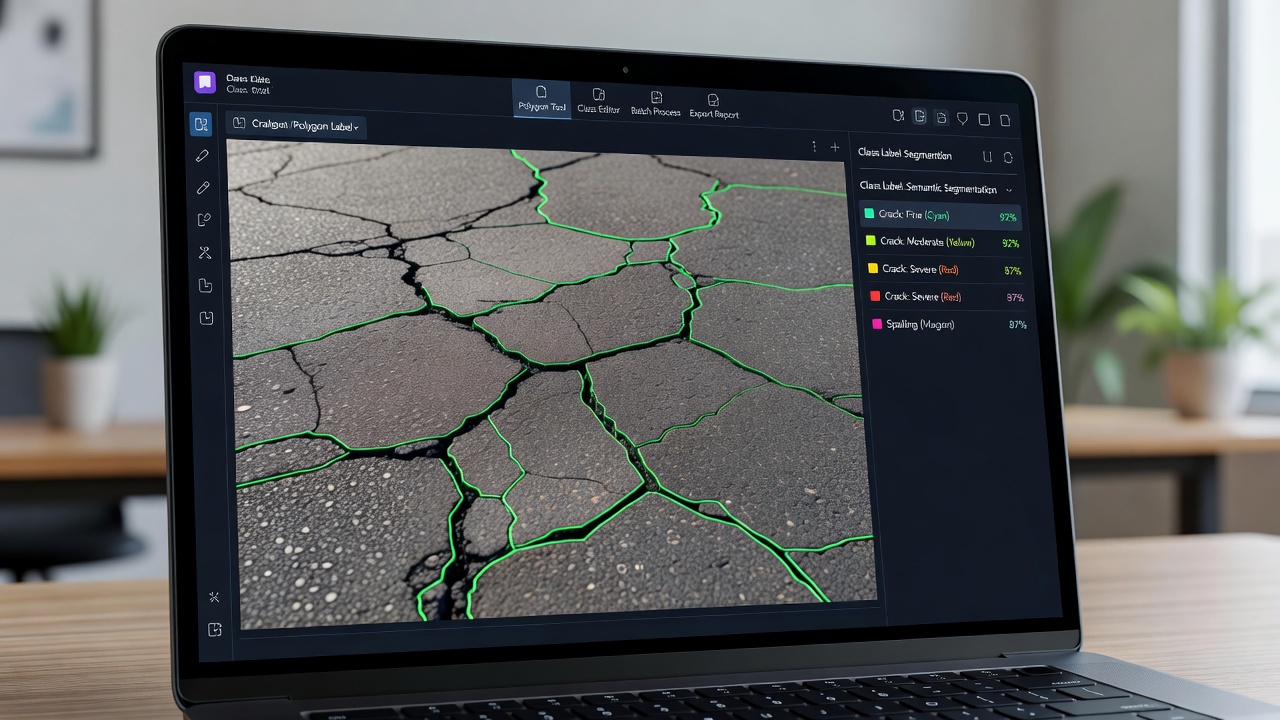
Segmentacja Semantyczna dla Rozumienia Scen Infrastrukturalnych
Segmentacja semantyczna przypisuje etykietę kategorii do każdego piksela obrazu, umożliwiając pełne zrozumienie sceny do inspekcji infrastruktury. Obejmuje architektury enkoder-dekoder (U-Net, DeepLabV3+, SegFormer, PSPNet, Mask2Former), enkodery bazowe (ResNet, EfficientNet, ViT), funkcje strat (cross-entropia, Dice, focal, brzegowa), trenowanie z etykietami na poziomie pikseli, segmentację wieloklasową dla scen drogowych i lotniskowych, segmentację pęknięć, mapowanie typów nawierzchni, metryki ewaluacyjne (IoU, Dice, dokładność pikseli) oraz optymalizację wdrożenia dla przepływów inspekcji w czasie rzeczywistym.
Czym jest Segmentacja Semantyczna dla Rozumienia Scen Infrastrukturalnych?
Definicja i Odróżnienie od Powiązanych Zadań Wizji Komputerowej
Segmentacja semantyczna to zadanie wizji komputerowej polegające na przypisaniu predefiniowanej etykiety klasy do każdego piksela obrazu wejściowego, tworząc kompletną pikselową mapę klasyfikacji, gdzie każdy piksel jest przypisany do kategorii takiej jak pęknięcie, nawierzchnia bez pęknięć, oznakowanie poziome, roślinność, FOD lub typ nawierzchni. Wynikiem jest gęsta maska predykcyjna o tych samych wymiarach przestrzennych co obraz wejściowy, gdzie każda wartość piksela odpowiada indeksowi klasy.
To odróżnia segmentację semantyczną od trzech powiązanych, ale fundamentalnie różnych zadań wizji komputerowej:
Klasyfikacja obrazów przypisuje pojedynczą etykietę do całego obrazu — na przykład stwierdza „ten obraz zawiera pęknięcie" bez określania, gdzie pęknięcie się znajduje. Klasyfikacja nie dostarcza żadnych informacji przestrzennych o położeniu, kształcie ani zasięgu obiektu. Jest najprostszym zadaniem wizji komputerowej, ale też najmniej informatywnym dla inspekcji infrastruktury, gdzie znajomość lokalizacji, geometrii i zasięgu wad jest niezbędna do oceny stanu i planowania utrzymania.
Detekcja obiektów identyfikuje i lokalizuje obiekty poprzez rysowanie wokół nich ramek ograniczających (axis-aligned bounding boxes), przypisując każdej ramce etykietę klasy i wynik pewności. Detekcja odpowiada na pytanie „jakie obiekty są obecne i mniej więcej gdzie." W przypadku wykrywania pęknięć, ramka ograniczająca może obejmować obszar pęknięcia, ale nie jest w stanie określić dokładnego kształtu, szerokości ani łączności pęknięcia — informacji kluczowych dla klasyfikacji typu pęknięcia (podłużne, poprzeczne, siatkowe, blokowe) i oceny stopnia uszkodzenia według ASTM D5340.
Segmentacja instancyjna idzie o krok dalej, wykrywając każdy pojedynczy obiekt i tworząc dla niego maskę pikselową, przypisując unikalne identyfikatory instancji. W inspekcji infrastruktury pozwoliłoby to odróżnić poszczególne pęknięcia lub dziury od siebie. Jednak wiele wad powierzchni — szczególnie wzory pęknięć, takie jak pęknięcia siatkowe lub blokowe — tworzy połączone sieci, które trudno rozłożyć na dyskretne instancje, co sprawia, że segmentacja instancyjna jest mniej odpowiednia do ogólnej oceny stanu nawierzchni.
Segmentacja panoptyczna łączy segmentację semantyczną i instancyjną, przypisując etykietę semantyczną każdemu pikselowi (włączając klasy „stuff" — tła, takie jak nawierzchnia, niebo, roślinność) oraz jednocześnie wykrywając i segmentując poszczególne instancje obiektów (klasy „thing" — rzeczy, takie jak konkretne dziury lub elementy FOD). Segmentacja panoptyczna jest najbardziej kompleksowym podejściem, ale też najbardziej wymagającym obliczeniowo i złożonym w trenowaniu.
Zadanie
Wynik
Precyzja Przestrzenna
Zastosowanie w Infrastrukturze
Klasyfikacja obrazów
Pojedyncza etykieta na obraz
Brak
Tylko wykrywanie obecności pęknięć
Detekcja obiektów
Ramki ograniczające na obiekt
Gruba
Detekcja FOD, lokalizacja dziur
Segmentacja semantyczna
Etykiety klas na poziomie pikseli
Maksymalna (poziom piksela)
Mapowanie pęknięć, typ nawierzchni, ocena PCI
Segmentacja instancyjna
Indywidualne maski obiektów
Maksymalna + ID instancji
Liczenie dyskretnych wad
Segmentacja panoptyczna
Etykiety wszystkich pikseli + instancje
Maksymalna + ID instancji
Pełne zrozumienie sceny
W zastosowaniach inspekcji infrastruktury — szczególnie w ocenie stanu nawierzchni lotniskowej, mapowaniu pęknięć i klasyfikacji typów nawierzchni — segmentacja semantyczna jest najbardziej odpowiednim i powszechnie przyjętym podejściem, ponieważ zapewnia pełne zrozumienie sceny z precyzją na poziomie pikseli wymaganą do ilościowej oceny stanu, bez konieczności dekompozycji ciągłych sieci wad na pojedyncze instancje.
Architektonicznie, modele segmentacji semantycznej to zazwyczaj w pełni konwolucyjne sieci (FCN) lub modele oparte na transformerach, zaprojektowane do przyjmowania obrazu wejściowego o dowolnych wymiarach i generowania wyjściowej mapy segmentacji o tych samych wymiarach przestrzennych. Cechą definiującą jest brak w pełni połączonych warstw, które ustalałyby rozmiar wejścia — zamiast tego wszystkie warstwy są konwolucyjne lub oparte na mechanizmie uwagi, co umożliwia sieci przetwarzanie obrazów o różnych rozdzielczościach podczas wnioskowania.
Wyjściowa mapa segmentacji ma wymiary H × W × C, gdzie H i W odpowiadają wejściowym wymiarom przestrzennym (lub ich stałemu ułamkowi), a C to liczba klas. W każdej lokalizacji przestrzennej, wektor C-wymiarowy zawiera przewidywane prawdopodobieństwo dla każdej klasy, zazwyczaj normalizowane przez funkcję aktywacji softmax, tak aby prawdopodobieństwa sumowały się do 1. Ostateczne przypisanie klasy jest określane przez wybór argmax w wymiarze kanałów — klasa z najwyższym prawdopodobieństwem w każdym pikselu.
Architektury Segmentacji Semantycznej
U-Net
U-Net, wprowadzony przez Ronnebergera, Fischera i Broxa w ich artykule z 2015 roku „U-Net: Convolutional Networks for Biomedical Image Segmentation", jest najbardziej wpływową architekturą segmentacji semantycznej i pozostaje de facto standardem dla zadań inspekcji infrastruktury, szczególnie segmentacji pęknięć. Nazwa pochodzi od symetrycznej, w kształcie litery U architektury, składającej się ze zwężającej się ścieżki enkodera i rozszerzającej się ścieżki dekodera, połączonych połączeniami pomijającymi (skip connections).
