Apache Parquet je stĺpcový, komprimovaný binárny úložný formát optimalizovaný pre analytické dopyty na veľkých tabuľkových datasadoch. TarmacView ukladá všetky výsledky analýz v Parquet formáte pre efektívne ukladanie a rýchle dopyty. Pokrýva výhody Parquet, schému, čítanie/zápis s Pandas a Polars a porovnanie s CSV a JSON pre dáta z inšpekcií.
Apache Parquet Formát pre Dáta z Inšpekcií
Definícia a Model Stĺpcového Ukladania
Apache Parquet je bezplatný open-source stĺpcovo orientovaný binárny súborový formát navrhnutý od základov pre efektívne ukladanie a získavanie dát v analytických úlohách. Pôvodne vyvinutý ako spoločné úsilie medzi Twitter a Cloudera v ekosystéme Apache Hadoop, Parquet sa odvtedy stal de facto štandardom pre analytické ukladanie dát v celom dátovom inžinierskom prostredí. Každý významný engine na spracovanie dát — Apache Spark, DuckDB, ClickHouse, Presto, Trino, Snowflake, Google BigQuery, Amazon Redshift a Databricks — poskytuje natívnu podporu pre čítanie a zápis Parquet súborov. Formát bol navrhnutý tak, aby riešil zásadné výkonnostné obmedzenia riadkovo orientovaných formátov pri spracovaní analytických dopytov, ktoré skenujú veľké objemy dát, ale odkazujú len na podmnožinu stĺpcov alebo riadkov.
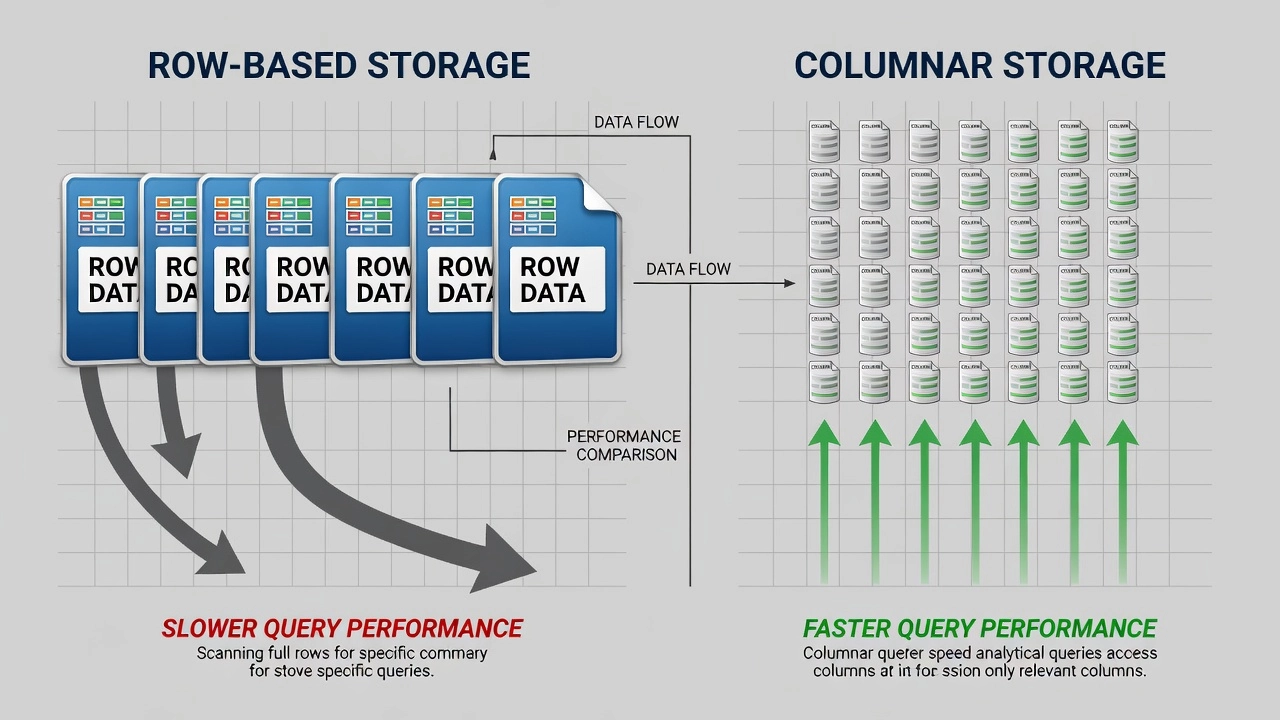
Stĺpcové ukladanie vs. Riadkovo orientované ukladanie. Definujúcou architektonickou charakteristikou Parquet je jeho stĺpcový úložný model. V tradičnom riadkovo orientovanom formáte ako CSV alebo JSON sú všetky polia patriace ku každému záznamu uložené súvisle na disku. Pre dataset inšpekcie vozovky so 100 atribútmi na jeden skúmaný bod — súradnice, hodnotenia stavu povrchu, merania poškodení, metadáta snímok — CSV ukladá všetkých 100 hodnôt pre riadok 1, za ním všetkých 100 hodnôt pre riadok 2 atď. Keď dopyt požaduje len dva atribúty, ako je šírka trhliny a GPS zemepisná šírka, úložný engine musí prečítať každý atribút pre každý riadok z disku, sparsovať celý dataset, extrahovať dva požadované stĺpce a zahodiť zvyšných 98 stĺpcov. Výsledkom je obrovské plytvanie I/O — približne 98 % dát prečítaných z disku je okamžite zahodených.
Parquet tento model úplne obracia. V rámci každej riadkovej skupiny (horizontálnej partície datasetu obsahujúcej súvislý blok riadkov) sú dáta ukladané po stĺpcoch namiesto po riadkoch. Všetky hodnoty pre stĺpec zemepisnej šírky sú uložené súvisle v jednom stĺpcovom bloku, všetky hodnoty pre šírku trhliny v inom stĺpcovom bloku atď. Dopyt požadujúci len zemepisnú šírku a šírku trhliny prečíta z disku len tieto dva stĺpcové bloky, čím zníži I/O o rovnakých 98 %, ktoré sú v riadkovo orientovaných formátoch plytvané. Toto stĺpcové usporiadanie je základom výkonnostnej výhody Parquet pre analytické dopyty.
Vnútorná Architektúra Súboru. Parquet súbor nasleduje prísnu hierarchickú štruktúru s tromi vnorenými úrovňami organizácie: riadkové skupiny, stĺpcové bloky a stránky. Pochopenie tejto hierarchie je nevyhnutné pre optimalizáciu výkonu Parquet v inšpekčných dátových pipelines.
Najvonkajšou úrovňou je riadková skupina, ktorá rozdeľuje dataset horizontálne na súvislé bloky riadkov. Každá riadková skupina je navrhnutá tak, aby bola nezávisle čitateľná a spracovateľná, čo umožňuje paralelné vykonávanie na viacerých CPU jadrách alebo pracovníkoch distribuovaného klastra. Typická riadková skupina obsahuje 64 000 až 1 000 000 riadkov, s cieľovou nekomprimovanou veľkosťou 64 MB až 1 GB v závislosti od pracovnej záťaže. Pre inšpekčné dáta TarmacView poskytujú riadkové skupiny približne 256 MB nekomprimované optimálnu rovnováhu medzi granularitou paralelizácie a réžiou metadát. Väčšie riadkové skupiny znižujú počet položiek metadát v pätičke súboru, ale obmedzujú paralelizmus; menšie riadkové skupiny zvyšujú réžiu metadát, ale umožňujú jemnozrnnejšie preskakovanie dát.
V rámci každej riadkovej skupiny sú dáta rozdelené po stĺpcoch do stĺpcových blokov. Každý stĺpcový blok ukladá všetky hodnoty pre jeden stĺpec naprieč všetkými riadkami v tejto riadkovej skupine. Pretože všetky hodnoty v stĺpcovom bloku zdieľajú rovnaký dátový typ a často vykazujú podobné štatistické vlastnosti — ako nízka kardinalita pre kategorické klasifikácie poškodení alebo monotónne usporiadanie pre časové pečiatky — stĺpcové bloky môžu byť komprimované a kódované oveľa efektívnejšie ako zmiešané riadkové dáta. Stĺpcové bloky sú tiež miestom, kde sa počítajú štatistické metadáta Parquet: každý stĺpcový blok voliteľne ukladá minimálnu hodnotu, maximálnu hodnotu a počet null hodnôt pre tento stĺpec v rámci bloku. Tieto štatistiky umožňujú predikátový pushdown, kde dopytovacie enginy preskakujú celé stĺpcové bloky, ktorých rozsahy hodnôt sa neprekrývajú s filtračnými podmienkami.
Každý stĺpcový blok je rozdelený na stránky, najmenšiu nedeliteľnú jednotku ukladania a úroveň, na ktorej sa aplikuje kompresia a kódovanie. Predvolená veľkosť stránky je približne 1 MB nekomprimované. Stĺpcový blok typicky pozostáva z viacerých dátových stránok obsahujúcich zakódované hodnoty stĺpca, voliteľne predchádzaných dikcionárovou stránkou, ktorá mapuje unikátne hodnoty na celočíselné indexy pre dikcionárové kódovanie. Parquet definuje niekoľko typov stránok vrátane DATA_PAGE (pôvodný formát v1), DATA_PAGE_V2 (vylepšený formát, ktorý ukladá úrovne opakovania a definície nekomprimované pre rýchlejšie preskakovanie null a vnorených hodnôt) a DICTIONARY_PAGE (obsahujúcu dikcionárové mapovanie pre dikcionárovo kódované stĺpce).
Pätička Súboru a Metadáta. Pätička súboru je kritickou súčasťou každého Parquet súboru. Nachádza sa na konci súboru a obsahuje kompletnú metadátovú informáciu serializovanú pomocou Apache Thrift TCompactProtocol — kompaktného binárneho serializačného formátu optimalizovaného pre schema-on-read pracovné záťaže. Metadáta pätičky zahŕňajú schému súboru (názvy stĺpcov, dátové typy a definície vnorenej štruktúry), počet riadkov, verziu súboru, zoznam riadkových skupín s ich umiestneniami stĺpcových blokov a veľkosťami, štatistiky na úrovni stĺpcových blokov (min, max, počet null), kompresný kodek použitý pre každý stĺpec a voliteľné kľúč-hodnota metadáta pre aplikáciu špecifické informácie. Pretože pätička je malá — typicky niekoľko kilobajtov až niekoľko stoviek kilobajtov pre súbory s mnohými riadkovými skupinami — dopytovacie enginy ju môžu rýchlo prečítať a naplánovať svoju stratégiu prístupu k dátam pred čítaním akýchkoľvek dátových stránok.
