 40 po pominięciu filtrów odczytałoby tylko grupy wierszy zawierające wartości PCI poniżej 40. Z tych grup wierszy przycinanie kolumn odczytuje tylko fragmenty kolumn latitude, longitude i pci — trzy kolumny z pełnego schematu. Jeśli pełny schemat zawiera 80 kolumn, a pomijanie filtrów eliminuje 95% grup wierszy, efektywne oszczędności wejścia/wyjścia wynoszą 99,8% w porównaniu do pełnego skanowania nieskompresowanego pliku.
Możliwości Pomijania Specyficzne dla Silników. Różne silniki zapytań implementują pomijanie filtrów i przycinanie kolumn na różnych poziomach zaawansowania. DuckDB zapewnia pełne pomijanie na poziomie grup wierszy z pomijaniem indeksów na poziomie stron dla plików Parquet zapisanych z nagłówkami stron v2. Apache Spark implementuje pomijanie poprzez swoje API DataSource v2, łącząc przycinanie partycji, filtrowanie min-max na poziomie grup wierszy i opcjonalne pomijanie przy użyciu filtrów Blooma. Presto i Trino obsługują przycinanie kolumn i filtrowanie min-max grup wierszy z konfigurowalnym zachowaniem predykatowego pomijania danych. PyArrow zapewnia jawne pomijanie filtrów poprzez parametr filters w read_table() i automatyczne przycinanie kolumn poprzez parametr columns. Polars zapewnia automatyczne leniwe pomijanie poprzez swoją metodę scan_parquet() bez wymaganej jawnej konfiguracji.
Parquet i Integracja GIS z GeoPandas
Analiza przestrzenna jest fundamentalna dla przepływów pracy inspekcji nawierzchni, a integracja Parquet z narzędziami geoprzestrzennymi poprzez specyfikację GeoParquet umożliwia bezproblemowe łączenie wydajności analitycznej z możliwościami zapytań przestrzennych.
Standard GeoParquet. GeoParquet to standard OGC (Open Geospatial Consortium), który dodaje interoperacyjne typy geoprzestrzenne do formatu Parquet. Wersja 1.0, opublikowana w 2022 roku, definiuje, jak kolumny geometrii są przechowywane w formacie Well-Known Binary (WKB) w binarnej kolumnie Parquet, z dodatkowymi metadanymi w stopce pliku opisującymi układ współrzędnych (CRS), typy geometrii obecne w każdej kolumnie oraz ogólny prostokąt otaczający zbioru danych. Wersja 1.1, opublikowana w 2024 roku, dodała obsługę natywnych typów geometrii ze statystykami prostokąta otaczającego przechowywanymi na grupę wierszy, umożliwiając przestrzenne predykatowe pomijanie danych — geoprzestrzenny odpowiednik standardowego predykatowego pomijania danych w Parquet. Dzięki przestrzennemu pomijaniu predykatów, zapytania używające filtrów przestrzennych, takich jak ST_Intersects(geometry, query_polygon), mogą pomijać całe grupy wierszy, których prostokąty otaczające nie pokrywają się z obszarem zapytania.
Integracja z GeoPandas. GeoPandas rozszerza DataFrame Pandas o operacje geoprzestrzenne i odczytuje pliki GeoParquet bezpośrednio poprzez swoją metodę read_parquet(). Integracja jest przejrzysta: pliki GeoParquet są odczytywane jako GeoDataFrame z kolumną geometrii, która obsługuje pełen zakres przestrzennych operacji Shapely, w tym przecięcie, zawieranie, buforowanie i obliczenia odległości.
import geopandas as gpd
import shapely.geometry
# Odczyt danych inspekcyjnych GeoParquetgdf = gpd.read_parquet('tiles.geoparquet')
# Definicja obszaru zainteresowania pasa startowegorunway_09_27 = shapely.geometry.box(
minx=-73.789, miny=40.635,
maxx=-73.771, maxy=40.645)
# Filtr przestrzenny z optymalizacją prostokąta otaczającegorunway_tiles = gdf[gdf.geometry.intersects(runway_09_27)]
# Agregacja według jakości kafelkasevere_distress = runway_tiles[runway_tiles['pci'] <40]
Gdy GeoPandas odczytuje plik GeoParquet utworzony ze statystykami prostokąta otaczającego na poziomie grup wierszy, bazowy czytnik PyArrow ocenia filtr przestrzenny względem prostokątów otaczających na grupę wierszy przed załadowaniem jakichkolwiek danych geometrii. Grupy wierszy, których prostokąty otaczające nie przecinają obszaru zapytania, są całkowicie pomijane. Dla ogólnokrajowego zbioru danych inspekcyjnych z tysiącami grup wierszy, zapytanie przestrzenne ukierunkowane na pojedynczy pas startowy może odczytać mniej niż 1% wszystkich grup wierszy.
Integracja z QGIS i Innymi Narzędziami GIS. GeoParquet jest obsługiwany natywnie przez QGIS (wersja 3.28 i nowsze), umożliwiając bezpośrednie ładowanie i wizualizację danych inspekcyjnych Parquet w wiodącej otwartoźródłowej aplikacji GIS. Ta integracja oznacza, że pliki Parquet TarmacView mogą być bezpośrednio otwierane w QGIS do mapowania tematycznego, klasyfikacji symboliki i tworzenia układów wydruku bez pośredniej konwersji danych. Apache Sedona zapewnia rozproszone zapytania SQL na GeoParquet z Apache Spark, umożliwiając zapytania przestrzenne na terabajtowych zbiorach danych inspekcyjnych w klastrach wielowęzłowych. Google BigQuery obsługuje bezpośrednie zapytania zewnętrznych tabel GeoParquet z funkcjami przestrzennymi, pozwalając na analizę danych inspekcyjnych w chmurze bez ładowania ich do bazy danych. Overture Maps Foundation dystrybuuje swój cały globalny zbiór danych mapowych jako GeoParquet, demonstrując żywotność formatu do dystrybucji wielkoskalowych danych geoprzestrzennych.
