Dymový test
Dymový test je rýchle, end-to-end overenie, že softvérový pipeline sa vykoná bez zlyhania na reprezentatívnych dátach a produkuje očakávané výstupy. Testy Tarma...
30 min čítania
testing
technology
+4
Smoke test hlavy defektov overuje, že pipeline detekcie štrukturálnych defektov TarmacView — backbone DINOv3 + 5-labelová MLP hlava pre praskliny/odlupovanie/eflorescenciu/odkrytú výstuž/koróziu — produkuje očakávané výstupy na testovacích dátach. Zahŕňa testovacie tvrdenia (kontrolný bod existuje; AP metriky; stĺpce defektov pre dlaždice/rámčeky vo výstupnom analyzovanom súbore) a čo smoke testy overujú oproti plnému vyhodnoteniu.
Smoke testovanie hlavy defektov je automatizovaný overovací postup, ktorý validuje štrukturálnu integritu a základnú funkcionalitu pipeline strojového učenia na detekciu defektov. Potvrdzuje, že pipeline — od predspracovania vstupného obrázka cez DINOv3 vision transformer backbone až po 5-labelovú viacvrstvovú perceptrónovú (MLP) klasifikačnú hlavu — produkuje očakávané výstupy na syntetických alebo malých statických testovacích dátach bez zlyhania, bez numerických chýb a bez generovania štrukturálne neplatných predikcií. Smoke test sa líši od plnohodnotného vyhodnotenia: overuje, že pipeline je správne zapojená a funkčná, nie že generalizuje na nevidané dáta s vysokou presnosťou.
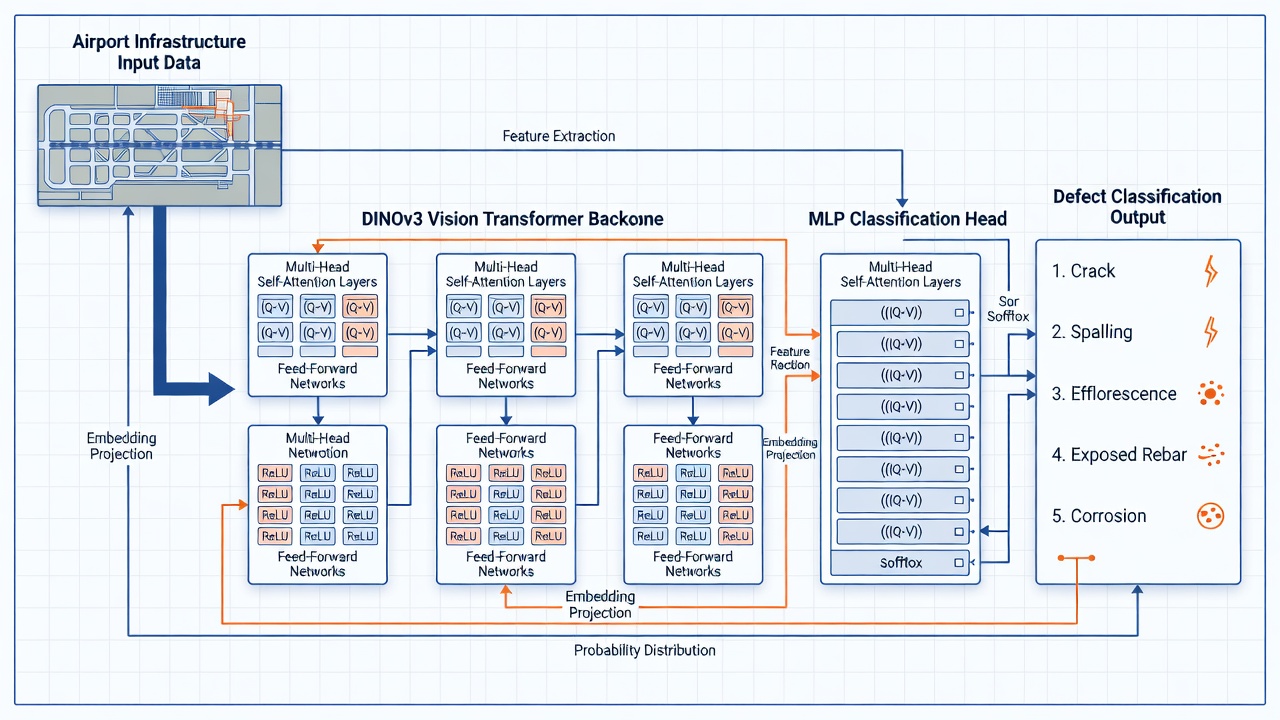
Hlava defektov je finálna komponenta pipeline detekcie štrukturálnych defektov TarmacView, zodpovedná za mapovanie bohatých reprezentácií príznakov extrahovaných backbone sieťou na diskrétne predikcie tried defektov. Pochopenie architektúry backbone aj hlavy je nevyhnutné pre navrhovanie efektívnych smoke testov, ktoré validujú integritu každej komponenty.
DINOv3 (self-DIstillation with NO labels, verzia 3) vision transformer, vyvinutý spoločnosťou Meta AI a vydaný v roku 2023, slúži ako backbone na extrakciu príznakov. DINOv3 bol trénovaný pomocou samoučiacej paradigmy na kurátorovanej sade 142 miliónov neoznačených obrázkov (LVD-142M), pričom sa naučil univerzálne vizuálne reprezentácie bez potreby akýchkoľvek ľudských anotácií. Tento prístup produkuje príznaky, ktoré sa efektívne prenášajú na downstream úlohy vrátane klasifikácie, segmentácie a detekcie defektov — často prekonávajúc supervidované predtrénovanie na ImageNet-1K.
DINOv3 je dostupný v niekoľkých variantoch modelov s rôznymi výpočtovými profilmi:
| Variant | Parametre | Dim. embeddingu | Veľkosť patcha | Vrstvy | Hlavy |
|---|---|---|---|---|---|
| ViT-S/14 | 22 miliónov | 384 | 14×14 | 12 | 6 |
| ViT-B/14 | 86 miliónov | 768 | 14×14 | 12 | 12 |
| ViT-L/14 | 300 miliónov | 1024 | 14×14 | 24 | 16 |
| ViT-g/14 | 1,1 miliardy | 1536 | 14×14 | 40 | 24 |
Pre pipeline detekcie defektov TarmacView je ViT-B/14 štandardnou konfiguráciou. S 86 miliónmi parametrov a 768-rozmerným embeddingovým priestorom vyvažuje reprezentačnú kapacitu s výpočtovou efektivitou vhodnou na spracovanie veľkých objemov inšpekčných snímok dráh. Veľkosť patcha 14×14 znamená, že vstupný obrázok 224×224 pixelov je rozdelený na 16×16 = 256 neprekrývajúcich sa patchov, pričom každý je projektovaný do 768-rozmerného embeddingového priestoru pomocou naučenej lineárnej projekcie.
Tréningová metodológia DINOv3 kombinuje niekoľko kľúčových techník. Samodistilácia s architektúrou učiteľ-študent zabezpečuje, že študentská sieť sa učí kopírovať reprezentácie učiteľa, pričom učiteľ je exponenciálny kĺzavý priemer študenta. iBOT (image BERT pre-training with Online Tokenizer) aplikuje maskované modelovanie obrázkov, kde sú náhodné patche maskované a model musí predpovedať reprezentácie maskovaných patchov. Sinkhorn-Knopp centrovanie z metódy SwAV zabraňuje kolapsu reprezentácie vynucovaním rovnomernej distribúcie naprieč vzorkami v dávke. KoLeo regularizátor podporuje diverzitu v naučených príznakoch penalizáciou podobnosti príznakov medzi blízkymi vzorkami.
Pre prípad použitia detekcie defektov je DINOv3 načítaný s predtrénovanými váhami a typicky zmrazený počas trénovania hlavy defektov. Zmrazený backbone extrahuje všeobecné vizuálne príznaky — hrany, textúry, gradienty, povrchové vzory — ktoré sú vysoko relevantné na rozlíšenie medzi neporušenou vozovkou a piatimi triedami defektov. Zmrazenie backbone znižuje počet trénovateľných parametrov z 86 miliónov na približne 1-3 milióny (v závislosti od hĺbky MLP hlavy), čo dramaticky znižuje tréningový čas, požiadavky na GPU pamäť a riziko katastrofického zabúdania na malých doménovo-špecifických datasetoch.
