FAISS (Facebook AI Similarity Search) je open-source knižnica na efektívne vyhľadávanie podobnosti a zhlukovanie hustých vektorov, ktorú TarmacView používa na ukladanie a dopytovanie približne 9 000 označených referenčných embeddingov pre klasifikáciu kvality povrchu na základe najbližších susedov. Zahŕňa typy indexov (Flat, IVF, HNSW), kosínusovú podobnosť prostredníctvom skalárneho súčinu na normalizovaných vektoroch, GPU akceleráciu a aplikáciu na vyhľadávanie inšpekčných snímok.
FAISS – Vysokovýkonné vyhľadávanie podobnosti vo vektorových embeddingoch
Definícia a možnosti
FAISS (Facebook AI Similarity Search) je open-source knižnica v C++ vyvinutá tímom Fundamental AI Research (FAIR) v Meta na efektívne vyhľadávanie podobnosti a zhlukovanie hustých vektorov. Prvýkrát vydaná v roku 2017, FAISS získala viac ako 40 000 hviezdičiek na GitHub a viac ako 5 200 citácií svojho článku o GPU implementácii. Balíky FAISS boli stiahnuté viac ako 6 miliónov krát z Conda repozitárov. Hlavné vektorové databázové spoločnosti vrátane Zilliz (Milvus) a Pinecone sa buď spoliehajú na FAISS ako svoj základný engine, alebo znovu implementovali algoritmy FAISS vo svojich produkčných systémoch.
FAISS je cielene navrhnutý na riešenie výpočtovej výzvy hľadania najbližších susedov vo vysokorozmerných vektorových priestoroch. Základnou operáciou je vyhľadávanie podobnosti: pre daný dopytovaný vektor q FAISS identifikuje vektory v referenčnej množine, ktoré sú najbližšie podľa zadanej metriky vzdialenosti. Formálne, pre množinu referenčných vektorov {x₁, …, xₙ} v dimenzii d, FAISS efektívne vypočíta j = argminᵢ ||q - xᵢ|| kde ||·|| je Euklidovská vzdialenosť. Knižnica tiež dokáže vykonávať vyhľadávanie maximálneho skalárneho súčinu argmaxᵢ ⟨q, xᵢ⟩ a podporuje ďalšie metriky vrátane L1, Linf, Canberra, Bray-Curtis, Jensen-Shannon a Hammingových vzdialeností prostredníctvom svojich implementácií IndexFlat a IndexHNSW. FAISS nevracia len jediného najbližšieho suseda, ale k najbližších susedov, podporuje dávkové spracovanie viacerých dopytov súčasne a dokáže vykonávať vyhľadávanie v rozsahu (range search), ktoré vracia všetky prvky v rámci daného polomeru.
Knižnica pracuje s hustými vektormi — poľami s pevnou dĺžkou 32-bitových čísel s pohyblivou rádovou čiarkou — ktoré reprezentujú dátové body vložené do spojitého vektorového priestoru. Tieto vektory sú typicky generované hlbokými neurónovými sieťami ako Vision Transformery (ViT), konvolučné neurónové siete (CNN) alebo veľké jazykové modely. V moderných pipeline strojového učenia slúžia embeddingy ako medziľahlé reprezentácie, ktoré mapujú komplexné vstupné médiá do vektorového priestoru, kde priestorová blízkosť kóduje sémantiku. FAISS je mostom medzi extrakciou embeddingov a downstream úlohami založenými na podobnosti: indexuje extrahované embeddingy a umožňuje rýchle vyhľadávacie operácie.
FAISS je rozsiahlo optimalizovaný pre moderné hardvérové architektúry. Na CPU využíva BLAS (Basic Linear Algebra Subprograms) knižnice ako Intel MKL, OpenBLAS alebo Apple Accelerate na vykonávanie rýchlych maticových operácií. Podporuje SIMD vektorizáciu (SSE, AVX2, AVX-512) na x86 architektúrach a Neon intrinsics na ARM procesoroch. Na GPU poskytuje FAISS natívne CUDA implementácie, ktoré môžu dosiahnuť 5–10x zlepšenie priepustnosti oproti CPU pre typické úlohy. GPU implementácia podporuje viacero GPU paralelne, čo umožňuje distribuované vyhľadávanie naprieč viacerými zariadeniami súčasne.
FAISS nie je vektorová databáza — je to knižnica na vyhľadávanie, ktorá môže byť vložená priamo do aplikácií. Na rozdiel od plnohodnotných databázových systémov (Pinecone, Milvus, Qdrant, Weaviate), FAISS neposkytuje vstavanú perzistenciu, replikáciu, riadenie prístupu, súbežný zápis, load balancing, sharding, správu transakcií ani optimalizáciu dopytov. Namiesto toho poskytuje čisté C++ a Python API na vytváranie, dopytovanie, ukladanie a načítavanie indexov. Toto zámerné obmedzenie rozsahu umožňuje FAISS dosiahnuť maximálny výkon pre základnú operáciu vyhľadávania najbližších susedov. Rozsah knižnice je zámerne obmedzený na implementáciu algoritmov Approximate Nearest Neighbor Search (ANNS), a ako uvádza pôvodný FAISS článok: “Faiss nie je databáza — neposkytuje súbežný zápis, load balancing, sharding, správu transakcií ani optimalizáciu dopytov.”
Typy indexov
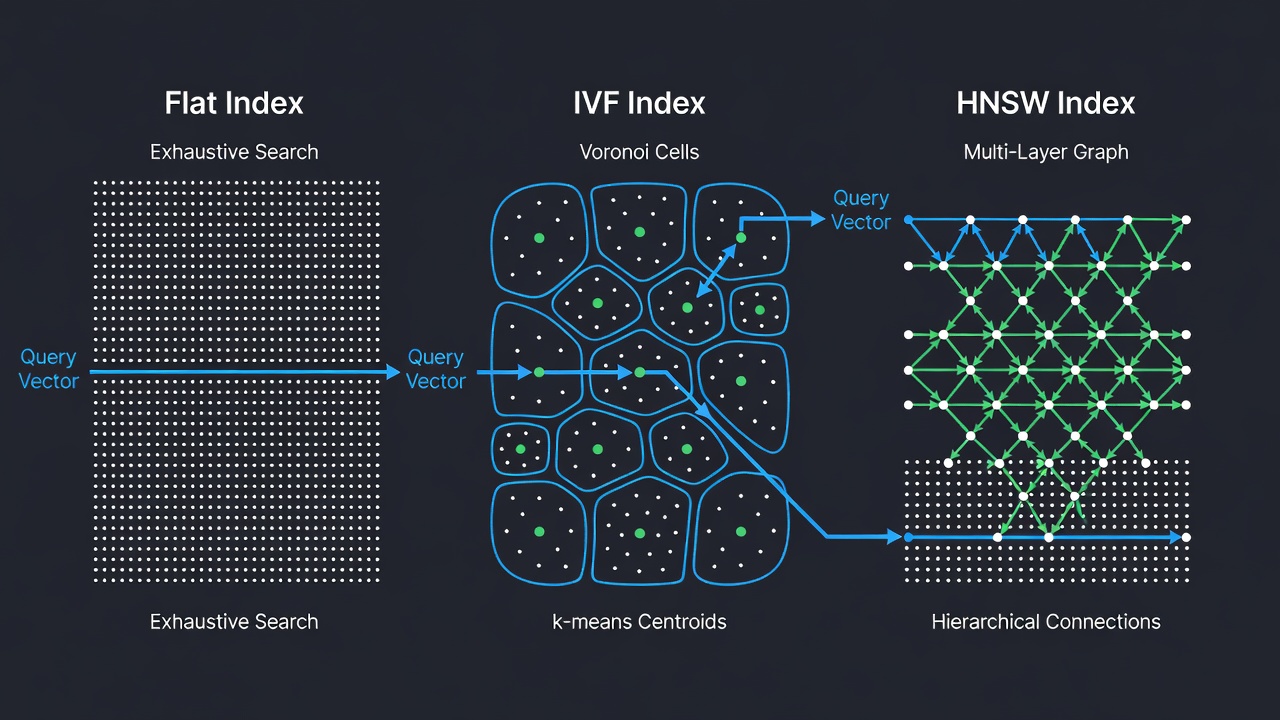
FAISS poskytuje viac ako dvadsať rôznych typov indexov, pričom každý je navrhnutý pre špecifickú kombináciu kompromisov medzi presnosťou, rýchlosťou a pamäťou. Tri najzákladnejšie a najpoužívanejšie typy indexov sú IndexFlat (presné vyhľadávanie), IndexIVF (invertovaný súbor s k-means zhlukovaním) a IndexHNSW (hierarchický navigovateľný graf malého sveta). Každý typ indexu je dostupný s rôznymi metrikami vzdialenosti a kódovanými variantmi (napr. FlatIP pre skalárny súčin, FlatL2 pre L2 vzdialenosť). FAISS indexy môžu byť hierarchicky zložené — napríklad použitím HNSW ako hrubého kvantizátora pre IVF index, čím vzniká zložená štruktúra IndexIVFPQ, ktorá poháňa nasadenia v miliardovom meradle.
