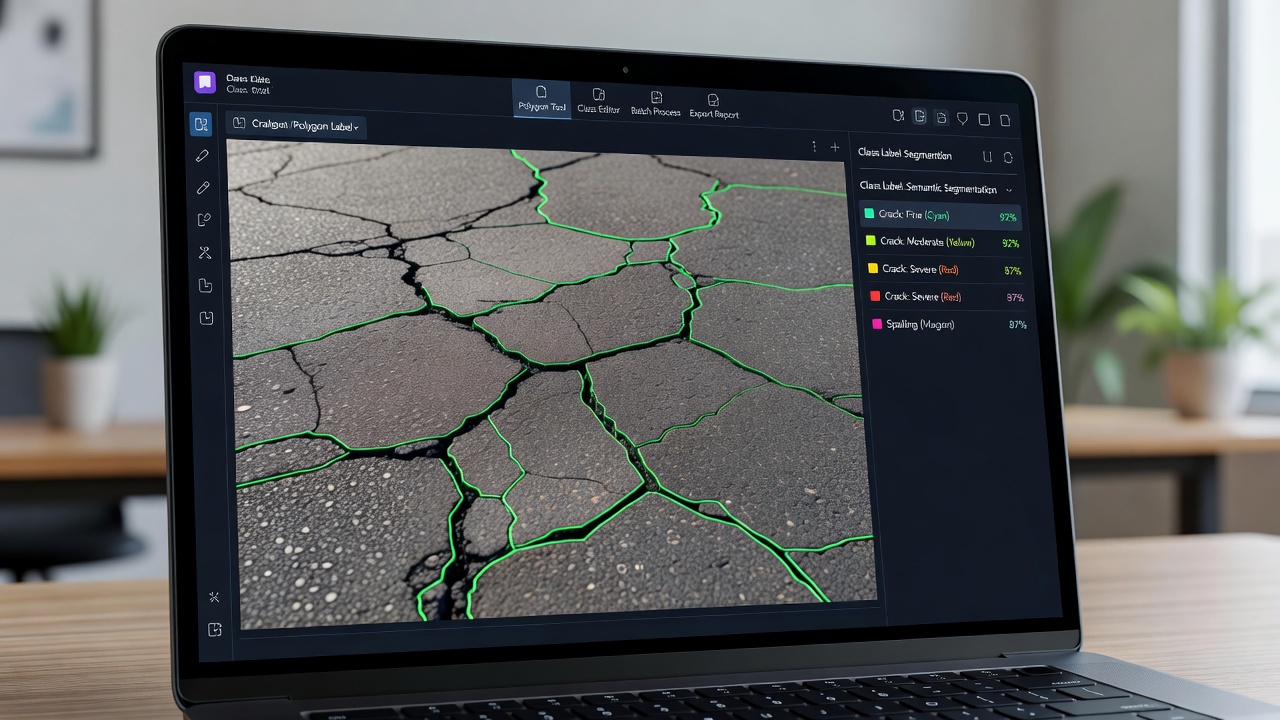
Sémantická segmentácia pre porozumenie infraštruktúrnych scén
Sémantická segmentácia priraďuje každomu pixelu v obraze kategóriovú značku, čo umožňuje porozumenie celej scéne pre infraštruktúrnu inšpekciu. Zahŕňa architektúry kódovač-dekódovač (U-Net, DeepLabV3+, SegFormer, PSPNet, Mask2Former), kódovacie chrbtice (ResNet, EfficientNet, ViT), stratové funkcie (krížová entropia, Dice, fokálna, hraničná), trénovanie s pixelovými značkami, viac triednu segmentáciu pre cestné a letiskové scény, segmentáciu trhlín, mapovanie typu povrchu, vyhodnocovacie metriky (IoU, Dice, pixelová presnosť) a optimalizáciu nasadenia pre pracovné postupy inšpekcie v reálnom čase.
Čo je sémantická segmentácia pre porozumenie infraštruktúrnym scénam?
Definícia a odlíšenie od súvisiacich úloh počítačového videnia
Sémantická segmentácia je úloha počítačového videnia, ktorá priraďuje vopred definovanú triednu značku každému pixelu vo vstupnom obraze, čím vytvára kompletnú pixelovú klasifikačnú mapu, kde je každý pixel priradený do kategórie ako trhlina, vozovka bez trhliny, značenie vozovky, vegetácia, FOD alebo typ povrchu. Výstupom je hustá predikčná maska rovnakých priestorových rozmerov ako vstupný obraz, kde každá hodnota pixelu zodpovedá indexu triedy.
Toto odlišuje sémantickú segmentáciu od troch súvisiacich, ale zásadne odlišných úloh počítačového videnia:
Klasifikácia obrazu priraďuje jedinú značku celému obrazu — napríklad vyhlási „tento obraz obsahuje trhlinu“ bez špecifikácie, kde sa trhlina nachádza. Klasifikácia neposkytuje žiadne priestorové informácie o polohe, tvare alebo rozsahu objektu. Je to najjednoduchšia úloha počítačového videnia, ale zároveň najmenej informatívna pre infraštruktúrnu inšpekciu, kde je znalosť polohy, geometrie a rozsahu chýb nevyhnutná pre hodnotenie stavu a plánovanie údržby.
Detekcia objektov identifikuje a lokalizuje objekty kreslením osovo zarovnaných ohraničujúcich rámčekov okolo nich, pričom každému rámčeku priraďuje triednu značku a skóre spoľahlivosti. Detekcia odpovedá „aké objekty sú prítomné a približne kde.“ Pre detekciu trhlín môže ohraničujúci rámček ohraničiť oblasť trhliny, ale nedokáže vyznačiť presný tvar, šírku alebo prepojenosť trhliny — informácie kritické pre klasifikáciu typu trhliny (pozdĺžna, priečna, aligátorová, bloková) a hodnotenie závažnosti podľa ASTM D5340.
Segmentácia inštancií ide o krok ďalej tým, že detekuje každú jednotlivú inštanciu objektu a vytvára pixelovú masku pre každú z nich, pričom priraďuje unikátne ID inštancií. Pre infraštruktúrnu inšpekciu by to rozlíšilo jednotlivé trhliny alebo výtlky od seba. Mnohé povrchové chyby — najmä vzory trhlín ako aligátorové alebo blokové praskanie — však tvoria prepojené siete, ktoré je ťažké rozložiť na diskrétne inštancie, čo robí segmentáciu inštancií menej vhodnou pre všeobecné hodnotenie stavu vozoviek.
Panoptická segmentácia spája sémantickú segmentáciu a segmentáciu inštancií priradením sémantickej značky každému pixelu (vrátane tried „hmoty“ ako vozovka, obloha, vegetácia) a súčasne detekuje a segmentuje jednotlivé inštancie objektov (triedy „veci“ ako konkrétne výtlky alebo predmety FOD). Panoptická segmentácia je najkomplexnejší prístup, ale zároveň najnáročnejší na výpočtové zdroje a najkomplexnejší na trénovanie.
Úloha
Výstup
Priestorová presnosť
Použiteľnosť pre infraštruktúru
Klasifikácia obrazu
Jediná značka na obraz
Žiadna
Len detekcia prítomnosti trhlín
Detekcia objektov
Ohraničujúce rámčeky na objekt
Hrubá
Detekcia FOD, lokalizácia výtlkov
Sémantická segmentácia
Triedne značky po pixeloch
Maximálna (úroveň pixelov)
Mapovanie trhlín, typ povrchu, hodnotenie PCI
Segmentácia inštancií
Masky jednotlivých objektov
Maximálna + ID inštancie
Počítanie diskrétnych chýb
Panoptická segmentácia
Značky všetkých pixelov + inštancie
Maximálna + ID inštancie
Úplné porozumenie scény
Pre aplikácie infraštruktúrnej inšpekcie — najmä hodnotenie stavu letiskových vozoviek, mapovanie trhlín a klasifikáciu typu povrchu — je sémantická segmentácia najvhodnejším a najviac používaným prístupom, pretože poskytuje úplné porozumenie scény s presnosťou na úrovni pixelov potrebnou pre kvantitatívne hodnotenie stavu, bez nutnosti rozkladania súvislých sietí chýb na jednotlivé inštancie.
Architektonicky sú modely sémantickej segmentácie typicky plne konvolučné siete (FCN) alebo modely založené na transformeroch navrhnuté tak, aby prijali vstupný obraz ľubovoľných rozmerov a vytvorili výstupnú segmentačnú mapu rovnakých priestorových rozmerov. Definujúcou charakteristikou je absencia plne prepojených vrstiev, ktoré by fixovali veľkosť vstupu — namiesto toho sú všetky vrstvy konvolučné alebo založené na pozornosti, čo umožňuje sieti spracovávať obrazy rôznych rozlíšení počas inferencie.
Výstupná segmentačná mapa má rozmery H × W × C, kde H a W zodpovedajú vstupným priestorovým rozmerom (alebo ich fixnému zlomku) a C je počet tried. Na každej priestorovej pozícii obsahuje C-rozmerný vektor predikovanú pravdepodobnosť pre každú triedu, typicky normalizovanú pomocou aktivácie softmax tak, aby sa pravdepodobnosti sčítali na 1. Konečné priradenie triedy je určené pomocou argmax cez dimenziu kanálov — trieda s najvyššou pravdepodobnosťou v každom pixeli.
Architektúry pre sémantickú segmentáciu
U-Net
U-Net, predstavený Ronnebergerom, Fischerom a Broxom v ich článku z roku 2015 „U-Net: Konvolučné siete pre biomedicínsku segmentáciu obrazov,“ je najvplyvnejšia architektúra sémantickej segmentácie a zostáva de facto štandardom pre úlohy infraštruktúrnej inšpekcie, najmä segmentácie trhlín. Názov je odvodený od symetrického tvaru U architektúry pozostávajúcej z kontrakčnej cesty kódovača a expanznej cesty dekódovača prepojených preskakovacími spojeniami.