Magic Bytes a Identifikácia Súboru. Každý platný Parquet súbor začína a končí 4-bajtovým magickým číslom PAR1 (hexadecimálne: 50 41 52 31). Magic bytes na začiatku identifikujú formát súboru pre čitateľov, zatiaľ čo magic bytes na konci potvrdzujú integritu súboru a poskytujú kotvu na lokalizáciu metadát pätičky. Na čítanie Parquet súboru nasleduje dopytovací engine tento kanonický algoritmus: posunúť sa na koniec súboru mínus 8 bajtov, prečítať 4-bajtové magic číslo na potvrdenie formátu PAR1, prečítať predchádzajúce 4 bajty ako little-endian 32-bitové celé číslo predstavujúce dĺžku metadát pätičky, posunúť sa späť o túto dĺžku, prečítať a deserializovať Thrift-kódované FileMetaData, sparsovať schému, lokalizovať požadované stĺpcové bloky podľa ich offsetov v súbore a prečítať len požadované stránky.
Výhody Parquet pre Inšpekčné Dáta
Kompresné Pomery. Stĺpcový úložný model Parquet prirodzene produkuje dramaticky menšie veľkosti súborov ako riadkovo orientované formáty, ešte pred aplikovaním kompresného kodeku. Toto zmenšenie veľkosti pochádza z dvoch zdrojov: techniky stĺpcového kódovania, ktoré využívajú charakteristiky dát na úrovni stĺpcov, a voliteľné kompresné kodeky aplikované na úrovni stránky. Porovnávacie štúdie na reálnych datasadoch konzistentne ukazujú, že nekomprimovaný Parquet je približne 25 % až 32 % veľkosti ekvivalentných CSV súborov. Pridanie kompresného kodeku ako Snappy alebo Zstd znižuje veľkosť súboru ďalej na 8 % až 18 % veľkosti CSV, čo predstavuje 5x až 12x zníženie úložného priestoru.
Pre inšpekčné dáta je táto kompresia obzvlášť výhodná, pretože datasety kombinujú vysoko-presné súradnice s plávajúcou desatinnou čiarkou (ktoré sa výborne delta-kódujú), kategorické klasifikácie poškodení (ktoré profitujú z dikcionárového kódovania) a časové pečiatky (ktoré sa efektívne komprimujú pomocou delta kódovania). Kompletný prieskum vozovky dráhy generujúci 50 miliónov dátových bodov s 80 atribútmi na bod produkuje približne 40 GB ako surový CSV. Rovnaké dáta uložené ako Parquet s kompresiou Zstd zaberajú približne 3 GB až 5 GB — zníženie úložného priestoru 8x až 12x. Pre letiskových prevádzkovateľov vykonávajúcich štvrťročné prieskumy na viacerých dráhach, rolovacích dráhach a odbavovacích plochách sa to priamo premieta do znížených nákladov na úložnú infraštruktúru, rýchlejších časov prenosu dát a efektívnejšieho využívania cloudového úložiska.
Predikátový Pushdown. Predikátový pushdown je jediná najvplyvnejšia optimalizácia výkonu umožnená stĺpcovým ukladaním Parquet a štatistikami na úrovni blokov. Keď dopyt obsahuje klauzulu WHERE — ako WHERE pci < 40 AND survey_date >= '2024-01-01' — dopytovací engine najprv prečíta pätičku súboru obsahujúcu štatistiky na úrovni stĺpcových blokov pre filtrované stĺpce. Pre každú riadkovú skupinu engine porovná filtračnú podmienku s uloženými minimálnymi a maximálnymi hodnotami. Riadkové skupiny, ktorých štatistický rozsah sa neprekrýva s filtračnou podmienkou, sú úplne preskočené, čo spotrebuje nulové I/O.
Zvážte archív inšpekcií TarmacView obsahujúci päť rokov štvrťročných prieskumov dráh, organizovaných do 200 riadkových skupín ročne, celkovo 1000 riadkových skupín. Dopyt filtrujúci na survey_date >= '2024-06-01' porovnáva dátum filtra s uloženými min a max časovými pečiatkami pre každú riadkovú skupinu. Iba riadkové skupiny zodpovedajúce prieskumom od polovice roku 2024 a neskôr sa prekrývajú s filtrom — približne 50 až 100 riadkových skupín z 1000, čiže 5 % až 10 % celkových dát. Zvyšných 900 až 950 riadkových skupín je preskočených bez čítania. Dopyt prečíta len 5 % až 10 % údajov súboru, čo poskytuje 10x až 20x zlepšenie výkonu oproti úplnému skenovaniu. V kombinácii so stĺpcovým prerezávaním môžu efektívne úspory I/O presiahnuť 100x pre selektívne dopyty na širokých datasadoch.
Evolúcia Schémy. Parquet podporuje evolúciu schémy — schopnosť pridávať, odstraňovať alebo upravovať stĺpce v čase bez prepisovania existujúcich súborov. Toto je kritické pre dlhodobé inšpekčné programy, kde sa požiadavky na zber dát vyvíjajú. Program inšpekcie dráh, ktorý na začiatku zaznamenáva len hodnotenia poškodení povrchu, môže neskôr pridať klasifikáciu trhlín, merania textúry alebo metadáta snímok, ako program dozrieva. S evolúciou schémy môžu nové Parquet súbory zapísané s rozšírenou schémou koexistovať bez problémov so staršími súbormi používajúcimi pôvodnú schému. Dopytovacie enginy čítajúce dataset vidia zlúčenú schému s null hodnotami doplnenými pre stĺpce, ktoré v starších súboroch neexistovali. Parquet tiež podporuje pridávanie stĺpcov s predvolenými hodnotami, premenovávanie stĺpcov pomocou metadát aliasov stĺpcov a spätne kompatibilné typové propagácie ako int32 na int64.
Stĺpcové Prerezávanie (Projekčný Pushdown). Stĺpcové prerezávanie je prax čítania z disku len tých stĺpcov, ktoré sú uvedené v dopyte. Pretože Parquet ukladá stĺpce do samostatných stĺpcových blokov v rámci každej riadkovej skupiny, dopytovací engine číta len stĺpcové bloky pre stĺpce vyskytujúce sa v klauzule SELECT. Pre inšpekčný súbor TarmacView so 100 atribútmi prečíta dopyt vyberajúci latitude, longitude, pci len tri stĺpcové bloky — približne 3 % celkových údajov súboru. Pri riadkovo orientovaných formátoch musí rovnaký dopyt prečítať 100 % dát a zahodiť 97 % v pamäti. Stĺpcové prerezávanie je automatické vo všetkých Parquet-kompatibilných dopytovacích enginoch a nevyžaduje žiadnu explicitnú konfiguráciu. Výkonnostný prínos sa lineárne škáluje s počtom stĺpcov v datasete: čím viac atribútov sa zbiera na jeden skúmaný bod, tým väčšie sú úspory zo stĺpcového prerezávania.
Sebapopisujúci Formát. Parquet súbory sú plne sebapopisujúce — schéma, kompresný kodek, kódovanie, štatistiky a aplikačné metadáta sú vložené priamo do samotného súboru. Na čítanie Parquet súboru nie je potrebný žiadny externý register schém, dátový slovník ani konfiguračný súbor. Táto vlastnosť zjednodušuje zdieľanie dát, archiváciu a dlhodobé uchovávanie. Parquet súbor zapísaný pred piatimi rokmi s neznámou schémou môže byť prečítaný moderným softvérom bez externej dokumentácie. Sebapopisujúca povaha tiež umožňuje validáciu schémy pri čítaní, zachytávajúc nezhody dátových typov a štrukturálne nezrovnalosti skôr, než sa rozšíria do analytických pipelines.
Deliteľný a Paralelne Čitateľný. Riadkové skupiny Parquet sú nezávisle čitateľné, čo umožňuje paralelné spracovanie na viacerých CPU jadrách, uzloch distribuovaného klastra alebo súbežných cloudových úložných pripojeniach. Jeden veľký Parquet súbor môže byť rozdelený na svoje základné riadkové skupiny a spracovaný súčasne, pričom každý pracovník spracúva podmnožinu riadkových skupín. Táto vlastnosť je nevyhnutná pre distribuované spracovateľské frameworky ako Apache Spark, ktorý prideľuje rôzne riadkové skupiny rôznym úlohám vykonávačov, a pre viacvláknové analytické knižnice ako Polars, ktoré čítajú viacero riadkových skupín paralelne v rámci jedného procesu. Pre dátové pipelines inšpekcií TarmacView spracúvajúce terabajty prieskumných dát znižuje paralelné čítanie riadkových skupín čas spracovania z hodín na minúty.
Parquet vs. CSV a JSON pre Inšpekčné Dáta
Výber dátového formátu zásadne ovplyvňuje každý aspekt inšpekčnej dátovej pipeline: náklady na ukladanie, výkon dopytov, integritu dát a dlhodobú udržiavateľnosť. Parquet, CSV a JSON majú každý odlišné charakteristiky, ktoré ich robia vhodnými pre rôzne prípady použitia v ekosystéme inšpekčných dát.
Efektivita Ukladania. CSV súbory ukladajú dáta ako obyčajný text s čiarkami ako oddeľovačmi a bez kompresie. Jedno číslo s plávajúcou desatinnou čiarkou ako 14,732859 je uložené ako 9 bajtov ASCII textu bez ohľadu na jeho požiadavky na presnosť. JSON je ešte rozsiahlejší, pridáva štrukturálne znaky ako zátvorky, hranaté zátvorky, úvodzovky a dvojbodky, ktoré môžu zdvojnásobiť alebo strojnásobiť veľkosť súboru v porovnaní s CSV pre rovnaké dáta. Parquet ukladá rovnakú hodnotu ako 4 bajty alebo 8 bajtov binárnych dát v závislosti od toho, či sa používa 32-bitová alebo 64-bitová presnosť. V kombinácii s dikcionárovým kódovaním pre kategorické stĺpce — ktoré nahrádza opakované reťazcové hodnoty kompaktnými celočíselnými indexmi — Parquet dosahuje zníženie úložného priestoru 5x až 20x v porovnaní s CSV a 8x až 30x v porovnaní s JSON.
Vlastnosť
Parquet
CSV
JSON
Úložný model
Stĺpcový binárny
Riadkovo orientovaný text
Riadkovo orientovaný text (vnerený)
Veľkosť súboru (1M inšpekčných riadkov, 80 stĺpcov)
50–200 MB
500 MB–2 GB
800 MB–3 GB
Vstavaná kompresia
Áno (kódovanie + kodek)
Žiadna (iba externá)
Žiadna (iba externá)
Čítanie: 2 stĺpce z 80
~2,5 % I/O súboru
100 % I/O súboru
100 % I/O súboru
Schéma
Sebapopisujúca, typovaná
Žiadna (odvodená)
Implicitná, netypovaná
Čitateľná pre človeka
Nie (binárna)
Áno
Áno
Podpora vnorených dát
Natívna (struct, list, map)
Nepodporovaná
Natívna
Rýchlosť dopytov (analytika)
10x–100x rýchlejšia ako CSV
Základná línia
Pomalšia ako CSV
Rýchlosť zápisu
Pomalšia (réžia kódovania)
Rýchla
Rýchla
Podpora v ekosystéme
Spark, DuckDB, BigQuery, Snowflake
Všetky nástroje
Všetky nástroje
Výkon Dopytov. Rozdiel vo výkone medzi Parquet a riadkovo orientovanými formátmi sa stáva výraznejším so zvyšujúcou sa veľkosťou datasetu a zložitosťou dopytu. Pre jednoduché count dopyty na malých datasadoch (menej ako 100 000 riadkov) môže CSV konkurovať Parquet pri použití optimalizovaných CSV čitateľov. Avšak pre typické inšpekčné pracovné záťaže zahŕňajúce filtrovanie, agregáciu a viacstĺpcovú analýzu na datasadoch v rozsahu miliónov až miliárd riadkov prekonáva Parquet CSV 10x až 100x. Výkonnostná výhoda pochádza z troch zdrojov: znížené I/O prostredníctvom stĺpcového prerezávania (čítanie len potrebných stĺpcov), znížené I/O prostredníctvom predikátového pushdown (preskakovanie irelevantných riadkových skupín) a rýchlejšia dekompresia a dekódovanie komprimovaných binárnych dát v porovnaní s parsovaním obyčajného textu.