IndexFlatIP – Presné hrubé vyhľadávanie
IndexFlatIP je najjednoduchší FAISS index. Ukladá všetky vektory v plochom poli a vykonáva vyčerpávajúce hrubé vyhľadávanie proti každému vektoru v datasete. Pre každý dopyt vypočíta skalárny súčin medzi dopytom a každým uloženým vektorom, potom vráti indexy a vzdialenosti top-k výsledkov. Tento index zaručene vráti presných najbližších susedov — žiadne aproximácie, žiadne zníženie recallu. Je to jediný FAISS index, ktorý poskytuje túto záruku; všetky ostatné indexy sú aproximatívne a obetujú určitý recall v prospech vyššej rýchlosti alebo nižšej spotreby pamäte.
Výpočtová komplexita IndexFlatIP je O(N × D) na dopyt, kde N je počet referenčných vektorov a D je dimenzionalita. Index používa vysoko optimalizovanú BLAS gemm (general matrix multiply) rutinu na výpočet všetkých skalárnych súčinov v jedinej maticovej multiplikácii. Pre dataset 100 000 vektorov so 768 dimenziami (typická veľkosť embeddingu z DINOv2 ViT) trvá jeden dopyt na CPU približne 5–15 milisekúnd v závislosti od hardvéru a optimalizácie BLAS. V dávkovom režime s 1 000 dopytmi spracúva index všetky naraz pomocou maticovo-maticovej multiplikácie, čím dosahuje výrazne vyššiu priepustnosť ako 1 000 individuálnych dopytov.
IndexFlatIP zohráva kritickú úlohu v ekosystéme FAISS ako orákulum základnej pravdy (ground-truth) pre hodnotenie presnosti aproximatívnych indexov. Praktici vytvárajú plochý index popri svojom aproximatívnom indexe, spúšťajú identické dopyty proti obom a vypočítavajú metriky recallu. Štandardná sada benchmarkov FAISS (faiss_benchmarks) používa túto metodológiu na kvantifikáciu degradácie presnosti IVF, HNSW a PQ indexov. V TarmacView sa IndexFlatIP používa ako základná referencia (baseline) pre validáciu systému, čím sa zaisťuje, že aproximatívne indexy používané v produkcii udržiavajú prijateľný recall.
Index sa vytvára s minimálnym kódom: index = faiss.IndexFlatIP(d) kde d je dimenzionalita embeddingu. Vektory sa pridávajú pomocou index.add(embeddings). Vyhľadávanie sa vykonáva pomocou index.search(query, k), ktoré vracia dve float32 polia: vzdialenosti (tvar [n_queries, k]) a indexy (tvar [n_queries, k], dtype int64). Pre skalárny súčin väčšie hodnoty vzdialenosti indikujú väčšiu podobnosť. Index nevyžaduje trénovací krok, pretože neexistujú žiadne parametre na učenie — vektory sú uložené a porovnávané doslovne.
IndexIVFFlat – Invertovaný súbor s k-Means zhlukovaním
IndexIVFFlat je aproximatívny index najbližších susedov, ktorý rozdeľuje vektorový priestor na Voronoiove bunky pomocou k-means zhlukovania. Architektúra je odvodená od prelomového článku “Video Google” od Sivica a Zissermana (ICCV 2003), ktorý adaptoval techniky vyhľadávania textu na vizuálne porovnávanie objektov. Počas indexovania je dataset zhlukovaný do nlist zhlukov pomocou k-means a každý vektor je priradený k svojmu najbližšiemu centroidu zhluku. Centroidy sú uložené v hrubom kvantizátore (typicky IndexFlatL2). Počas vyhľadávania sa skúmajú len vektory v nprobe najbližších zhlukov k dopytu, čím sa dramaticky znižuje počet potrebných výpočtov vzdialenosti.
Zrýchlenie oproti IndexFlatIP je približne N / ((N / nlist) × nprobe). Pri nlist=100 a nprobe=5 sa prehľadáva len 5 % databázy — dopyty, ktoré trvali 10 ms na plochom indexe, môžu byť dokončené za 0,5 ms. Kompromisom je však degradácia recallu: niektoré skutočné najbližšie susedy môžu ležať mimo prehľadávaných zhlukov a môžu byť vynechané. Krok trénovania k-means je kľúčový pre kvalitu recallu — centroidy musia presne reprezentovať distribúciu dát. FAISS vyžaduje, aby trénovacia množina obsahovala aspoň 30 × nlist vektorov pre spoľahlivý odhad centroidov.
Kľúčové parametre pre IndexIVFFlat:
Parameter
Popis
Typický rozsah
Vplyv
nlist
Počet Voronoiových buniek (zhlukov)
10 – 100 000
Vyššie = jemnejšie rozdelenie, viac pamäte pre centroidy, pomalšie k-means trénovanie
nprobe
Počet buniek prehľadávaných pri dopyte
1 – 100+
Vyššie = lepší recall (až 99%), lineárne pomalšie vyhľadávanie
metric
Metrika vzdialenosti (L2 alebo IP)
L2 alebo IP
Určuje, ako sa počítajú vzdialenosti medzi vektormi a centroidmi
Parameter nprobe je obzvlášť dôležitý, pretože riadi kompromis medzi rýchlosťou a presnosťou v čase vyhľadávania bez potreby rekonštrukcie indexu. V čase dopytu možno nprobe dynamicky nastaviť: na vysokú hodnotu (napr. 20–50) počas offline kritických operácií, kde je presnosť prvoradá, a na nízku hodnotu (napr. 1–5) počas vysokopriepustných produkčných behov, kde sa uprednostňuje rýchlosť. FAISS poskytuje mechanizmus automatického ladenia (AutoTune), ktorý prehľadáva hodnoty nprobe, aby našiel optimálnu konfiguráciu pre cieľový recall.
Vytvorenie IndexIVFFlat vyžaduje trojfázový pipeline: trénovanie, pridávanie a vyhľadávanie. Počas trénovania beží k-means na reprezentatívnej vzorke na naučenie centroidov zhlukov. Počas pridávania je každý databázový vektor priradený k svojmu najbližšiemu centroidu a pridaný do invertovaného zoznamu tohto centroidu. Počas vyhľadávania je dopyt porovnaný so všetkými centroidmi, vyberie sa nprobe najbližších a len vektory v týchto vybraných zoznamoch sú porovnávané vyčerpávajúco. Reťazcová špecifikácia pre IndexIVFFlat so skalárnym súčinom je "IVF100,Flat", kde 100 je hodnota nlist. V Pythone: index = faiss.index_factory(d, "IVF100,Flat", faiss.METRIC_INNER_PRODUCT).
Veľkosť datasetu
Odporúčané nlist
Odporúčané nprobe
Očakávaný recall
Zrýchlenie oproti Flat
10 000
10 – 100
1 – 5
95–98 %
5–20x
100 000
100 – 1 000
5 – 20
95–99 %
20–100x
1 000 000
1 000 – 10 000
10 – 50
95–99 %
100–500x
10 000 000
10 000 – 100 000
20 – 100
90–98 %
500–5000x
IndexHNSWFlat – Hierarchický navigovateľný graf malého sveta
IndexHNSWFlat je grafový aproximatívny index najbližších susedov, ktorý vytvára viacvrstvový hierarchický graf známy ako Navigovateľný malý svet. Algoritmus, pôvodne publikovaný Malkovom a Yashuninom (2016), je inšpirovaný dátovou štruktúrou skip list. Index organizuje vektory do vrstiev: spodná vrstva (vrstva 0) obsahuje všetky vektory a každá nasledujúca vrstva obsahuje postupne menšiu podmnožinu generovanú pravdepodobnostným priradením úrovne. Pri vkladaní je každému vektoru priradená úroveň l = floor(-ln(uniform(0,1)) × mL) kde mL = 1/ln(M). Vstupný bod je na najvyššej existujúcej vrstve, čo zaručuje logaritmické prechádzanie grafom.
Vyhľadávanie začína na najvyššej vrstve (najhrubšej, s najmenším počtom uzlov) a zostupuje cez vrstvy, pričom v každom kroku spresňuje množinu kandidátov. Na každej vrstve hladové vyhľadávanie prechádza grafom smerom k dopytu tým, že sa vždy presúva k susedovi, ktorý minimalizuje vzdialenosť. Po nájdení lokálneho minima na aktuálnej vrstve algoritmus zostúpi na ďalšiu vrstvu a zopakuje proces, pričom ako počiatočný bod použije výsledok z vyššej vrstvy. Táto hierarchická štruktúra umožňuje logaritmickú komplexitu vyhľadávania O(log N), čo robí HNSW jedným z najrýchlejších aproximatívnych algoritmov najbližších susedov pre stredne veľké až veľké datasety.