MLP (Multi-Layer Perceptron) hlava defektov je malá dopredná neurónová sieť, ktorá prijíma zmrazené DINOv3 embeddingy ako vstup a produkuje 5-rozmernú distribúciu pravdepodobností nad piatimi triedami defektov: prasklina, odlupovanie, eflorescencia, odkrytá výstuž a korózia.
Štandardná architektúra pozostáva z:
Vstupnej vrstvy: Prijíma DINOv3 embedding — buď [CLS] token (768-rozmerný vektor reprezentujúci globálny obsah obrázka) alebo agregovanú reprezentáciu všetkých patch tokenov. Prístup s [CLS] tokenom je štandardný, pretože DINOv3 je špecificky trénovaný na produkciu bohatých informácií v [CLS] tokene počas samodistilácie.
Skrytých vrstiev: Typicky 1-2 plne prepojené vrstvy s ReLU alebo GELU aktivačnými funkciami. Jednovrstvová konfigurácia môže byť 768 → 256 → 5, zatiaľ čo hlbšia konfigurácia môže byť 768 → 512 → 128 → 5. Každá skrytá vrstva je nasledovaná batch normalizáciou alebo layer normalizáciou na stabilizáciu trénovania a zníženie interného posunu kovariátov. Dropout (miera 0,2-0,5) je aplikovaný medzi skrytými vrstvami počas trénovania ako regularizátor na zabránenie pretrénovaniu, vzhľadom na to, že datasety defektov infraštruktúry sú typicky malé (500-5000 obrázkov).
Výstupnej vrstvy: Lineárna projekcia na 5 jednotiek zodpovedajúcich piatim triedam defektov, nasledovaná softmax aktiváciou, ktorá konvertuje logity na distribúciu pravdepodobností nad triedami. Softmax funkcia zabezpečuje, že výstupný vektor sa sčítava na 1,0, pričom každý prvok predstavuje predikovanú pravdepodobnosť, že vstupný obrázok patrí do danej triedy defektov.
Tréningového postupu: MLP hlava je trénovaná pomocou supervidovaného doladenia, zatiaľ čo DINOv3 backbone zostáva zmrazený. Loss funkciou je kategorická krížová entropia, porovnávajúca predikovanú distribúciu pravdepodobností s one-hot kódovanými ground truth labelmi. Trénovanie typicky používa AdamW optimalizátor s rýchlosťou učenia 1e-3 až 1e-4, veľkosťou dávky 32-128 a predčasným zastavením na základe validačnej loss. Počas trénovania sa aplikuje augmentácia dát (náhodná rotácia, horizontálne prevrátenie, farebný jitter, náhodný výrez) na zlepšenie generalizácie.
Pre inferenciu DINOv3 backbone spracováva každý vstupný obrázok na patch a [CLS] token embeddingy v jednom doprednom prechode. [CLS] embedding je extrahovaný a odovzdaný cez MLP hlavu. Výstupné softmax pravdepodobnosti sú prahované (typicky na 0,5 alebo optimalizované pomocou ROC analýzy) na produkciu binárnej predikcie pre každú triedu defektov. Keďže päť tried defektov nie je vzájomne sa vylučujúcich — jedna oblasť vozovky môže vykazovať súčasne praskliny aj odlupovanie — prahované predikcie pre každú triedu sú nezávislé a výstup je správne interpretovaný ako multi-label a nie ako predikcia jednej triedy.
V analytickej pipeline TarmacView pracuje hlava defektov na dvoch úrovniach granularity.
Analýza na úrovni dlaždíc: Povrch dráhy je rozdelený do mriežky obrázkových dlaždíc (typicky 224×224 alebo 512×512 pixelov pri inšpekčnom rozlíšení 0,5-2,0 mm/pixel). Každá dlaždica je spracovaná nezávisle cez DINOv3 backbone a MLP hlavu defektov, čím vzniká 5-prvkový vektor pravdepodobností pre každú dlaždicu. Predikcie na úrovni dlaždíc sú uložené ako stĺpce pre dlaždice vo výstupnom analyzovanom súbore: tile_crack_conf, tile_spalling_conf, tile_efflorescence_conf, tile_exposed_rebar_conf, tile_corrosion_conf.
Agregácia na úrovni rámčekov: Jednotlivé predikcie dlaždíc v rámci jedného kamerového rámčeka alebo úseku dráhy sú agregované na produkciu hodnotení defektov na úrovni rámčeka. Agregačné metódy zahŕňajú: max pooling (maximálna spoľahlivosť naprieč všetkými dlaždicami v rámčeku), mean pooling (priemerná spoľahlivosť), top-k hlasovanie (podiel dlaždíc prekračujúcich prah) a priestorovú hustotu (počet dlaždíc s defektom na rámček). Stĺpce na úrovni rámčekov vo výstupe zahŕňajú frame_crack_flag, frame_spalling_flag, frame_defect_count a frame_max_defect_conf.
Schéma výstupu analýzy je kritickou komponentou, ktorú musia smoke testy validovať. Ak stĺpce spoľahlivosti na úrovni dlaždíc alebo agregačné stĺpce na úrovni rámčekov chýbajú, sú premenované alebo obsahujú neplatné hodnoty (NaN, inf, záporné pravdepodobnosti), následné výpočty indexu stavu vozovky (PCI) a reportovacie pipeline zlyhajú.
Tvrdenia smoke testov sú špecifické, automatizované kontroly, ktoré overujú, či hlava defektov funguje správne. Každé tvrdenie cieli na konkrétny režim zlyhania a produkuje jasný výsledok prejdenia/zlyhania, ktorý možno integrovať do bránenia CI/CD pipeline.
Prvá kategória tvrdení smoke testov overuje, že kontrolný bod hlavy defektov — súbor s uloženými váhami modelu — je platný a načítateľný. Tvrdenia zahŕňajú:
Existencia súboru kontrolného bodu: Test tvrdí, že súbor kontrolného bodu existuje na zadanej ceste. Toto zachytáva problémy, keď tréningové spustenie zlyhalo, kontrolný bod nebol nahraný do registra modelov alebo cesta k súboru bola nesprávne nakonfigurovaná v nasadzovacom prostredí. Tvrdenie je: assert os.path.exists(checkpoint_path), f"Kontrolný bod nenájdený na {checkpoint_path}".
Validácia veľkosti súboru a kontrolného súčtu: Test overuje, že súbor kontrolného bodu má nenulovú veľkosť a voliteľne validuje jeho MD5 alebo SHA256 kontrolný súčet oproti uloženej bazálnej hodnote. Súbor s nulovou veľkosťou alebo poškodený download bude zachytený tu. Tvrdenie je: assert os.path.getsize(checkpoint_path) > 0 a voliteľne assert sha256(súbor) == očakávaný_sha256.
Načítateľnosť torchom: Test načíta kontrolný bod pomocou torch.load() a tvrdí, že operácia sa dokončí bez vyvolania výnimky. Toto zachytáva poškodené súbory, nekompatibility verzií (napr. kontrolný bod uložený s PyTorch 2.0 sa pokúša načítať s PyTorch 1.8) a chýbajúce závislosti. Tvrdenie obaľuje volanie načítania do try/except bloku a zlyhá pri akejkoľvek výnimke.
Štruktúra slovníka stavov: Po načítaní test tvrdí, že kontrolný bod obsahuje očakávané kľúče slovníka stavov. Pre DINOv3 backbone očakávané kľúče zahŕňajú backbone.cls_token, backbone.patch_embed.proj.weight a parametre transformer blokov. Pre MLP hlavu očakávané kľúče zahŕňajú head.0.weight, head.0.bias, head.2.weight, head.2.bias (pre 2-vrstvový MLP). Test tiež overuje, že všetky očakávané kľúče sú prítomné a že neexistujú žiadne neočakávané kľúče, čo by mohlo indikovať nezhodu architektúry modelu.
Druhá kategória overuje, že dopredný prechod cez kombinovaný backbone a hlavu produkuje platné výstupy.