Integrita Schémy. CSV nemá žiadnu vstavanú schému. Stĺpec obsahujúci celočíselné hodnoty v jednom súbore môže obsahovať reťazcové hodnoty alebo prázdne polia v inom, bez mechanizmu na detekciu alebo hlásenie nekonzistencie. Inferencia dátových typov v CSV čitateľoch je heuristická a môže produkovať nesprávne výsledky — napríklad interpretácia PSČ ako 02134 ako celého čísla 2134 po odstránení úvodnej nuly. JSON má implicitnú schému, ale žiadne vynucovanie typov; rovnaké pole môže byť reťazec v jednom zázname a číslo v nasledujúcom. Parquet vynucuje prísnu, explicitnú schému na úrovni súboru. Každá hodnota v stĺpci musí zodpovedať deklarovanému dátovému typu a validácia schémy sa vykonáva v čase zápisu. Táto typová bezpečnosť je kritická pre inšpekčné dáta, kde je integrita dát prvoradá pre bezpečnostne-kritické infraštruktúrne rozhodnutia.
Kedy Použiť Každý Formát. CSV zostáva užitočný pre malé datasety, ktoré musia byť čitateľné pre človeka, pre výmenu dát medzi systémami, ktoré nemajú podporu Parquet, a pre pracovné postupy, kde je jednoduchosť generovania dôležitejšia ako výkon dopytov. JSON je vhodný pre pološtruktúrované dáta s premennou schémou, pre API payloady a pre logy, kde je vnorená štruktúra nevyhnutná. Parquet je správnou voľbou pre akýkoľvek inšpekčný dataset presahujúci približne 100 MB, pre všetky analytické dopytovacie záťaže, pre dlhodobú archiváciu dát a pre akúkoľvek pipeline, kde sú prioritami výkon dopytov a efektivita ukladania. V architektúre TarmacView môžu byť surové prieskumné dáta na začiatku ingestované ako JSON alebo CSV zo senzorových systémov, ale všetky analytické dátové produkty — výsledky, dlaždice, hodnotenia — sú ukladané výhradne v Parquet.
Čítanie a Zápis Parquet v Pythone
Python poskytuje tri primárne knižnice na spracovanie Parquet — PyArrow, Pandas a Polars — každú s odlišnými silnými stránkami pre analýzu inšpekčných dát. Výber knižnice závisí od konkrétnych požiadaviek pracovného postupu: priepustnosť pipeline, rýchlosť interaktívnej analýzy, pamäťové obmedzenia a integrácia s existujúcimi nástrojmi.
PyArrow. PyArrow je Python väzba pre knižnicu Apache Arrow C++ a poskytuje najkompletnejšie, nízkoúrovňové API pre operácie s Parquet. Ponúka jemnozrnnú kontrolu nad všetkými parametrami Parquet vrátane veľkosti riadkovej skupiny, veľkosti stránky, kompresného kodeku, prahov dikcionárového kódovania a zberu štatistík. Modul pyarrow.parquet poskytuje funkcie read_table() a write_table() pre základné operácie.
import pyarrow.parquet as pq
import pyarrow as pa
# Čítanie so stĺpcovým prerezávaním a predikátovým pushdowntable = pq.read_table(
'survey_results.parquet',
columns=['latitude', 'longitude', 'pci', 'crack_width'],
filters=[('pci', '<', 40), ('survey_date', '>=', '2024-01-01')]
)
# Zápis s jemnozrnnou kontroloupq.write_table(
table,
'filtered_results.parquet',
row_group_size=100000,
compression='zstd',
compression_level=3,
use_dictionary=True,
write_statistics=True,
data_page_size=1048576# 1 MB predvolená veľkosť stránky)
Parameter columns umožňuje explicitné stĺpcové prerezávanie, čítajúc len špecifikované stĺpce zo súboru. Parameter filters umožňuje predikátový pushdown, prijímajúc zoznam filtrovacích výrazov vo formáte DNF (Disjunktívna normálna forma). PyArrow vyhodnocuje tieto filtre proti štatistikám na úrovni blokov pred čítaním akýchkoľvek dátových stránok. Pre rozdelené datasety — bežné v TarmacView, kde sú dáta organizované podľa dátumu prieskumu a sekcie dráhy — poskytuje pq.ParquetDataset() automatické objavovanie partícií s pushdown partičných filtrov aj stĺpcových štatistík.
Pandas. Pandas poskytuje jednoduchšie, vysokoúrovňové API pre operácie s Parquet prostredníctvom pd.read_parquet() a df.to_parquet(). Knižnica deleguje základnú implementáciu Parquet na PyArrow (predvolený pre novšie verzie Pandas) alebo fastparquet. Pandas je ideálny pre interaktívnu analýzu, pracovné postupy v Jupyter notebookoch a rýchly prieskum dát tam, kde sa cení jednoduchosť nad jemnozrnnou kontrolou.
Pandas načíta celý Parquet súbor do DataFrame v pamäti. Toto je vhodné pre datasety, ktoré sa zmestia do dostupnej RAM — až približne 10 GB až 50 GB v závislosti od hardvéru. Pre väčšie datasety môže Pandas vyžadovať dávkové čítanie alebo stratégie spracovania mimo pamäte. Parameter engine je predvolene nastavený na PyArrow v najnovších verziách Pandas, ale môže byť nastavený na fastparquet pre menšiu závislostnú stopu.
Polars. Polars je DataFrame knižnica postavená natívne na Apache Arrow s engine založeným na Ruste, ktorý poskytuje najrýchlejší výkon čítania Parquet spomedzi Python knižníc — typicky 3x až 10x rýchlejší ako Pandas. Polars to dosahuje prostredníctvom agresívneho viacvláknového spracovania, cache-efektívnych dátových layoutov a lazy optimalizácie dopytov, ktorá odkladá vykonanie, kým nie je známy kompletný plán dopytu.
Metóda scan_parquet() vytvára lazy výpočtový graf, ktorý zachytáva kompletný plán dopytu — filtre, výbery, agregácie — predtým, než sa z disku prečítajú akékoľvek dáta. Keď sa zavolá collect(), Polars pushdownuje všetky použiteľné filtre do Parquet čitateľa, preskakujúc celé riadkové skupiny prostredníctvom štatistík a čítajúc len požadované stĺpce zo zostávajúcich riadkových skupín. Táto lazy optimalizácia môže znížiť čítanie dát o 95 % alebo viac v porovnaní s dychtivým čítaním celého súboru nasledovaným filtrovaním v pamäti.
Porovnanie Výkonu. Výsledky benchmarkov z reálnych pracovných záťaží spracovania dát ukazujú relatívny výkon troch knižníc:
Operácia
Pandas (pyarrow engine)
Polars
PyArrow
Čítanie 10 GB Parquet, úplné skenovanie
~60 s
~15–20 s
~25 s
Filtrácia + agregácia na 10 GB
~45 s
~8–12 s
~15 s
Zápis 10 GB Parquet so Zstd
~80 s
~30 s
~40 s
Stĺpcové prerezávanie + pushdown filtra
~50 s
~3–5 s
~10 s
Polars vykazuje najsilnejšiu výhodu pre selektívne dopyty zahŕňajúce stĺpcové prerezávanie a predikátový pushdown, pretože jeho lazy optimalizátor eliminuje zbytočné I/O pred začatím vykonávania. Pre operácie s ťažiskom na zápise v kontexte dátových pipeline poskytuje PyArrow najspoľahlivejší výkon s najširšou sadou funkcií.
Schéma Parquet v TarmacView
TarmacView organizuje výsledky inšpekčných analýz do rodiny Parquet súborov, každý s vyhradenou schémou optimalizovanou pre špecifické vzory dopytov a prípady použitia. Tento návrh schémy nasleduje osvedčené postupy Parquet vrátane vhodného výberu dátových typov, stĺpcových štatistík pre predikátový pushdown a organizácie partícií pre časové a priestorové dopyty.
results.parquet. Primárny výstupný súbor inšpekcie ukladá jeden riadok na jednu skúmanú pozíciu pozdĺž dráhy alebo povrchu vozovky. Schéma zahŕňa presné GPS súradnice s presnosťou na submeter pomocou dátumu WGS84, časovú pečiatku prieskumu s informáciou o časovej zóne pre koreláciu s poveternostnými a prevádzkovými údajmi a komplexné merania stavu vozovky. Jednotlivé stĺpce poškodení ukladajú šírku trhliny v milimetroch, dĺžku trhliny v metroch, plochu odlupovania v metroch štvorcových, závažnosť vydrolovania na kategorickej škále a metriky textúry povrchu vrátane strednej hĺbky profilu. Polia výpočtu PCI ukladajú vypočítanú hodnotu indexu stavu vozovky podľa metodiky ASTM D5340, deduktívne hodnoty pre každý typ poškodenia a konečnú klasifikáciu PCI ratingu. Stĺpce kontroly kvality zaznamenávajú odhad presnosti GPS v metroch, skóre spoľahlivosti spracovania a indikátory kvality signalizujúce potenciálne anomálie dát. Každý riadok je jednoznačne identifikovaný identifikátorom prieskumnej jazdy a sekvenčným indexom bodu, čo umožňuje presné priestorové a časové referencovanie každého merania.
tiles.parquet. Súbor analýzy na základe dlaždíc rozdeľuje povrch vozovky do pravidelnej mriežky s konfigurovateľnou veľkosťou dlaždice, predvolene 1 meter x 1 meter pre detailné prieskumy a 5 metrov x 5 metrov pre rýchle hodnotenia. Každý riadok predstavuje jednu dlaždicu s jej geopriestorovými súradnicami ohraničujúceho rámca, stredovou zemepisnou šírkou a dĺžkou dlaždice a agregovanými štatistikami vypočítanými zo všetkých prieskumných bodov spadajúcich do dlaždice. Agregované polia zahŕňajú strednú, mediánovú, minimálnu a maximálnu hodnotu PCI v rámci dlaždice, dominantný typ poškodenia určený najvyššou deduktívnou hodnotou, hustotu poškodenia ako percento ovplyvnenej plochy dlaždice a počet dátových bodov prispievajúcich k štatistikám dlaždice. Schéma dlaždice tiež ukladá klasifikáciu PCI ratingu na úrovni dlaždice a odporúčané údržbárske opatrenie na základe analýzy prahov. Ukladanie na základe dlaždíc umožňuje rýchle priestorové dopyty a vizualizačné pracovné postupy, kde je zobrazovanie každého jednotlivého prieskumného bodu zbytočné a výpočtovo nákladné.