HNSW index má tri kritické parametre:
Parameter
Popis
Typický rozsah
Vplyv
M
Maximálny počet obojsmerných spojení na uzol
8 – 64 (štandardne 32)
Vyššie M = hustejšie prepojený graf, lepší recall, viac pamäte
efConstruction
Veľkosť dynamického zoznamu kandidátov počas vytvárania grafu
40 – 200 (štandardne 40)
Vyššie = dôkladnejšie vyhľadávanie počas budovania, kvalitnejší graf, pomalšia výstavba
efSearch
Veľkosť dynamického zoznamu kandidátov počas vyhľadávania
10 – 200 (nastavuje sa pri dopyte)
Vyššie = lepší recall, pomalšie vyhľadávanie (možno ladenie bez prestavby)
Parameter M priamo riadi prepojenosť grafu. Každý uzol udržiava až M obojsmerných hrán k svojim najbližším susedom. Graf používa heuristiku podporujúcu diverzitu počas výberu susedov: keď sa pridáva nový uzol, jeho kandidáti na susedov sú orezaní, aby sa zabezpečila rôznorodá prepojenosť, ktorá zabraňuje dominancii hubových uzlov v štruktúre grafu. Vyššie hodnoty M produkujú robustnejšie smerovanie, ale zvyšujú spotrebu pamäte: približne 4d + M × 2 × 4 bajtov na vektor pre štruktúru grafu plus ukladanie vektorov.
Parameter efConstruction riadi dôkladnosť vyhľadávania počas budovania indexu. Väčšie hodnoty produkujú kvalitnejšie grafy, ale lineárne zvyšujú čas výstavby. Ako pravidlo palca, efConstruction ≈ M × 2 poskytuje dobrú rovnováhu pre väčšinu úloh. Parameter efSearch je analogický s nprobe v IVF indexoch — riadi dôkladnosť vyhľadávania v čase dopytu a možno ho dynamicky nastaviť bez rekonštrukcie indexu.
HNSW indexy ponúkajú niekoľko výhod oproti IVF indexom. Typicky dosahujú vyšší recall pri ekvivalentnej rýchlosti vyhľadávania, najmä na vysokorozmerných dátech (d > 256). Nevyžadujú samostatný trénovací krok (na rozdiel od IVF, ktoré potrebuje k-means zhlukovanie, čo robí HNSW vhodným pre dynamické datasety, kde vektory prichádzajú inkrementálne). Vykazujú pozvoľnú degradáciu recallu pri znižovaní efSearch — recall sa zlepšuje plynule bez ostrých prahov. Avšak HNSW indexy používajú viac pamäte na vektor (zoznamy susedov v grafe pridávajú réžiu) a sú pomalšie na vytvorenie ako IVF indexy. HNSW tiež natívne nepodporuje mazanie vektorov, pretože odstránenie uzlov z grafovej štruktúry by ohrozilo prepojenosť.
Pre referenčnú množinu TarmacView s približne 9 000 embeddingmi dosahuje IndexHNSWFlat s M=32 a efSearch=64 viac ako 99% recall pri dopytoch pod 200 mikrosekúnd na CPU — 50-násobné zrýchlenie oproti IndexFlatIP so zanedbateľnou stratou presnosti. Reťazcová špecifikácia "HNSW32,Flat" vytvára tento index. V Pythone: index = faiss.index_factory(d, "HNSW32,Flat", faiss.METRIC_INNER_PRODUCT).
Kosínusová podobnosť prostredníctvom skalárneho súčinu na normalizovaných vektoroch
Kosínusová podobnosť meria kosínus uhla medzi dvoma nenulovými vektormi — kvantifikuje, ako podobné sú dva vektory bez ohľadu na ich veľkosť. Kosínusová podobnosť medzi vektormi a a b je definovaná ako cos(θ) = (a · b) / (||a|| × ||b||), kde a · b je bodový súčin a ||a|| je L2 norma a. Výsledok sa pohybuje od -1 (úplne opačný smer) po +1 (rovnaký smer), pričom 0 indikuje ortogonalitu.
FAISS neposkytuje špecializovanú metriku kosínusovej podobnosti. Namiesto toho je kosínusová podobnosť implementovaná prostredníctvom dvojkrokovej transformácie, ktorú vývojový tím FAISS považuje za kánonickú. Po prvé, všetky vektory sú L2-normalizované na jednotkovú dĺžku — každý vektor je vydelený svojou L2 normou tak, aby ||a|| = 1 a ||b|| = 1. Po druhé, METRIC_INNER_PRODUCT sa používa ako metrika vzdialenosti. Pre jednotkovo normalizované vektory sa skalárny súčin rovná kosínusovej podobnosti: a · b = cos(θ). Táto ekvivalencia priamo vyplýva z kosínusového vzorca: keď sa menovateľ rovná 1, vzorec sa redukuje na bodový súčin.
Táto normalizačná technika je štandardná v systémoch vektorového vyhľadávania, pretože skalárny súčin je efektívne vypočítateľný vysoko optimalizovanými BLAS maticovými multiplikačnými rutinami. Výpočtová náročnosť normalizácie všetkých vektorov v indexe je jednorazová operácia O(N × D) v čase budovania indexu a normalizácia každého dopytu je O(D) — zanedbateľná v porovnaní s nákladmi samotného vyhľadávania. L2 normalizácia sa aplikuje pred pridaním vektorov do indexu a pred odoslaním dopytov, čo zaisťuje, že všetky porovnania sú v priestore kosínusovej podobnosti.
Vo FAISS je normalizácia implementovaná pomocou wrappera IndexPreTransform v kombinácii s NormalizationTransform (v Pythone faiss.NormalizationTransform). Vzorec vytvorenia je:
import faiss
import numpy as np
dimension =768# Vytvorenie indexu skalárneho súčinubase_index = faiss.IndexFlatIP(dimension)
# Zabalenie s L2 normalizáciouindex = faiss.IndexPreTransform(
faiss.NormalizationTransform(dimension),
base_index
)
# Vektory pridané sem sú automaticky L2-normalizovanéindex.add(reference_embeddings)
# Dopyty odoslané sem sú automaticky L2-normalizovanédistances, indices = index.search(query_embeddings, k)
Alternatívne prístupy zahŕňajú manuálnu normalizáciu vektorov pomocou faiss.normalize_L2() pred pridaním a dopytovaním, alebo vytvorenie indexu prostredníctvom index_factory, ktorý podporuje vstavanú normalizáciu pomocou kroku predspracovania "L2norm". S factory metódou: index = faiss.index_factory(d, "L2norm,HNSW32,Flat") vytvára index, ktorý automaticky normalizuje vektory na jednotkovú dĺžku pred vybudovaním HNSW grafu.
Pre TarmacView je tento prístup nevyhnutný, pretože DINOv2 embeddingy, podobne ako väčšina výstupov Vision Transformerov, sa líšia veľkosťou naprieč rôznymi snímkami. Variácie expozície, svetelných podmienok a nastavení kamery počas inšpekcie letiskových vozoviek produkujú embeddingy rôznych veľkostí aj pri zachytávaní identických textúr povrchu. Normalizácia odstraňuje zložku veľkosti a zameriava porovnanie podobnosti na smerové zosúladenie — dve snímky povrchu, ktoré zachytávajú rovnakú textúru vozovky, ale pri rôznych úrovniach expozície, budú vyhodnotené ako vysoko podobné, pretože ich normalizované embeddingy smerujú rovnakým smerom, aj keď sa ich surové veľkosti výrazne líšia.
FAQ FAISS to explicitne uvádza: “Kosínusová podobnosť medzi vektormi x a y je definovaná ako cos(x, y) = ⟨x, y⟩ / (|x| × |y|). Normalizáciou dopytových a databázových vektorov vopred možno problém mapovať späť na vyhľadávanie maximálneho skalárneho súčinu.” FAISS tiež poznamenáva, že použitie skalárneho súčinu na normalizovaných vektoroch je matematicky ekvivalentné použitiu L2 vzdialenosti na normalizovaných vektoroch, so vzťahom ||x - y||² = 2 - 2 × ⟨x, y⟩ pre jednotkovo normalizované vektory.
Vytváranie a dopytovanie FAISS indexu
Životný cyklus FAISS indexu v produkcii zahŕňa päť odlišných fáz: konfiguráciu, trénovanie, napĺňanie, serializáciu a dopytovanie. Každá fáza má špecifické API volania, výkonnostné aspekty a osvedčené postupy.
