Test dymny (Smoke Test)
Test dymny to szybka, kompleksowa weryfikacja, czy pipeline oprogramowania wykonuje się bez awarii na reprezentatywnych danych, produkując oczekiwane wyniki. Sk...
25 min czytania
testing
technology
+4
Test dymny głowicy defektów weryfikuje, czy potok detekcji defektów strukturalnych TarmacView — szkielet DINOv3 + 5-etykietowa głowica MLP dla pęknięć/odprysków/wykwitów/odsłoniętego zbrojenia/korozji — generuje oczekiwane wyniki na danych testowych. Obejmuje asercje testowe (istnienie punktu kontrolnego; metryki AP; kolumny defektów na poziomie kafelka/klatki w wynikach analizy) oraz to, co testy dymne weryfikują w porównaniu z pełną ewaluacją.
Testy dymne głowicy defektów to zautomatyzowana procedura weryfikacyjna, która waliduje integralność strukturalną i podstawową funkcjonalność potoku uczenia maszynowego do detekcji defektów. Potwierdza, że potok — od wstępnego przetwarzania obrazu wejściowego przez transformer wizyjny DINOv3 do 5-etykietowej głowicy klasyfikacyjnej MLP (wielowarstwowy perceptron) — generuje oczekiwane wyniki na syntetycznych lub małych statycznych danych testowych bez awarii, błędów numerycznych lub strukturalnie nieprawidłowych predykcji. Test dymny różni się od pełnej ewaluacji: weryfikuje, że potok jest poprawnie podłączony i działa, a nie że generalizuje na niewidziane dane z wysoką dokładnością.
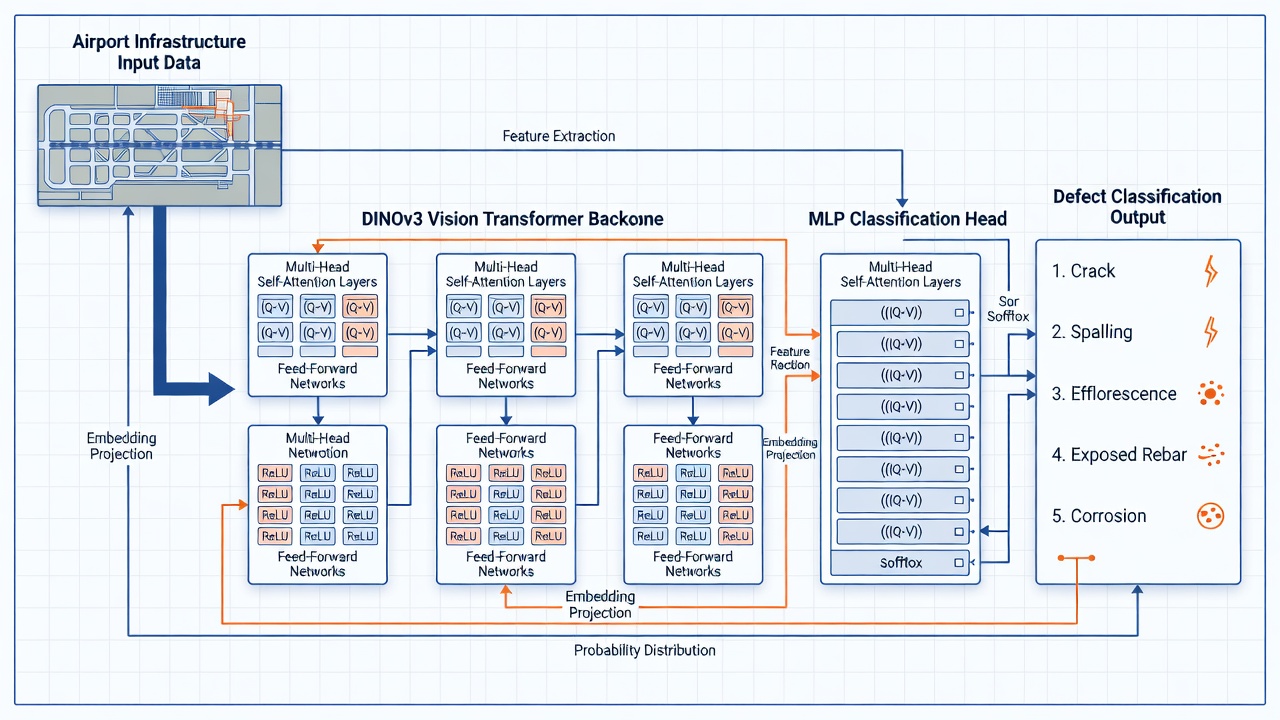
Głowica defektów to końcowy komponent potoku detekcji defektów strukturalnych TarmacView, odpowiedzialny za mapowanie bogatych reprezentacji cech wyodrębnionych przez szkielet sieciowy na dyskretne przewidywania klas defektów. Zrozumienie architektury zarówno szkieletu, jak i głowicy jest niezbędne do projektowania skutecznych testów dymnych, które walidują integralność każdego komponentu.
DINOv3 (samodestylacja bez etykiet, wersja 3), transformer wizyjny opracowany przez Meta AI i wydany w 2023 roku, służy jako szkielet ekstrakcji cech. DINOv3 został wytrenowany z użyciem paradygmatu uczenia samonadzorowanego na starannie dobranym zbiorze 142 milionów nieoznaczonych obrazów (LVD-142M), ucząc się ogólnych reprezentacji wizualnych bez potrzeby jakichkolwiek adnotacji ludzkich. To podejście produkuje cechy, które skutecznie transferują się do zadań downstream, w tym klasyfikacji defektów, segmentacji i detekcji — często przewyższając nadzorowane wstępne trenowanie na ImageNet-1K.
DINOv3 jest dostępny w wielu wariantach modelu o różnych profilach obliczeniowych:
| Wariant | Parametry | Wymiar osadzenia | Rozmiar kafelka | Warstwy | Głowice |
|---|---|---|---|---|---|
| ViT-S/14 | 22 miliony | 384 | 14×14 | 12 | 6 |
| ViT-B/14 | 86 milionów | 768 | 14×14 | 12 | 12 |
| ViT-L/14 | 300 milionów | 1024 | 14×14 | 24 | 16 |
| ViT-g/14 | 1,1 miliarda | 1536 | 14×14 | 40 | 24 |
Dla potoku detekcji defektów TarmacView wariant ViT-B/14 jest standardową konfiguracją. Z 86 milionami parametrów i 768-wymiarową przestrzenią osadzeń, równoważy zdolność reprezentacyjną z wydajnością obliczeniową odpowiednią do przetwarzania dużych ilości obrazów z inspekcji pasów startowych. Rozmiar kafelka 14×14 oznacza, że wejściowy obraz o rozdzielczości 224×224 pikseli jest dzielony na 16×16 = 256 nienakładających się kafelków, z których każdy jest projektowany w 768-wymiarową przestrzeń osadzeń poprzez wyuczoną projekcję liniową.
Metodologia trenowania DINOv3 łączy kilka kluczowych technik. Samodestylacja z architekturą nauczyciel-uczeń zapewnia, że sieć ucznia uczy się dopasowywać reprezentacje nauczyciela, przy czym nauczyciel jest wykładniczo średnią kroczącą ucznia. iBOT (wstępne trenowanie BERT-a obrazu z internetowym tokenizatorem) stosuje maskowane modelowanie obrazu, gdzie losowe kafelki są maskowane, a model musi przewidzieć reprezentacje zamaskowanych kafelków. Centrowanie Sinkhorn-Knopp z metody SwAV zapobiega zapadaniu się reprezentacji poprzez wymuszanie równomiernego rozkładu w próbkach batcha. Regularyzator KoLeo promuje różnorodność w wyuczonych cechach poprzez karanie podobieństwa cech między bliskimi próbkami.
Dla przypadku użycia detekcji defektów, DINOv3 jest ładowany z wstępnie wytrenowanymi wagami i zazwyczaj zamrażany podczas trenowania głowicy defektów. Zamrożony szkielet ekstrahuje ogólne cechy wizualne — krawędzie, tekstury, gradienty, wzory powierzchniowe — które są wysoce istotne do rozróżniania między nienaruszoną nawierzchnią a pięcioma klasami defektów. Zamrożenie szkieletu redukuje liczbę trenowalnych parametrów z 86 milionów do około 1-3 milionów (w zależności od głębokości głowicy MLP), drastycznie skracając czas trenowania, wymagania pamięci GPU i ryzyko katastroficznego zapominania na małych zbiorach danych specyficznych dla domeny.