Kodeki Kompresji Parquet
Parquet obsługuje wiele kodeków kompresji, z których każdy oferuje odrębne kompromisy między współczynnikiem kompresji, prędkością zapisu i prędkością odczytu. Wybór kodeka znacząco wpływa zarówno na koszty przechowywania, jak i wydajność zapytań dla obciążeń związanych z danymi inspekcyjnymi.
Porównanie Kodeków. Poniższa tabela podsumowuje charakterystyki najczęściej używanych kodeków kompresji Parquet, oparte na benchmarkach z użyciem rzeczywistych zbiorów danych, w tym danych przejazdów taksówek NYC (20 milionów wierszy) i danych inspekcji nawierzchni autostrad z opublikowanych badań:
Kodek
Szybkość zapisu (względna)
Szybkość odczytu (względna)
Współczynnik kompresji vs CSV
Najlepsze do
Brak (nieskompresowany)
Najszybsza
Najszybsza
~25–32% CSV
Dane pośrednie, szybkie lokalne wejście/wyjście
Snappy
Prawie nieskompresowany
Prawie nieskompresowany
~12–18% CSV
Domyślna równowaga dla większości systemów
LZ4_RAW
Najszybsza ogólnie
Najszybsza ogólnie
~12–18% CSV
Potoki z intensywnym zapisem, pozyskiwanie strumieniowe
Zstd (poziom 3)
~10% wolniejszy niż Snappy
Prawie Snappy
~8–14% CSV
Najlepszy ogólnie dla większości obciążeń
Gzip (poziom 6)
~50% wolniejszy
~10–20% wolniejszy
~8–15% CSV
Przechowywanie archiwalne, chłodne dane
Brotli
Najwolniejszy zapis
Umiarkowana
~7–12% CSV
Maksymalna kompresja dla chłodnego przechowywania
Snappy jest domyślnym kodekiem kompresji w Apache Spark, Apache Hive i wielu innych narzędziach ekosystemu Hadoop. Zapewnia doskonałą równowagę między współczynnikiem kompresji (4- do 6-krotna redukcja z CSV) a prędkością odczytu/zapisu, z narzutem zapisu około 3% do 5% w porównaniu do nieskompresowanego Parquet. Głównym ograniczeniem Snappy jest to, że nie obsługuje konfigurowalnych poziomów kompresji, podczas gdy Zstd może być dostrojony pod kątem prędkości lub współczynnika.
Zstandard (Zstd) jest rekomendowanym domyślnym kodekiem dla większości obciążeń związanych z danymi inspekcyjnymi. Na poziomie 3, Zstd osiąga 10% do 30% lepszą kompresję niż Snappy, utrzymując prawie równoważne prędkości odczytu i ponosząc tylko 10% kary w prędkości zapisu. Na wyższych poziomach (9 do 22), Zstd zbliża się do współczynników kompresji Gzip, pozostając znacznie szybszym w dekompresji. Możliwość dostrajania poziomu kompresji czyni Zstd wszechstronnym w różnych typach obciążeń: poziom 1 dla potoków strumieniowych z intensywnym zapisem, poziom 3 dla zrównoważonego ogólnego użytku oraz poziomy 9 do 22 dla przechowywania archiwalnego.
LZ4_RAW zapewnia najszybsze prędkości kompresji i dekompresji spośród wszystkich kodeków Parquet, marginalnie szybsze niż Snappy. LZ4 jest optymalnym wyborem dla potoków pozyskiwania danych, które priorytetyzują przepustowość zapisu, takich jak strumieniowanie danych pomiarowych w czasie rzeczywistym, gdzie pliki Parquet są zapisywane z pełną prędkością zbierania danych. Współczynnik kompresji jest podobny do Snappy, więc kompromis to prędkość zapisu kosztem nieco większych plików.
Gzip i Brotli osiągają najwyższe współczynniki kompresji, ale przy znaczących karach w prędkości zapisu — Gzip zapisuje około 50% wolniej niż Snappy, a Brotli może być od 100% do 200% wolniejszy w zależności od poziomu. Te kodeki są odpowiednie do chłodnego przechowywania i archiwizacji, gdzie dane są zapisywane raz i rzadko lub nigdy nadpisywane, a głównym celem jest minimalizacja kosztów przechowywania. Dla 40 TB archiwum inspekcyjnego CSV, użycie Parquet skompresowanego Gzip redukuje przechowywanie do około 3 TB do 5 TB w porównaniu do 5 TB do 7 TB z Snappy, co stanowi znaczące oszczędności kosztów dla przechowywania w chmurze rozliczanego za gigabajt na miesiąc.
Konfiguracja Kompresji na Poziomie Kolumny. Parquet pozwala na niezależną konfigurację kompresji dla każdej kolumny, umożliwiając optymalizację opartą na charakterystykach danych każdej kolumny. Dla danych inspekcyjnych, kolumny współrzędnych zmiennoprzecinkowych korzystają z kodowania delta, a następnie kompresji Zstd. Kolumny kategoryczne, takie jak typ uszkodzenia i klasyfikacja nawierzchni, korzystają z kodowania słownikowego, które może kompresować się odpowiednio bez dodatkowej kompresji kodekiem. Kolumny znaczników czasu korzystają z kodowania delta, które kompresuje sekwencyjne znaczniki czasu do średnio 3 do 5 bajtów na wartość, niezależnie od oryginalnej reprezentacji znacznika czasu. Konfiguracja kompresji na poziomie kolumny jest dostępna poprzez funkcję write_table() PyArrow oraz poprzez składnię tworzenia tabel w większości silników zapytań.