Kódovač (kontrakčná cesta) nasleduje typický dizajn konvolučnej siete: opakované aplikovanie dvoch 3×3 konvolúcií (každá nasledovaná rektifikovanou lineárnou jednotkou — ReLU) a 2×2 max pooling operácie s krokom 2 pre podvzorkovanie. Pri každom kroku podvzorkovania sa počet znakových kanálov zdvojnásobí: zo 64 na 128 na 256 na 512 na 1024 v najhlbšej vrstve (úzke miesto). Toto progresívne zvyšovanie hĺbky kanálov kompenzuje stratu priestorového rozlíšenia, umožňujúc sieti učiť sa čoraz abstraktnejšie a sémanticky zmysluplnejšie znaky na hrubších mierkach.
Dekódovač (expanzná cesta) zrkadlí kódovač v opačnom poradí: každý krok začína 2×2 up-konvolúciou (transponovanou konvolúciou), ktorá znižuje počet znakových kanálov na polovicu a zdvojnásobuje priestorové rozmery. Upvzorkovaná mapa znakov je potom spojená so zodpovedajúcou mapou znakov z kódovača pri rovnakom rozlíšení — toto je preskakovacie spojenie, ktoré definuje U-Net. Spojená mapa znakov prechádza cez dve 3×3 konvolúcie s aktiváciou ReLU. Posledná vrstva je 1×1 konvolúcia, ktorá mapuje reprezentáciu znakov na požadovaný počet výstupných tried.
Preskakovacie spojenia sú architektonickou inováciou, vďaka ktorej je U-Net efektívny pre presnú lokalizáciu. Počas kódovania sú priestorové informácie o hraniciach objektov, textúrnych gradientoch a jemných detailoch postupne stratené prostredníctvom podvzorkovania a poolingových operácií. Preskakovacie spojenia obchádzajú úzke miesto a priamo dodávajú vysokorozlíšené mapy znakov z kódovača do dekódovača pri zodpovedajúcich rozlíšeniach, čo umožňuje dekódovaču prístup k sémantickému kontextu z hlbších vrstiev aj k priestorovej presnosti z plytších vrstiev. Pre segmentáciu trhlín, kde musia byť rozlíšené šírky trhlín 0,5–3 mm, je zachovanie presnosti hraníc prostredníctvom preskakovacích spojení nevyhnutné.
Pôvodná implementácia U-Net obsahuje približne 31 miliónov parametrov pre segmentačnú úlohu s 2 triedami. Moderné implementácie v rámcoch ako Segmentation Models PyTorch (smp) podporujú konfigurovateľné hĺbky kódovača (3–5 etáp), vymeniteľné chrbtice kódovača (ResNet, EfficientNet, atď.) a špecifikácie kanálov dekódovača, vďaka čomu je U-Net vysoko prispôsobiteľný rôznym kompromisom medzi presnosťou a rýchlosťou. Architektúra spracuje vstupný obraz 256×256 približne za 15–30 milisekúnd na modernom GPU, čo umožňuje inferenciu v reálnom čase pri 30–60 snímkach za sekundu pre dávkové spracovanie veľkoplošných prieskumov.
DeepLabV3+
DeepLabV3+, vyvinutý Chenom a kol. v Google (2018), rozširuje rodinu architektúr DeepLab (DeepLabV1, V2, V3) pridaním štruktúry kódovač-dekódovač k modulu Atrous Spatial Pyramid Pooling (ASPP) zavedenému v DeepLabV3. Architektúra bola navrhnutá špecificky na riešenie obmedzení štandardnej segmentácie založenej na FCN: stratu priestorového rozlíšenia v dôsledku opakovaného podvzorkovania a ťažkosti so segmentáciou objektov vo viacerých mierkach.
Kľúčovou inováciou v DeepLabV3+ je atrous (dilatovaná) konvolúcia, ktorá umožňuje sieti kontrolovať rozlíšenie, v ktorom sú vypočítavané odozvy znakov, bez znižovania priestorových rozmerov. Atrous konvolúcia vkladá nuly (diery) medzi váhy filtra, čím efektívne rozširuje receptívne pole bez zvyšovania počtu parametrov. Pre konvolúciu s veľkosťou jadra k a mierou dilatácie r je efektívna veľkosť jadra k + (k-1)(r-1). DeepLabV3+ používa výstupný krok 16 — čo znamená, že rozlíšenie konečnej mapy znakov je 1/16 vstupu — v porovnaní s 1/32 pre štandardné chrbtice ResNet, čím sa zachováva jemnejší priestorový detail.
Modul Atrous Spatial Pyramid Pooling (ASPP) aplikuje paralelné atrous konvolúcie s rôznymi mierami dilatácie na zachytenie viacmierkového kontextu. Štandardná konfigurácia ASPP používa štyri paralelné vetvy s mierami dilatácie 1, 6, 12 a 18, keď je výstupný krok 16 (alebo 1, 12, 24, 36 pre výstupný krok 8). Každá vetva spracováva mapu znakov pomocou 3×3 konvolúcie s danou mierou dilatácie, nasledovanej dávkovou normalizáciou a ReLU. Výstupy sú spojené a prechádzajú cez 1×1 konvolúciu na vytvorenie konečnej reprezentácie znakov ASPP. Dodatočná vetva aplikuje globálne priemerné poolovanie na zachytenie kontextu celého obrazu, ktoré je bilineárne upvzorkované a spojené s príznakmi ASPP.
Modul dekódovača v DeepLabV3+ je relatívne ľahký komponent v porovnaní s plným dekódovačom U-Net. Znaky z kódovača (z ASPP) sú bilineárne upvzorkované faktorom 4. Tieto upvzorkované znaky sú spojené so zodpovedajúcimi nízkotrovňovými znakmi z chrbtice kódovača (konkrétne mapa znakov z prvého konvolučného bloku — typicky pri 1/4 rozlíšení). Spojené znaky prechádzajú cez 3×3 konvolúciu a druhé bilineárne upvzorkovanie faktorom 4 na obnovenie pôvodného vstupného rozlíšenia.
DeepLabV3+ dosahuje špičkový výkon na benchmarkových dataseroch ako Cityscapes (82,1 % mIoU s chrbticou ResNet-101) a PASCAL VOC 2012 (89,0 % mIoU s chrbticou Xception). Pre infraštruktúrnu inšpekciu vyniká DeepLabV3+ v segmentácii veľkých, kontextovo závislých povrchových prvkov ako typy vozoviek a zóny značenia, ale môže mať problémy s veľmi tenkými prvkami ako vlasové trhliny (šírka < 1 mm), kde výstupný krok 1/16 stále stráca kritické priestorové detaily.
SegFormer
SegFormer, predstavený Xieom a kol. v NVIDIA (2021), predstavuje zásadný odklon od konvolučných architektúr použitím čisto transformerového kódovača s ľahkým dekódovačom založeným na viacvrstvovom perceptróne (MLP). SegFormer bol prvou hierarchickou transformerovou segmentačnou architektúrou, ktorá demonštrovala, že transformery môžu dosahovať alebo prekonať konvolučné architektúry v celom spektre veľkostí modelov — od ľahkých (SegFormer-B0, 3,8 milióna parametrov) po ťažké (SegFormer-B5, 84,7 milióna parametrov).
Mix Transformer (MiT) kódovač používa hierarchický dizajn, ktorý produkuje viacmierkové mapy znakov pri 1/4, 1/8, 1/16 a 1/32 vstupného rozlíšenia, podobne ako hierarchia znakov v konvolučných chrbticiach ako ResNet. Každá etapa aplikuje prekrývajúce sa vloženie výrezov (namiesto neprekrývajúcich sa výrezov v štandardnom ViT), efektívnu vlastnú pozornosť so skrátenou dĺžkou sekvencie a dopredné siete Mix-FFN. Polohové kódovanie v SegFormer je inicializované nulami a učené — autori zistili, že odstránenie fixných polohových kódovaní úplne a spoliehanie sa na variant učenia inicializovaný nulami zlepšilo výkon pri inferencii s premenlivým rozlíšením, čo je kritické pre infraštruktúrne snímky zachytené v rôznych výškach letu a rôznych vzdialenostiach vzorkovania zeme.
MLP dekódovač je pozoruhodne jednoduchý v porovnaní s konvolučnými dekódovačmi: agreguje viacmierkové znaky z MiT kódovača bilineárnym upvzorkovaním všetkých máp znakov na 1/4 rozlíšenie, ich spojením, prechodom cez fúznu vrstvu 3×3 konvolúcie a aplikovaním MLP s dvoma skrytými vrstvami na vytvorenie konečnej segmentácie. Jednoduchosť dekódovača prispieva k výpočtovej efektivite SegFormer — dekódovač obsahuje len niekoľko miliónov parametrov aj pre najväčšie varianty modelu.
SegFormerovou kľúčovou výhodou pre infraštruktúrnu inšpekciu je jeho robustnosť voči variáciám vstupného rozlíšenia. Mechanizmus vlastnej pozornosti transformerového kódovača sa prirodzene prispôsobuje rôznym veľkostiam vstupu bez správania závislého od rozlíšenia, typického pre konvolučné jadrá. Pre úlohy inšpekcie vozoviek, kde môžu byť obrazy zachytené v rôznych výškach letu alebo rôznymi kamerovými snímačmi, SegFormer zachováva konzistentnú kvalitu segmentácie bez potreby dolaďovania špecifického pre rozlíšenie.
PSPNet
Pyramid Scene Parsing Network (PSPNet), predstavený Zhaoem a kol. (2017), rieši výzvu porozumenia globálnemu kontextu prostredníctvom pyramidového poolovania. Kľúčovým poznatkom je, že mnohé segmentačné chyby — najmä nesprávna klasifikácia oblastí, ktoré sú vizuálne podobné, ale sémanticky odlišné (napr. asfaltová vozovka vs. betónová vozovka, alebo utesnená trhlina vs. neutesnená trhlina) — vznikajú z nedostatočného globálneho kontextu.