Enkoder (ścieżka zwężająca) podąża za typowym projektem sieci konwolucyjnej: powtarzalne zastosowanie dwóch konwolucji 3×3 (każda z następującą po niej prostownikową liniową jednostką aktywacji — ReLU) oraz operacji max pooling 2×2 z krokiem 2 w celu próbkowania w dół. Na każdym etapie próbkowania w dół liczba kanałów cech podwaja się: z 64 do 128, do 256, do 512, do 1024 w najgłębszej warstwie (wąskie gardło). Ten progresywny wzrost głębokości kanałów kompensuje utratę rozdzielczości przestrzennej, umożliwiając sieci uczenie się coraz bardziej abstrakcyjnych i semantycznie znaczących cech na grubszych skalach.
Dekoder (ścieżka rozszerzająca) stanowi lustrzane odbicie enkodera: każdy krok zaczyna się od up-konwolucji 2×2 (transponowanej konwolucji), która zmniejsza o połowę liczbę kanałów cech i podwaja wymiary przestrzenne. Próbkowana w górę mapa cech jest następnie łączona (konkatenowana) z odpowiadającą jej mapą cech z enkodera na tej samej rozdzielczości — jest to połączenie pomijające (skip connection) , które definiuje U-Net. Połączona mapa cech przechodzi przez dwie konwolucje 3×3 z aktywacją ReLU. Ostatnia warstwa to konwolucja 1×1, która mapuje reprezentację cech do żądanej liczby klas wyjściowych.
Połączenia pomijające są innowacją architektoniczną, która sprawia, że U-Net jest skuteczny w precyzyjnej lokalizacji. Podczas kodowania informacje przestrzenne o granicach obiektów, gradientach tekstury i drobnych szczegółach są stopniowo tracone poprzez operacje próbkowania w dół i poolingu. Połączenia pomijające omijają wąskie gardło i bezpośrednio dostarczają mapy cech o wysokiej rozdzielczości z enkodera do dekodera na odpowiadających im rozdzielczościach, umożliwiając dekoderowi dostęp zarówno do kontekstu semantycznego z głębszych warstw, jak i do precyzji przestrzennej z płytszych warstw. Dla segmentacji pęknięć, gdzie szerokości pęknięć rzędu 0,5–3 mm muszą być rozpoznawane, zachowanie precyzji granic poprzez połączenia pomijające jest niezbędne.
Oryginalna implementacja U-Net zawiera około 31 milionów parametrów dla zadania segmentacji 2-klasowej. Nowoczesne implementacje w frameworkach takich jak Segmentation Models PyTorch (smp) obsługują konfigurowalną głębokość enkodera (3–5 etapów), wymienne enkodery bazowe (ResNet, EfficientNet itp.) oraz specyfikacje kanałów dekodera, co czyni U-Net wysoce adaptowalnym do różnych kompromisów między dokładnością a szybkością. Architektura przetwarza obraz wejściowy 256×256 w około 15–30 milisekund na nowoczesnym GPU, umożliwiając wnioskowanie w czasie rzeczywistym z szybkością 30–60 klatek na sekundę dla przetwarzania kafelkowego dużych obszarów.
DeepLabV3+
DeepLabV3+, opracowany przez Chena i in. w Google (2018), rozszerza rodzinę architektur DeepLab (DeepLabV1, V2, V3) poprzez dodanie struktury enkoder-dekoder do modułu Atrous Spatial Pyramid Pooling (ASPP) wprowadzonego w DeepLabV3. Architektura została zaprojektowana specjalnie do rozwiązania ograniczeń standardowej segmentacji opartej na FCN: utraty rozdzielczości przestrzennej z powodu wielokrotnego próbkowania w dół oraz trudności w segmentowaniu obiektów w wielu skalach.
Kluczową innowacją w DeepLabV3+ jest konwolucja atrous (dylatacyjna) , która umożliwia sieci kontrolowanie rozdzielczości, w jakiej obliczane są odpowiedzi cech, bez zmniejszania wymiarów przestrzennych. Konwolucja atrous wstawia zera (dziury) między wagi filtra, skutecznie zwiększając pole recepcyjne bez zwiększania liczby parametrów. Dla konwolucji o rozmiarze jądra k i współczynniku dylatacji r, efektywny rozmiar jądra wynosi k + (k-1)(r-1). DeepLabV3+ używa output stride równego 16 — co oznacza, że końcowa rozdzielczość mapy cech wynosi 1/16 wejścia — w porównaniu do 1/32 dla standardowych enkoderów ResNet, zachowując drobniejsze szczegóły przestrzenne.
Moduł Atrous Spatial Pyramid Pooling (ASPP) stosuje równoległe konwolucje atrous z różnymi współczynnikami dylatacji, aby przechwytywać kontekst w wielu skalach. Standardowa konfiguracja ASPP używa czterech równoległych gałęzi ze współczynnikami dylatacji 1, 6, 12 i 18, gdy output stride wynosi 16 (lub 1, 12, 24, 36 dla output stride 8). Każda gałąź przetwarza mapę cech przez konwolucję 3×3 z określonym współczynnikiem dylatacji, a następnie przez normalizację wsadową i ReLU. Wyniki są łączone i przepuszczane przez konwolucję 1×1, aby uzyskać końcową reprezentację cech ASPP. Dodatkowa gałąź stosuje globalne uśrednianie puli, aby przechwycić kontekst całego obrazu, który jest następnie próbkowany w górę metodą dwuliniową i łączony z cechami ASPP.
Moduł dekodera w DeepLabV3+ jest stosunkowo lekkim komponentem w porównaniu z pełnym dekoderem U-Net. Cechy enkodera (z ASPP) są próbkowane w górę dwuliniowo o współczynnik 4. Te próbkowane w górę cechy są łączone z odpowiadającymi im cechami niskiego poziomu z enkodera bazowego (konkretnie mapa cech z pierwszego bloku konwolucyjnego — zazwyczaj w rozdzielczości 1/4). Połączone cechy przechodzą przez konwolucję 3×3 i drugie dwuliniowe próbkowanie w górę o współczynnik 4, aby przywrócić oryginalną rozdzielczość wejściową.
DeepLabV3+ osiąga wyniki na poziomie najnowocześniejszych rozwiązań na benchmarkowych zbiorach danych, takich jak Cityscapes (82,1% mIoU z enkoderem ResNet-101) i PASCAL VOC 2012 (89,0% mIoU z enkoderem Xception). W inspekcji infrastruktury DeepLabV3+ doskonale radzi sobie z segmentacją dużych, zależnych od kontekstu cech powierzchni, takich jak typy nawierzchni i strefy oznakowań, ale może mieć trudności z bardzo cienkimi cechami, takimi jak pęknięcia włoskowate (szerokość < 1 mm), gdzie output stride 1/16 wciąż traci krytyczne szczegóły przestrzenne.
SegFormer
SegFormer, wprowadzony przez Xie i in. w NVIDIA (2021), stanowi fundamentalne odejście od architektur konwolucyjnych, wykorzystując enkoder oparty wyłącznie na transformerze z lekkim dekoderem MLP (multilayer perceptron). SegFormer był pierwszą hierarchiczną architekturą segmentacji opartą na transformerze, która wykazała, że transformery mogą dorównywać lub przewyższać architektury konwolucyjne w pełnym zakresie rozmiarów modeli — od lekkich (SegFormer-B0, 3,8 miliona parametrów) do ciężkich (SegFormer-B5, 84,7 miliona parametrów).
Enkoder Mix Transformer (MiT) wykorzystuje hierarchiczny projekt, który generuje mapy cech w wielu skalach w rozdzielczościach 1/4, 1/8, 1/16 i 1/32 wejścia, podobnie jak hierarchia cech w konwolucyjnych enkoderach bazowych, takich jak ResNet. Każdy etap stosuje nakładające się osadzanie fragmentów (zamiast nienakładających się fragmentów w standardowym ViT), wydajną mechanikę self-attention ze zredukowaną długością sekwencji oraz sieci typu Mix-FFN. Kodowanie pozycyjne w SegFormer jest inicjalizowane zerami i uczone — autorzy odkryli, że całkowite usunięcie stałych kodowań pozycyjnych i poleganie na uczonej wersji inicjalizowanej zerami poprawiło wydajność przy wnioskowaniu na zmiennych rozdzielczościach, co jest kluczowe dla obrazów infrastruktury rejestrowanych na różnych wysokościach lotu i przy różnych odległościach próbkowania terenu.
Dekoder MLP jest niezwykle prosty w porównaniu z dekoderami konwolucyjnymi: agreguje wieloskalowe cechy z enkodera MiT poprzez dwuliniowe próbkowanie wszystkich map cech do rozdzielczości 1/4, łączenie ich, przepuszczenie przez konwolucyjną warstwę fuzji 3×3 i zastosowanie MLP z dwiema ukrytymi warstwami w celu uzyskania końcowej segmentacji. Prostota dekodera przyczynia się do wydajności obliczeniowej SegFormer — dekoder zawiera zaledwie kilka milionów parametrów nawet w największych wariantach modelu.
Kluczową zaletą SegFormer dla inspekcji infrastruktury jest jego odporność na zmienność rozdzielczości wejściowej. Mechanizm self-attention enkodera transformerowego naturalnie dostosowuje się do różnych rozmiarów wejściowych, bez zależnego od rozdzielczości zachowania jąder konwolucyjnych. W zadaniach inspekcji nawierzchni, gdzie obrazy mogą być rejestrowane na różnych wysokościach lotu lub z różnymi sensorami kamer, SegFormer utrzymuje spójną jakość segmentacji bez konieczności dostrajania do konkretnej rozdzielczości.
PSPNet
Pyramid Scene Parsing Network (PSPNet), wprowadzony przez Zhao i in. (2017), rozwiązuje problem zrozumienia globalnego kontekstu poprzez piramidowe pooling. Kluczowym spostrzeżeniem jest to, że wiele błędów segmentacji — szczególnie błędna klasyfikacja regionów, które są wizualnie podobne, ale semantycznie różne (np. nawierzchnia asfaltowa vs. betonowa, lub pęknięcie uszczelnione vs. nieuszczelnione) — wynika z niewystarczającego globalnego kontekstu.
Moduł Pyramid Pooling (PPM) stosuje adaptacyjne uśrednianie puli w czterech różnych skalach: 1×1 (globalna), 2×2, 3×3 i 6×6. Każda mapa cech po puli jest przepuszczana przez konwolucję 1×1 w celu zmniejszenia kanałów do 1/N wejścia (gdzie N=4, liczba poziomów piramidy), a następnie dwuliniowo próbkowana w górę do oryginalnej rozdzielczości mapy cech. Próbkowane w górę cechy ze wszystkich czterech poziomów są łączone z oryginalną mapą cech, tworząc końcową reprezentację, która koduje zarówno lokalne szczegóły, jak i globalny kontekst w wielu skalach.
