Visión fotópica
La visión fotópica es el modo de percepción visual bajo iluminación intensa, mediada por los fotorreceptores conos, que permite una alta agudeza y discriminació...
9 min de lectura
Vision Science
Lighting
+2
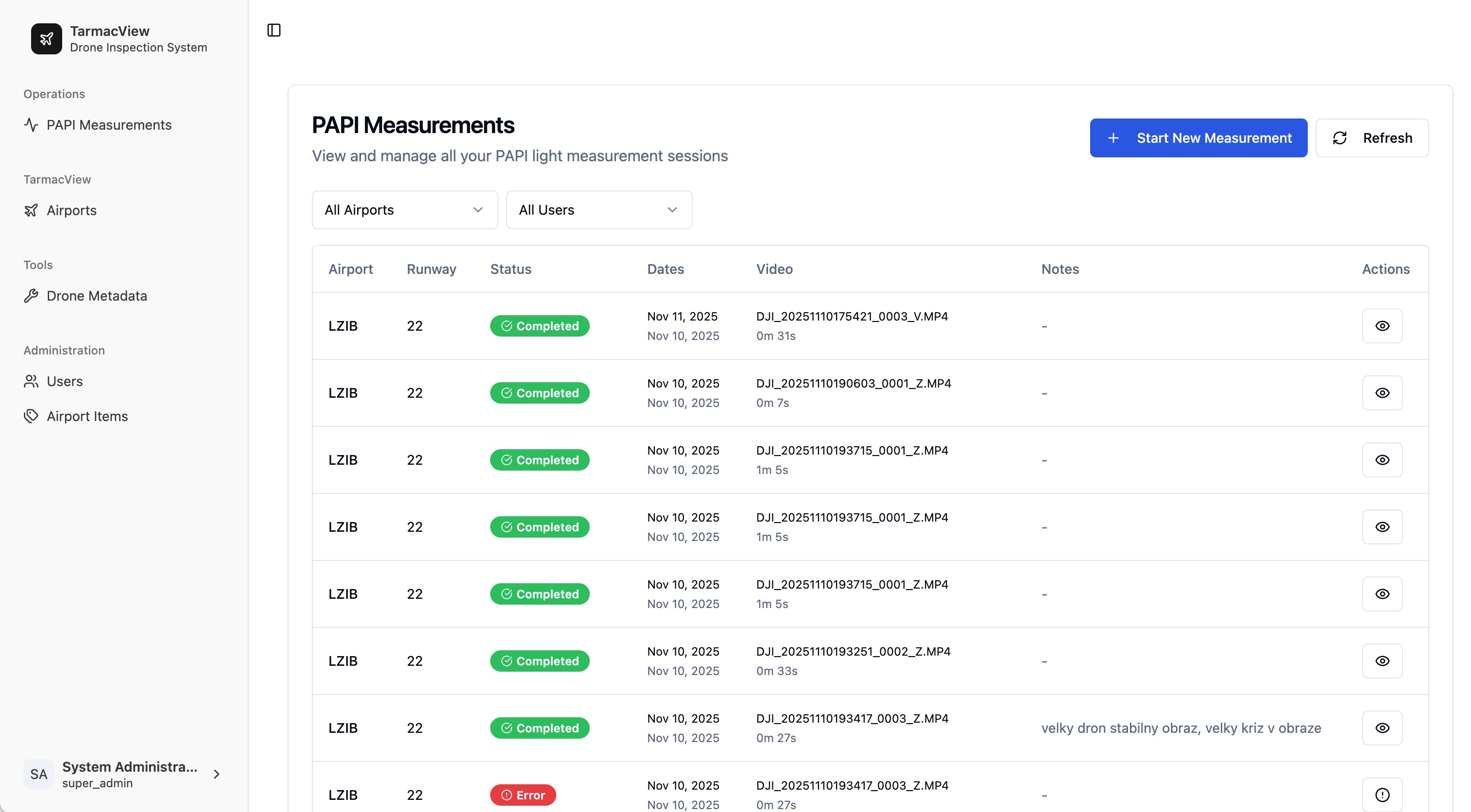
La visión por computadora utiliza IA para interpretar datos visuales, permitiendo que las máquinas analicen imágenes y videos para tareas como la detección de objetos y la inspección automatizada.