Parquet w Potoku Danych Inspekcyjnych
Parquet służy jako centralny format danych w architekturze danych inspekcyjnych TarmacView, umożliwiając potok obejmujący zakres od pozyskiwania surowych czujników przez analityczne zapytania po wizualizację i raportowanie. Architektura potoku demonstruje praktyczne zalety Parquet na każdym etapie przetwarzania.
Przegląd Architektury Potoku. Potok inspekcyjny TarmacView podąża za wieloetapową architekturą podobną do wzorca data lakehouse. Surowe dane czujników z pojazdów pomiarowych — obrazy z kamer, profile laserowe, ślady GPS i telemetria — są początkowo pozyskiwane i przechowywane w magazynie obiektów jako warstwa surowych danych. Algorytmy przetwarzania obrazu i wizji komputerowej analizują obrazy w celu wykrycia i klasyfikacji uszkodzeń nawierzchni, produkując ustrukturyzowane dane pomiarowe, które są zapisywane do Parquet jako warstwa danych rafinowanych. Zadania analityczne i agregacyjne obliczają oceny stanu na poziomie kafelków i odcinków, zapisując wyniki do Parquet jako warstwa analityczna. Wreszcie, narzędzia wizualizacyjne i systemy raportowania wysyłają zapytania do plików Parquet warstwy analitycznej, aby obsługiwać interaktywne pulpity nawigacyjne i generować raporty zgodności.
Warstwa Surowa: Pozyskiwanie Danych Czujników. Na warstwie surowej dane pomiarowe docierają jako heterogeniczna mieszanka formatów. Dane GPS strumieniują jako zdania NMEA lub binarne logi. Dane z profilerów laserowych docierają jako pliki binarne w zastrzeżonym formacie. Obrazy wysokiej rozdzielczości docierają jako sekwencyjne pliki obrazów z metadanymi EXIF. Potok wstępnego przetwarzania normalizuje te różnorodne formaty do wspólnego schematu i zapisuje ustrukturyzowaną część — współrzędne, znaczniki czasu, odczyty czujników i wartości pomiarowe — do Parquet. Obrazy pozostają w swoim natywnym formacie (GeoTIFF lub JPEG2000) z odnośnikami przechowywanymi w metadanych Parquet do celów krzyżowego odwoływania. To hybrydowe podejście łączy wydajność analityczną Parquet dla ustrukturyzowanych danych z wyspecjalizowanymi formatami obrazów zoptymalizowanymi do przechowywania rastrowego.
Warstwa Rafinowana: Wykrywanie i Klasyfikacja Uszkodzeń. Etap przetwarzania wizji komputerowej odczytuje surowe obrazy i stosuje modele uczenia maszynowego do wykrywania i klasyfikacji uszkodzeń nawierzchni, w tym pęknięć podłużnych, pęknięć poprzecznych, spękań siatkowych, łat, ravelingu i dziur. Wyniki modeli są zapisywane do Parquet jako warstwa danych rafinowanych, z każdym wykrytym uszkodzeniem zapisanym jako wiersz zawierający klasyfikację typu uszkodzenia, wynik ufności, współrzędne wielokąta otaczającego, wymiary (długość, szerokość, obszar) i ocenę stopnia nasilenia. Pliki Parquet warstwy rafinowanej są zazwyczaj największe w potoku, zawierając miliony do miliardów rekordów uszkodzeń na inspekcję lotniska. Przycinanie kolumn jest tutaj niezbędne: przepływy pracy kontroli jakości, które potrzebują tylko detekcji o wysokiej ufności, odczytują najpierw kolumnę ufności, a następnie selektywnie odczytują kolumny geometrii dla kwalifikujących się rekordów.
Warstwa Analityczna: Ocena Stanu i Obliczenia PCI. Warstwa analityczna agreguje rafinowane dane uszkodzeń w oceny stanu nawierzchni zgodnie z metodyką ASTM D5340. Dla każdego zdefiniowanego odcinka nawierzchni, silnik agregacji oblicza gęstości uszkodzeń, odpowiednie wartości potrąceń i końcowe PCI. Wyniki są zapisywane do Parquet jako pliki ocen na poziomie odcinka. Ta warstwa oblicza również agregacje na poziomie kafelków do wizualizacji, wstępnie obliczając statystyki, które byłyby kosztowne do obliczenia na bieżąco w interaktywnych pulpitach nawigacyjnych. Pliki Parquet warstwy analitycznej są stosunkowo małe w porównaniu do warstwy rafinowanej — zazwyczaj kilkaset megabajtów dla dużego lotniska — i są zoptymalizowane pod kątem szybkiego interaktywnego zapytywania z rozmiarami grup wierszy 64 MB do 128 MB.
Architektura Lakehouse i Formaty Tabel. Parquet służy również jako bazowy format plików dla formatów tabel, które zapewniają transakcje ACID, podróże w czasie i ewolucję schematu na plikach Parquet. Apache Iceberg, Delta Lake i Apache Hudi wszystkie używają Parquet jako swojego domyślnego lub podstawowego formatu przechowywania, dodając logi transakcyjne, zarządzanie migawkami i narzędzia optymalizacyjne. Dla wdrożeń TarmacView wymagających równoczesnego dostępu do odczytu i zapisu — takich jak jednoczesne pozyskiwanie danych pomiarowych i zapytania analityków — warstwy Iceberg lub Delta Lake na bazie Parquet zapewniają niezbędne gwarancje izolacji. Format tabeli obsługuje równoczesne konflikty zapisu, zapewnia spójne widoki migawek dla czytników oraz zarządza metadanymi dla ewolucji partycji i kompakcji plików.