W przypadku segmentacji nawierzchni, piramidowe pooling umożliwia sieci rozróżnianie typów nawierzchni na podstawie kontekstu: fragment asfaltu na środku pasa startowego ma inną oczekiwaną teksturę i stan niż asfalt na krawędzi pasa lub na drodze kołowania. Globalne pooling w skali 1×1 przechwytuje ogólny typ sceny (pas startowy, droga kołowania, płyta postojowa, droga), podczas gdy drobniejsze skale poolingu przechwytują lokalne wzory tekstury i stanu.
Mask2Former
Mask2Former, wprowadzony przez Chenga i in. w Meta AI (2022), łączy segmentację semantyczną, instancyjną i panoptyczną w ramach jednej architektury poprzez sformułowanie wszystkich zadań segmentacji jako klasyfikacji maski. Zamiast bezpośredniego tworzenia pikselowych map klasyfikacji, Mask2Former przewiduje zestaw binarnych masek z powiązanymi etykietami klas, podobnie jak detekcja obiektów przewiduje ramki ograniczające z etykietami klas.
Architektura składa się z trzech komponentów: enkodera bazowego (zazwyczaj Swin Transformer lub ResNet), który wydobywa cechy w wielu skalach, dekodera transformerowego z mechanizmem masked attention, który iteracyjnie udoskonala przewidywania masek, oraz dekodera pikselowego, który generuje osadzenia na poziomie pikseli. Mechanizm masked attention ogranicza self-attention transformerów do regionów wewnątrz każdej przewidywanej maski, znacząco redukując złożoność obliczeniową (z O(N²) do O(NM), gdzie M to liczba pikseli maski) i skupiając pojemność modelu na cechach specyficznych dla regionu.
W inspekcji infrastruktury zaletą Mask2Former jest zdolność do naturalnego obsługiwania obiektów o różnorodnych rozmiarach — od dużych ciągłych regionów (typy nawierzchni, strefy roślinności) po małe dyskretne obiekty (elementy FOD, pojedyncze wykruszenia) — w ramach jednolitej struktury. Jednak formuła klasyfikacji maski może być mniej intuicyjna dla ciągłych, amorficznych wzorców wad niż bezpośrednia klasyfikacja pikselowa, a Mask2Former zazwyczaj wymaga więcej danych treningowych i zasobów obliczeniowych niż U-Net czy DeepLabV3+.
Enkodery Bazowe
ResNet (Residual Network)
ResNet, wprowadzony przez He i in. w Microsoft Research (2015), jest najszerzej stosowanym enkoderem bazowym do segmentacji semantycznej. Kluczową innowacją jest ramy uczenia rezydualnego: zamiast uczyć się funkcji bez referencji H(x) = output, każda warstwa (lub stos warstw) uczy się rezyduum F(x) = H(x) − x. Oryginalne wejście x jest dodawane do wyuczonego rezyduum poprzez połączenie skrócone (skip connection), dając wynik warstwy H(x) = F(x) + x.
Blok rezydualny formalizuje to: dla bloku z dwiema konwolucyjnymi warstwami 3×3, wynik bloku to σ(F(x) + x), gdzie σ to aktywacja ReLU, a F(x) to złożenie dwóch konwolucji, normalizacji wsadowej i pośredniej ReLU. Jeśli wymiary x i F(x) różnią się (np. gdy krok > 1 zmniejsza rozdzielczość przestrzenną), połączenie skrócone wykorzystuje konwolucję 1×1, aby dopasować wymiary. Formuła rezydualna umożliwia trenowanie sieci o bezprecedensowej głębokości — ResNet-152 ma 152 warstwy — poprzez łagodzenie problemu zanikającego gradientu dzięki bezpośredniemu przepływowi gradientu wzdłuż ścieżek skróconych.
Warianty ResNet są oznaczane według głębokości: ResNet-18 (18 warstw, 11,7 miliona parametrów), ResNet-34 (34 warstwy, 21,8M), ResNet-50 (50 warstw, 25,6M), ResNet-101 (101 warstw, 44,5M) i ResNet-152 (152 warstwy, 60,2M). W segmentacji infrastruktury ResNet-50 i ResNet-101 są najczęściej wybierane, równoważąc dokładność z pamięcią i czasem wnioskowania.
W zadaniach segmentacji standardowy enkoder ResNet jest modyfikowany w celu uzyskania dylatacyjnych (atrous) map cech poprzez usunięcie kroku w ostatnim jednym lub dwóch blokach i zastąpienie kolejnych konwolucji konwolucjami dylatacyjnymi. Ten dylatacyjny wariant ResNet utrzymuje mapy cech o wyższej rozdzielczości (1/8 lub 1/16 rozdzielczości wejściowej zamiast 1/32), zachowując jednocześnie rozmiar pola recepcyjnego — jest to krytyczna modyfikacja dla zadań gęstej predykcji.
EfficientNet
EfficientNet, wprowadzony przez Tana i Le w Google (2019), osiąga najnowocześniejszą dokładność przy znacznie mniejszej liczbie parametrów i FLOPs w porównaniu z porównywalnymi architekturami, dzięki skalowaniu złożonemu (compound scaling). Kluczowym spostrzeżeniem jest to, że skalowanie głębokości sieci, szerokości i rozdzielczości wejściowej powinno być wykonywane wspólnie, a nie niezależnie. EfficientNet używa złożonego współczynnika φ, który jednocześnie skaluje wszystkie trzy wymiary: głębokość α^φ, szerokość β^φ i rozdzielczość γ^φ, z zastrzeżeniem, że α·β²·γ² ≈ 2 (zapewniając, że całkowite FLOPs skalują się o około 2^φ).
Podstawowym blokiem konstrukcyjnym EfficientNet jest MBConv (Mobile Inverted Bottleneck Convolution) , pierwotnie wprowadzony w MobileNetV2. Każdy blok MBConv używa: konwolucji ekspansji 1×1 (zwiększającej liczbę kanałów o czynnik 4–6), konwolucji depthwise 3×3 lub 5×5 (działającej na każdym kanale niezależnie), uwagi kanałowej squeeze-and-excitation (SE) (globalne uśrednianie puli → dwie warstwy FC → aktywacja sigmoidalna → skalowanie kanałów) oraz konwolucji projekcyjnej 1×1 (zmniejszającej kanały z powrotem do docelowego wymiaru). Uwaga SE umożliwia EfficientNet skupianie się na informacyjnych kanałach — w inspekcji nawierzchni oznacza to podkreślanie kanałów tekstury odróżniających pęknięcie od braku pęknięcia, przy jednoczesnym tłumieniu regionów o płaskiej teksturze.
Warianty EfficientNet obejmują zakres od EfficientNet-B0 (5,3M parametrów, 0,4 GFLOPs dla wejścia 224×224) do EfficientNet-B7 (66M parametrów, 37 GFLOPs). Do wdrożenia brzegowego na dronach inspekcyjnych lub systemach wbudowanych, EfficientNet-B0 do B3 oferują doskonały stosunek dokładności do mocy obliczeniowej, osiągając IoU segmentacji pęknięć w granicach 2–3% ResNet-50, przy jednoczesnym wymaganiu 5–10× mniej FLOPs.
Vision Transformer (ViT)
Vision Transformer (ViT) , wprowadzony przez Dosovitskiy’ego i in. w Google (2020), stosuje architekturę transformerową — pierwotnie opracowaną do przetwarzania języka naturalnego — bezpośrednio do fragmentów obrazu. Obraz wejściowy jest dzielony na fragmenty o stałym rozmiarze (zazwyczaj 16×16 pikseli), każdy fragment jest liniowo rzutowany na osadzenie tokena, a tokeny te są przetwarzane przez szereg warstw enkodera transformerowego, które stosują wielogłowicowy self-attention i bloki MLP.
Mechanizm self-attention oblicza parami wagi uwagi między wszystkimi parami tokenów, umożliwiając każdej reprezentacji fragmentu włączenie informacji z każdego innego fragmentu obrazu. Waga uwagi między tokenem i a tokenem j jest obliczana jako: Attention(Q,K,V) = softmax(QK^T/√d_k)V, gdzie Q (zapytanie), K (klucz) i V (wartość) to wyuczone liniowe projekcje osadzeń tokenów, a d_k to wymiar klucza. To globalne pole recepcyjne — każda pozycja wyjściowa integruje informacje z każdej pozycji wejściowej — jest fundamentalną zaletą ViT w porównaniu z sieciami konwolucyjnymi, które mają ograniczone pola recepcyjne określone przez rozmiar jądra i głębokość sieci.
W segmentacji semantycznej enkodery ViT są używane w ramach hierarchicznych struktur (jak Swin Transformer, który stosuje self-attention w przesuniętych oknach dla wydajności obliczeniowej) lub w połączeniu z dekoderami konwolucyjnymi. Architektura SegFormer używa hierarchicznego wariantu ViT zaprojektowanego specjalnie do segmentacji, podczas gdy SETR (Segmentation Transformer) używa standardowego ViT z progresywnym dekoderem próbkującym w górę.
Modele segmentacji oparte na ViT generalnie osiągają wyższą dokładność na dużych zbiorach danych (wymagających >10 milionów obrazów treningowych do wstępnego trenowania enkodera), ale wymagają znacznie więcej danych treningowych i zasobów obliczeniowych niż enkodery konwolucyjne. W inspekcji infrastruktury z ograniczoną ilością oznaczonych danych, enkodery konwolucyjne, takie jak ResNet i EfficientNet, pozostają bardziej praktyczne, chyba że dostępne jest obszerne wstępne trenowanie na danych odpowiednich dla domeny.
Funkcje Strat dla Segmentacji Semantycznej
Strata Cross-Entropii
Strata cross-entropii jest bazową funkcją straty dla segmentacji semantycznej, bezpośrednio wyprowadzoną z zasady estymacji maksymalnego prawdopodobieństwa. Dla każdego piksela i, przewidywany rozkład prawdopodobieństwa klasy p_i(c) jest porównywany z referencyjnym kodowaniem one-hot y_i(c) (1 dla poprawnej klasy, 0 dla wszystkich pozostałych). Strata na piksel wynosi: L_i = −Σ_c y_i(c) · log(p_i(c)) = −log(p_i(ĉ)), gdzie ĉ to klasa referencyjna.