Głowica defektów MLP (wielowarstwowy perceptron) to mała sieć neuronowa z przesyłaniem w przód, która przyjmuje zamrożone osadzenia DINOv3 jako dane wejściowe i generuje 5-wymiarowy rozkład prawdopodobieństwa dla pięciu klas defektów: pęknięcie, odprysk, wykwit, odsłonięte zbrojenie i korozja.
Standardowa architektura składa się z:
Warstwy wejściowej: Przyjmuje osadzenie DINOv3 — albo token [CLS] (768-wymiarowy wektor reprezentujący globalną zawartość obrazu), albo zagregowaną reprezentację wszystkich tokenów kafelków. Podejście z tokenem [CLS] jest standardowe, ponieważ DINOv3 jest specjalnie trenowany do produkowania bogatych informacji w tokenie [CLS] podczas samodestylacji.
Warstw ukrytych: Zazwyczaj 1-2 w pełni połączone warstwy z funkcjami aktywacji ReLU lub GELU. Pojedyncza warstwa ukryta może mieć konfigurację 768 → 256 → 5, podczas gdy głębsza konfiguracja może być 768 → 512 → 128 → 5. Każda warstwa ukryta jest followed przez normalizację batcha lub normalizację warstwy w celu stabilizacji trenowania i redukcji wewnętrznego przesunięcia kowariancji. Dropout (wskaźnik 0,2-0,5) jest stosowany między warstwami ukrytymi podczas trenowania jako regularyzator zapobiegający nadmiernemu dopasowaniu, biorąc pod uwagę, że zbiory danych defektów infrastruktury są zazwyczaj małe (500-5000 obrazów).
Warstwy wyjściowej: Liniowa projekcja do 5 jednostek odpowiadających pięciu klasom defektów, po której następuje aktywacja softmax, przekształcająca logity w rozkład prawdopodobieństwa dla klas. Funkcja softmax zapewnia, że wektor wyjściowy sumuje się do 1,0, a każdy element reprezentuje przewidywane prawdopodobieństwo, że obraz wejściowy należy do tej klasy defektu.
Procedura trenowania: Głowica MLP jest trenowana poprzez nadzorowane dostrajanie, podczas gdy szkielet DINOv3 pozostaje zamrożony. Funkcja straty to kategoryczna entropia krzyżowa, porównująca przewidywany rozkład prawdopodobieństwa z zakodowanymi w formacie one-hot etykietami prawdy podstawowej. Trenowanie zazwyczaj używa optymalizatora AdamW ze współczynnikiem uczenia 1e-3 do 1e-4, rozmiarem batcha 32-128 i wczesnym zatrzymywaniem na podstawie straty walidacyjnej. Augmentacja danych (losowa rotacja, poziome odbicie, szum koloru, losowe przycięcie) jest stosowana podczas trenowania w celu poprawy generalizacji.
Dla inferencji, szkielet DINOv3 przetwarza każdy obraz wejściowy w osadzenia tokenów kafelków i [CLS] w jednym przejściu w przód. Osadzenie [CLS] jest ekstrahowane i przepuszczane przez głowicę MLP. Wyjściowe prawdopodobieństwa softmax są progowane (zazwyczaj na poziomie 0,5 lub optymalizowane poprzez analizę ROC), aby wygenerować binarną predykcję dla każdej klasy defektu. Ponieważ pięć klas defektów nie wyklucza się wzajemnie — pojedynczy obszar nawierzchni może wykazywać jednocześnie pęknięcia i odpryski — prognozowane predykcje dla każdej klasy są niezależne, a wynik jest interpretowany jako wieloetykietowy, a nie jednoklasowy.
W potoku analitycznym TarmacView głowica defektów działa na dwóch poziomach granularności.
Analiza na poziomie kafelka: Powierzchnia pasa startowego jest dzielona na siatkę kafelków obrazu (typowe 224×224 lub 512×512 pikseli przy rozdzielczości inspekcji 0,5-2,0 mm/piksel). Każdy kafelek jest przetwarzany niezależnie przez szkielet DINOv3 i głowicę MLP defektów, generując 5-elementowy wektor prawdopodobieństwa na kafelek. Predykcje na poziomie kafelka są przechowywane jako kolumny na kafelek w wynikach analizy: tile_crack_conf, tile_spalling_conf, tile_efflorescence_conf, tile_exposed_rebar_conf, tile_corrosion_conf.
Agregacja na poziomie klatki: Poszczególne predykcje kafelków w ramach jednej klatki kamery lub sekcji pasa startowego są agregowane w celu uzyskania ocen defektów na poziomie klatki. Metody agregacji obejmują: maksymalne łączenie (maksymalna ufność wśród wszystkich kafelków w klatce), średnie łączenie (średnia ufność), głosowanie top-k (proporcja kafelków przekraczających próg) oraz gęstość przestrzenną (liczba kafelków z defektami na jednostkę powierzchni). Kolumny na poziomie klatki w wynikach obejmują frame_crack_flag, frame_spalling_flag, frame_defect_count i frame_max_defect_conf.
Schemat wyników analizy jest krytycznym komponentem, który testy dymne muszą walidować. Jeśli kolumny ufności na poziomie kafelka lub kolumny agregacji na poziomie klatki brakuje, zostały przemianowane lub zawierają nieprawidłowe wartości (NaN, inf, ujemne prawdopodobieństwa), obliczenia wskaźnika stanu nawierzchni (PCI) i potoki raportowania ulegną awarii.
Asercje testów dymnych to konkretne, zautomatyzowane sprawdzenia, które weryfikują, czy potok głowicy defektów działa poprawnie. Każda asercja celuje w konkretny tryb awarii i generuje jasny wynik zaliczenia/niezaliczenia, który może być zintegrowany z bramkowaniem potoku CI/CD.
Pierwsza kategoria asercji testów dymnych weryfikuje, czy punkt kontrolny głowicy defektów — zapisany plik wag modelu — jest prawidłowy i możliwy do załadowania. Asercje obejmują:
Istnienie pliku punktu kontrolnego: Test sprawdza, czy plik punktu kontrolnego istnieje pod określoną ścieżką. Wyłapuje to problemy, gdy sesja trenowania nie powiodła się, punkt kontrolny nie został przesłany do rejestru modeli lub ścieżka pliku została nieprawidłowo skonfigurowana w środowisku wdrożeniowym. Asercja to: assert os.path.exists(checkpoint_path), f"Punkt kontrolny nie znaleziony pod {checkpoint_path}".
Walidacja rozmiaru pliku i sumy kontrolnej: Test weryfikuje, że plik punktu kontrolnego ma niezerowy rozmiar i opcjonalnie waliduje jego sumę kontrolną MD5 lub SHA256 względem przechowywanej wartości bazowej. Plik o zerowej liczbie bajtów lub uszkodzone pobranie zostaną tutaj wychwycone. Asercja to: assert os.path.getsize(checkpoint_path) > 0 i opcjonalnie assert sha256(plik) == oczekiwane_sha256.
Możliwość załadowania przez torch: Test ładuje punkt kontrolny za pomocą torch.load() i sprawdza, czy operacja kończy się bez zgłoszenia wyjątku. Wyłapuje to uszkodzone pliki, niezgodności wersji (np. punkt kontrolny zapisany PyTorchem 2.0 próbujący załadować się w PyTorch 1.8) oraz brakujące zależności. Asercja otacza wywołanie ładowania blokiem try/except i kończy się niepowodzeniem przy każdym wyjątku.
Struktura słownika stanu: Po załadowaniu test sprawdza, czy punkt kontrolny zawiera oczekiwane klucze słownika stanu. Dla szkieletu DINOv3 oczekiwane klucze obejmują backbone.cls_token, backbone.patch_embed.proj.weight oraz parametry bloków transformera. Dla głowicy MLP oczekiwane klucze obejmują head.0.weight, head.0.bias, head.2.weight, head.2.bias (dla 2-warstwowego MLP). Test weryfikuje również, że wszystkie oczekiwane klucze są obecne i że nie istnieją nieoczekiwane klucze, co mogłoby wskazywać na niezgodność architektury modelu.
Druga kategoria weryfikuje, że przejście w przód przez połączony szkielet i głowicę generuje prawidłowe wyniki.