Konfigurácia začína výberom typu indexu a metriky vzdialenosti. FAISS poskytuje mechanizmus factory reťazca — kompaktnú reťazcovú špecifikáciu, ktorá vytvára komplexné indexy. Factory vzor je odporúčaným prístupom, pretože abstrahuje konkrétnu hierarchiu tried a automaticky vyberá optimálnu implementáciu:
Factory reťazec
Typ indexu
Pamäť na vektor (d=768)
Prípad použitia
"Flat"
IndexFlat (presné L2 vyhľadávanie)
3 072 bajtov
Malé referenčné množiny, ground truth
"IVF100,Flat"
IndexIVFFlat so 100 centroidmi
~3 100 bajtov
Stredné množiny, rýchle približné vyhľadávanie
"HNSW32,Flat"
IndexHNSWFlat s M=32
~3 328 bajtov
Rýchle približné vyhľadávanie, dynamické dáta
"IVF100,PQ16"
IndexIVFPQ, 16 podvektorov
~80 bajtov
Veľké meradlo, obmedzená pamäť
"IVF100,SQ8"
IndexIVF so skalárnou kvantizáciou
~784 bajtov
Vyvážené, vynikajúca rýchlosť
Trénovanie je potrebné len pre indexy, ktoré sa učia distribúciu dát (IVF, PQ, SQ, atď.). Počas trénovania index spúšťa k-means zhlukovanie na reprezentatívnej vzorke vektorov. Pre algoritmus k-means FAISS používa viacnásobné náhodné inicializácie a vyberá tú s najnižšou distorziou. Trénovacia množina by mala byť reprezentatívna pre dáta, ktoré budú indexované — bežnou praxou je použitie náhodnej podmnožiny 1–10 % celého datasetu. FAISS vyžaduje, aby trénovacie vektory mali rovnakú dimenzionalitu ako dáta, ktoré budú indexované. Príznak index.is_trained indikuje, či bolo trénovanie dokončené. Volanie trénovania je: index.train(training_vectors). Pre datasety, kde už bol index natrénovaný (napr. predtrénované centroidy sú načítané zo súboru), je volanie train znova zbytočné a prepíše naučené parametre.
Napĺňanie pridáva vektory do natrénovaného indexu: index.add(reference_vectors). Vlastnosť ntotal sleduje počet pridaných vektorov. Pre IVF indexy je každý vektor priradený k svojmu najbližšiemu centroidu zhluku a pridaný do invertovaného zoznamu tohto centroidu počas operácie add. Pre HNSW indexy je graf inkrementálne budovaný: každému novému vektoru je priradená úroveň vrstvy a hrany sú vytvorené k jeho M najbližším susedom na každej vrstve pomocou parametra efConstruction. Pridávanie vektorov je typicky pomalšie ako dopytovanie, najmä pre HNSW, kde musí byť graf aktualizovaný.
Serializácia ukladá index na disk: faiss.write_index(index, "index.faissindex"). Index sa načíta späť pomocou index = faiss.read_index("index.faissindex"). Serializácia zachováva kompletný stav indexu vrátane natrénovaných centroidov, štruktúry grafu, všetkých uložených vektorov, konfigurácie metriky vzdialenosti a interných parametrov. Štandardná prípona súboru je .faissindex. Veľkosť serializácie závisí od typu indexu a počtu vektorov — pre IndexFlat s N vektormi dimenzie D je to približne N × D × 4 bajty plus malá réžia.
Dopytovanie získava k najbližších susedov: distances, indices = index.search(query_vectors, k). Pole distances obsahuje hodnoty podobnosti alebo vzdialenosti v závislosti od metriky. Pole indices obsahuje pozície zodpovedajúcich referenčných vektorov v poradí, v akom boli pridané (indexované od 0). Pre dávkové dopyty FAISS efektívne spracúva viacero dopytov súčasne pomocou maticovo-maticovej multiplikácie, čím dosahuje výrazne lepšiu priepustnosť ako individuálne volania jeden dopyt po druhom. Indexové objekty sú thread-safe pre vyhľadávacie operácie na samostatných inštanciách indexu, čo umožňuje paralelné poskytovanie dopytov v produkčných nasadeniach.
FAISS pre kNN klasifikáciu
FAISS sa často používa na implementáciu klasifikácie k-Najbližších susedov (kNN) — neparametrickej metódy strojového učenia, ktorá klasifikuje dopytovaný bod na základe väčšinového označenia medzi jeho k najbližšími susedmi v referenčnej množine. Tento prístup je obzvlášť atraktívny, keď: (1) referenčná množina je pravidelne aktualizovaná novými označenými vzorkami, (2) embeddingový priestor zachytáva zmysluplné sémantické vzťahy medzi dátovými bodmi, a (3) interpretovateľné rozhodnutia založené na inštanciách sú preferované pred čiernymi skrinkami neurónových klasifikátorov.
Klasifikačný pipeline s použitím FAISS nasleduje päť krokov:
Vytvorenie označenej referenčnej množiny: Každý referenčný vektor je spárovaný s označením základnej pravdy (napr. “asfalt – dobrý stav”, “betón – prasknutý povrch”, “tarmac – opravený”). Označenia sú uložené v samostatnom poli zosúladenom s poradím FAISS indexu. TarmacView udržiava približne 9 000 takýchto označených referenčných embeddingov pokrývajúcich viacero typov povrchov a stavov kvality.
Indexovanie referenčných vektorov: Všetky referenčné embeddingy sú pridané do FAISS indexu. Pre presné vyhľadávanie s dokonalým recallom sa používa IndexFlatIP. Pre približné vyhľadávanie vo veľkom meradle poskytujú IndexHNSWFlat alebo IndexIVFFlat časy dopytov pod milisekundu s viac ako 99% recallom pri správnom nastavení.
Odoslanie dopytovaných embeddingov: Pre každú novú snímku na klasifikáciu extrahujte jej embedding pomocou rovnakého embeddingového modelu (DINOv2 s 768-rozmerným výstupom) a normalizujte na jednotkovú dĺžku pre kosínusovú podobnosť.
Získanie k najbližších susedov: FAISS vracia indexy a vzdialenosti k najpodobnejších referenčných vektorov. Parameter k riadi kompromis medzi biasom a varianciou. Menšie k (napr. 3–5) produkuje rozhodovacie hranice citlivé na lokálnu štruktúru, ale náchylné na preučenie šumu. Väčšie k (napr. 15–20) produkuje hladšie hranice s lepšou generalizáciou, ale môže stratiť jemné rozdiely. TarmacView používa k=10, čo vyvažuje robustnosť voči odľahlým hodnotám s citlivosťou na jemné variácie kvality povrchu.
Vykonanie väčšinového hlasovania: Spočítajte označenia medzi k susedmi a vyberte najčastejšie označenie ako výsledok klasifikácie. Voliteľne hlasovanie vážené vzdialenosťou priraďuje vyššiu váhu bližším susedom: váha = 1,0 / (vzdialenosť + ε) kde ε je malá konštanta na zabránenie deleniu nulou. Vážené hlasovanie je obzvlášť výhodné, keď má referenčná množina nerovnomerné rozdelenie tried alebo keď sa hustota susedov líši v rámci embeddingového priestoru.
Hodnota k
Bias
Variancia
Najlepšie pre
1 – 3
Nízky
Vysoká
Veľké, čisté referenčné množiny, jemné hranice
5 – 10
Mierny
Mierna
Vyvážená, všeobecná klasifikácia
15 – 30
Vyšší
Nižšia
Hlučné označenia, hladké rozhodovacie hranice
Skóre vzdialenosti vrátené FAISS tiež informujú o odhade spoľahlivosti. Ak všetci top-k susedia zdieľajú rovnaké označenie a majú vysoké skóre podobnosti (kosínusová podobnosť > 0,95), klasifikácia je vysoko spoľahlivá. Ak je hlasovanie rozdelené (napr. 6 z 10 pre víťazné označenie) alebo sú skóre podobnosti nízke (< 0,70), systém môže označiť výsledok na ľudské posúdenie. Táto architektúra uvedomujúca si spoľahlivosť je kritická pre aplikácie, kde je bezpečnosť dôležitá, ako je inšpekcia letiskových vozoviek, kde by chybná klasifikácia mohla ovplyvniť priority údržby a prevádzkovú bezpečnosť.
Embeddingový kontrakt medzi modelom DINOv2 a FAISS indexom je základom presnosti klasifikácie. Extraktor embeddingov je natrénovaný prostredníctvom samousmerneného učenia tak, aby vzdialenosti medzi embeddingmi odrážali vizuálnu podobnosť medzi snímkami povrchu vozovky. FAISS index verne vyhľadáva najbližších susedov podľa metriky kosínusovej podobnosti. Keď tento kontrakt platí — keď vizuálne podobné stavy povrchu produkujú blízke embeddingy — kNN klasifikácia dosahuje vysokú presnosť s inherentnou interpretovateľnosťou, ktorá ukazuje, ktoré referenčné snímky informovali každé klasifikačné rozhodnutie.
GPU akcelerácia
GPU podpora FAISS je prvotriednou funkciou, ktorá poskytuje výrazné zlepšenie výkonu pre vytváranie indexov aj vyhľadávanie. GPU implementácia, opísaná v článku “Billion-scale similarity search with GPUs” (Johnson, Douze, Jégou, 2017), je napísaná v CUDA C++ a využíva NVIDIA GPU architektúry od Kepler (Compute Capability 3.5) cez Hopper (Compute Capability 9.0+) a ďalej.