Całkowita strata to średnia po wszystkich pikselach: L_CE = (1/N) · Σ_i L_i, gdzie N to całkowita liczba pikseli. Cross-entropia jest różniczkowalna, wypukła w logitach softmax i gwarantuje, że globalne minimum odpowiada prawdziwemu rozkładowi danych.
Jednak cross-entropia działa słabo na danych z niezbalansowanymi klasami, co jest dominującą cechą obrazów z inspekcji infrastruktury. Piksele pęknięć stanowią zazwyczaj 0,1% do 3% pikseli obrazu, oznakowania poziome 2–5%, a FOD mniej niż 0,01%. Cross-entropia traktuje wszystkie piksele równo, więc zdecydowana większość sygnału gradientu pochodzi z klas dominujących (nawierzchnia bez pęknięć, roślinność), a sieć uczy się ignorować klasy mniejszościowe. Ważona cross-entropia rozwiązuje ten problem, przypisując wyższą wagę klasom mniejszościowym: L_WCE = −(1/N) · Σ_i w(ĉ) · log(p_i(ĉ)), gdzie w(c) to zazwyczaj odwrotność częstości klasy lub ręcznie dostrojona waga.
Strata Dice
Strata Dice bezpośrednio optymalizuje współczynnik Dice (wynik F1), czyli metrykę nakładania się przewidywanej i referencyjnej segmentacji. Dla segmentacji binarnej współczynnik Dice wynosi: Dice = 2|P ∩ G| / (|P| + |G|), gdzie P to zbiór przewidywanych pikseli pozytywnych, a G to zbiór referencyjnych pikseli pozytywnych. Strata Dice wynosi: L_Dice = 1 − Dice = 1 − (2Σ_i p_i · y_i + ε) / (Σ_i p_i + Σ_i y_i + ε), gdzie ε to składnik wygładzający (zazwyczaj 1e-6) zapobiegający dzieleniu przez zero, p_i to przewidywane prawdopodobieństwo, a y_i to binarna etykieta referencyjna.
Dla segmentacji wieloklasowej, uogólniona strata Dice oblicza współczynnik Dice dla każdej klasy niezależnie i uśrednia je (potencjalnie z wagami klas). Strata Dice jest bardziej odporna na niezbalansowanie klas niż cross-entropia, ponieważ traktuje region nakładania się (prawdziwie pozytywne) jako proporcję całkowitej powierzchni przewidywania i referencji, zamiast liczyć piksele indywidualnie.
Badanie nad segmentacją pęknięć nawierzchni pasa startowego na lotnisku Zadar wykazało, że zastosowanie straty Dice poprawiło IoU dla klasy pęknięcia o 5,9 punktu procentowego w porównaniu z ważoną cross-entropią, podczas gdy połączona strata Dice + Focal dodatkowo poprawiła precyzję granic o 2–3%.
Strata Focal
Strata Focal, wprowadzona przez Lina i in. w Facebook AI Research (2017) dla gęstej detekcji obiektów, jest zaprojektowana specjalnie dla ekstremalnego niezbalansowania klas. Modyfikuje standardową cross-entropię poprzez dodanie czynnika modulującego (1 − p_t)^γ, gdzie p_t to przewidywane prawdopodobieństwo klasy referencyjnej, a γ ≥ 0 to parametr skupienia: L_Focal = −(1/N) · Σ_i (1 − p_t)^γ · log(p_t).
Gdy γ = 0, strata Focal redukuje się do cross-entropii. Wraz ze wzrostem γ, czynnik modulujący zmniejsza wagę dobrze sklasyfikowanych przykładów (wysokie p_t) i skupia trenowanie na trudnych, błędnie sklasyfikowanych przykładach (niskie p_t). W segmentacji pęknięć, gdzie γ jest zazwyczaj ustawione na 2, piksel z przewidywanym prawdopodobieństwem 0,9 (dobrze sklasyfikowane tło) wnosi (1−0,9)^2 = 0,01 wagi straty w porównaniu ze standardową cross-entropią, podczas gdy piksel pęknięcia z przewidywanym prawdopodobieństwem 0,3 (trudny przykład) wnosi (1−0,3)^2 = 0,49 wagi straty — skutecznie 49× więcej uwagi poświęcanej trudnemu przykładowi w stosunku do łatwego.
Strata Focal jest szczególnie skuteczna w wykrywaniu FOD na obrazach lotniskowych, gdzie elementy FOD zajmują 0,001–0,1% pikseli, ale są klasą krytyczną dla bezpieczeństwa. Połączona strata Dice + Focal (L = α·L_Dice + β·L_Focal, gdzie α i β są zazwyczaj ustawione na 0,5–1,0) jest najczęściej stosowaną formułą straty w inspekcji infrastruktury, łącząc optymalizację nakładania Dice z koncentracją Focal na trudnych przykładach.
Strata Brzegowa (Boundary Loss)
Strata brzegowa (boundary loss) rozwiązuje ograniczenie strat opartych na regionach (Dice, IoU): optymalizują one nakładanie objętościowe, ale nie karzą bezpośrednio błędów brzegowych. W segmentacji pęknięć, gdzie precyzja granic określa dokładność pomiaru szerokości pęknięcia, optymalizacja granic jest kluczowa.
Strata brzegowa oblicza transformację odległości na referencyjnej granicy segmentacji i mnoży przewidywaną mapę prawdopodobieństwa przez mapę brzegową ważoną odległością: L_Boundary = Σ_i D(i) · |p_i − y_i|, gdzie D(i) to odległość od piksela i do najbliższego referencyjnego piksela granicznego (zazwyczaj obcięta do maksymalnej odległości, np. 5–10 pikseli). Piksele w pobliżu granic (małe D) otrzymują wysoką wagę, podczas gdy piksele wewnętrzne (duże D) otrzymują wagę pomijalną.
Strata odległości Hausdorffa (HD loss) to pokrewna formuła, która minimalizuje maksymalną odległość między przewidywanymi a referencyjnymi granicami, zachęcając, aby przewidywana granica nie odbiegała daleko od prawdziwej granicy w żadnym punkcie. W połączeniu ze stratą Dice, strata brzegowa wykazała poprawę dokładności pomiaru szerokości pęknięcia o 15–25% w porównaniu z samą stratą Dice, mierzoną średnim błędem bezwzględnym między przewidywaną a referencyjną szerokością pęknięcia.
Funkcja Straty
Formuła
Najlepsza Dla
Ograniczenie
Cross-Entropia
−log(p_c)
Zrównoważone klasy, podstawa
Słaba przy niezbalansowaniu
Ważona Cross-Entropia
−w(c)·log(p_c)
Umiarkowane niezbalansowanie
Stałe wagi, brak skupienia na trudnych przykładach
Dice
1 − 2
P∩G
/(
Focal
−(1−p_t)^γ·log(p_t)
Ekstremalne niezbalansowanie
Dwa hiperparametry (γ, α)
Dice + Focal
α·L_Dice + β·L_Focal
Inspekcja infrastruktury (standard)
Wymaga dostrojenia α, β
Brzegowa (Boundary)
Σ D(i)·
p_i−y_i
Dane Treningowe do Segmentacji Semantycznej
Wymagania dotyczące Adnotacji na Poziomie Pikseli
Trenowanie modeli segmentacji semantycznej wymaga referencyjnych adnotacji na poziomie pikseli — każdy piksel w każdym obrazie treningowym musi być oznaczony etykietą klasy. Jest to najbardziej pracochłonny i kosztowny aspekt opracowywania modelu segmentacji do inspekcji infrastruktury. Pojedynczy obraz 1920×1080 zawiera ponad 2 miliony pikseli, z których każdy wymaga adnotacji, a typowy zestaw danych treningowych do segmentacji pęknięć nawierzchni zawiera 500–5 000 obrazów.
Narzędzia do adnotacji do segmentacji na poziomie pikseli obejmują:
LabelMe (MIT CSAIL) to otwartoźródłowe narzędzie do adnotacji opartej na wielokątach, działające w przeglądarce internetowej. Anotatorzy rysują wielokąty wokół interesujących obiektów (pęknięcia, dziury, oznakowania), a narzędzie wypełnia wnętrze wielokąta przypisaną etykietą klasy. W przypadku adnotacji pęknięć, gdzie pęknięcia są cienkie i rozgałęzione, rysowanie wielokątów może być niezwykle czasochłonne — pojedyncze pęknięcie o długości 1000 pikseli może wymagać 50–200 wierzchołków wielokąta do dokładnego odwzorowania.
CVAT (Computer Vision Annotation Tool) , opracowany przez Intel, obsługuje zarówno adnotację opartą na wielokątach, jak i pędzlu. Inteligentny pędzel (interaktywne narzędzie segmentacji oparte na algorytmie Deep Extreme Cut) pozwala anotatorom umieszczać pozytywne i negatywne kliknięcia na obrazie, aby kierować automatyczną segmentacją, która może być ręcznie poprawiana. W przypadku pęknięć nawierzchni, inteligentny pędzel skraca czas adnotacji o 40–60% w porównaniu z ręcznym rysowaniem wielokątów.
Supervisely zapewnia adnotację wspomaganą AI z wstępnie wytrenowanymi modelami segmentacji, które mogą być interaktywnie dostrajane. Anotatorzy mogą zastosować przybliżony bazgroł lub ramkę ograniczającą, a model generuje początkową segmentację, która jest udoskonalana poprzez iteracyjne poprawki. W przypadku zbiorów danych pęknięć, to podejście skraca czas adnotacji do 30–90 sekund na obraz dla doświadczonych anotatorów, w porównaniu z 5–15 minutami dla ręcznej adnotacji wielokątami.