Validácia tvaru tensoru: Test vytvorí syntetický vstupný tensor očakávaného tvaru (typicky [batch_size, 3, height, width] s batch_size=1-4, height=width=224 pre ViT-B/14), prejde ním cez model a tvrdí, že tvar výstupného tensoru je [batch_size, 5] — presne 5 logitov zodpovedajúcich 5 triedam defektov. Tvrdenie je: assert output.shape == (batch_size, 5), f"Očakávaný tvar (batch_size, 5), získaný {output.shape}".
Validácia numerickej stability: Test tvrdí, že žiadna výstupná hodnota nie je NaN (Not a Number), nekonečno alebo záporné nekonečno. NaN hodnoty môžu vzniknúť z numerickej nestability v transformer backbone (napr. pretečenie attention logitov), delenia nulou v normalizačných vrstvách alebo poškodených váh. Tvrdenie je: assert not torch.isnan(output).any(), "Výstup obsahuje NaN hodnoty" a assert not torch.isinf(output).any(), "Výstup obsahuje inf hodnoty".
Validácia softmax pravdepodobností: Test aplikuje softmax na surové logity a tvrdí, že výsledné pravdepodobnosti sa sčítavajú na 1,0 pre každú vzorku v dávke (v rámci tolerancie pohyblivej rádovej čiarky, typicky 1e-5). Toto potvrdzuje, že výstupná vrstva je správne nakonfigurovaná a že žiadny krok následného spracovania nekazí distribúciu pravdepodobností. Tvrdenie je: assert torch.allclose(probs.sum(dim=1), torch.ones(batch_size), atol=1e-5).
Tretia kategória overuje, že model produkuje rozumné distribúcie predikcií a nie degenerované výstupy.
Kontrola nerovnomernej distribúcie: Test tvrdí, že predikované pravdepodobnosti nie sú rovnomerné naprieč všetkými triedami (čo by indikovalo model, ktorý sa nenaučil žiadne diskriminačné príznaky). Entropia predikovanej distribúcie je vypočítaná a porovnaná s minimálnym prahom. Úplne rovnomerná distribúcia má maximálnu entropiu (log(5) ≈ 1,61 nats pre 5 tried), zatiaľ čo sebavedomá predikcia má nízku entropiu. Tvrdenie je: assert entropy < 1.5, "Predikcie sú takmer rovnomerné, model pravdepodobne nie je trénovaný".
Kontrola pokrytia tried: Test spúšťa inferenciu na malej sade rôznorodých vstupných obrázkov a tvrdí, že každá z 5 tried defektov je predikciou s najvyššou spoľahlivosťou pre aspoň jeden vstup. Toto overuje, že žiadna trieda nie je systematicky potláčaná — napríklad model, ktorý nikdy nepredpovedá “eflorescenciu”, by indikoval nevyváženosť tréningových dát alebo problém s konfiguráciou hlavy. Tvrdenie je: assert set(predicted_classes) == set(range(5)), f"Triedy {missing} neboli nikdy predpovedané".
Spracovanie triedy pozadia: Ak model zahŕňa implicitnú triedu pozadia alebo “žiadny defekt”, smoke test overuje, že obrázok neporušenej vozovky — bez akéhokoľvek defektu — produkuje predikciu pozadia so spoľahlivosťou nad prahom (typicky 0,8). Toto potvrdzuje, že model dokáže správne odmietnuť negatívne príklady, čo je kritické pre predchádzanie falošným poplachom v produkčných inšpekciách.
Validácia kontrolného bodu je základnou komponentou smoke testu, ktorá potvrdzuje, že artefakt modelu — uložené váhy neurónovej siete — je neporušený, načítateľný a štrukturálne konzistentný s očakávanou architektúrou. V produkčných ML systémoch je poškodenie kontrolného bodu alebo nezhoda verzií jedným z najčastejších režimov zlyhania a jeho včasné zachytenie v CI/CD predchádza kaskádovým zlyhaniam downstream.
Kontrolné body hlavy defektov TarmacView sú uložené v registri modelov — centralizovanom úložisku artefaktov s verzovaním, metadátami a sledovaním pôvodu (MLflow Model Registry alebo DVC). Každý kontrolný bod je identifikovaný jedinečnou kombináciou názvu modelu, čísla verzie a ID spustenia. Samotný súbor kontrolného bodu je serializovaný slovník stavov PyTorch (typicky model.pt alebo checkpoint.pt) obsahujúci naučené parametre DINOv3 backbone (ak bol doladený) aj MLP hlavy.
Smoke test najprv vyrieši cestu ku kontrolnému bodu z registra modelov, pričom spracúva nasledujúce prípady:
defect-head:v3) a test načíta túto presnú verziu.DINOv3 backbone je veľký model s 86 miliónmi parametrov pre variant ViT-B/14. Smoke test overuje, že načítaný backbone zodpovedá očakávanej architektúre kontrolou:
Tvarov váhových tensorov: Každý parameter tensor v načítanom slovníku stavov je overený oproti očakávanému tvaru. Napríklad tensor backbone.patch_embed.proj.weight by mal mať tvar (768, 3, 14, 14) pre ViT-B/14 s 3 vstupnými kanálmi, 768 výstupnými kanálmi a patch kernelom 14×14. Nezhoda tvaru by indikovala, že kontrolný bod bol trénovaný s inou konfiguráciou (iná veľkosť patcha, iná dimenzia embeddingu, iné vstupné kanály).
Kontrola numerického rozsahu: Test overuje, že hodnoty váh spadajú do očakávaných numerických rozsahov. Transformer attention váhy by mali mať hodnoty distribuované približne ako N(0, σ²) s σ závislým od inicializačnej schémy. Extrémne hodnoty (|w| > 10) naprieč všetkými vrstvami by indikovali divergenciu trénovania alebo poškodenie kontrolného bodu. Kontrola počíta priemer a štandardnú odchýlku každého parametra tensoru a označuje odľahlé hodnoty.
Konzistencia výstupného embeddingu: Test spustí fixný syntetický vstup cez backbone a porovná distribúciu výstupného embeddingu oproti uloženej bazálnej hodnote. Bazálna hodnota je vygenerovaná počas prvého úspešného spustenia smoke testu a uložená ako referencia. Tvrdenie kontroluje, že priemer a rozptyl embeddingu sa neodchýlia nad toleranciu (typicky ±5%). Toto zachytáva tichú degradáciu modelu, ktorá neprodukuje NaN alebo inf hodnoty, ale stále produkuje anomálne embeddingy.
MLP hlava je menšia ako backbone, ale rovnako kritická. Smoke test overuje:
Počet vrstiev: Hlava by mala mať presne očakávaný počet vrstiev. Pre 2-vrstvový MLP so skrytou dimenziou 256 očakávané kľúče zahŕňajú head.0.weight (768×256), head.0.bias (256), head.2.weight (256×5), head.2.bias (5). Číslovanie vrstiev zohľadňuje aktivačnú funkciu (vrstva 1) medzi lineárnymi vrstvami.
Výstupná dimenzia: Výstupná dimenzia finálnej lineárnej vrstvy musí byť presne 5, zodpovedajúca 5 triedam defektov. Toto je overené kontrolou head.2.weight.shape[0] == 5.
Konzistencia inicializácie váh: Test kontroluje, že váhy nie sú zmrazené na inicializačných hodnotách (všetky nuly alebo všetky jednotky). Hlava s váhami všetkých núl by produkovala rovnomerné logity bez ohľadu na vstup, čo by indikovalo zlyhanie trénovania. Kontrola overuje, že head.2.weight.std() > 0.001.
Zatiaľ čo smoke test je primárne o integrite pipeline a nie o kvalite modelu, zahrnutie ľahkého výpočtu metrík do smoke testu poskytuje včasné varovanie pred významnou regresiou modelu. Smoke test počíta metríky účinnosti na syntetických alebo malých statických testovacích dátach a porovnáva ich s bazálnymi hodnotami uloženými z predchádzajúcich validovaných spustení.
Priemerná presnosť (AP) je plocha pod precision-recall krivkou, vypočítaná naprieč prahmi spoľahlivosti od 0 do 1. Smoke test počíta AP pre každú z 5 tried defektov pomocou COCO-štýlovej evaluácie:
Tvrdenia AP smoke testu zahŕňajú:
AP@0.50 (metrika PASCAL VOC): AP pri prahu IoU 0,50. Tvrdenie je, že AP@0.50 pre každú triedu presahuje minimálny prah. Pre syntetické testovacie dáta so známymi, čistými vzormi defektov je typický prah AP@0.50 > 0,85 pre všetkých 5 tried. Ak model dosiahne AP@0.50 pod týmto prahom na triviálnych syntetických dátach, indikuje to vážnu regresiu.