La visión por computadora es una rama de la inteligencia artificial (IA) enfocada en permitir que las máquinas “vean”, interpreten y actúen sobre datos visuales del mundo. A diferencia del procesamiento de imágenes tradicional, que se centra principalmente en mejorar imágenes, la visión por computadora busca extraer información y comprensión de alto nivel de la entrada visual, replicando o incluso superando las capacidades visuales humanas. El proceso implica una secuencia de pasos técnicos: adquisición de imágenes o videos, preprocesamiento para mejorar la calidad de los datos, extracción de características para identificar patrones relevantes y, finalmente, análisis y toma de decisiones en función del contenido interpretado. Los sistemas de visión por computadora se utilizan ampliamente en áreas como el reconocimiento facial, la detección de objetos, la comprensión de escenas, la imagen médica y la automatización industrial.
El desarrollo de la visión por computadora ha sido impulsado por avances en el aprendizaje automático y el aprendizaje profundo, particularmente por las redes neuronales convolucionales (CNN) que destacan en el aprendizaje de patrones directamente a partir de datos de píxeles. Son esenciales para el campo los grandes conjuntos de datos y recursos computacionales potentes, que permiten el entrenamiento de modelos sofisticados capaces de manejar una amplia gama de tareas visuales. Según la Organización de Aviación Civil Internacional (OACI) y los principales proveedores tecnológicos, la visión por computadora sustenta infraestructuras críticas en aviación, como la vigilancia automatizada, el manejo de equipaje y la monitorización de áreas aeroportuarias, mejorando la seguridad y eficiencia al reducir el error humano y mejorar los tiempos de respuesta. La integración de la visión por computadora en dispositivos de borde y plataformas en la nube también ha democratizado el acceso a la IA visual, convirtiéndola en una tecnología fundamental en los ecosistemas digitales modernos.
Las aplicaciones de la visión por computadora van desde productos de consumo cotidianos—como cámaras de teléfonos inteligentes que reconocen rostros o códigos QR—hasta sistemas avanzados en salud, transporte y seguridad. En aviación, la visión por computadora es fundamental para sistemas que monitorean el estado de las pistas, detectan objetos extraños (FOD) y automatizan inspecciones visuales de aeronaves. La capacidad de estos sistemas para procesar grandes cantidades de datos visuales en tiempo real, identificar anomalías y proporcionar información accionable ha transformado tanto las operaciones rutinarias como los estándares de seguridad en múltiples industrias.
La interpretación automatizada de imágenes es el proceso mediante el cual los sistemas informáticos, a menudo impulsados por inteligencia artificial y aprendizaje profundo, analizan e interpretan imágenes o videos sin intervención humana. Esta tecnología está diseñada para replicar las capacidades analíticas de la inspección visual humana, pero a una velocidad y escala mucho mayores. La interpretación automatizada implica varias tareas clave: detección de objetos, clasificación de escenas, segmentación de regiones de interés y extracción de información cuantitativa o cualitativa relevante para una aplicación particular.
El proceso comienza con la adquisición de datos visuales a través de cámaras, sensores o escáneres. A continuación, los algoritmos preprocesan las imágenes para mejorar su claridad y eliminar el ruido, garantizando que el análisis posterior sea preciso. La extracción de características identifica entonces señales visuales clave como bordes, texturas o formas específicas. Modelos avanzados de aprendizaje automático—como las CNN o Vision Transformers—analizan estas características para reconocer objetos o clasificar escenas completas. Por ejemplo, en aviación, los sistemas de interpretación automatizada de imágenes pueden detectar incursiones en pistas, monitorear la posición de aeronaves o identificar necesidades de mantenimiento mediante análisis continuo de video.