Wyzwania adnotacyjne dla obrazów infrastrukturalnych obejmują:
Łączność pęknięć: Zapewnienie, że cienkie, rozgałęzione pęknięcia są adnotowane jako ciągłe cechy bez przerw lub pęknięć, co mogłoby zdezorientować model segmentacji co do topologii pęknięcia
Precyzja granic: Adnotacja krawędzi pęknięć z precyzją subpikselową (±1–2 piksele) w celu trenowania modeli, które generują dokładne pomiary szerokości pęknięć
Niejednoznaczność klas: Rozróżnianie pęknięć od cech powierzchni niebędących pęknięciami — uszczelnione pęknięcia (wypełnione masą uszczelniającą) mogą wizualnie przypominać otaczającą nawierzchnię, krawędzie cieni mogą być mylone z pęknięciami, a złącza konstrukcyjne w betonie mogą być lub nie być uważane za wady
Zgodność między anotatorami: Różni anotatorzy tworzą różne maski segmentacji dla tego samego obrazu; mierzona współczynnikiem kappa Cohena lub IoU między anotatorami, typowa zgodność dla segmentacji pęknięć wynosi IoU = 0,65–0,80, co stanowi górną granicę osiągalnej wydajności modelu
Augmentacja Danych dla Segmentacji
Augmentacja danych jest niezbędna do trenowania solidnych modeli segmentacji, szczególnie przy pracy z ograniczonymi oznaczonymi zbiorami danych (częste ograniczenie w inspekcji infrastruktury, gdzie etykietowanie jest kosztowne). Augmentacja zwiększa efektywny rozmiar zestawu danych i poprawia generalizację do zmian w oświetleniu, teksturze powierzchni, kącie kamery i stanie nawierzchni.
Augmentacje geometryczne przekształcają układ przestrzenny obrazu i maski segmentacji razem:
Losowa rotacja (−180° do +180°): Pęknięcia nie mają kanonicznej orientacji na nawierzchniach, więc niezmienność na rotację jest kluczowa
Losowe odbicie poziome/pionowe: Podwaja efektywny rozmiar zestawu danych
Losowe skalowanie (0,5× do 2,0×): Symuluje różne wysokości lotu i odległości próbkowania terenu
Losowy przycinek (crop) : Wyodrębnia fragmenty z większych obrazów, umożliwiając modelowi uczenie się z lokalnych wzorców tekstury
Odkształcenie elastyczne: Stosuje kontrolowane losowe pola przemieszczeń do obrazu i maski jednocześnie, symulując nie-sztywne odkształcenia nawierzchni spowodowane rozszerzalnością cieplną i obciążeniem ruchem
Augmentacje fotometryczne modyfikują intensywność pikseli bez zmiany struktury przestrzennej:
Regulacja jasności i kontrastu (±20%): Symuluje zmienne warunki oświetlenia od zachmurzenia do bezpośredniego światła słonecznego
Dodanie szumu Gaussa (σ = 0,01–0,03): Symuluje szum sensora przy wyższych ustawieniach ISO lub niższej jakości kamerach
Rozmycie Gaussa (σ = 0,5–1,5 piksela): Symuluje nieostrość z różnych odległości kamery lub rozmycie ruchu
Drganie kolorów (color jitter): Niewielkie zmiany odcienia, nasycenia i wartości, które nie zmieniają treści semantycznej
Specjalistyczne augmentacje dla inspekcji nawierzchni obejmują:
Synteza cieni: Dodawanie syntetycznych wzorców cieni w celu symulacji cieni od samolotów, budynków lub infrastruktury oświetleniowej, które mogą częściowo zasłaniać pęknięcia
Symulacja plam wody/oleju: Dodawanie lokalnych zmian kolorystycznych w celu symulacji zanieczyszczenia powierzchni, które zmienia wygląd nawierzchni bez zmiany stanu wad
Symulacja kompresji JPEG: Symulacja artefaktów kompresji z systemów transmisji obrazu, które mogą pogorszyć widoczność krawędzi pęknięć
Wymagania dotyczące Wielkości Zbioru Danych
Liczba obrazów treningowych wymagana do skutecznej segmentacji semantycznej zależy od złożoności zadania, rozkładu klas i dostępności wstępnie wytrenowanych wag enkodera. W przypadku segmentacji pęknięć nawierzchni z wykorzystaniem uczenia transferowego z enkoderów wstępnie wytrenowanych na ImageNet (ResNet-50, EfficientNet-B3):
500–1 000 oznaczonych obrazów: Osiąga IoU dla pęknięć na poziomie 0,65–0,75, wystarczające do jakościowego mapowania pęknięć i szacowania stopnia PCI
1 000–3 000 oznaczonych obrazów: Osiąga IoU dla pęknięć na poziomie 0,75–0,82, odpowiednie do automatycznego pomiaru szerokości pęknięć i rutynowej oceny stanu
3 000–10 000 oznaczonych obrazów: Osiąga IoU dla pęknięć na poziomie 0,82–0,88, wymagane do raportowania zgodnego z regulacjami i subpikselowej estymacji szerokości pęknięć
10 000+ oznaczonych obrazów: Osiąga IoU dla pęknięć na poziomie 0,88+, niezbędne do autonomicznej inspekcji bez weryfikacji człowieka
W przypadku segmentacji wieloklasowej (pęknięcie, oznakowanie, typ nawierzchni, FOD, roślinność) wymagany rozmiar zbioru danych wzrasta o około 2–3× na każdą dodatkową klasę, ponieważ model musi nauczyć się rozróżniać wizualnie podobne cechy powierzchni.
Segmentacja Wieloklasowa dla Scen Drogowych i Lotniskowych
Taksonomia Klas dla Nawierzchni Lotniskowych
Segmentacja semantyczna wieloklasowa dla scen nawierzchni lotniskowych i drogowych wymaga zdefiniowania taksonomii klas, która obejmuje wszystkie cechy powierzchni istotne dla oceny stanu, oceny bezpieczeństwa i planowania utrzymania. W oparciu o ASTM D5340 (Standard Test Method for Airport Pavement Condition Index Surveys), wymagania ICAO Annex 14 i praktyczne przepływy pracy inspekcji, kompleksowa taksonomia do segmentacji nawierzchni lotniskowych obejmuje:
Klasa
Opis
Typowy Udział Pikseli
Znaczenie dla PCI
Nawierzchnia bez pęknięć
Zdrowa nawierzchnia bez wad
75–92%
Wartość bazowa (brak odliczeń)
Pęknięcie podłużne
Pęknięcia równoległe do osi nawierzchni
0,5–3%
Odliczenie zależne od stopnia
Pęknięcie poprzeczne
Pęknięcia prostopadłe do osi
0,3–2%
Odliczenie zależne od stopnia
Pęknięcie siatkowe/blokowe
Połączone pęknięcia tworzące wielokąty
1–8%
Wysokie wartości odliczeń
Pęknięcie krawędziowe
Pęknięcia w odległości do 0,6m od krawędzi
0,1–0,5%
Umiarkowane odliczenie
Wykruszenie złącza (beton)
Pęknięcie na złączach nawierzchni betonowej
0,5–2%
Wysokie odliczenie
Złamanie narożnika (beton)
Przekątne pęknięcie w narożniku płyty
0,1–0,5%
Wysokie odliczenie
Wykruszanie (raveling)
Utrata kruszywa z powierzchni asfaltowej
1–5%
Umiarkowane odliczenie
Łatanie
Naprawiony obszar nawierzchni
1–10%
Niskie-umiarkowane odliczenie
Oznakowanie poziome
Malowane, termoplastyczne lub taśmowe oznakowania
3–8%
Nie dotyczy bezpośrednio PCI
Osad gumy
Nagromadzenie gumy z opon w strefie przyziemienia
1–5%
Związane z przyczepnością
Roślinność
Trawa, chwasty rosnące przez pęknięcia/krawędzie
0,5–3%
Problem drenażu krawędzi
FOD
Obce przedmioty na powierzchni
0,001–0,1%
Krytyczne dla bezpieczeństwa
Uszczelnione pęknięcie
Pęknięcie wcześniej wypełnione masą uszczelniającą
0,3–2%
Zależy od stanu uszczelnienia
Dziura (pothole)
Lokalne zagłębienie nawierzchni
0,01–0,5%
Wysokie odliczenie, krytyczne dla bezpieczeństwa
Rozkład klas jest ekstremalnie niezbalansowany: nawierzchnia bez pęknięć dominuje w 75–92% pikseli, podczas gdy FOD zajmuje mniej niż 0,1%. To niezbalansowanie wymusza stosowanie specjalistycznych funkcji strat (Dice + Focal) i strategii treningowych, takich jak próbkowanie świadome klas (class-aware sampling) (nadpróbkowanie minipartii zawierających klasy mniejszościowe) lub online hard example mining (wybór próbek treningowych z najwyższą stratą do aktualizacji gradientu).
Mitrygacja Niezbalansowania Klas
Poza wyborem funkcji straty, kilka strategii treningowych łagodzi niezbalansowanie klas w wieloklasowej segmentacji nawierzchni:
Próbkowanie ważone klasami dostosowuje prawdopodobieństwo wyboru każdej łatki treningowej, aby zapewnić, że klasy mniejszościowe są reprezentowane z minimalną częstotliwością. Łatki zawierające piksele pęknięć, FOD lub dziur są nadpróbkowane 3–10× w porównaniu z łatkami zawierającymi tylko nawierzchnię bez pęknięć. Implementacja zazwyczaj utrzymuje kolejkę priorytetową łątek treningowych uszeregowanych według obecności klas mniejszościowych.
Modulacja Focal w funkcji straty stosuje parametry skupienia specyficzne dla klas: wyższe wartości γ dla klas większościowych i niższe γ dla klas mniejszościowych, zapewniając, że model alokuje więcej zdolności uczenia się do rzadkich, ale krytycznych klas wad.
Trenowanie dwuetapowe najpierw trenuje model na zbalansowanym podzbiorze klas, gdzie klasy mniejszościowe są nadpróbkowane do 20–30% wszystkich pikseli, a następnie dostraja na pełnym zbiorze danych z oryginalnym rozkładem klas. To podejście zapobiega zbiegnięciu się modelu do trywialnego rozwiązania, które klasyfikuje wszystkie piksele jako tło.
Segmentacja Semantyczna Pęknięć
Specjalistyczne Podejścia do Wykrywania Pęknięć
Segmentacja semantyczna pęknięć stawia unikalne wyzwania, które odróżniają ją od segmentacji ogólnego przeznaczenia: pęknięcia zajmują bardzo mały ułamek pikseli obrazu (0,1–3%), mają wysokie współczynniki kształtu z ekstremalnym wydłużeniem (stosunek szerokości do długości 1:100 do 1:1000), wykazują niski kontrast względem otaczającej nawierzchni i są wizualnie podobne do cech niebędących pęknięciami, takich jak cienie, złącza konstrukcyjne i zmiany tekstury powierzchni.