Pyramid Pooling Module (PPM) aplikuje adaptívne priemerné poolovanie v štyroch rôznych mierkach: 1×1 (globálna), 2×2, 3×3 a 6×6. Každá poolovaná mapa znakov prechádza cez 1×1 konvolúciu na zníženie kanálov na 1/N vstupu (kde N=4, počet pyramidových úrovní), potom je bilineárne upvzorkovaná späť na pôvodné rozlíšenie mapy znakov. Upvzorkované znaky zo všetkých štyroch úrovní sú spojené s pôvodnou mapou znakov, čím vzniká konečná reprezentácia, ktorá kóduje lokálne detaily aj globálny kontext vo viacerých mierkach.
Pre segmentáciu vozoviek umožňuje pyramidové poolovanie sieti rozlišovať medzi typmi povrchu na základe kontextu: kúsok asfaltu v strede dráhy má inú očakávanú textúru a stav ako asfalt na okraji dráhy alebo na pojazdovej dráhe. Globálne poolovanie 1×1 zachytáva celkový typ scény (dráha, pojazdová dráha, plocha, cesta), zatiaľ čo jemnejšie mierky poolovania zachytávajú lokálne vzory textúry a stavu.
Mask2Former
Mask2Former, predstavený Chengom a kol. v Meta AI (2022), spája sémantickú, inštančnú a panoptickú segmentáciu v rámci jednej architektúry formulovaním všetkých segmentačných úloh ako klasifikácie masiek. Namiesto priameho vytvárania pixelových klasifikačných máp Mask2Former predikuje množinu binárnych masiek so súvisiacimi triednymi značkami, podobne ako detekcia objektov predikuje ohraničujúce rámčeky s triednymi značkami.
Architektúra pozostáva z troch komponentov: chrbtice (typicky Swin Transformer alebo ResNet), ktorá extrahuje viacmierkové znaky, transformerového dekódovača s maskovanou pozornosťou, ktorý iteratívne spresňuje predikcie masiek, a pixelového dekódovača, ktorý generuje vloženia na úrovni pixelov. Mechanizmus maskovanej pozornosti obmedzuje transformerovú vlastnú pozornosť na oblasti v rámci každej predikovanej masky, čím výrazne znižuje výpočtovú zložitosť (z O(N²) na O(NM), kde M je počet pixelov masky) a zameriava kapacitu modelu na znaky špecifické pre danú oblasť.
Pre infraštruktúrnu inšpekciu je výhodou Mask2Former schopnosť prirodzene spracovávať rôznorodé veľkosti objektov — od veľkých súvislých oblastí (typy vozoviek, zóny vegetácie) po malé diskrétne objekty (predmety FOD, jednotlivé odlupnutia) — v rámci jednotného rámca. Avšak formulácia klasifikácie masiek môže byť menej intuitívna pre súvislé, amorfné vzory chýb ako priama pixelová klasifikácia a Mask2Former typicky vyžaduje viac trénovacích dát a výpočtových zdrojov ako U-Net alebo DeepLabV3+.
Kódovacie chrbtice
ResNet (reziduálna sieť)
ResNet, predstavený Heom a kol. v Microsoft Research (2015), je najpoužívanejšia kódovacia chrbtica pre sémantickú segmentáciu. Kľúčovou inováciou je reziduálny učebný rámec: namiesto učenia sa nereferencovanej funkcie H(x) = výstup, každá vrstva (alebo zásobník vrstiev) sa učí rezíduum F(x) = H(x) − x. Pôvodný vstup x je pripočítaný k naučenému rezíduu cez skratové (preskakovacie) spojenie, čím vzniká výstup vrstvy H(x) = F(x) + x.
Reziduálny blok to formalizuje: pre blok s dvomi 3×3 konvolučnými vrstvami je výstup bloku σ(F(x) + x), kde σ je aktivácia ReLU a F(x) je zloženie dvoch konvolúcií, dávkovej normalizácie a medziľahlej ReLU. Ak sa rozmery x a F(x) líšia (napr. keď krok > 1 znižuje priestorové rozlíšenie), skratové spojenie používa 1×1 konvolúciu na prispôsobenie rozmerov. Reziduálna formulácia umožňuje trénovanie sietí bezprecedentnej hĺbky — ResNet-152 má 152 vrstiev — zmierňovaním problému miznúcich gradientov prostredníctvom priameho toku gradientov pozdĺž skratových ciest.
Varianty ResNet sú označené svojou hĺbkou: ResNet-18 (18 vrstiev, 11,7 milióna parametrov), ResNet-34 (34 vrstiev, 21,8M), ResNet-50 (50 vrstiev, 25,6M), ResNet-101 (101 vrstiev, 44,5M) a ResNet-152 (152 vrstiev, 60,2M). Pre infraštruktúrnu segmentáciu sú ResNet-50 a ResNet-101 najčastejšou voľbou, vyvažujúc presnosť s pamäťou a časom inferencie.
Pre segmentačné úlohy je štandardná chrbtica ResNet modifikovaná na vytváranie dilatovaných (atrous) máp znakov odstránením krokovania v posledných jednom alebo dvoch blokoch a nahradením nasledujúcich konvolúcií dilatovanými konvolúciami. Tento dilatovaný ResNet variant zachováva mapy znakov s vyšším rozlíšením (1/8 alebo 1/16 vstupného rozlíšenia namiesto 1/32) pri zachovaní veľkosti receptívneho poľa — kritická modifikácia pre úlohy hustej predikcie.
EfficientNet
EfficientNet, predstavený Tanom a Leom v Google (2019), dosahuje špičkovú presnosť s výrazne menej parametrami a FLOPs ako porovnateľné architektúry prostredníctvom zloženého škálovania. Kľúčovým poznatkom je, že škálovanie hĺbky, šírky a vstupného rozlíšenia siete by sa malo vykonávať spoločne, nie nezávisle. EfficientNet používa zložený koeficient φ, ktorý súčasne škáluje všetky tri dimenzie: hĺbku α^φ, šírku β^φ a rozlíšenie γ^φ, pri dodržaní obmedzenia α·β²·γ² ≈ 2 (zabezpečujúc, že celkové FLOPs sa škálujú približne 2^φ).
Základným stavebným blokom EfficientNet je MBConv (Mobile Inverted Bottleneck Convolution) , pôvodne predstavený v MobileNetV2. Každý blok MBConv používa: 1×1 expanznú konvolúciu (zvyšujúcu počet kanálov faktorom 4–6), hĺbkovú 3×3 alebo 5×5 konvolúciu (operujúcu na každom kanáli nezávisle), squeeze-and-excitation (SE) pozornosť kanálov (globálne priemerné poolovanie → dve FC vrstvy → sigmoidná aktivácia → škálovanie kanálov) a 1×1 projekčnú konvolúciu (znižujúcu kanály späť na cieľový rozmer). SE pozornosť umožňuje EfficientNet sústrediť sa na informatívne kanály — pre inšpekciu vozoviek to znamená zdôraznenie textúrnych kanálov, ktoré odlišujú trhlinu od netrhlín, pri potláčaní oblastí s plochou textúrou.
Varianty EfficientNet siahajú od EfficientNet-B0 (5,3M parametrov, 0,4 GFLOPs pre 224×224 vstup) po EfficientNet-B7 (66M parametrov, 37 GFLOPs). Pre nasadenie na okraji na inšpekčných dronoch alebo vstavaných systémoch ponúkajú EfficientNet-B0 až B3 vynikajúce pomery presnosti k výpočtom, dosahujúc IoU segmentácie trhlín v rozmedzí 2–3 % od ResNet-50 pri 5–10× menšom počte FLOPs.
Vision Transformer (ViT)
Vision Transformer (ViT) , predstavený Dosovitským a kol. v Google (2020), aplikuje transformerovú architektúru — pôvodne vyvinutú pre spracovanie prirodzeného jazyka — priamo na obrazové výrezy. Vstupný obraz je rozdelený na výrezy fixnej veľkosti (typicky 16×16 pixelov), každý výrez je lineárne projektovaný na vloženie tokenu a tieto tokeny sú spracované sériou transformerových vrstiev kódovača, ktoré aplikujú viachlavovú vlastnú pozornosť a bloky MLP.
Mechanizmus vlastnej pozornosti vypočítava párové váhy pozornosti medzi všetkými pármi tokenov, čo umožňuje reprezentácii každého výrezu začleniť informácie z každého iného výrezu v obraze. Váha pozornosti medzi tokenom i a tokenom j sa vypočíta ako: Attention(Q,K,V) = softmax(QK^T/√d_k)V, kde Q (dotaz), K (kľúč) a V (hodnota) sú naučené lineárne projekcie vložení tokenov a d_k je dimenzia kľúča. Toto globálne receptívne pole — každá výstupná pozícia integruje informácie z každej vstupnej pozície — je základnou výhodou ViT oproti konvolučným sieťam, ktoré majú obmedzené receptívne polia určené veľkosťou jadra a hĺbkou siete.
Pre sémantickú segmentáciu sa chrbtice ViT používajú v rámci hierarchických rámcov (ako Swin Transformer, ktorý aplikuje vlastnú pozornosť v rámci posunutých okien pre výpočtovú efektivitu) alebo v kombinácii s konvolučnými dekódovačmi. Architektúra SegFormer používa hierarchický variant ViT špecificky navrhnutý pre segmentáciu, zatiaľ čo SETR (Segmentation Transformer) používa štandardný ViT s progresívnym upvzorkovacím dekódovačom.
Modely segmentácie založené na ViT všeobecne dosahujú vyššiu presnosť na veľkých dataseroch (vyžadujúcich >10 miliónov trénovacích obrázkov pre predtrénovanie chrbtice), ale vyžadujú podstatne viac trénovacích dát a výpočtových zdrojov ako konvolučné chrbtice. Pre infraštruktúrnu inšpekciu s obmedzenými anotovanými dátami zostávajú konvolučné chrbtice ako ResNet a EfficientNet praktickejšie, pokiaľ nie je k dispozícii rozsiahle predtrénovanie na doménovo relevantných dátech.
Stratové funkcie pre sémantickú segmentáciu
Stratová funkcia krížovej entropie
Stratová funkcia krížovej entropie je základná stratová funkcia pre sémantickú segmentáciu, priamo odvodená z princípu maximálnej vierohodnosti. Pre každý pixel i sa predikované rozdelenie pravdepodobnosti triedy p_i(c) porovnáva s referenčným one-hot kódovaním y_i(c) (1 pre správnu triedu, 0 pre všetky ostatné). Strata na pixel je: L_i = −Σ_c y_i(c) · log(p_i(c)) = −log(p_i(ĉ)), kde ĉ je referenčná trieda.