Según los estándares de la OACI, la interpretación automatizada de imágenes es cada vez más vital en aviación para el cumplimiento, la seguridad y la eficiencia operativa. Los sistemas se implementan para monitorear áreas restringidas, detectar accesos no autorizados y automatizar la documentación de incidentes. En seguridad e infraestructuras críticas, la interpretación automatizada apoya la detección de amenazas en tiempo real y la conciencia situacional, reduciendo la carga de trabajo de los operadores humanos y minimizando el riesgo de omisiones. Además, la escalabilidad de estos sistemas permite la monitorización continua de grandes entornos, convirtiéndolos en herramientas indispensables para las operaciones modernas en aeropuertos, manufactura, agricultura y otros sectores donde los datos visuales son abundantes y las decisiones críticas dependen de un análisis oportuno y preciso.
Los sistemas de visión por computadora siguen una canalización estructurada, convirtiendo datos visuales en bruto en información accionable. Esta canalización es fundamental para garantizar que el gran volumen de datos de imagen o video generado en aplicaciones como aviación, seguridad, salud y manufactura pueda ser procesado de manera eficiente y precisa.
La adquisición de imágenes es la etapa inicial en cualquier proceso de visión por computadora, e implica la captura de datos visuales del entorno. Se utilizan dispositivos como cámaras digitales, sensores especializados (como infrarrojos o térmicos), escáneres o sistemas de imagen avanzados para recolectar imágenes de alta resolución o secuencias de video continuas. En aviación, la adquisición de imágenes puede implicar cámaras instaladas en pistas, plataformas o exteriores de aeronaves, capturando datos para la monitorización en tiempo real o el análisis posterior a un evento. La elección del sensor y su ubicación son cruciales, ya que afectan directamente la calidad, resolución y relevancia de los datos capturados. Por ejemplo, se pueden usar cámaras de alta velocidad para monitorear objetos en rápido movimiento en un aeródromo, mientras que sensores multiespectrales o hiperespectrales recogen datos más allá del espectro visible para inspecciones especializadas.
Factores ambientales como las condiciones de iluminación, el clima y la calibración de la cámara también desempeñan un papel significativo. La documentación de la OACI enfatiza la importancia de protocolos de adquisición de imágenes consistentes para garantizar el rendimiento fiable del sistema, especialmente en entornos críticos para la seguridad. La integración de sistemas de adquisición de imágenes con otras infraestructuras aeroportuarias—como radar, sensores de movimiento en tierra y redes de comunicación—permite una conciencia situacional integral que mejora tanto la eficiencia operativa como la seguridad.
El preprocesamiento de imágenes abarca una variedad de técnicas diseñadas para preparar los datos de imagen en bruto para su posterior análisis. Los objetivos principales son mejorar la calidad de la imagen, corregir distorsiones y estandarizar las entradas para reducir la variabilidad. Los pasos comunes de preprocesamiento incluyen reducción de ruido (usando filtros como Gaussiano o mediana), normalización del brillo y contraste, redimensionamiento de imágenes a una dimensión estándar y corrección de distorsiones geométricas causadas por aberraciones de lente o ángulos de cámara. En aviación, el preprocesamiento es crítico para garantizar que las imágenes de pistas o aeronaves sean claras y consistentes, independientemente de las variaciones de luz o clima.
El preprocesamiento avanzado también puede implicar conversión de espacio de color, ecualización de histograma y sustracción de fondo para aislar características relevantes. Por ejemplo, el preprocesamiento de una imagen del tren de aterrizaje de una aeronave puede implicar la eliminación de sombras y reflejos para revelar claramente cualquier defecto. Según las directrices de la OACI, los pasos de preprocesamiento deben ser robustos y repetibles, minimizando el riesgo de introducir artefactos que puedan afectar el análisis posterior. Las canalizaciones automatizadas a menudo incluyen preprocesamiento en tiempo real, asegurando que los sistemas de alto rendimiento—como los que monitorean entornos aeroportuarios concurridos—puedan mantener la precisión y fiabilidad a gran escala.