assessment.parquet. Konečný súbor hodnotenia stavu ukladá vyhodnotenie na úrovni sekcií s jedným riadkom na homogénnu sekciu vozovky na jednu prieskumnú kampaň. Každá sekcia je definovaná identifikátorom dráhy alebo rolovacej dráhy, začiatočnými a koncovými staničnými súradnicami a dĺžkou sekcie. Schéma hodnotenia zahŕňa vypočítané PCI sekcie podľa metodiky ASTM D5340 so všetkými výpočtami deduktívnych hodnôt, hodnotenie stavu povrchu podľa ICAO Annex 14 pre medzinárodné reportovanie zhody, hustoty jednotlivých typov poškodení vyjadrené ako percento plochy sekcie, opravené deduktívne hodnoty pre každé poškodenie a konečné PCI. Polia odporúčaní údržby ukladajú vypočítanú prioritu na základe prahov PCI, odporúčaný typ ošetrenia, ako je tesnenie trhlín, prekrytie alebo rekonštrukcia, a odhadovanú naliehavosť ošetrenia. Súbor hodnotenia tiež zaznamenáva metadáta o prieskume vrátane identifikátora prieskumného vozidla, konfigurácie senzorov, verzie analytického softvéru a verzie pipeline spracovania dát pre plnú vysledovateľnosť.
telemetry.parquet. Súbor telemetrického toku prieskumného vozidla zaznamenáva časovo-radové senzorové dáta zozbierané počas inšpekčnej jazdy. Každý riadok predstavuje telemetrické čítanie v konkrétnom časovom okamihu vrátane GPS času, rýchlosti vozidla v kilometroch za hodinu, smeru v stupňoch od skutočného severu, pozdĺžneho a priečneho zrýchlenia v metroch za sekundu na druhú, nadmorskej výšky z GPS a počtu satelitov použitých na GPS fix. Senzorovo-špecifické stĺpce zaznamenávajú stav každého zobrazovacieho a meracieho senzora vrátane snímkovej frekvencie kamery, stavu laserového riadkového skenera a orientačných uhlov inerciálnej meracej jednotky. Telemetrický súbor umožňuje analýzu kvality po spracovaní, ako je detekcia prieskumných jázd vykonaných nadmernou rýchlosťou, ktorá môže ohroziť kvalitu dát, identifikácia oblastí, kde sa prieskumné vozidlo odchýlilo od predpísanej trasy, a korelácia meraní stavu vozovky s dynamikou vozidla pre výskumné a optimalizačné účely.
Rozdeľovanie a Organizácia Súborov. Parquet súbory TarmacView sú rozdelené podľa dátumu prieskumu a sekcie dráhy, aby sa optimalizovali časové a priestorové dopyty. Štruktúra partičného adresára nasleduje vzor survey_date=YYYY-MM-DD/runway_id=RWY09/section=SECTION_A/. Prerezávanie partícií umožňuje dopytom filtrujúcim na dátum prieskumu alebo sekciu dráhy čítať len relevantné adresáre, preskakujúc všetky ostatné partície. V rámci každej partície sú riadkové skupiny Parquet veľké približne 256 MB nekomprimované, čo vyvažuje granularitu paralelizácie oproti réžii metadát. Všetky súbory používajú kompresiu Zstd na úrovni 3 s povoleným dikcionárovým kódovaním pre kategorické stĺpce a delta kódovaním pre monotónne polia, ako sú staničné súradnice.
Parquet pre Veľké Video Prieskumné Dáta
Prieskumy letiskových vozoviek produkujú výnimočne veľké datasety, ktoré posúvajú limity tradičných prístupov k ukladaniu dát. Jediný prieskum dráhy v rozlíšení 1 mm pomocou kamerového systému namontovaného na vozidle môže generovať 500 GB až 2 TB surových obrazových dát na kilometer vozovky, s príslušnými meracími dátami z laserových profilometrov, inerciálnych senzorov a GPS prijímačov produkujúcich dodatočné štruktúrované dátové toky. Parquet hrá ústrednú úlohu pri správe štruktúrovanej meracej zložky týchto dát — vysokorozmerných, viacrozmerných tabuľkových dát, ktoré popisujú stav vozovky v každom skúmanom bode.
Správa Vysokorozmerných Inšpekčných Dát. Moderné systémy inšpekcie vozoviek zberajú desiatky až stovky atribútov na jeden skúmaný bod. Typická sada senzorov prieskumného vozidla zahŕňa viacero vysokorozlíšených kamier poskytujúcich vizuálne snímky s rozlíšením pod milimeter, laserové riadkové skenery produkujúce 3D povrchové profily s vertikálnou presnosťou na úrovni mikrónov, infračervené termografické senzory merajúce povrchovú teplotu pre detekciu delaminácie, ground-penetračný radar pre hodnotenie podpovrchových vrstiev, inerciálne meracie jednotky pre presné určovanie polohy a orientácie a GPS prijímače pre absolútne georeferencovanie. Každý senzor produkuje štruktúrované merania, ktoré sú priestorovo a časovo korelované. Kombinovaný dataset pre jednu prieskumnú kampaň na veľkom medzinárodnom letisku môže presiahnuť 100 miliárd dátových bodov pri zohľadnení všetkých senzorových kanálov pri plnej vzorkovacej frekvencii.
Parquet umožňuje efektívne ukladanie a dopytovanie týchto vysokorozmerných datasetov prostredníctvom svojej kombinácie stĺpcového ukladania pre husté sady atribútov, dikcionárového kódovania pre opakujúce sa kategorické polia, delta kódovania pre monotónne narastajúce časové pečiatky a staničné súradnice a bežného kódovania dĺžky pre sekvencie identických hodnôt bežné v klasifikačných poliach poškodení. Typický záznam prieskumného bodu s 80 atribútmi zaberá približne 70 bajtov v Parquet s kompresiou Zstd, v porovnaní s približne 400 bajtmi ako nekomprimované CSV a približne 800 bajtmi ako JSON. Pre 100 miliárd prieskumných bodov to predstavuje rozdiel v ukladaní 7 TB pre Parquet oproti 40 TB pre CSV oproti 80 TB pre JSON.
Časové a Priestorové Vzory Dopytov. Dopyty na inšpekčné dáta nasledujú charakteristické vzory, ktorým architektúra Parquet dobre slúži. Časovo-rozsahové dopyty ako “Zobraziť všetky prieskumné dáta medzi marcom a septembrom 2024” profitujú z prerezávania partícií Parquet, keď sú súbory organizované podľa dátumu prieskumu, a z predikátového pushdown na stĺpci časovej pečiatky v rámci súborov. Priestorové dopyty ako “Nájsť všetky poškodenia do 100 metrov od prahu dráhy” profitujú z delta-kódovaných staničných súradníc, ktoré sa efektívne komprimujú a umožňujú rýchle sekvenčné skenovanie súvislých priestorových rozsahov. Viacatribútové dopyty ako “Lokalizovať oblasti s PCI pod 40 a šírkou trhliny presahujúcou 3 mm” profitujú zo stĺpcového prerezávania, ktoré číta len tri relevantné stĺpce — PCI, šírku trhliny a súradnice — z celej sady atribútov.
Streamované a Prírastkové Spracovanie. Veľké video prieskumné dáta často vyžadujú prírastkové spracovanie, kde sú surové senzorové dáta ingestované, spracované a zapísané do Parquet v etapách. Parquet podporuje streamované zápisy prostredníctvom svojej architektúry riadkových skupín: dáta môžu byť akumulované v pamäti, kým riadková skupina nedosiahne cieľovú veľkosť, potom flushnuté na disk. To umožňuje spracovateľské pipelines, ktoré spotrebúvajú živé senzorové toky počas prieskumných jázd a produkujú Parquet súbory prírastkovo bez potreby držať celý dataset v pamäti. Spracovateľská pipeline TarmacView implementuje tento vzor, zapisujúc výsledky prieskumu do Parquet takmer v reálnom čase, keď prieskumné vozidlo prechádza dráhu.
Dopytovanie Parquet s Pushdown Filtrov a Stĺpcovým Prerezávaním
Kombinácia pushdown filtrov a stĺpcového prerezávania je primárnym mechanizmom, ktorým Parquet dosahuje svoju výkonnostnú výhodu oproti riadkovo orientovaným formátom. Pochopenie toho, ako tieto optimalizácie fungujú, umožňuje analytikom inšpekčných dát a vývojárom pipeline štruktúrovať dopyty pre maximálnu efektivitu.
Mechanizmus Pushdown Filtrov. Keď dopytovací engine číta Parquet súbor, jeho prvou operáciou je prečítanie pätičky súboru obsahujúcej definíciu schémy a zoznam riadkových skupín s ich štatistikami na úrovni stĺpcových blokov. Pre každý stĺpec uvedený v klauzulách WHERE engine extrahuje uložené minimálne a maximálne hodnoty zo štatistík každého stĺpcového bloku. Engine potom vyhodnocuje každú filtračnú podmienku oproti min-max rozsahu každého stĺpcového bloku pomocou nasledujúcej logiky: ak filtračná podmienka vyžaduje hodnoty väčšie ako X a maximálna hodnota stĺpcového bloku je menšia alebo rovná X, potom blok neobsahuje žiadne zodpovedajúce riadky a môže byť úplne preskočený. Podobne, ak filtračná podmienka vyžaduje hodnoty menšie ako Y a minimálna hodnota stĺpcového bloku je väčšia alebo rovná Y, blok môže byť preskočený. Engine iteruje cez všetky stĺpcové bloky paralelne, vytvárajúc masku riadkových skupín, ktoré musia byť prečítané, a riadkových skupín, ktoré môžu byť preskočené.
Zvážte konkrétny príklad z inšpekčných dát TarmacView. Analytik dopytuje: “Nájsť všetky sekcie s PCI pod 40 skúmané po 1. júni 2024.” Engine prečíta pätičku a preskúma štatistiky pre stĺpcové bloky pci a survey_date naprieč všetkými riadkovými skupinami. Riadková skupina pokrývajúca dátumy prieskumu od januára do marca 2024 má maximum survey_date 31. marca 2024 — to je pod prahom filtra 1. júna 2024, takže celá riadková skupina je preskočená. Ďalšia riadková skupina pokrývajúca hodnoty PCI od 45 do 95 má minimum pci 45 — to je nad prahom filtra 40, takže táto riadková skupina je tiež preskočená. Po vyhodnotení všetkých riadkových skupín engine identifikuje, že len riadkové skupiny s prekrývajúcimi sa min-max rozsahmi obsahujú potenciálne zodpovedajúce riadky — typicky 1 % až 10 % celkového objemu dát pre selektívne dopyty na veľkých archívoch.