AP@0.50 :0.95 (primárna metrika COCO): Priemer hodnôt AP vypočítaných pri prahoch IoU 0,50, 0,55, …, 0,95. Prah tvrdenia je nižší — typicky AP@0.50 :0.95 > 0,50 — pretože prísnejšie prahy IoU sú náročnejšie aj na syntetických dátach.
Konzistencia AP naprieč triedami: Rozptyl AP naprieč 5 triedami je kontrolovaný. Štandardná odchýlka presahujúca 0,15 by indikovala, že jedna trieda výrazne regredovala v porovnaní s ostatnými, čo naznačuje problém špecifický pre daný typ defektu (napr. nedostatočné tréningové príklady pre eflorescenciu).
Syntetický testovací dataset je starostlivo skonštruovaný na zabezpečenie stability metrík. Každý syntetický obrázok obsahuje presne jeden typ defektu prekrytý na textúre pripomínajúcej vozovku. Defekty sú generované pomocou procedurálnych techník: praskliny ako tenké, rozvetvené čierne čiary s Gaussovským rozmazaním pre realizmus; odlupovanie ako nepravidelné kruhové/oválne oblasti s drsnosťou okrajov; eflorescencia ako biele, amorfné škvrny s rôznou nepriehľadnosťou; odkrytá výstuž ako periodické tmavé kruhové vzory; korózia ako hrdzavo sfarbené nepravidelné škvrny. Syntetický dataset je verzovaný a skontrolovaný do repozitára na zabezpečenie deterministických, reprodukovateľných výsledkov smoke testu.
F1-skóre je harmonický priemer presnosti a recallu, poskytujúci jedinú vyváženú mieru výkonnosti modelu. Smoke test počíta F1 pri fixnom prahu spoľahlivosti (typicky 0,5) pre každú triedu defektov.
Tvrdenia F1 zahŕňajú:
Minimálne F1 na triedu: Každá trieda musí dosiahnuť F1 > 0,80 na syntetickej testovacej sade. Multi-label povaha úlohy predikcie defektov znamená, že F1 je počítané nezávisle pre každú triedu.
Makro-priemerné F1: Nevážený priemer F1 naprieč všetkými 5 triedami je vypočítaný. Prah tvrdenia je makro-F1 > 0,85. Makro-priemer zaobchádza so všetkými triedami rovnako, takže regresia na zriedkavej triede (napr. odkrytá výstuž) je okamžite viditeľná.
Vyváženosť presnosti a recallu: Pomer presnosti k recallu je kontrolovaný pre každú triedu. Pomer nad 1,5 alebo pod 0,67 indikuje nevyváženosť — model je buď príliš konzervatívny (vysoká presnosť, nízky recall, chýbajúce mnohé defekty) alebo príliš agresívny (vysoký recall, nízka presnosť, generovanie mnohých falošných poplachov). Tvrdenie označuje každú triedu, kde je pomer mimo [0,67; 1,5].
| Metrika | Prah syntetického testu | Účel |
|---|---|---|
| AP@0.50 | > 0,85 | Základná detekčná schopnosť na triedu |
| AP@0.50 :0.95 | > 0,50 | Komplexná kvalita detekcie |
| Štandardná odchýlka AP naprieč triedami | < 0,15 | Kontrola vyváženosti tried |
| F1 na triedu | > 0,80 | Vyvážená presnosť-recall na triedu |
| Makro-priemerné F1 | > 0,85 | Celková kvalita modelu |
| Pomer presnosť/recall | [0,67; 1,5] | Vyváženosť presnosti a recallu na triedu |
Smoke test ukladá bazálne hodnoty metrík z posledného validovaného spustenia a porovnáva aktuálne metriky s týmito bazálnymi hodnotami. Významný pokles (>5% relatívny pokles) v akejkoľvek metrike spúšťa zlyhanie smoke testu, aj keď je absolútna hodnota metriky nad minimálnym prahom. Toto zachytáva postupnú degradáciu — modely, ktoré prechádzajú absolútnymi prahmi, ale konzistentne klesajú vo výkonnosti naprieč postupnými tréningovými spusteniami alebo aktualizáciami dát.
Histórie metrík sú logované do časovo-radovej databázy (MLflow, Weights & Biases alebo jednoduchý CSV súbor v repozitári). Smoke test prečíta posledných 10 validovaných hodnôt metrík a preloží lineárny trend. Ak je sklon negatívny a štatisticky významný (p < 0,05), test vypíše varovanie, ale nezlyhá — pre bránenie CI/CD sa používa len zlyhanie na základe prahu, aby sa predišlo hlučným zlyhaniam pipeline z menších fluktuácií metrík.
Kritický smoke test validuje, že výstup analýzy — štruktúrované dáta produkované spustením hlavy defektov na inšpekčných snímkach — obsahuje všetky očakávané stĺpce so správnymi dátovými typmi a platnými hodnotami. Toto prepája medzeru medzi inferenciou modelu a downstream výpočtom indexu stavu vozovky (PCI), reportovaním a GIS integráciou.
Výstup analýzy TarmacView je tabuľkový formát (Parquet, CSV alebo databázová tabuľka) so stĺpcami organizovanými do úrovní:
Stĺpce spoľahlivosti defektov na úrovni dlaždíc — jeden float stĺpec na triedu defektov, reprezentujúci softmax spoľahlivosť MLP hlavy, že dlaždica obsahuje daný defekt:
| Názov stĺpca | Dátový typ | Platný rozsah | Popis |
|---|---|---|---|
tile_crack_conf | Float32 | [0,0; 1,0] | Pravdepodobnosť prítomnosti praskliny |
tile_spalling_conf | Float32 | [0,0; 1,0] | Pravdepodobnosť prítomnosti odlupovania |
tile_efflorescence_conf | Float32 | [0,0; 1,0] | Pravdepodobnosť prítomnosti eflorescencie |
tile_exposed_rebar_conf | Float32 | [0,0; 1,0] | Pravdepodobnosť prítomnosti odkrytej výstuže |
tile_corrosion_conf | Float32 | [0,0; 1,0] | Pravdepodobnosť prítomnosti korózie |
Agregačné stĺpce na úrovni rámčekov — sumarizujúce prítomnosť defektov naprieč všetkými dlaždicami v kamerovom rámčeku alebo úseku dráhy:
| Názov stĺpca | Dátový typ | Platný rozsah | Popis |
|---|---|---|---|
frame_defect_count | Int32 | [0, max_tiles] | Počet dlaždíc s akýmkoľvek defektom nad prahom |
frame_max_defect_conf | Float32 | [0,0; 1,0] | Maximálna spoľahlivosť naprieč všetkými defektmi a dlaždicami |
frame_crack_flag | Boolean | {0, 1} | Akákoľvek dlaždica má crack_conf > prah |
frame_spalling_flag | Boolean | {0, 1} | Akákoľvek dlaždica má spalling_conf > prah |
frame_efflorescence_flag | Boolean | {0, 1} | Akákoľvek dlaždica má efflorescence_conf > prah |
frame_exposed_rebar_flag | Boolean | {0, 1} | Akákoľvek dlaždica má exposed_rebar_conf > prah |
frame_corrosion_flag | Boolean | {0, 1} | Akákoľvek dlaždica má corrosion_conf > prah |
Metadatové stĺpce — identifikujúce priestorový a časový kontext každého záznamu analýzy:
| Názov stĺpca | Dátový typ | Popis |
|---|---|---|
image_id | String | Jedinečný identifikátor zdrojového obrázka |
tile_x | Int32 | Index stĺpca dlaždice v mriežke dráhy |
tile_y | Int32 | Index riadku dlaždice v mriežke dráhy |
frame_timestamp | DateTime | Čas zachytenia zdrojového rámčeka |
gps_lat | Float64 | GPS zemepisná šírka stredu dlaždice |
gps_lon | Float64 | GPS zemepisná dĺžka stredu dlaždice |
Smoke test načíta výstup analýzy a tvrdí, že každý očakávaný stĺpec existuje pomocou jednoduchého porovnania názvov stĺpcov:
expected_tile_cols = ["tile_crack_conf", "tile_spalling_conf",
"tile_efflorescence_conf", "tile_exposed_rebar_conf",
"tile_corrosion_conf"]
expected_frame_cols = ["frame_defect_count", "frame_max_defect_conf",
"frame_crack_flag", "frame_spalling_flag",
"frame_efflorescence_flag", "frame_exposed_rebar_flag",
"frame_corrosion_flag"]
expected_meta_cols = ["image_id", "tile_x", "tile_y",
"frame_timestamp", "gps_lat", "gps_lon"]
actual_cols = set(df.columns)
assert expected_cols.issubset(actual_cols), f"Chýbajúce stĺpce: {expected_cols - actual_cols}"
Pre každý stĺpec spoľahlivosti defektov smoke test tvrdí:
Float typ: Dátový typ stĺpca je float32 alebo float64. Neočakávané typy (int, string, object) indikujú chybu serializácie alebo pipeline. Tvrdenie používa assert df[col].dtype in [np.float32, np.float64].