Walidacja kształtu tensora: Test tworzy syntetyczny tensor wejściowy o oczekiwanym kształcie (typowe [batch_size, 3, height, width] z batch_size=1-4, height=width=224 dla ViT-B/14), przepuszcza go przez model i sprawdza, czy kształt tensora wyjściowego to [batch_size, 5] — dokładnie 5 logitów odpowiadających 5 klasom defektów. Asercja to: assert output.shape == (rozmiar_batcha, 5), f"Oczekiwany kształt (rozmiar_batcha, 5), otrzymano {output.shape}".
Walidacja stabilności numerycznej: Test sprawdza, że żadna wartość wyjściowa nie jest NaN (Nie Liczba), nieskończonością lub ujemną nieskończonością. Wartości NaN mogą powstawać z niestabilności numerycznej w szkielecie transformera (np. przepełnienie logitów atencji), dzielenia przez zero w warstwach normalizacji lub uszkodzonych wag. Asercja to: assert not torch.isnan(output).any(), "Wynik zawiera wartości NaN" i assert not torch.isinf(output).any(), "Wynik zawiera wartości inf".
Walidacja prawdopodobieństwa softmax: Test stosuje softmax do surowych logitów i sprawdza, czy wynikowe prawdopodobieństwa sumują się do 1,0 dla każdej próbki w batchu (w ramach tolerancji zmiennoprzecinkowej, typowo 1e-5). Potwierdza to, że warstwa wyjściowa jest poprawnie skonfigurowana i że żaden krok post-processingu nie uszkadza rozkładu prawdopodobieństwa. Asercja to: assert torch.allclose(probs.sum(dim=1), torch.ones(rozmiar_batcha), atol=1e-5).
Trzecia kategoria weryfikuje, że model generuje rozsądne rozkłady predykcji, a nie zdegenerowane wyniki.
Sprawdzenie nierównomierności rozkładu: Test sprawdza, że przewidywane prawdopodobieństwa nie są równomierne we wszystkich klasach (co wskazywałoby na model, który nie nauczył się żadnych dyskryminacyjnych cech). Entropia przewidywanego rozkładu jest obliczana i porównywana z minimalnym progiem. Całkowicie równomierny rozkład ma maksymalną entropię (log(5) ≈ 1,61 natów dla 5 klas), podczas gdy pewna predykcja ma niską entropię. Asercja to: assert entropia < 1.5, "Predykcje są prawie równomierne, model może nie być wytrenowany".
Sprawdzenie pokrycia klas: Test uruchamia inferencję na małym zestawie różnorodnych obrazów wejściowych i sprawdza, że każda z 5 klas defektów jest predykcją o najwyższej ufności dla co najmniej jednego wejścia. Weryfikuje to, że żadna klasa nie jest systematycznie tłumiona — na przykład model, który nigdy nie przewiduje “wykwitu”, wskazywałby na brak równowagi w danych treningowych lub problem z konfiguracją głowicy. Asercja to: assert set(przewidziane_klasy) == set(range(5)), f"Klasy {brakujace} nigdy nie przewidziane".
Obsługa klasy tła: Jeśli model zawiera domyślną klasę “brak defektu” lub tła, test dymny weryfikuje, że obraz nienaruszonej nawierzchni — wolny od jakichkolwiek defektów — generuje predykcję tła z ufnością powyżej progu (typowe 0,8). Potwierdza to, że model może poprawnie odrzucać negatywne przykłady, co jest krytyczne dla unikania fałszywych alarmów w inspekcjach produkcyjnych.
Walidacja punktu kontrolnego to podstawowy komponent testu dymnego, który potwierdza, że artefakt modelu — zapisane wagi sieci neuronowej — jest nienaruszony, możliwy do załadowania i strukturalnie zgodny z oczekiwaną architekturą. W produkcyjnych systemach ML uszkodzenie punktu kontrolnego lub niezgodność wersji jest jednym z najczęstszych trybów awarii, a wychwycenie go wcześnie w CI/CD zapobiega kaskadowym awariom w dalszych etapach.
Punkty kontrolne głowicy defektów TarmacView są przechowywane w rejestrze modeli — scentralizowanym magazynie artefaktów z wersjonowaniem, metadanymi i śledzeniem pochodzenia (MLflow Model Registry lub DVC). Każdy punkt kontrolny jest identyfikowany przez unikalną kombinację nazwy modelu, numeru wersji i ID uruchomienia. Sam plik punktu kontrolnego to serializowany słownik stanu PyTorch (typowy model.pt lub checkpoint.pt) zawierający wyuczone parametry zarówno szkieletu DINOv3 (jeśli dostrajany), jak i głowicy MLP.
Test dymny najpierw rozwiązuje ścieżkę punktu kontrolnego z rejestru modeli, obsługując następujące przypadki:
defect-head:v3), a test ładuje tę dokładną wersję.Szkielet DINOv3 to duży model z 86 milionami parametrów dla wariantu ViT-B/14. Test dymny weryfikuje, że załadowany szkielet odpowiada oczekiwanej architekturze poprzez sprawdzenie:
Kształtów tensorów wag: Każdy tensor parametrów w załadowanym słowniku stanu jest weryfikowany względem oczekiwanego kształtu. Na przykład tensor backbone.patch_embed.proj.weight powinien mieć kształt (768, 3, 14, 14) dla ViT-B/14 z 3 kanałami wejściowymi, 768 kanałami wyjściowymi i jądrem kafelka 14×14. Niezgodność kształtu wskazywałaby, że punkt kontrolny był trenowany z inną konfiguracją (inny rozmiar kafelka, inny wymiar osadzenia, inne kanały wejściowe).
Sprawdzenie zakresu numerycznego: Test weryfikuje, że wartości wag mieszczą się w oczekiwanych zakresach numerycznych. Wagi atencji transformera powinny mieć wartości rozłożone w przybliżeniu jako N(0, σ²) z σ zależnym od schematu inicjalizacji. Ekstremalne wartości (|w| > 10) we wszystkich warstwach wskazywałyby na dywergencję trenowania lub uszkodzenie punktu kontrolnego. Sprawdzenie oblicza średnią i odchylenie standardowe każdego tensora parametrów i oznacza wartości odstające.
Spójność osadzenia wyjściowego: Test uruchamia stałe syntetyczne wejście przez szkielet i porównuje rozkład osadzenia wyjściowego z przechowywaną wartością bazową. Wartość bazowa jest generowana podczas pierwszego udanego uruchomienia testu dymnego i przechowywana jako referencja. Asercja sprawdza, że średnia i wariancja osadzenia nie dryfują poza tolerancję (typowe ±5%). Wyłapuje to cichą degradację modelu, która nie generuje wartości NaN lub inf, ale nadal produkuje anormalne osadzenia.
Głowica MLP jest mniejsza niż szkielet, ale równie krytyczna. Test dymny weryfikuje:
Liczbę warstw: Głowica powinna mieć dokładnie oczekiwaną liczbę warstw. Dla 2-warstwowego MLP z wymiarem ukrytym 256, oczekiwane klucze obejmują head.0.weight (768×256), head.0.bias (256), head.2.weight (256×5), head.2.bias (5). Numeracja warstw uwzględnia funkcję aktywacji (warstwa 1) między warstwami liniowymi.
Wymiar wyjściowy: Wymiar wyjściowy końcowej warstwy liniowej musi wynosić dokładnie 5, odpowiadający 5 klasom defektów. Jest to weryfikowane przez sprawdzenie head.2.weight.shape[0] == 5.
Spójność inicjalizacji wag: Test sprawdza, że wagi nie są zamrożone na wartościach inicjalizacyjnych (wszystkie zera lub wszystkie jedynki). Głowica z wagami wszystkimi zerowymi generowałaby jednolite logity niezależnie od wejścia, wskazując na niepowodzenie trenowania. Sprawdzenie weryfikuje, że head.2.weight.std() > 0.001.
Podczas gdy test dymny dotyczy przede wszystkim integralności potoku, a nie jakości modelu, włączenie lekkiego obliczania metryk do testu dymnego zapewnia wczesne ostrzeżenie o znaczącej regresji modelu. Test dymny oblicza metryki skuteczności na syntetycznych lub małych statycznych danych testowych, porównując je z wartościami bazowymi przechowywanymi z poprzednich zwalidowanych uruchomień.