Stĺpcové Prerezávanie v Praxi. Stĺpcové prerezávanie operuje na rovnakej úrovni ako pushdown filtrov, ale rieši iný rozmer zníženia I/O. Zatiaľ čo pushdown filtrov znižuje počet prečítaných riadkov preskakovaním celých riadkových skupín, stĺpcové prerezávanie znižuje počet prečítaných stĺpcov výberom len stĺpcových blokov pre referencované stĺpce. Tieto dve optimalizácie sa kombinujú: pushdown filtrov eliminuje irelevantné riadkové skupiny úplne a stĺpcové prerezávanie číta len potrebné stĺpce zo zostávajúcich riadkových skupín.
Dopyt ako SELECT latitude, longitude, pci FROM assessment WHERE pci < 40 by po pushdown filtrov prečítal len riadkové skupiny obsahujúce hodnoty PCI pod 40. Z týchto riadkových skupín stĺpcové prerezávanie číta len stĺpcové bloky latitude, longitude a pci — tri stĺpce z celej schémy. Ak plná schéma obsahuje 80 stĺpcov a pushdown filtrov eliminuje 95 % riadkových skupín, efektívna úspora I/O je 99,8 % v porovnaní s úplným skenovaním nekomprimovaného súboru.
Pushdown Schopnosti Špecifické pre Engine. Rôzne dopytovacie enginy implementujú pushdown filtrov a stĺpcové prerezávanie na rôznych úrovniach sofistikovanosti. DuckDB poskytuje úplný pushdown na úrovni riadkových skupín s preskakovaním na úrovni stránok pre Parquet súbory zapísané s v2 hlavičkami stránok. Apache Spark implementuje pushdown prostredníctvom svojho DataSource v2 API, kombinujúc prerezávanie partícií, min-max filtrovanie na úrovni riadkových skupín a voliteľné preskakovanie Bloom filtrov. Presto a Trino podporujú stĺpcové prerezávanie a min-max filtrovanie riadkových skupín s konfigurovateľným správaním predikátového pushdown. PyArrow poskytuje explicitný pushdown filtrov prostredníctvom parametra filters na read_table() a automatické stĺpcové prerezávanie prostredníctvom parametra columns. Polars poskytuje automatický lazy pushdown prostredníctvom svojej metódy scan_parquet() bez potreby explicitnej konfigurácie.
Parquet a GIS Integrácia s GeoPandas
Priestorová analýza je základom pracovných postupov inšpekcie vozoviek a integrácia Parquet s geopriestorovými nástrojmi prostredníctvom špecifikácie GeoParquet umožňuje bezproblémové kombinovanie analytického výkonu s priestorovými dopytovacími schopnosťami.
GeoParquet Štandard. GeoParquet je štandard OGC (Open Geospatial Consortium), ktorý pridáva interoperabilné geopriestorové typy do formátu Parquet. Verzia 1.0, publikovaná v roku 2022, definuje, ako sú geometrické stĺpce ukladané ako Well-Known Binary (WKB) v binárnom stĺpci Parquet, s dodatočnými metadátami v pätičke súboru popisujúcimi súradnicový referenčný systém (CRS), typy geometrií prítomné v každom stĺpci a celkový ohraničujúci rámec datasetu. Verzia 1.1, publikovaná v roku 2024, pridala podporu pre natívne typy geometrií so štatistikami ohraničujúceho rámca uloženými na riadkovú skupinu, čo umožňuje priestorový predikátový pushdown — geopriestorovú obdobu štandardného predikátového pushdown Parquet. S priestorovým predikátovým pushdown môžu dopyty používajúce priestorové filtre ako ST_Intersects(geometry, query_polygon) preskakovať celé riadkové skupiny, ktorých ohraničujúce rámce sa neprekrývajú s oblasťou dopytu.
GeoPandas Integrácia. GeoPandas rozširuje Pandas DataFrame o geopriestorové operácie a číta GeoParquet súbory priamo prostredníctvom svojej metódy read_parquet(). Integrácia je transparentná: GeoParquet súbory sú čítané ako GeoDataFrames so stĺpcom geometrie, ktorý podporuje celú škálu Shapely priestorových operácií vrátane prieniku, obsiahnutia, vytvárania obalov a výpočtov vzdialenosti.
import geopandas as gpd
import shapely.geometry
# Čítanie GeoParquet inšpekčných dátgdf = gpd.read_parquet('tiles.geoparquet')
# Definovanie oblasti záujmu dráhyrunway_09_27 = shapely.geometry.box(
minx=-73.789, miny=40.635,
maxx=-73.771, maxy=40.645)
# Priestorový filter s optimalizáciou ohraničujúceho rámcarunway_tiles = gdf[gdf.geometry.intersects(runway_09_27)]
# Agregácia podľa kvality dlaždicesevere_distress = runway_tiles[runway_tiles['pci'] <40]
Keď GeoPandas číta GeoParquet súbor vytvorený so štatistikami ohraničujúceho rámca na úrovni riadkových skupín, základný PyArrow čitateľ vyhodnocuje priestorový filter oproti ohraničujúcim rámcom na úroveň riadkovej skupiny pred načítaním akýchkoľvek geometrických dát. Riadkové skupiny, ktorých ohraničujúce rámce nepretínajú oblasť dopytu, sú úplne preskočené. Pre celoštátny inšpekčný dataset s tisíckami riadkových skupín môže priestorový dopyt cieliaci na jednu dráhu prečítať menej ako 1 % všetkých riadkových skupín.
Integrácia s QGIS a Inými GIS Nástrojmi. GeoParquet je natívne podporovaný QGIS (verzia 3.28 a novšie), čo umožňuje priame načítanie a vizualizáciu Parquet inšpekčných dát v poprednej open-source GIS aplikácii. Táto integrácia znamená, že Parquet súbory TarmacView môžu byť priamo otvorené v QGIS pre tematické mapovanie, klasifikáciu symbologie a tvorbu tlačových layoutov bez medzikonverzie dát. Apache Sedona poskytuje distribuovaný priestorový SQL na GeoParquet s Apache Spark, čo umožňuje priestorové dopyty na inšpekčných datasadoch v rozsahu terabajtov naprieč viacuzlovými klastrami. Google BigQuery podporuje priame dopytovanie externých GeoParquet tabuliek s priestorovými funkciami, čo umožňuje cloudovú analýzu inšpekčných dát bez ich nahrávania do databázy. Overture Maps Foundation distribuuje svoj celý globálny mapový dataset ako GeoParquet, čo demonštruje životaschopnosť formátu pre distribúciu rozsiahlych geopriestorových dát.
Parquet Kompresné Kodeky
Parquet podporuje viacero kompresných kodekov, každý ponúkajúci odlišné kompromisy medzi kompresným pomerom, rýchlosťou zápisu a rýchlosťou čítania. Výber kodeku výrazne ovplyvňuje náklady na ukladanie aj výkon dopytov pre pracovné záťaže inšpekčných dát.
Porovnanie Kodekov. Nasledujúca tabuľka sumarizuje charakteristiky najčastejšie používaných Parquet kompresných kodekov, na základe benchmarkov s použitím reálnych datasetov vrátane dát o jazdách NYC Taxi (20 miliónov riadkov) a diaľničných inšpekčných dát z publikovaných štúdií:
Kodek
Rýchlosť zápisu (relatívna)
Rýchlosť čítania (relatívna)
Kompresný pomer vs CSV
Najlepšie pre
Žiadny (nekomprimovaný)
Najrýchlejší
Najrýchlejší
~25–32 % CSV
Medzidáta, rýchle lokálne I/O
Snappy
Takmer nekomprimovaný
Takmer nekomprimovaný
~12–18 % CSV
Predvolená rovnováha pre väčšinu systémov
LZ4_RAW
Celkovo najrýchlejší
Celkovo najrýchlejší
~12–18 % CSV
Pipeline s ťažiskom na zápise, streamovaná ingescia
Zstd (úroveň 3)
~10 % pomalší ako Snappy
Blízko Snappy
~8–14 % CSV
Najlepší celkovo pre väčšinu záťaží
Gzip (úroveň 6)
~50 % pomalší
~10–20 % pomalší
~8–15 % CSV
Archivačné ukladanie, studené dáta
Brotli
Najpomalší zápis
Mierny
~7–12 % CSV
Maximálna kompresia pre studené úložisko
Snappy je predvolený kompresný kodek v Apache Spark, Apache Hive a mnohých ďalších nástrojoch ekosystému Hadoop. Poskytuje vynikajúcu rovnováhu medzi kompresným pomerom (4x až 6x zníženie oproti CSV) a rýchlosťou čítania/zápisu, s réžiou zápisu približne 3 % až 5 % v porovnaní s nekomprimovaným Parquet. Primárnym obmedzením Snappy je, že nepodporuje konfigurovateľné úrovne kompresie, zatiaľ čo Zstd môže byť ladený buď pre rýchlosť alebo pomer.
Zstandard (Zstd) je odporúčaný predvolený kodek pre väčšinu pracovných záťaží inšpekčných dát. Na úrovni 3 dosahuje Zstd o 10 % až 30 % lepšiu kompresiu ako Snappy, pričom udržiava takmer ekvivalentné rýchlosti čítania a spôsobuje len 10 % penalizáciu rýchlosti zápisu. Na vyšších úrovniach (9 až 22) sa Zstd približuje kompresným pomerom Gzip, pričom zostáva výrazne rýchlejší na dekompresiu. Schopnosť ladenia úrovne kompresie robí Zstd všestranným naprieč typmi záťaže: úroveň 1 pre pipeline s ťažiskom na zápise, úroveň 3 pre vyvážené všeobecné použitie a úrovne 9 až 22 pre archivačné ukladanie.
LZ4_RAW poskytuje najrýchlejšie kompresné a dekompresné rýchlosti spomedzi všetkých Parquet kodekov, okrajovo rýchlejšie ako Snappy. LZ4 je optimálnou voľbou pre ingescné pipelines, ktoré uprednostňujú priepustnosť zápisu, ako je streamovanie prieskumných dát v reálnom čase, kde sú Parquet súbory zapisované plnou rýchlosťou zberu dát. Kompresný pomer je podobný Snappy, takže kompromisom je rýchlosť zápisu za cenu mierne väčších súborov.
Gzip a Brotli dosahujú najvyššie kompresné pomery, ale za cenu významných penalizácií rýchlosti zápisu — Gzip zapisuje približne 50 % pomalšie ako Snappy a Brotli môže byť 100 % až 200 % pomalší v závislosti od úrovne. Tieto kodeky sú vhodné pre studené úložisko a archivačné prípady použitia, kde sú dáta zapísané raz a zriedka alebo nikdy prepísané a kde je primárnym cieľom minimalizovať náklady na ukladanie. Pre 40 TB CSV inšpekčného archívu znižuje použitie Gzip-komprimovaného Parquet ukladanie na približne 3 TB až 5 TB v porovnaní s 5 TB až 7 TB so Snappy, čo predstavuje podstatné úspory nákladov pre cloudové úložisko účtované za gigabajt mesačne.