Rozsah hodnôt: Všetky hodnoty sú v [0,0; 1,0]. Hodnoty mimo tohto rozsahu indikujú zlyhanie softmax alebo normalizácie. Tvrdenie používa assert df[col].between(0.0, 1.0).all().
Kontrola chýbajúcich hodnôt: Žiadne hodnoty nie sú NaN alebo None. NaN hodnoty v stĺpcoch spoľahlivosti indikujú, že inferenčná pipeline neprodukovala výstup pre niektoré dlaždice — vážne zlyhanie. Tvrdenie používa assert df[col].notna().all().
Stĺpce na úrovni rámčekov by mali byť konzistentné s dátami na úrovni dlaždíc, z ktorých sú odvodené. Smoke test validuje:
frame_defect_count sa rovná počtu dlaždíc, kde maximálna spoľahlivosť presahuje prah: Pre každú skupinu rámčekov test prepočíta počet defektov z dát na úrovni dlaždíc a tvrdí, že sa zhoduje s uloženou hodnotou rámčeka. Toto zachytáva chyby agregačnej logiky v pipeline.
frame_max_defect_conf sa rovná maximu všetkých hodnôt spoľahlivosti dlaždíc: Test prepočíta maximum z dát na úrovni dlaždíc a tvrdí zhodu.
frame_flag je konzistentný s tile_conf: Pre každý rámček by mala byť flag hodnota 1, ak ktorákoľvek dlaždica má zodpovedajúcu spoľahlivosť nad prahom, a 0 inak. Test to overuje pre všetkých 5 typov defektov.
Tieto kontroly konzistencie fungujú na princípe, že stĺpce na úrovni rámčekov by mali byť deterministicky odvoditeľné zo stĺpcov na úrovni dlaždíc. Ak je agregačná logika správna, kontroly by mali vždy prejsť. Zlyhanie indikuje chybu v kroku následného spracovania analytickej pipeline, nie v samotnom modeli.
Smoke test porovnáva očakávanú sadu stĺpcov so skutočnou sadou stĺpcov a generuje varovania pre:
tile_moisture_conf), test varuje, ale nezlyhá, pretože to môže indikovať vylepšenie pipeline vyžadujúce aktualizácie downstream integrácie.tile_crack_conf → tile_cracking_conf), test zlyhá, čím sa predchádza tichému zlyhaniu downstream, keď reportovacie dashboardy, API alebo databázy odkazujú na staré názvy stĺpcov.Logika bránenia určuje, či hlava defektov prejde alebo zlyhá v smoke teste ako celku, na základe váženej kombinácie výsledkov jednotlivých tvrdení. Bránenie je mechanizmus, ktorý zabraňuje nasadeniu zlyhávajúceho modelu do produkcie.
Nie všetky tvrdenia smoke testu sú rovnako kritické. Systém bránenia priraďuje každému tvrdeniu úroveň závažnosti:
| Úroveň | Váha | Vplyv na bránenie | Príklady |
|---|---|---|---|
| Fatálne | 1,0 | Okamžite bráni | Zlyhanie načítania kontrolného bodu, NaN vo výstupoch |
| Kritické | 0,8 | Bráni ak >1 zlyhanie | Chýbajúce stĺpce, nezhoda tvaru výstupu |
| Varovanie | 0,4 | Bráni ak >3 zlyhania | AP triedy pod prahom |
| Info | 0,0 | Len loguje, nebráni | Varovania trendov metrík, oznámenia o deprecácii stĺpcov |
Fatálne tvrdenia sú tie, pri ktorých nie je možné žiadne platné vykonanie pipeline — kontrolný bod je poškodený, model sa nedá načítať alebo inferencia produkuje neplatné numerické hodnoty. Jediné fatálne zlyhanie bráni nasadeniu.
Kritické tvrdenia indikujú, že pipeline produkuje štrukturálne platné, ale potenciálne nesprávne výsledky — chýbajúce stĺpce by spôsobili zlyhania downstream reportovania, nezhoda tvaru výstupu indikuje nezhodu architektúry modelu so serving infraštruktúrou.
Varovné tvrdenia indikujú, že metriky modelu sú pod nominálnymi prahmi, ale pipeline je štrukturálne v poriadku. Tieto sú agregované: ak v jednom spustení aktivuje viac ako 3 varovania, bránenie sa aktivuje.
Info tvrdenia sú čisto observačné — logujú trendy driftu metrík, oznámenia o deprecácii stĺpcov a porovnania výkonnosti oproti predchádzajúcim spusteniam — ale nikdy nebránia nasadeniu.
Celkový výsledok smoke testu je vypočítaný ako:
gate_score = max(fatal_failures,
critical_failures > 1 ? 1,0 : 0,0,
warning_failures > 3 ? 1,0 : 0,0)
Ak gate_score >= 1,0, smoke test zlyhá a nasadenie je zablokované. Ak gate_score < 1,0, smoke test prejde a pipeline pokračuje k plnému vyhodnoteniu alebo nasadeniu.
Kompozitná správa prejdenia/zlyhania sumarizuje výsledok:
SMOKE TEST: ZLYHANIE
- Fatálne: 1 [checkpoint_load_failure]
- Kritické: 0
- Varovanie: 2 [class_crack_ap_below_threshold, class_efflorescence_f1_below_threshold]
- Info: 1 [metric_class_crack_ap poklesla o 3,2 % od posledného spustenia]
Bránenie smoke testu sa integruje s pipeline nasadenia prostredníctvom:
Post-commit hooku: Smoke test beží pri každom commite do pull requestu. Ak bránenie zlyhá, CI/CD systém blokuje merge (pravidlo ochrany vetvy GitHub, zlyhanie pipeline merge requestu GitLab).
Prednasadzovacieho bránenia: Pred povýšením modelu zo stagingu do produkcie sa smoke test spustí znova na presnom kandidátskom artefakte nasadenia. Toto zachytáva problémy, ktoré nemuseli byť prítomné počas vývoja — napríklad vývojové prostredie s inou verziou CUDA ako produkčné serving prostredie.
Spúšťača rollbacku: Ak smoke test prejde nasadením, ale následný produkčný incident je vysledovaný k hlave defektov, logika bránenia smoke testu je auditovaná. Ak malo byť varovné tvrdenie kritickým tvrdením, konfigurácia bránenia je aktualizovaná, aby sa predišlo opakovaniu.
Testy doménovej aplikovateľnosti rozširujú základný smoke test na overenie, že hlava defektov funguje správne naprieč špecifickými prevádzkovými podmienkami, s ktorými sa TarmacView stretáva pri inšpekcii letiskových vozoviek a infraštruktúry. Tieto testy zabezpečujú, že pipeline je nielen funkčná, ale aj vhodná na účel v cieľovej doméne.
Hlava defektov musí fungovať konzistentne naprieč rôznymi typmi vozoviek na letiskových povrchoch:
Asfaltové (flexibilné) vozovky: Dráhy, rolovacie dráhy a odstavné plochy konštruované z horúcej asfaltovej zmesi (HMA). Defekty na asfalte zahŕňajú únavové praskliny (aligátorový vzor), pozdĺžne praskliny, priečne praskliny, vyjazdené koľaje a odlupovanie kameniva. Smoke test zahŕňa syntetické obrázky s textúrami pripomínajúcimi asfalt (tmavošedá, viditeľné kamenivo, rôzna drsnosť povrchu) a overuje, že detekcia prasklín a odlupovania udržiava nominálne úrovne spoľahlivosti.