DeepCrack (Zou i in., 2019) był jedną z pierwszych architektur głębokiego uczenia zaprojektowanych specjalnie do segmentacji pęknięć. Używa zmodyfikowanego enkodera-dekodera SegNet z wieloskalową fuzją cech i warstwami wyjść bocznych, które generują przewidywania na wielu etapach dekodera. Ostateczna predykcja jest generowana poprzez fuzję wyników ze wszystkich warstw bocznych, umożliwiając sieci przechwytywanie pęknięć w wielu skalach jednocześnie — cienkich pęknięć włoskowatych z wczesnych etapów dekodera i szerszych pęknięć strukturalnych z późniejszych etapów.
CrackU-Net (Liu i in., 2021) rozszerza standardowy U-Net o: (1) bramki uwagi (attention gates) w połączeniach pomijających, które ważą mapy cech na podstawie znaczenia przestrzennego dla regionów pęknięć, tłumiąc cechy tła i wzmacniając cechy pęknięć; (2) głęboki nadzór (deep supervision) , który stosuje obliczanie straty na wielu etapach dekodera, dostarczając sygnały gradientu w wielu skalach; oraz (3) konwolucję dylatacyjną w wąskim gardle, aby rozszerzyć pole recepcyjne bez utraty rozdzielczości. CrackU-Net osiąga IoU dla pęknięć na poziomie 0,78–0,84 na benchmarkowych zbiorach danych nawierzchni.
CrackTransformer (Chen i in., 2022) stosuje hybrydową architekturę CNN-transformer specjalnie do segmentacji pęknięć. Enkoder ResNet-50 wydobywa początkowe mapy cech, które są następnie przetwarzane przez enkoder transformerowy z 8 głowicami self-attention, który modeluje zależności dalekiego zasięgu między segmentami pęknięć. Pęknięcia, które są wizualnie niepołączone (z powodu zmian oświetlenia lub zanieczyszczenia powierzchni), ale należą do tego samego fizycznego pęknięcia, mogą być łączone poprzez self-attention, poprawiając kompletność łączności — metrykę mierzącą, jaka część referencyjnych pikseli pęknięć w połączonych komponentach jest poprawnie przewidziana.
Wyzwania Cienkich Pęknięć
Pęknięcia węższe niż 2–3 piksele szerokości stanowią fundamentalne wyzwanie dla segmentacji semantycznej opartej na konwolucyjnych sieciach neuronowych z próbkowaniem w dół. Standardowy enkoder z 5 etapami próbkowania w dół i output stride 1/32 reprezentuje pęknięcia o szerokości 3 pikseli lub mniejszej jako pojedynczy piksel lub mniej w najgłębszych mapach cech — niewystarczające do niezawodnej detekcji.
Rozwiązania do segmentacji cienkich pęknięć obejmują:
Ograniczenie minimalnej odległości próbkowania terenu (GSD) : GSD obrazów wejściowych musi spełniać GSD ≤ W_min / 3, gdzie W_min to minimalna wykrywalna szerokość pęknięcia. Do wykrywania włoskowatych pęknięć o szerokości 0,3 mm, obrazy muszą być rejestrowane przy GSD ≤ 0,1 mm/piksel, co wymaga wysokości lotu 3–8 m przy typowych kamerach o wysokiej rozdzielczości. Do operacyjnej inspekcji pęknięć o szerokości 1 mm wymagane jest GSD ≤ 0,33 mm/piksel.
Subpikselowa detekcja pęknięć wykorzystuje ciągłą mapę prawdopodobieństwa pęknięcia (przed progrowaniem na poziomie 0,5) do estymacji obecności pęknięcia w rozdzielczości subpikselowej. Linia środkowa pęknięcia jest wyodrębniana na poziomie subpikselowym poprzez dopasowanie funkcji Gaussa lub kwadratowej do profilu prawdopodobieństwa prostopadle do kierunku pęknięcia, określając pozycję pęknięcia z precyzją 0,1–0,3 piksela.
Wejście wieloskalowe przetwarza obraz w wielu rozdzielczościach (np. 0,5×, 1×, 1,5×) i łączy przewidywania. Gałąź o wysokiej rozdzielczości zachowuje szczegóły cienkich pęknięć, podczas gdy gałąź o niskiej rozdzielczości zapewnia kontekst i tłumi szum. Sieci piramid cech (FPN) zintegrowane z U-Net zapewniają to wieloskalowe zachowanie w ramach jednego przejścia w przód.
Zachowanie Łączności
Łączność pęknięć — właściwość topologiczna, że piksele pęknięć tworzą ciągłe sieci, a nie izolowane punkty — jest kluczowa dla klasyfikacji typu pęknięcia (podłużne, poprzeczne, siatkowe) i oceny stopnia. Standardowe straty segmentacji nie wymuszają jawnie łączności, często produkując niepołączone fragmenty pęknięć.
Strata świadoma szkieletu (skeleton-aware loss) oblicza szkielet (oś środkową) referencyjnej maski pęknięcia i stosuje wyższą wagę straty do pikseli szkieletu, zachęcając model do poprawnego przewidywania linii środkowej pęknięcia. Szkielet zajmuje 5–10% pikseli pęknięcia, ale przenosi 50% informacji topologicznej.
Strata topologiczna oparta na homologii persystentnej karze różnice w liczbach Bettiego (β₀: liczba połączonych komponentów, β₁: liczba otworów) między przewidywanymi a referencyjnymi maskami pęknięć. Model trenowany ze stratą topologiczną produkuje 30–60% mniej niepołączonych fragmentów pęknięć w porównaniu z samą stratą Dice.
Przetwarzanie końcowe CRF (conditional random field) stosuje w pełni połączony CRF jako końcowy krok udoskonalania. CRF zachęca sąsiednie piksele o podobnym kolorze i intensywności do współdzielenia tej samej etykiety klasy, wypełniając luki w przewidywanych maskach pęknięć i wygładzając postrzępione granice. Implementacja DenseCRF (Krähenbühl & Koltun, 2011) jest powszechnie stosowana jako krok przetwarzania końcowego, poprawiając łączność pęknięć o 5–10% kosztem 50–200 ms dodatkowego czasu wnioskowania na obraz.
Estymacja Szerokości Pęknięć
Segmentacja semantyczna dostarcza maskę przestrzenną, z której można oszacować szerokość pęknięcia. Pomiar szerokości jest niezbędny do oceny stopnia PCI: ASTM D5340 definiuje kategorie stopnia pęknięć na podstawie średniej szerokości (np. niski stopień: <3 mm, średni stopień: 3–6 mm, wysoki stopień: >6 mm dla pęknięć podłużnych w asfalcie).
Standardowy potok estymacji szerokości: (1) wyodrębnienie linii środkowej pęknięcia poprzez szkieletyzację (iteracyjne algorytmy pocieniania, takie jak Zhang-Suen lub Medial Axis Transform); (2) dla każdego piksela linii środkowej, obliczenie odległości euklidesowej do najbliższego piksela tła (transformacja odległości); (3) szerokość pęknięcia w tym punkcie wynosi 2× wartość transformacji odległości. Lokalny pomiar szerokości umożliwia raportowanie średniej szerokości, maksymalnej szerokości i rozkładu szerokości dla każdego segmentu pęknięcia.
Dla subpikselowej dokładności szerokości, zamiast binarnej maski używana jest ciągła przewidywana mapa prawdopodobieństwa (przed binaryzacją). Profil prawdopodobieństwa prostopadle do pęknięcia jest dopasowywany funkcją Gaussa, a szerokość jest definiowana jako pełna szerokość w połowie maksimum (FWHM) dopasowanego Gaussa. To podejście osiąga precyzję pomiaru szerokości na poziomie 0,1–0,3 piksela, umożliwiając niezawodną klasyfikację stopnia dla pęknięć tak wąskich jak 0,3 mm na obrazach o rozdzielczości 1 mm/piksel.
Segmentacja Typów Nawierzchni
Rozróżnianie Materiałów Nawierzchni
Segmentacja typów nawierzchni — rozróżnianie powierzchni asfaltowej, betonowej, żwirowej, tarmac, uszczelnionej i nieuszczelnionej w ramach tego samego obrazu — jest odrębnym zadaniem od segmentacji wad. Typy nawierzchni mają charakterystyczne wzory spektralnej reflektancji, tekstury i rozkładu przestrzennego, które mogą być uczone przez modele segmentacji.
Rozróżnianie asfaltu od betonu opiera się na wskazówkach spektralnych i teksturalnych:
Nawierzchnie asfaltowe wykazują stosunkowo jednolity ciemnoszary wygląd z niską wariancją spektralną, drobnoziarnistą teksturą z cząstek kruszywa (0,5–5 mm) i częstymi wzorami pęknięć i łat
Nawierzchnie betonowe są jaśniejsze z wyższą wariancją spektralną, widocznym grubym kruszywem (10–30 mm), poprzecznymi złączami skurczowymi w regularnych odstępach (zazwyczaj co 5–8 m) i innymi wzorami uszkodzeń (wykruszenia, przemieszczenia, złamania narożników)
Nawierzchnie żwirowe wykazują wysoką wariancję spektralną w skali ziarna (2–20 mm), brak wzorów pęknięć (nawierzchnia niezwiązana) i luźny wygląd cząstek
Cechy spektralne z obrazów wielospektralnych (RGB + bliska podczerwień) poprawiają rozróżnianie typów nawierzchni. Asfalt pochłania więcej promieniowania NIR niż beton (reflektancja NIR: asfalt 5–10%, beton 20–40%), zapewniając wyraźną separację spektralną. Wskaźnik NDVI (Normalized Difference Vegetation Index) odróżnia roślinność (NDVI > 0,3) od nawierzchni (NDVI < 0,1). Pasma krótkofalowej podczerwieni (SWIR) różnicują typy asfaltu i wykrywają materiały uszczelniające.
Cechy teksturalne obliczane ze statystyk macierzy GLCM (Gray-Level Co-occurrence Matrix) (kontrast, niepodobieństwo, jednorodność, energia, korelacja), lokalnych wzorców binarnych (LBP) i odpowiedzi filtrów Gabora dostarczają ilościowych miar tekstury, które wzmacniają klasyfikację typów nawierzchni. Enkoder ResNet-50 lub EfficientNet-B4 trenowany na obrazach nawierzchni z dodatkowym kanałem wejściowym dla entropii (obliczonej z lokalnej wariancji intensywności) poprawia dokładność klasyfikacji typów nawierzchni o 3–5% mIoU.