GPU akcelerácia FAISS poskytuje merateľné zlepšenie výkonu: 5–10x zlepšenie priepustnosti vyhľadávania oproti CPU pre typické IVF a HNSW indexy; až 12x rýchlejšie vytváranie indexov pre IVF indexy, pretože k-means zhlukovanie je vysoko paralelizovateľné; 8x nižšiu latenciu pre HNSW dopyty na GPU pomocou optimalizovaných kernelov na prechádzanie grafov; a natívnu podporu pre dávkové dopyty, kde GPU vynikajú pri spracovaní stoviek alebo tisícov dopytov súčasne prostredníctvom maticových operácií.
GPU implementácia pokrýva najčastejšie používané typy indexov prostredníctvom špecializovaných CUDA tried:
PQ vyhľadávacie tabuľky na GPU, rýchle priradenie kódu
GpuIndexIVFScalarQuantizer
IndexIVFScalarQuantizer
float16 podpora na Pascal+ GPU
GPU implementácia používa warp shuffles (dostupné na Compute Capability 3.0+) a read-only textúrovú cache prostredníctvom ld.nc / __ldg (Compute Capability 3.5+). Algoritmus k-selekcie — nájdenie top-k hodnôt z veľkého poľa vzdialeností — pracuje až na 55 % teoretického špičkového výkonu GPU, čo umožňuje implementáciu najbližšieho suseda 8,5x rýchlejšie ako predchádzajúci state-of-the-art na GPU podľa článku z roku 2017. Pre správu GPU pamäte objekt StandardGpuResources alokuje scratch priestor na GPU: približne 512 MiB na GPU s pamäťou ≤4 GiB a približne 1 536 MiB na väčších GPU. Tento scratch priestor sa vyhýba opakovaným volaniam cudaMalloc / cudaFree počas vyhľadávania.
FAISS poskytuje bezproblémovú interoperabilitu CPU-GPU prostredníctvom dvoch kľúčových funkcií: faiss.index_cpu_to_gpu(cpu_index, device_id) prenáša CPU index na špecifikované GPU zariadenie a faiss.index_gpu_to_cpu(gpu_index) prenáša GPU index späť do CPU pamäte. Pre multi-GPU nasadenia faiss.index_cpu_to_gpu_multiple_py(resources, cpu_index) distribuuje index cez všetky dostupné GPU zariadenia a dopyty sú automaticky load-balancované. Multi-GPU prístup dokáže škálovať na indexy obsahujúce stovky miliónov vektorov rozdelením naprieč pamäťovými priestormi GPU.
Scenár
CPU
GPU (1x)
GPU (8x)
Vyhľadávanie IndexFlat (100K x 768d), batch=8192
50 ms
5 ms
<1 ms
IVF k-means trénovanie (1M x 128d), nlist=1000
120 s
10 s
5 s
HNSW výstavba (100K x 128d), M=32
30 s
8 s
—
k-NN graf v miliardovom meradle
dni
12 hodín
4 hodiny
Pre TarmacView je GPU akcelerácia cenná počas fázy vytvárania indexu, keď sa pravidelne pridávajú nové referenčné snímky. Vytvorenie IVF indexu s k-means na 9 000 768-rozmerných vektoroch trvá približne 1–2 sekundy na modernom GPU (NVIDIA A100 alebo RTX 4090) oproti 30–60 sekundám na CPU. Počas inferencie zostáva index na CPU pre nákladovo efektívne nasadenie — latencia dopytu na CPU s IndexHNSWFlat je už pod 200 mikrosekúnd pre 9K referenčnú množinu a konverzia na GPU by pridala réžiu PCIe prenosu bez zmysluplného zlepšenia latencie.
Použitie FAISS v TarmacView
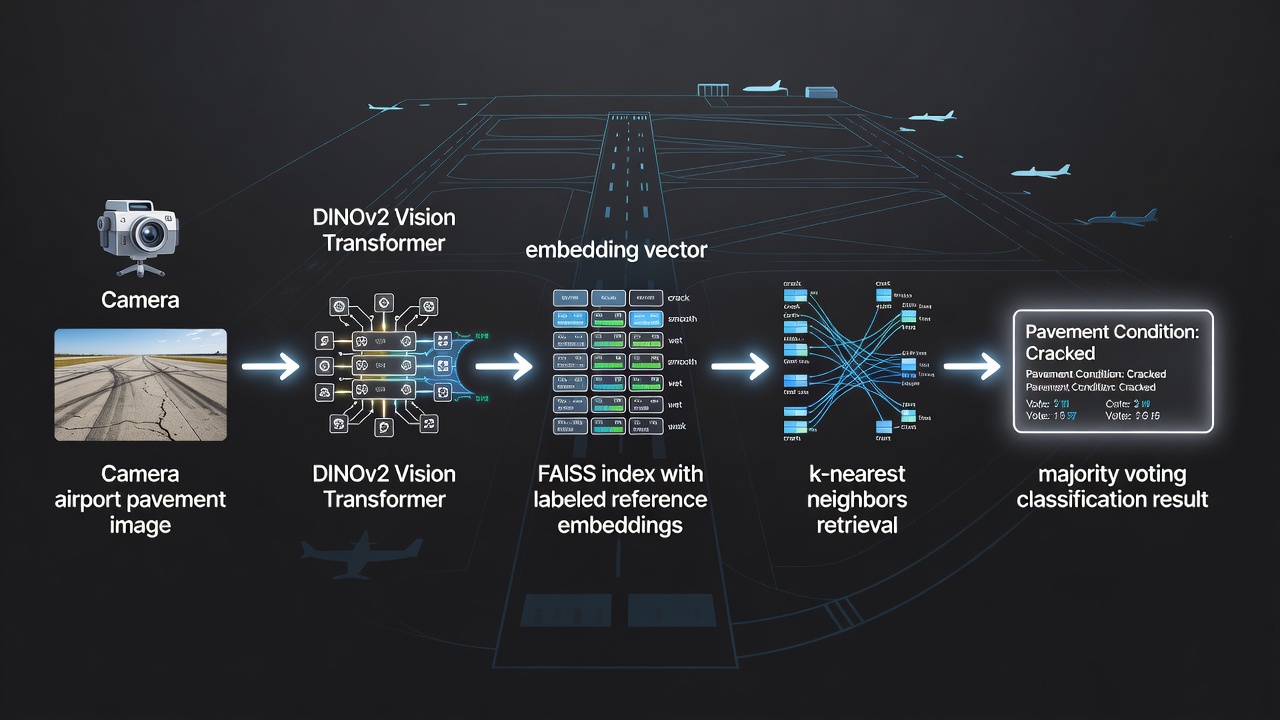
TarmacView integruje FAISS ako základný engine vyhľadávania podobnosti pre svoj automatizovaný systém klasifikácie kvality povrchu letiskových vozoviek. Systém klasifikuje typy povrchu vozoviek (asfalt, betón, tarmac) a stavy kvality povrchu (dobrý, uspokojivý, zlý, poškodený, prasknutý, opravený) porovnávaním inšpekčných snímok so starostlivo zostavenou referenčnou množinou približne 9 000 označených embeddingov.
Konštrukcia referenčnej množiny: Každý referenčný embedding je extrahovaný z vysokorozmernej snímky vozovky pomocou modelu DINOv2 Vision Transformer (ViT-B/14 alebo ekvivalent), ktorý produkuje 768-rozmerný vektor zachytávajúci vizuálne vlastnosti ako textúrové vzory, distribúciu farieb, morfológiu trhlín, obnaženie kameniva, opotrebovanie povrchu a stopy opráv. Každý embedding je anotovaný označeniami základnej pravdy stanovenými certifikovanými inšpektormi vozoviek počas počiatočnej fázy trénovania systému. Referenčná množina pokrýva viacero letísk, klimatických zón a vekov vozoviek, aby sa zabezpečila robustná klasifikácia naprieč rôznymi podmienkami.
Výber indexu: TarmacView vyberá typ indexu na základe požiadaviek nasadenia:
Scenár nasadenia
Typ indexu
Čas dopytu
Recall
Pamäť
Offline QA / validácia
IndexFlatIP
~2 ms
100 %
~28 MB
Real-time terénne nasadenie
IndexHNSWFlat (M=32, efSearch=64)
<200 μs
>99 %
~30 MB
Edge zariadenie (obmedzená RAM)
IndexIVFFlat (nlist=100, nprobe=10)
~300 μs
~97 %
~28 MB
Klasifikačný pracovný postup:
Kamera namontovaná na drone (napr. DJI Matrice série s vysokorozmerným nákladom) alebo ručné inšpekčné zariadenie zachytáva snímky vozoviek počas rutinných inšpekcií letiskových plôch v súlade s normami ICAO Annex 14 a FAA AC 150/5380-7B pre hodnotenie stavu vozoviek.