Celková strata je priemer cez všetky pixely: L_CE = (1/N) · Σ_i L_i, kde N je celkový počet pixelov. Krížová entropia je diferencovateľná, konvexná v logitoch softmax a zaručuje, že globálne minimum zodpovedá skutočnému rozdeleniu dát.
Avšak krížová entropia funguje zle na nevyvážených dátech, čo je dominantná charakteristika infraštruktúrnych inšpekčných snímok. Pixely trhlín typicky tvoria 0,1 % až 3 % pixelov obrazu, značenie vozoviek 2–5 % a FOD menej ako 0,01 %. Krížová entropia zaobchádza so všetkými pixelmi rovnako, takže veľká väčšina gradientného signálu pochádza z dominantných tried (vozovka bez trhlín, vegetácia) a sieť sa učí ignorovať menšinové triedy. Vážená krížová entropia rieši tento problém priradením vyššej váhy menšinovým triedam: L_WCE = −(1/N) · Σ_i w(ĉ) · log(p_i(ĉ)), kde w(c) je typicky inverzná frekvencia triedy alebo manuálne nastavená váha.
Dice loss
Dice loss priamo optimalizuje Diceov koeficient (F1 skóre), metriku prekryvu medzi predikovanou a referenčnou segmentáciou. Pre binárnu segmentáciu je Diceov koeficient: Dice = 2|P ∩ G| / (|P| + |G|), kde P je množina predikovaných pozitívnych pixelov a G je množina referenčných pozitívnych pixelov. Dice loss je: L_Dice = 1 − Dice = 1 − (2Σ_i p_i · y_i + ε) / (Σ_i p_i + Σ_i y_i + ε), kde ε je vyhladzovací člen (typicky 1e-6) na zabránenie deleniu nulou, p_i je predikovaná pravdepodobnosť a y_i je binárna referenčná značka.
Pre viac triednu segmentáciu generalizovaná Dice loss vypočítava Diceov koeficient pre každú triedu nezávisle a spriemeruje ich (potenciálne s váhami tried). Dice loss je robustnejšia voči nevyváženosti tried ako krížová entropia, pretože oblasť prekryvu (skutočne pozitívne) považuje za podiel celkovej predikovanej a referenčnej plochy, namiesto počítania pixelov po jednotlivých pixeloch.
Štúdia o segmentácii trhlín na letiskovej vozovke na letisku Zadar preukázala, že použitie Dice loss zlepšilo IoU triedy trhlín o 5,9 percentuálneho bodu v porovnaní s váženou krížovou entropiou, zatiaľ čo kombinovaná Dice + Fokálna strata ďalej zlepšila presnosť hraníc o 2–3 %.
Fokálna strata
Fokálna strata, predstavená Linom a kol. vo Facebook AI Research (2017) pre hustú detekciu objektov, je navrhnutá špecificky pre extrémnu nevyváženosť tried. Modifikuje štandardnú krížovú entropiu pridaním modulačného faktora (1 − p_t)^γ, kde p_t je predikovaná pravdepodobnosť referenčnej triedy a γ ≥ 0 je fokusačný parameter: L_Focal = −(1/N) · Σ_i (1 − p_t)^γ · log(p_t).
Keď γ = 0, fokálna strata sa redukuje na krížovú entropiu. So zvyšujúcim sa γ modulačný faktor znižuje váhu dobre klasifikovaných príkladov (vysoké p_t) a zameriava trénovanie na ťažké, nesprávne klasifikované príklady (nízke p_t). Pre segmentáciu trhlín, kde je γ typicky nastavené na 2, pixel s predikovanou pravdepodobnosťou 0,9 (dobre klasifikované pozadie) prispieva (1−0,9)^2 = 0,01 násobkom straty štandardnej krížovej entropie, zatiaľ čo pixel trhliny s predikovanou pravdepodobnosťou 0,3 (ťažký príklad) prispieva (1−0,3)^2 = 0,49 násobkom straty — efektívne 49× viac pozornosti venovanej ťažkému príkladu v porovnaní s jednoduchým.
Fokálna strata je obzvlášť účinná pre detekciu FOD na letiskových snímkach, kde predmety FOD zaberajú 0,001–0,1 % pixelov, ale sú bezpečnostne kritickou triedou. Kombinovaná Dice + Fokálna strata (L = α·L_Dice + β·L_Focal, s α a β typicky nastavenými na 0,5–1,0) je najbežnejšou formuláciou straty v infraštruktúrnej inšpekcii, kombinujúc optimalizáciu prekryvu Dice s fokusom na ťažké príklady z fokálnej straty.
Hraničná strata
Hraničná strata rieši obmedzenie oblastných strát (Dice, IoU): optimalizujú objemový prekryv, ale explicitne nepenalizujú hraničné chyby. Pre segmentáciu trhlín, kde presnosť hraníc určuje presnosť merania šírky trhliny, je optimalizácia hraníc kritická.
Hraničná strata vypočítava transformáciu vzdialenosti na referenčnej hranici segmentácie a násobí mapu predikovanej pravdepodobnosti váženou mapou hraníc podľa vzdialenosti: L_Boundary = Σ_i D(i) · |p_i − y_i|, kde D(i) je vzdialenosť pixelu i od najbližšieho referenčného hraničného pixelu (typicky orezaná na maximálnu vzdialenosť, napr. 5–10 pixelov). Pixely blízko hraníc (malé D) dostávajú vysokú váhu, zatiaľ čo vnútorné pixely (veľké D) dostávajú zanedbateľnú váhu.
Strata Hausdorffovej vzdialenosti (HD loss) je súvisiaca formulácia, ktorá minimalizuje maximálnu vzdialenosť medzi predikovanými a referenčnými hranicami, čím podporuje, aby sa predikovaná hranica v žiadnom bode príliš neodchýlila od skutočnej hranice. V kombinácii s Dice loss bolo preukázané, že hraničná strata zlepšuje presnosť merania šírky trhlín o 15–25 % v porovnaní s Dice loss samotnou, merané priemernou absolútnou chybou medzi predikovanou a referenčnou šírkou trhliny.
Stratová funkcia
Vzorec
Najlepšie pre
Obmedzenie
Krížová entropia
−log(p_c)
Vyvážené triedy, baseline
Slabý výkon pri nevyváženosti
Vážená krížová entropia
−w(c)·log(p_c)
Mierna nevyváženosť
Fixné váhy, bez fokusu na ťažké príklady
Dice
1 − 2
P∩G
/(
Fokálna
−(1−p_t)^γ·log(p_t)
Extrémna nevyváženosť
Dva hyperparametre (γ, α)
Dice + Fokálna
α·L_Dice + β·L_Focal
Infraštruktúrna inšpekcia (štandard)
Vyžaduje ladenie α, β
Hraničná
Σ D(i)·
p_i−y_i
Trénovacie dáta pre sémantickú segmentáciu
Požiadavky na pixelové anotácie
Trénovanie modelov sémantickej segmentácie vyžaduje pixelové referenčné anotácie — každému pixelu v každom trénovacom obraze musí byť priradená triedna značka. Toto je najnáročnejší a najdrahší aspekt vývoja segmentačného modelu pre infraštruktúrnu inšpekciu. Jeden obraz 1920×1080 obsahuje viac ako 2 milióny pixelov, z ktorých každý vyžaduje anotáciu, a typická trénovacia databáza pre segmentáciu trhlín vozoviek obsahuje 500–5 000 obrazov.
Anotačné nástroje pre pixelovú segmentáciu zahŕňajú:
LabelMe (MIT CSAIL) je open-source polygonový anotačný nástroj, ktorý beží vo webovom prehliadači. Anotátori kreslia polygóny okolo objektov záujmu (trhliny, výtlky, značenie) a nástroj vyplní vnútro polygónu priradenou triednou značkou. Pre anotáciu trhlín, kde sú trhliny tenké a vetviace sa, môže byť kreslenie polygónov mimoriadne časovo náročné — jedna trhlina dlhá 1 000 pixelov môže vyžadovať 50–200 vrcholov polygónu na presné obkreslenie.
CVAT (Computer Vision Annotation Tool) , vyvinutý spoločnosťou Intel, podporuje anotáciu pomocou polygónov aj štetca. Smart brush (interaktívny segmentačný nástroj založený na algoritme Deep Extreme Cut) umožňuje anotátorom umiestniť pozitívne a negatívne kliknutia na obraz na navigáciu automatickej segmentácie, ktorú je možné manuálne spresniť. Pre trhliny vozoviek smart brush znižuje čas anotácie o 40–60 % v porovnaní s manuálnym kreslením polygónov.
Supervisely poskytuje AI-asistovanú anotáciu s predtrénovanými segmentačnými modelmi, ktoré je možné interaktívne dolaďovať. Anotátori môžu aplikovať hrubú čmáranicu alebo ohraničujúci rámček a model generuje počiatočnú segmentáciu, ktorá je spresňovaná iteratívnymi korekciami. Pre databázy trhlín tento prístup znižuje čas anotácie na 30–90 sekúnd na obraz pre skúsených anotátorov v porovnaní s 5–15 minútami pre manuálnu polygonovú anotáciu.