Podsumowanie Korzyści Architektonicznych. Architektura potoku oparta na Parquet dostarcza kilka konkretnych korzyści dla zarządzania danymi inspekcyjnymi. Jedna kopia, wiele silników: Te same pliki Parquet mogą być odpytywane przez DuckDB do analizy interaktywnej, Apache Spark do przetwarzania wsadowego, Polars do skryptów ad-hoc i QGIS do wizualizacji geoprzestrzennej, wszystko bez duplikowania danych lub konwersji formatu. Opłacalne przechowywanie: Kompresja Parquet redukuje koszty przechowywania obiektów od 5 do 10 razy w porównaniu do CSV i od 10 do 20 razy w porównaniu do JSON, z bezpośrednimi oszczędnościami kosztów dla przechowywania w chmurze rozliczanego według objętości. Rozdzielenie obliczeń i przechowywania: Silniki zapytań odczytują Parquet bezpośrednio z magazynu obiektów bez konieczności etapu ładowania, umożliwiając elastyczne skalowanie obliczeń, gdzie zasoby analityczne mogą być uruchamiane i wyłączane niezależnie od trwałego magazynu danych. Długoterminowa ochrona danych: Samoopisujący się schemat Parquet i otwarty standard zapewniają, że dane inspekcyjne pozostają czytelne przez przyszłe oprogramowanie bez zależności od zastrzeżonych API lub przestarzałych bibliotek.
Najlepsze Praktyki dla Parquet w Przepływach Pracy Inspekcyjnych
Wybór Rozmiaru Grupy Wierszy. Optymalny rozmiar grupy wierszy zależy od wzorców dostępu dla konkretnego obciążenia inspekcyjnego. Dla interaktywnych zapytań na małych i średnich zbiorach danych — takich jak eksploracja pojedynczej kampanii pomiarowej podczas sesji przeglądu po przetwarzaniu — grupy wierszy o rozmiarze 64 MB do 128 MB zapewniają szybki odczyt metadanych i szybkie pomijanie grup wierszy. Dla przetwarzania wsadowego na dużych archiwach — takiego jak obliczanie rocznych trendów w pięciu latach kwartalnych pomiarów — grupy wierszy o rozmiarze 256 MB do 512 MB zapewniają lepsze współczynniki kompresji i redukują liczbę wpisów metadanych w stopce, poprawiając szybkość odczytu stopki. Ogólną zasadą jest celowanie w rozmiary grup wierszy takie, aby każda grupa wierszy wygodnie mieściła się w pamięci podręcznej stron systemu przechowywania obiektów, zapewniając jednocześnie wystarczającą granularność dla równoległego odczytu na dostępnych rdzeniach CPU.
Strategia Partycjonowania. Partycjonuj dane inspekcyjne według kolumn najczęściej używanych w warunkach filtrów. Dla obciążeń TarmacView, podstawowymi wymiarami partycji są data pomiaru (według dnia lub miesiąca) i identyfikator pasa startowego. Przycinanie partycji zapewnia, że zapytania filtrujące według tych wymiarów odczytują tylko odpowiednie katalogi, pomijając wszystkie inne partycje. Unikaj nadmiernego partycjonowania, które tworzy dużą liczbę małych plików z wysokim narzutem metadanych i pogorszoną wydajnością zapytań. Partycja powinna zawierać co najmniej 100 MB do 500 MB danych, aby uzasadnić narzut metadanych dodatkowego poziomu katalogu.
Konfiguracja Statystyk. Włącz statystyki na poziomie kolumn dla kolumn używanych w warunkach filtrów, aby umożliwić predykatowe pomijanie danych. PyArrow i inne czytniki Parquet włączają statystyki domyślnie, ale statystyki mogą być wyłączone, aby zmniejszyć rozmiar stopki dla plików z bardzo wąskimi schematami lub przewidywalnymi wzorcami dostępu. Dla danych inspekcyjnych, włącz statystyki dla wartości PCI, dat pomiarów, ocen stopnia nasilenia uszkodzeń i współrzędnych przestrzennych — wszystkie kolumny powszechnie używane jako filtry zapytań. Statystyki na kolumnach o wysokiej kardynalności, takich jak unikalne identyfikatory punktów, zapewniają minimalną korzyść z pomijania i zwiększają rozmiar metadanych stopki.
Wybór Kompresji. Używaj Zstd na poziomie 3 jako domyślnego kodeka kompresji dla danych inspekcyjnych. Zapewnia to najlepszą równowagę współczynnika kompresji, prędkości zapisu i prędkości odczytu dla typowych obciążeń. Dla potoków pozyskiwania strumieniowego, gdzie przepustowość zapisu jest wąskim gardłem, przełącz się na Snappy lub LZ4_RAW. Dla archiwów chłodnego przechowywania, gdzie koszt przechowywania jest głównym zmartwieniem, używaj Zstd na poziomie 9 do 22 lub Gzip na poziomie 6 do 9. Konfiguruj kompresję na poziomie kolumn, gdy kolumny mają znacząco różne charakterystyki kompresji — na przykład używaj kodowania słownikowego bez dodatkowego kodeka dla kolumn kategorycznych i kodowania delta z Zstd dla monotonicznych kolumn współrzędnych i znaczników czasu.