Každá snímka je predspracovaná (orezaná na odstránenie ne-vozovkových oblastí, normalizovaná na štandardné rozlíšenie) a prejdená cez model DINOv2 bežiaci na edge inferenčnom akcelerátore (NVIDIA Jetson alebo ekvivalent).
Výsledný 768-rozmerný embedding je L2-normalizovaný na jednotkovú dĺžku pre výpočet kosínusovej podobnosti. Normalizácia zaisťuje, že variácie expozície medzi inšpekčnými letmi neovplyvňujú poradie podobnosti.
FAISS dopytuje IndexHNSWFlat index s k=10, pričom vracia 10 indexov najbližších referenčných embeddingov a ich skóre podobnosti skalárneho súčinu (ekvivalentné kosínusovej podobnosti pre normalizované vektory).
Systém vykonáva väčšinové hlasovanie na označeniach 10 susedov. Ak má víťazné označenie aspoň 6 z 10 hlasov (60 % konsenzus), klasifikácia je akceptovaná so skóre spoľahlivosti vypočítaným ako pomer víťazných hlasov k celkovým hlasom.
Ak je hlasovanie rozdelené pod 60 % konsenzus, embedding snímky a top-10 referenčných snímok sú označené na ľudské posúdenie certifikovaným inšpektorom vozoviek prostredníctvom webového rozhrania TarmacView.
Klasifikácie sú zaznamenané v databáze TarmacView s časovými pečiatkami, GPS súradnicami, typom povrchu, stavom kvality, skóre spoľahlivosti a odkazmi na podporné referenčné snímky. Toto vytvára plne auditovateľnú stopu inšpekcií pre regulačnú zhodu.
Tento klasifikačný pipeline poháňaný FAISS umožňuje TarmacView spracúvať tisíce snímok vozoviek denne s konzistentným, objektívnym hodnotením kvality — čím sa znižuje závislosť od subjektívnej ľudskej vizuálnej inšpekcie a umožňuje sa škálovateľné monitorovanie stavu letiskových plôch naprieč celými sieťami letísk.
FAISS vs Ostatné vektorové databázy
FAISS zaujíma osobitné miesto v ekosystéme vektorového vyhľadávania. Je to knižnica, nie databáza, a tento rozdiel má významné dôsledky pre architektúru, nasadenie a prevádzkové charakteristiky. Knižnica FAISS poskytuje čistú funkcionalitu vyhľadávania najbližších susedov bez réžie plnohodnotného databázového systému.
Funkcia
FAISS
Pinecone
Milvus
Qdrant
Weaviate
Typ
Knižnica
Spravovaná služba
Databáza
Databáza
Databáza
Nasadenie
Vložené
Cloud / SaaS
Self-hosted / Cloud
Self-hosted / Cloud
Self-hosted / Cloud
Perzistencia
Manuálne uloženie/načítanie
Automatická
Automatická
Automatická
Automatická
CRUD
Nie je vstavané
Plné CRUD
Plné CRUD
Plné CRUD
Plné CRUD
Filtrovanie metadát
Len na základe ID
Bohaté filtre
Atribút + skalárne
Filtrovanie payloadu
Grafové
Škálovanie
Manuálny sharding
Auto-škálovanie
Distribuované Raft/Paxos
Distribuované
Distribuované
GPU podpora
Natívne CUDA
Nie
Obmedzené (CUDA)
Nie
Nie
Latencia dopytu
10 μs – 1 ms
2 – 10 ms
1 – 10 ms
1 – 5 ms
1 – 10 ms
Licencia
MIT
Proprietárna
Apache 2.0
Apache 2.0
BSD-3
Kľúčovou výhodou FAISS oproti plnohodnotným databázovým systémom je výkon a jednoduchosť. FAISS dopyty sú typicky 10–100x rýchlejšie ako ekvivalentné dopyty na databázových systémoch, pretože: knižnica beží v rámci procesu bez sieťových obchádzok; neexistuje žiadna réžia parsovania dopytov, autentifikácie alebo autorizácie; neexistuje žiadna nepriamosť úložného enginu ani správa buffer poolu; a FAISS indexy sú optimalizované lineárne algebraické dátové štruktúry bez transakčnej réžie. FAISS pracuje priamo s dátovými štruktúrami v pamäti pomocou optimalizovaných BLAS rutín, bez medziprocesovej komunikácie.
Kľúčovou výhodou databázových systémov oproti FAISS je prevádzkové pohodlie. Poskytujú automatickú trvanlivosť dát s write-ahead logovaním a replikáciou, podporujú bohaté filtrovanie metadát (napr. “nájdi podobné snímky zachytené po januári 2025, ktoré zobrazujú betónovú vozovku v juhozápadnom regióne USA”), ponúkajú REST alebo gRPC API pre jazyk-nezávislý prístup, zahŕňajú monitorovacie dashboardy a alerting, a zvládajú zálohovanie a obnovu po havárii. Podporujú súbežné čítacie a zapisovacie operácie s transakčnými zárukami a evolúciou schémy.
Pre TarmacView je používanie FAISS priamo namiesto vektorovej databázy správnym architektonickým rozhodnutím zo štyroch dôvodov: (1) referenčná množina je malá (~9K vektorov, približne 28 MB) a zmestí sa celá do pamäte; (2) požiadavky na latenciu dopytov sú agresívne (klasifikácia pod 200 mikrosekúnd je dosiahnuteľná s HNSW na CPU); (3) systém beží v edge nasadeniach na letiskách, kde by sieťový prístup k databázovému serveru mohol byť nepraktický alebo zavádzať neprijateľnú latenciu; a (4) index sa prestavuje zriedkavo (týždenne alebo mesačne, keď sa po validácii inšpektorom pridávajú nové referenčné snímky), čo robí manuálnu serializáciu a správu verzií zvládnuteľnou.
Serializácia indexu
Serializácia FAISS indexu konvertuje pamäťový indexový objekt na binárnu reprezentáciu, ktorú možno uložiť na disk, preniesť cez sieť alebo načítať do iného procesu či zariadenia. Serializácia zachováva kompletný stav indexu vrátane všetkých uložených vektorov, natrénovaných centroidov (pre IVF a PQ indexy), štruktúry grafu (pre HNSW), konfigurácie metriky vzdialenosti (L2 vs IP vs iné) a všetkých interných parametrov (efConstruction, M, nastavenia normalizácie, atď.).
Primárne serializačné funkcie sú:
Funkcia
Popis
Výstup
Prípad použitia
write_index(index, filename)
Zapíše index do súboru
Súbor .faissindex
Perzistentné úložisko na disku
read_index(filename)
Načíta index zo súboru
Objekt indexu
Načítanie pre poskytovanie služby
serialize_index(index)
Zapíše index do bajtov
Python bytes objekt
Ukladanie do databázy, fronty správ
deserialize_index(data)
Načíta index z bajtov
Objekt indexu
Načítanie z pamäťového buffera
Veľkosť serializácie závisí od typu indexu a počtu vektorov. Pre IndexFlatIP s N vektormi dimenzie D je veľkosť súboru približne N × D × 4 bajty (32-bitové float ukladanie) plus réžia pre hlavičku a metadáta. Pre IndexIVFFlat je dodatočné úložisko spotrebované centroidmi zhlukov: nlist × D × 4 bajty. Pre IndexHNSWFlat štruktúra grafu pridáva N × M × 2 × 4 bajty pre zoznamy susedov (za predpokladu 32-bitových indexov susedov uložených obojsmerne). Pre HNSW index TarmacView s 9 000 vektormi pri 768 dimenziách a M=32 je serializovaný súbor približne 25 MB: 9 000 × 768 × 4 = 27,6 MB pre vektory plus 9 000 × 32 × 2 × 4 = 2,3 MB pre štruktúru grafu, mínus skutočnosť, že HNSW ukladá vektory interne v plochom indexe.
Serializácia podporuje prenos naprieč kontextmi: index vytvorený na GPU možno uložiť na disk a načítať na CPU. Odporúčaným vzorom je vždy preniesť GPU indexy na CPU pred serializáciou:
cpu_index = faiss.index_gpu_to_cpu(gpu_index) # prenos na CPUfaiss.write_index(cpu_index, "production_index.faissindex") # uloženie na disk# Na inom zariadení (alebo neskôr):deployed_index = faiss.read_index("production_index.faissindex")
deployed_index.hnsw.efSearch =64# nastavenie parametrov v čase vyhľadávaniaD, I = deployed_index.search(queries, k)
Pre produkčné nasadenia môže byť serializovaný index verzovaný spolu s aplikačným kódom. TarmacView udržiava verzované súbory FAISS indexu vo svojich deploymentových artefaktoch, čím zaisťuje, že každé edge nasadenie používa identickú referenčnú množinu pre reprodukovateľné výsledky klasifikácie. Keď sa pridajú a validujú nové referenčné snímky, natrénuje sa nový index, jeho presnosť sa porovná s predchádzajúcim indexom pomocou ground-truth IndexFlatIP a nový index sa nasadí prostredníctvom štandardného CI/CD pipeline.