Anotačné výzvy pre infraštruktúrne snímky zahŕňajú:
Prepojenosť trhlín: Zabezpečenie, že tenké, vetviace sa trhliny sú anotované ako súvislé prvky bez medzier alebo prerušení, ktoré by zmiatli segmentačný model ohľadom topológie trhlín
Presnosť hraníc: Anotovanie okrajov trhlín s presnosťou na sub-pixelovej úrovni (±1–2 pixely) na trénovanie modelov, ktoré produkujú presné merania šírky trhlín
Nejednoznačnosť tried: Rozlišovanie medzi trhlinami a netrhlínovými povrchovými prvkami — utesnené trhliny (vyplnené tmelom) môžu vizuálne pripomínať okolitú vozovku, okraje tieňov môžu byť zamenené za trhliny a dilatačné škáry v betóne môžu, ale nemusia byť považované za chyby
Zhoda medzi anotátormi: Rôzni anotátori vytvárajú rôzne segmentačné masky pre ten istý obraz; merané Cohenovým kappa alebo IoU medzi anotátormi, typická zhoda pre segmentáciu trhlín sa pohybuje od IoU = 0,65–0,80, čo predstavuje hornú hranicu dosiahnuteľného výkonu modelu
Augmentácia dát pre segmentáciu
Augmentácia dát je nevyhnutná pre trénovanie robustných segmentačných modelov, najmä pri práci s obmedzenými anotovanými databázami (bežné obmedzenie v infraštruktúrnej inšpekcii, kde je označovanie drahé). Augmentácia zvyšuje efektívnu veľkosť databázy a zlepšuje generalizáciu na variácie v osvetlení, textúre povrchu, uhle kamery a stave vozovky.
Geometrické augmentácie transformujú priestorové usporiadanie obrazu a segmentačnej masky spoločne:
Náhodná rotácia (−180° až +180°): Trhliny nemajú kanonickú orientáciu na povrchoch vozoviek, takže rotačná invariancia je kritická
Náhodné horizontálne/vertikálne prevrátenie: Zdvojnásobuje efektívnu veľkosť databázy
Náhodné škálovanie (0,5× až 2,0×): Simuluje rôzne výšky letu a vzdialenosti vzorkovania zeme
Náhodný výrez: Extrahuje výrezy z väčších obrazov, umožňujúc modelu učiť sa z lokálnych textúrnych vzorov
Elastická deformácia: Aplikuje kontrolované náhodné pole posunov na obraz a masku súčasne, simulujúc nelineárne deformácie povrchov vozoviek z tepelnej rozťažnosti a zaťaženia dopravou
Fotometrické augmentácie modifikujú intenzity pixelov bez zmeny priestorovej štruktúry:
Úprava jasu a kontrastu (±20 %): Simuluje rôzne svetelné podmienky od zamračeného po priame slnečné svetlo
Pridanie Gaussovho šumu (σ = 0,01–0,03): Simuluje šum snímača pri vyšších nastaveniach ISO alebo kvalite kamery
Gaussovské rozostrenie (σ = 0,5–1,5 pixelov): Simuluje nezaostrenie z rôznych vzdialeností kamery alebo pohybové rozostrenie
Farebný jitter: Mierne variácie v odtieni, sýtosti a hodnote, ktoré nemenia sémantický obsah
Špecializované augmentácie pre inšpekciu vozoviek zahŕňajú:
Syntéza tieňov: Pridávanie syntetických tieňových vzorov na simuláciu tieňov z lietadiel, budov alebo osvetľovacej infraštruktúry, ktoré môžu čiastočne zakrývať trhliny
Simulácia škvŕn od vody/oleja: Pridávanie lokálnych farebných variácií na simuláciu povrchovej kontaminácie, ktorá mení vzhľad vozovky bez zmeny stavu chyby
Simulácia JPEG kompresie: Simulácia kompresných artefaktov z prenosových systémov obrazu, ktoré môžu zhoršiť viditeľnosť okrajov trhlín
Požiadavky na veľkosť databázy
Počet trénovacích obrazov potrebných pre efektívnu sémantickú segmentáciu závisí od zložitosti úlohy, distribúcie tried a dostupnosti predtrénovaných váh kódovača. Pre segmentáciu trhlín vozoviek s použitím transferového učenia z kódovačov predtrénovaných na ImageNet (ResNet-50, EfficientNet-B3):
500–1 000 anotovaných obrazov: Dosahuje IoU trhlín 0,65–0,75, dostatočné pre kvalitatívne mapovanie trhlín a odhad závažnosti PCI
1 000–3 000 anotovaných obrazov: Dosahuje IoU trhlín 0,75–0,82, vhodné pre automatizované meranie šírky trhlín a rutinné hodnotenie stavu
3 000–10 000 anotovaných obrazov: Dosahuje IoU trhlín 0,82–0,88, vyžadované pre reportovanie na úrovni regulácií a odhad šírky trhlín na sub-pixelovej úrovni
10 000+ anotovaných obrazov: Dosahuje IoU trhlín 0,88+, nevyhnutné pre autonómnu inšpekciu bez ľudského overenia
Pre viac triednu segmentáciu (trhlina, značenie, typ vozovky, FOD, vegetácia) sa požadovaná veľkosť databázy zvyšuje približne 2–3× na každú ďalšiu triedu, pretože model sa musí naučiť rozlišovať medzi vizuálne podobnými povrchovými prvkami.
Viac triedna segmentácia pre cestné a letiskové scény
Taxonómia tried pre letiskové vozovky
Viac triedna sémantická segmentácia pre letiskové a cestné vozovky vyžaduje definovanie taxonómie tried, ktorá zachytáva všetky povrchové prvky relevantné pre hodnotenie stavu, bezpečnostné hodnotenie a plánovanie údržby. Na základe ASTM D5340 (Štandardná skúšobná metóda pre prieskumy indexu stavu letiskových vozoviek), požiadaviek ICAO Annex 14 a praktických inšpekčných pracovných postupov komplexná taxonómia pre segmentáciu letiskových vozoviek zahŕňa:
Trieda
Popis
Typický podiel pixelov
Relevantnosť PCI
Vozovka bez trhliny
Zdravý povrch vozovky bez chýb
75–92 %
Baseline (bez odpočtu)
Pozdĺžna trhlina
Trhliny rovnobežné s osou vozovky
0,5–3 %
Odpočet závislý od závažnosti
Priečna trhlina
Trhliny kolmé na os
0,3–2 %
Odpočet závislý od závažnosti
Aligátorová/bloková trhlina
Prepojené praskanie tvoriace polygóny
1–8 %
Vysoké hodnoty odpočtu
Okrajová trhlina
Trhliny do 0,6 m od okraja vozovky
0,1–0,5 %
Mierny odpočet
Odštiepenie škáry (betón)
Lom na škárach betónovej vozovky
0,5–2 %
Vysoký odpočet
Rohová zlomenina (betón)
Diagonálny lom v rohu dosky
0,1–0,5 %
Vysoký odpočet
Rozpadávanie
Strata kameniva z asfaltového povrchu
1–5 %
Mierny odpočet
Záplata
Opravená oblasť vozovky
1–10 %
Nízko-mierny odpočet
Značenie vozovky
Farba, termoplast alebo páskové značenie
3–8 %
Nie priamy odpočet PCI
Gumový nános
Hromadenie gumy z pneumatík v dotykovej zóne
1–5 %
Súvisí s trením
Vegetácia
Tráva, burina rastúca cez trhliny/okraje
0,5–3 %
Problém okrajovej drenáže
FOD
Cudzie predmety na povrchu
0,001–0,1 %
Bezpečnostne kritické
Utesnená trhlina
Trhlina predtým vyplnená tmelom
0,3–2 %
Závisí od stavu tmelu
Výtlk
Lokalizovaná depresia povrchu vozovky
0,01–0,5 %
Vysoký odpočet, bezpečnostne kritické
Rozdelenie tried je extrémne nevyvážené: vozovka bez trhlín dominuje na 75–92 % pixelov, zatiaľ čo FOD zaberá menej ako 0,1 %. Táto nevyváženosť si vyžaduje špecializované stratové funkcie (Dice + Fokálna) a trénovacie stratégie ako vzorkovanie uvedomujúce si triedy (nadmerné vzorkovanie mini-dávok obsahujúcich menšinové triedy) alebo online dolovanie ťažkých príkladov (výber trénovacích vzoriek s najvyššou stratou pre gradientové aktualizácie).
Mitigácia nevyváženosti tried
Okrem výberu stratovej funkcie niekoľko trénovacích stratégií zmierňuje nevyváženosť tried vo viac triednej segmentácii vozoviek:
Vzorkovanie s váhami tried upravuje pravdepodobnosť výberu každého trénovacieho výrezu tak, aby boli menšinové triedy zastúpené s minimálnou frekvenciou. Výrezy obsahujúce pixely trhlín, FOD alebo výtlkov sú nadmerne vzorkované 3–10× v porovnaní s výrezmi obsahujúcimi len vozovku bez trhlín. Implementácia typicky udržiava prioritný rad trénovacích výrezov zoradených podľa prítomnosti menšinových tried.
Fokálna modulácia v stratovej funkcii aplikuje parametre fokusu špecifické pre triedu: vyššie hodnoty γ pre väčšinové triedy a nižšie γ pre menšinové triedy, čo zabezpečuje, že model prideľuje viac učebnej kapacity vzácnym, ale kritickým triedam chýb.
Dvojfázové trénovanie najprv trénuje model na poddatasete vyváženom podľa tried, kde sú menšinové triedy nadmerne vzorkované na 20–30 % všetkých pixelov, potom dolaďuje na celom datasete s pôvodným rozdelením tried. Tento prístup zabraňuje modelu konvergovať k triviálnemu riešeniu, ktoré klasifikuje všetky pixely ako pozadie.
Sémantická segmentácia trhlín
Špecializované prístupy pre detekciu trhlín
Sémantická segmentácia trhlín predstavuje jedinečné výzvy, ktoré ju odlišujú od segmentácie na všeobecné účely: trhliny zaberajú veľmi malý podiel pixelov obrazu (0,1–3 %), majú vysoký pomer strán s extrémnym predĺžením (pomer šírky k dĺžke 1:100 až 1:1000), vykazujú nízky kontrast voči okolitému povrchu vozovky a sú vizuálne podobné netrhlínovým prvkom ako tiene, dilatačné škáry a variácie textúry povrchu.
DeepCrack (Zou a kol., 2019) bola jednou z prvých architektúr hlbokého učenia špecificky navrhnutých pre segmentáciu trhlín. Používa modifikovaný kódovač-dekódovač SegNet s viacmierkovou fúziou znakov a bočnými výstupnými vrstvami, ktoré vytvárajú predikcie vo viacerých etapách dekódovača. Konečná predikcia je generovaná fúziou výstupov zo všetkých bočných vrstiev, čo umožňuje sieti zachytávať trhliny vo viacerých mierkach súčasne — tenké vlasové trhliny z prvých etáp dekódovača a širšie štrukturálne trhliny z neskorších etáp.