La extracción de características es el proceso de identificar y cuantificar patrones o elementos distintivos dentro de una imagen que son relevantes para el análisis posterior. Las características pueden ser de bajo nivel (bordes, esquinas, texturas) o de alto nivel (formas, objetos, regiones de interés). Los métodos tradicionales incluyen detectores de bordes como Canny o Sobel, detectores de esquinas como Harris y análisis de texturas usando Patrones Binarios Locales (LBP) o filtros de Gabor. En la visión por computadora moderna, los modelos de aprendizaje profundo—especialmente las CNN—aprenden representaciones jerárquicas de características directamente de los datos, identificando automáticamente patrones complejos que pueden ser difíciles de especificar para los analistas humanos.
En aplicaciones de aviación, la extracción de características se utiliza para identificar marcas en pistas, detectar objetos extraños o reconocer componentes específicos de una aeronave durante revisiones de mantenimiento. La documentación de la OACI destaca la importancia de una extracción de características robusta, especialmente en entornos sujetos a condiciones variables como cambios de iluminación, oclusiones o fondos complejos. Una extracción de características eficaz mejora la precisión de tareas posteriores como la detección o clasificación de objetos, permitiendo la automatización fiable de inspecciones visuales críticas y procesos de monitorización.
El análisis de imágenes implica interpretar las características extraídas para identificar objetos, clasificar escenas, reconocer actividades o derivar mediciones cuantitativas. Las técnicas van desde el reconocimiento clásico de patrones—usando modelos estadísticos o sistemas basados en reglas—hasta enfoques avanzados de aprendizaje automático y profundo. En el contexto de la aviación, el análisis de imágenes puede implicar reconocer la presencia y posición de aeronaves en calles de rodaje, identificar personal no autorizado en áreas restringidas o evaluar el estado de las superficies de las pistas.
El análisis de imágenes moderno aprovecha redes neuronales profundas capaces de razonamiento complejo sobre datos visuales, logrando altos niveles de precisión en tareas como segmentación de escenas o detección de anomalías. La integración con metadatos (como sello de tiempo, geolocalización o tipo de sensor) mejora aún más el valor del análisis, apoyando tareas como la reconstrucción de incidentes o el mantenimiento predictivo. Los estándares de la OACI enfatizan la necesidad de canalizaciones de análisis transparentes y auditables, especialmente cuando se utilizan para cumplimiento normativo o investigaciones de seguridad.
La toma de decisiones es la etapa final, donde los datos interpretados se utilizan para desencadenar acciones, generar informes o proporcionar recomendaciones. En sistemas automatizados, la lógica de decisión puede codificarse como reglas, umbrales o mediante clasificadores de aprendizaje automático que determinan la respuesta adecuada en función de los resultados del análisis. Por ejemplo, en un entorno aeroportuario, la detección de un objeto extraño en una pista puede activar automáticamente alertas, enviar equipos de inspección y detener temporalmente las operaciones para garantizar la seguridad.
Los marcos de toma de decisiones suelen incorporar bucles de retroalimentación, permitiendo que los sistemas aprendan de los resultados y mejoren con el tiempo. También pueden integrarse con plataformas operativas más amplias, como sistemas de gestión aeroportuaria o redes de respuesta a emergencias. La documentación de la OACI subraya la importancia de una toma de decisiones fiable y explicable, especialmente en entornos donde están en juego vidas humanas y activos significativos. Los sistemas automatizados de soporte a la toma de decisiones no solo incrementan la eficiencia, sino que también mejoran la consistencia y reducen el riesgo de error humano en escenarios de alta presión.