Integracja Cech Spektralnych i Teksturalnych
W przypadku segmentacji wieloklasowej łączącej typ nawierzchni i wykrywanie wad, powszechne są dwa podejścia architektoniczne:
Model jednociągowy wieloklasowy generuje C klas obejmujących zarówno typy nawierzchni, jak i wady (np. 5 typów nawierzchni × 10 typów wad = 15 klas wyjściowych). To podejście korzysta z wspólnego uczenia cech — te same cechy, które odróżniają asfalt od betonu, pomagają również różnicować wygląd pęknięć na tych powierzchniach. Hierarchia klas może być spłaszczona (każda kombinacja jest oddzielną klasą) lub hierarchiczna (typ nawierzchni przewidywany w grubej skali, wady w drobnej skali w obrębie każdego regionu typu nawierzchni).
Potok dwuetapowy uruchamia dwa oddzielne modele segmentacji: klasyfikator typu nawierzchni (szybki, lekki), a następnie model segmentacji wad specyficzny dla każdego typu nawierzchni (dokładny, wyspecjalizowany). Model typu nawierzchni przetwarza pełny obraz w niższej rozdzielczości, identyfikując regiony typów nawierzchni. Każdy region jest następnie przetwarzany przez odpowiedni model wad trenowany specjalnie na tym typie nawierzchni. To podejście osiąga wyższą dokładność dla poszczególnych typów, ale wymaga więcej obliczeń do wnioskowania (N typów nawierzchni × wnioskowanie modelu wad).
Metryki Ewaluacyjne dla Segmentacji
Intersection over Union (IoU)
Intersection over Union (IoU) , znany również jako indeks Jaccarda, jest podstawową metryką ewaluacyjną dla segmentacji semantycznej. Dla danej klasy c, IoU jest obliczane jako: IoU_c = TP_c / (TP_c + FP_c + FN_c), gdzie TP_c to liczba pikseli poprawnie przewidzianych jako klasa c (prawdziwie pozytywne), FP_c to liczba pikseli niepoprawnie przewidzianych jako klasa c (fałszywie pozytywne), a FN_c to liczba pikseli klasy c niepoprawnie przewidzianych jako inna klasa (fałszywie negatywne).
Średnie IoU (mIoU) uśrednia IoU dla wszystkich klas. Dla niezbalansowanych zbiorów danych infrastrukturalnych, nieważone mIoU jest standardową metryką raportową, ponieważ każda klasa wnosi tyle samo niezależnie od liczby pikseli — model, który ignoruje pęknięcia, ale poprawnie klasyfikuje całą nawierzchnię bez pęknięć, osiągnąłby wysoką dokładność pikseli (99%), ale niskie mIoU (50% dla modelu 2-klasowego).
Współczynnik Dice (Wynik F1)
Współczynnik Dice jest równoważny wynikowi F1 i jest blisko związany z IoU: Dice = 2TP / (2TP + FP + FN) = 2TP / (Całkowita przewidywana liczba pozytywnych + Całkowita referencyjna liczba pozytywnych). Współczynnik Dice i IoU są monotonicznie powiązane: Dice = 2IoU / (1 + IoU).
IoU
Dice (F1)
Interpretacja
0,90
0,947
Doskonała — segmentacja bliska idealnej
0,80
0,889
Bardzo dobra — wystarczająca do automatycznego PCI
W przypadku segmentacji pęknięć, Dice dla klasy pęknięcia na poziomie 0,70–0,80 jest uważany za wystarczający do automatycznego mapowania pęknięć, podczas gdy Dice > 0,85 jest wymagany do automatycznego pomiaru szerokości i klasyfikacji stopnia bez weryfikacji człowieka.
Dokładność Pikseli
Dokładność pikseli mierzy ułamek poprawnie sklasyfikowanych pikseli: PA = Σ TP_c / Σ (TP_c + FP_c). Dla silnie niezbalansowanych danych — nawierzchnia bez pęknięć stanowiąca 95% pikseli — model, który klasyfikuje każdy piksel jako brak pęknięcia, osiąga 95% dokładności pikseli przy 0% wykrywalności pęknięć. Dokładność pikseli jest zatem niezalecana jako podstawowa metryka dla segmentacji infrastrukturalnej. Powinna być raportowana tylko wraz z metrykami dla poszczególnych klas (IoU, Dice, precyzja, czułość).
Precyzja, Czułość i Metryki dla Poszczególnych Klas
Precyzja = TP / (TP + FP) mierzy proporcję pozytywnych przewidywań, które są poprawne — ważne dla minimalizowania fałszywych alarmów, które marnują zasoby inspekcyjne. Czułość (Recall) = TP / (TP + FN) mierzy proporcję rzeczywistych pozytywnych pikseli poprawnie zidentyfikowanych — ważne dla minimalizowania przeoczonych wad, które zagrażają bezpieczeństwu.
Kompromis między precyzją a czułością jest kontrolowany przez próg predykcji (zazwyczaj 0,5 dla wyjścia softmax). W inspekcji infrastruktury:
Cel wysokiej precyzji (0,90+): Używane do automatycznego raportowania PCI, gdzie fałszywie pozytywne wyniki zawyżałyby stopień zużycia. Próg podniesiony do 0,75–0,85, aby wyeliminować niepewne przewidywania.
Cel wysokiej czułości (0,90+): Używane do krytycznej dla bezpieczeństwa detekcji FOD, gdzie przeoczone zanieczyszczenia są niedopuszczalne. Próg obniżony do 0,3–0,4, aby wychwycić graniczne detekcje, z dalszą weryfikacją przez człowieka wszystkich alertów.
Ewaluacja Brzegowa
Metryki ewaluacji brzegowej oceniają jakość segmentacji na krawędziach obiektów — najbardziej wymagającym regionie dla wad infrastrukturalnych:
Boundary F1 (BF) oblicza precyzję i czułość w wąskim pasie (zazwyczaj 2–5 pikseli) wokół referencyjnej granicy segmentacji. Wysoki wynik BF (0,80+) wskazuje, że przewidywane granice pęknięć ściśle odpowiadają prawdziwym krawędziom pęknięć, co jest niezbędne do dokładnego pomiaru szerokości pęknięcia.
Odległość Hausdorffa (HD) mierzy maksymalną odległość między przewidywanymi a referencyjnymi granicami: HD = max(max_p min_g d(p,g), max_g min_p d(g,p)), gdzie p i g to punkty na przewidywanej i referencyjnej granicy. 95. percentyl odległości Hausdorffa (HD95) jest bardziej odporny na wartości odstające i jest zazwyczaj raportowany dla segmentacji pęknięć. HD95 < 3 piksele dla obrazu o rozdzielczości 1 mm/piksel odpowiada błędowi lokalizacji granicy < 3 mm.
Metryka
Formuła
Typowa Wartość dla Segmentacji Pęknięć
Interpretacja
IoU pęknięć
TP/(TP+FP+FN)
0,65–0,85
Nakładanie pikseli z referencją
Dice pęknięć
2TP/(2TP+FP+FN)
0,79–0,92
Nakładanie F1 z referencją
Dokładność pikseli
Poprawne piksele / Wszystkie piksele
0,95–0,99
Ogólna poprawność (myląca)
Precyzja
TP/(TP+FP)
0,75–0,90
Poprawność pozytywnych przewidywań
Czułość
TP/(TP+FN)
0,70–0,90
Kompletność wykrywania wad
Boundary F1
BF w paśmie 2 pikseli
0,60–0,80
Jakość lokalizacji krawędzi
HD95 (piksele)
95. percentyl odl. Hausdorffa
2–8 pikseli
Maksymalny błąd granicy
Wdrożenie i Szybkość Wnioskowania
Optymalizacja Modelu do Wdrożenia Brzegowego
Wdrażanie modeli segmentacji semantycznej do operacyjnej inspekcji infrastruktury wymaga równoważenia dokładności z szybkością wnioskowania i ograniczeniami pamięci. Drony inspekcyjne i urządzenia brzegowe (NVIDIA Jetson, Google Coral, Intel Neural Compute Stick) mają ograniczone zasoby obliczeniowe w porównaniu z GPU w chmurze.
Przycinanie modelu (pruning) usuwa zbędne wagi lub kanały z wytrenowanej sieci. Przycinanie niestrukturalne ustawia poszczególne wagi na zero (osiągając 50–80% rzadkości przy <2% utracie dokładności), podczas gdy przycinanie strukturalne usuwa całe kanały lub filtry (osiągając 30–50% redukcji kanałów). Przycinanie strukturalne jest preferowane do wdrożenia sprzętowego, ponieważ bezpośrednio redukuje operacje obliczeniowe i transfery pamięci.
Kwantyzacja zmniejsza precyzję numeryczną wag i aktywacji z 32-bitowego zmiennoprzecinkowego (FP32) do 16-bitowego (FP16) lub 8-bitowego całkowitoliczbowego (INT8). Kwantyzacja po trenowaniu (PTQ) kalibruje zakresy aktywacji modelu przy użyciu małego zestawu danych kalibracyjnych i konwertuje do INT8 bez ponownego trenowania — zazwyczaj osiągając 2–3× przyspieszenie przy 1–3% degradacji dokładności. Trenowanie świadome kwantyzacji (QAT) symuluje kwantyzację podczas trenowania, umożliwiając modelowi adaptację do zmniejszonej precyzji i ograniczając utratę dokładności do <1%.
ONNX Runtime zapewnia zoptymalizowane sprzętowo wnioskowanie na backendach CPU, GPU i NPU. Modele wyeksportowane z PyTorch lub TensorFlow do formatu ONNX (Open Neural Network Exchange) korzystają z optymalizacji grafu (fuzja operatorów, składanie stałych) i dostawców wykonawczych specyficznych dla celu (CUDA dla GPU NVIDIA, TensorRT dla platform Jetson, OpenVINO dla sprzętu Intel).
TensorRT (NVIDIA) stosuje dodatkową optymalizację dla GPU NVIDIA: automatyczne dostrajanie jąder (wybór najszybszej implementacji jądra dla każdej warstwy), fuzję warstw (łączenie sąsiednich warstw w pojedyncze jądra), kalibrację precyzji (automatyczna optymalizacja FP16/INT8) i dynamiczne zarządzanie pamięcią tensorów. Model U-Net przekonwertowany z PyTorch do TensorRT z wnioskowaniem FP16 osiąga 3–5× przyspieszenie na sprzęcie Jetson Orin.