Konfigurácia Kompresie na Úrovni Stĺpcov. Parquet umožňuje konfigurovať kompresiu nezávisle pre každý stĺpec, čo umožňuje optimalizáciu na základe charakteristík dát každého stĺpca. Pre inšpekčné dáta profitujú stĺpce súradníc s plávajúcou desatinnou čiarkou z delta kódovania nasledovaného kompresiou Zstd. Kategorické stĺpce ako typ poškodenia a klasifikácia vozovky profitujú z dikcionárového kódovania, ktoré môže komprimovať dostatočne bez dodatočnej kompresie kodekom. Časové pečiatky profitujú z delta kódovania, ktoré komprimuje sekvenčné časové pečiatky v priemere na 3 až 5 bajtov na hodnotu bez ohľadu na pôvodnú reprezentáciu časovej pečiatky. Konfigurácia kompresie na úrovni stĺpcov je dostupná prostredníctvom funkcie write_table() v PyArrow a prostredníctvom syntaxe vytvárania tabuliek väčšiny dopytovacích enginov.
Parquet v Inšpekčnej Dátovej Pipeline
Parquet slúži ako centrálny dátový formát v architektúre inšpekčných dát TarmacView, umožňujúc pipeline, ktorá siaha od surovej ingescie senzorov cez analytické dopytovanie až po vizualizáciu a reporting. Architektúra pipeline demonštruje praktické výhody Parquet v každej fáze spracovania.
Prehľad Architektúry Pipeline. Inšpekčná pipeline TarmacView nasleduje viacstupňovú architektúru podobnú vzoru data lakehouse. Surové senzorové dáta z prieskumných vozidiel — kamerové snímky, laserové profily, GPS stopy a telemetria — sú na začiatku ingestované a uložené v objektovom úložisku ako surová dátová vrstva. Algoritmy spracovania obrazu a počítačového videnia analyzujú snímky na detekciu a klasifikáciu poškodení vozovky, produkujúc štruktúrované meracie dáta, ktoré sú zapísané do Parquet ako rafinovaná dátová vrstva. Analytické a agregačné úlohy počítajú hodnotenia stavu na úrovni dlaždíc a sekcií, zapisujúc výsledky do Parquet ako analytická vrstva. Nakoniec, vizualizačné nástroje a reportovacie systémy dopytujú Parquet súbory analytickej vrstvy na obsluhu interaktívnych dashboardov a generovanie reportov zhody.
Surová Vrstva: Ingescia Senzorových Dát. Na surovej vrstve prichádzajú prieskumné dáta ako heterogénna zmes formátov. GPS dáta prúdia ako NMEA vety alebo binárne logy. Dáta z laserových profilomerov prichádzajú ako binárne súbory s proprietárnym formátom. Vysokorozlíšené snímky prichádzajú ako sekvenčné obrazové súbory s EXIF metadátami. Predspracovateľská pipeline normalizuje tieto rôznorodé formáty do spoločnej schémy a zapisuje štruktúrovanú časť — súradnice, časové pečiatky, údaje senzorov a merané hodnoty — do Parquet. Samotné snímky zostávajú vo svojom natívnom formáte (GeoTIFF alebo JPEG2000) s odkazmi uloženými v Parquet metadátach pre krížové referencovanie. Tento hybridný prístup kombinuje analytický výkon Parquet pre štruktúrované dáta so špecializovanými formátmi snímok optimalizovanými pre rastrové ukladanie.
Rafinovaná Vrstva: Detekcia a Klasifikácia Poškodení. Fáza spracovania počítačového videnia číta surové snímky a aplikuje modely strojového učenia na detekciu a klasifikáciu poškodení vozovky vrátane pozdĺžnych trhlín, priečnych trhlín, aligátorových trhlín, záplatovania, vydrolovania a výtlkov. Výstupy modelu sú zapísané do Parquet ako rafinovaná dátová vrstva, pričom každé detekované poškodenie je zaznamenané ako riadok obsahujúci klasifikáciu typu poškodenia, skóre spoľahlivosti, súradnice ohraničujúceho polygónu, namerané rozmery (dĺžka, šírka, plocha) a hodnotenie závažnosti. Parquet súbory rafinovanej vrstvy sú typicky najväčšie v pipeline, obsahujúce milióny až miliardy záznamov o poškodeniach na jedno letisko. Stĺpcové prerezávanie je tu nevyhnutné: pracovné postupy kontroly kvality, ktoré potrebujú len vysoko-spoľahlivé detekcie, čítajú najprv stĺpec spoľahlivosti, potom selektívne čítajú geometrické stĺpce pre kvalifikujúce sa záznamy.
Analytická Vrstva: Hodnotenie Stav a Výpočet PCI. Analytická vrstva agreguje rafinované dáta o poškodeniach do hodnotení stavu vozovky podľa metodiky ASTM D5340. Pre každú definovanú sekciu vozovky vypočíta agregačný engine hustoty poškodení, aplikovateľné deduktívne hodnoty a konečné PCI. Výsledky sú zapísané do Parquet ako súbory hodnotení na úrovni sekcií. Táto vrstva tiež počíta agregácie na úrovni dlaždíc pre vizualizáciu, pred-vypočítavajúc štatistiky, ktoré by bolo nákladné počítať za behu v interaktívnych dashboardoch. Parquet súbory analytickej vrstvy sú relatívne malé v porovnaní s rafinovanou vrstvou — typicky niekoľko stoviek megabajtov pre veľké letisko — a sú optimalizované pre rýchle interaktívne dopytovanie s veľkosťou riadkových skupín 64 MB až 128 MB.
Lakehouse Architektúra a Tabuľkové Formáty. Parquet tiež slúži ako základný súborový formát pre tabuľkové formáty, ktoré poskytujú ACID transakcie, časové cestovanie a evolúciu schémy na vrchu Parquet súborov. Apache Iceberg, Delta Lake a Apache Hudi všetky používajú Parquet ako svoj predvolený alebo primárny úložný formát, pridávajúc transakčné logy, správu snímkov a optimalizačné nástroje. Pre nasadenia TarmacView vyžadujúce súbežný čítací a zapisovací prístup — ako súčasná ingescia prieskumných dát a analytické dopytovanie — poskytujú vrstvy Iceberg alebo Delta Lake na vrchu Parquet potrebné izolačné záruky. Tabuľkový formát rieši súbežné konflikty zápisu, poskytuje konzistentné snímkové pohľady pre čitateľov a spravuje metadáta pre evolúciu partícií a kompakciu súborov.
Zhrnutie Architektonických Výhod. Pipeline architektúra založená na Parquet prináša niekoľko konkrétnych výhod pre správu inšpekčných dát. Jedna kópia, viacero enginov: Rovnaké Parquet súbory môžu byť dopytované DuckDB pre interaktívnu analýzu, Apache Spark pre dávkové spracovanie, Polars pre ad-hoc skriptovanie a QGIS pre geopriestorovú vizualizáciu, všetko bez duplikácie dát alebo konverzie formátu. Nákladovo efektívne ukladanie: Kompresia Parquet znižuje náklady na objektové úložisko 5x až 10x v porovnaní s CSV a 10x až 20x v porovnaní s JSON, s priamymi úsporami nákladov pre cloudové úložisko účtované podľa objemu. Oddelenie výpočtu a ukladania: Dopytovacie enginy čítajú Parquet priamo z objektového úložiska bez potreby kroku nahrávania, čo umožňuje elastické škálovanie výpočtu, kde môžu byť analytické zdroje spúšťané a zastavované nezávisle od perzistentného úložiska dát. Dlhodobé uchovávanie dát: Sebapopisujúca schéma a otvorený štandard Parquet zaisťujú, že inšpekčné dáta zostanú čitateľné budúcim softvérom bez závislosti na proprietárnych API alebo zastaraných knižniciach.
Osvedčené Postupy pre Parquet v Inšpekčných Pracovných Postupoch
Výber Veľkosti Riadkovej Skupiny. Optimálna veľkosť riadkovej skupiny závisí od vzorov prístupu pre konkrétnu inšpekčnú pracovnú záťaž. Pre interaktívne dopyty na malých až stredných datasadoch — ako je skúmanie jednej prieskumnej kampane počas revízneho sedenia po spracovaní — poskytujú riadkové skupiny 64 MB až 128 MB rýchle čítanie metadát a rýchle preskakovanie riadkových skupín. Pre dávkové spracovanie na veľkých archívoch — ako je výpočet ročných trendov naprieč piatimi rokmi štvrťročných prieskumov — poskytujú riadkové skupiny 256 MB až 512 MB lepšie kompresné pomery a znižujú počet položiek metadát v pätičke, čo zlepšuje rýchlosť čítania pätičky. Ako všeobecné pravidlo, cieľte na veľkosti riadkových skupín také, aby každá riadková skupina pohodlne zapadla do page cache systému objektového úložiska a zároveň poskytovala dostatočnú granularitu pre paralelné čítanie naprieč dostupnými CPU jadrami.
Stratégia Rozdeľovania. Rozdeľujte inšpekčné dáta podľa stĺpcov najčastejšie používaných vo filtračných podmienkach. Pre pracovné záťaže TarmacView sú primárnymi dimenziami rozdelenia dátum prieskumu (podľa dňa alebo mesiaca) a identifikátor dráhy. Prerezávanie partícií zaisťuje, že dopyty filtrujúce na tieto dimenzie čítajú len relevantné adresáre, preskakujúc všetky ostatné partície. Vyhnite sa prílišnému rozdeľovaniu, ktoré vytvára veľký počet malých súborov s vysokou réžiou metadát a zhoršeným výkonom dopytov. Partícia by mala obsahovať aspoň 100 MB až 500 MB dát, aby sa odôvodnila réžia metadát ďalšej úrovne adresára.
Konfigurácia Štatistík. Povoľte štatistiky na úrovni stĺpcov pre stĺpce používané vo filtračných podmienkach, aby ste umožnili predikátový pushdown. PyArrow a ďalšie Parquet čítače povoľujú štatistiky štandardne, ale štatistiky môžu byť zakázané na zníženie veľkosti pätičky pre súbory s veľmi úzkymi schémami alebo predvídateľnými vzormi prístupu. Pre inšpekčné dáta povoľte štatistiky na hodnotách PCI, dátumoch prieskumu, hodnoteniach závažnosti poškodení a priestorových ohraničujúcich súradniciach — všetky stĺpce bežne používané ako filtre dopytov. Štatistiky na stĺpcoch s vysokou kardinalitou, ako sú unikátne identifikátory bodov, poskytujú minimálny prínos pre pushdown a zvyšujú veľkosť metadát pätičky.