Średnia precyzja (AP) to pole pod krzywą precyzji i czułości, obliczane dla progów ufności od 0 do 1. Test dymny oblicza AP dla każdej z 5 klas defektów przy użyciu ewaluacji w stylu COCO:
Asercje AP testu dymnego obejmują:
AP@0.50 (metryka PASCAL VOC): AP przy progu IoU 0,50. Asercja to, że AP@0.50 dla każdej klasy przekracza minimalny próg. Dla syntetycznych danych testowych ze znanymi, czystymi wzorcami defektów, typowy próg to AP@0.50 > 0,85 dla wszystkich 5 klas. Jeśli model osiąga AP@0.50 poniżej tego progu na trywialnych danych syntetycznych, wskazuje to na poważną regresję.
AP@0.50 :0.95 (główna metryka COCO): Średnia wartości AP obliczonych przy progach IoU 0,50, 0,55, …, 0,95. Próg asercji jest niższy — typowo AP@0.50 :0.95 > 0,50 — ponieważ rygorystyczne progi IoU są bardziej wymagające nawet na danych syntetycznych.
Spójność AP między klasami: Wariancja AP między 5 klasami jest sprawdzana. Odchylenie standardowe przekraczające 0,15 wskazywałoby, że jedna klasa uległa znaczącej regresji względem innych, sugerując problem specyficzny dla tego typu defektu (np. niewystarczająca liczba przykładów treningowych dla wykwitów).
Syntetyczny zbiór danych testowych jest starannie skonstruowany, aby zapewnić stabilność metryk. Każdy syntetyczny obraz zawiera dokładnie jeden typ defektu nałożony na teksturę tła przypominającą nawierzchnię. Defekty są generowane przy użyciu technik proceduralnych: pęknięcia jako cienkie, rozgałęzione czarne linie z rozmyciem gaussowskim dla realizmu; odpryski jako nieregularne okrągłe/owalne obszary z chropowatymi krawędziami; wykwity jako białe, amorficzne plamy o zmiennej nieprzezroczystości; odsłonięte zbrojenie jako okresowe ciemne okrągłe wzory; korozja jako nieregularne plamy w kolorze rdzy. Syntetyczny zbiór danych jest wersjonowany i zatwierdzany w repozytorium, aby zapewnić deterministyczne, powtarzalne wyniki testów dymnych.
Wynik F1 to średnia harmoniczna precyzji i czułości, zapewniająca pojedynczą zrównoważoną miarę wydajności modelu. Test dymny oblicza F1 przy stałym progu ufności (typowe 0,5) dla każdej klasy defektów.
Asercje F1 obejmują:
Minimalne F1 na klasę: Każda klasa musi osiągnąć F1 > 0,80 na syntetycznym zestawie testowym. Wieloetykietowy charakter zadania predykcji defektów oznacza, że F1 jest obliczane niezależnie dla każdej klasy.
Makro-średnie F1: Nieważona średnia F1 we wszystkich 5 klasach jest obliczana. Próg asercji to makro-F1 > 0,85. Makro-średnia traktuje wszystkie klasy równo, więc regresja na rzadkiej klasie (np. odsłonięte zbrojenie) jest natychmiast widoczna.
Równowaga precyzji i czułości: Stosunek precyzji do czułości jest sprawdzany dla każdej klasy. Stosunek powyżej 1,5 lub poniżej 0,67 wskazuje na brak równowagi — model jest albo zbyt konserwatywny (wysoka precyzja, niska czułość, pomijając wiele defektów), albo zbyt agresywny (wysoka czułość, niska precyzja, generując wiele fałszywych alarmów). Asercja oznacza każdą klasę, w której stosunek jest poza zakresem [0,67, 1,5].
| Metryka | Próg syntetycznego testu | Cel |
|---|---|---|
| AP@0.50 | > 0,85 | Podstawowa zdolność detekcji na klasę |
| AP@0.50 :0.95 | > 0,50 | Kompleksowa jakość detekcji |
| Odchylenie std. AP między klasami | < 0,15 | Sprawdzenie równowagi klas |
| F1 na klasę | > 0,80 | Zrównoważona precyzja-czułość na klasę |
| Makro-średnie F1 | > 0,85 | Ogólna jakość modelu |
| Stosunek precyzji/czułości | [0,67, 1,5] | Równowaga precyzji-czułości na klasę |
Test dymny przechowuje wartości bazowe metryk z ostatniego zwalidowanego uruchomienia i porównuje bieżące metryki z tymi wartościami bazowymi. Znaczący spadek (>5% względnego spadku) w dowolnej metryce powoduje niepowodzenie testu dymnego, nawet jeśli bezwzględna wartość metryki jest powyżej minimalnego progu. Wyłapuje to stopniową degradację — modele, które przechodzą bezwzględne progi, ale stale tracą wydajność w kolejnych sesjach trenowania lub aktualizacjach danych.
Historie metryk są rejestrowane w bazie danych szeregów czasowych (MLflow, Weights & Biases lub prosty plik CSV w repozytorium). Test dymny odczytuje ostatnie 10 zwalidowanych wartości metryk i dopasowuje trend liniowy. Jeśli nachylenie jest ujemne i statystycznie istotne (p < 0,05), test generuje ostrzeżenie, ale nie kończy się niepowodzeniem — tylko niepowodzenie progowe jest używane do bramkowania CI/CD, aby uniknąć zakłóceń potoku z powodu drobnych wahań metryk.
Krytyczny test dymny waliduje, że wyniki analizy — dane strukturalne wyprodukowane przez uruchomienie głowicy defektów na obrazach inspekcyjnych — zawierają wszystkie oczekiwane kolumny z prawidłowymi typami danych i prawidłowymi wartościami. Wypełnia to lukę między inferencją modelu a dalszym obliczaniem wskaźnika stanu nawierzchni (PCI), raportowaniem i integracją GIS.
Wyniki analizy TarmacView to format tabelaryczny (Parquet, CSV lub tabela bazy danych) z kolumnami zorganizowanymi w poziomy:
Kolumny ufności defektów na poziomie kafelka — jedna kolumna zmiennoprzecinkowa na klasę defektu, reprezentująca ufność softmax głowicy MLP, że kafelek zawiera ten defekt:
| Nazwa kolumny | Typ danych | Prawidłowy zakres | Opis |
|---|---|---|---|
tile_crack_conf | Float32 | [0.0, 1.0] | Prawdopodobieństwo obecności pęknięcia |
tile_spalling_conf | Float32 | [0.0, 1.0] | Prawdopodobieństwo obecności odprysku |
tile_efflorescence_conf | Float32 | [0.0, 1.0] | Prawdopodobieństwo obecności wykwitu |
tile_exposed_rebar_conf | Float32 | [0.0, 1.0] | Prawdopodobieństwo obecności odsłoniętego zbrojenia |
tile_corrosion_conf | Float32 | [0.0, 1.0] | Prawdopodobieństwo obecności korozji |
Kolumny agregacji na poziomie klatki — podsumowujące obecność defektów we wszystkich kafelkach w klatce kamery lub sekcji pasa startowego:
| Nazwa kolumny | Typ danych | Prawidłowy zakres | Opis |
|---|---|---|---|
frame_defect_count | Int32 | [0, max_kafelki] | Liczba kafelków z dowolnym defektem powyżej progu |
frame_max_defect_conf | Float32 | [0.0, 1.0] | Maksymalna ufność we wszystkich defektach i kafelkach |
frame_crack_flag | Boolean | {0, 1} | Dowolny kafelek ma crack_conf > próg |
frame_spalling_flag | Boolean | {0, 1} | Dowolny kafelek ma spalling_conf > próg |
frame_efflorescence_flag | Boolean | {0, 1} | Dowolny kafelek ma efflorescence_conf > próg |
frame_exposed_rebar_flag | Boolean | {0, 1} | Dowolny kafelek ma exposed_rebar_conf > próg |
frame_corrosion_flag | Boolean | {0, 1} | Dowolny kafelek ma corrosion_conf > próg |
Kolumny metadanych — identyfikujące kontekst przestrzenny i czasowy każdego rekordu analizy:
| Nazwa kolumny | Typ danych | Opis |
|---|---|---|
image_id | String | Unikalny identyfikator obrazu źródłowego |
tile_x | Int32 | Indeks kolumny kafelka w siatce pasa startowego |
tile_y | Int32 | Indeks wiersza kafelka w siatce pasa startowego |
frame_timestamp | DateTime | Czas przechwycenia klatki źródłowej |
gps_lat | Float64 | Szerokość geograficzna GPS środka kafelka |
gps_lon | Float64 | Długość geograficzna GPS środka kafelka |
Test dymny ładuje wyniki analizy i sprawdza, że każda oczekiwana kolumna istnieje przy użyciu prostego dopasowania nazw kolumn:
expected_tile_cols = ["tile_crack_conf", "tile_spalling_conf",
"tile_efflorescence_conf", "tile_exposed_rebar_conf",
"tile_corrosion_conf"]
expected_frame_cols = ["frame_defect_count", "frame_max_defect_conf",
"frame_crack_flag", "frame_spalling_flag",
"frame_efflorescence_flag", "frame_exposed_rebar_flag",
"frame_corrosion_flag"]
expected_meta_cols = ["image_id", "tile_x", "tile_y",
"frame_timestamp", "gps_lat", "gps_lon"]
actual_cols = set(df.columns)
assert expected_cols.issubset(actual_cols), f"Brakujące kolumny: {expected_cols - actual_cols}"
Dla każdej kolumny ufności defektów test dymny sprawdza:
Typ zmiennoprzecinkowy: Typ danych kolumny to float32 lub float64. Nieoczekiwane typy (int, string, object) wskazują na błąd serializacji lub potoku. Asercja używa assert df[col].dtype in [np.float32, np.float64].