El panorama de la visión por computadora está conformado por una combinación de procesamiento clásico de imágenes, aprendizaje automático tradicional y metodologías de aprendizaje profundo de vanguardia. Las siguientes tecnologías y técnicas son centrales para las capacidades actuales y las tendencias futuras de la interpretación automatizada de imágenes.
Las Redes Neuronales Convolucionales (CNN) son arquitecturas especializadas de aprendizaje profundo diseñadas para manejar datos en forma de cuadrícula, como las imágenes. Consisten en múltiples capas que aprenden automáticamente a detectar jerarquías espaciales de características—desde bordes simples en las primeras capas hasta objetos complejos en las capas más profundas. El componente central, la capa convolucional, aplica filtros aprendibles a imágenes de entrada, permitiendo que el modelo se enfoque en características relevantes mientras ignora información de fondo irrelevante. Las capas de agrupamiento reducen las dimensiones espaciales, conservando información esencial y mejorando la eficiencia computacional.
Las CNN han revolucionado tareas como la clasificación de imágenes, detección de objetos, reconocimiento facial y segmentación de escenas. En aviación, las CNN se utilizan para identificar tipos de aeronaves, detectar anomalías en pistas y monitorear actividades en tierra. Su capacidad para aprender directamente de los píxeles elimina la necesidad de ingeniería manual de características, haciéndolas altamente adaptables a nuevas tareas y entornos. Los sistemas aprobados por la OACI suelen basarse en arquitecturas CNN por su robustez y escalabilidad, especialmente en aplicaciones críticas para la seguridad que requieren alta precisión bajo condiciones variables.
El éxito de las CNN está estrechamente ligado a la disponibilidad de grandes conjuntos de datos etiquetados y potentes GPUs para el entrenamiento. Técnicas como la aumento de datos y el aprendizaje por transferencia mejoran aún más su rendimiento, permitiendo que los modelos generalicen mejor y reduzcan el riesgo de sobreajuste. Las CNN siguen evolucionando, con innovaciones como conexiones residuales (ResNet), módulos de inception (GoogLeNet) y convoluciones separables por profundidad (MobileNet) que amplían los límites del análisis visual en tiempo real y eficiente en recursos.
Las Redes Generativas Antagónicas (GAN) son una clase de modelos de aprendizaje profundo compuesta por dos redes neuronales—el generador y el discriminador—en un proceso competitivo. El generador crea imágenes sintéticas a partir de ruido aleatorio, mientras que el discriminador evalúa si una imagen es real (del conjunto de datos) o falsa (del generador). A través de este entrenamiento adversario, las GAN aprenden a producir imágenes notablemente realistas, a menudo indistinguibles de fotografías genuinas.
Las GAN se utilizan para síntesis de imágenes, superresolución (mejora de calidad de imagen), aumento de datos y adaptación de dominios (traducción de imágenes de un estilo o modalidad a otra). En aviación, las GAN pueden generar datos sintéticos de entrenamiento para eventos raros (como incursiones en pista), mejorando la robustez del modelo sin requerir una extensa anotación manual. También se emplean para restaurar imágenes degradadas, como mejorar grabaciones de vigilancia de baja resolución para análisis de incidentes.
Una de las mayores contribuciones de las GAN es su capacidad para abordar la escasez de datos, un desafío común en dominios especializados como la aviación o la imagen médica. Sin embargo, las GAN son notoriamente difíciles de entrenar, requiriendo un equilibrio cuidadoso entre el generador y el discriminador para evitar problemas como el colapso de modo o el sobreajuste. Sus resultados deben validarse cuidadosamente, especialmente en aplicaciones críticas para la seguridad, para asegurar que las imágenes sintetizadas no introduzcan artefactos o sesgos que puedan afectar la toma de decisiones.