Škálovanie FAISS na veľké referenčné množiny
Zatiaľ čo súčasná referenčná množina TarmacView s približne 9 000 vektormi je skromná, FAISS je navrhnutý tak, aby škáloval až na miliardy vektorov na jednom serveri. Knižnica poskytuje komplexný nástrojový set na zvládanie veľkých nasadení prostredníctvom troch komplementárnych techník: kompresie vektorov, nevyčerpávajúceho vyhľadávania a distribuovaného indexovania.
Produktová kvantizácia
Produktová kvantizácia (PQ) je stratová kompresná technika, ktorá dramaticky znižuje pamäťovú stopu na vektor. PQ rozdeľuje každý D-rozmerný vektor na m podvektorov rovnakej veľkosti (D/m dimenzií každý). Každý podvektor je kvantizovaný nezávisle pomocou kódovej knihy s 256 položkami (8 bitov) naučenej prostredníctvom k-means zhlukovania. Pôvodný float32 vektor (4 × D bajtov) je komprimovaný na m bajtov kódových indexov plus malú kódovú knihu. PQ kompresné pomery 4x až 16x sú bežné, čo umožňuje jednému stroju indexovať stovky miliónov vektorov v hlavnej pamäti. FAISS IndexIVFPQ kombinuje IVF s PQ, pričom používa centroidy zhlukov ako hrubý kvantizátor a PQ kódy pre reziduálnu kompresiu. Výpočet vzdialenosti používa Asymmetric Distance Computation (ADC): dopyt zostáva nekomprimovaný a vzdialenosti k PQ-komprimovaným databázovým vektorom sú vypočítané prostredníctvom predvypočítaných vyhľadávacích tabuliek, čím sa predchádza réžii dekompresie.
PQ konfigurácia
Bajtov/vektor (d=768)
Pamäť, N=100M
Recall oproti nekomprimovanému
PQ32 (m=32, 8-bit)
40
3,7 GB
~90-95 %
PQ64 (m=64, 8-bit)
72
6,7 GB
~95-98 %
PQ96 (m=96, 8-bit)
104
9,7 GB
~97-99 %
Skalárna kvantizácia
Skalárna kvantizácia (SQ) konvertuje každú float32 komponentu na 8-bitové alebo 4-bitové celé číslo bez znamienka, čím znižuje úložisko 4x (SQ8) alebo 8x (SQ4) s minimálnou stratou presnosti. Factory reťazec "IVF100,SQ8" vytvára IVF index so skalárnou kvantizáciou. SQ je rýchlejšia ako PQ v čase dopytu, pretože výpočty vzdialenosti sa vykonávajú priamo na kvantizovaných hodnotách bez predvýpočtu vyhľadávacích tabuliek. SQ8 ukladá jeden bajt na dimenziu; SQ4 ukladá dve dimenzie na bajt.
Indexovanie v miliardovom meradle
Pre datasety v miliardovom meradle odporúčaná konfigurácia FAISS kombinuje HNSW ako hrubý kvantizátor s IVFPQ na kompresiu vektorov: quantizer = IndexHNSWFlat(d, hnsw_m); index = IndexIVFPQ(quantizer, d, nlist, M, nbits). HNSW kvantizátor urýchľuje vyhľadávanie centroidov v porovnaní s plochým vyhľadávaním v čase dopytu a PQ komprimuje databázové vektory na zlomok ich pôvodnej veľkosti. Pôvodný FAISS článok (2017) nameral vytvorenie k-NN grafu na 95 miliónoch obrázkov (z datasetu YFCC100M) za 35 minút na GPU a k-NN graf na 1 miliarde vektorov za menej ako 12 hodín na 4x Maxwell Titan X GPU.
Distribuované vyhľadávanie s IndexShards
FAISS IndexShards rozdeľuje veľký dataset naprieč viacerými sub-indexmi, každý potenciálne na inom zariadení alebo GPU. Každý shard dostane podmnožinu vektorov a spracúva dopyty nezávisle. Výsledky sú zlúčené prostredníctvom k-way merge top-k výsledkov z každého shardu. Tento prístup poskytuje lineárne škálovanie s počtom dostupných serverov: zdvojnásobenie počtu shardov znižuje čas vyhľadávania na polovicu pre danú veľkosť datasetu.
Diskové indexy
Pre datasety presahujúce dostupnú RAM poskytuje FAISS diskové indexy, ktoré udržiavajú štruktúru indexu (invertované zoznamy alebo graf) v pamäti, ale ukladajú vektorové dáta na SSD. Trieda IndexOnDisk a súvisiace utility transparentne načítavajú vektorové dáta z disku počas vyhľadávania pomocou pamäťovo mapovaných súborov alebo explicitných I/O operácií. S modernými NVMe SSD poskytujúcimi 3–7 GB/s sekvenčnú rýchlosť čítania sa diskové vyhľadávanie môže priblížiť výkonu v pamäti pre mnohé úlohy, najmä ak je udržiavaná priestorová lokalita (susedné vektory uložené súvisle na disku).
Pre TarmacView je súčasná 9K referenčná množina dobre v rámci optimálneho rozsahu FAISS pre presné vyhľadávanie s IndexFlatIP. Avšak, keď sa systém rozšíri na zahrnutie referenčných snímok zo stoviek letísk a viacerých inšpekčných kampaní — potenciálne rastúc na milióny označených embeddingov — škálovacie mechanizmy FAISS (IVF pre nevyčerpávajúce vyhľadávanie, PQ pre kompresiu, diskové úložisko pre datasety presahujúce RAM) poskytujú jasnú cestu upgrade bez potreby zásadne odlišnej architektúry. Typ indexu možno povýšiť z IndexFlatIP → IndexIVFFlat → IndexIVFPQ → IndexShards(IndexIVFPQ) ako referenčná množina rastie, pričom každý krok obetuje minimálnu presnosť za rádové zlepšenie rýchlosti vyhľadávania a pamäťovej efektivity.
Literatúra FAISS (vrátane komplexného arXiv článku z roku 2024 “The Faiss Library” od Douze, Guzhva, Deng, Johnson, Szilvasy, Mazaré, Lomeli, Hosseini a Jégou) poskytuje usmernenie k výberu indexu: “Existuje výber medzi tuctom typov indexov a optimálny zvyčajne závisí od obmedzení problému.” FAISS tiež obsahuje komplexnú sadu benchmarkov (faiss_benchmarks), ktorá meria recall a priepustnosť naprieč rôznymi konfiguráciami indexov, pričom spúšťa vyhľadávania s výsledkami základnej pravdy z IndexFlat na kvantifikáciu presnosti. Praktici sú povzbudzovaní, aby benchmarkovali svoju špecifickú distribúciu dát — optimálny index pre daný dataset závisí od dimenzionality vektorov, veľkosti datasetu, cieľového recallu, rozpočtu na latenciu a dostupnej pamäte.
Často kladené otázky
FAISS (Facebook AI Similarity Search) je open-source knižnica vyvinutá tímom Fundamental AI Research (FAIR) v Meta na efektívne vyhľadávanie podobnosti a zhlukovanie hustých vektorov. Poskytuje najmodernejšie implementácie algoritmov vyhľadávania najbližších susedov vrátane presného hrubého vyhľadávania (IndexFlat), invertovaného súborového indexu s k-means zhlukovaním (IndexIVF), hierarchických navigovateľných grafov malého sveta (IndexHNSW) a produktovej kvantizácie (IndexIVFPQ) s natívnou podporou pre CPU aj GPU. Knižnica bola prvýkrát zverejnená ako open-source v roku 2017 a získala viac ako 40 000 hviezdičiek na GitHub.
FAISS je knižnica, nie kompletný databázový systém. Zameriava sa výlučne na rýchle vektorové vyhľadávanie bez vstavanej distribuovanej úložnej kapacity, replikácie, CRUD operácií alebo dopytovacích jazykov. Vektorové databázy ako Pinecone, Milvus, Qdrant a Weaviate stavajú na FAISS alebo podobných engine, no pridávajú perzistenciu, škálovateľnosť, filtrovanie metadát a manažérske funkcie. FAISS dopyty sú typicky 10-100x rýchlejšie ako ekvivalentné databázové dopyty, pretože neexistuje žiadna sieťová réžia ani parsovanie dopytov, čo ho robí ideálnym, keď potrebujete ľahký, vložiteľný vyhľadávací komponent v rámci aplikácie.