CrackU-Net (Liu a kol., 2021) rozširuje štandardný U-Net o: (1) brány pozornosti v preskakovacích spojeniach, ktoré váhujú mapy znakov na základe priestorovej relevantnosti k oblastiam trhlín, potláčajúc znaky pozadia a zosilňujúc znaky trhlín; (2) hlboký dohľad, ktorý aplikuje výpočet straty vo viacerých etapách dekódovača, poskytujúc gradientné signály vo viacerých mierkach; a (3) dilatovanú konvolúciu v úzkom mieste na rozšírenie receptívneho poľa bez straty rozlíšenia. CrackU-Net dosahuje IoU trhlín 0,78–0,84 na benchmarkových dataseroch vozoviek.
CrackTransformer (Chen a kol., 2022) aplikuje hybridnú CNN-transformer architektúru špecificky pre segmentáciu trhlín. Kódovač ResNet-50 extrahuje počiatočné mapy znakov, ktoré sú potom spracované transformerovým kódovačom s 8 hlavami vlastnej pozornosti, ktorý modeluje závislosti medzi segmentmi trhlín. Trhliny, ktoré sú vizuálne neprepojené (kvôli variáciám osvetlenia alebo povrchovej kontaminácii), ale patria k rovnakej fyzickej trhline, môžu byť prepojené prostredníctvom vlastnej pozornosti, čo zlepšuje úplnosť prepojenia — metriku merajúcu, aký podiel referenčných pixelov trhlín v prepojených komponentoch je správne predikovaný.
Výzvy tenkých trhlín
Trhliny užšie ako 2–3 pixely na šírku predstavujú zásadnú výzvu pre sémantickú segmentáciu založenú na konvolučných neurónových sieťach s podvzorkovaním. Štandardný kódovač s 5 stupňami podvzorkovania a výstupným krokom 1/32 reprezentuje trhliny šírky 3 pixely alebo menej ako jediný pixel alebo menej v najhlbších mapách znakov — nedostatočné pre spoľahlivú detekciu.
Riešenia pre segmentáciu tenkých trhlín zahŕňajú:
Minimálne obmedzenie vzdialenosti vzorkovania zeme (GSD): GSD vstupných snímok musí spĺňať GSD ≤ W_min / 3, kde W_min je minimálna detekovateľná šírka trhliny. Pre detekciu vlasových trhlín s hrúbkou 0,3 mm musia byť snímky zachytené pri GSD ≤ 0,1 mm/pixel, čo vyžaduje výšky letu 3–8 m s typickými vysokorozlíšenými kamerami. Pre prevádzkovú inšpekciu trhlín 1 mm je potrebné GSD ≤ 0,33 mm/pixel.
Sub-pixelová detekcia trhlín používa spojitú mapu pravdepodobnosti trhlín (pred prahovaním na 0,5) na odhad prítomnosti trhlín v sub-pixelovom rozlíšení. Stredová línia trhliny je extrahovaná na sub-pixelovej úrovni fitovaním Gaussovej alebo kvadratickej funkcie na profil pravdepodobnosti kolmý na smer trhliny, čím sa určuje pozícia trhliny s presnosťou 0,1–0,3 pixela.
Viacmierkový vstup spracováva obraz vo viacerých rozlíšeniach (napr. 0,5×, 1×, 1,5×) a fúzuje predikcie. Vysokorozlíšená vetva zachováva detaily tenkých trhlín, zatiaľ čo nízkorozlíšená vetva poskytuje kontext a potláča šum. Pyramidové znakové siete (FPN) integrované s U-Net poskytujú toto viacmierkové správanie v rámci jedného dopredného priechodu.
Zachovanie prepojenosti
Prepojenosť trhlín — topologická vlastnosť, že pixely trhlín tvoria súvislé siete, nie izolované body — je kritická pre klasifikáciu typu trhlín (pozdĺžna, priečna, aligátorová) a hodnotenie závažnosti. Štandardné segmentačné straty explicitne nevynucujú prepojenosť, často produkujúc neprepojené fragmenty trhlín.
Kostre citlivá strata vypočítava kostru (mediálnu os) referenčnej masky trhlín a aplikuje vyššiu váhu straty na pixely kostry, čím podporuje model, aby správne predikoval stredovú líniu trhliny. Kostra zaberá 5–10 % pixelov trhlín, ale nesie 50 % topologických informácií.
Topologická strata založená na perzistentnej homológii penalizuje rozdiely v Bettiho číslach (β₀: počet prepojených komponentov, β₁: počet dier) medzi predikovanými a referenčnými maskami trhlín. Model trénovaný s topologickou stratou produkuje 30–60 % menej neprepojených fragmentov trhlín v porovnaní so samotnou Dice loss.
Post-processing pomocou podmienených náhodných polí (CRF) aplikuje plne prepojené CRF ako konečný krok spresnenia. CRF podporuje, aby susedné pixely s podobnou farbou a intenzitou zdieľali rovnakú triednu značku, vypĺňajúc medzery v predikovaných maskách trhlín a vyhladzujúc zubaté hranice. Implementácia DenseCRF (Krähenbühl & Koltun, 2011) sa bežne aplikuje ako post-processingový krok, zlepšujúc prepojenosť trhlín o 5–10 % za cenu 50–200 ms dodatočného času inferencie na obraz.
Odhad šírky trhlín
Sémantická segmentácia poskytuje priestorovú masku, z ktorej možno odhadnúť šírku trhliny. Meranie šírky je nevyhnutné pre hodnotenie závažnosti PCI: ASTM D5340 definuje kategórie závažnosti trhlín na základe strednej šírky (napr. nízka závažnosť: <3 mm, stredná závažnosť: 3–6 mm, vysoká závažnosť: >6 mm pre pozdĺžne trhliny v asfalte).
Štandardný pipeline odhadu šírky: (1) extrahovať stredovú líniu trhliny pomocou skeletonizácie (iteratívne stenčovacie algoritmy ako Zhang-Suen alebo Medial Axis Transform); (2) pre každý pixel stredovej línie vypočítať euklidovskú vzdialenosť k najbližšiemu pixelu pozadia (transformácia vzdialenosti); (3) šírka trhliny v danom bode je 2× hodnota transformácie vzdialenosti. Lokálne meranie šírky umožňuje reportovanie strednej šírky, maximálnej šírky a distribúcie šírky pre každý segment trhliny.
Pre sub-pixelovú presnosť šírky sa namiesto binárnej masky používa spojitá mapa predikovanej pravdepodobnosti (pred binarizáciou). Profil pravdepodobnosti kolmý na trhlinu je fitovaný Gaussovou funkciou a šírka je definovaná ako plná šírka v polovičnom maxime (FWHM) fitovanej Gaussovej funkcie. Tento prístup dosahuje presnosť merania šírky 0,1–0,3 pixela, čo umožňuje spoľahlivú klasifikáciu závažnosti pre trhliny také úzke ako 0,3 mm na snímkach s rozlíšením 1 mm/pixel.
Segmentácia typu povrchu
Rozlišovanie materiálov povrchu vozovky
Segmentácia typu povrchu — rozlišovanie asfaltu, betónu, štrku, tarmacu, utesnených a neutesnených povrchov v rámci jedného obrazu — je odlišná úloha od segmentácie chýb. Typy povrchov majú charakteristické spektrálne odrazy, textúru a priestorové distribučné vzory, ktoré sa môžu segmentačné modely naučiť.
Rozlišovanie asfaltu vs. betónu sa spolieha na spektrálne a textúrne indície:
Asfaltové vozovky vykazujú relatívne jednotný tmavosivý vzhľad s nízkou spektrálnou variabilitou, jemnú textúru z častíc kameniva (0,5–5 mm) a časté vzory trhlín a záplat
Betónové vozovky sa javia svetlejšie sivé s vyššou spektrálnou variabilitou, viditeľným hrubým kamenivom (10–30 mm), priečnymi dilatačnými škárami v pravidelných intervaloch (typicky 5–8 m rozostup) a odlišnými vzormi poškodenia (odštiepenie, zlomy, rohové zlomeniny)
Štrkové povrchy vykazujú vysokú spektrálnu variabilitu na úrovni zŕn (2–20 mm), žiadne vzory trhlín (nezviazaný povrch) a voľný vzhľad častíc
Spektrálne znaky z multispektrálnych snímok (RGB + blízke infračervené) zlepšujú rozlišovanie typov povrchu. Asfalt absorbuje viac NIR žiarenia ako betón (NIR odrazivosť: asfalt 5–10 %, betón 20–40 %), čo poskytuje jasné spektrálne oddelenie. Normalizovaný diferenčný vegetačný index (NDVI) rozlišuje vegetáciu (NDVI > 0,3) od povrchov vozoviek (NDVI < 0,1). Pásma krátkovlnného infračerveného žiarenia (SWIR) rozlišujú typy asfaltu a detegujú tmeliacie materiály.
Textúrne znaky vypočítané zo štatistík matice spoločného výskytu odtieňov sivej (GLCM) (kontrast, dissimilarita, homogenita, energia, korelácia), lokálnych binárnych vzorov (LBP) a odoziev Gaborových filtrov poskytujú kvantitatívne miery textúry, ktoré zlepšujú klasifikáciu typu povrchu. Chrbtica ResNet-50 alebo EfficientNet-B4 trénovaná na obrazoch povrchu vozoviek s dodatočným vstupným kanálom pre entropiu (vypočítanú z lokálneho rozptylu intenzity) zlepšuje presnosť klasifikácie typu povrchu o 3–5 % mIoU.
Integrácia spektrálnych a textúrnych znakov
Pre viac triednu segmentáciu kombinujúcu detekciu typu povrchu a chýb sú bežné dva architektonické prístupy:
Jednostupňový viac triedny model produkuje C tried pokrývajúcich typy povrchu aj chyby (napr. 5 typov povrchu × 10 typov chýb = 15 výstupných tried). Tento prístup profituje zo zdieľaného učenia znakov — rovnaké znaky, ktoré odlišujú asfalt od betónu, tiež pomáhajú rozlišovať vzhľad trhlín na týchto povrchoch. Hierarchia tried môže byť sploštená (každá kombinácia je samostatná trieda) alebo hierarchická (typ povrchu predikovaný v hrubej mierke, chyby v jemnej mierke v rámci každej oblasti typu povrchu).