Zakres wartości: Wszystkie wartości mieszczą się w [0.0, 1.0]. Wartości poza tym zakresem wskazują na awarię softmax lub normalizacji. Asercja używa assert df[col].between(0.0, 1.0).all().
Sprawdzenie brakujących wartości: Żadne wartości nie są NaN ani None. Wartości NaN w kolumnach ufności wskazują, że potok inferencji nie wyprodukował wyników dla niektórych kafelków — poważna awaria. Asercja używa assert df[col].notna().all().
Kolumny na poziomie klatki powinny być spójne z danymi na poziomie kafelka, z których pochodzą. Test dymny waliduje:
frame_defect_count równa się liczbie kafelków, gdzie maksymalna ufność przekracza próg: Dla każdej grupy klatek test ponownie oblicza liczbę defektów z danych na poziomie kafelka i sprawdza, czy odpowiada przechowywanej wartości klatki. Wyłapuje to błędy logiki agregacji w potoku.
frame_max_defect_conf równa się maksimum wszystkich wartości ufności kafelków: Test ponownie oblicza maksimum z danych na poziomie kafelka i sprawdza zgodność.
frame_flag jest zgodny z tile_conf: Dla każdej klatki flaga powinna wynosić 1, jeśli dowolny kafelek ma odpowiednią ufność powyżej progu, i 0 w przeciwnym razie. Test weryfikuje to dla wszystkich 5 typów defektów.
Te sprawdzenia spójności działają na zasadzie, że kolumny na poziomie klatki powinny być deterministycznie wyprowadzalne z kolumn na poziomie kafelka. Jeśli logika agregacji jest poprawna, sprawdzenia powinny zawsze przechodzić. Niepowodzenie wskazuje na błąd w kroku post-processingu potoku analitycznego, a nie w samym modelu.
Test dymny porównuje oczekiwany zbiór kolumn z rzeczywistym zbiorem kolumn i generuje ostrzeżenia dla:
tile_moisture_conf), test ostrzega, ale nie kończy się niepowodzeniem, ponieważ może to wskazywać na ulepszenie potoku wymagające aktualizacji integracji downstream.tile_crack_conf → tile_cracking_conf), test kończy się niepowodzeniem, zapobiegając cichej awarii downstream, gdy pulpity raportowania, API lub bazy danych odwołują się do starych nazw kolumn.Logika bramkowania określa, czy głowica defektów przechodzi czy nie przechodzi testu dymnego jako całość, w oparciu o ważoną kombinację wyników poszczególnych asercji. Bramkowanie to mechanizm, który zapobiega wdrożeniu zawodzącego modelu do produkcji.
Nie wszystkie asercje testów dymnych są równie krytyczne. System bramkowania przypisuje każdą asercję do poziomu ważności:
| Poziom | Waga | Wpływ na bramkę | Przykłady |
|---|---|---|---|
| Krytyczny | 1.0 | Bramkuje natychmiast | Niepowodzenie ładowania punktu kontrolnego, NaN w wynikach |
| Poważny | 0.8 | Bramkuje jeśli >1 niepowodzenie | Brakujące kolumny, niezgodność kształtu wyników |
| Ostrzeżenie | 0.4 | Bramkuje jeśli >3 niepowodzenia | AP na klasę poniżej progu |
| Informacja | 0.0 | Tylko logowanie, brak bramkowania | Trendy metryk, powiadomienia o wycofaniu kolumn |
Asercje Krytyczne to te, gdzie żadne prawidłowe wykonanie potoku nie jest możliwe — punkt kontrolny jest uszkodzony, model nie może się załadować lub inferencja generuje nieprawidłowe wartości numeryczne. Pojedyncze krytyczne niepowodzenie blokuje wdrożenie.
Asercje Poważne wskazują, że potok generuje strukturalnie prawidłowe, ale potencjalnie niepoprawne wyniki — brakujące kolumny spowodowałyby awarie raportowania downstream, niezgodność kształtu wyników wskazuje na niedopasowanie architektury modelu do infrastruktury serwującej.
Asercje Ostrzeżenia wskazują, że metryki modelu są poniżej nominalnych progów, ale potok jest strukturalnie sprawny. Są agregowane: jeśli więcej niż 3 ostrzeżenia wystąpią w pojedynczym uruchomieniu, bramka się aktywuje.
Asercje Informacyjne są czysto obserwacyjne — logują trendy dryfu metryk, powiadomienia o wycofaniu kolumn i porównania wydajności z poprzednimi uruchomieniami — ale nigdy nie bramkują wdrożenia.
Ogólny wynik testu dymnego jest obliczany jako:
gate_score = max(krytyczne_niepowodzenia,
poważne_niepowodzenia > 1 ? 1.0 : 0.0,
ostrzeżenia > 3 ? 1.0 : 0.0)
Jeśli gate_score >= 1.0, test dymny kończy się niepowodzeniem, a wdrożenie jest blokowane. Jeśli gate_score < 1.0, test dymny przechodzi, a potok przechodzi do pełnej ewaluacji lub wdrożenia.
Komunikat złożonego zaliczenia/niezaliczenia podsumowuje wynik:
TEST DYMNY: NIEPOWODZENIE
- Krytyczne: 1 [checkpoint_load_failure]
- Poważne: 0
- Ostrzeżenia: 2 [class_crack_ap_below_threshold, class_efflorescence_f1_below_threshold]
- Informacje: 1 [metric_class_crack_ap spadło o 3.2% od ostatniego uruchomienia]
Bramka testu dymnego integruje się z potokiem wdrożeniowym poprzez:
Hook po zatwierdzeniu: Test dymny jest uruchamiany przy każdym zatwierdzeniu pull requesta. Jeśli bramka nie przejdzie, system CI/CD blokuje scalenie (reguła ochrony gałęzi GitHub, niepowodzenie potoku scalania żądania GitLab).
Bramka przedwdrożeniowa: Zanim model zostanie promowany ze stagingu do produkcji, test dymny jest uruchamiany ponownie na dokładnym artefakcie kandydata do wdrożenia. Wyłapuje to problemy, które mogły nie występować podczas rozwoju — na przykład środowisko programistyczne z inną wersją CUDA niż środowisko produkcyjne.
Wyzwalacz wycofania: Jeśli test dymny przejdzie wdrożenie, ale późniejszy incydent produkcyjny zostanie powiązany z głowicą defektów, logika bramkowania testu dymnego jest audytowana. Jeśli asercja na poziomie ostrzeżenia powinna była być asercją poważną, konfiguracja bramkowania jest aktualizowana, aby zapobiec nawrotom.
Testy przydatności domenowej rozszerzają podstawowy test dymny, aby zweryfikować, że głowica defektów działa poprawnie w specyficznych warunkach operacyjnych, które TarmacView napotyka w inspekcji nawierzchni lotniskowych i infrastruktury. Testy te zapewniają, że potok jest nie tylko funkcjonalny, ale także odpowiedni do celu w docelowej domenie.
Głowica defektów musi działać spójnie na różnych typach nawierzchni spotykanych na powierzchniach lotniskowych:
Nawierzchnie asfaltowe (elastyczne): Pasy startowe, drogi kołowania i płyty postojowe zbudowane z mieszanki mineralno-asfaltowej (HMA). Defekty na asfalcie obejmują pęknięcia zmęczeniowe (wzór siatki), pęknięcia podłużne, pęknięcia poprzeczne, koleiny i wybrukowanie. Test dymny zawiera syntetyczne obrazy z teksturami podobnymi do asfaltu (ciemnoszary, widoczne kruszywo, zmienna chropowatość powierzchni) i weryfikuje, że detekcja pęknięć i odprysków utrzymuje nominalne poziomy ufności.