Výber Kompresie. Používajte Zstd na úrovni 3 ako predvolený kompresný kodek pre inšpekčné dáta. Toto poskytuje najlepšiu rovnováhu kompresného pomeru, rýchlosti zápisu a rýchlosti čítania naprieč typickými pracovnými záťažami. Pre streamované ingescné pipeline, kde je priepustnosť zápisu úzkym hrdlom, prepnite na Snappy alebo LZ4_RAW. Pre archívy studeného úložiska, kde sú náklady na ukladanie primárnym záujmom, použite Zstd na úrovni 9 až 22 alebo Gzip na úrovni 6 až 9. Konfigurujte kompresiu na úrovni stĺpcov, keď majú stĺpce výrazne odlišné kompresné charakteristiky — napríklad použite dikcionárové kódovanie bez dodatočného kodeku pre kategorické stĺpce a delta kódovanie so Zstd pre monotónne stĺpce súradníc a časových pečiatok.
Správa Veľkosti Súborov. Vyhnite sa vytváraniu veľmi malých Parquet súborov, definovaných ako súbory menšie ako približne 10 MB. Malé súbory majú neprimerane veľkú réžiu metadát v pomere k obsahu dát — 5 MB Parquet súbor môže obsahovať 1 MB metadát pätičky a len 4 MB skutočných dát. Malé súbory tiež znižujú paralelizmus, pretože každý súbor musí byť otvorený, prečítaný a zatvorený nezávisle, čo spôsobuje réžiu na súbor v systémoch objektového úložiska. V ETL pipeline, ktoré produkujú mnoho malých Parquet súborov, pridajte krok kompakcie alebo spájania po spracovaní na zlúčenie malých súborov do väčších. Cieľová veľkosť súboru 64 MB až 512 MB na súbor je vhodná pre väčšinu pracovných záťaží inšpekčných dát.
Návrh Schémy. Vyberte vhodné dátové typy pre každý stĺpec. Používajte 32-bitové celé čísla pre stĺpce, ktorých hodnoty sa zmestia do rozsahu signed 32-bit (približne ±2,1 miliardy), ako sú sekvenčné indexy bodov v rámci prieskumnej jazdy. Používajte 64-bitové celé čísla pre väčšie identifikátory, ako sú globálne unikátne identifikátory bodov. Používajte 32-bitovú plávajúcu desatinnú čiarku pre stĺpce súradníc, kde je dostatočná presnosť na submeter, pričom 64-bitovú dvojitú presnosť rezervujte pre vedecké merania vyžadujúce presnosť na úrovni milimetrov. Používajte dátové typy date32 alebo timestamp pre stĺpce dátumu a času namiesto ukladania ako reťazce — to umožňuje delta kódovanie a predikátový pushdown na časových stĺpcoch. Používajte dikcionárové kódovanie pre kategorické stĺpce s nízkou kardinalitou, ako sú klasifikácie typov poškodení a typy povrchov vozoviek.
Porovnanie s Inými Stĺpcovými Formátmi
Parquet nie je jediným stĺpcovým úložným formátom dostupným pre analytické pracovné záťaže. Pochopenie jeho vzťahu k iným formátom pomáha pri informovanom architektonickom rozhodovaní pre inšpekčné dátové pipelines.
ORC (Optimized Row Columnar). Apache ORC je primárnym alternatívnym stĺpcovým formátom v ekosystéme Hadoop, pôvodne vyvinutý spoločnosťou Hortonworks ako vylepšenie staršieho formátu RCFile. ORC a Parquet zdieľajú mnohé charakteristiky: oba sú stĺpcové, oba podporujú predikátový pushdown prostredníctvom vstavaných štatistík, oba ponúkajú výber kompresného kodeku a oba sú sebapopisujúce. ORC poskytuje mierne lepšie kompresné pomery pre niektoré dátové typy, najmä reťazcové stĺpce, a má robustnejšie vstavané indexovanie vrátane Bloom filtrov a min-max indexov. Parquet má však širšiu podporu v ekosystéme — každý významný dopytovací engine a cloudový dátový sklad podporuje Parquet, zatiaľ čo podpora ORC je sústredená v ekosystémoch Apache Hive a Spark. Pre inšpekčné dátové pipelines, ktoré vyžadujú maximálnu prenosnosť naprieč dopytovacími enginy a cloudovými platformami, je Parquet bezpečnejšou voľbou.
Arrow IPC Formát. Apache Arrow definuje pamäťový stĺpcový formát, ktorý je úzko príbuzný s Parquet, ale optimalizovaný pre zdieľanie dát s nulovou kópiou v rámci procesu, nie pre perzistentné ukladanie. Arrow IPC (Inter-Process Communication) súbory sú navrhnuté pre rýchlejšie operácie čítania a zápisu s minimálnou serializačnou réžiou, za cenu väčších veľkostí súborov a bez vstavanej kompresie alebo metadát pre predikátový pushdown. Parquet a Arrow sú komplementárne: Arrow sa používa pre spracovanie dát v pamäti a výmenu medzi procesmi, zatiaľ čo Parquet sa používa pre perzistentné ukladanie a dlhodobú archiváciu. PyArrow, Polars a DuckDB všetky operujú natívne na Arrow pamäti pri čítaní a zápise Parquet súborov, poskytujúc výhody oboch formátov.
CSV so Stĺpcovým Usporiadaním (Podobné Parquet). Niektoré systémy implementujú stĺpcové čítanie na CSV súboroch reorganizáciou dát v pamäti po prečítaní, ale tento prístup nemôže dosiahnuť stĺpcové usporiadanie na úrovni disku ako Parquet. Stĺpcové čítanie CSV stále vyžaduje prečítanie 100 % údajov súboru z disku, sparsovanie všetkých hodnôt z každého riadku a následnú reorganizáciu do stĺpcov — úspory I/O stĺpcového prerezávania nemôžu byť dosiahnuté na úrovni disku, pretože CSV ukladá dáta po riadkoch. Stĺpcové usporiadanie Parquet na disku je zásadnou architektonickou výhodou, ktorá nemôže byť replikovaná softvérom na vrchu riadkovo orientovaného formátu.
Záver
Apache Parquet je základným úložným formátom pre moderné analytické spracovanie dát a jeho charakteristiky ho robia obzvlášť vhodným pre náročné požiadavky inšpekčných dát letiskových vozoviek. Stĺpcový úložný model poskytuje 5x až 20x kompresiu v porovnaní s riadkovo orientovanými formátmi, čím znižuje náklady na ukladanie a umožňuje rýchlejšie prenosy dát. Predikátový pushdown a stĺpcové prerezávanie spolu prinášajú 10x až 100x zlepšenie výkonu dopytov pre selektívne dopyty na širokých inšpekčných datasadoch, čo robí interaktívny prieskum terabajtových archívov prieskumov praktickým. Evolúcia schémy podporuje prirodzený vývoj inšpekčných programov, keď sa požiadavky na zber dát v čase rozširujú. Sebapopisujúci formát zaisťuje dlhodobé uchovávanie dát bez závislosti na externých registroch schém alebo proprietárnom softvéri. Široká podpora v ekosystéme — zahŕňajúca Python knižnice pre dátovú vedu, distribuované spracovateľské frameworky, geopriestorové analytické nástroje a cloudové dátové sklady — umožňuje inšpekčným dátam plynule prúdiť celou analytickou pipeline od zberu surových senzorov až po konečné reportovanie. Pre TarmacView a širší priemysel inšpekcií vozoviek poskytuje Parquet efektivitu ukladania, výkon dopytov a kompatibilitu s ekosystémom potrebné na správu rastúceho objemu a sofistikovanosti dát o stave infraštruktúry.
Často kladené otázky
Apache Parquet sa zásadne líši od CSV a JSON tým, že používa stĺpcový úložný model namiesto riadkovo orientovaného ukladania. V CSV a JSON sú všetky polia každého riadku ukladané postupne na disk. V Parquet sú všetky hodnoty pre každý stĺpec ukladané súvisle v samostatných stĺpcových blokoch v rámci riadkových skupín. Tento architektonický rozdiel prináša dramatické praktické výhody pre analytické úlohy. Pre inšpekčné dáta s mnohými atribútmi – ako typ trhliny, závažnosť, súradnice polohy, hodnotenia stavu povrchu a časové pečiatky – dopyt, ktorý potrebuje iba súradnice trhlín a závažnosť z 50-stĺpcového datasetu, prečíta z disku iba tieto dva stĺpce, čím zníži I/O približne o 96 %. CSV a JSON musia prečítať každý stĺpec každého riadku predtým, ako zahodia nepotrebné dáta. Stĺpcové usporiadanie Parquet tiež umožňuje vynikajúcu kompresiu, pretože hodnoty v rámci jedného stĺpca sú rovnakého dátového typu a často majú nízku kardinalitu alebo opakujúce sa vzory. 10 GB CSV súbor s dátami z inšpekcie vozovky sa typicky skomprimuje na 500 MB až 1,5 GB v Parquet, čo predstavuje 7x až 20x zníženie úložného priestoru. Parquet je navyše binárny formát so vstavanými metadátami popisujúcimi schému, kódovanie a kompresiu, na rozdiel od CSV, ktoré nemá žiadnu vstavanú schému, a JSON, ktorý vkladá informácie o schéme redundantne do každého riadku. Pre inšpekčné dátové pipelines spracúvajúce tisíce záznamov o stave letiskových dráh poskytuje Parquet 10x až 100x rýchlejší analytický výkon dopytov v porovnaní s CSV alebo JSON.
Predikátový pushdown je optimalizačná technika dopytov, ktorá využíva štatistiky na úrovni stĺpcových blokov Parquet – konkrétne minimálnu hodnotu, maximálnu hodnotu a počet null hodnôt uložených v metadátach pätičky súboru – na preskakovanie celých riadkových skupín počas skenovania dát bez ich čítania. Keď dopyt obsahuje filtračnú podmienku ako WHERE severity = 'HIGH' alebo WHERE timestamp > '2024-06-01', dopytovací engine najprv prečíta ľahkú pätičku súboru, potom preskúma uložené min/max štatistiky pre každú riadkovú skupinu. Akákoľvek riadková skupina, ktorej štatistický rozsah sa neprekrýva s filtračnou podmienkou, je úplne preskočená, čo vedie k nulovému I/O pre túto riadkovú skupinu. Pre inšpekčné datasety zozbierané počas viacerých prieskumných kampaní môže dopyt filtrujúci na konkrétny dátumový rozsah preskočiť 90 % až 99 % riadkových skupín. Toto je kriticky dôležité pre dáta z inšpekcií letiskových vozoviek, pretože prieskumy produkujú veľké objemy vysokorozlíšených dát – jediný prieskum dráhy v rozlíšení 1 mm generuje milióny dátových bodov na kilometer. Bez predikátového pushdown by každý dopyt vyžadoval úplné skenovanie všetkých zozbieraných dát. S preskakovaním založeným na štatistikách Parquet sa bežné operatívne dopyty ako 'Nájsť všetky oblasti s PCI pod 40 skúmané v roku 2024' alebo 'Získať mapy trhlín pre dráhu 09/27 z posledných dvoch inšpekcií' vykonajú v sekundách namiesto minút, aj na datasadoch v rozsahu terabajtov. Výsledkom je interaktívny výkon dopytov na masívnych inšpekčných archívoch.