Dvojstupňový pipeline spúšťa dva samostatné segmentačné modely: klasifikátor typu povrchu (rýchly, ľahký) nasledovaný modelom segmentácie chýb špecifickým pre každý typ povrchu (presný, špecializovaný). Model typu povrchu spracováva celý obraz v nižšom rozlíšení, identifikujúc oblasti typu vozovky. Každá oblasť je potom spracovaná zodpovedajúcim modelom chýb trénovaným špecificky na daný typ povrchu. Tento prístup dosahuje vyššiu presnosť na jeden typ, ale vyžaduje viac výpočtov pre inferenciu (N typov povrchu × inferencia modelu chýb).
Vyhodnocovacie metriky pre segmentáciu
Intersection over Union (IoU)
Intersection over Union (IoU) , tiež známy ako Jaccardov index, je primárna vyhodnocovacia metrika pre sémantickú segmentáciu. Pre danú triedu c sa IoU vypočíta ako: IoU_c = TP_c / (TP_c + FP_c + FN_c), kde TP_c je počet pixelov správne predikovaných ako trieda c (skutočne pozitívne), FP_c je počet pixelov nesprávne predikovaných ako trieda c (falošne pozitívne) a FN_c je počet pixelov triedy c nesprávne predikovaných ako iná trieda (falošne negatívne).
Stredný IoU (mIoU) spriemeruje IoU cez všetky triedy. Pre nevyvážené infraštruktúrne datasety je nevážený mIoU štandardnou reportovacou metrikou, pretože každá trieda prispieva rovnako bez ohľadu na počet pixelov — model, ktorý ignoruje trhliny, ale správne klasifikuje všetku vozovku bez trhlín, by dosiahol vysokú pixelovú presnosť (99 %), ale nízky mIoU (50 % pre model s 2 triedami).
Diceov koeficient (F1 skóre)
Diceov koeficient je ekvivalentný F1 skóre a je úzko spojený s IoU: Dice = 2TP / (2TP + FP + FN) = 2TP / (Celkový počet predikovaných pozitívnych + Celkový počet referenčných pozitívnych). Diceov koeficient a IoU sú monotónne prepojené: Dice = 2IoU / (1 + IoU).
IoU
Dice (F1)
Interpretácia
0,90
0,947
Výborný — takmer dokonalá segmentácia
0,80
0,889
Veľmi dobrý — adekvátny pre automatizované PCI
0,70
0,824
Dobrý — vhodný pre asistovanú inšpekciu
0,60
0,750
Mierny — vyžaduje manuálne overenie
0,50
0,667
Uspokojivý — obmedzený na kvalitatívne použitie
0,40
0,571
Slabý — vysoká miera falošne pozitívnych/negatívnych
Pre segmentáciu trhlín sa Dice triedy trhlín 0,70–0,80 považuje za adekvátny pre automatizované mapovanie trhlín, zatiaľ čo Dice > 0,85 sa vyžaduje pre automatizované meranie šírky a klasifikáciu závažnosti bez ľudského overenia.
Pixelová presnosť
Pixelová presnosť meria podiel správne klasifikovaných pixelov: PA = Σ TP_c / Σ (TP_c + FP_c). Pre silne nevyvážené dáta — vozovka bez trhlín na 95 % pixelov — model, ktorý klasifikuje každý pixel ako vozovku bez trhlín, dosahuje 95 % pixelovú presnosť s 0 % detekciou trhlín. Pixelová presnosť sa preto neodporúča ako primárna metrika pre infraštruktúrnu segmentáciu. Mala by byť reportovaná len spolu s metrikami na triedu (IoU, Dice, precíznosť, úplnosť).
Precíznosť, úplnosť a metriky na triedu
Precíznosť = TP / (TP + FP) meria podiel pozitívnych predikcií, ktoré sú správne — dôležité pre minimalizáciu falošných poplachov, ktoré plytvajú inšpekčnými zdrojmi. Úplnosť = TP / (TP + FN) meria podiel skutočných pozitívnych pixelov správne identifikovaných — dôležité pre minimalizáciu prehliadnutých chýb, ktoré ohrozujú bezpečnosť.
Kompromis medzi precíznosťou a úplnosťou je riadený prahom predikcie (typicky 0,5 pre softmax výstup). Pre infraštruktúrnu inšpekciu:
Cieľ vysokej precíznosti (0,90+): Používa sa pre automatizované reportovanie PCI, kde by falošne pozitívne nadhodnotili zhoršenie. Prah zvýšený na 0,75–0,85 na elimináciu neistých predikcií.
Cieľ vysokej úplnosti (0,90+): Používa sa pre bezpečnostne kritickú detekciu FOD, kde je prehliadnutie trosiek neprijateľné. Prah znížený na 0,3–0,4 na zachytenie okrajových detekcií, s následným ľudským overením všetkých upozornení.
Hraničné vyhodnotenie
Hraničné vyhodnocovacie metriky posudzujú kvalitu segmentácie na okrajoch objektov — najnáročnejšej oblasti pre infraštruktúrne chyby:
Hraničné F1 (BF) vypočítava precíznosť a úplnosť v rámci úzkeho pásma (typicky 2–5 pixelov) okolo referenčnej hranice segmentácie. Vysoké BF skóre (0,80+) indikuje, že predikované hranice trhlín sa úzko zhodujú so skutočnými okrajmi trhlín, čo je nevyhnutné pre presné meranie šírky trhlín.
Hausdorffova vzdialenosť (HD) meria maximálnu vzdialenosť medzi predikovanými a referenčnými hranicami: HD = max(max_p min_g d(p,g), max_g min_p d(g,p)), kde p a g sú body na predikovaných a referenčných hraniciach. 95. percentil Hausdorffovej vzdialenosti (HD95) je robustnejší voči odľahlým hodnotám a typicky sa reportuje pre segmentáciu trhlín. HD95 < 3 pixely pre obraz s rozlíšením 1 mm/pixel zodpovedá chybe lokalizácie hranice < 3 mm.
Metrika
Vzorec
Typická hodnota pre segmentáciu trhlín
Interpretácia
IoU trhlín
TP/(TP+FP+FN)
0,65–0,85
Pixelový prekryv s referenciou
Dice trhlín
2TP/(2TP+FP+FN)
0,79–0,92
F1 prekryv s referenciou
Pixelová presnosť
Správne pixely / Celkom pixelov
0,95–0,99
Celková správnosť (zavádzajúca)
Precíznosť
TP/(TP+FP)
0,75–0,90
Správnosť pozitívnych predikcií
Úplnosť
TP/(TP+FN)
0,70–0,90
Úplnosť zachytenia chýb
Hraničné F1
BF v pásme 2 pixelov
0,60–0,80
Kvalita lokalizácie hrán
HD95 (pixely)
95. percentil Hausdorffovej vzdial.
2–8 pixelov
Maximálna hraničná chyba
Nasadenie a rýchlosť inferencie
Optimalizácia modelu pre nasadenie na okraji
Nasadenie modelov sémantickej segmentácie pre prevádzkovú infraštruktúrnu inšpekciu vyžaduje vyváženie presnosti s rýchlosťou inferencie a pamäťovými obmedzeniami. Inšpekčné drony a okrajové zariadenia (NVIDIA Jetson, Google Coral, Intel Neural Compute Stick) majú obmedzené výpočtové zdroje v porovnaní s cloudovými GPU.
Pruning modelu odstraňuje redundantné váhy alebo kanály z trénovanej siete. Neštruktúrovaný pruning nastavuje jednotlivé váhy na nulu (dosahujúc 50–80 % riedkosť so stratou presnosti <2 %), zatiaľ čo štruktúrovaný pruning odstraňuje celé kanály alebo filtre (dosahujúc 30–50 % redukciu kanálov). Štruktúrovaný pruning je preferovaný pre hardvérové nasadenie, pretože priamo znižuje výpočtové operácie a prenosy pamäte.
Kvantizácia znižuje numerickú presnosť váh a aktivácií z 32-bitovej pohyblivej rádovej čiarky (FP32) na 16-bitovú (FP16) alebo 8-bitové celé číslo (INT8). Pokvantizačné trénovanie (PTQ) kalibruje rozsahy aktivácií modelu pomocou malej kalibračnej databázy a konvertuje na INT8 bez pretrénovania — typicky dosahujúc 2–3× zrýchlenie s 1–3 % degradáciou presnosti. Kvantizácii uvedomujúce trénovanie (QAT) simuluje kvantizáciu počas trénovania, čo umožňuje modelu prispôsobiť sa zníženej presnosti a obmedziť stratu presnosti na <1 %.
ONNX Runtime poskytuje hardvérovo optimalizovanú inferenciu naprieč CPU, GPU a NPU backendmi. Modely exportované z PyTorch alebo TensorFlow do formátu ONNX (Open Neural Network Exchange) profitujú z grafovej optimalizácie (fúzia operátorov, konštantné skladanie) a cieľovo špecifických poskytovateľov vykonávania (CUDA pre NVIDIA GPU, TensorRT pre platformy Jetson, OpenVINO pre Intel hardvér).
TensorRT (NVIDIA) aplikuje dodatočnú optimalizáciu pre NVIDIA GPU: automatické ladenie jadier (výber najrýchlejšej implementácie jadra pre každú vrstvu), fúziu vrstiev (kombinovanie susedných vrstiev do jedného jadra), kalibráciu presnosti (automatická optimalizácia FP16/INT8) a dynamické riadenie tenzorovej pamäte. Model U-Net konvertovaný z PyTorch do TensorRT s FP16 inferenciou dosahuje 3–5× zrýchlenie na hardvéri Jetson Orin.