Nawierzchnie betonowe (sztywne): Pasy startowe i płyty postojowe zbudowane z cementu portlandzkiego (PCC). Defekty obejmują odpryski na stykach, pęknięcia narożne, pęknięcia liniowe, wykwity (białe osady wapnia na stykach), odsłonięte zbrojenie (w miejscach odprysków) i plamy korozji. Test dymny weryfikuje, że model poprawnie identyfikuje wykwity i odsłonięte zbrojenie — defekty znacznie częstsze na nawierzchniach betonowych niż asfaltowych.
Nawierzchnie kompozytowe: Nakładki asfaltowe na istniejącym betonie. Defekty obejmują pęknięcia odbite (pęknięcia asfaltu podążające za wzorem podłoża betonowego) i delaminację. Test weryfikuje, że model może wykrywać pęknięcia na powierzchniach kompozytowych bez pomyłek spowodowanych wzorem podłoża.
Porowate warstwy ścieralne (PFC): Wysokoprzepuszczalny asfalt stosowany na pasach startowych w celu poprawy drenażu i przyczepności. PFC ma charakterystyczną otwartą teksturę, która wygląda wizualnie inaczej niż gęstoziarnisty HMA. Test weryfikuje, że model nie generuje podwyższonego wskaźnika fałszywych alarmów na powierzchniach PFC, gdzie szorstka tekstura może być mylona z pęknięciami lub odpryskami.
Załącznik 14 ICAO i FAA AC 150/5320-5D określają, że oceny stanu nawierzchni pasów startowych muszą być ważne w warunkach operacyjnych. Test dymny przydatności domenowej weryfikuje, że głowica defektów utrzymuje wydajność w:
Bezpośrednim świetle słonecznym: Wysoki kontrast, silne cienie. Test weryfikuje, że wartości ufności nie są systematycznie niższe w warunkach wysokiego kontrastu z powodu fałszywych alarmów wywołanych cieniami.
Zachmurzeniu/świetle rozproszonym: Niski kontrast, brak cieni. Test weryfikuje, że drobne pęknięcia (wąskie, o niskim kontraście względem nawierzchni) są nadal wykrywalne przy obniżonych poziomach ufności.
Mokrej nawierzchni: Woda w pęknięciach zwiększa widoczność pęknięć, ale wprowadza odbicia zwierciadlane. Test weryfikuje, że mokre kafelki powierzchni nie generują podwyższonych fałszywych alarmów z powodu błysków odbitych mylonych z wykwitami (oba pojawiają się jako jasne obszary).
Świcie/zmierzchu: Niski poziom światła, długie cienie. Test weryfikuje, że model generuje wyniki w oczekiwanych zakresach ufności nawet przy obniżonych poziomach oświetlenia.
Test dymny symuluje te warunki poprzez stosowanie kontrolowanych przekształceń fotometrycznych do syntetycznych obrazów testowych: skalowanie jasności dla symulacji oświetlenia, rozmycie gaussowskie dla symulacji mgły i dostosowanie nasycenia dla symulacji mokrej powierzchni.
Obrazy inspekcyjne różnią się odległością próbkowania terenu (GSD) w zależności od platformy przechwytywania:
| Platforma | Typowa wysokość | GSD (mm/piksel) | Pokrycie kafelka |
|---|---|---|---|
| UAV (wysoka rozdzielczość) | 15-20 m | 0,5-1,0 | 0,1-0,5 m² |
| UAV (standard) | 30-50 m | 1,0-2,0 | 0,5-2,0 m² |
| Zamontowana na pojeździe | 2-3 m | 0,3-0,8 | 0,05-0,2 m² |
| Ręczna | 1-1,5 m | 0,2-0,5 | 0,02-0,08 m² |
Test dymny weryfikuje, że głowica defektów generuje spójne wyniki w zakresie różnych rozdzielczości wejściowych. Syntetyczne obrazy testowe są generowane w wielu skalach (0,5×, 1,0×, 2,0× nominalnego GSD) i przepuszczane przez model. Test sprawdza, że przewidywany rozkład klas nie przesuwa się o więcej niż 10% między rozdzielczościami, zapewniając, że model jest w przybliżeniu niezmienniczy względem skali w zakresie operacyjnym.
ASTM D5340 definiuje trzy poziomy nasilenia (Niski, Średni, Wysoki) dla każdego typu defektu. Test dymny weryfikuje, że wyniki ufności głowicy defektów korelują z nasileniem defektu:
Niskie nasilenie: Włoskowate pęknięcia (szerokość <1mm), małe odpryski (długość <150mm), lekkie wykwity, minimalne plamy korozji. Test sprawdza, że te generują wyniki ufności powyżej progu detekcji (>0,5), ale nie na maksymalnym poziomie ufności (<0,8).
Średnie nasilenie: Pęknięcia (szerokość 1-3mm), odpryski (długość 150-600mm), umiarkowane osady wykwitów, widoczne odsłonięte zbrojenie z lekką korozją. Test sprawdza, że wyniki ufności są wysokie (>0,7).
Wysokie nasilenie: Szerokie pęknięcia (szerokość >3mm), duże odpryski (długość >600mm), ciężkie wykwity z naruszeniem powierzchni, odsłonięte zbrojenie z silną korozją i utratą przekroju. Test sprawdza, że wyniki ufności są bardzo wysokie (>0,9).
Weryfikacja korelacji nasilenia jest asercją na poziomie ostrzeżenia w systemie bramkowania — model może nadal działać poprawnie, nawet jeśli korelacja nasilenia jest niedoskonała, ale test oznacza to jako obszar do poprawy modelu.
Zrozumienie różnicy między testem dymnym a pełną ewaluacją jest kluczowe dla zaprojektowania skutecznej strategii zapewnienia jakości ML. Te dwa podejścia służą zasadniczo różnym celom i działają w różnych punktach cyklu rozwoju i wdrożenia.
| Wymiar | Test Dymny | Pełna Ewaluacja |
|---|---|---|
| Cel | Weryfikacja integralności potoku | Pomiar jakości modelu |
| Pytanie | “Czy potok działa poprawnie?” | “Czy model jest wystarczająco dokładny?” |
| Dane | Syntetyczne / mały statyczny zestaw (10-100 obrazów) | Duży wstrzymany zbiór walidacyjny (500-5000+ obrazów) |
| Czas trwania | Sekundy do minut | Minuty do godzin |
| Obliczenia | CPU lub minimalny GPU | Pełny GPU (często multi-GPU) |
| Częstotliwość | Każde zatwierdzenie / PR | Nocnie, tygodniowo lub na wydanie |
| Progi metryk | Łagodne (AP > 0,50) | Rygorystyczne (AP > 0,75) |
| Zasięg | Tylko integralność strukturalna | Generalizacja statystyczna |
| Działanie po niepowodzeniu | Blokada scalenia/wdrożenia | Oznaczenie do przeglądu |
Test dymny ma na celu wyłapanie błędów potoku — klasy błędów, które powodują całkowitą awarię systemu lub generowanie bezwartościowych wyników. Obejmują one uszkodzenie punktu kontrolnego, niezgodność wersji, przerwy w potoku wstępnego przetwarzania, brakujące kolumny, wyniki NaN i niezgodności kształtu. Dane branżowe od zespołów inżynierii ML pokazują, że błędy potoku stanowią 60-70% nieudanych sesji trenowania i 40% wycofań wdrożeń. Testy dymne wyłapują te błędy w sekundach, zanim zostaną uruchomione kosztowne pełne ewaluacje.
Pełna ewaluacja ma na celu pomiar jakości modelu — statystycznej dokładności, precyzji, czułości i generalizacji predykcji modelu. Wykorzystuje duże, różnorodne, reprezentatywne zbiory walidacyjne, oblicza rygorystyczne metryki (AP@0.50 :0.95, F1 dla klas, macierze pomyłek, krzywe precyzji i czułości przy wielu progach) i porównuje wyniki zarówno z bezwzględnymi progami, jak i względnymi wartościami bazowymi z poprzednich wersji modelu. Pełne ewaluacje są kosztowne obliczeniowo i czasochłonne, co czyni je nieodpowiednimi do wykonywania przy każdym zatwierdzeniu.