Las Redes Neuronales Recurrentes (RNN) son arquitecturas de aprendizaje profundo diseñadas para el análisis de datos secuenciales, lo que las hace ideales para tareas que involucran series temporales o secuencias ordenadas. A diferencia de las redes feedforward tradicionales, las RNN tienen “memoria”, permitiendo que retengan información de entradas previas y la apliquen al procesamiento actual. Esta capacidad es crucial para el análisis de video, donde entender el contexto y las relaciones temporales entre cuadros es esencial.
Las variantes avanzadas como las Redes de Memoria a Largo Plazo (LSTM) y las Unidades Recurrentes con Puertas (GRU) abordan las limitaciones de las RNN estándar, como el problema del gradiente desvanecido, permitiendo modelar dependencias más largas y secuencias más complejas. En aviación, las RNN se utilizan para el reconocimiento de actividades (por ejemplo, seguimiento del movimiento de vehículos en tierra), generación de descripciones de video y detección de anomalías en grabaciones de vigilancia.
La combinación de RNN con CNN permite modelos espaciotemporales potentes que pueden analizar tanto el contenido espacial de las imágenes como la evolución temporal de las escenas. Por ejemplo, la detección de accesos no autorizados en zonas restringidas de un aeropuerto puede requerir el seguimiento de individuos a través de múltiples cámaras a lo largo del tiempo. La documentación de la OACI destaca la importancia de los modelos sensibles a la secuencia para aplicaciones que implican análisis de movimiento, predicción de comportamiento y reconstrucción de incidentes.
El aprendizaje por transferencia es una técnica que aprovecha modelos preentrenados—usualmente entrenados en grandes conjuntos de datos de propósito general como ImageNet—y los adapta a tareas específicas con datos etiquetados limitados. Al reutilizar representaciones de características ya aprendidas, el aprendizaje por transferencia reduce significativamente el tiempo, los recursos computacionales y los requisitos de datos necesarios para entrenar modelos de alto rendimiento.
En visión por computadora, el aprendizaje por transferencia se aplica comúnmente ajustando las últimas capas de una CNN preentrenada para una nueva tarea de clasificación o detección. Este enfoque es especialmente valioso en dominios como la aviación o la imagen médica, donde los datos anotados pueden ser escasos o costosos de obtener. Los sistemas compatibles con la OACI suelen utilizar el aprendizaje por transferencia para desplegar rápidamente nuevos modelos frente a amenazas emergentes o cambios operativos sin necesidad de un reentrenamiento extensivo.
El aprendizaje por transferencia también permite la adaptación entre dominios, permitiendo que modelos entrenados en un tipo de imagen (como fotos satelitales) se reutilicen para otro (como imágenes de drones). Esta flexibilidad acelera la innovación y respalda la mejora iterativa de los sistemas de visión, asegurando que se mantengan efectivos a medida que evolucionan los entornos operativos.
La segmentación semántica es una tarea de visión por computadora que asigna una etiqueta de clase a cada píxel de una imagen, permitiendo una comprensión detallada de la escena. A diferencia de la detección de objetos, que dibuja cajas delimitadoras alrededor de los elementos detectados, la segmentación semántica proporciona una delimitación a nivel de píxel de diferentes objetos o regiones, como separar carreteras, pistas, aeronaves y vegetación en una imagen aeroportuaria.
Los modelos de aprendizaje profundo para segmentación semántica—como las Fully Convolutional Networks (FCN), U-Net y DeepLab—están diseñados para captar tanto el contexto local como global, asegurando una detección precisa de bordes y asignación de clases. En aviación, la segmentación semántica se utiliza para la inspección de pistas, detección de obstáculos y mapeo de infraestructura aeroportuaria. Apoya la automatización del mantenimiento rutinario, mejora la conciencia situacional y refuerza la seguridad al permitir la localización precisa de peligros.