Požiadavky na inferenciu v reálnom čase
Scenár nasadenia
Požadovaná priepustnosť
Akceptovateľná latencia
Typický hardvér
Dávkové spracovanie po lete
1–10 obr./s
Minúty na prieskum
Cloud GPU (A10, A100)
Dronová inferencia na okraji
10–30 obr./s
<100 ms na obr.
Jetson Orin NX/Nano
Detekcia FOD v reálnom čase
30+ obr./s
<30 ms na obr.
Jetson AGX Orin
Smartfónová inšpekcia
1–5 obr./s
<500 ms na obr.
Snapdragon/Apple Neural Engine
Kompromisy medzi rýchlosťou a presnosťou
Vzťah medzi veľkosťou modelu, rýchlosťou inferencie a presnosťou segmentácie sa riadi zavedenými škálovacími zákonmi. Pre segmentáciu trhlín na snímkach s rozlíšením 1 mm/pixel:
Variant modelu
Chrbtica
Parametre
IoU trhlín
Inferencia (256² výrez)
Platforma
U-Net tiny
EfficientNet-B0
3,8M
0,72
3 ms
Jetson Nano
U-Net small
ResNet-18
14,3M
0,76
8 ms
Jetson Orin NX
U-Net medium
ResNet-50
34,5M
0,80
18 ms
Jetson Orin NX
U-Net large
ResNet-101
57,4M
0,83
35 ms
Jetson AGX Orin
DeepLabV3+
ResNet-50
40,1M
0,82
22 ms
Jetson AGX Orin
DeepLabV3+
ResNet-101
63,6M
0,84
42 ms
Jetson AGX Orin
SegFormer-B2
MiT-B2
24,5M
0,81
28 ms
Jetson AGX Orin
SegFormer-B3
MiT-B3
44,1M
0,84
45 ms
Jetson AGX Orin
Pre prevádzkové nasadenie na letisku spracovávajúcom dráhu 3 000 m × 45 m pri GSD 1 mm/pixel (približne 135 000 výrezov 2048×2048), model U-Net medium na Jetson Orin NX dokončí inferenciu celej dráhy približne za 40 minút — kompatibilné s nočným spracovaním pre rozhodnutia o údržbe na nasledujúci deň. Rovnaký model na cloudovom GPU znižuje spracovanie na 5–8 minút.
Dlaždicovanie a zošívanie pre veľkoplošné snímky
Infraštruktúrne inšpekčné snímky — najmä ortomozaily z dronových prieskumov — sú typicky príliš veľké pre jednopriechodovú modelovú inferenciu (10 000–500 000 pixelov na rozmer). Dlaždicovanie rozdeľuje obraz na prekrývajúce sa výrezy (typicky 512×512 až 2048×2048 pixelov), ktoré sú spracovávané nezávisle. Prekrývajúce sa oblasti (10–25 % rozmeru dlaždice) zabezpečujú, že chyby prekračujúce hranice dlaždíc sú konzistentne segmentované — predikcie v prekrývajúcich sa oblastiach sú spriemerované alebo zlúčené pomocou váženého prelínania.
Zošívanie znovu skladá predikcie dlaždíc do celorozlíšenovej segmentačnej mapy. Hladké prelínanie s lineárnymi rampami v prekrývajúcich sa oblastiach eliminuje viditeľné hranice dlaždíc. Zošitá mapa pri GSD 1 mm/pixel pre 45 m širokú dráhu je 45 000 pixelov široká — vyžadujúca starostlivé riadenie pamäte pre vizualizáciu a následnú analýzu.
Platforma TarmacView spracováva dlaždicové segmentačné predikcie pri GSD od 0,3 do 3 mm/pixel, s automatickým výberom veľkosti dlaždice na základe dostupnej GPU pamäte a architektúry modelu, čím vytvára bezproblémové segmentačné mapy celej dráhy s presnosťou lokalizácie trhlín na sub-pixelovej úrovni.
Často kladené otázky
Sémantická segmentácia priraďuje jedinú triednu značku každému pixelu bez rozlišovania jednotlivých objektov rovnakej triedy — všetky trhliny sú označené ako ‚trhlina‘, všetka vozovka ako ‚vozovka‘. Segmentácia inštancií detekuje a ohraničuje každý jednotlivý objekt samostatne, priraďujúc unikátne ID každému objektu — trhlina č. 1, trhlina č. 2. Panoptická segmentácia spája oba prístupy: priraďuje sémantickú značku každému pixelu (triedy typu hmota ako vozovka, obloha, vegetácia) a súčasne identifikuje a segmentuje jednotlivé inštancie objektov (triedy typu vec ako konkrétne trhliny, výtlky alebo predmety FOD). Pre infraštruktúrnu inšpekciu je sémantická segmentácia najčastejšie používaným prístupom, pretože mnohé povrchové chyby tvoria súvislé, prepojené oblasti, ktoré nemajú dobre definované jednotlivé inštancie.
U-Net je plne konvolučná architektúra kódovač-dekódovač predstavená Ronnebergerom a kol. v roku 2015 pre biomedicínsku segmentáciu obrazov. Kódovač (kontrakčná cesta) extrahuje hierarchické znaky prostredníctvom postupných konvolúcií a poolingových operácií, postupne znižujúc priestorové rozlíšenie pri zvyšovaní hĺbky kanálov. Dekódovač (expanzná cesta) upvzorkúva mapy znakov späť na pôvodné vstupné rozlíšenie pomocou transponovaných konvolúcií alebo bilineárnej interpolácie. Kľúčovou inováciou sú preskakovacie spojenia, ktoré priamo spájajú mapy znakov z kódovača so zodpovedajúcou vrstvou dekódovača pri rovnakom rozlíšení, čo umožňuje dekódovaču prístup k jemným priestorovým detailom strateným počas podvzorkovania. U-Net obsahuje približne 31 miliónov parametrov pre štandardnú implementáciu a zostáva široko používaný pre segmentáciu infraštruktúrnych trhlín vďaka svojej vynikajúcej lokalizačnej presnosti s obmedzenými trénovacími dátami.
Primárnymi vyhodnocovacími metrikami sú Intersection over Union (IoU), tiež známy ako Jaccardov index, a Diceov koeficient (F1 skóre). IoU vypočítava prekryv medzi predikovanou a referenčnou segmentačnou maskou vydelený ich zjednotením: TP / (TP + FP + FN). Diceov koeficient je ekvivalentný F1 skóre: 2TP / (2TP + FP + FN). Pixelová presnosť meria podiel správne klasifikovaných pixelov, ale je zavádzajúca pre nevyvážené datasety, kde dominujú pixely bez trhlín. Pre segmentáciu trhlín, kde trhliny typicky tvoria menej ako 1 % obrazu, sú najvýznamnejšími reportovacími metrikami IoU na triedu a najmä IoU triedy trhlín. Hraničné F1 skóre a Hausdorffova vzdialenosť poskytujú dodatočné informácie o kvalite segmentačných hraníc.
Stratová funkcia krížovej entropie vypočítava negatívnu log-pravdepodobnosť predikovanej pravdepodobnosti pre správnu triedu v každom pixeli, spriemerovanú cez všetky pixely. Je základnou stratovou funkciou, ale funguje zle na nevyvážených dátech. Dice loss minimalizuje 1 - Diceov koeficient, priamo optimalizujúc metriku prekryvu a dobre zvláda miernu nevyváženosť tried. Fokálna strata pridáva modulačný faktor (1-pᵗ)ᵞ ku krížovej entropii, znižujúc váhu jednoduchých príkladov a zameriavajúc trénovanie na ťažké pixely; je účinná pre extrémnu nevyváženosť tried, kde trhliny zaberajú menej ako 1 % pixelov. Hraničná strata používa transformácie vzdialenosti na penalizáciu chýb na segmentačných hraniciach. Hybridné straty (napr. Dice + Fokálna) sa bežne používajú v infraštruktúrnej inšpekcii na kombinovanie výhod viacerých formulácií.
ResNet (reziduálna sieť) je najpoužívanejšia chrbtica, dostupná vo variantoch ResNet-18, ResNet-34, ResNet-50, ResNet-101 a ResNet-152, pričom číslo označuje hĺbku vrstvy. Reziduálne spojenia s preskakovacími spojeniami umožňujú trénovanie veľmi hlbokých sietí. EfficientNet používa zložené škálovanie (hĺbka, šírka, rozlíšenie) s blokmi MBConv obsahujúcimi squeeze-and-excitation (SE) pozornosť pre výpočtovú efektivitu. Vision Transformer (ViT) aplikuje transformerovú vlastnú pozornosť na obrazové výrezy, zachytávajúc globálny kontext za cenu vyšších výpočtových nárokov. Voľba závisí od kompromisu medzi presnosťou a rýchlosťou: ľahké chrbtice (ResNet-18, EfficientNet-B0) sú vhodné pre nasadenie na okrajových zariadeniach v reálnom čase, zatiaľ čo ťažké chrbtice (ResNet-101, ViT-Base) maximalizujú presnosť pre offline analýzu.
Automatizujte svoju infraštruktúrnu inšpekciu
Využite sémantickú segmentáciu pre pixelovo presné hodnotenie stavu vozoviek, detekciu trhlín a mapovanie typu povrchu. Naša platforma poskytuje automatizovanú analýzu z dronových snímok s meraním trhlín s presnosťou pod milimeter a reportovaním v súlade s PCI.
Segmentácia inštancií pre identifikáciu jednotlivých defektov
Segmentácia inštancií identifikuje a ohraničuje každý jednotlivý objekt alebo defekt na úrovni pixelov, pričom priraďuje jedinečné ID každej trhline, výtlku ale...
Detekcia trhlín pomocou AI pre kontrolu infraštruktúry
Detekcia trhlín pomocou AI využíva počítačové videnie — konvolučné neurónové siete, vision transformery a modely sémantickej segmentácie — na automatickú identi...
Percentuálny podiel trhlín na vozovke a hodnotenie konštrukcie
Percentuálny podiel plochy trhlín (crack_area_pct) je pomer plochy masky trhlín k celkovej analyzovanej ploche obrazu, vyjadrený v percentách. Je to kľúčová kva...
27 min čítania
measurement
pavement
+3
Súhlas s cookies Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.