Dane testu dymnego są generowane syntetycznie, aby były proste, czyste i deterministyczne. Każdy syntetyczny obraz zawiera dokładnie jeden typ defektu na jednolitym tle, bez okluzji, nakładających się defektów i trudnych warunków oświetleniowych. Minimalizuje to zmienność i zapewnia, że każda fluktuacja metryki w teście dymnym jest przypisywana modelowi, a nie zmienności danych.
Pełne dane ewaluacyjne to rzeczywiste obrazy inspekcyjne o następujących cechach: różnorodne typy i wieki nawierzchni, wszystkie operacyjne warunki oświetleniowe, różne poziomy nasilenia defektów, nakładające się i sąsiadujące defekty, rzeczywiste okluzje (gruz, ślady opon, woda) oraz dokładne adnotacje prawdy podstawowej na poziomie wielokątów. Dane te reprezentują prawdziwy rozkład, z którym model spotyka się w produkcji, i zapewniają wiarygodne oszacowanie wydajności wdrożeniowej.
Zapobieganie wyciekom danych jest krytyczne dla pełnej ewaluacji, ale nieistotne dla testów dymnych — ponieważ test dymny używa danych syntetycznych, nie ma ryzyka wycieku rzeczywistych danych testowych do trenowania. Zbiór danych pełnej ewaluacji jest starannie podzielony: zestawy treningowe, walidacyjne i testowe są dzielone na poziomie klatki lub pasa startowego (nie na poziomie kafelka), aby zapobiec wyciekom autokorelacji przestrzennej, gdzie sąsiednie kafelki z tego samego pasa startowego pojawiają się zarówno w zestawie treningowym, jak i testowym.
Typowe uruchomienie testu dymnego dla potoku głowicy defektów:
Typowe uruchomienie pełnej ewaluacji:
Test dymny jest 10-100× szybszy niż pełna ewaluacja, umożliwiając wykonanie przy każdym zatwierdzeniu. Pełna ewaluacja jest uruchamiana w wolniejszym rytmie (na noc, na wydanie, na promocję do produkcji).
| Tryb awarii | Wykrywany przez |
|---|---|
| Uszkodzony plik punktu kontrolnego | Test dymny (krytyczny) |
| NaN/inf w wynikach modelu | Test dymny (krytyczny) |
| Brakujące kolumny wyjściowe | Test dymny (poważny) |
| Nieprawidłowy kształt tensora wyjściowego | Test dymny (poważny) |
| Niezgodność normalizacji wstępnego przetwarzania | Test dymny (krytyczny) |
| Zdegenerowane predykcje (wszystkie ta sama klasa) | Test dymny (ostrzeżenie) |
| 10% spadek AP na nowych danych | Pełna ewaluacja |
| Nadmierne dopasowanie do konkretnego typu nawierzchni | Pełna ewaluacja |
| Dryf kalibracji | Pełna ewaluacja |
| Szum etykiet w danych treningowych | Pełna ewaluacja |
Macierz pokrycia pokazuje, że testy dymne i pełne ewaluacje są komplementarne — każdy wyłapuje tryby awarii, które drugi pomija. Kompleksowa strategia testowania ML wymaga obu.
Integracja testu dymnego głowicy defektów z potokami ciągłej integracji (CI) jest niezbędna do wczesnego wyłapywania regresji i zapewnienia, że każda zmiana kodu jest walidowana przed wpływem na systemy produkcyjne.
Potok CI dla systemu detekcji defektów TarmacView jest zorganizowany w sekwencyjne etapy:
Etap 1 — Jakość kodu: Linting (flake8, pylint), sprawdzanie typów (mypy), testy jednostkowe (pytest dla narzędzi ładowania danych, funkcji wstępnego przetwarzania i funkcji obliczania metryk). Ten etap działa na CPU i kończy się w 1-3 minutach. Niepowodzenie blokuje wszystkie dalsze etapy.
Etap 2 — Walidacja danych: Walidacja schematu zbiorów danych treningowych i ewaluacyjnych przy użyciu Great Expectations lub TensorFlow Data Validation. Sprawdza obecność kolumn, typy danych, zakresy wartości i statystyki rozkładu względem oczekiwań zdefiniowanych w kontrakcie danych. Ten etap działa na CPU i kończy się w 2-5 minutach.
Etap 3 — Test dymny głowicy defektów: Pełny zestaw testów dymnych opisany w tym artykule. Działa na CPU (lub minimalnym GPU, jeśli dostępny) i kończy się w 15-60 sekundach. Niepowodzenie blokuje scalenie do gałęzi main.
Etap 4 — Testy jednostkowe ewaluacji: Testy obliczania metryk w małej skali, które weryfikują, że obliczanie AP, F1 i generowanie macierzy pomyłek generuje poprawne wyniki na ręcznie oznaczonych małych zbiorach danych (5-10 obrazów ze znaną prawdą podstawową). Działa na CPU, kończy się w 30 sekund.
Etap 5 — Trenowanie (na żądanie): Uruchamiane tylko wtedy, gdy oczekuje się zmiany wag modelu (nowe dane treningowe, zmiany architektury, dostrajanie hiperparametrów). Nie uruchamiane automatycznie przy każdym zatwierdzeniu. Działa na GPU i zajmuje 1-8 godzin w zależności od rozmiaru zbioru danych.
Etap 6 — Pełna ewaluacja (przy scalaniu do main): Uruchamiana, gdy kod jest scalany do gałęzi main. Uruchamia pełny zestaw ewaluacyjny na wstrzymanym zbiorze walidacyjnym, oblicza wszystkie metryki, porównuje z wartościami bazowymi i publikuje wyniki w rejestrze modeli. Działa na GPU i zajmuje 20-40 minut.
Test dymny jest uruchamiany:
Artefakty CI z testu dymnego są przechowywane i wersjonowane:
Te artefakty są przechowywane w rejestrze modeli obok samego artefaktu modelu, zapewniając pełny łańcuch audytu: “Ta wersja modelu przeszła test dymny z syntetycznymi danymi v3.2 w uruchomieniu CI #4827 z zatwierdzeniem a3f2c1.”
Gdy test dymny kończy się niepowodzeniem, powiadomienia są wysyłane przez wiele kanałów:
Powiadomienie zawiera ustrukturyzowany raport błędu:
Temat: [TEST DYMANY: NIEPOWODZENIE] potok defect-head - main - uruchomienie #4827
Treść:
Zatwierdzenie: a3f2c1 (scalone 12:34 UTC)
Punkt kontrolny: defect-head:v3 (kandydat produkcyjny)
Wynik: NIEPOWODZENIE (gate_score=1.0)
Krytyczne (1):
- [output_nan] Tensor wyjściowy zawiera wartości NaN
Przejście w przód szkieletu wyprodukowało NaN w normalizacji warstwy 8
Poważne (0):
Ostrzeżenia (2):
- [class_efflorescence_ap] AP@0.50 = 0,42 poniżej progu 0,50
- [class_efflorescence_f1] F1 = 0,55 poniżej progu 0,60
Wymagane działanie: Zbadaj NaN w normalizacji warstwy 8 szkieletu.
Możliwe przyczyny: uszkodzony punkt kontrolny, niezgodność wersji CUDA,
lub niestabilność numeryczna w obliczeniach atencji.
Poprawna interpretacja wyników testów dymnych jest niezbędna do diagnozowania problemów z potokiem i określania odpowiednich działań naprawczych.