Zarządzanie Rozmiarem Pliku. Unikaj tworzenia bardzo małych plików Parquet, zdefiniowanych jako pliki mniejsze niż około 10 MB. Małe pliki mają nieproporcjonalnie duży narzut metadanych w stosunku do zawartości danych — plik Parquet o rozmiarze 5 MB może zawierać 1 MB metadanych stopki i tylko 4 MB rzeczywistych danych. Małe pliki również zmniejszają równoległość, ponieważ każdy plik musi być otwarty, odczytany i zamknięty niezależnie, ponosząc narzut na plik w systemach przechowywania obiektów. W potokach ETL, które produkują wiele małych plików Parquet, dodaj etap kompakcji lub scalania po przetwarzaniu, aby połączyć małe pliki w większe. Docelowy rozmiar pliku od 64 MB do 512 MB na plik jest odpowiedni dla większości obciążeń danych inspekcyjnych.
Projektowanie Schematu. Wybierz odpowiednie typy danych dla każdej kolumny. Używaj 32-bitowych liczb całkowitych dla kolumn, których wartości mieszczą się w zakresie 32-bitowym ze znakiem (około ±2,1 miliarda), takich jak sekwencyjne indeksy punktów w ramach przejazdu pomiarowego. Używaj 64-bitowych liczb całkowitych dla większych identyfikatorów, takich jak globalne unikalne identyfikatory punktów. Używaj 32-bitowych liczb zmiennoprzecinkowych dla kolumn współrzędnych, gdzie wystarczająca jest precyzja poniżej metra, rezerwując 64-bitową podwójną precyzję dla pomiarów naukowych wymagających dokładności na poziomie milimetra. Używaj typu danych date32 lub timestamp dla kolumn dat i czasu, zamiast przechowywać je jako ciągi — umożliwia to kodowanie delta i predykatowe pomijanie danych na kolumnach czasowych. Używaj kodowania słownikowego dla kolumn kategorycznych o niskiej kardynalności, takich jak klasyfikacje typów uszkodzeń i typy powierzchni nawierzchni.
Porównanie z Innymi Formatami Kolumnowymi
Parquet nie jest jedynym kolumnowym formatem przechowywania dostępnym dla obciążeń analitycznych. Zrozumienie jego relacji z innymi formatami pomaga w podejmowaniu świadomych decyzji architektonicznych dla potoków danych inspekcyjnych.
ORC (Optimized Row Columnar). Apache ORC jest głównym alternatywnym formatem kolumnowym w ekosystemie Hadoop, pierwotnie opracowanym przez Hortonworks jako ulepszenie wcześniejszego formatu RCFile. ORC i Parquet dzielą wiele cech: oba są kolumnowe, oba obsługują predykatowe pomijanie danych poprzez osadzone statystyki, oba oferują wybór kodeka kompresji i oba są samoopisujące się. ORC zapewnia nieco lepsze współczynniki kompresji dla niektórych typów danych, szczególnie kolumn ciągów, i ma bardziej zaawansowane wbudowane indeksowanie, w tym filtry Blooma i indeksy min-max. Parquet ma jednak szersze wsparcie ekosystemowe — każdy główny silnik zapytań i chmurowy magazyn danych obsługuje Parquet, podczas gdy obsługa ORC jest skoncentrowana w ekosystemach Apache Hive i Spark. Dla potoków danych inspekcyjnych wymagających maksymalnej przenośności między silnikami zapytań i platformami chmurowymi, Parquet jest bezpieczniejszym wyborem.
Format IPC Arrow. Apache Arrow definiuje kolumnowy format w pamięci, który jest ściśle powiązany z Parquet, ale zoptymalizowany do współdzielenia danych bez kopiowania w ramach procesu, a nie do trwałego przechowywania. Pliki Arrow IPC (Inter-Process Communication) są zaprojektowane do szybszych operacji odczytu i zapisu z minimalnym narzutem serializacji, kosztem większych rozmiarów plików i braku wbudowanej kompresji lub metadanych predykatowego pomijania danych. Parquet i Arrow są komplementarne: Arrow jest używany do przetwarzania danych w pamięci i wymiany między procesami, podczas gdy Parquet jest używany do trwałego przechowywania i długoterminowej archiwizacji. PyArrow, Polars i DuckDB wszystkie działają natywnie na pamięci Arrow, odczytując i zapisując pliki Parquet, zapewniając korzyści obu formatów.
CSV z Układem Kolumnowym (Parquet-podobny). Niektóre systemy implementują kolumnowe odczytywanie plików CSV poprzez reorganizację danych w pamięci po odczycie, ale to podejście nie może dorównać kolumnowemu układowi Parquet na poziomie dysku. Kolumnowe odczytywanie CSV nadal wymaga odczytania 100% danych pliku z dysku, przeanalizowania wszystkich wartości z każdego wiersza, a następnie reorganizacji w kolumny — oszczędności wejścia/wyjścia z przycinania kolumn nie mogą być osiągnięte na poziomie dysku, ponieważ CSV przechowuje dane według wierszy. Kolumnowy układ Parquet na dysku jest fundamentalną przewagą architektoniczną, która nie może być replikowana przez oprogramowanie działające na formacie wierszowym.