IndexFlatIP vykonáva presné hrubé vyhľadávanie so skalárnym súčinom ako metrikou vzdialenosti — počíta vzdialenosti voči každému vektoru v indexe, čím garantuje presných najbližších susedov s komplexitou O(NxD) na dopyt. IndexIVFFlat používa k-means zhlukovanie na rozdelenie vektorového priestoru na nlist Voronoiových buniek a vyhľadáva len v nprobe najbližších bunkách, pričom obetuje určitú presnosť (typicky 90-99% recall) v prospech výrazného zrýchlenia úmerného nlist/nprobe. IndexHNSWFlat vytvára viacvrstvový hierarchický graf inšpirovaný skip listami, ktorý umožňuje vyhľadávanie v logaritmickom čase O(log N) a ponúka vynikajúci kompromis medzi rýchlosťou a presnosťou. HNSW typicky dosahuje vyšší recall pri ekvivalentnej rýchlosti vyhľadávania v porovnaní s IVF na vysokorozmerných dátech.
FAISS nemá natívnu kosínusovú metriku. Namiesto toho sa kosínusová podobnosť počíta L2-normalizáciou všetkých vektorov na jednotkovú dĺžku a následným použitím skalárneho súčinu (METRIC_INNER_PRODUCT). Pre jednotkovo normalizované vektory, kde ||a|| = ||b|| = 1, sa skalárny súčin rovná kosínusovej podobnosti: a·b = cos(θ). Tento prístup je implementovaný zabalením vektorov do IndexPreTransform, ktorý aplikuje NormalizationTransform pred odovzdaním indexu používajúcemu skalárny súčin. Normalizácia zaisťuje, že porovnania podobnosti sa zameriavajú na smerové zosúladenie, nie na veľkosť vektora.
Áno. FAISS sa bežne používa na implementáciu klasifikácie k-Najbližších susedov (kNN) — neparametrickej metódy, ktorá klasifikuje dopytovaný bod na základe väčšinového označenia medzi jeho k najbližšími susedmi v referenčnej množine. Proces zahŕňa vytvorenie označenej referenčnej množiny, indexovanie referenčných vektorov vo FAISS, odoslanie dopytovaných embeddingov, získanie k najbližších susedov a vykonanie väčšinového hlasovania (alebo hlasovania váženého vzdialenosťou) na označeniach. Tento prístup používa TarmacView na klasifikáciu kvality povrchu s k=10 a referenčnou množinou približne 9 000 označených embeddingov.
GPU akcelerácia FAISS využíva NVIDIA CUDA na spúšťanie operácií vytvárania indexov a vyhľadávania na GPU s natívnymi implementáciami pre IndexFlat, IndexIVF, IndexIVFPQ a skalárne kvantizované indexy. Poskytuje 5-10x zlepšenie priepustnosti vyhľadávania oproti CPU pre typické IVF a HNSW indexy, až 12x rýchlejšie vytváranie indexov pre IVF indexy (k-means zhlukovanie je vysoko paralelizovateľné) a natívnu podporu pre dávkové dopyty. FAISS poskytuje bezproblémovú interoperabilitu CPU-GPU prostredníctvom funkcií index_cpu_to_gpu a index_gpu_to_cpu, čo umožňuje hybridné pracovné postupy, kde sa indexy vytvárajú na GPU a nasadzujú na CPU.
FAISS indexy sa serializujú pomocou write_index(index, filename), ktorá uloží kompletný stav indexu vrátane všetkých vektorov, natrénovaných centroidov, štruktúry grafu, konfigurácie metriky vzdialenosti a interných parametrov do binárneho súboru. Funkcia read_index(filename) obnoví index do stavu pred serializáciou, pripravený na okamžité vyhľadávanie bez dodatočného trénovania. FAISS tiež poskytuje funkcie serialize_index a deserialize_index pre serializáciu do pamäťového bajtového buffera. GPU indexy nemožno ukladať priamo na disk — musia byť najprv prenesené na CPU prostredníctvom index_gpu_to_cpu.
TarmacView používa FAISS na ukladanie približne 9 000 označených referenčných embeddingov extrahovaných z modelu DINOv2 Vision Transformer. Každý 768-rozmerný referenčný embedding predstavuje známy typ povrchu alebo stav kvality povrchu na letiskovej vozovke. Keď sa získa nová inšpekčná snímka, jej embedding sa normalizuje na jednotkovú dĺžku a dopytuje sa voči FAISS indexu. Systém získa k=10 najbližších susedov pomocou IndexHNSWFlat s M=32 a efSearch=64 (>99% recall pri dopytoch pod milisekundu), potom vykoná väčšinové hlasovanie na klasifikáciu kvality povrchu. Ak víťazné označenie dosiahne menej ako 60% konsenzus, snímka je označená na ľudské posúdenie.
FAISS podporuje viac ako dvadsať typov indexov. Najpoužívanejšie sú IndexIVF (invertovaný súbor s k-means zhlukovaním, parametrizovaný nlist a nprobe), IndexHNSW (hierarchický navigovateľný graf malého sveta, parametrizovaný M, efConstruction a efSearch), IndexIVFPQ (invertovaný súbor s produktovou kvantizáciou pre pamäťovo efektívne ukladanie vo veľkom meradle), IndexIVFScalarQuantizer (skalárna kvantizácia na 8-bitové alebo 4-bitové celé čísla), IndexLSH (locality-sensitive hashovanie pre nízkorozmerné dáta) a IndexBinary (pre binárne vektorové vyhľadávanie). Dostupné sú aj zložené indexy kombinujúce viacero techník.
Produktová kvantizácia (PQ) je stratová kompresná technika pre vysokorozmerné vektory, ktorá rozdeľuje každý vektor na m podvektorov a kvantizuje každý podvektor nezávisle pomocou kódovej knihy naučenej k-means. FAISS IndexIVFPQ kombinuje IVF s PQ, čím komprimuje každý vektor na m bajtov (s 8-bitovými sub-kvantizátormi). Pre 128-rozmerný vektor PQ s m=64 znižuje úložisko z 512 bajtov (float32) na 72 bajtov vrátane réžie — 7-násobné zníženie. PQ umožňuje indexovanie stoviek miliónov až miliárd vektorov na jednom serveri, pričom výpočet vzdialenosti sa vykonáva v komprimovanej doméne pomocou Asymmetric Distance Computation (ADC).
FAISS spracúva indexovanie v miliardovom meradle kombináciou kompresie vektorov (produktová kvantizácia, skalárna kvantizácia) a nevyčerpávajúceho vyhľadávania (IVF, HNSW alebo oboje kombinované). Odporúčaný zásobník pre miliardové meradlo používa HNSW ako hrubý kvantizátor pre IVFPQ index: quantizer=IndexHNSWFlat, index=IndexIVFPQ(quantizer, d, nlist, M, nbits). Táto kombinácia dosahuje časy vyhľadávania pod sekundu na datasetoch v miliardovom meradle. Pôvodný FAISS GPU článok (2017) demonštroval k-NN graf na 95 miliónoch obrázkov vytvorený za 35 minút a k-NN graf s 1 miliardou vektorov vytvorený za menej ako 12 hodín na 4 GPU Titan X.
Embeddingový kontrakt je implicitná dohoda medzi extraktorom embeddingov (typicky neurónovou sieťou) a algoritmom vektorového vyhľadávania. Extraktor embeddingov je natrénovaný tak, aby vzdialenosti medzi embeddingmi odrážali sémantickú podobnosť medzi vstupmi. Vektorový index vykonáva vyhľadávanie susedov medzi embeddingmi čo najpresnejšie vzhľadom na dohodnutú metriku vzdialenosti (L2 alebo skalárny súčin/kosínus). Pri používaní FAISS s DINOv2 embeddingmi na klasifikáciu kvality povrchu kontrakt vyžaduje, aby embeddingy vizuálne podobných povrchov vozoviek boli blízko vo vektorovom priestore, čo umožňuje vyhľadávanie najbližších susedov fungovať ako spoľahlivý klasifikačný mechanizmus.
Posilnite svoju infraštruktúru vektorového vyhľadávania
Využite FAISS na vysokovýkonné vyhľadávanie podobnosti na vašich obrazových embeddingových dátech. Kontaktujte nás a zistite, ako TarmacView integruje FAISS pre klasifikáciu kvality povrchu v reálnom čase a vyhľadávanie inšpekčných snímok.
Sémantická segmentácia pre porozumenie infraštruktúrnych scén
Sémantická segmentácia priraďuje každomu pixelu v obraze kategóriovú značku, čo umožňuje porozumenie celej scéne pre infraštruktúrnu inšpekciu. Zahŕňa architekt...
Smoke test hlavy defektov overuje, že pipeline detekcie štrukturálnych defektov TarmacView — backbone DINOv3 + 5-labelová MLP hlava pre praskliny/odlupovanie/ef...
Apache Parquet je stĺpcový, komprimovaný binárny úložný formát optimalizovaný pre analytické dopyty na veľkých tabuľkových datasadoch. TarmacView ukladá všetky ...
37 min čítania
Data Format
Data Storage
+3
Súhlas s cookies Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.