Betónové (tuhé) vozovky: Dráhy a odstavné plochy konštruované z portlandského cementového betónu (PCC). Defekty zahŕňajú odlupovanie škár, rohové zlomy, lineárne praskliny, eflorescenciu (biele vápenaté usadeniny v škárach), odkrytú výstuž (v odlupených oblastiach) a korózne škvrny. Smoke test overuje, že model správne identifikuje eflorescenciu a odkrytú výstuž — defekty, ktoré sú oveľa častejšie na betónových ako na asfaltových povrchoch.
Kompozitné vozovky: Asfaltové prekrytia na existujúcom betóne. Defekty zahŕňajú reflexné praskliny (asfaltové praskliny nasledujúce vzor podkladových betónových škár) a delamináciu. Test overuje, že model dokáže detekovať praskliny na kompozitných povrchoch bez zmätku spôsobeného podkladovým vzorom škár.
Pórovité trecie vrstvy (PFC): Vysokopriepustný asfalt používaný na dráhach pre zlepšenú drenáž a trenie. PFC má výraznú otvorenú granulometrickú textúru, ktorá vyzerá vizuálne odlišne od husto gradovaného HMA. Test overuje, že model neprodukuje zvýšenú mieru falošných poplachov na PFC povrchoch, kde by drsná textúra mohla byť zamenená s prasklinami alebo odlupovaním.
ICAO Annex 14 a FAA AC 150/5320-5D špecifikujú, že hodnotenia stavu povrchu dráh musia byť platné za prevádzkových podmienok. Smoke test doménovej aplikovateľnosti overuje, že hlava defektov udržiava výkonnosť naprieč:
Priamym slnečným svetlom: Vysoký kontrast, silné tiene. Test overuje, že hodnoty spoľahlivosti nie sú systematicky nižšie v podmienkach vysokého kontrastu kvôli falošným poplachom spôsobeným tieňmi.
Zamračeným/rozptýleným svetlom: Nízky kontrast, žiadne tiene. Test overuje, že jemné praskliny (úzke, s nízkym kontrastom voči vozovke) sú stále detekovateľné so zníženými úrovňami spoľahlivosti.
Mokrou vozovkou: Voda v prasklinách zvyšuje viditeľnosť prasklín, ale zavádza zrkadlové odrazy. Test overuje, že dlaždice mokrého povrchu neprodukujú zvýšené falošné poplachy kvôli zámene zrkadlových odrazov s eflorescenciou (oba sa javia ako svetlé oblasti).
Svitanie/súmrakom: Nízke úrovne svetla, dlhé tiene. Test overuje, že model produkuje výstupy v očakávaných rozsahoch spoľahlivosti aj pri znížených úrovniach osvetlenia.
Smoke test simuluje tieto podmienky aplikovaním riadených fotometrických transformácií na syntetické testovacie obrázky: škálovanie jasu pre simuláciu osvetlenia, Gaussovské rozmazanie pre simuláciu hmly/hmlenia a úprava sýtosti pre simuláciu mokrého povrchu.
Inšpekčné snímky sa líšia v ground sampling distance (GSD) v závislosti od platformy zachytenia:
| Platforma | Typická výška | GSD (mm/pixel) | Pokrytie dlaždice |
|---|---|---|---|
| UAV (vysoké rozlíšenie) | 15-20 m | 0,5-1,0 | 0,1-0,5 m² |
| UAV (štandardné) | 30-50 m | 1,0-2,0 | 0,5-2,0 m² |
| Namontované na vozidle | 2-3 m | 0,3-0,8 | 0,05-0,2 m² |
| Ručné | 1-1,5 m | 0,2-0,5 | 0,02-0,08 m² |
Smoke test overuje, že hlava defektov produkuje konzistentné výstupy naprieč rozsahom vstupných rozlíšení. Syntetické testovacie obrázky sú generované v niekoľkých mierkach (0,5×, 1,0×, 2,0× nominálneho GSD) a prechádzajú cez model. Test tvrdí, že predikovaná distribúcia tried sa neposunie o viac ako 10 % medzi rozlíšeniami, čo zabezpečuje, že model je približne škálovo-invariantný v rámci prevádzkového rozsahu.
ASTM D5340 definuje tri úrovne závažnosti (Nízka, Stredná, Vysoká) pre každý typ defektu. Smoke test overuje, že skóre spoľahlivosti hlavy defektov koreluje so závažnosťou defektu:
Nízka závažnosť: Vlasové praskliny (<1 mm šírka), malé odlupovania (<150 mm dĺžka), ľahká eflorescencia, minimálne korózne škvrny. Test tvrdí, že tieto produkujú skóre spoľahlivosti nad prahom detekcie (>0,5), ale nie na maximálnej spoľahlivosti (<0,8).
Stredná závažnosť: Praskliny (1-3 mm šírka), odlupovania (150-600 mm dĺžka), mierne usadeniny eflorescencie, viditeľná odkrytá výstuž s ľahkou koróziou. Test tvrdí, že skóre spoľahlivosti je vysoké (>0,7).
Vysoká závažnosť: Široké praskliny (>3 mm šírka), veľké odlupovania (>600 mm dĺžka), ťažká eflorescencia s narušením povrchu, odkrytá výstuž s ťažkou koróziou a stratou prierezu. Test tvrdí, že skóre spoľahlivosti je veľmi vysoké (>0,9).
Overenie korelácie závažnosti je tvrdenie na úrovni varovania v systéme bránenia — model môže stále fungovať správne, aj keď je korelácia závažnosti nedokonalá, ale test ju označí ako oblasť na zlepšenie modelu.
Pochopenie rozdielu medzi smoke testovaním a plným vyhodnotením je kritické pre navrhovanie efektívnej stratégie zabezpečenia kvality ML. Tieto dva prístupy slúžia zásadne odlišným účelom a fungujú v rôznych bodoch životného cyklu vývoja a nasadenia.
| Dimenzia | Smoke Test | Plné Vyhodnotenie |
|---|---|---|
| Cieľ | Overiť integritu pipeline | Merať kvalitu modelu |
| Zodpovedaná otázka | “Beží pipeline správne?” | “Je model dostatočne presný?” |
| Dáta | Syntetické / malá statická sada (10-100 obrázkov) | Veľká zadržaná validačná sada (500-5000+ obrázkov) |
| Trvanie | Sekundy až minúty | Minúty až hodiny |
| Výpočtový výkon | CPU alebo minimálny GPU | Plný GPU (často multi-GPU) |
| Frekvencia | Každý commit / PR | Nočne, týždenne alebo pri vydaní |
| Prahové metriky | Veľkorysé (AP > 0,50) | Prísne (AP > 0,75) |
| Pokrytie | Len štrukturálna integrita | Štatistická generalizácia |
| Akcia pri zlyhaní | Blokovať merge/nasadenie | Označiť na kontrolu |
Smoke test je navrhnutý na zachytenie chýb pipeline — triedy chýb, ktoré spôsobia zlyhanie celého systému alebo produkciu nezmyselných výstupov. Patria sem poškodenie kontrolného bodu, nekompatibilita verzií, zlyhania predspracovania pipeline, chýbajúce stĺpce, NaN výstupy a nezhody tvarov. Priemyselné dáta z ML inžinierskych tímov ukazujú, že chyby pipeline predstavujú 60-70 % zlyhaných tréningových spustení a 40 % rollbackov nasadení. Smoke testy zachytávajú tieto chyby v sekundách, skôr než sa spustia drahé plné vyhodnotenia.
Plné vyhodnotenie je navrhnuté na meranie kvality modelu — štatistickej presnosti, precíznosti, recallu a generalizácie predikcií modelu. Používa veľké, rôznorodé, reprezentatívne validačné datasety, počíta prísne metriky (AP@0.50 :0.95, F1 podľa tried, matice zmätku, precision-recall krivky pri viacerých prahoch) a porovnáva výsledky oproti absolútnym prahom aj relatívnym bazálnym hodnotám z predchádzajúcich verzií modelu. Spustenia plného vyhodnotenia sú výpočtovo nákladné a časovo náročné, čo ich robí nevhodnými na vykonávanie pri každom commite.