Test dymny generuje kompleksowy raport JSON o następującej strukturze:
{
"pipeline_id": "defect-head-smoke",
"run_id": "2026-06-16-4827",
"timestamp": "2026-06-16T12:34:56Z",
"commit_sha": "a3f2c1d4e5b6...",
"checkpoint_version": "defect-head:v3",
"synthetic_data_version": "v3.2",
"gate_result": "FAIL",
"gate_score": 1.0,
"assertions": {
"checkpoint_file_exists": {"status": "PASS", "detail": "checkpoint.pt (842MB)"},
"checkpoint_loadable": {"status": "PASS", "detail": "Stan załadowany pomyślnie"},
"forward_pass_shape": {"status": "PASS", "detail": "Kształt wyjścia (8, 5)"},
"output_no_nan": {"status": "FAIL", "detail": "NaN znalezione w 1 z 8 próbek batcha"},
"output_no_inf": {"status": "PASS", "detail": "Brak wartości inf"},
"softmax_sum": {"status": "PASS", "detail": "Wszystkie sumy w zakresie 1e-5 od 1.0"},
"tile_columns_exist": {"status": "PASS", "detail": "Wszystkie 5 kolumn kafelków obecne"},
"frame_columns_exist": {"status": "PASS", "detail": "Wszystkie 7 kolumn klatek obecne"},
"column_value_ranges": {"status": "PASS", "detail": "Wszystkie wartości w [0.0, 1.0]"},
"class_crack_ap50": {"status": "PASS", "detail": "AP@0.50 = 0.92"},
"class_spalling_ap50": {"status": "PASS", "detail": "AP@0.50 = 0.88"},
"class_efflorescence_ap50": {"status": "WARN", "detail": "AP@0.50 = 0.42"},
"class_exposed_rebar_ap50": {"status": "PASS", "detail": "AP@0.50 = 0.91"},
"class_corrosion_ap50": {"status": "PASS", "detail": "AP@0.50 = 0.90"}
}
}
Raport należy czytać od góry do dołu, najpierw zajmując się niepowodzeniami krytycznymi (ponieważ unieważniają one wszystkie dalsze wyniki), następnie poważnymi (problemy strukturalne, które spowodowałyby awarie produkcyjne), a na końcu ostrzeżeniami (regresje jakości, które mogą wymagać zbadania).
Niepowodzenia krytyczne wskazują, że potok jest całkowicie niefunkcjonalny. Najczęstsze przyczyny i działania naprawcze:
Plik punktu kontrolnego nie znaleziony: Ścieżka punktu kontrolnego określona w konfiguracji potoku nie wskazuje na istniejący plik. Działanie naprawcze: zweryfikuj ścieżkę rejestru modeli, sprawdź, czy sesja trenowania zakończyła się i przesłała artefakt, lub zaktualizuj konfigurację z poprawną ścieżką.
Niepowodzenie ładowania punktu kontrolnego: torch.load() zgłosił wyjątek. Typowe przyczyny obejmują: uszkodzenie pliku (ponownie uruchom trenowanie lub przywróć z kopii zapasowej), niezgodność wersji PyTorch (sprawdź, czy środowisko wdrożeniowe ma tę samą wersję PyTorch co środowisko trenowania — torch.save() w PyTorch 2.0 produkuje pliki, które ładują się inaczej na PyTorch 1.x) lub niezgodność CUDA/bez CUDA (punkt kontrolny zapisany z tensorami CUDA może nie załadować się w środowisku tylko CPU bez map_location='cpu').
NaN w wynikach: Najbardziej wymagające technicznie krytyczne niepowodzenie. Typowe przyczyny obejmują: niestabilność numeryczną w mechanizmie atencji DINOv3 (przepełnienie normalizacji warstwy przy ekstremalnych wartościach wejściowych), uszkodzone wagi w konkretnej warstwie (sprawdź, która warstwa produkuje NaN, uruchamiając z torch.autograd.set_detect_anomaly(True)), lub wstępne przetwarzanie generujące wejścia poza zakresem (np. wartości pikseli poza [0,1] po normalizacji).
Niezgodność kształtu wyników: Tensor wyjściowy ma inny kształt niż oczekiwany. Typowe przyczyny obejmują: głowica MLP została zastąpiona inną architekturą (inna liczba klas wyjściowych), zmienił się wymiar osadzenia szkieletu (punkt kontrolny z innego wariantu DINOv3) lub wymiar batcha został ściśnięty/rozciągnięty nieprawidłowo w kodzie post-processingu.
Niepowodzenia poważne wskazują na problemy strukturalne, które spowodowałyby nieprawidłowe działanie produkcyjne.
Brakujące kolumny: DataFrame wyników analizy nie zawiera oczekiwanych kolumn. Typowe przyczyny: konwencja nazewnictwa kolumn została zmieniona bez aktualizacji konsumentów downstream, logika agregacji została zmodyfikowana w celu zmiany nazw kolumn lub zmieniono wyniki głowicy defektów (np. z 5 klas na 4 klasy).
Naruszenia zakresu wartości: Wartości ufności poza [0.0, 1.0]. To prawie zawsze wskazuje na awarię softmax — albo softmax nie został zastosowany do logitów, albo użyto niewłaściwej osi do normalizacji softmax. Sprawdź, czy używane jest F.softmax(logits, dim=1) (wymiar klas, nie wymiar batcha).
NaN w kolumnach wyjściowych: Podobne do krytycznych NaN w wynikach modelu, ale występujące w kroku agregacji post-processingu. Sprawdź dzielenie przez zero w agregacji kafelek-do-klatki (np. dzielenie przez liczbę kafelków, gdy klatka ma zero kafelków) lub propagację brakujących wartości z NaN wyników modelu, które nie zostały wyłapane na poziomie modelu.
Niepowodzenia ostrzeżeń wskazują na degradację jakości, która może nie wymagać natychmiastowego blokowania wdrożenia, ale powinna być zbadana.
AP dla konkretnej klasy poniżej progu: Pojedyncza klasa defektu wykazuje znacząco niższą wydajność niż inne. Typowe przyczyny: niewystarczająca liczba syntetycznych przykładów treningowych dla tej klasy (generator danych syntetycznych może produkować nierealistyczne przykłady dla niektórych klas), brak równowagi klas w rzeczywistych danych treningowych wpływający na zdolność dyskryminacyjną głowicy dla rzadkich klas lub cechy szkieletu będące mniej informacyjne dla niektórych typów defektów (np. wykwit charakteryzuje się kolorem (białe osady) bardziej niż teksturą, podczas gdy cechy DINOv3 mogą kłaść nacisk na teksturę ponad kolor).
Brak równowagi precyzji i czułości: Model jest zbyt konserwatywny lub zbyt agresywny dla określonych klas. Typowe przyczyny: próg ufności został zoptymalizowany pod kątem ogólnej wydajności, ale jest suboptymalny dla poszczególnych klas, lub dane treningowe mają asymetryczny szum (więcej fałszywie negatywnych niż fałszywie pozytywnych dla określonej klasy).
Dryf metryk od wartości bazowej: Metryki zmieniły się o więcej niż 5% od ostatniego zwalidowanego uruchomienia bez zmian kodu lub danych. Może to wskazywać na: niedeterminizm w modelu (warstwy dropout lub normalizacji batcha zachowujące się inaczej w trybie trenowania vs ewaluacji — upewnij się, że model.eval() jest wywoływane przed inferencją), dryf numeryczny spowodowany różnicami sprzętowymi (kolejność akumulacji zmiennoprzecinkowej CPU vs GPU) lub zmiany generatora danych syntetycznych produkujące inne próbki testowe.
Wyniki testu dymnego zawierają sugestie naprawcze dla typowych trybów awarii:
| Niepowodzenie | Sugestia naprawcza |
|---|---|
| Punkt kontrolny nie znaleziony | Zweryfikuj ścieżkę rejestru modeli; uruchom trenowanie, aby wygenerować punkt kontrolny |
| NaN w szkielecie | Przełącz na precyzję float32, jeśli używasz float16; dodaj przycinanie gradientów |
| Brakująca kolumna | Zaktualizuj nazwy kolumn w logice agregacji, aby dopasować do schematu |
| Niska AP dla konkretnej klasy | Dodaj więcej syntetycznych przykładów treningowych dla tej klasy; sprawdź równowagę klas |
| Dryf metryk | Uruchom inferencję z torch.inference_mode() i model.eval(); sprawdź operacje niedeterministyczne |
Te sugestie są generowane przez system regułowy, który mapuje wzorce niepowodzeń asercji na znane działania naprawcze, redukując średni czas do rozwiązania (MTTR) dla typowych trybów awarii.

TarmacView wdraża rygorystyczne potoki testów dymnych i ewaluacji dla wykrywania defektów strukturalnych opartego na AI na nawierzchniach lotniskowych i infrastrukturze betonowej. Umów się na demo, aby zobaczyć, jak zautomatyzowane testowanie zapewnia niezawodność wdrożenia.
Test dymny to szybka, kompleksowa weryfikacja, czy pipeline oprogramowania wykonuje się bez awarii na reprezentatywnych danych, produkując oczekiwane wyniki. Sk...
Defect gating to strategia wnioskowania, która filtruje przewidywane etykiety wad w zależności od rodzaju nawierzchni i domeny strukturalnej, tłumiąc fałszywie ...
Lab-only odnosi się do właściwości nawierzchni, których nie można wiarygodnie określić na podstawie pojedynczych obrazów RGB — zawartości lepiszcza asfaltowego,...