Wymagania Wnioskowania w Czasie Rzeczywistym
Scenariusz Wdrożenia
Wymagana Przepustowość
Akceptowalne Opóźnienie
Typowy Sprzęt
Przetwarzanie wsadowe po locie
1–10 obrazów/sek
Minuty na przegląd
GPU w chmurze (A10, A100)
Wnioskowanie brzegowe na dronie
10–30 obrazów/sek
<100ms na obraz
Jetson Orin NX/Nano
Detekcja FOD w czasie rzeczywistym
30+ obrazów/sek
<30ms na obraz
Jetson AGX Orin
Inspekcja smartfonem
1–5 obrazów/sek
<500ms na obraz
Snapdragon/Apple Neural Engine
Kompromisy Między Szybkością a Dokładnością
Zależność między rozmiarem modelu, szybkością wnioskowania a dokładnością segmentacji podlega ustalonym prawom skalowania. Dla segmentacji pęknięć na obrazach o rozdzielczości 1 mm/piksel:
Wariant Modelu
Enkoder Bazowy
Parametry
IoU Pęknięć
Wnioskowanie (kafelek 256²)
Platforma
U-Net tiny
EfficientNet-B0
3,8M
0,72
3 ms
Jetson Nano
U-Net small
ResNet-18
14,3M
0,76
8 ms
Jetson Orin NX
U-Net medium
ResNet-50
34,5M
0,80
18 ms
Jetson Orin NX
U-Net large
ResNet-101
57,4M
0,83
35 ms
Jetson AGX Orin
DeepLabV3+
ResNet-50
40,1M
0,82
22 ms
Jetson AGX Orin
DeepLabV3+
ResNet-101
63,6M
0,84
42 ms
Jetson AGX Orin
SegFormer-B2
MiT-B2
24,5M
0,81
28 ms
Jetson AGX Orin
SegFormer-B3
MiT-B3
44,1M
0,84
45 ms
Jetson AGX Orin
W przypadku operacyjnego wdrożenia na lotnisku przetwarzającego pas startowy o wymiarach 3 000 m × 45 m przy GSD 1 mm/piksel (około 135 000 kafelków 2048×2048), model U-Net medium na Jetson Orin NX wykonuje pełne wnioskowanie pasa w około 40 minut — zgodne z przetwarzaniem nocnym na potrzeby decyzji o utrzymaniu następnego dnia. Ten sam model na GPU w chmurze skraca przetwarzanie do 5–8 minut.
Kafelkowanie i Łączenie dla Obrazów Dużych Obszarów
Obrazy z inspekcji infrastruktury — szczególnie ortomozaiki z przeglądów dronami — są zazwyczaj zbyt duże do wnioskowania modelu w jednym przebiegu (10 000–500 000 pikseli na wymiar). Kafelkowanie (tiling) dzieli obraz na nakładające się fragmenty (zazwyczaj 512×512 do 2048×2048 pikseli), które są przetwarzane niezależnie. Obszary nakładania się (10–25% wymiaru kafelka) zapewniają, że wady przechodzące przez granice kafelków są spójnie segmentowane — przewidywania w obszarach nakładania są uśredniane lub łączone przy użyciu ważonego mieszania.
Łączenie (stitching) ponownie składa przewidywania kafelków w pełną mapę segmentacji w oryginalnej rozdzielczości. Płynne mieszanie z liniowymi rampami w obszarach nakładania eliminuje widoczne granice kafelków. Zszyta mapa przy GSD 1 mm/piksel dla pasa o szerokości 45 m ma 45 000 pikseli szerokości — wymagając starannego zarządzania pamięcią do wizualizacji i dalszej analizy.
Platforma TarmacView przetwarza kafelkowe przewidywania segmentacji przy GSD od 0,3 do 3 mm/piksel, z automatycznym wyborem rozmiaru kafelka na podstawie dostępnej pamięci GPU i architektury modelu, tworząc bezszwowe mapy segmentacji całego pasa z subpikselową dokładnością lokalizacji pęknięć.
Najczęściej Zadawane Pytania
Segmentacja semantyczna przypisuje pojedynczą etykietę klasy do każdego piksela bez rozróżniania poszczególnych obiektów tej samej klasy — wszystkie pęknięcia są oznaczane jako „pęknięcie”, cała nawierzchnia jako „nawierzchnia”. Segmentacja instancyjna wykrywa i obrysowuje każdy odrębny obiekt oddzielnie, przypisując unikalne identyfikatory każdemu obiektowi — pęknięcie nr 1, pęknięcie nr 2. Segmentacja panoptyczna łączy oba podejścia: przypisuje etykietę semantyczną każdemu pikselowi (klasy „stuff” — tła, takie jak nawierzchnia, niebo, roślinność) oraz jednocześnie identyfikuje i segmentuje poszczególne instancje obiektów (klasy „thing” — rzeczy, takie jak konkretne pęknięcia, dziury czy elementy FOD). W inspekcji infrastruktury segmentacja semantyczna jest najczęściej stosowanym podejściem, ponieważ wiele wad powierzchni tworzy ciągłe, połączone regiony, które nie mają dobrze zdefiniowanych pojedynczych instancji.
U-Net to w pełni konwolucyjna architektura enkoder-dekoder, wprowadzona przez Ronnebergera i in. w 2015 roku do segmentacji obrazów biomedycznych. Enkoder (ścieżka kurczenia) wydobywa hierarchiczne cechy poprzez kolejne operacje konwolucji i pooling, stopniowo zmniejszając rozdzielczość przestrzenną przy jednoczesnym zwiększaniu głębokości kanałów. Dekoder (ścieżka rozszerzania) próbkuje mapy cech z powrotem do oryginalnej rozdzielczości wejściowej za pomocą transponowanych konwolucji lub interpolacji dwuliniowej. Kluczową innowacją są połączenia pomijające (skip connections), które łączą mapy cech enkodera bezpośrednio z odpowiadającą im warstwą dekodera na tej samej rozdzielczości, umożliwiając dekoderowi dostęp do drobnoziarnistych szczegółów przestrzennych utraconych podczas próbkowania w dół. Standardowa implementacja U-Net zawiera około 31 milionów parametrów i pozostaje szeroko stosowana do segmentacji pęknięć w infrastrukturze ze względu na doskonałą dokładność lokalizacji przy ograniczonej ilości danych treningowych.
Podstawowe metryki ewaluacyjne to Intersection over Union (IoU), znany również jako indeks Jaccarda, oraz współczynnik Dice (wynik F1). IoU oblicza nakładanie się przewidywanych maski segmentacji z maską referencyjną podzielone przez ich sumę: TP / (TP + FP + FN). Współczynnik Dice jest równoważny wynikowi F1: 2TP / (2TP + FP + FN). Dokładność pikseli mierzy ułamek poprawnie sklasyfikowanych pikseli, ale jest myląca dla niezbalansowanych zbiorów danych, gdzie dominują piksele bez pęknięć. W przypadku segmentacji pęknięć, gdzie piksele pęknięć stanowią zwykle mniej niż 1% obrazu, IoU dla poszczególnych klas, a zwłaszcza IoU dla klasy pęknięcia, są najbardziej miarodajnymi metrykami raportowymi. Wynik F1 dla granic (Boundary F1) i odległość Hausdorffa dostarczają dodatkowych informacji o jakości granic segmentacji.
Funkcja straty cross-entropii oblicza ujemne logarytmiczne prawdopodobieństwo przewidywanej probabilności dla poprawnej klasy w każdym pikselu, uśrednione po wszystkich pikselach. Jest to bazowa funkcja straty, ale działa słabo na danych z niezbalansowanymi klasami. Strata Dice minimalizuje 1 - współczynnik Dice, bezpośrednio optymalizując metrykę nakładania i dobrze radząc sobie z umiarkowanym niezbalansowaniem klas. Strata Focal dodaje do cross-entropii czynnik modulujący (1-pᵗ)ᵞ, zmniejszając wagę łatwych przykładów i skupiając trenowanie na trudnych pikselach; jest skuteczna przy ekstremalnym niezbalansowaniu klas, gdzie pęknięcia zajmują mniej niż 1% pikseli. Strata brzegowa (boundary loss) wykorzystuje transformacje odległości do karania błędów na granicach segmentacji. Straty hybrydowe (np. Dice + Focal) są powszechnie stosowane w inspekcji infrastruktury, aby łączyć zalety wielu formuł.
ResNet (Residual Network) jest najczęściej używanym enkoderem bazowym, dostępnym w wariantach ResNet-18, ResNet-34, ResNet-50, ResNet-101 i ResNet-152, gdzie liczba oznacza głębokość warstw. Połączenia rezydualne z połączeniami pomijającymi umożliwiają trenowanie bardzo głębokich sieci. EfficientNet wykorzystuje skalowanie złożone (głębokość, szerokość, rozdzielczość) z blokami MBConv zawierającymi uwagę typu squeeze-and-excitation (SE) dla wydajności obliczeniowej. Vision Transformer (ViT) stosuje mechanizm self-attention transformerów do fragmentów obrazu, przechwytując globalny kontekst kosztem wyższych wymagań obliczeniowych. Wybór zależy od kompromisu między dokładnością a szybkością: lekkie enkodery (ResNet-18, EfficientNet-B0) są odpowiednie do wdrożenia w czasie rzeczywistym na urządzeniach brzegowych, podczas gdy ciężkie enkodery (ResNet-101, ViT-Base) maksymalizują dokładność do analizy offline.
Zautomatyzuj Swoją Inspekcję Infrastruktury
Wykorzystaj segmentację semantyczną do oceny stanu nawierzchni z dokładnością do piksela, wykrywania pęknięć i mapowania typów nawierzchni. Nasza platforma dostarcza zautomatyzowaną analizę z obrazów z dronów z pomiarem pęknięć z dokładnością poniżej milimetra i raportowaniem zgodnym z PCI.
Segmentacja Instancji dla Identyfikacji Poszczególnych Uszkodzeń
Segmentacja instancji identyfikuje i wyznacza granice każdego indywidualnego obiektu lub uszkodzenia na poziomie piksela, przypisując unikalny identyfikator każ...
Wykrywanie pęknięć za pomocą AI w inspekcji infrastruktury
Wykrywanie pęknięć oparte na AI wykorzystuje widzenie komputerowe — konwolucyjne sieci neuronowe, transformery wizyjne i modele segmentacji semantycznej — do au...
Procentowy udział powierzchni spękań w ocenie nawierzchni i konstrukcji
Procentowy udział powierzchni spękań (crack_area_pct) to stosunek powierzchni maski spękań do całkowitej analizowanej powierzchni obrazu, wyrażony w procentach....
26 min czytania
measurement
pavement
+3
Zgoda na Pliki Cookie Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.