Podsumowanie
Apache Parquet jest podstawowym formatem przechowywania dla nowoczesnego analitycznego przetwarzania danych, a jego charakterystyki czynią go szczególnie odpowiednim dla wymagających wymagań danych z inspekcji nawierzchni lotniskowych. Kolumnowy model przechowywania zapewnia 5- do 20-krotną kompresję w porównaniu do formatów wierszowych, redukując koszty przechowywania i umożliwiając szybszy transfer danych. Predykatowe pomijanie danych i przycinanie kolumn razem zapewniają 10- do 100-krotną poprawę wydajności zapytań dla selektywnych zapytań na szerokich zbiorach danych inspekcyjnych, czyniąc interaktywną eksplorację terabajtowych archiwów pomiarowych praktyczną. Ewolucja schematu wspiera naturalną ewolucję programów inspekcyjnych w miarę rozszerzania się wymagań dotyczących zbierania danych w czasie. Samoopisujący się format zapewnia długoterminową ochronę danych bez zależności od zewnętrznych rejestrów schematów lub zastrzeżonego oprogramowania. Szerokie wsparcie ekosystemowe — obejmujące biblioteki Python do nauki o danych, rozproszone frameworki przetwarzania, narzędzia analizy geoprzestrzennej i chmurowe magazyny danych — umożliwia płynny przepływ danych inspekcyjnych przez cały potok analityczny, od pozyskiwania surowych czujników po końcowe raportowanie. Dla TarmacView i szerszej branży inspekcji nawierzchni, Parquet zapewnia wydajność przechowywania, wydajność zapytań i kompatybilność ekosystemową niezbędną do zarządzania rosnącą objętością i zaawansowaniem danych o stanie infrastruktury.
Najczęściej Zadawane Pytania
Apache Parquet różni się zasadniczo od CSV i JSON, ponieważ używa kolumnowego modelu przechowywania danych zamiast przechowywania zorientowanego wierszowo. W CSV i JSON wszystkie pola każdego wiersza są przechowywane razem, sekwencyjnie na dysku. W Parquet wszystkie wartości każdej kolumny są przechowywane w sposób ciągły w oddzielnych fragmentach kolumn w grupach wierszy. Ta różnica architektoniczna przynosi dramatyczne praktyczne korzyści dla obciążeń analitycznych. Dla danych inspekcyjnych z wieloma atrybutami — takimi jak typ pęknięcia, stopień nasilenia, współrzędne lokalizacji, oceny stanu nawierzchni i znaczniki czasu — zapytanie wymagające tylko współrzędnych pęknięć i stopnia nasilenia z 50-kolumnowego zbioru danych odczytuje tylko te dwie kolumny z dysku, redukując operacje wejścia/wyjścia o około 96%. CSV i JSON muszą odczytać każdą kolumnę każdego wiersza, zanim odrzucą niepotrzebne dane. Kolumnowy układ Parquet umożliwia również lepszą kompresję, ponieważ wartości w ramach pojedynczej kolumny są tego samego typu danych i często mają niską kardynalność lub powtarzające się wzorce. Plik CSV o rozmiarze 10 GB z danymi inspekcji nawierzchni zazwyczaj kompresuje się do 500 MB do 1,5 GB w formacie Parquet, co stanowi redukcję przechowywania od 7 do 20 razy. Dodatkowo Parquet jest formatem binarnym z osadzonymi metadanymi opisującymi schemat, kodowanie i kompresję, w przeciwieństwie do CSV, które nie ma wbudowanego schematu, oraz JSON, który osadza informacje o schemacie redundantnie w każdym wierszu. Dla potoków przetwarzania danych inspekcyjnych obsługujących tysiące rekordów stanu pasa startowego, Parquet zapewnia od 10 do 100 razy szybszą wydajność zapytań analitycznych w porównaniu do CSV lub JSON.
Predykatowe pomijanie danych to technika optymalizacji zapytań, która wykorzystuje statystyki na poziomie fragmentów kolumn w Parquet — konkretnie wartość minimalną, maksymalną i liczbę wartości null przechowywane w metadanych stopki pliku — aby pominąć całe grupy wierszy podczas skanowania danych bez ich odczytywania. Gdy zapytanie zawiera warunek filtrujący, taki jak WHERE severity = 'HIGH' lub WHERE timestamp > '2024-06-01', silnik zapytań najpierw odczytuje lekką stopkę pliku, a następnie bada przechowywane statystyki min/max dla każdej grupy wierszy. Każda grupa wierszy, której zakres statystyk nie pokrywa się z warunkiem filtru, jest całkowicie pomijana, co skutkuje zerowym wejściem/wyjściem dla tej grupy. Dla zbiorów danych inspekcyjnych zebranych podczas wielu kampanii pomiarowych, zapytanie filtrujące według konkretnego zakresu dat może pominąć od 90% do 99% grup wierszy. Jest to krytycznie ważne dla danych z inspekcji nawierzchni lotniskowych, ponieważ pomiary produkują duże ilości danych o wysokiej rozdzielczości — pojedynczy pomiar pasa startowego w rozdzielczości 1 mm generuje miliony punktów danych na kilometr. Bez predykatowego pomijania danych każde zapytanie wymagałoby pełnego skanowania wszystkich zebranych danych. Dzięki pomijaniu opartemu na statystykach w Parquet, typowe zapytania operacyjne, takie jak 'Znajdź wszystkie obszary z PCI poniżej 40 badane w 2024' lub 'Pobierz mapy pęknięć dla pasa 09/27 z dwóch ostatnich inspekcji', wykonują się w sekundach, a nie minutach, nawet na zbiorach danych rzędu terabajtów. Efektem jest interaktywna wydajność zapytań na ogromnych archiwach inspekcyjnych.