Optimálny Parquet kompresný kodek závisí od konkrétnych charakteristík pracovnej záťaže a kompromisu medzi kompresným pomerom a rýchlosťou čítania/zápisu. Pre inšpekčné dáta je Zstandard (Zstd) na úrovni kompresie 3 odporúčanou predvolenou voľbou, pretože poskytuje rýchlosť čítania blízku Snappy a zároveň dosahuje výrazne lepšie kompresné pomery. Porovnávacie údaje z reálnych datasetov ukazujú, že Parquet s kompresiou Zstd zmenšuje veľkosť CSV súboru na približne 8 % až 14 % pôvodnej veľkosti, v porovnaní s 12 % až 18 % pre Snappy a 25 % pre nekomprimovaný Parquet. Pre pipeline s ťažiskom na zápise, kde je rýchlosť príjmu dát prvoradá – ako napríklad streamovanie inšpekčných dát v reálnom čase z prieskumných vozidiel – poskytujú LZ4_RAW alebo Snappy najrýchlejší výkon zápisu so zanedbateľnou réžiou CPU, pričom stále dosahujú 5x až 8x kompresiu oproti CSV. Pre studené úložisko a archiváciu historických inšpekčných dát, kde je kompresný pomer najvyššou prioritou, Zstd na úrovniach 9 až 22 alebo Gzip na úrovni 9 znižujú náklady na ukladanie na iba 5 % až 8 % pôvodnej veľkosti CSV. Kompromisom je, že maximálna kompresia zvyšuje CPU čas zápisu o 30 % až 60 % v porovnaní so Snappy. Pre typické pracovné postupy TarmacView s inšpekčnými dátami, ktoré vyvažujú efektivitu ukladania s výkonom dopytov, poskytuje Zstd úroveň 3 najlepšiu celkovú hodnotu. Stĺpce inšpekčných dát ako hodnoty indexu stavu vozovky, klasifikácie trhlín a časové pečiatky prieskumov profitujú obzvlášť dobre z dikcionárového kódovania v kombinácii s kompresiou Zstd, pretože tieto stĺpce majú relatívne nízku kardinalitu, čo znamená, že slovník zachytí väčšinu unikátnych hodnôt v malom počte položiek.
Stĺpcové prerezávanie, tiež známe ako projekčný pushdown, je technika čítania iba tých stĺpcov, ktoré sú uvedené v dopyte, pričom všetky ostatné stĺpce sa úplne preskočia. V stĺpcovom úložnom modeli Parquet sú dáta každého stĺpca uložené v samostatných stĺpcových blokoch v rámci každej riadkovej skupiny, takže dopytovací engine môže selektívne čítať iba stĺpcové bloky pre požadované stĺpce. Pre inšpekčné dáta, kde jeden súbor môže obsahovať 50 až 100 alebo viac atribútov na jeden skúmaný bod – vrátane súradníc, viacerých typov poškodení, hodnotení závažnosti, metrík textúry povrchu, metadát snímok a indikátorov kvality – poskytuje stĺpcové prerezávanie obrovské výhody v oblasti výkonu. Dopyt, ktorý potrebuje iba geolokačné súradnice a merania šírky trhlín z datasetu so 100 atribútmi, prečíta približne 2 % celkových údajov súboru. Pri riadkovo orientovaných formátoch ako CSV alebo JSON vyžaduje rovnaký dopyt prečítanie a sparsovanie 100 % dát a následné zahodenie 98 % v pamäti. V praxi môže stĺpcové prerezávanie v kombinácii s kompresiou Parquet znížiť I/O dopytov 50x až 100x pre selektívne dopyty na širokých inšpekčných datasadoch. Toto je obzvlášť cenné v pracovných postupoch TarmacView, kde analytici interaktívne skúmajú dáta o stave vozovky, prepínajúc medzi rôznymi metrikami poškodení, historickými porovnaniami a priestorovými podmnožinami. Moderné dopytovacie enginy vrátane DuckDB, Polars a PyArrow všetky implementujú automatické stĺpcové prerezávanie pri čítaní Parquet súborov, bez potreby špeciálnej konfigurácie zo strany analytika.
Áno, Parquet spracováva geopriestorové dáta natívne prostredníctvom špecifikácie GeoParquet, čo je štandard OGC (Open Geospatial Consortium), ktorý pridáva interoperabilné geopriestorové typy do formátu Parquet. GeoParquet ukladá geometrické stĺpce ako Well-Known Binary (WKB) v binárnom stĺpci Parquet, s dodatočnými metadátami v pätičke súboru popisujúcimi súradnicový referenčný systém (CRS), prítomné typy geometrií a celkový ohraničujúci rámec. To umožňuje priestorový predikátový pushdown, kde dopyty používajúce priestorové filtre ako ST_Intersects alebo ST_Within môžu preskakovať riadkové skupiny, ktorých ohraničujúce rámce sa neprekrývajú s oblasťou dopytu. Pre inšpekčné dáta z dráh, ktoré pokrývajú kilometre povrchu vozovky, je priestorové filtrovanie nevyhnutné na izolovanie konkrétnych úsekov, križovaniek alebo zón s vysokým opotrebením. GeoPandas, QGIS, Apache Sedona, Google BigQuery a Snowflake všetky podporujú priame čítanie GeoParquet súborov, čo umožňuje jednoduchú integráciu výstupov inšpekcií TarmacView do širších geopriestorových analytických pracovných postupov. V TarmacView ukladajú Parquet súbory výsledky inšpekcií s presnými GPS súradnicami pre každý skúmaný bod alebo polygón poškodenia, čo umožňuje priestorové spojenia s geometriou dráh, osami rolovacích dráh a hranicami odbavovacích plôch. Kombinácia analytického výkonu Parquet s geopriestorovou schopnosťou ho robí ideálnym formátom pre rozsiahle prieskumy stavu vozoviek, kde musia byť efektívne dopytované priestorová poloha aj viacrozmerné atribúty.
Python ponúka tri primárne knižnice na čítanie a zápis Parquet súborov, každú s rôznymi silnými stránkami pre analýzu inšpekčných dát. PyArrow (Python väzby pre Apache Arrow C++) je najkompletnejšia knižnica, poskytujúca jemnozrnnú kontrolu nad veľkosťou riadkových skupín, kompresiou, kódovaním a štatistikami. Podporuje explicitné stĺpcové prerezávanie pomocou parametra columns, predikátový pushdown pomocou parametra filters a rozdelené datasety pomocou ParquetDataset. Pre pracovné postupy spracovania inšpekčných dát v TarmacView je PyArrow odporúčaným engine pre programové dátové pipelines. Pandas poskytuje jednoduchšie, vysokoúrovňové API prostredníctvom pd.read_parquet a df.to_parquet, pričom deleguje základnú implementáciu Parquet na PyArrow alebo fastparquet. Pandas je ideálny pre interaktívnu analýzu a prieskumnú prácu v Jupyter notebookoch, hoci načíta celý dataset do pamäte. Polars je DataFrame knižnica postavená na Apache Arrow, ktorá poskytuje najrýchlejší výkon čítania Parquet – typicky 3x až 10x rýchlejší ako Pandas – prostredníctvom svojho viacvláknového engine založeného na Ruste. Polars ponúka lazy API prostredníctvom pl.scan_parquet, ktoré vykonáva úplný predikátový pushdown a stĺpcové prerezávanie pred načítaním akýchkoľvek dát. Pre veľké inšpekčné datasety presahujúce dostupnú pamäť podporuje Polars streamované čítanie. Pre geopriestorové Parquet dáta rozširuje GeoPandas Pandas o geopriestorové operácie a dokáže čítať GeoParquet súbory priamo prostredníctvom gpd.read_parquet. Výber knižnice závisí od konkrétneho pracovného postupu: PyArrow pre vývoj pipeline, Pandas a GeoPandas pre interaktívnu analýzu a Polars pre maximálny výkon na veľkých inšpekčných datasadoch.
TarmacView organizuje výsledky inšpekčných analýz do niekoľkých samostatných Parquet súborov, každý s vyhradenou schémou optimalizovanou pre špecifické vzory dopytov. Súbor results.parquet ukladá primárny výstup inšpekcie s jedným riadkom na skúmanú pozíciu, vrátane stĺpcov pre GPS súradnice (zemepisná šírka, dĺžka, nadmorská výška), časovú pečiatku prieskumu, hodnoty indexu stavu vozovky (PCI), jednotlivé merania poškodení (šírka trhliny, dĺžka trhliny, plocha odlupovania, závažnosť vydrolovania), metriky textúry povrchu a indikátory kontroly kvality. Súbor tiles.parquet ukladá výsledky analýz na základe dlaždíc, kde je povrch vozovky rozdelený do pravidelnej mriežky (typicky 1 m x 1 m alebo 5 m x 5 m dlaždice, v závislosti od rozlíšenia prieskumu), pričom každý riadok predstavuje agregované hodnotenie stavu pre túto dlaždicu vrátane priemerného PCI, dominantného typu poškodenia a štatistického rozdelenia meraní. Súbor assessment.parquet ukladá konečné hodnotenie stavu na sekciu vozovky, vrátane vypočítaných hodnôt PCI podľa metodiky ASTM D5340 a ICAO Annex 14, hustôt poškodení na úrovni sekcií, odporúčaných údržbárskych opatrení a priorít. Súbor telemetry.parquet zaznamenáva telemetrický tok prieskumného vozidla vrátane rýchlosti, zrýchlenia, smeru a stavu senzorov v pravidelných intervaloch počas zberu dát. Každý Parquet súbor používa kompresiu Zstd úrovne 3, veľkosti riadkových skupín približne 256 MB nekomprimované a povoľuje štatistiky na úrovni stĺpcov pre optimálny výkon predikátového pushdown. Súbory sú rozdelené podľa dátumu prieskumu a sekcie dráhy, aby umožnili efektívne časové a priestorové dopyty. Táto štruktúra umožňuje analytikom dopytovať konkrétne sekcie, časové obdobia alebo typy poškodení bez skenovania celého archívu prieskumu.
Potrebujete Efektívne Ukladanie Dát pre Inšpekčnú Analytiku?
TarmacView používa Apache Parquet formát pre rýchle, efektívne a dopytovateľné ukladanie dát z inšpekcií letiskových vozoviek. Kontaktujte náš tím a zistite, ako môže naša stĺpcová dátová architektúra urýchliť vaše pracovné postupy analýzy infraštruktúry.
Formát údajov a štruktúra reprezentácie údajov v technológiách
Formát údajov určuje, ako sú informácie uložené a prenášané, zatiaľ čo štruktúra reprezentácie údajov sa týka ich vnútorného kódovania. Obe sú základom efektívn...
Archivácia dát je proces presunu neaktívnych dát z primárneho úložiska na dlhodobé, nákladovo efektívne médiá na účely uchovávania, dodržiavania predpisov a bud...
7 min čítania
Data Management
Compliance
+2
Súhlas s cookies Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.