Dáta smoke testu sú synteticky generované tak, aby boli jednoduché, čisté a deterministické. Každý syntetický obrázok obsahuje presne jeden typ defektu na jednotnom pozadí, bez oklúzie, prekrývajúcich sa defektov a náročných svetelných podmienok. Toto minimalizuje variabilitu a zabezpečuje, že akákoľvek fluktuácia metrík v smoke teste je pripísateľná modelu, nie variabilite dát.
Dáta plného vyhodnotenia sú reálne inšpekčné snímky s nasledujúcimi charakteristikami: rôznorodé typy a veky vozoviek, všetky prevádzkové svetelné podmienky, rôzne úrovne závažnosti defektov, prekrývajúce sa a susediace defekty, reálne oklúzie (sute, stopy pneumatík, voda) a presné anotácie ground truth na úrovni polygonov. Tieto dáta reprezentujú skutočnú distribúciu, s ktorou sa model stretáva v produkcii, a poskytujú spoľahlivý odhad výkonnosti pri nasadení.
Prevencia úniku dát je kritická pre plné vyhodnotenie, ale irelevantná pre smoke testy — keďže smoke test používa syntetické dáta, neexistuje riziko úniku reálnych testovacích dát do trénovania. Dataset plného vyhodnotenia je starostlivo rozdelený: tréningové, validačné a testovacie sady sú rozdelené na úrovni rámčekov alebo dráh (nie na úrovni dlaždíc), aby sa predišlo úniku priestorovej autokorelácie, kde by susediace dlaždice z tej istej dráhy boli v tréningovej aj testovacej sade.
Typické spustenie smoke testu pre pipeline hlavy defektov:
Typické spustenie plného vyhodnotenia:
Smoke test je 10-100× rýchlejší ako plné vyhodnotenie, čo umožňuje vykonávanie pri každom commite. Plné vyhodnotenie beží v pomalšom rytme (každú noc, pri vydaní, pri povýšení do produkcie).
| Režim zlyhania | Zistený pomocou |
|---|---|
| Poškodený súbor kontrolného bodu | Smoke test (fatálne) |
| NaN/inf vo výstupoch modelu | Smoke test (fatálne) |
| Chýbajúce výstupné stĺpce | Smoke test (kritické) |
| Nesprávny tvar výstupného tensoru | Smoke test (kritické) |
| Nezhoda normalizácie predspracovania | Smoke test (fatálne) |
| Degenerované predikcie (všetky rovnaká trieda) | Smoke test (varovanie) |
| 10% pokles AP na nových dátach | Plné vyhodnotenie |
| Pretrénovanie na konkrétny typ vozovky | Plné vyhodnotenie |
| Drift kalibrácie | Plné vyhodnotenie |
| Šum v labloch tréningových dát | Plné vyhodnotenie |
Matica pokrytia demonštruje, že smoke testy a plné vyhodnotenia sú komplementárne — každý zachytáva režimy zlyhania, ktoré ten druhý prehliada. Komplexná stratégia testovania ML vyžaduje oboje.
Integrácia smoke testu hlavy defektov do pipeline kontinuálnej integrácie (CI) je nevyhnutná pre včasné zachytenie regresií a zabezpečenie, že každá zmena kódu je validovaná pred ovplyvnením produkčných systémov.
CI pipeline pre systém detekcie defektov TarmacView je organizovaná do sekvenčných štádií:
Štádium 1 — Kvalita kódu: Lintovanie (flake8, pylint), typová kontrola (mypy), unit testy (pytest pre utility na načítavanie dát, funkcie predspracovania a funkcie výpočtu metrík). Toto štádium beží na CPU a dokončí sa za 1-3 minúty. Zlyhanie blokuje všetky downstream štádiá.
Štádium 2 — Validácia dát: Schémová validácia tréningových a validačných datasetov pomocou Great Expectations alebo TensorFlow Data Validation. Kontroluje prítomnosť stĺpcov, dátové typy, rozsahy hodnôt a štatistiky distribúcie oproti očakávaniam definovaným v dátovej zmluve. Toto štádium beží na CPU a dokončí sa za 2-5 minút.
Štádium 3 — Smoke test hlavy defektov: Plná sada smoke testov, ako je popísaná v tomto článku. Beží na CPU (alebo minimálnom GPU, ak je k dispozícii) a dokončí sa za 15-60 sekúnd. Zlyhanie blokuje merge do main vetvy.
Štádium 4 — Unit testy pre vyhodnotenie: Malé testy výpočtu metrík, ktoré overujú, že výpočet AP, výpočet F1 a generovanie matice zmätku produkujú správne výstupy na ručne označených malých datasetoch (5-10 obrázkov so známymi ground truth). Beží na CPU, dokončí sa za 30 sekúnd.
Štádium 5 — Trénovanie (na požiadanie): Spúšťané len vtedy, keď sa očakáva zmena váh modelu (nové tréningové dáta, zmeny architektúry, ladenie hyperparametrov). Nie je automaticky spúšťané pri každom commite. Beží na GPU a trvá 1-8 hodín v závislosti od veľkosti datasetu.
Štádium 6 — Plné vyhodnotenie (pri zlúčení do main): Spúšťané, keď je kód zlúčený do main vetvy. Spúšťa kompletnú evaluačnú sadu na zadržanej validačnej sade, počíta všetky metriky, porovnáva s bazálnymi hodnotami a publikuje výsledky do registra modelov. Beží na GPU a trvá 20-40 minút.
Smoke test je spúšťaný pri:
CI artefakty z smoke testu sú ukladané a verzované:
Tieto artefakty sú uložené v registri modelov popri samotnom artefakte modelu, poskytujúc úplný auditný záznam: “Táto verzia modelu prešla smoke testom so syntetickými dátami v3.2 v CI spustení #4827 s commitom a3f2c1.”
Keď smoke test zlyhá, notifikácie sú odosielané cez viacero kanálov:
Notifikácia obsahuje štruktúrovanú chybovú správu:
Predmet: [SMOKE ZLYHANIE] defect-head pipeline - main - spustenie #4827
Telo:
Commit: a3f2c1 (zlúčený 12:34 UTC)
Kontrolný bod: defect-head:v3 (produkčný-kandidát)
Výsledok: ZLYHANIE (gate_score=1,0)
Fatálne (1):
- [output_nan] Výstupný tensor obsahuje NaN hodnoty
Dopredný prechod backbone produkoval NaN v layer norm 8
Kritické (0):
Varovanie (2):
- [class_efflorescence_ap] AP@0.50 = 0,42 pod prahom 0,50
- [class_efflorescence_f1] F1 = 0,55 pod prahom 0,60
Vyžadovaná akcia: Prešetriť NaN v backbone layer norm 8.
Možné príčiny: poškodený kontrolný bod, nezhoda verzie CUDA,
alebo numerická nestabilita vo výpočte attention.
Správna interpretácia výstupov smoke testu je nevyhnutná pre diagnostiku problémov pipeline a určenie vhodných nápravných opatrení.
Smoke test generuje komplexný JSON report štruktúrovaný nasledovne:
{
"pipeline_id": "defect-head-smoke",
"run_id": "2026-06-16-4827",
"timestamp": "2026-06-16T12:34:56Z",
"commit_sha": "a3f2c1d4e5b6...",
"checkpoint_version": "defect-head:v3",
"synthetic_data_version": "v3.2",
"gate_result": "ZLYHANIE",
"gate_score": 1.0,
"assertions": {
"checkpoint_file_exists": {"status": "PREŠLO", "detail": "checkpoint.pt (842MB)"},
"checkpoint_loadable": {"status": "PREŠLO", "detail": "Slovník stavov úspešne načítaný"},
"forward_pass_shape": {"status": "PREŠLO", "detail": "Tvar výstupu (8, 5)"},
"output_no_nan": {"status": "ZLYHALO", "detail": "NaN nájdený v 1 z 8 dávkových vzoriek"},
"output_no_inf": {"status": "PREŠLO", "detail": "Žiadne inf hodnoty"},
"softmax_sum": {"status": "PREŠLO", "detail": "Všetky súčty v rámci 1e-5 od 1,0"},
"tile_columns_exist": {"status": "PREŠLO", "detail": "Všetkých 5 stĺpcov dlaždíc prítomných"},
"frame_columns_exist": {"status": "PREŠLO", "detail": "Všetkých 7 stĺpcov rámčekov prítomných"},
"column_value_ranges": {"status": "PREŠLO", "detail": "Všetky hodnoty v [0,0; 1,0]"},
"class_crack_ap50": {"status": "PREŠLO", "detail": "AP@0.50 = 0,92"},
"class_spalling_ap50": {"status": "PREŠLO", "detail": "AP@0.50 = 0,88"},
"class_efflorescence_ap50": {"status": "VAROVANIE", "detail": "AP@0.50 = 0,42"},
"class_exposed_rebar_ap50": {"status": "PREŠLO", "detail": "AP@0.50 = 0,91"},
"class_corrosion_ap50": {"status": "PREŠLO", "detail": "AP@0.50 = 0,90"}
}
}
Report by sa mal čítať zhora nadol, pričom sa najprv riešia fatálne zlyhania (pretože negujú všetky downstream výsledky), potom kritické zlyhania (štrukturálne problémy, ktoré by spôsobili zlyhania v produkcii) a nakoniec varovné zlyhania (regresie kvality, ktoré môžu vyžadovať prešetrenie).