Optymalny kodek kompresji Parquet zależy od konkretnych charakterystyk obciążenia oraz kompromisu między współczynnikiem kompresji a prędkością odczytu/zapisu. Dla obciążeń związanych z danymi inspekcyjnymi, Zstandard (Zstd) na poziomie kompresji 3 jest rekomendowanym domyślnym wyborem, ponieważ zapewnia prędkości odczytu zbliżone do Snappy, osiągając jednocześnie znacznie lepsze współczynniki kompresji. Dane benchmarkowe z rzeczywistych zbiorów danych pokazują, że Parquet z kompresją Zstd redukuje rozmiar pliku CSV do około 8% do 14% oryginału, w porównaniu do 12% do 18% dla Snappy i 25% dla nieskompresowanego Parquet. Dla potoków z intensywnym zapisem, gdzie priorytetem jest szybkość ingerencji danych — takich jak przesyłanie strumieniowe danych inspekcyjnych w czasie rzeczywistym z pojazdów pomiarowych — LZ4_RAW lub Snappy zapewniają najszybszą wydajność zapisu przy znikomym narzucie CPU, jednocześnie osiągając 5- do 8-krotną kompresję w porównaniu do CSV. Dla chłodnego przechowywania i archiwizacji historycznych danych inspekcyjnych, gdzie współczynnik kompresji jest najwyższym priorytetem, Zstd na poziomach 9 do 22 lub Gzip na poziomie 9 redukują koszty przechowywania do zaledwie 5% do 8% oryginalnego rozmiaru CSV. Kompromis polega na tym, że maksymalna kompresja zwiększa czas CPU zapisu o 30% do 60% w porównaniu do Snappy. Dla typowych przepływów pracy TarmacView z danymi inspekcyjnymi, które balansują wydajność przechowywania z wydajnością zapytań, Zstd poziom 3 zapewnia najlepszy ogólny stosunek jakości do ceny. Kolumny danych inspekcyjnych, takie jak wartości wskaźnika stanu nawierzchni, klasyfikacje pęknięć i znaczniki czasu pomiarów, szczególnie dobrze korzystają z kodowania słownikowego połączonego z kompresją Zstd, ponieważ te kolumny mają stosunkowo niską kardynalność, co oznacza, że słownik przechowuje większość unikalnych wartości w niewielkiej liczbie wpisów.
Przycinanie kolumn, znane również jako projekcyjne pomijanie danych, to technika odczytywania z dysku tylko tych kolumn, do których odwołuje się zapytanie, z całkowitym pominięciem wszystkich innych kolumn. W kolumnowym modelu przechowywania Parquet dane każdej kolumny są przechowywane w oddzielnych fragmentach kolumn w ramach każdej grupy wierszy, więc silnik zapytań może selektywnie odczytać tylko fragmenty kolumn dla żądanych kolumn. Dla danych inspekcyjnych, gdzie pojedynczy plik może zawierać od 50 do 100 lub więcej atrybutów na punkt pomiarowy — w tym współrzędne, wiele typów uszkodzeń, oceny stopnia nasilenia, metryki tekstury powierzchni, metadane obrazów i flagi jakości — przycinanie kolumn zapewnia ogromne korzyści wydajnościowe. Zapytanie wymagające tylko współrzędnych geolokalizacyjnych i pomiarów szerokości pęknięć ze zbioru danych ze 100 atrybutami odczytuje około 2% wszystkich danych pliku. W przypadku formatów zorientowanych wierszowo, takich jak CSV czy JSON, to samo zapytanie wymaga odczytania i przetworzenia 100% danych, a następnie odrzucenia 98% w pamięci. W praktyce przycinanie kolumn w połączeniu z kompresją Parquet może zredukować wejście/wyjście zapytań od 50 do 100 razy dla selektywnych zapytań na szerokich zbiorach danych inspekcyjnych. Jest to szczególnie cenne w przepływach pracy TarmacView, gdzie analitycy interaktywnie eksplorują dane o stanie nawierzchni, przełączając się między różnymi metrykami uszkodzeń, porównaniami historycznymi i podzbiorami przestrzennymi. Nowoczesne silniki zapytań, w tym DuckDB, Polars i PyArrow, wszystkie implementują automatyczne przycinanie kolumn podczas odczytu plików Parquet, nie wymagając specjalnej konfiguracji od analityka.
Tak, Parquet natywnie obsługuje dane geoprzestrzenne poprzez specyfikację GeoParquet, która jest standardem OGC (Open Geospatial Consortium) dodającym interoperacyjne typy geoprzestrzenne do formatu Parquet. GeoParquet przechowuje kolumny geometrii w formacie Well-Known Binary (WKB) w binarnej kolumnie Parquet, z dodatkowymi metadanymi w stopce pliku opisującymi układ współrzędnych (CRS), obecne typy geometrii oraz ogólny prostokąt otaczający. Umożliwia to przestrzenne predykatowe pomijanie danych, gdzie zapytania używające filtrów przestrzennych, takich jak ST_Intersects lub ST_Within, mogą pomijać grupy wierszy, których prostokąty otaczające nie pokrywają się z obszarem zapytania. Dla danych z inspekcji pasów startowych obejmujących kilometry powierzchni nawierzchni, filtrowanie przestrzenne jest niezbędne do izolowania konkretnych odcinków, skrzyżowań lub stref o wysokim zużyciu. GeoPandas, QGIS, Apache Sedona, Google BigQuery i Snowflake wszystkie obsługują bezpośredni odczyt plików GeoParquet, co ułatwia integrację wyników inspekcji TarmacView z szerszymi geoprzestrzennymi przepływami pracy. W TarmacView pliki Parquet przechowują wyniki inspekcji z precyzyjnymi współrzędnymi GPS dla każdego badanego punktu lub poligonu uszkodzenia, umożliwiając przestrzenne łączenie z geometrią pasa startowego, liniami środkowymi dróg kołowania i granicami płyt postojowych. Połączenie wydajności analitycznej Parquet z możliwościami geoprzestrzennymi czyni go idealnym formatem do wielkoskalowych pomiarów stanu nawierzchni, gdzie zarówno lokalizacja przestrzenna, jak i wielowymiarowe atrybuty muszą być efektywnie przetwarzane.