Las directrices de la OACI enfatizan la importancia de una segmentación de alta precisión en entornos críticos para la seguridad, donde incluso pequeños errores pueden derivar en interrupciones operativas o incidentes de seguridad. Los modelos avanzados de segmentación suelen integrar extracción de características a múltiples escalas, mecanismos de atención y técnicas de posprocesamiento como los Campos Aleatorios Condicionales (CRF) para lograr un rendimiento de última generación.
La detección de objetos es el proceso de identificar y localizar múltiples objetos dentro de una imagen o cuadro de video, generalmente dibujando cajas delimitadoras alrededor de ellos y asignando etiquetas de clase. Combina elementos de la clasificación de imágenes (¿qué es?) y la localización (¿dónde está?), por lo que es una de las tareas más desafiantes y ampliamente utilizadas en la visión por computadora.
Los algoritmos populares de detección de objetos incluyen YOLO (You Only Look Once), Faster R-CNN y SSD (Single Shot MultiBox Detector), cada uno ofreciendo diferentes equilibrios entre velocidad y precisión. En aviación, la detección de objetos se utiliza para monitorear pistas en busca de objetos extraños, rastrear aeronaves y vehículos en tierra, y automatizar el manejo de equipaje. Una detección precisa permite alertas e intervenciones en tiempo real, reduciendo el riesgo de accidentes y retrasos operativos.
Según la OACI, los sistemas de detección de objetos deben ser robustos frente a condiciones variables de luz, clima y oclusión que se encuentran comúnmente en entornos aeroportuarios. La evaluación y reentrenamiento continuos son esenciales para mantener altas tasas de detección y minimizar falsos positivos o negativos, especialmente a medida que evolucionan los contextos operativos y los panoramas de amenazas.
Mientras que el procesamiento de imágenes se centra en mejorar o transformar imágenes para una mejor calidad, la visión por computadora busca extraer información significativa de los datos visuales para apoyar decisiones automáticas y comprensión. La visión por computadora va más allá de simples transformaciones al permitir que las máquinas detecten, clasifiquen, segmenten y analicen objetos y escenas.
En aviación, la visión por computadora se utiliza para la monitorización automatizada de pistas y áreas aeroportuarias, la detección de objetos extraños, inspecciones visuales de aeronaves, manejo de equipaje, vigilancia y cumplimiento de la seguridad. Estos sistemas mejoran la seguridad operacional, la eficiencia y el cumplimiento normativo.
La visión por computadora moderna se basa en modelos de aprendizaje profundo como las Redes Neuronales Convolucionales (CNN), Redes Generativas Antagónicas (GAN), Redes Neuronales Recurrentes (RNN), Vision Transformers (ViT) y técnicas como aprendizaje por transferencia, segmentación semántica y detección de objetos. Estas permiten una interpretación de alta precisión de datos visuales complejos.
La precisión se mantiene mediante un preprocesamiento robusto, evaluación continua y reentrenamiento de modelos, integración de múltiples modalidades de sensores, estricta adhesión a los estándares de la industria (como los de la OACI) y el uso de IA explicable para proporcionar decisiones transparentes.
Sí. Los avances en hardware, computación en la nube e IA en el borde permiten que los sistemas de visión por computadora procesen datos visuales en tiempo real, incluso bajo condiciones desafiantes como baja luminosidad, mal clima y entornos concurridos. Estos sistemas están diseñados para ser robustos y escalables para la monitorización continua.
Impulse la seguridad, eficiencia y toma de decisiones con soluciones de visión por computadora de última generación. Permítanos ayudarle a automatizar inspecciones visuales, monitorizar operaciones y asegurar el cumplimiento en su industria.
La visión fotópica es el modo de percepción visual bajo iluminación intensa, mediada por los fotorreceptores conos, que permite una alta agudeza y discriminació...
El Campo de Visión (FOV) es la extensión angular o física del área observable visible a través de un sistema óptico, como una cámara, un microscopio o el ojo hu...
Algoritmos de última generación e infraestructura segura en la nube
Consentimiento de Cookies
Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.