Fatálne zlyhania indikujú, že pipeline je úplne nefunkčná. Najčastejšie koreňové príčiny a náprava:
Súbor kontrolného bodu nenájdený: Cesta ku kontrolnému bodu špecifikovaná v konfigurácii pipeline neukazuje na existujúci súbor. Náprava: overte cestu v registri modelov, skontrolujte, že tréningové spustenie bolo dokončené a artefakt bol nahraný, alebo aktualizujte konfiguráciu so správnou cestou.
Zlyhanie načítania kontrolného bodu: torch.load() vyvolal výnimku. Bežné príčiny zahŕňajú: poškodenie súboru (znovu spustite trénovanie alebo obnovte zo zálohy), nezhoda verzie PyTorch (skontrolujte, že nasadzovacie prostredie má rovnakú verziu PyTorch ako tréningové prostredie — torch.save() s PyTorch 2.0 produkuje súbory, ktoré sa načítavajú inak na PyTorch 1.x) alebo nezhoda CUDA/bez CUDA (kontrolný bod uložený s CUDA tensormi môže zlyhať pri načítaní v prostredí len s CPU bez map_location='cpu').
NaN vo výstupoch: Technicky najnáročnejšie fatálne zlyhanie. Bežné príčiny zahŕňajú: numerickú nestabilitu v DINOv3 attention mechanizme (pretečenie layer normalizácie s extrémnymi vstupnými hodnotami), poškodené váhy v konkrétnej vrstve (skontrolujte, ktorá vrstva produkuje NaN spustením s torch.autograd.set_detect_anomaly(True)) alebo predspracovanie, ktoré produkuje vstupy mimo rozsahu (napr. hodnoty pixelov mimo [0,1] po normalizácii).
Nezhoda tvaru výstupu: Výstupný tensor má iný tvar, než sa očakávalo. Bežné príčiny zahŕňajú: MLP hlava bola nahradená inou architektúrou (iný počet výstupných tried), dimenzia embeddingu backbone sa zmenila (kontrolný bod z iného variantu DINOv3) alebo dávková dimenzia bola nesprávne stlačená/rozšírená v kóde následného spracovania.
Kritické zlyhania indikujú štrukturálne problémy, ktoré by spôsobili nesprávne správanie v produkcii.
Chýbajúce stĺpce: DataFrame výstupu analýzy postráda očakávané stĺpce. Bežné príčiny: konvencia pomenovania stĺpcov bola zmenená bez aktualizácie downstream konzumentov, agregačná logika bola modifikovaná tak, aby premenovala stĺpce, alebo bol zmenený výstup hlavy defektov (napr. z 5 tried na 4 triedy).
Porušenie rozsahu hodnôt: Hodnoty spoľahlivosti mimo [0,0; 1,0]. Toto takmer vždy indikuje poruchu softmax — buď softmax nebol aplikovaný na logity, alebo bol použitý nesprávny axis pre softmax normalizáciu. Skontrolujte, že sa používa F.softmax(logits, dim=1) (dimenzia tried, nie dávková dimenzia).
NaN vo výstupných stĺpcoch: Podobné ako fatálne NaN vo výstupoch modelu, ale vyskytujúce sa v kroku agregácie následného spracovania. Skontrolujte delenie nulou v agregácii dlaždíc na rámčeky (napr. delenie počtom dlaždíc, keď má rámček nula dlaždíc) alebo propagáciu chýbajúcich hodnôt z NaN výstupov modelu, ktoré neboli zachytené na úrovni modelu.
Varovné zlyhania indikujú degradáciu kvality, ktorá nemusí vyžadovať okamžité blokovanie nasadenia, ale mala by byť prešetrená.
AP špecifickej triedy pod prahom: Jedna trieda defektov vykazuje výrazne nižšiu výkonnosť ako ostatné. Bežné príčiny: nedostatočné syntetické tréningové príklady pre túto triedu (generátor syntetických dát môže produkovať nerealistické príklady pre niektoré triedy), nevyváženosť tried v reálnych tréningových dátach ovplyvňujúca diskriminačnú schopnosť hlavy pre zriedkavé triedy, alebo príznaky backbone sú menej informatívne pre určité typy defektov (napr. eflorescencia je charakterizovaná farbou (biele usadeniny) viac než textúrou, zatiaľ čo DINOv3 príznaky môžu zdôrazňovať textúru nad farbou).
Nevyváženosť presnosti a recallu: Model je príliš konzervatívny alebo príliš agresívny pre špecifické triedy. Bežné príčiny: prah spoľahlivosti bol optimalizovaný pre celkovú výkonnosť, ale je suboptimálny pre jednotlivé triedy, alebo tréningové dáta majú asymetrický šum (viac falošne negatívnych ako falošne pozitívnych pre konkrétnu triedu).
Drift metriky od bazálnej hodnoty: Metriky sa zmenili o viac ako 5 % od posledného validovaného spustenia bez zmien kódu alebo dát. Toto môže indikovať: nedeterminizmus v modeli (dropout alebo batch norm vrstvy sa správajú inak v tréningovom vs eval móde — zabezpečte, že model.eval() je volané pred inferenciou), numerický drift v dôsledku rozdielov v hardvéri (poradie sčítavania s pohyblivou rádovou čiarkou na CPU vs GPU) alebo zmeny generátora syntetických dát produkujúce odlišné testovacie vzorky.
Výstup smoke testu obsahuje návrhy nápravy pre bežné režimy zlyhania:
| Zlyhanie | Návrh nápravy |
|---|---|
| Kontrolný bod nenájdený | Overte cestu v registri modelov; spustite trénovanie na vygenerovanie kontrolného bodu |
| NaN v backbone | Prepnite na presnosť float32, ak používate float16; pridajte gradient clipping |
| Chýbajúci stĺpec | Aktualizujte názvy stĺpcov v agregačnej logike, aby zodpovedali schéme |
| Nízka AP na konkrétnej triede | Pridajte viac syntetických tréningových príkladov pre túto triedu; skontrolujte vyváženosť tried |
| Drift metriky | Spustite inferenciu s torch.inference_mode() a model.eval(); skontrolujte nedeterministické operácie |
Tieto návrhy sú generované pravidlovým systémom, ktorý mapuje vzory zlyhania tvrdení na známe nápravné akcie, čím sa znižuje stredný čas do nápravy (MTTR) pre bežné režimy zlyhania.

TarmacView implementuje dôkladné smoke testovanie a vyhodnocovacie pipeline pre AI-based detekciu štrukturálnych defektov na letiskových vozovkách a betónových infraštruktúrach. Dohodnite si demo a zistite, ako automatizované testovanie zabezpečuje spoľahlivosť nasadenia.
Dymový test je rýchle, end-to-end overenie, že softvérový pipeline sa vykoná bez zlyhania na reprezentatívnych dátach a produkuje očakávané výstupy. Testy Tarma...
+++ title = “Prenosové učenie” description = “Prenosové učenie aplikuje poznatky z modelu predtrénovaného na veľkých všeobecných datasetoch (I...
Defect gating je inferenčná stratégia, ktorá filtruje predikované štítky defektov podľa typu povrchu a štrukturálnej domény, aby potlačila falošne pozitívne výs...