Python oferuje trzy główne biblioteki do odczytu i zapisu plików Parquet, każda o różnych mocnych stronach do analizy danych inspekcyjnych. PyArrow (wiązania Python dla biblioteki Apache Arrow C++) jest biblioteką o najbardziej kompletnych funkcjach, zapewniającą szczegółową kontrolę nad rozmiarem grup wierszy, kompresją, kodowaniem i statystykami. Obsługuje jawne przycinanie kolumn poprzez parametr columns, predykatowe pomijanie danych poprzez parametr filters oraz partycjonowane zbiory danych poprzez ParquetDataset. Dla przepływów pracy związanych z przetwarzaniem danych inspekcyjnych w TarmacView, PyArrow jest rekomendowanym silnikiem dla programistycznych potoków przetwarzania danych. Pandas zapewnia prostsze, wyższego poziomu API poprzez pd.read_parquet i df.to_parquet, delegując podstawową implementację Parquet do PyArrow lub fastparquet. Pandas jest idealny do interaktywnej analizy i prac eksploracyjnych w notebookach Jupyter, choć odczytuje cały zbiór danych do pamięci. Polars to biblioteka DataFrame zbudowana na Apache Arrow, która zapewnia najszybszą wydajność odczytu Parquet — zazwyczaj 3 do 10 razy szybciej niż Pandas — dzięki swojemu wielowątkowemu silnikowi opartemu na Rust. Polars oferuje leniwe API poprzez pl.scan_parquet, które wykonuje pełne predykatowe pomijanie danych i przycinanie kolumn przed załadowaniem jakichkolwiek danych. Dla dużych zbiorów danych inspekcyjnych przekraczających dostępną pamięć, Polars obsługuje odczyt strumieniowy. Dla geoprzestrzennych danych Parquet, GeoPandas rozszerza Pandas o operacje geoprzestrzenne i może bezpośrednio odczytywać pliki GeoParquet poprzez gpd.read_parquet. Wybór biblioteki zależy od konkretnego przepływu pracy: PyArrow do tworzenia potoków, Pandas i GeoPandas do interaktywnej analizy oraz Polars do maksymalnej wydajności na dużych zbiorach danych inspekcyjnych.
TarmacView organizuje wyniki analiz inspekcyjnych w kilka odrębnych plików Parquet, każdy z dedykowanym schematem zoptymalizowanym pod kątem konkretnych wzorców zapytań. Plik results.parquet przechowuje podstawowe wyniki inspekcji z jednym wierszem na badaną pozycję, zawierającym kolumny dla współrzędnych GPS (szerokość, długość geograficzna, wysokość), znacznika czasu pomiaru, wartości wskaźnika stanu nawierzchni (PCI), poszczególnych pomiarów uszkodzeń (szerokość pęknięcia, długość pęknięcia, obszar spękań, stopień ravelingu), metryk tekstury powierzchni i flag kontroli jakości. Plik tiles.parquet przechowuje wyniki analizy opartej na kafelkach, gdzie powierzchnia nawierzchni jest podzielona na regularną siatkę (zazwyczaj kafelki 1 m x 1 m lub 5 m x 5 m, w zależności od rozdzielczości pomiaru), a każdy wiersz reprezentuje zagregowaną ocenę stanu dla tego kafelka, w tym średnie PCI, dominujący typ uszkodzenia i statystyczny rozkład pomiarów. Plik assessment.parquet przechowuje końcową ocenę stanu dla każdego odcinka nawierzchni, w tym obliczone wartości PCI zgodnie z ASTM D5340 i metodyką ICAO Annex 14, gęstości uszkodzeń na poziomie odcinka, rekomendowane działania naprawcze i rankingi priorytetów. Plik telemetry.parquet rejestruje strumień telemetrii pojazdu pomiarowego, w tym prędkość, przyspieszenie, kurs i status czujników w regularnych odstępach czasu podczas przejazdu pomiarowego. Każdy plik Parquet używa kompresji Zstd poziom 3, rozmiarów grup wierszy około 256 MB nieskompresowanych oraz włącza statystyki na poziomie kolumn dla optymalnej wydajności predykatowego pomijania danych. Pliki są partycjonowane według daty pomiaru i odcinka pasa startowego, aby umożliwić wydajne zapytania dotyczące zakresów czasu i przestrzeni. Taka struktura pozwala analitykom na zapytania o konkretne odcinki, okresy czasu lub typy uszkodzeń bez skanowania całego archiwum pomiarowego.
Potrzebujesz wydajnego przechowywania danych dla analityki inspekcyjnej?
TarmacView używa formatu Apache Parquet do zapewnienia szybkiego, wydajnego podlegającego zapytaniom przechowywania danych z inspekcji nawierzchni lotniskowych. Skontaktuj się z naszym zespołem, aby dowiedzieć się, jak nasza kolumnowa architektura danych może przyspieszyć przepływy pracy w analizie infrastruktury.
Format danych i struktura reprezentacji danych w technologii
Format danych odnosi się do sposobu przechowywania i przesyłania informacji, natomiast struktura reprezentacji danych obejmuje wewnętrzne kodowanie tych danych....
Archiwizacja danych to proces przenoszenia nieaktywnych danych z podstawowej pamięci masowej na długoterminowe, ekonomiczne nośniki w celu ich przechowywania, z...